MapReduce - Giới thiệu
MapReduce là một mô hình lập trình để viết các ứng dụng có thể xử lý Big Data song song trên nhiều nút. MapReduce cung cấp khả năng phân tích để phân tích khối lượng dữ liệu phức tạp khổng lồ.
Dữ liệu lớn là gì?
Dữ liệu lớn là một tập hợp các bộ dữ liệu lớn không thể được xử lý bằng các kỹ thuật tính toán truyền thống. Ví dụ, khối lượng dữ liệu Facebook hoặc Youtube cần yêu cầu nó thu thập và quản lý hàng ngày, có thể thuộc danh mục Dữ liệu lớn. Tuy nhiên, Dữ liệu lớn không chỉ là về quy mô và khối lượng, nó còn liên quan đến một hoặc nhiều khía cạnh sau - Tốc độ, Sự đa dạng, Khối lượng và Độ phức tạp.
Tại sao sử dụng MapReduce?
Hệ thống Doanh nghiệp truyền thống thường có một máy chủ tập trung để lưu trữ và xử lý dữ liệu. Hình minh họa sau đây mô tả một cái nhìn sơ đồ về hệ thống doanh nghiệp truyền thống. Mô hình truyền thống chắc chắn không phù hợp để xử lý khối lượng lớn dữ liệu có thể mở rộng và không thể đáp ứng được bởi các máy chủ cơ sở dữ liệu tiêu chuẩn. Hơn nữa, hệ thống tập trung tạo ra quá nhiều nút cổ chai trong khi xử lý nhiều tệp cùng một lúc.

Google đã giải quyết vấn đề tắc nghẽn này bằng cách sử dụng một thuật toán có tên là MapReduce. MapReduce chia một nhiệm vụ thành các phần nhỏ và giao chúng cho nhiều máy tính. Sau đó, kết quả được thu thập tại một nơi và tích hợp để tạo thành tập dữ liệu kết quả.

MapReduce hoạt động như thế nào?
Thuật toán MapReduce chứa hai tác vụ quan trọng, đó là Bản đồ và Giảm.
Tác vụ Bản đồ nhận một tập dữ liệu và chuyển đổi nó thành một tập dữ liệu khác, trong đó các phần tử riêng lẻ được chia nhỏ thành các bộ giá trị (cặp khóa-giá trị).
Tác vụ Reduce lấy đầu ra từ Bản đồ làm đầu vào và kết hợp các bộ dữ liệu đó (cặp khóa-giá trị) thành một bộ bộ giá trị nhỏ hơn.
Tác vụ thu gọn luôn được thực hiện sau tác vụ bản đồ.
Bây giờ chúng ta hãy xem xét kỹ từng giai đoạn và cố gắng hiểu ý nghĩa của chúng.
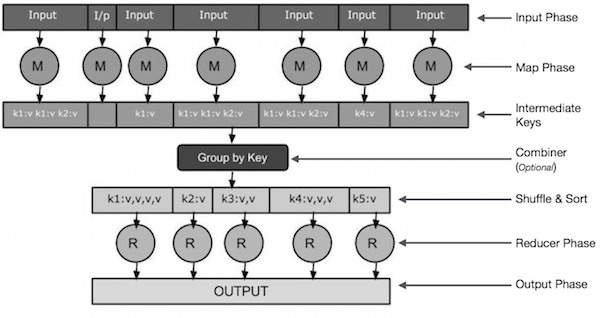
Input Phase - Ở đây chúng ta có Trình đọc bản ghi dịch từng bản ghi trong tệp đầu vào và gửi dữ liệu đã được phân tích cú pháp tới trình ánh xạ dưới dạng các cặp khóa-giá trị.
Map - Bản đồ là một chức năng do người dùng định nghĩa, nó nhận một loạt các cặp khóa-giá trị và xử lý từng cặp một trong số chúng để tạo ra không hoặc nhiều cặp khóa-giá trị.
Intermediate Keys - Các cặp khóa-giá trị do trình ánh xạ tạo ra được gọi là khóa trung gian.
Combiner- Bộ kết hợp là một loại Bộ giảm cục bộ nhóm dữ liệu tương tự từ giai đoạn bản đồ thành các bộ có thể nhận dạng. Nó lấy các khóa trung gian từ trình ánh xạ làm đầu vào và áp dụng mã do người dùng xác định để tổng hợp các giá trị trong một phạm vi nhỏ của một trình ánh xạ. Nó không phải là một phần của thuật toán MapReduce chính; nó là tùy chọn.
Shuffle and Sort- Tác vụ Bộ giảm tốc bắt đầu với bước Xáo trộn và Sắp xếp. Nó tải các cặp khóa-giá trị đã nhóm vào máy cục bộ, nơi Bộ giảm tốc đang chạy. Các cặp khóa-giá trị riêng lẻ được sắp xếp theo khóa thành một danh sách dữ liệu lớn hơn. Danh sách dữ liệu nhóm các khóa tương đương với nhau để các giá trị của chúng có thể được lặp lại một cách dễ dàng trong tác vụ Bộ giảm.
Reducer- Bộ giảm tốc lấy dữ liệu được ghép nối khóa-giá trị đã nhóm làm đầu vào và chạy chức năng Bộ giảm tốc trên mỗi dữ liệu trong số chúng. Tại đây, dữ liệu có thể được tổng hợp, lọc và kết hợp theo một số cách và nó yêu cầu nhiều quá trình xử lý. Khi quá trình thực thi kết thúc, nó không cung cấp hoặc nhiều cặp khóa-giá trị cho bước cuối cùng.
Output Phase - Trong giai đoạn đầu ra, chúng ta có một trình định dạng đầu ra để dịch các cặp khóa-giá trị cuối cùng từ chức năng Reducer và ghi chúng vào một tệp bằng trình ghi bản ghi.
Chúng ta hãy cố gắng hiểu hai tác vụ Map & f Reduce với sự trợ giúp của một sơ đồ nhỏ -

MapReduce-Ví dụ
Chúng ta hãy lấy một ví dụ trong thế giới thực để hiểu được sức mạnh của MapReduce. Twitter nhận được khoảng 500 triệu tweet mỗi ngày, tức là gần 3000 tweet mỗi giây. Hình minh họa sau đây cho thấy cách Tweeter quản lý các tweet của mình với sự trợ giúp của MapReduce.
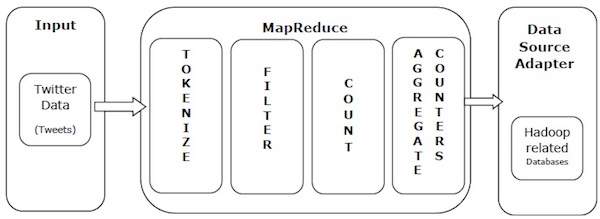
Như thể hiện trong hình minh họa, thuật toán MapReduce thực hiện các hành động sau:
Tokenize - Mã hóa các tweet thành bản đồ mã thông báo và viết chúng dưới dạng cặp khóa-giá trị.
Filter - Lọc các từ không mong muốn khỏi bản đồ mã thông báo và viết các bản đồ đã lọc dưới dạng các cặp khóa-giá trị.
Count - Tạo bộ đếm mã thông báo trên mỗi từ.
Aggregate Counters - Chuẩn bị tổng hợp các giá trị bộ đếm tương tự thành các đơn vị nhỏ có thể quản lý được.