Mahout - Học máy
Apache Mahout là một thư viện học máy có khả năng mở rộng cao cho phép các nhà phát triển sử dụng các thuật toán được tối ưu hóa. Mahout triển khai các kỹ thuật học máy phổ biến như khuyến nghị, phân loại và phân cụm. Do đó, cần thận trọng khi có một phần ngắn gọn về học máy trước khi chúng ta tiến xa hơn.
Học máy là gì?
Học máy là một nhánh của khoa học liên quan đến việc lập trình các hệ thống theo cách mà chúng tự động học hỏi và cải thiện theo kinh nghiệm. Ở đây, học có nghĩa là nhận ra và hiểu dữ liệu đầu vào và đưa ra quyết định khôn ngoan dựa trên dữ liệu được cung cấp.
Rất khó để đưa ra tất cả các quyết định dựa trên tất cả các đầu vào có thể. Để giải quyết vấn đề này, các thuật toán được phát triển. Các thuật toán này xây dựng kiến thức từ dữ liệu cụ thể và kinh nghiệm trong quá khứ với các nguyên tắc thống kê, lý thuyết xác suất, logic, tối ưu hóa tổ hợp, tìm kiếm, học củng cố và lý thuyết điều khiển.
Các thuật toán được phát triển tạo nền tảng cho các ứng dụng khác nhau như:
- Xử lý tầm nhìn
- Xử lý ngôn ngữ
- Dự báo (ví dụ: xu hướng thị trường chứng khoán)
- Nhận dạng mẫu
- Games
- Khai thác dữ liệu
- Những hệ thống chuyên gia
- Robotics
Học máy là một lĩnh vực rộng lớn và nó nằm ngoài phạm vi của hướng dẫn này để bao gồm tất cả các tính năng của nó. Có một số cách để triển khai các kỹ thuật học máy, tuy nhiên những cách thường được sử dụng nhất làsupervised và unsupervised learning.
Học tập có giám sát
Việc học có giám sát liên quan đến việc học một chức năng từ dữ liệu đào tạo có sẵn. Một thuật toán học có giám sát phân tích dữ liệu đào tạo và tạo ra một hàm suy luận, có thể được sử dụng để ánh xạ các ví dụ mới. Các ví dụ phổ biến về học có giám sát bao gồm:
- phân loại e-mail là thư rác,
- gắn nhãn các trang web dựa trên nội dung của chúng và
- nhận diện giọng nói.
Có nhiều thuật toán học có giám sát như mạng nơ-ron, Máy vectơ hỗ trợ (SVM) và bộ phân loại Naive Bayes. Mahout triển khai bộ phân loại Naive Bayes.
Học tập không giám sát
Học không giám sát có nghĩa là dữ liệu không được gắn nhãn mà không có bất kỳ tập dữ liệu xác định trước nào để đào tạo. Học không giám sát là một công cụ cực kỳ mạnh mẽ để phân tích dữ liệu có sẵn và tìm kiếm các mẫu và xu hướng. Nó được sử dụng phổ biến nhất để phân cụm đầu vào tương tự thành các nhóm logic. Các cách tiếp cận phổ biến để học tập không giám sát bao gồm:
- k-means
- bản đồ tự tổ chức và
- phân cụm phân cấp
sự giới thiệu
Đề xuất là một kỹ thuật phổ biến cung cấp các đề xuất gần đúng dựa trên thông tin của người dùng, chẳng hạn như các lần mua, nhấp chuột và xếp hạng trước đó.
Amazon sử dụng kỹ thuật này để hiển thị danh sách các mục được đề xuất mà bạn có thể quan tâm, rút ra thông tin từ các hành động trước đây của bạn. Có các công cụ giới thiệu hoạt động đằng sau Amazon để nắm bắt hành vi của người dùng và đề xuất các mặt hàng đã chọn dựa trên các hành động trước đó của bạn.
Facebook sử dụng kỹ thuật giới thiệu để xác định và giới thiệu “danh sách những người bạn có thể biết”.

Phân loại
Phân loại, còn được gọi là categorization, là một kỹ thuật máy học sử dụng dữ liệu đã biết để xác định cách dữ liệu mới sẽ được phân loại thành một tập hợp các danh mục hiện có. Phân loại là một hình thức học tập có giám sát.
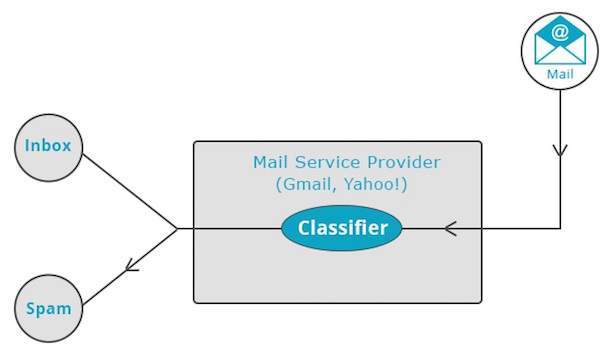
Các nhà cung cấp dịch vụ thư như Yahoo! và Gmail sử dụng kỹ thuật này để quyết định xem một thư mới có được phân loại là thư rác hay không. Thuật toán phân loại tự đào tạo bằng cách phân tích thói quen đánh dấu một số thư nhất định của người dùng là thư rác. Dựa vào đó, bộ phân loại quyết định xem một thư trong tương lai sẽ được gửi vào hộp thư đến của bạn hay trong thư mục thư rác.
Ứng dụng iTunes sử dụng phân loại để chuẩn bị danh sách phát.
Phân cụm
Phân cụm được sử dụng để tạo thành các nhóm hoặc cụm dữ liệu tương tự nhau dựa trên các đặc điểm chung. Clustering là một hình thức học tập không có giám sát.
Các công cụ tìm kiếm như Google và Yahoo! sử dụng kỹ thuật phân cụm để nhóm dữ liệu có đặc điểm tương tự.
Nhóm tin sử dụng kỹ thuật phân cụm để nhóm các bài báo khác nhau dựa trên các chủ đề liên quan.
Công cụ phân cụm sẽ xem xét toàn bộ dữ liệu đầu vào và dựa trên các đặc điểm của dữ liệu, nó sẽ quyết định xem nó nên được nhóm theo cụm nào. Hãy xem ví dụ sau.
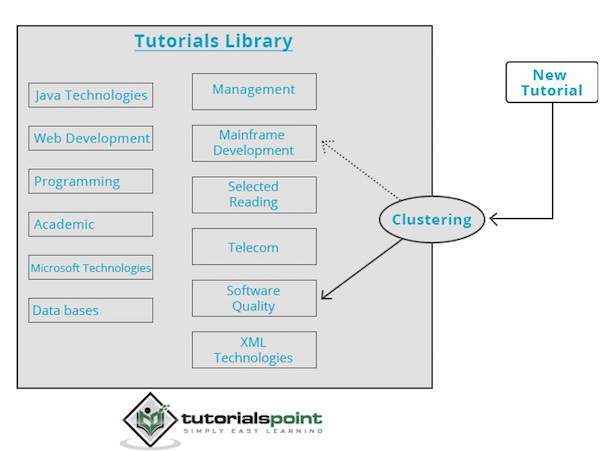
Thư viện hướng dẫn của chúng tôi chứa các chủ đề về các chủ đề khác nhau. Khi chúng tôi nhận được một hướng dẫn mới tại TutorialsPoint, nó sẽ được xử lý bởi một công cụ phân cụm quyết định, dựa trên nội dung của nó, nơi nó sẽ được nhóm lại.