Kubernetes - Hướng dẫn nhanh
Kubernetes trong một công cụ quản lý vùng chứa mã nguồn mở được tổ chức bởi Cloud Native Computing Foundation (CNCF). Đây còn được gọi là phiên bản nâng cao của Borg được phát triển tại Google để quản lý cả các quy trình đang chạy dài và các công việc hàng loạt, trước đó được xử lý bởi các hệ thống riêng biệt.
Kubernetes đi kèm với khả năng tự động hóa việc triển khai, mở rộng ứng dụng và hoạt động của các vùng chứa ứng dụng trên các cụm. Nó có khả năng tạo ra cơ sở hạ tầng tập trung vào container.
Đặc điểm của Kubernetes
Sau đây là một số tính năng quan trọng của Kubernetes.
Tiếp tục phát triển, tích hợp và triển khai
Cơ sở hạ tầng container
Quản lý tập trung vào ứng dụng
Cơ sở hạ tầng có thể mở rộng tự động
Tính nhất quán của môi trường trong quá trình sản xuất và thử nghiệm phát triển
Cơ sở hạ tầng được kết hợp lỏng lẻo, nơi mỗi thành phần có thể hoạt động như một đơn vị riêng biệt
Mật độ sử dụng tài nguyên cao hơn
Cơ sở hạ tầng có thể dự đoán sẽ được tạo ra
Một trong những thành phần quan trọng của Kubernetes là nó có thể chạy ứng dụng trên các cụm cơ sở hạ tầng máy vật lý và máy ảo. Nó cũng có khả năng chạy các ứng dụng trên đám mây.It helps in moving from host-centric infrastructure to container-centric infrastructure.
Trong chương này, chúng ta sẽ thảo luận về kiến trúc cơ bản của Kubernetes.
Kubernetes - Kiến trúc cụm
Như được thấy trong sơ đồ sau, Kubernetes tuân theo kiến trúc máy khách-máy chủ. Trong đó, chúng tôi đã cài đặt chính trên một máy và nút trên các máy Linux riêng biệt.
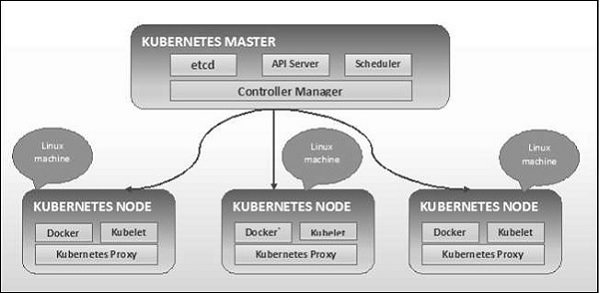
Các thành phần chính của nút chính và nút được định nghĩa trong phần sau.
Kubernetes - Thành phần máy chính
Sau đây là các thành phần của Kubernetes Master Machine.
vvd
Nó lưu trữ thông tin cấu hình có thể được sử dụng bởi từng nút trong cụm. Nó là một kho lưu trữ giá trị khóa có tính khả dụng cao có thể được phân phối giữa nhiều nút. Nó chỉ có thể truy cập được bằng máy chủ Kubernetes API vì nó có thể có một số thông tin nhạy cảm. Nó là một Kho lưu trữ giá trị khóa phân phối mà tất cả mọi người đều có thể truy cập được.
Máy chủ API
Kubernetes là một máy chủ API cung cấp tất cả hoạt động trên cụm bằng cách sử dụng API. Máy chủ API triển khai một giao diện, có nghĩa là các công cụ và thư viện khác nhau có thể dễ dàng giao tiếp với nó.Kubeconfiglà một gói cùng với các công cụ phía máy chủ có thể được sử dụng để giao tiếp. Nó tiết lộ API Kubernetes.
Người quản lý điều khiển
Thành phần này chịu trách nhiệm cho hầu hết các bộ sưu tập điều chỉnh trạng thái của cụm và thực hiện một tác vụ. Nói chung, nó có thể được coi là một daemon chạy trong vòng lặp liên tục và chịu trách nhiệm thu thập và gửi thông tin đến máy chủ API. Nó hoạt động theo hướng nhận trạng thái chia sẻ của cụm và sau đó thực hiện các thay đổi để đưa trạng thái hiện tại của máy chủ đến trạng thái mong muốn. Các bộ điều khiển chính là bộ điều khiển sao chép, bộ điều khiển điểm cuối, bộ điều khiển không gian tên và bộ điều khiển tài khoản dịch vụ. Trình quản lý bộ điều khiển chạy các loại bộ điều khiển khác nhau để xử lý các nút, điểm cuối, v.v.
Người lập kế hoạch
Đây là một trong những thành phần quan trọng của Kubernetes master. Nó là một dịch vụ tổng thể chịu trách nhiệm phân phối khối lượng công việc. Nó chịu trách nhiệm theo dõi việc sử dụng tải làm việc trên các nút cụm và sau đó đặt khối lượng công việc vào tài nguyên nào có sẵn và chấp nhận khối lượng công việc. Nói cách khác, đây là cơ chế chịu trách nhiệm phân bổ nhóm cho các nút có sẵn. Bộ lập lịch chịu trách nhiệm sử dụng khối lượng công việc và phân bổ nhóm cho nút mới.
Kubernetes - Các thành phần nút
Sau đây là các thành phần chính của máy chủ Node cần thiết để giao tiếp với Kubernetes master.
Docker
Yêu cầu đầu tiên của mỗi nút là Docker giúp chạy các vùng chứa ứng dụng được đóng gói trong một môi trường hoạt động tương đối cô lập nhưng nhẹ.
Dịch vụ Kubelet
Đây là một dịch vụ nhỏ trong mỗi nút chịu trách nhiệm chuyển tiếp thông tin đến và đi từ dịch vụ máy bay điều khiển. Nó tương tác vớietcdlưu trữ để đọc chi tiết cấu hình và giá trị wright. Điều này giao tiếp với thành phần chủ để nhận lệnh và hoạt động. Cáckubeletquy trình sau đó đảm nhận trách nhiệm duy trì trạng thái công việc và máy chủ nút. Nó quản lý các quy tắc mạng, chuyển tiếp cổng, v.v.
Dịch vụ proxy Kubernetes
Đây là một dịch vụ proxy chạy trên mỗi nút và giúp cung cấp dịch vụ cho máy chủ bên ngoài. Nó giúp chuyển tiếp yêu cầu sửa vùng chứa và có khả năng thực hiện cân bằng tải nguyên thủy. Nó đảm bảo rằng môi trường mạng có thể dự đoán được và có thể truy cập được, đồng thời nó cũng bị cô lập. Nó quản lý các nhóm trên nút, khối lượng, bí mật, tạo kiểm tra sức khỏe của vùng chứa mới, v.v.
Kubernetes - Cấu trúc Master và Node
Các hình minh họa sau đây cho thấy cấu trúc của Kubernetes Master và Node.
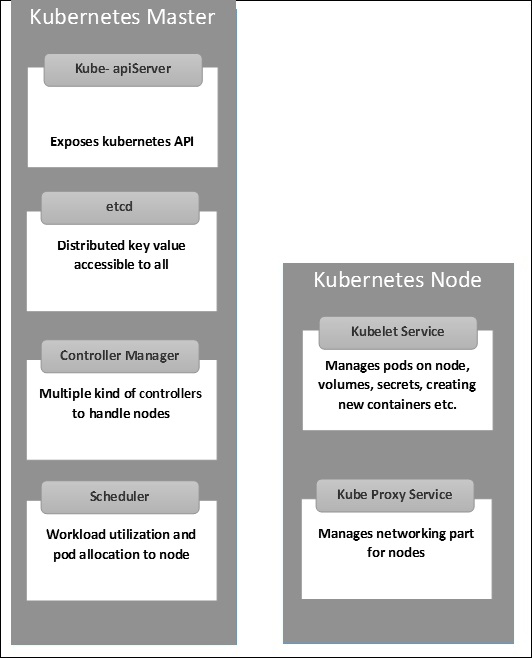
Điều quan trọng là phải thiết lập Trung tâm dữ liệu ảo (vDC) trước khi thiết lập Kubernetes. Đây có thể coi là một tập hợp các máy mà chúng có thể giao tiếp với nhau qua mạng. Đối với phương pháp thực hành, bạn có thể thiết lập vDC trênPROFITBRICKS nếu bạn chưa thiết lập cơ sở hạ tầng vật lý hoặc đám mây.
Sau khi thiết lập IaaS trên bất kỳ đám mây nào hoàn tất, bạn cần phải định cấu hình Master và Node.
Note- Thiết lập được hiển thị cho các máy Ubuntu. Điều này cũng có thể được thiết lập trên các máy Linux khác.
Điều kiện tiên quyết
Installing Docker- Cần có Docker trên tất cả các phiên bản của Kubernetes. Sau đây là các bước để cài đặt Docker.
Step 1 - Đăng nhập vào máy bằng tài khoản người dùng root.
Step 2- Cập nhật thông tin gói hàng. Đảm bảo rằng gói apt đang hoạt động.
Step 3 - Chạy các lệnh sau.
$ sudo apt-get update $ sudo apt-get install apt-transport-https ca-certificatesStep 4 - Thêm khóa GPG mới.
$ sudo apt-key adv \ --keyserver hkp://ha.pool.sks-keyservers.net:80 \ --recv-keys 58118E89F3A912897C070ADBF76221572C52609D $ echo "deb https://apt.dockerproject.org/repo ubuntu-trusty main" | sudo tee
/etc/apt/sources.list.d/docker.listStep 5 - Cập nhật hình ảnh gói API.
$ sudo apt-get updateKhi tất cả các tác vụ trên hoàn tất, bạn có thể bắt đầu với việc cài đặt thực tế công cụ Docker. Tuy nhiên, trước khi điều này, bạn cần xác minh rằng phiên bản hạt nhân bạn đang sử dụng là chính xác.
Cài đặt Docker Engine
Chạy các lệnh sau để cài đặt công cụ Docker.
Step 1 - Đăng nhập vào máy.
Step 2 - Cập nhật chỉ mục gói.
$ sudo apt-get updateStep 3 - Cài đặt Docker Engine bằng lệnh sau.
$ sudo apt-get install docker-engineStep 4 - Khởi động trình nền Docker.
$ sudo apt-get install docker-engineStep 5 - Để xem Docker đã được cài đặt chưa, hãy sử dụng lệnh sau.
$ sudo docker run hello-worldCài đặt etcd 2.0
Điều này cần được cài đặt trên Kubernetes Master Machine. Để cài đặt nó, hãy chạy các lệnh sau.
$ curl -L https://github.com/coreos/etcd/releases/download/v2.0.0/etcd
-v2.0.0-linux-amd64.tar.gz -o etcd-v2.0.0-linux-amd64.tar.gz ->1
$ tar xzvf etcd-v2.0.0-linux-amd64.tar.gz ------>2 $ cd etcd-v2.0.0-linux-amd64 ------------>3
$ mkdir /opt/bin ------------->4 $ cp etcd* /opt/bin ----------->5Trong tập lệnh trên -
- Đầu tiên, chúng tôi tải xuống etcd. Lưu cái này với tên được chỉ định.
- Sau đó, chúng ta phải tháo gói tar.
- Chúng tôi thực hiện một dir. bên trong thùng có tên / opt.
- Sao chép tệp đã giải nén vào vị trí đích.
Bây giờ chúng tôi đã sẵn sàng xây dựng Kubernetes. Chúng ta cần cài đặt Kubernetes trên tất cả các máy trong cụm.
$ git clone https://github.com/GoogleCloudPlatform/kubernetes.git $ cd kubernetes
$ make releaseLệnh trên sẽ tạo ra một _outputdir trong thư mục gốc của thư mục kubernetes. Tiếp theo, chúng tôi có thể trích xuất thư mục vào bất kỳ thư mục nào mà chúng tôi chọn / opt / bin, v.v.
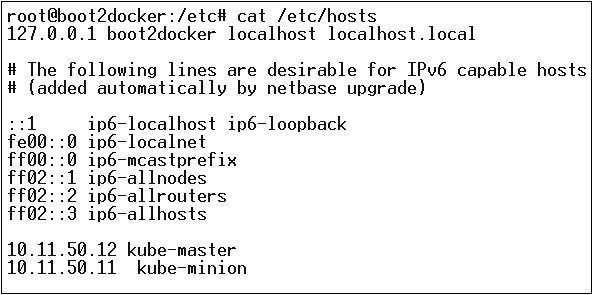
Tiếp theo, đến phần mạng, trong đó chúng ta cần thực sự bắt đầu với việc thiết lập nút chính và nút Kubernetes. Để làm điều này, chúng tôi sẽ tạo một mục nhập trong tệp máy chủ lưu trữ có thể được thực hiện trên máy nút.
$ echo "<IP address of master machine> kube-master
< IP address of Node Machine>" >> /etc/hostsSau đây sẽ là kết quả của lệnh trên.
Bây giờ, chúng ta sẽ bắt đầu với cấu hình thực tế trên Kubernetes Master.
Đầu tiên, chúng tôi sẽ bắt đầu sao chép tất cả các tệp cấu hình vào đúng vị trí của chúng.
$ cp <Current dir. location>/kube-apiserver /opt/bin/ $ cp <Current dir. location>/kube-controller-manager /opt/bin/
$ cp <Current dir. location>/kube-kube-scheduler /opt/bin/ $ cp <Current dir. location>/kubecfg /opt/bin/
$ cp <Current dir. location>/kubectl /opt/bin/ $ cp <Current dir. location>/kubernetes /opt/bin/Lệnh trên sẽ sao chép tất cả các tệp cấu hình vào vị trí cần thiết. Bây giờ chúng ta sẽ quay lại cùng một thư mục mà chúng ta đã xây dựng thư mục Kubernetes.
$ cp kubernetes/cluster/ubuntu/init_conf/kube-apiserver.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/init_conf/kube-controller-manager.conf /etc/init/
$ cp kubernetes/cluster/ubuntu/init_conf/kube-kube-scheduler.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-apiserver /etc/init.d/
$ cp kubernetes/cluster/ubuntu/initd_scripts/kube-controller-manager /etc/init.d/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-kube-scheduler /etc/init.d/
$ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/ $ cp kubernetes/cluster/ubuntu/default_scripts/kube-proxy /etc/default/
$ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/Bước tiếp theo là cập nhật tệp cấu hình đã sao chép trong / etc. dir.
Định cấu hình etcd trên master bằng lệnh sau.
$ ETCD_OPTS = "-listen-client-urls = http://kube-master:4001"Định cấu hình kube-apiserver
Đối với điều này trên trang cái, chúng tôi cần chỉnh sửa /etc/default/kube-apiserver tệp mà chúng tôi đã sao chép trước đó.
$ KUBE_APISERVER_OPTS = "--address = 0.0.0.0 \
--port = 8080 \
--etcd_servers = <The path that is configured in ETCD_OPTS> \
--portal_net = 11.1.1.0/24 \
--allow_privileged = false \
--kubelet_port = < Port you want to configure> \
--v = 0"Định cấu hình Trình quản lý bộ điều khiển kube
Chúng ta cần thêm nội dung sau vào /etc/default/kube-controller-manager.
$ KUBE_CONTROLLER_MANAGER_OPTS = "--address = 0.0.0.0 \
--master = 127.0.0.1:8080 \
--machines = kube-minion \ -----> #this is the kubernatics node
--v = 0Tiếp theo, định cấu hình bộ lập lịch kube trong tệp tương ứng.
$ KUBE_SCHEDULER_OPTS = "--address = 0.0.0.0 \
--master = 127.0.0.1:8080 \
--v = 0"Khi tất cả các nhiệm vụ trên đã hoàn thành, chúng ta nên tiếp tục bằng cách đưa Kubernetes Master lên. Để làm điều này, chúng tôi sẽ khởi động lại Docker.
$ service docker restartCấu hình nút Kubernetes
Nút Kubernetes sẽ chạy hai dịch vụ kubelet and the kube-proxy. Trước khi tiếp tục, chúng ta cần sao chép các tệp nhị phân mà chúng ta đã tải xuống vào các thư mục yêu cầu của chúng, nơi chúng ta muốn định cấu hình nút kubernetes.
Sử dụng cùng một phương pháp sao chép các tệp mà chúng tôi đã làm cho kubernetes master. Vì nó sẽ chỉ chạy kubelet và kube-proxy, chúng tôi sẽ định cấu hình chúng.
$ cp <Path of the extracted file>/kubelet /opt/bin/ $ cp <Path of the extracted file>/kube-proxy /opt/bin/
$ cp <Path of the extracted file>/kubecfg /opt/bin/ $ cp <Path of the extracted file>/kubectl /opt/bin/
$ cp <Path of the extracted file>/kubernetes /opt/bin/Bây giờ, chúng tôi sẽ sao chép nội dung vào dir thích hợp.
$ cp kubernetes/cluster/ubuntu/init_conf/kubelet.conf /etc/init/
$ cp kubernetes/cluster/ubuntu/init_conf/kube-proxy.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kubelet /etc/init.d/
$ cp kubernetes/cluster/ubuntu/initd_scripts/kube-proxy /etc/init.d/ $ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/
$ cp kubernetes/cluster/ubuntu/default_scripts/kube-proxy /etc/default/Chúng tôi sẽ cấu hình kubelet và kube-proxy conf các tập tin.
Chúng tôi sẽ cấu hình /etc/init/kubelet.conf.
$ KUBELET_OPTS = "--address = 0.0.0.0 \
--port = 10250 \
--hostname_override = kube-minion \
--etcd_servers = http://kube-master:4001 \
--enable_server = true
--v = 0"
/Đối với kube-proxy, chúng tôi sẽ cấu hình bằng lệnh sau.
$ KUBE_PROXY_OPTS = "--etcd_servers = http://kube-master:4001 \
--v = 0"
/etc/init/kube-proxy.confCuối cùng, chúng tôi sẽ khởi động lại dịch vụ Docker.
$ service docker restartBây giờ chúng ta đã hoàn tất cấu hình. Bạn có thể kiểm tra bằng cách chạy các lệnh sau.
$ /opt/bin/kubectl get minionsHình ảnh Kubernetes (Docker) là các khối xây dựng chính của Cơ sở hạ tầng được chứa đựng. Hiện tại, chúng tôi chỉ hỗ trợ Kubernetes hỗ trợ hình ảnh Docker. Mỗi vùng chứa trong một nhóm có hình ảnh Docker của nó chạy bên trong nó.
Khi chúng tôi đang định cấu hình một nhóm, thuộc tính hình ảnh trong tệp cấu hình có cùng cú pháp như lệnh Docker. Tệp cấu hình có một trường để xác định tên hình ảnh mà chúng tôi định lấy từ sổ đăng ký.
Sau đây là cấu trúc cấu hình chung sẽ kéo hình ảnh từ sổ đăng ký Docker và triển khai vào vùng chứa Kubernetes.
apiVersion: v1
kind: pod
metadata:
name: Tesing_for_Image_pull -----------> 1
spec:
containers:
- name: neo4j-server ------------------------> 2
image: <Name of the Docker image>----------> 3
imagePullPolicy: Always ------------->4
command: ["echo", "SUCCESS"] ------------------->Trong đoạn mã trên, chúng tôi đã xác định -
name: Tesing_for_Image_pull - Tên này được đặt để xác định và kiểm tra tên của vùng chứa sẽ được tạo sau khi kéo hình ảnh từ sổ đăng ký Docker.
name: neo4j-server- Đây là tên được đặt cho vùng chứa mà chúng tôi đang cố gắng tạo. Giống như chúng tôi đã cung cấp cho máy chủ neo4j.
image: <Name of the Docker image>- Đây là tên của hình ảnh mà chúng tôi đang cố gắng lấy từ Docker hoặc sổ đăng ký nội bộ của hình ảnh. Chúng tôi cần xác định một đường dẫn đăng ký hoàn chỉnh cùng với tên hình ảnh mà chúng tôi đang cố gắng kéo.
imagePullPolicy - Luôn luôn - Chính sách kéo hình ảnh này xác định rằng bất cứ khi nào chúng tôi chạy tệp này để tạo vùng chứa, nó sẽ kéo lại cùng một tên.
command: [“echo”, “SUCCESS”] - Với điều này, khi chúng ta tạo vùng chứa và nếu mọi thứ suôn sẻ, nó sẽ hiển thị thông báo khi chúng ta sẽ truy cập vùng chứa.
Để kéo hình ảnh và tạo vùng chứa, chúng ta sẽ chạy lệnh sau.
$ kubectl create –f Tesing_for_Image_pullKhi chúng tôi tìm nạp nhật ký, chúng tôi sẽ nhận được kết quả là thành công.
$ kubectl log Tesing_for_Image_pullLệnh trên sẽ tạo ra kết quả là thành công hoặc chúng ta sẽ nhận được kết quả là thất bại.
Note - Bạn nên tự mình thử tất cả các lệnh.
Chức năng chính của công việc là tạo một hoặc nhiều nhóm và theo dõi về sự thành công của các nhóm. Chúng đảm bảo rằng số lượng nhóm được chỉ định được hoàn thành thành công. Khi một số lần chạy nhóm thành công được chỉ định được hoàn thành, thì công việc được coi là hoàn thành.
Tạo công việc
Sử dụng lệnh sau để tạo một công việc:
apiVersion: v1
kind: Job ------------------------> 1
metadata:
name: py
spec:
template:
metadata
name: py -------> 2
spec:
containers:
- name: py ------------------------> 3
image: python----------> 4
command: ["python", "SUCCESS"]
restartPocliy: Never --------> 5Trong đoạn mã trên, chúng tôi đã xác định -
kind: Job → Chúng tôi đã định nghĩa loại này là Job sẽ cho biết kubectl rằng yaml tệp đang được sử dụng để tạo một nhóm loại công việc.
Name:py → Đây là tên của mẫu mà chúng tôi đang sử dụng và thông số xác định mẫu.
name: py → chúng tôi đã đặt một cái tên là py dưới thông số kỹ thuật của vùng chứa giúp xác định Pod sẽ được tạo ra từ nó.
Image: python → hình ảnh mà chúng ta sẽ kéo để tạo vùng chứa sẽ chạy bên trong nhóm.
restartPolicy: Never →Điều kiện khởi động lại hình ảnh này được đưa ra là không bao giờ có nghĩa là nếu vùng chứa bị chết hoặc nếu nó là sai, thì nó sẽ không tự khởi động lại.
Chúng tôi sẽ tạo công việc bằng cách sử dụng lệnh sau với yaml được lưu với tên py.yaml.
$ kubectl create –f py.yamlLệnh trên sẽ tạo một công việc. Nếu bạn muốn kiểm tra trạng thái của công việc, hãy sử dụng lệnh sau.
$ kubectl describe jobs/pyLệnh trên sẽ tạo một công việc. Nếu bạn muốn kiểm tra trạng thái của công việc, hãy sử dụng lệnh sau.
Công việc đã lên lịch
Công việc đã lên lịch trong Kubernetes sử dụng Cronetes, đảm nhận công việc của Kubernetes và khởi chạy chúng trong cụm Kubernetes.
- Lập lịch công việc sẽ chạy một nhóm tại một thời điểm xác định.
- Một công việc nhại được tạo cho nó tự động gọi nó.
Note - Tính năng của công việc đã lên lịch được hỗ trợ bởi phiên bản 1.4 và API betch / v2alpha 1 được bật bằng cách chuyển –runtime-config=batch/v2alpha1 trong khi đưa lên máy chủ API.
Chúng tôi sẽ sử dụng cùng một yaml mà chúng tôi đã sử dụng để tạo công việc và biến nó thành công việc theo lịch trình.
apiVersion: v1
kind: Job
metadata:
name: py
spec:
schedule: h/30 * * * * ? -------------------> 1
template:
metadata
name: py
spec:
containers:
- name: py
image: python
args:
/bin/sh -------> 2
-c
ps –eaf ------------> 3
restartPocliy: OnFailureTrong đoạn mã trên, chúng tôi đã xác định -
schedule: h/30 * * * * ? → Lên lịch để công việc chạy sau mỗi 30 phút.
/bin/sh: Điều này sẽ nhập vào vùng chứa với / bin / sh
ps –eaf → Sẽ chạy lệnh ps -eaf trên máy và liệt kê tất cả quá trình đang chạy bên trong một vùng chứa.
Khái niệm công việc theo lịch trình này hữu ích khi chúng ta đang cố gắng xây dựng và chạy một tập hợp các nhiệm vụ tại một thời điểm xác định và sau đó hoàn thành quy trình.
Nhãn
Nhãn là các cặp khóa-giá trị được gắn vào nhóm, bộ điều khiển sao chép và dịch vụ. Chúng được sử dụng để xác định các thuộc tính cho các đối tượng như nhóm và bộ điều khiển sao chép. Chúng có thể được thêm vào một đối tượng tại thời điểm tạo và có thể được thêm vào hoặc sửa đổi tại thời điểm chạy.
Bộ chọn
Nhãn không cung cấp tính duy nhất. Nói chung, chúng ta có thể nói nhiều đối tượng có thể mang các nhãn giống nhau. Bộ chọn nhãn là nguyên thủy phân nhóm cốt lõi trong Kubernetes. Chúng được người dùng sử dụng để chọn một tập hợp các đối tượng.
API Kubernetes hiện hỗ trợ hai loại bộ chọn -
- Bộ chọn dựa trên bình đẳng
- Bộ chọn dựa trên bộ
Bộ chọn dựa trên bình đẳng
Chúng cho phép lọc theo khóa và giá trị. Các đối tượng phù hợp phải thỏa mãn tất cả các nhãn được chỉ định.
Bộ chọn dựa trên bộ
Bộ chọn dựa trên tập hợp cho phép lọc các khóa theo một tập hợp giá trị.
apiVersion: v1
kind: Service
metadata:
name: sp-neo4j-standalone
spec:
ports:
- port: 7474
name: neo4j
type: NodePort
selector:
app: salesplatform ---------> 1
component: neo4j -----------> 2Trong đoạn mã trên, chúng tôi đang sử dụng bộ chọn nhãn như app: salesplatform và thành phần như component: neo4j.
Sau khi chúng tôi chạy tệp bằng cách sử dụng kubectl lệnh, nó sẽ tạo một dịch vụ với tên sp-neo4j-standalone sẽ giao tiếp trên cổng 7474. Ype là NodePort với bộ chọn nhãn mới là app: salesplatform và component: neo4j.
Không gian tên cung cấp một tiêu chuẩn bổ sung cho tên tài nguyên. Điều này rất hữu ích khi nhiều nhóm đang sử dụng cùng một cụm và có khả năng xảy ra xung đột tên. Nó có thể như một bức tường ảo giữa nhiều cụm.
Chức năng của không gian tên
Sau đây là một số chức năng quan trọng của Không gian tên trong Kubernetes:
Không gian tên giúp giao tiếp nhóm với nhóm bằng cách sử dụng cùng một không gian tên.
Không gian tên là các cụm ảo có thể nằm trên cùng một cụm vật lý.
Chúng cung cấp sự tách biệt hợp lý giữa các đội và môi trường của họ.
Tạo không gian tên
Lệnh sau được sử dụng để tạo một không gian tên.
apiVersion: v1
kind: Namespce
metadata
name: elkKiểm soát không gian tên
Lệnh sau được sử dụng để kiểm soát không gian tên.
$ kubectl create –f namespace.yml ---------> 1
$ kubectl get namespace -----------------> 2 $ kubectl get namespace <Namespace name> ------->3
$ kubectl describe namespace <Namespace name> ---->4 $ kubectl delete namespace <Namespace name>Trong đoạn mã trên,
- Chúng tôi đang sử dụng lệnh để tạo một không gian tên.
- Điều này sẽ liệt kê tất cả các không gian tên có sẵn.
- Thao tác này sẽ nhận được một không gian tên cụ thể có tên được chỉ định trong lệnh.
- Điều này sẽ mô tả chi tiết đầy đủ về dịch vụ.
- Thao tác này sẽ xóa một không gian tên cụ thể có trong cụm.
Sử dụng không gian tên trong dịch vụ - Ví dụ
Sau đây là một ví dụ về tệp mẫu để sử dụng không gian tên trong dịch vụ.
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCPTrong đoạn mã trên, chúng tôi đang sử dụng cùng một không gian tên trong siêu dữ liệu dịch vụ với tên của elk.
Một nút là một máy làm việc trong cụm Kubernetes, nó còn được gọi là một tay sai. Chúng là các đơn vị làm việc có thể là vật lý, VM hoặc một phiên bản đám mây.
Mỗi nút có tất cả cấu hình bắt buộc cần thiết để chạy một nhóm trên đó, chẳng hạn như dịch vụ proxy và dịch vụ kubelet cùng với Docker, được sử dụng để chạy các vùng chứa Docker trên nhóm được tạo trên nút.
Chúng không được tạo bởi Kubernetes nhưng chúng được tạo ra bên ngoài bởi nhà cung cấp dịch vụ đám mây hoặc trình quản lý cụm Kubernetes trên máy vật lý hoặc máy ảo.
Thành phần quan trọng của Kubernetes để xử lý nhiều nút là trình quản lý bộ điều khiển, chạy nhiều loại bộ điều khiển để quản lý các nút. Để quản lý các nút, Kubernetes tạo một đối tượng thuộc loại nút sẽ xác thực rằng đối tượng được tạo là một nút hợp lệ.
Dịch vụ với Bộ chọn
apiVersion: v1
kind: node
metadata:
name: < ip address of the node>
labels:
name: <lable name>Ở định dạng JSON, đối tượng thực được tạo ra trông như sau:
{
Kind: node
apiVersion: v1
"metadata":
{
"name": "10.01.1.10",
"labels"
{
"name": "cluster 1 node"
}
}
}Bộ điều khiển nút
Chúng là tập hợp các dịch vụ chạy trong Kubernetes master và liên tục giám sát nút trong cụm trên cơ sở metadata.name. Nếu tất cả các dịch vụ được yêu cầu đang chạy, thì nút đó sẽ được xác thực và một nhóm mới được tạo sẽ được bộ điều khiển gán cho nút đó. Nếu nó không hợp lệ, thì master sẽ không gán bất kỳ nhóm nào cho nó và sẽ đợi cho đến khi nó trở nên hợp lệ.
Kubernetes master đăng ký nút tự động, nếu –register-node cờ là sự thật.
–register-node = trueTuy nhiên, nếu quản trị viên cụm muốn quản lý nó theo cách thủ công thì điều đó có thể được thực hiện bằng cách chuyển sang -
–register-node = falseMột dịch vụ có thể được định nghĩa là một tập hợp các nhóm hợp lý. Nó có thể được định nghĩa là một phần trừu tượng trên đầu nhóm cung cấp một địa chỉ IP và tên DNS duy nhất để nhóm có thể được truy cập. Với Service, rất dễ dàng quản lý cấu hình cân bằng tải. Nó giúp các nhóm mở rộng quy mô rất dễ dàng.
A service is a REST object in Kubernetes whose definition can be posted to Kubernetes apiServer on the Kubernetes master to create a new instance.
Service without Selector
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
ports:
- port: 8080
targetPort: 31999The above configuration will create a service with the name Tutorial_point_service.
Service Config File with Selector
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
selector:
application: "My Application" -------------------> (Selector)
ports:
- port: 8080
targetPort: 31999In this example, we have a selector; so in order to transfer traffic, we need to create an endpoint manually.
apiVersion: v1
kind: Endpoints
metadata:
name: Tutorial_point_service
subnets:
address:
"ip": "192.168.168.40" -------------------> (Selector)
ports:
- port: 8080In the above code, we have created an endpoint which will route the traffic to the endpoint defined as “192.168.168.40:8080”.
Multi-Port Service Creation
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
selector:
application: “My Application” -------------------> (Selector)
ClusterIP: 10.3.0.12
ports:
-name: http
protocol: TCP
port: 80
targetPort: 31999
-name:https
Protocol: TCP
Port: 443
targetPort: 31998Types of Services
ClusterIP − This helps in restricting the service within the cluster. It exposes the service within the defined Kubernetes cluster.
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: NodeportServiceNodePort − It will expose the service on a static port on the deployed node. A ClusterIP service, to which NodePort service will route, is automatically created. The service can be accessed from outside the cluster using the NodeIP:nodePort.
spec:
ports:
- port: 8080
nodePort: 31999
name: NodeportService
clusterIP: 10.20.30.40Load Balancer − It uses cloud providers’ load balancer. NodePort and ClusterIP services are created automatically to which the external load balancer will route.
A full service yaml file with service type as Node Port. Try to create one yourself.
apiVersion: v1
kind: Service
metadata:
name: appname
labels:
k8s-app: appname
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: omninginx
selector:
k8s-app: appname
component: nginx
env: env_nameA pod is a collection of containers and its storage inside a node of a Kubernetes cluster. It is possible to create a pod with multiple containers inside it. For example, keeping a database container and data container in the same pod.
Types of Pod
There are two types of Pods −
- Single container pod
- Multi container pod
Single Container Pod
They can be simply created with the kubctl run command, where you have a defined image on the Docker registry which we will pull while creating a pod.
$ kubectl run <name of pod> --image=<name of the image from registry>Example − We will create a pod with a tomcat image which is available on the Docker hub.
$ kubectl run tomcat --image = tomcat:8.0This can also be done by creating the yaml file and then running the kubectl create command.
apiVersion: v1
kind: Pod
metadata:
name: Tomcat
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
containerPort: 7500
imagePullPolicy: AlwaysOnce the above yaml file is created, we will save the file with the name of tomcat.yml and run the create command to run the document.
$ kubectl create –f tomcat.ymlIt will create a pod with the name of tomcat. We can use the describe command along with kubectl to describe the pod.
Multi Container Pod
Multi container pods are created using yaml mail with the definition of the containers.
apiVersion: v1
kind: Pod
metadata:
name: Tomcat
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
containerPort: 7500
imagePullPolicy: Always
-name: Database
Image: mongoDB
Ports:
containerPort: 7501
imagePullPolicy: AlwaysIn the above code, we have created one pod with two containers inside it, one for tomcat and the other for MongoDB.
Replication Controller is one of the key features of Kubernetes, which is responsible for managing the pod lifecycle. It is responsible for making sure that the specified number of pod replicas are running at any point of time. It is used in time when one wants to make sure that the specified number of pod or at least one pod is running. It has the capability to bring up or down the specified no of pod.
It is a best practice to use the replication controller to manage the pod life cycle rather than creating a pod again and again.
apiVersion: v1
kind: ReplicationController --------------------------> 1
metadata:
name: Tomcat-ReplicationController --------------------------> 2
spec:
replicas: 3 ------------------------> 3
template:
metadata:
name: Tomcat-ReplicationController
labels:
app: App
component: neo4j
spec:
containers:
- name: Tomcat- -----------------------> 4
image: tomcat: 8.0
ports:
- containerPort: 7474 ------------------------> 5Setup Details
Kind: ReplicationController → In the above code, we have defined the kind as replication controller which tells the kubectl that the yaml file is going to be used for creating the replication controller.
name: Tomcat-ReplicationController → This helps in identifying the name with which the replication controller will be created. If we run the kubctl, get rc < Tomcat-ReplicationController > it will show the replication controller details.
replicas: 3 → This helps the replication controller to understand that it needs to maintain three replicas of a pod at any point of time in the pod lifecycle.
name: Tomcat → In the spec section, we have defined the name as tomcat which will tell the replication controller that the container present inside the pods is tomcat.
containerPort: 7474 → It helps in making sure that all the nodes in the cluster where the pod is running the container inside the pod will be exposed on the same port 7474.

Here, the Kubernetes service is working as a load balancer for three tomcat replicas.
Replica Set ensures how many replica of pod should be running. It can be considered as a replacement of replication controller. The key difference between the replica set and the replication controller is, the replication controller only supports equality-based selector whereas the replica set supports set-based selector.
apiVersion: extensions/v1beta1 --------------------->1
kind: ReplicaSet --------------------------> 2
metadata:
name: Tomcat-ReplicaSet
spec:
replicas: 3
selector:
matchLables:
tier: Backend ------------------> 3
matchExpression:
{ key: tier, operation: In, values: [Backend]} --------------> 4
template:
metadata:
lables:
app: Tomcat-ReplicaSet
tier: Backend
labels:
app: App
component: neo4j
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
- containerPort: 7474Setup Details
apiVersion: extensions/v1beta1 → In the above code, the API version is the advanced beta version of Kubernetes which supports the concept of replica set.
kind: ReplicaSet → We have defined the kind as the replica set which helps kubectl to understand that the file is used to create a replica set.
tier: Backend → We have defined the label tier as backend which creates a matching selector.
{key: tier, operation: In, values: [Backend]} → This will help matchExpression to understand the matching condition we have defined and in the operation which is used by matchlabel to find details.
Run the above file using kubectl and create the backend replica set with the provided definition in the yaml file.

Deployments are upgraded and higher version of replication controller. They manage the deployment of replica sets which is also an upgraded version of the replication controller. They have the capability to update the replica set and are also capable of rolling back to the previous version.
They provide many updated features of matchLabels and selectors. We have got a new controller in the Kubernetes master called the deployment controller which makes it happen. It has the capability to change the deployment midway.
Changing the Deployment
Updating − The user can update the ongoing deployment before it is completed. In this, the existing deployment will be settled and new deployment will be created.
Deleting − The user can pause/cancel the deployment by deleting it before it is completed. Recreating the same deployment will resume it.
Rollback − We can roll back the deployment or the deployment in progress. The user can create or update the deployment by using DeploymentSpec.PodTemplateSpec = oldRC.PodTemplateSpec.
Deployment Strategies
Deployment strategies help in defining how the new RC should replace the existing RC.
Recreate − This feature will kill all the existing RC and then bring up the new ones. This results in quick deployment however it will result in downtime when the old pods are down and the new pods have not come up.
Rolling Update − This feature gradually brings down the old RC and brings up the new one. This results in slow deployment, however there is no deployment. At all times, few old pods and few new pods are available in this process.
The configuration file of Deployment looks like this.
apiVersion: extensions/v1beta1 --------------------->1
kind: Deployment --------------------------> 2
metadata:
name: Tomcat-ReplicaSet
spec:
replicas: 3
template:
metadata:
lables:
app: Tomcat-ReplicaSet
tier: Backend
spec:
containers:
- name: Tomcatimage:
tomcat: 8.0
ports:
- containerPort: 7474In the above code, the only thing which is different from the replica set is we have defined the kind as deployment.
Create Deployment
$ kubectl create –f Deployment.yaml -–record
deployment "Deployment" created Successfully.Fetch the Deployment
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVILABLE AGE
Deployment 3 3 3 3 20sCheck the Status of Deployment
$ kubectl rollout status deployment/DeploymentUpdating the Deployment
$ kubectl set image deployment/Deployment tomcat=tomcat:6.0Rolling Back to Previous Deployment
$ kubectl rollout undo deployment/Deployment –to-revision=2In Kubernetes, a volume can be thought of as a directory which is accessible to the containers in a pod. We have different types of volumes in Kubernetes and the type defines how the volume is created and its content.
The concept of volume was present with the Docker, however the only issue was that the volume was very much limited to a particular pod. As soon as the life of a pod ended, the volume was also lost.
On the other hand, the volumes that are created through Kubernetes is not limited to any container. It supports any or all the containers deployed inside the pod of Kubernetes. A key advantage of Kubernetes volume is, it supports different kind of storage wherein the pod can use multiple of them at the same time.
Types of Kubernetes Volume
Here is a list of some popular Kubernetes Volumes −
emptyDir − It is a type of volume that is created when a Pod is first assigned to a Node. It remains active as long as the Pod is running on that node. The volume is initially empty and the containers in the pod can read and write the files in the emptyDir volume. Once the Pod is removed from the node, the data in the emptyDir is erased.
hostPath − This type of volume mounts a file or directory from the host node’s filesystem into your pod.
gcePersistentDisk − This type of volume mounts a Google Compute Engine (GCE) Persistent Disk into your Pod. The data in a gcePersistentDisk remains intact when the Pod is removed from the node.
awsElasticBlockStore − This type of volume mounts an Amazon Web Services (AWS) Elastic Block Store into your Pod. Just like gcePersistentDisk, the data in an awsElasticBlockStore remains intact when the Pod is removed from the node.
nfs − An nfs volume allows an existing NFS (Network File System) to be mounted into your pod. The data in an nfs volume is not erased when the Pod is removed from the node. The volume is only unmounted.
iscsi − An iscsi volume allows an existing iSCSI (SCSI over IP) volume to be mounted into your pod.
flocker − It is an open-source clustered container data volume manager. It is used for managing data volumes. A flocker volume allows a Flocker dataset to be mounted into a pod. If the dataset does not exist in Flocker, then you first need to create it by using the Flocker API.
glusterfs − Glusterfs is an open-source networked filesystem. A glusterfs volume allows a glusterfs volume to be mounted into your pod.
rbd − RBD stands for Rados Block Device. An rbd volume allows a Rados Block Device volume to be mounted into your pod. Data remains preserved after the Pod is removed from the node.
cephfs − A cephfs volume allows an existing CephFS volume to be mounted into your pod. Data remains intact after the Pod is removed from the node.
gitRepo − A gitRepo volume mounts an empty directory and clones a git repository into it for your pod to use.
secret − A secret volume is used to pass sensitive information, such as passwords, to pods.
persistentVolumeClaim − A persistentVolumeClaim volume is used to mount a PersistentVolume into a pod. PersistentVolumes are a way for users to “claim” durable storage (such as a GCE PersistentDisk or an iSCSI volume) without knowing the details of the particular cloud environment.
downwardAPI − A downwardAPI volume is used to make downward API data available to applications. It mounts a directory and writes the requested data in plain text files.
azureDiskVolume − An AzureDiskVolume is used to mount a Microsoft Azure Data Disk into a Pod.
Persistent Volume and Persistent Volume Claim
Persistent Volume (PV) − It’s a piece of network storage that has been provisioned by the administrator. It’s a resource in the cluster which is independent of any individual pod that uses the PV.
Persistent Volume Claim (PVC) − The storage requested by Kubernetes for its pods is known as PVC. The user does not need to know the underlying provisioning. The claims must be created in the same namespace where the pod is created.
Creating Persistent Volume
kind: PersistentVolume ---------> 1
apiVersion: v1
metadata:
name: pv0001 ------------------> 2
labels:
type: local
spec:
capacity: -----------------------> 3
storage: 10Gi ----------------------> 4
accessModes:
- ReadWriteOnce -------------------> 5
hostPath:
path: "/tmp/data01" --------------------------> 6In the above code, we have defined −
kind: PersistentVolume → We have defined the kind as PersistentVolume which tells kubernetes that the yaml file being used is to create the Persistent Volume.
name: pv0001 → Name of PersistentVolume that we are creating.
capacity: → This spec will define the capacity of PV that we are trying to create.
storage: 10Gi → This tells the underlying infrastructure that we are trying to claim 10Gi space on the defined path.
ReadWriteOnce → This tells the access rights of the volume that we are creating.
path: "/tmp/data01" → This definition tells the machine that we are trying to create volume under this path on the underlying infrastructure.
Creating PV
$ kubectl create –f local-01.yaml
persistentvolume "pv0001" createdChecking PV
$ kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 10Gi RWO Available 14sDescribing PV
$ kubectl describe pv pv0001Creating Persistent Volume Claim
kind: PersistentVolumeClaim --------------> 1
apiVersion: v1
metadata:
name: myclaim-1 --------------------> 2
spec:
accessModes:
- ReadWriteOnce ------------------------> 3
resources:
requests:
storage: 3Gi ---------------------> 4In the above code, we have defined −
kind: PersistentVolumeClaim → It instructs the underlying infrastructure that we are trying to claim a specified amount of space.
name: myclaim-1 → Name of the claim that we are trying to create.
ReadWriteOnce → This specifies the mode of the claim that we are trying to create.
storage: 3Gi → This will tell kubernetes about the amount of space we are trying to claim.
Tạo PVC
$ kubectl create –f myclaim-1
persistentvolumeclaim "myclaim-1" createdNhận thông tin chi tiết về PVC
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
myclaim-1 Bound pv0001 10Gi RWO 7sMô tả PVC
$ kubectl describe pv pv0001Sử dụng PV và PVC với POD
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
name: frontendhttp
spec:
containers:
- name: myfrontend
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts: ----------------------------> 1
- mountPath: "/usr/share/tomcat/html"
name: mypd
volumes: -----------------------> 2
- name: mypd
persistentVolumeClaim: ------------------------->3
claimName: myclaim-1Trong đoạn mã trên, chúng tôi đã xác định -
volumeMounts: → Đây là đường dẫn trong vùng chứa mà quá trình lắp sẽ diễn ra.
Volume: → Định nghĩa này xác định định nghĩa khối lượng mà chúng ta sẽ xác nhận.
persistentVolumeClaim: → Dưới đây, chúng tôi xác định tên ổ đĩa mà chúng tôi sẽ sử dụng trong nhóm đã xác định.
Bí mật có thể được định nghĩa là các đối tượng Kubernetes được sử dụng để lưu trữ dữ liệu nhạy cảm như tên người dùng và mật khẩu có mã hóa.
Có nhiều cách để tạo ra bí mật trong Kubernetes.
- Tạo từ tệp txt.
- Tạo từ tệp yaml.
Tạo từ tệp văn bản
Để tạo bí mật từ tệp văn bản như tên người dùng và mật khẩu, trước tiên chúng ta cần lưu trữ chúng trong tệp txt và sử dụng lệnh sau.
$ kubectl create secret generic tomcat-passwd –-from-file = ./username.txt –fromfile = ./.
password.txtTạo từ tệp Yaml
apiVersion: v1
kind: Secret
metadata:
name: tomcat-pass
type: Opaque
data:
password: <User Password>
username: <User Name>Tạo bí mật
$ kubectl create –f Secret.yaml
secrets/tomcat-passSử dụng bí mật
Khi chúng tôi đã tạo ra các bí mật, nó có thể được sử dụng trong một nhóm hoặc bộ điều khiển sao chép dưới dạng:
- Biến môi trường
- Volume
Như môi trường biến
Để sử dụng bí mật làm biến môi trường, chúng tôi sẽ sử dụng env trong phần thông số kỹ thuật của tệp pod yaml.
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: tomcat-passNhư âm lượng
spec:
volumes:
- name: "secretstest"
secret:
secretName: tomcat-pass
containers:
- image: tomcat:7.0
name: awebserver
volumeMounts:
- mountPath: "/tmp/mysec"
name: "secretstest"Cấu hình bí mật làm biến môi trường
apiVersion: v1
kind: ReplicationController
metadata:
name: appname
spec:
replicas: replica_count
template:
metadata:
name: appname
spec:
nodeSelector:
resource-group:
containers:
- name: appname
image:
imagePullPolicy: Always
ports:
- containerPort: 3000
env: -----------------------------> 1
- name: ENV
valueFrom:
configMapKeyRef:
name: appname
key: tomcat-secretsTrong mã trên, dưới env định nghĩa, chúng tôi đang sử dụng bí mật làm biến môi trường trong bộ điều khiển sao chép.
Secrets As Volume Mount
apiVersion: v1
kind: pod
metadata:
name: appname
spec:
metadata:
name: appname
spec:
volumes:
- name: "secretstest"
secret:
secretName: tomcat-pass
containers:
- image: tomcat: 8.0
name: awebserver
volumeMounts:
- mountPath: "/tmp/mysec"
name: "secretstest"Chính sách mạng xác định cách các nhóm trong cùng một không gian tên sẽ giao tiếp với nhau và điểm cuối của mạng. Nó yêu cầuextensions/v1beta1/networkpoliciesđược bật trong cấu hình thời gian chạy trong máy chủ API. Tài nguyên của nó sử dụng các nhãn để chọn các nhóm và xác định các quy tắc để cho phép lưu lượng truy cập đến một nhóm cụ thể ngoài nhóm được xác định trong không gian tên.
Đầu tiên, chúng ta cần cấu hình Chính sách cách ly không gian tên. Về cơ bản, loại chính sách mạng này được yêu cầu trên bộ cân bằng tải.
kind: Namespace
apiVersion: v1
metadata:
annotations:
net.beta.kubernetes.io/network-policy: |
{
"ingress":
{
"isolation": "DefaultDeny"
}
}$ kubectl annotate ns <namespace> "net.beta.kubernetes.io/network-policy =
{\"ingress\": {\"isolation\": \"DefaultDeny\"}}"Khi không gian tên được tạo, chúng ta cần tạo Chính sách mạng.
Chính sách mạng Yaml
kind: NetworkPolicy
apiVersion: extensions/v1beta1
metadata:
name: allow-frontend
namespace: myns
spec:
podSelector:
matchLabels:
role: backend
ingress:
- from:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379Kubernetes API đóng vai trò là nền tảng cho lược đồ cấu hình khai báo cho hệ thống. KubectlCông cụ dòng lệnh có thể được sử dụng để tạo, cập nhật, xóa và lấy đối tượng API. Kubernetes API đóng vai trò giao tiếp giữa các thành phần khác nhau của Kubernetes.
Thêm API vào Kubernetes
Việc thêm một API mới vào Kubernetes sẽ bổ sung các tính năng mới cho Kubernetes, điều này sẽ làm tăng chức năng của Kubernetes. Tuy nhiên, cùng với nó cũng sẽ làm tăng chi phí và khả năng bảo trì của hệ thống. Để tạo ra sự cân bằng giữa chi phí và độ phức tạp, có một số bộ được xác định cho nó.
API đang được thêm vào sẽ hữu ích cho hơn 50% người dùng. Không có cách nào khác để triển khai chức năng trong Kubernetes. Các trường hợp ngoại lệ được thảo luận trong cuộc họp cộng đồng của Kubernetes, và sau đó API được thêm vào.
Thay đổi API
Để tăng khả năng của Kubernetes, các thay đổi liên tục được đưa vào hệ thống. Nhóm Kubernetes thực hiện để thêm chức năng vào Kubernetes mà không xóa hoặc ảnh hưởng đến chức năng hiện có của hệ thống.
Để chứng minh quy trình chung, đây là một ví dụ (giả định) -
Người dùng ĐĂNG một đối tượng Pod lên /api/v7beta1/...
JSON không được quản lý thành một v7beta1.Pod kết cấu
Giá trị mặc định được áp dụng cho v7beta1.Pod
Các v7beta1.Pod được chuyển đổi thành một api.Pod kết cấu
Các api.Pod được xác thực và mọi lỗi đều được trả lại cho người dùng
Các api.Pod được chuyển đổi thành v6.Pod (vì v6 là phiên bản ổn định mới nhất)
Các v6.Pod được sắp xếp thành JSON và được ghi vào etcd
Bây giờ chúng ta đã lưu trữ đối tượng Pod, người dùng có thể NHẬN đối tượng đó trong bất kỳ phiên bản API nào được hỗ trợ. Ví dụ -
Người dùng NHẬN Pod từ /api/v5/...
JSON được đọc từ etcd và unmarshalled thành một v6.Pod kết cấu
Giá trị mặc định được áp dụng cho v6.Pod
Các v6.Pod được chuyển đổi thành cấu trúc api.Pod
Các api.Pod được chuyển đổi thành v5.Pod kết cấu
Các v5.Pod được sắp xếp thành JSON và được gửi đến người dùng
Hàm ý của quá trình này là các thay đổi API phải được thực hiện cẩn thận và tương thích ngược.
Phiên bản API
Để hỗ trợ nhiều cấu trúc dễ dàng hơn, Kubernetes hỗ trợ nhiều phiên bản API, mỗi phiên bản API khác nhau, chẳng hạn như /api/v1 hoặc là /apsi/extensions/v1beta1
Các tiêu chuẩn về phiên bản tại Kubernetes được xác định theo nhiều tiêu chuẩn.
Cấp độ Alpha
Phiên bản này chứa alpha (ví dụ: v1alpha1)
Phiên bản này có thể có lỗi; phiên bản đã kích hoạt có thể có lỗi
Hỗ trợ cho lỗi có thể bị loại bỏ bất kỳ lúc nào.
Được khuyến nghị chỉ sử dụng trong thử nghiệm ngắn hạn vì hỗ trợ có thể không có mặt mọi lúc.
Cấp độ Beta
Tên phiên bản chứa beta (ví dụ: v2beta3)
Mã được kiểm tra đầy đủ và phiên bản được kích hoạt được cho là ổn định.
Hỗ trợ của tính năng sẽ không bị bỏ; có thể có một số thay đổi nhỏ.
Chỉ được đề xuất cho các mục đích sử dụng không quan trọng trong kinh doanh vì khả năng xảy ra các thay đổi không tương thích trong các bản phát hành tiếp theo.
Mức ổn định
Tên phiên bản là vX Ở đâu X là một số nguyên.
Phiên bản ổn định của các tính năng sẽ xuất hiện trong phần mềm được phát hành cho nhiều phiên bản tiếp theo.
Kubectl là tiện ích dòng lệnh để tương tác với Kubernetes API. Nó là một giao diện được sử dụng để giao tiếp và quản lý các nhóm trong Kubernetes cluster.
Người ta cần thiết lập kubectl thành cục bộ để tương tác với Kubernetes cluster.
Đặt Kubectl
Tải tệp thực thi xuống máy trạm cục bộ bằng lệnh curl.
Trên Linux
$ curl -O https://storage.googleapis.com/kubernetesrelease/
release/v1.5.2/bin/linux/amd64/kubectlTrên máy trạm OS X
$ curl -O https://storage.googleapis.com/kubernetesrelease/
release/v1.5.2/bin/darwin/amd64/kubectlSau khi tải xuống xong, hãy di chuyển các tệp nhị phân trong đường dẫn của hệ thống.
$ chmod +x kubectl
$ mv kubectl /usr/local/bin/kubectlĐịnh cấu hình Kubectl
Sau đây là các bước để thực hiện thao tác cấu hình.
$ kubectl config set-cluster default-cluster --server = https://${MASTER_HOST} -- certificate-authority = ${CA_CERT}
$ kubectl config set-credentials default-admin --certificateauthority = ${
CA_CERT} --client-key = ${ADMIN_KEY} --clientcertificate = ${
ADMIN_CERT}
$ kubectl config set-context default-system --cluster = default-cluster -- user = default-admin $ kubectl config use-context default-systemThay thế ${MASTER_HOST} với địa chỉ nút chính hoặc tên được sử dụng trong các bước trước.
Thay thế ${CA_CERT} với con đường tuyệt đối đến ca.pem đã tạo ở các bước trước.
Thay thế ${ADMIN_KEY} với con đường tuyệt đối đến admin-key.pem đã tạo ở các bước trước.
Thay thế ${ADMIN_CERT} với con đường tuyệt đối đến admin.pem đã tạo ở các bước trước.
Xác minh thiết lập
Để xác minh xem kubectl đang hoạt động tốt hay không, hãy kiểm tra xem ứng dụng Kubernetes có được thiết lập chính xác hay không.
$ kubectl get nodes
NAME LABELS STATUS
Vipin.com Kubernetes.io/hostname = vipin.mishra.com ReadyKubectlkiểm soát Cụm Kubernetes. Nó là một trong những thành phần quan trọng của Kubernetes chạy trên máy trạm trên bất kỳ máy nào khi thiết lập xong. Nó có khả năng quản lý các nút trong cụm.
Kubectlcác lệnh được sử dụng để tương tác và quản lý các đối tượng Kubernetes và cụm. Trong chương này, chúng ta sẽ thảo luận về một số lệnh được sử dụng trong Kubernetes thông qua kubectl.
kubectl annotate - Nó cập nhật chú thích trên một tài nguyên.
$kubectl annotate [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ...
KEY_N = VAL_N [--resource-version = version]Ví dụ,
kubectl annotate pods tomcat description = 'my frontend'kubectl api-versions - Nó in các phiên bản API được hỗ trợ trên cụm.
$ kubectl api-version;kubectl apply - Nó có khả năng định cấu hình tài nguyên theo tệp hoặc stdin.
$ kubectl apply –f <filename>kubectl attach - Cái này gắn các thứ vào thùng đang chạy.
$ kubectl attach <pod> –c <container> $ kubectl attach 123456-7890 -c tomcat-conatinerkubectl autoscale - Điều này được sử dụng để tự động mở rộng các nhóm được xác định như Triển khai, bộ bản sao, Bộ điều khiển nhân bản.
$ kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min = MINPODS] -- max = MAXPODS [--cpu-percent = CPU] [flags] $ kubectl autoscale deployment foo --min = 2 --max = 10kubectl cluster-info - Nó hiển thị thông tin cụm.
$ kubectl cluster-infokubectl cluster-info dump - Nó kết xuất thông tin liên quan đến cụm để gỡ lỗi và chẩn đoán.
$ kubectl cluster-info dump
$ kubectl cluster-info dump --output-directory = /path/to/cluster-statekubectl config - Sửa đổi tệp kubeconfig.
$ kubectl config <SUBCOMMAD>
$ kubectl config –-kubeconfig <String of File name>kubectl config current-context - Nó hiển thị bối cảnh hiện tại.
$ kubectl config current-context
#deploys the current contextkubectl config delete-cluster - Xóa cụm được chỉ định khỏi kubeconfig.
$ kubectl config delete-cluster <Cluster Name>kubectl config delete-context - Xóa một ngữ cảnh được chỉ định khỏi kubeconfig.
$ kubectl config delete-context <Context Name>kubectl config get-clusters - Hiển thị cụm được xác định trong kubeconfig.
$ kubectl config get-cluster $ kubectl config get-cluster <Cluser Name>kubectl config get-contexts - Mô tả một hoặc nhiều ngữ cảnh.
$ kubectl config get-context <Context Name>kubectl config set-cluster - Đặt mục nhập cụm trong Kubernetes.
$ kubectl config set-cluster NAME [--server = server] [--certificateauthority =
path/to/certificate/authority] [--insecure-skip-tls-verify = true]kubectl config set-context - Đặt một mục ngữ cảnh trong điểm nhập kubernetes.
$ kubectl config set-context NAME [--cluster = cluster_nickname] [-- user = user_nickname] [--namespace = namespace] $ kubectl config set-context prod –user = vipin-mishrakubectl config set-credentials - Đặt mục nhập người dùng trong kubeconfig.
$ kubectl config set-credentials cluster-admin --username = vipin --
password = uXFGweU9l35qcifkubectl config set - Đặt một giá trị riêng lẻ trong tệp kubeconfig.
$ kubectl config set PROPERTY_NAME PROPERTY_VALUEkubectl config unset - Nó bỏ thiết lập một thành phần cụ thể trong kubectl.
$ kubectl config unset PROPERTY_NAME PROPERTY_VALUEkubectl config use-context - Đặt ngữ cảnh hiện tại trong tệp kubectl.
$ kubectl config use-context <Context Name>kubectl config view
$ kubectl config view $ kubectl config view –o jsonpath='{.users[?(@.name == "e2e")].user.password}'kubectl cp - Sao chép các tập tin và thư mục đến và từ các vùng chứa.
$ kubectl cp <Files from source> <Files to Destinatiion> $ kubectl cp /tmp/foo <some-pod>:/tmp/bar -c <specific-container>kubectl create- Để tạo tài nguyên theo tên tệp của hoặc stdin. Để làm điều này, các định dạng JSON hoặc YAML được chấp nhận.
$ kubectl create –f <File Name> $ cat <file name> | kubectl create –f -Theo cách tương tự, chúng ta có thể tạo nhiều thứ như được liệt kê bằng cách sử dụng create lệnh cùng với kubectl.
- deployment
- namespace
- quota
- docker-registry bí mật
- secret
- bí mật chung chung
- tls bí mật
- serviceaccount
- nhóm dịch vụ
- bộ cân bằng dịch vụ
- dịch vụ gật đầu
kubectl delete - Xóa tài nguyên theo tên tệp, stdin, tài nguyên và tên.
$ kubectl delete –f ([-f FILENAME] | TYPE [(NAME | -l label | --all)])kubectl describe- Mô tả bất kỳ tài nguyên cụ thể nào trong kubernetes. Hiển thị chi tiết của tài nguyên hoặc một nhóm tài nguyên.
$ kubectl describe <type> <type name>
$ kubectl describe pod tomcatkubectl drain- Điều này được sử dụng để tiêu một nút cho mục đích bảo trì. Nó chuẩn bị cho nút để bảo trì. Điều này sẽ đánh dấu nút là không khả dụng để nó không được gán với một vùng chứa mới sẽ được tạo.
$ kubectl drain tomcat –forcekubectl edit- Nó được sử dụng để kết thúc tài nguyên trên máy chủ. Điều này cho phép chỉnh sửa trực tiếp tài nguyên mà người ta có thể nhận được thông qua công cụ dòng lệnh.
$ kubectl edit <Resource/Name | File Name) Ex. $ kubectl edit rc/tomcatkubectl exec - Điều này giúp thực hiện một lệnh trong vùng chứa.
$ kubectl exec POD <-c CONTAINER > -- COMMAND < args...> $ kubectl exec tomcat 123-5-456 datekubectl expose- Điều này được sử dụng để hiển thị các đối tượng Kubernetes như pod, bộ điều khiển sao chép và dịch vụ như một dịch vụ Kubernetes mới. Điều này có khả năng hiển thị nó qua một vùng chứa đang chạy hoặc từ mộtyaml tập tin.
$ kubectl expose (-f FILENAME | TYPE NAME) [--port=port] [--protocol = TCP|UDP] [--target-port = number-or-name] [--name = name] [--external-ip = external-ip-ofservice] [--type = type] $ kubectl expose rc tomcat –-port=80 –target-port = 30000
$ kubectl expose –f tomcat.yaml –port = 80 –target-port =kubectl get - Lệnh này có khả năng tìm nạp dữ liệu trên cụm về tài nguyên Kubernetes.
$ kubectl get [(-o|--output=)json|yaml|wide|custom-columns=...|custom-columnsfile=...|
go-template=...|go-template-file=...|jsonpath=...|jsonpath-file=...]
(TYPE [NAME | -l label] | TYPE/NAME ...) [flags]Ví dụ,
$ kubectl get pod <pod name> $ kubectl get service <Service name>kubectl logs- Chúng được sử dụng để lấy các bản ghi của vật chứa trong một vỏ. Việc in nhật ký có thể xác định tên vùng chứa trong nhóm. Nếu POD chỉ có một vùng chứa thì không cần xác định tên của nó.
$ kubectl logs [-f] [-p] POD [-c CONTAINER] Example $ kubectl logs tomcat.
$ kubectl logs –p –c tomcat.8kubectl port-forward - Chúng được sử dụng để chuyển tiếp một hoặc nhiều cổng cục bộ tới nhóm.
$ kubectl port-forward POD [LOCAL_PORT:]REMOTE_PORT
[...[LOCAL_PORT_N:]REMOTE_PORT_N]
$ kubectl port-forward tomcat 3000 4000 $ kubectl port-forward tomcat 3000:5000kubectl replace - Có khả năng thay thế tài nguyên theo tên tệp hoặc stdin.
$ kubectl replace -f FILENAME $ kubectl replace –f tomcat.yml
$ cat tomcat.yml | kubectl replace –f -kubectl rolling-update- Thực hiện cập nhật liên tục trên bộ điều khiển nhân rộng. Thay thế bộ điều khiển sao chép được chỉ định bằng bộ điều khiển sao chép mới bằng cách cập nhật POD tại một thời điểm.
$ kubectl rolling-update OLD_CONTROLLER_NAME ([NEW_CONTROLLER_NAME] --
image = NEW_CONTAINER_IMAGE | -f NEW_CONTROLLER_SPEC)
$ kubectl rolling-update frontend-v1 –f freontend-v2.yamlkubectl rollout - Nó có khả năng quản lý việc triển khai triển khai.
$ Kubectl rollout <Sub Command>
$ kubectl rollout undo deployment/tomcatNgoài những điều trên, chúng tôi có thể thực hiện nhiều tác vụ bằng cách sử dụng bản giới thiệu như:
- lịch sử phát hành
- tạm dừng triển khai
- tiếp tục triển khai
- tình trạng phát hành
- hoàn tác triển khai
kubectl run - Lệnh Run có khả năng chạy một hình ảnh trên Kubernetes cluster.
$ kubectl run NAME --image = image [--env = "key = value"] [--port = port] [--
replicas = replicas] [--dry-run = bool] [--overrides = inline-json] [--command] --
[COMMAND] [args...]
$ kubectl run tomcat --image = tomcat:7.0 $ kubectl run tomcat –-image = tomcat:7.0 –port = 5000kubectl scale - Nó sẽ mở rộng quy mô của Kubernetes Deployments, ReplicaSet, Replication Controller hoặc công việc.
$ kubectl scale [--resource-version = version] [--current-replicas = count] -- replicas = COUNT (-f FILENAME | TYPE NAME ) $ kubectl scale –-replica = 3 rs/tomcat
$ kubectl scale –replica = 3 tomcat.yamlkubectl set image - Nó cập nhật hình ảnh của một mẫu nhóm.
$ kubectl set image (-f FILENAME | TYPE NAME)
CONTAINER_NAME_1 = CONTAINER_IMAGE_1 ... CONTAINER_NAME_N = CONTAINER_IMAGE_N
$ kubectl set image deployment/tomcat busybox = busybox ngnix = ngnix:1.9.1 $ kubectl set image deployments, rc tomcat = tomcat6.0 --allkubectl set resources- Nó được sử dụng để thiết lập nội dung của tài nguyên. Nó cập nhật tài nguyên / giới hạn trên đối tượng với mẫu nhóm.
$ kubectl set resources (-f FILENAME | TYPE NAME) ([--limits = LIMITS & -- requests = REQUESTS] $ kubectl set resources deployment tomcat -c = tomcat --
limits = cpu = 200m,memory = 512Mikubectl top node- Nó hiển thị mức sử dụng CPU / Bộ nhớ / Bộ nhớ. Lệnh trên cùng cho phép bạn xem mức tiêu thụ tài nguyên cho các nút.
$ kubectl top node [node Name]Lệnh tương tự cũng có thể được sử dụng với một nhóm.
Để tạo ứng dụng cho việc triển khai Kubernetes, trước tiên chúng ta cần tạo ứng dụng trên Docker. Điều này có thể được thực hiện theo hai cách -
- Bằng cách tải xuống
- Từ tệp Docker
Bằng cách tải xuống
Hình ảnh hiện có có thể được tải xuống từ trung tâm Docker và có thể được lưu trữ trên sổ đăng ký Docker cục bộ.
Để làm điều đó, hãy chạy Docker pull chỉ huy.
$ docker pull --help
Usage: docker pull [OPTIONS] NAME[:TAG|@DIGEST]
Pull an image or a repository from the registry
-a, --all-tags = false Download all tagged images in the repository
--help = false Print usageSau đây sẽ là đầu ra của đoạn mã trên.

Ảnh chụp màn hình ở trên hiển thị một tập hợp các hình ảnh được lưu trữ trong sổ đăng ký Docker cục bộ của chúng tôi.
Nếu chúng ta muốn xây dựng một vùng chứa từ hình ảnh bao gồm một ứng dụng để kiểm tra, chúng ta có thể thực hiện bằng cách sử dụng lệnh Docker run.
$ docker run –i –t unbunt /bin/bashTừ tệp Docker
Để tạo ứng dụng từ tệp Docker, trước tiên chúng ta cần tạo tệp Docker.
Sau đây là một ví dụ về tệp Jenkins Docker.
FROM ubuntu:14.04
MAINTAINER [email protected]
ENV REFRESHED_AT 2017-01-15
RUN apt-get update -qq && apt-get install -qqy curl
RUN curl https://get.docker.io/gpg | apt-key add -
RUN echo deb http://get.docker.io/ubuntu docker main > /etc/apt/↩
sources.list.d/docker.list
RUN apt-get update -qq && apt-get install -qqy iptables ca-↩
certificates lxc openjdk-6-jdk git-core lxc-docker
ENV JENKINS_HOME /opt/jenkins/data
ENV JENKINS_MIRROR http://mirrors.jenkins-ci.org
RUN mkdir -p $JENKINS_HOME/plugins
RUN curl -sf -o /opt/jenkins/jenkins.war -L $JENKINS_MIRROR/war-↩ stable/latest/jenkins.war RUN for plugin in chucknorris greenballs scm-api git-client git ↩ ws-cleanup ;\ do curl -sf -o $JENKINS_HOME/plugins/${plugin}.hpi \ -L $JENKINS_MIRROR/plugins/${plugin}/latest/${plugin}.hpi ↩
; done
ADD ./dockerjenkins.sh /usr/local/bin/dockerjenkins.sh
RUN chmod +x /usr/local/bin/dockerjenkins.sh
VOLUME /var/lib/docker
EXPOSE 8080
ENTRYPOINT [ "/usr/local/bin/dockerjenkins.sh" ]Khi tệp trên được tạo, hãy lưu nó với tên Dockerfile và cd vào đường dẫn tệp. Sau đó, chạy lệnh sau.

$ sudo docker build -t jamtur01/Jenkins .Sau khi hình ảnh được tạo, chúng tôi có thể kiểm tra xem hình ảnh có hoạt động tốt hay không và có thể chuyển đổi thành vùng chứa.
$ docker run –i –t jamtur01/Jenkins /bin/bashTriển khai là một phương pháp chuyển đổi hình ảnh sang vùng chứa và sau đó phân bổ những hình ảnh đó vào các nhóm trong cụm Kubernetes. Điều này cũng giúp thiết lập cụm ứng dụng bao gồm triển khai dịch vụ, nhóm, bộ điều khiển nhân rộng và tập hợp bản sao. Cụm có thể được thiết lập theo cách mà các ứng dụng được triển khai trên nhóm có thể giao tiếp với nhau.
Trong thiết lập này, chúng tôi có thể có cài đặt cân bằng tải trên đầu một ứng dụng chuyển hướng lưu lượng truy cập đến một nhóm các nhóm và sau đó chúng giao tiếp với các nhóm phụ trợ. Giao tiếp giữa các nhóm xảy ra thông qua đối tượng dịch vụ được tích hợp trong Kubernetes.
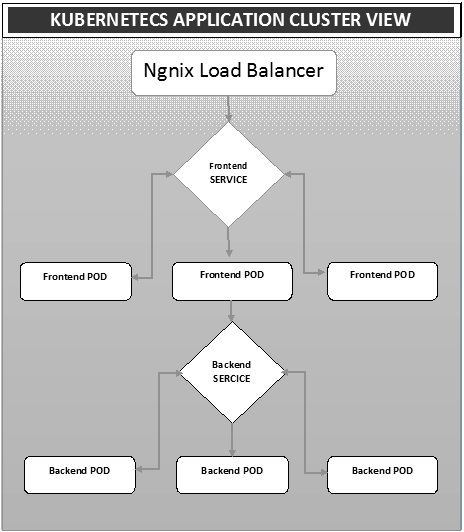
Tệp Yaml của Trình cân bằng tải Ngnix
apiVersion: v1
kind: Service
metadata:
name: oppv-dev-nginx
labels:
k8s-app: omni-ppv-api
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: omninginx
selector:
k8s-app: appname
component: nginx
env: devNgnix Replication Controller Yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: appname
spec:
replicas: replica_count
template:
metadata:
name: appname
labels:
k8s-app: appname
component: nginx
env: env_name
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 8080
resources:
requests:
memory: "request_mem"
cpu: "request_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
env:
- name: BACKEND_HOST
value: oppv-env_name-node:3000Tệp Yaml của Dịch vụ Frontend
apiVersion: v1
kind: Service
metadata:
name: appname
labels:
k8s-app: appname
spec:
type: NodePort
ports:
- name: http
port: 3000
protocol: TCP
targetPort: 3000
selector:
k8s-app: appname
component: nodejs
env: devTrình điều khiển nhân bản Frontend Tệp Yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: Frontend
spec:
replicas: 3
template:
metadata:
name: frontend
labels:
k8s-app: Frontend
component: nodejs
env: Dev
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 3000
resources:
requests:
memory: "request_mem"
cpu: "limit_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
env:
- name: ENV
valueFrom:
configMapKeyRef:
name: appname
key: config-envDịch vụ phụ trợ Tệp Yaml
apiVersion: v1
kind: Service
metadata:
name: backend
labels:
k8s-app: backend
spec:
type: NodePort
ports:
- name: http
port: 9010
protocol: TCP
targetPort: 9000
selector:
k8s-app: appname
component: play
env: devBộ điều khiển sao chép sao lưu Tệp Yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: backend
spec:
replicas: 3
template:
metadata:
name: backend
labels:
k8s-app: beckend
component: play
env: dev
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 9000
command: [ "./docker-entrypoint.sh" ]
resources:
requests:
memory: "request_mem"
cpu: "request_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
volumeMounts:
- name: config-volume
mountPath: /app/vipin/play/conf
volumes:
- name: config-volume
configMap:
name: appnameAutoscalinglà một trong những tính năng chính trong Kubernetes cluster. Đây là một tính năng trong đó cụm có khả năng tăng số lượng nút khi nhu cầu đáp ứng dịch vụ tăng và giảm số lượng nút khi yêu cầu giảm. Tính năng tự động mở rộng quy mô này hiện được hỗ trợ trong Google Cloud Engine (GCE) và Google Container Engine (GKE) và sẽ sớm bắt đầu với AWS.
Để thiết lập cơ sở hạ tầng có thể mở rộng trong GCE, trước tiên chúng ta cần có một dự án GCE đang hoạt động với các tính năng giám sát đám mây của Google, ghi nhật ký đám mây của Google và trình xếp chồng được bật.
Đầu tiên, chúng tôi sẽ thiết lập cụm với vài nút chạy trong đó. Sau khi hoàn tất, chúng ta cần thiết lập biến môi trường sau.
Biến môi trường
export NUM_NODES = 2
export KUBE_AUTOSCALER_MIN_NODES = 2
export KUBE_AUTOSCALER_MAX_NODES = 5
export KUBE_ENABLE_CLUSTER_AUTOSCALER = trueSau khi hoàn tất, chúng tôi sẽ bắt đầu cụm bằng cách chạy kube-up.sh. Điều này sẽ tạo một cụm cùng với tính năng bổ sung tự động vô hướng của cụm.
./cluster/kube-up.shKhi tạo cụm, chúng ta có thể kiểm tra cụm của mình bằng lệnh kubectl sau.
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 10m
kubernetes-minion-group-de5q Ready 10m
kubernetes-minion-group-yhdx Ready 8mBây giờ, chúng ta có thể triển khai một ứng dụng trên cụm và sau đó kích hoạt tính năng tự động phân loại pod ngang. Điều này có thể được thực hiện bằng cách sử dụng lệnh sau.
$ kubectl autoscale deployment <Application Name> --cpu-percent = 50 --min = 1 --
max = 10Lệnh trên cho thấy rằng chúng tôi sẽ duy trì ít nhất một và tối đa 10 bản sao của POD khi tải trên ứng dụng tăng lên.
Chúng tôi có thể kiểm tra trạng thái của autoscaler bằng cách chạy $kubclt get hpachỉ huy. Chúng tôi sẽ tăng tải trên các nhóm bằng lệnh sau.
$ kubectl run -i --tty load-generator --image = busybox /bin/sh
$ while true; do wget -q -O- http://php-apache.default.svc.cluster.local; doneChúng tôi có thể kiểm tra hpa bằng cách chạy $ kubectl get hpa chỉ huy.
$ kubectl get hpa NAME REFERENCE TARGET CURRENT php-apache Deployment/php-apache/scale 50% 310% MINPODS MAXPODS AGE 1 20 2m $ kubectl get deployment php-apache
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
php-apache 7 7 7 3 4mChúng ta có thể kiểm tra số lượng pod đang chạy bằng lệnh sau.
jsz@jsz-desk2:~/k8s-src$ kubectl get pods
php-apache-2046965998-3ewo6 0/1 Pending 0 1m
php-apache-2046965998-8m03k 1/1 Running 0 1m
php-apache-2046965998-ddpgp 1/1 Running 0 5m
php-apache-2046965998-lrik6 1/1 Running 0 1m
php-apache-2046965998-nj465 0/1 Pending 0 1m
php-apache-2046965998-tmwg1 1/1 Running 0 1m
php-apache-2046965998-xkbw1 0/1 Pending 0 1mVà cuối cùng, chúng ta có thể nhận được trạng thái nút.
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 9m
kubernetes-minion-group-6z5i Ready 43s
kubernetes-minion-group-de5q Ready 9m
kubernetes-minion-group-yhdx Ready 9mThiết lập bảng điều khiển Kubernetes bao gồm một số bước với một bộ công cụ được yêu cầu làm điều kiện tiên quyết để thiết lập nó.
- Docker (1.3+)
- đi (1.5+)
- nodejs (4.2.2+)
- npm (1,3+)
- java (7+)
- nuốt nước bọt (3,9+)
- Kubernetes (1.1.2+)
Thiết lập Trang tổng quan
$ sudo apt-get update && sudo apt-get upgrade Installing Python $ sudo apt-get install python
$ sudo apt-get install python3 Installing GCC $ sudo apt-get install gcc-4.8 g++-4.8
Installing make
$ sudo apt-get install make Installing Java $ sudo apt-get install openjdk-7-jdk
Installing Node.js
$ wget https://nodejs.org/dist/v4.2.2/node-v4.2.2.tar.gz $ tar -xzf node-v4.2.2.tar.gz
$ cd node-v4.2.2 $ ./configure
$ make $ sudo make install
Installing gulp
$ npm install -g gulp $ npm install gulpXác minh các phiên bản
Java Version
$ java –version java version "1.7.0_91" OpenJDK Runtime Environment (IcedTea 2.6.3) (7u91-2.6.3-1~deb8u1+rpi1) OpenJDK Zero VM (build 24.91-b01, mixed mode) $ node –v
V4.2.2
$ npn -v 2.14.7 $ gulp -v
[09:51:28] CLI version 3.9.0
$ sudo gcc --version
gcc (Raspbian 4.8.4-1) 4.8.4
Copyright (C) 2013 Free Software Foundation, Inc. This is free software;
see the source for copying conditions. There is NO warranty; not even for
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.Cài đặt GO
$ git clone https://go.googlesource.com/go
$ cd go $ git checkout go1.4.3
$ cd src Building GO $ ./all.bash
$ vi /root/.bashrc In the .bashrc export GOROOT = $HOME/go
export PATH = $PATH:$GOROOT/bin
$ go version
go version go1.4.3 linux/armCài đặt Bảng điều khiển Kubernetes
$ git clone https://github.com/kubernetes/dashboard.git
$ cd dashboard $ npm install -g bowerChạy Bảng điều khiển
$ git clone https://github.com/kubernetes/dashboard.git $ cd dashboard
$ npm install -g bower $ gulp serve
[11:19:12] Requiring external module babel-core/register
[11:20:50] Using gulpfile ~/dashboard/gulpfile.babel.js
[11:20:50] Starting 'package-backend-source'...
[11:20:50] Starting 'kill-backend'...
[11:20:50] Finished 'kill-backend' after 1.39 ms
[11:20:50] Starting 'scripts'...
[11:20:53] Starting 'styles'...
[11:21:41] Finished 'scripts' after 50 s
[11:21:42] Finished 'package-backend-source' after 52 s
[11:21:42] Starting 'backend'...
[11:21:43] Finished 'styles' after 49 s
[11:21:43] Starting 'index'...
[11:21:44] Finished 'index' after 1.43 s
[11:21:44] Starting 'watch'...
[11:21:45] Finished 'watch' after 1.41 s
[11:23:27] Finished 'backend' after 1.73 min
[11:23:27] Starting 'spawn-backend'...
[11:23:27] Finished 'spawn-backend' after 88 ms
[11:23:27] Starting 'serve'...
2016/02/01 11:23:27 Starting HTTP server on port 9091
2016/02/01 11:23:27 Creating API client for
2016/02/01 11:23:27 Creating Heapster REST client for http://localhost:8082
[11:23:27] Finished 'serve' after 312 ms
[BS] [BrowserSync SPA] Running...
[BS] Access URLs:
--------------------------------------
Local: http://localhost:9090/
External: http://192.168.1.21:9090/
--------------------------------------
UI: http://localhost:3001
UI External: http://192.168.1.21:3001
--------------------------------------
[BS] Serving files from: /root/dashboard/.tmp/serve
[BS] Serving files from: /root/dashboard/src/app/frontend
[BS] Serving files from: /root/dashboard/src/appBảng điều khiển Kubernetes
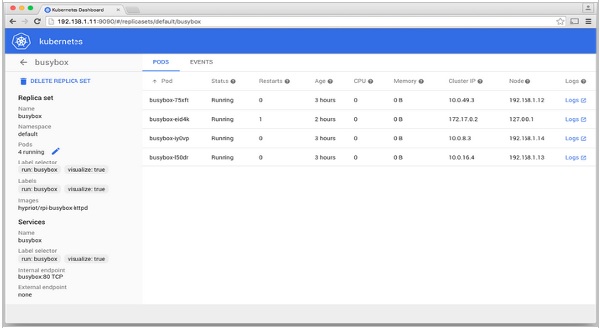
Giám sát là một trong những thành phần quan trọng để quản lý các cụm lớn. Đối với điều này, chúng tôi có một số công cụ.
Giám sát với Prometheus
Nó là một hệ thống giám sát và cảnh báo. Nó được xây dựng tại SoundCloud và có nguồn mở vào năm 2012. Nó xử lý dữ liệu đa chiều rất tốt.
Prometheus có nhiều thành phần tham gia giám sát -
Prometheus - Nó là thành phần cốt lõi có chức năng quét và lưu trữ dữ liệu.
Prometheus node explore - Nhận ma trận cấp máy chủ và đưa chúng cho Prometheus.
Ranch-eye - là một haproxy và phơi bày cAdvisor số liệu thống kê để Prometheus.
Grafana - Trực quan hóa dữ liệu.
InfuxDB - Cơ sở dữ liệu chuỗi thời gian được sử dụng đặc biệt để lưu trữ dữ liệu từ chủ trang trại.
Prom-ranch-exporter - Đây là một ứng dụng node.js đơn giản, giúp truy vấn máy chủ Rancher về trạng thái của ngăn xếp dịch vụ.
Sematext Docker Agent
Nó là một đại lý thu thập nhật ký, sự kiện và chỉ số nhận biết Docker hiện đại. Nó chạy như một vùng chứa nhỏ trên mọi máy chủ Docker và thu thập nhật ký, số liệu và sự kiện cho tất cả các nút và vùng chứa cụm. Nó phát hiện ra tất cả các vùng chứa (một nhóm có thể chứa nhiều vùng chứa) bao gồm các vùng chứa cho các dịch vụ cốt lõi của Kubernetes, nếu các dịch vụ cốt lõi được triển khai trong vùng chứa Docker. Sau khi triển khai, tất cả nhật ký và chỉ số sẽ có sẵn ngay lập tức.
Triển khai đại lý cho các nút
Kubernetes cung cấp DeamonSets đảm bảo các nhóm được thêm vào cụm.
Định cấu hình SemaText Docker Agent
Nó được cấu hình thông qua các biến môi trường.
Nhận một tài khoản miễn phí tại apps.sematext.com , nếu bạn chưa có.
Tạo Ứng dụng SPM loại “Docker” để nhận Mã thông báo ứng dụng SPM. Ứng dụng SPM sẽ giữ các chỉ số và sự kiện hiệu suất Kubernetes của bạn.
Tạo Ứng dụng Logsene để nhận Mã thông báo ứng dụng Logsene. Ứng dụng Logsene sẽ lưu giữ nhật ký Kubernetes của bạn.
Chỉnh sửa các giá trị của LOGSENE_TOKEN và SPM_TOKEN trong định nghĩa DaemonSet như hình dưới đây.
Tải mẫu sematext-agent-daemonset.yml (văn bản thuần thô) mới nhất (cũng được hiển thị bên dưới).
Lưu trữ nó ở đâu đó trên đĩa.
Thay thế các trình giữ chỗ SPM_TOKEN và LOGSENE_TOKEN bằng mã thông báo SPM và Logsene App của bạn.
Tạo đối tượng DaemonSet
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: sematext-agent
spec:
template:
metadata:
labels:
app: sematext-agent
spec:
selector: {}
dnsPolicy: "ClusterFirst"
restartPolicy: "Always"
containers:
- name: sematext-agent
image: sematext/sematext-agent-docker:latest
imagePullPolicy: "Always"
env:
- name: SPM_TOKEN
value: "REPLACE THIS WITH YOUR SPM TOKEN"
- name: LOGSENE_TOKEN
value: "REPLACE THIS WITH YOUR LOGSENE TOKEN"
- name: KUBERNETES
value: "1"
volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-sock
- mountPath: /etc/localtime
name: localtime
volumes:
- name: docker-sock
hostPath:
path: /var/run/docker.sock
- name: localtime
hostPath:
path: /etc/localtimeChạy Sematext Agent Docker với kubectl
$ kubectl create -f sematext-agent-daemonset.yml
daemonset "sematext-agent-daemonset" createdNhật ký Kubernetes
Nhật ký của vùng chứa Kubernetes không khác nhiều so với nhật ký vùng chứa Docker. Tuy nhiên, người dùng Kubernetes cần xem nhật ký cho các nhóm được triển khai. Do đó, rất hữu ích nếu có sẵn thông tin cụ thể về Kubernetes để tìm kiếm nhật ký, chẳng hạn như -
- Không gian tên Kubernetes
- Tên nhóm Kubernetes
- Tên vùng chứa Kubernetes
- Tên hình ảnh Docker
- Kubernetes UID
Sử dụng ELK Stack và LogSpout
Ngăn xếp ELK bao gồm Elasticsearch, Logstash và Kibana. Để thu thập và chuyển tiếp các bản ghi tới nền tảng ghi nhật ký, chúng tôi sẽ sử dụng LogSpout (mặc dù có các tùy chọn khác như FluentD).
Đoạn mã sau đây cho thấy cách thiết lập cụm ELK trên Kubernetes và tạo dịch vụ cho ElasticSearch -
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCPTạo bộ điều khiển sao chép
apiVersion: v1
kind: ReplicationController
metadata:
name: es
namespace: elk
labels:
component: elasticsearch
spec:
replicas: 1
template:
metadata:
labels:
component: elasticsearch
spec:
serviceAccount: elasticsearch
containers:
- name: es
securityContext:
capabilities:
add:
- IPC_LOCK
image: quay.io/pires/docker-elasticsearch-kubernetes:1.7.1-4
env:
- name: KUBERNETES_CA_CERTIFICATE_FILE
value: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: "CLUSTER_NAME"
value: "myesdb"
- name: "DISCOVERY_SERVICE"
value: "elasticsearch"
- name: NODE_MASTER
value: "true"
- name: NODE_DATA
value: "true"
- name: HTTP_ENABLE
value: "true"
ports:
- containerPort: 9200
name: http
protocol: TCP
- containerPort: 9300
volumeMounts:
- mountPath: /data
name: storage
volumes:
- name: storage
emptyDir: {}URL Kibana
Đối với Kibana, chúng tôi cung cấp URL Elasticsearch dưới dạng biến môi trường.
- name: KIBANA_ES_URL
value: "http://elasticsearch.elk.svc.cluster.local:9200"
- name: KUBERNETES_TRUST_CERT
value: "true"Kibana UI sẽ có thể truy cập được tại cổng container 5601 và tổ hợp máy chủ / cổng nút tương ứng. Khi bạn bắt đầu, sẽ không có bất kỳ dữ liệu nào trong Kibana (dự kiến là bạn chưa đẩy bất kỳ dữ liệu nào).