Spark SQL - Giới thiệu
Spark giới thiệu một mô-đun lập trình để xử lý dữ liệu có cấu trúc được gọi là Spark SQL. Nó cung cấp một chương trình trừu tượng gọi là DataFrame và có thể hoạt động như một công cụ truy vấn SQL phân tán.
Các tính năng của Spark SQL
Sau đây là các tính năng của Spark SQL:
Integrated- Kết hợp liền mạch các truy vấn SQL với các chương trình Spark. Spark SQL cho phép bạn truy vấn dữ liệu có cấu trúc dưới dạng tập dữ liệu phân tán (RDD) trong Spark, với các API tích hợp bằng Python, Scala và Java. Sự tích hợp chặt chẽ này giúp bạn dễ dàng chạy các truy vấn SQL cùng với các thuật toán phân tích phức tạp.
Unified Data Access- Tải và truy vấn dữ liệu từ nhiều nguồn khác nhau. Schema-RDDs cung cấp một giao diện duy nhất để làm việc hiệu quả với dữ liệu có cấu trúc, bao gồm bảng Apache Hive, tệp parquet và tệp JSON.
Hive Compatibility- Chạy các truy vấn Hive chưa sửa đổi trên các kho hiện có. Spark SQL sử dụng lại giao diện người dùng Hive và MetaStore, mang lại cho bạn khả năng tương thích hoàn toàn với dữ liệu Hive, truy vấn và UDF hiện có. Chỉ cần cài đặt nó cùng với Hive.
Standard Connectivity- Kết nối thông qua JDBC hoặc ODBC. Spark SQL bao gồm một chế độ máy chủ với kết nối JDBC và ODBC tiêu chuẩn công nghiệp.
Scalability- Sử dụng cùng một công cụ cho cả truy vấn tương tác và truy vấn dài. Spark SQL tận dụng lợi thế của mô hình RDD để hỗ trợ khả năng chịu lỗi ở giữa truy vấn, cho phép nó mở rộng thành các công việc lớn. Đừng lo lắng về việc sử dụng một công cụ khác cho dữ liệu lịch sử.
Kiến trúc Spark SQL
Hình minh họa sau đây giải thích kiến trúc của Spark SQL:
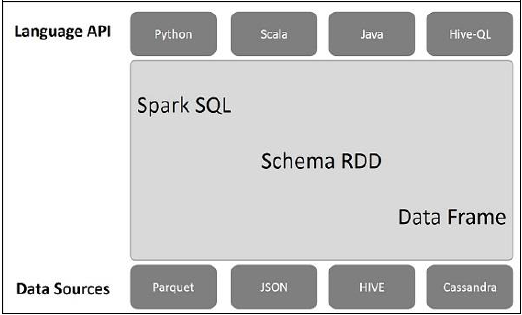
Kiến trúc này chứa ba lớp cụ thể là, API ngôn ngữ, lược đồ RDD và nguồn dữ liệu.
Language API- Spark tương thích với các ngôn ngữ khác nhau và Spark SQL. Nó cũng được hỗ trợ bởi các ngôn ngữ này- API (python, scala, java, HiveQL).
Schema RDD- Spark Core được thiết kế với cấu trúc dữ liệu đặc biệt gọi là RDD. Nói chung, Spark SQL hoạt động trên lược đồ, bảng và bản ghi. Do đó, chúng ta có thể sử dụng Schema RDD làm bảng tạm thời. Chúng ta có thể gọi lược đồ RDD này là Khung dữ liệu.
Data Sources- Thông thường Nguồn dữ liệu cho spark-core là tệp văn bản, tệp Avro,… Tuy nhiên, Nguồn dữ liệu cho Spark SQL thì khác. Đó là tệp Parquet, tài liệu JSON, bảng HIVE và cơ sở dữ liệu Cassandra.
Chúng ta sẽ thảo luận thêm về những điều này trong các chương tiếp theo.