PySpark - Hướng dẫn nhanh
Trong chương này, chúng ta sẽ tự làm quen với Apache Spark là gì và PySpark đã được phát triển như thế nào.
Spark - Tổng quan
Apache Spark là một khung xử lý thời gian thực nhanh như chớp. Nó thực hiện các tính toán trong bộ nhớ để phân tích dữ liệu trong thời gian thực. Nó đi vào hình ảnh nhưApache Hadoop MapReducechỉ thực hiện xử lý hàng loạt và thiếu tính năng xử lý thời gian thực. Do đó, Apache Spark được giới thiệu vì nó có thể thực hiện xử lý luồng trong thời gian thực và cũng có thể xử lý hàng loạt.
Ngoài thời gian thực và xử lý hàng loạt, Apache Spark cũng hỗ trợ các truy vấn tương tác và các thuật toán lặp lại. Apache Spark có trình quản lý cụm riêng, nơi nó có thể lưu trữ ứng dụng của mình. Nó tận dụng Apache Hadoop cho cả lưu trữ và xử lý. Nó sử dụngHDFS (Hệ thống tệp phân tán Hadoop) để lưu trữ và nó có thể chạy các ứng dụng Spark trên YARN cũng.
PySpark - Tổng quan
Apache Spark được viết bằng Scala programming language. Để hỗ trợ Python với Spark, Apache Spark Community đã phát hành một công cụ, PySpark. Sử dụng PySpark, bạn có thể làm việc vớiRDDscũng bằng ngôn ngữ lập trình Python. Đó là vì một thư viện được gọi làPy4j rằng họ có thể đạt được điều này.
PySpark cung cấp PySpark Shellliên kết API Python với lõi tia lửa và khởi tạo ngữ cảnh Spark. Đa số các nhà khoa học dữ liệu và chuyên gia phân tích ngày nay sử dụng Python vì bộ thư viện phong phú của nó. Tích hợp Python với Spark là một lợi ích cho họ.
Trong chương này, chúng ta sẽ hiểu thiết lập môi trường của PySpark.
Note - Đây là việc bạn đã cài đặt Java và Scala trên máy tính của mình.
Bây giờ chúng ta hãy tải xuống và thiết lập PySpark với các bước sau.
Step 1- Truy cập trang tải xuống Apache Spark chính thức và tải xuống phiên bản Apache Spark mới nhất có sẵn tại đó. Trong hướng dẫn này, chúng tôi đang sử dụngspark-2.1.0-bin-hadoop2.7.
Step 2- Bây giờ, giải nén tệp Spark tar đã tải xuống. Theo mặc định, nó sẽ được tải xuống trong thư mục Tải xuống.
# tar -xvf Downloads/spark-2.1.0-bin-hadoop2.7.tgzNó sẽ tạo một thư mục spark-2.1.0-bin-hadoop2.7. Trước khi bắt đầu PySpark, bạn cần đặt các môi trường sau để đặt đường dẫn Spark vàPy4j path.
export SPARK_HOME = /home/hadoop/spark-2.1.0-bin-hadoop2.7
export PATH = $PATH:/home/hadoop/spark-2.1.0-bin-hadoop2.7/bin
export PYTHONPATH = $SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH
export PATH = $SPARK_HOME/python:$PATHHoặc, để đặt các môi trường trên trên toàn cầu, hãy đặt chúng vào .bashrc file. Sau đó chạy lệnh sau để các môi trường hoạt động.
# source .bashrcBây giờ chúng ta đã thiết lập tất cả các môi trường, hãy vào thư mục Spark và gọi trình bao PySpark bằng cách chạy lệnh sau:
# ./bin/pysparkThao tác này sẽ khởi động trình bao PySpark của bạn.
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
Using Python version 2.7.12 (default, Nov 19 2016 06:48:10)
SparkSession available as 'spark'.
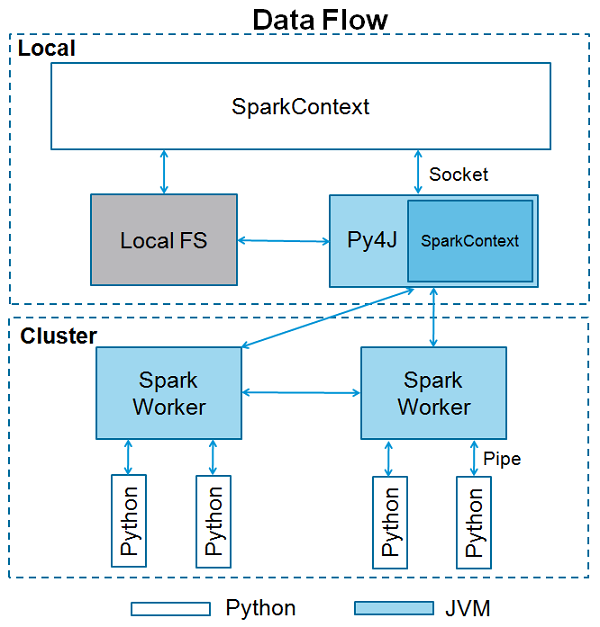
<<<SparkContext là điểm vào của bất kỳ chức năng tia lửa nào. Khi chúng tôi chạy bất kỳ ứng dụng Spark nào, chương trình trình điều khiển sẽ khởi động, chương trình này có chức năng chính và SparkContext của bạn sẽ được khởi chạy ở đây. Chương trình trình điều khiển sau đó chạy các hoạt động bên trong các trình thực thi trên các nút công nhân.
SparkContext sử dụng Py4J để khởi chạy một JVM và tạo ra một JavaSparkContext. Theo mặc định, PySpark có sẵn SparkContext dưới dạng‘sc’, do đó, việc tạo SparkContext mới sẽ không hoạt động.
Khối mã sau có các chi tiết của lớp PySpark và các tham số, mà SparkContext có thể nhận.
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls = <class 'pyspark.profiler.BasicProfiler'>
)Thông số
Sau đây là các thông số của SparkContext.
Master - Đây là URL của cụm mà nó kết nối.
appName - Tên công việc của bạn.
sparkHome - Thư mục cài đặt Spark.
pyFiles - Các tệp .zip hoặc .py để gửi đến cụm và thêm vào PYTHONPATH.
Environment - Biến môi trường các nút công nhân.
batchSize- Số lượng đối tượng Python được biểu diễn dưới dạng một đối tượng Java duy nhất. Đặt 1 để tắt hàng loạt, 0 để tự động chọn kích thước lô dựa trên kích thước đối tượng hoặc -1 để sử dụng kích thước lô không giới hạn.
Serializer - Bộ nối tiếp RDD.
Conf - Một đối tượng của L {SparkConf} để thiết lập tất cả các thuộc tính Spark.
Gateway - Sử dụng cổng và JVM hiện có, nếu không sẽ khởi tạo JVM mới.
JSC - Phiên bản JavaSparkContext.
profiler_cls - Một lớp Hồ sơ tùy chỉnh được sử dụng để làm hồ sơ (mặc định là pyspark.profiler.BasicProfiler).
Trong số các thông số trên, master và appnamehầu hết được sử dụng. Hai dòng đầu tiên của bất kỳ chương trình PySpark nào trông như hình dưới đây:
from pyspark import SparkContext
sc = SparkContext("local", "First App")Ví dụ SparkContext - PySpark Shell
Bây giờ bạn đã biết đủ về SparkContext, chúng ta hãy chạy một ví dụ đơn giản về trình bao PySpark. Trong ví dụ này, chúng tôi sẽ đếm số dòng có ký tự 'a' hoặc 'b' trongREADME.mdtập tin. Vì vậy, giả sử nếu có 5 dòng trong một tệp và 3 dòng có ký tự 'a', thì đầu ra sẽ là →Line with a: 3. Tương tự sẽ được thực hiện cho ký tự 'b'.
Note- Chúng tôi không tạo bất kỳ đối tượng SparkContext nào trong ví dụ sau vì theo mặc định, Spark sẽ tự động tạo đối tượng SparkContext có tên là sc, khi trình bao PySpark khởi động. Trong trường hợp bạn cố gắng tạo một đối tượng SparkContext khác, bạn sẽ gặp lỗi sau:"ValueError: Cannot run multiple SparkContexts at once".

<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
<<< logData = sc.textFile(logFile).cache()
<<< numAs = logData.filter(lambda s: 'a' in s).count()
<<< numBs = logData.filter(lambda s: 'b' in s).count()
<<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
Lines with a: 62, lines with b: 30Ví dụ SparkContext - Chương trình Python
Hãy để chúng tôi chạy cùng một ví dụ bằng cách sử dụng một chương trình Python. Tạo một tệp Python có tênfirstapp.py và nhập mã sau vào tệp đó.
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
----------------------------------------firstapp.py---------------------------------------Sau đó, chúng tôi sẽ thực hiện lệnh sau trong terminal để chạy tệp Python này. Chúng ta sẽ nhận được đầu ra tương tự như trên.
$SPARK_HOME/bin/spark-submit firstapp.py
Output: Lines with a: 62, lines with b: 30Bây giờ chúng ta đã cài đặt và cấu hình PySpark trên hệ thống của mình, chúng ta có thể lập trình bằng Python trên Apache Spark. Tuy nhiên trước khi làm như vậy, chúng ta hãy hiểu một khái niệm cơ bản trong Spark - RDD.
RDD là viết tắt của Resilient Distributed Dataset, đây là những phần tử chạy và hoạt động trên nhiều nút để thực hiện xử lý song song trên một cụm. RDD là các phần tử bất biến, có nghĩa là một khi bạn tạo RDD, bạn không thể thay đổi nó. RDD cũng có khả năng chịu lỗi, do đó trong trường hợp có bất kỳ lỗi nào, chúng sẽ tự động phục hồi. Bạn có thể áp dụng nhiều thao tác trên các RDD này để đạt được một nhiệm vụ nhất định.
Để áp dụng các hoạt động trên các RDD này, có hai cách:
- Chuyển đổi và
- Action
Hãy để chúng tôi hiểu chi tiết hai cách này.
Transformation- Đây là các hoạt động được áp dụng trên RDD để tạo ra một RDD mới. Filter, groupBy và map là những ví dụ về phép biến đổi.
Action - Đây là các thao tác được áp dụng trên RDD, hướng dẫn Spark thực hiện tính toán và gửi kết quả trở lại trình điều khiển.
Để áp dụng bất kỳ thao tác nào trong PySpark, chúng ta cần tạo PySpark RDDĐầu tiên. Khối mã sau có chi tiết về Lớp RDD của PySpark:
class pyspark.RDD (
jrdd,
ctx,
jrdd_deserializer = AutoBatchedSerializer(PickleSerializer())
)Hãy để chúng tôi xem cách chạy một vài thao tác cơ bản bằng PySpark. Đoạn mã sau trong tệp Python tạo ra các từ RDD, lưu trữ một tập hợp các từ được đề cập.
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)Bây giờ chúng ta sẽ chạy một vài thao tác trên các từ.
đếm()
Số phần tử trong RDD được trả về.
----------------------------------------count.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
counts = words.count()
print "Number of elements in RDD -> %i" % (counts)
----------------------------------------count.py---------------------------------------Command - Lệnh cho count () là -
$SPARK_HOME/bin/spark-submit count.pyOutput - Đầu ra cho lệnh trên là -
Number of elements in RDD → 8sưu tầm()
Tất cả các phần tử trong RDD được trả về.
----------------------------------------collect.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Collect app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
coll = words.collect()
print "Elements in RDD -> %s" % (coll)
----------------------------------------collect.py---------------------------------------Command - Lệnh cho collect () là -
$SPARK_HOME/bin/spark-submit collect.pyOutput - Đầu ra cho lệnh trên là -
Elements in RDD -> [
'scala',
'java',
'hadoop',
'spark',
'akka',
'spark vs hadoop',
'pyspark',
'pyspark and spark'
]foreach (f)
Chỉ trả về những phần tử đáp ứng điều kiện của hàm bên trong foreach. Trong ví dụ sau, chúng ta gọi một hàm in trong foreach, hàm này in tất cả các phần tử trong RDD.
----------------------------------------foreach.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "ForEach app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
def f(x): print(x)
fore = words.foreach(f)
----------------------------------------foreach.py---------------------------------------Command - Lệnh cho foreach (f) là -
$SPARK_HOME/bin/spark-submit foreach.pyOutput - Đầu ra cho lệnh trên là -
scala
java
hadoop
spark
akka
spark vs hadoop
pyspark
pyspark and sparkbộ lọc (f)
Một RDD mới được trả về chứa các phần tử, đáp ứng chức năng bên trong bộ lọc. Trong ví dụ sau, chúng tôi lọc ra các chuỗi chứa '' spark ".
----------------------------------------filter.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Filter app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_filter = words.filter(lambda x: 'spark' in x)
filtered = words_filter.collect()
print "Fitered RDD -> %s" % (filtered)
----------------------------------------filter.py----------------------------------------Command - Lệnh cho bộ lọc (f) là -
$SPARK_HOME/bin/spark-submit filter.pyOutput - Đầu ra cho lệnh trên là -
Fitered RDD -> [
'spark',
'spark vs hadoop',
'pyspark',
'pyspark and spark'
]map (f, securePartitioning = False)
Một RDD mới được trả về bằng cách áp dụng một hàm cho mỗi phần tử trong RDD. Trong ví dụ sau, chúng tôi tạo một cặp giá trị khóa và ánh xạ mọi chuỗi với giá trị 1.
----------------------------------------map.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Map app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_map = words.map(lambda x: (x, 1))
mapping = words_map.collect()
print "Key value pair -> %s" % (mapping)
----------------------------------------map.py---------------------------------------Command - Lệnh cho map (f, keepvesPartitioning = False) là -
$SPARK_HOME/bin/spark-submit map.pyOutput - Đầu ra của lệnh trên là -
Key value pair -> [
('scala', 1),
('java', 1),
('hadoop', 1),
('spark', 1),
('akka', 1),
('spark vs hadoop', 1),
('pyspark', 1),
('pyspark and spark', 1)
]giảm (f)
Sau khi thực hiện thao tác nhị phân giao hoán và kết hợp được chỉ định, phần tử trong RDD được trả về. Trong ví dụ sau, chúng tôi đang nhập gói thêm từ toán tử và áp dụng nó trên 'num' để thực hiện một thao tác thêm đơn giản.
----------------------------------------reduce.py---------------------------------------
from pyspark import SparkContext
from operator import add
sc = SparkContext("local", "Reduce app")
nums = sc.parallelize([1, 2, 3, 4, 5])
adding = nums.reduce(add)
print "Adding all the elements -> %i" % (adding)
----------------------------------------reduce.py---------------------------------------Command - Lệnh giảm (f) là -
$SPARK_HOME/bin/spark-submit reduce.pyOutput - Đầu ra của lệnh trên là -
Adding all the elements -> 15tham gia (khác, numPartitions = Không có)
Nó trả về RDD với một cặp phần tử với các khóa phù hợp và tất cả các giá trị cho khóa cụ thể đó. Trong ví dụ sau, có hai cặp phần tử trong hai RDD khác nhau. Sau khi kết hợp hai RDD này, chúng ta nhận được một RDD với các phần tử có khóa phù hợp và giá trị của chúng.
----------------------------------------join.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Join app")
x = sc.parallelize([("spark", 1), ("hadoop", 4)])
y = sc.parallelize([("spark", 2), ("hadoop", 5)])
joined = x.join(y)
final = joined.collect()
print "Join RDD -> %s" % (final)
----------------------------------------join.py---------------------------------------Command - Lệnh tham gia (other, numPartitions = None) là -
$SPARK_HOME/bin/spark-submit join.pyOutput - Đầu ra cho lệnh trên là -
Join RDD -> [
('spark', (1, 2)),
('hadoop', (4, 5))
]cache ()
Duy trì RDD này với mức lưu trữ mặc định (MEMORY_ONLY). Bạn cũng có thể kiểm tra xem RDD có được lưu vào bộ nhớ đệm hay không.
----------------------------------------cache.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Cache app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words.cache()
caching = words.persist().is_cached
print "Words got chached > %s" % (caching)
----------------------------------------cache.py---------------------------------------Command - Lệnh cho cache () là -
$SPARK_HOME/bin/spark-submit cache.pyOutput - Đầu ra của chương trình trên là -
Words got cached -> TrueĐây là một số hoạt động quan trọng nhất được thực hiện trên PySpark RDD.
Để xử lý song song, Apache Spark sử dụng các biến được chia sẻ. Một bản sao của biến được chia sẻ sẽ đi trên mỗi nút của cụm khi trình điều khiển gửi một tác vụ đến người thực thi trên cụm, để nó có thể được sử dụng để thực hiện các tác vụ.
Có hai loại biến chia sẻ được hỗ trợ bởi Apache Spark -
- Broadcast
- Accumulator
Hãy để chúng tôi hiểu chúng một cách chi tiết.
Phát thanh
Các biến quảng bá được sử dụng để lưu bản sao dữ liệu trên tất cả các nút. Biến này được lưu trong bộ nhớ đệm trên tất cả các máy và không được gửi trên các máy có tác vụ. Khối mã sau có các chi tiết của một lớp Broadcast cho PySpark.
class pyspark.Broadcast (
sc = None,
value = None,
pickle_registry = None,
path = None
)Ví dụ sau đây cho thấy cách sử dụng biến Broadcast. Biến Broadcast có một thuộc tính gọi là value, thuộc tính này lưu trữ dữ liệu và được sử dụng để trả về một giá trị được broadcast.
----------------------------------------broadcast.py--------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Broadcast app")
words_new = sc.broadcast(["scala", "java", "hadoop", "spark", "akka"])
data = words_new.value
print "Stored data -> %s" % (data)
elem = words_new.value[2]
print "Printing a particular element in RDD -> %s" % (elem)
----------------------------------------broadcast.py--------------------------------------Command - Lệnh cho một biến quảng bá như sau:
$SPARK_HOME/bin/spark-submit broadcast.pyOutput - Đầu ra cho lệnh sau được đưa ra bên dưới.
Stored data -> [
'scala',
'java',
'hadoop',
'spark',
'akka'
]
Printing a particular element in RDD -> hadoopTích lũy
Các biến tích lũy được sử dụng để tổng hợp thông tin thông qua các phép toán liên kết và giao hoán. Ví dụ: bạn có thể sử dụng bộ tích lũy cho một phép tính tổng hoặc các bộ đếm (trong MapReduce). Khối mã sau có các chi tiết của một lớp Accumulator cho PySpark.
class pyspark.Accumulator(aid, value, accum_param)Ví dụ sau đây cho thấy cách sử dụng một biến Accumulator. Một biến Accumulator có một thuộc tính được gọi là giá trị tương tự như những gì một biến quảng bá có. Nó lưu trữ dữ liệu và được sử dụng để trả về giá trị của bộ tích lũy, nhưng chỉ có thể sử dụng trong chương trình trình điều khiển.
Trong ví dụ này, một biến tích lũy được sử dụng bởi nhiều công nhân và trả về một giá trị tích lũy.
----------------------------------------accumulator.py------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Accumulator app")
num = sc.accumulator(10)
def f(x):
global num
num+=x
rdd = sc.parallelize([20,30,40,50])
rdd.foreach(f)
final = num.value
print "Accumulated value is -> %i" % (final)
----------------------------------------accumulator.py------------------------------------Command - Lệnh cho một biến tích lũy như sau:
$SPARK_HOME/bin/spark-submit accumulator.pyOutput - Đầu ra cho lệnh trên được đưa ra bên dưới.
Accumulated value is -> 150Để chạy một ứng dụng Spark trên local / cluster, bạn cần thiết lập một vài cấu hình và thông số, đây là những gì SparkConf giúp bạn. Nó cung cấp các cấu hình để chạy một ứng dụng Spark. Khối mã sau có các chi tiết của lớp SparkConf cho PySpark.
class pyspark.SparkConf (
loadDefaults = True,
_jvm = None,
_jconf = None
)Ban đầu, chúng tôi sẽ tạo một đối tượng SparkConf với SparkConf (), đối tượng này sẽ tải các giá trị từ spark.*Các thuộc tính hệ thống Java cũng vậy. Bây giờ bạn có thể đặt các tham số khác nhau bằng cách sử dụng đối tượng SparkConf và các tham số của chúng sẽ được ưu tiên hơn các thuộc tính hệ thống.
Trong một lớp SparkConf, có các phương thức setter, hỗ trợ chuỗi. Ví dụ, bạn có thể viếtconf.setAppName(“PySpark App”).setMaster(“local”). Khi chúng tôi chuyển một đối tượng SparkConf cho Apache Spark, thì bất kỳ người dùng nào cũng không thể sửa đổi nó.
Sau đây là một số thuộc tính thường được sử dụng nhất của SparkConf:
set(key, value) - Để thiết lập thuộc tính cấu hình.
setMaster(value) - Để đặt URL chính.
setAppName(value) - Để đặt tên ứng dụng.
get(key, defaultValue=None) - Để nhận giá trị cấu hình của một khóa.
setSparkHome(value) - Để thiết lập đường dẫn cài đặt Spark trên các nút công nhân.
Chúng ta hãy xem xét ví dụ sau về việc sử dụng SparkConf trong chương trình PySpark. Trong ví dụ này, chúng tôi đang đặt tên ứng dụng tia lửa làPySpark App và đặt URL chính cho ứng dụng spark thành → spark://master:7077.
Khối mã sau có các dòng, khi chúng được thêm vào tệp Python, nó sẽ đặt các cấu hình cơ bản để chạy ứng dụng PySpark.
---------------------------------------------------------------------------------------
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("PySpark App").setMaster("spark://master:7077")
sc = SparkContext(conf=conf)
---------------------------------------------------------------------------------------Trong Apache Spark, bạn có thể tải lên các tệp của mình bằng sc.addFile (sc là SparkContext mặc định của bạn) và lấy đường dẫn trên worker bằng cách sử dụng SparkFiles.get. Do đó, SparkFiles giải quyết các đường dẫn đến các tệp được thêm vàoSparkContext.addFile().
SparkFiles chứa các phân loại sau:
- get(filename)
- getrootdirectory()
Hãy để chúng tôi hiểu chúng một cách chi tiết.
get (tên tệp)
Nó chỉ định đường dẫn của tệp được thêm vào thông qua SparkContext.addFile ().
getrootdirectory ()
Nó chỉ định đường dẫn đến thư mục gốc, chứa tệp được thêm vào thông qua SparkContext.addFile ().
----------------------------------------sparkfile.py------------------------------------
from pyspark import SparkContext
from pyspark import SparkFiles
finddistance = "/home/hadoop/examples_pyspark/finddistance.R"
finddistancename = "finddistance.R"
sc = SparkContext("local", "SparkFile App")
sc.addFile(finddistance)
print "Absolute Path -> %s" % SparkFiles.get(finddistancename)
----------------------------------------sparkfile.py------------------------------------Command - Lệnh như sau:
$SPARK_HOME/bin/spark-submit sparkfiles.pyOutput - Đầu ra cho lệnh trên là -
Absolute Path ->
/tmp/spark-f1170149-af01-4620-9805-f61c85fecee4/userFiles-641dfd0f-240b-4264-a650-4e06e7a57839/finddistance.RStorageLevel quyết định cách RDD nên được lưu trữ. Trong Apache Spark, StorageLevel quyết định liệu RDD nên được lưu trữ trong bộ nhớ hay nên lưu trữ trên đĩa hoặc cả hai. Nó cũng quyết định xem có nên tuần tự hóa RDD hay không và có tái tạo các phân vùng RDD hay không.
Khối mã sau có định nghĩa lớp của StorageLevel:
class pyspark.StorageLevel(useDisk, useMemory, useOffHeap, deserialized, replication = 1)Bây giờ, để quyết định việc lưu trữ RDD, có các mức lưu trữ khác nhau, được đưa ra bên dưới:
DISK_ONLY = StorageLevel (Đúng, Sai, Sai, Sai, 1)
DISK_ONLY_2 = StorageLevel (Đúng, Sai, Sai, Sai, 2)
MEMORY_AND_DISK = StorageLevel (Đúng, Đúng, Sai, Sai, 1)
MEMORY_AND_DISK_2 = StorageLevel (Đúng, Đúng, Sai, Sai, 2)
MEMORY_AND_DISK_SER = StorageLevel (Đúng, Đúng, Sai, Sai, 1)
MEMORY_AND_DISK_SER_2 = StorageLevel (Đúng, Đúng, Sai, Sai, 2)
MEMORY_ONLY = StorageLevel (Sai, Đúng, Sai, Sai, 1)
MEMORY_ONLY_2 = StorageLevel (Sai, Đúng, Sai, Sai, 2)
MEMORY_ONLY_SER = StorageLevel (Sai, Đúng, Sai, Sai, 1)
MEMORY_ONLY_SER_2 = StorageLevel (Sai, Đúng, Sai, Sai, 2)
OFF_HEAP = StorageLevel (Đúng, Đúng, Đúng, Sai, 1)
Chúng ta hãy xem xét ví dụ sau về StorageLevel, nơi chúng tôi sử dụng mức lưu trữ MEMORY_AND_DISK_2, có nghĩa là các phân vùng RDD sẽ có bản sao của 2.
------------------------------------storagelevel.py-------------------------------------
from pyspark import SparkContext
import pyspark
sc = SparkContext (
"local",
"storagelevel app"
)
rdd1 = sc.parallelize([1,2])
rdd1.persist( pyspark.StorageLevel.MEMORY_AND_DISK_2 )
rdd1.getStorageLevel()
print(rdd1.getStorageLevel())
------------------------------------storagelevel.py-------------------------------------Command - Lệnh như sau:
$SPARK_HOME/bin/spark-submit storagelevel.pyOutput - Đầu ra cho lệnh trên được đưa ra dưới đây:
Disk Memory Serialized 2x ReplicatedApache Spark cung cấp một API học máy có tên là MLlib. PySpark cũng có API học máy này bằng Python. Nó hỗ trợ các loại thuật toán khác nhau, được đề cập bên dưới -
mllib.classification - Sự spark.mllibgói hỗ trợ các phương pháp khác nhau để phân loại nhị phân, phân loại đa lớp và phân tích hồi quy. Một số thuật toán phổ biến nhất trong phân loại làRandom Forest, Naive Bayes, Decision Tree, Vân vân.
mllib.clustering - Phân cụm là một vấn đề học tập không có giám sát, theo đó bạn nhằm mục đích nhóm các tập con của các thực thể với nhau dựa trên một số khái niệm về sự giống nhau.
mllib.fpm- Đối sánh mẫu thường xuyên là khai thác các mục thường xuyên, tập phổ biến, chuỗi con hoặc các cấu trúc con khác thường nằm trong số các bước đầu tiên để phân tích một tập dữ liệu quy mô lớn. Đây đã là một chủ đề nghiên cứu tích cực trong việc khai thác dữ liệu trong nhiều năm.
mllib.linalg - Các tiện ích MLlib cho đại số tuyến tính.
mllib.recommendation- Lọc cộng tác thường được sử dụng cho các hệ thống khuyến nghị. Các kỹ thuật này nhằm mục đích điền vào các mục còn thiếu của ma trận liên kết mục người dùng.
spark.mllib- Nó hiện hỗ trợ lọc cộng tác dựa trên mô hình, trong đó người dùng và sản phẩm được mô tả bằng một tập hợp nhỏ các yếu tố tiềm ẩn có thể được sử dụng để dự đoán các mục nhập bị thiếu. spark.mllib sử dụng thuật toán Bình phương tối thiểu xen kẽ (ALS) để tìm hiểu các yếu tố tiềm ẩn này.
mllib.regression- Hồi quy tuyến tính thuộc họ thuật toán hồi quy. Mục tiêu của hồi quy là tìm mối quan hệ và sự phụ thuộc giữa các biến. Giao diện làm việc với mô hình hồi quy tuyến tính và tóm tắt mô hình tương tự như trường hợp hồi quy logistic.
Có các thuật toán, lớp và chức năng khác cũng là một phần của gói mllib. Hiện tại, hãy để chúng tôi hiểu một minh chứng vềpyspark.mllib.
Ví dụ sau về lọc cộng tác sử dụng thuật toán ALS để xây dựng mô hình đề xuất và đánh giá nó trên dữ liệu đào tạo.
Dataset used - test.data
1,1,5.0
1,2,1.0
1,3,5.0
1,4,1.0
2,1,5.0
2,2,1.0
2,3,5.0
2,4,1.0
3,1,1.0
3,2,5.0
3,3,1.0
3,4,5.0
4,1,1.0
4,2,5.0
4,3,1.0
4,4,5.0--------------------------------------recommend.py----------------------------------------
from __future__ import print_function
from pyspark import SparkContext
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
if __name__ == "__main__":
sc = SparkContext(appName="Pspark mllib Example")
data = sc.textFile("test.data")
ratings = data.map(lambda l: l.split(','))\
.map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2])))
# Build the recommendation model using Alternating Least Squares
rank = 10
numIterations = 10
model = ALS.train(ratings, rank, numIterations)
# Evaluate the model on training data
testdata = ratings.map(lambda p: (p[0], p[1]))
predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
ratesAndPreds = ratings.map(lambda r: ((r[0], r[1]), r[2])).join(predictions)
MSE = ratesAndPreds.map(lambda r: (r[1][0] - r[1][1])**2).mean()
print("Mean Squared Error = " + str(MSE))
# Save and load model
model.save(sc, "target/tmp/myCollaborativeFilter")
sameModel = MatrixFactorizationModel.load(sc, "target/tmp/myCollaborativeFilter")
--------------------------------------recommend.py----------------------------------------Command - Lệnh sẽ như sau:
$SPARK_HOME/bin/spark-submit recommend.pyOutput - Đầu ra của lệnh trên sẽ là -
Mean Squared Error = 1.20536041839e-05Serialization được sử dụng để điều chỉnh hiệu suất trên Apache Spark. Tất cả dữ liệu được gửi qua mạng hoặc ghi vào đĩa hoặc vẫn còn trong bộ nhớ phải được tuần tự hóa. Tuần tự hóa đóng một vai trò quan trọng trong các hoạt động tốn kém.
PySpark hỗ trợ bộ tuần tự hóa tùy chỉnh để điều chỉnh hiệu suất. Hai bộ tuần tự sau được hỗ trợ bởi PySpark:
MarshalSerializer
Sắp xếp thứ tự các đối tượng bằng cách sử dụng Trình tuần tự nguyên tử của Python. Bộ tuần tự này nhanh hơn PickleSerializer, nhưng hỗ trợ ít kiểu dữ liệu hơn.
class pyspark.MarshalSerializerPickleSerializer
Serialize các đối tượng bằng cách sử dụng Pickle Serializer của Python. Bộ tuần tự này hỗ trợ gần như bất kỳ đối tượng Python nào, nhưng có thể không nhanh bằng các trình tuần tự chuyên dụng hơn.
class pyspark.PickleSerializerChúng ta hãy xem một ví dụ về tuần tự hóa PySpark. Ở đây, chúng tôi tuần tự hóa dữ liệu bằng MarshalSerializer.
--------------------------------------serializing.py-------------------------------------
from pyspark.context import SparkContext
from pyspark.serializers import MarshalSerializer
sc = SparkContext("local", "serialization app", serializer = MarshalSerializer())
print(sc.parallelize(list(range(1000))).map(lambda x: 2 * x).take(10))
sc.stop()
--------------------------------------serializing.py-------------------------------------Command - Lệnh như sau:
$SPARK_HOME/bin/spark-submit serializing.pyOutput - Đầu ra của lệnh trên là -
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]