OpenNLP - Hướng dẫn nhanh
NLP là một bộ công cụ được sử dụng để lấy thông tin có ý nghĩa và hữu ích từ các nguồn ngôn ngữ tự nhiên như các trang web và tài liệu văn bản.
Open NLP là gì?
Apache OpenNLPlà một thư viện Java mã nguồn mở được sử dụng để xử lý văn bản ngôn ngữ tự nhiên. Bạn có thể xây dựng một dịch vụ xử lý văn bản hiệu quả bằng cách sử dụng thư viện này.
OpenNLP cung cấp các dịch vụ như mã hóa, phân đoạn câu, gắn thẻ một phần giọng nói, trích xuất thực thể được đặt tên, phân đoạn, phân tích cú pháp và phân giải đồng tham chiếu, v.v.
Các tính năng của OpenNLP
Sau đây là các tính năng đáng chú ý của OpenNLP:
Named Entity Recognition (NER) - Open NLP hỗ trợ NER, sử dụng nó bạn có thể trích xuất tên của vị trí, người và mọi thứ ngay cả khi đang xử lý các truy vấn.
Summarize - Sử dụng summarize , bạn có thể tóm tắt Đoạn văn, bài báo, tài liệu hoặc bộ sưu tập của chúng trong NLP.
Searching - Trong OpenNLP, một chuỗi tìm kiếm nhất định hoặc các từ đồng nghĩa của nó có thể được xác định trong văn bản nhất định, ngay cả khi từ đã cho bị thay đổi hoặc sai chính tả.
Tagging (POS) - Gắn thẻ trong NLP được sử dụng để chia văn bản thành các yếu tố ngữ pháp khác nhau để phân tích thêm.
Translation - Trong NLP, Dịch thuật giúp dịch ngôn ngữ này sang ngôn ngữ khác.
Information grouping - Tùy chọn này trong NLP nhóm thông tin dạng văn bản trong nội dung của tài liệu, giống như Các phần của bài phát biểu.
Natural Language Generation - Nó được sử dụng để tạo thông tin từ cơ sở dữ liệu và tự động hóa các báo cáo thông tin như phân tích thời tiết hoặc báo cáo y tế.
Feedback Analysis - Như tên của nó, NLP sẽ thu thập nhiều loại phản hồi từ mọi người, về sản phẩm, để phân tích mức độ thành công của sản phẩm trong việc chiếm được cảm tình của họ.
Speech recognition - Mặc dù khó phân tích giọng nói của con người, NLP có một số tính năng tích hợp cho yêu cầu này.
Mở API NLP
Thư viện Apache OpenNLP cung cấp các lớp và giao diện để thực hiện các tác vụ khác nhau của xử lý ngôn ngữ tự nhiên như phát hiện câu, mã hóa, tìm tên, gắn thẻ các phần của giọng nói, phân đoạn một câu, phân tích cú pháp, phân giải đồng tham chiếu và phân loại tài liệu.
Ngoài các nhiệm vụ này, chúng tôi cũng có thể đào tạo và đánh giá các mô hình của riêng mình cho bất kỳ nhiệm vụ nào trong số này.
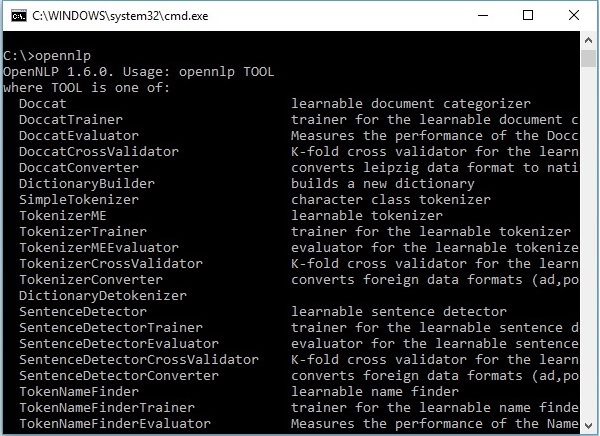
OpenNLP CLI
Ngoài thư viện, OpenNLP cũng cung cấp Giao diện dòng lệnh (CLI), nơi chúng ta có thể đào tạo và đánh giá các mô hình. Chúng ta sẽ thảo luận chi tiết về chủ đề này trong chương cuối của hướng dẫn này.
Mở mô hình NLP
Để thực hiện các tác vụ NLP khác nhau, OpenNLP cung cấp một tập hợp các mô hình được xác định trước. Bộ này bao gồm các mô hình cho các ngôn ngữ khác nhau.
Tải xuống các mô hình
Bạn có thể làm theo các bước dưới đây để tải xuống các mô hình được xác định trước do OpenNLP cung cấp.
Step 1 - Mở trang chỉ mục của các mô hình OpenNLP bằng cách nhấp vào liên kết sau - http://opennlp.sourceforge.net/models-1.5/.

Step 2- Khi truy cập vào liên kết đã cho, bạn sẽ thấy danh sách các thành phần của nhiều ngôn ngữ khác nhau và các liên kết để tải chúng xuống. Tại đây, bạn có thể nhận danh sách tất cả các mô hình được xác định trước do OpenNLP cung cấp.
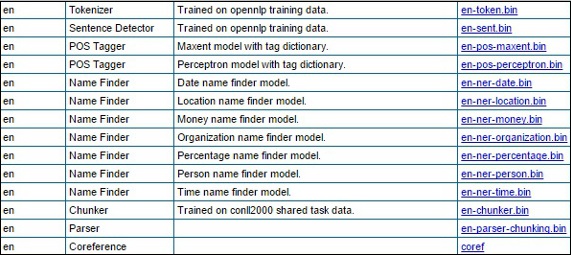
Tải xuống tất cả các mô hình này vào thư mục C:/OpenNLP_models/>, bằng cách nhấp vào các liên kết tương ứng của họ. Tất cả các mô hình này đều phụ thuộc vào ngôn ngữ và trong khi sử dụng chúng, bạn phải đảm bảo rằng ngôn ngữ mô hình khớp với ngôn ngữ của văn bản đầu vào.
Lịch sử của OpenNLP
Năm 2010, OpenNLP tham gia vào quá trình ấp Apache.
Năm 2011, Apache OpenNLP 1.5.2 Incubating được phát hành và cùng năm đó, nó trở thành một dự án Apache cấp cao nhất.
Vào năm 2015, OpenNLP đã được phát hành 1.6.0.
Trong chương này, chúng ta sẽ thảo luận về cách bạn có thể thiết lập môi trường OpenNLP trong hệ thống của mình. Hãy bắt đầu với quá trình cài đặt.
Cài đặt OpenNLP
Sau đây là các bước để tải xuống Apache OpenNLP library trong hệ thống của bạn.
Step 1 - Mở trang chủ của Apache OpenNLP bằng cách nhấp vào liên kết sau - https://opennlp.apache.org/.
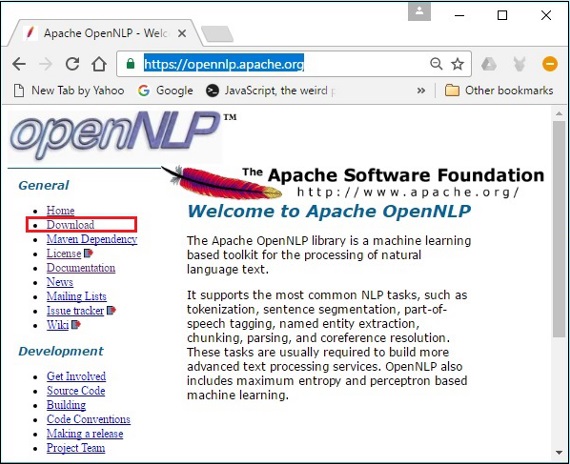
Step 2 - Bây giờ, hãy nhấp vào Downloadsliên kết. Khi nhấp vào, bạn sẽ được dẫn đến một trang nơi bạn có thể tìm thấy nhiều bản sao khác nhau sẽ chuyển hướng bạn đến thư mục Phân phối Tổ chức Phần mềm Apache.
Step 3- Trong trang này, bạn có thể tìm thấy các liên kết để tải xuống các bản phân phối Apache khác nhau. Duyệt qua chúng và tìm bản phân phối OpenNLP và nhấp vào nó.
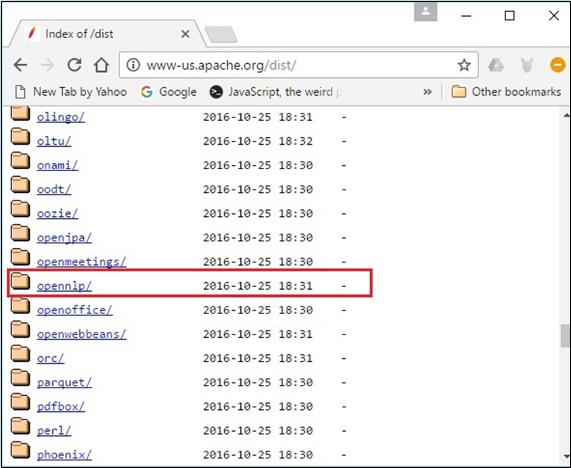
Step 4 - Khi nhấp vào, bạn sẽ được chuyển đến thư mục nơi bạn có thể xem chỉ mục của bản phân phối OpenNLP, như hình dưới đây.
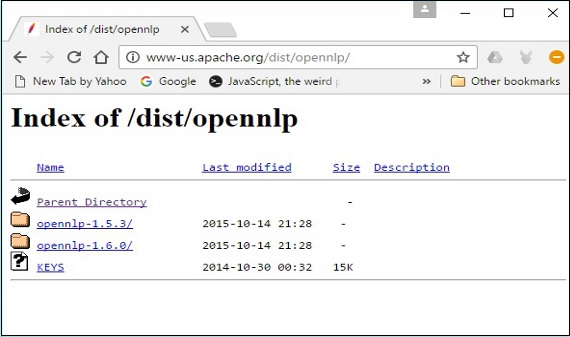
Nhấp vào phiên bản mới nhất từ các bản phân phối có sẵn.
Step 5- Mỗi bản phân phối cung cấp các tệp Nguồn và Nhị phân của thư viện OpenNLP ở nhiều định dạng khác nhau. Tải xuống tệp nguồn và tệp nhị phân,apache-opennlp-1.6.0-bin.zip và apache-opennlp1.6.0-src.zip (cho cửa sổ).

Đặt Classpath
Sau khi tải xuống thư viện OpenNLP, bạn cần đặt đường dẫn của nó đến bindanh mục. Giả sử rằng bạn đã tải thư viện OpenNLP xuống ổ đĩa E của hệ thống.
Bây giờ, hãy làm theo các bước được đưa ra bên dưới -
Step 1 - Nhấp chuột phải vào 'My Computer' và chọn 'Properties'.
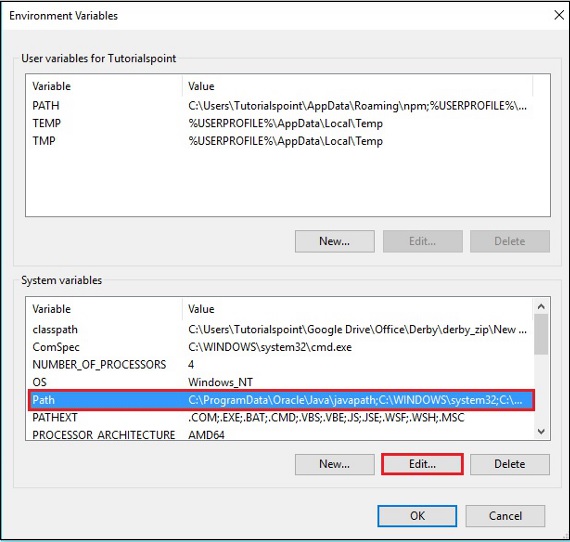
Step 2 - Nhấp vào nút 'Biến Môi trường' trong tab 'Nâng cao'.
Step 3 - Chọn path và nhấp vào Edit , như được hiển thị trong ảnh chụp màn hình sau.
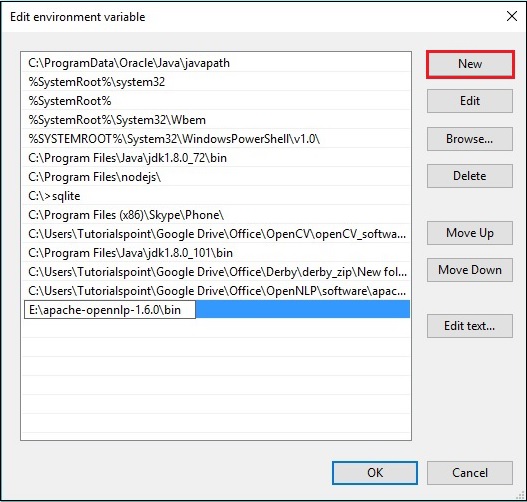
Step 4 - Trong cửa sổ Chỉnh sửa Biến Môi trường, nhấp vào New và thêm đường dẫn cho thư mục OpenNLP E:\apache-opennlp-1.6.0\bin và nhấp vào OK , như được hiển thị trong ảnh chụp màn hình sau.
Cài đặt Eclipse
Bạn có thể đặt môi trường Eclipse cho thư viện OpenNLP, bằng cách đặt Build path vào các tệp JAR hoặc bằng cách sử dụng pom.xml.
Đặt đường dẫn xây dựng đến tệp JAR
Làm theo các bước dưới đây để cài đặt OpenNLP trong Eclipse -
Step 1 - Đảm bảo rằng bạn đã cài đặt môi trường Eclipse trong hệ thống của mình.
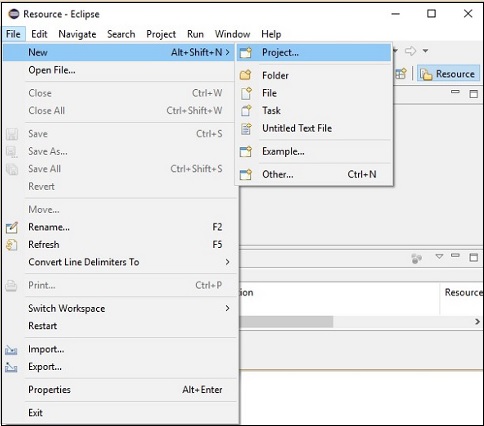
Step 2- Mở Eclipse. Nhấp vào Tệp → Mới → Mở một dự án mới, như hình dưới đây.
Step 3 - Bạn sẽ nhận được New ProjectThuật sĩ. Trong trình hướng dẫn này, hãy chọn dự án Java và tiếp tục bằng cách nhấp vàoNext cái nút.
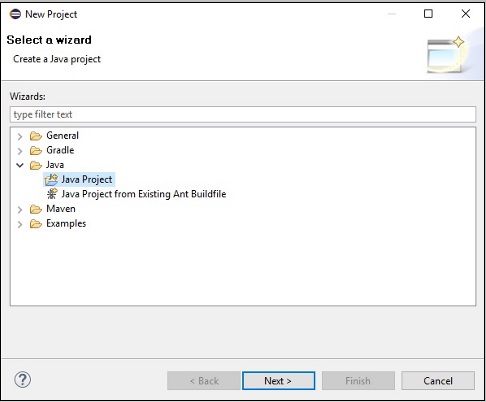
Step 4 - Tiếp theo, bạn sẽ nhận được New Java Project wizard. Tại đây, bạn cần tạo một dự án mới và nhấp vàoNext như hình dưới đây.
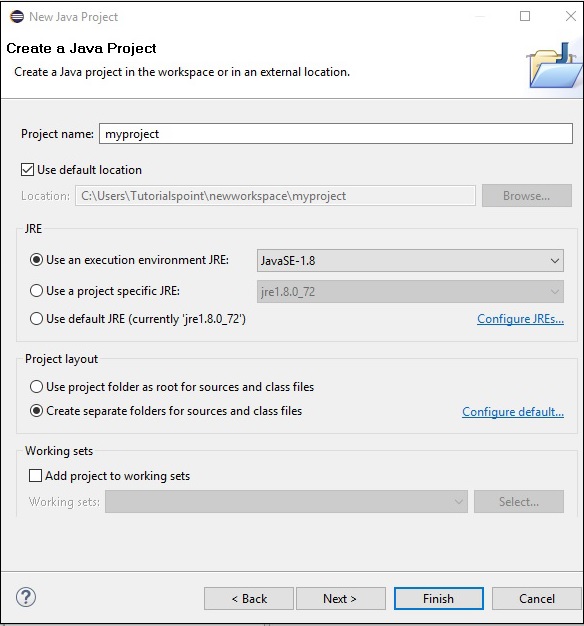
Step 5 - Sau khi tạo dự án mới, nhấp chuột phải vào dự án đó, chọn Build Path và bấm vào Configure Build Path.
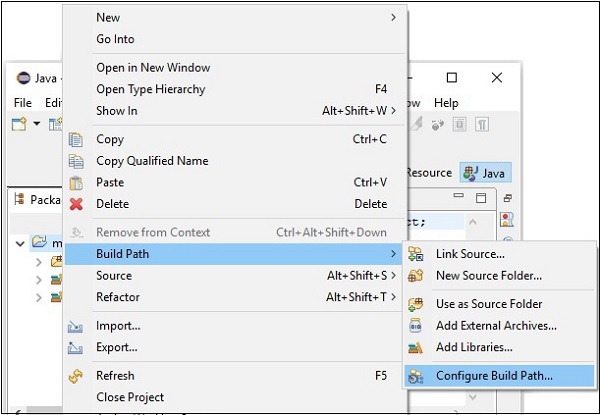
Step 6 - Tiếp theo, bạn sẽ nhận được Java Build PathThuật sĩ. Tại đây, nhấp vàoAdd External JARs như hình dưới đây.
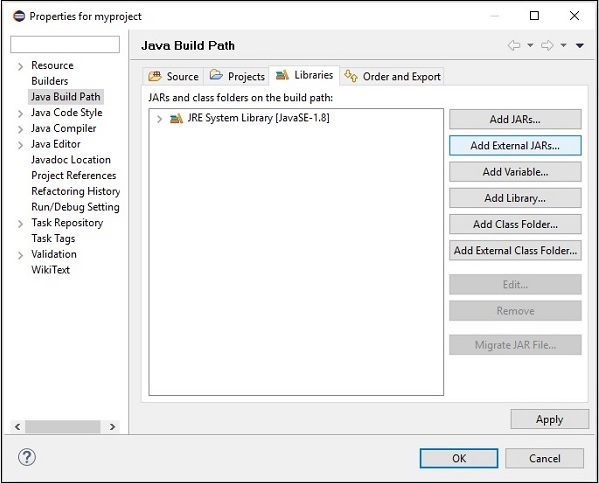
Step 7 - Chọn các tệp jar opennlp-tools-1.6.0.jar và opennlp-uima-1.6.0.jar nằm ở lib thư mục của apache-opennlp-1.6.0 folder.
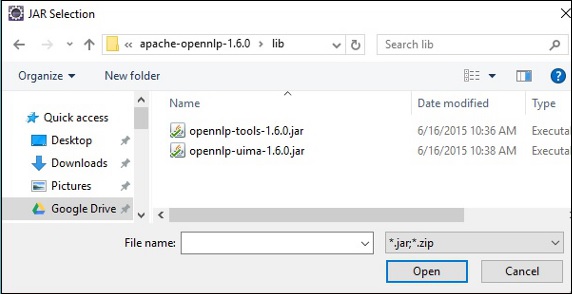
Khi nhấp vào Open trong màn hình trên, các tệp đã chọn sẽ được thêm vào thư viện của bạn.
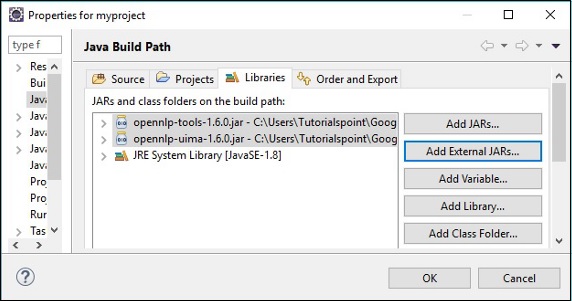
Khi nhấp vào OK, bạn sẽ thêm thành công các tệp JAR cần thiết vào dự án hiện tại và bạn có thể xác minh các thư viện đã thêm này bằng cách mở rộng Thư viện được tham chiếu, như được hiển thị bên dưới.

Sử dụng pom.xml
Chuyển đổi dự án thành dự án Maven và thêm mã sau vào pom.xml.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>myproject</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-uima</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>Trong chương này, chúng ta sẽ thảo luận về các lớp và phương thức mà chúng ta sẽ sử dụng trong các chương tiếp theo của hướng dẫn này.
Phát hiện câu
Lớp CâuMô hình
Lớp này đại diện cho mô hình được xác định trước được sử dụng để phát hiện các câu trong văn bản thô đã cho. Lớp này thuộc về góiopennlp.tools.sentdetect.
Hàm tạo của lớp này chấp nhận một InputStream đối tượng của tệp mô hình dò câu (en-sent.bin).
Lớp QuestionDetectorME
Lớp này thuộc về gói opennlp.tools.sentdetectvà nó chứa các phương thức để tách văn bản thô thành các câu. Lớp này sử dụng mô hình entropy tối đa để đánh giá các ký tự end-ofsentence trong một chuỗi để xác định xem chúng có biểu thị sự kết thúc của một câu hay không.
Sau đây là các phương thức quan trọng của lớp này.
| S. không | Phương pháp và Mô tả |
|---|---|
| 1 | sentDetect() Phương pháp này được sử dụng để phát hiện các câu trong văn bản thô được chuyển đến nó. Nó chấp nhận một biến Chuỗi làm tham số và trả về một mảng Chuỗi chứa các câu từ văn bản thô đã cho. |
| 2 | sentPosDetect() Phương pháp này được sử dụng để phát hiện vị trí của các câu trong văn bản đã cho. Phương thức này chấp nhận một biến chuỗi, đại diện cho câu và trả về một mảng các đối tượng thuộc kiểuSpan. Lớp có tên Span sau đó opennlp.tools.util gói được sử dụng để lưu trữ số nguyên bắt đầu và kết thúc của bộ. |
| 3 | getSentenceProbabilities() Phương thức này trả về các xác suất được liên kết với các lệnh gọi gần đây nhất đến sentDetect() phương pháp. |
Mã hóa
Lớp TokenizerModel
Lớp này đại diện cho mô hình được xác định trước được sử dụng để mã hóa câu đã cho. Lớp này thuộc về góiopennlp.tools.tokenizer.
Hàm tạo của lớp này chấp nhận một InputStream đối tượng của tệp mô hình tokenizer (entoken.bin).
Các lớp học
Để thực hiện mã hóa, thư viện OpenNLP cung cấp ba lớp chính. Tất cả ba lớp đều triển khai giao diện được gọi làTokenizer.
| S. không | Lớp và Mô tả |
|---|---|
| 1 | SimpleTokenizer Lớp này mã hóa văn bản thô đã cho bằng cách sử dụng các lớp ký tự. |
| 2 | WhitespaceTokenizer Lớp này sử dụng khoảng trắng để mã hóa văn bản đã cho. |
| 3 | TokenizerME Lớp này chuyển đổi văn bản thô thành các mã thông báo riêng biệt. Nó sử dụng Maximum Entropy để đưa ra quyết định của mình. |
Các lớp này chứa các phương thức sau.
| S. không | Phương pháp và Mô tả |
|---|---|
| 1 | tokenize() Phương pháp này được sử dụng để mã hóa văn bản thô. Phương thức này chấp nhận một biến Chuỗi làm tham số và trả về một mảng Chuỗi (mã thông báo). |
| 2 | sentPosDetect() Phương pháp này được sử dụng để lấy vị trí hoặc khoảng cách của mã thông báo. Nó chấp nhận câu (hoặc) văn bản thô ở dạng chuỗi và trả về một mảng đối tượng kiểuSpan. |
Ngoài hai phương pháp trên, TokenizerME lớp học có getTokenProbabilities() phương pháp.
| S. không | Phương pháp và Mô tả |
|---|---|
| 1 | getTokenProbabilities() Phương pháp này được sử dụng để nhận xác suất liên quan đến các lệnh gọi gần đây nhất đến tokenizePos() phương pháp. |
NameEntityRecognition
Lớp TokenNameFinderModel
Lớp này đại diện cho mô hình được xác định trước được sử dụng để tìm các thực thể được đặt tên trong câu đã cho. Lớp này thuộc về góiopennlp.tools.namefind.
Hàm tạo của lớp này chấp nhận một InputStream đối tượng của tệp mô hình công cụ tìm tên (enner-person.bin).
Lớp NameFinderME
Lớp thuộc về gói opennlp.tools.namefindvà nó chứa các phương thức để thực hiện các tác vụ NER. Lớp này sử dụng mô hình entropy tối đa để tìm các thực thể được đặt tên trong văn bản thô đã cho.
| S. không | Phương pháp và Mô tả |
|---|---|
| 1 | find() Phương pháp này được sử dụng để phát hiện tên trong văn bản thô. Nó chấp nhận một biến Chuỗi đại diện cho văn bản thô như một tham số và trả về một mảng đối tượng kiểu Span. |
| 2 | probs() Phương pháp này được sử dụng để lấy xác suất của chuỗi được giải mã cuối cùng. |
Tìm các phần của bài phát biểu
Lớp POSModel
Lớp này đại diện cho mô hình được xác định trước được sử dụng để gắn thẻ các phần lời nói của câu đã cho. Lớp này thuộc về góiopennlp.tools.postag.
Hàm tạo của lớp này chấp nhận một InputStream đối tượng của tệp mô hình pos-tagger (enpos-maxent.bin).
Lớp POSTaggerME
Lớp này thuộc về gói opennlp.tools.postagvà nó được sử dụng để dự đoán các phần của bài phát biểu của văn bản thô nhất định. Nó sử dụng Maximum Entropy để đưa ra quyết định của mình.
| S. không | Phương pháp và Mô tả |
|---|---|
| 1 | tag() Phương thức này được sử dụng để gán câu của thẻ POS. Phương thức này chấp nhận một mảng mã thông báo (Chuỗi) làm tham số và trả về một thẻ (mảng). |
| 2 | getSentenceProbabilities() Phương pháp này được sử dụng để lấy xác suất cho mỗi thẻ của câu được gắn thẻ gần đây. |
Phân tích cú pháp câu
Lớp ParserModel
Lớp này đại diện cho mô hình được xác định trước được sử dụng để phân tích cú pháp câu đã cho. Lớp này thuộc về góiopennlp.tools.parser.
Hàm tạo của lớp này chấp nhận một InputStream đối tượng của tệp mô hình phân tích cú pháp (en-parserchunking.bin).
Lớp nhà máy phân tích cú pháp
Lớp này thuộc về gói opennlp.tools.parser và nó được sử dụng để tạo trình phân tích cú pháp.
| S. không | Phương pháp và Mô tả |
|---|---|
| 1 | create() Đây là một phương thức tĩnh và nó được sử dụng để tạo một đối tượng phân tích cú pháp. Phương thức này chấp nhận đối tượng Filestream của tệp mô hình phân tích cú pháp. |
Lớp ParserTool
Lớp này thuộc về opennlp.tools.cmdline.parser gói và, nó được sử dụng để phân tích nội dung.
| S. không | Phương pháp và Mô tả |
|---|---|
| 1 | parseLine() Phương pháp này của ParserToollớp được sử dụng để phân tích cú pháp văn bản thô trong OpenNLP. Phương thức này chấp nhận -
|
Chunking
ChunkerModel class
Lớp này đại diện cho mô hình được xác định trước được sử dụng để chia một câu thành các phần nhỏ hơn. Lớp này thuộc về góiopennlp.tools.chunker.
Hàm tạo của lớp này chấp nhận một InputStream đối tượng của chunker tệp mô hình (enchunker.bin).
Lớp ChunkerME
Lớp này thuộc về gói có tên opennlp.tools.chunker và nó được sử dụng để chia câu đã cho thành nhiều phần nhỏ hơn.
| S. không | Phương pháp và Mô tả |
|---|---|
| 1 | chunk() Phương pháp này được sử dụng để chia câu đã cho thành nhiều phần nhỏ hơn. Nó chấp nhận mã thông báo của một câu vàPnghệ thuật Of Sthẻ peech làm thông số. |
| 2 | probs() Phương thức này trả về xác suất của dãy được giải mã cuối cùng. |
Trong khi xử lý một ngôn ngữ tự nhiên, việc quyết định phần đầu và phần cuối của câu là một trong những vấn đề cần giải quyết. Quá trình này được gọi làSsự dụ dỗ Boundary Disambiguation (SBD) hoặc đơn giản là ngắt câu.
Các kỹ thuật chúng tôi sử dụng để phát hiện các câu trong văn bản đã cho, phụ thuộc vào ngôn ngữ của văn bản.
Phát hiện câu bằng Java
Chúng ta có thể phát hiện các câu trong văn bản đã cho bằng Java bằng cách sử dụng Biểu thức chính quy và một tập hợp các quy tắc đơn giản.
Ví dụ: giả sử một dấu chấm, dấu chấm hỏi hoặc dấu chấm than kết thúc một câu trong văn bản đã cho, sau đó chúng ta có thể tách câu bằng cách sử dụng split() phương pháp của Stringlớp học. Ở đây, chúng ta phải chuyển một biểu thức chính quy ở định dạng Chuỗi.
Sau đây là chương trình xác định các câu trong một văn bản nhất định bằng cách sử dụng các biểu thức chính quy Java (split method). Lưu chương trình này trong một tệp có tênSentenceDetection_RE.java.
public class SentenceDetection_RE {
public static void main(String args[]){
String sentence = " Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
String simple = "[.?!]";
String[] splitString = (sentence.split(simple));
for (String string : splitString)
System.out.println(string);
}
}Biên dịch và thực thi tệp java đã lưu từ dấu nhắc lệnh bằng các lệnh sau.
javac SentenceDetection_RE.java
java SentenceDetection_REKhi thực thi, chương trình trên sẽ tạo một tài liệu PDF hiển thị thông báo sau.
Hi
How are you
Welcome to Tutorialspoint
We provide free tutorials on various technologiesPhát hiện câu bằng OpenNLP
Để phát hiện các câu, OpenNLP sử dụng một mô hình được xác định trước, một tệp có tên en-sent.bin. Mô hình xác định trước này được đào tạo để phát hiện các câu trong một văn bản thô nhất định.
Các opennlp.tools.sentdetect gói chứa các lớp và giao diện được sử dụng để thực hiện nhiệm vụ phát hiện câu.
Để phát hiện một câu bằng thư viện OpenNLP, bạn cần phải -
Tải en-sent.bin mô hình sử dụng SentenceModel lớp học
Khởi tạo SentenceDetectorME lớp học.
Phát hiện các câu bằng cách sử dụng sentDetect() phương thức của lớp này.
Sau đây là các bước cần làm để viết một chương trình phát hiện các câu từ văn bản thô đã cho.
Bước 1: Tải mô hình
Mô hình phát hiện câu được đại diện bởi lớp có tên SentenceModel, thuộc về gói opennlp.tools.sentdetect.
Để tải một mô hình phát hiện câu -
Tạo ra một InputStream đối tượng của mô hình (Khởi tạo FileInputStream và chuyển đường dẫn của mô hình ở định dạng Chuỗi đến phương thức khởi tạo của nó).
Khởi tạo SentenceModel lớp và vượt qua InputStream (đối tượng) của mô hình như một tham số cho phương thức khởi tạo của nó như được hiển thị trong khối mã sau:
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/ensent.bin");
SentenceModel model = new SentenceModel(inputStream);Bước 2: Khởi tạo lớp QuestionDetectorME
Các SentenceDetectorME lớp của gói opennlp.tools.sentdetectchứa các phương thức để tách văn bản thô thành các câu. Lớp này sử dụng mô hình Maximum Entropy để đánh giá các ký tự cuối câu trong một chuỗi để xác định xem chúng có biểu thị sự kết thúc của một câu hay không.
Khởi tạo lớp này và chuyển đối tượng mô hình đã tạo ở bước trước, như hình dưới đây.
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);Bước 3: Phát hiện câu
Các sentDetect() phương pháp của SentenceDetectorMElớp được sử dụng để phát hiện các câu trong văn bản thô được chuyển cho nó. Phương thức này chấp nhận một biến Chuỗi làm tham số.
Gọi phương thức này bằng cách chuyển định dạng Chuỗi của câu cho phương thức này.
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);Example
Sau đây là chương trình phát hiện các câu trong một văn bản thô nhất định. Lưu chương trình này trong một tệp có tênSentenceDetectionME.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionME {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac SentenceDetectorME.java
java SentenceDetectorMEKhi thực thi, chương trình trên đọc Chuỗi đã cho và phát hiện các câu trong đó và hiển thị kết quả sau.
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologiesPhát hiện vị trí của câu
Chúng tôi cũng có thể phát hiện vị trí của các câu bằng cách sử dụng phương thức sentPosDetect () của SentenceDetectorME class.
Sau đây là các bước cần làm để viết một chương trình phát hiện vị trí của các câu từ văn bản thô đã cho.
Bước 1: Tải mô hình
Mô hình phát hiện câu được đại diện bởi lớp có tên SentenceModel, thuộc về gói opennlp.tools.sentdetect.
Để tải một mô hình phát hiện câu -
Tạo ra một InputStream đối tượng của mô hình (Khởi tạo FileInputStream và chuyển đường dẫn của mô hình ở định dạng Chuỗi đến phương thức khởi tạo của nó).
Khởi tạo SentenceModel lớp và vượt qua InputStream (đối tượng) của mô hình như một tham số cho phương thức khởi tạo của nó, như được hiển thị trong khối mã sau.
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);Bước 2: Khởi tạo lớp QuestionDetectorME
Các SentenceDetectorME lớp của gói opennlp.tools.sentdetectchứa các phương thức để tách văn bản thô thành các câu. Lớp này sử dụng mô hình Maximum Entropy để đánh giá các ký tự cuối câu trong một chuỗi để xác định xem chúng có biểu thị sự kết thúc của một câu hay không.
Khởi tạo lớp này và chuyển đối tượng mô hình đã tạo ở bước trước.
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);Bước 3: Phát hiện vị trí của câu
Các sentPosDetect() phương pháp của SentenceDetectorMElớp được sử dụng để phát hiện vị trí của các câu trong văn bản thô được chuyển cho nó. Phương thức này chấp nhận một biến Chuỗi làm tham số.
Gọi phương thức này bằng cách chuyển định dạng Chuỗi của câu làm tham số cho phương thức này.
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sentence);Bước 4: In các nhịp của câu
Các sentPosDetect() phương pháp của SentenceDetectorME lớp trả về một mảng các đối tượng kiểu Span. Lớp có tên Span of theopennlp.tools.util gói được sử dụng để lưu trữ số nguyên bắt đầu và kết thúc của bộ.
Bạn có thể lưu trữ các nhịp được trả về bởi sentPosDetect() trong mảng Span và in chúng, như được hiển thị trong khối mã sau.
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);Example
Sau đây là chương trình phát hiện các câu trong văn bản thô nhất định. Lưu chương trình này trong một tệp có tênSentenceDetectionME.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencePosDetection {
public static void main(String args[]) throws Exception {
String paragraph = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the raw text
Span spans[] = detector.sentPosDetect(paragraph);
//Printing the spans of the sentences in the paragraph
for (Span span : spans)
System.out.println(span);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac SentencePosDetection.java
java SentencePosDetectionKhi thực thi, chương trình trên đọc Chuỗi đã cho và phát hiện các câu trong đó và hiển thị kết quả sau.
[0..16)
[17..43)
[44..93)Câu cùng với vị trí của họ
Các substring() phương thức của lớp String chấp nhận begin và end offsetsvà trả về chuỗi tương ứng. Chúng ta có thể sử dụng phương pháp này để in các câu và khoảng cách (vị trí) của chúng với nhau, như được hiển thị trong khối mã sau.
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);Sau đây là chương trình để phát hiện các câu từ văn bản thô đã cho và hiển thị chúng cùng với vị trí của chúng. Lưu chương trình này trong một tệp có tênSentencesAndPosDetection.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencesAndPosDetection {
public static void main(String args[]) throws Exception {
String sen = "Hi. How are you? Welcome to Tutorialspoint."
+ " We provide free tutorials on various technologies";
//Loading a sentence model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sen);
//Printing the sentences and their spans of a paragraph
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac SentencesAndPosDetection.java
java SentencesAndPosDetectionKhi thực thi, chương trình trên đọc Chuỗi đã cho và phát hiện các câu cùng với vị trí của chúng và hiển thị kết quả sau.
Hi. How are you? [0..16)
Welcome to Tutorialspoint. [17..43)
We provide free tutorials on various technologies [44..93)Phát hiện xác suất câu
Các getSentenceProbabilities() phương pháp của SentenceDetectorME lớp trả về các xác suất được liên kết với các cuộc gọi gần đây nhất đến phương thức sentDetect ().
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();Sau đây là chương trình để in các xác suất được liên kết với các cuộc gọi đến phương thức sentDetect (). Lưu chương trình này trong một tệp có tênSentenceDetectionMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionMEProbs {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac SentenceDetectionMEProbs.java
java SentenceDetectionMEProbsKhi thực thi, chương trình trên đọc Chuỗi đã cho và phát hiện các câu và in ra. Ngoài ra, nó cũng trả về các xác suất được liên kết với các cuộc gọi gần đây nhất đến phương thức sentDetect (), như được hiển thị bên dưới.
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologies
0.9240246995179983
0.9957680129995953
1.0Quá trình cắt câu đã cho thành các phần nhỏ hơn (mã thông báo) được gọi là tokenization. Nói chung, văn bản thô nhất định được mã hóa dựa trên một tập hợp các dấu phân cách (chủ yếu là khoảng trắng).
Tokenization được sử dụng trong các tác vụ như kiểm tra chính tả, xử lý tìm kiếm, xác định các phần của giọng nói, phát hiện câu, phân loại tài liệu của tài liệu, v.v.
Mã hóa bằng OpenNLP
Các opennlp.tools.tokenize gói chứa các lớp và giao diện được sử dụng để thực hiện mã hóa.
Để mã hóa các câu đã cho thành các đoạn đơn giản hơn, thư viện OpenNLP cung cấp ba lớp khác nhau:
SimpleTokenizer - Lớp này mã hóa văn bản thô đã cho bằng cách sử dụng các lớp ký tự.
WhitespaceTokenizer - Lớp này sử dụng khoảng trắng để mã hóa văn bản đã cho.
TokenizerME- Lớp này chuyển đổi văn bản thô thành các mã thông báo riêng biệt. Nó sử dụng Maximum Entropy để đưa ra quyết định của mình.
SimpleTokenizer
Để mã hóa một câu bằng cách sử dụng SimpleTokenizer lớp học, bạn cần phải -
Tạo một đối tượng của lớp tương ứng.
Mã hóa câu bằng cách sử dụng tokenize() phương pháp.
In mã thông báo.
Sau đây là các bước cần thực hiện để viết một chương trình mã hóa văn bản thô đã cho.
Step 1 - Khởi tạo lớp tương ứng
Trong cả hai lớp, không có hàm tạo nào có sẵn để khởi tạo chúng. Do đó, chúng ta cần tạo các đối tượng của các lớp này bằng cách sử dụng biến tĩnhINSTANCE.
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;Step 2 - Mã hóa các câu
Cả hai lớp này đều chứa một phương thức được gọi là tokenize(). Phương thức này chấp nhận một văn bản thô ở định dạng Chuỗi. Khi gọi, nó mã hóa Chuỗi đã cho và trả về một mảng Chuỗi (mã thông báo).
Mã hóa câu bằng cách sử dụng tokenizer() như hình dưới đây.
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 - In mã thông báo
Sau khi mã hóa câu, bạn có thể in mã thông báo bằng cách sử dụng for loop, như hình dưới đây.
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
Sau đây là chương trình mã hóa câu đã cho bằng cách sử dụng lớp SimpleTokenizer. Lưu chương trình này trong một tệp có tênSimpleTokenizerExample.java.
import opennlp.tools.tokenize.SimpleTokenizer;
public class SimpleTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Tokenizing the given sentence
String tokens[] = simpleTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens) {
System.out.println(token);
}
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac SimpleTokenizerExample.java
java SimpleTokenizerExampleKhi thực thi, chương trình trên đọc Chuỗi đã cho (văn bản thô), mã hóa nó và hiển thị đầu ra sau:
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologiesWhitespaceTokenizer
Để mã hóa một câu bằng cách sử dụng WhitespaceTokenizer lớp học, bạn cần phải -
Tạo một đối tượng của lớp tương ứng.
Mã hóa câu bằng cách sử dụng tokenize() phương pháp.
In mã thông báo.
Sau đây là các bước cần thực hiện để viết một chương trình mã hóa văn bản thô đã cho.
Step 1 - Khởi tạo lớp tương ứng
Trong cả hai lớp, không có hàm tạo nào có sẵn để khởi tạo chúng. Do đó, chúng ta cần tạo các đối tượng của các lớp này bằng cách sử dụng biến tĩnhINSTANCE.
WhitespaceTokenizer tokenizer = WhitespaceTokenizer.INSTANCE;Step 2 - Mã hóa các câu
Cả hai lớp này đều chứa một phương thức được gọi là tokenize(). Phương thức này chấp nhận một văn bản thô ở định dạng Chuỗi. Khi gọi, nó mã hóa Chuỗi đã cho và trả về một mảng Chuỗi (mã thông báo).
Mã hóa câu bằng cách sử dụng tokenizer() như hình dưới đây.
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 - In mã thông báo
Sau khi mã hóa câu, bạn có thể in mã thông báo bằng cách sử dụng for loop, như hình dưới đây.
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
Sau đây là chương trình mã hóa câu đã cho bằng cách sử dụng WhitespaceTokenizerlớp học. Lưu chương trình này trong một tệp có tênWhitespaceTokenizerExample.java.
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class WhitespaceTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating whitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Tokenizing the given paragraph
String tokens[] = whitespaceTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens)
System.out.println(token);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac WhitespaceTokenizerExample.java
java WhitespaceTokenizerExampleKhi thực thi, chương trình trên đọc Chuỗi đã cho (văn bản thô), mã hóa nó và hiển thị kết quả sau.
Hi.
How
are
you?
Welcome
to
Tutorialspoint.
We
provide
free
tutorials
on
various
technologiesLớp TokenizerME
OpenNLP cũng sử dụng một mô hình được xác định trước, một tệp có tên de-token.bin, để mã hóa các câu. Nó được đào tạo để mã hóa các câu trong một văn bản thô nhất định.
Các TokenizerME lớp của opennlp.tools.tokenizergói được sử dụng để tải mô hình này và mã hóa văn bản thô đã cho bằng thư viện OpenNLP. Để làm như vậy, bạn cần phải -
Tải en-token.bin mô hình sử dụng TokenizerModel lớp học.
Khởi tạo TokenizerME lớp học.
Mã hóa các câu bằng cách sử dụng tokenize() phương thức của lớp này.
Sau đây là các bước cần thực hiện để viết một chương trình mã hóa các câu từ văn bản thô đã cho bằng cách sử dụng TokenizerME lớp học.
Step 1 - Đang tải mô hình
Mô hình mã hóa được đại diện bởi lớp có tên TokenizerModel, thuộc về gói opennlp.tools.tokenize.
Để tải một mô hình tokenizer -
Tạo ra một InputStream đối tượng của mô hình (Khởi tạo FileInputStream và chuyển đường dẫn của mô hình ở định dạng Chuỗi đến phương thức khởi tạo của nó).
Khởi tạo TokenizerModel lớp và vượt qua InputStream (đối tượng) của mô hình như một tham số cho phương thức khởi tạo của nó, như được hiển thị trong khối mã sau.
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);Step 2 - Khởi tạo lớp TokenizerME
Các TokenizerME lớp của gói opennlp.tools.tokenizechứa các phương thức để cắt văn bản thô thành các phần nhỏ hơn (mã thông báo). Nó sử dụng Maximum Entropy để đưa ra quyết định của mình.
Khởi tạo lớp này và chuyển đối tượng mô hình đã tạo ở bước trước như hình dưới đây.
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);Step 3 - Mã hóa câu
Các tokenize() phương pháp của TokenizerMElớp được sử dụng để mã hóa văn bản thô được chuyển cho nó. Phương thức này chấp nhận một biến Chuỗi làm tham số và trả về một mảng Chuỗi (mã thông báo).
Gọi phương thức này bằng cách chuyển định dạng Chuỗi của câu cho phương thức này, như sau.
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(paragraph);Example
Sau đây là chương trình mã hóa văn bản thô đã cho. Lưu chương trình này trong một tệp có tênTokenizerMEExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
public class TokenizerMEExample {
public static void main(String args[]) throws Exception{
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(sentence);
//Printing the tokens
for (String a : tokens)
System.out.println(a);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac TokenizerMEExample.java
java TokenizerMEExampleKhi thực thi, chương trình trên đọc Chuỗi đã cho và phát hiện các câu trong đó và hiển thị kết quả sau:
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologieLấy vị trí của các mã thông báo
Chúng tôi cũng có thể nhận được các vị trí hoặc spans của các mã thông báo bằng cách sử dụng tokenizePos()phương pháp. Đây là phương thức của giao diện Tokenizer của góiopennlp.tools.tokenize. Vì tất cả (ba) lớp Tokenizer đều triển khai giao diện này, bạn có thể tìm thấy phương thức này trong tất cả chúng.
Phương thức này chấp nhận câu hoặc văn bản thô ở dạng một chuỗi và trả về một mảng đối tượng kiểu Span.
Bạn có thể nhận vị trí của các mã thông báo bằng cách sử dụng tokenizePos() phương pháp, như sau:
//Retrieving the tokens
tokenizer.tokenizePos(sentence);In các vị trí (nhịp)
Lớp có tên Span sau đó opennlp.tools.util gói được sử dụng để lưu trữ số nguyên bắt đầu và kết thúc của bộ.
Bạn có thể lưu trữ các nhịp được trả về bởi tokenizePos() trong mảng Span và in chúng, như được hiển thị trong khối mã sau.
//Retrieving the tokens
Span[] tokens = tokenizer.tokenizePos(sentence);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token);In mã thông báo và vị trí của chúng cùng nhau
Các substring() phương thức của lớp String chấp nhận begin và endbù trừ và trả về chuỗi tương ứng. Chúng ta có thể sử dụng phương pháp này để in các mã thông báo và khoảng cách (vị trí) của chúng với nhau, như được hiển thị trong khối mã sau.
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));Example(SimpleTokenizer)
Sau đây là chương trình lấy các khoảng mã thông báo của văn bản thô bằng cách sử dụng SimpleTokenizerlớp học. Nó cũng in các mã thông báo cùng với vị trí của chúng. Lưu chương trình này trong một tệp có tênSimpleTokenizerSpans.java.
import opennlp.tools.tokenize.SimpleTokenizer;
import opennlp.tools.util.Span;
public class SimpleTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Retrieving the boundaries of the tokens
Span[] tokens = simpleTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac SimpleTokenizerSpans.java
java SimpleTokenizerSpansKhi thực thi, chương trình trên đọc Chuỗi đã cho (văn bản thô), mã hóa nó và hiển thị đầu ra sau:
[0..2) Hi
[2..3) .
[4..7) How
[8..11) are
[12..15) you
[15..16) ?
[17..24) Welcome
[25..27) to
[28..42) Tutorialspoint
[42..43) .
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (WhitespaceTokenizer)
Sau đây là chương trình lấy các khoảng mã thông báo của văn bản thô bằng cách sử dụng WhitespaceTokenizerlớp học. Nó cũng in các mã thông báo cùng với vị trí của chúng. Lưu chương trình này trong một tệp có tênWhitespaceTokenizerSpans.java.
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class WhitespaceTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Retrieving the tokens
Span[] tokens = whitespaceTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
}
}Biên dịch và thực thi tệp java đã lưu từ dấu nhắc lệnh bằng các lệnh sau
javac WhitespaceTokenizerSpans.java
java WhitespaceTokenizerSpansKhi thực thi, chương trình trên đọc Chuỗi đã cho (văn bản thô), mã hóa nó và hiển thị kết quả sau.
[0..3) Hi.
[4..7) How
[8..11) are
[12..16) you?
[17..24) Welcome
[25..27) to
[28..43) Tutorialspoint.
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (TokenizerME)
Sau đây là chương trình lấy các khoảng mã thông báo của văn bản thô bằng cách sử dụng TokenizerMElớp học. Nó cũng in các mã thông báo cùng với vị trí của chúng. Lưu chương trình này trong một tệp có tênTokenizerMESpans.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMESpans {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac TokenizerMESpans.java
java TokenizerMESpansKhi thực thi, chương trình trên đọc Chuỗi đã cho (văn bản thô), mã hóa nó và hiển thị đầu ra sau:
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) TutorialspointXác suất Tokenizer
Phương thức getTokenProbabilities () của lớp TokenizerME được sử dụng để lấy các xác suất liên quan đến các cuộc gọi gần đây nhất đến phương thức tokenizePos ().
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();Sau đây là chương trình để in các xác suất liên quan đến các lệnh gọi đến phương thức tokenizePos (). Lưu chương trình này trong một tệp có tênTokenizerMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac TokenizerMEProbs.java
java TokenizerMEProbsKhi thực thi, chương trình trên đọc Chuỗi đã cho và mã hóa các câu và in ra. Ngoài ra, nó cũng trả về các xác suất được liên kết với các cuộc gọi gần đây nhất đến phương thức tokenizerPos ().
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0Quá trình tìm kiếm tên, người, địa điểm và các thực thể khác từ một văn bản nhất định được gọi là Named Entity Rđánh giá sinh thái (NER). Trong chương này, chúng ta sẽ thảo luận về cách thực hiện NER thông qua chương trình Java sử dụng thư viện OpenNLP.
Nhận dạng đối tượng được đặt tên bằng NLP mở
Để thực hiện các tác vụ NER khác nhau, OpenNLP sử dụng các mô hình được xác định trước khác nhau như en-nerdate.bn, en-ner-location.bin, en-ner-Organization.bin, en-ner-person.bin và en-ner-time. thùng rác. Tất cả các tệp này là các mô hình được xác định trước được đào tạo để phát hiện các thực thể tương ứng trong một văn bản thô nhất định.
Các opennlp.tools.namefindgói chứa các lớp và giao diện được sử dụng để thực hiện tác vụ NER. Để thực hiện tác vụ NER bằng thư viện OpenNLP, bạn cần -
Tải mô hình tương ứng bằng cách sử dụng TokenNameFinderModel lớp học.
Khởi tạo NameFinder lớp học.
Tìm tên và in chúng.
Sau đây là các bước cần làm để viết một chương trình phát hiện các thực thể tên từ một văn bản thô nhất định.
Bước 1: Tải mô hình
Mô hình phát hiện câu được đại diện bởi lớp có tên TokenNameFinderModel, thuộc về gói opennlp.tools.namefind.
Để tải một mô hình NER -
Tạo ra một InputStream đối tượng của mô hình (Khởi tạo FileInputStream và chuyển đường dẫn của mô hình NER thích hợp ở định dạng Chuỗi tới phương thức khởi tạo của nó).
Khởi tạo TokenNameFinderModel lớp và vượt qua InputStream (đối tượng) của mô hình như một tham số cho phương thức khởi tạo của nó, như được hiển thị trong khối mã sau.
//Loading the NER-person model
InputStream inputStreamNameFinder = new FileInputStream(".../en-nerperson.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);Bước 2: Khởi tạo lớp NameFinderME
Các NameFinderME lớp của gói opennlp.tools.namefindchứa các phương thức để thực hiện các tác vụ NER. Lớp này sử dụng mô hình Maximum Entropy để tìm các thực thể được đặt tên trong văn bản thô đã cho.
Khởi tạo lớp này và chuyển đối tượng mô hình được tạo ở bước trước như hình dưới đây:
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);Bước 3: Tìm tên trong câu
Các find() phương pháp của NameFinderMElớp được sử dụng để phát hiện tên trong văn bản thô được chuyển cho nó. Phương thức này chấp nhận một biến Chuỗi làm tham số.
Gọi phương thức này bằng cách chuyển định dạng Chuỗi của câu cho phương thức này.
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);Bước 4: In các nhịp của tên trong câu
Các find() phương pháp của NameFinderMElớp trả về một mảng các đối tượng kiểu Span. Lớp có tên Span of theopennlp.tools.util gói được sử dụng để lưu trữ start và end số nguyên của các bộ.
Bạn có thể lưu trữ các nhịp được trả về bởi find() trong mảng Span và in chúng, như được hiển thị trong khối mã sau.
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);NER Example
Sau đây là chương trình đọc câu đã cho và nhận ra các khoảng tên của những người trong đó. Lưu chương trình này trong một tệp có tênNameFinderME_Example.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.util.Span;
public class NameFinderME_Example {
public static void main(String args[]) throws Exception{
/Loading the NER - Person model InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStream);
//Instantiating the NameFinder class
NameFinderME nameFinder = new NameFinderME(model);
//Getting the sentence in the form of String array
String [] sentence = new String[]{
"Mike",
"and",
"Smith",
"are",
"good",
"friends"
};
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);
//Printing the spans of the names in the sentence
for(Span s: nameSpans)
System.out.println(s.toString());
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac NameFinderME_Example.java
java NameFinderME_ExampleKhi thực thi, chương trình trên đọc Chuỗi đã cho (văn bản thô), phát hiện tên của những người trong đó và hiển thị vị trí của họ (các khoảng), như được hiển thị bên dưới.
[0..1) person
[2..3) personTên cùng với vị trí của họ
Các substring() phương thức của lớp String chấp nhận begin và end offsetsvà trả về chuỗi tương ứng. Chúng ta có thể sử dụng phương pháp này để in tên và khoảng cách (vị trí) của chúng với nhau, như được hiển thị trong khối mã sau.
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);Sau đây là chương trình để phát hiện các tên từ văn bản thô đã cho và hiển thị chúng cùng với vị trí của chúng. Lưu chương trình này trong một tệp có tênNameFinderSentences.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class NameFinderSentences {
public static void main(String args[]) throws Exception{
//Loading the tokenizer model
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the sentence in to a string array
String sentence = "Mike is senior programming
manager and Rama is a clerk both are working at
Tutorialspoint";
String tokens[] = tokenizer.tokenize(sentence);
//Loading the NER-person model
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/enner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(tokens);
//Printing the names and their spans in a sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac NameFinderSentences.java
java NameFinderSentencesKhi thực thi, chương trình trên đọc Chuỗi đã cho (văn bản thô), phát hiện tên của những người trong đó và hiển thị vị trí của họ (các nhịp) như hình dưới đây.
[0..1) person MikeTìm tên của vị trí
Bằng cách tải các mô hình khác nhau, bạn có thể phát hiện các thực thể được đặt tên khác nhau. Sau đây là một chương trình Java tảien-ner-location.binmô hình và phát hiện tên vị trí trong câu đã cho. Lưu chương trình này trong một tệp có tênLocationFinder.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class LocationFinder {
public static void main(String args[]) throws Exception{
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//String paragraph = "Mike and Smith are classmates";
String paragraph = "Tutorialspoint is located in Hyderabad";
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
String tokens[] = tokenizer.tokenize(paragraph);
//Loading the NER-location moodel
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/en- ner-location.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names of a location
Span nameSpans[] = nameFinder.find(tokens);
//Printing the spans of the locations in the sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac LocationFinder.java
java LocationFinderKhi thực thi, chương trình trên đọc Chuỗi đã cho (văn bản thô), phát hiện tên của những người trong đó và hiển thị vị trí của họ (các khoảng), như được hiển thị bên dưới.
[4..5) location HyderabadXác suất công cụ tìm tên
Các probs()phương pháp của NameFinderME lớp được sử dụng để lấy xác suất của chuỗi được giải mã cuối cùng.
double[] probs = nameFinder.probs();Sau đây là chương trình để in các xác suất. Lưu chương trình này trong một tệp có tênTokenizerMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac TokenizerMEProbs.java
java TokenizerMEProbsKhi thực thi, chương trình trên đọc Chuỗi đã cho, mã hóa các câu và in ra. Ngoài ra, nó cũng trả về xác suất của chuỗi được giải mã cuối cùng, như được hiển thị bên dưới.
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0Sử dụng OpenNLP, bạn cũng có thể phát hiện các Phần của Bài phát biểu của một câu nhất định và in chúng. Thay vì tên đầy đủ của các phần của bài phát biểu, OpenNLP sử dụng các dạng ngắn của từng phần của bài phát biểu. Bảng sau đây chỉ ra các phần khác nhau của bài phát biểu được OpenNLP phát hiện và ý nghĩa của chúng.
| Các phần của bài phát biểu | Ý nghĩa của các phần của bài phát biểu |
|---|---|
| NN | Danh từ, số ít hoặc số lượng |
| DT | Người xác định |
| VB | Động từ, dạng cơ sở |
| VBD | Động từ, thì quá khứ |
| VBZ | Động từ, ngôi thứ ba thì hiện tại số ít |
| TRONG | Chuẩn bị hoặc kết hợp phụ |
| NNP | Danh từ riêng, số ít |
| ĐẾN | đến |
| JJ | Tính từ |
Gắn thẻ các phần của bài phát biểu
Để gắn thẻ các phần lời nói của một câu, OpenNLP sử dụng một mô hình, một tệp có tên en-posmaxent.bin. Đây là một mô hình được xác định trước được đào tạo để gắn thẻ các phần lời nói của văn bản thô nhất định.
Các POSTaggerME lớp của opennlp.tools.postaggói được sử dụng để tải mô hình này và gắn thẻ các phần lời nói của văn bản thô đã cho bằng thư viện OpenNLP. Để làm như vậy, bạn cần phải -
Tải en-pos-maxent.bin mô hình sử dụng POSModel lớp học.
Khởi tạo POSTaggerME lớp học.
Mã hóa câu.
Tạo các thẻ bằng cách sử dụng tag() phương pháp.
In mã thông báo và thẻ bằng cách sử dụng POSSample lớp học.
Sau đây là các bước cần thực hiện để viết một chương trình gắn thẻ các phần của bài phát biểu trong văn bản thô đã cho bằng cách sử dụng POSTaggerME lớp học.
Bước 1: Tải mô hình
Mô hình gắn thẻ POS được đại diện bởi lớp có tên POSModel, thuộc về gói opennlp.tools.postag.
Để tải một mô hình tokenizer -
Tạo ra một InputStream đối tượng của mô hình (Khởi tạo FileInputStream và chuyển đường dẫn của mô hình ở định dạng Chuỗi đến phương thức khởi tạo của nó).
Khởi tạo POSModel lớp và vượt qua InputStream (đối tượng) của mô hình như một tham số cho phương thức khởi tạo của nó, như được hiển thị trong khối mã sau:
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);Bước 2: Khởi tạo lớp POSTaggerME
Các POSTaggerME lớp của gói opennlp.tools.postagđược sử dụng để dự đoán các phần của bài phát biểu của văn bản thô đã cho. Nó sử dụng Maximum Entropy để đưa ra quyết định của mình.
Khởi tạo lớp này và chuyển đối tượng mô hình đã tạo ở bước trước, như được hiển thị bên dưới:
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);Bước 3: Mã hóa câu
Các tokenize() phương pháp của whitespaceTokenizerlớp được sử dụng để mã hóa văn bản thô được chuyển cho nó. Phương thức này chấp nhận một biến Chuỗi làm tham số và trả về một mảng Chuỗi (mã thông báo).
Khởi tạo whitespaceTokenizer lớp và gọi phương thức này bằng cách chuyển định dạng Chuỗi của câu cho phương thức này.
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);Bước 4: Tạo thẻ
Các tag() phương pháp của whitespaceTokenizerlớp gán thẻ POS cho câu mã thông báo. Phương thức này nhận một mảng mã thông báo (Chuỗi) làm tham số và trả về thẻ (mảng).
Gọi tag() bằng cách chuyển các mã thông báo được tạo ở bước trước cho nó.
//Generating tags
String[] tags = tagger.tag(tokens);Bước 5: In mã thông báo và thẻ
Các POSSamplelớp đại diện cho câu được gắn thẻ POS. Để khởi tạo lớp này, chúng tôi sẽ yêu cầu một mảng mã thông báo (của văn bản) và một mảng thẻ.
Các toString()phương thức của lớp này trả về câu được gắn thẻ. Khởi tạo lớp này bằng cách chuyển mã thông báo và các mảng thẻ được tạo ở các bước trước đó và gọitoString() , như được hiển thị trong khối mã sau đây.
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());Example
Sau đây là chương trình gắn thẻ các phần của bài phát biểu trong một văn bản thô nhất định. Lưu chương trình này trong một tệp có tênPosTaggerExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerExample {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
String sentence = "Hi welcome to Tutorialspoint";
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac PosTaggerExample.java
java PosTaggerExampleKhi thực thi, chương trình trên đọc văn bản đã cho và phát hiện các phần lời nói của những câu này và hiển thị chúng, như được hiển thị bên dưới.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VBHiệu suất trình gắn thẻ POS
Sau đây là chương trình gắn thẻ các phần của bài phát biểu của một văn bản thô nhất định. Nó cũng theo dõi hiệu suất và hiển thị hiệu suất của trình gắn thẻ. Lưu chương trình này trong một tệp có tênPosTagger_Performance.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTagger_Performance {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Monitoring the performance of POS tagger
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
perfMon.start();
perfMon.incrementCounter();
perfMon.stopAndPrintFinalResult();
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac PosTaggerExample.java
java PosTaggerExampleKhi thực thi, chương trình trên đọc văn bản đã cho và gắn thẻ các phần lời nói của những câu này và hiển thị chúng. Ngoài ra, nó cũng theo dõi hiệu suất của máy gắn thẻ POS và hiển thị nó.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
Average: 0.0 sent/s
Total: 1 sent
Runtime: 0.0sXác suất người gắn thẻ POS
Các probs() phương pháp của POSTaggerME lớp được sử dụng để tìm xác suất cho mỗi thẻ của câu được gắn thẻ gần đây.
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();Sau đây là chương trình hiển thị xác suất cho mỗi thẻ của câu được gắn thẻ cuối cùng. Lưu chương trình này trong một tệp có tênPosTaggerProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerProbs {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_mdl/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Probabilities for each tag of the last tagged sentence.
double [] probs = tagger.probs();
System.out.println(" ");
//Printing the probabilities
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac TokenizerMEProbs.java
java TokenizerMEProbsKhi thực thi, chương trình trên đọc văn bản thô đã cho, gắn thẻ các phần của bài phát biểu của mỗi mã thông báo trong đó và hiển thị chúng. Ngoài ra, nó cũng hiển thị xác suất cho từng phần của bài phát biểu trong câu đã cho, như hình dưới đây.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
0.6416834779738033
0.42983612874819177
0.8584513635863117
0.4394784478206072Sử dụng API OpenNLP, bạn có thể phân tích cú pháp các câu đã cho. Trong chương này, chúng ta sẽ thảo luận về cách phân tích cú pháp văn bản thô bằng API OpenNLP.
Phân tích cú pháp Văn bản thô bằng Thư viện OpenNLP
Để phát hiện các câu, OpenNLP sử dụng một mô hình được xác định trước, một tệp có tên en-parserchunking.bin. Đây là một mô hình được xác định trước được đào tạo để phân tích cú pháp văn bản thô đã cho.
Các Parser lớp của opennlp.tools.Parser gói được sử dụng để chứa các thành phần phân tích cú pháp và ParserTool lớp của opennlp.tools.cmdline.parser gói được sử dụng để phân tích nội dung.
Sau đây là các bước cần làm để viết một chương trình phân tích cú pháp văn bản thô đã cho bằng cách sử dụng ParserTool lớp học.
Bước 1: Tải mô hình
Mô hình phân tích cú pháp văn bản được đại diện bởi lớp có tên ParserModel, thuộc về gói opennlp.tools.parser.
Để tải một mô hình tokenizer -
Tạo ra một InputStream đối tượng của mô hình (Khởi tạo FileInputStream và chuyển đường dẫn của mô hình ở định dạng Chuỗi đến phương thức khởi tạo của nó).
Khởi tạo ParserModel lớp và vượt qua InputStream (đối tượng) của mô hình như một tham số cho phương thức khởi tạo của nó, như được hiển thị trong khối mã sau.
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);Bước 2: Tạo một đối tượng của lớp Parser
Các Parser lớp của gói opennlp.tools.parserđại diện cho một cấu trúc dữ liệu để chứa các thành phần phân tích cú pháp. Bạn có thể tạo một đối tượng của lớp này bằng cách sử dụng tĩnhcreate() phương pháp của ParserFactory lớp học.
Gọi create() phương pháp của ParserFactory bằng cách chuyển đối tượng mô hình được tạo ở bước trước, như hình dưới đây -
//Creating a parser Parser parser = ParserFactory.create(model);Bước 3: Phân tích cú pháp câu
Các parseLine() phương pháp của ParserToollớp được sử dụng để phân tích cú pháp văn bản thô trong OpenNLP. Phương thức này chấp nhận -
một biến chuỗi đại diện cho văn bản được phân tích cú pháp.
một đối tượng phân tích cú pháp.
một số nguyên đại diện cho số lượng phân tích cú pháp được thực hiện.
Gọi phương thức này bằng cách chuyển cho câu các tham số sau: đối tượng phân tích cú pháp được tạo ở các bước trước đó và một số nguyên đại diện cho số lượng phân tích cú pháp cần thiết được thực hiện.
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);Example
Sau đây là chương trình phân tích văn bản thô đã cho. Lưu chương trình này trong một tệp có tênParserExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.parser.ParserTool;
import opennlp.tools.parser.Parse;
import opennlp.tools.parser.Parser;
import opennlp.tools.parser.ParserFactory;
import opennlp.tools.parser.ParserModel;
public class ParserExample {
public static void main(String args[]) throws Exception{
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
//Creating a parser
Parser parser = ParserFactory.create(model);
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
for (Parse p : topParses)
p.show();
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac ParserExample.java
java ParserExampleKhi thực thi, chương trình trên đọc văn bản thô đã cho, phân tích cú pháp nó và hiển thị đầu ra sau:
(TOP (S (NP (NN Tutorialspoint)) (VP (VBZ is) (NP (DT the) (JJS largest) (NN
tutorial) (NN library.)))))Chunking một câu đề cập đến việc phá vỡ / chia một câu thành các phần của từ như nhóm từ và nhóm động từ.
Chunking một câu bằng OpenNLP
Để phát hiện các câu, OpenNLP sử dụng một mô hình, một tệp có tên en-chunker.bin. Đây là một mô hình được xác định trước, được đào tạo để chia nhỏ các câu trong văn bản thô nhất định.
Các opennlp.tools.chunker gói chứa các lớp và giao diện được sử dụng để tìm chú thích cú pháp không đệ quy, chẳng hạn như các khối cụm danh từ.
Bạn có thể phân đoạn một câu bằng phương pháp chunk() sau đó ChunkerMElớp học. Phương pháp này chấp nhận mã thông báo của một câu và thẻ POS làm tham số. Do đó, trước khi bắt đầu quá trình phân khúc, trước hết bạn cần Tokenize câu đó và tạo các thẻ POS các phần của nó.
Để phân đoạn một câu bằng thư viện OpenNLP, bạn cần phải -
Mã hóa câu.
Tạo thẻ POS cho nó.
Tải en-chunker.bin mô hình sử dụng ChunkerModel lớp học
Khởi tạo ChunkerME lớp học.
Chunk các câu bằng cách sử dụng chunk() phương thức của lớp này.
Sau đây là các bước cần làm để viết một chương trình phân đoạn các câu từ văn bản thô đã cho.
Bước 1: Mã hóa câu
Mã hóa các câu bằng cách sử dụng tokenize() phương pháp của whitespaceTokenizer lớp, như được hiển thị trong khối mã sau đây.
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);Bước 2: Tạo thẻ POS
Tạo các thẻ POS của câu bằng cách sử dụng tag() phương pháp của POSTaggerME lớp, như được hiển thị trong khối mã sau đây.
//Generating the POS tags
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);Bước 3: Tải mô hình
Mô hình phân đoạn một câu được đại diện bởi lớp có tên ChunkerModel, thuộc về gói opennlp.tools.chunker.
Để tải một mô hình phát hiện câu -
Tạo ra một InputStream đối tượng của mô hình (Khởi tạo FileInputStream và chuyển đường dẫn của mô hình ở định dạng Chuỗi đến phương thức khởi tạo của nó).
Khởi tạo ChunkerModel lớp và vượt qua InputStream (đối tượng) của mô hình như một tham số cho phương thức khởi tạo của nó, như được hiển thị trong khối mã sau:
//Loading the chunker model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);Bước 4: Khởi tạo lớp chunkerME
Các chunkerME lớp của gói opennlp.tools.chunkerchứa các phương thức để phân đoạn các câu. Đây là một khối dựa trên entropy cực đại.
Khởi tạo lớp này và chuyển đối tượng mô hình đã tạo ở bước trước.
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);Bước 5: Cắt câu
Các chunk() phương pháp của ChunkerMElớp được sử dụng để phân đoạn các câu trong văn bản thô được chuyển cho nó. Phương thức này chấp nhận hai mảng Chuỗi đại diện cho mã thông báo và thẻ, làm tham số.
Gọi phương thức này bằng cách chuyển mảng mã thông báo và mảng thẻ đã tạo ở các bước trước dưới dạng tham số.
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);Example
Sau đây là chương trình để phân đoạn các câu trong văn bản thô đã cho. Lưu chương trình này trong một tệp có tênChunkerExample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerExample{
public static void main(String args[]) throws IOException {
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating the POS tags
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);
for (String s : result)
System.out.println(s);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng lệnh sau:
javac ChunkerExample.java
java ChunkerExampleKhi thực thi, chương trình trên đọc Chuỗi đã cho và chia nhỏ các câu trong đó, và hiển thị chúng như hình dưới đây.
Loading POS Tagger model ... done (1.040s)
B-NP
I-NP
B-VP
I-VPPhát hiện vị trí của mã thông báo
Chúng tôi cũng có thể phát hiện vị trí hoặc nhịp của các khối bằng cách sử dụng chunkAsSpans() phương pháp của ChunkerMElớp học. Phương thức này trả về một mảng các đối tượng có kiểu Span. Lớp có tên Span of theopennlp.tools.util gói được sử dụng để lưu trữ start và end số nguyên của các bộ.
Bạn có thể lưu trữ các nhịp được trả về bởi chunkAsSpans() trong mảng Span và in chúng, như được hiển thị trong khối mã sau.
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());Example
Sau đây là chương trình phát hiện các câu trong văn bản thô nhất định. Lưu chương trình này trong một tệp có tênChunkerSpansEample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class ChunkerSpansEample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac ChunkerSpansEample.java
java ChunkerSpansEampleKhi thực thi, chương trình trên đọc Chuỗi đã cho và các khoảng của các phần trong đó, và hiển thị kết quả sau:
Loading POS Tagger model ... done (1.059s)
[0..2) NP
[2..4) VPPhát hiện xác suất Chunker
Các probs() phương pháp của ChunkerME lớp trả về xác suất của chuỗi được giải mã cuối cùng.
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();Sau đây là chương trình để in xác suất của chuỗi được giải mã cuối cùng bằng chunker. Lưu chương trình này trong một tệp có tênChunkerProbsExample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerProbsExample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel cModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(cModel);
//Generating the chunk tags
chunkerME.chunk(tokens, tags);
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Biên dịch và thực thi tệp Java đã lưu từ Dấu nhắc lệnh bằng các lệnh sau:
javac ChunkerProbsExample.java
java ChunkerProbsExampleKhi thực thi, chương trình trên đọc Chuỗi đã cho, phân đoạn nó và in ra xác suất của chuỗi được giải mã cuối cùng.
0.9592746040797778
0.6883933131241501
0.8830563473996004
0.8951150529746051OpenNLP cung cấp Giao diện dòng lệnh (CLI) để thực hiện các hoạt động khác nhau thông qua dòng lệnh. Trong chương này, chúng tôi sẽ lấy một số ví dụ để chỉ ra cách chúng tôi có thể sử dụng Giao diện dòng lệnh OpenNLP.
Mã hóa
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesCú pháp
> opennlp TokenizerME path_for_models../en-token.bin <inputfile..> outputfile..chỉ huy
C:\> opennlp TokenizerME C:\OpenNLP_models/en-token.bin <input.txt >output.txtđầu ra
Loading Tokenizer model ... done (0.207s)
Average: 214.3 sent/s
Total: 3 sent
Runtime: 0.014soutput.txt
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologiesPhát hiện câu
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesCú pháp
> opennlp SentenceDetector path_for_models../en-token.bin <inputfile..> outputfile..chỉ huy
C:\> opennlp SentenceDetector C:\OpenNLP_models/en-sent.bin <input.txt > output_sendet.txtĐầu ra
Loading Sentence Detector model ... done (0.067s)
Average: 750.0 sent/s
Total: 3 sent
Runtime: 0.004sOutput_sendet.txt
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologiesNhận dạng đối tượng được đặt tên
input.txt
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at TutorialspointCú pháp
> opennlp TokenNameFinder path_for_models../en-token.bin <inputfile..Chỉ huy
C:\>opennlp TokenNameFinder C:\OpenNLP_models\en-ner-person.bin <input_namefinder.txtĐầu ra
Loading Token Name Finder model ... done (0.730s)
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at Tutorialspoint
Average: 55.6 sent/s
Total: 1 sent
Runtime: 0.018sCác phần của gắn thẻ bằng giọng nói
Input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesCú pháp
> opennlp POSTagger path_for_models../en-token.bin <inputfile..Chỉ huy
C:\>opennlp POSTagger C:\OpenNLP_models/en-pos-maxent.bin < input.txtĐầu ra
Loading POS Tagger model ... done (1.315s)
Hi._NNP How_WRB are_VBP you?_JJ Welcome_NNP to_TO Tutorialspoint._NNP We_PRP
provide_VBP free_JJ tutorials_NNS on_IN various_JJ technologies_NNS
Average: 66.7 sent/s
Total: 1 sent
Runtime: 0.015s