Khái niệm cơ bản về gắn thẻ Part-of-Speech (POS)
Gắn thẻ POS là gì?
Gắn thẻ, một loại phân loại, là việc tự động gán mô tả của các mã thông báo. Chúng tôi gọi là 'thẻ' của bộ mô tả, đại diện cho một trong những phần của lời nói (danh từ, động từ, trạng từ, tính từ, đại từ, kết hợp và các tiểu loại của chúng), thông tin ngữ nghĩa, v.v.
Mặt khác, nếu chúng ta nói về gắn thẻ Part-of-Speech (POS), nó có thể được định nghĩa là quá trình chuyển đổi một câu dưới dạng một danh sách các từ, thành một danh sách các bộ giá trị. Ở đây, các bộ giá trị có dạng (từ, thẻ). Chúng ta cũng có thể gọi việc gắn thẻ POS là một quá trình gán một trong những phần của lời nói cho từ đã cho.
Bảng sau đại diện cho thông báo POS thường xuyên nhất được sử dụng trong kho tài liệu Penn Treebank -
| Sr.No | Nhãn | Sự miêu tả |
|---|---|---|
| 1 | NNP | Danh từ riêng, số ít |
| 2 | NNPS | Danh từ riêng, số nhiều |
| 3 | PDT | Người xác định trước |
| 4 | POS | Kết thúc có lợi |
| 5 | PRP | Đại từ nhân xưng |
| 6 | PRP $ | Đại từ sở hữu |
| 7 | RB | Trạng từ |
| số 8 | RBR | Trạng từ, so sánh |
| 9 | RBS | Trạng từ so sánh nhất |
| 10 | RP | Hạt |
| 11 | SYM | Biểu tượng (toán học hoặc khoa học) |
| 12 | ĐẾN | đến |
| 13 | UH | Thán từ |
| 14 | VB | Động từ, dạng cơ sở |
| 15 | VBD | Động từ, thì quá khứ |
| 16 | VBG | Động từ, phân từ / hiện tại phân từ |
| 17 | VBN | Động từ, quá khứ |
| 18 | WP | Đại từ wh |
| 19 | WP $ | Đại từ sở hữu |
| 20 | WRB | Trạng từ wh |
| 21 | # | Bảng Anh |
| 22 | $ | Ký hiệu đô la |
| 23 | . | Dấu câu cuối câu |
| 24 | , | Dấu phẩy |
| 25 | : | Dấu hai chấm, dấu chấm phẩy |
| 26 | ( | Ký tự trong ngoặc trái |
| 27 | ) | Ký tự trong ngoặc phải |
| 28 | " | Dấu ngoặc kép thẳng |
| 29 | ' | Còn mở một trích dẫn |
| 30 | " | Dấu ngoặc kép còn mở |
| 31 | ' | Dấu ngoặc kép phải đóng |
| 32 | " | Dấu ngoặc kép mở ngay |
Thí dụ
Hãy để chúng tôi hiểu nó bằng một thử nghiệm Python -
import nltk
from nltk import word_tokenize
sentence = "I am going to school"
print (nltk.pos_tag(word_tokenize(sentence)))Đầu ra
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]Tại sao phải gắn thẻ POS?
Gắn thẻ POS là một phần quan trọng của NLP vì nó hoạt động như điều kiện tiên quyết để phân tích thêm NLP như sau:
- Chunking
- Phân tích cú pháp
- Trích xuất thông tin
- Dịch máy
- Phân tích tình cảm
- Phân tích ngữ pháp & phân định từ ngữ
TaggerI - Lớp cơ sở
Tất cả các trình gắn thẻ nằm trong gói nltk.tag của NLTK. Lớp cơ sở của các trình gắn thẻ này làTaggerI, có nghĩa là tất cả các trình kích hoạt kế thừa từ lớp này.
Methods - Lớp TaggerI có hai phương thức sau đây phải được thực hiện bởi tất cả các lớp con của nó -
tag() method - Như tên của nó, phương thức này nhận danh sách các từ làm đầu vào và trả về danh sách các từ được gắn thẻ làm đầu ra.
evaluate() method - Với sự trợ giúp của phương pháp này, chúng tôi có thể đánh giá độ chính xác của trình gắn thẻ.
Cơ sở của việc gắn thẻ POS
Đường cơ sở hoặc bước cơ bản của việc gắn thẻ POS là Default Tagging, có thể được thực hiện bằng cách sử dụng lớp DefaultTagger của NLTK. Gắn thẻ mặc định chỉ cần gán cùng một thẻ POS cho mọi mã thông báo. Gắn thẻ mặc định cũng cung cấp đường cơ sở để đo lường các cải tiến về độ chính xác.
Lớp DefaultTagger
Gắn thẻ mặc định được thực hiện bằng cách sử dụng DefaultTagging lớp, nhận đối số duy nhất, tức là, thẻ mà chúng ta muốn áp dụng.
Làm thế nào nó hoạt động?
Như đã nói trước đó, tất cả các trình kích hoạt được kế thừa từ TaggerIlớp học. CácDefaultTagger được thừa kế từ SequentialBackoffTagger đó là một lớp con của TaggerI class. Hãy để chúng tôi hiểu nó với sơ đồ sau:
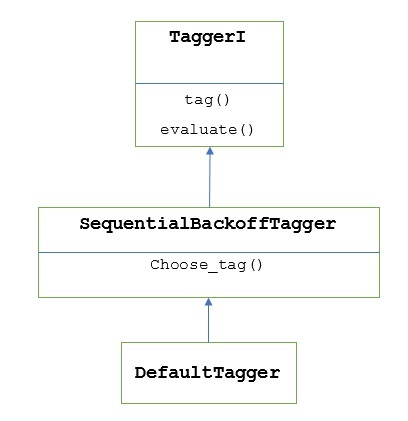
Là một phần của SeuentialBackoffTagger, các DefaultTagger phải triển khai phương thức select_tag () có ba đối số sau.
- Danh sách mã thông báo
- Chỉ mục của mã thông báo hiện tại
- Danh sách mã thông báo trước đó, tức là lịch sử
Thí dụ
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])Đầu ra
[('Tutorials', 'NN'), ('Point', 'NN')]Trong ví dụ này, chúng tôi chọn thẻ danh từ vì nó là loại từ phổ biến nhất. Hơn thế nữa,DefaultTagger cũng hữu ích nhất khi chúng tôi chọn thẻ POS phổ biến nhất.
Đánh giá độ chính xác
Các DefaultTaggercũng là cơ sở để đánh giá độ chính xác của các trình kích hoạt. Đó là lý do chúng ta có thể sử dụng nó cùng vớievaluate()phương pháp đo độ chính xác. Cácevaluate() phương pháp này lấy danh sách các mã thông báo được gắn thẻ làm tiêu chuẩn vàng để đánh giá trình gắn thẻ.
Sau đây là một ví dụ trong đó chúng tôi sử dụng trình gắn thẻ mặc định của mình, có tên exptagger, được tạo ở trên, để đánh giá độ chính xác của một tập hợp con treebank câu được gắn thẻ ngữ liệu -
Thí dụ
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)Đầu ra
0.13198749536374715Kết quả ở trên cho thấy rằng bằng cách chọn NN đối với mỗi thẻ, chúng tôi có thể đạt được kiểm tra độ chính xác khoảng 13% trên 1000 mục nhập của treebank ngữ liệu.
Gắn thẻ danh sách các câu
Thay vì gắn thẻ một câu duy nhất, NLTK của TaggerI lớp học cũng cung cấp cho chúng tôi một tag_sents()với sự trợ giúp của chúng tôi có thể gắn thẻ một danh sách các câu. Sau đây là ví dụ trong đó chúng tôi gắn thẻ hai câu đơn giản
Thí dụ
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])Đầu ra
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]Trong ví dụ trên, chúng tôi đã sử dụng trình gắn thẻ mặc định được tạo trước đó có tên exptagger.
Bỏ gắn thẻ một câu
Chúng tôi cũng có thể bỏ gắn thẻ một câu. NLTK cung cấp phương thức nltk.tag.untag () cho mục đích này. Nó sẽ lấy một câu được gắn thẻ làm đầu vào và cung cấp danh sách các từ không có thẻ. Hãy để chúng tôi xem một ví dụ -
Thí dụ
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])Đầu ra
['Tutorials', 'Point']