Agile Data Science - Kurzanleitung
Agile Data Science ist ein Ansatz zur Verwendung von Data Science mit agiler Methodik für die Entwicklung von Webanwendungen. Es konzentriert sich auf die Ausgabe des datenwissenschaftlichen Prozesses, der geeignet ist, Veränderungen für eine Organisation herbeizuführen. Data Science umfasst das Erstellen von Anwendungen, die den Forschungsprozess mit Analyse, interaktiver Visualisierung und jetzt auch angewandtem maschinellem Lernen beschreiben.
Das Hauptziel der agilen Datenwissenschaft ist -
Dokumentieren und führen Sie erklärende Datenanalysen, um den kritischen Pfad zu einem überzeugenden Produkt zu entdecken und zu verfolgen.
Agile Data Science ist nach folgenden Prinzipien organisiert:
Kontinuierliche Iteration
Dieser Prozess umfasst eine kontinuierliche Iteration mit Erstellungstabellen, Diagrammen, Berichten und Vorhersagen. Das Erstellen von Vorhersagemodellen erfordert viele Iterationen des Feature-Engineerings mit Extraktion und Erstellung von Erkenntnissen.
Zwischenausgabe
Dies ist die Titelliste der generierten Ausgaben. Es wird sogar gesagt, dass fehlgeschlagene Experimente auch Ergebnisse haben. Das Verfolgen der Ausgabe jeder Iteration hilft dabei, in der nächsten Iteration eine bessere Ausgabe zu erzielen.
Prototyp-Experimente
Prototyp-Experimente umfassen das Zuweisen von Aufgaben und das Generieren von Ausgabe gemäß den Experimenten. In einer bestimmten Aufgabe müssen wir iterieren, um Einsicht zu gewinnen, und diese Iterationen können am besten als Experimente erklärt werden.
Integration von Daten
Der Lebenszyklus der Softwareentwicklung umfasst verschiedene Phasen mit Daten, die für -
customers
Entwickler und
das Geschäft
Die Integration von Daten ebnet den Weg für bessere Aussichten und Ergebnisse.
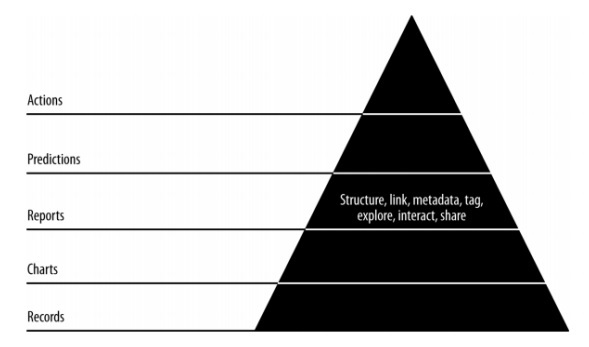
Pyramidendatenwert

Der obige Pyramidenwert beschreibt die Schichten, die für die Entwicklung von „Agile Data Science“ benötigt werden. Es beginnt mit einer Sammlung von Aufzeichnungen, die auf den Anforderungen basieren, und der Installation einzelner Aufzeichnungen. Die Diagramme werden nach Bereinigung und Aggregation von Daten erstellt. Die aggregierten Daten können zur Datenvisualisierung verwendet werden. Berichte werden mit der richtigen Struktur, Metadaten und Tags von Daten generiert. Die zweite Pyramidenschicht von oben enthält eine Vorhersageanalyse. In der Vorhersageebene wird mehr Wert geschaffen, hilft jedoch bei der Erstellung guter Vorhersagen, die sich auf das Feature-Engineering konzentrieren.
Die oberste Ebene umfasst Aktionen, bei denen der Wert von Daten effektiv gesteuert wird. Das beste Beispiel für diese Implementierung ist „Künstliche Intelligenz“.
In diesem Kapitel konzentrieren wir uns auf die Konzepte des Softwareentwicklungs-Lebenszyklus, die als „agil“ bezeichnet werden. Die Agile-Softwareentwicklungsmethode hilft beim Erstellen einer Software durch Inkrementsitzungen in kurzen Iterationen von 1 bis 4 Wochen, sodass die Entwicklung an sich ändernden Geschäftsanforderungen ausgerichtet ist.
Es gibt 12 Prinzipien, die die agile Methodik im Detail beschreiben -
Kundenzufriedenheit
Kunden, die sich durch frühzeitige und kontinuierliche Lieferung wertvoller Software auf die Anforderungen konzentrieren, haben höchste Priorität.
Neue Änderungen begrüßen
Änderungen sind während der Softwareentwicklung akzeptabel. Agile Prozesse funktionieren so, dass sie dem Wettbewerbsvorteil des Kunden entsprechen.
Lieferung
Die Lieferung einer funktionierenden Software erfolgt innerhalb von ein bis vier Wochen an Kunden.
Zusammenarbeit
Geschäftsanalysten, Qualitätsanalysten und Entwickler müssen während des gesamten Projektlebenszyklus zusammenarbeiten.
Motivation
Projekte sollten mit einem Clan motivierter Personen entworfen werden. Es bietet eine Umgebung zur Unterstützung einzelner Teammitglieder.
Persönliches Gespräch
Face-to-Face-Gespräche sind die effizienteste und effektivste Methode, um Informationen an und innerhalb eines Entwicklungsteams zu senden.
Fortschritt messen
Die Messung des Fortschritts ist der Schlüssel zur Definition des Fortschritts der Projekt- und Softwareentwicklung.
Konstantes Tempo beibehalten
Agiler Prozess konzentriert sich auf nachhaltige Entwicklung. Das Unternehmen, die Entwickler und die Benutzer sollten in der Lage sein, ein konstantes Tempo mit dem Projekt einzuhalten.
Überwachung
Es ist obligatorisch, regelmäßig auf technische Exzellenz und gutes Design zu achten, um die agile Funktionalität zu verbessern.
Einfachheit
Der agile Prozess hält alles einfach und verwendet einfache Begriffe, um die nicht abgeschlossene Arbeit zu messen.
Selbstorganisierte Begriffe
Ein agiles Team sollte selbst organisiert und unabhängig mit der besten Architektur sein. Anforderungen und Designs entstehen aus selbstorganisierten Teams.
Überprüfen Sie die Arbeit
Es ist wichtig, die Arbeit in regelmäßigen Abständen zu überprüfen, damit das Team über den Fortschritt der Arbeit nachdenken kann. Durch rechtzeitiges Überprüfen des Moduls wird die Leistung verbessert.
Tägliches Aufstehen
Tägliches Aufstehen bezieht sich auf das tägliche Statusmeeting unter den Teammitgliedern. Es enthält Updates zur Softwareentwicklung. Es bezieht sich auch auf die Beseitigung von Hindernissen bei der Projektentwicklung.
Tägliches Aufstehen ist eine obligatorische Praxis, unabhängig davon, wie ein agiles Team aufgebaut ist, unabhängig von seinem Bürostandort.
Die Liste der Funktionen eines täglichen Stand-Ups lautet wie folgt:
Die Dauer des täglichen Stand-up-Meetings sollte ungefähr 15 Minuten betragen. Es sollte nicht länger dauern.
Stand-up sollte Diskussionen zur Statusaktualisierung beinhalten.
Die Teilnehmer dieses Meetings haben normalerweise die Absicht, das Meeting schnell zu beenden.
Benutzer Geschichte
Eine Geschichte ist normalerweise eine Anforderung, die in wenigen Sätzen in einfacher Sprache formuliert ist und innerhalb einer Iteration abgeschlossen werden sollte. Eine User Story sollte die folgenden Merkmale enthalten:
Der gesamte zugehörige Code sollte über entsprechende Check-Ins verfügen.
Die Unit-Testfälle für die angegebene Iteration.
Alle Abnahmetestfälle sollten definiert werden.
Akzeptanz durch den Product Owner bei der Definition der Story.
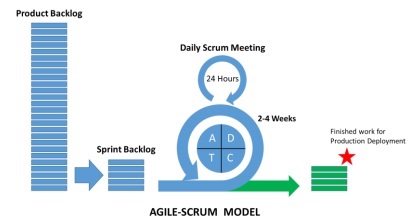
Was ist Scrum?
Scrum kann als Teilmenge der agilen Methodik betrachtet werden. Es ist ein leichter Prozess und umfasst die folgenden Funktionen:
Es handelt sich um einen Prozessrahmen, der eine Reihe von Praktiken enthält, die in konsistenter Reihenfolge befolgt werden müssen. Das beste Beispiel für Scrum sind Iterationen oder Sprints.
Es handelt sich um einen „leichten“ Prozess, bei dem der Prozess so klein wie möglich gehalten wird, um die produktive Leistung in der angegebenen Dauer zu maximieren.
Der Scrum-Prozess ist bekannt für seinen Unterscheidungsprozess im Vergleich zu anderen Methoden des traditionellen agilen Ansatzes. Es ist in die folgenden drei Kategorien unterteilt:
Roles
Artifacts
Zeitboxen
Rollen definieren die Teammitglieder und ihre Rollen, die während des gesamten Prozesses enthalten sind. Das Scrum-Team besteht aus den folgenden drei Rollen:
Scrum Master
Product Owner
Team
Die Scrum-Artefakte enthalten wichtige Informationen, die jedem Mitglied bekannt sein sollten. Die Informationen enthalten Details zum Produkt, zu geplanten Aktivitäten und zu abgeschlossenen Aktivitäten. Die im Scrum-Framework definierten Artefakte lauten wie folgt:
Produktrückstand
Sprint-Rückstand
Diagramm abbrennen
Increment
Zeitfelder sind die User Stories, die für jede Iteration geplant sind. Diese User Stories helfen bei der Beschreibung der Produktmerkmale, die Teil der Scrum-Artefakte sind. Das Product Backlog ist eine Liste von User Stories. Diese User Stories werden priorisiert und an die User Meetings weitergeleitet, um zu entscheiden, welche aufgenommen werden sollen.
Warum Scrum Master?
Scrum Master interagiert mit jedem Mitglied des Teams. Lassen Sie uns nun die Interaktion des Scrum Masters mit anderen Teams und Ressourcen sehen.
Product Owner
Der Scrum Master interagiert den Product Owner auf folgende Weise:
Finden von Techniken, um einen effektiven Produktstau von User Stories zu erzielen und diese zu verwalten.
Unterstützung des Teams beim Verständnis der Anforderungen klarer und präziser Produktrückstände.
Produktplanung mit spezifischer Umgebung.
Sicherstellen, dass der Product Owner weiß, wie er den Wert des Produkts steigern kann.
Ermöglichen von Scrum-Ereignissen nach Bedarf.
Scrum-Team
Der Scrum Master interagiert auf verschiedene Weise mit dem Team -
Coaching der Organisation bei der Einführung von Scrum.
Planen von Scrum-Implementierungen für die jeweilige Organisation.
Mitarbeiter und Stakeholder dabei unterstützen, die Anforderungen und Phasen der Produktentwicklung zu verstehen.
Zusammenarbeit mit Scrum Masters anderer Teams, um die Effektivität der Anwendung von Scrum des angegebenen Teams zu erhöhen.
Organisation
Der Scrum Master interagiert auf verschiedene Weise mit der Organisation. Einige sind unten aufgeführt -
Das Coaching- und Scrum-Team interagiert mit der Selbstorganisation und enthält eine Funktion mit unterschiedlichen Funktionen.
Coaching der Organisation und der Teams in solchen Bereichen, in denen Scrum noch nicht vollständig übernommen oder nicht akzeptiert wurde.
Vorteile von Scrum
Scrum hilft Kunden, Teammitgliedern und Stakeholdern bei der Zusammenarbeit. Es beinhaltet einen zeitgesteuerten Ansatz und ein kontinuierliches Feedback des Produktbesitzers, um sicherzustellen, dass das Produkt in einwandfreiem Zustand ist. Scrum bietet Vorteile für verschiedene Rollen des Projekts.
Kunde
Die Sprints oder Iterationen werden für eine kürzere Dauer berücksichtigt, und User Stories werden nach Priorität entworfen und bei der Sprintplanung berücksichtigt. Es stellt sicher, dass bei jeder Sprintlieferung die Kundenanforderungen erfüllt werden. Wenn nicht, werden die Anforderungen notiert und für den Sprint geplant und übernommen.
Organisation
Die Organisation mit Hilfe von Scrum und Scrum-Mastern kann sich auf die Anstrengungen konzentrieren, die für die Entwicklung von User Stories erforderlich sind, wodurch die Arbeitsüberlastung verringert und etwaige Nacharbeiten vermieden werden. Dies trägt auch dazu bei, die Effizienz des Entwicklungsteams und die Kundenzufriedenheit zu steigern. Dieser Ansatz trägt auch zur Steigerung des Marktpotenzials bei.
Produktmanager
Die Hauptverantwortung der Produktmanager besteht darin, sicherzustellen, dass die Qualität des Produkts erhalten bleibt. Mit Hilfe von Scrum Masters wird es einfach, die Arbeit zu erleichtern, schnelle Antworten zu sammeln und etwaige Änderungen zu absorbieren. Produktmanager überprüfen außerdem, ob das entworfene Produkt bei jedem Sprint gemäß den Kundenanforderungen ausgerichtet ist.
Entwicklungsteam
Das Entwicklungsteam ist begeistert, wenn es darum geht, die Arbeit zu reflektieren und ordnungsgemäß zu liefern. Das Arbeitsprodukt erhöht jede Ebene nach jeder Iteration, oder besser gesagt, wir können sie als "Sprint" bezeichnen. Die User Stories, die für jeden Sprint entwickelt wurden, werden zur Kundenpriorität, was der Iteration mehr Wert verleiht.
Fazit
Scrum ist ein effizientes Framework, in dem Sie Software in Teamarbeit entwickeln können. Es basiert vollständig auf agilen Prinzipien. ScrumMaster ist da, um das Team von Scrum auf jede erdenkliche Weise zu unterstützen und zusammenzuarbeiten. Er verhält sich wie ein persönlicher Trainer, der Ihnen hilft, sich an den geplanten Plan zu halten und alle Aktivitäten gemäß dem Plan auszuführen. Die Autorität von ScrumMaster sollte niemals über den Prozess hinausgehen. Er / sie sollte möglicherweise in der Lage sein, jede Situation zu bewältigen.
In diesem Kapitel werden wir den datenwissenschaftlichen Prozess und die Terminologien verstehen, die zum Verständnis des Prozesses erforderlich sind.
"Data Science ist die Mischung aus Datenschnittstelle, Algorithmusentwicklung und Technologie, um komplexe analytische Probleme zu lösen."
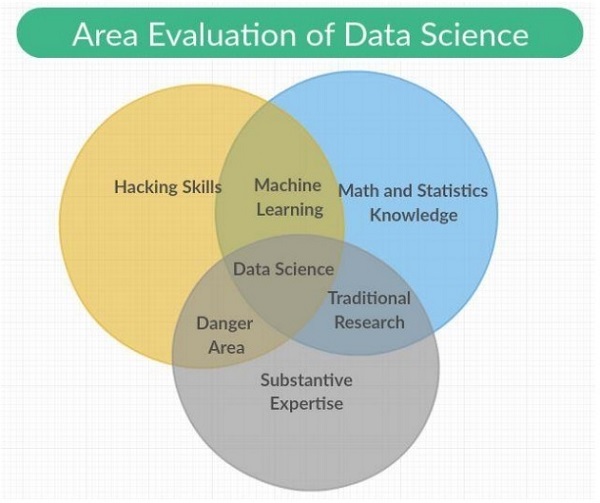
Die Datenwissenschaft ist ein interdisziplinäres Feld, das wissenschaftliche Methoden, Prozesse und Systeme mit Kategorien wie maschinelles Lernen, Mathematik und Statistikwissen mit traditioneller Forschung umfasst. Es beinhaltet auch eine Kombination von Hacking-Fähigkeiten mit fundiertem Fachwissen. Die Datenwissenschaft basiert auf Prinzipien aus Mathematik, Statistik, Informationswissenschaft und Informatik, Data Mining und prädiktiver Analyse.
Die verschiedenen Rollen, die Teil des Data Science-Teams sind, werden nachfolgend aufgeführt:
Kunden
Kunden sind die Personen, die das Produkt verwenden. Ihr Interesse bestimmt den Erfolg des Projekts und ihr Feedback ist in der Datenwissenschaft sehr wertvoll.
Geschäftsentwicklung
Dieses Team von Data Science meldet frühe Kunden entweder aus erster Hand oder durch die Erstellung von Zielseiten und Werbeaktionen an. Das Geschäftsentwicklungsteam liefert den Wert des Produkts.
Produktmanager
Produktmanager legen Wert darauf, das beste Produkt zu schaffen, das auf dem Markt wertvoll ist.
Interaktionsdesigner
Sie konzentrieren sich auf Entwurfsinteraktionen um Datenmodelle, damit Benutzer einen angemessenen Wert finden.
Datenwissenschaftler
Datenwissenschaftler untersuchen und transformieren die Daten auf neue Weise, um neue Funktionen zu erstellen und zu veröffentlichen. Diese Wissenschaftler kombinieren auch Daten aus verschiedenen Quellen, um einen neuen Wert zu schaffen. Sie spielen eine wichtige Rolle bei der Erstellung von Visualisierungen mit Forschern, Ingenieuren und Webentwicklern.
Forscher
Wie der Name schon sagt, sind Forscher an Forschungsaktivitäten beteiligt. Sie lösen komplizierte Probleme, die Datenwissenschaftler nicht lösen können. Diese Probleme beinhalten einen intensiven Fokus und eine intensive Zeit des Moduls für maschinelles Lernen und Statistik.
Anpassung an Veränderungen
Alle Teammitglieder von Data Science müssen sich an neue Änderungen anpassen und auf der Grundlage der Anforderungen arbeiten. Es sollten verschiedene Änderungen vorgenommen werden, um eine agile Methodik mit Data Science zu übernehmen, die wie folgt erwähnt werden:
Generalisten vor Spezialisten wählen.
Bevorzugung kleiner Teams gegenüber großen Teams.
Verwenden von Tools und Plattformen auf hoher Ebene.
Kontinuierliches und iteratives Teilen von Zwischenarbeiten.
Note
Im Agile Data Science-Team verwendet ein kleines Team von Generalisten hochrangige Tools, die skalierbar sind und Daten durch Iterationen in immer höhere Wertzustände verfeinern.
Betrachten Sie die folgenden Beispiele im Zusammenhang mit der Arbeit der Mitglieder des Data Science-Teams:
Designer liefern CSS.
Webentwickler erstellen ganze Anwendungen, verstehen die Benutzererfahrung und das Interface-Design.
Datenwissenschaftler sollten sowohl an der Forschung als auch am Aufbau von Webdiensten einschließlich Webanwendungen arbeiten.
Die Forscher arbeiten in der Codebasis, die Ergebnisse zeigt, die Zwischenergebnisse erklären.
Produktmanager versuchen, die Mängel in allen verwandten Bereichen zu identifizieren und zu verstehen.
In diesem Kapitel lernen wir die verschiedenen Agile-Tools und ihre Installation kennen. Der Entwicklungsstapel der agilen Methodik umfasst die folgenden Komponenten:
Veranstaltungen
Ein Ereignis ist ein Ereignis, das auftritt oder zusammen mit seinen Funktionen und Zeitstempeln protokolliert wird.
Ein Ereignis kann in vielen Formen auftreten, z. B. auf Servern, Sensoren, Finanztransaktionen oder Aktionen, die unsere Benutzer in unserer Anwendung ausführen. In diesem vollständigen Tutorial werden JSON-Dateien verwendet, die den Datenaustausch zwischen verschiedenen Tools und Sprachen erleichtern.
Sammler
Sammler sind Ereignisaggregatoren. Sie sammeln Ereignisse auf systematische Weise, um umfangreiche Daten zu speichern und zu aggregieren, die sie für Aktionen von Echtzeitarbeitern in die Warteschlange stellen.
Verteiltes Dokument
Diese Dokumente enthalten mehrere Knoten (mehrere Knoten), in denen Dokumente in einem bestimmten Format gespeichert werden. Wir werden uns in diesem Tutorial auf MongoDB konzentrieren.
Webanwendungsserver
Der Webanwendungsserver ermöglicht Daten als JSON über den Client durch Visualisierung mit minimalem Overhead. Dies bedeutet, dass der Webanwendungsserver beim Testen und Bereitstellen der mit agiler Methodik erstellten Projekte hilft.
Moderner Browser
Es ermöglicht modernen Browsern oder Anwendungen, Daten als interaktives Werkzeug für unsere Benutzer darzustellen.
Lokale Umgebung einrichten
Bei der Verwaltung von Datensätzen konzentrieren wir uns auf das Anaconda-Framework von Python, das Tools zum Verwalten von Excel-, CSV- und vielen weiteren Dateien enthält. Das einmal installierte Dashboard des Anaconda-Frameworks ist wie folgt. Es wird auch als "Anaconda Navigator" bezeichnet -

Der Navigator enthält das „Jupyter-Framework“, ein Notebook-System, mit dem Datensätze verwaltet werden können. Sobald Sie das Framework gestartet haben, wird es wie unten erwähnt im Browser gehostet.

In diesem Kapitel konzentrieren wir uns auf den Unterschied zwischen strukturierten, halbstrukturierten und unstrukturierten Daten.
Strukturierte Daten
Strukturierte Daten betreffen die im SQL-Format gespeicherten Daten in Tabellen mit Zeilen und Spalten. Es enthält einen relationalen Schlüssel, der vorgefertigten Feldern zugeordnet ist. Strukturierte Daten werden in größerem Maßstab verwendet.
Strukturierte Daten machen nur 5 bis 10 Prozent aller Informatikdaten aus.
Halbstrukturierte Daten
Halbstrukturierte Daten umfassen Daten, die sich nicht in einer relationalen Datenbank befinden. Sie enthalten einige organisatorische Eigenschaften, die die Analyse erleichtern. Es enthält den gleichen Prozess zum Speichern in einer relationalen Datenbank. Beispiele für halbstrukturierte Datenbanken sind CSV-Dateien, XML- und JSON-Dokumente. NoSQL-Datenbanken gelten als semistrukturiert.
Unstrukturierte Daten
Unstrukturierte Daten machen 80 Prozent der Daten aus. Es enthält häufig Text- und Multimedia-Inhalte. Die besten Beispiele für unstrukturierte Daten sind Audiodateien, Präsentationen und Webseiten. Beispiele für maschinengenerierte unstrukturierte Daten sind Satellitenbilder, wissenschaftliche Daten, Fotos und Videos sowie Radar- und Sonardaten.
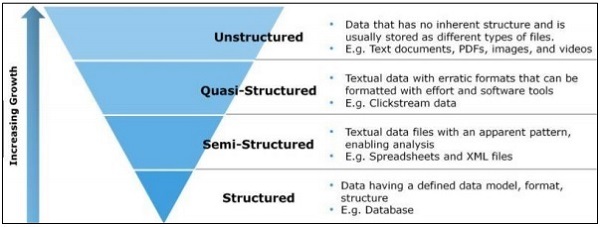
Die obige Pyramidenstruktur konzentriert sich speziell auf die Datenmenge und das Verhältnis, in dem sie gestreut wird.
Quasistrukturierte Daten erscheinen als Typ zwischen unstrukturierten und halbstrukturierten Daten. In diesem Tutorial konzentrieren wir uns auf halbstrukturierte Daten, was für die agile Methodik und die datenwissenschaftliche Forschung von Vorteil ist.
Halbstrukturierte Daten haben kein formales Datenmodell, sondern ein offensichtliches, selbstbeschreibendes Muster und eine Struktur, die durch ihre Analyse entwickelt werden.
Der vollständige Fokus dieses Tutorials liegt auf der Verfolgung einer agilen Methodik mit weniger Schritten und der Implementierung nützlicherer Tools. Um dies zu verstehen, ist es wichtig, den Unterschied zwischen SQL- und NoSQL-Datenbanken zu kennen.
Die meisten Benutzer kennen die SQL-Datenbank und verfügen über gute Kenntnisse in MySQL, Oracle oder anderen SQL-Datenbanken. In den letzten Jahren wurde die NoSQL-Datenbank in großem Umfang eingesetzt, um verschiedene geschäftliche Probleme und Projektanforderungen zu lösen.

Die folgende Tabelle zeigt den Unterschied zwischen SQL- und NoSQL-Datenbanken -
| SQL | NoSQL |
|---|---|
| SQL-Datenbanken werden hauptsächlich als Relational Database Management System (RDBMS) bezeichnet. | Die NoSQL-Datenbank wird auch als dokumentorientierte Datenbank bezeichnet. Es ist nicht relational und verteilt. |
| SQL-basierte Datenbanken enthalten eine Tabellenstruktur mit Zeilen und Spalten. Sammlung von Tabellen und anderen Schemastrukturen, die als Datenbank bezeichnet werden. | Die NoSQL-Datenbank enthält Dokumente als Hauptstruktur, und die Aufnahme von Dokumenten wird als Sammlung bezeichnet. |
| SQL-Datenbanken enthalten ein vordefiniertes Schema. | NoSQL-Datenbanken haben dynamische Daten und enthalten unstrukturierte Daten. |
| SQL-Datenbanken sind vertikal skalierbar. | NoSQL-Datenbanken sind horizontal skalierbar. |
| SQL-Datenbanken eignen sich gut für komplexe Abfrageumgebungen. | NoSQL verfügt nicht über Standardschnittstellen für die Entwicklung komplexer Abfragen. |
| SQL-Datenbanken sind für die hierarchische Datenspeicherung nicht möglich. | NoSQL-Datenbanken eignen sich besser für die hierarchische Datenspeicherung. |
| SQL-Datenbanken eignen sich am besten für umfangreiche Transaktionen in den angegebenen Anwendungen. | NoSQL-Datenbanken werden bei hoher Belastung für komplexe Transaktionsanwendungen immer noch nicht als vergleichbar angesehen. |
| SQL-Datenbanken bieten ihren Anbietern eine hervorragende Unterstützung. | Die NoSQL-Datenbank ist weiterhin auf Community-Unterstützung angewiesen. Für die Einrichtung und Bereitstellung für umfangreiche NoSQL-Bereitstellungen stehen nur wenige Experten zur Verfügung. |
| SQL-Datenbanken konzentrieren sich auf ACID-Eigenschaften - Atomic, Consistency, Isolation und Durability. | Die NoSQL-Datenbank konzentriert sich auf CAP-Eigenschaften - Konsistenz, Verfügbarkeit und Partitionstoleranz. |
| SQL-Datenbanken können basierend auf den Anbietern, die sie ausgewählt haben, als Open Source oder Closed Source klassifiziert werden. | NoSQL-Datenbanken werden basierend auf dem Speichertyp klassifiziert. NoSQL-Datenbanken sind standardmäßig Open Source. |
Warum NoSQL für Agile?
Der oben erwähnte Vergleich zeigt, dass die NoSQL-Dokumentendatenbank die agile Entwicklung vollständig unterstützt. Es ist schemalos und konzentriert sich nicht vollständig auf die Datenmodellierung. Stattdessen verschiebt NoSQL Anwendungen und Dienste, sodass Entwickler eine bessere Vorstellung davon bekommen, wie Daten modelliert werden können. NoSQL definiert das Datenmodell als Anwendungsmodell.
MongoDB-Installation
In diesem Tutorial werden wir uns mehr auf die Beispiele von MongoDB konzentrieren, da es als das beste „NoSQL-Schema“ gilt.
Es gibt Zeiten, in denen die Daten im relationalen Format nicht verfügbar sind und wir sie mithilfe von NoSQL-Datenbanken transaktional halten müssen.
In diesem Kapitel konzentrieren wir uns auf den Datenfluss von NoSQL. Wir werden auch lernen, wie es mit einer Kombination aus Agilität und Datenwissenschaft funktioniert.
Einer der Hauptgründe für die Verwendung von NoSQL mit Agilität ist die Steigerung der Geschwindigkeit im Wettbewerb auf dem Markt. Die folgenden Gründe zeigen, wie NoSQL am besten zu agilen Softwaremethoden passt:
Weniger Barrieren
Das Ändern des Modells, das derzeit mitten im Strom läuft, verursacht selbst bei einer agilen Entwicklung einige echte Kosten. Mit NoSQL arbeiten die Benutzer mit aggregierten Daten, anstatt Zeit mit der Normalisierung von Daten zu verschwenden. Der Hauptpunkt ist, etwas zu erledigen und mit dem Ziel zu arbeiten, modellgenaue Daten zu erstellen.
Erhöhte Skalierbarkeit
Wenn ein Unternehmen ein Produkt erstellt, legt es mehr Wert auf seine Skalierbarkeit. NoSQL ist immer für seine Skalierbarkeit bekannt, funktioniert jedoch besser, wenn es mit horizontaler Skalierbarkeit entworfen wurde.
Fähigkeit, Daten zu nutzen
NoSQL ist ein schemaloses Datenmodell, mit dem der Benutzer problemlos Datenmengen verwenden kann, die verschiedene Parameter für Variabilität und Geschwindigkeit enthalten. Wenn Sie sich für eine Technologie entscheiden, sollten Sie immer die berücksichtigen, bei der die Daten in größerem Umfang genutzt werden.
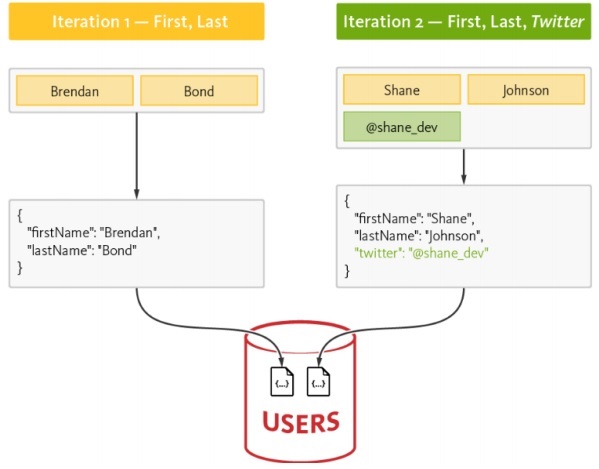
Datenfluss von NoSQL
Betrachten wir das folgende Beispiel, in dem wir gezeigt haben, wie sich ein Datenmodell auf die Erstellung des RDBMS-Schemas konzentriert.
Im Folgenden sind die verschiedenen Anforderungen des Schemas aufgeführt:
Die Benutzeridentifikation sollte aufgelistet sein.
Jeder Benutzer sollte mindestens eine Fähigkeit haben.
Die Details der Benutzererfahrung sollten ordnungsgemäß gepflegt werden.
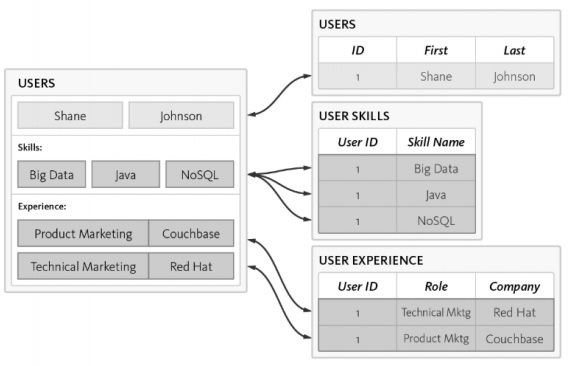
Die Benutzertabelle wird mit 3 separaten Tabellen normalisiert -
Users
Benutzerfähigkeiten
Benutzererfahrung
Die Komplexität nimmt bei der Abfrage der Datenbank zu, und der Zeitaufwand wird mit zunehmender Normalisierung festgestellt, was für die agile Methodik nicht gut ist. Das gleiche Schema kann mit der NoSQL-Datenbank wie unten beschrieben entworfen werden -
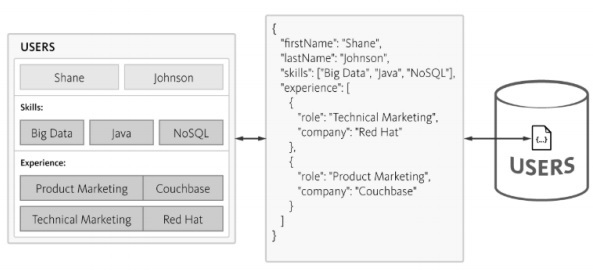
NoSQL behält die Struktur im JSON-Format bei, das eine leichte Struktur aufweist. Mit JSON können Anwendungen Objekte mit verschachtelten Daten als einzelne Dokumente speichern.
In diesem Kapitel konzentrieren wir uns auf die JSON-Struktur, die Teil der „Agilen Methodik“ ist. MongoDB ist eine weit verbreitete NoSQL-Datenstruktur und lässt sich problemlos zum Sammeln und Anzeigen von Datensätzen verwenden.
Schritt 1
In diesem Schritt wird eine Verbindung mit MongoDB hergestellt, um eine Sammlung und ein angegebenes Datenmodell zu erstellen. Alles, was Sie ausführen müssen, ist der Befehl „mongod“ zum Starten der Verbindung und der Befehl mongo, um eine Verbindung zum angegebenen Terminal herzustellen.
Schritt 2
Erstellen Sie eine neue Datenbank zum Erstellen von Datensätzen im JSON-Format. Derzeit erstellen wir eine Dummy-Datenbank mit dem Namen "mydb".
>use mydb
switched to db mydb
>db
mydb
>show dbs
local 0.78125GB
test 0.23012GB
>db.user.insert({"name":"Agile Data Science"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GBSchritt 3
Das Erstellen einer Sammlung ist obligatorisch, um die Liste der Datensätze abzurufen. Diese Funktion ist für datenwissenschaftliche Forschung und Ergebnisse von Vorteil.
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>show collections
mycollection
system.indexes
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>db.agiledatascience.insert({"name" : "demoname"})
>show collections
mycol
mycollection
system.indexes
demonameDie Datenvisualisierung spielt in der Datenwissenschaft eine sehr wichtige Rolle. Wir können Datenvisualisierung als ein Modul der Datenwissenschaft betrachten. Data Science umfasst mehr als die Erstellung von Vorhersagemodellen. Es enthält Erklärungen zu Modellen und deren Verwendung, um Daten zu verstehen und Entscheidungen zu treffen. Die Datenvisualisierung ist ein wesentlicher Bestandteil der überzeugendsten Darstellung von Daten.
Aus datenwissenschaftlicher Sicht ist die Datenvisualisierung eine Hervorhebungsfunktion, die die Änderungen und Trends zeigt.
Beachten Sie die folgenden Richtlinien für eine effektive Datenvisualisierung:
Positionsdaten entlang der gemeinsamen Skala.
Die Verwendung von Balken ist im Vergleich von Kreisen und Quadraten effektiver.
Für Streudiagramme sollte die richtige Farbe verwendet werden.
Verwenden Sie ein Kreisdiagramm, um die Proportionen anzuzeigen.
Die Sunburst-Visualisierung ist für hierarchische Diagramme effektiver.
Agile benötigt eine einfache Skriptsprache für die Datenvisualisierung und in Zusammenarbeit mit Data Science ist „Python“ die vorgeschlagene Sprache für die Datenvisualisierung.
Beispiel 1
Das folgende Beispiel zeigt die Datenvisualisierung des BIP, berechnet in bestimmten Jahren. "Matplotlib" ist die beste Bibliothek für die Datenvisualisierung in Python. Die Installation dieser Bibliothek ist unten dargestellt -
Betrachten Sie den folgenden Code, um dies zu verstehen:
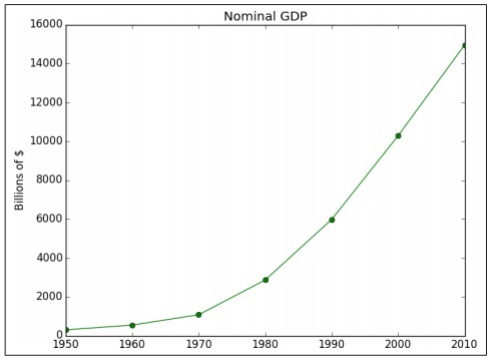
import matplotlib.pyplot as plt
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
# create a line chart, years on x-axis, gdp on y-axis
plt.plot(years, gdp, color='green', marker='o', linestyle='solid')
# add a title plt.title("Nominal GDP")
# add a label to the y-axis
plt.ylabel("Billions of $")
plt.show()Ausgabe
Der obige Code generiert die folgende Ausgabe:
Es gibt viele Möglichkeiten, die Diagramme mit Achsenbeschriftungen, Linienstilen und Punktmarkierungen anzupassen. Konzentrieren wir uns auf das nächste Beispiel, das die bessere Datenvisualisierung demonstriert. Diese Ergebnisse können für eine bessere Ausgabe verwendet werden.
Beispiel 2
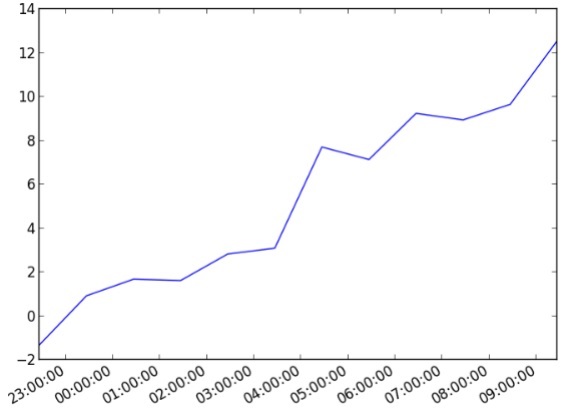
import datetime
import random
import matplotlib.pyplot as plt
# make up some data
x = [datetime.datetime.now() + datetime.timedelta(hours=i) for i in range(12)]
y = [i+random.gauss(0,1) for i,_ in enumerate(x)]
# plot
plt.plot(x,y)
# beautify the x-labels
plt.gcf().autofmt_xdate()
plt.show()Ausgabe
Der obige Code generiert die folgende Ausgabe:
Datenanreicherung bezieht sich auf eine Reihe von Prozessen, die zur Verbesserung, Verfeinerung und Verbesserung von Rohdaten verwendet werden. Es bezieht sich auf nützliche Datentransformation (Rohdaten zu nützlichen Informationen). Der Prozess der Datenanreicherung konzentriert sich darauf, Daten zu einem wertvollen Datenbestandteil für moderne Unternehmen zu machen.
Der häufigste Prozess zur Datenanreicherung umfasst die Korrektur von Rechtschreib- oder Tippfehlern in der Datenbank mithilfe spezifischer Entscheidungsalgorithmen. Datenanreicherungstools fügen einfachen Datentabellen nützliche Informationen hinzu.
Betrachten Sie den folgenden Code zur Rechtschreibkorrektur von Wörtern:
import re
from collections import Counter
def words(text): return re.findall(r'\w+', text.lower())
WORDS = Counter(words(open('big.txt').read()))
def P(word, N=sum(WORDS.values())):
"Probabilities of words"
return WORDS[word] / N
def correction(word):
"Spelling correction of word"
return max(candidates(word), key=P)
def candidates(word):
"Generate possible spelling corrections for word."
return (known([word]) or known(edits1(word)) or known(edits2(word)) or [word])
def known(words):
"The subset of `words` that appear in the dictionary of WORDS."
return set(w for w in words if w in WORDS)
def edits1(word):
"All edits that are one edit away from `word`."
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)
def edits2(word):
"All edits that are two edits away from `word`."
return (e2 for e1 in edits1(word) for e2 in edits1(e1))
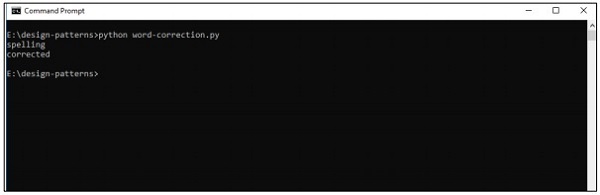
print(correction('speling'))
print(correction('korrectud'))In diesem Programm werden wir mit "big.txt" übereinstimmen, das korrigierte Wörter enthält. Wörter stimmen mit Wörtern überein, die in der Textdatei enthalten sind, und drucken die entsprechenden Ergebnisse entsprechend aus.
Ausgabe
Der obige Code generiert die folgende Ausgabe:
In diesem Kapitel lernen wir die Berichterstellung kennen, die ein wichtiges Modul der agilen Methodik darstellt. Agile Sprints Diagrammseiten, die durch Visualisierung erstellt wurden, in vollständigen Berichten. Mit Berichten werden Diagramme interaktiv, statische Seiten werden zu dynamischen und netzwerkbezogenen Daten. Die Merkmale der Berichtsphase der Datenwertpyramide sind nachstehend aufgeführt:
Wir werden mehr Wert darauf legen, eine CSV-Datei zu erstellen, die als Bericht für datenwissenschaftliche Analysen verwendet werden kann, und Schlussfolgerungen zu ziehen. Obwohl sich Agile auf weniger Dokumentation konzentriert, wird immer die Erstellung von Berichten berücksichtigt, um den Fortschritt der Produktentwicklung zu erwähnen.
import csv
#----------------------------------------------------------------------
def csv_writer(data, path):
"""
Write data to a CSV file path
"""
with open(path, "wb") as csv_file:
writer = csv.writer(csv_file, delimiter=',')
for line in data:
writer.writerow(line)
#----------------------------------------------------------------------
if __name__ == "__main__":
data = ["first_name,last_name,city".split(","),
"Tyrese,Hirthe,Strackeport".split(","),
"Jules,Dicki,Lake Nickolasville".split(","),
"Dedric,Medhurst,Stiedemannberg".split(",")
]
path = "output.csv"
csv_writer(data, path)Der obige Code hilft Ihnen beim Generieren der "CSV-Datei" wie unten gezeigt -
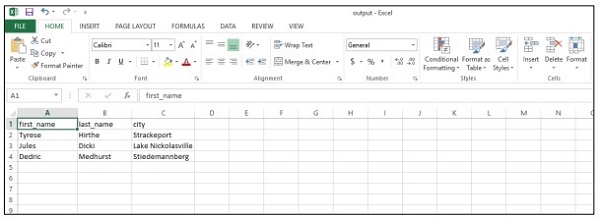
Betrachten wir die folgenden Vorteile von CSV-Berichten (durch Kommas getrennte Werte):
- Es ist menschenfreundlich und einfach manuell zu bearbeiten.
- Es ist einfach zu implementieren und zu analysieren.
- CSV kann in allen Anwendungen verarbeitet werden.
- Es ist kleiner und schneller zu handhaben.
- CSV folgt einem Standardformat.
- Es bietet Datenwissenschaftlern ein einfaches Schema.
In diesem Kapitel werden wir uns mit der Rolle von Vorhersagen in der agilen Datenwissenschaft befassen. Die interaktiven Berichte enthüllen verschiedene Aspekte von Daten. Vorhersagen bilden die vierte Schicht des agilen Sprints.
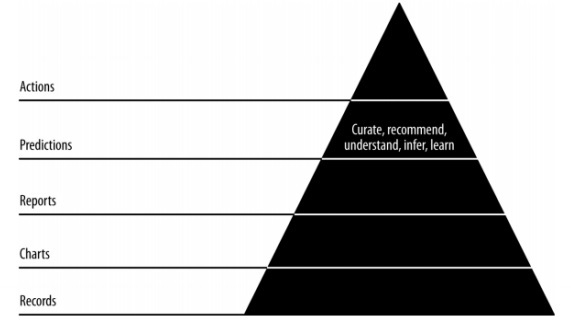
Bei Vorhersagen beziehen wir uns immer auf die vergangenen Daten und verwenden sie als Schlussfolgerungen für zukünftige Iterationen. In diesem vollständigen Prozess übertragen wir Daten von der Stapelverarbeitung historischer Daten auf Echtzeitdaten über die Zukunft.
Die Rolle von Vorhersagen umfasst Folgendes:
Vorhersagen helfen bei der Vorhersage. Einige Prognosen basieren auf statistischen Schlussfolgerungen. Einige der Vorhersagen basieren auf Meinungen von Experten.
Statistische Inferenzen sind mit Vorhersagen aller Art verbunden.
Manchmal sind Prognosen genau, manchmal sind Prognosen ungenau.
Predictive Analytics
Die prädiktive Analyse umfasst eine Vielzahl statistischer Techniken aus der prädiktiven Modellierung, dem maschinellen Lernen und dem Data Mining, die aktuelle und historische Fakten analysieren, um Vorhersagen über zukünftige und unbekannte Ereignisse zu treffen.
Predictive Analytics erfordert Trainingsdaten. Zu den geschulten Daten gehören unabhängige und abhängige Funktionen. Abhängige Funktionen sind die Werte, die ein Benutzer vorhersagen möchte. Unabhängige Features sind Features, die die Dinge beschreiben, die wir basierend auf abhängigen Features vorhersagen möchten.
Das Studium von Features wird als Feature Engineering bezeichnet. Dies ist entscheidend für Vorhersagen. Datenvisualisierung und explorative Datenanalyse sind Teile des Feature-Engineerings. diese bilden den Kern vonAgile data science.
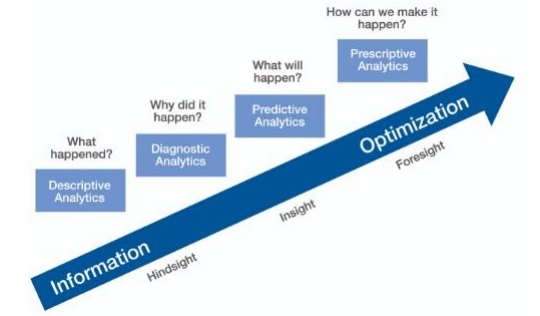
Vorhersagen treffen
In der agilen Datenwissenschaft gibt es zwei Möglichkeiten, Vorhersagen zu treffen:
Regression
Classification
Der Aufbau einer Regression oder Klassifizierung hängt vollständig von den Geschäftsanforderungen und deren Analyse ab. Die Vorhersage kontinuierlicher Variablen führt zu einem Regressionsmodell und die Vorhersage kategorialer Variablen führt zu einem Klassifizierungsmodell.
Regression
Die Regression berücksichtigt Beispiele, die Merkmale umfassen und dadurch eine numerische Ausgabe erzeugen.
Einstufung
Die Klassifizierung nimmt die Eingabe und erzeugt eine kategoriale Klassifizierung.
Note - Der Beispieldatensatz, der die Eingabe für die statistische Vorhersage definiert und das Lernen der Maschine ermöglicht, wird als "Trainingsdaten" bezeichnet.
In diesem Kapitel erfahren Sie mehr über die Anwendung der Extraktionsfunktionen mit PySpark in Agile Data Science.
Übersicht über Spark
Apache Spark kann als schnelles Echtzeit-Verarbeitungsframework definiert werden. Es führt Berechnungen durch, um Daten in Echtzeit zu analysieren. Apache Spark wird als Stream-Verarbeitungssystem in Echtzeit eingeführt und kann sich auch um die Stapelverarbeitung kümmern. Apache Spark unterstützt interaktive Abfragen und iterative Algorithmen.
Spark ist in der Programmiersprache Scala geschrieben.
PySpark kann als Kombination von Python mit Spark betrachtet werden. PySpark bietet die PySpark-Shell, die die Python-API mit dem Spark-Kern verknüpft und den Spark-Kontext initialisiert. Die meisten Datenwissenschaftler verwenden PySpark zum Verfolgen von Funktionen, wie im vorherigen Kapitel erläutert.
In diesem Beispiel konzentrieren wir uns auf die Transformationen, um ein Dataset namens count zu erstellen und es in einer bestimmten Datei zu speichern.
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")Mit PySpark kann ein Benutzer mit RDDs in der Programmiersprache Python arbeiten. Die eingebaute Bibliothek, die die Grundlagen datengesteuerter Dokumente und Komponenten abdeckt, hilft dabei.
Die logistische Regression bezieht sich auf den Algorithmus für maschinelles Lernen, mit dem die Wahrscheinlichkeit einer kategorial abhängigen Variablen vorhergesagt wird. Bei der logistischen Regression ist die abhängige Variable eine binäre Variable, die aus Daten besteht, die als 1 codiert sind (Boolesche Werte von wahr und falsch).
In diesem Kapitel konzentrieren wir uns auf die Entwicklung eines Regressionsmodells in Python unter Verwendung einer kontinuierlichen Variablen. Das Beispiel für ein lineares Regressionsmodell konzentriert sich auf die Datenexploration aus einer CSV-Datei.
Das Klassifizierungsziel besteht darin, vorherzusagen, ob der Kunde eine Festgeldeinzahlung (1/0) abonnieren wird.
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
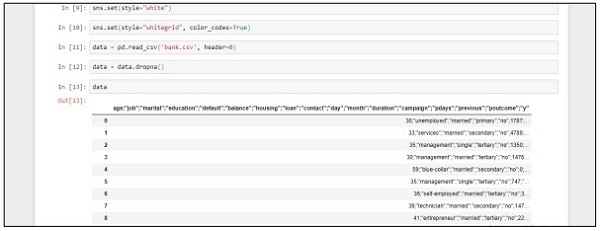
data = pd.read_csv('bank.csv', header=0)
data = data.dropna()
print(data.shape)
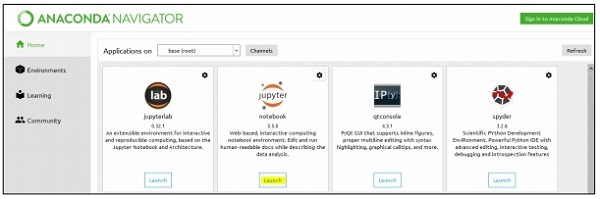
print(list(data.columns))Befolgen Sie diese Schritte, um den obigen Code in Anaconda Navigator mit "Jupyter Notebook" zu implementieren -
Step 1 - Starten Sie das Jupyter Notebook mit Anaconda Navigator.
Step 2 - Laden Sie die CSV-Datei hoch, um die Ausgabe des Regressionsmodells systematisch abzurufen.
Step 3 - Erstellen Sie eine neue Datei und führen Sie die oben genannte Codezeile aus, um die gewünschte Ausgabe zu erhalten.
In diesem Beispiel erfahren Sie, wie Sie ein Vorhersagemodell erstellen und bereitstellen, das bei der Vorhersage von Immobilienpreisen mithilfe von Python-Skripten hilft. Das wichtige Framework für die Bereitstellung des Vorhersagesystems umfasst Anaconda und „Jupyter Notebook“.
Befolgen Sie diese Schritte, um ein Vorhersagesystem bereitzustellen -
Step 1 - Implementieren Sie den folgenden Code, um Werte aus CSV-Dateien in zugehörige Werte zu konvertieren.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import mpl_toolkits
%matplotlib inline
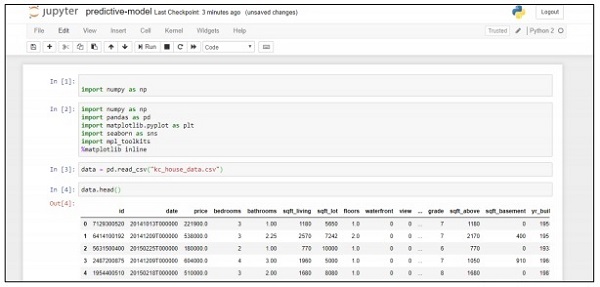
data = pd.read_csv("kc_house_data.csv")
data.head()Der obige Code generiert die folgende Ausgabe:
Step 2 - Führen Sie die Beschreibungsfunktion aus, um die Datentypen abzurufen, die in den CSV-Dateien enthalten sind.
data.describe()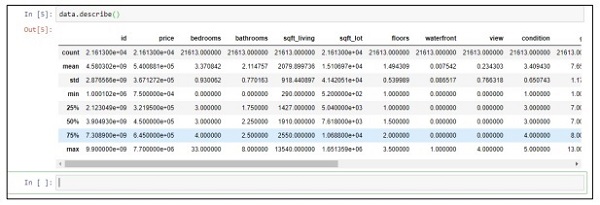
Step 3 - Wir können die zugehörigen Werte basierend auf der Bereitstellung des von uns erstellten Vorhersagemodells löschen.
train1 = data.drop(['id', 'price'],axis=1)
train1.head()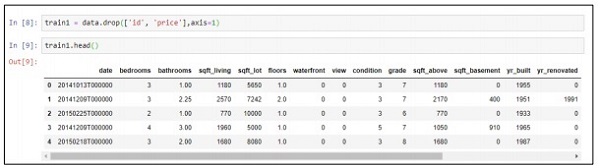
Step 4- Sie können die Daten gemäß den Datensätzen visualisieren. Die Daten können für die datenwissenschaftliche Analyse und Ausgabe von White Papers verwendet werden.
data.floors.value_counts().plot(kind='bar')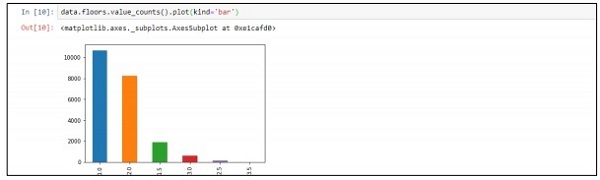
Die Bibliothek für maschinelles Lernen, auch als „SparkML“ oder „MLLib“ bezeichnet, besteht aus gängigen Lernalgorithmen, einschließlich Klassifizierung, Regression, Clustering und kollaborativer Filterung.
Warum SparkML for Agile lernen?
Spark wird zur De-facto-Plattform für die Erstellung von Algorithmen und Anwendungen für maschinelles Lernen. Die Entwickler arbeiten an Spark, um Maschinenalgorithmen im Spark-Framework skalierbar und präzise zu implementieren. Mit diesem Framework lernen wir die Konzepte des maschinellen Lernens, seine Dienstprogramme und Algorithmen. Agile entscheidet sich immer für ein Framework, das kurze und schnelle Ergebnisse liefert.
ML-Algorithmen
ML-Algorithmen umfassen gängige Lernalgorithmen wie Klassifizierung, Regression, Clustering und kollaborative Filterung.
Eigenschaften
Es umfasst das Extrahieren, Transformieren, Reduzieren und Auswählen von Features.
Pipelines
Pipelines bieten Tools zum Erstellen, Bewerten und Optimieren von Pipelines für maschinelles Lernen.
Beliebte Algorithmen
Im Folgenden sind einige beliebte Algorithmen aufgeführt:
Grundlegende Statistik
Regression
Classification
Empfehlungssystem
Clustering
Reduzierung der Dimensionalität
Feature-Extraktion
Optimization
Empfehlungssystem
Ein Empfehlungssystem ist eine Unterklasse von Informationsfiltersystemen, die eine Vorhersage von "Bewertung" und "Präferenz" anstreben, die ein Benutzer einem bestimmten Artikel vorschlägt.
Das Empfehlungssystem umfasst verschiedene Filtersysteme, die wie folgt verwendet werden:
Kollaboratives Filtern
Es umfasst das Erstellen eines Modells basierend auf dem Verhalten der Vergangenheit sowie ähnliche Entscheidungen anderer Benutzer. Dieses spezielle Filtermodell wird verwendet, um Elemente vorherzusagen, die ein Benutzer aufnehmen möchte.
Inhaltsbasierte Filterung
Es umfasst das Filtern diskreter Merkmale eines Elements, um neue Elemente mit ähnlichen Eigenschaften zu empfehlen und hinzuzufügen.
In unseren folgenden Kapiteln konzentrieren wir uns auf die Verwendung eines Empfehlungssystems zur Lösung eines bestimmten Problems und zur Verbesserung der Vorhersageleistung unter dem Gesichtspunkt der agilen Methodik.
In diesem Kapitel konzentrieren wir uns auf die Behebung eines Vorhersageproblems mithilfe eines bestimmten Szenarios.
Bedenken Sie, dass ein Unternehmen die Details zur Kreditwürdigkeit gemäß den über das Online-Antragsformular angegebenen Kundendaten automatisieren möchte. Zu den Angaben gehören Name des Kunden, Geschlecht, Familienstand, Darlehensbetrag und andere obligatorische Angaben.
Die Details werden in der CSV-Datei wie unten gezeigt aufgezeichnet -
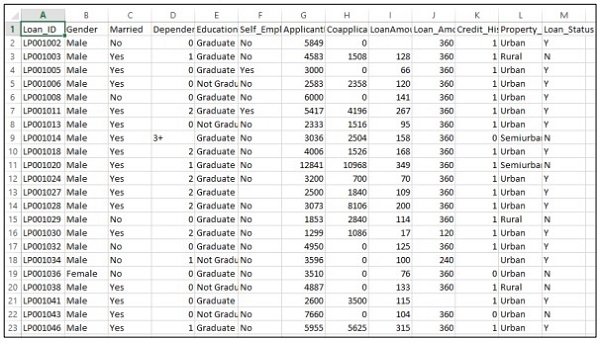
Führen Sie den folgenden Code aus, um das Vorhersageproblem zu bewerten:
import pandas as pd
from sklearn import ensemble
import numpy as np
from scipy.stats import mode
from sklearn import preprocessing,model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
#loading the dataset
data=pd.read_csv('train.csv',index_col='Loan_ID')
def num_missing(x):
return sum(x.isnull())
#imputing the the missing values from the data
data['Gender'].fillna(mode(list(data['Gender'])).mode[0], inplace=True)
data['Married'].fillna(mode(list(data['Married'])).mode[0], inplace=True)
data['Self_Employed'].fillna(mode(list(data['Self_Employed'])).mode[0], inplace=True)
# print (data.apply(num_missing, axis=0))
# #imputing mean for the missing value
data['LoanAmount'].fillna(data['LoanAmount'].mean(), inplace=True)
mapping={'0':0,'1':1,'2':2,'3+':3}
data = data.replace({'Dependents':mapping})
data['Dependents'].fillna(data['Dependents'].mean(), inplace=True)
data['Loan_Amount_Term'].fillna(method='ffill',inplace=True)
data['Credit_History'].fillna(method='ffill',inplace=True)
print (data.apply(num_missing,axis=0))
#converting the cateogorical data to numbers using the label encoder
var_mod = ['Gender','Married','Education','Self_Employed','Property_Area','Loan_Status']
le = LabelEncoder()
for i in var_mod:
le.fit(list(data[i].values))
data[i] = le.transform(list(data[i]))
#Train test split
x=['Gender','Married','Education','Self_Employed','Property_Area','LoanAmount', 'Loan_Amount_Term','Credit_History','Dependents']
y=['Loan_Status']
print(data[x])
X_train,X_test,y_train,y_test=model_selection.train_test_split(data[x],data[y], test_size=0.2)
#
# #Random forest classifier
# clf=ensemble.RandomForestClassifier(n_estimators=100,
criterion='gini',max_depth=3,max_features='auto',n_jobs=-1)
clf=ensemble.RandomForestClassifier(n_estimators=200,max_features=3,min_samples
_split=5,oob_score=True,n_jobs=-1,criterion='entropy')
clf.fit(X_train,y_train)
accuracy=clf.score(X_test,y_test)
print(accuracy)Ausgabe
Der obige Code generiert die folgende Ausgabe.

In diesem Kapitel konzentrieren wir uns auf die Erstellung eines Modells, das bei der Vorhersage der Schülerleistung mit einer Reihe von darin enthaltenen Attributen hilft. Der Fokus liegt darauf, das Fehlerergebnis von Studenten in einer Prüfung anzuzeigen.
Prozess
Der Zielwert der Bewertung ist G3. Diese Werte können zusammengefasst und weiter als Misserfolg und Erfolg klassifiziert werden. Wenn der G3-Wert größer oder gleich 10 ist, besteht der Schüler die Prüfung.
Beispiel
Betrachten Sie das folgende Beispiel, in dem ein Code ausgeführt wird, um die Leistung vorherzusagen, wenn Schüler -
import pandas as pd
""" Read data file as DataFrame """
df = pd.read_csv("student-mat.csv", sep=";")
""" Import ML helpers """
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.svm import LinearSVC # Support Vector Machine Classifier model
""" Split Data into Training and Testing Sets """
def split_data(X, Y):
return train_test_split(X, Y, test_size=0.2, random_state=17)
""" Confusion Matrix """
def confuse(y_true, y_pred):
cm = confusion_matrix(y_true=y_true, y_pred=y_pred)
# print("\nConfusion Matrix: \n", cm)
fpr(cm)
ffr(cm)
""" False Pass Rate """
def fpr(confusion_matrix):
fp = confusion_matrix[0][1]
tf = confusion_matrix[0][0]
rate = float(fp) / (fp + tf)
print("False Pass Rate: ", rate)
""" False Fail Rate """
def ffr(confusion_matrix):
ff = confusion_matrix[1][0]
tp = confusion_matrix[1][1]
rate = float(ff) / (ff + tp)
print("False Fail Rate: ", rate)
return rate
""" Train Model and Print Score """
def train_and_score(X, y):
X_train, X_test, y_train, y_test = split_data(X, y)
clf = Pipeline([
('reduce_dim', SelectKBest(chi2, k=2)),
('train', LinearSVC(C=100))
])
scores = cross_val_score(clf, X_train, y_train, cv=5, n_jobs=2)
print("Mean Model Accuracy:", np.array(scores).mean())
clf.fit(X_train, y_train)
confuse(y_test, clf.predict(X_test))
print()
""" Main Program """
def main():
print("\nStudent Performance Prediction")
# For each feature, encode to categorical values
class_le = LabelEncoder()
for column in df[["school", "sex", "address", "famsize", "Pstatus", "Mjob",
"Fjob", "reason", "guardian", "schoolsup", "famsup", "paid", "activities",
"nursery", "higher", "internet", "romantic"]].columns:
df[column] = class_le.fit_transform(df[column].values)
# Encode G1, G2, G3 as pass or fail binary values
for i, row in df.iterrows():
if row["G1"] >= 10:
df["G1"][i] = 1
else:
df["G1"][i] = 0
if row["G2"] >= 10:
df["G2"][i] = 1
else:
df["G2"][i] = 0
if row["G3"] >= 10:
df["G3"][i] = 1
else:
df["G3"][i] = 0
# Target values are G3
y = df.pop("G3")
# Feature set is remaining features
X = df
print("\n\nModel Accuracy Knowing G1 & G2 Scores")
print("=====================================")
train_and_score(X, y)
# Remove grade report 2
X.drop(["G2"], axis = 1, inplace=True)
print("\n\nModel Accuracy Knowing Only G1 Score")
print("=====================================")
train_and_score(X, y)
# Remove grade report 1
X.drop(["G1"], axis=1, inplace=True)
print("\n\nModel Accuracy Without Knowing Scores")
print("=====================================")
train_and_score(X, y)
main()Ausgabe
Der obige Code generiert die Ausgabe wie unten gezeigt
Die Vorhersage wird mit Bezug auf nur eine Variable behandelt. In Bezug auf eine Variable ist die Leistungsvorhersage für Schüler wie folgt:
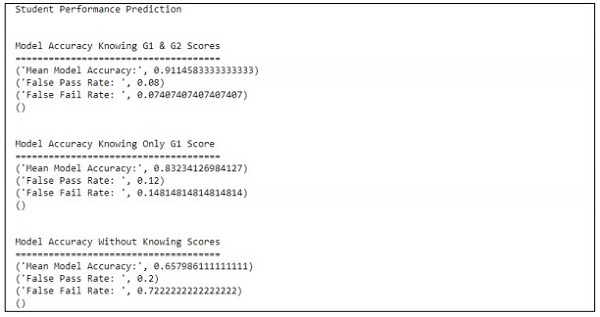
Die agile Methodik hilft Unternehmen, Veränderungen anzupassen, auf dem Markt zu bestehen und qualitativ hochwertige Produkte zu entwickeln. Es wird beobachtet, dass Unternehmen mit agilen Methoden reifen und sich die Anforderungen der Kunden zunehmend ändern. Das Zusammenstellen und Synchronisieren von Daten mit agilen Organisationsteams ist wichtig, um Daten gemäß dem erforderlichen Portfolio zusammenzufassen.
Erstellen Sie einen besseren Plan
Die standardisierte agile Leistung hängt ausschließlich vom Plan ab. Das geordnete Datenschema ermöglicht Produktivität, Qualität und Reaktionsfähigkeit des Unternehmensfortschritts. Die Datenkonsistenz wird mit historischen und Echtzeitszenarien beibehalten.
Betrachten Sie das folgende Diagramm, um den datenwissenschaftlichen Experimentzyklus zu verstehen:
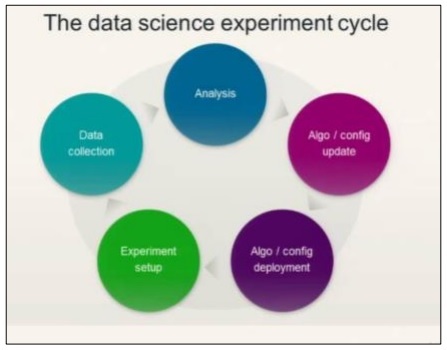
Data Science umfasst die Analyse von Anforderungen, gefolgt von der Erstellung von Algorithmen, die auf diesen basieren. Sobald die Algorithmen zusammen mit dem Umgebungssetup entworfen wurden, kann ein Benutzer Experimente erstellen und Daten zur besseren Analyse sammeln.
Diese Ideologie berechnet den letzten Sprint der Agilität, der als „Aktionen“ bezeichnet wird.
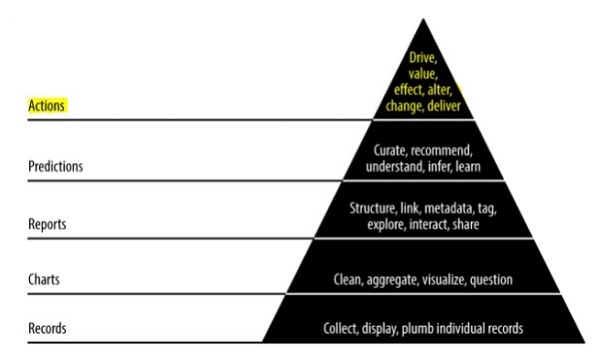
Actionsumfasst alle obligatorischen Aufgaben für den letzten Sprint oder die letzte Stufe der agilen Methodik. Die Verfolgung der datenwissenschaftlichen Phasen (in Bezug auf den Lebenszyklus) kann mit Story Cards als Aktionselementen beibehalten werden.
Predictive Analysis und Big Data
Die Zukunft der Planung liegt vollständig in der Anpassung der Datenberichte an die aus der Analyse gesammelten Daten. Dazu gehört auch die Manipulation mit Big-Data-Analyse. Mithilfe von Big Data können diskrete Informationen analysiert werden, indem die Metriken des Unternehmens effektiv aufgeteilt und in Würfel geschnitten werden. Die Analyse wird immer als bessere Lösung angesehen.
Im agilen Entwicklungsprozess werden verschiedene Methoden verwendet. Diese Methoden können auch für datenwissenschaftliche Forschungsprozesse verwendet werden.
Das unten angegebene Flussdiagramm zeigt die verschiedenen Methoden -
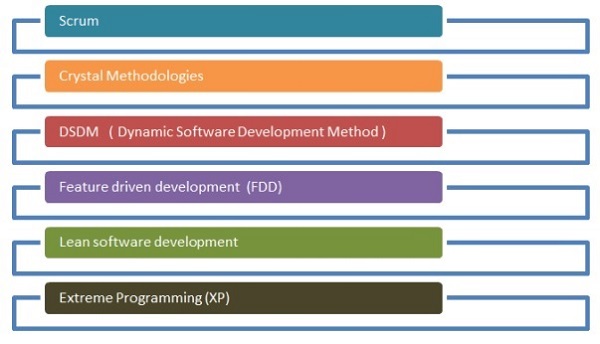
Gedränge
In Bezug auf die Softwareentwicklung bedeutet Scrum, die Arbeit mit einem kleinen Team zu verwalten und ein bestimmtes Projekt zu verwalten, um die Stärken und Schwächen des Projekts aufzudecken.
Kristallmethoden
Zu den Crystal-Methoden gehören innovative Techniken für das Produktmanagement und die Ausführung. Mit dieser Methode können Teams ähnliche Aufgaben auf unterschiedliche Weise ausführen. Die Kristallfamilie ist eine der am einfachsten anzuwendenden Methoden.
Dynamische Softwareentwicklungsmethode
Dieses Bereitstellungsframework wird hauptsächlich verwendet, um das aktuelle Wissenssystem in die Softwaremethodik zu implementieren.
Zukunftsorientierte Entwicklung
Der Schwerpunkt dieses Entwicklungslebenszyklus liegt auf projektbezogenen Merkmalen. Es eignet sich am besten für die Modellierung von Domänenobjekten, die Code- und Feature-Entwicklung für den Besitz.
Lean Software-Entwicklung
Extremes Programmieren
Extreme Programmierung ist eine einzigartige Softwareentwicklungsmethode, die sich auf die Verbesserung der Softwarequalität konzentriert. Dies wird wirksam, wenn der Kunde sich über die Funktionalität eines Projekts nicht sicher ist.
Agile Methoden haben Wurzeln im Data Science Stream und gelten als wichtige Softwaremethode. Mit agiler Selbstorganisation können funktionsübergreifende Teams effektiv zusammenarbeiten. Wie bereits erwähnt, gibt es sechs Hauptkategorien für agile Entwicklung, von denen jede gemäß den Anforderungen mit Data Science gestreamt werden kann. Data Science beinhaltet einen iterativen Prozess für statistische Erkenntnisse. Agile hilft bei der Aufteilung der Data Science-Module und bei der effektiven Verarbeitung von Iterationen und Sprints.
Der Prozess von Agile Data Science ist eine erstaunliche Methode, um zu verstehen, wie und warum das Data Science-Modul implementiert wird. Es löst Probleme auf kreative Weise.