PyBrain - Mô-đun học tập củng cố
Học tăng cường (RL) là một phần quan trọng trong Học máy. Học tập củng cố làm cho tác nhân học hành vi của nó dựa trên đầu vào từ môi trường.
Các thành phần tương tác với nhau trong quá trình Gia cố như sau:
- Environment
- Agent
- Task
- Experiment
Bố cục của Học tăng cường được đưa ra dưới đây:
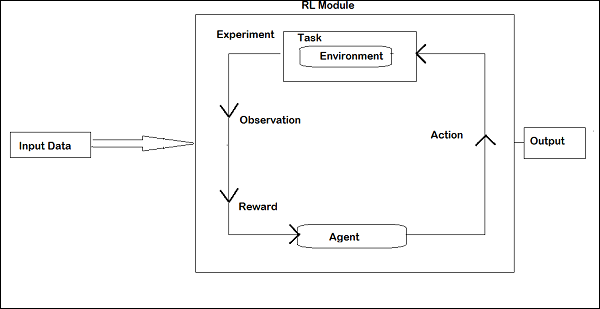
Trong RL, tác nhân nói chuyện với môi trường lặp đi lặp lại. Ở mỗi lần lặp lại, tác nhân nhận được một quan sát có phần thưởng. Sau đó, nó chọn hành động và gửi đến môi trường. Môi trường ở mỗi lần lặp lại chuyển sang trạng thái mới và phần thưởng nhận được mỗi lần sẽ được lưu lại.
Mục tiêu của đại lý RL là thu thập càng nhiều phần thưởng càng tốt. Giữa các lần lặp lại, hiệu suất của tác nhân được so sánh với hiệu suất của tác nhân hoạt động theo cách tốt và sự khác biệt về hiệu suất dẫn đến phần thưởng hoặc thất bại. RL về cơ bản được sử dụng trong các nhiệm vụ giải quyết vấn đề như điều khiển robot, thang máy, viễn thông, trò chơi, v.v.
Hãy cùng chúng tôi xem qua cách làm việc với RL trong Pybrain.
Chúng tôi sẽ làm việc trên mê cung environmentsẽ được biểu diễn bằng cách sử dụng mảng numpy 2 chiều, trong đó 1 là tường và 0 là trường tự do. Nhiệm vụ của người đại diện là di chuyển trên sân tự do và tìm điểm ghi bàn.
Đây là quy trình từng bước làm việc với môi trường mê cung.
Bước 1
Nhập các gói chúng tôi cần với mã bên dưới -
from scipy import *
import sys, time
import matplotlib.pyplot as pylab # for visualization we are using mathplotlib
from pybrain.rl.environments.mazes import Maze, MDPMazeTask
from pybrain.rl.learners.valuebased import ActionValueTable
from pybrain.rl.agents import LearningAgent
from pybrain.rl.learners import Q, QLambda, SARSA #@UnusedImport
from pybrain.rl.explorers import BoltzmannExplorer #@UnusedImport
from pybrain.rl.experiments import Experiment
from pybrain.rl.environments import TaskBước 2
Tạo môi trường mê cung bằng đoạn mã dưới đây -
# create the maze with walls as 1 and 0 is a free field
mazearray = array(
[[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
)
env = Maze(mazearray, (7, 7)) # create the environment, the first parameter is the
maze array and second one is the goal field tupleBước 3
Bước tiếp theo là tạo Đại lý.
Tác nhân đóng một vai trò quan trọng trong RL. Nó sẽ tương tác với môi trường mê cung bằng phương thức getAction () và integrationObservation ().
Tác nhân có một bộ điều khiển (sẽ ánh xạ các trạng thái thành các hành động) và một người học.
Bộ điều khiển trong PyBrain giống như một mô-đun, trong đó đầu vào là các trạng thái và chuyển đổi chúng thành các hành động.
controller = ActionValueTable(81, 4)
controller.initialize(1.)Các ActionValueTablecần 2 đầu vào, tức là số trạng thái và hành động. Môi trường mê cung tiêu chuẩn có 4 hành động: bắc, nam, đông, tây.
Bây giờ chúng ta sẽ tạo ra một người học. Chúng tôi sẽ sử dụng thuật toán học SARSA () để người học được sử dụng với tác nhân.
learner = SARSA()
agent = LearningAgent(controller, learner)Bước 4
Bước này là thêm Tác nhân vào Môi trường.
Để kết nối agent với môi trường, chúng ta cần một thành phần đặc biệt gọi là task. Vai trò của mộttask là tìm kiếm mục tiêu trong môi trường và cách người đại diện nhận được phần thưởng cho các hành động.
Môi trường có nhiệm vụ riêng của nó. Môi trường Maze mà chúng tôi đã sử dụng có tác vụ MDPMazeTask. MDP là viết tắt của“markov decision process”có nghĩa là, đặc vụ biết vị trí của nó trong mê cung. Môi trường sẽ là một tham số cho nhiệm vụ.
task = MDPMazeTask(env)Bước 5
Bước tiếp theo sau khi thêm tác nhân vào môi trường là tạo Thử nghiệm.
Bây giờ chúng ta cần tạo thử nghiệm, để chúng ta có thể có nhiệm vụ và tác nhân phối hợp với nhau.
experiment = Experiment(task, agent)Bây giờ chúng ta sẽ chạy thử nghiệm 1000 lần như hình dưới đây -
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()Môi trường sẽ chạy 100 lần giữa tác nhân và tác vụ khi đoạn mã sau được thực thi:
experiment.doInteractions(100)Sau mỗi lần lặp lại, nó trả lại một trạng thái mới cho nhiệm vụ quyết định thông tin và phần thưởng nào sẽ được chuyển cho đại lý. Chúng ta sẽ vẽ một bảng mới sau khi tìm hiểu và đặt lại tác nhân bên trong vòng lặp for.
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(table.params.reshape(81,4).max(1).reshape(9,9))
pylab.savefig("test.png")Đây là mã đầy đủ -
Thí dụ
maze.py
from scipy import *
import sys, time
import matplotlib.pyplot as pylab
from pybrain.rl.environments.mazes import Maze, MDPMazeTask
from pybrain.rl.learners.valuebased import ActionValueTable
from pybrain.rl.agents import LearningAgent
from pybrain.rl.learners import Q, QLambda, SARSA #@UnusedImport
from pybrain.rl.explorers import BoltzmannExplorer #@UnusedImport
from pybrain.rl.experiments import Experiment
from pybrain.rl.environments import Task
# create maze array
mazearray = array(
[[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
)
env = Maze(mazearray, (7, 7))
# create task
task = MDPMazeTask(env)
#controller in PyBrain is like a module, for which the input is states and
convert them into actions.
controller = ActionValueTable(81, 4)
controller.initialize(1.)
# create agent with controller and learner - using SARSA()
learner = SARSA()
# create agent
agent = LearningAgent(controller, learner)
# create experiment
experiment = Experiment(task, agent)
# prepare plotting
pylab.gray()
pylab.ion()
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(controller.params.reshape(81,4).max(1).reshape(9,9))
pylab.savefig("test.png")Đầu ra
python maze.py
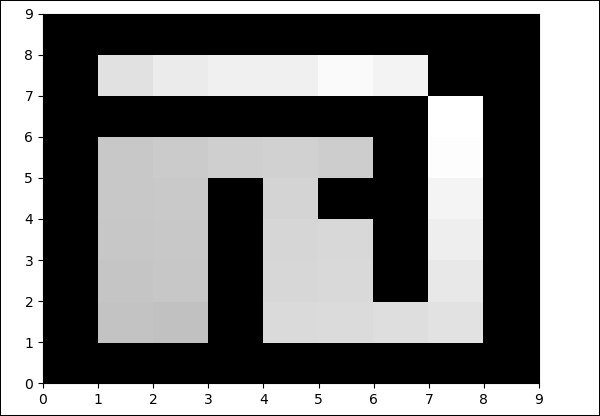
Màu trong trường tự do sẽ được thay đổi ở mỗi lần lặp lại.