XML - Hướng dẫn nhanh
XML là viết tắt của Extensible Mhòm Lđau khổ. Nó là một ngôn ngữ đánh dấu dựa trên văn bản có nguồn gốc từ Ngôn ngữ Đánh dấu Chung Chuẩn (SGML).
Các thẻ XML xác định dữ liệu và được sử dụng để lưu trữ và tổ chức dữ liệu, thay vì chỉ định cách hiển thị nó giống như các thẻ HTML, được sử dụng để hiển thị dữ liệu. XML sẽ không thay thế HTML trong tương lai gần, nhưng nó giới thiệu các khả năng mới bằng cách áp dụng nhiều tính năng thành công của HTML.
Có ba đặc điểm quan trọng của XML khiến nó trở nên hữu ích trong nhiều hệ thống và giải pháp khác nhau -
XML is extensible - XML cho phép bạn tạo các thẻ tự mô tả hoặc ngôn ngữ phù hợp với ứng dụng của bạn.
XML carries the data, does not present it - XML cho phép bạn lưu trữ dữ liệu bất kể nó sẽ được trình bày như thế nào.
XML is a public standard - XML được phát triển bởi một tổ chức có tên là World Wide Web Consortium (W3C) và có sẵn như một tiêu chuẩn mở.
Sử dụng XML
Một danh sách ngắn về việc sử dụng XML đã nói lên tất cả -
XML có thể hoạt động phía sau để đơn giản hóa việc tạo các tài liệu HTML cho các trang web lớn.
XML có thể được sử dụng để trao đổi thông tin giữa các tổ chức và hệ thống.
XML có thể được sử dụng để giảm tải và tải lại cơ sở dữ liệu.
XML có thể được sử dụng để lưu trữ và sắp xếp dữ liệu, có thể tùy chỉnh nhu cầu xử lý dữ liệu của bạn.
XML có thể dễ dàng được hợp nhất với các biểu định kiểu để tạo ra hầu hết mọi kết quả mong muốn.
Hầu như, bất kỳ loại dữ liệu nào cũng có thể được thể hiện dưới dạng tài liệu XML.
Đánh dấu là gì?
XML là một ngôn ngữ đánh dấu xác định tập hợp các quy tắc để mã hóa tài liệu ở định dạng vừa có thể đọc được cho con người vừa có thể đọc được bằng máy. Vậy chính xác thì ngôn ngữ đánh dấu là gì? Đánh dấu là thông tin được thêm vào tài liệu nhằm nâng cao ý nghĩa của nó theo những cách nhất định, trong đó nó xác định các phần và cách chúng liên quan với nhau. Cụ thể hơn, ngôn ngữ đánh dấu là một tập hợp các ký hiệu có thể được đặt trong văn bản của tài liệu để phân giới và gắn nhãn các phần của tài liệu đó.
Ví dụ sau đây cho thấy đánh dấu XML trông như thế nào, khi được nhúng vào một đoạn văn bản -
<message>
<text>Hello, world!</text>
</message>Đoạn mã này bao gồm các ký hiệu đánh dấu hoặc các thẻ như <message> ... </message> và <text> ... </text>. Các thẻ <message> và </message> đánh dấu phần bắt đầu và phần cuối của đoạn mã XML. Các thẻ <text> và </text> bao quanh dòng chữ Hello, world !.
XML có phải là một ngôn ngữ lập trình không?
Một ngôn ngữ lập trình bao gồm các quy tắc ngữ pháp và từ vựng riêng được sử dụng để tạo các chương trình máy tính. Các chương trình này hướng dẫn máy tính thực hiện các tác vụ cụ thể. XML không đủ điều kiện để trở thành một ngôn ngữ lập trình vì nó không thực hiện bất kỳ tính toán hoặc thuật toán nào. Nó thường được lưu trữ trong một tệp văn bản đơn giản và được xử lý bằng phần mềm đặc biệt có khả năng thông dịch XML.
Trong chương này, chúng ta sẽ thảo luận về các quy tắc cú pháp đơn giản để viết một tài liệu XML. Sau đây là một tài liệu XML hoàn chỉnh -
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>Bạn có thể nhận thấy có hai loại thông tin trong ví dụ trên:
Đánh dấu, như <contact-info>
Văn bản hoặc dữ liệu ký tự, Điểm hướng dẫn và (040) 123-4567 .
Sơ đồ sau mô tả các quy tắc cú pháp để viết các loại đánh dấu và văn bản khác nhau trong tài liệu XML.
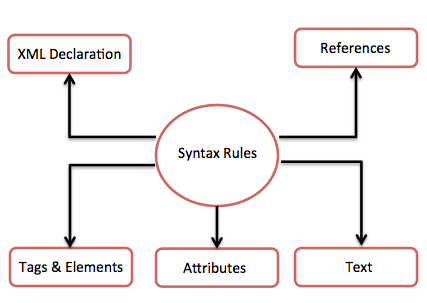
Chúng ta hãy xem chi tiết từng thành phần của sơ đồ trên.
Khai báo XML
Tài liệu XML có thể tùy chọn có một khai báo XML. Nó được viết như sau:
<?xml version = "1.0" encoding = "UTF-8"?>Trong đó phiên bản là phiên bản XML và mã hóa chỉ định mã hóa ký tự được sử dụng trong tài liệu.
Quy tắc cú pháp cho khai báo XML
Khai báo XML phân biệt chữ hoa chữ thường và phải bắt đầu bằng "<?xml>" Ở đâu "xml"được viết bằng chữ thường.
Nếu tài liệu chứa khai báo XML, thì nó cần phải là câu lệnh đầu tiên của tài liệu XML.
Khai báo XML cần phải là câu lệnh đầu tiên trong tài liệu XML.
Giao thức HTTP có thể ghi đè giá trị mã hóa mà bạn đặt trong khai báo XML.
Thẻ và phần tử
Một tệp XML được cấu trúc bởi một số phần tử XML, còn được gọi là các nút XML hoặc các thẻ XML. Tên của các phần tử XML được đặt trong dấu ngoặc nhọn <> như hình dưới đây -
<element>Quy tắc cú pháp cho thẻ và phần tử
Element Syntax - Mỗi phần tử XML cần được đóng bằng các phần tử bắt đầu hoặc kết thúc như được hiển thị bên dưới -
<element>....</element>hoặc trong những trường hợp đơn giản, chỉ theo cách này -
<element/>Nesting of Elements- Một phần tử XML có thể chứa nhiều phần tử XML làm phần tử con của nó, nhưng các phần tử con không được chồng chéo lên nhau. tức là, thẻ kết thúc của một phần tử phải có cùng tên với tên của thẻ bắt đầu chưa đối sánh gần đây nhất.
Ví dụ sau cho thấy các thẻ lồng nhau không chính xác -
<?xml version = "1.0"?>
<contact-info>
<company>TutorialsPoint
</contact-info>
</company>Ví dụ sau hiển thị các thẻ lồng nhau đúng -
<?xml version = "1.0"?>
<contact-info>
<company>TutorialsPoint</company>
<contact-info>Root Element- Một tài liệu XML chỉ có thể có một phần tử gốc. Ví dụ: sau đây không phải là một tài liệu XML chính xác, vì cả haix và y phần tử xảy ra ở cấp cao nhất mà không có phần tử gốc -
<x>...</x>
<y>...</y>Ví dụ sau cho thấy một tài liệu XML được định dạng đúng:
<root>
<x>...</x>
<y>...</y>
</root>Case Sensitivity- Tên của các phần tử XML có phân biệt chữ hoa chữ thường. Điều đó có nghĩa là tên của phần tử bắt đầu và kết thúc cần phải chính xác trong cùng một trường hợp.
Ví dụ, <contact-info> la khac nhau tư <Contact-Info>
Thuộc tính XML
An attributechỉ định một thuộc tính duy nhất cho phần tử, sử dụng cặp tên / giá trị. Một phần tử XML có thể có một hoặc nhiều thuộc tính. Ví dụ -
<a href = "http://www.tutorialspoint.com/">Tutorialspoint!</a>Đây href là tên thuộc tính và http://www.tutorialspoint.com/ là giá trị thuộc tính.
Quy tắc cú pháp cho các thuộc tính XML
Tên thuộc tính trong XML (không giống như HTML) phân biệt chữ hoa chữ thường. Nghĩa là, HREF và href được coi là hai thuộc tính XML khác nhau.
Thuộc tính giống nhau không thể có hai giá trị trong một cú pháp. Ví dụ sau cho thấy cú pháp không chính xác vì thuộc tính b được chỉ định hai lần
-
<a b = "x" c = "y" b = "z">....</a>Tên thuộc tính được xác định không có dấu ngoặc kép, trong khi giá trị thuộc tính phải luôn xuất hiện trong dấu ngoặc kép. Ví dụ sau minh họa cú pháp xml không chính xác
-
<a b = x>....</a>Trong cú pháp trên, giá trị thuộc tính không được xác định trong dấu ngoặc kép.
Tham chiếu XML
Các tham chiếu thường cho phép bạn thêm hoặc bao gồm văn bản bổ sung hoặc đánh dấu trong tài liệu XML. Tài liệu tham khảo luôn bắt đầu bằng ký hiệu"&" là một ký tự dành riêng và kết thúc bằng ký hiệu ";". XML có hai loại tham chiếu -
Entity References- Một tham chiếu thực thể chứa tên giữa các dấu phân cách đầu và cuối. Ví dụ&trong đó amp là tên . Các tên dùng để chỉ một chuỗi xác định trước của văn bản và / hoặc đánh dấu.
Character References - Chúng chứa các tham chiếu, chẳng hạn như A, chứa một dấu thăng (“#”) theo sau là một số. Số luôn đề cập đến mã Unicode của một ký tự. Trong trường hợp này, 65 đề cập đến bảng chữ cái "A".
Văn bản XML
Tên của các phần tử XML và các thuộc tính XML có phân biệt chữ hoa chữ thường, có nghĩa là tên của các phần tử bắt đầu và kết thúc cần được viết trong cùng một trường hợp. Để tránh các vấn đề về mã hóa ký tự, tất cả các tệp XML phải được lưu dưới dạng tệp Unicode UTF-8 hoặc UTF-16.
Các ký tự khoảng trắng như khoảng trống, tab và dấu ngắt dòng giữa các phần tử XML và giữa các thuộc tính XML sẽ bị bỏ qua.
Một số ký tự được dành riêng bởi chính cú pháp XML. Do đó, chúng không thể được sử dụng trực tiếp. Để sử dụng chúng, một số thực thể thay thế được sử dụng, được liệt kê bên dưới -
| Ký tự không được phép | Thực thể thay thế | Mô tả nhân vật |
|---|---|---|
| < | & lt; | ít hơn |
| > | & gt; | lớn hơn |
| & | & amp; | dấu và |
| ' | & apos; | dấu nháy đơn |
| " | & quot; | dấu ngoặc kép |
Tài liệu XML là một đơn vị cơ bản của thông tin XML bao gồm các phần tử và đánh dấu khác trong một gói có thứ tự. Một tài liệu XML có thể chứa nhiều loại dữ liệu. Ví dụ, cơ sở dữ liệu về số, số đại diện cho cấu trúc phân tử hoặc một phương trình toán học.
Ví dụ về tài liệu XML
Một tài liệu đơn giản được hiển thị trong ví dụ sau:
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>Hình ảnh sau đây mô tả các phần của tài liệu XML.

Phần Prolog Tài liệu
Document Prologở đầu tài liệu, trước phần tử gốc. Phần này chứa -
- Khai báo XML
- Khai báo loại tài liệu
Bạn có thể tìm hiểu thêm về khai báo XML trong chương này - Khai báo XML
Phần thành phần tài liệu
Document Elementslà các khối xây dựng của XML. Chúng chia tài liệu thành một hệ thống phân cấp các phần, mỗi phần phục vụ một mục đích cụ thể. Bạn có thể tách một tài liệu thành nhiều phần để chúng có thể được hiển thị khác nhau hoặc được sử dụng bởi công cụ tìm kiếm. Các phần tử có thể là vùng chứa, với sự kết hợp của văn bản và các phần tử khác.
Bạn có thể tìm hiểu thêm về các phần tử XML trong chương này - Phần tử XML
Chương này trình bày chi tiết về khai báo XML. XML declarationchứa các chi tiết chuẩn bị cho bộ xử lý XML để phân tích cú pháp tài liệu XML. Nó là tùy chọn, nhưng khi được sử dụng, nó phải xuất hiện trong dòng đầu tiên của tài liệu XML.
Cú pháp
Cú pháp sau hiển thị khai báo XML:
<?xml
version = "version_number"
encoding = "encoding_declaration"
standalone = "standalone_status"
?>Mỗi tham số bao gồm tên tham số, dấu bằng (=) và giá trị tham số bên trong dấu ngoặc kép. Bảng sau thể hiện chi tiết cú pháp trên:
| Tham số | Giá trị tham số | Mô tả về Thông Số |
|---|---|---|
| Phiên bản | 1,0 | Chỉ định phiên bản của tiêu chuẩn XML được sử dụng. |
| Mã hóa | UTF-8, UTF-16, ISO-10646-UCS-2, ISO-10646-UCS-4, ISO-8859-1 đến ISO-8859-9, ISO-2022-JP, Shift_JIS, EUC-JP | Nó xác định mã hóa ký tự được sử dụng trong tài liệu. UTF-8 là mã hóa mặc định được sử dụng. |
| Độc lập | có hay không | Nó thông báo cho trình phân tích cú pháp liệu tài liệu có dựa vào thông tin từ một nguồn bên ngoài, chẳng hạn như định nghĩa loại tài liệu bên ngoài (DTD), cho nội dung của nó hay không. Giá trị mặc định được đặt thành không . Đặt nó thành có cho bộ xử lý biết rằng không cần khai báo bên ngoài để phân tích cú pháp tài liệu. |
Quy tắc
Một khai báo XML phải tuân theo các quy tắc sau:
Nếu khai báo XML có trong XML, nó phải được đặt ở dòng đầu tiên trong tài liệu XML.
Nếu khai báo XML được bao gồm, nó phải chứa thuộc tính số phiên bản.
Tên và giá trị Tham số phân biệt chữ hoa chữ thường.
Tên luôn được viết thường.
Thứ tự đặt các tham số là quan trọng. Thứ tự đúng là: phiên bản, mã hóa và độc lập.
Có thể sử dụng dấu nháy đơn hoặc dấu ngoặc kép.
Khai báo XML không có thẻ đóng, tức là </?xml>
Ví dụ về khai báo XML
Sau đây là một số ví dụ về khai báo XML:
Khai báo XML không có tham số -
<?xml >Khai báo XML với định nghĩa phiên bản -
<?xml version = "1.0">Khai báo XML với tất cả các tham số được xác định -
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>Khai báo XML với tất cả các tham số được xác định trong dấu ngoặc kép -
<?xml version = '1.0' encoding = 'iso-8859-1' standalone = 'no' ?>Hãy để chúng tôi tìm hiểu về một trong những phần quan trọng nhất của XML, các thẻ XML. XML tagstạo thành nền tảng của XML. Chúng xác định phạm vi của một phần tử trong XML. Chúng cũng có thể được sử dụng để chèn nhận xét, khai báo các cài đặt cần thiết để phân tích cú pháp môi trường và chèn các hướng dẫn đặc biệt.
Chúng ta có thể phân loại rộng rãi các thẻ XML như sau:
Bắt đầu thẻ
Phần đầu của mỗi phần tử XML không trống được đánh dấu bằng thẻ bắt đầu. Sau đây là một ví dụ về thẻ bắt đầu -
<address>Thẻ kết thúc
Mọi phần tử có thẻ bắt đầu phải kết thúc bằng thẻ kết thúc. Sau đây là một ví dụ về thẻ kết thúc -
</address>Lưu ý rằng các thẻ kết thúc bao gồm một solidus ("/") trước tên của một phần tử.
Thẻ trống
Văn bản xuất hiện giữa thẻ bắt đầu và thẻ kết thúc được gọi là nội dung. Một phần tử không có nội dung được gọi là trống. Một phần tử trống có thể được biểu diễn theo hai cách như sau:
Một thẻ bắt đầu ngay sau đó là một thẻ kết thúc như hình dưới đây -
<hr></hr>Một thẻ phần tử trống hoàn chỉnh như được hiển thị bên dưới -
<hr />Thẻ phần tử trống có thể được sử dụng cho bất kỳ phần tử nào không có nội dung.
Quy tắc thẻ XML
Sau đây là các quy tắc cần phải tuân theo để sử dụng các thẻ XML:
Quy tắc 1
Các thẻ XML phân biệt chữ hoa chữ thường. Dòng mã sau là một ví dụ về cú pháp sai </Address>, do sự khác biệt về chữ hoa chữ thường trong hai thẻ, được coi là cú pháp sai trong XML.
<address>This is wrong syntax</Address>Đoạn mã sau cho thấy một cách chính xác, trong đó chúng ta sử dụng cùng một trường hợp để đặt tên cho thẻ bắt đầu và thẻ kết thúc.
<address>This is correct syntax</address>Quy tắc 2
Các thẻ XML phải được đóng theo một thứ tự thích hợp, tức là, một thẻ XML được mở bên trong một phần tử khác phải được đóng trước khi phần tử bên ngoài được đóng lại. Ví dụ -
<outer_element>
<internal_element>
This tag is closed before the outer_element
</internal_element>
</outer_element>XML elementscó thể được định nghĩa là các khối xây dựng của một XML. Các phần tử có thể hoạt động như một vùng chứa để chứa văn bản, phần tử, thuộc tính, đối tượng phương tiện hoặc tất cả những thứ này.
Mỗi tài liệu XML chứa một hoặc nhiều phần tử, phạm vi của chúng được phân định bằng thẻ bắt đầu và thẻ kết thúc, hoặc đối với các phần tử trống, bởi thẻ phần tử trống.
Cú pháp
Sau đây là cú pháp để viết một phần tử XML:
<element-name attribute1 attribute2>
....content
</element-name>Ở đâu,
element-namelà tên của phần tử. Các tên trường hợp của nó trong khi bắt đầu và kết thúc các thẻ phải khớp nhau.
attribute1, attribute2là các thuộc tính của phần tử được phân tách bằng khoảng trắng. Một thuộc tính xác định một thuộc tính của phần tử. Nó liên kết tên với một giá trị, là một chuỗi ký tự. Một thuộc tính được viết là -
name = "value"theo sau tên là dấu = và giá trị chuỗi bên trong dấu ngoặc kép ("") hoặc dấu nháy đơn ('').
Phần tử trống
Một phần tử trống (phần tử không có nội dung) có cú pháp sau:
<name attribute1 attribute2.../>Sau đây là một ví dụ về tài liệu XML sử dụng các phần tử XML khác nhau:
<?xml version = "1.0"?>
<contact-info>
<address category = "residence">
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>
</contact-info>Quy tắc phần tử XML
Các quy tắc sau đây là bắt buộc phải được tuân theo đối với các phần tử XML:
Tên phần tử có thể chứa bất kỳ ký tự chữ và số nào. Dấu câu duy nhất được phép trong tên là dấu gạch ngang (-), dấu gạch dưới (_) và dấu chấm (.).
Tên có phân biệt chữ hoa chữ thường. Ví dụ: Địa chỉ, địa chỉ và ĐỊA CHỈ là các tên khác nhau.
Thẻ bắt đầu và thẻ kết thúc của một phần tử phải giống hệt nhau.
Một phần tử, là một vùng chứa, có thể chứa văn bản hoặc các phần tử như trong ví dụ trên.
Chương này mô tả XML attributes. Các thuộc tính là một phần của các phần tử XML. Một phần tử có thể có nhiều thuộc tính duy nhất. Thuộc tính cung cấp thêm thông tin về các phần tử XML. Nói chính xác hơn, chúng xác định thuộc tính của các phần tử. Thuộc tính XML luôn là một cặp tên-giá trị.
Cú pháp
Thuộc tính XML có cú pháp sau:
<element-name attribute1 attribute2 >
....content..
< /element-name>trong đó thuộc tính1 và thuộc tính2 có dạng sau:
name = "value"giá trị phải nằm trong dấu ngoặc kép ("") hoặc đơn (''). Ở đây, thuộc tính1 và thuộc tính2 là các nhãn thuộc tính duy nhất.
Các thuộc tính được sử dụng để thêm nhãn duy nhất vào một phần tử, đặt nhãn vào danh mục, thêm cờ Boolean hoặc liên kết nó với một số chuỗi dữ liệu. Ví dụ sau minh họa việc sử dụng các thuộc tính -
<?xml version = "1.0" encoding = "UTF-8"?>
<!DOCTYPE garden [
<!ELEMENT garden (plants)*>
<!ELEMENT plants (#PCDATA)>
<!ATTLIST plants category CDATA #REQUIRED>
]>
<garden>
<plants category = "flowers" />
<plants category = "shrubs">
</plants>
</garden>Các thuộc tính được sử dụng để phân biệt giữa các phần tử có cùng tên, khi bạn không muốn tạo một phần tử mới cho mọi tình huống. Do đó, việc sử dụng một thuộc tính có thể thêm một chút chi tiết để phân biệt hai hoặc nhiều phần tử giống nhau.
Trong ví dụ trên, chúng tôi đã phân loại thực vật bằng cách bao gồm danh mục thuộc tính và gán các giá trị khác nhau cho từng phần tử. Do đó, chúng ta có hai loại thực vật , một loại hoa và các loại cây bụi khác . Như vậy, chúng ta có hai yếu tố thực vật với các thuộc tính khác nhau.
Bạn cũng có thể thấy rằng chúng tôi đã khai báo thuộc tính này ở phần đầu của XML.
Các loại thuộc tính
Bảng sau liệt kê loại thuộc tính:
| Loại thuộc tính | Sự miêu tả |
|---|---|
| StringType | Nó nhận bất kỳ chuỗi ký tự nào làm giá trị. CDATA là một StringType. CDATA là dữ liệu ký tự. Điều này có nghĩa là, bất kỳ chuỗi ký tự không đánh dấu nào đều là một phần hợp pháp của thuộc tính. |
| TokenizedType | Đây là một kiểu ràng buộc hơn. Các ràng buộc hợp lệ được lưu ý trong ngữ pháp được áp dụng sau khi giá trị thuộc tính được chuẩn hóa. Các thuộc tính TokenizedType được cung cấp dưới dạng:
|
| EnumeratedType | Điều này có một danh sách các giá trị được xác định trước trong khai báo của nó. trong số đó, nó phải gán một giá trị. Có hai loại thuộc tính liệt kê -
|
Quy tắc thuộc tính phần tử
Sau đây là các quy tắc cần phải tuân theo cho các thuộc tính:
Tên thuộc tính không được xuất hiện nhiều lần trong cùng một thẻ bắt đầu hoặc thẻ phần tử trống.
Một thuộc tính phải được khai báo trong Định nghĩa loại tài liệu (DTD) bằng cách sử dụng Khai báo danh sách thuộc tính.
Giá trị thuộc tính không được chứa tham chiếu thực thể trực tiếp hoặc gián tiếp đến các thực thể bên ngoài.
Văn bản thay thế của bất kỳ thực thể nào được tham chiếu trực tiếp hoặc gián tiếp trong một giá trị thuộc tính không được chứa dấu nhỏ hơn (<)
Chương này giải thích cách các chú thích hoạt động trong các tài liệu XML. XML commentstương tự như các nhận xét HTML. Các nhận xét được thêm vào dưới dạng ghi chú hoặc dòng để hiểu mục đích của mã XML.
Nhận xét có thể được sử dụng để bao gồm các liên kết, thông tin và điều khoản liên quan. Chúng chỉ hiển thị trong mã nguồn; không có trong mã XML. Nhận xét có thể xuất hiện ở bất kỳ đâu trong mã XML.
Cú pháp
Nhận xét XML có cú pháp sau:
<!--Your comment-->Một nhận xét bắt đầu bằng <!-- và kết thúc bằng -->. Bạn có thể thêm ghi chú văn bản dưới dạng nhận xét giữa các ký tự. Bạn không được lồng một bình luận vào bên trong bình luận kia.
Thí dụ
Ví dụ sau minh họa việc sử dụng các chú thích trong tài liệu XML:
<?xml version = "1.0" encoding = "UTF-8" ?>
<!--Students grades are uploaded by months-->
<class_list>
<student>
<name>Tanmay</name>
<grade>A</grade>
</student>
</class_list>Bất kỳ văn bản nào giữa <!-- và --> ký tự được coi là một bình luận.
Quy tắc nhận xét XML
Các quy tắc sau cần được tuân thủ đối với các nhận xét XML:
- Chú thích không thể xuất hiện trước khai báo XML.
- Nhận xét có thể xuất hiện ở bất kỳ đâu trong tài liệu.
- Nhận xét không được xuất hiện trong các giá trị thuộc tính.
- Nhận xét không thể được lồng vào bên trong các nhận xét khác.
Chương này mô tả XML Character Entities. Trước khi hiểu các Thực thể Ký tự, trước tiên chúng ta hãy hiểu thực thể XML là gì.
Như W3 Consortium đưa ra, định nghĩa về một thực thể như sau:
"Thực thể tài liệu đóng vai trò là gốc của cây thực thể và là điểm khởi đầu cho bộ xử lý XML".
Điều này có nghĩa là, các thực thể là trình giữ chỗ trong XML. Chúng có thể được khai báo trong phần mở đầu tài liệu hoặc trong DTD. Có nhiều loại thực thể khác nhau và trong chương này chúng ta sẽ thảo luận về Thực thể nhân vật.
Cả HTML và XML đều có một số ký hiệu dành riêng cho mục đích sử dụng của chúng, không thể được sử dụng làm nội dung trong mã XML. Ví dụ,< và >dấu hiệu được sử dụng để mở và đóng các thẻ XML. Để hiển thị các ký tự đặc biệt này, các thực thể ký tự được sử dụng.
Có một số ký tự hoặc biểu tượng đặc biệt không thể gõ trực tiếp từ bàn phím. Các Thực thể Ký tự cũng có thể được sử dụng để hiển thị các biểu tượng / ký tự đặc biệt đó.
Các loại thực thể nhân vật
Có ba loại thực thể ký tự -
- Các thực thể nhân vật được xác định trước
- Các đối tượng ký tự được đánh số
- Thực thể nhân vật được đặt tên
Các thực thể nhân vật được xác định trước
Chúng được giới thiệu để tránh sự mơ hồ trong khi sử dụng một số ký hiệu. Ví dụ, một sự không rõ ràng được quan sát thấy khi ít hơn (< ) hoặc lớn hơn ( > ) được sử dụng với thẻ góc (<>). Các thực thể ký tự về cơ bản được sử dụng để phân tách các thẻ trong XML. Sau đây là danh sách các thực thể ký tự được xác định trước từ đặc tả XML. Chúng có thể được sử dụng để diễn đạt các ký tự mà không mơ hồ.
Ký hiệu và - &
Trích dẫn duy nhất - '
Lớn hơn - >
Ít hơn - <
Dấu ngoặc kép - "
Thực thể ký tự số
Tham chiếu số được sử dụng để tham chiếu đến một thực thể ký tự. Tham chiếu số có thể ở định dạng thập phân hoặc thập lục phân. Vì có hàng ngàn tham chiếu số có sẵn, chúng hơi khó nhớ. Tham chiếu số đề cập đến ký tự bằng số của nó trong bộ ký tự Unicode.
Cú pháp chung cho tham chiếu số thập phân là -
&# decimal number ;Cú pháp chung cho tham chiếu số thập lục phân là -
&#x Hexadecimal number ;Bảng sau liệt kê một số thực thể ký tự được xác định trước với các giá trị số của chúng:
| Tên thực thể | Tính cách | Tham chiếu thập phân | Tham chiếu hệ thập lục phân |
|---|---|---|---|
| quot | " | & # 34; | & # x22; |
| amp | & | & # 38; | & # x26; |
| apos | ' | & # 39; | & # x27; |
| lt | < | & # 60; | & # x3C; |
| gt | > | & # 62; | & # x3E; |
Thực thể nhân vật được đặt tên
Vì khó nhớ các ký tự số, nên loại thực thể ký tự được ưu tiên nhất là thực thể ký tự được đặt tên. Ở đây, mỗi thực thể được xác định bằng một tên.
Ví dụ -
'Aacute' đại diện cho
ký tự viết hoa với dấu sắc.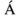
'ugrave' đại diện cho cái nhỏ
với trọng âm.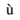
Trong chương này, chúng ta sẽ thảo luận về XML CDATA section. Thuật ngữ CDATA có nghĩa là Dữ liệu Ký tự. CDATA được định nghĩa là các khối văn bản không được phân tích cú pháp bởi trình phân tích cú pháp, nhưng được công nhận là đánh dấu.
Các thực thể được xác định trước như &lt;, &gt;, và &amp;yêu cầu nhập và thường khó đọc trong phần đánh dấu. Trong trường hợp đó, phần CDATA có thể được sử dụng. Bằng cách sử dụng phần CDATA, bạn đang ra lệnh cho trình phân tích cú pháp rằng phần cụ thể của tài liệu không chứa đánh dấu và phải được coi là văn bản thông thường.
Cú pháp
Sau đây là cú pháp cho phần CDATA:
<![CDATA[
characters with markup
]]>Cú pháp trên bao gồm ba phần:
CDATA Start section - CDATA bắt đầu bằng dấu phân cách chín ký tự <![CDATA[
CDATA End section - Phần CDATA kết thúc bằng ]]> dấu phân cách.
CData section- Các ký tự giữa hai thùng này được hiểu là ký tự, không phải là ký hiệu. Phần này có thể chứa các ký tự đánh dấu (<,> và &), nhưng chúng bị bộ xử lý XML bỏ qua.
Thí dụ
Mã đánh dấu sau đây cho thấy một ví dụ về CDATA. Ở đây, mỗi ký tự được viết bên trong phần CDATA bị bộ phân tích cú pháp bỏ qua.
<script>
<![CDATA[
<message> Welcome to TutorialsPoint </message>
]] >
</script >Trong cú pháp trên, mọi thứ giữa <message> và </message> được coi là dữ liệu ký tự chứ không phải đánh dấu.
Quy tắc CDATA
Các quy tắc đã cho bắt buộc phải được tuân theo cho XML CDATA -
- CDATA không được chứa chuỗi "]]>" ở bất kỳ đâu trong tài liệu XML.
- Không được phép lồng trong phần CDATA.
Trong chương này, chúng ta sẽ thảo luận về whitespacexử lý trong các tài liệu XML. Khoảng trắng là một tập hợp các khoảng trắng, tab và dòng mới. Chúng thường được sử dụng để làm cho một tài liệu dễ đọc hơn.
Tài liệu XML chứa hai loại khoảng trắng - Khoảng trắng đáng kể và Khoảng trắng không đáng kể. Cả hai đều được giải thích bên dưới với các ví dụ.
Khoảng trắng đáng kể
Một Khoảng trắng quan trọng xuất hiện trong phần tử có chứa văn bản và đánh dấu xuất hiện cùng nhau. Ví dụ -
<name>TanmayPatil</name>và
<name>Tanmay Patil</name>Hai yếu tố trên khác nhau vì khoảng cách giữa Tanmay và Patil. Bất kỳ chương trình nào đọc phần tử này trong tệp XML đều có nghĩa vụ duy trì sự khác biệt.
Khoảng trắng không đáng kể
Khoảng trắng không đáng kể có nghĩa là khoảng trống chỉ cho phép nội dung phần tử. Ví dụ -
<address.category = "residence"><address....category = "..residence">Các ví dụ trên đều giống nhau. Ở đây, không gian được biểu diễn bằng dấu chấm (.). Trong ví dụ trên, khoảng cách giữa địa chỉ và danh mục là không đáng kể.
Thuộc tính đặc biệt có tên xml:spacecó thể được gắn vào một phần tử. Điều này chỉ ra rằng ứng dụng không nên loại bỏ khoảng trắng cho phần tử đó. Bạn có thể đặt thuộc tính này thànhdefault hoặc là preserve như thể hiện trong ví dụ sau:
<!ATTLIST address xml:space (default|preserve) 'preserve'>Ở đâu,
Giá trị default báo hiệu rằng các chế độ xử lý khoảng trắng mặc định của ứng dụng có thể chấp nhận được đối với phần tử này.
Giá trị preserve cho biết ứng dụng để bảo toàn tất cả các khoảng trắng.
Chương này mô tả Processing Instructions (PIs). Theo định nghĩa của Khuyến nghị XML 1.0,
"Hướng dẫn xử lý (PI) cho phép tài liệu chứa các hướng dẫn cho ứng dụng. PI không phải là một phần của dữ liệu ký tự của tài liệu, nhưng PHẢI được chuyển cho ứng dụng.
Hướng dẫn xử lý (PI) có thể được sử dụng để truyền thông tin đến các ứng dụng. PI có thể xuất hiện ở bất kỳ đâu trong tài liệu bên ngoài phần đánh dấu. Chúng có thể xuất hiện trong phần mở đầu, bao gồm định nghĩa loại tài liệu (DTD), trong nội dung văn bản hoặc sau tài liệu.
Cú pháp
Sau đây là cú pháp của PI:
<?target instructions?>Ở đâu
target - Xác định ứng dụng mà hướng dẫn hướng đến.
instruction - Một ký tự mô tả thông tin để ứng dụng xử lý.
PI bắt đầu bằng một thẻ đặc biệt <? và kết thúc bằng ?>. Quá trình xử lý nội dung kết thúc ngay sau chuỗi?> đang gặp phải.
Thí dụ
PI hiếm khi được sử dụng. Chúng chủ yếu được sử dụng để liên kết tài liệu XML với một biểu định kiểu. Sau đây là một ví dụ -
<?xml-stylesheet href = "tutorialspointstyle.css" type = "text/css"?>Ở đây, mục tiêu là biểu định kiểu xml . href = "tutorialspointstyle.css" và type = "text / css" là dữ liệu hoặc hướng dẫn mà ứng dụng đích sẽ sử dụng tại thời điểm xử lý tài liệu XML đã cho.
Trong trường hợp này, trình duyệt nhận ra mục tiêu bằng cách chỉ ra rằng XML nên được chuyển đổi trước khi được hiển thị; thuộc tính đầu tiên cho biết loại biến đổi là XSL và thuộc tính thứ hai trỏ đến vị trí của nó.
Quy tắc hướng dẫn xử lý
PI có thể chứa bất kỳ dữ liệu nào ngoại trừ sự kết hợp ?>, được hiểu là dấu phân cách đóng. Đây là hai ví dụ về PI hợp lệ -
<?welcome to pg = 10 of tutorials point?>
<?welcome?>Encodinglà quá trình chuyển đổi các ký tự unicode thành biểu diễn nhị phân tương đương của chúng. Khi bộ xử lý XML đọc một tài liệu XML, nó sẽ mã hóa tài liệu đó tùy thuộc vào kiểu mã hóa. Do đó, chúng ta cần chỉ định kiểu mã hóa trong khai báo XML.
Các loại mã hóa
Chủ yếu có hai loại mã hóa -
- UTF-8
- UTF-16
UTF là viết tắt của UCS Transformation Format , và bản thân UCS có nghĩa là Bộ ký tự chung . Số 8 hoặc 16 đề cập đến số bit được sử dụng để biểu diễn một ký tự. Chúng là 8 (1 đến 4 byte) hoặc 16 (2 hoặc 4 byte). Đối với các tài liệu không có thông tin mã hóa, UTF-8 được đặt theo mặc định.
Cú pháp
Kiểu mã hóa được bao gồm trong phần mở đầu của tài liệu XML. Cú pháp cho mã hóa UTF-8 như sau:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>Cú pháp cho mã hóa UTF-16 như sau:
<?xml version = "1.0" encoding = "UTF-16" standalone = "no" ?>Thí dụ
Ví dụ sau đây cho thấy khai báo của mã hóa:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>Trong ví dụ trên encoding="UTF-8", chỉ định rằng 8-bit được sử dụng để biểu diễn các ký tự. Để biểu diễn các ký tự 16 bit,UTF-16 mã hóa có thể được sử dụng.
Các tệp XML được mã hóa bằng UTF-8 có xu hướng có kích thước nhỏ hơn các tệp được mã hóa bằng định dạng UTF-16.
Validationlà một quá trình mà một tài liệu XML được xác thực. Một tài liệu XML được cho là hợp lệ nếu nội dung của nó phù hợp với các phần tử, thuộc tính và khai báo kiểu tài liệu liên quan (DTD) và nếu tài liệu tuân thủ các ràng buộc được thể hiện trong đó. Việc xác thực được trình phân tích cú pháp XML xử lý theo hai cách. Họ là -
- Tài liệu XML được định dạng tốt
- Tài liệu XML hợp lệ
Tài liệu XML được định dạng tốt
Một tài liệu XML được cho là well-formed nếu nó tuân thủ các quy tắc sau -
Các tệp XML không phải DTD phải sử dụng các thực thể ký tự được xác định trước cho amp(&), apos(single quote), gt(>), lt(<), quot(double quote).
Nó phải tuân theo thứ tự của thẻ. tức là, thẻ bên trong phải được đóng trước khi đóng thẻ bên ngoài.
Mỗi thẻ mở của nó phải có một thẻ đóng hoặc nó phải là một thẻ tự kết thúc. (<title> .... </title> hoặc <title />).
Nó phải chỉ có một thuộc tính trong thẻ bắt đầu, cần được trích dẫn.
amp(&), apos(single quote), gt(>), lt(<), quot(double quote) các thực thể khác với những thực thể này phải được khai báo.
Thí dụ
Sau đây là một ví dụ về một tài liệu XML được định dạng tốt:
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?>
<!DOCTYPE address
[
<!ELEMENT address (name,company,phone)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT company (#PCDATA)>
<!ELEMENT phone (#PCDATA)>
]>
<address>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>Ví dụ trên được cho là có dạng:
Nó xác định loại tài liệu. Đây, loại tài liệu làelement kiểu.
Nó bao gồm một phần tử gốc có tên là address.
Mỗi thành phần con giữa tên, công ty và điện thoại được bao gồm trong thẻ tự giải thích của nó.
Thứ tự của các thẻ được duy trì.
Valid XML Document
If an XML document is well-formed and has an associated Document Type Declaration (DTD), then it is said to be a valid XML document. We will study more about DTD in the chapter XML - DTDs.
The XML Document Type Declaration, commonly known as DTD, is a way to describe XML language precisely. DTDs check vocabulary and validity of the structure of XML documents against grammatical rules of appropriate XML language.
An XML DTD can be either specified inside the document, or it can be kept in a separate document and then liked separately.
Syntax
Basic syntax of a DTD is as follows −
<!DOCTYPE element DTD identifier
[
declaration1
declaration2
........
]>In the above syntax,
The DTD starts with <!DOCTYPE delimiter.
An element tells the parser to parse the document from the specified root element.
DTD identifier is an identifier for the document type definition, which may be the path to a file on the system or URL to a file on the internet. If the DTD is pointing to external path, it is called External Subset.
The square brackets [ ] enclose an optional list of entity declarations called Internal Subset.
Internal DTD
A DTD is referred to as an internal DTD if elements are declared within the XML files. To refer it as internal DTD, standalone attribute in XML declaration must be set to yes. This means, the declaration works independent of an external source.
Syntax
Following is the syntax of internal DTD −
<!DOCTYPE root-element [element-declarations]>where root-element is the name of root element and element-declarations is where you declare the elements.
Example
Following is a simple example of internal DTD −
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?>
<!DOCTYPE address [
<!ELEMENT address (name,company,phone)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT company (#PCDATA)>
<!ELEMENT phone (#PCDATA)>
]>
<address>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>Let us go through the above code −
Start Declaration − Begin the XML declaration with the following statement.
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?>DTD − Immediately after the XML header, the document type declaration follows, commonly referred to as the DOCTYPE −
<!DOCTYPE address [The DOCTYPE declaration has an exclamation mark (!) at the start of the element name. The DOCTYPE informs the parser that a DTD is associated with this XML document.
DTD Body − The DOCTYPE declaration is followed by body of the DTD, where you declare elements, attributes, entities, and notations.
<!ELEMENT address (name,company,phone)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT company (#PCDATA)>
<!ELEMENT phone_no (#PCDATA)>Several elements are declared here that make up the vocabulary of the <name> document. <!ELEMENT name (#PCDATA)> defines the element name to be of type "#PCDATA". Here #PCDATA means parse-able text data.
End Declaration − Finally, the declaration section of the DTD is closed using a closing bracket and a closing angle bracket (]>). This effectively ends the definition, and thereafter, the XML document follows immediately.
Rules
The document type declaration must appear at the start of the document (preceded only by the XML header) − it is not permitted anywhere else within the document.
Similar to the DOCTYPE declaration, the element declarations must start with an exclamation mark.
The Name in the document type declaration must match the element type of the root element.
External DTD
In external DTD elements are declared outside the XML file. They are accessed by specifying the system attributes which may be either the legal .dtd file or a valid URL. To refer it as external DTD, standalone attribute in the XML declaration must be set as no. This means, declaration includes information from the external source.
Syntax
Following is the syntax for external DTD −
<!DOCTYPE root-element SYSTEM "file-name">where file-name is the file with .dtd extension.
Example
The following example shows external DTD usage −
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
<!DOCTYPE address SYSTEM "address.dtd">
<address>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>The content of the DTD file address.dtd is as shown −
<!ELEMENT address (name,company,phone)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT company (#PCDATA)>
<!ELEMENT phone (#PCDATA)>Types
You can refer to an external DTD by using either system identifiers or public identifiers.
System Identifiers
A system identifier enables you to specify the location of an external file containing DTD declarations. Syntax is as follows −
<!DOCTYPE name SYSTEM "address.dtd" [...]>As you can see, it contains keyword SYSTEM and a URI reference pointing to the location of the document.
Public Identifiers
Public identifiers provide a mechanism to locate DTD resources and is written as follows −
<!DOCTYPE name PUBLIC "-//Beginning XML//DTD Address Example//EN">As you can see, it begins with keyword PUBLIC, followed by a specialized identifier. Public identifiers are used to identify an entry in a catalog. Public identifiers can follow any format, however, a commonly used format is called Formal Public Identifiers, or FPIs.
XML Schema is commonly known as XML Schema Definition (XSD). It is used to describe and validate the structure and the content of XML data. XML schema defines the elements, attributes and data types. Schema element supports Namespaces. It is similar to a database schema that describes the data in a database.
Syntax
You need to declare a schema in your XML document as follows −
Example
The following example shows how to use schema −
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema">
<xs:element name = "contact">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
<xs:element name = "phone" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>The basic idea behind XML Schemas is that they describe the legitimate format that an XML document can take.
Elements
As we saw in the XML - Elements chapter, elements are the building blocks of XML document. An element can be defined within an XSD as follows −
<xs:element name = "x" type = "y"/>Definition Types
You can define XML schema elements in the following ways −
Simple Type
Simple type element is used only in the context of the text. Some of the predefined simple types are: xs:integer, xs:boolean, xs:string, xs:date. For example −
<xs:element name = "phone_number" type = "xs:int" />Complex Type
A complex type is a container for other element definitions. This allows you to specify which child elements an element can contain and to provide some structure within your XML documents. For example −
<xs:element name = "Address">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
<xs:element name = "phone" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>In the above example, Address element consists of child elements. This is a container for other <xs:element> definitions, that allows to build a simple hierarchy of elements in the XML document.
Global Types
With the global type, you can define a single type in your document, which can be used by all other references. For example, suppose you want to generalize the person and company for different addresses of the company. In such case, you can define a general type as follows −
<xs:element name = "AddressType">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>Now let us use this type in our example as follows −
<xs:element name = "Address1">
<xs:complexType>
<xs:sequence>
<xs:element name = "address" type = "AddressType" />
<xs:element name = "phone1" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name = "Address2">
<xs:complexType>
<xs:sequence>
<xs:element name = "address" type = "AddressType" />
<xs:element name = "phone2" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>Instead of having to define the name and the company twice (once for Address1 and once for Address2), we now have a single definition. This makes maintenance simpler, i.e., if you decide to add "Postcode" elements to the address, you need to add them at just one place.
Attributes
Attributes in XSD provide extra information within an element. Attributes have name and type property as shown below −
<xs:attribute name = "x" type = "y"/>An XML document is always descriptive. The tree structure is often referred to as XML Tree and plays an important role to describe any XML document easily.
The tree structure contains root (parent) elements, child elements and so on. By using tree structure, you can get to know all succeeding branches and sub-branches starting from the root. The parsing starts at the root, then moves down the first branch to an element, take the first branch from there, and so on to the leaf nodes.
Example
Following example demonstrates simple XML tree structure −
<?xml version = "1.0"?>
<Company>
<Employee>
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
<Address>
<City>Bangalore</City>
<State>Karnataka</State>
<Zip>560212</Zip>
</Address>
</Employee>
</Company>Following tree structure represents the above XML document −
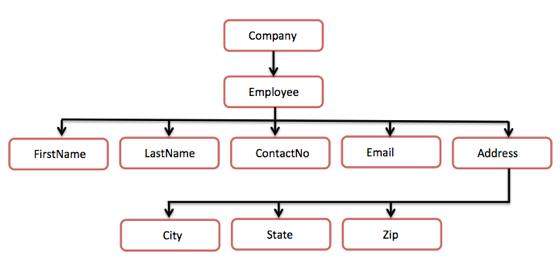
In the above diagram, there is a root element named as <company>. Inside that, there is one more element <Employee>. Inside the employee element, there are five branches named <FirstName>, <LastName>, <ContactNo>, <Email>, and <Address>. Inside the <Address> element, there are three sub-branches, named <City> <State> and <Zip>.
The Document Object Model (DOM) is the foundation of XML. XML documents have a hierarchy of informational units called nodes; DOM is a way of describing those nodes and the relationships between them.
A DOM document is a collection of nodes or pieces of information organized in a hierarchy. This hierarchy allows a developer to navigate through the tree looking for specific information. Because it is based on a hierarchy of information, the DOM is said to be tree based.
The XML DOM, on the other hand, also provides an API that allows a developer to add, edit, move, or remove nodes in the tree at any point in order to create an application.
Example
The following example (sample.htm) parses an XML document ("address.xml") into an XML DOM object and then extracts some information from it with JavaScript −
<!DOCTYPE html>
<html>
<body>
<h1>TutorialsPoint DOM example </h1>
<div>
<b>Name:</b> <span id = "name"></span><br>
<b>Company:</b> <span id = "company"></span><br>
<b>Phone:</b> <span id = "phone"></span>
</div>
<script>
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/xml/address.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("name").innerHTML=
xmlDoc.getElementsByTagName("name")[0].childNodes[0].nodeValue;
document.getElementById("company").innerHTML=
xmlDoc.getElementsByTagName("company")[0].childNodes[0].nodeValue;
document.getElementById("phone").innerHTML=
xmlDoc.getElementsByTagName("phone")[0].childNodes[0].nodeValue;
</script>
</body>
</html>Contents of address.xml are as follows −
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>Now let us keep these two files sample.htm and address.xml in the same directory /xml and execute the sample.htm file by opening it in any browser. This should produce the following output.

Here, you can see how each of the child nodes is extracted to display their values.
A Namespace is a set of unique names. Namespace is a mechanisms by which element and attribute name can be assigned to a group. The Namespace is identified by URI(Uniform Resource Identifiers).
Namespace Declaration
A Namespace is declared using reserved attributes. Such an attribute name must either be xmlns or begin with xmlns: shown as below −
<element xmlns:name = "URL">Syntax
The Namespace starts with the keyword xmlns.
The word name is the Namespace prefix.
The URL is the Namespace identifier.
Example
Namespace affects only a limited area in the document. An element containing the declaration and all of its descendants are in the scope of the Namespace. Following is a simple example of XML Namespace −
<?xml version = "1.0" encoding = "UTF-8"?>
<cont:contact xmlns:cont = "www.tutorialspoint.com/profile">
<cont:name>Tanmay Patil</cont:name>
<cont:company>TutorialsPoint</cont:company>
<cont:phone>(011) 123-4567</cont:phone>
</cont:contact>Here, the Namespace prefix is cont, and the Namespace identifier (URI) as www.tutorialspoint.com/profile. This means, the element names and attribute names with the cont prefix (including the contact element), all belong to the www.tutorialspoint.com/profile namespace.
XML Database is used to store huge amount of information in the XML format. As the use of XML is increasing in every field, it is required to have a secured place to store the XML documents. The data stored in the database can be queried using XQuery, serialized, and exported into a desired format.
XML Database Types
There are two major types of XML databases −
- XML- enabled
- Native XML (NXD)
XML - Enabled Database
XML enabled database is nothing but the extension provided for the conversion of XML document. This is a relational database, where data is stored in tables consisting of rows and columns. The tables contain set of records, which in turn consist of fields.
Native XML Database
Native XML database is based on the container rather than table format. It can store large amount of XML document and data. Native XML database is queried by the XPath-expressions.
Native XML database has an advantage over the XML-enabled database. It is highly capable to store, query and maintain the XML document than XML-enabled database.
Example
Following example demonstrates XML database −
<?xml version = "1.0"?>
<contact-info>
<contact1>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact1>
<contact2>
<name>Manisha Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 789-4567</phone>
</contact2>
</contact-info>Here, a table of contacts is created that holds the records of contacts (contact1 and contact2), which in turn consists of three entities − name, company and phone.
This chapter describes THE various methods to view an XML document. An XML document can be viewed using a simple text editor or any browser. Most of the major browsers supports XML. XML files can be opened in the browser by just double-clicking the XML document (if it is a local file) or by typing the URL path in the address bar (if the file is located on the server), in the same way as we open other files in the browser. XML files are saved with a ".xml" extension.
Let us explore various methods by which we can view an XML file. Following example (sample.xml) is used to view all the sections of this chapter.
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>Text Editors
Any simple text editor such as Notepad, TextPad, or TextEdit can be used to create or view an XML document as shown below −
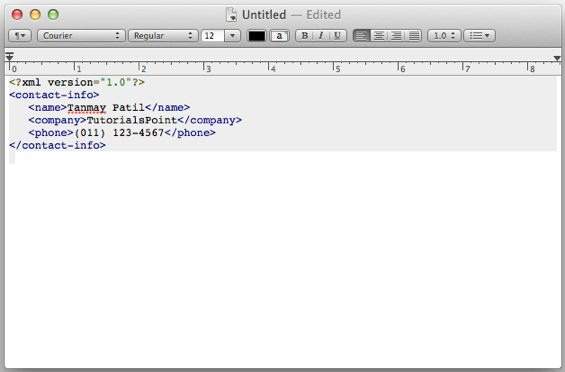
Firefox Browser
Open the above XML code in Chrome by double-clicking the file. The XML code displays coding with color, which makes the code readable. It shows plus(+) or minus (-) sign at the left side in the XML element. When we click the minus sign (-), the code hides. When we click the plus (+) sign, the code lines get expanded. The output in Firefox is as shown below −

Chrome Browser
Open the above XML code in Chrome browser. The code gets displayed as shown below −

Errors in XML Document
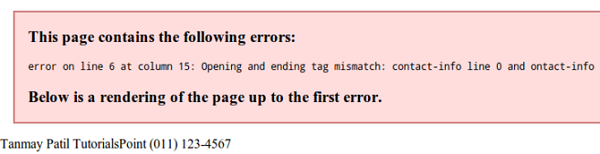
If your XML code has some tags missing, then a message is displayed in the browser. Let us try to open the following XML file in Chrome −
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>In the above code, the start and end tags are not matching (refer the contact_info tag), hence an error message is displayed by the browser as shown below −
XML Editor is a markup language editor. The XML documents can be edited or created using existing editors such as Notepad, WordPad, or any similar text editor. You can also find a professional XML editor online or for downloading, which has more powerful editing features such as −
- It automatically closes the tags that are left open.
- It strictly checks syntax.
- It highlights XML syntax with colour for increased readability.
- It helps you write a valid XML code.
- It provides automatic verification of XML documents against DTDs and Schemas.
Open Source XML Editors
Following are some open source XML editors −
Online XML Editor − This is a light weight XML editor which you can use online.
Xerlin − Xerlin is an open source XML editor for Java 2 platform released under an Apache license. It is a Java based XML modelling application, for creating and editing XML files easily.
CAM - Content Assembly Mechanism − CAM XML Editor tool comes with XML+JSON+SQL Open-XDX sponsored by Oracle.
XML parser is a software library or a package that provides interface for client applications to work with XML documents. It checks for proper format of the XML document and may also validate the XML documents. Modern day browsers have built-in XML parsers.
Following diagram shows how XML parser interacts with XML document −
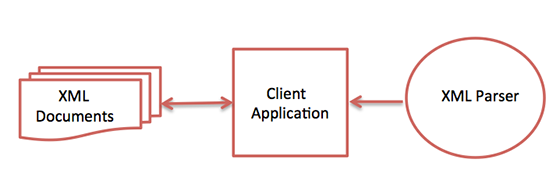
The goal of a parser is to transform XML into a readable code.
To ease the process of parsing, some commercial products are available that facilitate the breakdown of XML document and yield more reliable results.
Some commonly used parsers are listed below −
MSXML (Microsoft Core XML Services) − This is a standard set of XML tools from Microsoft that includes a parser.
System.Xml.XmlDocument − This class is part of .NET library, which contains a number of different classes related to working with XML.
Java built-in parser − The Java library has its own parser. The library is designed such that you can replace the built-in parser with an external implementation such as Xerces from Apache or Saxon.
Saxon − Saxon offers tools for parsing, transforming, and querying XML.
Xerces − Xerces is implemented in Java and is developed by the famous open source Apache Software Foundation.
When a software program reads an XML document and takes actions accordingly, this is called processing the XML. Any program that can read and process XML documents is known as an XML processor. An XML processor reads the XML file and turns it into in-memory structures that the rest of the program can access.
The most fundamental XML processor reads an XML document and converts it into an internal representation for other programs or subroutines to use. This is called a parser, and it is an important component of every XML processing program.
Processor involves processing the instructions, that can be studied in the chapter Processing Instruction.
Types
XML processors are classified as validating or non-validating types, depending on whether or not they check XML documents for validity. A processor that discovers a validity error must be able to report it, but may continue with normal processing.
A few validating parsers are − xml4c (IBM, in C++), xml4j (IBM, in Java), MSXML (Microsoft, in Java), TclXML (TCL), xmlproc (Python), XML::Parser (Perl), Java Project X (Sun, in Java).
A few non-validating parsers are − OpenXML (Java), Lark (Java), xp (Java), AElfred (Java), expat (C), XParse (JavaScript), xmllib (Python).