Mahout - Phân loại
Phân loại là gì?
Phân loại là một kỹ thuật học máy sử dụng dữ liệu đã biết để xác định cách dữ liệu mới sẽ được phân loại thành một tập hợp các danh mục hiện có. Ví dụ,
Ứng dụng iTunes sử dụng phân loại để chuẩn bị danh sách phát.
Các nhà cung cấp dịch vụ thư như Yahoo! và Gmail sử dụng kỹ thuật này để quyết định xem một thư mới có được phân loại là thư rác hay không. Thuật toán phân loại tự đào tạo bằng cách phân tích thói quen đánh dấu một số thư nhất định của người dùng là thư rác. Dựa vào đó, bộ phân loại quyết định xem một thư trong tương lai sẽ được gửi vào hộp thư đến của bạn hay trong thư mục thư rác.
Cách phân loại hoạt động
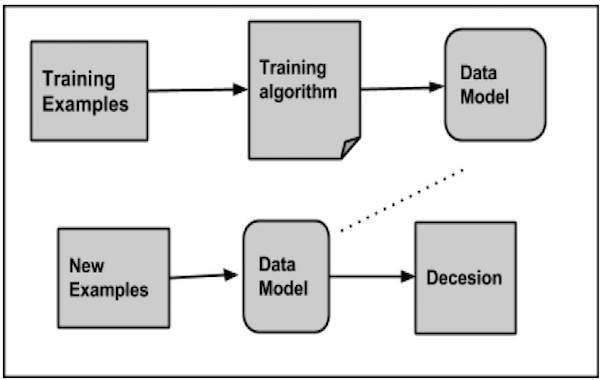
Trong khi phân loại một tập dữ liệu nhất định, hệ thống phân loại thực hiện các hành động sau:
- Ban đầu, một mô hình dữ liệu mới được chuẩn bị bằng cách sử dụng bất kỳ thuật toán học nào.
- Sau đó, mô hình dữ liệu đã chuẩn bị được kiểm tra.
- Sau đó, mô hình dữ liệu này được sử dụng để đánh giá dữ liệu mới và xác định lớp của nó.
Ứng dụng của phân loại
Credit card fraud detection- Cơ chế phân loại được sử dụng để dự đoán các gian lận thẻ tín dụng. Sử dụng thông tin lịch sử của các gian lận trước đó, bộ phân loại có thể dự đoán giao dịch nào trong tương lai có thể chuyển thành gian lận.
Spam e-mails - Tùy thuộc vào đặc điểm của các thư rác trước đó, bộ phân loại quyết định xem một thư điện tử mới gặp có nên được gửi vào thư mục thư rác hay không.
Naive Bayes Classifier
Mahout sử dụng thuật toán phân loại Naive Bayes. Nó sử dụng hai cách triển khai:
- Phân loại Naive Bayes phân tán
- Phân loại Naive Bayes bổ sung
Naive Bayes là một kỹ thuật đơn giản để xây dựng bộ phân loại. Nó không phải là một thuật toán duy nhất để đào tạo các bộ phân loại như vậy, mà là một họ các thuật toán. Bộ phân loại Bayes xây dựng các mô hình để phân loại các trường hợp vấn đề. Các phân loại này được thực hiện bằng cách sử dụng dữ liệu có sẵn.
Một lợi thế của Bayes ngây thơ là nó chỉ yêu cầu một lượng nhỏ dữ liệu huấn luyện để ước tính các tham số cần thiết cho việc phân loại.
Đối với một số loại mô hình xác suất, các bộ phân loại Bayes ngây thơ có thể được đào tạo rất hiệu quả trong môi trường học có giám sát.
Bất chấp các giả định đơn giản hóa quá mức, các bộ phân loại Bayes ngây thơ đã hoạt động khá tốt trong nhiều tình huống phức tạp trong thế giới thực.
Thủ tục phân loại
Các bước sau cần được thực hiện để thực hiện Phân loại:
- Tạo dữ liệu mẫu
- Tạo tệp trình tự từ dữ liệu
- Chuyển đổi các tệp trình tự thành vectơ
- Đào tạo các vectơ
- Kiểm tra các vectơ
Bước 1: Tạo dữ liệu mẫu
Tạo hoặc tải xuống dữ liệu được phân loại. Ví dụ, bạn có thể lấy20 newsgroups dữ liệu mẫu từ liên kết sau: http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz
Tạo thư mục để lưu trữ dữ liệu đầu vào. Tải xuống ví dụ như hình bên dưới.
$ mkdir classification_example
$ cd classification_example
$tar xzvf 20news-bydate.tar.gz
wget http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gzBước 2: Tạo tệp trình tự
Tạo tệp trình tự từ ví dụ bằng cách sử dụng seqdirectorytiện ích. Cú pháp để tạo chuỗi được đưa ra dưới đây:
mahout seqdirectory -i <input file path> -o <output directory>Bước 3: Chuyển đổi tệp trình tự thành Vectơ
Tạo tệp vectơ từ tệp trình tự bằng cách sử dụng seq2parsetiện ích. Các tùy chọn củaseq2parse tiện ích được đưa ra dưới đây:
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.Bước 4: Đào tạo các Vectơ
Đào tạo các vectơ được tạo bằng cách sử dụng trainnbtiện ích. Các tùy chọn để sử dụngtrainnb tiện ích được đưa ra dưới đây:
mahout trainnb
-i ${PATH_TO_TFIDF_VECTORS}
-el
-o ${PATH_TO_MODEL}/model
-li ${PATH_TO_MODEL}/labelindex
-ow
-cBước 5: Kiểm tra các Vectơ
Kiểm tra các vectơ bằng cách sử dụng testnbtiện ích. Các tùy chọn để sử dụngtestnb tiện ích được đưa ra dưới đây:
mahout testnb
-i ${PATH_TO_TFIDF_TEST_VECTORS}
-m ${PATH_TO_MODEL}/model
-l ${PATH_TO_MODEL}/labelindex
-ow
-o ${PATH_TO_OUTPUT}
-c
-seq