Bộ công cụ ngôn ngữ tự nhiên - Unigram Tagger
Unigram Tagger là gì?
Như tên của nó, trình gắn thẻ unigram là trình gắn thẻ chỉ sử dụng một từ duy nhất làm ngữ cảnh để xác định thẻ POS (Part-of-Speech). Nói một cách dễ hiểu, Unigram Tagger là một trình gắn thẻ dựa trên ngữ cảnh có ngữ cảnh là một từ đơn, tức là Unigram.
Làm thế nào nó hoạt động?
NLTK cung cấp một mô-đun có tên UnigramTaggervì mục đích này. Nhưng trước khi đi sâu vào hoạt động của nó, chúng ta hãy hiểu hệ thống phân cấp với sự trợ giúp của sơ đồ sau:
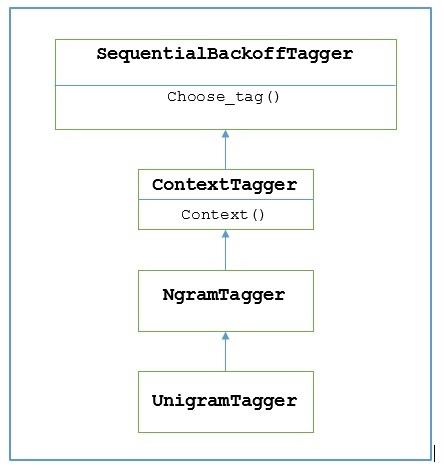
Từ sơ đồ trên, có thể hiểu rằng UnigramTagger được thừa kế từ NgramTagger đó là một lớp con của ContextTagger, kế thừa từ SequentialBackoffTagger.
Công việc của UnigramTagger được giải thích với sự trợ giúp của các bước sau:
Như chúng ta đã thấy, UnigramTagger kế thừa từ ContextTagger, nó thực hiện một context()phương pháp. Điều nàycontext() phương thức nhận ba đối số giống như choose_tag() phương pháp.
Kết quả của context()phương thức sẽ là mã thông báo từ được sử dụng để tạo mô hình. Khi mô hình được tạo, mã thông báo từ cũng được sử dụng để tra cứu thẻ tốt nhất.
Bằng cách này, UnigramTagger sẽ xây dựng mô hình ngữ cảnh từ danh sách các câu được gắn thẻ.
Đào tạo một Unigram Tagger
Của NLTK UnigramTaggercó thể được đào tạo bằng cách cung cấp danh sách các câu được gắn thẻ tại thời điểm khởi tạo. Trong ví dụ dưới đây, chúng ta sẽ sử dụng các câu được gắn thẻ của kho ngữ liệu ngân hàng cây. Chúng tôi sẽ sử dụng 2500 câu đầu tiên từ kho ngữ liệu đó.
Thí dụ
Đầu tiên nhập mô-đun UniframTagger từ nltk -
from nltk.tag import UnigramTaggerTiếp theo, nhập kho dữ liệu bạn muốn sử dụng. Ở đây chúng tôi đang sử dụng kho tài liệu ngân hàng cây -
from nltk.corpus import treebankBây giờ, lấy các câu cho mục đích đào tạo. Chúng tôi sẽ lấy 2500 câu đầu tiên cho mục đích đào tạo và sẽ gắn thẻ chúng -
train_sentences = treebank.tagged_sents()[:2500]Tiếp theo, áp dụng UnigramTagger trên các câu được sử dụng cho mục đích đào tạo -
Uni_tagger = UnigramTagger(train_sentences)Lấy một số câu, bằng hoặc ít hơn cho mục đích đào tạo, tức là 2500, cho mục đích kiểm tra. Ở đây, chúng tôi đang lấy 1500 đầu tiên cho mục đích thử nghiệm -
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)Đầu ra
0.8942306156033808Ở đây, chúng tôi có độ chính xác khoảng 89 phần trăm cho một trình gắn thẻ sử dụng tra cứu từ đơn để xác định thẻ POS.
Hoàn thành ví dụ triển khai
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Đầu ra
0.8942306156033808Ghi đè mô hình ngữ cảnh
Từ sơ đồ trên, hiển thị phân cấp cho UnigramTagger, chúng tôi biết tất cả các trình kích hoạt kế thừa từ ContextTagger, thay vì đào tạo của riêng họ, có thể lấy một mô hình được tạo sẵn. Mô hình được xây dựng trước này chỉ đơn giản là ánh xạ từ điển Python của một khóa ngữ cảnh với một thẻ. Va choUnigramTagger, các khóa ngữ cảnh là các từ riêng lẻ trong khi đối với các NgramTagger các lớp con, nó sẽ là các bộ giá trị.
Chúng tôi có thể ghi đè mô hình ngữ cảnh này bằng cách chuyển một mô hình đơn giản khác đến UnigramTaggerlớp thay vì vượt qua tập huấn luyện. Hãy để chúng tôi hiểu nó với sự trợ giúp của một ví dụ đơn giản bên dưới -
Thí dụ
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])Đầu ra
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]Vì mô hình của chúng tôi chứa 'Vinken' làm khóa ngữ cảnh duy nhất, bạn có thể quan sát từ đầu ra ở trên rằng chỉ từ này có thẻ và mọi từ khác đều không có thẻ.
Đặt ngưỡng tần suất tối thiểu
Để quyết định thẻ nào có nhiều khả năng nhất cho một ngữ cảnh nhất định, ContextTaggerlớp sử dụng tần suất xuất hiện. Nó sẽ làm điều đó theo mặc định ngay cả khi từ ngữ cảnh và thẻ chỉ xuất hiện một lần, nhưng chúng tôi có thể đặt ngưỡng tần suất tối thiểu bằng cách chuyểncutoff giá trị của UnigramTaggerlớp học. Trong ví dụ dưới đây, chúng tôi đang chuyển giá trị giới hạn trong công thức trước đó mà chúng tôi đã đào tạo một UnigramTagger -
Thí dụ
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Đầu ra
0.7357651629613641