Lucene - Hướng dẫn nhanh
Lucene là một nền tảng Java đơn giản nhưng mạnh mẽ Searchthư viện. Nó có thể được sử dụng trong bất kỳ ứng dụng nào để thêm khả năng tìm kiếm cho nó. Lucene là một dự án mã nguồn mở. Nó có thể mở rộng. Thư viện hiệu suất cao này được sử dụng để lập chỉ mục và tìm kiếm hầu như bất kỳ loại văn bản nào. Thư viện Lucene cung cấp các hoạt động cốt lõi được yêu cầu bởi bất kỳ ứng dụng tìm kiếm nào. Lập chỉ mục và Tìm kiếm.
Ứng dụng Tìm kiếm hoạt động như thế nào?
Ứng dụng Tìm kiếm thực hiện tất cả hoặc một số thao tác sau:
| Bươc | Tiêu đề | Sự miêu tả |
|---|---|---|
| 1 | Acquire Raw Content |
Bước đầu tiên của bất kỳ ứng dụng tìm kiếm nào là thu thập nội dung mục tiêu mà ứng dụng tìm kiếm sẽ được tiến hành. |
| 2 | Build the document |
Bước tiếp theo là xây dựng (các) tài liệu từ nội dung thô mà ứng dụng tìm kiếm có thể hiểu và diễn giải dễ dàng. |
| 3 | Analyze the document |
Trước khi quá trình lập chỉ mục bắt đầu, tài liệu phải được phân tích xem phần nào của văn bản là ứng cử viên cần được lập chỉ mục. Quá trình này là nơi tài liệu được phân tích. |
| 4 | Indexing the document |
Khi tài liệu được xây dựng và phân tích, bước tiếp theo là lập chỉ mục chúng để tài liệu này có thể được truy xuất dựa trên các khóa nhất định thay vì toàn bộ nội dung của tài liệu. Quy trình lập chỉ mục tương tự như lập chỉ mục ở cuối sách, trong đó các từ phổ biến được hiển thị cùng với số trang của chúng để có thể theo dõi nhanh những từ này thay vì tìm kiếm toàn bộ cuốn sách. |
| 5 | User Interface for Search |
Khi cơ sở dữ liệu chỉ mục đã sẵn sàng thì ứng dụng có thể thực hiện bất kỳ tìm kiếm nào. Để tạo điều kiện cho người dùng thực hiện tìm kiếm, ứng dụng phải cung cấp cho người dùnga mean hoặc là a user interface nơi người dùng có thể nhập văn bản và bắt đầu quá trình tìm kiếm. |
| 6 | Build Query |
Khi người dùng đưa ra yêu cầu tìm kiếm văn bản, ứng dụng sẽ chuẩn bị một đối tượng Truy vấn bằng cách sử dụng văn bản đó để truy vấn cơ sở dữ liệu chỉ mục để có được các chi tiết liên quan. |
| 7 | Search Query |
Sử dụng đối tượng truy vấn, cơ sở dữ liệu chỉ mục sau đó được kiểm tra để lấy các chi tiết liên quan và tài liệu nội dung. |
| số 8 | Render Results |
Sau khi nhận được kết quả, ứng dụng sẽ quyết định cách hiển thị kết quả cho người dùng bằng Giao diện người dùng. Có bao nhiêu thông tin được hiển thị ngay từ cái nhìn đầu tiên, v.v. |
Ngoài các thao tác cơ bản này, ứng dụng tìm kiếm cũng có thể cung cấp administration user interfacevà giúp quản trị viên của ứng dụng kiểm soát mức độ tìm kiếm dựa trên hồ sơ người dùng. Phân tích kết quả tìm kiếm là một khía cạnh quan trọng và nâng cao khác của bất kỳ ứng dụng tìm kiếm nào.
Vai trò của Lucene trong ứng dụng tìm kiếm
Lucene đóng vai trò từ bước 2 đến bước 7 đã đề cập ở trên và cung cấp các lớp để thực hiện các thao tác cần thiết. Tóm lại, Lucene là trái tim của bất kỳ ứng dụng tìm kiếm nào và cung cấp các hoạt động quan trọng liên quan đến lập chỉ mục và tìm kiếm. Việc tiếp thu nội dung và hiển thị kết quả được để cho phần ứng dụng xử lý.
Trong chương tiếp theo, chúng ta sẽ thực hiện ứng dụng Tìm kiếm đơn giản bằng thư viện Lucene Search.
Hướng dẫn này sẽ hướng dẫn bạn cách chuẩn bị một môi trường phát triển để bắt đầu công việc của bạn với Spring Framework. Hướng dẫn này cũng sẽ dạy bạn cách thiết lập JDK, Tomcat và Eclipse trên máy tính của bạn trước khi bạn thiết lập Spring Framework -
Bước 1 - Thiết lập Bộ phát triển Java (JDK)
Bạn có thể tải xuống phiên bản SDK mới nhất từ trang web Java của Oracle: Tải xuống Java SE . Bạn sẽ tìm thấy hướng dẫn cài đặt JDK trong các tệp đã tải xuống; làm theo các hướng dẫn đã cho để cài đặt và định cấu hình thiết lập. Cuối cùng đặt các biến môi trường PATH và JAVA_HOME để tham chiếu đến thư mục chứa Java và javac, thường là java_install_dir / bin và java_install_dir tương ứng.
Nếu bạn đang chạy Windows và cài đặt JDK trong C: \ jdk1.6.0_15, bạn sẽ phải đặt dòng sau vào tệp C: \ autoexec.bat của mình.
set PATH = C:\jdk1.6.0_15\bin;%PATH%
set JAVA_HOME = C:\jdk1.6.0_15Ngoài ra, trên Windows NT / 2000 / XP, bạn cũng có thể nhấp chuột phải vào My Computer, lựa chọn Properties, sau đó Advanced, sau đó Environment Variables. Sau đó, bạn sẽ cập nhậtPATH giá trị và nhấn OK cái nút.
Trên Unix (Solaris, Linux, v.v.), nếu SDK được cài đặt trong /usr/local/jdk1.6.0_15 và bạn sử dụng trình bao C, bạn sẽ đưa phần sau vào tệp .cshrc của mình.
setenv PATH /usr/local/jdk1.6.0_15/bin:$PATH
setenv JAVA_HOME /usr/local/jdk1.6.0_15Ngoài ra, nếu bạn sử dụng Integrated Development Environment (IDE) như Borland JBuilder, Eclipse, IntelliJ IDEA hoặc Sun ONE Studio, biên dịch và chạy một chương trình đơn giản để xác nhận rằng IDE biết bạn đã cài đặt Java ở đâu, nếu không hãy thực hiện thiết lập thích hợp như được cung cấp trong tài liệu của IDE.
Bước 2 - Thiết lập IDE Eclipse
Tất cả các ví dụ trong hướng dẫn này đã được viết bằng Eclipse IDE. Vì vậy, tôi khuyên bạn nên cài đặt phiên bản Eclipse mới nhất trên máy của mình.
Để cài đặt Eclipse IDE, hãy tải xuống các tệp nhị phân Eclipse mới nhất từ https://www.eclipse.org/downloads/. Sau khi bạn tải xuống bản cài đặt, hãy giải nén bản phân phối nhị phân vào một vị trí thuận tiện. Ví dụ, trongC:\eclipse on windows, hoặc là /usr/local/eclipse on Linux/Unix và cuối cùng đặt biến PATH một cách thích hợp.
Eclipse có thể được khởi động bằng cách thực hiện các lệnh sau trên máy tính windows hoặc bạn có thể chỉ cần nhấp đúp vào eclipse.exe
%C:\eclipse\eclipse.exeEclipse có thể được khởi động bằng cách thực hiện các lệnh sau trên máy Unix (Solaris, Linux, v.v.) -
$/usr/local/eclipse/eclipseSau khi khởi động thành công, nó sẽ hiển thị kết quả sau:
Bước 3 - Thiết lập thư viện khung Lucene
Nếu khởi động thành công, thì bạn có thể tiến hành thiết lập khung Lucene của mình. Sau đây là các bước đơn giản để tải xuống và cài đặt framework trên máy tính của bạn.
https://archive.apache.org/dist/lucene/java/3.6.2/
Chọn xem bạn muốn cài đặt Lucene trên Windows hay Unix, sau đó tiến hành bước tiếp theo để tải xuống tệp .zip cho windows và .tz cho Unix.
Tải xuống phiên bản phù hợp của hệ thống nhị phân khung Lucene từ https://archive.apache.org/dist/lucene/java/.
Tại thời điểm viết hướng dẫn này, tôi đã tải xuống lucene-3.6.2.zip trên máy Windows của mình và khi bạn giải nén tệp đã tải xuống, nó sẽ cung cấp cho bạn cấu trúc thư mục bên trong C: \ lucene-3.6.2 như sau.
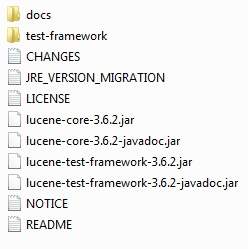
Bạn sẽ tìm thấy tất cả các thư viện Lucene trong thư mục C:\lucene-3.6.2. Đảm bảo rằng bạn đặt biến CLASSPATH của mình trên thư mục này đúng cách, nếu không, bạn sẽ gặp sự cố khi chạy ứng dụng của mình. Nếu bạn đang sử dụng Eclipse, thì không bắt buộc phải đặt CLASSPATH vì tất cả cài đặt sẽ được thực hiện thông qua Eclipse.
Khi bạn đã hoàn tất bước cuối cùng này, bạn đã sẵn sàng tiếp tục cho Ví dụ Lucene đầu tiên mà bạn sẽ thấy trong chương tiếp theo.
Trong chương này, chúng ta sẽ học lập trình thực tế với Lucene Framework. Trước khi bắt đầu viết ví dụ đầu tiên bằng cách sử dụng khung công tác Lucene, bạn phải đảm bảo rằng bạn đã thiết lập môi trường Lucene đúng cách như đã giải thích trong hướng dẫn Thiết lập Môi trường - Lucene . Bạn nên có kiến thức về Eclipse IDE.
Bây giờ chúng ta hãy tiếp tục bằng cách viết một Ứng dụng Tìm kiếm đơn giản sẽ in ra số lượng kết quả tìm kiếm được tìm thấy. Chúng tôi cũng sẽ thấy danh sách các chỉ mục được tạo trong quá trình này.
Bước 1 - Tạo dự án Java
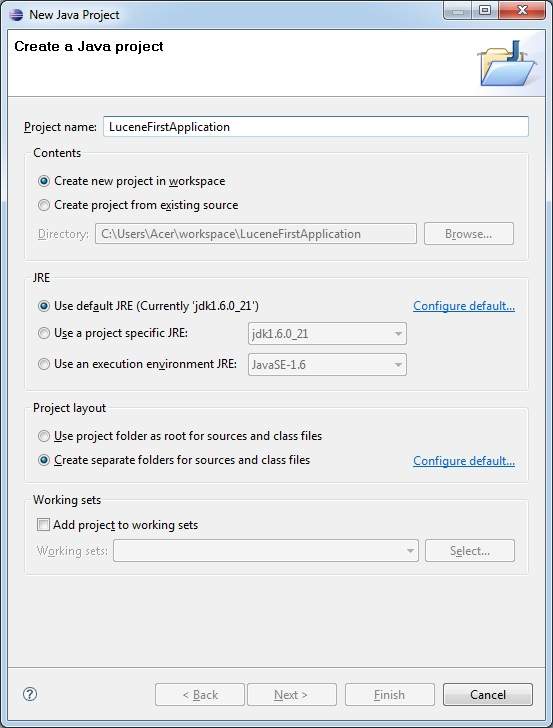
Bước đầu tiên là tạo một Dự án Java đơn giản bằng Eclipse IDE. Làm theo tùy chọnFile > New -> Project và cuối cùng chọn Java Projectwizard từ danh sách wizard. Bây giờ đặt tên cho dự án của bạn làLuceneFirstApplication bằng cách sử dụng cửa sổ thuật sĩ như sau:
Khi dự án của bạn được tạo thành công, bạn sẽ có nội dung sau trong Project Explorer -
Bước 2 - Thêm Thư viện Bắt buộc
Bây giờ chúng ta hãy thêm thư viện Lucene core Framework trong dự án của mình. Để làm điều này, hãy nhấp chuột phải vào tên dự án của bạnLuceneFirstApplication và sau đó làm theo tùy chọn sau có sẵn trong menu ngữ cảnh: Build Path -> Configure Build Path để hiển thị cửa sổ Java Build Path như sau:

Bây giờ sử dụng Add External JARs nút có sẵn dưới Libraries để thêm JAR cốt lõi sau từ thư mục cài đặt Lucene -
- lucene-core-3.6.2
Bước 3 - Tạo tệp nguồn
Bây giờ chúng ta hãy tạo các tệp nguồn thực tế trong LuceneFirstApplicationdự án. Trước tiên, chúng ta cần tạo một gói có têncom.tutorialspoint.lucene. Để làm điều này, nhấp chuột phải vào src trong phần trình khám phá gói và làm theo tùy chọn: New -> Package.
Tiếp theo chúng ta sẽ tạo LuceneTester.java và các lớp java khác trong com.tutorialspoint.lucene gói hàng.
LuceneConstants.java
Lớp này được sử dụng để cung cấp các hằng số khác nhau được sử dụng trong ứng dụng mẫu.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
Lớp này được sử dụng như một .txt file bộ lọc.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Indexer.java
Lớp này được sử dụng để lập chỉ mục dữ liệu thô để chúng ta có thể tìm kiếm nó bằng thư viện Lucene.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}Searcher.java
Lớp này dùng để tìm kiếm các chỉ mục do Indexer tạo ra để tìm kiếm nội dung được yêu cầu.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}LuceneTester.java
Lớp này được sử dụng để kiểm tra khả năng lập chỉ mục và tìm kiếm của thư viện lucene.
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime));
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "
+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}Bước 4 - Tạo thư mục Data & Index
Chúng tôi đã sử dụng 10 tệp văn bản từ record1.txt sang record10.txt chứa tên và các thông tin chi tiết khác của học sinh và đưa chúng vào thư mục E:\Lucene\Data. Dữ liệu thử nghiệm . Một đường dẫn thư mục chỉ mục nên được tạo nhưE:\Lucene\Index. Sau khi chạy chương trình này, bạn có thể xem danh sách các tệp chỉ mục được tạo trong thư mục đó.
Bước 5 - Chạy chương trình
Khi bạn đã hoàn tất việc tạo nguồn, dữ liệu thô, thư mục dữ liệu và thư mục chỉ mục, bạn đã sẵn sàng cho việc biên dịch và chạy chương trình của mình. Để làm điều này, hãy giữLuceneTester.Java tab tệp đang hoạt động và sử dụng Run tùy chọn có sẵn trong IDE Eclipse hoặc sử dụng Ctrl + F11 để biên dịch và chạy LuceneTesterứng dụng. Nếu ứng dụng chạy thành công, nó sẽ in thông báo sau trong bảng điều khiển của Eclipse IDE:
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 ms
1 documents found. Time :0
File: E:\Lucene\Data\record4.txtKhi bạn đã chạy chương trình thành công, bạn sẽ có nội dung sau trong index directory -
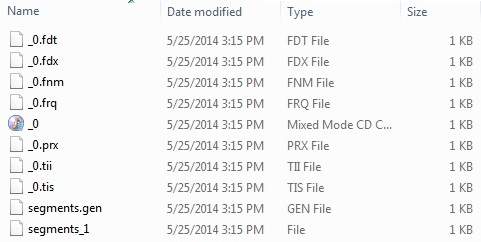
Quá trình lập chỉ mục là một trong những chức năng cốt lõi được cung cấp bởi Lucene. Sơ đồ sau minh họa quá trình lập chỉ mục và việc sử dụng các lớp.IndexWriter là thành phần quan trọng nhất và cốt lõi của quá trình lập chỉ mục.
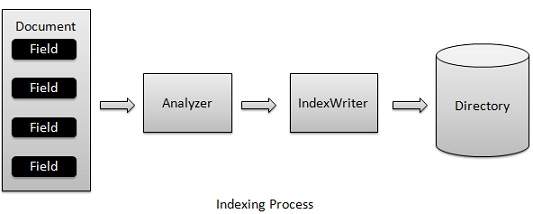
Chúng tôi thêm Document(s) chứa đựng Field(s) để IndexWriter phân tích Document(s) sử dụng Analyzer và sau đó tạo / mở / chỉnh sửa chỉ mục theo yêu cầu và lưu trữ / cập nhật chúng trong một Directory. IndexWriter được sử dụng để cập nhật hoặc tạo chỉ mục. Nó không được sử dụng để đọc các chỉ mục.
Các lớp lập chỉ mục
Sau đây là danh sách các lớp thường được sử dụng trong quá trình lập chỉ mục.
| Không. | Lớp & Mô tả |
|---|---|
| 1 | IndexWriter Lớp này hoạt động như một thành phần cốt lõi tạo / cập nhật các chỉ mục trong quá trình lập chỉ mục. |
| 2 | Danh mục Lớp này đại diện cho vị trí lưu trữ của các chỉ mục. |
| 3 | Máy phân tích Lớp này chịu trách nhiệm phân tích một tài liệu và lấy các thẻ / từ từ văn bản sẽ được lập chỉ mục. Nếu không thực hiện phân tích, IndexWriter không thể tạo chỉ mục. |
| 4 | Tài liệu Lớp này đại diện cho một tài liệu ảo với các Trường trong đó Trường là một đối tượng có thể chứa nội dung của tài liệu vật lý, siêu dữ liệu của nó, v.v. Trình phân tích chỉ có thể hiểu một Tài liệu. |
| 5 | Cánh đồng Đây là đơn vị thấp nhất hoặc điểm bắt đầu của quá trình lập chỉ mục. Nó đại diện cho mối quan hệ cặp giá trị khóa trong đó khóa được sử dụng để xác định giá trị được lập chỉ mục. Giả sử một trường được sử dụng để biểu thị nội dung của tài liệu sẽ có khóa là "nội dung" và giá trị có thể chứa một phần hoặc toàn bộ nội dung văn bản hoặc số của tài liệu. Lucene chỉ có thể lập chỉ mục nội dung văn bản hoặc số mà thôi. |
Quá trình Tìm kiếm lại là một trong những chức năng cốt lõi được cung cấp bởi Lucene. Luồng của nó tương tự như quy trình lập chỉ mục. Tìm kiếm cơ bản của Lucene có thể được thực hiện bằng cách sử dụng các lớp sau đây cũng có thể được gọi là các lớp nền tảng cho tất cả các hoạt động liên quan đến tìm kiếm.
Tìm kiếm lớp học
Sau đây là danh sách các lớp thường được sử dụng trong quá trình tìm kiếm.
| Không. | Lớp & Mô tả |
|---|---|
| 1 | IndexSearcher Lớp này hoạt động như một thành phần cốt lõi đọc / tìm kiếm các chỉ mục được tạo sau quá trình lập chỉ mục. Nó có trường hợp thư mục trỏ đến vị trí chứa các chỉ mục. |
| 2 | Kỳ hạn Lớp này là đơn vị tìm kiếm thấp nhất. Nó tương tự như Field trong quá trình lập chỉ mục. |
| 3 | Truy vấn Truy vấn là một lớp trừu tượng và chứa nhiều phương thức tiện ích khác nhau và là cha của tất cả các loại truy vấn mà Lucene sử dụng trong quá trình tìm kiếm. |
| 4 | TermQuery TermQuery là đối tượng truy vấn được sử dụng phổ biến nhất và là nền tảng của nhiều truy vấn phức tạp mà Lucene có thể sử dụng. |
| 5 | TopDocs TopDocs trỏ đến N kết quả tìm kiếm hàng đầu phù hợp với tiêu chí tìm kiếm. Nó là một vùng chứa các con trỏ đơn giản để trỏ đến các tài liệu là đầu ra của kết quả tìm kiếm. |
Quy trình lập chỉ mục là một trong những chức năng cốt lõi được cung cấp bởi Lucene. Sơ đồ sau minh họa quá trình lập chỉ mục và sử dụng các lớp. IndexWriter là thành phần cốt lõi và quan trọng nhất của quá trình lập chỉ mục.
Chúng tôi thêm (các) Tài liệu chứa (các) Trường vào IndexWriter để phân tích (các) Tài liệu bằng Trình phân tích và sau đó tạo / mở / chỉnh sửa chỉ mục theo yêu cầu và lưu trữ / cập nhật chúng trong Thư mục . IndexWriter được sử dụng để cập nhật hoặc tạo chỉ mục. Nó không được sử dụng để đọc các chỉ mục.
Bây giờ chúng tôi sẽ chỉ cho bạn quy trình từng bước để bắt đầu tìm hiểu về quy trình lập chỉ mục bằng cách sử dụng một ví dụ cơ bản.
Tạo một tài liệu
Tạo một phương thức để lấy một tài liệu lucene từ một tệp văn bản.
Tạo nhiều loại trường khác nhau là các cặp giá trị khóa có chứa khóa là tên và giá trị là nội dung được lập chỉ mục.
Đặt trường được phân tích hoặc không. Trong trường hợp của chúng tôi, chỉ nội dung được phân tích vì nó có thể chứa dữ liệu như a, am, are, v.v. không bắt buộc trong các thao tác tìm kiếm.
Thêm các trường mới được tạo vào đối tượng tài liệu và trả nó về phương thức người gọi.
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}Tạo một IndexWriter
Lớp IndexWriter hoạt động như một thành phần cốt lõi tạo / cập nhật các chỉ mục trong quá trình lập chỉ mục. Làm theo các bước sau để tạo IndexWriter -
Step 1 - Tạo đối tượng của IndexWriter.
Step 2 - Tạo một thư mục Lucene trỏ đến vị trí lưu trữ các chỉ mục.
Step 3 - Khởi tạo đối tượng IndexWriter được tạo bằng thư mục chỉ mục, một bộ phân tích tiêu chuẩn có thông tin phiên bản và các tham số bắt buộc / tùy chọn khác.
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}Bắt đầu quá trình lập chỉ mục
Chương trình sau đây trình bày cách bắt đầu quá trình lập chỉ mục:
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}Ứng dụng mẫu
Để kiểm tra quá trình lập chỉ mục, chúng ta cần tạo một bài kiểm tra ứng dụng Lucene.
| Bươc | Sự miêu tả |
|---|---|
| 1 | Tạo một dự án với tên LuceneFirstApplication trong gói com.tutorialspoint.lucene như đã giải thích trong chương Lucene - Ứng dụng đầu tiên . Bạn cũng có thể sử dụng dự án được tạo trong chương Lucene - First Application như vậy cho chương này để hiểu quá trình lập chỉ mục. |
| 2 | Tạo LuceneConstants.java, TextFileFilter.java và Indexer.java như được giải thích trong chương Lucene - Ứng dụng đầu tiên . Giữ phần còn lại của các tệp không thay đổi. |
| 3 | Tạo LuceneTester.java như được đề cập bên dưới. |
| 4 | Làm sạch và xây dựng ứng dụng để đảm bảo logic nghiệp vụ đang hoạt động theo yêu cầu. |
LuceneConstants.java
Lớp này được sử dụng để cung cấp các hằng số khác nhau được sử dụng trong ứng dụng mẫu.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
Lớp này được sử dụng như một .txt bộ lọc tệp.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Indexer.java
Lớp này được sử dụng để lập chỉ mục dữ liệu thô để chúng ta có thể tìm kiếm nó bằng thư viện Lucene.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}LuceneTester.java
Lớp này được sử dụng để kiểm tra khả năng lập chỉ mục của thư viện Lucene.
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
}Tạo thư mục dữ liệu & chỉ mục
Chúng tôi đã sử dụng 10 tệp văn bản từ record1.txt sang record10.txt chứa tên và các thông tin chi tiết khác của học sinh và đưa chúng vào thư mục E:\Lucene\Data. Dữ liệu thử nghiệm . Một đường dẫn thư mục chỉ mục nên được tạo nhưE:\Lucene\Index. Sau khi chạy chương trình này, bạn có thể xem danh sách các tệp chỉ mục được tạo trong thư mục đó.
Chạy chương trình
Khi bạn đã hoàn tất việc tạo nguồn, dữ liệu thô, thư mục dữ liệu và thư mục chỉ mục, bạn có thể tiếp tục bằng cách biên dịch và chạy chương trình của mình. Để thực hiện việc này, hãy giữ cho tab tệp LuceneTester.Java hoạt động và sử dụngRun tùy chọn có sẵn trong IDE Eclipse hoặc sử dụng Ctrl + F11 để biên dịch và chạy LuceneTesterứng dụng. Nếu ứng dụng của bạn chạy thành công, nó sẽ in thông báo sau trong bảng điều khiển của Eclipse IDE:
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 msKhi bạn đã chạy chương trình thành công, bạn sẽ có nội dung sau trong index directory −
Trong chương này, chúng ta sẽ thảo luận về bốn hoạt động chính của lập chỉ mục. Các thao tác này hữu ích tại nhiều thời điểm khác nhau và được sử dụng xuyên suốt ứng dụng tìm kiếm phần mềm.
Hoạt động lập chỉ mục
Sau đây là danh sách các thao tác thường được sử dụng trong quá trình lập chỉ mục.
| Không. | Hoạt động Mô tả |
|---|---|
| 1 | Thêm tài liệu Thao tác này được sử dụng trong giai đoạn đầu của quá trình lập chỉ mục để tạo các chỉ mục trên nội dung mới có sẵn. |
| 2 | Cập nhật tài liệu Thao tác này được sử dụng để cập nhật các chỉ mục nhằm phản ánh những thay đổi trong nội dung được cập nhật. Nó tương tự như việc tạo lại chỉ mục. |
| 3 | Xóa tài liệu Thao tác này được sử dụng để cập nhật các chỉ mục nhằm loại trừ các tài liệu không bắt buộc phải lập chỉ mục / tìm kiếm. |
| 4 | Tùy chọn trường Các tùy chọn trường chỉ định một cách hoặc kiểm soát các cách mà nội dung của một trường có thể được tìm kiếm. |
Quá trình tìm kiếm là một trong những chức năng cốt lõi được cung cấp bởi Lucene. Sơ đồ sau minh họa quy trình và việc sử dụng nó. IndexSearcher là một trong những thành phần cốt lõi của quá trình tìm kiếm.
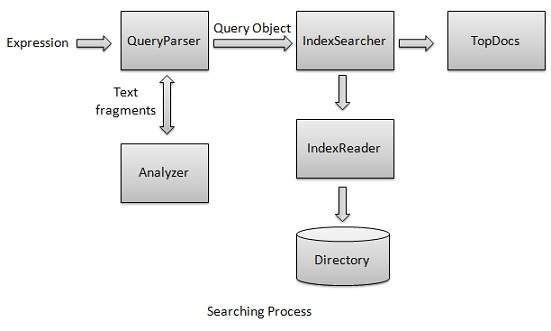
Đầu tiên chúng ta tạo (các) Thư mục chứa các chỉ mục và sau đó chuyển nó đến IndexSearcher để mở Thư mục bằng cách sử dụng IndexReader . Sau đó, chúng tôi tạo ra một truy vấn với một hạn và thực hiện một tìm kiếm sử dụng IndexSearcher bằng cách thông qua các truy vấn cho người tìm kiếm. IndexSearcher trả về đối tượng TopDocs chứa các chi tiết tìm kiếm cùng với (các) ID tài liệu của Tài liệu là kết quả của thao tác tìm kiếm.
Bây giờ chúng tôi sẽ chỉ cho bạn một cách tiếp cận khôn ngoan và giúp bạn hiểu quy trình lập chỉ mục bằng cách sử dụng một ví dụ cơ bản.
Tạo một QueryParser
Lớp QueryParser phân tích cú pháp người dùng đã nhập đầu vào thành truy vấn định dạng dễ hiểu Lucene. Làm theo các bước sau để tạo QueryParser -
Step 1 - Tạo đối tượng của QueryParser.
Step 2 - Khởi tạo đối tượng QueryParser được tạo bằng bộ phân tích tiêu chuẩn có thông tin phiên bản và tên chỉ mục mà truy vấn này sẽ được chạy.
QueryParser queryParser;
public Searcher(String indexDirectoryPath) throws IOException {
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}Tạo IndexSearcher
Lớp IndexSearcher hoạt động như một thành phần cốt lõi mà người tìm kiếm lập chỉ mục được tạo ra trong quá trình lập chỉ mục. Làm theo các bước sau để tạo IndexSearcher -
Step 1 - Tạo đối tượng của IndexSearcher.
Step 2 - Tạo một thư mục Lucene trỏ đến vị trí lưu trữ các chỉ mục.
Step 3 - Khởi tạo đối tượng IndexSearcher được tạo bằng thư mục chỉ mục.
IndexSearcher indexSearcher;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
}Thực hiện tìm kiếm
Làm theo các bước sau để thực hiện tìm kiếm -
Step 1 - Tạo đối tượng Truy vấn bằng cách phân tích cú pháp biểu thức tìm kiếm thông qua QueryParser.
Step 2 - Thực hiện tìm kiếm bằng cách gọi phương thức IndexSearcher.search ().
Query query;
public TopDocs search( String searchQuery) throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}Nhận tài liệu
Chương trình sau đây cho biết cách lấy tài liệu.
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}Đóng IndexSearcher
Chương trình sau đây cho biết cách đóng IndexSearcher.
public void close() throws IOException {
indexSearcher.close();
}Ứng dụng mẫu
Hãy để chúng tôi tạo một ứng dụng Lucene thử nghiệm để kiểm tra quá trình tìm kiếm.
| Bươc | Sự miêu tả |
|---|---|
| 1 | Tạo một dự án với tên LuceneFirstApplication theo gói com.tutorialspoint.lucene như đã giải thích trong chương Lucene - Ứng dụng đầu tiên . Bạn cũng có thể sử dụng dự án được tạo trong chương Lucene - First Application như vậy cho chương này để hiểu quá trình tìm kiếm. |
| 2 | Tạo LuceneConstants.java, TextFileFilter.java và Searcher.java như đã giải thích trong chương Lucene - Ứng dụng đầu tiên . Giữ phần còn lại của các tệp không thay đổi. |
| 3 | Tạo LuceneTester.java như được đề cập bên dưới. |
| 4 | Làm sạch và xây dựng ứng dụng để đảm bảo logic nghiệp vụ đang hoạt động theo yêu cầu. |
LuceneConstants.java
Lớp này được sử dụng để cung cấp các hằng số khác nhau được sử dụng trong ứng dụng mẫu.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
Lớp này được sử dụng như một .txt bộ lọc tệp.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Searcher.java
Lớp này được sử dụng để đọc các chỉ mục được tạo trên dữ liệu thô và tìm kiếm dữ liệu bằng thư viện Lucene.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}LuceneTester.java
Lớp này dùng để kiểm tra khả năng tìm kiếm của thư viện Lucene.
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) +" ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}Tạo thư mục dữ liệu & chỉ mục
Chúng tôi đã sử dụng 10 tệp văn bản có tên record1.txt để ghi10.txt chứa tên và các thông tin chi tiết khác của học sinh và đưa chúng vào thư mục E: \ Lucene \ Data. Dữ liệu thử nghiệm . Đường dẫn thư mục chỉ mục nên được tạo dưới dạng E: \ Lucene \ Index. Sau khi chạy chương trình lập chỉ mục trong chươngLucene - Indexing Process, bạn có thể xem danh sách các tệp chỉ mục được tạo trong thư mục đó.
Chạy chương trình
Khi bạn đã hoàn tất việc tạo nguồn, dữ liệu thô, thư mục dữ liệu, thư mục chỉ mục và các chỉ mục, bạn có thể tiếp tục bằng cách biên dịch và chạy chương trình của mình. Để làm điều này, hãy giữLuceneTester.Java tab tệp đang hoạt động và sử dụng tùy chọn Chạy có sẵn trong IDE Eclipse hoặc sử dụng Ctrl + F11 để biên dịch và chạy LuceneTesterapplication. Nếu ứng dụng của bạn chạy thành công, nó sẽ in thông báo sau trong bảng điều khiển của Eclipse IDE:
1 documents found. Time :29 ms
File: E:\Lucene\Data\record4.txtChúng ta đã thấy trong chương trước Lucene - Search Operation, Lucene sử dụng IndexSearcher để thực hiện tìm kiếm và nó sử dụng đối tượng Truy vấn do QueryParser tạo ra làm đầu vào. Trong chương này, chúng ta sẽ thảo luận về các loại đối tượng Truy vấn khác nhau và các cách khác nhau để tạo chúng theo chương trình. Tạo các loại đối tượng truy vấn khác nhau cho phép kiểm soát loại tìm kiếm được thực hiện.
Hãy xem xét trường hợp của Tìm kiếm nâng cao, được cung cấp bởi nhiều ứng dụng trong đó người dùng được cung cấp nhiều tùy chọn để giới hạn kết quả tìm kiếm. Bằng cách lập trình truy vấn, chúng ta có thể đạt được điều tương tự rất dễ dàng.
Sau đây là danh sách các loại Truy vấn mà chúng ta sẽ thảo luận trong khóa học.
| Không. | Lớp & Mô tả |
|---|---|
| 1 | TermQuery Lớp này hoạt động như một thành phần cốt lõi tạo / cập nhật các chỉ mục trong quá trình lập chỉ mục. |
| 2 | TermRangeQuery TermRangeQuery được sử dụng khi một loạt các thuật ngữ văn bản được tìm kiếm. |
| 3 | PrefixQuery PrefixQuery được sử dụng để so khớp các tài liệu có chỉ mục bắt đầu bằng một chuỗi được chỉ định. |
| 4 | BooleanQuery BooleanQuery được sử dụng để tìm kiếm tài liệu là kết quả của nhiều truy vấn bằng cách sử dụng AND, OR hoặc là NOT các toán tử. |
| 5 | PhraseQuery Truy vấn cụm từ được sử dụng để tìm kiếm các tài liệu chứa một chuỗi thuật ngữ cụ thể. |
| 6 | WildCardQuery WildcardQuery được sử dụng để tìm kiếm tài liệu bằng các ký tự đại diện như '*' cho bất kỳ chuỗi ký tự nào,? khớp với một ký tự duy nhất. |
| 7 | FuzzyQuery FuzzyQuery được sử dụng để tìm kiếm tài liệu bằng cách sử dụng triển khai mờ là một tìm kiếm gần đúng dựa trên thuật toán chỉnh sửa khoảng cách. |
| số 8 | MatchAllDocsQuery MatchAllDocsQuery như tên cho thấy khớp với tất cả các tài liệu. |
Trong một trong các chương trước, chúng ta đã thấy Lucene sử dụng IndexWriter để phân tích (các) Tài liệu bằng Trình phân tích và sau đó tạo / mở / chỉnh sửa các chỉ mục theo yêu cầu. Trong chương này, chúng ta sẽ thảo luận về các loại đối tượng Analyzer và các đối tượng liên quan khác được sử dụng trong quá trình phân tích. Hiểu được quy trình Phân tích và cách hoạt động của các bộ phân tích sẽ cung cấp cho bạn cái nhìn sâu sắc về cách Lucene lập chỉ mục các tài liệu.
Sau đây là danh sách các đối tượng mà chúng ta sẽ thảo luận trong khóa học.
| Không. | Lớp & Mô tả |
|---|---|
| 1 | Mã thông báo Mã thông báo đại diện cho văn bản hoặc từ trong tài liệu với các chi tiết liên quan như siêu dữ liệu của nó (vị trí, độ lệch đầu, độ lệch cuối, loại mã thông báo và gia số vị trí của nó). |
| 2 | TokenStream TokenStream là một đầu ra của quá trình phân tích và nó bao gồm một loạt các mã thông báo. Nó là một lớp trừu tượng. |
| 3 | Máy phân tích Đây là một lớp cơ sở trừu tượng cho mỗi và mọi loại Trình phân tích. |
| 4 | Khoảng trắng Bộ phân tích này phân chia văn bản trong tài liệu dựa trên khoảng trắng. |
| 5 | SimpleAnalyzer Bộ phân tích này tách văn bản trong tài liệu dựa trên các ký tự không phải chữ cái và đặt văn bản ở dạng chữ thường. |
| 6 | StopAnalyzer Trình phân tích này hoạt động giống như Trình phân tích đơn giản và loại bỏ các từ phổ biến như 'a', 'an', 'the', Vân vân. |
| 7 | StandardAnalyzer Đây là trình phân tích phức tạp nhất và có khả năng xử lý tên, địa chỉ email, v.v. Nó viết thường mỗi mã thông báo và loại bỏ các từ và dấu chấm câu phổ biến, nếu có. |
Trong chương này, chúng ta sẽ xem xét các thứ tự sắp xếp trong đó Lucene đưa ra kết quả tìm kiếm theo mặc định hoặc có thể được thao tác theo yêu cầu.
Sắp xếp theo mức độ liên quan
Đây là chế độ sắp xếp mặc định được Lucene sử dụng. Lucene cung cấp kết quả theo lượt truy cập có liên quan nhất ở trên cùng.
private void sortUsingRelevance(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.RELEVANCE);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}Sắp xếp theo IndexOrder
Chế độ sắp xếp này được sử dụng bởi Lucene. Tại đây, tài liệu đầu tiên được lập chỉ mục được hiển thị đầu tiên trong kết quả tìm kiếm.
private void sortUsingIndex(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.INDEXORDER);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}Ứng dụng mẫu
Hãy để chúng tôi tạo một ứng dụng Lucene thử nghiệm để kiểm tra quá trình sắp xếp.
| Bươc | Sự miêu tả |
|---|---|
| 1 | Tạo một dự án với tên LuceneFirstApplication theo gói com.tutorialspoint.lucene như đã giải thích trong chương Lucene - Ứng dụng đầu tiên . Bạn cũng có thể sử dụng dự án được tạo trong chương Lucene - First Application như vậy cho chương này để hiểu quá trình tìm kiếm. |
| 2 | Tạo LuceneConstants.java và Searcher.java như đã giải thích trong chương Lucene - Ứng dụng đầu tiên . Giữ phần còn lại của các tệp không thay đổi. |
| 3 | Tạo LuceneTester.java như được đề cập bên dưới. |
| 4 | Làm sạch và xây dựng ứng dụng để đảm bảo logic nghiệp vụ đang hoạt động theo yêu cầu. |
LuceneConstants.java
Lớp này được sử dụng để cung cấp các hằng số khác nhau được sử dụng trong ứng dụng mẫu.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}Searcher.java
Lớp này được sử dụng để đọc các chỉ mục được tạo trên dữ liệu thô và tìm kiếm dữ liệu bằng thư viện Lucene.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory
= FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query)
throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query,Sort sort)
throws IOException, ParseException {
return indexSearcher.search(query,
LuceneConstants.MAX_SEARCH,sort);
}
public void setDefaultFieldSortScoring(boolean doTrackScores,
boolean doMaxScores) {
indexSearcher.setDefaultFieldSortScoring(
doTrackScores,doMaxScores);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}LuceneTester.java
Lớp này dùng để kiểm tra khả năng tìm kiếm của thư viện Lucene.
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.sortUsingRelevance("cord3.txt");
tester.sortUsingIndex("cord3.txt");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void sortUsingRelevance(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.RELEVANCE);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
private void sortUsingIndex(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.INDEXORDER);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}Tạo thư mục dữ liệu & chỉ mục
Chúng tôi đã sử dụng 10 tệp văn bản từ record1.txt sang record10.txt chứa tên và các thông tin chi tiết khác của học sinh và đưa chúng vào thư mục E:\Lucene\Data. Dữ liệu thử nghiệm . Đường dẫn thư mục chỉ mục nên được tạo dưới dạng E: \ Lucene \ Index. Sau khi chạy chương trình lập chỉ mục trong chươngLucene - Indexing Process, bạn có thể xem danh sách các tệp chỉ mục được tạo trong thư mục đó.
Chạy chương trình
Khi bạn đã hoàn tất việc tạo nguồn, dữ liệu thô, thư mục dữ liệu, thư mục chỉ mục và các chỉ mục, bạn có thể biên dịch và chạy chương trình của mình. Để làm điều này, hãy giữLuceneTester.Java tab tệp đang hoạt động và sử dụng tùy chọn Chạy có sẵn trong IDE Eclipse hoặc sử dụng Ctrl + F11 để biên dịch và chạy LuceneTesterứng dụng. Nếu ứng dụng của bạn chạy thành công, nó sẽ in thông báo sau trong bảng điều khiển của Eclipse IDE:
10 documents found. Time :31ms
Score: 1.3179655 File: E:\Lucene\Data\record3.txt
Score: 0.790779 File: E:\Lucene\Data\record1.txt
Score: 0.790779 File: E:\Lucene\Data\record2.txt
Score: 0.790779 File: E:\Lucene\Data\record4.txt
Score: 0.790779 File: E:\Lucene\Data\record5.txt
Score: 0.790779 File: E:\Lucene\Data\record6.txt
Score: 0.790779 File: E:\Lucene\Data\record7.txt
Score: 0.790779 File: E:\Lucene\Data\record8.txt
Score: 0.790779 File: E:\Lucene\Data\record9.txt
Score: 0.2635932 File: E:\Lucene\Data\record10.txt
10 documents found. Time :0ms
Score: 0.790779 File: E:\Lucene\Data\record1.txt
Score: 0.2635932 File: E:\Lucene\Data\record10.txt
Score: 0.790779 File: E:\Lucene\Data\record2.txt
Score: 1.3179655 File: E:\Lucene\Data\record3.txt
Score: 0.790779 File: E:\Lucene\Data\record4.txt
Score: 0.790779 File: E:\Lucene\Data\record5.txt
Score: 0.790779 File: E:\Lucene\Data\record6.txt
Score: 0.790779 File: E:\Lucene\Data\record7.txt
Score: 0.790779 File: E:\Lucene\Data\record8.txt
Score: 0.790779 File: E:\Lucene\Data\record9.txt