MapReduce - Hướng dẫn nhanh
MapReduce là một mô hình lập trình để viết các ứng dụng có thể xử lý Big Data song song trên nhiều nút. MapReduce cung cấp khả năng phân tích để phân tích khối lượng dữ liệu phức tạp khổng lồ.
Dữ liệu lớn là gì?
Dữ liệu lớn là một tập hợp các bộ dữ liệu lớn không thể được xử lý bằng các kỹ thuật tính toán truyền thống. Ví dụ, khối lượng dữ liệu Facebook hoặc Youtube cần yêu cầu nó phải thu thập và quản lý hàng ngày, có thể thuộc danh mục Dữ liệu lớn. Tuy nhiên, Dữ liệu lớn không chỉ là về quy mô và khối lượng, nó còn liên quan đến một hoặc nhiều khía cạnh sau - Tốc độ, Sự đa dạng, Khối lượng và Độ phức tạp.
Tại sao sử dụng MapReduce?
Hệ thống Doanh nghiệp truyền thống thường có một máy chủ tập trung để lưu trữ và xử lý dữ liệu. Hình minh họa sau đây mô tả một cái nhìn sơ đồ về hệ thống doanh nghiệp truyền thống. Mô hình truyền thống chắc chắn không phù hợp để xử lý khối lượng lớn dữ liệu có thể mở rộng và không thể đáp ứng được bởi các máy chủ cơ sở dữ liệu tiêu chuẩn. Hơn nữa, hệ thống tập trung tạo ra quá nhiều nút cổ chai trong khi xử lý nhiều tệp đồng thời.

Google đã giải quyết vấn đề tắc nghẽn này bằng cách sử dụng một thuật toán có tên là MapReduce. MapReduce chia một nhiệm vụ thành các phần nhỏ và giao chúng cho nhiều máy tính. Sau đó, kết quả được thu thập tại một nơi và tích hợp để tạo thành tập dữ liệu kết quả.

MapReduce hoạt động như thế nào?
Thuật toán MapReduce chứa hai nhiệm vụ quan trọng, đó là Bản đồ và Giảm.
Tác vụ Bản đồ lấy một tập hợp dữ liệu và chuyển đổi nó thành một tập dữ liệu khác, trong đó các phần tử riêng lẻ được chia nhỏ thành các bộ giá trị (cặp khóa-giá trị).
Tác vụ Reduce lấy đầu ra từ Bản đồ làm đầu vào và kết hợp các bộ dữ liệu đó (cặp khóa-giá trị) thành một bộ bộ giá nhỏ hơn.
Tác vụ thu gọn luôn được thực hiện sau tác vụ bản đồ.
Bây giờ chúng ta hãy xem xét kỹ từng giai đoạn và cố gắng hiểu ý nghĩa của chúng.
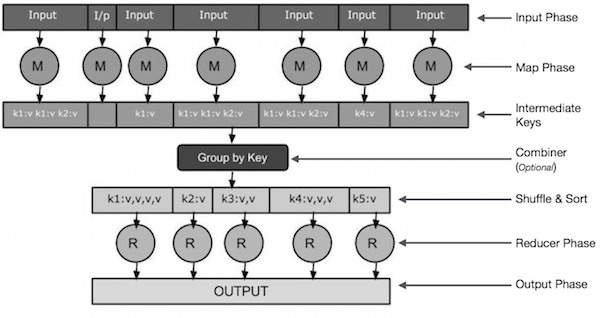
Input Phase - Ở đây chúng ta có Trình đọc Bản ghi dịch từng bản ghi trong một tệp đầu vào và gửi dữ liệu đã được phân tích cú pháp tới trình ánh xạ dưới dạng các cặp khóa-giá trị.
Map - Bản đồ là một chức năng do người dùng định nghĩa, lấy một loạt các cặp khóa-giá trị và xử lý từng cặp một trong số chúng để tạo ra không hoặc nhiều cặp khóa-giá trị.
Intermediate Keys - Các cặp khóa-giá trị do trình ánh xạ tạo ra được gọi là khóa trung gian.
Combiner- Bộ kết hợp là một loại Bộ giảm cục bộ nhóm dữ liệu tương tự từ giai đoạn bản đồ thành các tập hợp có thể xác định được. Nó lấy các khóa trung gian từ trình ánh xạ làm đầu vào và áp dụng mã do người dùng xác định để tổng hợp các giá trị trong một phạm vi nhỏ của một trình ánh xạ. Nó không phải là một phần của thuật toán MapReduce chính; nó là tùy chọn.
Shuffle and Sort- Tác vụ Giảm tốc bắt đầu với bước Xáo trộn và Sắp xếp. Nó tải các cặp khóa-giá trị đã được nhóm vào máy cục bộ, nơi Bộ giảm tốc đang chạy. Các cặp khóa-giá trị riêng lẻ được sắp xếp theo khóa thành một danh sách dữ liệu lớn hơn. Danh sách dữ liệu nhóm các khóa tương đương với nhau để các giá trị của chúng có thể được lặp lại dễ dàng trong tác vụ Bộ giảm.
Reducer- Bộ giảm tốc lấy dữ liệu được ghép nối khóa-giá trị được nhóm làm đầu vào và chạy chức năng Bộ giảm tốc trên mỗi một trong số chúng. Tại đây, dữ liệu có thể được tổng hợp, lọc và kết hợp theo một số cách và nó yêu cầu nhiều quá trình xử lý. Khi quá trình thực thi kết thúc, nó không cung cấp hoặc nhiều cặp khóa-giá trị cho bước cuối cùng.
Output Phase - Trong giai đoạn đầu ra, chúng ta có một trình định dạng đầu ra để dịch các cặp khóa-giá trị cuối cùng từ chức năng Reducer và ghi chúng vào tệp bằng trình ghi bản ghi.
Chúng ta hãy cố gắng hiểu hai tác vụ Map & f Reduce với sự trợ giúp của một sơ đồ nhỏ -

MapReduce-Ví dụ
Chúng ta hãy lấy một ví dụ trong thế giới thực để hiểu được sức mạnh của MapReduce. Twitter nhận được khoảng 500 triệu tweet mỗi ngày, tức là gần 3000 tweet mỗi giây. Hình minh họa sau đây cho thấy cách Tweeter quản lý các tweet của mình với sự trợ giúp của MapReduce.
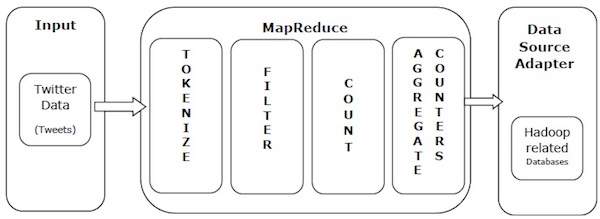
Như trong hình minh họa, thuật toán MapReduce thực hiện các hành động sau:
Tokenize - Mã hóa các tweet thành bản đồ mã thông báo và viết chúng dưới dạng các cặp khóa-giá trị.
Filter - Lọc các từ không mong muốn từ bản đồ mã thông báo và viết các bản đồ đã lọc dưới dạng các cặp khóa-giá trị.
Count - Tạo bộ đếm mã thông báo trên mỗi từ.
Aggregate Counters - Chuẩn bị tổng hợp các giá trị bộ đếm tương tự thành các đơn vị nhỏ có thể quản lý được.
Thuật toán MapReduce chứa hai nhiệm vụ quan trọng, đó là Bản đồ và Giảm.
- Nhiệm vụ bản đồ được thực hiện bởi Mapper Class
- Nhiệm vụ giảm thiểu được thực hiện bằng Lớp giảm tốc.
Lớp Mapper lấy đầu vào, mã hóa nó, ánh xạ và sắp xếp nó. Đầu ra của lớp Mapper được sử dụng làm đầu vào bởi lớp Reduceer, lớp này lần lượt tìm kiếm các cặp phù hợp và giảm chúng.

MapReduce thực hiện các thuật toán toán học khác nhau để chia một nhiệm vụ thành các phần nhỏ và gán chúng cho nhiều hệ thống. Về mặt kỹ thuật, thuật toán MapReduce giúp gửi các tác vụ Bản đồ & Rút gọn đến các máy chủ thích hợp trong một cụm.
Các thuật toán toán học này có thể bao gồm những điều sau:
- Sorting
- Searching
- Indexing
- TF-IDF
Sắp xếp
Sắp xếp là một trong những thuật toán MapReduce cơ bản để xử lý và phân tích dữ liệu. MapReduce triển khai thuật toán sắp xếp để tự động sắp xếp các cặp khóa-giá trị đầu ra từ trình ánh xạ theo khóa của chúng.
Các phương thức sắp xếp được thực hiện trong chính lớp ánh xạ.
Trong giai đoạn Trộn và Sắp xếp, sau khi mã hóa các giá trị trong lớp ánh xạ, Context lớp (lớp do người dùng định nghĩa) thu thập các khóa có giá trị phù hợp như một tập hợp.
Để thu thập các cặp khóa-giá trị tương tự (khóa trung gian), lớp Mapper có sự trợ giúp của RawComparator lớp để sắp xếp các cặp khóa-giá trị.
Tập hợp các cặp khóa-giá trị trung gian cho một Bộ giảm tốc nhất định được Hadoop tự động sắp xếp để tạo thành các khóa-giá trị (K2, {V2, V2,…}) trước khi chúng được hiển thị cho Bộ giảm tốc.
Đang tìm kiếm
Tìm kiếm đóng một vai trò quan trọng trong thuật toán MapReduce. Nó giúp ích trong giai đoạn kết hợp (tùy chọn) và trong giai đoạn Bộ giảm tốc. Hãy để chúng tôi cố gắng hiểu cách Tìm kiếm hoạt động với sự trợ giúp của một ví dụ.
Thí dụ
Ví dụ sau đây cho thấy cách MapReduce sử dụng thuật toán Tìm kiếm để tìm ra chi tiết của nhân viên có mức lương cao nhất trong một tập dữ liệu nhân viên nhất định.
Giả sử chúng ta có dữ liệu nhân viên trong bốn tệp khác nhau - A, B, C và D. Hãy giả sử rằng có các bản ghi nhân viên trùng lặp trong cả bốn tệp do nhập dữ liệu nhân viên từ tất cả các bảng cơ sở dữ liệu nhiều lần. Xem hình minh họa sau đây.

The Map phasexử lý từng tệp đầu vào và cung cấp dữ liệu nhân viên theo cặp khóa-giá trị (<k, v>: <tên tôi, lương>). Xem hình minh họa sau đây.

The combiner phase(kỹ thuật tìm kiếm) sẽ chấp nhận đầu vào từ giai đoạn Bản đồ dưới dạng một cặp khóa-giá trị với tên và lương của nhân viên. Sử dụng kỹ thuật tìm kiếm, bộ kết hợp sẽ kiểm tra tất cả mức lương của nhân viên để tìm ra nhân viên có mức lương cao nhất trong mỗi tệp. Xem đoạn mã sau.
<k: employee name, v: salary>
Max= the salary of an first employee. Treated as max salary
if(v(second employee).salary > Max){
Max = v(salary);
}
else{
Continue checking;
}Kết quả mong đợi như sau:
|
Reducer phase- Lập từng hồ sơ, bạn sẽ tìm được nhân viên có mức lương cao nhất. Để tránh dư thừa, hãy kiểm tra tất cả các cặp <k, v> và loại bỏ các mục trùng lặp, nếu có. Thuật toán tương tự được sử dụng giữa bốn cặp <k, v>, đến từ bốn tệp đầu vào. Kết quả cuối cùng sẽ như sau:
<gopal, 50000>Lập chỉ mục
Thông thường, lập chỉ mục được sử dụng để trỏ đến một dữ liệu cụ thể và địa chỉ của nó. Nó thực hiện lập chỉ mục hàng loạt trên các tệp đầu vào cho một Mapper cụ thể.
Kỹ thuật lập chỉ mục thường được sử dụng trong MapReduce được gọi là inverted index.Các công cụ tìm kiếm như Google và Bing sử dụng kỹ thuật lập chỉ mục ngược. Hãy để chúng tôi tìm hiểu cách hoạt động của Lập chỉ mục với sự trợ giúp của một ví dụ đơn giản.
Thí dụ
Văn bản sau đây là đầu vào để lập chỉ mục ngược. Ở đây T [0], T [1] và t [2] là tên tệp và nội dung của chúng được đặt trong dấu ngoặc kép.
T[0] = "it is what it is"
T[1] = "what is it"
T[2] = "it is a banana"Sau khi áp dụng thuật toán Lập chỉ mục, chúng tôi nhận được kết quả sau:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}Ở đây "a": {2} ngụ ý thuật ngữ "a" xuất hiện trong tệp T [2]. Tương tự, "là": {0, 1, 2} ngụ ý thuật ngữ "là" xuất hiện trong các tệp T [0], T [1] và T [2].
TF-IDF
TF-IDF là một thuật toán xử lý văn bản, viết tắt của Cụm từ Tần số kỳ hạn - Tần suất Tài liệu Nghịch đảo. Nó là một trong những thuật toán phân tích web phổ biến. Ở đây, thuật ngữ 'tần suất' đề cập đến số lần một thuật ngữ xuất hiện trong tài liệu.
Tần suất kỳ hạn (TF)
Nó đo lường tần suất một thuật ngữ cụ thể xuất hiện trong tài liệu. Nó được tính bằng số lần một từ xuất hiện trong tài liệu chia cho tổng số từ trong tài liệu đó.
TF(the) = (Number of times term the ‘the’ appears in a document) / (Total number of terms in the document)Tần suất tài liệu nghịch đảo (IDF)
Nó đo tầm quan trọng của một thuật ngữ. Nó được tính bằng số lượng tài liệu trong cơ sở dữ liệu văn bản chia cho số lượng tài liệu mà một thuật ngữ cụ thể xuất hiện.
Trong khi tính toán TF, tất cả các thuật ngữ đều được coi là quan trọng như nhau. Điều đó có nghĩa là, TF đếm tần suất thuật ngữ cho các từ bình thường như “là”, “a”, “cái gì”, v.v. Vì vậy, chúng ta cần biết các thuật ngữ thường gặp trong khi mở rộng các thuật ngữ hiếm, bằng cách tính toán sau:
IDF(the) = log_e(Total number of documents / Number of documents with term ‘the’ in it).Thuật toán được giải thích dưới đây với sự trợ giúp của một ví dụ nhỏ.
Thí dụ
Hãy xem xét một tài liệu chứa 1000 từ, trong đó từ hivexuất hiện 50 lần. TF chohive sau đó là (50/1000) = 0,05.
Bây giờ, giả sử chúng ta có 10 triệu tài liệu và từ hivexuất hiện trong 1000 trong số này. Sau đó, IDF được tính là log (10.000.000 / 1.000) = 4.
Trọng lượng TF-IDF là tích của các đại lượng này - 0,05 × 4 = 0,20.
MapReduce chỉ hoạt động trên các hệ điều hành có hương vị Linux và nó được tích hợp sẵn với Khung Hadoop. Chúng ta cần thực hiện các bước sau để cài đặt Hadoop framework.
Xác minh cài đặt JAVA
Java phải được cài đặt trên hệ thống của bạn trước khi cài đặt Hadoop. Sử dụng lệnh sau để kiểm tra xem bạn đã cài đặt Java trên hệ thống của mình chưa.
$ java –versionNếu Java đã được cài đặt trên hệ thống của bạn, bạn sẽ thấy phản hồi sau:
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Trong trường hợp bạn chưa cài đặt Java trên hệ thống của mình, hãy làm theo các bước dưới đây.
Cài đặt Java
Bước 1
Tải xuống phiên bản Java mới nhất từ liên kết sau - liên kết này .
Sau khi tải xuống, bạn có thể định vị tệp jdk-7u71-linux-x64.tar.gz trong thư mục Tải xuống của bạn.
Bước 2
Sử dụng các lệnh sau để trích xuất nội dung của jdk-7u71-linux-x64.gz.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzBước 3
Để cung cấp Java cho tất cả người dùng, bạn phải chuyển nó đến vị trí “/ usr / local /”. Truy cập root và nhập các lệnh sau:
$ su
password:
# mv jdk1.7.0_71 /usr/local/java
# exitBước 4
Để thiết lập các biến PATH và JAVA_HOME, hãy thêm các lệnh sau vào tệp ~ / .bashrc.
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/binÁp dụng tất cả các thay đổi cho hệ thống đang chạy hiện tại.
$ source ~/.bashrcBước 5
Sử dụng các lệnh sau để định cấu hình các lựa chọn thay thế Java:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarBây giờ hãy xác minh cài đặt bằng lệnh java -version từ thiết bị đầu cuối.
Xác minh cài đặt Hadoop
Hadoop phải được cài đặt trên hệ thống của bạn trước khi cài đặt MapReduce. Hãy để chúng tôi xác minh cài đặt Hadoop bằng lệnh sau:
$ hadoop versionNếu Hadoop đã được cài đặt trên hệ thống của bạn, thì bạn sẽ nhận được phản hồi sau:
Hadoop 2.4.1
--
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Nếu Hadoop chưa được cài đặt trên hệ thống của bạn, hãy tiến hành các bước sau.
Tải xuống Hadoop
Tải xuống Hadoop 2.4.1 từ Apache Software Foundation và trích xuất nội dung của nó bằng các lệnh sau.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitCài đặt Hadoop ở chế độ Pseudo Distributed
Các bước sau được sử dụng để cài đặt Hadoop 2.4.1 ở chế độ phân tán giả.
Bước 1 - Thiết lập Hadoop
Bạn có thể đặt các biến môi trường Hadoop bằng cách thêm các lệnh sau vào tệp ~ / .bashrc.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binÁp dụng tất cả các thay đổi cho hệ thống đang chạy hiện tại.
$ source ~/.bashrcBước 2 - Cấu hình Hadoop
Bạn có thể tìm thấy tất cả các tệp cấu hình Hadoop ở vị trí “$ HADOOP_HOME / etc / hadoop”. Bạn cần thực hiện các thay đổi phù hợp trong các tệp cấu hình đó theo cơ sở hạ tầng Hadoop của mình.
$ cd $HADOOP_HOME/etc/hadoopĐể phát triển các chương trình Hadoop bằng Java, bạn phải đặt lại các biến môi trường Java trong hadoop-env.sh bằng cách thay thế giá trị JAVA_HOME bằng vị trí của Java trong hệ thống của bạn.
export JAVA_HOME=/usr/local/javaBạn phải chỉnh sửa các tệp sau để định cấu hình Hadoop -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
core-site.xml chứa thông tin sau
- Số cổng được sử dụng cho phiên bản Hadoop
- Bộ nhớ được phân bổ cho hệ thống tệp
- Giới hạn bộ nhớ để lưu trữ dữ liệu
- Kích thước của bộ đệm Đọc / Ghi
Mở core-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configuration> và </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000 </value>
</property>
</configuration>hdfs-site.xml
hdfs-site.xml chứa thông tin sau:
- Giá trị của dữ liệu sao chép
- Đường dẫn nút tên
- Đường dẫn datanode của hệ thống tệp cục bộ của bạn (nơi bạn muốn lưu trữ cơ sở hạ tầng Hadoop)
Hãy để chúng tôi giả sử dữ liệu sau đây.
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeMở tệp này và thêm các thuộc tính sau vào giữa các thẻ <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>Note - Trong tệp trên, tất cả các giá trị thuộc tính đều do người dùng xác định và bạn có thể thực hiện thay đổi theo cơ sở hạ tầng Hadoop của mình.
fiber-site.xml
Tệp này được sử dụng để cấu hình sợi thành Hadoop. Mở tệp fiber-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configuration>, </configuration>.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Tệp này được sử dụng để chỉ định khung MapReduce mà chúng tôi đang sử dụng. Theo mặc định, Hadoop chứa một mẫu sợi-site.xml. Trước hết, bạn cần sao chép tệp từ mapred-site.xml.template sang tệp mapred-site.xml bằng lệnh sau.
$ cp mapred-site.xml.template mapred-site.xmlMở tệp mapred-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configuration>, </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Xác minh cài đặt Hadoop
Các bước sau được sử dụng để xác minh cài đặt Hadoop.
Bước 1 - Thiết lập nút đặt tên
Thiết lập nút tên bằng lệnh “hdfs namenode -format” như sau:
$ cd ~ $ hdfs namenode -formatKết quả mong đợi như sau:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Bước 2 - Xác minh dfs Hadoop
Thực thi lệnh sau để khởi động hệ thống tệp Hadoop của bạn.
$ start-dfs.shSản lượng dự kiến như sau:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Bước 3 - Xác minh Tập lệnh Sợi
Lệnh sau được sử dụng để bắt đầu tập lệnh sợi. Việc thực thi lệnh này sẽ bắt đầu các daemon sợi của bạn.
$ start-yarn.shSản lượng dự kiến như sau:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outBước 4 - Truy cập Hadoop trên trình duyệt
Số cổng mặc định để truy cập Hadoop là 50070. Sử dụng URL sau để tải các dịch vụ Hadoop trên trình duyệt của bạn.
http://localhost:50070/Ảnh chụp màn hình sau đây cho thấy trình duyệt Hadoop.

Bước 5 - Xác minh tất cả các ứng dụng của một cụm
Số cổng mặc định để truy cập tất cả các ứng dụng của một cụm là 8088. Sử dụng URL sau để sử dụng dịch vụ này.
http://localhost:8088/Ảnh chụp màn hình sau đây cho thấy một trình duyệt cụm Hadoop.

Trong chương này, chúng ta sẽ xem xét kỹ các lớp và phương thức của chúng liên quan đến các hoạt động của lập trình MapReduce. Chúng tôi chủ yếu sẽ tập trung vào những điều sau:
- Giao diện JobContext
- Hạng công việc
- Lớp vẽ bản đồ
- Lớp giảm tốc
Giao diện JobContext
Giao diện JobContext là siêu giao diện cho tất cả các lớp, định nghĩa các công việc khác nhau trong MapReduce. Nó cung cấp cho bạn chế độ xem chỉ đọc về công việc được cung cấp cho các nhiệm vụ trong khi chúng đang chạy.
Sau đây là các giao diện con của giao diện JobContext.
| Không. | Mô tả giao diện phụ |
|---|---|
| 1. | MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> Xác định ngữ cảnh được cung cấp cho Người lập bản đồ. |
| 2. | ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> Xác định ngữ cảnh được chuyển đến Bộ giảm tốc. |
Lớp công việc là lớp chính thực hiện giao diện JobContext.
Hạng công việc
Lớp Công việc là lớp quan trọng nhất trong API MapReduce. Nó cho phép người dùng định cấu hình công việc, đệ trình nó, kiểm soát việc thực thi nó và truy vấn trạng thái. Các phương thức đã đặt chỉ hoạt động cho đến khi công việc được gửi, sau đó chúng sẽ ném ra một IllegalStateException.
Thông thường, người dùng tạo ứng dụng, mô tả các khía cạnh khác nhau của công việc, sau đó gửi công việc và theo dõi tiến trình của nó.
Đây là một ví dụ về cách gửi một công việc -
// Create a new Job
Job job = new Job(new Configuration());
job.setJarByClass(MyJob.class);
// Specify various job-specific parameters
job.setJobName("myjob");
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);Người xây dựng
Sau đây là tóm tắt hàm tạo của lớp Job.
| S.Không | Tóm tắt về hàm tạo |
|---|---|
| 1 | Job() |
| 2 | Job(Cấu hình cấu hình) |
| 3 | Job(Cấu hình cấu hình, String jobName) |
Phương pháp
Một số phương thức quan trọng của lớp Job như sau:
| S.Không | Mô tả phương pháp |
|---|---|
| 1 | getJobName() Tên công việc do người dùng chỉ định. |
| 2 | getJobState() Trả về trạng thái hiện tại của Công việc. |
| 3 | isComplete() Kiểm tra xem công việc đã hoàn thành hay chưa. |
| 4 | setInputFormatClass() Đặt Định dạng đầu vào cho công việc. |
| 5 | setJobName(String name) Đặt tên công việc do người dùng chỉ định. |
| 6 | setOutputFormatClass() Đặt Định dạng trang kết quả cho công việc. |
| 7 | setMapperClass(Class) Đặt Mapper cho công việc. |
| số 8 | setReducerClass(Class) Đặt Bộ giảm tốc cho công việc. |
| 9 | setPartitionerClass(Class) Đặt Phân vùng cho công việc. |
| 10 | setCombinerClass(Class) Đặt Combiner cho công việc. |
Lớp vẽ bản đồ
Lớp Mapper định nghĩa công việc Bản đồ. Bản đồ nhập các cặp khóa-giá trị vào một tập hợp các cặp khóa-giá trị trung gian. Bản đồ là các tác vụ riêng lẻ biến đổi các bản ghi đầu vào thành các bản ghi trung gian. Các bản ghi trung gian đã chuyển đổi không cần phải cùng loại với các bản ghi đầu vào. Một cặp đầu vào nhất định có thể ánh xạ tới không hoặc nhiều cặp đầu ra.
phương pháp
maplà phương thức nổi bật nhất của lớp Mapper. Cú pháp được định nghĩa bên dưới:
map(KEYIN key, VALUEIN value, org.apache.hadoop.mapreduce.Mapper.Context context)Phương thức này được gọi một lần cho mỗi cặp khóa-giá trị trong phần tách đầu vào.
Lớp giảm tốc
Lớp Reduceer định nghĩa công việc Reduce trong MapReduce. Nó làm giảm một tập hợp các giá trị trung gian chia sẻ khóa thành một tập giá trị nhỏ hơn. Việc triển khai bộ giảm có thể truy cập Cấu hình cho một công việc thông qua phương thức JobContext.getConfiguration (). Hộp giảm tốc có ba giai đoạn chính - Trộn, Sắp xếp và Giảm.
Shuffle - Trình giảm sao chép đầu ra được sắp xếp từ mỗi Người lập bản đồ bằng HTTP qua mạng.
Sort- Khung hợp nhất sắp xếp các đầu vào của Bộ giảm tốc theo các khóa (vì các Trình lập bản đồ khác nhau có thể có cùng một khóa). Các giai đoạn xáo trộn và sắp xếp xảy ra đồng thời, tức là, trong khi các đầu ra đang được tìm nạp, chúng được hợp nhất.
Reduce - Trong giai đoạn này, phương thức Reduce (Object, Iterable, Context) được gọi cho mỗi <khóa, (tập hợp các giá trị)> trong các đầu vào đã sắp xếp.
phương pháp
reducelà phương thức nổi bật nhất của lớp Reduceer. Cú pháp được định nghĩa bên dưới:
reduce(KEYIN key, Iterable<VALUEIN> values, org.apache.hadoop.mapreduce.Reducer.Context context)Phương thức này được gọi một lần cho mỗi khóa trên tập hợp các cặp khóa-giá trị.
MapReduce là một khuôn khổ được sử dụng để viết các ứng dụng nhằm xử lý khối lượng dữ liệu khổng lồ trên các cụm phần cứng hàng hóa lớn một cách đáng tin cậy. Chương này sẽ đưa bạn qua hoạt động của MapReduce trong khuôn khổ Hadoop sử dụng Java.
Thuật toán MapReduce
Nói chung, mô hình MapReduce dựa trên việc gửi các chương trình thu nhỏ bản đồ đến các máy tính có dữ liệu thực.
Trong một công việc MapReduce, Hadoop gửi các tác vụ Bản đồ và Rút gọn tới các máy chủ thích hợp trong cụm.
Khung quản lý tất cả các chi tiết của việc truyền dữ liệu như phát hành nhiệm vụ, xác minh việc hoàn thành nhiệm vụ và sao chép dữ liệu xung quanh cụm giữa các nút.
Hầu hết việc tính toán diễn ra trên các nút với dữ liệu trên các đĩa cục bộ làm giảm lưu lượng mạng.
Sau khi hoàn thành một nhiệm vụ nhất định, cụm thu thập và giảm dữ liệu để tạo thành một kết quả thích hợp và gửi nó trở lại máy chủ Hadoop.

Đầu vào và đầu ra (Phối cảnh Java)
Khung công tác MapReduce hoạt động trên các cặp khóa-giá trị, nghĩa là, khung công tác xem đầu vào của công việc như một tập hợp các cặp khóa-giá trị và tạo ra một tập hợp các cặp khóa-giá trị làm đầu ra của công việc, có thể hình dung ra các loại khác nhau.
Các lớp giá trị và khóa phải có thể được tuần tự hóa bởi khuôn khổ và do đó, nó được yêu cầu để triển khai giao diện ghi. Ngoài ra, các lớp khóa phải triển khai giao diện WordsComp so sánh được để tạo điều kiện phân loại theo khuôn khổ.
Cả định dạng đầu vào và đầu ra của công việc MapReduce đều ở dạng các cặp khóa-giá trị -
(Đầu vào) <k1, v1> -> bản đồ -> <k2, v2> -> giảm -> <k3, v3> (Đầu ra).
| Đầu vào | Đầu ra | |
|---|---|---|
| Bản đồ | <k1, v1> | danh sách (<k2, v2>) |
| Giảm | <k2, list (v2)> | danh sách (<k3, v3>) |
Triển khai MapReduce
Bảng sau đây cho thấy dữ liệu về mức tiêu thụ điện của một tổ chức. Bảng này bao gồm mức tiêu thụ điện hàng tháng và mức trung bình hàng năm trong năm năm liên tiếp.
| tháng một | Tháng hai | Mar | Tháng tư | có thể | Tháng sáu | Thg 7 | Tháng 8 | Tháng chín | Tháng 10 | Tháng 11 | Tháng mười hai | Trung bình | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Chúng ta cần viết các ứng dụng để xử lý dữ liệu đầu vào trong bảng đã cho để tìm năm sử dụng tối đa, năm sử dụng tối thiểu, v.v. Nhiệm vụ này rất dễ dàng đối với các lập trình viên với số lượng bản ghi hữu hạn, vì họ sẽ chỉ cần viết logic để tạo ra đầu ra cần thiết và chuyển dữ liệu đến ứng dụng đã viết.
Bây giờ chúng ta hãy nâng quy mô của dữ liệu đầu vào. Giả sử chúng ta phải phân tích mức tiêu thụ điện của tất cả các ngành công nghiệp quy mô lớn của một bang cụ thể. Khi chúng tôi viết ứng dụng để xử lý dữ liệu hàng loạt như vậy,
Họ sẽ mất rất nhiều thời gian để thực hiện.
Sẽ có nhiều lưu lượng mạng khi chúng ta di chuyển dữ liệu từ nguồn đến máy chủ mạng.
Để giải quyết những vấn đề này, chúng tôi có khung công tác MapReduce.
Dữ liệu đầu vào
Dữ liệu trên được lưu dưới dạng sample.txtvà được cung cấp dưới dạng đầu vào. Tệp đầu vào trông như hình dưới đây.
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Chương trình mẫu
Chương trình sau cho dữ liệu mẫu sử dụng khung MapReduce.
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits
{
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable, /*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()){
lasttoken=s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements
Reducer< Text, IntWritable, Text, IntWritable >
{
//Reduce function
public void reduce(Text key, Iterator <IntWritable> values, OutputCollector>Text, IntWritable> output, Reporter reporter) throws IOException
{
int maxavg=30;
int val=Integer.MIN_VALUE;
while (values.hasNext())
{
if((val=values.next().get())>maxavg)
{
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception
{
JobConf conf = new JobConf(Eleunits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}Lưu chương trình trên vào ProcessUnits.java. Việc biên dịch và thực hiện chương trình được đưa ra dưới đây.
Biên soạn và thực hiện chương trình ProcessUnits
Giả sử chúng tôi đang ở trong thư mục chính của người dùng Hadoop (ví dụ: / home / hadoop).
Làm theo các bước dưới đây để biên dịch và thực thi chương trình trên.
Step 1 - Sử dụng lệnh sau để tạo thư mục lưu các lớp java đã biên dịch.
$ mkdir unitsStep 2- Tải xuống Hadoop-core-1.2.1.jar, được sử dụng để biên dịch và thực thi chương trình MapReduce. Tải xuống jar từ mvnrepository.com . Giả sử thư mục tải xuống là / home / hadoop /.
Step 3 - Các lệnh sau được sử dụng để biên dịch ProcessUnits.java chương trình và để tạo một jar cho chương trình.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java
$ jar -cvf units.jar -C units/ .Step 4 - Lệnh sau dùng để tạo thư mục đầu vào trong HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 5 - Lệnh sau dùng để sao chép tệp đầu vào có tên sample.txt trong thư mục đầu vào của HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dirStep 6 - Lệnh sau được sử dụng để xác minh các tệp trong thư mục đầu vào
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7 - Lệnh sau được sử dụng để chạy ứng dụng Eleunit_max bằng cách lấy các tệp đầu vào từ thư mục đầu vào.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirChờ một lúc cho đến khi tệp được thực thi. Sau khi thực thi, đầu ra chứa một số phân tách đầu vào, tác vụ Bản đồ, tác vụ Bộ giảm tốc, v.v.
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=61
FILE: Number of bytes written=279400
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=546
HDFS: Number of bytes written=40
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2 Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=146137
Total time spent by all reduces in occupied slots (ms)=441
Total time spent by all map tasks (ms)=14613
Total time spent by all reduce tasks (ms)=44120
Total vcore-seconds taken by all map tasks=146137
Total vcore-seconds taken by all reduce tasks=44120
Total megabyte-seconds taken by all map tasks=149644288
Total megabyte-seconds taken by all reduce tasks=45178880
Map-Reduce Framework
Map input records=5
Map output records=5
Map output bytes=45
Map output materialized bytes=67
Input split bytes=208
Combine input records=5
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=6
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=948
CPU time spent (ms)=5160
Physical memory (bytes) snapshot=47749120
Virtual memory (bytes) snapshot=2899349504
Total committed heap usage (bytes)=277684224
File Output Format Counters
Bytes Written=40Step 8 - Lệnh sau được sử dụng để xác minh các tệp kết quả trong thư mục đầu ra.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9 - Lệnh sau được sử dụng để xem kết quả đầu ra trong Part-00000tập tin. Tệp này được tạo bởi HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Sau đây là đầu ra do chương trình MapReduce tạo ra:
| 1981 | 34 |
| 1984 | 40 |
| 1985 | 45 |
Step 10 - Lệnh sau được sử dụng để sao chép thư mục đầu ra từ HDFS vào hệ thống tệp cục bộ.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs -get output_dir /home/hadoopMột trình phân vùng hoạt động giống như một điều kiện để xử lý một tập dữ liệu đầu vào. Giai đoạn phân vùng diễn ra sau giai đoạn Bản đồ và trước giai đoạn Rút gọn.
Số bộ phân vùng bằng số bộ giảm bớt. Điều đó có nghĩa là một trình phân vùng sẽ chia dữ liệu theo số lượng bộ giảm. Do đó, dữ liệu được truyền từ một bộ phân vùng duy nhất được xử lý bởi một Bộ giảm tốc duy nhất.
Người phân vùng
Một trình phân vùng phân vùng các cặp khóa-giá trị của các đầu ra Bản đồ trung gian. Nó phân vùng dữ liệu bằng cách sử dụng một điều kiện do người dùng xác định, hoạt động giống như một hàm băm. Tổng số phân vùng cũng giống như số tác vụ của Bộ giảm cho công việc. Chúng ta hãy lấy một ví dụ để hiểu cách hoạt động của trình phân vùng.
Triển khai phân vùng MapReduce
Để thuận tiện, chúng ta hãy giả sử chúng ta có một bảng nhỏ được gọi là Nhân viên với dữ liệu sau. Chúng tôi sẽ sử dụng dữ liệu mẫu này làm bộ dữ liệu đầu vào để chứng minh cách hoạt động của trình phân vùng.
| Tôi | Tên | Tuổi tác | Giới tính | Tiền lương |
|---|---|---|---|---|
| 1201 | gopal | 45 | Nam giới | 50.000 |
| 1202 | manisha | 40 | Giống cái | 50.000 |
| 1203 | khalil | 34 | Nam giới | 30.000 |
| 1204 | prasanth | 30 | Nam giới | 30.000 |
| 1205 | kiran | 20 | Nam giới | 40.000 |
| 1206 | laxmi | 25 | Giống cái | 35.000 |
| 1207 | bhavya | 20 | Giống cái | 15.000 |
| 1208 | reshma | 19 | Giống cái | 15.000 |
| 1209 | kranthi | 22 | Nam giới | 22.000 |
| 1210 | Hài lòng | 24 | Nam giới | 25.000 |
| 1211 | Krishna | 25 | Nam giới | 25.000 |
| 1212 | Arshad | 28 | Nam giới | 20.000 |
| 1213 | lavanya | 18 | Giống cái | 8.000 |
Chúng tôi phải viết một ứng dụng để xử lý bộ dữ liệu đầu vào để tìm ra nhân viên được trả lương cao nhất theo giới tính ở các nhóm tuổi khác nhau (ví dụ: dưới 20, từ 21 đến 30, trên 30).
Dữ liệu đầu vào
Dữ liệu trên được lưu dưới dạng input.txt trong thư mục “/ home / hadoop / hadoopPartitioner” và được cung cấp dưới dạng đầu vào.
| 1201 | gopal | 45 | Nam giới | 50000 |
| 1202 | manisha | 40 | Giống cái | 51000 |
| 1203 | khaleel | 34 | Nam giới | 30000 |
| 1204 | prasanth | 30 | Nam giới | 31000 |
| 1205 | kiran | 20 | Nam giới | 40000 |
| 1206 | laxmi | 25 | Giống cái | 35000 |
| 1207 | bhavya | 20 | Giống cái | 15000 |
| 1208 | reshma | 19 | Giống cái | 14000 |
| 1209 | kranthi | 22 | Nam giới | 22000 |
| 1210 | Hài lòng | 24 | Nam giới | 25000 |
| 1211 | Krishna | 25 | Nam giới | 26000 |
| 1212 | Arshad | 28 | Nam giới | 20000 |
| 1213 | lavanya | 18 | Giống cái | 8000 |
Dựa trên đầu vào đã cho, sau đây là giải thích thuật toán của chương trình.
Nhiệm vụ bản đồ
Tác vụ bản đồ chấp nhận các cặp khóa-giá trị làm đầu vào trong khi chúng ta có dữ liệu văn bản trong tệp văn bản. Đầu vào cho nhiệm vụ bản đồ này như sau:
Input - Khóa sẽ là một mẫu chẳng hạn như “bất kỳ khóa đặc biệt nào + tên tệp + số dòng” (ví dụ: key = @ input1) và giá trị sẽ là dữ liệu trong dòng đó (ví dụ: value = 1201 \ t gopal \ t 45 \ t Nam 50000).
Method - Hoạt động của nhiệm vụ bản đồ này như sau:
Đọc value (dữ liệu bản ghi), xuất phát dưới dạng giá trị đầu vào từ danh sách đối số trong một chuỗi.
Sử dụng hàm phân tách, tách giới tính và lưu trữ trong một biến chuỗi.
String[] str = value.toString().split("\t", -3);
String gender=str[3];Gửi thông tin giới tính và dữ liệu hồ sơ value dưới dạng cặp khóa-giá trị đầu ra từ nhiệm vụ bản đồ đến partition task.
context.write(new Text(gender), new Text(value));Lặp lại tất cả các bước trên cho tất cả các bản ghi trong tệp văn bản.
Output - Bạn sẽ nhận được dữ liệu giới tính và giá trị dữ liệu bản ghi dưới dạng các cặp khóa-giá trị.
Tác vụ phân vùng
Tác vụ phân vùng chấp nhận các cặp khóa-giá trị từ tác vụ bản đồ làm đầu vào của nó. Phân vùng ngụ ý chia dữ liệu thành các phân đoạn. Theo tiêu chí có điều kiện nhất định của phân vùng, dữ liệu ghép nối khóa-giá trị đầu vào có thể được chia thành ba phần dựa trên tiêu chí tuổi.
Input - Toàn bộ dữ liệu trong tập hợp các cặp khóa-giá trị.
key = Giá trị trường giới tính trong bản ghi.
value = Giá trị dữ liệu bản ghi toàn bộ của giới tính đó.
Method - Quá trình logic phân vùng chạy như sau.
- Đọc giá trị trường tuổi từ cặp khóa-giá trị đầu vào.
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);Kiểm tra giá trị tuổi với các điều kiện sau.
- Tuổi nhỏ hơn hoặc bằng 20
- Tuổi Dưới 20 và Nhỏ hơn hoặc bằng 30.
- Tuổi Trên 30.
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}Output- Toàn bộ dữ liệu của các cặp khóa-giá trị được phân đoạn thành ba bộ sưu tập các cặp khóa-giá trị. Bộ giảm tốc hoạt động riêng lẻ trên mỗi bộ sưu tập.
Giảm công việc
Số tác vụ phân vùng bằng số tác vụ bộ giảm tốc. Ở đây chúng ta có ba tác vụ của bộ phân vùng và do đó chúng ta có ba tác vụ của Bộ giảm sẽ được thực thi.
Input - Bộ giảm sẽ thực hiện ba lần với các bộ sưu tập các cặp khóa-giá trị khác nhau.
key = giá trị trường giới tính trong bản ghi.
value = toàn bộ dữ liệu bản ghi của giới tính đó.
Method - Logic sau đây sẽ được áp dụng trên mỗi bộ sưu tập.
- Đọc giá trị trường Lương của mỗi bản ghi.
String [] str = val.toString().split("\t", -3);
Note: str[4] have the salary field value.Kiểm tra mức lương với biến max. Nếu str [4] là mức lương tối đa, thì gán str [4] là tối đa, nếu không thì bỏ qua bước.
if(Integer.parseInt(str[4])>max)
{
max=Integer.parseInt(str[4]);
}Lặp lại các Bước 1 và 2 cho mỗi bộ sưu tập khóa (Nam & Nữ là bộ sưu tập khóa). Sau khi thực hiện ba bước này, bạn sẽ tìm thấy một mức lương tối đa từ bộ sưu tập khóa Nam và một mức lương tối đa từ bộ sưu tập khóa Nữ.
context.write(new Text(key), new IntWritable(max));Output- Cuối cùng, bạn sẽ nhận được một bộ dữ liệu cặp khóa-giá trị trong ba bộ sưu tập của các nhóm tuổi khác nhau. Nó chứa mức lương tối đa từ bộ sưu tập Nam và mức lương tối đa từ bộ sưu tập Nữ tương ứng với từng nhóm tuổi.
Sau khi thực hiện các tác vụ Bản đồ, Bộ phân vùng và Rút gọn, ba bộ sưu tập dữ liệu cặp khóa-giá trị được lưu trữ trong ba tệp khác nhau dưới dạng đầu ra.
Tất cả ba tác vụ được coi là công việc MapReduce. Các yêu cầu và thông số kỹ thuật sau đây của những công việc này cần được chỉ rõ trong Cấu hình -
- Tên công việc
- Định dạng đầu vào và đầu ra của các khóa và giá trị
- Các lớp cá nhân cho các tác vụ Bản đồ, Rút gọn và Phân vùng
Configuration conf = getConf();
//Create Job
Job job = new Job(conf, "topsal");
job.setJarByClass(PartitionerExample.class);
// File Input and Output paths
FileInputFormat.setInputPaths(job, new Path(arg[0]));
FileOutputFormat.setOutputPath(job,new Path(arg[1]));
//Set Mapper class and Output format for key-value pair.
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//set partitioner statement
job.setPartitionerClass(CaderPartitioner.class);
//Set Reducer class and Input/Output format for key-value pair.
job.setReducerClass(ReduceClass.class);
//Number of Reducer tasks.
job.setNumReduceTasks(3);
//Input and Output format for data
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);Chương trình mẫu
Chương trình sau đây chỉ ra cách triển khai các trình phân vùng cho các tiêu chí đã cho trong chương trình MapReduce.
package partitionerexample;
import java.io.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
import org.apache.hadoop.util.*;
public class PartitionerExample extends Configured implements Tool
{
//Map class
public static class MapClass extends Mapper<LongWritable,Text,Text,Text>
{
public void map(LongWritable key, Text value, Context context)
{
try{
String[] str = value.toString().split("\t", -3);
String gender=str[3];
context.write(new Text(gender), new Text(value));
}
catch(Exception e)
{
System.out.println(e.getMessage());
}
}
}
//Reducer class
public static class ReduceClass extends Reducer<Text,Text,Text,IntWritable>
{
public int max = -1;
public void reduce(Text key, Iterable <Text> values, Context context) throws IOException, InterruptedException
{
max = -1;
for (Text val : values)
{
String [] str = val.toString().split("\t", -3);
if(Integer.parseInt(str[4])>max)
max=Integer.parseInt(str[4]);
}
context.write(new Text(key), new IntWritable(max));
}
}
//Partitioner class
public static class CaderPartitioner extends
Partitioner < Text, Text >
{
@Override
public int getPartition(Text key, Text value, int numReduceTasks)
{
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);
if(numReduceTasks == 0)
{
return 0;
}
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}
}
}
@Override
public int run(String[] arg) throws Exception
{
Configuration conf = getConf();
Job job = new Job(conf, "topsal");
job.setJarByClass(PartitionerExample.class);
FileInputFormat.setInputPaths(job, new Path(arg[0]));
FileOutputFormat.setOutputPath(job,new Path(arg[1]));
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//set partitioner statement
job.setPartitionerClass(CaderPartitioner.class);
job.setReducerClass(ReduceClass.class);
job.setNumReduceTasks(3);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true)? 0 : 1);
return 0;
}
public static void main(String ar[]) throws Exception
{
int res = ToolRunner.run(new Configuration(), new PartitionerExample(),ar);
System.exit(0);
}
}Lưu mã trên dưới dạng PartitionerExample.javatrong “/ home / hadoop / hadoopPartitioner”. Việc biên dịch và thực hiện chương trình được đưa ra dưới đây.
Biên dịch và Thực hiện
Giả sử chúng ta đang ở trong thư mục chính của người dùng Hadoop (ví dụ: / home / hadoop).
Làm theo các bước dưới đây để biên dịch và thực thi chương trình trên.
Step 1- Tải xuống Hadoop-core-1.2.1.jar, được sử dụng để biên dịch và thực thi chương trình MapReduce. Bạn có thể tải xuống jar từ mvnrepository.com .
Giả sử thư mục đã tải xuống là “/ home / hadoop / hadoopPartitioner”
Step 2 - Các lệnh sau được sử dụng để biên dịch chương trình PartitionerExample.java và tạo một jar cho chương trình.
$ javac -classpath hadoop-core-1.2.1.jar -d ProcessUnits.java $ jar -cvf PartitionerExample.jar -C .Step 3 - Sử dụng lệnh sau để tạo thư mục đầu vào trong HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 4 - Sử dụng lệnh sau để sao chép tệp đầu vào có tên input.txt trong thư mục đầu vào của HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/hadoopPartitioner/input.txt input_dirStep 5 - Sử dụng lệnh sau để xác minh các tệp trong thư mục đầu vào.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 6 - Sử dụng lệnh sau để chạy ứng dụng Top lương bằng cách lấy các tập tin đầu vào từ thư mục đầu vào.
$HADOOP_HOME/bin/hadoop jar PartitionerExample.jar partitionerexample.PartitionerExample input_dir/input.txt output_dirChờ một lúc cho đến khi tệp được thực thi. Sau khi thực thi, đầu ra chứa một số phân tách đầu vào, tác vụ bản đồ và tác vụ Bộ giảm tốc.
15/02/04 15:19:51 INFO mapreduce.Job: Job job_1423027269044_0021 completed successfully
15/02/04 15:19:52 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=467
FILE: Number of bytes written=426777
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=480
HDFS: Number of bytes written=72
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Job Counters
Launched map tasks=1
Launched reduce tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=8212
Total time spent by all reduces in occupied slots (ms)=59858
Total time spent by all map tasks (ms)=8212
Total time spent by all reduce tasks (ms)=59858
Total vcore-seconds taken by all map tasks=8212
Total vcore-seconds taken by all reduce tasks=59858
Total megabyte-seconds taken by all map tasks=8409088
Total megabyte-seconds taken by all reduce tasks=61294592
Map-Reduce Framework
Map input records=13
Map output records=13
Map output bytes=423
Map output materialized bytes=467
Input split bytes=119
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=467
Reduce input records=13
Reduce output records=6
Spilled Records=26
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=224
CPU time spent (ms)=3690
Physical memory (bytes) snapshot=553816064
Virtual memory (bytes) snapshot=3441266688
Total committed heap usage (bytes)=334102528
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=361
File Output Format Counters
Bytes Written=72Step 7 - Sử dụng lệnh sau để xác minh các tệp kết quả trong thư mục đầu ra.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Bạn sẽ tìm thấy kết quả đầu ra trong ba tệp vì bạn đang sử dụng ba bộ phân vùng và ba bộ giảm bớt trong chương trình của mình.
Step 8 - Sử dụng lệnh sau để xem kết quả đầu ra trong Part-00000tập tin. Tệp này được tạo bởi HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Output in Part-00000
Female 15000
Male 40000Sử dụng lệnh sau để xem kết quả trong Part-00001 tập tin.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00001Output in Part-00001
Female 35000
Male 31000Sử dụng lệnh sau để xem kết quả trong Part-00002 tập tin.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00002Output in Part-00002
Female 51000
Male 50000Combiner, còn được gọi là semi-reducer, là một lớp tùy chọn hoạt động bằng cách chấp nhận các đầu vào từ lớp Bản đồ và sau đó chuyển các cặp khóa-giá trị đầu ra cho lớp Giảm.
Chức năng chính của Combiner là tóm tắt các bản ghi đầu ra bản đồ với cùng một khóa. Đầu ra (tập hợp khóa-giá trị) của bộ kết hợp sẽ được gửi qua mạng tới tác vụ Bộ giảm tốc thực tế làm đầu vào.
Combiner
Lớp Combiner được sử dụng giữa lớp Map và lớp Reduce để giảm khối lượng truyền dữ liệu giữa Map và Reduce. Thông thường, kết quả đầu ra của tác vụ bản đồ lớn và dữ liệu được chuyển sang tác vụ giảm sẽ cao.
Sơ đồ nhiệm vụ MapReduce sau đây cho thấy GIAI ĐOẠN KẾT HỢP.
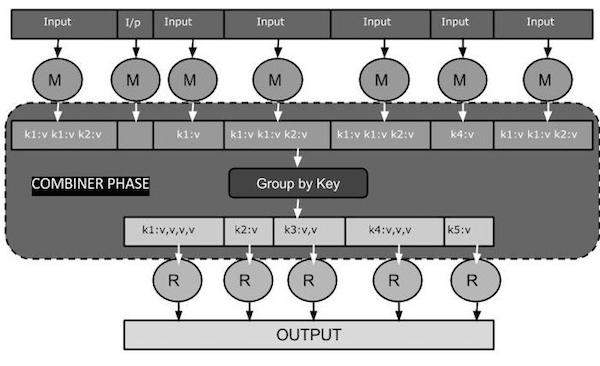
Combiner hoạt động như thế nào?
Đây là bản tóm tắt ngắn gọn về cách hoạt động của MapReduce Combiner -
Một trình kết hợp không có giao diện được xác định trước và nó phải triển khai phương thức Reduce () của giao diện Reducer.
Một bộ kết hợp hoạt động trên mỗi khóa xuất bản đồ. Nó phải có cùng loại khóa-giá trị đầu ra như lớp Giảm tốc.
Một bộ kết hợp có thể tạo ra thông tin tóm tắt từ một tập dữ liệu lớn vì nó thay thế đầu ra Bản đồ gốc.
Mặc dù, Combiner là tùy chọn nhưng nó giúp tách dữ liệu thành nhiều nhóm cho giai đoạn Reduce, giúp xử lý dễ dàng hơn.
Triển khai MapReduce Combiner
Ví dụ sau đây cung cấp một ý tưởng lý thuyết về bộ kết hợp. Giả sử chúng tôi có tệp văn bản đầu vào sau có têninput.txt cho MapReduce.
What do you mean by Object
What do you know about Java
What is Java Virtual Machine
How Java enabled High PerformanceCác giai đoạn quan trọng của chương trình MapReduce với Combiner được thảo luận dưới đây.
Trình đọc ghi
Đây là giai đoạn đầu tiên của MapReduce trong đó Trình đọc Bản ghi đọc mọi dòng từ tệp văn bản đầu vào dưới dạng văn bản và cho kết quả đầu ra dưới dạng các cặp khóa-giá trị.
Input - Từng dòng văn bản từ tệp đầu vào.
Output- Hình thành các cặp khóa-giá trị. Sau đây là tập hợp các cặp khóa-giá trị mong đợi.
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>Giai đoạn bản đồ
Giai đoạn Bản đồ lấy đầu vào từ Trình đọc bản ghi, xử lý nó và tạo ra đầu ra dưới dạng một tập hợp các cặp khóa-giá trị khác.
Input - Cặp khóa-giá trị sau là đầu vào được lấy từ Trình đọc bản ghi.
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>Giai đoạn Bản đồ đọc từng cặp khóa-giá trị, chia từng từ khỏi giá trị bằng cách sử dụng StringTokenizer, coi mỗi từ là khóa và số lượng từ đó là giá trị. Đoạn mã sau đây hiển thị lớp Mapper và hàm bản đồ.
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}Output - Sản lượng dự kiến như sau -
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>Giai đoạn kết hợp
Giai đoạn Kết hợp lấy từng cặp khóa-giá trị từ giai đoạn Bản đồ, xử lý nó và tạo ra kết quả là key-value collection cặp.
Input - Cặp khóa-giá trị sau là đầu vào được lấy từ pha Bản đồ.
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>Giai đoạn Combiner đọc từng cặp khóa-giá trị, kết hợp các từ chung làm khóa và giá trị dưới dạng tập hợp. Thông thường, mã và hoạt động của Bộ kết hợp tương tự như của Bộ giảm tốc. Sau đây là đoạn mã cho khai báo lớp Mapper, Combiner và Reducer.
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);Output - Sản lượng dự kiến như sau -
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Pha giảm tốc
Giai đoạn Bộ giảm nhận từng cặp thu thập khóa-giá trị từ giai đoạn Bộ kết hợp, xử lý nó và chuyển đầu ra dưới dạng các cặp khóa-giá trị. Lưu ý rằng chức năng Bộ kết hợp giống như Bộ giảm tốc.
Input - Cặp khóa-giá trị sau là đầu vào được lấy từ pha Combiner.
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Giai đoạn Bộ giảm đọc từng cặp khóa-giá trị. Sau đây là đoạn mã cho Combiner.
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}Output - Đầu ra dự kiến từ giai đoạn Bộ giảm tốc như sau:
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,3>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Người viết ghi
Đây là giai đoạn cuối cùng của MapReduce trong đó Record Writer ghi mọi cặp khóa-giá trị từ giai đoạn Giảm và gửi đầu ra dưới dạng văn bản.
Input - Mỗi cặp khóa-giá trị từ pha Bộ giảm cùng với định dạng Đầu ra.
Output- Nó cung cấp cho bạn các cặp khóa-giá trị ở định dạng văn bản. Sau đây là kết quả mong đợi.
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1Chương trình mẫu
Khối mã sau đếm số từ trong một chương trình.
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Lưu chương trình trên thành WordCount.java. Việc biên dịch và thực hiện chương trình được đưa ra dưới đây.
Biên dịch và Thực hiện
Giả sử chúng ta đang ở trong thư mục chính của người dùng Hadoop (ví dụ: / home / hadoop).
Làm theo các bước dưới đây để biên dịch và thực thi chương trình trên.
Step 1 - Sử dụng lệnh sau để tạo thư mục lưu các lớp java đã biên dịch.
$ mkdir unitsStep 2- Tải xuống Hadoop-core-1.2.1.jar, được sử dụng để biên dịch và thực thi chương trình MapReduce. Bạn có thể tải xuống jar từ mvnrepository.com .
Giả sử thư mục đã tải xuống là / home / hadoop /.
Step 3 - Sử dụng các lệnh sau để biên dịch WordCount.java chương trình và để tạo một jar cho chương trình.
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java
$ jar -cvf units.jar -C units/ .Step 4 - Sử dụng lệnh sau để tạo thư mục đầu vào trong HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 5 - Sử dụng lệnh sau để sao chép tệp đầu vào có tên input.txt trong thư mục đầu vào của HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dirStep 6 - Sử dụng lệnh sau để xác minh các tệp trong thư mục đầu vào.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7 - Sử dụng lệnh sau để chạy ứng dụng Word count bằng cách lấy các tập tin đầu vào từ thư mục đầu vào.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirChờ một lúc cho đến khi tệp được thực thi. Sau khi thực thi, đầu ra chứa một số phân tách đầu vào, tác vụ Bản đồ và tác vụ Bộ giảm.
Step 8 - Sử dụng lệnh sau để xác minh các tệp kết quả trong thư mục đầu ra.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9 - Sử dụng lệnh sau để xem kết quả đầu ra trong Part-00000tập tin. Tệp này được tạo bởi HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Sau đây là kết quả do chương trình MapReduce tạo ra.
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1Chương này giải thích quản trị Hadoop bao gồm cả quản trị HDFS và MapReduce.
Quản trị HDFS bao gồm giám sát cấu trúc tệp HDFS, vị trí và các tệp được cập nhật.
Quản trị MapReduce bao gồm giám sát danh sách các ứng dụng, cấu hình các nút, trạng thái ứng dụng, v.v.
Giám sát HDFS
HDFS (Hệ thống tệp phân tán Hadoop) chứa các thư mục người dùng, tệp đầu vào và tệp đầu ra. Sử dụng các lệnh MapReduce,put và get, để lưu trữ và truy xuất.
Sau khi khởi động khung công tác Hadoop (daemons) bằng cách truyền lệnh “start-all.sh” trên “/ $ HADOOP_HOME / sbin”, hãy chuyển URL sau vào trình duyệt “http: // localhost: 50070”. Bạn sẽ thấy màn hình sau trên trình duyệt của mình.
Ảnh chụp màn hình sau đây cho thấy cách duyệt HDFS duyệt.

Ảnh chụp màn hình sau đây cho thấy cấu trúc tệp của HDFS. Nó hiển thị các tệp trong thư mục “/ user / hadoop”.

Ảnh chụp màn hình sau đây hiển thị thông tin Datanode trong một cụm. Tại đây bạn có thể tìm thấy một nút với cấu hình và dung lượng của nó.

MapReduce Giám sát công việc
Một ứng dụng MapReduce là một tập hợp các công việc (Công việc bản đồ, Bộ kết hợp, Bộ phân vùng và Giảm công việc). Bắt buộc phải theo dõi và duy trì những điều sau:
- Cấu hình datanode nơi ứng dụng phù hợp.
- Số lượng nút dữ liệu và tài nguyên được sử dụng cho mỗi ứng dụng.
Để giám sát tất cả những điều này, bắt buộc chúng ta phải có một giao diện người dùng. Sau khi khởi động khung công tác Hadoop bằng cách chuyển lệnh “start-all.sh” trên “/ $ HADOOP_HOME / sbin”, hãy chuyển URL sau vào trình duyệt “http: // localhost: 8080”. Bạn sẽ thấy màn hình sau trên trình duyệt của mình.

Trong ảnh chụp màn hình ở trên, con trỏ tay nằm trên ID ứng dụng. Chỉ cần nhấp vào nó để tìm màn hình sau trên trình duyệt của bạn. Nó mô tả những điều sau:
Ứng dụng hiện tại đang chạy trên người dùng nào
Tên ứng dụng
Loại ứng dụng đó
Tình trạng hiện tại, tình trạng cuối cùng
Thời gian bắt đầu ứng dụng, đã trôi qua (thời gian hoàn thành), nếu nó đã hoàn tất tại thời điểm giám sát
Lịch sử của ứng dụng này, tức là thông tin nhật ký
Và cuối cùng là thông tin về nút, tức là các nút đã tham gia chạy ứng dụng.
Ảnh chụp màn hình sau đây hiển thị chi tiết của một ứng dụng cụ thể:

Ảnh chụp màn hình sau đây mô tả thông tin các nút hiện đang chạy. Ở đây, ảnh chụp màn hình chỉ chứa một nút. Một con trỏ tay hiển thị địa chỉ localhost của nút đang chạy.
