Bộ công cụ ngôn ngữ tự nhiên - Hướng dẫn nhanh
Xử lý ngôn ngữ tự nhiên (NLP) là gì?
Phương thức giao tiếp với sự trợ giúp mà con người có thể nói, đọc và viết, là ngôn ngữ. Nói cách khác, con người chúng ta có thể suy nghĩ, lập kế hoạch, đưa ra quyết định bằng ngôn ngữ tự nhiên của mình. Câu hỏi lớn đặt ra ở đây là trong thời đại trí tuệ nhân tạo, máy học và học sâu, liệu con người có thể giao tiếp bằng ngôn ngữ tự nhiên với máy tính / máy móc không? Phát triển các ứng dụng NLP là một thách thức rất lớn đối với chúng tôi bởi vì máy tính yêu cầu dữ liệu có cấu trúc, nhưng mặt khác, lời nói của con người là phi cấu trúc và thường không rõ ràng về bản chất.
Ngôn ngữ tự nhiên là lĩnh vực con của khoa học máy tính, cụ thể hơn là của AI, cho phép máy tính / máy móc hiểu, xử lý và vận dụng ngôn ngữ của con người. Nói một cách dễ hiểu, NLP là một cách máy móc phân tích, hiểu và rút ra ý nghĩa từ các ngôn ngữ tự nhiên của con người như tiếng Hindi, tiếng Anh, tiếng Pháp, tiếng Hà Lan, v.v.
Làm thế nào nó hoạt động?
Trước khi đi sâu vào hoạt động của NLP, chúng ta phải hiểu cách con người sử dụng ngôn ngữ. Mỗi ngày, con người chúng ta sử dụng hàng trăm hoặc hàng nghìn từ và con người khác giải thích chúng và trả lời tương ứng. Đó là một giao tiếp đơn giản của con người, phải không? Nhưng chúng ta biết từ ngữ còn sâu sắc hơn thế nhiều và chúng ta luôn lấy bối cảnh từ những gì chúng ta nói và cách chúng ta nói. Đó là lý do tại sao chúng ta có thể nói thay vì tập trung vào điều chế giọng nói, NLP thực hiện dựa trên mẫu ngữ cảnh.
Hãy để chúng tôi hiểu nó bằng một ví dụ -
Man is to woman as king is to what?
We can interpret it easily and answer as follows:
Man relates to king, so woman can relate to queen.
Hence the answer is Queen.Làm thế nào con người biết từ có nghĩa là gì? Câu trả lời cho câu hỏi này là chúng tôi học được qua kinh nghiệm của mình. Nhưng, làm thế nào để máy móc / máy tính học giống nhau?
Hãy để chúng tôi hiểu nó với các bước đơn giản sau:
Đầu tiên, chúng ta cần cung cấp cho máy đủ dữ liệu để máy rút kinh nghiệm.
Sau đó, máy sẽ tạo ra các vectơ từ, bằng cách sử dụng các thuật toán học sâu, từ dữ liệu chúng tôi đã cung cấp trước đó cũng như từ dữ liệu xung quanh của nó.
Sau đó, bằng cách thực hiện các phép toán đại số đơn giản trên các vectơ từ này, máy sẽ có thể đưa ra câu trả lời như con người.
Các thành phần của NLP
Sơ đồ sau thể hiện các thành phần của xử lý ngôn ngữ tự nhiên (NLP) -
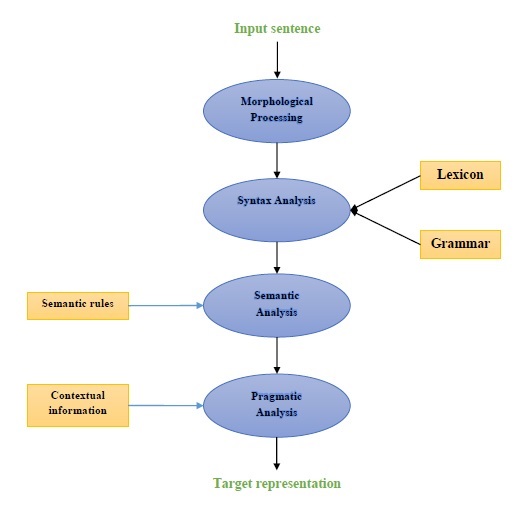
Xử lý hình thái
Xử lý hình thái là thành phần đầu tiên của NLP. Nó bao gồm việc chia nhỏ các đầu vào ngôn ngữ thành các bộ mã thông báo tương ứng với các đoạn văn, câu và từ. Ví dụ, một từ như“everyday” có thể được chia thành hai mã thông báo từ phụ như “every-day”.
Phân tích cú pháp
Phân tích cú pháp, thành phần thứ hai, là một trong những thành phần quan trọng nhất của NLP. Mục đích của thành phần này như sau:
Để kiểm tra xem một câu có được hình thành tốt hay không.
Để chia nó thành một cấu trúc thể hiện mối quan hệ cú pháp giữa các từ khác nhau.
Vd: Những câu như “The school goes to the student” sẽ bị từ chối bởi trình phân tích cú pháp.
Phân tích ngữ nghĩa
Phân tích ngữ nghĩa là thành phần thứ ba của NLP được sử dụng để kiểm tra ý nghĩa của văn bản. Nó bao gồm vẽ nghĩa chính xác, hoặc chúng ta có thể nói nghĩa từ điển từ văn bản. Ví dụ: Những câu như "Đó là một cây kem nóng." sẽ bị loại bỏ bởi trình phân tích ngữ nghĩa.
Phân tích thực dụng
Phân tích thực dụng là thành phần thứ tư của NLP. Nó bao gồm việc kết hợp các đối tượng hoặc sự kiện thực tế tồn tại trong mỗi ngữ cảnh với các tham chiếu đối tượng có được bởi thành phần trước đó tức là phân tích ngữ nghĩa. Vd: Những câu như“Put the fruits in the basket on the table” có thể có hai cách giải thích ngữ nghĩa do đó bộ phân tích thực dụng sẽ chọn giữa hai khả năng này.
Ví dụ về ứng dụng NLP
NLP, một công nghệ mới nổi, tạo ra nhiều dạng AI khác nhau mà chúng ta thường thấy ngày nay. Đối với các ứng dụng nhận thức ngày càng tăng của ngày nay và ngày mai, việc sử dụng NLP trong việc tạo ra một giao diện tương tác và liền mạch giữa con người và máy móc sẽ tiếp tục là ưu tiên hàng đầu. Sau đây là một số ứng dụng rất hữu ích của NLP.
Dịch máy
Dịch máy (MT) là một trong những ứng dụng quan trọng nhất của xử lý ngôn ngữ tự nhiên. MT về cơ bản là một quá trình dịch một ngôn ngữ nguồn hoặc văn bản sang một ngôn ngữ khác. Hệ thống dịch máy có thể là Song ngữ hoặc Đa ngôn ngữ.
Chống Spam
Do số lượng email không mong muốn tăng lên rất nhiều, các bộ lọc thư rác trở nên quan trọng vì nó là tuyến phòng thủ đầu tiên chống lại vấn đề này. Bằng cách coi các vấn đề dương tính giả và tiêu cực giả là những vấn đề chính, chức năng của NLP có thể được sử dụng để phát triển hệ thống lọc thư rác.
Mô hình N-gram, Lập trình từ và phân loại Bayes là một số mô hình NLP hiện có có thể được sử dụng để lọc thư rác.
Truy xuất thông tin & tìm kiếm trên web
Hầu hết các công cụ tìm kiếm như Google, Yahoo, Bing, WolframAlpha, v.v., dựa trên công nghệ dịch máy (MT) của họ dựa trên mô hình học sâu NLP. Các mô hình học sâu như vậy cho phép các thuật toán đọc văn bản trên trang web, diễn giải ý nghĩa của nó và dịch nó sang một ngôn ngữ khác.
Tóm tắt văn bản tự động
Tóm tắt văn bản tự động là một kỹ thuật tạo ra một bản tóm tắt ngắn, chính xác của các tài liệu văn bản dài hơn. Do đó, nó giúp chúng tôi nhận được thông tin liên quan trong thời gian ngắn hơn. Trong kỷ nguyên kỹ thuật số này, chúng ta đang rất cần tự động tóm tắt văn bản vì chúng ta có một lượng lớn thông tin qua internet sẽ không dừng lại. NLP và các chức năng của nó đóng một vai trò quan trọng trong việc phát triển một bản tóm tắt văn bản tự động.
Sửa ngữ pháp
Sửa lỗi chính tả & sửa ngữ pháp là một tính năng rất hữu ích của phần mềm xử lý văn bản như Microsoft Word. Xử lý ngôn ngữ tự nhiên (NLP) được sử dụng rộng rãi cho mục đích này.
Câu trả lời
Trả lời câu hỏi, một ứng dụng chính khác của xử lý ngôn ngữ tự nhiên (NLP), tập trung vào việc xây dựng các hệ thống tự động trả lời câu hỏi do người dùng đăng bằng ngôn ngữ tự nhiên của họ.
Phân tích tình cảm
Phân tích cảm xúc là một trong những ứng dụng quan trọng khác của xử lý ngôn ngữ tự nhiên (NLP). Như tên gọi của nó, Phân tích cảm xúc được sử dụng để -
Xác định tình cảm giữa một số bài đăng và
Xác định tình cảm mà cảm xúc không được thể hiện rõ ràng.
Các công ty thương mại điện tử trực tuyến như Amazon, ebay, v.v., đang sử dụng phân tích tâm lý để xác định quan điểm và cảm nhận của khách hàng trực tuyến. Nó sẽ giúp họ hiểu khách hàng nghĩ gì về sản phẩm và dịch vụ của họ.
Công cụ giọng nói
Các công cụ giọng nói như Siri, Google Voice, Alexa được xây dựng trên NLP để chúng ta có thể giao tiếp với chúng bằng ngôn ngữ tự nhiên của mình.
Thực hiện NLP
Để xây dựng các ứng dụng nói trên, chúng ta cần có một bộ kỹ năng cụ thể với sự hiểu biết sâu rộng về ngôn ngữ và các công cụ để xử lý ngôn ngữ một cách hiệu quả. Để đạt được điều này, chúng tôi có sẵn nhiều công cụ nguồn mở khác nhau. Một số trong số chúng có nguồn mở trong khi một số khác được các tổ chức phát triển để xây dựng các ứng dụng NLP của riêng họ. Sau đây là danh sách một số công cụ NLP -
Bộ công cụ ngôn ngữ tự nhiên (NLTK)
Mallet
GATE
Mở NLP
UIMA
Genism
Bộ công cụ Stanford
Hầu hết các công cụ này được viết bằng Java.
Bộ công cụ ngôn ngữ tự nhiên (NLTK)
Trong số các công cụ NLP nói trên, NLTK đạt điểm rất cao khi nói đến sự dễ sử dụng và giải thích khái niệm. Đường cong học tập của Python rất nhanh và NLTK được viết bằng Python nên NLTK cũng đang có bộ học tập rất tốt. NLTK đã kết hợp hầu hết các nhiệm vụ như mã hóa, viết gốc, bổ sung hóa, chấm câu, đếm ký tự và đếm từ. Nó rất thanh lịch và dễ làm việc.
Để cài đặt NLTK, chúng ta phải cài đặt Python trên máy tính của mình. Bạn có thể truy cập liên kết www.python.org/downloads và chọn phiên bản mới nhất cho hệ điều hành của mình, tức là Windows, Mac và Linux / Unix. Để có hướng dẫn cơ bản về Python, bạn có thể tham khảo liên kết www.tutorialspoint.com/python3/index.htm .
Bây giờ, khi bạn đã cài đặt Python trên hệ thống máy tính của mình, hãy cho chúng tôi hiểu cách chúng tôi có thể cài đặt NLTK.
Cài đặt NLTK
Chúng tôi có thể cài đặt NLTK trên các hệ điều hành khác nhau như sau:
Trên Windows
Để cài đặt NLTK trên HĐH Windows, hãy làm theo các bước sau:
Đầu tiên, mở dấu nhắc lệnh Windows và điều hướng đến vị trí của pip thư mục.
Tiếp theo, nhập lệnh sau để cài đặt NLTK -
pip3 install nltkBây giờ, hãy mở PythonShell từ Menu Start của Windows và nhập lệnh sau để xác minh cài đặt NLTK -
Import nltkNếu bạn không gặp lỗi, bạn đã cài đặt thành công NLTK trên hệ điều hành Windows có Python3.
Trên Mac / Linux
Để cài đặt NLTK trên Mac / Linux OS, hãy viết lệnh sau:
sudo pip install -U nltkNếu bạn chưa cài đặt pip trên máy tính của mình, hãy làm theo hướng dẫn dưới đây để cài đặt lần đầu pip -
Đầu tiên, hãy cập nhật chỉ mục gói bằng cách sử dụng lệnh sau:
sudo apt updateBây giờ, hãy gõ lệnh sau để cài đặt pip cho python 3 -
sudo apt install python3-pipThông qua Anaconda
Để cài đặt NLTK qua Anaconda, hãy làm theo các bước sau:
Đầu tiên, để cài đặt Anaconda, hãy truy cập liên kết www.anaconda.com/distribution/#download-section và sau đó chọn phiên bản Python bạn cần cài đặt.
Khi bạn có Anaconda trên hệ thống máy tính của mình, hãy chuyển đến dấu nhắc lệnh của nó và viết lệnh sau:
conda install -c anaconda nltk
Bạn cần xem lại kết quả đầu ra và nhập 'có'. NLTK sẽ được tải xuống và cài đặt trong gói Anaconda của bạn.
Tải xuống tập dữ liệu và gói của NLTK
Bây giờ chúng ta đã cài đặt NLTK trên máy tính của mình nhưng để sử dụng nó, chúng ta cần tải xuống bộ dữ liệu (tập dữ liệu) có sẵn trong đó. Một số bộ dữ liệu quan trọng có sẵn làstpwords, guntenberg, framenet_v15 và như thế.
Với sự trợ giúp của các lệnh sau, chúng tôi có thể tải xuống tất cả các bộ dữ liệu NLTK -
import nltk
nltk.download()
Bạn sẽ nhận được cửa sổ tải xuống NLTK sau.
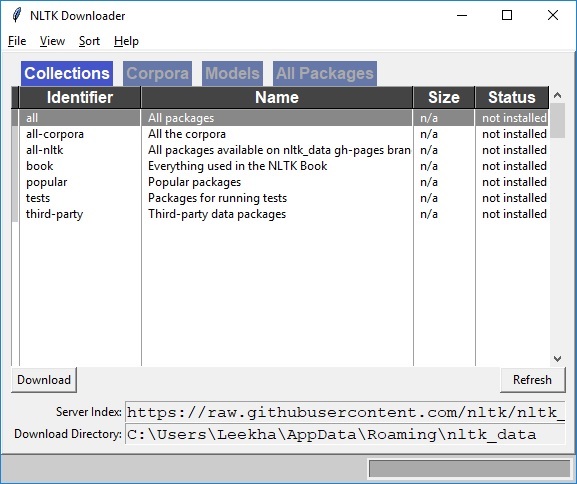
Bây giờ, nhấp vào nút tải xuống để tải xuống bộ dữ liệu.
Làm thế nào để chạy tập lệnh NLTK?
Sau đây là ví dụ mà chúng tôi đang triển khai thuật toán Porter Stemmer bằng cách sử dụng PorterStemmerlớp nltk. với ví dụ này, bạn sẽ có thể hiểu cách chạy tập lệnh NLTK.
Đầu tiên, chúng ta cần nhập bộ công cụ ngôn ngữ tự nhiên (nltk).
import nltkBây giờ, hãy nhập PorterStemmer lớp để thực hiện thuật toán Porter Stemmer.
from nltk.stem import PorterStemmerTiếp theo, tạo một thể hiện của lớp Porter Stemmer như sau:
word_stemmer = PorterStemmer()Bây giờ, hãy nhập từ bạn muốn xuất phát. -
word_stemmer.stem('writing')Đầu ra
'write'word_stemmer.stem('eating')Đầu ra
'eat'Mã hóa mã hóa là gì?
Nó có thể được định nghĩa là quá trình chia nhỏ một đoạn văn bản thành các phần nhỏ hơn, chẳng hạn như câu và từ. Những phần nhỏ hơn này được gọi là mã thông báo. Ví dụ, một từ là một mã thông báo trong một câu và một câu là một mã thông báo trong một đoạn văn.
Như chúng ta biết rằng NLP được sử dụng để xây dựng các ứng dụng như phân tích tình cảm, hệ thống QA, dịch ngôn ngữ, chatbot thông minh, hệ thống giọng nói, v.v., do đó, để xây dựng chúng, điều quan trọng là phải hiểu mẫu trong văn bản. Các mã thông báo, được đề cập ở trên, rất hữu ích trong việc tìm kiếm và hiểu các mẫu này. Chúng ta có thể coi tokenization là bước cơ bản cho các công thức nấu ăn khác như tạo gốc và lemmatization.
Gói NLTK
nltk.tokenize là gói được cung cấp bởi mô-đun NLTK để đạt được quá trình mã hóa.
Mã hóa câu thành từ
Tách câu thành các từ hoặc tạo danh sách các từ từ một chuỗi là một phần thiết yếu của mọi hoạt động xử lý văn bản. Hãy để chúng tôi hiểu nó với sự trợ giúp của các chức năng / mô-đun khác nhau được cung cấp bởinltk.tokenize gói hàng.
mô-đun word_tokenize
word_tokenizemô-đun được sử dụng để mã hóa từ cơ bản. Ví dụ sau sẽ sử dụng mô-đun này để chia một câu thành các từ.
Thí dụ
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('Tutorialspoint.com provides high quality technical tutorials for free.')Đầu ra
['Tutorialspoint.com', 'provides', 'high', 'quality', 'technical', 'tutorials', 'for', 'free', '.']Lớp TreebankWordTokenizer
word_tokenize , được sử dụng ở trên về cơ bản là một hàm wrapper gọi hàm tokenize () như một thể hiện của TreebankWordTokenizerlớp học. Nó sẽ cung cấp cùng một kết quả như chúng ta nhận được khi sử dụng mô-đun word_tokenize () để tách các câu thành từng từ. Chúng ta hãy xem ví dụ tương tự được triển khai ở trên -
Thí dụ
Đầu tiên, chúng ta cần nhập bộ công cụ ngôn ngữ tự nhiên (nltk).
import nltkBây giờ, hãy nhập TreebankWordTokenizer lớp để triển khai thuật toán tokenizer từ -
from nltk.tokenize import TreebankWordTokenizerTiếp theo, tạo một thể hiện của lớp TreebankWordTokenizer như sau:
Tokenizer_wrd = TreebankWordTokenizer()Bây giờ, hãy nhập câu bạn muốn chuyển đổi thành mã thông báo -
Tokenizer_wrd.tokenize(
'Tutorialspoint.com provides high quality technical tutorials for free.'
)Đầu ra
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials', 'for', 'free', '.'
]Hoàn thành ví dụ triển khai
Hãy cho chúng tôi xem ví dụ triển khai đầy đủ bên dưới
import nltk
from nltk.tokenize import TreebankWordTokenizer
tokenizer_wrd = TreebankWordTokenizer()
tokenizer_wrd.tokenize('Tutorialspoint.com provides high quality technical
tutorials for free.')Đầu ra
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials','for', 'free', '.'
]Quy ước quan trọng nhất của thuốc tokenizer là tách các cơn co thắt. Ví dụ: nếu chúng ta sử dụng mô-đun word_tokenize () cho mục đích này, nó sẽ cho kết quả như sau:
Thí dụ
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('won’t')Đầu ra
['wo', "n't"]]Loại quy ước như vậy bởi TreebankWordTokenizerlà không thể chấp nhận được. Đó là lý do tại sao chúng tôi có hai từ tokenizers thay thế cụ thể làPunktWordTokenizer và WordPunctTokenizer.
Lớp WordPunktTokenizer
Một công cụ mã hóa từ thay thế chia tất cả các dấu câu thành các mã thông báo riêng biệt. Hãy để chúng tôi hiểu nó với ví dụ đơn giản sau:
Thí dụ
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
tokenizer.tokenize(" I can't allow you to go home early")Đầu ra
['I', 'can', "'", 't', 'allow', 'you', 'to', 'go', 'home', 'early']Mã hóa văn bản thành câu
Trong phần này, chúng ta sẽ chia văn bản / đoạn văn thành các câu. NLTK cung cấpsent_tokenize cho mục đích này.
Tại sao nó cần thiết?
Một câu hỏi hiển nhiên xuất hiện trong đầu chúng ta là khi chúng ta có từ tokenizer thì tại sao chúng ta cần mã hóa câu hoặc tại sao chúng ta cần mã hóa văn bản thành câu. Giả sử chúng ta cần đếm số từ trung bình trong câu, làm thế nào chúng ta có thể làm điều này? Để hoàn thành nhiệm vụ này, chúng ta cần cả mã hóa câu và mã hóa từ.
Hãy để chúng tôi hiểu sự khác biệt giữa trình mã hóa câu và từ với sự trợ giúp của ví dụ đơn giản sau:
Thí dụ
import nltk
from nltk.tokenize import sent_tokenize
text = "Let us understand the difference between sentence & word tokenizer.
It is going to be a simple example."
sent_tokenize(text)Đầu ra
[
"Let us understand the difference between sentence & word tokenizer.",
'It is going to be a simple example.'
]Mã hóa câu sử dụng biểu thức chính quy
Nếu bạn cảm thấy đầu ra của tokenizer từ không được chấp nhận và muốn kiểm soát hoàn toàn cách mã hóa văn bản, chúng tôi có biểu thức chính quy có thể được sử dụng trong khi thực hiện mã hóa câu. NLTK cung cấpRegexpTokenizer lớp để đạt được điều này.
Hãy để chúng tôi hiểu khái niệm này với sự trợ giúp của hai ví dụ dưới đây.
Trong ví dụ đầu tiên, chúng tôi sẽ sử dụng biểu thức chính quy để đối sánh mã thông báo chữ và số cộng với dấu ngoặc kép để chúng tôi không chia nhỏ các phần như “won’t”.
ví dụ 1
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer("[\w']+")
tokenizer.tokenize("won't is a contraction.")
tokenizer.tokenize("can't is a contraction.")Đầu ra
["won't", 'is', 'a', 'contraction']
["can't", 'is', 'a', 'contraction']Trong ví dụ đầu tiên, chúng tôi sẽ sử dụng biểu thức chính quy để mã hóa trên khoảng trắng.
Ví dụ 2
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = True)
tokenizer.tokenize("won't is a contraction.")Đầu ra
["won't", 'is', 'a', 'contraction']Từ kết quả trên, chúng ta có thể thấy rằng dấu chấm câu vẫn còn trong các thẻ. Khoảng trống tham số = True có nghĩa là mẫu sẽ xác định các khoảng trống để mã hóa. Mặt khác, nếu chúng ta sử dụng tham số gap = False thì mẫu sẽ được sử dụng để xác định các mã thông báo có thể thấy trong ví dụ sau:
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = False)
tokenizer.tokenize("won't is a contraction.")Đầu ra
[ ]Nó sẽ cung cấp cho chúng tôi đầu ra trống.
Tại sao phải đào tạo tokenizer câu riêng?
Đây là câu hỏi rất quan trọng mà nếu chúng ta có trình mã hóa câu mặc định của NLTK thì tại sao chúng ta cần đào tạo trình mã hóa câu? Câu trả lời cho câu hỏi này nằm ở chất lượng của trình mã hóa câu mặc định của NLTK. Tokenizer mặc định của NLTK về cơ bản là một tokenizer có mục đích chung. Mặc dù nó hoạt động rất tốt nhưng nó có thể không phải là một lựa chọn tốt cho văn bản không chuẩn, có lẽ là văn bản của chúng ta hoặc đối với văn bản có định dạng độc đáo. Để mã hóa văn bản như vậy và đạt được kết quả tốt nhất, chúng ta nên đào tạo trình mã hóa câu của riêng mình.
Ví dụ triển khai
Đối với ví dụ này, chúng tôi sẽ sử dụng kho văn bản webtext. Tệp văn bản mà chúng tôi sẽ sử dụng từ kho tài liệu này có văn bản được định dạng như các hộp thoại được hiển thị bên dưới -
Guy: How old are you?
Hipster girl: You know, I never answer that question. Because to me, it's about
how mature you are, you know? I mean, a fourteen year old could be more mature
than a twenty-five year old, right? I'm sorry, I just never answer that question.
Guy: But, uh, you're older than eighteen, right?
Hipster girl: Oh, yeah.Chúng tôi đã lưu tệp văn bản này với tên training_tokenizer. NLTK cung cấp một lớp có tênPunktSentenceTokenizervới sự trợ giúp của chúng tôi có thể đào tạo trên văn bản thô để tạo ra một trình mã hóa câu tùy chỉnh. Chúng ta có thể lấy văn bản thô bằng cách đọc trong một tệp hoặc từ một kho tài liệu NLTK bằng cách sử dụngraw() phương pháp.
Hãy cùng chúng tôi xem ví dụ dưới đây để hiểu rõ hơn về nó -
Đầu tiên, nhập PunktSentenceTokenizer lớp từ nltk.tokenize gói -
from nltk.tokenize import PunktSentenceTokenizerBây giờ, nhập webtext kho dữ liệu từ nltk.corpus gói hàng
from nltk.corpus import webtextTiếp theo, bằng cách sử dụng raw() lấy văn bản thô từ training_tokenizer.txt tập tin như sau -
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')Bây giờ, hãy tạo một phiên bản của PunktSentenceTokenizer và in các câu mã hóa từ tệp văn bản như sau:
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Đầu ra
White guy: So, do you have any plans for this evening?
print(sents_1[1])
Output:
Asian girl: Yeah, being angry!
print(sents_1[670])
Output:
Guy: A hundred bucks?
print(sents_1[675])
Output:
Girl: But you already have a Big Mac...Hoàn thành ví dụ triển khai
from nltk.tokenize import PunktSentenceTokenizer
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Đầu ra
White guy: So, do you have any plans for this evening?Để hiểu sự khác biệt giữa trình mã hóa câu mặc định của NLTK và trình mã hóa câu được đào tạo của riêng chúng ta, chúng ta hãy mã hóa cùng một tệp với trình mã hóa câu mặc định tức là sent_tokenize ().
from nltk.tokenize import sent_tokenize
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sents_2 = sent_tokenize(text)
print(sents_2[0])
Output:
White guy: So, do you have any plans for this evening?
print(sents_2[675])
Output:
Hobo: Y'know what I'd do if I was rich?Với sự trợ giúp của sự khác biệt trong đầu ra, chúng ta có thể hiểu khái niệm rằng tại sao việc đào tạo trình mã hóa câu của chính chúng ta lại hữu ích.
Từ dừng là gì?
Một số từ phổ biến có trong văn bản nhưng không góp phần tạo nên ý nghĩa của câu. Những từ như vậy hoàn toàn không quan trọng đối với mục đích truy xuất thông tin hoặc xử lý ngôn ngữ tự nhiên. Các từ dừng phổ biến nhất là 'the' và 'a'.
Kho ngữ liệu từ dừng NLTK
Trên thực tế, bộ công cụ Natural Language Tool đi kèm với một kho ngữ liệu từ khóa chứa danh sách từ cho nhiều ngôn ngữ. Hãy để chúng tôi hiểu cách sử dụng của nó với sự trợ giúp của ví dụ sau:
Đầu tiên, nhập từ khóa tạm dừng từ gói nltk.corpus -
from nltk.corpus import stopwordsBây giờ, chúng tôi sẽ sử dụng từ dừng từ Ngôn ngữ tiếng Anh
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Đầu ra
['I', 'writer']Hoàn thành ví dụ triển khai
from nltk.corpus import stopwords
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Đầu ra
['I', 'writer']Tìm danh sách đầy đủ các ngôn ngữ được hỗ trợ
Với sự trợ giúp của tập lệnh Python sau, chúng tôi cũng có thể tìm thấy danh sách đầy đủ các ngôn ngữ được hỗ trợ bởi kho ngữ liệu từ dừng NLTK -
from nltk.corpus import stopwords
stopwords.fileids()Đầu ra
[
'arabic', 'azerbaijani', 'danish', 'dutch', 'english', 'finnish', 'french',
'german', 'greek', 'hungarian', 'indonesian', 'italian', 'kazakh', 'nepali',
'norwegian', 'portuguese', 'romanian', 'russian', 'slovene', 'spanish',
'swedish', 'tajik', 'turkish'
]Wordnet là gì?
Wordnet là một cơ sở dữ liệu từ vựng lớn về tiếng Anh, được tạo ra bởi Princeton. Nó là một phần của kho ngữ liệu NLTK. Tất cả các danh từ, động từ, tính từ và trạng từ đều được nhóm lại thành tập hợp các synsets, tức là các từ đồng nghĩa nhận thức. Ở đây mỗi tập hợp mã biểu thị một ý nghĩa riêng biệt. Sau đây là một số trường hợp sử dụng của Wordnet -
- Nó có thể được sử dụng để tra cứu định nghĩa của một từ
- Chúng ta có thể tìm thấy các từ đồng nghĩa và trái nghĩa của một từ
- Các quan hệ từ và các điểm tương đồng có thể được khám phá bằng Wordnet
- Phân biệt nghĩa từ cho những từ có nhiều cách sử dụng và định nghĩa
Làm cách nào để nhập Wordnet?
Wordnet có thể được nhập với sự trợ giúp của lệnh sau:
from nltk.corpus import wordnetĐể có lệnh nhỏ gọn hơn, hãy sử dụng lệnh sau:
from nltk.corpus import wordnet as wnPhiên bản Synset
Synset là nhóm các từ đồng nghĩa thể hiện cùng một khái niệm. Khi bạn sử dụng Wordnet để tra từ, bạn sẽ nhận được danh sách các phiên bản Synset.
wordnet.synsets (word)
Để có danh sách Synsets, chúng ta có thể tra cứu bất kỳ từ nào trong Wordnet bằng cách sử dụng wordnet.synsets(word). Ví dụ, trong công thức Python tiếp theo, chúng ta sẽ tìm kiếm Synset cho 'dog' cùng với một số thuộc tính và phương thức của Synset -
Thí dụ
Đầu tiên, nhập wordnet như sau:
from nltk.corpus import wordnet as wnBây giờ, hãy cung cấp từ bạn muốn tra cứu Synset -
syn = wn.synsets('dog')[0]Ở đây, chúng tôi đang sử dụng phương thức name () để lấy tên duy nhất cho synset có thể được sử dụng để lấy Synset trực tiếp -
syn.name()
Output:
'dog.n.01'Tiếp theo, chúng tôi đang sử dụng phương thức định nghĩa () sẽ cung cấp cho chúng tôi định nghĩa của từ -
syn.definition()
Output:
'a member of the genus Canis (probably descended from the common wolf) that has
been domesticated by man since prehistoric times; occurs in many breeds'Một phương thức khác là example () sẽ cung cấp cho chúng ta các ví dụ liên quan đến từ -
syn.examples()
Output:
['the dog barked all night']Hoàn thành ví dụ triển khai
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.name()
syn.definition()
syn.examples()Nhận từ siêu nghĩa
Synsets được tổ chức trong một cây kế thừa giống như cấu trúc trong đó Hypernyms đại diện cho các thuật ngữ trừu tượng hơn trong khi Hyponymsđại diện cho các điều khoản cụ thể hơn. Một trong những điều quan trọng là cây này có thể được truy tìm đến tận gốc một ẩn danh. Hãy để chúng tôi hiểu khái niệm này với sự trợ giúp của ví dụ sau:
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()Đầu ra
[Synset('canine.n.02'), Synset('domestic_animal.n.01')]Ở đây, chúng ta có thể thấy rằng canine và domestic_animal là từ viết tắt của 'dog'.
Bây giờ, chúng ta có thể tìm thấy những từ viết tắt của 'dog' như sau:
syn.hypernyms()[0].hyponyms()Đầu ra
[
Synset('bitch.n.04'),
Synset('dog.n.01'),
Synset('fox.n.01'),
Synset('hyena.n.01'),
Synset('jackal.n.01'),
Synset('wild_dog.n.01'),
Synset('wolf.n.01')
]Từ kết quả ở trên, chúng ta có thể thấy rằng 'dog' chỉ là một trong rất nhiều từ trái nghĩa của 'domestic_animals'.
Để tìm gốc của tất cả những thứ này, chúng ta có thể sử dụng lệnh sau:
syn.root_hypernyms()Đầu ra
[Synset('entity.n.01')]Từ đầu ra ở trên, chúng ta có thể thấy nó chỉ có một gốc.
Hoàn thành ví dụ triển khai
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()
syn.hypernyms()[0].hyponyms()
syn.root_hypernyms()Đầu ra
[Synset('entity.n.01')]Bổ đề trong Wordnet
Trong ngôn ngữ học, hình thức chính tắc hoặc hình thái của một từ được gọi là bổ đề. Để tìm một từ đồng nghĩa cũng như trái nghĩa của một từ, chúng ta cũng có thể tra cứu bổ đề trong Mạng từ. Hãy để chúng tôi xem làm thế nào.
Tìm từ đồng nghĩa
Bằng cách sử dụng phương thức bổ đề (), chúng ta có thể tìm thấy số lượng từ đồng nghĩa của một Synset. Hãy để chúng tôi áp dụng phương pháp này trên synset 'dog' -
Thí dụ
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
lemmas = syn.lemmas()
len(lemmas)Đầu ra
3Kết quả trên cho thấy 'dog' có ba bổ đề.
Lấy tên của bổ đề đầu tiên như sau:
lemmas[0].name()
Output:
'dog'Lấy tên của bổ đề thứ hai như sau:
lemmas[1].name()
Output:
'domestic_dog'Lấy tên của bổ đề thứ ba như sau:
lemmas[2].name()
Output:
'Canis_familiaris'Trên thực tế, một Synset đại diện cho một nhóm các bổ đề có ý nghĩa tương tự trong khi một bổ đề biểu thị một dạng từ riêng biệt.
Tìm từ trái nghĩa
Trong Mạng từ, một số bổ đề cũng có từ trái nghĩa. Ví dụ, từ 'good' có tổng cộng 27 synets, trong số đó, 5 synets có bổ đề với từ trái nghĩa. Chúng ta hãy tìm các từ trái nghĩa (khi từ 'tốt' được sử dụng như danh từ và khi từ 'tốt' được sử dụng như tính từ).
ví dụ 1
from nltk.corpus import wordnet as wn
syn1 = wn.synset('good.n.02')
antonym1 = syn1.lemmas()[0].antonyms()[0]
antonym1.name()Đầu ra
'evil'antonym1.synset().definition()Đầu ra
'the quality of being morally wrong in principle or practice'Ví dụ trên cho thấy từ 'tốt', khi được sử dụng như danh từ, có từ trái nghĩa đầu tiên là 'ác'.
Ví dụ 2
from nltk.corpus import wordnet as wn
syn2 = wn.synset('good.a.01')
antonym2 = syn2.lemmas()[0].antonyms()[0]
antonym2.name()Đầu ra
'bad'antonym2.synset().definition()Đầu ra
'having undesirable or negative qualities’Ví dụ trên cho thấy rằng từ 'tốt', khi được sử dụng như một tính từ, có từ trái nghĩa đầu tiên là 'xấu'.
Stemming là gì?
Stemming là một kỹ thuật được sử dụng để trích xuất dạng cơ sở của các từ bằng cách loại bỏ các phụ tố khỏi chúng. Nó cũng giống như việc chặt các cành cây đến thân của nó. Ví dụ, gốc của các từeating, eats, eaten Là eat.
Các công cụ tìm kiếm sử dụng phần gốc để lập chỉ mục các từ. Đó là lý do tại sao thay vì lưu trữ tất cả các dạng của một từ, một công cụ tìm kiếm chỉ có thể lưu trữ các phần gốc. Bằng cách này, việc tạo gốc làm giảm kích thước của chỉ mục và tăng độ chính xác của việc truy xuất.
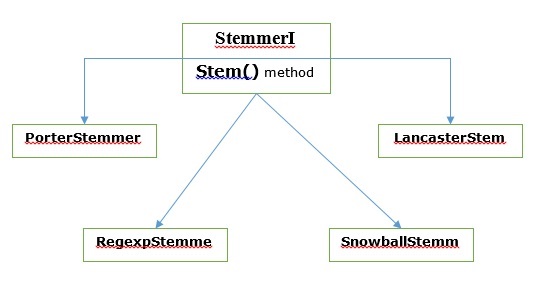
Các thuật toán tạo gốc khác nhau
Trong NLTK, stemmerI, có stem()phương pháp, giao diện có tất cả các trình gốc mà chúng ta sẽ trình bày tiếp theo. Hãy để chúng tôi hiểu nó với sơ đồ sau
Thuật toán gốc Porter
Đây là một trong những thuật toán gốc phổ biến nhất được thiết kế cơ bản để loại bỏ và thay thế các hậu tố nổi tiếng của các từ tiếng Anh.
Lớp PorterStemmer
NLTK có PorterStemmervới sự trợ giúp của chúng tôi có thể dễ dàng triển khai các thuật toán Porter Stemmer cho từ chúng tôi muốn gốc. Lớp này biết một số dạng và hậu tố từ thông thường với sự trợ giúp của nó có thể biến đổi từ đầu vào thành gốc cuối cùng. Từ gốc thường là một từ ngắn hơn có cùng nghĩa gốc. Hãy để chúng tôi xem một ví dụ -
Đầu tiên, chúng ta cần nhập bộ công cụ ngôn ngữ tự nhiên (nltk).
import nltkBây giờ, hãy nhập PorterStemmer lớp để thực hiện thuật toán Porter Stemmer.
from nltk.stem import PorterStemmerTiếp theo, tạo một thể hiện của lớp Porter Stemmer như sau:
word_stemmer = PorterStemmer()Bây giờ, hãy nhập từ bạn muốn xuất phát.
word_stemmer.stem('writing')Đầu ra
'write'word_stemmer.stem('eating')Đầu ra
'eat'Hoàn thành ví dụ triển khai
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')Đầu ra
'write'Thuật toán tạo gốc Lancaster
Nó được phát triển tại Đại học Lancaster và nó là một thuật toán gốc rất phổ biến khác.
Lớp LancasterStemmer
NLTK có LancasterStemmervới sự trợ giúp của chúng tôi có thể dễ dàng triển khai các thuật toán Lancaster Stemmer cho từ chúng tôi muốn gốc. Hãy để chúng tôi xem một ví dụ -
Đầu tiên, chúng ta cần nhập bộ công cụ ngôn ngữ tự nhiên (nltk).
import nltkBây giờ, hãy nhập LancasterStemmer lớp triển khai thuật toán Lancaster Stemmer
from nltk.stem import LancasterStemmerTiếp theo, tạo một phiên bản của LancasterStemmer lớp như sau -
Lanc_stemmer = LancasterStemmer()Bây giờ, hãy nhập từ bạn muốn xuất phát.
Lanc_stemmer.stem('eats')Đầu ra
'eat'Hoàn thành ví dụ triển khai
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')Đầu ra
'eat'Thuật toán gốc Biểu thức chính quy
Với sự trợ giúp của thuật toán tạo gốc này, chúng tôi có thể tạo trình tạo gốc của riêng mình.
Lớp RegexpStemmer
NLTK có RegexpStemmervới sự trợ giúp của chúng tôi có thể dễ dàng triển khai các thuật toán Trình tạo biểu thức chính quy. Về cơ bản, nó nhận một biểu thức chính quy và loại bỏ bất kỳ tiền tố hoặc hậu tố nào phù hợp với biểu thức. Hãy để chúng tôi xem một ví dụ -
Đầu tiên, chúng ta cần nhập bộ công cụ ngôn ngữ tự nhiên (nltk).
import nltkBây giờ, hãy nhập RegexpStemmer lớp để triển khai thuật toán Trình tạo biểu thức chính quy.
from nltk.stem import RegexpStemmerTiếp theo, tạo một phiên bản của RegexpStemmer và cung cấp hậu tố hoặc tiền tố bạn muốn xóa khỏi từ như sau:
Reg_stemmer = RegexpStemmer(‘ing’)Bây giờ, hãy nhập từ bạn muốn xuất phát.
Reg_stemmer.stem('eating')Đầu ra
'eat'Reg_stemmer.stem('ingeat')Đầu ra
'eat'
Reg_stemmer.stem('eats')Đầu ra
'eat'Hoàn thành ví dụ triển khai
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')Đầu ra
'eat'Thuật toán tạo gốc quả cầu tuyết
Đó là một thuật toán tạo gốc rất hữu ích khác.
Lớp SnowballStemmer
NLTK có SnowballStemmervới sự trợ giúp của chúng tôi có thể dễ dàng triển khai các thuật toán Snowball Stemmer. Nó hỗ trợ 15 ngôn ngữ không phải tiếng Anh. Để sử dụng lớp steam này, chúng ta cần tạo một thể hiện với tên của ngôn ngữ chúng ta đang sử dụng và sau đó gọi phương thức stem (). Hãy để chúng tôi xem một ví dụ -
Đầu tiên, chúng ta cần nhập bộ công cụ ngôn ngữ tự nhiên (nltk).
import nltkBây giờ, hãy nhập SnowballStemmer lớp triển khai thuật toán Snowball Stemmer
from nltk.stem import SnowballStemmerHãy cho chúng tôi xem các ngôn ngữ mà nó hỗ trợ -
SnowballStemmer.languagesĐầu ra
(
'arabic',
'danish',
'dutch',
'english',
'finnish',
'french',
'german',
'hungarian',
'italian',
'norwegian',
'porter',
'portuguese',
'romanian',
'russian',
'spanish',
'swedish'
)Tiếp theo, tạo một thể hiện của lớp SnowballStemmer với ngôn ngữ bạn muốn sử dụng. Ở đây, chúng tôi đang tạo trình tự gốc cho ngôn ngữ 'Pháp'.
French_stemmer = SnowballStemmer(‘french’)Bây giờ, hãy gọi phương thức gốc () và nhập từ bạn muốn gốc.
French_stemmer.stem (‘Bonjoura’)Đầu ra
'bonjour'Hoàn thành ví dụ triển khai
import nltk
from nltk.stem import SnowballStemmer
French_stemmer = SnowballStemmer(‘french’)
French_stemmer.stem (‘Bonjoura’)Đầu ra
'bonjour'Lemmatization là gì?
Kỹ thuật Lemmatization giống như kỹ thuật chiết cành. Đầu ra chúng ta sẽ nhận được sau khi bổ đề được gọi là 'bổ đề', là một từ gốc chứ không phải gốc, đầu ra của việc tạo gốc. Sau khi lemmatization, chúng ta sẽ nhận được một từ hợp lệ có nghĩa tương tự.
NLTK cung cấp WordNetLemmatizer lớp là một lớp bao bọc mỏng xung quanh wordnetngữ liệu. Lớp này sử dụngmorphy() chức năng của WordNet CorpusReaderlớp để tìm một bổ đề. Hãy để chúng tôi hiểu nó bằng một ví dụ -
Thí dụ
Đầu tiên, chúng ta cần nhập bộ công cụ ngôn ngữ tự nhiên (nltk).
import nltkBây giờ, hãy nhập WordNetLemmatizer lớp để thực hiện kỹ thuật bổ sung.
from nltk.stem import WordNetLemmatizerTiếp theo, tạo một phiên bản của WordNetLemmatizer lớp học.
lemmatizer = WordNetLemmatizer()Bây giờ, gọi phương thức lemmatize () và nhập từ mà bạn muốn tìm bổ đề.
lemmatizer.lemmatize('eating')Đầu ra
'eating'lemmatizer.lemmatize('books')Đầu ra
'book'Hoàn thành ví dụ triển khai
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')Đầu ra
'book'Sự khác biệt giữa Stemming & Lemmatization
Hãy để chúng tôi hiểu sự khác biệt giữa Lập trình và bổ sung hóa với sự trợ giúp của ví dụ sau:
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')Đầu ra
believimport nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')Đầu ra
believKết quả đầu ra của cả hai chương trình cho biết sự khác biệt chính giữa tạo gốc và lemmatization. PorterStemmerlớp cắt bỏ 'es' khỏi từ. Mặt khác,WordNetLemmatizerlớp tìm một từ hợp lệ. Nói một cách dễ hiểu, kỹ thuật tạo gốc chỉ xem xét hình thức của từ trong khi kỹ thuật bổ ngữ nhìn vào nghĩa của từ. Nó có nghĩa là sau khi áp dụng lemmatization, chúng ta sẽ luôn nhận được một từ hợp lệ.
Stemming and lemmatization có thể được coi là một kiểu nén ngôn ngữ. Theo nghĩa tương tự, thay thế từ có thể được coi là chuẩn hóa văn bản hoặc sửa lỗi.
Nhưng tại sao chúng ta cần thay thế từ? Giả sử nếu chúng ta nói về mã hóa, thì nó đang gặp vấn đề với sự co lại (như không thể, sẽ không, v.v.). Vì vậy, để xử lý những vấn đề như vậy chúng ta cần thay thế từ. Ví dụ, chúng ta có thể thay thế các cơn co thắt bằng các dạng mở rộng của chúng.
Thay thế từ sử dụng biểu thức chính quy
Đầu tiên, chúng ta sẽ thay thế các từ phù hợp với biểu thức chính quy. Nhưng đối với điều này, chúng ta phải có hiểu biết cơ bản về biểu thức chính quy cũng như mô-đun python re. Trong ví dụ dưới đây, chúng tôi sẽ thay thế co rút bằng các dạng mở rộng của chúng (ví dụ: “không thể” sẽ được thay thế bằng “không thể”), tất cả điều đó bằng cách sử dụng biểu thức chính quy.
Thí dụ
Đầu tiên, hãy nhập lại gói cần thiết để hoạt động với các biểu thức chính quy.
import re
from nltk.corpus import wordnetTiếp theo, xác định các mẫu thay thế mà bạn chọn như sau:
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]Bây giờ, hãy tạo một lớp có thể được sử dụng để thay thế các từ -
class REReplacer(object):
def __init__(self, pattern = R_patterns):
self.pattern = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.pattern:
s = re.sub(pattern, repl, s)
return sLưu chương trình python này (giả sử repRE.py) và chạy nó từ dấu nhắc lệnh python. Sau khi chạy nó, hãy nhập lớp REReplacer khi bạn muốn thay thế các từ. Hãy để chúng tôi xem làm thế nào.
from repRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")
Output:
'I will not do it'
rep_word.replace("I can’t do it")
Output:
'I cannot do it'Hoàn thành ví dụ triển khai
import re
from nltk.corpus import wordnet
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]
class REReplacer(object):
def __init__(self, patterns=R_patterns):
self.patterns = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.patterns:
s = re.sub(pattern, repl, s)
return sBây giờ khi bạn đã lưu chương trình trên và chạy nó, bạn có thể nhập lớp và sử dụng nó như sau:
from replacerRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")Đầu ra
'I will not do it'Thay thế trước khi xử lý văn bản
Một trong những phương pháp phổ biến khi làm việc với xử lý ngôn ngữ tự nhiên (NLP) là làm sạch văn bản trước khi xử lý văn bản. Vì mối quan tâm này, chúng tôi cũng có thể sử dụngREReplacer lớp được tạo ở trên trong ví dụ trước, như một bước sơ bộ trước khi xử lý văn bản tức là mã hóa.
Thí dụ
from nltk.tokenize import word_tokenize
from replacerRE import REReplacer
rep_word = REReplacer()
word_tokenize("I won't be able to do this now")
Output:
['I', 'wo', "n't", 'be', 'able', 'to', 'do', 'this', 'now']
word_tokenize(rep_word.replace("I won't be able to do this now"))
Output:
['I', 'will', 'not', 'be', 'able', 'to', 'do', 'this', 'now']Trong công thức Python ở trên, chúng ta có thể dễ dàng hiểu sự khác biệt giữa đầu ra của từ tokenizer mà không có và sử dụng thay thế biểu thức chính quy.
Loại bỏ các ký tự lặp lại
Chúng ta có đúng ngữ pháp trong ngôn ngữ hàng ngày của chúng ta không? Không chúng ta không phải. Ví dụ, đôi khi chúng ta viết 'Hiiiiiiiiiiii Mohan' để nhấn mạnh từ 'Hi'. Nhưng hệ thống máy tính không biết rằng 'Hiiiiiiiiiiii' là một biến thể của từ "Hi". Trong ví dụ dưới đây, chúng tôi sẽ tạo một lớp có tênrep_word_removal có thể được sử dụng để loại bỏ các từ lặp lại.
Thí dụ
Đầu tiên, hãy nhập gói cần thiết để hoạt động với các biểu thức chính quy
import re
from nltk.corpus import wordnetBây giờ, hãy tạo một lớp có thể được sử dụng để xóa các từ lặp lại -
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
repl_word = self.repeat_regexp.sub(self.repl, word)
if repl_word != word:
return self.replace(repl_word)
else:
return repl_wordLưu chương trình python này (giả sử removerepeat.py) và chạy nó từ dấu nhắc lệnh python. Sau khi chạy nó, hãy nhậpRep_word_removallớp khi bạn muốn loại bỏ các từ lặp lại. Hãy để chúng tôi xem như thế nào?
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")
Output:
'Hi'
rep_word.replace("Hellooooooooooooooo")
Output:
'Hello'Hoàn thành ví dụ triển khai
import re
from nltk.corpus import wordnet
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
replace_word = self.repeat_regexp.sub(self.repl, word)
if replace_word != word:
return self.replace(replace_word)
else:
return replace_wordBây giờ khi bạn đã lưu chương trình trên và chạy nó, bạn có thể nhập lớp và sử dụng nó như sau:
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")Đầu ra
'Hi'Thay thế các từ bằng các từ đồng nghĩa phổ biến
Trong khi làm việc với NLP, đặc biệt là trong trường hợp phân tích tần số và lập chỉ mục văn bản, việc nén từ vựng mà không bị mất nghĩa luôn có lợi vì nó tiết kiệm rất nhiều bộ nhớ. Để đạt được điều này, chúng ta phải xác định ánh xạ của một từ với các từ đồng nghĩa của nó. Trong ví dụ dưới đây, chúng tôi sẽ tạo một lớp có tênword_syn_replacer có thể được sử dụng để thay thế các từ bằng các từ đồng nghĩa phổ biến của chúng.
Thí dụ
Đầu tiên, nhập gói cần thiết re để làm việc với các biểu thức chính quy.
import re
from nltk.corpus import wordnetTiếp theo, tạo lớp có ánh xạ thay thế từ -
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Lưu chương trình python này (nói thay thếyn.py) và chạy nó từ dấu nhắc lệnh python. Sau khi chạy nó, hãy nhậpword_syn_replacerlớp khi bạn muốn thay thế các từ bằng các từ đồng nghĩa thông thường. Hãy để chúng tôi xem làm thế nào.
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Đầu ra
'birthday'Hoàn thành ví dụ triển khai
import re
from nltk.corpus import wordnet
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Bây giờ khi bạn đã lưu chương trình trên và chạy nó, bạn có thể nhập lớp và sử dụng nó như sau:
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Đầu ra
'birthday'Nhược điểm của phương pháp trên là chúng ta phải mã hóa các từ đồng nghĩa trong từ điển Python. Chúng tôi có hai lựa chọn thay thế tốt hơn ở dạng tệp CSV và YAML. Chúng tôi có thể lưu từ vựng đồng nghĩa của mình vào bất kỳ tệp nào được đề cập ở trên và có thể tạoword_maptừ điển của họ. Hãy để chúng tôi hiểu khái niệm này với sự trợ giúp của các ví dụ.
Sử dụng tệp CSV
Để sử dụng tệp CSV cho mục đích này, tệp phải có hai cột, cột đầu tiên bao gồm từ và cột thứ hai bao gồm các từ đồng nghĩa để thay thế nó. Hãy để chúng tôi lưu tệp này dưới dạngsyn.csv. Trong ví dụ dưới đây, chúng tôi sẽ tạo một lớp có tên CSVword_syn_replacer cái nào sẽ mở rộng word_syn_replacer trong replacesyn.py và sẽ được sử dụng để xây dựng word_map từ điển từ syn.csv tập tin.
Thí dụ
Đầu tiên, nhập các gói cần thiết.
import csvTiếp theo, tạo lớp có ánh xạ thay thế từ -
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Sau khi chạy nó, hãy nhập CSVword_syn_replacerlớp khi bạn muốn thay thế các từ bằng các từ đồng nghĩa thông thường. Hãy để chúng tôi xem như thế nào?
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Đầu ra
'birthday'Hoàn thành ví dụ triển khai
import csv
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Bây giờ khi bạn đã lưu chương trình trên và chạy nó, bạn có thể nhập lớp và sử dụng nó như sau:
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Đầu ra
'birthday'Sử dụng tệp YAML
Vì chúng tôi đã sử dụng tệp CSV, chúng tôi cũng có thể sử dụng tệp YAML cho mục đích này (chúng tôi phải cài đặt PyYAML). Hãy để chúng tôi lưu tệp dưới dạngsyn.yaml. Trong ví dụ dưới đây, chúng tôi sẽ tạo một lớp có tên YAMLword_syn_replacer cái nào sẽ mở rộng word_syn_replacer trong replacesyn.py và sẽ được sử dụng để xây dựng word_map từ điển từ syn.yaml tập tin.
Thí dụ
Đầu tiên, nhập các gói cần thiết.
import yamlTiếp theo, tạo lớp có ánh xạ thay thế từ -
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Sau khi chạy nó, hãy nhập YAMLword_syn_replacerlớp khi bạn muốn thay thế các từ bằng các từ đồng nghĩa thông thường. Hãy để chúng tôi xem như thế nào?
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Đầu ra
'birthday'Hoàn thành ví dụ triển khai
import yaml
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Bây giờ khi bạn đã lưu chương trình trên và chạy nó, bạn có thể nhập lớp và sử dụng nó như sau:
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Đầu ra
'birthday'Thay thế từ trái nghĩa
Như chúng ta biết rằng một từ trái nghĩa là một từ có nghĩa trái ngược với một từ khác, và sự thay thế trái nghĩa của từ đồng nghĩa được gọi là thay thế trái nghĩa. Trong phần này, chúng ta sẽ giải quyết vấn đề thay thế từ trái nghĩa, tức là thay thế các từ bằng các từ trái nghĩa rõ ràng bằng cách sử dụng Mạng từ. Trong ví dụ dưới đây, chúng tôi sẽ tạo một lớp có tênword_antonym_replacer có hai phương pháp, một phương pháp để thay thế từ và phương pháp khác để loại bỏ các phủ định.
Thí dụ
Đầu tiên, nhập các gói cần thiết.
from nltk.corpus import wordnetTiếp theo, tạo lớp có tên word_antonym_replacer -
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsLưu chương trình python này (nói thay thếantonym.py) và chạy nó từ dấu nhắc lệnh python. Sau khi chạy nó, hãy nhậpword_antonym_replacerlớp khi bạn muốn thay thế các từ bằng các từ trái nghĩa rõ ràng của chúng. Hãy để chúng tôi xem làm thế nào.
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)Đầu ra
['beautify'']
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Đầu ra
["Let us", 'beautify', 'our', 'country']Hoàn thành ví dụ triển khai
nltk.corpus import wordnet
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsBây giờ khi bạn đã lưu chương trình trên và chạy nó, bạn có thể nhập lớp và sử dụng nó như sau:
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Đầu ra
["Let us", 'beautify', 'our', 'country']Kho ngữ liệu là gì?
Kho ngữ liệu là một bộ sưu tập lớn, ở định dạng có cấu trúc, các văn bản có thể đọc được bằng máy được tạo ra trong môi trường giao tiếp tự nhiên. Từ Corpora là số nhiều của Corpus. Corpus có thể được bắt nguồn theo nhiều cách như sau:
- Từ văn bản ban đầu là điện tử
- Từ bản ghi của ngôn ngữ nói
- Từ nhận dạng ký tự quang học, v.v.
Tính đại diện của Corpus, Số dư Corpus, Lấy mẫu, Kích thước Corpus là những yếu tố đóng vai trò quan trọng trong khi thiết kế kho dữ liệu. Một số ngữ liệu phổ biến nhất cho các nhiệm vụ NLP là TreeBank, PropBank, VarbNet và WordNet.
Làm thế nào để xây dựng kho dữ liệu tùy chỉnh?
Trong khi tải xuống NLTK, chúng tôi cũng đã cài đặt gói dữ liệu NLTK. Vì vậy, chúng tôi đã cài đặt gói dữ liệu NLTK trên máy tính của mình. Nếu chúng ta nói về Windows, chúng ta sẽ giả định rằng gói dữ liệu này được cài đặt tạiC:\natural_language_toolkit_data và nếu chúng ta nói về Linux, Unix và Mac OS X, chúng ta sẽ giả định rằng gói dữ liệu này được cài đặt tại /usr/share/natural_language_toolkit_data.
Trong công thức Python sau đây, chúng ta sẽ tạo kho ngữ liệu tùy chỉnh phải nằm trong một trong các đường dẫn được xác định bởi NLTK. Nó là như vậy bởi vì nó có thể được tìm thấy bởi NLTK. Để tránh xung đột với gói dữ liệu NLTK chính thức, chúng ta hãy tạo một thư mục natural_language_toolkit_data tùy chỉnh trong thư mục chính của chúng ta.
import os, os.path
path = os.path.expanduser('~/natural_language_toolkit_data')
if not os.path.exists(path):
os.mkdir(path)
os.path.exists(path)Đầu ra
TrueBây giờ, chúng ta hãy kiểm tra xem chúng ta có thư mục natural_language_toolkit_data trong thư mục chính hay không -
import nltk.data
path in nltk.data.pathĐầu ra
TrueKhi chúng ta có kết quả True, nghĩa là chúng ta có nltk_data thư mục trong thư mục chính của chúng tôi.
Bây giờ chúng ta sẽ tạo một tệp danh sách từ, có tên wordfile.txt và đặt nó trong một thư mục, có tên là kho tài liệu trong nltk_data danh mục (~/nltk_data/corpus/wordfile.txt) và sẽ tải nó bằng cách sử dụng nltk.data.load -
import nltk.data
nltk.data.load(‘corpus/wordfile.txt’, format = ‘raw’)Đầu ra
b’tutorialspoint\n’Độc giả Corpus
NLTK cung cấp nhiều lớp CorpusReader khác nhau. Chúng tôi sẽ giới thiệu chúng trong các công thức nấu ăn từ trăn sau đây
Tạo kho ngữ liệu danh sách từ
NLTK có WordListCorpusReaderlớp cung cấp quyền truy cập vào tệp chứa danh sách các từ. Đối với công thức Python sau, chúng ta cần tạo một tệp danh sách từ có thể là tệp CSV hoặc tệp văn bản bình thường. Ví dụ: chúng tôi đã tạo một tệp có tên 'danh sách' chứa dữ liệu sau:
tutorialspoint
Online
Free
TutorialsBây giờ Hãy để chúng tôi khởi tạo một WordListCorpusReader lớp tạo ra danh sách các từ từ tệp đã tạo của chúng tôi ‘list’.
from nltk.corpus.reader import WordListCorpusReader
reader_corpus = WordListCorpusReader('.', ['list'])
reader_corpus.words()Đầu ra
['tutorialspoint', 'Online', 'Free', 'Tutorials']Tạo kho ngữ liệu từ được gắn thẻ POS
NLTK có TaggedCorpusReadervới sự trợ giúp của chúng tôi có thể tạo một kho ngữ liệu từ được gắn thẻ POS. Trên thực tế, gắn thẻ POS là quá trình xác định thẻ phần của giọng nói cho một từ.
Một trong những định dạng đơn giản nhất cho ngữ liệu được gắn thẻ là có dạng 'từ / thẻ' giống như đoạn trích sau từ kho ngữ liệu màu nâu -
The/at-tl expense/nn and/cc time/nn involved/vbn are/ber
astronomical/jj ./.Trong đoạn trích trên, mỗi từ có một thẻ biểu thị POS của nó. Ví dụ,vb đề cập đến một động từ.
Bây giờ Hãy để chúng tôi khởi tạo một TaggedCorpusReaderlớp sản xuất các từ được gắn thẻ POS tạo thành tệp ‘list.pos’, trong đó có đoạn trích trên.
from nltk.corpus.reader import TaggedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.pos')
reader_corpus.tagged_words()Đầu ra
[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ...]Tạo kho ngữ liệu cụm từ Chunked
NLTK có ChnkedCorpusReadervới sự trợ giúp của chúng tôi có thể tạo một kho ngữ liệu cụm từ Chunked. Trên thực tế, một đoạn là một cụm từ ngắn trong một câu.
Ví dụ: chúng tôi có đoạn trích sau từ thẻ được gắn thẻ treebank ngữ liệu -
[Earlier/JJR staff-reduction/NN moves/NNS] have/VBP trimmed/VBN about/
IN [300/CD jobs/NNS] ,/, [the/DT spokesman/NN] said/VBD ./.Trong đoạn trích trên, mọi đoạn đều là một cụm danh từ nhưng những từ không nằm trong ngoặc đều thuộc cây câu và không thuộc bất kỳ cây con cụm danh từ nào.
Bây giờ Hãy để chúng tôi khởi tạo một ChunkedCorpusReader lớp sản xuất cụm từ phân đoạn từ tệp ‘list.chunk’, trong đó có đoạn trích trên.
from nltk.corpus.reader import ChunkedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.chunk')
reader_corpus.chunked_words()Đầu ra
[
Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS')]),
('have', 'VBP'), ...
]Tạo kho văn bản được phân loại
NLTK có CategorizedPlaintextCorpusReadervới sự trợ giúp của chúng tôi có thể tạo một kho ngữ liệu văn bản được phân loại. Nó rất hữu ích trong trường hợp chúng ta có một kho văn bản lớn và muốn phân loại nó thành các phần riêng biệt.
Ví dụ, kho ngữ liệu màu nâu có một số loại khác nhau. Hãy để chúng tôi tìm hiểu chúng với sự trợ giúp của mã Python sau:
from nltk.corpus import brown^M
brown.categories()Đầu ra
[
'adventure', 'belles_lettres', 'editorial', 'fiction', 'government',
'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion',
'reviews', 'romance', 'science_fiction'
]Một trong những cách dễ nhất để phân loại một kho tài liệu là có một tệp cho mọi danh mục. Ví dụ: chúng ta hãy xem hai đoạn trích từmovie_reviews ngữ liệu -
movie_pos.txt
Đường kẻ mỏng màu đỏ là thiếu sót nhưng nó gây ấn tượng.
movie_neg.txt
Kinh phí lớn và sản xuất hào nhoáng không thể bù đắp cho sự thiếu tự nhiên tràn ngập chương trình truyền hình của họ.
Vì vậy, từ hai tệp trên, chúng ta có hai danh mục cụ thể là pos và neg.
Bây giờ hãy để chúng tôi khởi tạo một CategorizedPlaintextCorpusReader lớp học.
from nltk.corpus.reader import CategorizedPlaintextCorpusReader
reader_corpus = CategorizedPlaintextCorpusReader('.', r'movie_.*\.txt',
cat_pattern = r'movie_(\w+)\.txt')
reader_corpus.categories()
reader_corpus.fileids(categories = [‘neg’])
reader_corpus.fileids(categories = [‘pos’])Đầu ra
['neg', 'pos']
['movie_neg.txt']
['movie_pos.txt']Gắn thẻ POS là gì?
Gắn thẻ, một loại phân loại, là việc chỉ định tự động mô tả của các mã thông báo. Chúng tôi gọi 'thẻ' của bộ mô tả, đại diện cho một trong các phần của lời nói (danh từ, động từ, trạng từ, tính từ, đại từ, kết hợp và các tiểu loại của chúng), thông tin ngữ nghĩa, v.v.
Mặt khác, nếu chúng ta nói về gắn thẻ Part-of-Speech (POS), nó có thể được định nghĩa là quá trình chuyển đổi một câu dưới dạng một danh sách các từ, thành một danh sách các bộ giá trị. Ở đây, các bộ giá trị có dạng (từ, thẻ). Chúng ta cũng có thể gọi việc gắn thẻ POS là một quá trình gán một trong các phần của lời nói cho từ đã cho.
Bảng sau đại diện cho thông báo POS thường xuyên nhất được sử dụng trong kho tài liệu Penn Treebank -
| Sr.No | Nhãn | Sự miêu tả |
|---|---|---|
| 1 | NNP | Danh từ riêng, số ít |
| 2 | NNPS | Danh từ riêng, số nhiều |
| 3 | PDT | Xác định trước |
| 4 | POS | Kết thúc có lợi |
| 5 | PRP | Đại từ nhân xưng |
| 6 | PRP $ | Đại từ sở hữu |
| 7 | RB | Trạng từ |
| số 8 | RBR | Trạng từ, so sánh |
| 9 | RBS | Trạng từ, so sánh nhất |
| 10 | RP | Hạt |
| 11 | SYM | Biểu tượng (toán học hoặc khoa học) |
| 12 | ĐẾN | đến |
| 13 | UH | Thán từ |
| 14 | VB | Động từ, dạng cơ sở |
| 15 | VBD | Động từ, thì quá khứ |
| 16 | VBG | Động từ, phân từ / hiện tại phân từ |
| 17 | VBN | Động từ, quá khứ |
| 18 | WP | Đại từ wh |
| 19 | WP $ | Đại từ sở hữu |
| 20 | WRB | Trạng từ wh |
| 21 | # | Bảng Anh |
| 22 | $ | Ký hiệu đô la |
| 23 | . | Dấu câu cuối câu |
| 24 | , | Dấu phẩy |
| 25 | : | Dấu hai chấm, dấu chấm phẩy |
| 26 | ( | Ký tự trong ngoặc trái |
| 27 | ) | Ký tự trong ngoặc phải |
| 28 | " | Dấu ngoặc kép thẳng |
| 29 | ' | Còn mở trích dẫn đơn |
| 30 | " | Dấu ngoặc kép còn mở |
| 31 | ' | Dấu ngoặc kép phải đóng |
| 32 | " | Dấu ngoặc kép mở ngay |
Thí dụ
Hãy để chúng tôi hiểu nó bằng một thử nghiệm Python -
import nltk
from nltk import word_tokenize
sentence = "I am going to school"
print (nltk.pos_tag(word_tokenize(sentence)))Đầu ra
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]Tại sao phải gắn thẻ POS?
Gắn thẻ POS là một phần quan trọng của NLP vì nó hoạt động như điều kiện tiên quyết để phân tích NLP tiếp theo như sau:
- Chunking
- Phân tích cú pháp
- Trích xuất thông tin
- Dịch máy
- Phân tích cảm xúc
- Phân tích ngữ pháp & phân định từ ngữ
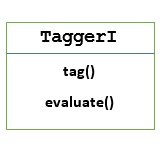
TaggerI - Base class
All the taggers reside in NLTK’s nltk.tag package. The base class of these taggers is TaggerI, means all the taggers inherit from this class.
Methods − TaggerI class have the following two methods which must be implemented by all its subclasses −
tag() method − As the name implies, this method takes a list of words as input and returns a list of tagged words as output.
evaluate() method − With the help of this method, we can evaluate the accuracy of the tagger.
The Baseline of POS Tagging
The baseline or the basic step of POS tagging is Default Tagging, which can be performed using the DefaultTagger class of NLTK. Default tagging simply assigns the same POS tag to every token. Default tagging also provides a baseline to measure accuracy improvements.
DefaultTagger class
Default tagging is performed by using DefaultTagging class, which takes the single argument, i.e., the tag we want to apply.
How does it work?
As told earlier, all the taggers are inherited from TaggerI class. The DefaultTagger is inherited from SequentialBackoffTagger which is a subclass of TaggerI class. Let us understand it with the following diagram −
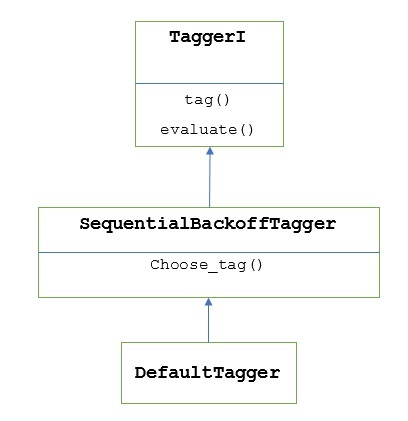
As being the part of SeuentialBackoffTagger, the DefaultTagger must implement choose_tag() method which takes the following three arguments.
- Token’s list
- Current token’s index
- Previous token’s list, i.e., the history
Example
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])Output
[('Tutorials', 'NN'), ('Point', 'NN')]In this example, we chose a noun tag because it is the most common types of words. Moreover, DefaultTagger is also most useful when we choose the most common POS tag.
Accuracy evaluation
The DefaultTagger is also the baseline for evaluating accuracy of taggers. That is the reason we can use it along with evaluate() method for measuring accuracy. The evaluate() method takes a list of tagged tokens as a gold standard to evaluate the tagger.
Following is an example in which we used our default tagger, named exptagger, created above, to evaluate the accuracy of a subset of treebank corpus tagged sentences −
Example
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)Output
0.13198749536374715The output above shows that by choosing NN for every tag, we can achieve around 13% accuracy testing on 1000 entries of the treebank corpus.
Tagging a list of sentences
Rather than tagging a single sentence, the NLTK’s TaggerI class also provides us a tag_sents() method with the help of which we can tag a list of sentences. Following is the example in which we tagged two simple sentences
Example
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])Output
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]In the above example, we used our earlier created default tagger named exptagger.
Un-tagging a sentence
We can also un-tag a sentence. NLTK provides nltk.tag.untag() method for this purpose. It will take a tagged sentence as input and provides a list of words without tags. Let us see an example −
Example
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])Output
['Tutorials', 'Point']What is Unigram Tagger?
As the name implies, unigram tagger is a tagger that only uses a single word as its context for determining the POS(Part-of-Speech) tag. In simple words, Unigram Tagger is a context-based tagger whose context is a single word, i.e., Unigram.
How does it work?
NLTK provides a module named UnigramTagger for this purpose. But before getting deep dive into its working, let us understand the hierarchy with the help of following diagram −
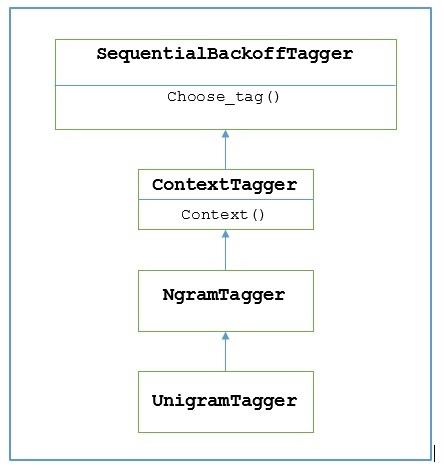
From the above diagram, it is understood that UnigramTagger is inherited from NgramTagger which is a subclass of ContextTagger, which inherits from SequentialBackoffTagger.
The working of UnigramTagger is explained with the help of following steps −
As we have seen, UnigramTagger inherits from ContextTagger, it implements a context() method. This context() method takes the same three arguments as choose_tag() method.
The result of context() method will be the word token which is further used to create the model. Once the model is created, the word token is also used to look up the best tag.
In this way, UnigramTagger will build a context model from the list of tagged sentences.
Training a Unigram Tagger
NLTK’s UnigramTagger can be trained by providing a list of tagged sentences at the time of initialization. In the example below, we are going to use the tagged sentences of the treebank corpus. We will be using first 2500 sentences from that corpus.
Example
First import the UniframTagger module from nltk −
from nltk.tag import UnigramTaggerNext, import the corpus you want to use. Here we are using treebank corpus −
from nltk.corpus import treebankNow, take the sentences for training purpose. We are taking first 2500 sentences for training purpose and will tag them −
train_sentences = treebank.tagged_sents()[:2500]Next, apply UnigramTagger on the sentences used for training purpose −
Uni_tagger = UnigramTagger(train_sentences)Take some sentences, either equal to or less taken for training purpose i.e. 2500, for testing purpose. Here we are taking first 1500 for testing purpose −
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)Output
0.8942306156033808Here, we got around 89 percent accuracy for a tagger that uses single word lookup to determine the POS tag.
Complete implementation example
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Output
0.8942306156033808Overriding the context model
From the above diagram showing hierarchy for UnigramTagger, we know all the taggers that inherit from ContextTagger, instead of training their own, can take a pre-built model. This pre-built model is simply a Python dictionary mapping of a context key to a tag. And for UnigramTagger, context keys are individual words while for other NgramTagger subclasses, it will be tuples.
We can override this context model by passing another simple model to the UnigramTagger class instead of passing training set. Let us understand it with the help of an easy example below −
Example
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])Output
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]As our model contains ‘Vinken’ as the only context key, you can observe from the output above that only this word got tag and every other word has None as a tag.
Setting a minimum frequency threshold
For deciding which tag is most likely for a given context, the ContextTagger class uses frequency of occurrence. It will do it by default even if the context word and tag occur only once, but we can set a minimum frequency threshold by passing a cutoff value to the UnigramTagger class. In the example below, we are passing the cutoff value in previous recipe in which we trained a UnigramTagger −
Example
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Output
0.7357651629613641Combining Taggers
Combining taggers or chaining taggers with each other is one of the important features of NLTK. The main concept behind combining taggers is that, in case if one tagger doesn’t know how to tag a word, it would be passed to the chained tagger. To achieve this purpose, SequentialBackoffTagger provides us the Backoff tagging feature.
Backoff Tagging
As told earlier, backoff tagging is one of the important features of SequentialBackoffTagger, which allows us to combine taggers in a way that if one tagger doesn’t know how to tag a word, the word would be passed to the next tagger and so on until there are no backoff taggers left to check.
How does it work?
Actually, every subclass of SequentialBackoffTagger can take a ‘backoff’ keyword argument. The value of this keyword argument is another instance of a SequentialBackoffTagger. Now whenever this SequentialBackoffTagger class is initialized, an internal list of backoff taggers (with itself as the first element) will be created. Moreover, if a backoff tagger is given, the internal list of this backoff taggers would be appended.
In the example below, we are taking DefaulTagger as the backoff tagger in the above Python recipe with which we have trained the UnigramTagger.
Example
In this example, we are using DefaulTagger as the backoff tagger. Whenever the UnigramTagger is unable to tag a word, backoff tagger, i.e. DefaulTagger, in our case, will tag it with ‘NN’.
from nltk.tag import UnigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Uni_tagger = UnigramTagger(train_sentences, backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Output
0.9061975746536931From the above output, you can observe that by adding a backoff tagger the accuracy is increased by around 2%.
Saving taggers with pickle
As we have seen that training a tagger is very cumbersome and also takes time. To save time, we can pickle a trained tagger for using it later. In the example below, we are going to do this to our already trained tagger named ‘Uni_tagger’.
Example
import pickle
f = open('Uni_tagger.pickle','wb')
pickle.dump(Uni_tagger, f)
f.close()
f = open('Uni_tagger.pickle','rb')
Uni_tagger = pickle.load(f)NgramTagger Class
From the hierarchy diagram discussed in previous unit, UnigramTagger is inherited from NgarmTagger class but we have two more subclasses of NgarmTagger class −
BigramTagger subclass
Actually an ngram is a subsequence of n items, hence, as name implies, BigramTagger subclass looks at the two items. First item is the previous tagged word and the second item is current tagged word.
TrigramTagger subclass
On the same note of BigramTagger, TrigramTagger subclass looks at the three items i.e. two previous tagged words and one current tagged word.
Practically if we apply BigramTagger and TrigramTagger subclasses individually as we did with UnigramTagger subclass, they both perform very poorly. Let us see in the examples below:
Using BigramTagger Subclass
from nltk.tag import BigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Bi_tagger = BigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Bi_tagger.evaluate(test_sentences)Output
0.44669191071913594Using TrigramTagger Subclass
from nltk.tag import TrigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Tri_tagger = TrigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Tri_tagger.evaluate(test_sentences)Output
0.41949863394526193You can compare the performance of UnigramTagger, we used previously (gave around 89% accuracy) with BigramTagger (gave around 44% accuracy) and TrigramTagger (gave around 41% accuracy). The reason is that Bigram and Trigram taggers cannot learn context from the first word(s) in a sentence. On the other hand, UnigramTagger class doesn’t care about the previous context and guesses the most common tag for each word, hence able to have high baseline accuracy.
Combining ngram taggers
As from the above examples, it is obvious that Bigram and Trigram taggers can contribute when we combine them with backoff tagging. In the example below, we are combining Unigram, Bigram and Trigram taggers with backoff tagging. The concept is same as the previous recipe while combining the UnigramTagger with backoff tagger. The only difference is that we are using the function named backoff_tagger() from tagger_util.py, given below, for backoff operation.
def backoff_tagger(train_sentences, tagger_classes, backoff=None):
for cls in tagger_classes:
backoff = cls(train_sentences, backoff=backoff)
return backoffExample
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Output
0.9234530029238365From the above output, we can see it increases the accuracy by around 3%.
Affix Tagger
One another important class of ContextTagger subclass is AffixTagger. In AffixTagger class, the context is either prefix or suffix of a word. That is the reason AffixTagger class can learn tags based on fixed-length substrings of the beginning or ending of a word.
How does it work?
Its working depends upon the argument named affix_length which specifies the length of the prefix or suffix. The default value is 3. But how it distinguishes whether AffixTagger class learned word’s prefix or suffix?
affix_length=positive − If the value of affix_lenght is positive then it means that the AffixTagger class will learn word’s prefixes.
affix_length=negative − If the value of affix_lenght is negative then it means that the AffixTagger class will learn word’s suffixes.
To make it clearer, in the example below, we will be using AffixTagger class on tagged treebank sentences.
Example
In this example, AffixTagger will learn word’s prefix because we are not specifying any value for affix_length argument. The argument will take default value 3 −
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Output
0.2800492099250667Let us see in the example below what will be the accuracy when we provide value 4 to affix_length argument −
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences, affix_length=4 )
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Output
0.18154947354966527Example
In this example, AffixTagger will learn word’s suffix because we will specify negative value for affix_length argument.
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Suffix_tagger = AffixTagger(train_sentences, affix_length = -3)
test_sentences = treebank.tagged_sents()[1500:]
Suffix_tagger.evaluate(test_sentences)Output
0.2800492099250667Brill Tagger
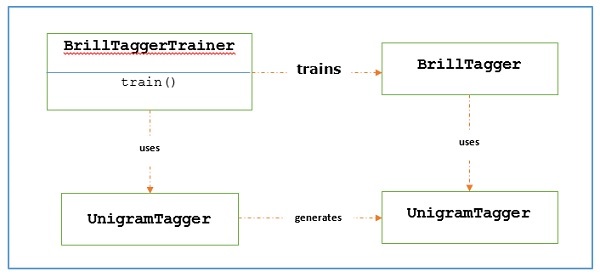
Brill Tagger is a transformation-based tagger. NLTK provides BrillTagger class which is the first tagger that is not a subclass of SequentialBackoffTagger. Opposite to it, a series of rules to correct the results of an initial tagger is used by BrillTagger.
How does it work?
To train a BrillTagger class using BrillTaggerTrainer we define the following function −
def train_brill_tagger(initial_tagger, train_sentences, **kwargs) −
templates = [
brill.Template(brill.Pos([-1])),
brill.Template(brill.Pos([1])),
brill.Template(brill.Pos([-2])),
brill.Template(brill.Pos([2])),
brill.Template(brill.Pos([-2, -1])),
brill.Template(brill.Pos([1, 2])),
brill.Template(brill.Pos([-3, -2, -1])),
brill.Template(brill.Pos([1, 2, 3])),
brill.Template(brill.Pos([-1]), brill.Pos([1])),
brill.Template(brill.Word([-1])),
brill.Template(brill.Word([1])),
brill.Template(brill.Word([-2])),
brill.Template(brill.Word([2])),
brill.Template(brill.Word([-2, -1])),
brill.Template(brill.Word([1, 2])),
brill.Template(brill.Word([-3, -2, -1])),
brill.Template(brill.Word([1, 2, 3])),
brill.Template(brill.Word([-1]), brill.Word([1])),
]
trainer = brill_trainer.BrillTaggerTrainer(initial_tagger, templates, deterministic=True)
return trainer.train(train_sentences, **kwargs)As we can see, this function requires initial_tagger and train_sentences. It takes an initial_tagger argument and a list of templates, which implements the BrillTemplate interface. The BrillTemplate interface is found in the nltk.tbl.template module. One of such implementation is brill.Template class.
The main role of transformation-based tagger is to generate transformation rules that correct the initial tagger’s output to be more in-line with the training sentences. Let us see the workflow below −
Example
For this example, we will be using combine_tagger which we created while combing taggers (in the previous recipe) from a backoff chain of NgramTagger classes, as initial_tagger. First, let us evaluate the result using Combine.tagger and then use that as initial_tagger to train brill tagger.
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(
train_sentences, [UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger
)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Output
0.9234530029238365Now, let us see the evaluation result when Combine_tagger is used as initial_tagger to train brill tagger −
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Output
0.9246832510505041We can notice that BrillTagger class has slight increased accuracy over the Combine_tagger.
Complete implementation example
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Output
0.9234530029238365
0.9246832510505041TnT Tagger
TnT Tagger, stands for Trigrams’nTags, is a statistical tagger which is based on second order Markov models.
How does it work?
We can understand the working of TnT tagger with the help of following steps −
First based on training data, TnT tegger maintains several internal FreqDist and ConditionalFreqDist instances.
After that unigrams, bigrams and trigrams will be counted by these frequency distributions.
Now, during tagging, by using frequencies, it will calculate the probabilities of possible tags for each word.
That’s why instead of constructing a backoff chain of NgramTagger, it uses all the ngram models together to choose the best tag for each word. Let us evaluate the accuracy with TnT tagger in the following example −
from nltk.tag import tnt
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
tnt_tagger = tnt.TnT()
tnt_tagger.train(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
tnt_tagger.evaluate(test_sentences)Output
0.9165508316157791We have a slight less accuracy than we got with Brill Tagger.
Please note that we need to call train() before evaluate() otherwise we will get 0% accuracy.
Parsing and its relevance in NLP
The word ‘Parsing’ whose origin is from Latin word ‘pars’ (which means ‘part’), is used to draw exact meaning or dictionary meaning from the text. It is also called Syntactic analysis or syntax analysis. Comparing the rules of formal grammar, syntax analysis checks the text for meaningfulness. The sentence like “Give me hot ice-cream”, for example, would be rejected by parser or syntactic analyzer.
In this sense, we can define parsing or syntactic analysis or syntax analysis as follows −
It may be defined as the process of analyzing the strings of symbols in natural language conforming to the rules of formal grammar.
We can understand the relevance of parsing in NLP with the help of following points −
Parser is used to report any syntax error.
It helps to recover from commonly occurring error so that the processing of the remainder of program can be continued.
Parse tree is created with the help of a parser.
Parser is used to create symbol table, which plays an important role in NLP.
Parser is also used to produce intermediate representations (IR).
Deep Vs Shallow Parsing
| Deep Parsing | Shallow Parsing |
|---|---|
| In deep parsing, the search strategy will give a complete syntactic structure to a sentence. | It is the task of parsing a limited part of the syntactic information from the given task. |
| It is suitable for complex NLP applications. | It can be used for less complex NLP applications. |
| Dialogue systems and summarization are the examples of NLP applications where deep parsing is used. | Information extraction and text mining are the examples of NLP applications where deep parsing is used. |
| It is also called full parsing. | It is also called chunking. |
Various types of parsers
As discussed, a parser is basically a procedural interpretation of grammar. It finds an optimal tree for the given sentence after searching through the space of a variety of trees. Let us see some of the available parsers below −
Recursive descent parser
Recursive descent parsing is one of the most straightforward forms of parsing. Following are some important points about recursive descent parser −
It follows a top down process.
It attempts to verify that the syntax of the input stream is correct or not.
It reads the input sentence from left to right.
One necessary operation for recursive descent parser is to read characters from the input stream and matching them with the terminals from the grammar.
Shift-reduce parser
Following are some important points about shift-reduce parser −
It follows a simple bottom-up process.
It tries to find a sequence of words and phrases that correspond to the right-hand side of a grammar production and replaces them with the left-hand side of the production.
The above attempt to find a sequence of word continues until the whole sentence is reduced.
In other simple words, shift-reduce parser starts with the input symbol and tries to construct the parser tree up to the start symbol.
Chart parser
Following are some important points about chart parser −
It is mainly useful or suitable for ambiguous grammars, including grammars of natural languages.
It applies dynamic programing to the parsing problems.
Because of dynamic programing, partial hypothesized results are stored in a structure called a ‘chart’.
The ‘chart’ can also be re-used.
Regexp parser
Regexp parsing is one of the mostly used parsing technique. Following are some important points about Regexp parser −
As the name implies, it uses a regular expression defined in the form of grammar on top of a POS-tagged string.
It basically uses these regular expressions to parse the input sentences and generate a parse tree out of this.
Example
Following is a working example of Regexp Parser −
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()Đầu ra
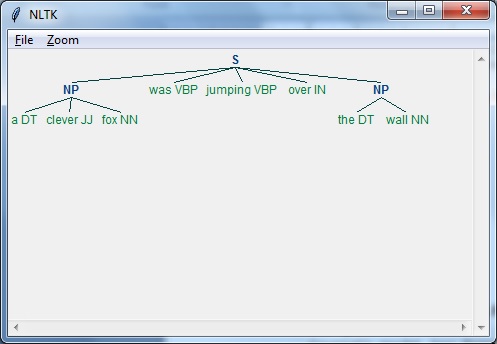
Phân tích cú pháp phụ thuộc
Dependency Parsing (DP), một cơ chế phân tích cú pháp hiện đại, có khái niệm chính là mỗi đơn vị ngôn ngữ tức là các từ liên quan với nhau bằng một liên kết trực tiếp. Các liên kết trực tiếp này thực sự là‘dependencies’trong ngôn ngữ học. Ví dụ: sơ đồ sau đây cho thấy ngữ pháp phụ thuộc cho câu“John can hit the ball”.

Gói NLTK
Chúng tôi đã làm theo hai cách để thực hiện phân tích cú pháp phụ thuộc với NLTK -
Trình phân tích cú pháp phụ thuộc theo xác suất, xạ ảnh
Đây là cách đầu tiên chúng ta có thể thực hiện phân tích cú pháp phụ thuộc với NLTK. Nhưng trình phân tích cú pháp này có hạn chế là đào tạo với một bộ dữ liệu đào tạo hạn chế.
Trình phân tích cú pháp Stanford
Đây là một cách khác mà chúng ta có thể thực hiện phân tích cú pháp phụ thuộc với NLTK. Trình phân tích cú pháp Stanford là một trình phân tích cú pháp phụ thuộc tiên tiến nhất. NLTK có một trình bao bọc xung quanh nó. Để sử dụng nó, chúng ta cần tải xuống hai thứ sau:
Trình phân tích cú pháp CoreNLP của Stanford .
Mô hình ngôn ngữ cho ngôn ngữ mong muốn. Ví dụ, mô hình ngôn ngữ tiếng Anh.
Thí dụ
Sau khi bạn tải xuống mô hình, chúng tôi có thể sử dụng nó thông qua NLTK như sau:
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())Đầu ra
[
((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')),
((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')),
((u'elephant', u'NN'), u'det', (u'an', u'DT')),
((u'shot', u'VBD'), u'prep', (u'in', u'IN')),
((u'in', u'IN'), u'pobj', (u'sleep', u'NN')),
((u'sleep', u'NN'), u'poss', (u'my', u'PRP$'))
]Chunking là gì?
Chunking, một trong những quy trình quan trọng trong xử lý ngôn ngữ tự nhiên, được sử dụng để xác định các phần của giọng nói (POS) và các cụm từ ngắn. Nói cách khác, với phân đoạn, chúng ta có thể có được cấu trúc của câu. Nó còn được gọi làpartial parsing.
Các mẫu và chi tiết nhỏ
Chunk patternslà các mẫu thẻ part-of-speech (POS) xác định loại từ nào tạo thành một đoạn. Chúng ta có thể xác định các mẫu phân đoạn với sự trợ giúp của các biểu thức chính quy đã sửa đổi.
Hơn nữa, chúng ta cũng có thể xác định các mẫu cho loại từ nào không nên có trong một đoạn và những từ không phân tách này được gọi là chinks.
Ví dụ triển khai
Trong ví dụ dưới đây, cùng với kết quả phân tích cú pháp câu “the book has many chapters”, có một ngữ pháp cho các cụm danh từ kết hợp cả một mẫu và một mẫu -
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()Đầu ra
Như đã thấy ở trên, mẫu để chỉ định một đoạn là sử dụng dấu ngoặc nhọn như sau:
{<DT><NN>}Và để chỉ định một chink, chúng ta có thể lật các dấu ngoặc nhọn như sau:
}<VB>{.Bây giờ, đối với một loại cụm từ cụ thể, các quy tắc này có thể được kết hợp thành một ngữ pháp.
Trích xuất thông tin
Chúng tôi đã xem xét các trình kích hoạt cũng như trình phân tích cú pháp có thể được sử dụng để xây dựng công cụ khai thác thông tin. Hãy cho chúng tôi xem đường dẫn khai thác thông tin cơ bản -
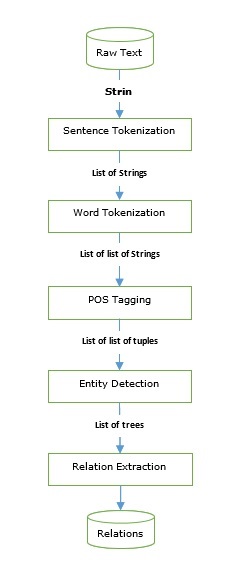
Khai thác thông tin có nhiều ứng dụng bao gồm -
- Kinh doanh thông minh
- Tiếp tục thu hoạch
- Phân tích phương tiện
- Phát hiện tình cảm
- Tìm kiếm bằng sáng chế
- Quét email
Nhận dạng thực thể được đặt tên (NER)
Nhận dạng thực thể được đặt tên (NER) thực sự là một cách trích xuất một số thực thể phổ biến nhất như tên, tổ chức, vị trí, v.v. Hãy để chúng tôi xem một ví dụ đã thực hiện tất cả các bước xử lý trước như mã hóa câu, gắn thẻ POS, phân khúc, NER, và đi theo đường ống được cung cấp trong hình trên.
Thí dụ
Import nltk
file = open (
# provide here the absolute path for the file of text for which we want NER
)
data_text = file.read()
sentences = nltk.sent_tokenize(data_text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences]
for sent in tagged_sentences:
print nltk.ne_chunk(sent)Một số công nhận thực thể được đặt tên (NER) được sửa đổi cũng có thể được sử dụng để trích xuất các thực thể như tên sản phẩm, thực thể y tế sinh học, tên thương hiệu và nhiều hơn nữa.
Trích xuất quan hệ
Khai thác quan hệ, một hoạt động khai thác thông tin thường được sử dụng khác, là quá trình trích xuất các mối quan hệ khác nhau giữa các thực thể khác nhau. Có thể có các mối quan hệ khác nhau như kế thừa, từ đồng nghĩa, tương tự, v.v., mà định nghĩa của chúng phụ thuộc vào nhu cầu thông tin. Ví dụ: giả sử nếu chúng ta muốn tìm viết một cuốn sách thì quyền tác giả sẽ là mối quan hệ giữa tên tác giả và tên cuốn sách.
Thí dụ
Trong ví dụ sau, chúng tôi sử dụng cùng một đường dẫn IE, như được hiển thị trong sơ đồ trên, chúng tôi đã sử dụng cho đến quan hệ Thực thể được đặt tên (NER) và mở rộng nó với một mẫu quan hệ dựa trên các thẻ NER.
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))Đầu ra
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia']
[ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo']
[ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington']
[ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington']
[ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles']
[ORG: 'Open Text'] ', based in' [LOC: 'Waterloo']
[ORG: 'WGBH'] 'in' [LOC: 'Boston']
[ORG: 'Bastille Opera'] 'in' [LOC: 'Paris']
[ORG: 'Omnicom'] 'in' [LOC: 'New York']
[ORG: 'DDB Needham'] 'in' [LOC: 'New York']
[ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York']
[ORG: 'BBDO South'] 'in' [LOC: 'Atlanta']
[ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']Trong đoạn mã trên, chúng ta đã sử dụng một kho ngữ liệu có sẵn tên là ieer. Trong ngữ liệu này, các câu được gắn thẻ cho đến quan hệ Thực thể được đặt tên (NER). Ở đây chúng ta chỉ cần xác định mẫu quan hệ mà chúng ta muốn và loại NER mà chúng ta muốn quan hệ xác định. Trong ví dụ của chúng tôi, chúng tôi đã xác định mối quan hệ giữa một tổ chức và một vị trí. Chúng tôi trích xuất tất cả các kết hợp của các mẫu này.
Tại sao lại biến đổi Chunks?
Cho đến bây giờ chúng ta đã có các đoạn hoặc cụm từ câu nhưng chúng ta phải làm gì với chúng. Một trong những nhiệm vụ quan trọng là chuyển hóa chúng. Nhưng tại sao? Nó là để làm như sau -
- sửa ngữ pháp và
- sắp xếp lại các cụm từ
Lọc các từ không quan trọng / vô ích
Giả sử nếu bạn muốn đánh giá nghĩa của một cụm từ thì có nhiều từ thường được sử dụng như, 'the', 'a', là không quan trọng hoặc vô dụng. Ví dụ, hãy xem cụm từ sau:
'Bộ phim rất hay'.
Ở đây những từ quan trọng nhất là 'phim' và 'hay'. Các từ khác, 'the' và 'was' đều vô dụng hoặc không đáng kể. Đó là bởi vì không có chúng, chúng ta cũng có thể nhận được cùng một ý nghĩa của cụm từ. 'Phim hay'.
Trong công thức python sau, chúng ta sẽ học cách loại bỏ các từ vô dụng / không quan trọng và giữ lại các từ quan trọng với sự trợ giúp của thẻ POS.
Thí dụ
Đầu tiên, bằng cách xem qua treebankngữ liệu cho từ dừng, chúng tôi cần quyết định thẻ phần lời nói nào quan trọng và thẻ nào không. Hãy để chúng tôi xem bảng các từ và thẻ không quan trọng sau đây -
| Word | Nhãn |
|---|---|
| a | DT |
| Tất cả | PDT |
| An | DT |
| Và | CC |
| Hoặc là | CC |
| Cái đó | WDT |
| Các | DT |
Từ bảng trên, chúng ta có thể thấy ngoài CC, tất cả các thẻ khác đều kết thúc bằng DT, nghĩa là chúng ta có thể lọc ra những từ không quan trọng bằng cách nhìn vào hậu tố của thẻ.
Đối với ví dụ này, chúng ta sẽ sử dụng một hàm có tên filter()lấy một đoạn duy nhất và trả về một đoạn mới mà không có bất kỳ từ được gắn thẻ quan trọng nào. Chức năng này lọc ra bất kỳ thẻ nào kết thúc bằng DT hoặc CC.
Thí dụ
import nltk
def filter(chunk, tag_suffixes=['DT', 'CC']):
significant = []
for word, tag in chunk:
ok = True
for suffix in tag_suffixes:
if tag.endswith(suffix):
ok = False
break
if ok:
significant.append((word, tag))
return (significant)Bây giờ, chúng ta hãy sử dụng hàm filter () này trong công thức Python của chúng tôi để xóa các từ không quan trọng -
from chunk_parse import filter
filter([('the', 'DT'),('good', 'JJ'),('movie', 'NN')])Đầu ra
[('good', 'JJ'), ('movie', 'NN')]Sửa động từ
Nhiều lần, trong ngôn ngữ thực tế, chúng ta thấy các dạng động từ không chính xác. Ví dụ, 'bạn khỏe chứ?' không đúng. Dạng động từ không đúng trong câu này. Câu nên là 'bạn ổn chứ?' NLTK cung cấp cho chúng ta cách để sửa những lỗi như vậy bằng cách tạo ánh xạ sửa động từ. Các ánh xạ hiệu chỉnh này được sử dụng tùy thuộc vào việc có một danh từ số nhiều hay số ít trong đoạn này.
Thí dụ
Để triển khai công thức Python, trước tiên chúng ta cần xác định ánh xạ sửa động từ. Hãy để chúng tôi tạo hai ánh xạ như sau:
Plural to Singular mappings
plural= {
('is', 'VBZ'): ('are', 'VBP'),
('was', 'VBD'): ('were', 'VBD')
}Singular to Plural mappings
singular = {
('are', 'VBP'): ('is', 'VBZ'),
('were', 'VBD'): ('was', 'VBD')
}Như đã thấy ở trên, mỗi ánh xạ có một động từ được gắn thẻ ánh xạ tới một động từ được gắn thẻ khác. Các ánh xạ ban đầu trong ví dụ của chúng tôi bao gồm cơ bản của ánh xạis to are, was to were, và ngược lại.
Tiếp theo, chúng ta sẽ định nghĩa một hàm có tên verbs(), trong đó bạn có thể chuyển một đoạn với dạng động từ không chính xác và sẽ lấy lại một đoạn đã sửa. Để hoàn thành,verb() hàm sử dụng một hàm trợ giúp có tên index_chunk() sẽ tìm kiếm phần nhỏ cho vị trí của từ được gắn thẻ đầu tiên.
Hãy cho chúng tôi xem các chức năng này -
def index_chunk(chunk, pred, start = 0, step = 1):
l = len(chunk)
end = l if step > 0 else -1
for i in range(start, end, step):
if pred(chunk[i]):
return i
return None
def tag_startswith(prefix):
def f(wt):
return wt[1].startswith(prefix)
return f
def verbs(chunk):
vbidx = index_chunk(chunk, tag_startswith('VB'))
if vbidx is None:
return chunk
verb, vbtag = chunk[vbidx]
nnpred = tag_startswith('NN')
nnidx = index_chunk(chunk, nnpred, start = vbidx+1)
if nnidx is None:
nnidx = index_chunk(chunk, nnpred, start = vbidx-1, step = -1)
if nnidx is None:
return chunk
noun, nntag = chunk[nnidx]
if nntag.endswith('S'):
chunk[vbidx] = plural.get((verb, vbtag), (verb, vbtag))
else:
chunk[vbidx] = singular.get((verb, vbtag), (verb, vbtag))
return chunkLưu các hàm này trong tệp Python trong thư mục cục bộ của bạn nơi Python hoặc Anaconda được cài đặt và chạy nó. Tôi đã lưu nó làverbcorrect.py.
Bây giờ, hãy để chúng tôi gọi verbs() chức năng trên máy POS được gắn thẻ is you fine khúc -
from verbcorrect import verbs
verbs([('is', 'VBZ'), ('you', 'PRP$'), ('fine', 'VBG')])Đầu ra
[('are', 'VBP'), ('you', 'PRP$'), ('fine','VBG')]Loại bỏ giọng nói thụ động khỏi các cụm từ
Một nhiệm vụ hữu ích khác là loại bỏ giọng nói thụ động khỏi các cụm từ. Điều này có thể được thực hiện với sự trợ giúp của việc hoán đổi các từ xung quanh một động từ. Ví dụ,‘the tutorial was great’ có thể được chuyển đổi thành ‘the great tutorial’.
Thí dụ
Để đạt được điều này, chúng tôi đang xác định một hàm có tên eliminate_passive()điều đó sẽ hoán đổi phía bên phải của đoạn văn bản với phía bên trái bằng cách sử dụng động từ làm điểm xoay. Để tìm động từ xoay quanh, nó cũng sẽ sử dụngindex_chunk() chức năng được xác định ở trên.
def eliminate_passive(chunk):
def vbpred(wt):
word, tag = wt
return tag != 'VBG' and tag.startswith('VB') and len(tag) > 2
vbidx = index_chunk(chunk, vbpred)
if vbidx is None:
return chunk
return chunk[vbidx+1:] + chunk[:vbidx]Bây giờ, hãy để chúng tôi gọi eliminate_passive() chức năng trên máy POS được gắn thẻ the tutorial was great khúc -
from passiveverb import eliminate_passive
eliminate_passive(
[
('the', 'DT'), ('tutorial', 'NN'), ('was', 'VBD'), ('great', 'JJ')
]
)Đầu ra
[('great', 'JJ'), ('the', 'DT'), ('tutorial', 'NN')]Hoán đổi danh từ cardinals
Như chúng ta đã biết, một từ chính như 5, được gắn thẻ là CD trong một đoạn. Những từ chính này thường xuất hiện trước hoặc sau một danh từ nhưng với mục đích bình thường hóa, rất hữu ích khi đặt chúng trước danh từ luôn. Ví dụ, ngàyJanuary 5 có thể được viết như 5 January. Hãy để chúng tôi hiểu nó với ví dụ sau.
Thí dụ
Để đạt được điều này, chúng tôi đang xác định một hàm có tên swapping_cardinals()điều đó sẽ hoán đổi bất kỳ thẻ nào xuất hiện ngay sau một danh từ với danh từ. Với điều này, cardinal sẽ xuất hiện ngay trước danh từ. Để so sánh bình đẳng với thẻ đã cho, nó sử dụng hàm trợ giúp mà chúng tôi đặt tên làtag_eql().
def tag_eql(tag):
def f(wt):
return wt[1] == tag
return fBây giờ chúng ta có thể định nghĩa swapping_cardinals () -
def swapping_cardinals (chunk):
cdidx = index_chunk(chunk, tag_eql('CD'))
if not cdidx or not chunk[cdidx-1][1].startswith('NN'):
return chunk
noun, nntag = chunk[cdidx-1]
chunk[cdidx-1] = chunk[cdidx]
chunk[cdidx] = noun, nntag
return chunkBây giờ, hãy để chúng tôi gọi swapping_cardinals() chức năng vào một ngày “January 5” -
from Cardinals import swapping_cardinals()
swapping_cardinals([('Janaury', 'NNP'), ('5', 'CD')])Đầu ra
[('10', 'CD'), ('January', 'NNP')]
10 JanuarySau đây là hai lý do để biến đổi cây -
- Để sửa đổi cây phân tích cú pháp sâu và
- Để làm phẳng cây phân tích sâu
Chuyển đổi cây hoặc cây con thành câu
Công thức đầu tiên chúng ta sẽ thảo luận ở đây là chuyển đổi một Cây hoặc cây con trở lại thành một câu hoặc chuỗi phân đoạn. Điều này rất đơn giản, chúng ta hãy xem trong ví dụ sau:
Thí dụ
from nltk.corpus import treebank_chunk
tree = treebank_chunk.chunked_sents()[2]
' '.join([w for w, t in tree.leaves()])Đầu ra
'Rudolph Agnew , 55 years old and former chairman of Consolidated Gold Fields
PLC , was named a nonexecutive director of this British industrial
conglomerate .'Cây sâu san phẳng
Cây sâu của các cụm từ lồng nhau không thể được sử dụng để đào tạo một đoạn, do đó chúng ta phải làm phẳng chúng trước khi sử dụng. Trong ví dụ sau, chúng ta sẽ sử dụng câu được phân tích cú pháp thứ 3, là cây sâu của các cụm từ lồng nhau, từtreebank ngữ liệu.
Thí dụ
Để đạt được điều này, chúng tôi đang xác định một hàm có tên deeptree_flat()sẽ lấy một Cây duy nhất và sẽ trả về một Cây mới chỉ giữ lại những cây cấp thấp nhất. Để thực hiện hầu hết công việc, nó sử dụng một chức năng trợ giúp mà chúng tôi đặt tên làchildtree_flat().
from nltk.tree import Tree
def childtree_flat(trees):
children = []
for t in trees:
if t.height() < 3:
children.extend(t.pos())
elif t.height() == 3:
children.append(Tree(t.label(), t.pos()))
else:
children.extend(flatten_childtrees([c for c in t]))
return children
def deeptree_flat(tree):
return Tree(tree.label(), flatten_childtrees([c for c in tree]))Bây giờ, hãy để chúng tôi gọi deeptree_flat() chức năng trên câu được phân tích cú pháp thứ 3, là cây sâu của các cụm từ lồng nhau, từ treebankngữ liệu. Chúng tôi đã lưu các chức năng này trong một tệp có tên deeptree.py.
from deeptree import deeptree_flat
from nltk.corpus import treebank
deeptree_flat(treebank.parsed_sents()[2])Đầu ra
Tree('S', [Tree('NP', [('Rudolph', 'NNP'), ('Agnew', 'NNP')]),
(',', ','), Tree('NP', [('55', 'CD'),
('years', 'NNS')]), ('old', 'JJ'), ('and', 'CC'),
Tree('NP', [('former', 'JJ'),
('chairman', 'NN')]), ('of', 'IN'), Tree('NP', [('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC',
'NNP')]), (',', ','), ('was', 'VBD'),
('named', 'VBN'), Tree('NP-SBJ', [('*-1', '-NONE-')]),
Tree('NP', [('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN')]),
('of', 'IN'), Tree('NP',
[('this', 'DT'), ('British', 'JJ'),
('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Xây dựng cây nông
Trong phần trước, chúng ta san bằng một cây sâu gồm các cụm từ lồng nhau bằng cách chỉ giữ lại các cây con cấp thấp nhất. Trong phần này, chúng ta sẽ chỉ giữ lại các cây con cấp cao nhất, tức là để xây dựng cây nông. Trong ví dụ sau, chúng ta sẽ sử dụng câu được phân tích cú pháp thứ 3, là cây sâu của các cụm từ lồng nhau, từtreebank ngữ liệu.
Thí dụ
Để đạt được điều này, chúng tôi đang xác định một hàm có tên tree_shallow() điều đó sẽ loại bỏ tất cả các cây con lồng nhau bằng cách chỉ giữ lại các nhãn của cây con trên cùng.
from nltk.tree import Tree
def tree_shallow(tree):
children = []
for t in tree:
if t.height() < 3:
children.extend(t.pos())
else:
children.append(Tree(t.label(), t.pos()))
return Tree(tree.label(), children)Bây giờ, hãy để chúng tôi gọi tree_shallow()chức năng trên câu được phân tích cú pháp thứ 3 , là cây sâu của các cụm từ lồng nhau, từtreebankngữ liệu. Chúng tôi đã lưu các hàm này trong một tệp có tên là nôngtree.py.
from shallowtree import shallow_tree
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2])Đầu ra
Tree('S', [Tree('NP-SBJ-1', [('Rudolph', 'NNP'), ('Agnew', 'NNP'), (',', ','),
('55', 'CD'), ('years', 'NNS'), ('old', 'JJ'), ('and', 'CC'),
('former', 'JJ'), ('chairman', 'NN'), ('of', 'IN'), ('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC', 'NNP'), (',', ',')]),
Tree('VP', [('was', 'VBD'), ('named', 'VBN'), ('*-1', '-NONE-'), ('a', 'DT'),
('nonexecutive', 'JJ'), ('director', 'NN'), ('of', 'IN'), ('this', 'DT'),
('British', 'JJ'), ('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Chúng ta có thể thấy sự khác biệt với sự trợ giúp của việc lấy chiều cao của cây -
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2]).height()Đầu ra
3from nltk.corpus import treebank
treebank.parsed_sents()[2].height()Đầu ra
9Chuyển đổi nhãn cây
Trong cây phân tích cú pháp có nhiều loại Treeloại nhãn không có trong cây phân nhánh. Tuy nhiên, trong khi sử dụng cây phân tích để đào tạo một con chạch, chúng tôi muốn giảm sự đa dạng này bằng cách chuyển đổi một số nhãn Cây sang các loại nhãn phổ biến hơn. Ví dụ, chúng ta có hai cây con NP thay thế là NP-SBL và NP-TMP. Chúng ta có thể chuyển cả hai thành NP. Hãy để chúng tôi xem cách làm điều đó trong ví dụ sau.
Thí dụ
Để đạt được điều này, chúng tôi đang xác định một hàm có tên tree_convert() có hai đối số sau:
- Cây chuyển đổi
- Ánh xạ chuyển đổi nhãn
Hàm này sẽ trả về một Cây mới với tất cả các nhãn phù hợp được thay thế dựa trên các giá trị trong ánh xạ.
from nltk.tree import Tree
def tree_convert(tree, mapping):
children = []
for t in tree:
if isinstance(t, Tree):
children.append(convert_tree_labels(t, mapping))
else:
children.append(t)
label = mapping.get(tree.label(), tree.label())
return Tree(label, children)Bây giờ, hãy để chúng tôi gọi tree_convert() chức năng trên câu được phân tích cú pháp thứ 3, là cây sâu của các cụm từ lồng nhau, từ treebankngữ liệu. Chúng tôi đã lưu các chức năng này trong một tệp có tênconverttree.py.
from converttree import tree_convert
from nltk.corpus import treebank
mapping = {'NP-SBJ': 'NP', 'NP-TMP': 'NP'}
convert_tree_labels(treebank.parsed_sents()[2], mapping)Đầu ra
Tree('S', [Tree('NP-SBJ-1', [Tree('NP', [Tree('NNP', ['Rudolph']),
Tree('NNP', ['Agnew'])]), Tree(',', [',']),
Tree('UCP', [Tree('ADJP', [Tree('NP', [Tree('CD', ['55']),
Tree('NNS', ['years'])]),
Tree('JJ', ['old'])]), Tree('CC', ['and']),
Tree('NP', [Tree('NP', [Tree('JJ', ['former']),
Tree('NN', ['chairman'])]), Tree('PP', [Tree('IN', ['of']),
Tree('NP', [Tree('NNP', ['Consolidated']),
Tree('NNP', ['Gold']), Tree('NNP', ['Fields']),
Tree('NNP', ['PLC'])])])])]), Tree(',', [','])]),
Tree('VP', [Tree('VBD', ['was']),Tree('VP', [Tree('VBN', ['named']),
Tree('S', [Tree('NP', [Tree('-NONE-', ['*-1'])]),
Tree('NP-PRD', [Tree('NP', [Tree('DT', ['a']),
Tree('JJ', ['nonexecutive']), Tree('NN', ['director'])]),
Tree('PP', [Tree('IN', ['of']), Tree('NP',
[Tree('DT', ['this']), Tree('JJ', ['British']), Tree('JJ', ['industrial']),
Tree('NN', ['conglomerate'])])])])])])]), Tree('.', ['.'])])Phân loại văn bản là gì?
Phân loại văn bản, như tên của nó, là cách để phân loại các phần văn bản hoặc tài liệu. Nhưng ở đây câu hỏi đặt ra là tại sao chúng ta cần sử dụng bộ phân loại văn bản? Sau khi kiểm tra việc sử dụng từ trong một tài liệu hoặc đoạn văn bản, bộ phân loại sẽ có thể quyết định nhãn lớp nào nên được gán cho nó.
Bộ phân loại nhị phân
Như tên của nó, bộ phân loại nhị phân sẽ quyết định giữa hai nhãn. Ví dụ, tích cực hoặc tiêu cực. Trong trường hợp này, đoạn văn bản hoặc tài liệu có thể là nhãn này hoặc nhãn khác, nhưng không phải cả hai.
Bộ phân loại nhiều nhãn
Trái ngược với trình phân loại nhị phân, trình phân loại nhiều nhãn có thể gán một hoặc nhiều nhãn cho một đoạn văn bản hoặc tài liệu.
Bộ tính năng không gắn nhãn Vs được gắn nhãn
Ánh xạ khóa-giá trị của tên đối tượng với giá trị đối tượng được gọi là tập hợp đối tượng. Tập hợp tính năng được gắn nhãn hoặc dữ liệu huấn luyện rất quan trọng đối với việc huấn luyện phân loại để sau này nó có thể phân loại tập tính năng không được gắn nhãn.
| Bộ tính năng được gắn nhãn | Bộ tính năng không được gắn nhãn |
|---|---|
| Nó là một bộ tuple trông giống như (kỳ công, nhãn). | Bản thân nó đã là một kỳ công. |
| Nó là một thể hiện có nhãn lớp đã biết. | Nếu không có nhãn liên kết, chúng ta có thể gọi nó là một phiên bản. |
| Được sử dụng để đào tạo một thuật toán phân loại. | Sau khi được đào tạo, thuật toán phân loại có thể phân loại một tập hợp tính năng không được gắn nhãn. |
Trích xuất tính năng văn bản
Trích xuất tính năng văn bản, như tên của nó, là quá trình chuyển đổi danh sách các từ thành một tập hợp tính năng có thể sử dụng được bởi bộ phân loại. Chúng ta phải chuyển đổi văn bản của mình thành‘dict’ bộ tính năng kiểu do Bộ công cụ ngôn ngữ tự nhiên (NLTK) mong đợi ‘dict’ bộ đặc điểm phong cách.
Mô hình Bag of Words (BoW)
BoW, một trong những mô hình đơn giản nhất trong NLP, được sử dụng để trích xuất các tính năng từ đoạn văn bản hoặc tài liệu để nó có thể được sử dụng trong mô hình hóa như vậy trong các thuật toán ML. Về cơ bản, nó xây dựng một tập hợp tính năng hiện diện từ từ tất cả các từ của một thể hiện. Khái niệm đằng sau phương pháp này là nó không quan tâm đến việc một từ xuất hiện bao nhiêu lần hoặc về thứ tự của các từ, nó chỉ quan tâm thời tiết từ đó có trong danh sách các từ hay không.
Thí dụ
Đối với ví dụ này, chúng ta sẽ định nghĩa một hàm có tên là bow () -
def bow(words):
return dict([(word, True) for word in words])Bây giờ, hãy để chúng tôi gọi bow()chức năng trên từ. Chúng tôi đã lưu các chức năng này trong một tệp có tên bagwords.py.
from bagwords import bow
bow(['we', 'are', 'using', 'tutorialspoint'])Đầu ra
{'we': True, 'are': True, 'using': True, 'tutorialspoint': True}Đào tạo phân loại
Trong các phần trước, chúng ta đã học cách trích xuất các đối tượng từ văn bản. Vì vậy, bây giờ chúng ta có thể đào tạo một bộ phân loại. Bộ phân loại đầu tiên và dễ nhất làNaiveBayesClassifier lớp học.
Naïve Bayes Classifier
Để dự đoán xác suất mà một tập đặc trưng nhất định thuộc về một nhãn cụ thể, nó sử dụng định lý Bayes. Công thức của định lý Bayes như sau.
$$P(A|B)=\frac{P(B|A)P(A)}{P(B)}$$Đây,
P(A|B) - Nó còn được gọi là xác suất hậu nghĩa tức là xác suất của sự kiện thứ nhất tức là A xảy ra cho biết sự kiện thứ hai tức là B xảy ra.
P(B|A) - Là xác suất của sự kiện thứ hai tức là B xảy ra sau sự kiện thứ nhất tức là A xảy ra.
P(A), P(B) - Nó còn được gọi là xác suất trước tức là xác suất của sự kiện thứ nhất tức là A hoặc sự kiện thứ hai tức là B xảy ra.
Để đào tạo bộ phân loại Naïve Bayes, chúng tôi sẽ sử dụng movie_reviewsngữ liệu từ NLTK. Kho tài liệu này có hai loại văn bản, đó là:pos và neg. Các danh mục này làm cho một bộ phân loại được đào tạo trên chúng trở thành một bộ phân loại nhị phân. Mỗi tệp trong kho tài liệu bao gồm hai, một là đánh giá phim tích cực và một là đánh giá phim tiêu cực. Trong ví dụ của chúng tôi, chúng tôi sẽ sử dụng mỗi tệp như một phiên bản duy nhất cho cả việc đào tạo và kiểm tra trình phân loại.
Thí dụ
Đối với trình phân loại huấn luyện, chúng ta cần một danh sách các tập hợp tính năng được gắn nhãn, sẽ có dạng [(featureset, label)]. Đâyfeatureset biến là một dict và nhãn là nhãn lớp đã biết cho featureset. Chúng ta sẽ tạo một hàm có tênlabel_corpus() sẽ lấy một kho ngữ liệu có tên movie_reviewsvà cũng là một hàm có tên feature_detector, mặc định là bag of words. Nó sẽ xây dựng và trả về một ánh xạ của biểu mẫu, {label: [featureset]}. Sau đó, chúng tôi sẽ sử dụng ánh xạ này để tạo danh sách các phiên bản đào tạo được gắn nhãn và các phiên bản thử nghiệm.
import collections
def label_corpus(corp, feature_detector=bow):
label_feats = collections.defaultdict(list)
for label in corp.categories():
for fileid in corp.fileids(categories=[label]):
feats = feature_detector(corp.words(fileids=[fileid]))
label_feats[label].append(feats)
return label_featsVới sự trợ giúp của hàm trên, chúng ta sẽ nhận được một ánh xạ {label:fetaureset}. Bây giờ chúng ta sẽ định nghĩa một hàm nữa có tênsplit điều đó sẽ lấy một ánh xạ trả về từ label_corpus() chức năng và chia từng danh sách các tập hợp tính năng thành các phiên bản huấn luyện có nhãn cũng như thử nghiệm.
def split(lfeats, split=0.75):
train_feats = []
test_feats = []
for label, feats in lfeats.items():
cutoff = int(len(feats) * split)
train_feats.extend([(feat, label) for feat in feats[:cutoff]])
test_feats.extend([(feat, label) for feat in feats[cutoff:]])
return train_feats, test_featsBây giờ, chúng ta hãy sử dụng các hàm này trên kho tài liệu của chúng ta, tức là movie_reviews -
from nltk.corpus import movie_reviews
from featx import label_feats_from_corpus, split_label_feats
movie_reviews.categories()Đầu ra
['neg', 'pos']Thí dụ
lfeats = label_feats_from_corpus(movie_reviews)
lfeats.keys()Đầu ra
dict_keys(['neg', 'pos'])Thí dụ
train_feats, test_feats = split_label_feats(lfeats, split = 0.75)
len(train_feats)Đầu ra
1500Thí dụ
len(test_feats)Đầu ra
500Chúng tôi đã thấy điều đó trong movie_reviewskho văn bản, có 1000 tệp pos và 1000 tệp neg. Chúng tôi cũng kết thúc với 1500 phiên bản đào tạo được gắn nhãn và 500 phiên bản thử nghiệm được gắn nhãn.
Bây giờ hãy để chúng tôi đào tạo NaïveBayesClassifier sử dụng nó train() phương pháp lớp -
from nltk.classify import NaiveBayesClassifier
NBC = NaiveBayesClassifier.train(train_feats)
NBC.labels()Đầu ra
['neg', 'pos']Bộ phân loại cây quyết định
Một bộ phân loại quan trọng khác là bộ phân loại cây quyết định. Ở đây để đào tạo nóDecisionTreeClassifierlớp sẽ tạo ra một cấu trúc cây. Trong cấu trúc cây này, mỗi nút tương ứng với một tên đối tượng và các nhánh tương ứng với các giá trị đối tượng. Và xuống các cành, chúng ta sẽ đến lá của cây tức là các nhãn phân loại.
Để đào tạo bộ phân loại cây quyết định, chúng tôi sẽ sử dụng các tính năng đào tạo và kiểm tra tương tự, tức là train_feats và test_feats, các biến chúng tôi đã tạo từ movie_reviews ngữ liệu.
Thí dụ
Để đào tạo bộ phân loại này, chúng tôi sẽ gọi DecisionTreeClassifier.train() phương thức lớp như sau:
from nltk.classify import DecisionTreeClassifier
decisiont_classifier = DecisionTreeClassifier.train(
train_feats, binary = True, entropy_cutoff = 0.8,
depth_cutoff = 5, support_cutoff = 30
)
accuracy(decisiont_classifier, test_feats)Đầu ra
0.725Bộ phân loại Entropy tối đa
Một bộ phân loại quan trọng khác là MaxentClassifier mà còn được gọi là conditional exponential classifier hoặc là logistic regression classifier. Ở đây để đào tạo nó,MaxentClassifier lớp sẽ chuyển đổi các bộ đặc trưng có nhãn thành vectơ bằng cách sử dụng mã hóa.
Để đào tạo bộ phân loại cây quyết định, chúng tôi sẽ sử dụng các tính năng đào tạo và kiểm tra tương tự, tức là train_featsvà test_feats, các biến chúng tôi đã tạo từ movie_reviews ngữ liệu.
Thí dụ
Để đào tạo bộ phân loại này, chúng tôi sẽ gọi MaxentClassifier.train() phương thức lớp như sau:
from nltk.classify import MaxentClassifier
maxent_classifier = MaxentClassifier
.train(train_feats,algorithm = 'gis', trace = 0, max_iter = 10, min_lldelta = 0.5)
accuracy(maxent_classifier, test_feats)Đầu ra
0.786Bộ phân loại Scikit-learning
Một trong những thư viện máy học (ML) tốt nhất là Scikit-learning. Nó thực sự chứa tất cả các loại thuật toán ML cho các mục đích khác nhau, nhưng chúng đều có cùng một mẫu thiết kế phù hợp như sau:
- Phù hợp mô hình với dữ liệu
- Và sử dụng mô hình đó để đưa ra dự đoán
Thay vì truy cập trực tiếp vào các mô hình scikit-learning, ở đây chúng tôi sẽ sử dụng NLTK's SklearnClassifierlớp học. Lớp này là một lớp bao bọc xung quanh một mô hình scikit-learning để làm cho nó phù hợp với giao diện Bộ phân loại của NLTK.
Chúng tôi sẽ làm theo các bước sau để đào tạo một SklearnClassifier lớp học -
Step 1 - Đầu tiên chúng ta sẽ tạo các tính năng luyện tập như đã làm ở các công thức trước.
Step 2 - Bây giờ, chọn và nhập một thuật toán Scikit-learning.
Step 3 - Tiếp theo, chúng ta cần xây dựng một SklearnClassifier lớp với thuật toán đã chọn.
Step 4 - Cuối cùng, chúng tôi sẽ đào tạo SklearnClassifier lớp với các tính năng đào tạo của chúng tôi.
Hãy để chúng tôi thực hiện các bước này trong công thức Python bên dưới -
from nltk.classify.scikitlearn import SklearnClassifier
from sklearn.naive_bayes import MultinomialNB
sklearn_classifier = SklearnClassifier(MultinomialNB())
sklearn_classifier.train(train_feats)
<SklearnClassifier(MultinomialNB(alpha = 1.0,class_prior = None,fit_prior = True))>
accuracy(sk_classifier, test_feats)Đầu ra
0.885Đo độ chính xác và thu hồi
Trong khi đào tạo các bộ phân loại khác nhau, chúng tôi cũng đã đo độ chính xác của chúng. Nhưng ngoài độ chính xác, còn có một số chỉ số khác được sử dụng để đánh giá các bộ phân loại. Hai trong số các chỉ số này làprecision và recall.
Thí dụ
Trong ví dụ này, chúng ta sẽ tính toán độ chính xác và gọi lại lớp NaiveBayesClassifier mà chúng ta đã đào tạo trước đó. Để đạt được điều này, chúng tôi sẽ tạo một hàm có tên metrics_PR () sẽ nhận hai đối số, một là bộ phân loại được đào tạo và một là các tính năng kiểm tra được gắn nhãn. Cả hai đối số đều giống như chúng ta đã truyền trong khi tính độ chính xác của bộ phân loại -
import collections
from nltk import metrics
def metrics_PR(classifier, testfeats):
refsets = collections.defaultdict(set)
testsets = collections.defaultdict(set)
for i, (feats, label) in enumerate(testfeats):
refsets[label].add(i)
observed = classifier.classify(feats)
testsets[observed].add(i)
precisions = {}
recalls = {}
for label in classifier.labels():
precisions[label] = metrics.precision(refsets[label],testsets[label])
recalls[label] = metrics.recall(refsets[label], testsets[label])
return precisions, recallsChúng ta hãy gọi hàm này để tìm độ chính xác và nhớ lại -
from metrics_classification import metrics_PR
nb_precisions, nb_recalls = metrics_PR(nb_classifier,test_feats)
nb_precisions['pos']Đầu ra
0.6713532466435213Thí dụ
nb_precisions['neg']Đầu ra
0.9676271186440678Thí dụ
nb_recalls['pos']Đầu ra
0.96Thí dụ
nb_recalls['neg']Đầu ra
0.478Sự kết hợp của trình phân loại và biểu quyết
Kết hợp các bộ phân loại là một trong những cách tốt nhất để cải thiện hiệu suất phân loại. Và bỏ phiếu là một trong những cách tốt nhất để kết hợp nhiều bộ phân loại. Để bỏ phiếu, chúng ta cần có số phân loại lẻ. Trong công thức Python sau, chúng ta sẽ kết hợp ba bộ phân loại là lớp NaiveBayesClassifier, lớp DecisionTreeClassifier và lớp MaxentClassifier.
Để đạt được điều này, chúng ta sẽ định nghĩa một hàm có tên là vote_classifiers () như sau.
import itertools
from nltk.classify import ClassifierI
from nltk.probability import FreqDist
class Voting_classifiers(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
self._labels = sorted(set(itertools.chain(*[c.labels() for c in classifiers])))
def labels(self):
return self._labels
def classify(self, feats):
counts = FreqDist()
for classifier in self._classifiers:
counts[classifier.classify(feats)] += 1
return counts.max()Chúng ta hãy gọi hàm này để kết hợp ba bộ phân loại và tìm độ chính xác -
from vote_classification import Voting_classifiers
combined_classifier = Voting_classifiers(NBC, decisiont_classifier, maxent_classifier)
combined_classifier.labels()Đầu ra
['neg', 'pos']Thí dụ
accuracy(combined_classifier, test_feats)Đầu ra
0.948Từ kết quả trên, chúng ta có thể thấy rằng các bộ phân loại kết hợp có độ chính xác cao hơn các bộ phân loại riêng lẻ.