CNTK - Mạng nơron tái diễn
Bây giờ, chúng ta hãy hiểu cách xây dựng Mạng nơ-ron tuần hoàn (RNN) trong CNTK.
Giới thiệu
Chúng tôi đã học cách phân loại hình ảnh bằng mạng nơ-ron và đó là một trong những công việc mang tính biểu tượng trong học sâu. Tuy nhiên, một lĩnh vực khác mà mạng nơ-ron vượt trội và có nhiều nghiên cứu đang diễn ra là Mạng thần kinh tái tạo (RNN). Ở đây, chúng ta sẽ biết RNN là gì và nó có thể được sử dụng như thế nào trong các tình huống mà chúng ta cần xử lý dữ liệu chuỗi thời gian.
Mạng thần kinh tái phát là gì?
Mạng nơ-ron lặp lại (RNN) có thể được định nghĩa là một giống NN đặc biệt có khả năng suy luận theo thời gian. RNN chủ yếu được sử dụng trong các tình huống, nơi chúng ta cần xử lý các giá trị thay đổi theo thời gian, tức là dữ liệu chuỗi thời gian. Để hiểu nó một cách tốt hơn, chúng ta hãy có một so sánh nhỏ giữa mạng nơ-ron thông thường và mạng nơ-ron tuần hoàn -
Như chúng ta biết rằng, trong một mạng nơ ron thông thường, chúng ta chỉ có thể cung cấp một đầu vào. Điều này giới hạn nó chỉ dẫn đến một dự đoán. Để cung cấp cho bạn một ví dụ, chúng tôi có thể thực hiện công việc dịch văn bản bằng cách sử dụng mạng thần kinh thông thường.
Mặt khác, trong các mạng nơ-ron tuần hoàn, chúng ta có thể cung cấp một chuỗi các mẫu dẫn đến một dự đoán duy nhất. Nói cách khác, sử dụng RNN, chúng ta có thể dự đoán một chuỗi đầu ra dựa trên một chuỗi đầu vào. Ví dụ, đã có khá nhiều thử nghiệm thành công với RNN trong các tác vụ dịch thuật.
Sử dụng mạng thần kinh tái phát
RNN có thể được sử dụng theo một số cách. Một số trong số chúng như sau:
Dự đoán một đầu ra duy nhất
Trước khi đi sâu vào các bước, rằng cách RNN có thể dự đoán một đầu ra dựa trên một chuỗi, hãy xem RNN cơ bản trông như thế nào−

Như chúng ta có thể thấy trong sơ đồ trên, RNN chứa một kết nối lặp lại đến đầu vào và bất cứ khi nào, chúng tôi cung cấp một chuỗi giá trị, nó sẽ xử lý từng phần tử trong chuỗi như các bước thời gian.
Hơn nữa, do kết nối lặp lại, RNN có thể kết hợp đầu ra được tạo với đầu vào cho phần tử tiếp theo trong chuỗi. Bằng cách này, RNN sẽ xây dựng một bộ nhớ trên toàn bộ chuỗi có thể được sử dụng để đưa ra dự đoán.
Để đưa ra dự đoán với RNN, chúng ta có thể thực hiện các bước sau:
Đầu tiên, để tạo một trạng thái ẩn ban đầu, chúng ta cần nạp phần tử đầu tiên của chuỗi đầu vào.
Sau đó, để tạo ra một trạng thái ẩn được cập nhật, chúng ta cần lấy trạng thái ẩn ban đầu và kết hợp nó với phần tử thứ hai trong chuỗi đầu vào.
Cuối cùng, để tạo ra trạng thái ẩn cuối cùng và để dự đoán đầu ra cho RNN, chúng ta cần lấy phần tử cuối cùng trong chuỗi đầu vào.
Bằng cách này, với sự trợ giúp của kết nối lặp lại này, chúng ta có thể dạy RNN nhận ra các mẫu xảy ra theo thời gian.
Dự đoán một chuỗi
Mô hình cơ bản, được thảo luận ở trên, của RNN cũng có thể được mở rộng cho các trường hợp sử dụng khác. Ví dụ, chúng ta có thể sử dụng nó để dự đoán chuỗi giá trị dựa trên một đầu vào duy nhất. Trong trường hợp này, để đưa ra dự đoán với RNN, chúng ta có thể thực hiện các bước sau:
Đầu tiên, để tạo một trạng thái ẩn ban đầu và dự đoán phần tử đầu tiên trong chuỗi đầu ra, chúng ta cần đưa một mẫu đầu vào vào mạng nơ-ron.
Sau đó, để tạo ra một trạng thái ẩn được cập nhật và phần tử thứ hai trong chuỗi đầu ra, chúng ta cần kết hợp trạng thái ẩn ban đầu với cùng một mẫu.
Cuối cùng, để cập nhật trạng thái ẩn thêm một lần nữa và dự đoán phần tử cuối cùng trong trình tự đầu ra, chúng tôi nạp mẫu vào lần khác.
Dự đoán trình tự
Như chúng ta đã thấy cách dự đoán một giá trị dựa trên một chuỗi và cách dự đoán một chuỗi dựa trên một giá trị duy nhất. Bây giờ chúng ta hãy xem cách chúng ta có thể dự đoán trình tự cho các chuỗi. Trong trường hợp này, để đưa ra dự đoán với RNN, chúng ta có thể thực hiện các bước sau:
Đầu tiên, để tạo một trạng thái ẩn ban đầu và dự đoán phần tử đầu tiên trong chuỗi đầu ra, chúng ta cần lấy phần tử đầu tiên trong chuỗi đầu vào.
Sau đó, để cập nhật trạng thái ẩn và dự đoán phần tử thứ hai trong chuỗi đầu ra, chúng ta cần lấy trạng thái ẩn ban đầu.
Cuối cùng, để dự đoán phần tử cuối cùng trong chuỗi đầu ra, chúng ta cần lấy trạng thái ẩn được cập nhật và phần tử cuối cùng trong chuỗi đầu vào.
Hoạt động của RNN
Để hiểu hoạt động của mạng nơ-ron tuần hoàn (RNN), trước tiên chúng ta cần hiểu cách thức hoạt động của các lớp tuần hoàn trong mạng. Vì vậy, trước tiên chúng ta hãy thảo luận về cách e có thể dự đoán đầu ra với một lớp định kỳ chuẩn.
Dự đoán đầu ra với lớp RNN tiêu chuẩn
Như chúng ta đã thảo luận trước đó rằng một lớp cơ bản trong RNN khá khác với một lớp thông thường trong mạng nơ-ron. Trong phần trước, chúng tôi cũng đã trình bày trong sơ đồ kiến trúc cơ bản của RNN. Để cập nhật trạng thái ẩn cho chuỗi bước lần đầu tiên, chúng ta có thể sử dụng công thức sau:

Trong phương trình trên, ta tính trạng thái ẩn mới bằng cách tính tích số chấm giữa ẩn trạng thái ban đầu và một tập trọng số.
Bây giờ đối với bước tiếp theo, trạng thái ẩn cho bước thời gian hiện tại được sử dụng làm trạng thái ẩn ban đầu cho bước thời gian tiếp theo trong chuỗi. Đó là lý do tại sao, để cập nhật trạng thái ẩn cho bước lần thứ hai, chúng ta có thể lặp lại các phép tính đã thực hiện trong bước lần đầu tiên như sau:
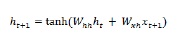
Tiếp theo, chúng ta có thể lặp lại quá trình cập nhật trạng thái ẩn cho bước thứ ba và bước cuối cùng trong trình tự như dưới đây:

Và khi chúng ta đã xử lý tất cả các bước trên theo trình tự, chúng ta có thể tính toán đầu ra như sau:

Đối với công thức trên, chúng ta đã sử dụng bộ trọng số thứ ba và trạng thái ẩn từ bước thời gian cuối cùng.
Đơn vị định kỳ nâng cao
Vấn đề chính với lớp lặp lại cơ bản là vấn đề gradient biến mất và do đó, nó không tốt lắm trong việc học các mối tương quan dài hạn. Nói cách đơn giản, lớp lặp lại cơ bản không xử lý tốt các chuỗi dài. Đó là lý do tại sao một số loại lớp lặp lại khác phù hợp hơn nhiều để làm việc với các chuỗi dài hơn như sau:
Bộ nhớ dài hạn (LSTM)

Mạng bộ nhớ ngắn hạn (LSTM) được giới thiệu bởi Hochreiter & Schmidhuber. Nó giải quyết vấn đề nhận được một lớp lặp lại cơ bản để ghi nhớ mọi thứ trong một thời gian dài. Kiến trúc của LSTM được đưa ra ở trên trong sơ đồ. Như chúng ta thấy, nó có các tế bào thần kinh đầu vào, tế bào bộ nhớ và tế bào thần kinh đầu ra. Để chống lại vấn đề gradient biến mất, các mạng bộ nhớ ngắn hạn sử dụng một ô nhớ rõ ràng (lưu trữ các giá trị trước đó) và các cổng sau:
Forget gate- Như tên của nó, nó báo cho ô nhớ quên các giá trị trước đó. Ô nhớ lưu trữ các giá trị cho đến khi cổng tức là 'cổng quên' yêu cầu nó quên chúng.
Input gate- Như tên của nó, nó thêm những thứ mới vào ô.
Output gate- Như tên của nó, cổng ra quyết định thời điểm truyền các vectơ từ ô sang trạng thái ẩn tiếp theo.
Đơn vị định kỳ được xác định (GRU)

Gradient recurrent units(GRUs) là một biến thể nhỏ của mạng LSTMs. Nó có một cổng ít hơn và có dây hơi khác so với LSTM. Kiến trúc của nó được thể hiện trong sơ đồ trên. Nó có các tế bào thần kinh đầu vào, các tế bào bộ nhớ được kiểm soát và các tế bào thần kinh đầu ra. Mạng Gated Recurrent Units có hai cổng sau:
Update gate- Nó quyết định hai điều sau
Số lượng thông tin nên được giữ từ trạng thái cuối cùng?
Lượng thông tin nên được đưa vào từ lớp trước?
Reset gate- Chức năng của cổng thiết lập lại giống như chức năng của cổng quên của mạng LSTMs. Sự khác biệt duy nhất là nó nằm hơi khác một chút.
Trái ngược với mạng bộ nhớ dài hạn, mạng Bộ nhớ định kỳ Gated lại nhanh hơn và dễ chạy hơn một chút.
Tạo cấu trúc RNN
Trước khi chúng ta có thể bắt đầu, đưa ra dự đoán về đầu ra từ bất kỳ nguồn dữ liệu nào của chúng ta, trước tiên chúng ta cần xây dựng RNN và việc xây dựng RNN hoàn toàn giống như chúng ta đã xây dựng mạng nơ-ron thông thường trong phần trước. Sau đây là mã để tạo một
from cntk.losses import squared_error
from cntk.io import CTFDeserializer, MinibatchSource, INFINITELY_REPEAT, StreamDefs, StreamDef
from cntk.learners import adam
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
BATCH_SIZE = 14 * 10
EPOCH_SIZE = 12434
EPOCHS = 10Xếp chồng nhiều lớp
Chúng ta cũng có thể xếp chồng nhiều lớp lặp lại trong CNTK. Ví dụ, chúng ta có thể sử dụng sự kết hợp sau của các lớp−
from cntk import sequence, default_options, input_variable
from cntk.layers import Recurrence, LSTM, Dropout, Dense, Sequential, Fold
features = sequence.input_variable(1)
with default_options(initial_state = 0.1):
model = Sequential([
Fold(LSTM(15)),
Dense(1)
])(features)
target = input_variable(1, dynamic_axes=model.dynamic_axes)Như chúng ta thấy trong đoạn mã trên, chúng ta có hai cách sau đây để chúng ta có thể lập mô hình RNN trong CNTK:
Đầu tiên, nếu chúng ta chỉ muốn đầu ra cuối cùng của một lớp lặp lại, chúng ta có thể sử dụng Fold kết hợp với một lớp lặp lại, chẳng hạn như GRU, LSTM hoặc thậm chí RNNStep.
Thứ hai, như một cách thay thế, chúng tôi cũng có thể sử dụng Recurrence khối.
Huấn luyện RNN với dữ liệu chuỗi thời gian
Sau khi chúng tôi xây dựng mô hình, hãy xem cách chúng tôi có thể đào tạo RNN trong CNTK -
from cntk import Function
@Function
def criterion_factory(z, t):
loss = squared_error(z, t)
metric = squared_error(z, t)
return loss, metric
loss = criterion_factory(model, target)
learner = adam(model.parameters, lr=0.005, momentum=0.9)Bây giờ để tải dữ liệu vào quá trình đào tạo, chúng ta phải giải mã chuỗi từ một tập hợp các tệp CTF. Mã sau cócreate_datasource , là một chức năng tiện ích hữu ích để tạo cả nguồn dữ liệu đào tạo và kiểm tra.
target_stream = StreamDef(field='target', shape=1, is_sparse=False)
features_stream = StreamDef(field='features', shape=1, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(features=features_stream, target=target_stream))
datasource = MinibatchSource(deserializer, randomize=True, max_sweeps=sweeps)
return datasource
train_datasource = create_datasource('Training data filename.ctf')#we need to provide the location of training file we created from our dataset.
test_datasource = create_datasource('Test filename.ctf', sweeps=1) #we need to provide the location of testing file we created from our dataset.Bây giờ, khi chúng ta đã thiết lập các nguồn dữ liệu, mô hình và hàm mất mát, chúng ta có thể bắt đầu quá trình đào tạo. Nó hoàn toàn tương tự như chúng ta đã làm trong các phần trước với mạng nơ-ron cơ bản.
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
target: train_datasource.streams.target
}
history = loss.train(
train_datasource,
epoch_size=EPOCH_SIZE,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config],
minibatch_size=BATCH_SIZE,
max_epochs=EPOCHS
)Chúng ta sẽ nhận được kết quả tương tự như sau:
Đầu ra−
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.005
0.4 0.4 0.4 0.4 19
0.4 0.4 0.4 0.4 59
0.452 0.495 0.452 0.495 129
[…]Xác thực mô hình
Trên thực tế, việc tạo lại bằng RNN khá giống với việc tạo dự đoán với bất kỳ mô hình CNK nào khác. Sự khác biệt duy nhất là, chúng tôi cần cung cấp các trình tự hơn là các mẫu đơn lẻ.
Bây giờ, khi RNN của chúng tôi cuối cùng đã được đào tạo xong, chúng tôi có thể xác thực mô hình bằng cách kiểm tra nó bằng cách sử dụng một số chuỗi mẫu như sau:
import pickle
with open('test_samples.pkl', 'rb') as test_file:
test_samples = pickle.load(test_file)
model(test_samples) * NORMALIZEĐầu ra−
array([[ 8081.7905],
[16597.693 ],
[13335.17 ],
...,
[11275.804 ],
[15621.697 ],
[16875.555 ]], dtype=float32)