Độ bền dữ liệu Python - Trình điều khiển Cassandra
Cassandra là một cơ sở dữ liệu NoSQL phổ biến khác. Khả năng mở rộng, tính nhất quán và khả năng chịu lỗi cao - đây là một số tính năng quan trọng của Cassandra. Đây làColumn storecơ sở dữ liệu. Dữ liệu được lưu trữ trên nhiều máy chủ hàng hóa. Kết quả là, dữ liệu có sẵn rất cao.
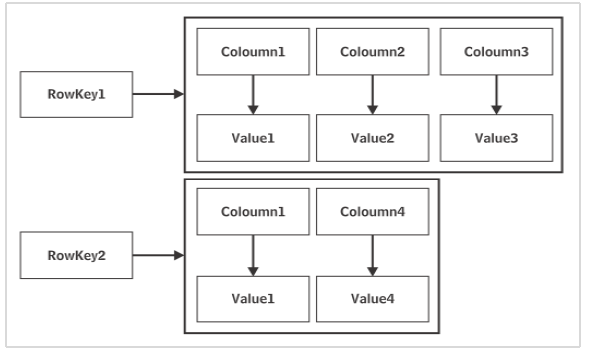
Cassandra là một sản phẩm từ nền tảng Apache Software. Dữ liệu được lưu trữ theo cách phân tán trên nhiều nút. Mỗi nút là một máy chủ duy nhất bao gồm các không gian phím. Khối xây dựng cơ bản của cơ sở dữ liệu Cassandra làkeyspace có thể được coi là tương tự với cơ sở dữ liệu.
Dữ liệu trong một nút của Cassandra, được sao chép trong các nút khác qua mạng ngang hàng gồm các nút. Điều đó làm cho Cassandra trở thành một cơ sở dữ liệu tuyệt vời. Mạng được gọi là trung tâm dữ liệu. Nhiều trung tâm dữ liệu có thể được kết nối với nhau để tạo thành một cụm. Bản chất của sao chép được cấu hình bằng cách thiết lập Chiến lược sao chép và hệ số sao chép tại thời điểm tạo không gian khóa.
Một keyspace có thể có nhiều hơn một họ Cột - cũng giống như một cơ sở dữ liệu có thể chứa nhiều bảng. Keyspace của Cassandra không có một lược đồ xác định trước. Có thể mỗi hàng trong bảng Cassandra có thể có các cột có tên khác nhau và có số lượng biến.
Phần mềm Cassandra cũng có sẵn trong hai phiên bản: cộng đồng và doanh nghiệp. Phiên bản doanh nghiệp mới nhất của Cassandra có sẵn để tải xuống tạihttps://cassandra.apache.org/download/. Phiên bản cộng đồng được tìm thấy tạihttps://academy.datastax.com/planet-cassandra/cassandra.
Cassandra có ngôn ngữ truy vấn riêng được gọi là Cassandra Query Language (CQL). Các truy vấn CQL có thể được thực thi từ bên trong trình bao CQLASH - tương tự như trình bao MySQL hoặc SQLite. Cú pháp CQL xuất hiện tương tự như SQL chuẩn.
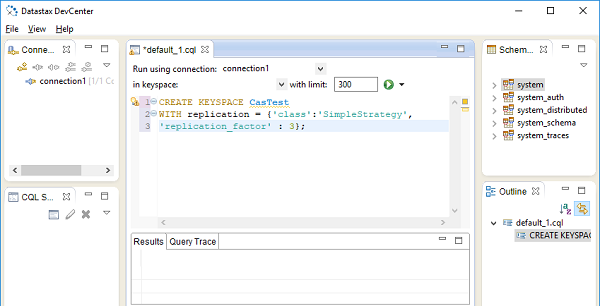
Phiên bản cộng đồng Datastax, cũng đi kèm với một IDE Develcenter được hiển thị trong hình sau:
Mô-đun Python để làm việc với cơ sở dữ liệu Cassandra được gọi là Cassandra Driver. Nó cũng được phát triển bởi Apache foundation. Mô-đun này chứa API ORM, cũng như API cốt lõi về bản chất tương tự như DB-API cho cơ sở dữ liệu quan hệ.
Cài đặt trình điều khiển Cassandra dễ dàng thực hiện bằng cách sử dụng pip utility.
pip3 install cassandra-driverTương tác với cơ sở dữ liệu Cassandra, được thực hiện thông qua đối tượng Cluster. Mô-đun Cassandra.cluster định nghĩa lớp Cụm. Đầu tiên chúng ta cần khai báo đối tượng Cluster.
from cassandra.cluster import Cluster
clstr=Cluster()Tất cả các giao dịch như chèn / cập nhật, v.v., được thực hiện bằng cách bắt đầu một phiên với một không gian khóa.
session=clstr.connect()Để tạo một không gian phím mới, hãy sử dụng execute()phương thức của đối tượng phiên. Phương thức execute () nhận đối số chuỗi phải là một chuỗi truy vấn. CQL có câu lệnh CREATE KEYSPACE như sau. Mã hoàn chỉnh như dưới đây -
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(“create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};”Đây, SimpleStrategy là một giá trị cho replication strategy và replication factorđược đặt thành 3. Như đã đề cập trước đó, một keyspace chứa một hoặc nhiều bảng. Mỗi bảng được đặc trưng bởi kiểu dữ liệu của nó. Các kiểu dữ liệu Python được tự động phân tích cú pháp với các kiểu dữ liệu CQL tương ứng theo bảng sau:
| Loại Python | Loại CQL |
|---|---|
| không ai | VÔ GIÁ TRỊ |
| Bool | Boolean |
| Phao nổi | phao, gấp đôi |
| int, dài | int, bigint, varint, smallint, tinyint, counter |
| thập phân. thập phân | Thập phân |
| str, Unicode | ascii, varchar, text |
| bộ đệm, bytearray | Bãi |
| Ngày | Ngày |
| Ngày giờ | Dấu thời gian |
| Thời gian | Thời gian |
| danh sách, tuple, máy phát điện | Danh sách |
| thiết lập, băng giá | Bộ |
| dict, OrderDict | Bản đồ |
| uuid.UUID | timeuuid, uuid |
Để tạo bảng, hãy sử dụng đối tượng phiên để thực hiện truy vấn CQL để tạo bảng.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)Không gian phím được tạo có thể được sử dụng thêm để chèn hàng. Phiên bản CQL của truy vấn INSERT tương tự như câu lệnh SQL Insert. Mã sau sẽ chèn một hàng trong bảng sinh viên.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"Như bạn mong đợi, câu lệnh SELECT cũng được sử dụng với Cassandra. Trong trường hợp phương thức execute () chứa chuỗi truy vấn SELECT, nó trả về một đối tượng tập kết quả có thể được duyệt qua bằng vòng lặp.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))Truy vấn SELECT của Cassandra hỗ trợ sử dụng mệnh đề WHERE để áp dụng bộ lọc trên tập kết quả được tìm nạp. Các toán tử logic truyền thống như <,> ==, v.v. được công nhận. Để truy xuất, chỉ những hàng từ bảng sinh viên cho các tên có tuổi> 20, chuỗi truy vấn trong phương thức execute () phải như sau:
rows=session.execute("select * from students WHERE age>20 allow filtering;")Lưu ý, việc sử dụng ALLOW FILTERING. Phần CHO PHÉP LỌC trong câu lệnh này cho phép rõ ràng cho phép (một số) truy vấn yêu cầu lọc.
API trình điều khiển Cassandra xác định các lớp sau của loại Statement trong mô-đun cassendra.query của nó.
Câu lệnh đơn giản
Một truy vấn CQL đơn giản, không chuẩn bị được chứa trong một chuỗi truy vấn. Tất cả các ví dụ trên là ví dụ của SimpleStatement.
BatchStatement
Nhiều truy vấn (chẳng hạn như CHÈN, CẬP NHẬT và XÓA) được đặt trong một lô và thực hiện cùng một lúc. Trước tiên, mỗi hàng được chuyển đổi thành một Câu lệnh đơn giản và sau đó được thêm vào trong một đợt.
Chúng ta hãy đặt các hàng cần thêm vào bảng Học sinh dưới dạng danh sách các bộ giá trị như sau:
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]Để thêm các hàng phía trên bằng cách sử dụng BathStatement, hãy chạy tập lệnh sau:
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)Chuẩn bị sẵn sàng
Câu lệnh chuẩn bị giống như một truy vấn được tham số hóa trong DB-API. Chuỗi truy vấn của nó được Cassandra lưu lại để sử dụng sau này. Phương thức Session.prepare () trả về một thể hiện PreparedStatement.
Đối với bảng sinh viên của chúng tôi, câu hỏi Chuẩn bị sẵn cho truy vấn INSERT như sau:
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")Sau đó, nó chỉ cần gửi giá trị của các tham số để ràng buộc. Ví dụ -
qry=stmt.bind([1,'Ram', 23,175])Cuối cùng, thực hiện câu lệnh ràng buộc ở trên.
session.execute(qry)Điều này làm giảm lưu lượng mạng và mức sử dụng CPU vì Cassandra không phải phân tích lại truy vấn mỗi lần.