Xử lý ngôn ngữ tự nhiên - Hướng dẫn nhanh
Ngôn ngữ là một phương pháp giao tiếp với sự trợ giúp của chúng ta có thể nói, đọc và viết. Ví dụ, chúng ta nghĩ, chúng ta đưa ra quyết định, kế hoạch và hơn thế nữa bằng ngôn ngữ tự nhiên; chính xác, bằng lời nói. Tuy nhiên, câu hỏi lớn đặt ra cho chúng ta trong kỷ nguyên AI này là liệu chúng ta có thể giao tiếp theo cách tương tự với máy tính hay không. Nói cách khác, con người có thể giao tiếp với máy tính bằng ngôn ngữ tự nhiên của họ không? Đó là một thách thức đối với chúng tôi khi phát triển các ứng dụng NLP vì máy tính cần dữ liệu có cấu trúc, nhưng lời nói của con người là không có cấu trúc và thường mơ hồ về bản chất.
Theo nghĩa này, chúng ta có thể nói rằng Xử lý ngôn ngữ tự nhiên (NLP) là một lĩnh vực phụ của Khoa học máy tính đặc biệt là Trí tuệ nhân tạo (AI) liên quan đến việc cho phép máy tính hiểu và xử lý ngôn ngữ của con người. Về mặt kỹ thuật, nhiệm vụ chính của NLP sẽ là lập trình máy tính để phân tích và xử lý lượng dữ liệu ngôn ngữ tự nhiên khổng lồ.
Lịch sử của NLP
Chúng tôi đã chia lịch sử của NLP thành bốn giai đoạn. Các giai đoạn có mối quan tâm và phong cách riêng biệt.
Giai đoạn đầu (Giai đoạn dịch máy) - Cuối những năm 1940 đến cuối những năm 1960
Công việc được thực hiện trong giai đoạn này chủ yếu tập trung vào dịch máy (MT). Giai đoạn này là một giai đoạn nhiệt tình và lạc quan.
Bây giờ chúng ta hãy xem tất cả những gì mà giai đoạn đầu có trong đó -
Nghiên cứu về NLP bắt đầu vào đầu những năm 1950 sau cuộc điều tra của Booth & Richens và bản ghi nhớ của Weaver về dịch máy vào năm 1949.
Năm 1954 là năm mà một thử nghiệm hạn chế về dịch tự động từ tiếng Nga sang tiếng Anh được trình diễn trong thử nghiệm của Georgetown-IBM.
Cùng năm, tạp chí MT (Máy dịch) bắt đầu được xuất bản.
Hội nghị quốc tế đầu tiên về Dịch máy (MT) được tổ chức vào năm 1952 và lần thứ hai được tổ chức vào năm 1956.
Năm 1961, công trình được trình bày trong Hội nghị Quốc tế Teddington về Máy dịch các Ngôn ngữ và Phân tích Ngôn ngữ Ứng dụng là điểm cao của giai đoạn này.
Giai đoạn thứ hai (Giai đoạn chịu ảnh hưởng của AI) - Cuối những năm 1960 đến cuối những năm 1970
Trong giai đoạn này, công việc được thực hiện chủ yếu liên quan đến tri thức thế giới và vai trò của nó trong việc xây dựng và vận dụng các biểu diễn ý nghĩa. Đó là lý do tại sao, giai đoạn này còn được gọi là giai đoạn hương vị AI.
Giai đoạn có trong đó, như sau -
Vào đầu năm 1961, công việc bắt đầu về các vấn đề giải quyết và xây dựng dữ liệu hoặc cơ sở tri thức. Công việc này bị ảnh hưởng bởi AI.
Cùng năm đó, hệ thống trả lời câu hỏi BASEBALL cũng được phát triển. Đầu vào cho hệ thống này bị hạn chế và quá trình xử lý ngôn ngữ liên quan rất đơn giản.
Một hệ thống tiên tiến hơn đã được mô tả trong Minsky (1968). Hệ thống này, khi so sánh với hệ thống trả lời câu hỏi BASEBALL, đã được công nhận và cung cấp cho nhu cầu suy luận trên cơ sở kiến thức trong việc diễn giải và trả lời đầu vào ngôn ngữ.
Giai đoạn thứ ba (Giai đoạn ngữ pháp-lôgic) - Cuối những năm 1970 đến cuối những năm 1980
Giai đoạn này có thể được mô tả là giai đoạn ngữ pháp-lôgic. Do thất bại trong việc xây dựng hệ thống thực tế trong giai đoạn trước, các nhà nghiên cứu đã chuyển sang sử dụng logic để biểu diễn và lập luận tri thức trong AI.
Giai đoạn thứ ba có những điều sau đây trong đó:
Cách tiếp cận ngữ pháp-lôgic, vào cuối thập kỷ, đã giúp chúng tôi có những bộ xử lý câu đa năng mạnh mẽ như Công cụ ngôn ngữ cốt lõi và Lý thuyết biểu diễn diễn ngôn của SRI, cung cấp một phương tiện giải quyết diễn ngôn mở rộng hơn.
Trong giai đoạn này, chúng tôi có một số tài nguyên & công cụ thực tế như trình phân tích cú pháp, ví dụ: Alvey Natural Language Tools cùng với các hệ thống thương mại và hoạt động hơn, ví dụ như truy vấn cơ sở dữ liệu.
Công trình nghiên cứu về từ điển học năm 1980 cũng chỉ ra hướng tiếp cận ngữ pháp-lôgic.
Giai đoạn thứ tư (Giai đoạn Lexical & Corpus) - Những năm 1990
Chúng tôi có thể mô tả điều này như một giai đoạn từ vựng & ngữ liệu. Giai đoạn có cách tiếp cận từ vựng hóa ngữ pháp xuất hiện vào cuối những năm 1980 và ngày càng có ảnh hưởng lớn. Đã có một cuộc cách mạng trong xử lý ngôn ngữ tự nhiên trong thập kỷ này với sự ra đời của các thuật toán học máy để xử lý ngôn ngữ.
Nghiên cứu ngôn ngữ của con người
Ngôn ngữ là một thành phần quan trọng đối với cuộc sống của con người và cũng là khía cạnh cơ bản nhất trong hành vi của chúng ta. Chúng ta có thể trải nghiệm nó ở hai dạng chủ yếu - viết và nói. Dưới dạng văn bản, đó là một cách để truyền kiến thức của chúng ta từ thế hệ này sang thế hệ khác. Ở dạng nói, nó là phương tiện chính để con người phối hợp với nhau trong hành vi hàng ngày của họ. Ngôn ngữ được nghiên cứu trong các ngành học khác nhau. Mỗi ngành học đều có những vấn đề riêng và một loạt giải pháp để giải quyết những vấn đề đó.
Hãy xem xét bảng sau để hiểu điều này -
| Kỷ luật | Các vấn đề | Công cụ |
|---|---|---|
Nhà ngôn ngữ học |
Làm thế nào các cụm từ và câu có thể được tạo thành với các từ? Điều gì hạn chế ý nghĩa có thể có cho một câu? |
Trực quan về khả năng hình thành tốt và ý nghĩa. Mô hình toán học của cấu trúc. Ví dụ, ngữ nghĩa lý thuyết mô hình, lý thuyết ngôn ngữ hình thức. |
Nhà tâm lý học |
Làm thế nào con người có thể xác định được cấu trúc của câu? Làm thế nào để xác định nghĩa của từ? Sự hiểu biết diễn ra khi nào? |
Kỹ thuật thực nghiệm chủ yếu để đo lường hiệu suất của con người. Phân tích thống kê các quan sát. |
Triết gia |
Làm thế nào để các từ và câu có được ý nghĩa? Làm thế nào các đối tượng được xác định bởi các từ? Nghĩa là gì? |
Lập luận ngôn ngữ tự nhiên bằng cách sử dụng trực giác. Các mô hình toán học như logic và lý thuyết mô hình. |
Nhà ngôn ngữ học tính toán |
Làm thế nào chúng ta có thể xác định cấu trúc của một câu Làm thế nào kiến thức và lý luận có thể được mô hình hóa? Làm thế nào chúng ta có thể sử dụng ngôn ngữ để hoàn thành các nhiệm vụ cụ thể? |
Thuật toán Cấu trúc dữ liệu Các mô hình chính thức về biểu diễn và lập luận. Các kỹ thuật AI như phương pháp tìm kiếm và biểu diễn. |
Sự mơ hồ và không chắc chắn trong ngôn ngữ
Sự mơ hồ, thường được sử dụng trong xử lý ngôn ngữ tự nhiên, có thể được coi là khả năng được hiểu theo nhiều cách. Nói một cách dễ hiểu, chúng ta có thể nói rằng sự mơ hồ là khả năng được hiểu theo nhiều cách. Ngôn ngữ tự nhiên rất mơ hồ. NLP có các loại mơ hồ sau:
Sự mơ hồ về ngôn ngữ
Sự mơ hồ của một từ được gọi là sự mơ hồ về mặt từ vựng. Ví dụ, xử lý từsilver như một danh từ, một tính từ hoặc một động từ.
Sự mơ hồ về cú pháp
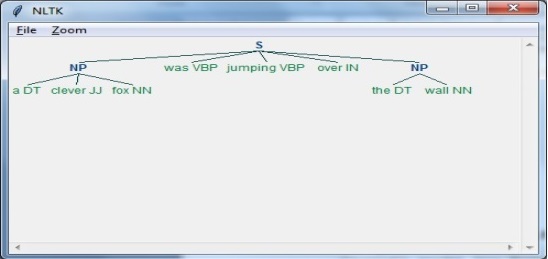
Loại mơ hồ này xảy ra khi một câu được phân tích cú pháp theo nhiều cách khác nhau. Ví dụ, câu “Người đàn ông nhìn thấy cô gái bằng kính thiên văn”. Không rõ liệu người đàn ông nhìn thấy cô gái mang theo kính viễn vọng hay anh ta nhìn thấy cô ấy qua kính viễn vọng của mình.
Sự mơ hồ về ngữ nghĩa
Loại mơ hồ này xảy ra khi bản thân ý nghĩa của các từ có thể bị hiểu sai. Nói cách khác, sự mơ hồ về ngữ nghĩa xảy ra khi một câu chứa một từ hoặc cụm từ không rõ ràng. Ví dụ, câu “Chiếc ô tô đâm vào cột khi nó đang di chuyển” có sự mơ hồ về ngữ nghĩa vì cách hiểu có thể là “Chiếc ô tô, khi đang di chuyển, đâm vào cột” và “Chiếc ô tô đâm vào cột khi cột đang chuyển động”.
Sự mơ hồ tương tự
Loại mơ hồ này nảy sinh do việc sử dụng các thực thể anaphora trong diễn ngôn. Ví dụ, con ngựa chạy lên đồi. Nó rất dốc. Nó đã sớm trở nên mệt mỏi. Ở đây, tham chiếu đảo ngữ của “it” trong hai tình huống gây ra sự mơ hồ.
Sự mơ hồ thực dụng
Loại mơ hồ như vậy đề cập đến tình huống mà ngữ cảnh của một cụm từ cung cấp cho nó nhiều cách hiểu. Nói một cách dễ hiểu, chúng ta có thể nói rằng sự mơ hồ thực dụng nảy sinh khi tuyên bố không cụ thể. Ví dụ, câu “I like you too” có thể có nhiều cách hiểu như tôi thích bạn (giống như bạn thích tôi), tôi thích bạn (giống như người khác liều).
Các giai đoạn NLP
Sơ đồ sau đây cho thấy các giai đoạn hoặc các bước logic trong xử lý ngôn ngữ tự nhiên:
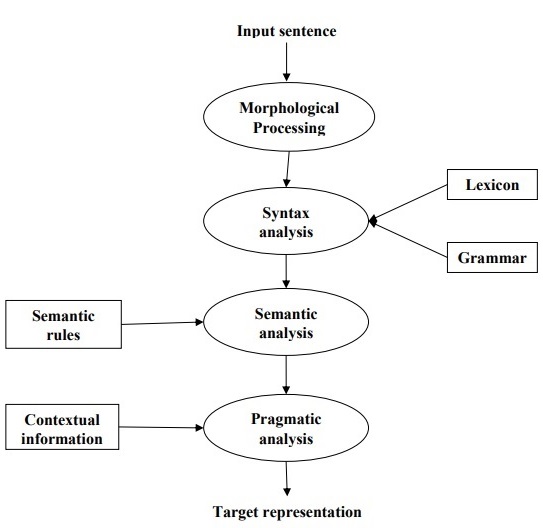
Xử lý hình thái
Đây là giai đoạn đầu tiên của NLP. Mục đích của giai đoạn này là chia nhỏ các đầu vào ngôn ngữ thành các bộ mã thông báo tương ứng với các đoạn văn, câu và từ. Ví dụ, một từ như“uneasy” có thể được chia thành hai mã thông báo từ phụ như “un-easy”.
Phân tích cú pháp
Đó là giai đoạn thứ hai của NLP. Mục đích của giai đoạn này là hai lần: để kiểm tra xem một câu có được hình thành tốt hay không và để chia nó thành một cấu trúc thể hiện mối quan hệ cú pháp giữa các từ khác nhau. Ví dụ, câu like“The school goes to the boy” sẽ bị từ chối bởi trình phân tích cú pháp hoặc trình phân tích cú pháp.
Phân tích ngữ nghĩa
Đó là giai đoạn thứ ba của NLP. Mục đích của giai đoạn này là rút ra ý nghĩa chính xác, hoặc bạn có thể nói nghĩa từ điển từ văn bản. Văn bản được kiểm tra xem có ý nghĩa hay không. Ví dụ: trình phân tích ngữ nghĩa sẽ từ chối một câu như "Kem nóng".
Phân tích thực dụng
Đó là giai đoạn thứ tư của NLP. Phân tích thực dụng chỉ đơn giản là phù hợp với các đối tượng / sự kiện thực tế, tồn tại trong một bối cảnh nhất định với các tham chiếu đối tượng thu được trong giai đoạn cuối cùng (phân tích ngữ nghĩa). Ví dụ, câu “Đặt chuối vào giỏ trên kệ” có thể có hai cách diễn giải ngữ nghĩa và bộ phân tích ngữ dụng sẽ chọn giữa hai khả năng này.
Trong chương này, chúng ta sẽ tìm hiểu về các nguồn ngôn ngữ trong Xử lý Ngôn ngữ Tự nhiên.
Corpus
Ngữ liệu là một tập hợp lớn và có cấu trúc gồm các văn bản có thể đọc được bằng máy được tạo ra trong môi trường giao tiếp tự nhiên. Số nhiều của nó là corpora. Chúng có thể được bắt nguồn theo nhiều cách khác nhau như văn bản ban đầu là điện tử, bản ghi của ngôn ngữ nói và nhận dạng ký tự quang học, v.v.
Các yếu tố của Thiết kế Corpus
Ngôn ngữ là vô hạn nhưng một kho ngữ liệu phải có kích thước hữu hạn. Để ngữ liệu có kích thước hữu hạn, chúng ta cần lấy mẫu và bao gồm nhiều loại văn bản theo tỷ lệ để đảm bảo thiết kế ngữ liệu tốt.
Bây giờ chúng ta hãy tìm hiểu về một số yếu tố quan trọng đối với thiết kế kho tài liệu -
Tính đại diện của tập đoàn
Tính đại diện là một đặc điểm xác định của thiết kế kho dữ liệu. Các định nghĩa sau đây từ hai nhà nghiên cứu vĩ đại - Leech và Biber, sẽ giúp chúng ta hiểu tính đại diện của ngữ liệu -
According to Leech (1991), “Một kho ngữ liệu được cho là đại diện cho sự đa dạng ngôn ngữ mà nó được cho là đại diện nếu những phát hiện dựa trên nội dung của nó có thể được khái quát hóa cho sự đa dạng ngôn ngữ nói trên”.
According to Biber (1993), “Tính đại diện đề cập đến mức độ mà một mẫu bao gồm đầy đủ các biến thể trong tổng thể”.
Bằng cách này, chúng ta có thể kết luận rằng tính đại diện của một kho tài liệu được xác định bởi hai yếu tố sau:
Balance - Phạm vi thể loại bao gồm trong một kho ngữ liệu
Sampling - Cách chọn các phần cho từng thể loại.
Số dư Corpus
Một yếu tố rất quan trọng khác của thiết kế ngữ liệu là cân bằng ngữ liệu - phạm vi thể loại được bao gồm trong ngữ liệu. Chúng tôi đã nghiên cứu rằng tính đại diện của một kho dữ liệu chung phụ thuộc vào mức độ cân bằng của kho ngữ liệu. Một kho ngữ liệu cân bằng bao gồm một loạt các danh mục văn bản, được cho là đại diện cho ngôn ngữ. Chúng tôi không có bất kỳ thước đo khoa học đáng tin cậy nào để cân bằng nhưng ước tính và trực giác tốt nhất hoạt động trong mối quan tâm này. Nói cách khác, chúng ta có thể nói rằng số dư được chấp nhận chỉ được xác định bởi mục đích sử dụng của nó.
Lấy mẫu
Một yếu tố quan trọng khác của thiết kế kho dữ liệu là lấy mẫu. Tính đại diện và cân bằng của Corpus có liên quan rất chặt chẽ với việc lấy mẫu. Đó là lý do tại sao chúng ta có thể nói rằng việc lấy mẫu là không thể tránh khỏi trong việc xây dựng kho dữ liệu.
Dựa theo Biber(1993), “Một số cân nhắc đầu tiên khi xây dựng ngữ liệu liên quan đến thiết kế tổng thể: ví dụ, các loại văn bản được bao gồm, số lượng văn bản, lựa chọn các văn bản cụ thể, lựa chọn các mẫu văn bản từ bên trong văn bản và độ dài của văn bản mẫu. Mỗi điều này liên quan đến một quyết định lấy mẫu, có thể là có ý thức hoặc không. ”
Trong khi lấy mẫu đại diện, chúng ta cần xem xét những điều sau:
Sampling unit- Nó đề cập đến đơn vị yêu cầu mẫu. Ví dụ, đối với văn bản viết, đơn vị lấy mẫu có thể là một tờ báo, tạp chí hoặc một cuốn sách.
Sampling frame - Danh sách các đơn vị lấy mẫu al được gọi là khung lấy mẫu.
Population- Nó có thể được gọi là tập hợp của tất cả các đơn vị lấy mẫu. Nó được định nghĩa theo nghĩa sản xuất ngôn ngữ, tiếp nhận ngôn ngữ hoặc ngôn ngữ như một sản phẩm.
Kích thước khối lượng
Một yếu tố quan trọng khác của thiết kế kho văn bản là kích thước của nó. Kho dữ liệu phải lớn như thế nào? Không có câu trả lời cụ thể cho câu hỏi này. Kích thước của kho tài liệu phụ thuộc vào mục đích của nó cũng như một số cân nhắc thực tế như sau:
Loại truy vấn dự đoán từ người dùng.
Phương pháp được người dùng sử dụng để nghiên cứu dữ liệu.
Tính sẵn có của nguồn dữ liệu.
Với sự tiến bộ trong công nghệ, kích thước tập tin cũng tăng lên. Bảng so sánh sau đây sẽ giúp bạn hiểu cách thức hoạt động của kích thước tập tin -
| Năm | Tên của Corpus | Kích thước (bằng chữ) |
|---|---|---|
| Những năm 1960 - 70 | Nâu và LOB | 1 triệu từ |
| Những năm 1980 | Kho tài liệu Birmingham | 20 triệu từ |
| Những năm 1990 | Cơ quan quốc gia Anh | 100 triệu từ |
| Đầu 21 st thế kỷ | Kho ngữ liệu Ngân hàng tiếng Anh | 650 Triệu từ |
Trong các phần tiếp theo, chúng ta sẽ xem xét một vài ví dụ về ngữ liệu.
TreeBank Corpus
Nó có thể được định nghĩa là ngữ liệu văn bản được phân tích cú pháp theo ngôn ngữ để chú thích cấu trúc câu cú pháp hoặc ngữ nghĩa. Geoffrey Leech đã đặt ra thuật ngữ 'treebank', đại diện cho rằng cách phổ biến nhất để biểu thị phân tích ngữ pháp là sử dụng cấu trúc cây. Nói chung, Treebanks được tạo trên đầu một kho ngữ liệu, vốn đã được chú thích bằng các thẻ part-of-speech.
Các loại TreeBank Corpus
Ngân hàng ngữ nghĩa và ngân sách cú pháp là hai loại ngân hàng cây phổ biến nhất trong ngôn ngữ học. Bây giờ chúng ta hãy tìm hiểu thêm về những loại này -
Ngân hàng ngữ nghĩa
Những Treebanks này sử dụng một đại diện chính thức cho cấu trúc ngữ nghĩa của câu. Chúng khác nhau về độ sâu của biểu diễn ngữ nghĩa của chúng. Các lệnh Robot Treebank, Geoquery, Groningen Nghĩa Ngân hàng, RoboCup Corpus là một số ví dụ về Semantic Treebanks.
Ngân hàng cây tổng hợp
Trái ngược với Ngân hàng cây ngữ nghĩa, đầu vào cho hệ thống Ngân hàng cây cú pháp là các biểu thức của ngôn ngữ chính thức thu được từ việc chuyển đổi dữ liệu Ngân hàng cây được phân tích cú pháp. Đầu ra của các hệ thống như vậy là biểu diễn ý nghĩa dựa trên logic vị từ. Các ngân hàng cây cú pháp khác nhau trong các ngôn ngữ khác nhau đã được tạo cho đến nay. Ví dụ,Penn Arabic Treebank, Columbia Arabic Treebank là những Treebanks cú pháp được tạo ra bằng ngôn ngữ Arabia. Sininca Cú pháp Treebank được tạo bằng ngôn ngữ Trung Quốc. Lucy, Susane và BLLIP WSJ ngữ liệu cú pháp được tạo bằng ngôn ngữ tiếng Anh.
Các ứng dụng của TreeBank Corpus
Tiếp theo là một số ứng dụng của TreeBanks -
Trong ngôn ngữ học tính toán
Nếu chúng ta nói về Ngôn ngữ tính toán thì cách sử dụng tốt nhất của TreeBanks là thiết kế các hệ thống xử lý ngôn ngữ tự nhiên tiên tiến nhất như trình gắn thẻ bán phần, trình phân tích cú pháp, trình phân tích ngữ nghĩa và hệ thống dịch máy.
Trong Ngôn ngữ học Corpus
Trong trường hợp ngôn ngữ học Corpus, việc sử dụng Treebanks tốt nhất là nghiên cứu các hiện tượng cú pháp.
Trong Ngôn ngữ học Lý thuyết và Ngôn ngữ học Tâm lý học
Việc sử dụng Treebanks tốt nhất trong ngôn ngữ học lý thuyết và tâm lý học là bằng chứng tương tác.
PropBank Corpus
PropBank được gọi cụ thể hơn là “Ngân hàng đề xuất” là một kho ngữ liệu, được chú thích bằng các mệnh đề bằng lời nói và lập luận của chúng. Ngữ liệu là một nguồn định hướng động từ; các chú thích ở đây liên quan chặt chẽ hơn đến cấp độ cú pháp. Martha Palmer và cộng sự, Khoa Ngôn ngữ, Đại học Colorado Boulder đã phát triển nó. Chúng ta có thể sử dụng thuật ngữ PropBank như một danh từ chung đề cập đến bất kỳ ngữ liệu nào đã được chú thích bằng các mệnh đề và lập luận của chúng.
Trong xử lý ngôn ngữ tự nhiên (NLP), dự án PropBank đã đóng một vai trò rất quan trọng. Nó giúp gắn nhãn vai trò ngữ nghĩa.
VerbNet (VN)
VerbNet (VN) là tài nguyên từ vựng lớn nhất và độc lập với miền phân cấp bằng tiếng Anh kết hợp cả thông tin ngữ nghĩa cũng như cú pháp về nội dung của nó. VN là một từ vựng động từ có phạm vi rộng có ánh xạ tới các nguồn từ vựng khác như WordNet, Xtag và FrameNet. Nó được tổ chức thành các lớp động từ mở rộng các lớp Levin bằng cách tinh chỉnh và bổ sung các lớp con để đạt được sự thống nhất về cú pháp và ngữ nghĩa giữa các thành viên trong lớp.
Mỗi lớp VerbNet (VN) chứa:
Một tập hợp các mô tả cú pháp hoặc khung cú pháp
Để mô tả các nhận thức bề mặt có thể có của cấu trúc đối số cho các cấu trúc như bắc cầu, nội chuyển, cụm từ giới từ, kết quả và một tập hợp lớn các thay thế dấu chấm.
Một tập hợp các mô tả ngữ nghĩa như hoạt hình, con người, tổ chức
Đối với các ràng buộc, các loại vai trò chủ đề được các đối số cho phép và các hạn chế khác có thể được áp đặt. Điều này sẽ giúp chỉ ra bản chất cú pháp của thành phần có khả năng được liên kết với vai trò chủ đề.
Mạng từ
Mạng từ do Princeton tạo ra là một cơ sở dữ liệu từ vựng cho ngôn ngữ tiếng Anh. Nó là một phần của kho ngữ liệu NLTK. Trong Mạng từ, danh từ, động từ, tính từ và trạng từ được nhóm thành các tập hợp các từ đồng nghĩa nhận thức được gọi làSynsets. Tất cả các synsets được liên kết với sự trợ giúp của các quan hệ khái niệm-ngữ nghĩa và từ vựng. Cấu trúc của nó làm cho nó rất hữu ích cho việc xử lý ngôn ngữ tự nhiên (NLP).
Trong hệ thống thông tin, Mạng từ được sử dụng cho nhiều mục đích khác nhau như phân định nghĩa từ, truy xuất thông tin, phân loại văn bản tự động và dịch máy. Một trong những cách sử dụng quan trọng nhất của Mạng từ là tìm ra sự giống nhau giữa các từ. Đối với nhiệm vụ này, các thuật toán khác nhau đã được triển khai trong các gói khác nhau như Tương tự trong Perl, NLTK trong Python và ADW trong Java.
Trong chương này, chúng ta sẽ hiểu phân tích mức độ thế giới trong Xử lý ngôn ngữ tự nhiên.
Biểu thức chính quy
Biểu thức chính quy (RE) là một ngôn ngữ để chỉ định các chuỗi tìm kiếm văn bản. RE giúp chúng ta so khớp hoặc tìm các chuỗi hoặc bộ chuỗi khác, sử dụng cú pháp chuyên biệt được tổ chức trong một mẫu. Biểu thức chính quy được sử dụng để tìm kiếm văn bản trong UNIX cũng như trong MS WORD theo cách giống hệt nhau. Chúng tôi có nhiều công cụ tìm kiếm sử dụng một số tính năng RE.
Thuộc tính của Biểu thức chính quy
Tiếp theo là một số thuộc tính quan trọng của RE -
Nhà toán học người Mỹ Stephen Cole Kleene đã chính thức hóa ngôn ngữ Biểu thức chính quy.
RE là một công thức trong một ngôn ngữ đặc biệt, có thể được sử dụng để chỉ định các lớp đơn giản của chuỗi, một chuỗi ký hiệu. Nói cách khác, chúng ta có thể nói rằng RE là một ký hiệu đại số để đặc trưng cho một tập hợp các chuỗi.
Biểu thức chính quy yêu cầu hai thứ, một là mẫu mà chúng ta muốn tìm kiếm và hai là một kho văn bản mà chúng ta cần tìm kiếm.
Về mặt toán học, Biểu thức chính quy có thể được định nghĩa như sau:
ε là một Biểu thức chính quy, cho biết rằng ngôn ngữ đang có một chuỗi trống.
φ là một Biểu thức chính quy biểu thị rằng nó là một ngôn ngữ trống.
Nếu X và Y là Biểu thức chính quy, sau đó là
X, Y
X.Y(Concatenation of XY)
X+Y (Union of X and Y)
X*, Y* (Kleen Closure of X and Y)
cũng là các biểu thức chính quy.
Nếu một chuỗi có nguồn gốc từ các quy tắc trên thì đó cũng sẽ là một biểu thức chính quy.
Ví dụ về Cụm từ Thông dụng
Bảng sau đây cho thấy một vài ví dụ về Biểu thức chính quy:
| Biểu thức chính quy | Bộ thông thường |
|---|---|
| (0 + 10 *) | {0, 1, 10, 100, 1000, 10000,…} |
| (0 * 10 *) | {1, 01, 10, 010, 0010,…} |
| (0 + ε) (1 + ε) | {ε, 0, 1, 01} |
| (a + b) * | Nó sẽ là tập hợp các chuỗi a và b có độ dài bất kỳ bao gồm cả chuỗi rỗng tức là {ε, a, b, aa, ab, bb, ba, aaa …….} |
| (a + b) * abb | Nó sẽ là tập hợp các chuỗi a's và b's kết thúc bằng chuỗi abb tức là {abb, aabb, babb, aaabb, ababb, ………… ..} |
| (11) * | Nó sẽ được đặt bao gồm số chẵn của số 1 cũng bao gồm một chuỗi rỗng, tức là {ε, 11, 1111, 111111, ……….} |
| (aa) * (bb) * b | Nó sẽ là tập hợp các chuỗi bao gồm số chẵn của a theo sau là số lẻ của b tức là {b, aab, aabbb, aabbbbb, aaaab, aaaabbb, ………… ..} |
| (aa + ab + ba + bb) * | Nó sẽ là một chuỗi a và b có độ dài chẵn có thể thu được bằng cách ghép bất kỳ tổ hợp nào của các chuỗi aa, ab, ba và bb bao gồm null tức là {aa, ab, ba, bb, aaab, aaba, …………. .} |
Bộ thông thường & Thuộc tính của chúng
Nó có thể được định nghĩa là tập hợp đại diện cho giá trị của biểu thức chính quy và bao gồm các thuộc tính cụ thể.
Thuộc tính của tập hợp thông thường
Nếu chúng ta kết hợp hai tập hợp thông thường thì tập kết quả cũng sẽ là chính quy.
Nếu chúng ta thực hiện giao của hai tập hợp chính quy thì tập hợp kết quả cũng sẽ là tập hợp chính quy.
Nếu chúng ta bổ sung các tập hợp thông thường, thì tập hợp kết quả cũng sẽ là tập hợp chính quy.
Nếu chúng ta thực hiện sự khác biệt của hai tập hợp thông thường, thì tập hợp kết quả cũng sẽ là tập hợp chính quy.
Nếu chúng ta đảo ngược các tập hợp thông thường, thì tập hợp kết quả cũng sẽ là tập hợp chính quy.
Nếu chúng ta thực hiện việc đóng các tập hợp thông thường, thì tập hợp kết quả cũng sẽ là tập hợp chính quy.
Nếu chúng ta thực hiện việc nối hai tập hợp chính quy, thì tập hợp kết quả cũng sẽ là tập hợp chính quy.
Dữ liệu tự động trạng thái hữu hạn
Thuật ngữ automata, có nguồn gốc từ tiếng Hy Lạp "αὐτόματα" có nghĩa là "tự hoạt động", là số nhiều của automaton có thể được định nghĩa là một thiết bị tính toán tự hành trừu tượng tuân theo một trình tự hoạt động định trước một cách tự động.
Một ô tô tự động có một số trạng thái hữu hạn được gọi là Ô tô tự động hữu hạn (FA) hoặc Ô tô tự động trạng thái hữu hạn (FSA).
Về mặt toán học, một automaton có thể được biểu diễn bằng 5 bộ (Q, Σ, δ, q0, F), trong đó -
Q là một tập hữu hạn các trạng thái.
Σ là một tập hợp hữu hạn các ký hiệu, được gọi là bảng chữ cái của ô tô.
δ là hàm chuyển tiếp
q0 là trạng thái ban đầu mà từ đó bất kỳ đầu vào nào được xử lý (q0 ∈ Q).
F là tập hợp các trạng thái / trạng thái cuối cùng của Q (F ⊆ Q).
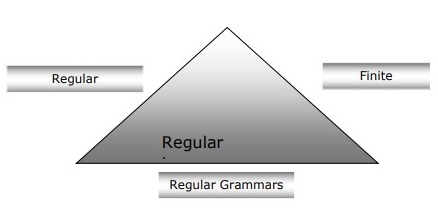
Mối quan hệ giữa dữ liệu tự động hữu hạn, ngữ pháp thông thường và biểu thức chính quy
Những điểm sau đây sẽ cho chúng ta một cái nhìn rõ ràng về mối quan hệ giữa các ô tự động hữu hạn, ngữ pháp thông thường và biểu thức chính quy -
Như chúng ta biết rằng otomat trạng thái hữu hạn là nền tảng lý thuyết của công việc tính toán và biểu thức chính quy là một cách để mô tả chúng.
Chúng ta có thể nói rằng bất kỳ biểu thức chính quy nào cũng có thể được triển khai dưới dạng FSA và mọi FSA có thể được mô tả bằng biểu thức chính quy.
Mặt khác, biểu thức chính quy là một cách để đặc trưng cho một loại ngôn ngữ được gọi là ngôn ngữ chính quy. Do đó, chúng ta có thể nói rằng ngôn ngữ thông thường có thể được mô tả với sự trợ giúp của cả FSA và biểu thức chính quy.
Ngữ pháp thông thường, một ngữ pháp chính thức có thể là từ phải thông thường hoặc trái thông thường, là một cách khác để mô tả đặc điểm của ngôn ngữ thông thường.
Sơ đồ sau cho thấy rằng các tự động hữu hạn, biểu thức chính quy và ngữ pháp thông thường là những cách tương đương để mô tả các ngôn ngữ thông thường.
Các loại tự động hóa trạng thái hữu hạn (FSA)
Tự động hóa trạng thái hữu hạn có hai loại. Hãy để chúng tôi xem các loại là gì.
Tự động hóa hữu hạn xác định (DFA)
Nó có thể được định nghĩa là loại tự động hóa hữu hạn, trong đó, đối với mọi ký hiệu đầu vào, chúng ta có thể xác định trạng thái mà máy sẽ di chuyển. Nó có một số trạng thái hữu hạn, đó là lý do tại sao máy được gọi là Máy tự động hữu hạn xác định (DFA).
Về mặt toán học, DFA có thể được biểu diễn bằng 5 bộ (Q, Σ, δ, q0, F), trong đó -
Q là một tập hữu hạn các trạng thái.
Σ là một tập hợp hữu hạn các ký hiệu, được gọi là bảng chữ cái của ô tô.
δ là hàm chuyển đổi trong đó δ: Q × Σ → Q.
q0 là trạng thái ban đầu mà từ đó bất kỳ đầu vào nào được xử lý (q0 ∈ Q).
F là tập hợp các trạng thái / trạng thái cuối cùng của Q (F ⊆ Q).
Trong khi đó bằng đồ thị, một DFA có thể được biểu diễn bằng các biểu đồ được gọi là biểu đồ trạng thái trong đó -
Các tiểu bang được đại diện bởi vertices.
Các chuyển đổi được hiển thị bằng nhãn arcs.
Trạng thái ban đầu được đại diện bởi một empty incoming arc.
Trạng thái cuối cùng được đại diện bởi double circle.
Ví dụ về DFA
Giả sử một DFA là
Q = {a, b, c},
Σ = {0, 1},
q 0 = {a},
F = {c},
Hàm chuyển đổi δ được thể hiện trong bảng như sau:
| Tình trạng hiện tại | Trạng thái tiếp theo cho đầu vào 0 | Trạng thái tiếp theo cho đầu vào 1 |
|---|---|---|
| A | a | B |
| B | b | A |
| C | c | C |
Biểu diễn đồ họa của DFA này sẽ như sau:

Tự động hóa hữu hạn không xác định (NDFA)
Nó có thể được định nghĩa là loại tự động hóa hữu hạn mà đối với mọi ký hiệu đầu vào, chúng ta không thể xác định trạng thái mà máy sẽ di chuyển, tức là máy có thể di chuyển đến bất kỳ tổ hợp trạng thái nào. Nó có một số trạng thái hữu hạn, đó là lý do tại sao máy được gọi là Tự động hóa hữu hạn không xác định (NDFA).
Về mặt toán học, NDFA có thể được biểu diễn bằng 5 bộ (Q, Σ, δ, q0, F), trong đó -
Q là một tập hữu hạn các trạng thái.
Σ là một tập hợp hữu hạn các ký hiệu, được gọi là bảng chữ cái của ô tô.
δ: -là các chức năng chuyển nơi δ: Q × Σ → 2 Q .
q0: -là trạng thái ban đầu mà từ đó bất kỳ đầu vào nào được xử lý (q0 ∈ Q).
F: -là tập hợp các trạng thái / trạng thái cuối cùng của Q (F ⊆ Q).
Trong khi bằng đồ thị (giống như DFA), một NDFA có thể được biểu diễn bằng các biểu đồ được gọi là biểu đồ trạng thái trong đó -
Các tiểu bang được đại diện bởi vertices.
Các chuyển đổi được hiển thị bằng nhãn arcs.
Trạng thái ban đầu được đại diện bởi một empty incoming arc.
Trạng thái cuối cùng được biểu thị bằng đôi circle.
Ví dụ về NDFA
Giả sử một NDFA là
Q = {a, b, c},
Σ = {0, 1},
q 0 = {a},
F = {c},
Hàm chuyển đổi δ được thể hiện trong bảng như sau:
| Tình trạng hiện tại | Trạng thái tiếp theo cho đầu vào 0 | Trạng thái tiếp theo cho đầu vào 1 |
|---|---|---|
| A | a, b | B |
| B | C | AC |
| C | b, c | C |
Biểu diễn đồ họa của NDFA này sẽ như sau:

Phân tích cú pháp hình thái
Thuật ngữ phân tích cú pháp hình thái có liên quan đến việc phân tích cú pháp các morphemes. Chúng ta có thể định nghĩa phân tích hình thái học là vấn đề nhận biết rằng một từ được chia thành các đơn vị có nghĩa nhỏ hơn được gọi là morphemes tạo ra một số loại cấu trúc ngôn ngữ cho nó. Ví dụ, chúng ta có thể chia từ foxes thành hai, fox và -es . Chúng ta có thể thấy rằng từ foxes , được tạo thành từ hai hình thái, một là cáo và một là -es .
Theo nghĩa khác, chúng ta có thể nói rằng hình thái học là nghiên cứu của -
Sự hình thành của từ.
Nguồn gốc của các từ.
Các dạng ngữ pháp của các từ.
Sử dụng tiền tố và hậu tố trong việc hình thành từ.
Cách các phần của giọng nói (PoS) của một ngôn ngữ được hình thành.
Các loại Morphemes
Morphemes, đơn vị mang ý nghĩa nhỏ nhất, có thể được chia thành hai loại -
Stems
Trật tự từ
Thân cây
Nó là đơn vị ý nghĩa cốt lõi của một từ. Chúng ta cũng có thể nói rằng nó là gốc của từ. Ví dụ, trong từ foxes, cái gốc là con cáo.
Affixes- Như tên cho thấy, chúng bổ sung một số ý nghĩa và chức năng ngữ pháp cho các từ. Ví dụ, trong từ foxes, phụ tố là - es.
Hơn nữa, các phụ tố cũng có thể được chia thành bốn loại sau:
Prefixes- Như tên cho thấy, các tiền tố đứng trước thân cây. Ví dụ, trong từ unbuckle, un là tiền tố.
Suffixes- Như tên cho thấy, các hậu tố theo sau thân cây. Ví dụ, trong từ mèo, -s là hậu tố.
Infixes- Như tên cho thấy, các bản in được chèn vào bên trong thân cây. Ví dụ, từ cupful, có thể được đa nghĩa là cupful bằng cách sử dụng -s làm tiền tố.
Circumfixes- Họ đi trước và theo sau thân cây. Có rất ít ví dụ về dấu ngoặc kép trong ngôn ngữ tiếng Anh. Một ví dụ rất phổ biến là 'A-ing' nơi chúng ta có thể sử dụng -A đứng trước và -ing đứng sau gốc.
Trật tự từ
Thứ tự của các từ sẽ được quyết định bằng cách phân tích hình thái học. Bây giờ chúng ta hãy xem các yêu cầu để xây dựng trình phân tích cú pháp hình thái học -
Lexicon
Yêu cầu đầu tiên để xây dựng bộ phân tích cú pháp hình thái là từ vựng, bao gồm danh sách các thân và phụ tố cùng với thông tin cơ bản về chúng. Ví dụ: thông tin như gốc là danh từ hay gốc động từ, v.v.
Hình thái học
Về cơ bản, nó là mô hình sắp xếp hình cầu. Theo nghĩa khác, mô hình giải thích lớp morphemes nào có thể theo sau các lớp morpheme khác bên trong một từ. Ví dụ, thực tế về hình thái là hình cầu số nhiều trong tiếng Anh luôn đứng sau danh từ hơn là đứng trước nó.
Quy tắc chỉnh hình
Các quy tắc chính tả này được sử dụng để mô hình hóa những thay đổi xảy ra trong một từ. Ví dụ, quy tắc chuyển đổi y thành ie trong từ như city + s = thành phố không phải thành phố.
Phân tích cú pháp hoặc phân tích cú pháp hoặc phân tích cú pháp là giai đoạn thứ ba của NLP. Mục đích của giai đoạn này là rút ra ý nghĩa chính xác, hoặc bạn có thể nói nghĩa từ điển từ văn bản. Phân tích cú pháp kiểm tra tính có nghĩa của văn bản so với các quy tắc của ngữ pháp chính thức. Ví dụ, câu như "kem nóng" sẽ bị từ chối bởi trình phân tích ngữ nghĩa.
Theo nghĩa này, phân tích cú pháp hoặc phân tích cú pháp có thể được định nghĩa là quá trình phân tích các chuỗi ký hiệu trong ngôn ngữ tự nhiên tuân theo các quy tắc của ngữ pháp chính thức. Nguồn gốc của từ‘parsing’ là từ tiếng Latinh ‘pars’ nghĩa là ‘part’.
Khái niệm về trình phân tích cú pháp
Nó được sử dụng để thực hiện nhiệm vụ phân tích cú pháp. Nó có thể được định nghĩa là thành phần phần mềm được thiết kế để lấy dữ liệu đầu vào (văn bản) và đưa ra biểu diễn cấu trúc của dữ liệu đầu vào sau khi kiểm tra cú pháp chính xác theo ngữ pháp chính thức. Nó cũng xây dựng một cấu trúc dữ liệu nói chung dưới dạng cây phân tích cú pháp hoặc cây cú pháp trừu tượng hoặc cấu trúc phân cấp khác.

Các vai trò chính của phân tích cú pháp bao gồm:
Để báo cáo bất kỳ lỗi cú pháp nào.
Để khôi phục lỗi thường xảy ra để có thể tiếp tục xử lý phần còn lại của chương trình.
Để tạo cây phân tích cú pháp.
Để tạo bảng ký hiệu.
Để tạo ra các biểu diễn trung gian (IR).
Các loại phân tích cú pháp
Derivation chia phân tích cú pháp thành hai loại sau:
Phân tích cú pháp từ trên xuống
Phân tích cú pháp từ dưới lên
Phân tích cú pháp từ trên xuống
Trong kiểu phân tích cú pháp này, trình phân tích cú pháp bắt đầu xây dựng cây phân tích cú pháp từ biểu tượng bắt đầu và sau đó cố gắng chuyển đổi biểu tượng bắt đầu thành đầu vào. Dạng phân tích cú pháp từ trên xuống phổ biến nhất sử dụng thủ tục đệ quy để xử lý đầu vào. Nhược điểm chính của phân tích cú pháp gốc đệ quy là quay lui.
Phân tích cú pháp từ dưới lên
Trong kiểu phân tích cú pháp này, trình phân tích cú pháp bắt đầu bằng ký hiệu đầu vào và cố gắng xây dựng cây phân tích cú pháp lên đến ký hiệu bắt đầu.
Khái niệm về nguồn gốc
Để có được chuỗi đầu vào, chúng ta cần một chuỗi các quy tắc sản xuất. Nguồn gốc là một tập hợp các quy tắc sản xuất. Trong quá trình phân tích cú pháp, chúng ta cần quyết định thiết bị đầu cuối sẽ được thay thế cùng với việc quyết định quy tắc sản xuất với sự trợ giúp của thiết bị không đầu cuối sẽ được thay thế.
Các loại nguồn gốc
Trong phần này, chúng ta sẽ tìm hiểu về hai loại dẫn xuất, có thể được sử dụng để quyết định loại không đầu cuối sẽ được thay thế bằng quy tắc sản xuất -
Xuất phát ngoài cùng bên trái
Trong phái sinh ngoài cùng bên trái, biểu mẫu thông tin của một đầu vào được quét và thay thế từ trái sang phải. Biểu mẫu thông tin gửi trong trường hợp này được gọi là biểu mẫu thông tin gửi trái.
Nguồn gốc bên phải nhất
Trong phái sinh ngoài cùng bên trái, biểu mẫu thông tin của một đầu vào được quét và thay thế từ phải sang trái. Biểu mẫu thông tin gửi trong trường hợp này được gọi là biểu mẫu thông tin xác thực.
Khái niệm về cây phân tích cú pháp
Nó có thể được định nghĩa là mô tả đồ họa của một dẫn xuất. Biểu tượng bắt đầu của dẫn xuất đóng vai trò là gốc của cây phân tích cú pháp. Trong mọi cây phân tích cú pháp, các nút lá là thiết bị đầu cuối và các nút bên trong là không đầu cuối. Một thuộc tính của cây phân tích cú pháp là việc duyệt theo thứ tự sẽ tạo ra chuỗi đầu vào ban đầu.
Khái niệm về ngữ pháp
Ngữ pháp là rất cần thiết và quan trọng để mô tả cấu trúc cú pháp của các chương trình được hình thành tốt. Theo nghĩa văn học, chúng biểu thị các quy tắc cú pháp để hội thoại trong ngôn ngữ tự nhiên. Ngôn ngữ học đã cố gắng xác định ngữ pháp kể từ khi ra đời các ngôn ngữ tự nhiên như tiếng Anh, tiếng Hindi, v.v.
Lý thuyết về ngôn ngữ hình thức cũng được áp dụng trong các lĩnh vực Khoa học máy tính chủ yếu là ngôn ngữ lập trình và cấu trúc dữ liệu. Ví dụ, trong ngôn ngữ 'C', các quy tắc ngữ pháp chính xác nêu rõ cách các hàm được tạo từ danh sách và câu lệnh.
Một mô hình toán học về ngữ pháp đã được đưa ra bởi Noam Chomsky vào năm 1956, hiệu quả cho việc viết ngôn ngữ máy tính.
Về mặt toán học, ngữ pháp G có thể được viết chính thức dưới dạng 4 bộ (N, T, S, P) trong đó -
N hoặc là VN = tập hợp các ký hiệu không phải đầu cuối, tức là, các biến.
T hoặc là ∑ = tập hợp các ký hiệu đầu cuối.
S = Ký hiệu bắt đầu trong đó S ∈ N
Pbiểu thị các quy tắc Sản xuất cho Thiết bị đầu cuối cũng như Thiết bị đầu cuối không. Nó có dạng α → β, trong đó α và β là các chuỗi trên V N ∪ ∑ và ít nhất một ký hiệu của α thuộc V N
Cấu trúc cụm từ hoặc ngữ pháp cấu thành
Ngữ pháp cấu trúc cụm từ, do Noam Chomsky giới thiệu, dựa trên quan hệ thành phần. Đó là lý do tại sao nó còn được gọi là ngữ pháp cấu thành. Nó ngược lại với ngữ pháp phụ thuộc.
Thí dụ
Trước khi đưa ra một ví dụ về ngữ pháp thành phần, chúng ta cần biết những điểm cơ bản về ngữ pháp thành phần và quan hệ thành phần.
Tất cả các khung liên quan xem cấu trúc câu theo quan hệ thành phần.
Quan hệ thành phần có nguồn gốc từ sự phân chia chủ ngữ-vị ngữ trong ngữ pháp tiếng Latinh cũng như tiếng Hy Lạp.
Cấu trúc mệnh đề cơ bản được hiểu theo nghĩa noun phrase NP và verb phrase VP.
Chúng ta có thể viết câu “This tree is illustrating the constituency relation” như sau -

Ngữ pháp phụ thuộc
Nó đối lập với ngữ pháp cấu thành và dựa trên quan hệ phụ thuộc. Nó được giới thiệu bởi Lucien Tesniere. Ngữ pháp phụ thuộc (DG) đối lập với ngữ pháp thành phần vì nó thiếu các nút cụm từ.
Thí dụ
Trước khi đưa ra ví dụ về ngữ pháp Phụ thuộc, chúng ta cần biết những điểm cơ bản về ngữ pháp Phụ thuộc và quan hệ Phụ thuộc.
Trong DG, các đơn vị ngôn ngữ, tức là các từ được kết nối với nhau bằng các liên kết có hướng.
Động từ trở thành trung tâm của cấu trúc mệnh đề.
Mọi đơn vị cú pháp khác đều được kết nối với động từ theo liên kết có hướng. Các đơn vị cú pháp này được gọi làdependencies.
Chúng ta có thể viết câu “This tree is illustrating the dependency relation” như sau;

Cây phân tích cú pháp sử dụng ngữ pháp Thành phần được gọi là cây phân tích cú pháp dựa trên thành phần; và cây phân tích cú pháp sử dụng ngữ pháp phụ thuộc được gọi là cây phân tích cú pháp dựa trên phụ thuộc.
Ngữ pháp miễn phí theo ngữ cảnh
Ngữ pháp tự do theo ngữ cảnh, còn được gọi là CFG, là một ký hiệu để mô tả các ngôn ngữ và một tập hợp ngữ pháp chính quy. Nó có thể được nhìn thấy trong sơ đồ sau:

Định nghĩa của CFG
CFG bao gồm một tập hợp hữu hạn các quy tắc ngữ pháp với bốn thành phần sau:
Tập hợp các thiết bị đầu cuối
Nó được ký hiệu là V. Các biến không phải là biến cú pháp biểu thị các tập hợp các chuỗi, giúp xác định thêm ngôn ngữ, được tạo ra bởi ngữ pháp.
Bộ thiết bị đầu cuối
Nó còn được gọi là mã thông báo và được định nghĩa bởi Σ. Các chuỗi được hình thành với các ký hiệu cơ bản của thiết bị đầu cuối.
Bộ sản xuất
Nó được ký hiệu là P. Tập xác định cách các thiết bị đầu cuối và không đầu cuối có thể được kết hợp. Mọi sản xuất (P) đều bao gồm các thiết bị đầu cuối không, một mũi tên và các thiết bị đầu cuối (chuỗi các thiết bị đầu cuối). Các thiết bị đầu cuối không được gọi là bên trái của sản xuất và các thiết bị đầu cuối được gọi là bên phải của sản xuất.
Biểu tượng Bắt đầu
Việc sản xuất bắt đầu từ ký hiệu bắt đầu. Nó được ký hiệu bằng ký hiệu S. Ký hiệu không đầu cuối luôn được chỉ định là ký hiệu bắt đầu.
Mục đích của phân tích ngữ nghĩa là để rút ra ý nghĩa chính xác, hoặc bạn có thể nói nghĩa từ điển của văn bản. Công việc của bộ phân tích ngữ nghĩa là kiểm tra tính có nghĩa của văn bản.
Chúng ta đã biết rằng phân tích từ vựng cũng giải quyết nghĩa của từ, vậy phân tích ngữ nghĩa khác với phân tích từ vựng như thế nào? Phân tích từ vựng dựa trên mã thông báo nhỏ hơn nhưng ở mặt khác, phân tích ngữ nghĩa tập trung vào các khối lớn hơn. Đó là lý do tại sao phân tích ngữ nghĩa có thể được chia thành hai phần sau:
Nghiên cứu nghĩa của từng từ
Đây là phần đầu tiên của phân tích ngữ nghĩa, trong đó việc nghiên cứu ý nghĩa của từng từ được thực hiện. Phần này được gọi là ngữ nghĩa từ vựng.
Nghiên cứu sự kết hợp của các từ riêng lẻ
Trong phần thứ hai, các từ riêng lẻ sẽ được kết hợp để cung cấp ý nghĩa trong câu.
Nhiệm vụ quan trọng nhất của phân tích ngữ nghĩa là tìm ra ý nghĩa thích hợp của câu. Ví dụ, phân tích câu“Ram is great.”Trong câu này, người nói đang nói về Chúa Ram hoặc về một người có tên là Ram. Đó là lý do tại sao công việc, để có được ý nghĩa thích hợp của câu, của bộ phân tích ngữ nghĩa là quan trọng.
Các yếu tố của phân tích ngữ nghĩa
Tiếp theo là một số yếu tố quan trọng của phân tích ngữ nghĩa -
Từ ghép nghĩa
Nó có thể được định nghĩa là mối quan hệ giữa một thuật ngữ chung và các trường hợp của thuật ngữ chung đó. Ở đây thuật ngữ chung được gọi là ẩn danh và các thể hiện của nó được gọi là từ ghép. Ví dụ, màu của từ là từ siêu nghĩa và màu xanh, vàng, v.v. là từ ghép.
Từ đồng âm
Nó có thể được định nghĩa là những từ có cùng cách viết hoặc cùng hình thức nhưng có nghĩa khác nhau và không liên quan. Ví dụ, từ “Bat” là một từ đồng âm vì dơi có thể là nông cụ để đánh bóng hoặc dơi cũng là một loài động vật có vú bay về đêm.
Polysemy
Polysemy là một từ Hy Lạp, có nghĩa là "nhiều dấu hiệu". Nó là một từ hoặc cụm từ có nghĩa khác nhau nhưng có liên quan. Nói cách khác, chúng ta có thể nói rằng polysemy có cùng cách viết nhưng ý nghĩa khác nhau và có liên quan. Ví dụ: từ "ngân hàng" là một từ đa nghĩa có các nghĩa sau:
Một tổ chức tài chính.
Tòa nhà mà một tổ chức như vậy tọa lạc.
Một từ đồng nghĩa với "dựa vào".
Sự khác biệt giữa Polysemy và Homonymy
Cả từ đa nghĩa và từ đồng âm đều có cú pháp hoặc cách viết giống nhau. Sự khác biệt chính giữa chúng là trong từ đa nghĩa, nghĩa của các từ có liên quan với nhau nhưng trong từ đồng âm, nghĩa của các từ không liên quan với nhau. Ví dụ, nếu chúng ta nói về cùng một từ "Ngân hàng", chúng ta có thể viết nghĩa là "một tổ chức tài chính" hoặc "một bờ sông". Trong trường hợp đó, nó sẽ là ví dụ về từ đồng âm bởi vì các nghĩa không liên quan đến nhau.
Từ đồng nghĩa
Là quan hệ giữa hai từ vựng có hình thức khác nhau nhưng cùng biểu hiện một nghĩa hoặc gần giống nhau. Ví dụ như 'tác giả / nhà văn', 'số phận / số phận'.
Từ trái nghĩa
Đó là quan hệ giữa hai mục từ vựng có sự đối xứng giữa các thành phần ngữ nghĩa của chúng so với một trục. Phạm vi của từ trái nghĩa như sau:
Application of property or not - Ví dụ là 'life / death', 'certitude / incertitude'
Application of scalable property - Ví dụ là 'giàu / nghèo', 'nóng / lạnh'
Application of a usage - Ví dụ là 'cha / con trai', 'mặt trăng / mặt trời'.
Đại diện ý nghĩa
Phân tích ngữ nghĩa tạo ra sự trình bày ý nghĩa của câu. Nhưng trước khi đi vào khái niệm và các cách tiếp cận liên quan đến biểu diễn ý nghĩa, chúng ta cần hiểu các cơ sở xây dựng của hệ thống ngữ nghĩa.
Xây dựng các khối của hệ thống ngữ nghĩa
Trong biểu diễn từ hoặc biểu diễn ý nghĩa của từ, các khối xây dựng sau đây đóng một vai trò quan trọng:
Entities- Nó đại diện cho cá nhân như một người cụ thể, vị trí, v.v. Ví dụ, Haryana. Ấn Độ, Ram đều là thực thể.
Concepts - Nó đại diện cho danh mục chung của các cá nhân như một người, thành phố, v.v.
Relations- Nó thể hiện mối quan hệ giữa thực thể và khái niệm. Ví dụ, Ram là một người.
Predicates- Nó đại diện cho các cấu trúc động từ. Ví dụ, vai trò ngữ nghĩa và ngữ pháp trường hợp là những ví dụ về vị ngữ.
Bây giờ, chúng ta có thể hiểu rằng biểu diễn ý nghĩa cho thấy cách kết hợp các khối xây dựng của hệ thống ngữ nghĩa lại với nhau. Nói cách khác, nó chỉ ra cách kết hợp các thực thể, khái niệm, quan hệ và vị ngữ để mô tả một tình huống. Nó cũng cho phép lý luận về thế giới ngữ nghĩa.
Phương pháp tiếp cận để trình bày ý nghĩa
Phân tích ngữ nghĩa sử dụng các cách tiếp cận sau đây để biểu diễn ý nghĩa:
Logic vị từ bậc nhất (FOPL)
Nets ngữ nghĩa
Frames
Phụ thuộc khái niệm (CD)
Kiến trúc dựa trên quy tắc
Ngữ pháp trường hợp
Đồ thị khái niệm
Cần trình bày ý nghĩa
Một câu hỏi đặt ra ở đây là tại sao chúng ta cần biểu diễn ý nghĩa? Theo dõi là những lý do giống nhau -
Liên kết các yếu tố ngôn ngữ với các yếu tố phi ngôn ngữ
Lý do đầu tiên là với sự trợ giúp của biểu diễn ý nghĩa, việc liên kết các yếu tố ngôn ngữ với các yếu tố phi ngôn ngữ có thể được thực hiện.
Thể hiện sự đa dạng ở cấp độ từ vựng
Với sự trợ giúp của biểu diễn ý nghĩa, các hình thức chính tắc, rõ ràng có thể được biểu diễn ở cấp độ từ vựng.
Có thể được sử dụng để lập luận
Biểu diễn ý nghĩa có thể được sử dụng để lập luận xác minh điều gì là đúng trên thế giới cũng như để suy ra kiến thức từ biểu diễn ngữ nghĩa.
Ngữ nghĩa từ vựng
Phần đầu tiên của phân tích ngữ nghĩa, nghiên cứu ý nghĩa của từng từ được gọi là ngữ nghĩa từ vựng. Nó bao gồm các từ, tiểu từ, phụ tố (đơn vị phụ), từ ghép và cả cụm từ. Tất cả các từ láy, tiểu từ,… được gọi chung là từ vựng. Nói cách khác, ta có thể nói ngữ nghĩa từ vựng là mối quan hệ giữa các mục từ vựng, nghĩa của câu và cú pháp của câu.
Sau đây là các bước liên quan đến ngữ nghĩa từ vựng -
Việc phân loại các mục từ vựng như từ, phụ từ, phụ tố, v.v. được thực hiện theo ngữ nghĩa từ vựng.
Việc phân rã các mục từ vựng như từ, tiểu từ, phụ tố, v.v. được thực hiện theo ngữ nghĩa từ vựng.
Sự khác biệt cũng như sự tương đồng giữa các cấu trúc ngữ nghĩa từ vựng khác nhau cũng được phân tích.
Chúng tôi hiểu rằng các từ có nghĩa khác nhau dựa trên ngữ cảnh sử dụng nó trong câu. Nếu chúng ta nói về ngôn ngữ của con người, thì chúng cũng mơ hồ bởi vì nhiều từ có thể được giải thích theo nhiều cách tùy thuộc vào bối cảnh xuất hiện của chúng.
Phân biệt ý nghĩa từ, trong xử lý ngôn ngữ tự nhiên (NLP), có thể được định nghĩa là khả năng xác định nghĩa nào của từ được kích hoạt bằng cách sử dụng từ trong một ngữ cảnh cụ thể. Sự mơ hồ về từ vựng, cú pháp hoặc ngữ nghĩa, là một trong những vấn đề đầu tiên mà bất kỳ hệ thống NLP nào phải đối mặt. Trình gắn thẻ Part-of-speech (POS) với mức độ chính xác cao có thể giải quyết sự mơ hồ về cú pháp của Word. Mặt khác, vấn đề giải quyết sự mơ hồ về ngữ nghĩa được gọi là WSD (phân loại ý nghĩa từ). Giải quyết sự mơ hồ về ngữ nghĩa khó hơn giải quyết được sự mơ hồ về cú pháp.
Ví dụ, hãy xem xét hai ví dụ về nghĩa khác biệt tồn tại cho từ “bass” -
Tôi có thể nghe thấy âm thanh trầm.
Anh ấy thích ăn cá vược nướng.
Sự xuất hiện của từ bassbiểu thị rõ ràng ý nghĩa riêng biệt. Trong câu đầu tiên, nó có nghĩa làfrequency và thứ hai, nó có nghĩa là fish. Do đó, nếu nó được WSD phân biệt thì nghĩa đúng cho các câu trên có thể được gán như sau:
Tôi có thể nghe thấy âm trầm / âm tần.
Anh ấy thích ăn cá vược / cá nướng.
Đánh giá WSD
Việc đánh giá WSD yêu cầu hai đầu vào sau:
Một cuốn từ điển
Đầu vào đầu tiên để đánh giá WSD là từ điển, được sử dụng để chỉ định các giác quan cần phân loại.
Kiểm tra Corpus
Một đầu vào khác được yêu cầu bởi WSD là kho dữ liệu kiểm tra được chú thích cao có mục tiêu hoặc giác quan chính xác. Kho tài liệu kiểm tra có thể có hai loại & minsu;
Lexical sample - Loại ngữ liệu này được sử dụng trong hệ thống, nơi nó được yêu cầu phân biệt một mẫu từ nhỏ.
All-words - Loại kho ngữ liệu này được sử dụng trong hệ thống, nơi nó dự kiến sẽ phân biệt tất cả các từ trong một đoạn văn bản đang chạy.
Các cách tiếp cận và phương pháp để định vị từ giác (WSD)
Các cách tiếp cận và phương pháp đối với WSD được phân loại theo nguồn kiến thức được sử dụng trong việc phân định từ.
Bây giờ chúng ta hãy xem bốn phương pháp thông thường để WSD -
Phương pháp dựa trên từ điển hoặc dựa trên kiến thức
Như tên cho thấy, để định hướng, các phương pháp này chủ yếu dựa vào từ điển, kho tàng và cơ sở kiến thức từ vựng. Họ không sử dụng bằng chứng ngữ liệu để phân định. Phương pháp Lesk là phương pháp dựa trên từ điển được giới thiệu bởi Michael Lesk vào năm 1986. Định nghĩa Lesk, dựa trên thuật toán Lesk là“measure overlap between sense definitions for all words in context”. Tuy nhiên, vào năm 2000, Kilgarriff và Rosensweig đã đưa ra định nghĩa Lesk đơn giản là“measure overlap between sense definitions of word and current context”, điều đó có nghĩa là xác định đúng nghĩa cho từng từ một. Ở đây ngữ cảnh hiện tại là tập hợp các từ trong câu hoặc đoạn văn xung quanh.
Phương pháp được giám sát
Đối với định hướng, các phương pháp học máy sử dụng kho ngữ liệu có chú thích hợp lý để đào tạo. Các phương pháp này giả định rằng ngữ cảnh có thể tự cung cấp đủ bằng chứng để phân biệt ý nghĩa. Trong các phương pháp này, các từ kiến thức và lý luận được coi là không cần thiết. Ngữ cảnh được biểu diễn dưới dạng một tập hợp các "đặc điểm" của các từ. Nó cũng bao gồm thông tin về các từ xung quanh. Máy vector hỗ trợ và học tập dựa trên bộ nhớ là những phương pháp học tập có giám sát thành công nhất đối với WSD. Những phương pháp này dựa vào một lượng đáng kể kho ngữ liệu được gắn thẻ theo cách thủ công, rất tốn kém để tạo.
Phương pháp bán giám sát
Do thiếu kho ngữ liệu đào tạo, hầu hết các thuật toán phân định nghĩa của từ sử dụng phương pháp học bán giám sát. Đó là bởi vì các phương pháp bán giám sát sử dụng cả dữ liệu được gắn nhãn cũng như không được gắn nhãn. Các phương pháp này yêu cầu một lượng rất nhỏ văn bản có chú thích và một lượng lớn văn bản thuần túy không có chú thích. Kỹ thuật được sử dụng bởi các phương pháp bán giám sát là khởi động từ dữ liệu hạt giống.
Phương pháp không được giám sát
Các phương pháp này giả định rằng các giác quan tương tự xảy ra trong bối cảnh tương tự. Đó là lý do tại sao các giác quan có thể được tạo ra từ văn bản bằng cách nhóm các lần xuất hiện từ bằng cách sử dụng một số biện pháp về sự tương đồng của ngữ cảnh. Nhiệm vụ này được gọi là cảm ứng từ hoặc phân biệt từ. Các phương pháp không được giám sát có tiềm năng lớn để khắc phục nút thắt tiếp thu kiến thức do không phụ thuộc vào các nỗ lực thủ công.
Các ứng dụng của Word Sense Disambiguation (WSD)
Phân loại ý nghĩa từ (WSD) được áp dụng trong hầu hết các ứng dụng của công nghệ ngôn ngữ.
Bây giờ chúng ta hãy xem phạm vi của WSD -
Dịch máy
Dịch máy hoặc MT là ứng dụng rõ ràng nhất của WSD. Trong MT, lựa chọn Lexical cho các từ có cách dịch riêng biệt cho các nghĩa khác nhau, được thực hiện bởi WSD. Các giác quan trong MT được biểu diễn dưới dạng các từ trong ngôn ngữ đích. Hầu hết các hệ thống dịch máy không sử dụng mô-đun WSD rõ ràng.
Truy xuất thông tin (IR)
Truy xuất thông tin (IR) có thể được định nghĩa là một chương trình phần mềm liên quan đến việc tổ chức, lưu trữ, truy xuất và đánh giá thông tin từ các kho tài liệu, đặc biệt là thông tin dạng văn bản. Về cơ bản, hệ thống hỗ trợ người dùng tìm kiếm thông tin họ yêu cầu nhưng nó không trả về câu trả lời của các câu hỏi một cách rõ ràng. WSD được sử dụng để giải quyết sự không rõ ràng của các truy vấn được cung cấp cho hệ thống IR. Giống như MT, các hệ thống IR hiện tại không sử dụng mô-đun WSD một cách rõ ràng và chúng dựa vào khái niệm rằng người dùng sẽ nhập đủ ngữ cảnh trong truy vấn để chỉ truy xuất các tài liệu có liên quan.
Khai thác văn bản và trích xuất thông tin (IE)
Trong hầu hết các ứng dụng, WSD là cần thiết để phân tích chính xác văn bản. Ví dụ, WSD giúp hệ thống thu thập thông minh thực hiện gắn cờ các từ đúng. Ví dụ: hệ thống thông minh y tế có thể cần gắn cờ "thuốc bất hợp pháp" thay vì "thuốc y tế"
Lexicography
WSD và từ vựng có thể làm việc cùng nhau theo vòng lặp vì từ vựng hiện đại dựa trên ngữ liệu. Với từ điển học, WSD cung cấp các nhóm cảm giác thực nghiệm thô cũng như các chỉ báo ngữ cảnh có ý nghĩa thống kê về cảm giác.
Khó khăn trong phân định định dạng từ giác quan (WSD)
Tiếp theo là một số khó khăn khi phân định nghĩa từ (WSD) -
Sự khác biệt giữa các từ điển
Vấn đề chính của WSD là quyết định ý nghĩa của từ vì các giác quan khác nhau có thể liên quan rất chặt chẽ. Ngay cả các từ điển và từ điển khác nhau cũng có thể cung cấp các cách phân chia từ khác nhau thành các nghĩa.
Các thuật toán khác nhau cho các ứng dụng khác nhau
Một vấn đề khác của WSD là thuật toán hoàn toàn khác có thể cần thiết cho các ứng dụng khác nhau. Ví dụ, trong dịch máy, nó có dạng lựa chọn từ đích; và trong việc truy xuất thông tin, không bắt buộc phải có kiểm kê giác quan.
Phương sai giữa các thẩm phán
Một vấn đề khác của WSD là các hệ thống WSD thường được kiểm tra bằng cách lấy kết quả của chúng trong một nhiệm vụ so với nhiệm vụ của con người. Đây được gọi là vấn đề phương sai đánh giá.
Sự rời rạc của cảm giác từ
Một khó khăn khác trong WSD là không thể dễ dàng chia các từ thành các phụ nghĩa rời rạc.
Bài toán khó nhất của AI là xử lý ngôn ngữ tự nhiên bằng máy tính hay nói cách khác là xử lý ngôn ngữ tự nhiên là bài toán khó nhất của trí tuệ nhân tạo. Nếu chúng ta nói về các vấn đề chính trong NLP, thì một trong những vấn đề chính trong NLP là xử lý diễn ngôn - xây dựng các lý thuyết và mô hình về cách các lời nói kết hợp với nhau để hình thànhcoherent discourse. Trên thực tế, ngôn ngữ luôn bao gồm các nhóm câu được sắp xếp, cấu trúc và mạch lạc hơn là những câu tách biệt và không liên quan như phim. Những nhóm câu mạch lạc này được gọi là diễn ngôn.
Khái niệm về mạch lạc
Tính mạch lạc và cấu trúc diễn ngôn liên kết với nhau theo nhiều cách. Tính mạch lạc, cùng với tính chất của văn bản tốt, được sử dụng để đánh giá chất lượng đầu ra của hệ thống tạo ngôn ngữ tự nhiên. Câu hỏi đặt ra ở đây là nó có ý nghĩa gì đối với một văn bản mạch lạc? Giả sử chúng ta thu thập một câu từ mỗi trang báo, thì đó sẽ là một bài nghị luận? Dĩ nhiên là không. Đó là vì những câu này không thể hiện sự mạch lạc. Bài văn nghị luận mạch lạc phải có các tính chất sau:
Mối quan hệ mạch lạc giữa các phát ngôn
Diễn ngôn sẽ mạch lạc nếu nó có các mối liên hệ có ý nghĩa giữa các phát ngôn của nó. Thuộc tính này được gọi là quan hệ mạch lạc. Ví dụ, phải có một số loại giải thích để chứng minh mối liên hệ giữa các lời nói.
Mối quan hệ giữa các thực thể
Một tính chất khác làm cho một diễn ngôn trở nên mạch lạc là phải có một loại mối quan hệ nhất định với các thực thể. Loại kết hợp như vậy được gọi là kết hợp dựa trên thực thể.
Cấu trúc diễn văn
Một câu hỏi quan trọng liên quan đến diễn ngôn là loại cấu trúc diễn ngôn phải có. Câu trả lời cho câu hỏi này phụ thuộc vào cách phân đoạn mà chúng ta áp dụng trong diễn ngôn. Phân đoạn diễn ngôn có thể được định nghĩa là xác định các kiểu cấu trúc cho diễn ngôn lớn. Khá khó để triển khai phân đoạn diễn ngôn, nhưng nó rất quan trọng đối vớiinformation retrieval, text summarization and information extraction các loại ứng dụng.
Các thuật toán cho phân đoạn diễn văn
Trong phần này, chúng ta sẽ tìm hiểu về các thuật toán phân đoạn diễn ngôn. Các thuật toán được mô tả bên dưới:
Phân đoạn diễn văn không được giám sát
Loại phân đoạn diễn ngôn không giám sát thường được biểu diễn dưới dạng phân đoạn tuyến tính. Chúng ta có thể hiểu nhiệm vụ của phân đoạn tuyến tính với sự trợ giúp của một ví dụ. Trong ví dụ, có một nhiệm vụ phân đoạn văn bản thành các đơn vị nhiều đoạn; các đơn vị thể hiện đoạn văn của văn bản gốc. Các thuật toán này phụ thuộc vào sự gắn kết có thể được định nghĩa là việc sử dụng các thiết bị ngôn ngữ nhất định để gắn kết các đơn vị văn bản với nhau. Mặt khác, sự gắn kết từ vựng là sự gắn kết được chỉ ra bởi mối quan hệ giữa hai hoặc nhiều từ trong hai đơn vị giống như việc sử dụng các từ đồng nghĩa.
Phân đoạn diễn văn được giám sát
Phương pháp trước đó không có bất kỳ ranh giới phân đoạn được gắn nhãn thủ công nào. Mặt khác, phân đoạn diễn ngôn được giám sát cần phải có dữ liệu đào tạo được gắn nhãn ranh giới. Nó là rất dễ dàng để có được như nhau. Trong phân đoạn diễn ngôn có giám sát, điểm đánh dấu diễn ngôn hoặc từ gợi ý đóng một vai trò quan trọng. Dấu hiệu diễn ngôn hoặc từ gợi ý là một từ hoặc cụm từ có chức năng báo hiệu cấu trúc diễn ngôn. Các điểm đánh dấu diễn ngôn này là dành riêng cho từng miền.
Tính mạch lạc của văn bản
Lặp lại từ vựng là một cách để tìm ra cấu trúc trong một bài văn, nhưng nó không đáp ứng được yêu cầu là bài văn mạch lạc. Để đạt được bài nghị luận mạch lạc, chúng ta phải tập trung vào các quan hệ mạch lạc trong cụ thể. Như chúng ta biết rằng quan hệ mạch lạc xác định mối liên hệ có thể có giữa các phát ngôn trong một diễn ngôn. Hebb đã đề xuất những kiểu quan hệ như sau:
Chúng tôi đang thực hiện hai điều khoản S0 và S1 để trình bày ý nghĩa của hai câu liên quan -
Kết quả
Nó cho rằng trạng thái được xác nhận theo thời hạn S0 có thể gây ra trạng thái được khẳng định bởi S1. Ví dụ, hai câu lệnh cho thấy kết quả của mối quan hệ: Ram đã bị bốc cháy. Da anh bị bỏng.
Giải trình
Nó cho rằng trạng thái được khẳng định bởi S1 có thể gây ra trạng thái được khẳng định bởi S0. Ví dụ, hai câu nói cho thấy mối quan hệ - Ram đánh nhau với bạn của Shyam. Anh đã say.
Song song, tương đông
Nó suy ra p (a1, a2,…) từ khẳng định của S0 và p (b1, b2,…) từ khẳng định S1. Ở đây ai và bi là tương tự cho tất cả i. Ví dụ, hai câu lệnh song song - Ram muốn xe. Shyam muốn tiền.
Công phu
Nó đưa ra cùng một mệnh đề P từ cả hai khẳng định - S0 và S1Ví dụ, hai câu lệnh cho thấy sự xây dựng quan hệ: Ram đến từ Chandigarh. Shyam đến từ Kerala.
Dịp
Nó xảy ra khi một sự thay đổi trạng thái có thể được suy ra từ khẳng định của S0, trạng thái cuối cùng có thể được suy ra từ S1và ngược lại. Ví dụ, hai câu cho thấy sự kiện quan hệ: Ram nhặt cuốn sách. Anh ấy đưa nó cho Shyam.
Xây dựng cấu trúc diễn văn thứ bậc
Tính liên kết của toàn bộ diễn ngôn cũng có thể được xem xét theo cấu trúc thứ bậc giữa các quan hệ mạch lạc. Ví dụ, đoạn văn sau có thể được biểu diễn dưới dạng cấu trúc phân cấp:
S1 - Ram đến ngân hàng để gửi tiền.
S2 - Sau đó anh ấy đi tàu đến cửa hàng vải của Shyam.
S3 - Anh ấy muốn mua một số quần áo.
S4 - Anh ấy không có quần áo mới để dự tiệc.
S5 - Anh ấy cũng muốn nói chuyện với Shyam về sức khỏe của anh ấy
Độ phân giải tham chiếu
Việc diễn giải các câu từ bất kỳ diễn ngôn nào là một nhiệm vụ quan trọng khác và để đạt được điều này, chúng ta cần biết ai hoặc thực thể nào đang được nói đến. Ở đây, tham chiếu giải thích là yếu tố chính.Referencecó thể được định nghĩa là biểu thức ngôn ngữ để biểu thị một thực thể hoặc cá nhân. Ví dụ, trong đoạn văn, Ram , giám đốc của ngân hàng ABC , đã nhìn thấy người bạn của mình là Shyam tại một cửa hàng. Anh đến gặp anh, những ngôn ngữ biểu đạt như Ram, His, He đều là tham khảo.
Trên cùng một lưu ý, reference resolution có thể được định nghĩa là nhiệm vụ xác định những thực thể nào được gọi bằng biểu thức ngôn ngữ nào.
Thuật ngữ được sử dụng trong độ phân giải tham chiếu
Chúng tôi sử dụng các thuật ngữ sau trong giải pháp tham chiếu -
Referring expression- Biểu thức ngôn ngữ tự nhiên được sử dụng để thực hiện quy chiếu được gọi là biểu thức quy chiếu. Ví dụ, đoạn văn được sử dụng ở trên là một biểu thức giới thiệu.
Referent- Nó là thực thể được giới thiệu. Ví dụ, trong ví dụ cuối cùng, Ram là một tham chiếu.
Corefer- Khi hai biểu thức được sử dụng để chỉ cùng một thực thể, chúng được gọi là corefers. Ví dụ,Ram và he là những con lõi.
Antecedent- Thời hạn có phép sử dụng thuật ngữ khác. Ví dụ,Ram là tiền thân của tham chiếu he.
Anaphora & Anaphoric- Nó có thể được định nghĩa là tham chiếu đến một thực thể đã được đưa vào câu trước đó. Và, biểu thức giới thiệu được gọi là đảo ngữ.
Discourse model - Mô hình chứa các đại diện của các thực thể đã được đề cập đến trong diễn ngôn và mối quan hệ mà chúng tham gia vào.
Các loại biểu thức giới thiệu
Bây giờ chúng ta hãy xem các loại biểu thức giới thiệu khác nhau. Năm loại biểu thức giới thiệu được mô tả dưới đây:
Cụm danh từ không xác định
Loại tham chiếu như vậy đại diện cho các thực thể mới đối với người nghe vào bối cảnh diễn ngôn. Ví dụ - trong câu Ram đã đi xung quanh một ngày để mang cho anh ta một số thức ăn - một số là một tham chiếu không xác định.
Cụm danh từ xác định
Đối lập với ở trên, loại tham chiếu như vậy đại diện cho các thực thể không mới hoặc không thể nhận dạng đối với người nghe trong ngữ cảnh diễn ngôn. Ví dụ, trong câu - I used to read The Times of India - Thời báo Ấn Độ là một tham chiếu xác định.
Đại từ
Nó là một hình thức tham chiếu xác định. Ví dụ, Ram cười lớn hết mức có thể. Từhe biểu thị đại từ giới thiệu.
Người biểu tình
Những điều này thể hiện và hoạt động khác với các đại từ xác định đơn giản. Ví dụ: this and that là đại từ biểu thị.
Tên
Đây là loại biểu thức giới thiệu đơn giản nhất. Nó có thể là tên của một người, tổ chức và địa điểm. Ví dụ, trong các ví dụ trên, Ram là biểu thức tham chiếu tên.
Tham chiếu nhiệm vụ giải quyết
Hai tác vụ giải quyết tham chiếu được mô tả bên dưới.
Độ phân giải lõi
Nó có nhiệm vụ tìm các biểu thức tham chiếu trong một văn bản tham chiếu đến cùng một thực thể. Nói một cách dễ hiểu, nó có nhiệm vụ tìm ra các biểu thức corefer. Một tập hợp các biểu thức lõi được gọi là chuỗi lõi. Ví dụ - He, Chief Manager và His - đây là những cách diễn đạt trong đoạn văn đầu tiên được đưa ra làm ví dụ.
Ràng buộc về độ phân giải lõi
Trong tiếng Anh, vấn đề chính để giải quyết vấn đề chính là đại từ nó. Lý do đằng sau điều này là đại từ nó có rất nhiều cách sử dụng. Ví dụ, nó có thể đề cập đến nhiều như anh ấy và cô ấy. Đại từ nó cũng chỉ sự vật mà không chỉ sự vật cụ thể. Ví dụ, Trời đang mưa. Nó thực sự là tốt.
Độ phân giải tương tự danh nghĩa
Không giống như độ phân giải lõi, độ phân giải đảo ngữ tiền thân có thể được định nghĩa là nhiệm vụ tìm tiền thân cho một đại từ duy nhất. Ví dụ, đại từ là của anh ta và nhiệm vụ của việc phân giải đại từ nhân xưng là tìm từ Ram vì Ram là tiền thân.
Gắn thẻ là một loại phân loại có thể được định nghĩa là việc tự động gán mô tả cho các mã thông báo. Ở đây, bộ mô tả được gọi là thẻ, có thể đại diện cho một trong những thông tin về ngữ nghĩa, phần lời nói, v.v.
Bây giờ, nếu chúng ta nói về gắn thẻ Part-of-Speech (PoS), thì nó có thể được định nghĩa là quá trình gán một trong các phần của lời nói cho từ đã cho. Nó thường được gọi là gắn thẻ POS. Nói một cách dễ hiểu, chúng ta có thể nói rằng gắn thẻ POS là một nhiệm vụ gắn nhãn mỗi từ trong một câu với phần lời nói thích hợp của nó. Chúng ta đã biết rằng các phần của lời nói bao gồm danh từ, động từ, trạng từ, tính từ, đại từ, kết hợp và các tiểu loại của chúng.
Hầu hết việc gắn thẻ POS đều thuộc tính năng gắn thẻ POS cơ sở theo quy tắc, gắn thẻ POS Stochastic và gắn thẻ dựa trên chuyển đổi.
Gắn thẻ POS dựa trên quy tắc
Một trong những kỹ thuật gắn thẻ lâu đời nhất là gắn thẻ POS dựa trên quy tắc. Trình gắn thẻ dựa trên quy tắc sử dụng từ điển hoặc từ vựng để nhận các thẻ khả thi để gắn thẻ từng từ. Nếu từ có thể có nhiều hơn một thẻ, thì các trình gắn thẻ dựa trên quy tắc sẽ sử dụng các quy tắc viết tay để xác định đúng thẻ. Việc phân định cũng có thể được thực hiện trong việc gắn thẻ dựa trên quy tắc bằng cách phân tích các đặc điểm ngôn ngữ của một từ cùng với các từ đứng trước cũng như sau nó. Ví dụ: giả sử nếu từ đứng trước của một từ là mạo từ thì từ đó phải là một danh từ.
Như tên cho thấy, tất cả các loại thông tin như vậy trong gắn thẻ POS dựa trên quy tắc được mã hóa dưới dạng quy tắc. Các quy tắc này có thể là -
Quy tắc mẫu ngữ cảnh
Hoặc, như Biểu thức chính quy được biên dịch thành tự động ở trạng thái hữu hạn, xen kẽ với biểu diễn câu không rõ ràng về mặt từ vựng.
Chúng tôi cũng có thể hiểu việc gắn thẻ POS dựa trên Quy tắc bằng kiến trúc hai giai đoạn của nó -
First stage - Trong giai đoạn đầu, nó sử dụng từ điển để gán cho mỗi từ một danh sách các phần tiềm năng của bài phát biểu.
Second stage - Trong giai đoạn thứ hai, nó sử dụng danh sách lớn các quy tắc phân định viết tay để sắp xếp danh sách xuống một phần của giọng nói cho mỗi từ.
Thuộc tính của gắn thẻ POS dựa trên quy tắc
Trình gắn thẻ POS dựa trên quy tắc có các thuộc tính sau:
Những trình gắn thẻ này là những trình kích hoạt dựa trên kiến thức.
Các quy tắc trong gắn thẻ POS dựa trên quy tắc được xây dựng theo cách thủ công.
Thông tin được mã hóa dưới dạng các quy tắc.
Chúng tôi có một số quy tắc giới hạn khoảng 1000.
Làm mượt và mô hình hóa ngôn ngữ được xác định rõ ràng trong các trình gắn thẻ dựa trên quy tắc.
Gắn thẻ POS Stochastic
Một kỹ thuật gắn thẻ khác là Gắn thẻ POS Stochastic. Bây giờ, câu hỏi đặt ra ở đây là mô hình nào có thể là ngẫu nhiên. Mô hình bao gồm tần suất hoặc xác suất (thống kê) có thể được gọi là ngẫu nhiên. Bất kỳ cách tiếp cận nào khác nhau đối với vấn đề gắn thẻ một phần giọng nói đều có thể được gọi là trình gắn thẻ ngẫu nhiên.
Trình gắn thẻ ngẫu nhiên đơn giản nhất áp dụng các cách tiếp cận sau để gắn thẻ POS:
Phương pháp tiếp cận tần số từ
Trong cách tiếp cận này, các thẻ ngẫu nhiên kích hoạt phân biệt các từ dựa trên xác suất một từ xuất hiện với một thẻ cụ thể. Chúng ta cũng có thể nói rằng thẻ gặp phải thường xuyên nhất với từ trong tập huấn luyện là thẻ được gán cho một phiên bản không rõ ràng của từ đó. Vấn đề chính với cách tiếp cận này là nó có thể mang lại chuỗi thẻ không thể chấp nhận được.
Xác suất trình tự thẻ
Đó là một cách tiếp cận khác của gắn thẻ ngẫu nhiên, trong đó trình gắn thẻ tính toán xác suất xuất hiện của một chuỗi thẻ nhất định. Nó còn được gọi là phương pháp tiếp cận n-gram. Nó được gọi như vậy bởi vì thẻ tốt nhất cho một từ nhất định được xác định bởi xác suất mà nó xuất hiện với n thẻ trước đó.
Thuộc tính của gắn thẻ BÀI ĐĂNG Stochastic
Trình gắn thẻ Stochastic POS có các thuộc tính sau:
Việc gắn thẻ POS này dựa trên xác suất xuất hiện của thẻ.
Nó yêu cầu tài liệu đào tạo
Sẽ không có xác suất cho các từ không tồn tại trong kho ngữ liệu.
Nó sử dụng ngữ liệu thử nghiệm khác nhau (không phải ngữ liệu đào tạo).
Đây là cách gắn thẻ POS đơn giản nhất vì nó chọn các thẻ thường xuyên nhất được liên kết với một từ trong kho ngữ liệu đào tạo.
Gắn thẻ dựa trên chuyển đổi
Gắn thẻ dựa trên chuyển đổi còn được gọi là gắn thẻ Brill. Đây là một ví dụ của học tập dựa trên chuyển đổi (TBL), là một thuật toán dựa trên quy tắc để tự động gắn thẻ POS cho văn bản nhất định. TBL, cho phép chúng ta có kiến thức ngôn ngữ ở dạng có thể đọc được, chuyển trạng thái này sang trạng thái khác bằng cách sử dụng các quy tắc chuyển đổi.
Nó lấy cảm hứng từ cả các trình kích hoạt được giải thích trước đó - dựa trên quy tắc và ngẫu nhiên. Nếu chúng ta thấy sự giống nhau giữa trình gắn thẻ dựa trên quy tắc và chuyển đổi, thì giống như dựa trên quy tắc, nó cũng dựa trên các quy tắc chỉ định thẻ nào cần được gán cho những từ nào. Mặt khác, nếu chúng ta thấy sự giống nhau giữa ngẫu nhiên và trình gắn thẻ chuyển đổi thì cũng giống như ngẫu nhiên, đó là kỹ thuật học máy trong đó các quy tắc được tự động tạo ra từ dữ liệu.
Làm việc của Học tập Dựa trên Chuyển đổi (TBL)
Để hiểu hoạt động và khái niệm của các trình kích hoạt dựa trên chuyển đổi, chúng ta cần hiểu hoạt động của học tập dựa trên chuyển đổi. Hãy xem xét các bước sau để hiểu hoạt động của TBL -
Start with the solution - TBL thường bắt đầu với một số giải pháp cho vấn đề và hoạt động theo chu kỳ.
Most beneficial transformation chosen - Trong mỗi chu kỳ, TBL sẽ chọn cách biến đổi có lợi nhất.
Apply to the problem - Phép biến đổi được chọn ở bước cuối cùng sẽ được áp dụng cho bài toán.
Thuật toán sẽ dừng khi phép biến đổi đã chọn ở bước 2 không thêm giá trị nào nữa hoặc không còn phép biến đổi nào được chọn. Kiểu học như vậy là phù hợp nhất trong các nhiệm vụ phân loại.
Ưu điểm của Học tập dựa trên Chuyển đổi (TBL)
Các ưu điểm của TBL như sau:
Chúng tôi tìm hiểu một tập hợp nhỏ các quy tắc đơn giản và những quy tắc này đủ để gắn thẻ.
Việc phát triển cũng như gỡ lỗi rất dễ dàng trong TBL vì các quy tắc đã học rất dễ hiểu.
Sự phức tạp trong việc gắn thẻ được giảm bớt vì trong TBL có sự xen kẽ của các quy tắc do máy móc và con người tạo ra.
Trình gắn thẻ dựa trên chuyển đổi nhanh hơn nhiều so với trình gắn thẻ mô hình Markov.
Nhược điểm của Học tập dựa trên Chuyển đổi (TBL)
Những nhược điểm của TBL như sau:
Học tập dựa trên chuyển đổi (TBL) không cung cấp xác suất thẻ.
Trong TBL, thời gian đào tạo rất dài, đặc biệt là trên kho ngữ liệu lớn.
Gắn thẻ POS Mô hình Markov ẩn (HMM)
Trước khi đi sâu vào gắn thẻ POS HMM, chúng ta phải hiểu khái niệm về Mô hình Markov ẩn (HMM).
Mô hình Markov ẩn
Mô hình HMM có thể được định nghĩa là mô hình ngẫu nhiên được nhúng kép, trong đó quá trình ngẫu nhiên cơ bản bị ẩn. Quá trình ngẫu nhiên ẩn này chỉ có thể được quan sát thông qua một tập hợp các quá trình ngẫu nhiên khác tạo ra chuỗi các quan sát.
Thí dụ
Ví dụ, một chuỗi thí nghiệm tung đồng xu ẩn được thực hiện và chúng ta chỉ thấy chuỗi quan sát gồm đầu và đuôi. Các chi tiết thực tế của quá trình - bao nhiêu đồng xu được sử dụng, thứ tự mà chúng được chọn - được ẩn với chúng tôi. Bằng cách quan sát chuỗi đầu và đuôi này, chúng ta có thể xây dựng một số HMM để giải thích trình tự. Sau đây là một dạng của Mô hình Markov ẩn cho vấn đề này:

Chúng tôi giả định rằng có hai trạng thái trong HMM và mỗi trạng thái tương ứng với việc lựa chọn đồng xu thiên vị khác nhau. Ma trận sau cung cấp các xác suất chuyển đổi trạng thái:
$$A = \begin{bmatrix}a11 & a12 \\a21 & a22 \end{bmatrix}$$
Đây,
aij = xác suất chuyển từ trạng thái này sang trạng thái khác từ i sang j.
a11 + a12= 1 và a 21 + a 22 = 1
P1 = xác suất của các đầu của đồng xu đầu tiên tức là độ lệch của đồng xu đầu tiên.
P2 = xác suất các đầu của đồng xu thứ hai tức là độ lệch của đồng xu thứ hai.
Chúng ta cũng có thể tạo mô hình HMM giả sử rằng có 3 đồng xu trở lên.
Bằng cách này, chúng ta có thể mô tả HMM theo các yếu tố sau:
N, số trạng thái trong mô hình (trong ví dụ trên N = 2, chỉ có hai trạng thái).
M, số lượng các quan sát khác biệt có thể xuất hiện với mỗi trạng thái trong ví dụ trên M = 2, tức là, H hoặc T).
A, phân bố xác suất chuyển trạng thái - ma trận A trong ví dụ trên.
P, phân bố xác suất của các ký hiệu có thể quan sát được ở mỗi trạng thái (trong ví dụ P1 và P2 của chúng ta).
I, phân phối trạng thái ban đầu.
Sử dụng HMM để gắn thẻ POS
Quy trình gắn thẻ POS là quy trình tìm kiếm chuỗi thẻ có nhiều khả năng đã tạo ra một chuỗi từ nhất định. Chúng tôi có thể lập mô hình quy trình POS này bằng cách sử dụng Mô hình Markov ẩn (HMM), trong đótags là hidden states điều đó tạo ra observable output, tức là words.
Về mặt toán học, trong gắn thẻ POS, chúng tôi luôn quan tâm đến việc tìm kiếm chuỗi thẻ (C) tối đa hóa -
P (C|W)
Ở đâu,
C = C 1 , C 2 , C 3 ... C T
W = W 1 , W 2 , W 3 , W T
Mặt khác, thực tế là chúng ta cần rất nhiều dữ liệu thống kê để ước tính hợp lý các loại trình tự như vậy. Tuy nhiên, để đơn giản hóa vấn đề, chúng ta có thể áp dụng một số phép biến đổi toán học cùng với một số giả thiết.
Việc sử dụng HMM để gắn thẻ POS là một trường hợp đặc biệt của sự can thiệp của Bayes. Do đó, chúng ta sẽ bắt đầu bằng cách trình bày lại vấn đề bằng cách sử dụng quy tắc Bayes, quy tắc này nói rằng xác suất có điều kiện nói trên bằng:
(PROB (C1,..., CT) * PROB (W1,..., WT | C1,..., CT)) / PROB (W1,..., WT)
Chúng ta có thể loại bỏ mẫu số trong tất cả các trường hợp này vì chúng ta quan tâm đến việc tìm dãy C có giá trị lớn nhất ở trên. Điều này sẽ không ảnh hưởng đến câu trả lời của chúng tôi. Bây giờ, vấn đề của chúng ta chỉ là tìm ra dãy C tối đa hóa -
PROB (C1,..., CT) * PROB (W1,..., WT | C1,..., CT) (1)
Ngay cả sau khi giảm vấn đề trong biểu thức trên, nó sẽ yêu cầu một lượng lớn dữ liệu. Chúng ta có thể đưa ra các giả định độc lập hợp lý về hai xác suất trong biểu thức trên để khắc phục vấn đề.
Giả định đầu tiên
Xác suất của một thẻ phụ thuộc vào thẻ trước đó (mô hình bigram) hoặc hai thẻ trước đó (mô hình trigram) hoặc n thẻ trước đó (mô hình n-gram), về mặt toán học, có thể được giải thích như sau:
PROB (C1,..., CT) = Πi=1..T PROB (Ci|Ci-n+1…Ci-1) (n-gram model)
PROB (C1,..., CT) = Πi=1..T PROB (Ci|Ci-1) (bigram model)
Đầu câu có thể được tính bằng cách giả sử một xác suất ban đầu cho mỗi thẻ.
PROB (C1|C0) = PROB initial (C1)
Giả định thứ hai
Xác suất thứ hai trong phương trình (1) ở trên có thể được tính gần đúng bằng cách giả định rằng một từ xuất hiện trong một danh mục độc lập với các từ trong các danh mục trước hoặc sau, có thể được giải thích bằng toán học như sau:
PROB (W1,..., WT | C1,..., CT) = Πi=1..T PROB (Wi|Ci)
Bây giờ, trên cơ sở hai giả định trên, mục tiêu của chúng ta giảm xuống việc tìm ra một chuỗi C tối đa hóa
Πi=1...T PROB(Ci|Ci-1) * PROB(Wi|Ci)
Bây giờ câu hỏi đặt ra ở đây là việc chuyển đổi vấn đề sang dạng trên có thực sự giúp ích cho chúng tôi không. Câu trả lời là - có, nó có. Nếu chúng ta có một kho dữ liệu được gắn thẻ lớn, thì hai xác suất trong công thức trên có thể được tính là:
PROB (Ci=VERB|Ci-1=NOUN) = (# of instances where Verb follows Noun) / (# of instances where Noun appears) (2)
PROB (Wi|Ci) = (# of instances where Wi appears in Ci) /(# of instances where Ci appears) (3)
Trong chương này, chúng ta sẽ thảo luận về sự khởi đầu của ngôn ngữ tự nhiên trong Xử lý ngôn ngữ tự nhiên. Để bắt đầu, trước tiên chúng ta hãy hiểu Ngữ pháp Ngôn ngữ Tự nhiên là gì.
Ngữ pháp ngôn ngữ tự nhiên
Đối với ngôn ngữ học, ngôn ngữ là một nhóm các dấu hiệu phát âm tùy ý. Chúng ta có thể nói rằng ngôn ngữ là sáng tạo, bị chi phối bởi các quy tắc, bẩm sinh cũng như phổ quát cùng một lúc. Mặt khác, nó cũng là con người. Bản chất của ngôn ngữ là khác nhau đối với những người khác nhau. Có rất nhiều quan niệm sai lầm về bản chất của ngôn ngữ. Đó là lý do tại sao điều rất quan trọng là phải hiểu ý nghĩa của thuật ngữ mơ hồ‘grammar’. Trong ngôn ngữ học, thuật ngữ ngữ pháp có thể được định nghĩa là các quy tắc hoặc nguyên tắc với sự trợ giúp của ngôn ngữ hoạt động. Theo nghĩa rộng, chúng ta có thể chia ngữ pháp thành hai loại:
Ngữ pháp mô tả
Tập hợp các quy tắc, trong đó ngôn ngữ học và các nhà ngữ pháp hình thành ngữ pháp của người nói được gọi là ngữ pháp mô tả.
Ngữ pháp phối cảnh
Đó là một ý nghĩa ngữ pháp rất khác, cố gắng duy trì một tiêu chuẩn về tính đúng đắn trong ngôn ngữ. Loại này không liên quan nhiều đến hoạt động thực tế của ngôn ngữ.
Các thành phần của ngôn ngữ
Ngôn ngữ nghiên cứu được chia thành các thành phần liên quan với nhau, đó là sự phân chia thông thường cũng như tùy ý của nghiên cứu ngôn ngữ học. Giải thích về các thành phần này như sau:
Âm vị học
Thành phần đầu tiên của ngôn ngữ là âm vị học. Nó là nghiên cứu về âm thanh lời nói của một ngôn ngữ cụ thể. Nguồn gốc của từ này có thể bắt nguồn từ tiếng Hy Lạp, trong đó 'phone' có nghĩa là âm thanh hoặc giọng nói. Ngữ âm học, một phân ngành của âm vị học là nghiên cứu về âm thanh lời nói của ngôn ngữ con người dưới góc độ sản xuất, tri giác hoặc các tính chất vật lý của chúng. IPA (Bảng chữ cái phiên âm quốc tế) là một công cụ biểu thị âm thanh của con người một cách thông thường trong khi nghiên cứu âm vị học. Trong IPA, mỗi ký hiệu được viết đại diện cho một và chỉ một âm thanh giọng nói và ngược lại.
Âm vị
Nó có thể được định nghĩa là một trong những đơn vị âm thanh giúp phân biệt từ này với từ khác trong một ngôn ngữ. Trong ngôn ngữ học, âm vị được viết giữa các dấu gạch chéo. Ví dụ, âm vị/k/ xảy ra trong các từ như kit, skit.
Hình thái học
Nó là thành phần thứ hai của ngôn ngữ. Nó là nghiên cứu về cấu trúc và phân loại của các từ trong một ngôn ngữ cụ thể. Nguồn gốc của từ này là từ tiếng Hy Lạp, trong đó từ 'morphe' có nghĩa là 'hình thức'. Hình thái học xem xét các nguyên tắc hình thành từ trong một ngôn ngữ. Nói cách khác, cách âm thanh kết hợp thành các đơn vị có nghĩa như tiền tố, hậu tố và gốc. Nó cũng xem xét cách các từ có thể được nhóm thành các phần của bài phát biểu.
Lexeme
Trong ngôn ngữ học, đơn vị trừu tượng của phép phân tích hình thái tương ứng với một tập hợp các dạng được thực hiện bởi một từ duy nhất được gọi là lexeme. Cách mà lexeme được sử dụng trong một câu được xác định bởi phạm trù ngữ pháp của nó. Lexeme có thể là từ riêng lẻ hoặc nhiều từ. Ví dụ, từ talk là một ví dụ của từ lexeme riêng lẻ, có thể có nhiều biến thể ngữ pháp như nói chuyện, nói chuyện và nói chuyện. Lexeme nhiều từ có thể được tạo thành từ nhiều hơn một từ chính tả. Ví dụ, nói lên, kéo qua, v.v. là những ví dụ về từ vựng nhiều từ vựng.
Cú pháp
Nó là thành phần thứ ba của ngôn ngữ. Nó là nghiên cứu về trật tự và sắp xếp của các từ thành các đơn vị lớn hơn. Từ này có thể bắt nguồn từ tiếng Hy Lạp, trong đó từ suntassein có nghĩa là 'sắp xếp theo thứ tự'. Nó nghiên cứu loại câu và cấu trúc của chúng, mệnh đề, cụm từ.
Ngữ nghĩa
Nó là thành phần thứ tư của ngôn ngữ. Nó là nghiên cứu về cách ý nghĩa được truyền đạt. Ý nghĩa có thể liên quan đến thế giới bên ngoài hoặc có thể liên quan đến ngữ pháp của câu. Từ này có thể bắt nguồn từ tiếng Hy Lạp, trong đó từ semainein có nghĩa là 'biểu thị', 'hiển thị', 'tín hiệu'.
Ngữ dụng học
Nó là thành phần thứ năm của ngôn ngữ. Nó là nghiên cứu về các chức năng của ngôn ngữ và việc sử dụng nó trong ngữ cảnh. Nguồn gốc của từ này có thể bắt nguồn từ tiếng Hy Lạp, nơi từ 'pragma' có nghĩa là 'hành động', 'sự việc'.
Danh mục ngữ pháp
Một phạm trù ngữ pháp có thể được định nghĩa là một lớp các đơn vị hoặc đặc điểm trong ngữ pháp của một ngôn ngữ. Các đơn vị này là các khối xây dựng của ngôn ngữ và có chung một tập hợp các đặc điểm. Phạm trù ngữ pháp còn được gọi là đặc điểm ngữ pháp.
Danh mục ngữ pháp được mô tả dưới đây:
Con số
Nó là phạm trù ngữ pháp đơn giản nhất. Chúng ta có hai thuật ngữ liên quan đến danh mục này là số ít và số nhiều. Số ít là khái niệm về 'một' trong khi số nhiều là khái niệm về 'nhiều hơn một'. Ví dụ, con chó / những con chó, cái này / những cái này.
Giới tính
Giới tính ngữ pháp được thể hiện bằng sự biến đổi của đại từ nhân xưng và ngôi thứ 3. Ví dụ về giới tính ngữ pháp là số ít - he, she, it; hình thức ngôi thứ nhất và thứ hai - tôi, chúng tôi và bạn; ngôi thứ 3 dạng số nhiều họ, là giới tính chung hoặc giới tính ngoài.
Người
Một phạm trù ngữ pháp đơn giản khác là người. Theo điều này, ba thuật ngữ sau được công nhận:
1st person - Người đang nói được công nhận là ngôi thứ nhất.
2nd person - Người nghe hoặc người được nói chuyện được coi là người thứ hai.
3rd person - Người hoặc sự vật mà chúng ta đang nói được coi là người thứ ba.
Trường hợp
Đây là một trong những phạm trù ngữ pháp khó nhất. Nó có thể được định nghĩa như một chỉ dẫn về chức năng của cụm danh từ (NP) hoặc mối quan hệ của cụm danh từ với động từ hoặc với các cụm danh từ khác trong câu. Chúng ta có ba trường hợp sau được diễn đạt bằng đại từ nhân xưng và nghi vấn:
Nominative case- Đó là chức năng của chủ thể. Ví dụ, tôi, chúng tôi, bạn, anh ấy, cô ấy, nó, họ và những người được đề cử.
Genitive case- Là chức năng của người chiếm hữu. Ví dụ, của tôi / của tôi, của chúng ta / của chúng ta, của anh ấy, của cô ấy / của cô ấy, của nó, của họ / của họ, những người có tính cách di truyền.
Objective case- Nó là chức năng của đối tượng. Ví dụ, tôi, chúng tôi, bạn, anh ấy, cô ấy, họ, những người khách quan.
Trình độ
Loại ngữ pháp này có liên quan đến tính từ và trạng từ. Nó có ba thuật ngữ sau:
Positive degree- Nó thể hiện một phẩm chất. Ví dụ, to, nhanh, đẹp là độ dương.
Comparative degree- Nó thể hiện mức độ hoặc cường độ cao hơn của chất lượng ở một trong hai mục. Ví dụ, lớn hơn, nhanh hơn, đẹp hơn là các mức độ so sánh.
Superlative degree- Nó thể hiện mức độ hoặc cường độ lớn nhất của chất lượng ở một trong ba hoặc nhiều mục. Ví dụ, lớn nhất, nhanh nhất, đẹp nhất là các độ bậc nhất.
Tính xác định và tính không xác định
Cả hai khái niệm này đều rất đơn giản. Tính xác định như chúng ta biết đại diện cho một tham chiếu, được người nói hoặc người nghe biết, quen thuộc hoặc có thể nhận dạng được. Mặt khác, tính không xác định đại diện cho một tham chiếu không được biết đến hoặc không quen thuộc. Khái niệm này có thể được hiểu khi một mạo từ đồng xuất hiện với một danh từ -
definite article- cái
indefinite article- a / an
Bẩn quá
Phạm trù ngữ pháp này có liên quan đến động từ và có thể được định nghĩa như một chỉ dẫn ngôn ngữ về thời gian của một hành động. Một thì thiết lập một quan hệ bởi vì nó chỉ thời gian của một sự kiện so với thời điểm nói. Nói chung, nó thuộc ba loại sau:
Present tense- Đại diện cho sự xuất hiện của một hành động trong thời điểm hiện tại. Ví dụ, Ram làm việc chăm chỉ.
Past tense- Đại diện cho sự xuất hiện của một hành động trước thời điểm hiện tại. Ví dụ, trời mưa.
Future tense- Đại diện cho sự xuất hiện của một hành động sau thời điểm hiện tại. Ví dụ, trời sẽ mưa.
Khía cạnh
Phạm trù ngữ pháp này có thể được định nghĩa là khung cảnh của một sự kiện. Nó có thể thuộc các loại sau:
Perfective aspect- Góc nhìn được chụp toàn bộ và đầy đủ về khía cạnh. Ví dụ, thì quá khứ đơn nhưyesterday I met my friend, trong tiếng Anh là hoàn hảo về khía cạnh vì nó xem sự kiện là hoàn chỉnh và toàn bộ.
Imperfective aspect- Quan điểm được coi là liên tục và không đầy đủ về khía cạnh. Ví dụ, thì hiện tại phân từ nhưI am working on this problem, trong tiếng Anh là không hoàn hảo về khía cạnh vì nó coi sự kiện là không hoàn chỉnh và đang diễn ra.
Tâm trạng
Phạm trù ngữ pháp này hơi khó xác định nhưng có thể nói đơn giản nó là biểu thị thái độ của người nói đối với những gì họ đang nói. Nó cũng là đặc điểm ngữ pháp của động từ. Nó khác biệt với các thì ngữ pháp và khía cạnh ngữ pháp. Các ví dụ về tâm trạng là biểu thị, nghi vấn, mệnh lệnh, mệnh lệnh, mệnh lệnh, tiềm năng, lựa chọn, mầm mống và phân từ.
Hợp đồng
Nó còn được gọi là concord. Nó xảy ra khi một từ thay đổi từ phụ thuộc vào các từ khác mà nó có liên quan. Nói cách khác, nó liên quan đến việc làm cho giá trị của một số phạm trù ngữ pháp nhất trí giữa các từ hoặc một phần của lời nói khác nhau. Tiếp theo là các thỏa thuận dựa trên các phạm trù ngữ pháp khác -
Agreement based on Person- Đó là sự thống nhất giữa chủ ngữ và động từ. Ví dụ, chúng ta luôn sử dụng "Tôi là" và "Anh ấy là" nhưng không bao giờ sử dụng "Anh ấy" và "Tôi là".
Agreement based on Number- Sự thống nhất này là giữa chủ ngữ và động từ. Trong trường hợp này, có những dạng động từ cụ thể cho ngôi thứ nhất số ít, ngôi thứ hai số nhiều, v.v. Ví dụ, ngôi thứ 1 số ít: I really am, ngôi thứ 2 số nhiều: Chúng tôi thực sự như vậy, ngôi thứ 3 số ít: The boy sings, ngôi thứ 3 số nhiều: The boys sing.
Agreement based on Gender- Trong tiếng Anh, có sự thống nhất về giới tính giữa đại từ và tiền thân. Ví dụ, Ngài đã đến đích. Con tàu đã đến đích.
Agreement based on Case- Loại thỏa thuận này không phải là một tính năng quan trọng của tiếng Anh. Ví dụ, ai đến trước - anh ấy hay em gái anh ấy?
Cú pháp ngôn ngữ nói
Ngữ pháp tiếng Anh viết và tiếng Anh nói có nhiều điểm chung nhưng cùng với đó, chúng cũng khác nhau ở một số khía cạnh. Các đặc điểm sau phân biệt ngữ pháp tiếng Anh nói và viết:
Disfluencies và sửa chữa
Đặc điểm nổi bật này làm cho ngữ pháp tiếng Anh nói và viết khác xa nhau. Nó được gọi riêng là hiện tượng không phù hợp và gọi chung là hiện tượng sửa chữa. Sự không phù hợp bao gồm việc sử dụng sau:
Fillers words- Đôi khi ở giữa câu ta sử dụng một số từ phụ. Chúng được gọi là chất làm đầy tạm dừng chất làm đầy. Ví dụ về những từ như vậy là uh và um.
Reparandum and repair- Đoạn từ được lặp lại ở giữa câu được gọi là đoạn lặp lại. Trong cùng một phân đoạn, từ thay đổi được gọi là sửa chữa. Hãy xem xét ví dụ sau để hiểu điều này -
Does ABC airlines offer any one-way flights uh one-way fares for 5000 rupees?
Trong câu trên, chuyến bay một chiều là sửa chữa và chuyến bay một chiều là sửa chữa.
Khởi động lại
Sau khi tạm dừng bộ nạp, khởi động lại xảy ra. Ví dụ, trong câu trên, khởi động lại xảy ra khi người nói bắt đầu hỏi về các chuyến bay một chiều sau đó dừng lại, tự sửa bằng cách điền tạm dừng và sau đó bắt đầu lại hỏi về giá vé một chiều.
Các đoạn từ
Đôi khi chúng ta nói những câu với những đoạn từ nhỏ hơn. Ví dụ,wwha-what is the time? Đây các từ w-wha là các đoạn từ.
Truy xuất thông tin (IR) có thể được định nghĩa là một chương trình phần mềm liên quan đến việc tổ chức, lưu trữ, truy xuất và đánh giá thông tin từ các kho tài liệu, đặc biệt là thông tin dạng văn bản. Hệ thống hỗ trợ người dùng tìm kiếm thông tin họ yêu cầu nhưng nó không trả về câu trả lời của các câu hỏi một cách rõ ràng. Nó thông báo sự tồn tại và vị trí của các tài liệu có thể bao gồm thông tin cần thiết. Các tài liệu đáp ứng yêu cầu của người dùng được gọi là tài liệu liên quan. Một hệ thống IR hoàn hảo sẽ chỉ lấy các tài liệu có liên quan.
Với sự trợ giúp của sơ đồ sau, chúng ta có thể hiểu quá trình truy xuất thông tin (IR) -

Từ sơ đồ trên rõ ràng là người dùng cần thông tin sẽ phải hình thành một yêu cầu dưới dạng truy vấn bằng ngôn ngữ tự nhiên. Sau đó, hệ thống IR sẽ phản hồi bằng cách truy xuất đầu ra liên quan, dưới dạng tài liệu, về thông tin được yêu cầu.
Vấn đề cổ điển trong hệ thống truy xuất thông tin (IR)
Mục tiêu chính của nghiên cứu IR là phát triển một mô hình để lấy thông tin từ các kho tài liệu. Ở đây, chúng ta sẽ thảo luận về một vấn đề cổ điển, có tên làad-hoc retrieval problem, liên quan đến hệ thống IR.
Trong truy xuất đặc biệt, người dùng phải nhập truy vấn bằng ngôn ngữ tự nhiên mô tả thông tin được yêu cầu. Sau đó hệ thống IR sẽ trả về các tài liệu cần thiết liên quan đến thông tin mong muốn. Ví dụ: giả sử chúng tôi đang tìm kiếm thứ gì đó trên Internet và nó cung cấp một số trang chính xác có liên quan theo yêu cầu của chúng tôi nhưng cũng có thể có một số trang không liên quan. Điều này là do sự cố truy xuất đặc biệt.
Các khía cạnh của Truy xuất Ad-hoc
Tiếp theo là một số khía cạnh của truy xuất đặc biệt được giải quyết trong nghiên cứu IR -
Người dùng với sự trợ giúp của phản hồi về mức độ liên quan có thể cải thiện công thức ban đầu của truy vấn như thế nào?
Làm thế nào để thực hiện hợp nhất cơ sở dữ liệu, tức là, làm thế nào kết quả từ các cơ sở dữ liệu văn bản khác nhau có thể được hợp nhất thành một tập kết quả?
Làm thế nào để xử lý dữ liệu bị hỏng một phần? Những mô hình nào là thích hợp cho cùng một?
Mô hình Truy xuất Thông tin (IR)
Về mặt toán học, các mô hình được sử dụng trong nhiều lĩnh vực khoa học nhằm mục đích hiểu được một số hiện tượng trong thế giới thực. Mô hình truy xuất thông tin dự đoán và giải thích những gì người dùng sẽ tìm thấy có liên quan đến truy vấn nhất định. Mô hình IR về cơ bản là một mẫu xác định các khía cạnh được đề cập ở trên của thủ tục truy xuất và bao gồm những điều sau:
Một mô hình cho các tài liệu.
Một mô hình cho các truy vấn.
Một hàm đối sánh so sánh các truy vấn với tài liệu.
Về mặt toán học, một mô hình truy xuất bao gồm:
D - Đại diện cho các tài liệu.
R - Biểu diễn cho các truy vấn.
F - Khung mô hình cho D, Q cùng với mối quan hệ giữa chúng.
R (q,di)- Một chức năng tương tự sắp xếp các tài liệu liên quan đến truy vấn. Nó còn được gọi là xếp hạng.
Các loại mô hình truy xuất thông tin (IR)
Mô hình mô hình thông tin (IR) có thể được phân loại thành ba mô hình sau:
Mô hình IR cổ điển
Đây là mô hình IR đơn giản nhất và dễ thực hiện. Mô hình này dựa trên kiến thức toán học đã được dễ dàng nhận ra và dễ hiểu. Boolean, Vector và Probabilistic là ba mô hình IR cổ điển.
Mô hình IR không cổ điển
Nó hoàn toàn ngược lại với mô hình IR cổ điển. Loại mô hình IR như vậy dựa trên các nguyên tắc khác với tính tương tự, xác suất, các phép toán Boolean. Mô hình logic thông tin, mô hình lý thuyết tình huống và các mô hình tương tác là những ví dụ của mô hình IR phi cổ điển.
Mô hình IR thay thế
Đó là sự nâng cao của mô hình IR cổ điển sử dụng một số kỹ thuật cụ thể từ một số lĩnh vực khác. Mô hình cụm, mô hình mờ và mô hình chỉ mục ngữ nghĩa tiềm ẩn (LSI) là ví dụ của mô hình IR thay thế.
Tính năng thiết kế của hệ thống truy xuất thông tin (IR)
Bây giờ chúng ta hãy tìm hiểu về các tính năng thiết kế của hệ thống IR -
Chỉ mục đảo ngược
Cấu trúc dữ liệu chính của hầu hết các hệ thống IR là ở dạng chỉ mục đảo ngược. Chúng ta có thể định nghĩa một chỉ mục đảo ngược là một cấu trúc dữ liệu liệt kê, đối với mọi từ, tất cả các tài liệu có chứa nó và tần suất xuất hiện trong tài liệu. Nó giúp bạn dễ dàng tìm kiếm 'lượt truy cập' của một từ truy vấn.
Dừng loại bỏ từ
Từ dừng là những từ có tần suất cao được cho là không hữu ích cho việc tìm kiếm. Chúng có ít trọng số ngữ nghĩa hơn. Tất cả những từ như vậy nằm trong danh sách gọi là danh sách dừng. Ví dụ, các mạo từ “a”, “an”, “the” và các giới từ như “in”, “of”, “for”, “at”, v.v. là những ví dụ về các từ dừng. Kích thước của chỉ mục đảo ngược có thể được giảm đáng kể bằng danh sách dừng. Theo định luật Zipf, một danh sách dừng bao gồm vài chục từ làm giảm kích thước của chỉ mục đảo ngược gần một nửa. Mặt khác, đôi khi việc loại bỏ từ dừng có thể gây ra việc loại bỏ cụm từ hữu ích cho việc tìm kiếm. Ví dụ, nếu chúng ta loại bỏ bảng chữ cái “A” khỏi “Vitamin A” thì nó sẽ không có ý nghĩa gì.
Gốc
Stemming, một dạng đơn giản của phân tích hình thái học, là quá trình heuristic để rút ra dạng cơ sở của từ bằng cách cắt bỏ các đầu của từ. Ví dụ, các từ cười, cười, cười sẽ bắt nguồn từ từ gốc là cười.
Trong các phần tiếp theo, chúng ta sẽ thảo luận về một số mô hình IR quan trọng và hữu ích.
Mô hình Boolean
Đây là mô hình truy xuất thông tin (IR) lâu đời nhất. Mô hình dựa trên lý thuyết tập hợp và đại số Boolean, trong đó các tài liệu là các tập hợp các thuật ngữ và truy vấn là các biểu thức Boolean trên các số hạng. Mô hình Boolean có thể được định nghĩa là:
D- Một tập hợp các từ, tức là các thuật ngữ lập chỉ mục có trong một tài liệu. Ở đây, mỗi thuật ngữ đều có mặt (1) hoặc vắng mặt (0).
Q - Một biểu thức Boolean, trong đó các số hạng là các thuật ngữ chỉ mục và toán tử là các tích logic - AND, tổng logic - HOẶC và hiệu số logic - KHÔNG
F - Đại số Boolean trên các bộ điều khoản cũng như trên các bộ tài liệu
Nếu chúng ta nói về phản hồi về mức độ liên quan, thì trong mô hình Boolean IR, dự đoán về mức độ liên quan có thể được định nghĩa như sau:
R - Một tài liệu được dự đoán là có liên quan đến biểu thức truy vấn nếu và chỉ khi nó thỏa mãn biểu thức truy vấn là -
((˅) ˄ ˄ ˜ ℎ)
Chúng ta có thể giải thích mô hình này bằng một thuật ngữ truy vấn như một định nghĩa rõ ràng về một bộ tài liệu.
Ví dụ, thuật ngữ truy vấn “economic” xác định bộ tài liệu được lập chỉ mục với thuật ngữ “economic”.
Bây giờ, kết quả sẽ là gì sau khi kết hợp các điều khoản với Toán tử Boolean AND? Nó sẽ xác định một bộ tài liệu nhỏ hơn hoặc bằng bộ tài liệu của bất kỳ thuật ngữ đơn lẻ nào. Ví dụ: truy vấn với các điều khoản“social” và “economic”sẽ tạo ra tập hợp các tài liệu được lập chỉ mục với cả hai điều khoản. Nói cách khác, tập hợp tài liệu với giao của cả hai tập hợp.
Bây giờ, kết quả sẽ như thế nào sau khi kết hợp các thuật ngữ với toán tử Boolean OR? Nó sẽ xác định một tập tài liệu lớn hơn hoặc bằng tập tài liệu của bất kỳ thuật ngữ đơn lẻ nào. Ví dụ: truy vấn với các điều khoản“social” hoặc là “economic” sẽ tạo ra bộ tài liệu gồm các tài liệu được lập chỉ mục với thuật ngữ “social” hoặc là “economic”. Nói cách khác, tập hợp tài liệu với sự kết hợp của cả hai tập hợp.
Ưu điểm của Chế độ Boolean
Các ưu điểm của mô hình Boolean như sau:
Mô hình đơn giản nhất, dựa trên các tập hợp.
Dễ hiểu và dễ thực hiện.
Nó chỉ lấy các kết quả phù hợp chính xác
Nó mang lại cho người dùng cảm giác kiểm soát được hệ thống.
Nhược điểm của Mô hình Boolean
Những nhược điểm của mô hình Boolean như sau:
Hàm tương tự của mô hình là Boolean. Do đó, sẽ không có trận đấu từng phần. Điều này có thể gây khó chịu cho người dùng.
Trong mô hình này, việc sử dụng toán tử Boolean có nhiều ảnh hưởng hơn là một từ chỉ trích.
Ngôn ngữ truy vấn là biểu cảm, nhưng nó cũng phức tạp.
Không có xếp hạng cho các tài liệu được truy xuất.
Mô hình không gian vector
Do những nhược điểm trên của mô hình Boolean, Gerard Salton và các đồng nghiệp đã đề xuất một mô hình dựa trên tiêu chí tương tự của Luhn. Tiêu chí tương tự do Luhn đưa ra tuyên bố, “càng có nhiều sự thống nhất giữa hai cách biểu diễn trong các phần tử nhất định và sự phân bố của chúng, thì xác suất của chúng thể hiện thông tin tương tự càng cao.”
Hãy xem xét những điểm quan trọng sau để hiểu thêm về Mô hình không gian vectơ -
Các biểu diễn chỉ mục (tài liệu) và các truy vấn được coi là các vectơ được nhúng trong không gian Euclid chiều cao.
Độ đo tương tự của một vectơ tài liệu với một vectơ truy vấn thường là cosin của góc giữa chúng.
Công thức đo độ tương đồng cosine
Cosine là một sản phẩm chấm chuẩn hóa, có thể được tính toán với sự trợ giúp của công thức sau:
$$Score \lgroup \vec{d} \vec{q} \rgroup= \frac{\sum_{k=1}^m d_{k}\:.q_{k}}{\sqrt{\sum_{k=1}^m\lgroup d_{k}\rgroup^2}\:.\sqrt{\sum_{k=1}^m}m\lgroup q_{k}\rgroup^2 }$$
$$Score \lgroup \vec{d} \vec{q}\rgroup =1\:when\:d =q $$
$$Score \lgroup \vec{d} \vec{q}\rgroup =0\:when\:d\:and\:q\:share\:no\:items$$
Biểu diễn không gian vectơ với truy vấn và tài liệu
Truy vấn và tài liệu được biểu diễn bằng không gian vectơ hai chiều. Các điều khoản làcar và insurance. Có một truy vấn và ba tài liệu trong không gian vectơ.

Tài liệu được xếp hạng hàng đầu đáp ứng các điều khoản về xe hơi và bảo hiểm sẽ là tài liệu d2 bởi vì góc giữa q và d2Là nhỏ nhất. Lý do đằng sau điều này là cả hai khái niệm xe hơi và bảo hiểm đều nổi bật ở d 2 và do đó có trọng số cao. Mặt khác,d1 và d3 cũng đề cập đến cả hai thuật ngữ nhưng trong mỗi trường hợp, một trong số chúng không phải là thuật ngữ quan trọng trong tài liệu.
Trọng số kỳ hạn
Trọng số thuật ngữ có nghĩa là trọng số của các thuật ngữ trong không gian vectơ. Trọng số của thuật ngữ càng cao thì tác động của thuật ngữ đối với cosin càng lớn. Nên gán nhiều trọng số hơn cho các điều khoản quan trọng hơn trong mô hình. Bây giờ câu hỏi đặt ra ở đây là làm thế nào chúng ta có thể mô hình hóa điều này.
Một cách để làm điều này là đếm các từ trong một tài liệu làm trọng số của nó. Tuy nhiên, bạn có nghĩ rằng nó sẽ là phương pháp hiệu quả?
Một phương pháp khác, hiệu quả hơn, là sử dụng term frequency (tfij), document frequency (dfi) và collection frequency (cfi).
Tần suất kỳ hạn (tf ij )
Nó có thể được định nghĩa là số lần xuất hiện của wi trong dj. Thông tin được thu thập theo tần suất thuật ngữ là mức độ nổi bật của một từ trong tài liệu đã cho hoặc nói cách khác, chúng ta có thể nói rằng tần suất thuật ngữ càng cao thì từ đó càng mô tả tốt nội dung của tài liệu đó.
Tần suất tài liệu (df i )
Nó có thể được định nghĩa là tổng số tài liệu trong bộ sưu tập mà trong đó tôi xuất hiện. Nó là một chỉ số của tính thông tin. Các từ tập trung vào ngữ nghĩa sẽ xuất hiện nhiều lần trong tài liệu không giống như các từ không tập trung về ngữ nghĩa.
Tần suất thu thập (cf i )
Nó có thể được định nghĩa là tổng số lần xuất hiện của wi trong bộ sưu tập.
Về mặt toán học, $df_{i}\leq cf_{i}\:and\:\sum_{j}tf_{ij} = cf_{i}$
Các dạng trọng số tần suất tài liệu
Bây giờ chúng ta hãy tìm hiểu về các dạng khác nhau của trọng số tần suất tài liệu. Các hình thức được mô tả dưới đây -
Yếu tố tần suất thời hạn
Đây cũng được phân loại là yếu tố tần suất thuật ngữ, có nghĩa là nếu một thuật ngữ t thường xuất hiện trong một tài liệu sau đó là một truy vấn chứa tnên lấy tài liệu đó. Chúng ta có thể kết hợp từterm frequency (tfij) và document frequency (dfi) thành một trọng lượng duy nhất như sau:
$$weight \left ( i,j \right ) =\begin{cases}(1+log(tf_{ij}))log\frac{N}{df_{i}}\:if\:tf_{i,j}\:\geq1\\0 \:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\: if\:tf_{i,j}\:=0\end{cases}$$
Ở đây N là tổng số tài liệu.
Tần suất tài liệu nghịch đảo (idf)
Đây là một dạng khác của trọng số tần suất tài liệu và thường được gọi là trọng số idf hoặc trọng số tần suất tài liệu nghịch đảo. Điểm quan trọng của trọng số idf là sự khan hiếm của thuật ngữ trên toàn bộ tập hợp là thước đo tầm quan trọng của nó và tầm quan trọng tỷ lệ nghịch với tần suất xuất hiện.
Về mặt toán học,
$$idf_{t} = log\left(1+\frac{N}{n_{t}}\right)$$
$$idf_{t} = log\left(\frac{N-n_{t}}{n_{t}}\right)$$
Đây,
N = tài liệu trong bộ sưu tập
n t = tài liệu chứa thuật ngữ t
Cải tiến Truy vấn Người dùng
Mục tiêu chính của bất kỳ hệ thống truy xuất thông tin nào phải là tính chính xác - để tạo ra các tài liệu liên quan theo yêu cầu của người dùng. Tuy nhiên, câu hỏi đặt ra ở đây là làm cách nào chúng ta có thể cải thiện kết quả đầu ra bằng cách cải thiện phong cách hình thành truy vấn của người dùng. Chắc chắn, đầu ra của bất kỳ hệ thống IR nào phụ thuộc vào truy vấn của người dùng và một truy vấn được định dạng tốt sẽ tạo ra kết quả chính xác hơn. Người dùng có thể cải thiện truy vấn của mình với sự trợ giúp củarelevance feedback, một khía cạnh quan trọng của bất kỳ mô hình IR nào.
Phản hồi về mức độ liên quan
Phản hồi về mức độ liên quan lấy đầu ra được trả về ban đầu từ truy vấn đã cho. Đầu ra ban đầu này có thể được sử dụng để thu thập thông tin người dùng và để biết liệu đầu ra đó có liên quan để thực hiện một truy vấn mới hay không. Các phản hồi có thể được phân loại như sau:
Phản hồi rõ ràng
Nó có thể được định nghĩa là phản hồi thu được từ những người đánh giá mức độ phù hợp. Những người đánh giá này cũng sẽ chỉ ra mức độ liên quan của một tài liệu được lấy từ truy vấn. Để cải thiện hiệu suất truy xuất truy vấn, thông tin phản hồi về mức độ liên quan cần được nội suy với truy vấn ban đầu.
Người đánh giá hoặc những người dùng khác của hệ thống có thể chỉ ra mức độ liên quan một cách rõ ràng bằng cách sử dụng các hệ thống mức độ liên quan sau:
Binary relevance system - Hệ thống phản hồi về mức độ liên quan này chỉ ra rằng một tài liệu có liên quan (1) hoặc không liên quan (0) cho một truy vấn nhất định.
Graded relevance system- Hệ thống phản hồi về mức độ phù hợp được phân loại cho biết mức độ liên quan của một tài liệu, đối với một truy vấn nhất định, trên cơ sở phân loại bằng cách sử dụng số, chữ cái hoặc mô tả. Mô tả có thể như "không liên quan", "hơi liên quan", "rất liên quan" hoặc "có liên quan".
Phản hồi ngầm
Đó là phản hồi được suy ra từ hành vi của người dùng. Hành vi bao gồm khoảng thời gian người dùng đã dành để xem tài liệu, tài liệu nào được chọn để xem và tài liệu nào không, các hành động duyệt và cuộn trang, v.v. Một trong những ví dụ tốt nhất về phản hồi ngầm làdwell time, là thước đo thời gian người dùng dành để xem trang được liên kết đến trong kết quả tìm kiếm.
Phản hồi giả
Nó còn được gọi là phản hồi mù. Nó cung cấp một phương pháp để phân tích cục bộ tự động. Phần thủ công của phản hồi về mức độ liên quan được tự động hóa với sự trợ giúp của phản hồi về mức độ liên quan của Pseudo để người dùng nhận được hiệu suất truy xuất được cải thiện mà không cần tương tác mở rộng. Ưu điểm chính của hệ thống phản hồi này là nó không yêu cầu người đánh giá như trong hệ thống phản hồi liên quan rõ ràng.
Hãy xem xét các bước sau để triển khai phản hồi này -
Step 1- Đầu tiên, kết quả trả về bởi truy vấn ban đầu phải được coi là kết quả có liên quan. Phạm vi kết quả phù hợp phải nằm trong 10-50 kết quả hàng đầu.
Step 2 - Bây giờ, chọn 20-30 thuật ngữ hàng đầu từ các tài liệu sử dụng cho trọng số tần suất thuật ngữ ví dụ (tf) -tần số tài liệu nghịch đảo (idf).
Step 3- Thêm các điều khoản này vào truy vấn và khớp với các tài liệu trả về. Sau đó trả lại các tài liệu liên quan nhất.
Xử lý ngôn ngữ tự nhiên (NLP) là một công nghệ mới nổi tạo ra nhiều dạng AI khác nhau mà chúng ta thấy trong thời điểm hiện tại và việc sử dụng nó để tạo ra một giao diện tương tác cũng như liền mạch giữa con người và máy móc sẽ tiếp tục là ưu tiên hàng đầu cho ngày nay và mai sau ngày càng ứng dụng nhận thức. Ở đây, chúng ta sẽ thảo luận về một số ứng dụng rất hữu ích của NLP.
Dịch máy
Dịch máy (MT), quá trình dịch một ngôn ngữ nguồn hoặc văn bản sang ngôn ngữ khác, là một trong những ứng dụng quan trọng nhất của NLP. Chúng ta có thể hiểu quá trình dịch máy với sự trợ giúp của sơ đồ sau:
Các loại hệ thống dịch máy
Có nhiều loại hệ thống dịch máy khác nhau. Hãy để chúng tôi xem các loại khác nhau là gì.
Hệ thống MT song ngữ
Hệ thống MT song ngữ tạo ra bản dịch giữa hai ngôn ngữ cụ thể.
Hệ thống MT đa ngôn ngữ
Hệ thống MT đa ngôn ngữ tạo ra bản dịch giữa bất kỳ cặp ngôn ngữ nào. Chúng có thể là một hướng hoặc hai hướng trong tự nhiên.
Phương pháp tiếp cận dịch máy (MT)
Bây giờ chúng ta hãy tìm hiểu về các phương pháp tiếp cận quan trọng đối với Dịch máy. Các cách tiếp cận với MT như sau:
Phương pháp tiếp cận MT trực tiếp
Nó ít phổ biến hơn nhưng là cách tiếp cận lâu đời nhất của MT. Các hệ thống sử dụng cách tiếp cận này có khả năng dịch SL (ngôn ngữ nguồn) trực tiếp sang TL (ngôn ngữ đích). Các hệ thống như vậy có bản chất là song ngữ và đơn hướng.
Phương pháp tiếp cận Interlingua
Các hệ thống sử dụng cách tiếp cận Interlingua dịch SL sang một ngôn ngữ trung gian gọi là Interlingua (IL) và sau đó dịch IL sang TL. Phương pháp Interlingua có thể được hiểu với sự trợ giúp của kim tự tháp MT sau:

Phương pháp chuyển giao
Ba giai đoạn liên quan đến cách tiếp cận này.
Trong giai đoạn đầu, các văn bản của ngôn ngữ nguồn (SL) được chuyển đổi thành các biểu diễn hướng SL trừu tượng.
Trong giai đoạn thứ hai, các biểu diễn hướng SL được chuyển đổi thành các biểu diễn hướng ngôn ngữ đích (TL) tương đương.
Trong giai đoạn thứ ba, văn bản cuối cùng được tạo ra.
Phương pháp tiếp cận MT theo kinh nghiệm
Đây là một cách tiếp cận mới nổi cho MT. Về cơ bản, nó sử dụng một lượng lớn dữ liệu thô dưới dạng kho văn bản song song. Dữ liệu thô bao gồm văn bản và bản dịch của chúng. Kỹ thuật dịch máy dựa trên tương tự, dựa trên ví dụ, dựa trên bộ nhớ sử dụng MTapproach theo kinh nghiệm.
Chống Spam
Một trong những vấn đề phổ biến nhất ngày nay là những email không mong muốn. Điều này làm cho bộ lọc Spam trở nên quan trọng hơn vì nó là tuyến phòng thủ đầu tiên chống lại vấn đề này.
Hệ thống lọc thư rác có thể được phát triển bằng cách sử dụng chức năng NLP bằng cách xem xét các vấn đề âm tính giả và âm tính giả.
Các mô hình NLP hiện có để lọc thư rác
Tiếp theo là một số mô hình NLP hiện có để lọc thư rác -
N-gram mô hình hóa
Mô hình N-Gram là một lát N ký tự của một chuỗi dài hơn. Trong mô hình này, N gam có độ dài khác nhau được sử dụng đồng thời để xử lý và phát hiện email spam.
Word Stemming
Người gửi thư rác, người tạo ra email spam, thường thay đổi một hoặc nhiều ký tự của các từ tấn công trong thư rác của họ để chúng có thể vi phạm bộ lọc thư rác dựa trên nội dung. Đó là lý do tại sao chúng ta có thể nói rằng các bộ lọc dựa trên nội dung sẽ không hữu ích nếu chúng không thể hiểu ý nghĩa của các từ hoặc cụm từ trong email. Để loại bỏ các vấn đề như vậy trong việc lọc thư rác, một kỹ thuật tạo gốc từ dựa trên quy tắc, có thể khớp các từ trông giống nhau và nghe giống nhau, được phát triển.
Phân loại Bayes
Đây hiện đã trở thành một công nghệ được sử dụng rộng rãi để lọc thư rác. Tỷ lệ xuất hiện của các từ trong email được đo lường dựa trên sự xuất hiện điển hình của nó trong cơ sở dữ liệu gồm các thư email không được yêu cầu (spam) và hợp pháp (ham) bằng một kỹ thuật thống kê.
Tóm tắt tự động
Trong thời đại kỹ thuật số này, thứ quý giá nhất là dữ liệu, hay có thể nói là thông tin. Tuy nhiên, chúng ta có thực sự nhận được sự hữu ích cũng như lượng thông tin cần thiết? Câu trả lời là 'KHÔNG' vì thông tin bị quá tải và khả năng tiếp cận kiến thức và thông tin của chúng ta vượt xa khả năng hiểu nó. Chúng tôi đang rất cần thông tin và tóm tắt văn bản tự động bởi vì làn sóng thông tin trên internet sẽ không dừng lại.
Tóm tắt văn bản có thể được định nghĩa là kỹ thuật tạo ra bản tóm tắt ngắn, chính xác của các tài liệu văn bản dài hơn. Tóm tắt văn bản tự động sẽ giúp chúng tôi có thông tin liên quan trong thời gian ngắn hơn. Xử lý ngôn ngữ tự nhiên (NLP) đóng một vai trò quan trọng trong việc phát triển một bản tóm tắt văn bản tự động.
Câu trả lời
Một ứng dụng chính khác của xử lý ngôn ngữ tự nhiên (NLP) là trả lời câu hỏi. Các công cụ tìm kiếm đặt thông tin của thế giới trong tầm tay của chúng ta, nhưng chúng vẫn còn thiếu sót khi trả lời các câu hỏi do con người đăng tải bằng ngôn ngữ tự nhiên của họ. Chúng tôi có các công ty công nghệ lớn như Google cũng đang làm việc theo hướng này.
Trả lời câu hỏi là một ngành Khoa học Máy tính trong các lĩnh vực AI và NLP. Nó tập trung vào việc xây dựng các hệ thống tự động trả lời các câu hỏi do con người đăng bằng ngôn ngữ tự nhiên của họ. Một hệ thống máy tính hiểu ngôn ngữ tự nhiên có khả năng của một hệ thống chương trình để dịch các câu do con người viết thành một biểu diễn bên trong để hệ thống có thể tạo ra các câu trả lời hợp lệ. Các câu trả lời chính xác có thể được tạo ra bằng cách thực hiện phân tích cú pháp và ngữ nghĩa của các câu hỏi. Khoảng cách từ vựng, sự mơ hồ và đa ngôn ngữ là một số thách thức đối với NLP trong việc xây dựng hệ thống trả lời câu hỏi tốt.
Phân tích cảm xúc
Một ứng dụng quan trọng khác của xử lý ngôn ngữ tự nhiên (NLP) là phân tích cảm xúc. Như tên cho thấy, phân tích tình cảm được sử dụng để xác định tình cảm giữa một số bài đăng. Nó cũng được sử dụng để xác định tình cảm mà cảm xúc không được thể hiện một cách rõ ràng. Các công ty đang sử dụng phân tích cảm xúc, một ứng dụng của xử lý ngôn ngữ tự nhiên (NLP) để xác định quan điểm và cảm xúc của khách hàng trực tuyến. Nó sẽ giúp các công ty hiểu được khách hàng của họ nghĩ gì về sản phẩm và dịch vụ. Các công ty có thể đánh giá danh tiếng tổng thể của họ từ các bài đăng của khách hàng với sự trợ giúp của phân tích tình cảm. Theo cách này, chúng ta có thể nói rằng ngoài việc xác định cực đơn giản, phân tích tình cảm còn hiểu cảm xúc trong ngữ cảnh để giúp chúng ta hiểu rõ hơn điều gì đằng sau ý kiến được bày tỏ.
Trong chương này, chúng ta sẽ tìm hiểu về xử lý ngôn ngữ bằng Python.
Các tính năng sau làm cho Python khác với các ngôn ngữ khác:
Python is interpreted - Chúng ta không cần biên dịch chương trình Python của mình trước khi thực thi vì trình thông dịch xử lý Python trong thời gian chạy.
Interactive - Chúng tôi có thể tương tác trực tiếp với trình thông dịch để viết các chương trình Python của mình.
Object-oriented - Python có bản chất là hướng đối tượng và nó giúp ngôn ngữ này viết chương trình dễ dàng hơn vì với sự trợ giúp của kỹ thuật lập trình này, nó sẽ đóng gói mã bên trong các đối tượng.
Beginner can easily learn - Python còn được gọi là ngôn ngữ dành cho người mới bắt đầu vì nó rất dễ hiểu và nó hỗ trợ phát triển nhiều loại ứng dụng.
Điều kiện tiên quyết
Phiên bản mới nhất của Python 3 được phát hành là Python 3.7.1 có sẵn cho Windows, Mac OS và hầu hết các phiên bản của Linux OS.
Đối với windows, chúng ta có thể vào link www.python.org/downloads/windows/ để tải và cài đặt Python.
Đối với MAC OS, chúng ta có thể sử dụng liên kết www.python.org/downloads/mac-osx/ .
Trong trường hợp Linux, các phiên bản Linux khác nhau sử dụng các trình quản lý gói khác nhau để cài đặt các gói mới.
Ví dụ: để cài đặt Python 3 trên Ubuntu Linux, chúng ta có thể sử dụng lệnh sau từ terminal:
$sudo apt-get install python3-minimalĐể nghiên cứu thêm về lập trình Python, hãy đọc hướng dẫn cơ bản về Python 3 - Python 3
Bắt đầu với NLTK
Chúng tôi sẽ sử dụng thư viện Python NLTK (Bộ công cụ ngôn ngữ tự nhiên) để thực hiện phân tích văn bản bằng tiếng Anh. Bộ công cụ ngôn ngữ tự nhiên (NLTK) là một tập hợp các thư viện Python được thiết kế đặc biệt để xác định và gắn thẻ các phần của giọng nói được tìm thấy trong văn bản của ngôn ngữ tự nhiên như tiếng Anh.
Cài đặt NLTK
Trước khi bắt đầu sử dụng NLTK, chúng ta cần cài đặt nó. Với sự trợ giúp của lệnh sau, chúng ta có thể cài đặt nó trong môi trường Python của mình -
pip install nltkNếu chúng tôi đang sử dụng Anaconda, thì một gói Conda cho NLTK có thể được tạo bằng cách sử dụng lệnh sau:
conda install -c anaconda nltkTải xuống dữ liệu của NLTK
Sau khi cài đặt NLTK, một nhiệm vụ quan trọng khác là tải các kho văn bản cài sẵn của nó để có thể dễ dàng sử dụng. Tuy nhiên, trước đó chúng ta cần nhập NLTK theo cách chúng ta nhập bất kỳ mô-đun Python nào khác. Lệnh sau sẽ giúp chúng ta nhập NLTK -
import nltkBây giờ, hãy tải xuống dữ liệu NLTK với sự trợ giúp của lệnh sau:
nltk.download()Sẽ mất một khoảng thời gian để cài đặt tất cả các gói có sẵn của NLTK.
Các gói cần thiết khác
Một số gói Python khác như gensim và patterncũng rất cần thiết cho việc phân tích văn bản cũng như xây dựng các ứng dụng xử lý ngôn ngữ tự nhiên bằng cách sử dụng NLTK. các gói có thể được cài đặt như hình dưới đây -
gensim
gensim là một thư viện mô hình ngữ nghĩa mạnh mẽ có thể được sử dụng cho nhiều ứng dụng. Chúng ta có thể cài đặt nó bằng lệnh sau:
pip install gensimmẫu
Nó có thể được sử dụng để làm gensimgói hoạt động đúng cách. Lệnh sau giúp cài đặt mẫu:
pip install patternMã hóa
Tokenization có thể được định nghĩa là Quá trình phá vỡ văn bản đã cho, thành các đơn vị nhỏ hơn được gọi là mã thông báo. Từ, số hoặc dấu chấm câu có thể là mã thông báo. Nó cũng có thể được gọi là phân đoạn từ.
Thí dụ
Input - Giường và ghế là loại nội thất.

Chúng tôi có các gói mã hóa khác nhau do NLTK cung cấp. Chúng tôi có thể sử dụng các gói này dựa trên yêu cầu của chúng tôi. Các gói và chi tiết cài đặt của chúng như sau:
gói sent_tokenize
Gói này có thể được sử dụng để chia văn bản đầu vào thành các câu. Chúng ta có thể nhập nó bằng cách sử dụng lệnh sau:
from nltk.tokenize import sent_tokenizegói word_tokenize
Gói này có thể được sử dụng để chia văn bản đầu vào thành các từ. Chúng ta có thể nhập nó bằng cách sử dụng lệnh sau:
from nltk.tokenize import word_tokenizeGói WordPunctTokenizer
Gói này có thể được sử dụng để chia văn bản đầu vào thành các từ và dấu chấm câu. Chúng ta có thể nhập nó bằng cách sử dụng lệnh sau:
from nltk.tokenize import WordPuncttokenizerGốc
Vì lý do ngữ pháp, ngôn ngữ bao gồm rất nhiều biến thể. Các biến thể theo nghĩa là ngôn ngữ, tiếng Anh cũng như các ngôn ngữ khác, có các dạng khác nhau của một từ. Ví dụ, những từ nhưdemocracy, democraticvà democratization. Đối với các dự án học máy, điều rất quan trọng là máy móc phải hiểu rằng những từ khác nhau này, như ở trên, có cùng dạng cơ sở. Đó là lý do tại sao nó rất hữu ích để trích xuất các dạng cơ sở của các từ trong khi phân tích văn bản.
Cắt ghép là một quá trình nghiên cứu giúp rút ra các dạng cơ bản của các từ bằng cách cắt các đầu của chúng.
Các gói khác nhau để tạo gốc do mô-đun NLTK cung cấp như sau:
Gói PorterStemmer
Thuật toán của Porter được gói gốc này sử dụng để trích xuất dạng cơ sở của các từ. Với sự trợ giúp của lệnh sau, chúng ta có thể nhập gói này:
from nltk.stem.porter import PorterStemmerVí dụ, ‘write’ sẽ là đầu ra của từ ‘writing’ được đưa ra làm đầu vào cho trình gốc này.
Gói LancasterStemmer
Thuật toán Lancaster được gói gốc này sử dụng để trích xuất dạng cơ sở của các từ. Với sự trợ giúp của lệnh sau, chúng ta có thể nhập gói này -
from nltk.stem.lancaster import LancasterStemmerVí dụ, ‘writ’ sẽ là đầu ra của từ ‘writing’ được đưa ra làm đầu vào cho trình gốc này.
Gói SnowballStemmer
Thuật toán của Snowball được gói gốc này sử dụng để trích xuất dạng cơ sở của các từ. Với sự trợ giúp của lệnh sau, chúng ta có thể nhập gói này -
from nltk.stem.snowball import SnowballStemmerVí dụ, ‘write’ sẽ là đầu ra của từ ‘writing’ được đưa ra làm đầu vào cho trình gốc này.
Bổ sung
Đó là một cách khác để trích xuất dạng cơ sở của từ, thông thường nhằm mục đích loại bỏ các kết thúc không theo chiều hướng bằng cách sử dụng phân tích từ vựng và hình thái. Sau khi bổ đề, dạng cơ sở của bất kỳ từ nào được gọi là bổ đề.
Mô-đun NLTK cung cấp gói sau để lemmatization -
Gói WordNetLemmatizer
Gói này sẽ trích xuất dạng cơ sở của từ tùy thuộc vào việc nó được sử dụng như một danh từ hay một động từ. Lệnh sau có thể được sử dụng để nhập gói này:
from nltk.stem import WordNetLemmatizerĐếm thẻ POS – Chunking
Việc xác định các phần của giọng nói (POS) và các cụm từ ngắn có thể được thực hiện với sự trợ giúp của phân khúc. Nó là một trong những quá trình quan trọng trong xử lý ngôn ngữ tự nhiên. Như chúng ta đã biết về quá trình mã hóa để tạo ra các mã thông báo, phân khúc thực sự là thực hiện việc ghi nhãn cho các mã thông báo đó. Nói cách khác, chúng ta có thể nói rằng chúng ta có thể có được cấu trúc của câu với sự trợ giúp của quá trình phân khúc.
Thí dụ
Trong ví dụ sau, chúng ta sẽ triển khai phân đoạn Danh từ-Cụm từ, một loại phân đoạn sẽ tìm các khối cụm danh từ trong câu, bằng cách sử dụng mô-đun NLTK Python.
Hãy xem xét các bước sau để thực hiện tách cụm danh từ -
Step 1: Chunk grammar definition
Trong bước này, chúng ta cần xác định ngữ pháp để phân khúc. Nó sẽ bao gồm các quy tắc mà chúng ta cần tuân theo.
Step 2: Chunk parser creation
Tiếp theo, chúng ta cần tạo một trình phân tích cú pháp chunk. Nó sẽ phân tích ngữ pháp và đưa ra kết quả.
Step 3: The Output
Trong bước này, chúng tôi sẽ nhận được đầu ra ở dạng cây.
Chạy Tập lệnh NLP
Bắt đầu bằng cách nhập gói NLTK -
import nltkBây giờ, chúng ta cần xác định câu.
Đây,
DT là yếu tố quyết định
VBP là động từ
JJ là tính từ
IN là giới từ
NN là danh từ
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Tiếp theo, ngữ pháp nên được đưa ra dưới dạng biểu thức chính quy.
grammar = "NP:{<DT>?<JJ>*<NN>}"Bây giờ, chúng ta cần xác định một trình phân tích cú pháp để phân tích ngữ pháp.
parser_chunking = nltk.RegexpParser(grammar)Bây giờ, trình phân tích cú pháp sẽ phân tích cú pháp câu như sau:
parser_chunking.parse(sentence)Tiếp theo, đầu ra sẽ ở trong biến như sau: -
Output = parser_chunking.parse(sentence)Bây giờ, đoạn mã sau sẽ giúp bạn vẽ đầu ra của mình dưới dạng cây.
output.draw()