SAS - Hướng dẫn nhanh
SAS viết tắt của Statistical Analysis Software. Nó được tạo ra vào năm 1960 bởi Viện SAS. Từ ngày 1 tháng 1 năm 1960, SAS được sử dụng để quản lý dữ liệu, thông tin kinh doanh, Phân tích dự đoán, Phân tích mô tả và mô tả, v.v. Từ đó, nhiều thủ tục và thành phần thống kê mới đã được giới thiệu trong phần mềm.
Với sự ra đời của JMP (Jump) cho thống kê, SAS đã tận dụng lợi thế của Graphical user Interfaceđược giới thiệu bởi Macintosh. Về cơ bản, Jump được sử dụng cho các ứng dụng như Six Sigma, thiết kế, kiểm soát chất lượng và phân tích kỹ thuật và khoa học.
SAS độc lập với nền tảng, có nghĩa là bạn có thể chạy SAS trên bất kỳ hệ điều hành nào, Linux hoặc Windows. SAS được thúc đẩy bởi các lập trình viên SAS, những người sử dụng một số chuỗi hoạt động trên bộ dữ liệu SAS để tạo báo cáo thích hợp cho việc phân tích dữ liệu.
Trong những năm qua, SAS đã bổ sung nhiều giải pháp vào danh mục sản phẩm của mình. Nó có giải pháp cho Quản trị dữ liệu, Chất lượng dữ liệu, Phân tích dữ liệu lớn, Khai thác văn bản, Quản lý gian lận, Khoa học sức khỏe, v.v. Chúng ta có thể yên tâm cho rằng SAS có giải pháp cho mọi lĩnh vực kinh doanh.
Để xem qua danh sách các sản phẩm có sẵn, bạn có thể truy cập SAS Components
Tại sao chúng tôi sử dụng SAS
SAS về cơ bản được làm việc trên các tập dữ liệu lớn. Với sự trợ giúp của phần mềm SAS, bạn có thể thực hiện các thao tác khác nhau trên dữ liệu như -
- Quản lý dữ liệu
- Phân tích thống kê
- Báo cáo hình thành với đồ họa hoàn hảo
- Kế hoạch kinh doanh
- Nghiên cứu hoạt động và quản lý dự án
- Cải thiện chất lượng
- Phát triển ứng dụng
- Trích xuất dữ liệu
- Chuyển đổi dữ liệu
- Cập nhật và sửa đổi dữ liệu
Nếu chúng ta nói về các thành phần của SAS thì hơn 200 thành phần có sẵn trong SAS.
| Sr.No. | Thành phần SAS & Cách sử dụng của chúng |
|---|---|
| 1 | Base SAS Nó là một thành phần cốt lõi chứa cơ sở quản lý dữ liệu và một ngôn ngữ lập trình để phân tích dữ liệu. Nó cũng được sử dụng rộng rãi nhất. |
| 2 | SAS/GRAPH Tạo đồ thị, bản trình bày để hiểu rõ hơn và hiển thị kết quả ở định dạng phù hợp. |
| 3 | SAS/STAT Thực hiện phân tích Thống kê với phân tích phương sai, hồi quy, phân tích đa biến, phân tích tồn tại và phân tích tâm lý, phân tích mô hình hỗn hợp. |
| 4 | SAS/OR Hoạt động nghiên cứu. |
| 5 | SAS/ETS Kinh tế lượng và phân tích chuỗi thời gian. |
| 6 | SAS/IML Ngôn ngữ ma trận tương tác. |
| 7 | SAS/AF Cơ sở ứng dụng. |
| số 8 | SAS/QC Kiểm soát chất lượng. |
| 9 | SAS/INSIGHT Khai thác dữ liệu. |
| 10 | SAS/PH Phân tích thử nghiệm lâm sàng. |
| 11 | SAS/Enterprise Miner Khai thác dữ liệu. |
Các loại phần mềm SAS
- Windows hoặc PC SAS
- SAS EG (Hướng dẫn Doanh nghiệp)
- SAS EM (Công cụ khai thác doanh nghiệp tức là để phân tích dự đoán)
- SAS có nghĩa là
- Số liệu thống kê SAS
Chủ yếu chúng tôi sử dụng Window SAS trong tổ chức cũng như trong viện đào tạo. Một số tổ chức sử dụng Linux nhưng không có giao diện người dùng đồ họa, vì vậy bạn phải viết mã cho mọi truy vấn. Nhưng trong window SAS có sẵn rất nhiều tiện ích giúp ích cho người lập trình rất nhiều và nó cũng giảm thời gian viết code.
Một Cửa sổ SaS có 5 phần.
| Sr.No. | Cửa sổ SAS & Cách sử dụng của chúng |
|---|---|
| 1 | Log Window Một cửa sổ nhật ký giống như một cửa sổ thực thi, nơi chúng ta có thể kiểm tra việc thực thi chương trình SAS. Trong cửa sổ này, chúng tôi cũng có thể kiểm tra các lỗi. Điều rất quan trọng là phải kiểm tra mỗi khi cửa sổ nhật ký sau khi chạy chương trình. Để chúng ta có thể hiểu đúng về việc thực thi chương trình của mình. |
| 2 | Editor Window
Cửa sổ biên tập là một phần của SAS nơi chúng tôi viết tất cả các mã. Nó giống như một cuốn sổ tay. |
| 3 | Output Window Cửa sổ đầu ra là cửa sổ kết quả nơi chúng ta có thể xem kết quả đầu ra của chương trình của mình. |
| 4 | Result Window Nó giống như một chỉ mục cho tất cả các đầu ra. Tất cả các chương trình mà chúng tôi đã chạy trong một phiên của SAS được liệt kê ở đó và bạn có thể mở đầu ra bằng cách nhấp vào kết quả đầu ra. Nhưng những điều này chỉ được đề cập trong một phiên họp của SAS. Nếu chúng ta đóng phần mềm và sau đó mở nó thì Cửa sổ Kết quả sẽ trống. |
| 5 | Explore Window Đây là tất cả các thư viện được liệt kê. Bạn cũng có thể duyệt các tệp được hỗ trợ SAS hệ thống của mình từ đây. |
Các thư viện trong SAS
Các thư viện giống như lưu trữ trong SAS. Bạn có thể tạo một thư viện và lưu tất cả các chương trình tương tự trong thư viện đó. SAS cung cấp cho bạn cơ sở để tạo nhiều thư viện. Thư viện SAS chỉ dài 8 ký tự.
Có hai loại thư viện có sẵn trong SAS -
| Sr.No. | Cửa sổ SAS & Cách sử dụng của chúng |
|---|---|
| 1 | Temporary or Work Library Đây là thư viện mặc định của SAS. Tất cả các chương trình mà chúng tôi tạo được lưu trữ trong thư viện công việc này nếu chúng tôi không gán bất kỳ thư viện nào khác cho chúng. Bạn có thể kiểm tra thư viện công việc này trong Cửa sổ Khám phá. Nếu bạn tạo một chương trình SAS và chưa gán bất kỳ thư viện cố định nào cho nó thì nếu bạn kết thúc phiên làm việc sau đó bạn khởi động lại phần mềm thì chương trình này sẽ không có trong thư viện công việc. Bởi vì nó sẽ chỉ ở đó trong thư viện Work miễn là phiên hoạt động. |
| 2 | Permanent Library Đây là các thư viện thường trực của SAS. Chúng ta có thể tạo một thư viện SAS mới bằng cách sử dụng các tiện ích SAS hoặc bằng cách viết mã trong cửa sổ trình soạn thảo. Các thư viện này được đặt tên là vĩnh viễn bởi vì nếu chúng ta tạo một chương trình trong SAS và lưu nó trong các thư viện cố định này thì chúng sẽ có sẵn miễn là chúng ta muốn. |
SAS Institute Inc. đã phát hành một SAS University Editionđủ tốt để học lập trình SAS. Nó cung cấp tất cả các tính năng mà bạn cần học trong lập trình BASE SAS, từ đó cho phép bạn học bất kỳ thành phần SAS nào khác.
Quá trình tải xuống và cài đặt SAS University Edition diễn ra rất đơn giản. Nó có sẵn dưới dạng một máy ảo cần chạy trên môi trường ảo. Bạn cần phải cài đặt phần mềm ảo hóa trong PC trước khi có thể chạy phần mềm SAS. Trong hướng dẫn này, chúng tôi sẽ sử dụngVMware. Dưới đây là chi tiết các bước để tải xuống, thiết lập môi trường SAS và xác minh cài đặt.
Tải xuống SAS University Edition
SAS University Editioncó sẵn để tải xuống tại URL SAS University Edition . Vui lòng cuộn xuống để đọc các yêu cầu hệ thống trước khi bạn bắt đầu tải xuống. Màn hình sau xuất hiện khi truy cập URL này.
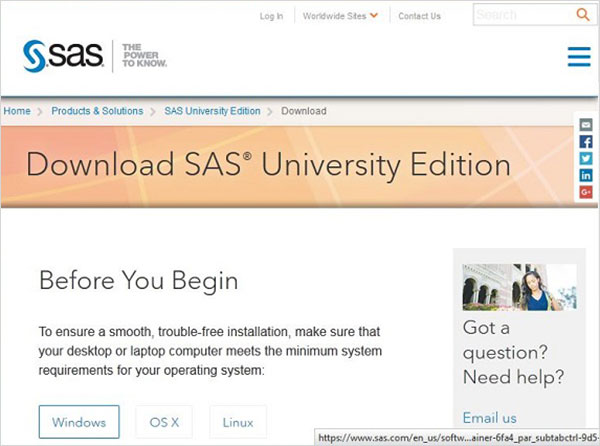
Thiết lập phần mềm ảo hóa
Cuộn xuống trên cùng một trang để tìm bước cài đặt-1. Bước này cung cấp các liên kết để có được phần mềm ảo hóa phù hợp với bạn. Trong trường hợp bạn đã cài đặt bất kỳ một trong những phần mềm này trong hệ thống của mình, bạn có thể bỏ qua bước này.

Khởi động nhanh phần mềm ảo hóa
Trong trường hợp bạn hoàn toàn mới làm quen với môi trường ảo hóa, bạn có thể tự làm quen với nó bằng cách xem qua các hướng dẫn và video sau đây ở bước 2. Một lần nữa, bạn có thể bỏ qua bước này trong trường hợp bạn đã quen thuộc.

Tải xuống tệp Zip
Trong bước 3, bạn có thể chọn phiên bản thích hợp của SAS University Edition tương thích với môi trường ảo hóa mà bạn có. Nó tải xuống dưới dạng tệp zip có tên tương tự như unvbasicvapp__9411005__vmx__en__sp0__1.zip
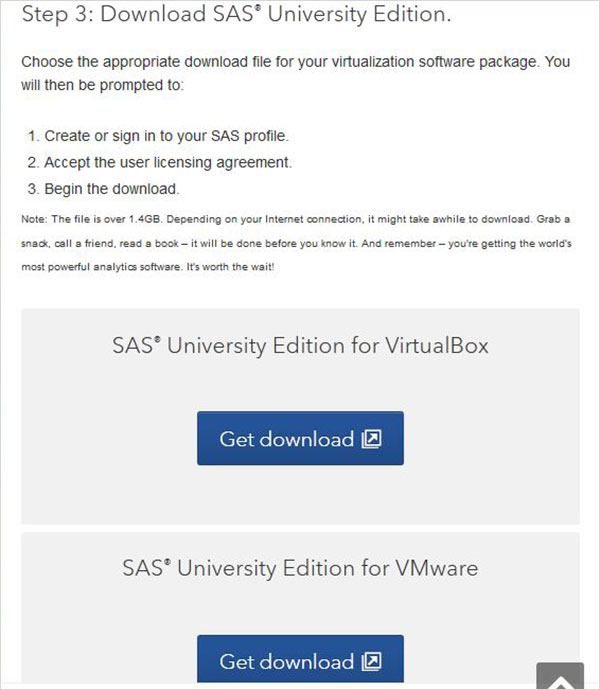
Giải nén tệp zip
Tệp zip ở trên cần được giải nén và lưu trữ trong một thư mục thích hợp. Trong trường hợp của chúng tôi, chúng tôi đã chọn tệp zip VMware hiển thị các tệp sau sau khi giải nén.
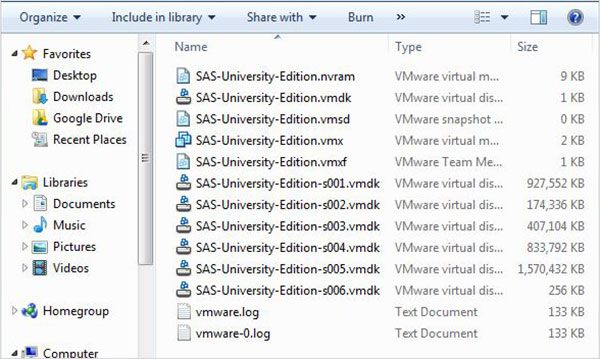
Đang tải máy ảo
Khởi động trình phát VMware (hoặc máy trạm) và mở tệp kết thúc bằng phần mở rộng .vmx. Màn hình dưới đây xuất hiện. Vui lòng lưu ý các cài đặt cơ bản như bộ nhớ và không gian đĩa cứng được phân bổ cho vm.
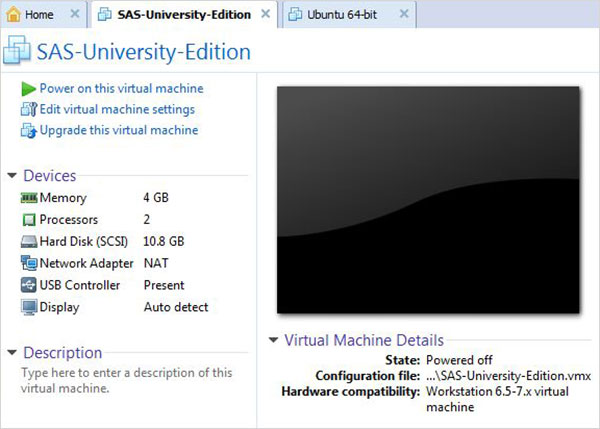
Bật máy ảo
Nhấn vào Power on this virtual machinecùng với dấu mũi tên màu xanh lục để khởi động máy ảo. Màn hình sau xuất hiện.

Màn hình bên dưới xuất hiện khi SAS vm ở trạng thái tải, sau đó vm đang chạy đưa ra lời nhắc chuyển đến vị trí URL sẽ mở môi trường SAS.
Khởi động SAS studio
Mở tab trình duyệt mới và tải URL ở trên (URL này khác với PC này sang PC khác). Màn hình bên dưới xuất hiện cho biết môi trường SAS đã sẵn sàng.
Môi trường SAS
Khi nhấp vào Start SAS Studio chúng ta nhận được môi trường SAS theo mặc định sẽ mở ở chế độ lập trình viên trực quan như hình dưới đây.
Chúng tôi cũng có thể thay đổi nó thành chế độ lập trình viên SAS bằng cách nhấp vào trình đơn thả xuống.
Bây giờ chúng tôi đã sẵn sàng để viết các Chương trình SAS.
Chương trình SAS được tạo bằng giao diện người dùng được gọi là SAS Studio.
Dưới đây là mô tả về các cửa sổ khác nhau và cách sử dụng chúng.
Cửa sổ chính của SAS
Đây là cửa sổ bạn thấy khi vào môi trường SAS. Ở bên trái làNavigation Paneđược sử dụng để điều hướng các tính năng lập trình khác nhau. Ở bên phải làWork Area được sử dụng để viết mã và thực thi nó.

Tự động điền mã
Đây là một tính năng rất mạnh giúp nhận được cú pháp chính xác của các từ khóa SAS cũng như cung cấp liên kết đến tài liệu cho từ khóa đó.
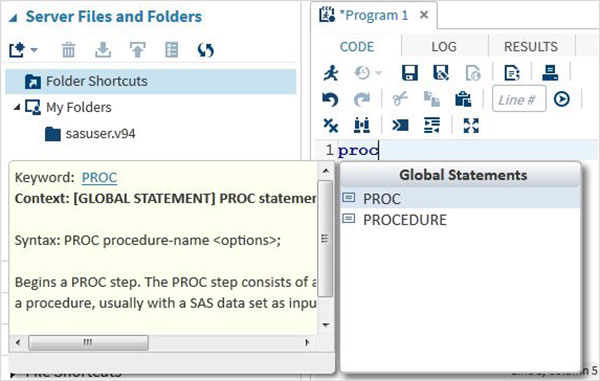
Thực hiện chương trình
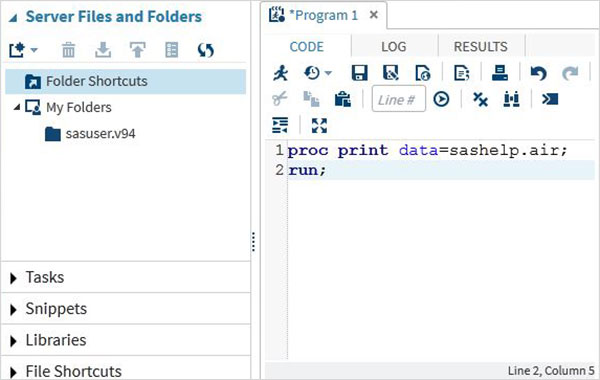
Việc thực thi mã được thực hiện bằng cách nhấn biểu tượng chạy, là biểu tượng đầu tiên từ bên trái hoặc nút F3.
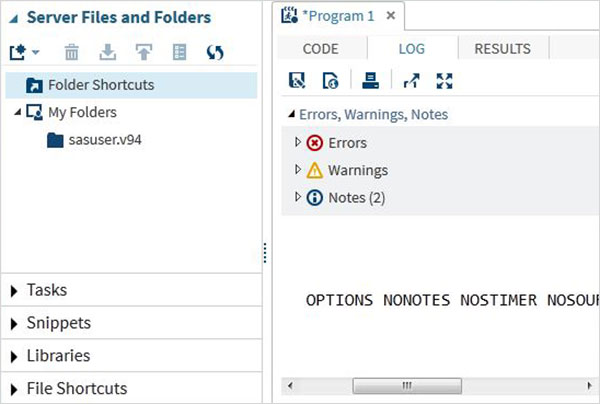
Nhật ký chương trình
Nhật ký của mã được thực thi có sẵn trong Logchuyển hướng. Nó mô tả các lỗi, cảnh báo hoặc ghi chú về việc thực hiện chương trình. Đây là cửa sổ nơi bạn nhận được tất cả các manh mối để khắc phục sự cố mã của mình.
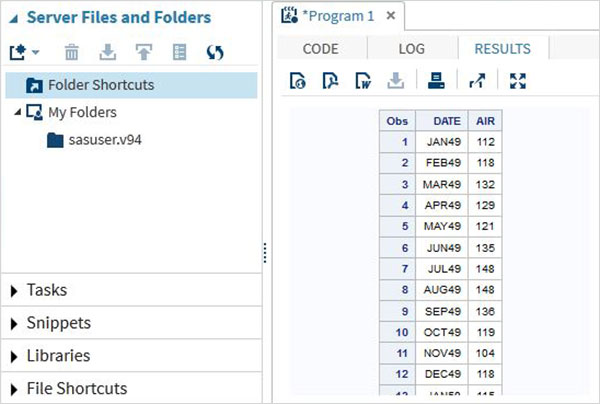
Kết quả chương trình
Kết quả của việc thực thi mã được xem trong tab KẾT QUẢ. Theo mặc định, chúng được định dạng dưới dạng bảng html.
Tab chương trình
The Navigation Area contains features to create and manage programs. It also provides the pre-built functionalities to be used with your program.
Server Files and Folders
Under this tab we can create additional programs, import data to be analyzed and query the existing data. It can also be used to create folder shortcuts.
Tasks
The Tasks tab provides features to use in-built SAS programs by supplying only the input variables. For example under the statistics folder you can find a SAS program to do linear regression by only supplying the SAS data set name and variable names.
Snippets
The snippets tab provides features to write SAS Macro and generate files from the existing data set

Program Libraries
SAS stores the datasets in SAS libraries. The temporary library is available only for a single session and it is named as WORK. But the permanent libraries are available always.
File Shortcuts
This tab is used to access files which are stored outside the SAS environment. The shortcuts to such files are stored under this tab.
The SAS Programming involves first creating/reading the data sets into the memory and then doing the analysis on this data. We need to understand the flow in which a program is written to achieve this.
SAS Program Structure
The below diagram shows the steps to be written in the given sequence to create a SAS Program.
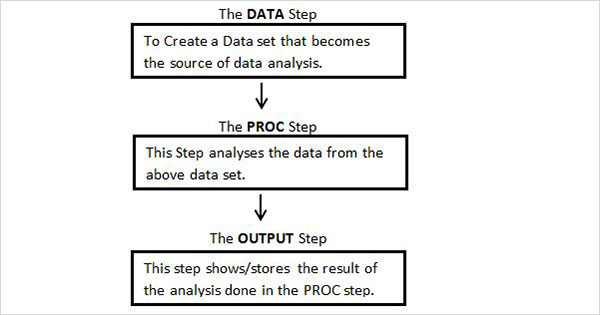
Every SAS program must have all these steps to complete reading the input data, analysing the data and giving the output of the analysis. Also the RUN statement at the end of each step is required to complete the execution of that step.
DATA Step
This step involves loading the required data set into SAS memory and identifying the variables (also called columns) of the data set. It also captures the records (also called observations or subjects). The syntax for DATA statement is as below.
Syntax
DATA data_set_name; #Name the data set.
INPUT var1,var2,var3; #Define the variables in this data set.
NEW_VAR; #Create new variables.
LABEL; #Assign labels to variables.
DATALINES; #Enter the data.
RUN;Example
The below example shows a simple case of naming the data set, defining the variables, creating new variables and entering the data. Here the string variables have a $ at the end and numeric values are without it.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
comm = SALARY*0.25;
LABEL ID = 'Employee ID' comm = 'COMMISION';
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;PROC Step
This step involves invoking a SAS built-in procedure to analyse the data.
Syntax
PROC procedure_name options; #The name of the proc.
RUN;Example
The below example shows using the MEANS procedure to print the mean values of the numeric variables in the data set.
PROC MEANS;
RUN;The OUTPUT Step
The data from the data sets can be displayed with conditional output statements.
Syntax
PROC PRINT DATA = data_set;
OPTIONS;
RUN;Example
The below example shows using the where clause in the output to produce only few records from the data set.
PROC PRINT DATA = TEMP;
WHERE SALARY > 700;
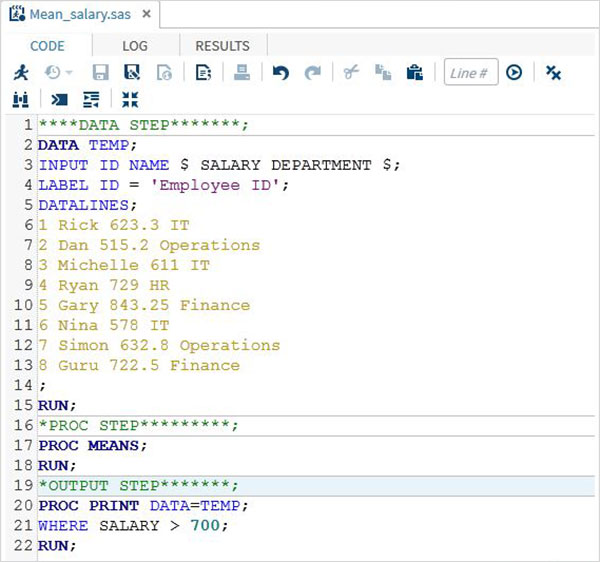
RUN;The complete SAS Program
Below is the complete code for each of the above steps.
Program Output
RESULTS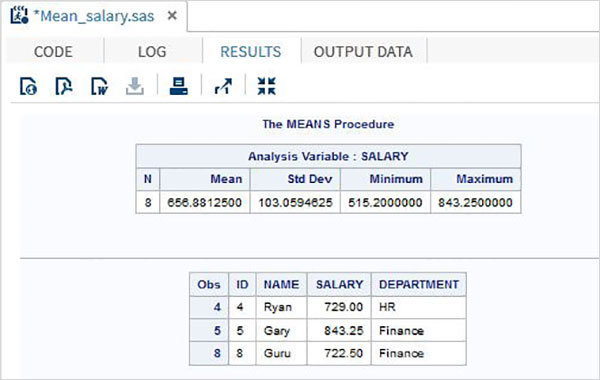
Like any other programming language, the SAS language has its own rules of syntax to create the SAS programs.
The three components of any SAS program - Statements, Variables and Data sets follow the below rules on Syntax.
SAS Statements
Statements can start anywhere and end anywhere. A semicolon at the end of the last line marks the end of the statement.
Many SAS statements can be on the same line, with each statement ending with a semicolon.
Space can be used to separate the components in a SAS program statement.
SAS keywords are not case sensitive.
Every SAS program must end with a RUN statement.
SAS Variable Names
Variables in SAS represent a column in the SAS data set. The variable names follow the below rules.
It can be maximum 32 characters long.
It can not include blanks.
It must start with the letters A through Z (not case sensitive) or an underscore (_).
Can include numbers but not as the first character.
Variable names are case insensitive.
Example
# Valid Variable Names
REVENUE_YEAR
MaxVal
_Length
# Invalid variable Names
Miles Per Liter #contains Space.
RainfFall% # contains apecial character other than underscore.
90_high # Starts with a number.SAS Data Set
The DATA statement marks the creation of a new SAS data set. The rules for DATA set creation are as below.
A single word after the DATA statement indicates a temporary data set name. Which means the data set gets erased at the end of the session.
The data set name can be prefixed with a library name which makes it a permanent data set. Which means the data set persists after the session is over.
If the SAS data set name is omitted then SAS creates a temporary data set with a name generated by SAS like - DATA1, DATA2 etc.
Example
# Temporary data sets.
DATA TempData;
DATA abc;
DATA newdat;
# Permanent data sets.
DATA LIBRARY1.DATA1
DATA MYLIB.newdat;SAS File Extensions
The SAS programs, data files and the results of the programs are saved with various extensions in windows.
*.sas − It represents the SAS code file which can be edited using the SAS Editor or any text editor.
*.log − It represents the SAS Log File it contains information such as errors, warnings, and data set details for a submitted SAS program.
*.mht / *.html −It represents the SAS Results file.
*.sas7bdat −It represents SAS Data File which contains a SAS data set including variable names, labels, and the results of calculations.
Comments in SAS
Comments in SAS code are specified in two ways. Below are these two formats.
*message; type comment
A comment in the form of *message; can not contain semicolons or unmatched quotation mark inside it. Also there should not be any reference to any macro statements inside such comments. It can span multiple lines and can be of any length.. Following is a single line comment example −
* This is comment ;Following is a multiline comment example −
* This is first line of the comment
* This is second line of the comment;/*message*/ type comment
A comment in the form of /*message*/ is used more frequently and it can not be nested. But it can span multiple lines and can be of any length. Following is a single line comment example −
/* This is comment */Following is a multiline comment example −
/* This is first line of the comment
* This is second line of the comment */The data that is available to a SAS program for analysis is referred as a SAS Data Set. It is created using the DATA step.SAS can read a variety of files as its data sources like CSV, Excel, Access, SPSS and also raw data. It also has many in-built data sources available for use.
The Data Sets are called temporary Data Set if they are used by the SAS program and then discarded after the session is run.
But if it is stored permanently for future use then it is called a permanent Data set. All permanent Data Sets are stored under a specific library.
The SAS Data set is stored in form of rows and columns and also referred as SAS Data table.Below we see the examples of permanent Data sets which are in-built as well as red from external sources.
SAS Built-In Data Sets
These Data Sets are already available in the installed SAS software. They can be explored and used in formulating sample expressions for data analysis. To explore these data sets go to Libraries -> My Libraries -> SASHELP. On expanding it we see the list of names of all the built-in Data Sets available.
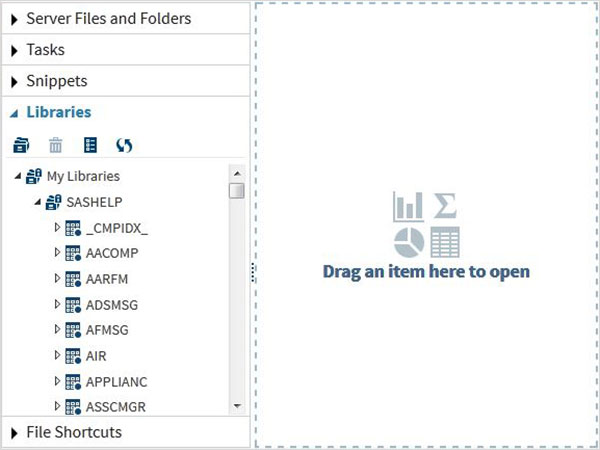
Lets scroll down to locate a Data Set named CARS.Double clicking on this Data Set opens it in the right window pane where we can explore it further.We can also minimize the left pane by using the maximize view button under the right pane.
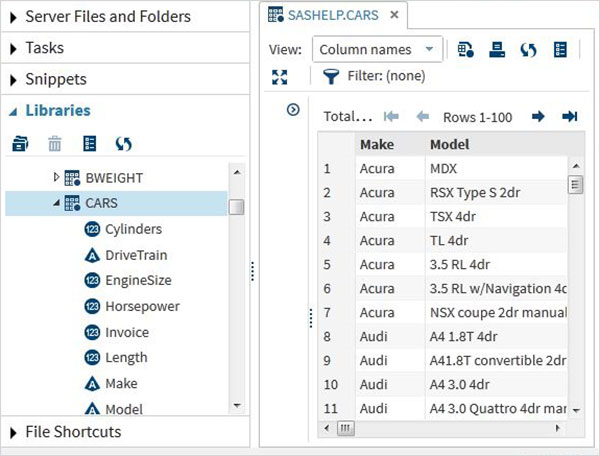
We can scroll to the right using the scroll bar in the bottom to explore all the columns and theirs values in the table.
Importing External Data Sets
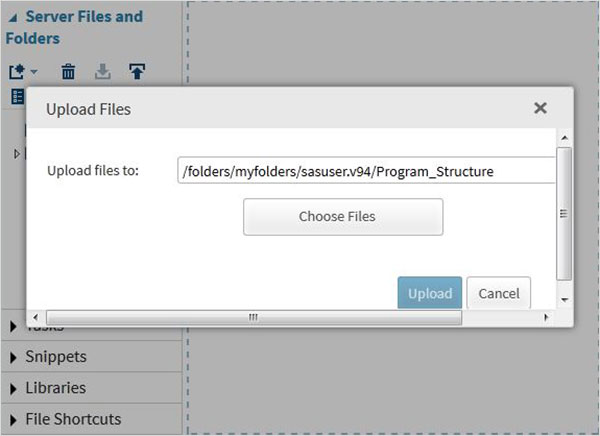
We can export our own files as Data sets by using the import feature available in SAS Studio. But these files must be available in the SAS server folders. So we have to upload the source data files to SAS folder by using the upload option under the Server Files and Folders.
Next we use the above file in a SAS program by importing it. To do this we use the option Tasks -> Utilities -> Import data as shown below. Double click the Import Data button which opens up the window in the right to choose the file for the Data Set.
Next Click on the Select Files button under the import data program in the right pane. The following are the list of the file types which can be imported.
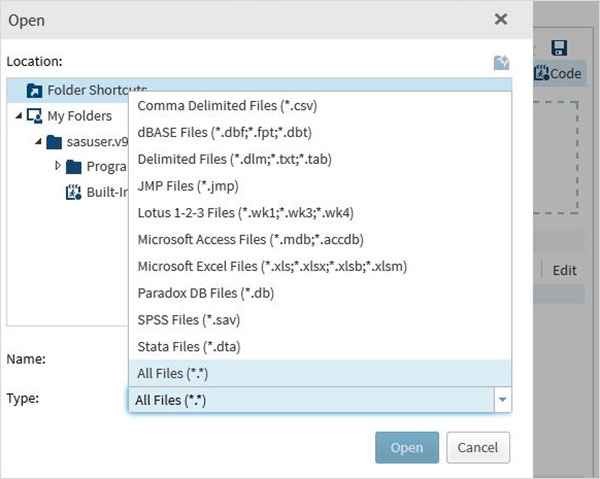
We choose the "employee.txt" file stored in the local system and get the file imported as shown below.
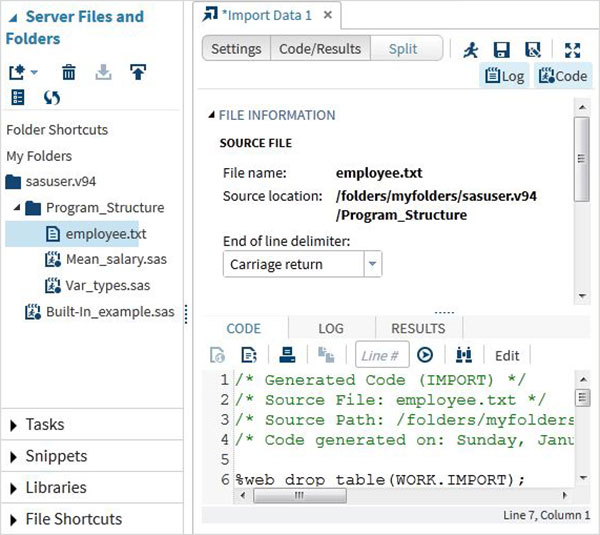
View the imported data
We can view the imported data by running the default import code generated using the Run option
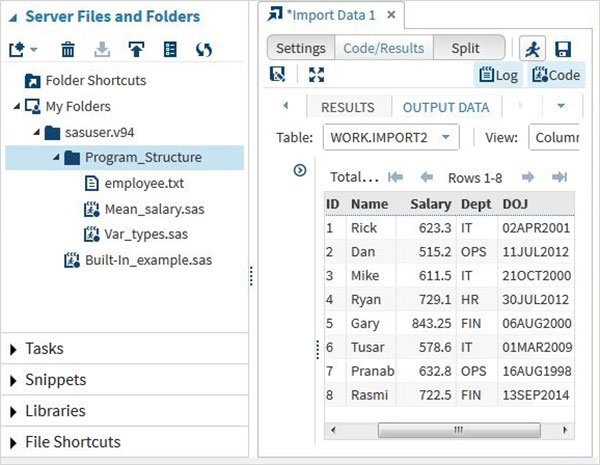
We can import any other file types using the same approach as above and use it in various SAS programs.
In general variables in SAS represent the column names of the data tables it is analysing. But it can also be used for other purpose like using it as a counter in a programming loop. In the current chapter we will see the use of SAS variables as column names of SAS Data Set.
SAS Variable Types
SAS has three types of variables as below −
Numeric Variables
This is the default variable type. These variables are used in mathematical expressions.
Syntax
INPUT VAR1 VAR2 VAR3; #Define numeric variables in the data set.In the above syntax, the INPUT statement shows the declaration of numeric variables.
Example
INPUT ID SALARY COMM_PERCENT;Character Variables
Character variables are used for values that are not used in Mathematical expressions. They are treated as text or strings. A variable becomes a character variable by adding a $ sing with a space at the end of the variable name.
Syntax
INPUT VAR1 $ VAR2 $ VAR3 $; #Define character variables in the data set.In the above syntax, the INPUT statement shows the declaration of character variables.
Example
INPUT FNAME $ LNAME $ ADDRESS $;Date Variables
These variables are treated only as dates and they need to be in valid date formats. A variable becomes a date variable by adding a date format with a space at the end of the variable name.
Syntax
INPUT VAR1 DATE11. VAR2 MMDDYY10. ; #Define date variables in the data set.In the above syntax, the INPUT statement shows the declaration of date variables.
Example
INPUT DOB DATE11. START_DATE MMDDYY10. ;Use of Variables in SAS Program
The above variables are used in SAS program as shown in below examples.
Example
The below code shows how the three types of variables are declared and used in a SAS Program
DATA TEMP;
INPUT ID NAME $ SALARY DEPT $ DOJ DATE9. ;
FORMAT DOJ DATE9. ;
DATALINES;
1 Rick 623.3 IT 02APR2001
2 Dan 515.2 OPS 11JUL2012
3 Michelle 611 IT 21OCT2000
4 Ryan 729 HR 30JUL2012
5 Gary 843.25 FIN 06AUG2000
6 Tusar 578 IT 01MAR2009
7 Pranab 632.8 OPS 16AUG1998
8 Rasmi 722.5 FIN 13SEP2014
;
PROC PRINT DATA = TEMP;
RUN;In the above example all the character variables are declared followed by a $ sign and the date variables are declared followed by a date format. The output of the above program is as below.
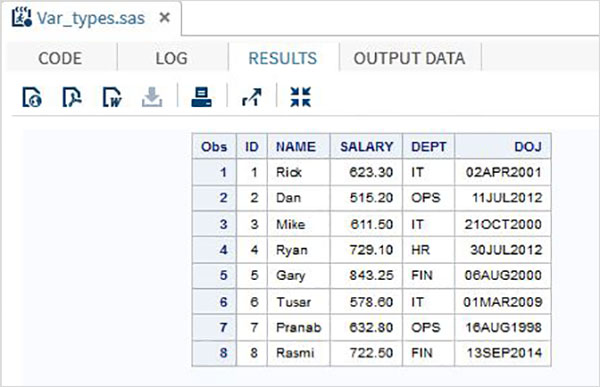
Using the Variables
The variables are very useful in analysing the data. They are used in expressions in which the statistical analysis is applied. Let’s see an example of analysing the built-in Data Set named CARS which is present under Libraries → My Libraries → SASHELP. Double click on it to explore the variables and their data types.

Next we can produce a summary statistics of some of these variables using the Tasks options in SAS studio. Go to Tasks -> Statistics -> Summary Statistics and double click it to open the window as shown below. Choose Data Set SASHELP.CARS and select the three variables - MPG_CITY, MPG_Highway and Weight under the Analysis Variables. Hold the Ctrl key while selecting the variables by clicking. Click run.

Click on the results tab after the above steps. It shows the statistical summary of the three variables chosen. The last column indicates number of observations (records) used in the analysis.
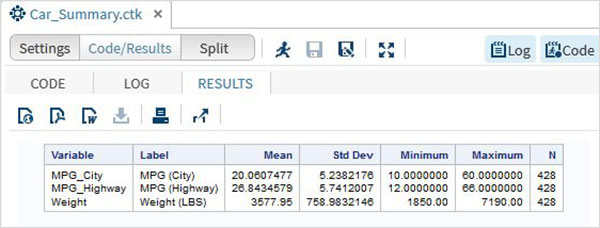
Strings in SAS are the values which are enclosed with in a pair of single quotes. Also the string variables are declared by adding a space and $ sign at the end of the variable declaration. SAS has many powerful functions to analyze and manipulate strings.
Declaring String Variables
We can declare the string variables and their values as shown below. In the code below we declare two character variables of lengths 6 and 5. The LENGTH keyword is used for declaring variables without creating multiple observations.
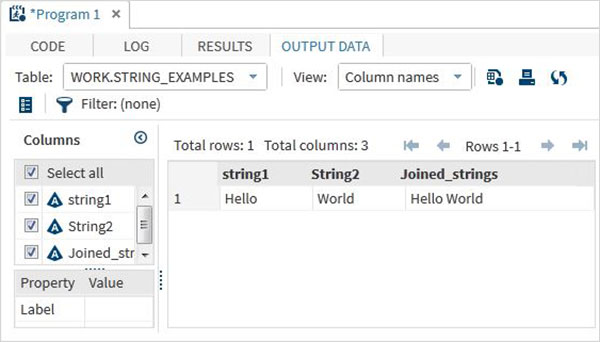
data string_examples;
LENGTH string1 $ 6 String2 $ 5;
/*String variables of length 6 and 5 */
String1 = 'Hello';
String2 = 'World';
Joined_strings = String1 ||String2 ;
run;
proc print data = string_examples noobs;
run;On running the above code we get the output which shows the variable names and their values.
String Functions
Below are the examples of some SAS functions which are used frequently.
SUBSTRN
This function extracts a substring using the start and end positions. In case of no end position is mentioned it extracts all the characters till end of the string.
Syntax
SUBSTRN('stringval',p1,p2)Following is the description of the parameters used −
- stringval is the value of the string variable.
- p1 is the start position of extraction.
- p2 is the final position of extraction.
Example
data string_examples;
LENGTH string1 $ 6 ;
String1 = 'Hello';
sub_string1 = substrn(String1,2,4) ;
/*Extract from position 2 to 4 */
sub_string2 = substrn(String1,3) ;
/*Extract from position 3 onwards */
run;
proc print data = string_examples noobs;
run;On running the above code we get the output which shows the result of substrn function.

TRIMN
This function removes the trailing space form a string.
Syntax
TRIMN('stringval')Following is the description of the parameters used −
- stringval is the value of the string variable.
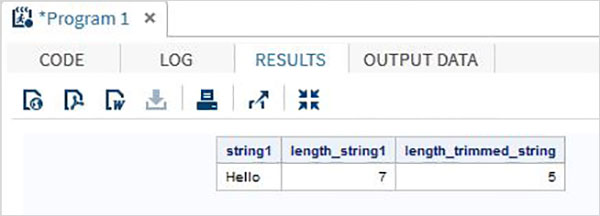
data string_examples;
LENGTH string1 $ 7 ;
String1='Hello ';
length_string1 = lengthc(String1);
length_trimmed_string = lengthc(TRIMN(String1));
run;
proc print data = string_examples noobs;
run;On running the above code we get the output which shows the result of TRIMN function.
Arrays in SAS are used to store and retrieve a series of values using an index value. The index represents the location in a reserved memory area.
Syntax
In SAS an array is declared by using the following syntax −
ARRAY ARRAY-NAME(SUBSCRIPT) ($) VARIABLE-LIST ARRAY-VALUESIn the above syntax −
ARRAY is the SAS keyword to declare an array.
ARRAY-NAME is the name of the array which follows the same rule as variable names.
SUBSCRIPT is the number of values the array is going to store.
($) is an optional parameter to be used only if the array is going to store character values.
VARIABLE-LIST is the optional list of variables which are the place holders for array values.
ARRAY-VALUES are the actual values that are stored in the array. They can be declared here or can be read from a file or dataline.
Examples of Array Declaration
Arrays can be declared in many ways using the above syntax. Below are the examples.
# Declare an array of length 5 named AGE with values.
ARRAY AGE[5] (12 18 5 62 44);
# Declare an array of length 5 named COUNTRIES with values starting at index 0.
ARRAY COUNTRIES(0:8) A B C D E F G H I;
# Declare an array of length 5 named QUESTS which contain character values.
ARRAY QUESTS(1:5) $ Q1-Q5;
# Declare an array of required length as per the number of values supplied.
ARRAY ANSWER(*) A1-A100;Accessing Array Values
The values stored in an array can be accessed by using the print procedure as shown below. After it is declared using one of the above methods, the data is supplied using DATALINES statement.
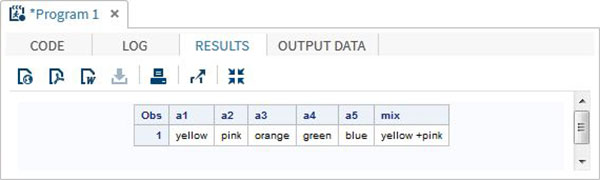
DATA array_example;
INPUT a1 $ a2 $ a3 $ a4 $ a5 $; ARRAY colours(5) $ a1-a5;
mix = a1||'+'||a2;
DATALINES;
yello pink orange green blue
;
RUN;
PROC PRINT DATA = array_example;
RUN;When we execute above code, it produces following result −
Using the OF operator
The OF operator is used when analysing the data forma an Array to perform calculations on the entire row of an array. In the below example we apply the Sum and Mean of values in each row.
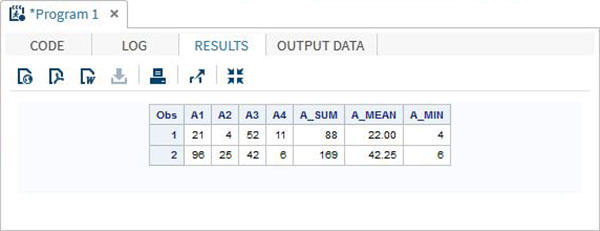
DATA array_example_OF;
INPUT A1 A2 A3 A4;
ARRAY A(4) A1-A4;
A_SUM = SUM(OF A(*));
A_MEAN = MEAN(OF A(*));
A_MIN = MIN(OF A(*));
DATALINES;
21 4 52 11
96 25 42 6
;
RUN;
PROC PRINT DATA = array_example_OF;
RUN;When we execute above code, it produces following result −
Using the IN operator
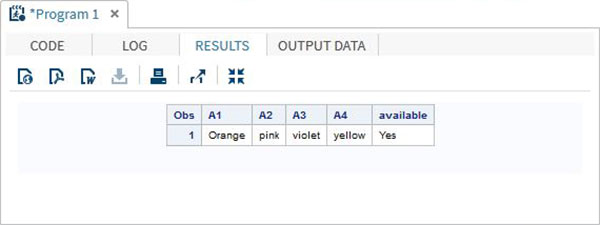
The value in an array can also be accessed using the IN operator which checks for the presence of a value in the row of the array. In the below example we check for the availability of the colour "Yellow" in the data. This value is case sensitive.
DATA array_in_example;
INPUT A1 $ A2 $ A3 $ A4 $;
ARRAY COLOURS(4) A1-A4;
IF 'yellow' IN COLOURS THEN available = 'Yes';ELSE available = 'No';
DATALINES;
Orange pink violet yellow
;
RUN;
PROC PRINT DATA = array_in_example;
RUN;When we execute above code, it produces following result −
SAS can handle a wide variety of numeric data formats. It uses these formats at the end of the variable names to apply a specific numeric format to the data. SAS use two kinds of numeric formats. One for reading specific formats of the numeric data which is called informat and another for displaying the numeric data in specific format called as output format.
Syntax
The Syntax for a numeric informat is −
Varname Formatnamew.dFollowing is the description of the parameters used −
Varname is the name of the variable.
Formatname is the name of the name of the numeric format applied to the variable.
w is the maximum number of data columns (including digits after decimal & the decimal point itself) allowed to be stored for the variable.
d is the number of digits to the right of the decimal.
Reading Numeric formats
Below is a list of formats used for reading the data into SAS.
Input Numeric Formats
| Format | Use |
|---|---|
| n. | Maximum "n" number of columns with no decimal point. |
| n.p | Maximum "n" number of columns with "p" decimal points. |
| COMMAn.p | Maximum "n" number of columns with "p" decimal places which removes any comma or dollar signs. |
| COMMAn.p | Maximum "n" number of columns with "p" decimal places which removes any comma or dollar signs. |
Displaying Numeric formats
Similar to applying format while reading the data, below is a list of formats used for displaying the data in the output of a SAS program.
Output Numeric Formats
| Format | Use |
|---|---|
| n. | Write maximum "n" number of digits with no decimal point. |
| n.p | Write maximum "n.p" number of columns with "p" decimal points. |
| DOLLARn.p | Write maximum "n" number of columns with p decimal places, leading dollar sign and a comma at the thousandth place. |
Please Note −
If the number of digits after the decimal point is less than the format specifier thenzeros will be appended at the end.
If the number of digits after the decimal point is greater than the format specifier then the last digit will be rounded off.
Examples
Below examples illustrate above scenarios.
DATA MYDATA1;
input x 6.; /*maxiiuum width of the data*/
format x 6.3;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA1;
RUN;
DATA MYDATA2;
input x 6.; /*maximum width of the data*/
format x 5.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA2;
RUN;
DATA MYDATA3;
input x 6.; /*maximum width of the data*/
format x DOLLAR10.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA3;
RUN;When we execute above code, it produces following result −
# MYDATA1.
Obs x
1 8722.0 # Display 6 columns with zero appended after decimal.
2 93.200 # Display 6 columns with zero appended after decimal.
3 0.112 # No integers before decimal, so display 3 available digits after decimal.
4 15.116 # Display 6 columns with 3 available digits after decimal.
# MYDATA2
Obs x
1 8722 # Display 5 columns. Only 4 are available.
2 93.20 # Display 5 columns with zero appended after decimal.
3 0.11 # Display 5 columns with 2 places after decimal.
4 15.12 # Display 5 columns with 2 places after decimal.
# MYDATA3
Obs x
1 $8,722.00 # Display 10 columns with leading $ sign, comma at thousandth place and zeros appended after decimal.
2 $93.20 # Only 2 integers available before decimal and one available after the decimal. 3 $0.11 # No integers available before decimal and two available after the decimal.
4 $15.12 # Only 2 integers available before decimal and two available after the decimal.An operator in SAS is a symbol which is used in a mathematical, logical or comparison expression. These symbols are in-built into the SAS language and many operators can be combined in a single expression to give a final output.
Below is a list of SAS category of operators.
- Arithmetic Operators
- Logical Operators
- Comparison Operators
- Minimum/Maximum Operators
- Concatenation Operator
We will look at each of the one by one. The operators are always used with variables that are part of the data that is being analyzed by the SAS program.
Arithmetic Operators
The below table describes the details of the arithmetic operators. Let’s assume two data variables V1 and V2with values 8 and 4 respectively.
| Operator | Description | Example |
|---|---|---|
| + | Addition | V1+V2=12 |
| - | Subtraction | V1-V2=4 |
| * | Multiplication | V1*V2=32 |
| / | Division | V1/V2=2 |
| ** | Exponentiation | V1**V2=4096 |
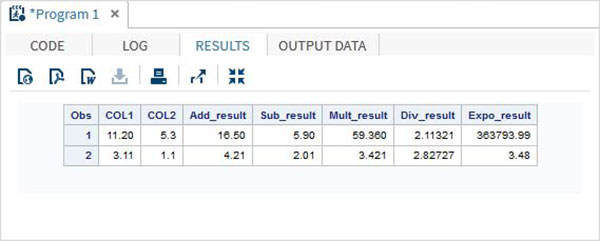
Example
DATA MYDATA1;
input @1 COL1 4.2 @7 COL2 3.1;
Add_result = COL1+COL2;
Sub_result = COL1-COL2;
Mult_result = COL1*COL2;
Div_result = COL1/COL2;
Expo_result = COL1**COL2;
datalines;
11.21 5.3
3.11 11
;
PROC PRINT DATA = MYDATA1;
RUN;On running the above code, we get the following output.
Logical Operators
The below table describes the details of the logical operators. These operators evaluate the Truth value of an expression. So the result of logical operators is always a 1 or a 0. Let’s assume two data variables V1 and V2with values 8 and 4 respectively.
| Operator | Description | Example |
|---|---|---|
| & | The AND Operator. If both data values evaluate to true then the result is 1 else it is 0. | (V1>2 & V2 > 3) gives 0. |
| | | The OR Operator. If any one of the data values evaluate to true then the result is 1 else it is 0. | (V1>9 & V2 > 3) is 1. |
| ~ | The NOT Operator. The result of NOT operator in form of an expression whose value is FALSE or a missing value is 1 else it is 0. | NOT(V1 > 3) is 1. |
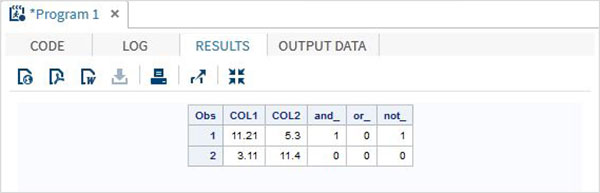
Example
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
and_=(COL1 > 10 & COL2 > 5 );
or_ = (COL1 > 12 | COL2 > 15 );
not_ = ~( COL2 > 7 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;On running the above code, we get the following output.
Comparison Operators
The below table describes the details of the comparison operators. These operators compare the values of the variables and the result is a truth value presented by 1 for TRUE and 0 for False. Let’s assume two data variables V1 and V2with values 8 and 4 respectively.
| Operator | Description | Example |
|---|---|---|
| = | The EQUAL Operator. If both data values are equal then the result is 1 else it is 0. | (V1 = 8) gives 1. |
| ^= | The NOT EQUAL Operator. If both data values are unequal then the result is 1 else it is 0. | (V1 ^= V2) gives 1. |
| < | The LESS THAN Operator. | (V2 < V2) gives 1. |
| <= | The LESS THAN or EQUAL TO Operator. | (V2 <= 4) gives 1. |
| > | The GREATER THAN Operator. | (V2 > V1) gives 1. |
| >= | The GREATER THAN or EQUAL TO Operator. | (V2 >= V1) gives 0. |
| IN | The IN Operator. If the value of the variable is equal to any one of the values in a given list of values, then it returns 1 else it returns 0. | V1 in (5,7,9,8) gives 1. |
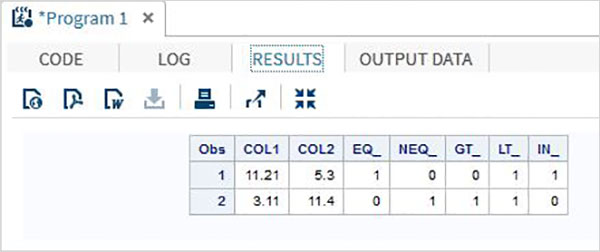
Example
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
EQ_ = (COL1 = 11.21);
NEQ_= (COL1 ^= 11.21);
GT_ = (COL2 => 8);
LT_ = (COL2 <= 12);
IN_ = COL2 in( 6.2,5.3,12 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;On running the above code, we get the following output.
Minimum/Maximum Operators
The below table describes the details of the Minimum/Maximum operators. These operators compare the values of the variables across a row and the minimum or maximum value from the list of values in the rows is returned.
| Operator | Description | Example |
|---|---|---|
| MIN | The MIN Operator. It returns the minimum value form the list of values in the row. | MIN(45.2,11.6,15.41) gives 11.6 |
| MAX | The MAX Operator. It returns the maximum value form the list of values in the row. | MAX(45.2,11.6,15.41) gives 45.2 |
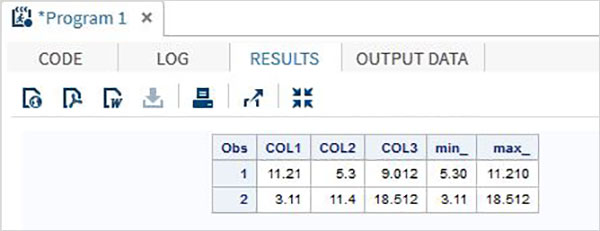
Example
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1 @12 COL3 6.3;
min_ = MIN(COL1 , COL2 , COL3);
max_ = MAX( COL1, COl2 , COL3);
datalines;
11.21 5.3 29.012
3.11 11.4 18.512
;
PROC PRINT DATA = MYDATA1;
RUN;On running the above code, we get the following output.
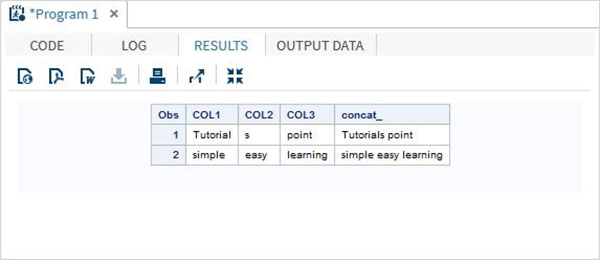
Concatenation Operator
The below table describes the details of the Concatenation operator. This operator concatenates two or more string values. A single character value is returned.
| Operator | Description | Example |
|---|---|---|
| || | The concatenate Operator. It returns the concatenation of two or more values. | 'Hello'||' World' gives Hello World |
Example
DATA MYDATA1;
input COL1 $ COL2 $ COL3 $;
concat_ = (COL1 || COL2 || COL3);
datalines;
Tutorial s point
simple easy learning
;
PROC PRINT DATA = MYDATA1;
RUN;On running the above code, we get the following output.
Operators Precedence
The operator precedence indicates the order of evaluation of the multiple operators present in complex expression. The below table describes the order of precedence with in a group of operators.
| Group | Order | Symbols |
|---|---|---|
| Group I | Right to Left | ** + - NOT MIN MAX |
| Group II | Left to Right | * / |
| Group III | Left to Right | + - |
| Group IV | Left to Right | || |
| Group V | Left to Right | < <= = >= > |
You may encounter situations, when a block of code needs to be executed several number of times. In general, statements are executed sequentially − The first statement in a function is executed first, followed by the second, and so on. But when you want the same set of statements to be executed again and again, we need the help of Loops.
In SAS looping is done by using DO statement. It is also called DO Loop. Given below is the general form of a DO loop statements in SAS.
Flow Diagram

Following are the types of DO loops in SAS.
| Sr.No. | Loop Type & Description |
|---|---|
| 1 | DO Index. The loop continues from the start value till the stop value of the index variable. |
| 2 | DO WHILE. The loop continues till the while condition becomes false. |
| 3 | DO UNTIL. The loop continues till the UNTIL condition becomes True. |
Decision making structures require the programmer to specify one or more conditions to be evaluated or tested by the program, along with a statement or statements to be executed if the condition is determined to be true, and optionally, other statements to be executed if the condition is determined to be false.
Following is the general form of a typical decision making structure found in most of the programming languages −
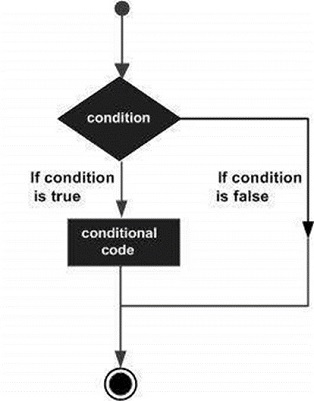
SAS provides following types of decision making statements. Click the following links to check their detail.
| Sr.No. | Statement Type & Description |
|---|---|
| 1 | IF Statement. An if statement consists of a condition. If the condition is true then the specific data is fetched. |
| 2 | IF-THEN-ELSE Statement. An if statement followed by else statement, which executes when the boolean condition is false. |
| 3 | IF-THEN-ELSE-IF Statement. An if statement followed by else statement, which is again followed by another pair of IF-THEN Statement. |
| 4 | IF-THEN-DELETE Statement. An if statement consists of acondition, which when true deletes the specific data from the observations. |
SAS has a wide variety of in built functions which help in analysing and processing the data. These functions are used as part of the DATA statements. They take the data variables as arguments and return the result which is stored into another variable. Depending on the type of function, the number of arguments it takes can vary. Some functions accept zero arguments while some other accept fixed number of variables. Below is a list of types of functions SAS provides.
Syntax
The general syntax for using a function in SAS is as below.
FUNCTIONNAME(argument1, argument2...argumentn)Here the argument can be a constant, variable, expression or another function.
Function Categories
Depending on their usage, the functions in SAS are categorised as below.
- Mathematical
- Date and Time
- Character
- Truncation
- Miscellaneous
Mathematical Functions
These are the functions used to apply some mathematical calculations on the variable values.
Examples
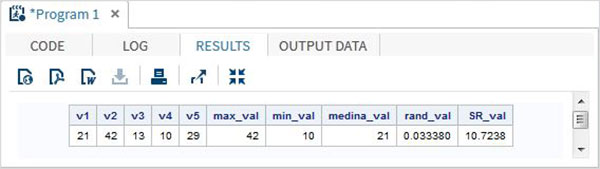
The below SAS program shows the use of some important mathematical functions.
data Math_functions;
v1=21; v2=42; v3=13; v4=10; v5=29;
/* Get Maximum value */
max_val = MAX(v1,v2,v3,v4,v5);
/* Get Minimum value */
min_val = MIN (v1,v2,v3,v4,v5);
/* Get Median value */
med_val = MEDIAN (v1,v2,v3,v4,v5);
/* Get a random number */
rand_val = RANUNI(0);
/* Get Square root of sum of the values */
SR_val= SQRT(sum(v1,v2,v3,v4,v5));
proc print data = Math_functions noobs;
run;When the above code is run, we get the following output −
Date and Time Functions
These are the functions used to process date and time values.
Examples
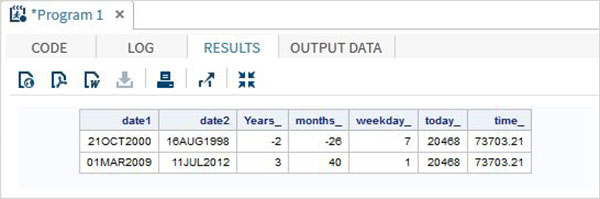
The below SAS program shows the use of date and time functions.
data date_functions;
INPUT @1 date1 date9. @11 date2 date9.;
format date1 date9. date2 date9.;
/* Get the interval between the dates in years*/
Years_ = INTCK('YEAR',date1,date2);
/* Get the interval between the dates in months*/
months_ = INTCK('MONTH',date1,date2);
/* Get the week day from the date*/
weekday_ = WEEKDAY(date1);
/* Get Today's date in SAS date format */
today_ = TODAY();
/* Get current time in SAS time format */
time_ = time();
DATALINES;
21OCT2000 16AUG1998
01MAR2009 11JUL2012
;
proc print data = date_functions noobs;
run;When the above code is run, we get the following output −
Character Functions
These are the functions used to process character or text values.
Examples
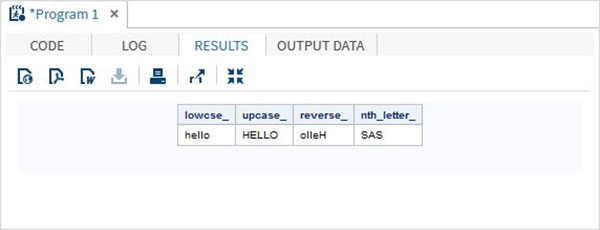
The below SAS program shows the use of character functions.
data character_functions;
/* Convert the string into lower case */
lowcse_ = LOWCASE('HELLO');
/* Convert the string into upper case */
upcase_ = UPCASE('hello');
/* Reverse the string */
reverse_ = REVERSE('Hello');
/* Return the nth word */
nth_letter_ = SCAN('Learn SAS Now',2);
run;
proc print data = character_functions noobs;
run;When the above code is run, we get the following output −
Truncation Functions
These are the functions used to truncate numeric values.
Examples
The below SAS program shows the use of truncation functions.
data trunc_functions;
/* Nearest greatest integer */
ceil_ = CEIL(11.85);
/* Nearest greatest integer */
floor_ = FLOOR(11.85);
/* Integer portion of a number */
int_ = INT(32.41);
/* Round off to nearest value */
round_ = ROUND(5621.78);
run;
proc print data = trunc_functions noobs;
run;Khi đoạn mã trên được chạy, chúng tôi nhận được kết quả sau:

Các chức năng khác
Bây giờ chúng ta hãy hiểu các chức năng khác nhau của SAS với một số ví dụ.
Ví dụ
Chương trình SAS dưới đây cho thấy việc sử dụng các chức năng Khác.
data misc_functions;
/* Nearest greatest integer */
state2=zipstate('01040');
/* Amortization calculation */
payment = mort(50000, . , .10/12,30*12);
proc print data = misc_functions noobs;
run;Khi đoạn mã trên được chạy, chúng tôi nhận được kết quả sau:

Các phương thức đầu vào được sử dụng để đọc dữ liệu thô. Dữ liệu thô có thể từ nguồn bên ngoài hoặc từ trong chuỗi dữ liệu. Câu lệnh đầu vào tạo một biến với tên mà bạn gán cho mỗi trường. Vì vậy, bạn phải tạo một biến trong Câu lệnh đầu vào. Biến tương tự sẽ được hiển thị trong đầu ra của SAS Dataset. Dưới đây là các phương thức nhập khác nhau có sẵn trong SAS.
- Danh sách phương thức nhập
- Phương thức nhập được đặt tên
- Phương thức nhập cột
- Phương thức nhập được định dạng
Chi tiết của từng phương thức nhập được mô tả như bên dưới.
Danh sách phương thức nhập
Trong phương pháp này, các biến được liệt kê với các kiểu dữ liệu. Dữ liệu thô được phân tích cẩn thận để thứ tự của các biến được khai báo khớp với dữ liệu. Dấu phân cách (thường là khoảng trắng) phải đồng nhất giữa bất kỳ cặp cột liền kề nào. Bất kỳ dữ liệu nào bị thiếu sẽ gây ra vấn đề trong đầu ra vì kết quả sẽ sai.
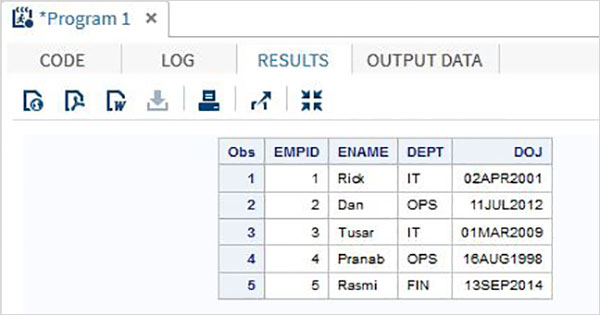
Thí dụ
Đoạn mã sau và đầu ra cho thấy việc sử dụng phương thức nhập danh sách.
DATA TEMP;
INPUT EMPID ENAME $ DEPT $ ;
DATALINES;
1 Rick IT
2 Dan OPS
3 Tusar IT
4 Pranab OPS
5 Rasmi FIN
;
PROC PRINT DATA = TEMP;
RUN;Khi chạy mã bove, chúng tôi nhận được kết quả sau.
Phương thức nhập được đặt tên
Trong phương pháp này, các biến được liệt kê với các kiểu dữ liệu. Dữ liệu thô được sửa đổi để có các tên biến được khai báo trước dữ liệu khớp. Dấu phân cách (thường là khoảng trắng) phải đồng nhất giữa bất kỳ cặp cột liền kề nào.
Thí dụ
Đoạn mã sau và đầu ra cho thấy việc sử dụng Phương thức nhập được đặt tên.
DATA TEMP;
INPUT
EMPID= ENAME= $ DEPT= $ ;
DATALINES;
EMPID = 1 ENAME = Rick DEPT = IT
EMPID = 2 ENAME = Dan DEPT = OPS
EMPID = 3 ENAME = Tusar DEPT = IT
EMPID = 4 ENAME = Pranab DEPT = OPS
EMPID = 5 ENAME = Rasmi DEPT = FIN
;
PROC PRINT DATA = TEMP;
RUN;Khi chạy mã bove, chúng tôi nhận được kết quả sau.
Phương thức nhập cột
Trong phương pháp này, các biến được liệt kê với các kiểu dữ liệu và độ rộng của các cột chỉ định giá trị của một cột dữ liệu. Ví dụ: nếu tên nhân viên chứa tối đa 9 ký tự và mỗi tên nhân viên bắt đầu từ cột thứ 10, thì độ rộng cột cho biến tên nhân viên sẽ là 10-19.
Thí dụ
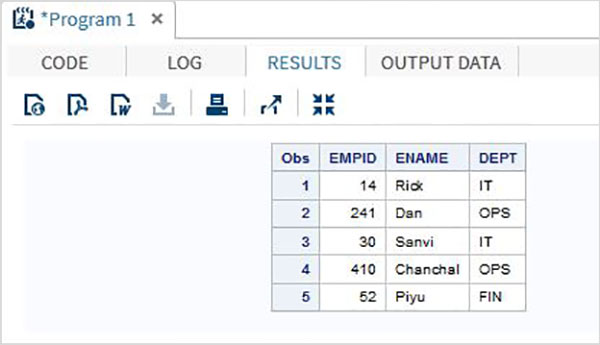
Đoạn mã sau cho thấy việc sử dụng Phương thức nhập cột.
DATA TEMP;
INPUT EMPID 1-3 ENAME $ 4-12 DEPT $ 13-16;
DATALINES;
14 Rick IT
241Dan OPS
30 Sanvi IT
410Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Phương thức nhập được định dạng
Trong phương pháp này, các biến được đọc từ một điểm bắt đầu cố định cho đến khi gặp phải khoảng trắng. Vì mọi biến đều có điểm bắt đầu cố định, số cột giữa bất kỳ cặp biến nào sẽ trở thành chiều rộng của biến đầu tiên. Ký tự '@n' được sử dụng để chỉ định vị trí cột bắt đầu của một biến là cột thứ n.
Thí dụ
Đoạn mã sau cho thấy việc sử dụng Phương thức nhập được định dạng
DATA TEMP;
INPUT @1 EMPID $ @4 ENAME $ @13 DEPT $ ;
DATALINES;
14 Rick IT
241 Dan OPS
30 Sanvi IT
410 Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
SAS có một tính năng lập trình mạnh mẽ được gọi là Macrosđiều này cho phép chúng tôi tránh các phần mã lặp đi lặp lại và sử dụng chúng lặp đi lặp lại khi cần thiết. Nó cũng giúp tạo các biến động trong mã có thể nhận các giá trị khác nhau cho các phiên bản chạy khác nhau của cùng một mã. Macro cũng có thể được khai báo cho các khối mã sẽ được sử dụng lại nhiều lần theo cách tương tự như các biến macro. Chúng ta sẽ thấy cả hai điều này trong các ví dụ dưới đây.
Biến vĩ mô
Đây là những biến giữ một giá trị được sử dụng nhiều lần bởi một chương trình SAS. Chúng được khai báo ở phần đầu của chương trình SAS và được gọi sau đó trong phần nội dung của chương trình. Chúng có thể là Toàn cầu hoặc Địa phương trong phạm vi.
Biến Macro toàn cục
Chúng được gọi là các biến vĩ mô toàn cục vì chúng có thể được truy cập bởi bất kỳ chương trình SAS nào có sẵn trong môi trường SAS. Nói chung, chúng là các biến được gán hệ thống được nhiều chương trình truy cập. Một ví dụ chung là ngày hệ thống.
Thí dụ
Dưới đây là một ví dụ về biến SAS được gọi là SYSDATE đại diện cho ngày hệ thống. Hãy xem xét một kịch bản để in ngày hệ thống trong tiêu đề của báo cáo SAS mỗi ngày báo cáo được tạo. Tiêu đề sẽ hiển thị ngày và ngày hiện tại mà chúng tôi không cần mã hóa bất kỳ giá trị nào cho chúng. Chúng tôi sử dụng tập dữ liệu SAS dựng sẵn có tên là CARS có sẵn trong thư viện SASHELP.
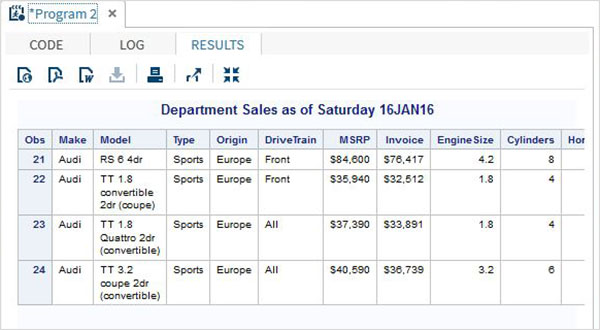
proc print data = sashelp.cars;
where make = 'Audi' and type = 'Sports' ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;Khi đoạn mã trên được chạy, chúng ta nhận được kết quả sau.
Biến Macro cục bộ
Các biến này có thể được truy cập bởi các chương trình SAS trong đó chúng được khai báo như một phần của chương trình. Chúng thường được sử dụng để cung cấp các varaibel khác nhau cho cùng một câu lệnh SAS mà chúng có thể xử lý các quan sát khác nhau của một tập dữ liệu.
Cú pháp
Các biến cục bộ được gắn với cú pháp bên dưới.
% LET (Macro Variable Name) = Value;Ở đây trường Giá trị có thể nhận bất kỳ giá trị số, văn bản hoặc ngày nào theo yêu cầu của chương trình. Tên biến Macro là bất kỳ biến SAS hợp lệ nào.
Thí dụ
Các biến được sử dụng bởi các câu lệnh SAS bằng cách sử dụng & ký tự nối vào đầu tên biến. Chương trình dưới đây cung cấp cho chúng ta tất cả các quan sát về kiểu dáng 'Audi' và loại 'Thể thao'. Trong trường hợp chúng tôi muốn kết quả củadifferent make, chúng ta cần thay đổi giá trị của biến make_namemà không thay đổi bất kỳ phần nào khác của chương trình. Trong trường hợp mang chương trình, biến này có thể được tham chiếu lặp lại trong bất kỳ câu lệnh SAS nào.
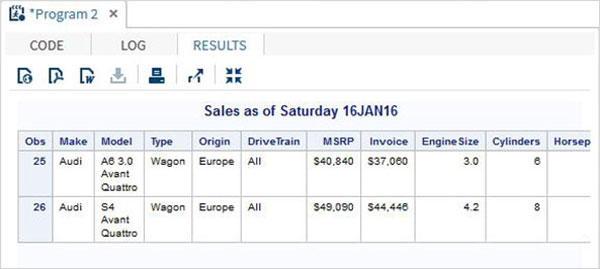
%LET make_name = 'Audi';
%LET type_name = 'Sports';
proc print data = sashelp.cars;
where make = &make_name and type = &type_name ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;Khi đoạn mã trên được chạy, chúng ta nhận được đầu ra giống như chương trình trước đó. Nhưng hãy thay đổitype name đến 'Wagon'và chạy cùng một chương trình. Chúng tôi sẽ nhận được kết quả bên dưới.
Chương trình Macro
Macro là một nhóm các câu lệnh SAS được gọi bằng một tên và để sử dụng nó trong chương trình ở bất kỳ đâu, bằng cách sử dụng tên đó. Nó bắt đầu bằng câu lệnh% MACRO và kết thúc bằng câu lệnh% MEND.
Cú pháp
Các biến cục bộ được khai báo với cú pháp dưới đây.
# Creating a Macro program.
%MACRO <macro name>(Param1, Param2,….Paramn);
Macro Statements;
%MEND;
# Calling a Macro program.
%MacroName (Value1, Value2,…..Valuen);Thí dụ
Chương trình dưới đây mô tả một nhóm các sao SAT dưới một macro có tên 'show_result'; Macro này đang được gọi bởi các câu lệnh SAS khác.
%MACRO show_result(make_ , type_);
proc print data = sashelp.cars;
where make = "&make_" and type = "&type_" ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;
%MEND;
%show_result(BMW,SUV);Khi đoạn mã trên được chạy, chúng ta nhận được kết quả sau.

Macro thường được sử dụng
SAS có nhiều câu lệnh MACRO được tích hợp sẵn trong ngôn ngữ lập trình SAS. Chúng được sử dụng bởi các chương trình SAS khác mà không cần khai báo rõ ràng. Ví dụ phổ biến là - kết thúc chương trình khi một số điều kiện được đáp ứng hoặc nắm bắt giá trị thời gian chạy của một biến trong nhật ký chương trình. Dưới đây là một số ví dụ.
Macro% PUT
Câu lệnh macro này ghi văn bản hoặc thông tin biến macro vào nhật ký SAS. Trong ví dụ dưới đây, giá trị của biến 'hôm nay' được ghi vào nhật ký chương trình.
data _null_;
CALL SYMPUT ('today',
TRIM(PUT("&sysdate"d,worddate22.)));
run;
%put &today;Khi đoạn mã trên được chạy, chúng ta nhận được kết quả sau.

Macro% RETURN
Việc thực thi macro này gây ra sự kết thúc bình thường của macro hiện đang thực thi khi điều kiện nhất định được đánh giá là đúng. Trong ví dụ dưới đây, khi giá trị của biến"val" trở thành 10, macro kết thúc nếu nó tiếp tục.
%macro check_condition(val);
%if &val = 10 %then %return;
data p;
x = 34.2;
run;
%mend check_condition;
%check_condition(11) ;Khi đoạn mã trên được chạy, chúng ta nhận được kết quả sau.

Macro% END
Định nghĩa macro này chứa một %DO %WHILEvòng lặp kết thúc, theo yêu cầu, bằng câu lệnh% END. Trong ví dụ dưới đây, kiểm tra có tên macro nhận đầu vào của người dùng và chạy vòng lặp DO sử dụng giá trị đầu vào này. Kết thúc của vòng lặp DO đạt được thông qua câu lệnh% end trong khi phần cuối của macro đạt được thông qua câu lệnh% mend.
%macro test(finish);
%let i = 1;
%do %while (&i <&finish);
%put the value of i is &i;
%let i=%eval(&i+1);
%end;
%mend test;
%test(5)Khi đoạn mã trên được chạy, chúng ta nhận được kết quả sau.

IN SAS Ngày là một trường hợp đặc biệt của giá trị số. Mỗi ngày được gán một giá trị số cụ thể bắt đầu từ ngày 1 tháng 1 năm 1960. Ngày này được gán giá trị ngày là 0 và ngày tiếp theo có giá trị ngày là 1, v.v. Các ngày trước đó cho đến ngày nay được biểu thị bằng -1, -2, v.v. Với cách tiếp cận này, SAS có thể đại diện cho bất kỳ ngày nào trong tương lai và bất kỳ ngày nào trong quá khứ.
Khi SAS đọc dữ liệu từ một nguồn, nó sẽ chuyển đổi dữ liệu đã đọc thành một định dạng ngày cụ thể như định dạng ngày đã chỉ định. Biến để lưu trữ giá trị ngày tháng được khai báo với thông tin thích hợp được yêu cầu. Ngày đầu ra được hiển thị bằng cách sử dụng các định dạng dữ liệu đầu ra.
Thông báo ngày của SAS
Dữ liệu nguồn có thể được đọc đúng cách bằng cách sử dụng thông tin ngày cụ thể như hình dưới đây. Chữ số ở cuối thông tin cho biết độ rộng tối thiểu của chuỗi ngày tháng được đọc hoàn toàn bằng cách sử dụng thông tin. Chiều rộng nhỏ hơn sẽ cho kết quả không chính xác. với SAS V9, có một định dạng ngày chunganydtdte15. có thể xử lý bất kỳ đầu vào ngày tháng nào.
| Ngày nhập | Chiều rộng ngày | Informat |
|---|---|---|
| 03/11/2014 | 10 | mmddyy10. |
| 03/11/14 | số 8 | mmddyy8. |
| Ngày 11 tháng 12 năm 2012 | 20 | worddate20. |
| 14mar2011 | 9 | ngày tháng9. |
| 14 tháng 3 năm 2011 | 11 | ngày 11. |
| 14 tháng 3 năm 2011 | 15 | anydtdte15. |
Thí dụ
Đoạn mã dưới đây hiển thị cách đọc các định dạng ngày tháng khác nhau. Xin lưu ý rằng tất cả các giá trị đầu ra chỉ là số vì chúng tôi chưa áp dụng bất kỳ câu lệnh định dạng nào cho các giá trị đầu ra.
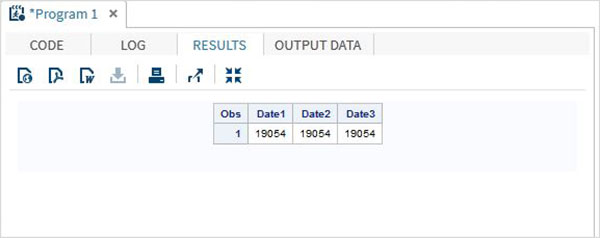
DATA TEMP;
INPUT @1 Date1 date11. @12 Date2 anydtdte15. @23 Date3 mmddyy10. ;
DATALINES;
02-mar-2012 3/02/2012 3/02/2012
;
PROC PRINT DATA = TEMP;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
SAS Định dạng đầu ra ngày
Ngày sau khi được đọc, có thể được chuyển đổi sang định dạng khác theo yêu cầu của màn hình. Điều này đạt được bằng cách sử dụng câu lệnh định dạng cho các loại ngày. Chúng có các định dạng giống như thông tin.
Thí dụ
Trong exampel dưới đây, ngày được đọc ở một định dạng nhưng được hiển thị ở định dạng khác.
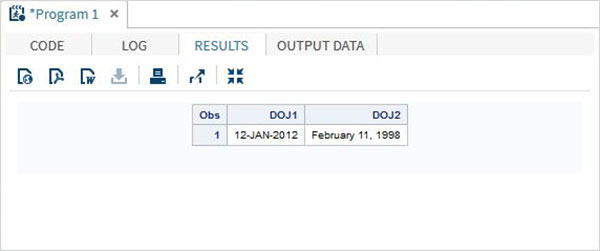
DATA TEMP;
INPUT @1 DOJ1 mmddyy10. @12 DOJ2 mmddyy10.;
format DOJ1 date11. DOJ2 worddate20. ;
DATALINES;
01/12/2012 02/11/1998
;
PROC PRINT DATA = TEMP;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
SAS có thể đọc dữ liệu từ nhiều nguồn khác nhau, bao gồm nhiều định dạng tệp. Các định dạng tệp được sử dụng trong môi trường SAS được thảo luận dưới đây.
- Tập dữ liệu ASCII (Văn bản)
- Dữ liệu được phân tách
- Dữ liệu Excel
- Dữ liệu phân cấp
Đọc Tập dữ liệu ASCII (Văn bản)
Đây là những tệp chứa dữ liệu ở định dạng văn bản. Dữ liệu thường được phân cách bằng dấu cách, nhưng cũng có thể có nhiều loại dấu phân cách khác nhau mà SAS có thể xử lý. Hãy xem xét một tệp ASCII chứa dữ liệu nhân viên. Chúng tôi đọc tệp này bằng cách sử dụngInfile tuyên bố có sẵn trong SAS.
Thí dụ
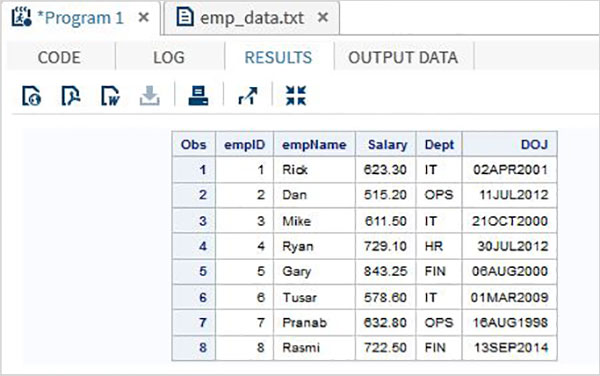
Trong ví dụ dưới đây, chúng tôi đọc tệp dữ liệu có tên emp_data.txt từ môi trường địa phương.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt';
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
Đọc dữ liệu được phân cách
Đây là các tệp dữ liệu trong đó các giá trị cột được phân tách bằng ký tự phân tách như dấu phẩy hoặc đường dẫn, v.v. Trong trường hợp này, chúng tôi sử dụng dlm tùy chọn trong infile tuyên bố.
Thí dụ
Trong ví dụ dưới đây, chúng tôi đọc tệp dữ liệu có tên emp.csv từ môi trường cục bộ.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=",";
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
Đọc dữ liệu Excel
SAS có thể đọc trực tiếp tệp excel bằng cơ sở nhập. Như đã thấy trong chương Bộ dữ liệu SAS, nó có thể xử lý nhiều loại tệp khác nhau bao gồm MS excel. Giả sử tệp emp.xls có sẵn cục bộ trong môi trường SAS.
Thí dụ
FILENAME REFFILE
"/folders/myfolders/TutorialsPoint/emp.xls"
TERMSTR = CR;
PROC IMPORT DATAFILE = REFFILE
DBMS = XLS
OUT = WORK.IMPORT;
GETNAMES = YES;
RUN;
PROC PRINT DATA = WORK.IMPORT RUN;Đoạn mã trên đọc dữ liệu từ tệp excel và cho kết quả tương tự như hai loại tệp trên.
Đọc tệp phân cấp
Trong các tệp này, dữ liệu hiện diện ở định dạng phân cấp. Đối với một quan sát nhất định, có một bản ghi tiêu đề bên dưới có nhiều bản ghi chi tiết được đề cập. Số lượng bản ghi chi tiết có thể thay đổi từ quan sát này sang quan sát khác. Dưới đây là hình ảnh minh họa của một tệp phân cấp.
Trong tệp tin dưới đây, thông tin chi tiết của từng nhân viên thuộc từng bộ phận được liệt kê. Bản ghi đầu tiên là bản ghi tiêu đề đề cập đến bộ phận và bản ghi tiếp theo vài bản ghi bắt đầu bằng DTLS là bản ghi chi tiết.
DEPT:IT
DTLS:1:Rick:623
DTLS:3:Mike:611
DTLS:6:Tusar:578
DEPT:OPS
DTLS:7:Pranab:632
DTLS:2:Dan:452
DEPT:HR
DTLS:4:Ryan:487
DTLS:2:Siyona:452Thí dụ
Để đọc tệp phân cấp, chúng tôi sử dụng đoạn mã dưới đây, trong đó chúng tôi xác định bản ghi tiêu đề bằng mệnh đề IF và sử dụng vòng lặp do để xử lý bản ghi chi tiết.
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @; if Type = 'DEP' then input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.

Tương tự như việc đọc bộ dữ liệu, SAS có thể viết bộ dữ liệu ở các định dạng khác nhau. Nó có thể ghi dữ liệu từ các tệp SAS vào tệp văn bản bình thường. Các tệp này có thể được đọc bởi các chương trình phần mềm khác. SAS sử dụngPROC EXPORT để ghi các tập dữ liệu.
XUẤT KHẨU PROC
Nó là một thủ tục sẵn có của SAS được sử dụng để xuất các bộ dữ liệu SAS để ghi dữ liệu vào các tệp có định dạng khác nhau.
Cú pháp
Cú pháp cơ bản để viết thủ tục trong SAS là:
PROC EXPORT
DATA = libref.SAS data-set (SAS data-set-options)
OUTFILE = "filename"
DBMS = identifier LABEL(REPLACE);Sau đây là mô tả về các tham số được sử dụng:
SAS data-setlà tên tập dữ liệu đang được xuất. SAS có thể chia sẻ các tập dữ liệu từ môi trường của nó với các ứng dụng khác bằng cách tạo các tệp mà các hệ điều hành khác nhau có thể đọc được. Nó sử dụng chức năng EXPORT có sẵn để đưa ra các tệp tập dữ liệu ở nhiều định dạng khác nhau. Trong chương này, chúng ta sẽ thấy việc viết các tập dữ liệu SAS bằng cách sử dụngproc export cùng với các tùy chọn dlm và dbms.
SAS data-set-options được sử dụng để chỉ định một tập hợp con các cột sẽ được xuất.
filename là tên của tệp mà dữ liệu được ghi vào.
identifier được sử dụng để đề cập đến dấu phân cách sẽ được ghi vào tệp.
LABEL tùy chọn được sử dụng để đề cập đến tên của các biến được ghi vào tệp.
Thí dụ
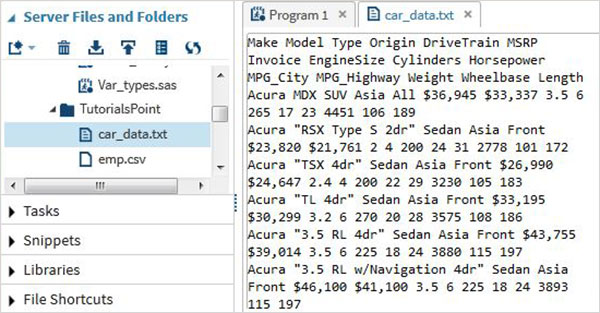
Chúng tôi sẽ sử dụng tập dữ liệu SAS có tên những chiếc ô tô có sẵn trong thư viện SASHELP. Chúng tôi xuất nó dưới dạng tệp văn bản được phân cách bằng dấu cách với mã như được hiển thị trong chương trình sau.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.txt'
dbms = dlm;
delimiter = ' ';
run;Khi thực hiện đoạn mã trên, chúng ta có thể thấy đầu ra là một tệp văn bản và nhấp chuột phải vào nó để xem nội dung của nó như hình dưới đây.
Viết tệp CSV
Để viết tệp được phân tách bằng dấu phẩy, chúng ta có thể sử dụng tùy chọn dlm với giá trị "csv". Đoạn mã sau ghi tệp car_data.csv.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.csv'
dbms = csv;
run;Khi thực hiện đoạn mã trên, chúng tôi nhận được kết quả bên dưới.

Viết tệp được phân cách bằng tab
Để viết tệp được phân tách bằng tab, chúng ta có thể sử dụng dlmtùy chọn với giá trị "tab". Đoạn mã sau ghi tệpcar_tab.txt.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_tab.txt'
dbms = csv;
run;Dữ liệu cũng có thể được viết dưới dạng tệp HTML mà chúng ta sẽ thấy trong chương hệ thống phân phối đầu ra.
Nhiều tập dữ liệu SAS có thể được nối để tạo ra một tập dữ liệu duy nhất bằng cách sử dụng SETtuyên bố. Tổng số quan sát trong tập dữ liệu nối là tổng số quan sát trong tập dữ liệu gốc. Thứ tự các quan sát là tuần tự. Tất cả các quan sát từ tập dữ liệu đầu tiên được theo sau bởi tất cả các quan sát từ tập dữ liệu thứ hai, v.v.
Lý tưởng nhất là tất cả các tập dữ liệu kết hợp đều có các biến giống nhau, nhưng trong trường hợp chúng có số lượng biến khác nhau, thì trong kết quả tất cả các biến sẽ xuất hiện, thiếu giá trị cho tập dữ liệu nhỏ hơn.
Cú pháp
Cú pháp cơ bản cho câu lệnh SET trong SAS là:
SET data-set 1 data-set 2 data-set 3.....;Sau đây là mô tả về các tham số được sử dụng:
data-set1,data-set2 là các tên tập dữ liệu được viết nối tiếp nhau.
Thí dụ
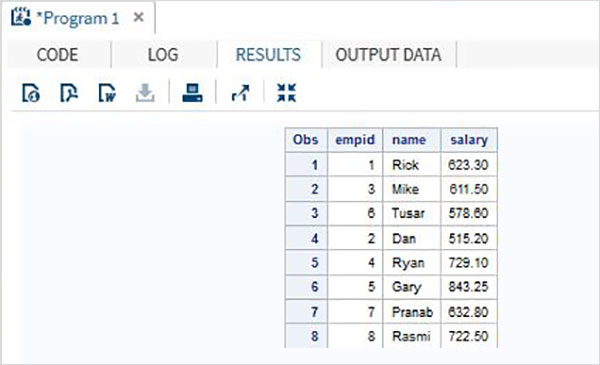
Hãy xem xét dữ liệu nhân viên của một tổ chức có sẵn trong hai bộ dữ liệu khác nhau, một cho bộ phận CNTT và một cho bộ phận Không phải của nó. Để có được thông tin chi tiết đầy đủ về tất cả các nhân viên, chúng tôi nối cả hai tập dữ liệu bằng cách sử dụng câu lệnh SET được hiển thị như bên dưới.
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
Các tình huống
Khi chúng ta có nhiều biến thể trong tập dữ liệu để ghép, kết quả của các biến có thể khác nhau nhưng tổng số quan sát trong tập dữ liệu được ghép luôn là tổng số quan sát trong mỗi tập dữ liệu. Chúng tôi sẽ xem xét bên dưới nhiều tình huống về biến thể này.
Số lượng biến khác nhau
Nếu một trong các tập dữ liệu ban đầu có nhiều biến hơn thì các biến khác, thì các tập dữ liệu vẫn được kết hợp nhưng trong tập dữ liệu nhỏ hơn, các biến đó xuất hiện như bị thiếu.
Thí dụ
Trong ví dụ dưới đây, tập dữ liệu đầu tiên có một biến phụ có tên là DOJ. Kết quả là giá trị DOJ cho tập dữ liệu thứ hai sẽ xuất hiện như bị thiếu.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.

Tên biến khác
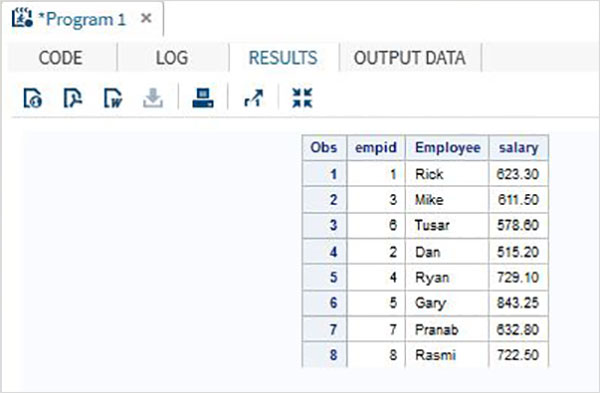
Trong trường hợp này, các tập dữ liệu có cùng số lượng biến nhưng tên biến khác nhau giữa chúng. Trong trường hợp đó, một phép ghép thông thường sẽ tạo ra tất cả các biến trong tập kết quả và đưa ra kết quả bị thiếu cho hai biến khác nhau. Mặc dù chúng ta không thể thay đổi tên biến trong các tập dữ liệu gốc, chúng ta có thể áp dụng hàm RENAME trong tập dữ liệu nối mà chúng ta tạo. Điều đó sẽ tạo ra cùng một kết quả như một phép ghép bình thường nhưng tất nhiên với một tên biến mới thay cho hai tên biến khác nhau có trong tập dữ liệu ban đầu.
Thí dụ
Trong tập dữ liệu ví dụ dưới đây ITDEPT có tên biến ename trong khi tập dữ liệu NON_ITDEPT có tên biến empname.Nhưng cả hai biến này đều đại diện cho cùng một kiểu (ký tự). Chúng tôi áp dụngRENAME trong câu lệnh SET như hình dưới đây.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
Độ dài biến đổi khác nhau
Nếu độ dài biến trong hai tập dữ liệu khác với tập dữ liệu được nối sẽ có các giá trị trong đó một số dữ liệu bị cắt bớt cho biến có độ dài nhỏ hơn. Nó xảy ra nếu tập dữ liệu đầu tiên có độ dài nhỏ hơn. Để giải quyết vấn đề này, chúng tôi áp dụng độ dài cao hơn cho cả tập dữ liệu như hình dưới đây.
Thí dụ
Trong ví dụ dưới đây, biến enamecó độ dài 5 trong tập dữ liệu đầu tiên và 7 trong tập dữ liệu thứ hai. Khi nối chúng ta áp dụng câu lệnh LENGTH trong tập dữ liệu đã nối để đặt độ dài ename thành 7.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
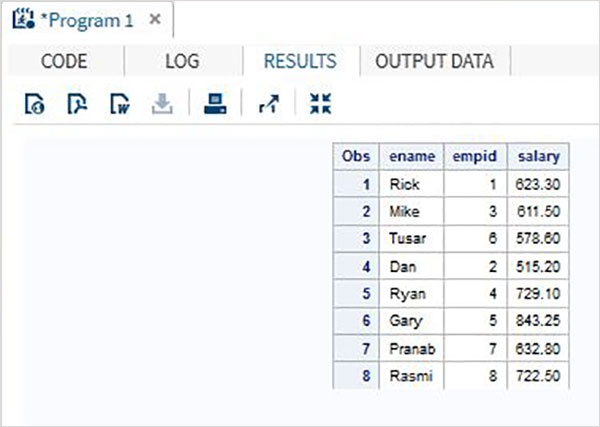
Nhiều tập dữ liệu SAS có thể được hợp nhất dựa trên một biến chung cụ thể để tạo ra một tập dữ liệu duy nhất. Điều này được thực hiện bằng cách sử dụngMERGE tuyên bố và BYtuyên bố. Tổng số quan sát trong tập dữ liệu được hợp nhất thường nhỏ hơn tổng số quan sát trong tập dữ liệu ban đầu. Đó là vì các biến tạo thành cả hai tập dữ liệu được hợp nhất thành một bản ghi dựa trên giá trị của biến chung.
Có hai điều kiện tiên quyết để hợp nhất các tập dữ liệu được đưa ra dưới đây:
- tập dữ liệu đầu vào phải có ít nhất một biến chung để hợp nhất.
- các tập dữ liệu đầu vào phải được sắp xếp theo (các) biến chung sẽ được sử dụng để hợp nhất.
Cú pháp
Cú pháp cơ bản cho câu lệnh MERGE và BY trong SAS là:
MERGE Data-Set 1 Data-Set 2
BY Common VariableSau đây là mô tả về các tham số được sử dụng:
Data-set1,Data-set2 là các tên tập dữ liệu được viết nối tiếp nhau.
Common Variable là biến dựa trên các giá trị phù hợp mà các tập dữ liệu sẽ được hợp nhất.
Hợp nhất dữ liệu
Hãy để chúng tôi hiểu việc hợp nhất dữ liệu với sự trợ giúp của một ví dụ.
Thí dụ
Hãy xem xét hai bộ dữ liệu SAS, một bộ chứa ID nhân viên với tên và tiền lương và một bộ khác chứa ID nhân viên với ID nhân viên và bộ phận. Trong trường hợp này để có thông tin đầy đủ cho từng nhân viên, chúng ta có thể hợp nhất hai tập dữ liệu này. Tập dữ liệu cuối cùng sẽ vẫn có một quan sát cho mỗi nhân viên nhưng nó sẽ chứa cả biến tiền lương và biến bộ phận.
# Data set 1
ID NAME SALARY
1 Rick 623.3
2 Dan 515.2
3 Mike 611.5
4 Ryan 729.1
5 Gary 843.25
6 Tusar 578.6
7 Pranab 632.8
8 Rasmi 722.5
# Data set 2
ID DEPT
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
# Merged data set
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINKết quả trên đạt được bằng cách sử dụng đoạn mã sau, trong đó biến chung (ID) được sử dụng trong câu lệnh BY. Xin lưu ý rằng các quan sát trong cả hai tập dữ liệu đã được sắp xếp trong cột ID.
DATA SALARY;
INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 ; RUN; DATA DEPT; INPUT empid dEPT $ ;
DATALINES;
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
;
RUN;
DATA All_details;
MERGE SALARY DEPT;
BY (empid);
RUN;
PROC PRINT DATA = All_details;
RUN;Thiếu giá trị trong cột phù hợp
Có thể có trường hợp một số giá trị của biến chung sẽ không khớp giữa các tập dữ liệu. Trong những trường hợp như vậy, các tập dữ liệu vẫn được hợp nhất nhưng cung cấp các giá trị bị thiếu trong kết quả.
Thí dụ
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 . . IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 .
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINChỉ hợp nhất các Kết quả phù hợp
Để tránh các giá trị bị thiếu trong kết quả, chúng ta có thể xem xét chỉ giữ lại các quan sát có giá trị phù hợp cho biến chung. Điều đó đạt được bằng cách sử dụngINtuyên bố. Câu lệnh hợp nhất của chương trình SAS cần được thay đổi.
Thí dụ
Trong ví dụ dưới đây, IN= value chỉ giữ lại các quan sát trong đó các giá trị từ cả hai tập dữ liệu SALARY và DEPT trận đấu.
DATA All_details;
MERGE SALARY(IN = a) DEPT(IN = b);
BY (empid);
IF a = 1 and b = 1;
RUN;
PROC PRINT DATA = All_details;
RUN;Khi thực hiện chương trình SAS ở trên với phần đã thay đổi ở trên, chúng ta nhận được kết quả sau.
1 Rick 623.3 IT
2 Dan 515.2 OPS
4 Ryan 729.1 HR
5 Gary 843.25 FIN
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINThiết lập con một tập dữ liệu SAS có nghĩa là trích xuất một phần của tập dữ liệu bằng cách chọn số lượng biến ít hơn hoặc số lượng quan sát ít hơn hoặc cả hai. Trong khi tập hợp con các biến được thực hiện bằng cách sử dụngKEEP và DROP tuyên bố, thiết lập phụ của các quan sát được thực hiện bằng cách sử dụng DELETE tuyên bố.
Ngoài ra, dữ liệu kết quả từ hoạt động tập hợp con được giữ trong một tập dữ liệu mới có thể được sử dụng để phân tích thêm. Thiết lập phụ chủ yếu được sử dụng cho mục đích phân tích một phần của tập dữ liệu mà không sử dụng các biến hoặc quan sát có thể không liên quan đến phân tích.
Đặt các biến
Trong phương pháp này, chúng tôi chỉ trích xuất một số biến từ toàn bộ tập dữ liệu.
Cú pháp
Cú pháp cơ bản cho các biến thiết lập phụ trong SAS là:
KEEP var1 var2 ... ;
DROP var1 var2 ... ;Sau đây là mô tả về các tham số được sử dụng:
var1 and var2 là các tên biến từ tập dữ liệu cần được giữ lại hoặc loại bỏ.
Thí dụ
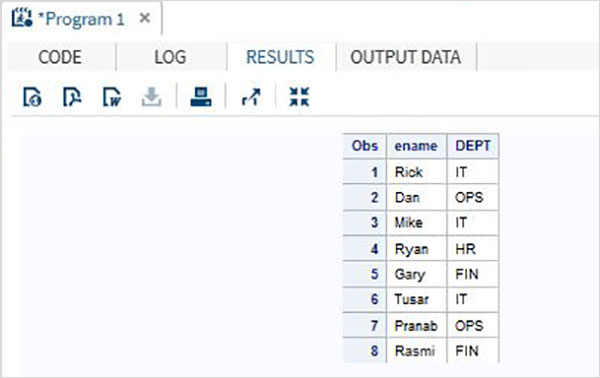
Hãy xem xét tập dữ liệu SAS dưới đây chứa thông tin chi tiết về nhân viên của một tổ chức. Nếu chúng ta chỉ quan tâm đến việc lấy các giá trị Tên và Phòng ban từ tập dữ liệu, thì chúng ta có thể sử dụng mã dưới đây.
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
KEEP ename DEPT;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
Kết quả tương tự có thể đạt được bằng cách bỏ các biến không bắt buộc. Đoạn mã dưới đây minh họa điều này.
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
DROP empid salary;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Thiết lập các quan sát
Trong phương pháp này, chúng tôi chỉ trích xuất một số quan sát từ toàn bộ tập dữ liệu.
Cú pháp
Chúng tôi sử dụng PROC FREQ để theo dõi các quan sát được chọn cho tập dữ liệu mới.
Cú pháp cho các quan sát thiết lập phụ là:
IF Var Condition THEN DELETE ;Sau đây là mô tả về các tham số được sử dụng:
Var là tên của biến dựa trên giá trị của nó mà các quan sát sẽ bị xóa khi sử dụng điều kiện đã chỉ định.
Thí dụ
Hãy xem xét tập dữ liệu SAS dưới đây chứa thông tin chi tiết về nhân viên của một tổ chức. Nếu chúng tôi chỉ quan tâm đến việc lấy dữ liệu cho nhân viên có mức lương lớn hơn 700, thì chúng tôi sử dụng mã bên dưới.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
IF salary < 700 THEN DELETE;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
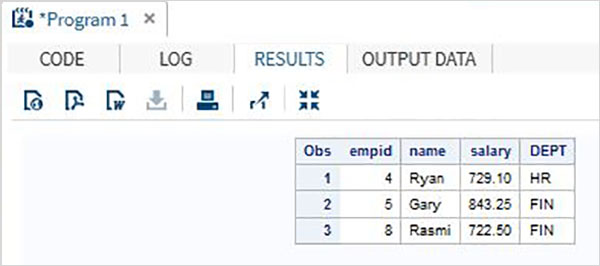
Đôi khi, chúng tôi muốn hiển thị dữ liệu đã phân tích ở định dạng khác với định dạng mà dữ liệu đã có trong tập dữ liệu. Ví dụ: chúng tôi muốn thêm ký hiệu đô la và hai chữ số thập phân vào một biến có thông tin giá. Hoặc chúng tôi có thể muốn hiển thị một biến văn bản, tất cả đều được viết hoa. Chúng ta có thể sử dụngFORMAT để áp dụng các định dạng SAS có sẵn và PROC FORMATlà áp dụng các định dạng do người dùng xác định. Ngoài ra, một định dạng duy nhất có thể được áp dụng cho nhiều biến.
Cú pháp
Cú pháp cơ bản để áp dụng các định dạng SAS có sẵn là:
format variable name format nameSau đây là mô tả về các tham số được sử dụng:
variable name là tên biến được sử dụng trong tập dữ liệu.
format name là định dạng dữ liệu sẽ được áp dụng trên biến.
Thí dụ
Hãy xem xét tập dữ liệu SAS dưới đây chứa thông tin chi tiết về nhân viên của một tổ chức. Chúng tôi muốn hiển thị tất cả các tên bằng chữ hoa. Cácformatstatement được sử dụng để đạt được điều này.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
format name $upcase9. ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
PROC PRINT DATA = Employee;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.

Sử dụng PROC FORMAT
Chúng tôi cũng có thể sử dụng PROC FORMATđể định dạng dữ liệu. Trong ví dụ dưới đây, chúng tôi gán giá trị mới cho biến DEPT trừ tên của bộ phận.
DATA Employee;
INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; proc format; value $DEP 'IT' = 'Information Technology'
'OPS'= 'Operations' ;
RUN;
PROC PRINT DATA = Employee;
format name $upcase9. DEPT $DEP.;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
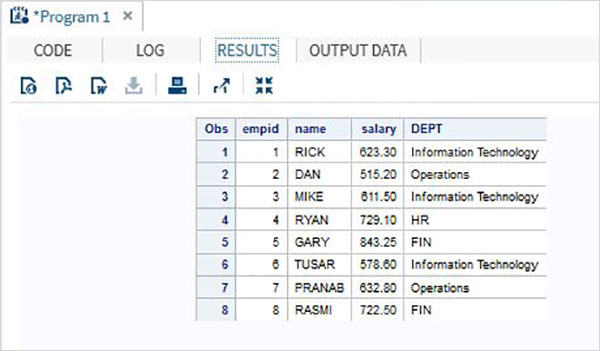
SAS cung cấp hỗ trợ rộng rãi cho hầu hết các cơ sở dữ liệu quan hệ phổ biến bằng cách sử dụng các truy vấn SQL bên trong các chương trình SAS. Hầu hết cácANSI SQLcú pháp được hỗ trợ. Thủ tụcPROC SQLđược sử dụng để xử lý các câu lệnh SQL. Thủ tục này không chỉ có thể trả lại kết quả của một truy vấn SQL mà còn có thể tạo các bảng và biến SAS. Ví dụ về tất cả các tình huống này được mô tả dưới đây.
Cú pháp
Cú pháp cơ bản để sử dụng PROC SQL trong SAS là:
PROC SQL;
SELECT Columns
FROM TABLE
WHERE Columns
GROUP BY Columns
;
QUIT;Sau đây là mô tả về các tham số được sử dụng:
truy vấn SQL được viết bên dưới câu lệnh SQL PROC theo sau câu lệnh QUIT.
Dưới đây, chúng tôi sẽ xem cách thủ tục SAS này có thể được sử dụng cho CRUD (Tạo, Đọc, Cập nhật và Xóa) hoạt động trong SQL.
Thao tác tạo SQL
Sử dụng SQL, chúng ta có thể tạo dữ liệu thô dạng tập dữ liệu mới. Trong ví dụ dưới đây, đầu tiên chúng ta khai báo một tập dữ liệu có tên TEMP chứa dữ liệu thô. Sau đó, chúng tôi viết một truy vấn SQL để tạo một bảng từ các biến của tập dữ liệu này.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES AS
SELECT * FROM TEMP;
QUIT;
PROC PRINT data = EMPLOYEES;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:
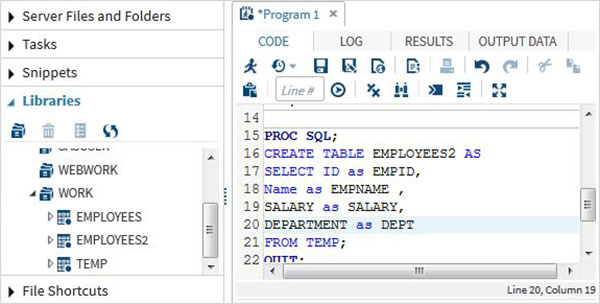
Thao tác đọc SQL
Thao tác Đọc trong SQL liên quan đến việc viết các truy vấn SQL SELECT để đọc dữ liệu từ các bảng. Trong chương trình dưới đây truy vấn tập dữ liệu SAS có tên CARS có sẵn trong thư viện SASHELP. Truy vấn tìm nạp một số cột của tập dữ liệu.
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
;
QUIT;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:
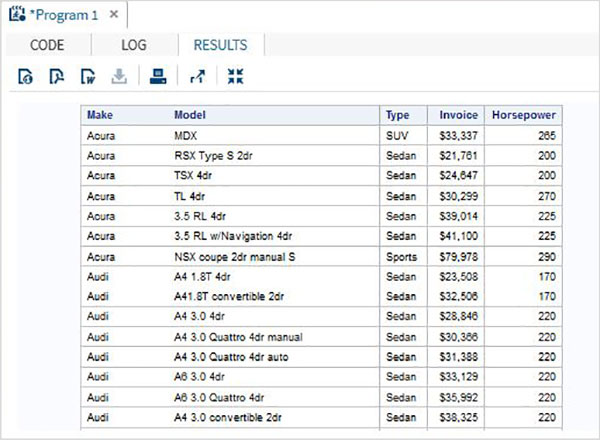
SQL SELECT với mệnh đề WHERE
Chương trình dưới đây truy vấn tập dữ liệu CARS với wheremệnh đề. Kết quả là chúng tôi chỉ nhận được quan sát có tên là "Audi" và nhập là "Thể thao".
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
Where make = 'Audi'
and Type = 'Sports'
;
QUIT;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:
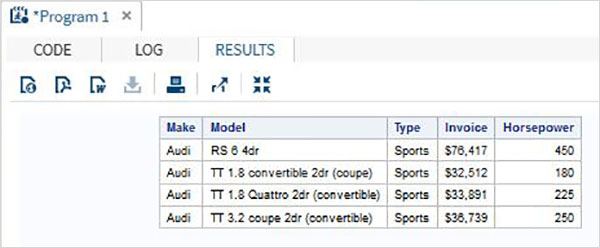
Hoạt động CẬP NHẬT SQL
Chúng ta có thể cập nhật bảng SAS bằng câu lệnh SQL Update. Dưới đây, trước tiên chúng ta tạo một bảng mới có tên EMPLOYEES2 và sau đó cập nhật nó bằng cách sử dụng câu lệnh SQL UPDATE.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES2 AS
SELECT ID as EMPID,
Name as EMPNAME ,
SALARY as SALARY,
DEPARTMENT as DEPT,
SALARY*0.23 as COMMISION
FROM TEMP;
QUIT;
PROC SQL;
UPDATE EMPLOYEES2
SET SALARY = SALARY*1.25;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:

Thao tác XÓA SQL
Thao tác xóa trong SQL liên quan đến việc xóa các giá trị nhất định khỏi bảng bằng câu lệnh SQL DELETE. Chúng tôi tiếp tục sử dụng dữ liệu từ ví dụ trên và xóa các hàng khỏi bảng trong đó mức lương của nhân viên lớn hơn 900.
PROC SQL;
DELETE FROM EMPLOYEES2
WHERE SALARY > 900;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:

Đầu ra từ chương trình SAS có thể được chuyển đổi sang các dạng thân thiện với người dùng hơn như .html hoặc là PDF. Điều này được thực hiện bằng cách sử dụng ODStuyên bố có sẵn trong SAS. ODS là viết tắt củaoutput delivery system.Nó chủ yếu được sử dụng để định dạng dữ liệu đầu ra của chương trình SAS thành các báo cáo đẹp, dễ xem và dễ hiểu. Điều đó cũng giúp chia sẻ đầu ra với các nền tảng và sản phẩm mềm khác. Nó cũng có thể kết hợp các kết quả từ nhiều câu lệnh PROC trong một tệp duy nhất.
Cú pháp
Cú pháp cơ bản để sử dụng câu lệnh ODS trong SAS là:
ODS outputtype
PATH path name
FILE = Filename and Path
STYLE = StyleName
;
PROC some proc
;
ODS outputtype CLOSE;Sau đây là mô tả về các tham số được sử dụng:
PATHđại diện cho câu lệnh được sử dụng trong trường hợp xuất HTML. Trong các loại đầu ra khác, chúng tôi bao gồm đường dẫn trong tên tệp.
Style đại diện cho một trong những kiểu dựng sẵn có sẵn trong môi trường SAS.
Tạo đầu ra HTML
Chúng tôi tạo đầu ra HTML bằng cách sử dụng câu lệnh HTML ODS. Trong ví dụ dưới đây, chúng tôi tạo một tệp html theo đường dẫn mong muốn của chúng tôi. Chúng tôi áp dụng một kiểu có sẵn trong thư viện kiểu. Chúng ta có thể thấy tệp đầu ra trong đường dẫn được đề cập và chúng ta có thể tải xuống để lưu trong môi trường khác với môi trường SAS. Xin lưu ý rằng chúng tôi có hai câu lệnh SQL proc và cả hai câu lệnh đầu ra của chúng đều được lưu vào một tệp duy nhất.
ODS HTML
PATH = '/folders/myfolders/sasuser.v94/TutorialsPoint/'
FILE = 'CARS2.html'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS HTML CLOSE;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:
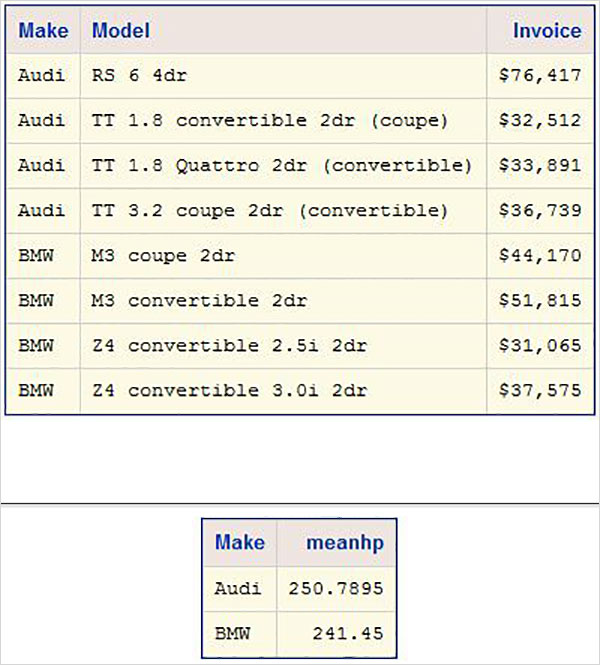
Tạo đầu ra PDF
Trong ví dụ dưới đây, chúng tôi tạo một tệp PDF theo đường dẫn mong muốn của chúng tôi. Chúng tôi áp dụng một kiểu có sẵn trong thư viện kiểu. Chúng ta có thể thấy tệp đầu ra trong đường dẫn được đề cập và chúng ta có thể tải xuống để lưu trong môi trường khác với môi trường SAS. Xin lưu ý rằng chúng tôi có hai câu lệnh SQL proc và cả hai câu lệnh đầu ra của chúng đều được lưu vào một tệp duy nhất.
ODS PDF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS2.pdf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS PDF CLOSE;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:
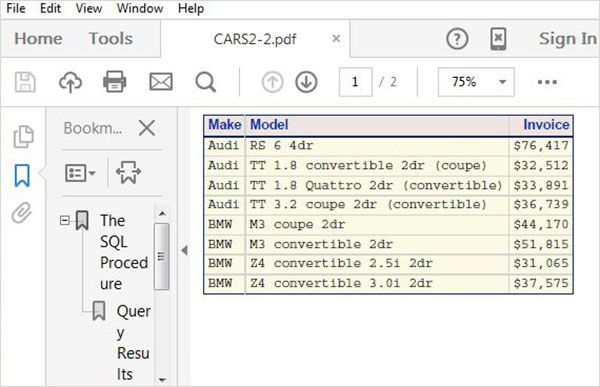
Tạo đầu ra TRF (Word)
Trong ví dụ dưới đây, chúng tôi tạo tệp RTF theo đường dẫn mong muốn của chúng tôi. Chúng tôi áp dụng một kiểu có sẵn trong thư viện kiểu. Chúng ta có thể thấy tệp đầu ra trong đường dẫn được đề cập và chúng ta có thể tải xuống để lưu trong môi trường khác với môi trường SAS. Xin lưu ý rằng chúng tôi có hai câu lệnh SQL proc và cả hai câu lệnh đầu ra của chúng đều được lưu vào một tệp duy nhất.
ODS RTF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS.rtf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS rtf CLOSE;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:
Mô phỏng là một kỹ thuật tính toán sử dụng phép tính lặp lại trên nhiều mẫu ngẫu nhiên khác nhau để ước tính một đại lượng thống kê. Sử dụng SAS, chúng tôi có thể mô phỏng dữ liệu phức tạp có các thuộc tính thống kê cụ thể trong hệ thống thế giới thực. Chúng tôi sử dụng phần mềm để xây dựng một mô hình của hệ thống và tạo dữ liệu bằng số mà bạn có thể sử dụng để hiểu rõ hơn về hoạt động của hệ thống trong thế giới thực. Một phần của nghệ thuật thiết kế mô hình mô phỏng máy tính là quyết định những khía cạnh nào của hệ thống thực tế là cần thiết để đưa vào mô hình để dữ liệu do mô hình tạo ra có thể được sử dụng để đưa ra quyết định hiệu quả. Vì sự phức tạp này, SAS có một thành phần phần mềm chuyên dụng cho Mô phỏng.
Thành phần phần mềm SAS được sử dụng để tạo mô phỏng SAS được gọi là SAS Simulation Studio. Giao diện người dùng đồ họa của nó cung cấp một bộ công cụ đầy đủ để xây dựng, thực thi và phân tích kết quả của các mô hình mô phỏng sự kiện rời rạc.
Các dạng phân bố thống kê khác nhau mà mô phỏng SAS có thể được áp dụng được liệt kê dưới đây.
- DỮ LIỆU MÔ PHỎNG TỪ PHÂN PHỐI LIÊN TỤC
- SIMULATE DATA FROM A DISCRETE DISTRIBUTION
- SIMULATE DATA FROM A MIXTURE OF DISTRIBUTIONS
- SIMULATE DATA FROM A COMPLEX DISTRIBUTION
- SIMULATE DATA FROM A MULTIVARIATE DISTRIBUTION
- APPROXIMATE A SAMPLING DISTRIBUTION
- ASSESS REGRESSION ESTIMATES
A Histogram is graphical display of data using bars of different heights. It groups the various numbers in the data set into many ranges. It also represents the estimation of the probability of distribution of a continuous variable. In SAS the PROC UNIVARIATE is used to create histograms with the below options.
Syntax
The basic syntax to create a histogram in SAS is −
PROC UNIVARAITE DATA = DATASET;
HISTOGRAM variables;
RUN;DATASET is the name of the dataset used.
variables are the values used to plot the histogram.
Simple Histogram
A simple histogram is created by specifying the name of the variable and the range to be considered to group the values.
Example
In the below example, we consider the minimum and maximum values of the variable horsepower and take a range of 50. So the values form a group in steps of 50.
proc univariate data = sashelp.cars;
histogram horsepower
/ midpoints = 176 to 350 by 50;
run;When we execute the above code, we get the following output −
Histogram with Curve Fitting
We can fit some distribution curves into the histogram using additional options.
Example
In the below example we fit a distribution curve with mean and standard deviation values mentioned as EST. This option uses and estimate of the parameters.
proc univariate data = sashelp.cars noprint;
histogram horsepower
/
normal (
mu = est
sigma = est
color = blue
w = 2.5
)
barlabel = percent
midpoints = 70 to 550 by 50;
run;When we execute the above code, we get the following output −

A bar chart represents data in rectangular bars with length of the bar proportional to the value of the variable. SAS uses the procedure PROC SGPLOT to create bar charts. We can draw both simple and stacked bars in the bar chart. In bar chart each of the bars can be given different colors.
Cú pháp
Cú pháp cơ bản để tạo biểu đồ thanh trong SAS là:
PROC SGPLOT DATA = DATASET;
VBAR variables;
RUN;DATASET - là tên của tập dữ liệu được sử dụng.
variables - là các giá trị được sử dụng để vẽ biểu đồ.
Biểu đồ thanh đơn giản
Biểu đồ thanh đơn giản là biểu đồ thanh trong đó một biến từ tập dữ liệu được biểu diễn dưới dạng các thanh.
Thí dụ
Tập lệnh dưới đây sẽ tạo một biểu đồ thanh đại diện cho chiều dài của ô tô dưới dạng thanh.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc SGPLOT data = work.cars1;
vbar length ;
title 'Lengths of cars';
run;
quit;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:
Biểu đồ thanh xếp chồng
Biểu đồ thanh xếp chồng là biểu đồ thanh trong đó một biến từ tập dữ liệu được tính toán đối với một biến khác.
Thí dụ
Tập lệnh dưới đây sẽ tạo một biểu đồ thanh xếp chồng lên nhau, trong đó chiều dài của ô tô được tính toán cho từng loại ô tô. Chúng tôi sử dụng tùy chọn nhóm để chỉ định biến thứ hai.
proc SGPLOT data = work.cars1;
vbar length /group = type ;
title 'Lengths of Cars by Types';
run;
quit;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:
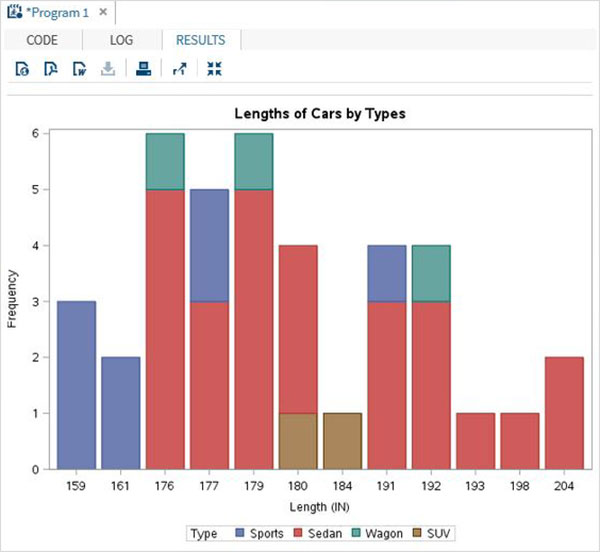
Biểu đồ thanh theo cụm
Biểu đồ thanh nhóm được tạo ra để hiển thị cách các giá trị của một biến được lan truyền trong một nền văn hóa.
Thí dụ
Đoạn mã dưới đây sẽ tạo ra một biểu đồ dạng nhóm trong đó chiều dài của các ô tô được tập hợp xung quanh loại ô tô. .
proc SGPLOT data = work.cars1;
vbar length /group = type GROUPDISPLAY = CLUSTER;
title 'Cluster of Cars by Types';
run;
quit;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:

Biểu đồ hình tròn là biểu diễn các giá trị dưới dạng các lát của hình tròn với các màu khác nhau. Các lát được dán nhãn và các số tương ứng với mỗi lát cũng được thể hiện trong biểu đồ.
Trong SAS, biểu đồ hình tròn được tạo bằng cách sử dụng PROC TEMPLATE trong đó có các tham số để kiểm soát tỷ lệ phần trăm, nhãn, màu sắc, tiêu đề, v.v.
Cú pháp
Cú pháp cơ bản để tạo biểu đồ tròn trong SAS là:
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = variable /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = ' ';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;variable là giá trị mà chúng tôi tạo biểu đồ hình tròn.
Biểu đồ hình tròn đơn giản
Trong biểu đồ hình tròn này, chúng tôi lấy một biến duy nhất tạo thành tập dữ liệu. Biểu đồ hình tròn được tạo với giá trị của các lát thể hiện phần nhỏ của số lượng biến so với tổng giá trị của biến.
Thí dụ
Trong ví dụ dưới đây, mỗi lát cắt đại diện cho một phần của loại ô tô trong tổng số ô tô.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:
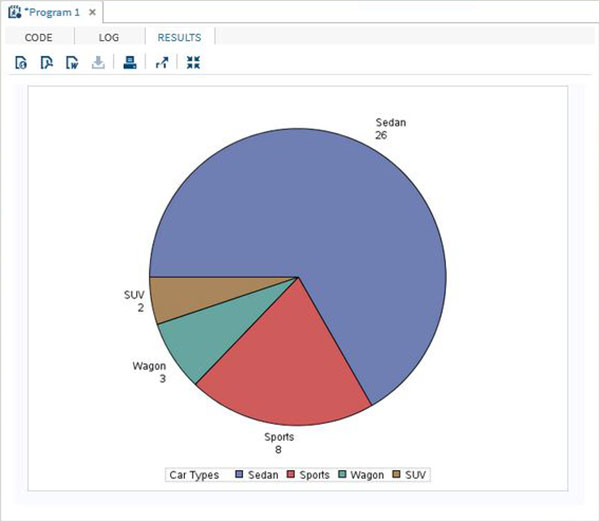
Biểu đồ hình tròn có nhãn dữ liệu
Trong biểu đồ hình tròn này, chúng tôi đại diện cho cả giá trị phân số cũng như giá trị phần trăm cho mỗi lát. Chúng tôi cũng thay đổi vị trí của nhãn bên trong biểu đồ. Kiểu hiển thị của biểu đồ được sửa đổi bằng cách sử dụng tùy chọn DATASKIN. Nó sử dụng một trong những kiểu có sẵn, có sẵn trong môi trường SAS.
Thí dụ
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:
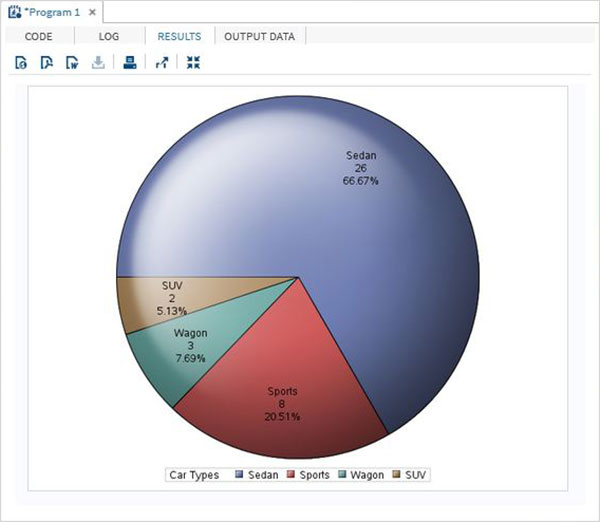
Biểu đồ hình tròn được nhóm
Trong biểu đồ hình tròn này, giá trị của biến được trình bày trong biểu đồ được nhóm lại với một biến khác của cùng một tập dữ liệu. Mỗi nhóm trở thành một vòng tròn và biểu đồ có bao nhiêu vòng tròn đồng tâm bằng số lượng nhóm có sẵn.
Thí dụ
Trong ví dụ dưới đây, chúng tôi nhóm biểu đồ theo biến có tên "Make". Vì có sẵn hai giá trị ("Audi" và "BMW"), vì vậy chúng tôi nhận được hai vòng tròn đồng tâm, mỗi vòng tròn đại diện cho các lát của loại ô tô theo cách riêng của nó.
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type / Group = make
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:
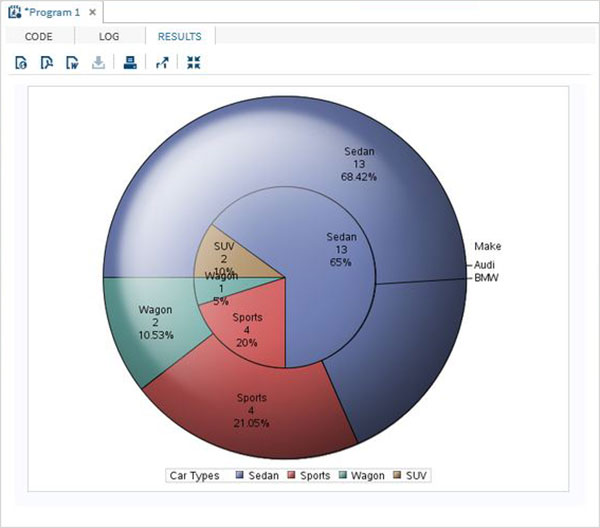
Biểu đồ phân tán là một loại biểu đồ sử dụng các giá trị từ hai biến được vẽ trong mặt phẳng Descartes. Nó thường được sử dụng để tìm ra mối quan hệ giữa hai biến. Trong SAS, chúng tôi sử dụngPROC SGSCATTER để tạo biểu đồ phân tán.
Xin lưu ý rằng chúng tôi tạo tập dữ liệu có tên CARS1 trong ví dụ đầu tiên và sử dụng cùng một tập dữ liệu cho tất cả các tập dữ liệu tiếp theo. Tập dữ liệu này vẫn còn trong thư viện công việc cho đến khi kết thúc phiên SAS.
Cú pháp
Cú pháp cơ bản để tạo biểu đồ phân tán trong SAS là:
PROC sgscatter DATA = DATASET;
PLOT VARIABLE_1 * VARIABLE_2
/ datalabel = VARIABLE group = VARIABLE;
RUN;Sau đây là mô tả các tham số được sử dụng:
DATASET là tên của tập dữ liệu.
VARIABLE là biến được sử dụng từ tập dữ liệu.
Scatterplot đơn giản
Trong biểu đồ phân tán đơn giản, chúng tôi chọn hai biến tạo thành tập dữ liệu và nhóm chúng lại với một biến thứ ba. Chúng tôi cũng có thể gắn nhãn dữ liệu. Kết quả cho thấy hai biến phân tán như thế nào trongCartesian plane.
Thí dụ
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
TITLE 'Scatterplot - Two Variables';
PROC sgscatter DATA = CARS1;
PLOT horsepower*Invoice
/ datalabel = make group = type grid;
title 'Horsepower vs. Invoice for car makers by types';
RUN;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:
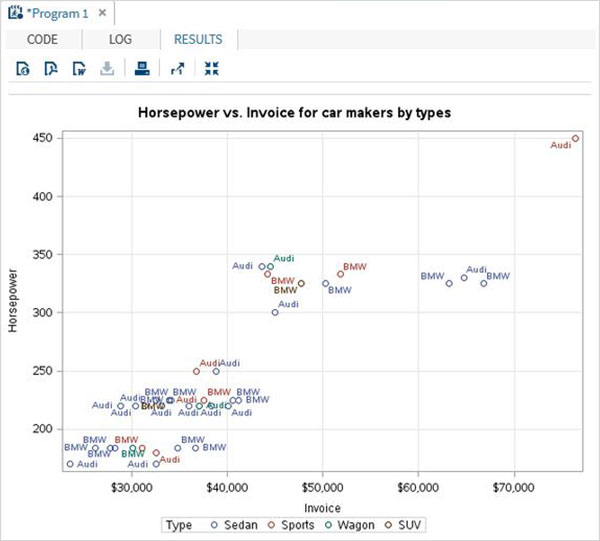
Scatterplot với dự đoán
chúng ta có thể sử dụng một tham số ước lượng để dự đoán độ tương quan giữa các giá trị bằng cách vẽ một hình elip xung quanh các giá trị. Chúng tôi sử dụng các tùy chọn bổ sung trong quy trình để vẽ hình elip như hình dưới đây.
Thí dụ
proc sgscatter data = cars1;
compare y = Invoice x = (horsepower length)
/ group = type ellipse =(alpha = 0.05 type = predicted);
title
'Average Invoice vs. horsepower for cars by length';
title2
'-- with 95% prediction ellipse --'
;
format
Invoice dollar6.0;
run;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:

Ma trận phân tán
Chúng ta cũng có thể có biểu đồ phân tán liên quan đến nhiều hơn hai biến bằng cách nhóm chúng thành từng cặp. Trong ví dụ dưới đây, chúng tôi xem xét ba biến và vẽ một ma trận biểu đồ phân tán. Chúng tôi nhận được 3 cặp ma trận kết quả.
Thí dụ
PROC sgscatter DATA = CARS1;
matrix horsepower invoice length
/ group = type;
title 'Horsepower vs. Invoice vs. Length for car makers by types';
RUN;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:
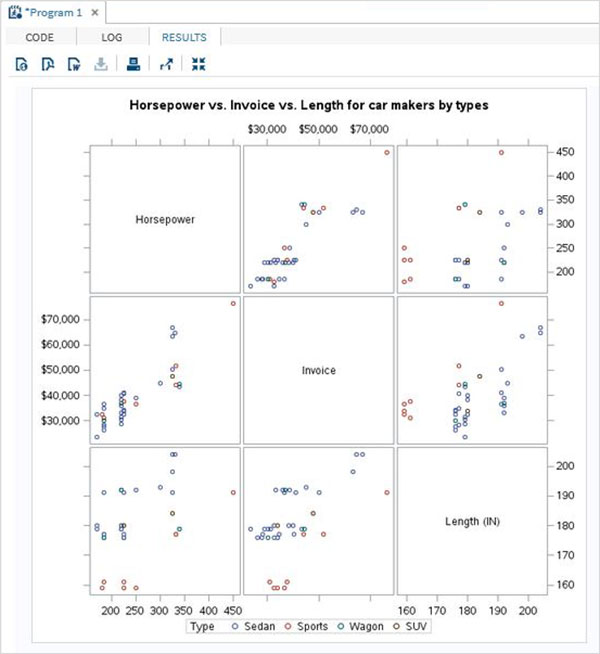
Boxplot là biểu diễn đồ họa của các nhóm dữ liệu số thông qua các phần tư của chúng. Ô hộp cũng có thể có các đường kéo dài theo chiều dọc từ các ô (râu) cho biết sự biến đổi bên ngoài phần tư trên và dưới. Dưới cùng và trên cùng của hộp luôn là phần tư thứ nhất và thứ ba, và dải bên trong hộp luôn là phần tư thứ hai (trung vị). Trong SAS, một Boxplot đơn giản được tạo bằng cách sử dụngPROC SGPLOT và boxplot có bảng được tạo bằng cách sử dụng PROC SGPANEL.
Xin lưu ý rằng chúng tôi tạo tập dữ liệu có tên CARS1 trong ví dụ đầu tiên và sử dụng cùng một tập dữ liệu cho tất cả các tập dữ liệu tiếp theo. Tập dữ liệu này vẫn còn trong thư viện công việc cho đến khi kết thúc phiên SAS.
Cú pháp
Cú pháp cơ bản để tạo boxplot trong SAS là:
PROC SGPLOT DATA = DATASET;
VBOX VARIABLE / category = VARIABLE;
RUN;
PROC SGPANEL DATA = DATASET;;
PANELBY VARIABLE;
VBOX VARIABLE> / category = VARIABLE;
RUN;DATASET - là tên của tập dữ liệu được sử dụng.
VARIABLE - là giá trị được sử dụng để vẽ Boxplot.
Boxplot đơn giản
Trong một Boxplot đơn giản, chúng tôi chọn một biến từ tập dữ liệu và một biến khác để tạo thành một danh mục. Các giá trị của biến đầu tiên được phân loại thành nhiều nhóm bằng số lượng giá trị khác biệt trong biến thứ hai.
Thí dụ
Trong ví dụ dưới đây, chúng tôi chọn biến mã lực làm biến đầu tiên và nhập làm biến danh mục. Vì vậy, chúng tôi nhận được các hộp để phân phối các giá trị mã lực cho từng loại ô tô.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC SGPLOT DATA = CARS1;
VBOX horsepower
/ category = type;
title 'Horsepower of cars by types';
RUN;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:
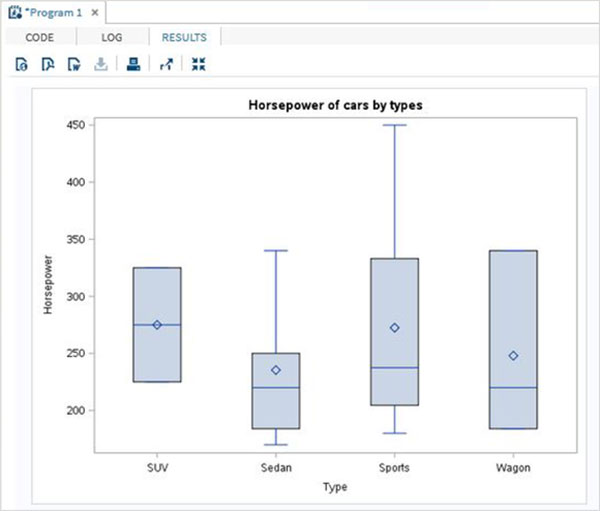
Boxplot trong Bảng dọc
Chúng ta có thể chia Boxplots của một biến thành nhiều ô dọc (cột). Mỗi bảng điều khiển chứa các ô cho tất cả các biến phân loại. Nhưng các ô hộp được nhóm lại bằng cách sử dụng một biến thứ ba khác chia biểu đồ thành nhiều ô.
Thí dụ
Trong ví dụ dưới đây, chúng tôi đã phân tích đồ thị bằng cách sử dụng biến 'make'. Vì có hai giá trị khác nhau của 'make' nên chúng ta nhận được hai bảng dọc.
PROC SGPANEL DATA = CARS1;
PANELBY MAKE;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:
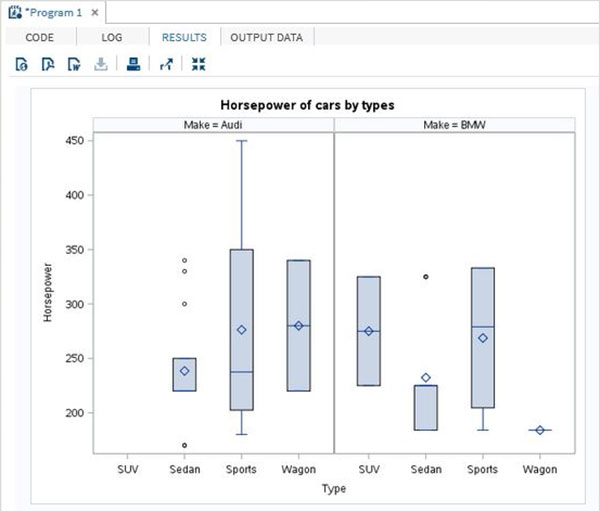
Boxplot trong Bảng ngang
Chúng ta có thể chia Boxplots của một biến thành nhiều ô ngang (hàng). Mỗi bảng điều khiển chứa các ô cho tất cả các biến phân loại. Nhưng các ô hộp được nhóm lại bằng cách sử dụng một biến thứ ba khác chia biểu đồ thành nhiều ô. Trong ví dụ dưới đây, chúng tôi đã phân tích đồ thị bằng cách sử dụng biến 'make'. Vì có hai giá trị khác nhau của 'make' nên chúng tôi nhận được hai bảng nằm ngang.
PROC SGPANEL DATA = CARS1;
PANELBY MAKE / columns = 1 novarname;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;Khi chúng tôi thực thi đoạn mã trên, chúng tôi nhận được kết quả sau:
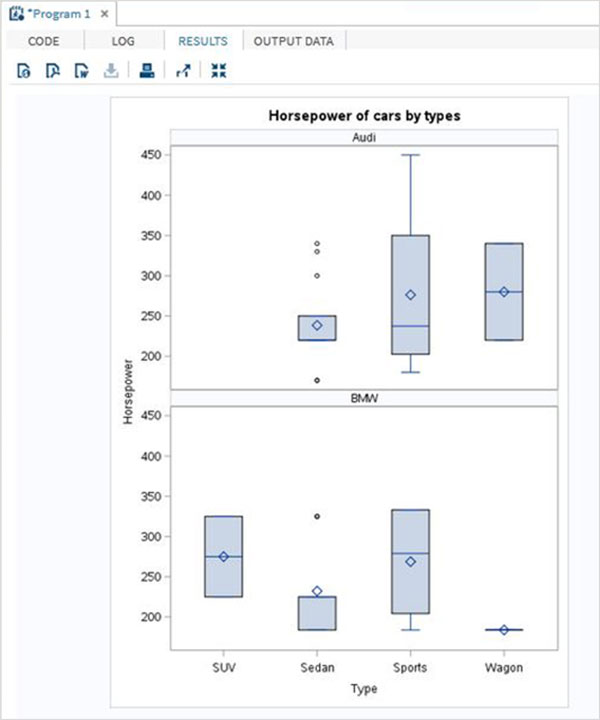
Giá trị trung bình cộng là giá trị thu được bằng cách tính tổng giá trị của các biến số và sau đó chia tổng với số lượng biến. Nó còn được gọi là Trung bình. Trong SAS, giá trị trung bình số học được tính bằngPROC MEANS. Sử dụng thủ tục SAS này, chúng ta có thể tìm giá trị trung bình của tất cả các biến hoặc một số biến của tập dữ liệu. Chúng ta cũng có thể tạo nhóm và tìm giá trị trung bình của các biến có giá trị cụ thể cho nhóm đó.
Cú pháp
Cú pháp cơ bản để tính trung bình cộng trong SAS là:
PROC MEANS DATA = DATASET;
CLASS Variables ;
VAR Variables;Sau đây là mô tả các tham số được sử dụng:
DATASET - là tên của tập dữ liệu được sử dụng.
Variables - là tên của biến từ tập dữ liệu.
Trung bình của một tập dữ liệu
Giá trị trung bình của mỗi biến số trong tập dữ liệu được tính bằng cách sử dụng PROC bằng cách chỉ cung cấp tên tập dữ liệu mà không có bất kỳ biến nào.
Thí dụ
Trong ví dụ dưới đây, chúng tôi tìm giá trị trung bình của tất cả các biến số trong tập dữ liệu SAS có tên CARS. Chúng tôi chỉ định các chữ số lớn nhất sau vị trí thập phân là 2 và cũng tìm tổng của các biến đó.
PROC MEANS DATA = sashelp.CARS Mean SUM MAXDEC=2;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:
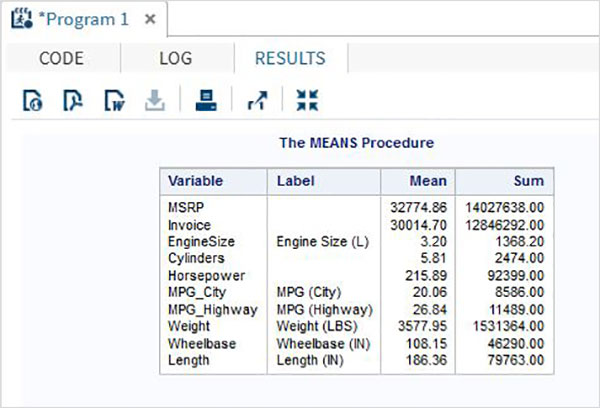
Giá trị trung bình của các biến được chọn
Chúng ta có thể lấy giá trị trung bình của một số biến bằng cách cung cấp tên của chúng trong var Lựa chọn.
Thí dụ
Trong phần dưới đây, chúng tôi tính giá trị trung bình của ba biến.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2 ;
var horsepower invoice EngineSize;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:
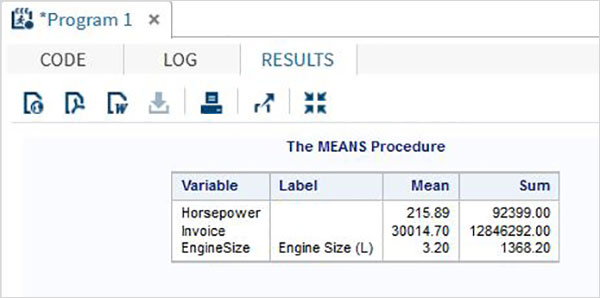
Trung bình theo lớp
Chúng ta có thể tìm giá trị trung bình của các biến số bằng cách sắp xếp chúng thành các nhóm bằng cách sử dụng một số biến khác.
Thí dụ
Trong ví dụ dưới đây, chúng tôi tìm thấy giá trị trung bình của mã lực thay đổi cho từng loại dưới mỗi cấu tạo của ô tô.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2;
class make type;
var horsepower;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau:
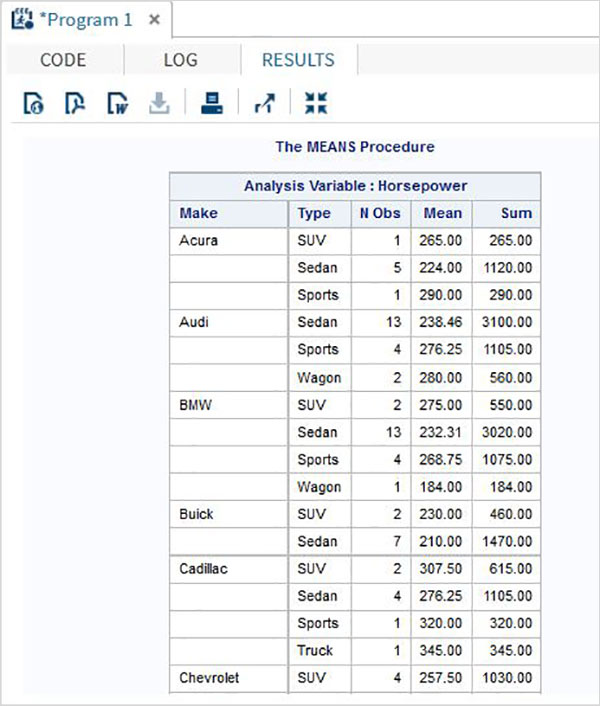
Độ lệch chuẩn (SD) là thước đo mức độ thay đổi của dữ liệu trong một tập dữ liệu. Về mặt toán học, nó đo lường mức độ xa hoặc gần của mỗi giá trị với giá trị trung bình của tập dữ liệu. Giá trị độ lệch chuẩn gần bằng 0 cho biết rằng các điểm dữ liệu có xu hướng rất gần với giá trị trung bình của tập dữ liệu và độ lệch chuẩn cao cho thấy rằng các điểm dữ liệu được trải rộng trên một phạm vi giá trị rộng hơn
Trong SAS, các giá trị SD được đo bằng PROC MEAN cũng như PROC SURVEYMEANS.
Sử dụng phương tiện PROC
Để đo SD bằng cách sử dụng proc meanschúng tôi chọn tùy chọn STD trong bước PROC. Nó đưa ra các giá trị SD cho mỗi biến số có trong tập dữ liệu.
Cú pháp
Cú pháp cơ bản để tính toán độ lệch chuẩn trong SAS là:
PROC means DATA = dataset STD;Sau đây là mô tả về các tham số được sử dụng:
Dataset - là tên của tập dữ liệu.
Thí dụ
Trong ví dụ dưới đây, chúng tôi tạo tập dữ liệu CARS1 tạo thành tập dữ liệu CARS trong thư viện SASHELP. Chúng tôi chọn tùy chọn STD với bước phương tiện PROC.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc means data = CARS1 STD;
run;Khi chúng tôi thực thi đoạn mã trên, nó sẽ đưa ra kết quả sau:
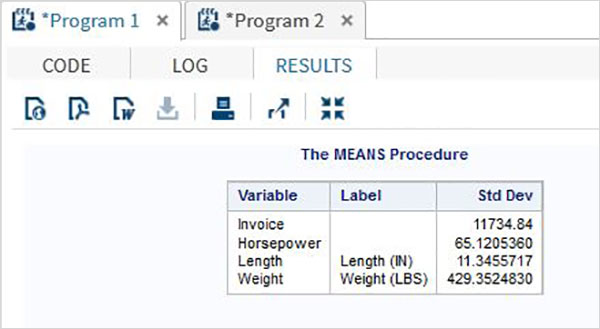
Sử dụng PROC SURVEYMEANS
Quy trình này cũng được sử dụng để đo lường SD cùng với một số tính năng nâng cao như đo SD cho các biến phân loại cũng như cung cấp các ước tính theo phương sai.
Cú pháp
Cú pháp để sử dụng PROC SURVEYMEANS là -
PROC SURVEYMEANS options statistic-keywords ;
BY variables ;
CLASS variables ;
VAR variables ;Sau đây là mô tả về các tham số được sử dụng:
BY - chỉ ra các biến được sử dụng để tạo các nhóm quan sát.
CLASS - chỉ ra các biến được sử dụng cho các biến phân loại.
VAR - cho biết các biến mà SD sẽ được tính toán.
Thí dụ
Ví dụ dưới đây mô tả việc sử dụng class tùy chọn tạo thống kê cho từng giá trị trong biến lớp.
proc surveymeans data = CARS1 STD;
class type;
var type horsepower;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;Khi chúng tôi thực thi đoạn mã trên, nó sẽ đưa ra kết quả sau:
Sử dụng tùy chọn BY
Đoạn mã dưới đây đưa ra ví dụ về tùy chọn BY. Trong đó, kết quả được nhóm cho từng giá trị trong tùy chọn BY.
Thí dụ
proc surveymeans data = CARS1 STD;
var horsepower;
BY make;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;Khi chúng tôi thực thi đoạn mã trên, nó sẽ đưa ra kết quả sau:
Kết quả cho make = "Audi"

Kết quả cho make = "BMW"
Phân bố tần suất là một bảng hiển thị tần suất của các điểm dữ liệu trong tập dữ liệu. Mỗi mục nhập trong bảng chứa tần suất hoặc số lần xuất hiện của các giá trị trong một nhóm hoặc khoảng thời gian cụ thể và theo cách này, bảng tóm tắt sự phân bố của các giá trị trong mẫu.
SAS cung cấp một thủ tục được gọi là PROC FREQ để tính toán sự phân bố tần suất của các điểm dữ liệu trong một tập dữ liệu.
Cú pháp
Cú pháp cơ bản để tính toán phân bố tần số trong SAS là:
PROC FREQ DATA = Dataset ;
TABLES Variable_1 ;
BY Variable_2 ;Sau đây là mô tả về các tham số được sử dụng:
Dataset là tên của tập dữ liệu.
Variables_1 là các tên biến của tập dữ liệu có phân bố tần số cần được tính toán.
Variables_2 là các biến đã phân loại kết quả phân phối tần số.
Phân phối tần số biến đơn
Chúng ta có thể xác định phân phối tần suất của một biến đơn lẻ bằng cách sử dụng PROC FREQ.Trong trường hợp này, kết quả sẽ hiển thị tần số của từng giá trị của biến. Kết quả cũng cho thấy phân phối phần trăm, tần suất tích lũy và phần trăm tích lũy.
Thí dụ
Trong ví dụ dưới đây, chúng tôi tìm thấy phân phối tần số của mã lực biến đổi cho tập dữ liệu có tên CARS1 được tạo thành thư viện SASHELP.CARS.Chúng ta có thể thấy kết quả được chia thành hai loại kết quả. Một chiếc cho mỗi chiếc xe.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:

Phân phối nhiều tần số biến đổi
Chúng ta có thể tìm thấy phân bố tần số cho nhiều biến để nhóm chúng thành tất cả các kết hợp có thể có.
Thí dụ
Trong ví dụ dưới đây, chúng tôi tính toán phân bố tần số cho việc tạo ra một chiếc ô tô grouped by car type và cả phân bố tần suất của từng loại ô tô grouped by each make.
proc FREQ data = CARS1 ;
tables make type;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
Phân bố tần số với trọng lượng
Với tùy chọn trọng số, chúng ta có thể tính toán phân phối tần số thiên vị với trọng số của biến. Ở đây giá trị của biến được lấy làm số lần quan sát thay vì đếm giá trị.
Thí dụ
Trong ví dụ dưới đây, chúng tôi tính toán phân bố tần số của các biến được tạo và loại với trọng lượng được gán cho mã lực.
proc FREQ data = CARS1 ;
tables make type;
weight horsepower;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
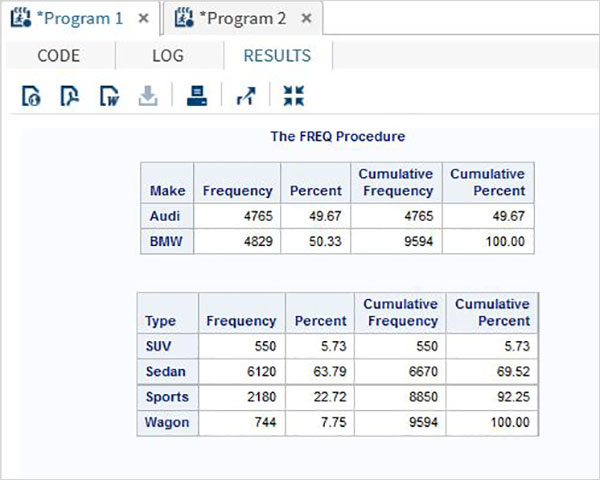
Lập bảng chéo bao gồm việc tạo ra các bảng chéo còn được gọi là bảng ngẫu nhiên sử dụng tất cả các kết hợp có thể có của hai hoặc nhiều biến. Trong SAS, nó được tạo bằng cách sử dụngPROC FREQ cùng với TABLESLựa chọn. Ví dụ - nếu chúng ta cần tần suất của từng kiểu xe cho từng sản phẩm trong từng danh mục loại ô tô, thì chúng ta cần sử dụng tùy chọn TABLES của PROC FREQ.
Cú pháp
Cú pháp cơ bản để áp dụng lập bảng chéo trong SAS là:
PROC FREQ DATA = dataset;
TABLES variable_1*Variable_2;Sau đây là mô tả về các tham số được sử dụng:
Dataset là tên của tập dữ liệu.
Variable_1 and Variable_2 là các tên biến của tập dữ liệu có sự phân bố tần số cần được tính toán.
Thí dụ
Hãy xem xét trường hợp tìm bao nhiêu loại ô tô có sẵn cho mỗi nhãn hiệu ô tô từ tập dữ liệu ô tô1 được tạo biểu mẫu SASHELP.CARSnhư hình bên dưới. Trong trường hợp này, chúng tôi cần các giá trị tần số riêng lẻ cũng như tổng các giá trị tần số trên các sản phẩm và trên các loại. Chúng ta có thể quan sát rằng kết quả hiển thị các giá trị trên các hàng và cột.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1;
tables make*type;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
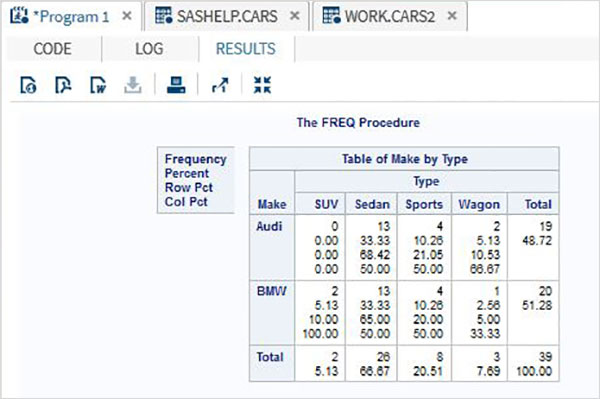
Lập bảng chéo của 3 biến
Khi chúng ta có ba biến, chúng ta có thể nhóm 2 trong số chúng và lập bảng chéo từng biến trong số hai biến này với biến thứ ba có thể thay đổi được. Vì vậy, kết quả chúng ta có hai bảng chéo.
Thí dụ
Trong ví dụ dưới đây, chúng ta tìm thấy tần suất xuất hiện của từng loại ô tô và từng mẫu ô tô liên quan đến cấu tạo của ô tô. Ngoài ra, chúng tôi sử dụng tùy chọn nocol và norow để tránh các giá trị tổng và phần trăm.
proc FREQ data = CARS2 ;
tables make * (type model) / nocol norow nopercent;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
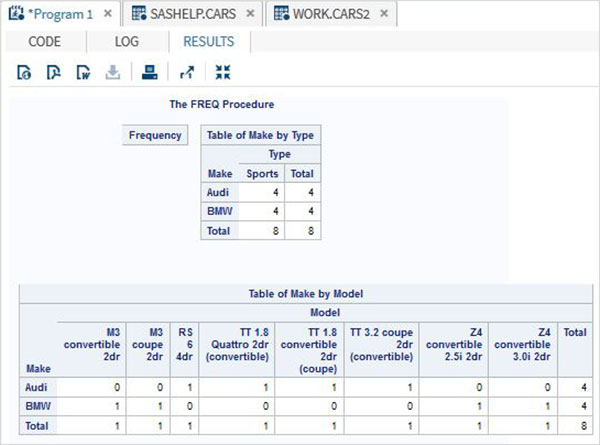
Lập bảng chéo của 4 biến
Với 4 biến, số lượng kết hợp được ghép đôi tăng lên 4. Mỗi biến từ nhóm 1 được ghép nối với mỗi biến của nhóm 2.
Thí dụ
Trong ví dụ dưới đây, chúng tôi tìm tần suất chiều dài của ô tô cho từng sản phẩm và từng kiểu xe. Tương tự như vậy tần số mã lực cho mỗi sản xuất và mỗi mô hình.
proc FREQ data = CARS2 ;
tables (make model) * (length horsepower) / nocol norow nopercent;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
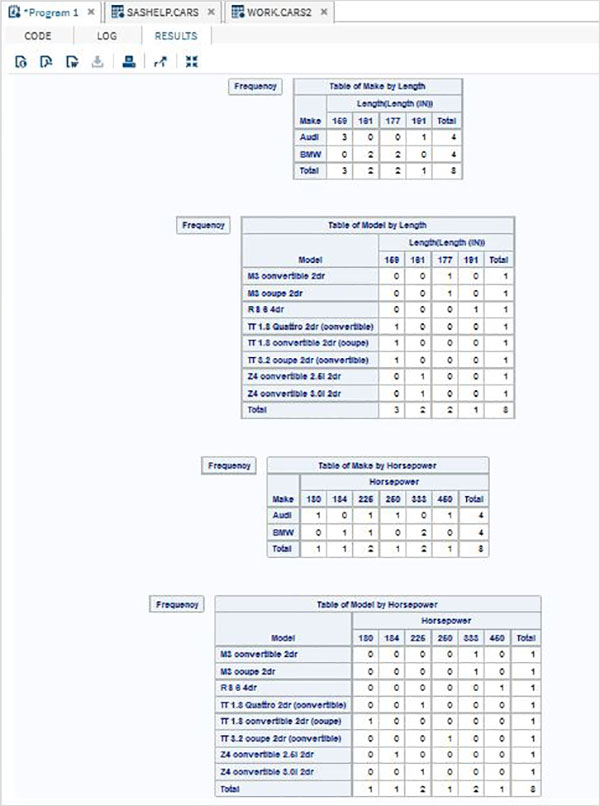
Phép thử T được thực hiện để tính toán các giới hạn tin cậy cho một mẫu hoặc hai mẫu độc lập bằng cách so sánh trung bình và chênh lệch trung bình của chúng. Thủ tục SAS có tênPROC TTEST được sử dụng để thực hiện kiểm định t trên một biến đơn và cặp biến.
Cú pháp
Cú pháp cơ bản để áp dụng TTEST PROC trong SAS là:
PROC TTEST DATA = dataset;
VAR variable;
CLASS Variable;
PAIRED Variable_1 * Variable_2;Sau đây là mô tả về các tham số được sử dụng:
Dataset là tên của tập dữ liệu.
Variable_1 and Variable_2 là các tên biến của tập dữ liệu được sử dụng trong thử nghiệm t.
Thí dụ
Dưới đây, chúng tôi thấy một thử nghiệm t mẫu trong đó tìm ước lượng thử nghiệm t cho mã lực biến đổi với giới hạn tin cậy 95 phần trăm.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc ttest data = cars1 alpha = 0.05 h0 = 0;
var horsepower;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
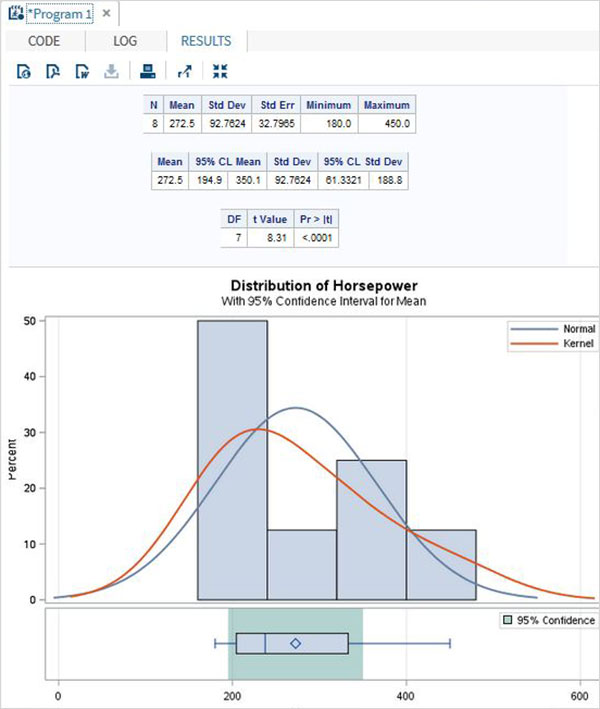
Kiểm tra
Phép thử T theo cặp được thực hiện để kiểm tra xem hai biến phụ thuộc có khác nhau về mặt thống kê hay không.
Thí dụ
Vì chiều dài và trọng lượng của ô tô sẽ phụ thuộc vào nhau, chúng tôi áp dụng thử nghiệm T ghép nối như hình dưới đây.
proc ttest data = cars1 ;
paired weight*length;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
Hai thử nghiệm t mẫu
Phép thử t này được thiết kế để so sánh các phương tiện của cùng một biến giữa hai nhóm.
Thí dụ
Trong trường hợp của chúng tôi, chúng tôi so sánh giá trị trung bình của mã lực thay đổi giữa hai loại xe khác nhau ("Audi" và "BMW").
proc ttest data = cars1 sides = 2 alpha = 0.05 h0 = 0;
title "Two sample t-test example";
class make;
var horsepower;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
Phân tích tương quan giải quyết mối quan hệ giữa các biến. Hệ số tương quan là thước đo sự liên kết tuyến tính giữa hai biến, giá trị của hệ số tương quan luôn nằm trong khoảng từ -1 đến +1. SAS cung cấp quy trìnhPROC CORR để tìm hệ số tương quan giữa một cặp biến trong tập dữ liệu.
Cú pháp
Cú pháp cơ bản để áp dụng PROC CORR trong SAS là:
PROC CORR DATA = dataset options;
VAR variable;Sau đây là mô tả về các tham số được sử dụng:
Dataset là tên của tập dữ liệu.
Options là tùy chọn bổ sung với quy trình như vẽ ma trận, v.v.
Variable là tên biến của tập dữ liệu được sử dụng để tìm mối tương quan.
Thí dụ
Hệ số tương quan giữa một cặp biến có sẵn trong tập dữ liệu có thể thu được bằng cách sử dụng tên của chúng trong câu lệnh VAR. Trong ví dụ dưới đây, chúng tôi sử dụng tập dữ liệu CARS1 và nhận được kết quả hiển thị hệ số tương quan giữa mã lực và trọng lượng.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc corr data = cars1 ;
VAR horsepower weight ;
BY make;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
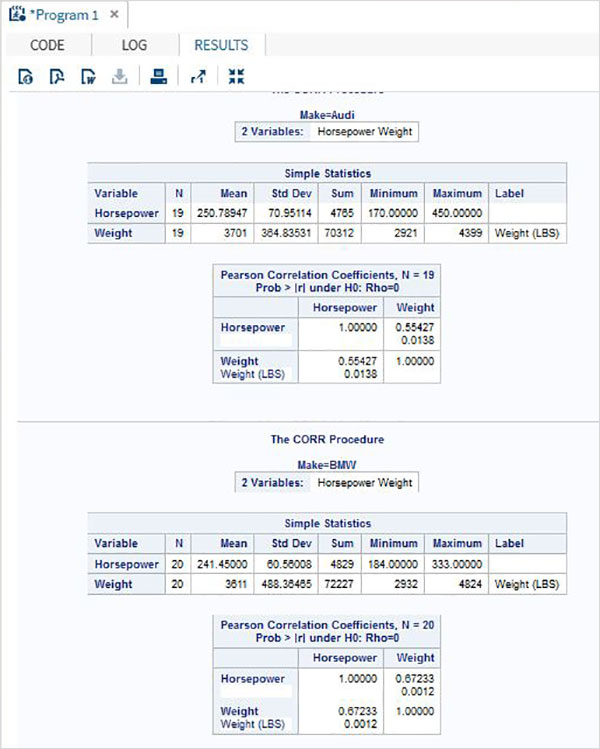
Tương quan giữa tất cả các biến
Hệ số tương quan giữa tất cả các biến có sẵn trong tập dữ liệu có thể thu được bằng cách đơn giản áp dụng thủ tục với tên tập dữ liệu.
Thí dụ
Trong ví dụ dưới đây, chúng tôi sử dụng tập dữ liệu CARS1 và nhận được kết quả hiển thị các hệ số tương quan giữa mỗi cặp biến.
proc corr data = cars1 ;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
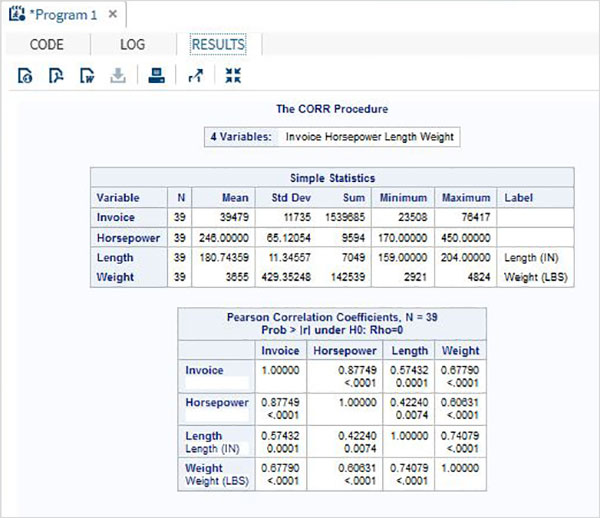
Ma trận tương quan
Chúng ta có thể có được một ma trận biểu đồ phân tán giữa các biến bằng cách chọn tùy chọn để vẽ biểu đồ ma trận trong PROC tuyên bố.
Thí dụ
Trong ví dụ dưới đây, chúng tôi nhận được ma trận giữa mã lực và trọng lượng.
proc corr data = cars1 plots = matrix ;
VAR horsepower weight ;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
Hồi quy tuyến tính được sử dụng để xác định mối quan hệ giữa một biến phụ thuộc và một hoặc nhiều biến độc lập. Một mô hình của mối quan hệ được đề xuất và các ước lượng của các giá trị tham số được sử dụng để phát triển một phương trình hồi quy ước tính.
Sau đó, các thử nghiệm khác nhau được sử dụng để xác định xem mô hình có đạt yêu cầu hay không. Nếu đúng như vậy, phương trình hồi quy ước lượng có thể được sử dụng để dự đoán giá trị của biến phụ thuộc các giá trị đã cho cho các biến độc lập. Trong SAS thủ tụcPROC REG được sử dụng để tìm mô hình hồi quy tuyến tính giữa hai biến.
Cú pháp
Cú pháp cơ bản để áp dụng PROC REG trong SAS là:
PROC REG DATA = dataset;
MODEL variable_1 = variable_2;Sau đây là mô tả về các tham số được sử dụng:
Dataset là tên của tập dữ liệu.
variable_1 and variable_2 là các tên biến của tập dữ liệu được sử dụng để tìm mối tương quan.
Thí dụ
Ví dụ dưới đây cho thấy quá trình để tìm mối tương quan giữa hai biến mã lực và trọng lượng của một chiếc ô tô bằng cách sử dụng PROC REG. Trong kết quả, chúng ta thấy các giá trị chặn có thể được sử dụng để lập phương trình hồi quy.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc reg data = cars1;
model horsepower = weight ;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
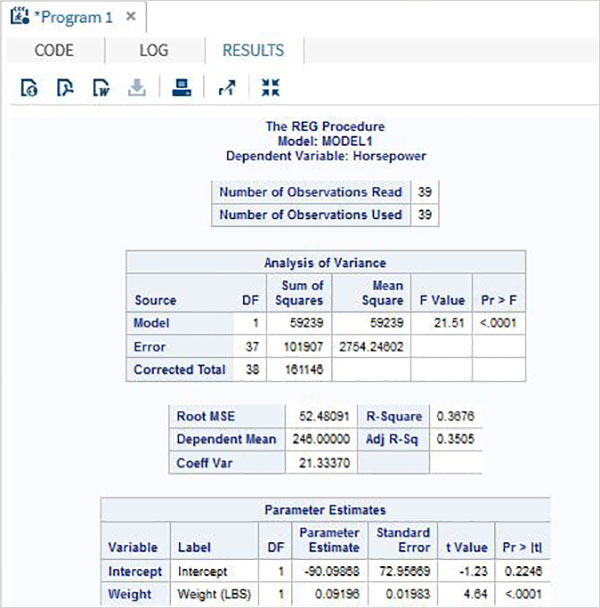
Đoạn mã trên cũng cung cấp chế độ xem đồ họa của các ước tính khác nhau của mô hình như được hiển thị bên dưới. Là một thủ tục SAS nâng cao, nó không đơn giản chỉ dừng lại ở việc đưa ra các giá trị chặn làm đầu ra.
Phân tích Bland-Altman là một quá trình để xác minh mức độ đồng ý hoặc bất đồng giữa hai phương pháp được thiết kế để đo các thông số giống nhau. Mối tương quan cao giữa các phương pháp cho thấy rằng mẫu đủ tốt đã được chọn trong phân tích dữ liệu. Trong SAS, chúng tôi tạo biểu đồ Bland-Altman bằng cách tính giá trị trung bình, giới hạn trên và giới hạn dưới của các giá trị biến. Sau đó, chúng tôi sử dụng PROC SGPLOT để tạo âm mưu Bland-Altman.
Cú pháp
Cú pháp cơ bản để áp dụng PROC SGPLOT trong SAS là:
PROC SGPLOT DATA = dataset;
SCATTER X = variable Y = Variable;
REFLINE value;Sau đây là mô tả về các tham số được sử dụng:
Dataset là tên của tập dữ liệu.
SCATTER câu lệnh ngừng biểu đồ biểu đồ phân tán của giá trị được cung cấp ở dạng X và Y.
REFLINE tạo một đường tham chiếu ngang hoặc dọc.
Thí dụ
Trong ví dụ dưới đây, chúng tôi lấy kết quả của hai thử nghiệm được tạo bởi hai phương pháp có tên mới và cũ. Chúng tôi tính toán sự khác biệt về giá trị của các biến và cả giá trị trung bình của các biến của cùng một quan sát. Chúng tôi cũng tính toán các giá trị độ lệch chuẩn được sử dụng trong giới hạn trên và giới hạn dưới của phép tính.
Kết quả cho thấy một biểu đồ Bland-Altman là một biểu đồ phân tán.
data mydata;
input new old;
datalines;
31 45
27 12
11 37
36 25
14 8
27 15
3 11
62 42
38 35
20 9
35 54
62 67
48 25
77 64
45 53
32 42
16 19
15 27
22 9
8 38
24 16
59 25
;
data diffs ;
set mydata ;
/* calculate the difference */
diff = new-old ;
/* calculate the average */
mean = (new+old)/2 ;
run ;
proc print data = diffs;
run;
proc sql noprint ;
select mean(diff)-2*std(diff), mean(diff)+2*std(diff)
into :lower, :upper
from diffs ;
quit;
proc sgplot data = diffs ;
scatter x = mean y = diff;
refline 0 &upper &lower / LABEL = ("zero bias line" "95% upper limit" "95%
lower limit");
TITLE 'Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
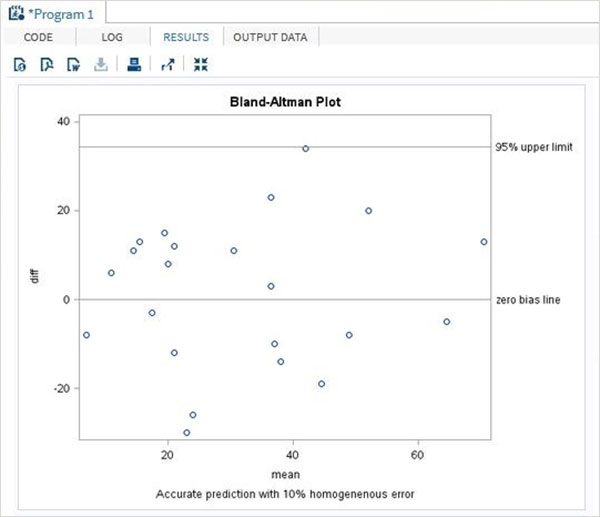
Mô hình nâng cao
Trong mô hình nâng cao của chương trình trên, chúng tôi nhận được sự phù hợp đường cong mức tin cậy 95 phần trăm.
proc sgplot data = diffs ;
reg x = new y = diff/clm clmtransparency = .5;
needle x = new y = diff/baseline = 0;
refline 0 / LABEL = ('No diff line');
TITLE 'Enhanced Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
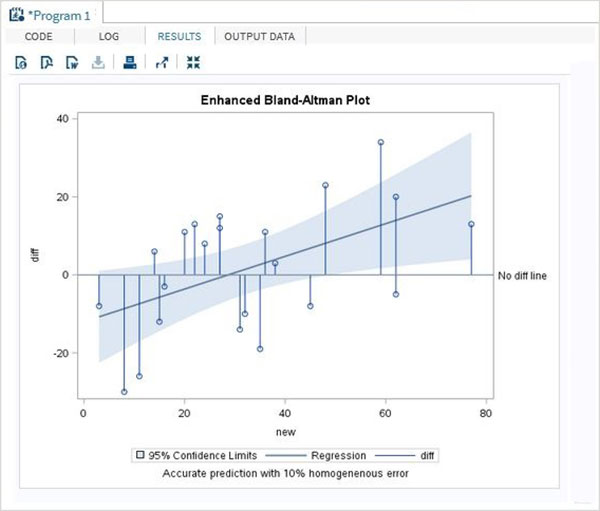
Kiểm định chi bình phương được sử dụng để kiểm tra mối liên hệ giữa hai biến phân loại. Nó có thể được sử dụng để kiểm tra cả mức độ phụ thuộc và mức độ độc lập giữa các Biến. SAS sử dụngPROC FREQ cùng với tùy chọn chisq để xác định kết quả của phép thử Chi-Square.
Cú pháp
Cú pháp cơ bản để áp dụng PROC FREQ cho kiểm tra Chi-Square trong SAS là:
PROC FREQ DATA = dataset;
TABLES variables
/CHISQ TESTP = (percentage values);Sau đây là mô tả về các tham số được sử dụng:
Dataset là tên của tập dữ liệu.
Variables là các tên biến của tập dữ liệu được sử dụng trong kiểm tra chi-square.
Percentage Values trong câu lệnh TESTP đại diện cho phần trăm các mức của biến.
Thí dụ
Trong ví dụ dưới đây, chúng tôi xem xét kiểm tra chi-bình phương trên biến có tên kiểu trong tập dữ liệu SASHELP.CARS. Biến này có sáu cấp độ và chúng tôi chỉ định tỷ lệ phần trăm cho từng cấp độ theo thiết kế của bài kiểm tra.
proc freq data = sashelp.cars;
tables type
/chisq
testp = (0.20 0.12 0.18 0.10 0.25 0.15);
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:

Chúng tôi cũng nhận được biểu đồ thanh hiển thị độ lệch của loại biến như thể hiện trong ảnh chụp màn hình sau.
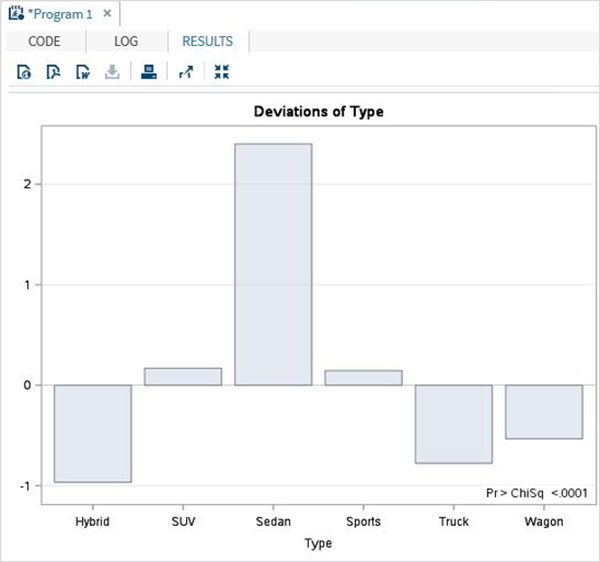
Hai chiều chi-vuông
Kiểm tra Chi-Square hai cách được sử dụng khi chúng tôi áp dụng các kiểm tra cho hai biến của tập dữ liệu.
Thí dụ
Trong ví dụ dưới đây, chúng tôi áp dụng kiểm định chi-square trên hai biến có tên là kiểu và nguồn gốc. Kết quả cho thấy dạng bảng của tất cả các kết hợp của hai biến này.
proc freq data = sashelp.cars;
tables type*origin
/chisq
;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
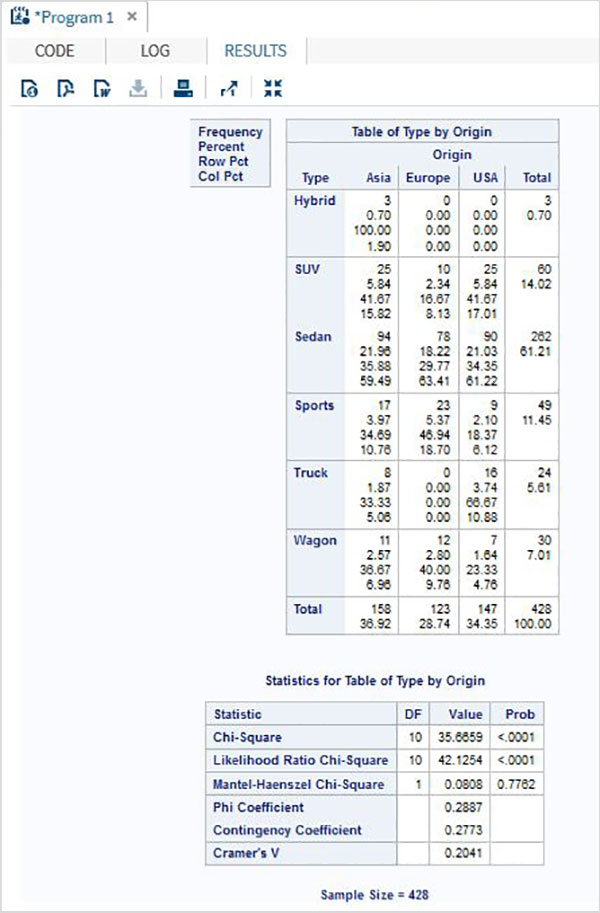
Kiểm định chính xác của Fisher là một kiểm định thống kê được sử dụng để xác định xem có mối liên hệ phi nguyên tử giữa hai biến phân loại hay không. Trong SAS, điều này được thực hiện bằng cách sử dụng PROC FREQ. Chúng tôi sử dụng tùy chọn Tables để sử dụng hai biến được kiểm định Fisher Exact.
Cú pháp
Cú pháp cơ bản để áp dụng kiểm tra Fisher Exact trong SAS là:
PROC FREQ DATA = dataset ;
TABLES Variable_1*Variable_2 / fisher;Sau đây là mô tả về các tham số được sử dụng:
dataset là tên của tập dữ liệu.
Variable_1*Variable_2 là các biến tạo thành tập dữ liệu.
Áp dụng Kiểm tra Chính xác Fisher
Để áp dụng Kiểm tra Chính xác của Fisher, chúng tôi chọn hai biến phân loại có tên là Test1 và Test2 và kết quả của chúng. Chúng tôi sử dụng PROC FREQ để áp dụng kiểm tra được hiển thị bên dưới.
Thí dụ
data temp;
input Test1 Test2 Result @@;
datalines;
1 1 3 1 2 1 2 1 1 2 2 3
;
proc freq;
tables Test1*Test2 / fisher;
run;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
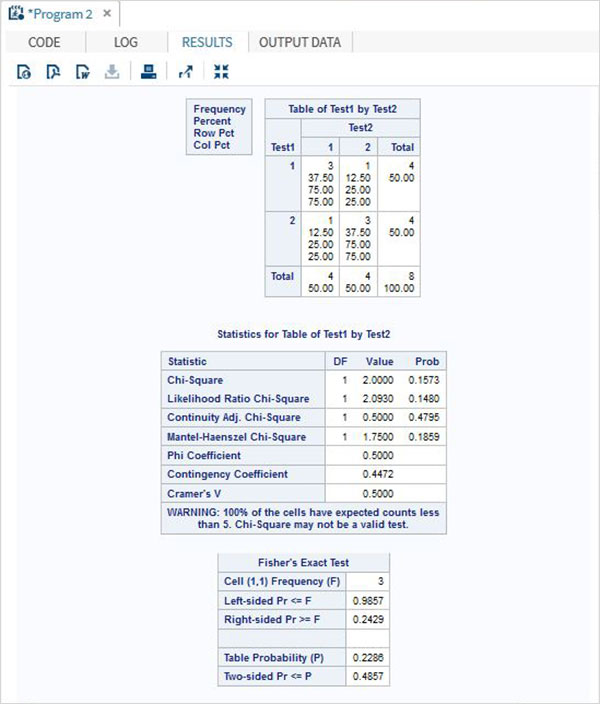
Phép phân tích đo lặp lại được sử dụng khi tất cả các thành viên của một mẫu ngẫu nhiên được đo trong một số điều kiện khác nhau. Khi mẫu tiếp xúc với từng điều kiện lần lượt, phép đo của biến phụ thuộc được lặp lại. Sử dụng ANOVA tiêu chuẩn trong trường hợp này là không phù hợp vì nó không mô hình hóa được mối tương quan giữa các biện pháp lặp lại.
Người ta phải rõ ràng về sự khác biệt giữa repeated measures design và một simple multivariate design. Đối với cả hai, các thành viên mẫu được đo trong nhiều lần hoặc thử nghiệm, nhưng trong thiết kế các phép đo lặp lại, mỗi phép thử đại diện cho phép đo của cùng một đặc tính trong một điều kiện khác nhau.
Trong SAS PROC GLM được sử dụng để thực hiện phân tích biện pháp lặp lại.
Cú pháp
Cú pháp cơ bản cho PROC GLM trong SAS là:
PROC GLM DATA = dataset;
CLASS variable;
MODEL variables = group / NOUNI;
REPEATED TRIAL n;Sau đây là mô tả về các tham số được sử dụng:
dataset là tên của tập dữ liệu.
CLASS cung cấp cho các biến là biến được sử dụng làm biến phân loại.
MODEL xác định mô hình phù hợp bằng cách sử dụng các biến nhất định tạo thành tập dữ liệu.
REPEATED xác định số lượng các biện pháp lặp lại của mỗi nhóm để kiểm tra giả thuyết.
Thí dụ
Hãy xem xét ví dụ dưới đây, trong đó chúng ta có hai nhóm người bị thử tác dụng của một loại thuốc. Thời gian phản ứng của mỗi người được ghi lại đối với từng loại trong bốn loại thuốc được thử nghiệm. Dưới đây là 5 thử nghiệm được thực hiện cho từng nhóm người để xem mức độ tương quan giữa tác dụng của 4 loại thuốc.
DATA temp;
INPUT person group $ r1 r2 r3 r4;
CARDS;
1 A 2 1 6 5
2 A 5 4 11 9
3 A 6 14 12 10
4 A 2 4 5 8
5 A 0 5 10 9
6 B 9 11 16 13
7 B 12 4 13 14
8 B 15 9 13 8
9 B 6 8 12 5
10 B 5 7 11 9
;
RUN;
PROC PRINT DATA = temp ;
RUN;
PROC GLM DATA = temp;
CLASS group;
MODEL r1-r4 = group / NOUNI ;
REPEATED trial 5;
RUN;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:
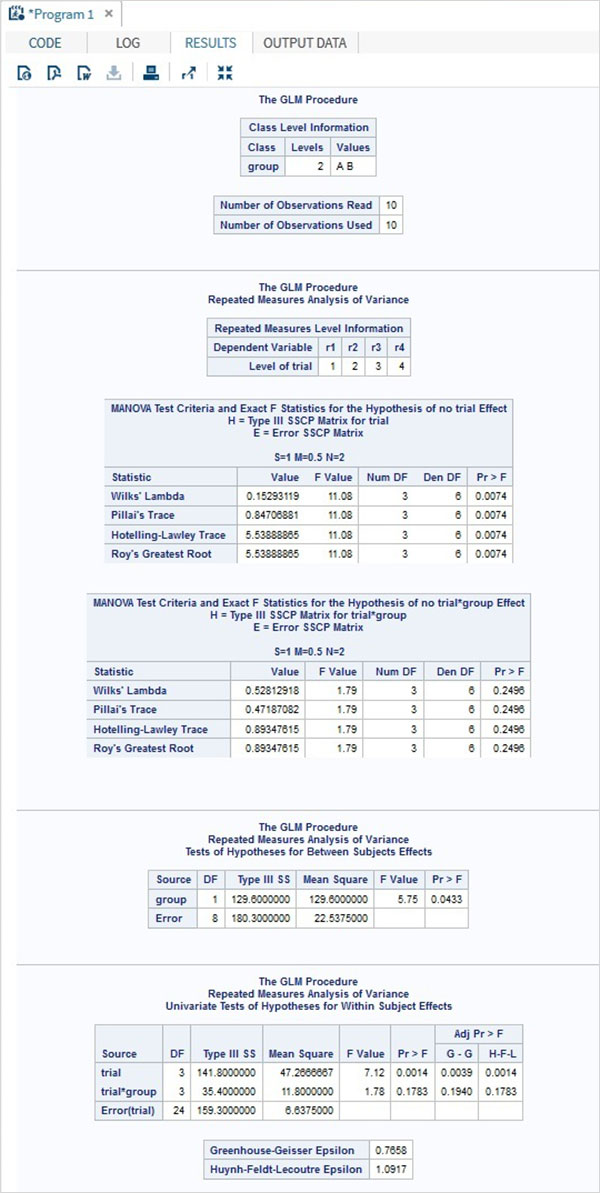
ANOVA là viết tắt của Analysis of Variance. Trong SAS, nó được thực hiện bằng cách sử dụngPROC ANOVA. Nó thực hiện phân tích dữ liệu từ nhiều loại thiết kế thử nghiệm. Trong quá trình này, một biến phản ứng liên tục, được gọi là biến phụ thuộc, được đo lường trong các điều kiện thực nghiệm được xác định bởi các biến phân loại, được gọi là biến độc lập. Sự thay đổi trong câu trả lời được giả định là do ảnh hưởng trong phân loại, với sai số ngẫu nhiên tính đến sự thay đổi còn lại.
Cú pháp
Cú pháp cơ bản để áp dụng PROC ANOVA trong SAS là:
PROC ANOVA dataset ;
CLASS Variable;
MODEL Variable1 = variable2 ;
MEANS ;Sau đây là mô tả về các tham số được sử dụng:
dataset là tên của tập dữ liệu.
CLASS cung cấp cho các biến là biến được sử dụng làm biến phân loại.
MODEL xác định mô hình phù hợp bằng cách sử dụng các biến nhất định từ tập dữ liệu.
Variable_1 and Variable_2 là các tên biến của tập dữ liệu được sử dụng trong phân tích.
MEANS xác định kiểu tính toán và so sánh các phương tiện.
Áp dụng ANOVA
Bây giờ chúng ta hãy hiểu khái niệm áp dụng ANOVA trong SAS.
Thí dụ
Hãy xem xét tập dữ liệu SASHELP.CARS. Ở đây chúng tôi nghiên cứu sự phụ thuộc giữa các biến loại xe và mã lực của chúng. Vì kiểu ô tô là một biến có giá trị phân loại, chúng tôi coi nó là biến lớp và sử dụng cả hai biến này trong MODEL.
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
RUN;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:

Áp dụng ANOVA với MEANS
Bây giờ chúng ta hãy hiểu khái niệm áp dụng ANOVA với MEANS trong SAS.
Thí dụ
Chúng tôi cũng có thể mở rộng mô hình bằng cách áp dụng tuyên bố MEANS, trong đó chúng tôi sử dụng phương pháp Studentized của Thổ Nhĩ Kỳ để so sánh giá trị trung bình của các loại ô tô khác nhau. Danh mục loại ô tô được liệt kê với giá trị mã lực trung bình trong mỗi loại cùng với một số giá trị bổ sung như lỗi có nghĩa là hình vuông, v.v.
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
MEANS type / tukey lines;
RUN;Khi đoạn mã trên được thực thi, chúng tôi nhận được kết quả sau:

Kiểm tra giả thuyết là việc sử dụng thống kê để xác định xác suất một giả thuyết đã cho là đúng. Quy trình kiểm tra giả thuyết thông thường bao gồm bốn bước như hình dưới đây.
Bước 1
Xây dựng giả thuyết vô hiệu H0 (thông thường, các quan sát là kết quả của cơ hội thuần túy) và giả thuyết thay thế H1 (thông thường, các quan sát cho thấy một tác động thực sự kết hợp với một thành phần của biến đổi cơ hội).
Bước 2
Xác định một thống kê kiểm định có thể được sử dụng để đánh giá sự thật của giả thuyết vô hiệu.
Bước 3
Tính giá trị P, là xác suất mà thống kê thử nghiệm ít nhất có ý nghĩa như thống kê quan sát được giả sử rằng giả thuyết rỗng là đúng. Giá trị P càng nhỏ thì bằng chứng chống lại giả thuyết vô hiệu càng mạnh.
Bước 4
So sánh giá trị p với giá trị ý nghĩa có thể chấp nhận được alpha (đôi khi được gọi là giá trị alpha). Nếu p <= alpha, rằng tác động quan sát được là có ý nghĩa thống kê, thì giả thuyết vô hiệu bị loại trừ và giả thuyết thay thế là hợp lệ.
Ngôn ngữ lập trình SAS có các tính năng để thực hiện các loại kiểm định giả thuyết như hình dưới đây.
| Kiểm tra | Sự miêu tả | SAS PROC |
|---|---|---|
| T-Test | Phép thử t được sử dụng để kiểm tra xem giá trị trung bình của một biến có khác đáng kể so với giá trị được giả thuyết hay không. | PROC TTEST |
| ANOVA | Nó cũng được sử dụng để so sánh các phương tiện khi có một biến phân loại độc lập. Chúng tôi muốn sử dụng ANOVA một chiều khi kiểm tra để xem liệu giá trị trung bình của biến phụ thuộc khoảng có khác nhau theo biến phân loại độc lập hay không. | PROC ANOVA |
| Chi-Square | Chúng tôi sử dụng độ phù hợp chi bình phương để đánh giá xem tần số của một biến phân loại có khả năng xảy ra do ngẫu nhiên hay không. Việc sử dụng kiểm định chi bình phương là cần thiết cho dù tỷ lệ của một biến phân loại có phải là một giá trị giả định hay không. | PROC FREQ |
| Linear Regression | Hồi quy tuyến tính đơn giản được sử dụng khi người ta muốn kiểm tra xem một biến dự đoán biến khác tốt như thế nào. Quá trình đa tuyến tính cho phép người ta kiểm tra mức độ nhiều biến dự đoán một biến quan tâm. Khi sử dụng nhiều hồi quy tuyến tính, chúng tôi cũng giả định rằng các biến dự báo là độc lập. | PROC REG |