SAS - Đọc dữ liệu thô
SAS có thể đọc dữ liệu từ nhiều nguồn khác nhau, bao gồm nhiều định dạng tệp. Các định dạng tệp được sử dụng trong môi trường SAS được thảo luận dưới đây.
- Tập dữ liệu ASCII (Văn bản)
- Dữ liệu được phân tách
- Dữ liệu Excel
- Dữ liệu phân cấp
Đọc Tập dữ liệu ASCII (Văn bản)
Đây là những tệp chứa dữ liệu ở định dạng văn bản. Dữ liệu thường được phân cách bằng dấu cách, nhưng cũng có thể có nhiều loại dấu phân cách khác nhau mà SAS có thể xử lý. Hãy xem xét một tệp ASCII chứa dữ liệu nhân viên. Chúng tôi đọc tệp này bằng cách sử dụngInfile tuyên bố có sẵn trong SAS.
Thí dụ
Trong ví dụ dưới đây, chúng tôi đọc tệp dữ liệu có tên emp_data.txt từ môi trường địa phương.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt';
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
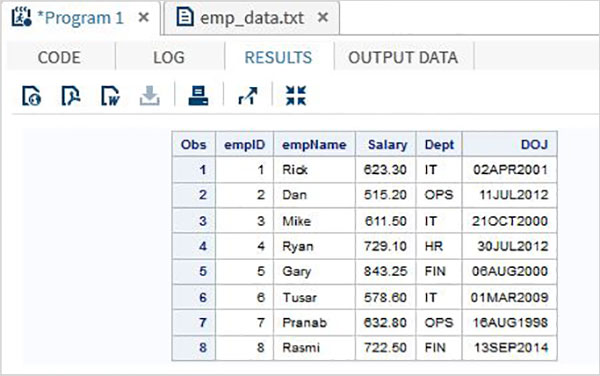
Đọc dữ liệu được phân cách
Đây là các tệp dữ liệu trong đó các giá trị cột được phân tách bằng ký tự phân tách như dấu phẩy hoặc đường dẫn, v.v. Trong trường hợp này, chúng tôi sử dụng dlm tùy chọn trong infile tuyên bố.
Thí dụ
Trong ví dụ dưới đây, chúng tôi đọc tệp dữ liệu có tên emp.csv từ môi trường cục bộ.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=",";
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
Đọc dữ liệu Excel
SAS có thể đọc trực tiếp tệp excel bằng cơ sở nhập. Như đã thấy trong chương Bộ dữ liệu SAS, nó có thể xử lý nhiều loại tệp khác nhau bao gồm MS excel. Giả sử tệp emp.xls có sẵn cục bộ trong môi trường SAS.
Thí dụ
FILENAME REFFILE
"/folders/myfolders/TutorialsPoint/emp.xls"
TERMSTR = CR;
PROC IMPORT DATAFILE = REFFILE
DBMS = XLS
OUT = WORK.IMPORT;
GETNAMES = YES;
RUN;
PROC PRINT DATA = WORK.IMPORT RUN;Đoạn mã trên đọc dữ liệu từ tệp excel và cho kết quả tương tự như hai loại tệp trên.
Đọc tệp phân cấp
Trong các tệp này, dữ liệu hiện diện ở định dạng phân cấp. Đối với một quan sát nhất định, có một bản ghi tiêu đề bên dưới có nhiều bản ghi chi tiết được đề cập. Số lượng bản ghi chi tiết có thể thay đổi từ quan sát này sang quan sát khác. Dưới đây là hình minh họa của một tệp phân cấp.
Trong tệp tin dưới đây, thông tin chi tiết của từng nhân viên thuộc từng bộ phận được liệt kê. Bản ghi đầu tiên là bản ghi tiêu đề đề cập đến bộ phận và bản ghi tiếp theo vài bản ghi bắt đầu bằng DTLS là bản ghi chi tiết.
DEPT:IT
DTLS:1:Rick:623
DTLS:3:Mike:611
DTLS:6:Tusar:578
DEPT:OPS
DTLS:7:Pranab:632
DTLS:2:Dan:452
DEPT:HR
DTLS:4:Ryan:487
DTLS:2:Siyona:452Thí dụ
Để đọc tệp phân cấp, chúng tôi sử dụng đoạn mã dưới đây, trong đó chúng tôi xác định bản ghi tiêu đề bằng mệnh đề IF và sử dụng vòng lặp do để xử lý bản ghi chi tiết.
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @;
if Type = 'DEP' then
input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
