PyBrain - Các loại tập dữ liệu
Tập dữ liệu là dữ liệu được cung cấp để kiểm tra, xác nhận và đào tạo trên mạng. Loại tập dữ liệu được sử dụng phụ thuộc vào các nhiệm vụ mà chúng ta sẽ thực hiện với học máy. Chúng ta sẽ thảo luận về các loại tập dữ liệu khác nhau trong chương này.
Chúng tôi có thể làm việc với tập dữ liệu bằng cách thêm gói sau:
pybrain.datasetSupervisedDataSet
SupervisedDataSet bao gồm các trường input và target. Đây là dạng đơn giản nhất của tập dữ liệu và chủ yếu được sử dụng cho các nhiệm vụ học tập có giám sát.
Dưới đây là cách bạn có thể sử dụng nó trong mã -
from pybrain.datasets import SupervisedDataSetCác phương pháp có sẵn trên SupervisedDataSet như sau:
addSample (inp, target)
Phương pháp này sẽ thêm một mẫu đầu vào và mục tiêu mới.
splitWithProportion (tỷ lệ = 0,10)
Điều này sẽ chia bộ dữ liệu thành hai phần. Phần đầu tiên sẽ có% của tập dữ liệu được cung cấp làm đầu vào, tức là nếu đầu vào là .10, thì nó là 10% của tập dữ liệu và 90% dữ liệu. Bạn có thể quyết định tỷ lệ theo sự lựa chọn của bạn. Các tập dữ liệu được chia có thể được sử dụng để kiểm tra và đào tạo mạng của bạn.
copy() - Trả về bản sao sâu của tập dữ liệu.
clear() - Xóa tập dữ liệu.
saveToFile (tên tệp, định dạng = Không có, ** kwargs)
Lưu đối tượng vào tệp được cung cấp bởi tên tệp.
Thí dụ
Đây là một ví dụ làm việc bằng cách sử dụng SupervisedDataset -
testnetwork.py
from pybrain.tools.shortcuts import buildNetwork
from pybrain.structure import TanhLayer
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
# Create a network with two inputs, three hidden, and one output
nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer)
# Create a dataset that matches network input and output sizes:
norgate = SupervisedDataSet(2, 1)
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
norgate.addSample((0, 0), (1,))
norgate.addSample((0, 1), (0,))
norgate.addSample((1, 0), (0,))
norgate.addSample((1, 1), (0,))
# Add input and target values to dataset
# Values for NOR truth table
nortrain.addSample((0, 0), (1,))
nortrain.addSample((0, 1), (0,))
nortrain.addSample((1, 0), (0,))
nortrain.addSample((1, 1), (0,))
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, norgate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()
trainer.testOnData(dataset=nortrain, verbose = True)Đầu ra
Kết quả của chương trình trên như sau:
python testnetwork.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218, 0.005227359234093431
, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)Phân loại dữ liệu
Bộ dữ liệu này chủ yếu được sử dụng để giải quyết các vấn đề phân loại. Nó nhận đầu vào, trường mục tiêu và một trường bổ sung được gọi là "lớp", là một bản sao lưu tự động của các mục tiêu đã cho. Ví dụ: đầu ra sẽ là 1 hoặc 0 hoặc đầu ra sẽ được nhóm lại với nhau với các giá trị dựa trên đầu vào đã cho, tức là nó sẽ thuộc một lớp cụ thể.
Đây là cách bạn có thể sử dụng nó trong mã -
from pybrain.datasets import ClassificationDataSet
Syntax
// ClassificationDataSet(inp, target=1, nb_classes=0, class_labels=None)Các phương pháp có sẵn trên ClassDataSet như sau:
addSample(inp, target) - Phương pháp này sẽ thêm một mẫu đầu vào và mục tiêu mới.
splitByClass() - Phương thức này sẽ đưa ra hai tập dữ liệu mới, tập dữ liệu đầu tiên sẽ có lớp được chọn (0..nClasses-1), tập thứ hai sẽ có các mẫu còn lại.
_convertToOneOfMany() - Phương thức này sẽ chuyển đổi các lớp mục tiêu thành biểu diễn 1 trên k, giữ lại các mục tiêu cũ dưới dạng một lớp trường
Đây là một ví dụ hoạt động của ClassificationDataSet.
Thí dụ
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample( training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1] )
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(trainer.testOnClassData(dataset=test_data), test_data['class']))Tập dữ liệu được sử dụng trong ví dụ trên là tập dữ liệu chữ số và các lớp là từ 0-9, do đó có 10 lớp. Đầu vào là 64, mục tiêu là 1 và các lớp, 10.
Mã huấn luyện mạng với tập dữ liệu và xuất biểu đồ cho lỗi huấn luyện và lỗi xác thực. Nó cũng đưa ra lỗi phần trăm trên testdata như sau:
Đầu ra
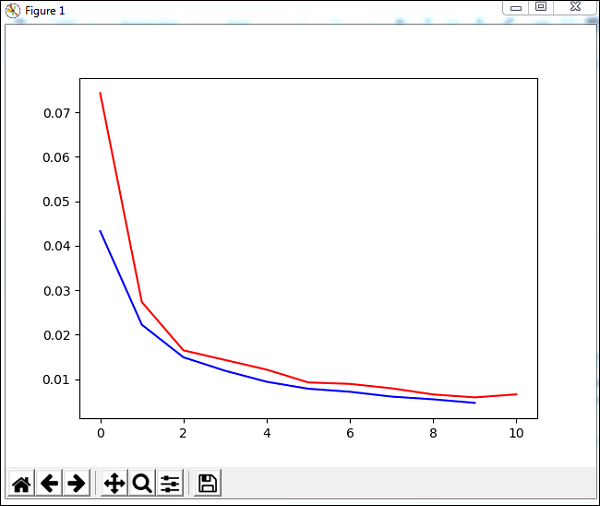
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
Percent Error on testData: 3.34075723830735