Chuỗi thời gian - Hướng dẫn nhanh
Chuỗi thời gian là một chuỗi các quan sát trong một khoảng thời gian nhất định. Chuỗi thời gian đơn biến bao gồm các giá trị được lấy bởi một biến duy nhất tại các phiên bản thời gian định kỳ trong một khoảng thời gian và chuỗi thời gian đa biến bao gồm các giá trị được lấy bởi nhiều biến tại cùng một thời điểm định kỳ trong một khoảng thời gian. Ví dụ đơn giản nhất về một chuỗi thời gian mà tất cả chúng ta đều gặp phải hàng ngày là sự thay đổi nhiệt độ trong ngày hoặc tuần hoặc tháng hoặc năm.
Việc phân tích dữ liệu thời gian có thể cung cấp cho chúng ta những hiểu biết hữu ích về cách một biến thay đổi theo thời gian hoặc nó phụ thuộc vào sự thay đổi giá trị của (các) biến khác như thế nào. Mối quan hệ này của một biến đối với các giá trị trước đó của nó và / hoặc các biến khác có thể được phân tích để dự báo chuỗi thời gian và có nhiều ứng dụng trong trí tuệ nhân tạo.
Sự hiểu biết cơ bản về bất kỳ ngôn ngữ lập trình nào là điều cần thiết để người dùng làm việc với hoặc phát triển các vấn đề học máy. Dưới đây là danh sách các ngôn ngữ lập trình ưu tiên cho bất kỳ ai muốn làm việc trên máy học:
Python
Nó là một ngôn ngữ lập trình thông dịch cấp cao, nhanh và dễ viết mã. Python có thể tuân theo các mô hình lập trình thủ tục hoặc hướng đối tượng. Sự hiện diện của nhiều loại thư viện làm cho việc thực hiện các thủ tục phức tạp trở nên đơn giản hơn. Trong hướng dẫn này, chúng ta sẽ viết mã bằng Python và các thư viện tương ứng hữu ích cho việc lập mô hình chuỗi thời gian sẽ được thảo luận trong các chương sắp tới.
R
Tương tự như Python, R là một ngôn ngữ đa mô hình được thông dịch, hỗ trợ tính toán thống kê và đồ họa. Sự đa dạng của các gói giúp dễ dàng triển khai mô hình học máy trong R.
Java
Nó là một ngôn ngữ lập trình hướng đối tượng thông dịch, nổi tiếng rộng rãi với một loạt các gói sẵn có và các kỹ thuật trực quan hóa dữ liệu phức tạp.
C / C ++
Đây là những ngôn ngữ biên dịch và là hai trong số những ngôn ngữ lập trình lâu đời nhất. Những ngôn ngữ này thường được ưu tiên kết hợp các khả năng ML trong các ứng dụng đã có sẵn vì chúng cho phép bạn tùy chỉnh việc triển khai các thuật toán ML một cách dễ dàng.
MATLAB
MATrix LABoratory là một ngôn ngữ đa mô hình cho phép hoạt động để làm việc với ma trận. Nó cho phép thực hiện các phép toán cho các bài toán phức tạp. Nó chủ yếu được sử dụng cho các hoạt động số nhưng một số gói cũng cho phép mô phỏng đa miền đồ họa và thiết kế dựa trên mô hình.
Các ngôn ngữ lập trình ưa thích khác cho các vấn đề máy học bao gồm JavaScript, LISP, Prolog, SQL, Scala, Julia, SAS, v.v.
Python đã trở nên phổ biến trong số các cá nhân thực hiện học máy vì cấu trúc mã dễ viết và dễ hiểu cũng như nhiều loại thư viện mã nguồn mở. Dưới đây là một số thư viện mã nguồn mở mà chúng ta sẽ sử dụng trong các chương tới.
NumPy
Numerical Python là một thư viện được sử dụng cho tính toán khoa học. Nó hoạt động trên đối tượng mảng N chiều và cung cấp chức năng toán học cơ bản như kích thước, hình dạng, giá trị trung bình, độ lệch chuẩn, tối thiểu, tối đa cũng như một số hàm phức tạp hơn như hàm đại số tuyến tính và biến đổi Fourier. Bạn sẽ tìm hiểu thêm về những điều này khi chúng tôi tiếp tục hướng dẫn này.
Gấu trúc
Thư viện này cung cấp cấu trúc dữ liệu hiệu quả cao và dễ sử dụng như chuỗi, khung dữ liệu và bảng điều khiển. Nó đã nâng cao chức năng của Python từ việc thu thập và chuẩn bị dữ liệu đơn thuần đến phân tích dữ liệu. Hai thư viện, Pandas và NumPy, làm cho bất kỳ hoạt động nào trên tập dữ liệu từ nhỏ đến rất lớn trở nên rất đơn giản. Để biết thêm về các chức năng này, hãy làm theo hướng dẫn này.
SciPy
Science Python là một thư viện được sử dụng cho tính toán khoa học và kỹ thuật. Nó cung cấp các chức năng để tối ưu hóa, xử lý tín hiệu và hình ảnh, tích hợp, nội suy và đại số tuyến tính. Thư viện này rất hữu ích khi thực hiện học máy. Chúng tôi sẽ thảo luận về các chức năng này khi chúng tôi tiếp tục trong hướng dẫn này.
Học Scikit
Thư viện này là một Bộ công cụ SciPy được sử dụng rộng rãi để lập mô hình thống kê, máy học và học sâu, vì nó chứa các mô hình hồi quy, phân loại và phân cụm có thể tùy chỉnh khác nhau. Nó hoạt động tốt với Numpy, Pandas và các thư viện khác, giúp dễ sử dụng hơn.
Statsmodels
Giống như Scikit Learn, thư viện này được sử dụng để thăm dò dữ liệu thống kê và mô hình thống kê. Nó cũng hoạt động tốt với các thư viện Python khác.
Matplotlib
Thư viện này được sử dụng để trực quan hóa dữ liệu ở nhiều định dạng khác nhau như biểu đồ đường, biểu đồ thanh, bản đồ nhiệt, biểu đồ phân tán, biểu đồ, v.v. Nó chứa tất cả các chức năng liên quan đến biểu đồ được yêu cầu từ việc vẽ biểu đồ đến dán nhãn. Chúng tôi sẽ thảo luận về các chức năng này khi chúng tôi tiếp tục trong hướng dẫn này.
Những thư viện này rất cần thiết để bắt đầu với học máy với bất kỳ loại dữ liệu nào.
Bên cạnh những cái được thảo luận ở trên, một thư viện khác đặc biệt quan trọng để xử lý chuỗi thời gian là:
Ngày giờ
Thư viện này, với hai mô-đun - ngày giờ và lịch, cung cấp tất cả các chức năng ngày giờ cần thiết để đọc, định dạng và thao tác thời gian.
Chúng tôi sẽ sử dụng các thư viện này trong các chương tới.
Chuỗi thời gian là một chuỗi các quan sát được lập chỉ mục trong các khoảng thời gian cách đều nhau. Do đó, thứ tự và tính liên tục nên được duy trì trong bất kỳ chuỗi thời gian nào.
Tập dữ liệu mà chúng tôi sẽ sử dụng là một chuỗi thời gian nhiều biến thể có dữ liệu hàng giờ trong khoảng một năm, về chất lượng không khí ở một thành phố bị ô nhiễm nghiêm trọng của Ý. Tập dữ liệu có thể được tải xuống từ liên kết dưới đây -https://archive.ics.uci.edu/ml/datasets/air+quality.
Cần phải đảm bảo rằng -
Chuỗi thời gian cách đều nhau và
Không có giá trị thừa hoặc khoảng trống trong đó.
Trong trường hợp chuỗi thời gian không liên tục, chúng tôi có thể lấy mẫu lên hoặc lấy mẫu xuống.
Hiển thị df.head ()
Trong [122]:
import pandasTrong [123]:
df = pandas.read_csv("AirQualityUCI.csv", sep = ";", decimal = ",")
df = df.iloc[ : , 0:14]Trong [124]:
len(df)Hết [124]:
9471Trong [125]:
df.head()Ra [125]:

Để xử lý trước chuỗi thời gian, chúng tôi đảm bảo không có giá trị NaN (NULL) nào trong tập dữ liệu; nếu có, chúng ta có thể thay thế chúng bằng 0 hoặc giá trị trung bình hoặc giá trị đứng trước hoặc kế tiếp. Thay thế là một lựa chọn ưu tiên hơn là giảm xuống để duy trì tính liên tục của chuỗi thời gian. Tuy nhiên, trong tập dữ liệu của chúng tôi, một số giá trị cuối cùng dường như là NULL và do đó việc giảm sẽ không ảnh hưởng đến tính liên tục.
Bỏ NaN (Not-a-Number)
Trong [126]:
df.isna().sum()
Out[126]:
Date 114
Time 114
CO(GT) 114
PT08.S1(CO) 114
NMHC(GT) 114
C6H6(GT) 114
PT08.S2(NMHC) 114
NOx(GT) 114
PT08.S3(NOx) 114
NO2(GT) 114
PT08.S4(NO2) 114
PT08.S5(O3) 114
T 114
RH 114
dtype: int64Trong [127]:
df = df[df['Date'].notnull()]Trong [128]:
df.isna().sum()Ra [128]:
Date 0
Time 0
CO(GT) 0
PT08.S1(CO) 0
NMHC(GT) 0
C6H6(GT) 0
PT08.S2(NMHC) 0
NOx(GT) 0
PT08.S3(NOx) 0
NO2(GT) 0
PT08.S4(NO2) 0
PT08.S5(O3) 0
T 0
RH 0
dtype: int64Chuỗi thời gian thường được vẽ dưới dạng biểu đồ đường theo thời gian. Đối với điều đó, bây giờ chúng ta sẽ kết hợp cột ngày và giờ và chuyển đổi nó thành một đối tượng datetime từ các chuỗi. Điều này có thể được thực hiện bằng cách sử dụng thư viện datetime.
Chuyển đổi sang đối tượng datetime
Trong [129]:
df['DateTime'] = (df.Date) + ' ' + (df.Time)
print (type(df.DateTime[0]))<class 'str'>
Trong [130]:
import datetime
df.DateTime = df.DateTime.apply(lambda x: datetime.datetime.strptime(x, '%d/%m/%Y %H.%M.%S'))
print (type(df.DateTime[0]))<class 'pandas._libs.tslibs.timestamps.Timestamp'>
Hãy để chúng tôi xem một số biến như nhiệt độ thay đổi theo thời gian như thế nào.
Hiển thị các lô
Trong [131]:
df.index = df.DateTimeTrong [132]:
import matplotlib.pyplot as plt
plt.plot(df['T'])Hết [132]:
[<matplotlib.lines.Line2D at 0x1eaad67f780>]
Trong [208]:
plt.plot(df['C6H6(GT)'])Hết [208]:
[<matplotlib.lines.Line2D at 0x1eaaeedff28>]Biểu đồ hộp là một loại biểu đồ hữu ích khác cho phép bạn cô đọng nhiều thông tin về tập dữ liệu thành một biểu đồ duy nhất. Nó cho thấy phần tư trung bình, 25% và 75% và các giá trị ngoại lệ của một hoặc nhiều biến. Trong trường hợp số lượng giá trị ngoại lệ ít và rất xa giá trị trung bình, chúng ta có thể loại bỏ các giá trị ngoại lệ bằng cách đặt chúng thành giá trị trung bình hoặc 75% giá trị phần tư.
Hiển thị Boxplots
Trong [134]:
plt.boxplot(df[['T','C6H6(GT)']].values)Hết [134]:
{'whiskers': [<matplotlib.lines.Line2D at 0x1eaac16de80>,
<matplotlib.lines.Line2D at 0x1eaac16d908>,
<matplotlib.lines.Line2D at 0x1eaac177a58>,
<matplotlib.lines.Line2D at 0x1eaac177cf8>],
'caps': [<matplotlib.lines.Line2D at 0x1eaac16d2b0>,
<matplotlib.lines.Line2D at 0x1eaac16d588>,
<matplotlib.lines.Line2D at 0x1eaac1a69e8>,
<matplotlib.lines.Line2D at 0x1eaac1a64a8>],
'boxes': [<matplotlib.lines.Line2D at 0x1eaac16dc50>,
<matplotlib.lines.Line2D at 0x1eaac1779b0>],
'medians': [<matplotlib.lines.Line2D at 0x1eaac16d4a8>,
<matplotlib.lines.Line2D at 0x1eaac1a6c50>],
'fliers': [<matplotlib.lines.Line2D at 0x1eaac177dd8>,
<matplotlib.lines.Line2D at 0x1eaac1a6c18>],'means': []
}
Giới thiệu
Chuỗi thời gian có 4 thành phần như dưới đây:
Level - Đây là giá trị trung bình mà chuỗi khác nhau.
Trend - Là hành vi tăng giảm của một biến số theo thời gian.
Seasonality - Đó là hành vi tuần hoàn của chuỗi thời gian.
Noise - Đó là sai số trong các quan sát được thêm vào do các yếu tố môi trường.
Kỹ thuật lập mô hình chuỗi thời gian
Để nắm bắt các thành phần này, có một số kỹ thuật mô hình chuỗi thời gian phổ biến. Phần này giới thiệu ngắn gọn về từng kỹ thuật, tuy nhiên chúng ta sẽ thảo luận chi tiết về chúng trong các chương sắp tới -
Phương pháp ngây thơ
Đây là các kỹ thuật ước tính đơn giản, chẳng hạn như giá trị dự đoán được cung cấp giá trị bằng giá trị trung bình của các giá trị trước đó của biến phụ thuộc thời gian hoặc giá trị thực tế trước đó. Chúng được sử dụng để so sánh với các kỹ thuật mô hình phức tạp.
Tự động hồi quy
Hồi quy tự động dự đoán giá trị của các khoảng thời gian trong tương lai dưới dạng hàm của các giá trị ở khoảng thời gian trước đó. Các dự đoán về hồi quy tự động có thể phù hợp với dữ liệu hơn so với các phương pháp đơn thuần, nhưng nó có thể không tính đến tính thời vụ.
Mô hình ARIMA
Đường trung bình động tích hợp tự động hồi quy mô hình hóa giá trị của một biến dưới dạng hàm tuyến tính của các giá trị trước đó và sai số còn lại ở các bước thời gian trước đó của thời gian cố định. Tuy nhiên, dữ liệu thế giới thực có thể không cố định và có tính thời vụ, do đó, Seasonal-ARIMA và Fractional-ARIMA đã được phát triển. ARIMA hoạt động trên chuỗi thời gian đơn biến, để xử lý nhiều biến VARIMA đã được giới thiệu.
Làm mịn theo cấp số nhân
Nó mô hình hóa giá trị của một biến dưới dạng một hàm tuyến tính có trọng số mũ của các giá trị trước đó. Mô hình thống kê này cũng có thể xử lý xu hướng và tính thời vụ.
LSTM
Mô hình Bộ nhớ Ngắn hạn Dài (LSTM) là một mạng nơ-ron tuần hoàn được sử dụng cho chuỗi thời gian để tính đến sự phụ thuộc dài hạn. Nó có thể được đào tạo với lượng lớn dữ liệu để nắm bắt các xu hướng trong chuỗi thời gian đa dạng.
Các kỹ thuật mô hình nói trên được sử dụng cho hồi quy chuỗi thời gian. Trong các chương tới, bây giờ chúng ta hãy khám phá tất cả từng thứ một.
Giới thiệu
Bất kỳ mô hình thống kê hoặc máy học nào cũng có một số tham số ảnh hưởng lớn đến cách dữ liệu được mô hình hóa. Ví dụ, ARIMA có các giá trị p, d, q. Các tham số này phải được quyết định sao cho sai số giữa giá trị thực và giá trị được mô hình hóa là nhỏ nhất. Hiệu chuẩn tham số được cho là công việc quan trọng và tốn thời gian nhất của việc lắp mô hình. Do đó, chúng tôi rất cần thiết để chọn các thông số tối ưu.
Phương pháp hiệu chuẩn các tham số
Có nhiều cách khác nhau để hiệu chỉnh các thông số. Phần này nói về một số chi tiết trong số chúng.
Đánh và thử
Một cách phổ biến để hiệu chuẩn mô hình là hiệu chuẩn bằng tay, trong đó bạn bắt đầu bằng cách hình dung chuỗi thời gian và thử trực quan một số giá trị tham số và thay đổi chúng nhiều lần cho đến khi bạn đạt được sự phù hợp đủ tốt. Nó đòi hỏi sự hiểu biết tốt về mô hình mà chúng tôi đang thử. Đối với mô hình ARIMA, hiệu chuẩn tay được thực hiện với sự trợ giúp của biểu đồ tương quan tự động cho tham số 'p', biểu đồ tương quan tự động một phần cho tham số 'q' và kiểm tra ADF để xác nhận tính ổn định của chuỗi thời gian và cài đặt tham số 'd' . Chúng ta sẽ thảo luận chi tiết về tất cả những điều này trong các chương tới.
Tìm kiếm lưới
Một cách khác để hiệu chỉnh mô hình là tìm kiếm theo lưới, về cơ bản có nghĩa là bạn thử xây dựng một mô hình cho tất cả các kết hợp có thể có của các tham số và chọn một mô hình có sai số tối thiểu. Điều này tốn thời gian và do đó hữu ích khi số lượng tham số được hiệu chỉnh và phạm vi giá trị mà chúng lấy ít hơn vì điều này liên quan đến nhiều vòng lặp for lồng nhau.
Thuật toán di truyền
Thuật toán di truyền hoạt động dựa trên nguyên tắc sinh học rằng một giải pháp tốt cuối cùng sẽ phát triển thành giải pháp 'tối ưu' nhất. Nó sử dụng các hoạt động sinh học về đột biến, lai chéo và chọn lọc để cuối cùng đạt được giải pháp tối ưu.
Để có thêm kiến thức, bạn có thể đọc về các kỹ thuật tối ưu hóa tham số khác như tối ưu hóa Bayesian và tối ưu hóa Swarm.
Giới thiệu
Các phương pháp ngây thơ, chẳng hạn như giả định giá trị dự đoán tại thời điểm 't' là giá trị thực tế của biến tại thời điểm 't-1' hoặc giá trị trung bình của chuỗi, được sử dụng để cân nhắc mức độ hoạt động của các mô hình thống kê và mô hình học máy và nhấn mạnh nhu cầu của họ.
Trong chương này, chúng ta hãy thử các mô hình này trên một trong những tính năng của dữ liệu chuỗi thời gian của chúng tôi.
Đầu tiên, chúng ta sẽ xem giá trị trung bình của đặc điểm 'nhiệt độ' trong dữ liệu của chúng ta và độ lệch xung quanh nó. Nó cũng hữu ích để xem các giá trị nhiệt độ tối đa và tối thiểu. Chúng ta có thể sử dụng các chức năng của thư viện numpy tại đây.
Hiển thị số liệu thống kê
Trong [135]:
import numpy
print (
'Mean: ',numpy.mean(df['T']), ';
Standard Deviation: ',numpy.std(df['T']),';
\nMaximum Temperature: ',max(df['T']),';
Minimum Temperature: ',min(df['T'])
)Chúng tôi có số liệu thống kê cho tất cả 9357 quan sát trên dòng thời gian cách đều nhau, rất hữu ích để chúng tôi hiểu dữ liệu.
Bây giờ chúng ta sẽ thử phương pháp ngây thơ đầu tiên, đặt giá trị dự đoán ở thời điểm hiện tại bằng giá trị thực tại thời điểm trước đó và tính toán sai số bình phương trung bình gốc (RMSE) để nó định lượng hiệu suất của phương pháp này.
Hiển thị 1 st phương pháp ngây thơ
Trong [136]:
df['T']
df['T_t-1'] = df['T'].shift(1)Trong [137]:
df_naive = df[['T','T_t-1']][1:]Trong [138]:
from sklearn import metrics
from math import sqrt
true = df_naive['T']
prediction = df_naive['T_t-1']
error = sqrt(metrics.mean_squared_error(true,prediction))
print ('RMSE for Naive Method 1: ', error)RMSE cho Phương pháp Naive 1: 12.901140576492974
Chúng ta hãy xem phương pháp ngây thơ tiếp theo, trong đó giá trị dự đoán ở thời điểm hiện tại được tính bằng giá trị trung bình của khoảng thời gian trước nó. Chúng tôi cũng sẽ tính toán RMSE cho phương pháp này.
Hiển thị phương pháp ngây thơ thứ 2
Trong [139]:
df['T_rm'] = df['T'].rolling(3).mean().shift(1)
df_naive = df[['T','T_rm']].dropna()Trong [140]:
true = df_naive['T']
prediction = df_naive['T_rm']
error = sqrt(metrics.mean_squared_error(true,prediction))
print ('RMSE for Naive Method 2: ', error)RMSE for Naive Method 2: 14.957633272839242
Tại đây, bạn có thể thử nghiệm với nhiều khoảng thời gian trước đó cũng được gọi là 'độ trễ' mà bạn muốn xem xét, được giữ là 3 ở đây. Trong dữ liệu này, có thể thấy rằng khi bạn tăng số độ trễ và lỗi tăng lên. Nếu độ trễ được giữ là 1, nó sẽ giống như phương pháp ngây thơ được sử dụng trước đó.
Points to Note
Bạn có thể viết một hàm rất đơn giản để tính toán sai số bình phương trung bình gốc. Ở đây, chúng tôi đã sử dụng hàm lỗi bình phương trung bình từ gói 'sklearn' và sau đó lấy căn bậc hai của nó.
Trong gấu trúc, df ['column_name'] cũng có thể được viết là df.column_name, tuy nhiên đối với tập dữ liệu này, df.T sẽ không hoạt động giống như df ['T'] vì df.T là hàm để chuyển một khung dữ liệu. Vì vậy, chỉ sử dụng df ['T'] hoặc xem xét đổi tên cột này trước khi sử dụng cú pháp khác.
Đối với chuỗi thời gian tĩnh, mô hình hồi quy tự động xem giá trị của một biến tại thời điểm 't' là một hàm tuyến tính của các giá trị 'p' bước thời gian trước nó. Về mặt toán học, nó có thể được viết là -
$$y_{t} = \:C+\:\phi_{1}y_{t-1}\:+\:\phi_{2}Y_{t-2}+...+\phi_{p}y_{t-p}+\epsilon_{t}$$
Trong đó, 'p' là tham số xu hướng tự động hồi quy
$\epsilon_{t}$ là tiếng ồn trắng, và
$y_{t-1}, y_{t-2}\:\: ...y_{t-p}$ biểu thị giá trị của biến ở các khoảng thời gian trước đó.
Giá trị của p có thể được hiệu chuẩn bằng nhiều phương pháp khác nhau. Một cách để tìm giá trị apt của 'p' là vẽ biểu đồ tương quan tự động.
Note- Chúng ta nên tách dữ liệu thành huấn luyện và kiểm tra theo tỷ lệ 8: 2 trên tổng dữ liệu có sẵn trước khi thực hiện bất kỳ phân tích nào trên dữ liệu vì dữ liệu thử nghiệm chỉ để tìm ra độ chính xác của mô hình của chúng tôi và giả định là, nó không có sẵn cho chúng tôi cho đến khi các dự đoán đã được thực hiện. Trong trường hợp chuỗi thời gian, chuỗi các điểm dữ liệu là rất cần thiết vì vậy người ta cần lưu ý để không bị mất thứ tự trong quá trình chia nhỏ dữ liệu.
Biểu đồ tương quan tự động hoặc biểu đồ tương quan cho thấy mối quan hệ của một biến với chính nó ở các bước thời gian trước. Nó sử dụng mối tương quan của Pearson và hiển thị các mối tương quan trong khoảng tin cậy 95%. Hãy xem nó trông như thế nào đối với biến 'nhiệt độ' của dữ liệu của chúng tôi.
Hiển thị ACP
Trong [141]:
split = len(df) - int(0.2*len(df))
train, test = df['T'][0:split], df['T'][split:]Trong [142]:
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(train, lags = 100)
plt.show()
Tất cả các giá trị độ trễ nằm ngoài vùng màu xanh lam được tô bóng được giả định là có tương quan.
Đối với chuỗi thời gian đứng yên, mô hình trung bình động xem giá trị của một biến tại thời điểm 't' là một hàm tuyến tính của sai số dư từ các bước thời gian 'q' trước nó. Sai số còn lại được tính bằng cách so sánh giá trị tại thời điểm 't' với giá trị trung bình động của các giá trị trước đó.
Về mặt toán học, nó có thể được viết là -
$$y_{t} = c\:+\:\epsilon_{t}\:+\:\theta_{1}\:\epsilon_{t-1}\:+\:\theta_{2}\:\epsilon_{t-2}\:+\:...+:\theta_{q}\:\epsilon_{t-q}\:$$
Trong đó 'q' là tham số xu hướng trung bình động
$\epsilon_{t}$ là tiếng ồn trắng, và
$\epsilon_{t-1}, \epsilon_{t-2}...\epsilon_{t-q}$ là các điều khoản lỗi ở khoảng thời gian trước đó.
Giá trị của 'q' có thể được hiệu chỉnh bằng nhiều phương pháp khác nhau. Một cách để tìm giá trị apt của 'q' là vẽ biểu đồ tương quan tự động một phần.
Biểu đồ tương quan tự động một phần hiển thị mối quan hệ của một biến với chính nó ở các bước thời gian trước với các tương quan gián tiếp bị loại bỏ, không giống như biểu đồ tương quan tự động hiển thị tương quan trực tiếp cũng như gián tiếp, hãy xem nó trông như thế nào đối với biến 'nhiệt độ' dữ liệu.
Hiển thị PACP
Trong [143]:
from statsmodels.graphics.tsaplots import plot_pacf
plot_pacf(train, lags = 100)
plt.show()
Tương quan tự động một phần được đọc giống như một biểu đồ tương quan.
Chúng ta đã hiểu rằng đối với một chuỗi thời gian tĩnh, một biến tại thời điểm 't' là một hàm tuyến tính của các quan sát trước đó hoặc sai số dư. Do đó, đã đến lúc chúng ta kết hợp cả hai và có mô hình Đường trung bình động tự động hồi quy (ARMA).
Tuy nhiên, đôi khi chuỗi thời gian không đứng yên, tức là các thuộc tính thống kê của chuỗi như giá trị trung bình, phương sai thay đổi theo thời gian. Và các mô hình thống kê mà chúng tôi đã nghiên cứu cho đến nay giả định chuỗi thời gian là đứng yên, do đó, chúng ta có thể đưa vào một bước xử lý trước là khác biệt chuỗi thời gian để làm cho nó đứng yên. Bây giờ, điều quan trọng là chúng ta phải tìm hiểu xem chuỗi thời gian chúng ta đang xử lý có đứng yên hay không.
Các phương pháp khác nhau để tìm tính ổn định của một chuỗi thời gian là tìm kiếm tính thời vụ hoặc xu hướng trong cốt truyện của chuỗi thời gian, kiểm tra sự khác biệt về giá trị trung bình và phương sai trong các khoảng thời gian khác nhau, kiểm tra Augmented Dickey-Fuller (ADF), kiểm tra KPSS, số mũ của Hurst, v.v. .
Hãy để chúng tôi xem liệu biến 'nhiệt độ' của tập dữ liệu của chúng tôi có phải là một chuỗi thời gian tĩnh hay không bằng cách sử dụng thử nghiệm ADF.
Trong [74]:
from statsmodels.tsa.stattools import adfuller
result = adfuller(train)
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
print('Critical Values:')
for key, value In result[4].items()
print('\t%s: %.3f' % (key, value))Thống kê ADF: -10.406056
giá trị p: 0,000000
Giá trị quan trọng:
1%: -3,431
5%: -2,862
10%: -2,567
Bây giờ chúng tôi đã chạy kiểm tra ADF, hãy để chúng tôi giải thích kết quả. Đầu tiên, chúng tôi sẽ so sánh Thống kê ADF với các giá trị tới hạn, giá trị tới hạn thấp hơn cho chúng ta biết chuỗi có nhiều khả năng là không cố định. Tiếp theo, chúng ta thấy giá trị p. Giá trị p lớn hơn 0,05 cũng gợi ý rằng chuỗi thời gian là không dừng.
Ngoài ra, giá trị p nhỏ hơn hoặc bằng 0,05, hoặc Thống kê ADF nhỏ hơn giá trị tới hạn cho thấy chuỗi thời gian là đứng yên.
Do đó, chuỗi thời gian mà chúng ta đang xử lý đã cố định. Trong trường hợp chuỗi thời gian tĩnh, chúng tôi đặt tham số 'd' là 0.
Chúng tôi cũng có thể xác nhận tính ổn định của chuỗi thời gian bằng cách sử dụng số mũ Hurst.
Trong [75]:
import hurst
H, c,data = hurst.compute_Hc(train)
print("H = {:.4f}, c = {:.4f}".format(H,c))H = 0,1660, c = 5,0740
Giá trị H <0,5 cho thấy hành vi chống đối và H> 0,5 cho thấy hành vi dai dẳng hoặc một chuỗi xu hướng. H = 0,5 cho thấy bước đi ngẫu nhiên / chuyển động Brown. Giá trị của H <0,5, xác nhận rằng chuỗi của chúng tôi là đứng yên.
Đối với chuỗi thời gian không dừng, chúng tôi đặt tham số 'd' là 1. Ngoài ra, giá trị của tham số xu hướng tự động hồi quy 'p' và tham số xu hướng trung bình động 'q', được tính toán trên chuỗi thời gian tĩnh, tức là bằng cách vẽ biểu đồ ACP và PACP sau khi phân biệt chuỗi thời gian.
Mô hình ARIMA, được đặc trưng bởi 3 tham số, (p, d, q) hiện đã rõ ràng đối với chúng ta, vì vậy chúng ta hãy lập mô hình chuỗi thời gian của mình và dự đoán các giá trị nhiệt độ trong tương lai.
Trong [156]:
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(train.values, order=(5, 0, 2))
model_fit = model.fit(disp=False)Trong [157]:
predictions = model_fit.predict(len(test))
test_ = pandas.DataFrame(test)
test_['predictions'] = predictions[0:1871]Trong [158]:
plt.plot(df['T'])
plt.plot(test_.predictions)
plt.show()
Trong [167]:
error = sqrt(metrics.mean_squared_error(test.values,predictions[0:1871]))
print ('Test RMSE for ARIMA: ', error)Kiểm tra RMSE cho ARIMA: 43.21252940234892
Trong chương trước, chúng ta đã thấy cách hoạt động của mô hình ARIMA và những hạn chế của nó là nó không thể xử lý dữ liệu theo mùa hoặc chuỗi thời gian đa biến và do đó, các mô hình mới đã được giới thiệu để bao gồm các tính năng này.
Một cái nhìn sơ lược về các mô hình mới này được đưa ra ở đây -
Tự động hồi quy vectơ (VAR)
Đây là một phiên bản tổng quát của mô hình hồi quy tự động cho chuỗi thời gian tĩnh đa biến. Nó được đặc trưng bởi tham số 'p'.
Đường trung bình trượt vectơ (VMA)
Nó là một phiên bản tổng quát của mô hình trung bình động cho chuỗi thời gian tĩnh đa biến. Nó được đặc trưng bởi tham số 'q'.
Đường trung bình trượt hồi quy tự động vectơ (VARMA)
Nó là sự kết hợp giữa VAR và VMA và một phiên bản tổng quát của mô hình ARMA cho chuỗi thời gian tĩnh đa biến. Nó được đặc trưng bởi các tham số 'p' và 'q'. Tương tự như vậy, ARMA có khả năng hoạt động giống như một mô hình AR bằng cách đặt tham số 'q' là 0 và như một mô hình MA bằng cách đặt tham số 'p' là 0, VARMA cũng có khả năng hoạt động giống như một mô hình VAR bằng cách đặt tham số 'q' dưới dạng 0 và dưới dạng mô hình VMA bằng cách đặt tham số 'p' là 0.
Trong [209]:
df_multi = df[['T', 'C6H6(GT)']]
split = len(df) - int(0.2*len(df))
train_multi, test_multi = df_multi[0:split], df_multi[split:]Trong [211]:
from statsmodels.tsa.statespace.varmax import VARMAX
model = VARMAX(train_multi, order = (2,1))
model_fit = model.fit()
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\tsa\statespace\varmax.py:152:
EstimationWarning: Estimation of VARMA(p,q) models is not generically robust,
due especially to identification issues.
EstimationWarning)
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\tsa\base\tsa_model.py:171:
ValueWarning: No frequency information was provided, so inferred frequency H will be used.
% freq, ValueWarning)
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\base\model.py:508:
ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
"Check mle_retvals", ConvergenceWarning)Trong [213]:
predictions_multi = model_fit.forecast( steps=len(test_multi))
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\tsa\base\tsa_model.py:320:
FutureWarning: Creating a DatetimeIndex by passing range endpoints is deprecated. Use `pandas.date_range` instead.
freq = base_index.freq)
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\tsa\statespace\varmax.py:152:
EstimationWarning: Estimation of VARMA(p,q) models is not generically robust, due especially to identification issues.
EstimationWarning)Trong [231]:
plt.plot(train_multi['T'])
plt.plot(test_multi['T'])
plt.plot(predictions_multi.iloc[:,0:1], '--')
plt.show()
plt.plot(train_multi['C6H6(GT)'])
plt.plot(test_multi['C6H6(GT)'])
plt.plot(predictions_multi.iloc[:,1:2], '--')
plt.show()

Đoạn mã trên cho thấy cách mô hình VARMA có thể được sử dụng để lập mô hình chuỗi thời gian đa biến, mặc dù mô hình này có thể không phù hợp nhất trên dữ liệu của chúng tôi.
VARMA với các biến ngoại sinh (VARMAX)
Nó là một phần mở rộng của mô hình VARMA trong đó các biến phụ được gọi là hiệp biến được sử dụng để lập mô hình cho biến chính mà chúng ta quan tâm.
Đường trung bình trượt tích hợp tự động hồi quy theo mùa (SARIMA)
Đây là phần mở rộng của mô hình ARIMA để xử lý dữ liệu theo mùa. Nó chia dữ liệu thành các thành phần theo mùa và không theo mùa và lập mô hình chúng theo kiểu tương tự. Nó được đặc trưng bởi 7 thông số, đối với các thông số phần không theo mùa (p, d, q) giống như đối với mô hình ARIMA và cho các thông số phần theo mùa (P, D, Q, m) trong đó 'm' là số khoảng thời gian theo mùa và P, D, Q tương tự như các tham số của mô hình ARIMA. Các thông số này có thể được hiệu chỉnh bằng cách sử dụng tìm kiếm lưới hoặc thuật toán di truyền.
SARIMA với các biến ngoại sinh (SARIMAX)
Đây là phần mở rộng của mô hình SARIMA để bao gồm các biến ngoại sinh giúp chúng tôi lập mô hình biến mà chúng tôi quan tâm.
Có thể hữu ích khi thực hiện phân tích mối quan hệ đồng trên các biến trước khi đưa chúng làm biến ngoại sinh.
Trong [251]:
from scipy.stats.stats import pearsonr
x = train_multi['T'].values
y = train_multi['C6H6(GT)'].values
corr , p = pearsonr(x,y)
print ('Corelation Coefficient =', corr,'\nP-Value =',p)
Corelation Coefficient = 0.9701173437269858
P-Value = 0.0Pearson's Correlation cho thấy mối quan hệ tuyến tính giữa 2 biến, để giải thích kết quả, trước tiên chúng ta nhìn vào giá trị p, nếu nó nhỏ hơn 0,05 thì giá trị của hệ số là có ý nghĩa, còn lại giá trị của hệ số không có ý nghĩa. Đối với giá trị p có ý nghĩa, giá trị dương của hệ số tương quan cho biết mối tương quan thuận và giá trị âm cho biết mối tương quan âm.
Do đó, đối với dữ liệu của chúng tôi, "nhiệt độ" và "C6H6" dường như có mối tương quan tích cực cao. Do đó, chúng tôi sẽ
Trong [297]:
from statsmodels.tsa.statespace.sarimax import SARIMAX
model = SARIMAX(x, exog = y, order = (2, 0, 2), seasonal_order = (2, 0, 1, 1), enforce_stationarity=False, enforce_invertibility = False)
model_fit = model.fit(disp = False)
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\base\model.py:508:
ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
"Check mle_retvals", ConvergenceWarning)Trong [298]:
y_ = test_multi['C6H6(GT)'].values
predicted = model_fit.predict(exog=y_)
test_multi_ = pandas.DataFrame(test)
test_multi_['predictions'] = predicted[0:1871]Trong [299]:
plt.plot(train_multi['T'])
plt.plot(test_multi_['T'])
plt.plot(test_multi_.predictions, '--')Hết [299]:
[<matplotlib.lines.Line2D at 0x1eab0191c18>]Các dự đoán ở đây dường như có các biến thể lớn hơn bây giờ trái ngược với mô hình ARIMA đơn biến.
Không cần phải nói, SARIMAX có thể được sử dụng như một mô hình ARX, MAX, ARMAX hoặc ARIMAX bằng cách chỉ đặt các tham số tương ứng thành các giá trị khác không.
Đường trung bình trượt tích hợp tự động hồi quy phân số (FARIMA)
Đôi khi, có thể xảy ra trường hợp chuỗi của chúng ta không đứng yên, nhưng sự khác biệt với tham số 'd' nhận giá trị 1 có thể làm sai lệch nó quá mức. Vì vậy, chúng ta cần khác biệt chuỗi thời gian bằng cách sử dụng giá trị phân số.
Trong thế giới của khoa học dữ liệu không có một mô hình nào vượt trội, mô hình hoạt động trên dữ liệu của bạn phụ thuộc rất nhiều vào tập dữ liệu của bạn. Kiến thức về các mô hình khác nhau cho phép chúng tôi chọn một mô hình hoạt động trên dữ liệu của chúng tôi và thử nghiệm với mô hình đó để đạt được kết quả tốt nhất. Và kết quả nên được xem như âm mưu cũng như các thước đo lỗi, đôi khi một lỗi nhỏ cũng có thể là xấu, do đó, việc vẽ và hình dung kết quả là điều cần thiết.
Trong chương tiếp theo, chúng ta sẽ xem xét một mô hình thống kê khác, làm trơn theo cấp số nhân.
Trong chương này, chúng ta sẽ nói về các kỹ thuật liên quan đến việc làm trơn chuỗi thời gian theo cấp số nhân.
Làm trơn theo cấp số nhân đơn giản
Làm trơn theo cấp số nhân là một kỹ thuật để làm trơn chuỗi thời gian đơn biến bằng cách gán trọng số giảm dần theo cấp số nhân cho dữ liệu trong một khoảng thời gian.
Về mặt toán học, giá trị của biến tại thời điểm 't + 1' giá trị đã cho tại thời điểm t, y_ (t + 1 | t) được định nghĩa là -
$$y_{t+1|t}\:=\:\alpha y_{t}\:+\:\alpha\lgroup1 -\alpha\rgroup y_{t-1}\:+\alpha\lgroup1-\alpha\rgroup^{2}\:y_{t-2}\:+\:...+y_{1}$$
Ở đâu,$0\leq\alpha \leq1$ là thông số làm mịn và
$y_{1},....,y_{t}$ là các giá trị trước đó của lưu lượng mạng tại các thời điểm 1, 2, 3,…, t.
Đây là một phương pháp đơn giản để lập mô hình chuỗi thời gian không có xu hướng hoặc tính thời vụ rõ ràng. Nhưng làm mịn theo cấp số nhân cũng có thể được sử dụng cho chuỗi thời gian với xu hướng và tính thời vụ.
Làm mịn ba hàm mũ
Làm mịn ba lần theo cấp số nhân (TES) hoặc phương pháp Holt's Winter, áp dụng làm mịn theo cấp số nhân ba lần - làm mịn cấp độ $l_{t}$, làm mịn xu hướng $b_{t}$và làm mịn theo mùa $S_{t}$, với $\alpha$, $\beta^{*}$ và $\gamma$ làm thông số làm mịn với 'm' là tần suất của tính thời vụ, tức là số mùa trong năm.
Theo bản chất của thành phần theo mùa, TES có hai loại:
Holt-Winter's Additive Method - Khi tính thời vụ có tính chất phụ gia.
Holt-Winter’s Multiplicative Method - Khi tính thời vụ có tính chất nhân đôi.
Đối với chuỗi thời gian không theo mùa, chúng tôi chỉ có làm mịn xu hướng và làm mịn mức, được gọi là Phương pháp xu hướng tuyến tính của Holt.
Hãy thử áp dụng làm mịn cấp số nhân ba trên dữ liệu của chúng tôi.
Trong [316]:
from statsmodels.tsa.holtwinters import ExponentialSmoothing
model = ExponentialSmoothing(train.values, trend= )
model_fit = model.fit()Trong [322]:
predictions_ = model_fit.predict(len(test))Trong [325]:
plt.plot(test.values)
plt.plot(predictions_[1:1871])Ra [325]:
[<matplotlib.lines.Line2D at 0x1eab00f1cf8>]
Ở đây, chúng tôi đã đào tạo mô hình một lần với tập huấn luyện và sau đó chúng tôi tiếp tục đưa ra các dự đoán. Một cách tiếp cận thực tế hơn là đào tạo lại mô hình sau một hoặc nhiều bước thời gian. Khi chúng tôi nhận được dự đoán cho thời gian 't + 1' từ dữ liệu đào tạo 'đến thời điểm' t ', dự đoán tiếp theo cho thời gian' t + 2 'có thể được thực hiện bằng cách sử dụng dữ liệu đào tạo' đến thời gian 't + 1' như thực tế giá trị tại 't + 1' sẽ được biết sau đó. Phương pháp đưa ra dự đoán cho một hoặc nhiều bước trong tương lai và sau đó đào tạo lại mô hình này được gọi là dự báo luân phiên hoặc xác thực bước tiếp.
Trong mô hình chuỗi thời gian, các dự đoán theo thời gian ngày càng trở nên kém chính xác hơn và do đó, cách tiếp cận thực tế hơn để đào tạo lại mô hình với dữ liệu thực tế khi nó có sẵn cho các dự đoán tiếp theo. Vì việc đào tạo các mô hình thống kê không tốn nhiều thời gian, nên xác thực từng bước là giải pháp ưu tiên nhất để có được kết quả chính xác nhất.
Hãy để chúng tôi áp dụng xác thực từng bước một trên dữ liệu của mình và so sánh nó với kết quả chúng tôi nhận được trước đó.
Trong [333]:
prediction = []
data = train.values
for t In test.values:
model = (ExponentialSmoothing(data).fit())
y = model.predict()
prediction.append(y[0])
data = numpy.append(data, t)Trong [335]:
test_ = pandas.DataFrame(test)
test_['predictionswf'] = predictionTrong [341]:
plt.plot(test_['T'])
plt.plot(test_.predictionswf, '--')
plt.show()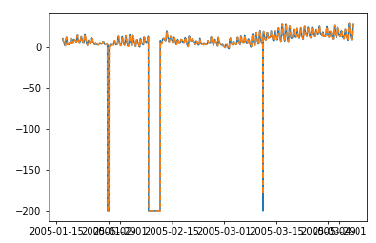
Trong [340]:
error = sqrt(metrics.mean_squared_error(test.values,prediction))
print ('Test RMSE for Triple Exponential Smoothing with Walk-Forward Validation: ', error)
Test RMSE for Triple Exponential Smoothing with Walk-Forward Validation: 11.787532205759442Chúng tôi có thể thấy rằng mô hình của chúng tôi hiện đang hoạt động tốt hơn đáng kể. Trên thực tế, xu hướng được tuân thủ chặt chẽ đến mức các dự đoán về cốt truyện trùng lặp với các giá trị thực tế. Bạn cũng có thể thử áp dụng xác thực đi bộ trên các mô hình ARIMA.
Năm 2017, Facebook mở nguồn mô hình nhà tiên tri có khả năng lập mô hình chuỗi thời gian với nhiều thời vụ mạnh mẽ ở cấp ngày, cấp tuần, cấp năm, v.v. và xu hướng. Nó có các thông số trực quan mà một nhà khoa học dữ liệu không chuyên có thể điều chỉnh để đưa ra các dự báo tốt hơn. Về cốt lõi, nó là một mô hình hồi quy cộng tính có thể phát hiện các điểm thay đổi để lập mô hình chuỗi thời gian.
Nhà tiên tri phân tích chuỗi thời gian thành các thành phần của xu hướng $g_{t}$, tính thời vụ $S_{t}$ và ngày lễ $h_{t}$.
$$y_{t}=g_{t}+s_{t}+h_{t}+\epsilon_{t}$$
Ở đâu, $\epsilon_{t}$ là thuật ngữ lỗi.
Các gói tương tự cho dự báo chuỗi thời gian như tác động nhân quả và phát hiện bất thường đã được google và twitter giới thiệu lần lượt trong R.
Bây giờ, chúng ta đã quen với việc lập mô hình thống kê trên chuỗi thời gian, nhưng máy học đang là cơn thịnh nộ hiện nay, vì vậy điều cần thiết là phải làm quen với một số mô hình máy học. Chúng ta sẽ bắt đầu với mô hình phổ biến nhất trong miền chuỗi thời gian - Mô hình Bộ nhớ Ngắn hạn Dài hạn.
LSTM là một lớp của mạng nơ-ron tuần hoàn. Vì vậy, trước khi chúng ta có thể chuyển sang LSTM, điều cần thiết là phải hiểu mạng nơ-ron và mạng nơ-ron tuần hoàn.
Mạng thần kinh
Mạng nơ-ron nhân tạo là một cấu trúc phân lớp của các nơ-ron kết nối, lấy cảm hứng từ mạng nơ-ron sinh học. Nó không phải là một thuật toán mà là sự kết hợp của nhiều thuật toán khác nhau cho phép chúng ta thực hiện các hoạt động phức tạp trên dữ liệu.
Mạng thần kinh tái diễn
Nó là một lớp mạng nơ-ron được thiết kế riêng để xử lý dữ liệu tạm thời. Các nơ-ron của RNN có trạng thái tế bào / bộ nhớ và đầu vào được xử lý theo trạng thái bên trong này, điều này đạt được với sự trợ giúp của các vòng lặp trong mạng nơ-ron. Có (các) mô-đun định kỳ của các lớp 'tanh' trong RNN cho phép chúng lưu giữ thông tin. Tuy nhiên, không phải trong một thời gian dài, đó là lý do tại sao chúng ta cần các mô hình LSTM.
LSTM
Đó là một loại mạng nơ-ron tái phát đặc biệt có khả năng học các phụ thuộc lâu dài trong dữ liệu. Điều này đạt được là do mô-đun định kỳ của mô hình có sự kết hợp của bốn lớp tương tác với nhau.

Hình trên mô tả bốn lớp mạng nơ-ron trong các hộp màu vàng, trỏ các toán tử khôn ngoan trong vòng tròn màu xanh lá cây, đầu vào trong vòng tròn màu vàng và trạng thái ô trong vòng tròn màu xanh lam. Một mô-đun LSTM có trạng thái ô và ba cổng cung cấp cho chúng sức mạnh để tìm hiểu, giải phóng hoặc lưu giữ thông tin một cách có chọn lọc từ mỗi đơn vị. Trạng thái tế bào trong LSTM giúp thông tin chảy qua các đơn vị mà không bị thay đổi bằng cách chỉ cho phép một số tương tác tuyến tính. Mỗi đơn vị có một đầu vào, đầu ra và một cổng quên có thể thêm hoặc bớt thông tin về trạng thái ô. Cổng quên quyết định thông tin nào từ trạng thái ô trước đó sẽ bị quên mà nó sử dụng hàm sigmoid. Cổng đầu vào điều khiển luồng thông tin đến trạng thái ô hiện tại bằng cách sử dụng phép toán nhân điểm khôn ngoan của 'sigmoid' và 'tanh' tương ứng. Cuối cùng, cổng ra quyết định thông tin nào sẽ được chuyển sang trạng thái ẩn tiếp theo
Bây giờ chúng ta đã hiểu về hoạt động bên trong của mô hình LSTM, chúng ta hãy triển khai nó. Để hiểu việc triển khai LSTM, chúng ta sẽ bắt đầu với một ví dụ đơn giản - một đường thẳng. Hãy để chúng tôi xem, nếu LSTM có thể tìm hiểu mối quan hệ của một đường thẳng và dự đoán nó.
Đầu tiên, chúng ta hãy tạo tập dữ liệu mô tả một đường thẳng.
Trong [402]:
x = numpy.arange (1,500,1)
y = 0.4 * x + 30
plt.plot(x,y)Ra [402]:
[<matplotlib.lines.Line2D at 0x1eab9d3ee10>]
Trong [403]:
trainx, testx = x[0:int(0.8*(len(x)))], x[int(0.8*(len(x))):]
trainy, testy = y[0:int(0.8*(len(y)))], y[int(0.8*(len(y))):]
train = numpy.array(list(zip(trainx,trainy)))
test = numpy.array(list(zip(trainx,trainy)))Bây giờ, dữ liệu đã được tạo và chia thành huấn luyện và thử nghiệm. Hãy chuyển đổi dữ liệu chuỗi thời gian thành dạng dữ liệu học tập có giám sát theo giá trị của khoảng thời gian nhìn lại, về cơ bản là số độ trễ được nhìn thấy để dự đoán giá trị tại thời điểm 't'.
Vì vậy, một chuỗi thời gian như thế này -
time variable_x
t1 x1
t2 x2
: :
: :
T xTKhi khoảng thời gian nhìn lại là 1, được chuyển đổi thành -
x1 x2
x2 x3
: :
: :
xT-1 xTTrong [404]:
def create_dataset(n_X, look_back):
dataX, dataY = [], []
for i in range(len(n_X)-look_back):
a = n_X[i:(i+look_back), ]
dataX.append(a)
dataY.append(n_X[i + look_back, ])
return numpy.array(dataX), numpy.array(dataY)Trong [405]:
look_back = 1
trainx,trainy = create_dataset(train, look_back)
testx,testy = create_dataset(test, look_back)
trainx = numpy.reshape(trainx, (trainx.shape[0], 1, 2))
testx = numpy.reshape(testx, (testx.shape[0], 1, 2))Bây giờ chúng tôi sẽ đào tạo mô hình của chúng tôi.
Các lô nhỏ dữ liệu đào tạo được hiển thị trên mạng, một lần chạy khi toàn bộ dữ liệu đào tạo được hiển thị cho mô hình theo lô và lỗi được tính toán được gọi là kỷ nguyên. Các kỷ nguyên sẽ được chạy cho đến khi thời gian lỗi giảm.
Trong [ ]:
from keras.models import Sequential
from keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(256, return_sequences = True, input_shape = (trainx.shape[1], 2)))
model.add(LSTM(128,input_shape = (trainx.shape[1], 2)))
model.add(Dense(2))
model.compile(loss = 'mean_squared_error', optimizer = 'adam')
model.fit(trainx, trainy, epochs = 2000, batch_size = 10, verbose = 2, shuffle = False)
model.save_weights('LSTMBasic1.h5')Trong [407]:
model.load_weights('LSTMBasic1.h5')
predict = model.predict(testx)Bây giờ chúng ta hãy xem dự đoán của chúng tôi như thế nào.
Trong [408]:
plt.plot(testx.reshape(398,2)[:,0:1], testx.reshape(398,2)[:,1:2])
plt.plot(predict[:,0:1], predict[:,1:2])Ra [408]:
[<matplotlib.lines.Line2D at 0x1eac792f048>]
Bây giờ, chúng ta nên thử và lập mô hình sóng sin hoặc sóng cosine theo kiểu tương tự. Bạn có thể chạy đoạn mã dưới đây và thử với các thông số của mô hình để xem kết quả thay đổi như thế nào.
Trong [409]:
x = numpy.arange (1,500,1)
y = numpy.sin(x)
plt.plot(x,y)Ra [409]:
[<matplotlib.lines.Line2D at 0x1eac7a0b3c8>]
Trong [410]:
trainx, testx = x[0:int(0.8*(len(x)))], x[int(0.8*(len(x))):]
trainy, testy = y[0:int(0.8*(len(y)))], y[int(0.8*(len(y))):]
train = numpy.array(list(zip(trainx,trainy)))
test = numpy.array(list(zip(trainx,trainy)))Trong [411]:
look_back = 1
trainx,trainy = create_dataset(train, look_back)
testx,testy = create_dataset(test, look_back)
trainx = numpy.reshape(trainx, (trainx.shape[0], 1, 2))
testx = numpy.reshape(testx, (testx.shape[0], 1, 2))Trong [ ]:
model = Sequential()
model.add(LSTM(512, return_sequences = True, input_shape = (trainx.shape[1], 2)))
model.add(LSTM(256,input_shape = (trainx.shape[1], 2)))
model.add(Dense(2))
model.compile(loss = 'mean_squared_error', optimizer = 'adam')
model.fit(trainx, trainy, epochs = 2000, batch_size = 10, verbose = 2, shuffle = False)
model.save_weights('LSTMBasic2.h5')Trong [413]:
model.load_weights('LSTMBasic2.h5')
predict = model.predict(testx)Trong [415]:
plt.plot(trainx.reshape(398,2)[:,0:1], trainx.reshape(398,2)[:,1:2])
plt.plot(predict[:,0:1], predict[:,1:2])Hết [415]:
[<matplotlib.lines.Line2D at 0x1eac7a1f550>]
Bây giờ bạn đã sẵn sàng chuyển sang bất kỳ tập dữ liệu nào.
Điều quan trọng là chúng tôi phải định lượng hiệu suất của một mô hình để sử dụng nó làm phản hồi và so sánh. Trong hướng dẫn này, chúng tôi đã sử dụng một trong những lỗi phổ biến nhất của lỗi bình phương gốc trung bình. Có nhiều số liệu lỗi khác có sẵn. Chương này thảo luận ngắn gọn về chúng.
Lỗi bình phương trung bình
Nó là giá trị trung bình của bình phương chênh lệch giữa các giá trị dự đoán và giá trị thực. Sklearn cung cấp nó như một chức năng. Nó có cùng đơn vị với giá trị thực và giá trị dự đoán được bình phương và luôn dương.
$$MSE = \frac{1}{n} \displaystyle\sum\limits_{t=1}^n \lgroup y'_{t}\:-y_{t}\rgroup^{2}$$
Ở đâu $y'_{t}$ là giá trị dự đoán,
$y_{t}$ là giá trị thực và
n là tổng số giá trị trong tập kiểm tra.
Rõ ràng là MSE bị phạt nhiều hơn đối với các lỗi lớn hơn hoặc các lỗi ngoại lệ.
Lỗi hình vuông gốc trung bình
Nó là căn bậc hai của sai số bình phương trung bình. Nó cũng luôn luôn tích cực và nằm trong phạm vi của dữ liệu.
$$RMSE = \sqrt{\frac{1}{n} \displaystyle\sum\limits_{t=1}^n \lgroup y'_{t}-y_{t}\rgroup ^2}$$
Ở đâu, $y'_{t}$ là giá trị dự đoán
$y_{t}$ là giá trị thực tế, và
n là tổng số giá trị trong tập kiểm tra.
Nó có sức mạnh của sự thống nhất và do đó dễ hiểu hơn so với MSE. RMSE cũng bị phạt nhiều hơn đối với các lỗi lớn hơn. Chúng tôi đã sử dụng số liệu RMSE trong hướng dẫn của mình.
Lỗi tuyệt đối trung bình
Đây là giá trị trung bình của sự khác biệt tuyệt đối giữa giá trị dự đoán và giá trị thực. Nó có cùng đơn vị như dự đoán và giá trị thực và luôn dương.
$$MAE = \frac{1}{n}\displaystyle\sum\limits_{t=1}^{t=n} | y'{t}-y_{t}\lvert$$
Ở đâu, $y'_{t}$ là giá trị dự đoán,
$y_{t}$ là giá trị thực tế, và
n là tổng số giá trị trong tập kiểm tra.
Tỷ lệ phần trăm lỗi trung bình
Nó là phần trăm trung bình của sự khác biệt tuyệt đối giữa các giá trị dự đoán và giá trị thực, chia cho giá trị thực.
$$MAPE = \frac{1}{n}\displaystyle\sum\limits_{t=1}^n\frac{y'_{t}-y_{t}}{y_{t}}*100\: \%$$
Ở đâu, $y'_{t}$ là giá trị dự đoán,
$y_{t}$ là giá trị thực và n là tổng số giá trị trong tập kiểm tra.
Tuy nhiên, nhược điểm của việc sử dụng lỗi này là sai số dương và sai số âm có thể bù trừ cho nhau. Do đó, có nghĩa là sai số phần trăm tuyệt đối được sử dụng.
Lỗi tỷ lệ phần trăm tuyệt đối trung bình
Nó là phần trăm trung bình của sự khác biệt tuyệt đối giữa các giá trị dự đoán và giá trị thực, chia cho giá trị thực.
$$MAPE = \frac{1}{n}\displaystyle\sum\limits_{t=1}^n\frac{|y'_{t}-y_{t}\lvert}{y_{t}}*100\: \%$$
Ở đâu $y'_{t}$ là giá trị dự đoán
$y_{t}$ là giá trị thực tế, và
n là tổng số giá trị trong tập kiểm tra.
Chúng ta đã thảo luận về phân tích chuỗi thời gian trong hướng dẫn này, giúp chúng ta hiểu rằng các mô hình chuỗi thời gian trước tiên nhận ra xu hướng và tính thời vụ từ các quan sát hiện có và sau đó dự báo giá trị dựa trên xu hướng và tính thời vụ này. Phân tích như vậy rất hữu ích trong các lĩnh vực khác nhau như -
Financial Analysis - Nó bao gồm dự báo bán hàng, phân tích hàng tồn kho, phân tích thị trường chứng khoán, ước tính giá cả.
Weather Analysis - Nó bao gồm ước tính nhiệt độ, biến đổi khí hậu, nhận dạng sự chuyển dịch theo mùa, dự báo thời tiết.
Network Data Analysis - Nó bao gồm dự đoán sử dụng mạng, phát hiện bất thường hoặc xâm nhập, bảo trì dự đoán.
Healthcare Analysis - Nó bao gồm dự đoán điều tra dân số, dự đoán quyền lợi bảo hiểm, theo dõi bệnh nhân.
Máy học giải quyết các loại vấn đề khác nhau. Trên thực tế, hầu hết tất cả các lĩnh vực đều có phạm vi được tự động hóa hoặc cải thiện với sự trợ giúp của học máy. Dưới đây là một vài vấn đề mà rất nhiều công việc đang được thực hiện.
Dữ liệu chuỗi thời gian
Đây là dữ liệu thay đổi theo thời gian và do đó thời gian đóng một vai trò quan trọng trong đó, mà chúng ta đã thảo luận phần lớn trong hướng dẫn này.
Dữ liệu chuỗi phi thời gian
Đây là dữ liệu độc lập với thời gian và một tỷ lệ phần trăm lớn các vấn đề ML là trên dữ liệu chuỗi thời gian. Để đơn giản, chúng tôi sẽ phân loại nó thêm là -
Numerical Data - Máy tính, không giống như con người, chỉ hiểu các con số, vì vậy tất cả các loại dữ liệu cuối cùng được chuyển đổi thành dữ liệu số để học máy, ví dụ: dữ liệu hình ảnh được chuyển đổi thành các giá trị (r, b, g), các ký tự được chuyển đổi thành mã ASCII hoặc từ được lập chỉ mục thành số, dữ liệu giọng nói được chuyển đổi thành tệp mfcc chứa dữ liệu số.
Image Data - Thị giác máy tính đã cách mạng hóa thế giới máy tính, nó có nhiều ứng dụng khác nhau trong lĩnh vực y học, chụp ảnh vệ tinh, v.v.
Text Data- Xử lý ngôn ngữ tự nhiên (NLP) được sử dụng để phân loại văn bản, phát hiện diễn giải và tóm tắt ngôn ngữ. Đây là điều làm cho Google và Facebook trở nên thông minh.
Speech Data- Xử lý giọng nói bao gồm nhận dạng giọng nói và hiểu cảm xúc. Nó đóng một vai trò quan trọng trong việc truyền đạt cho máy tính những phẩm chất giống như con người.