Agile Data Science - Rolle von Vorhersagen
In diesem Kapitel werden wir uns mit der Rolle von Vorhersagen in der agilen Datenwissenschaft befassen. Die interaktiven Berichte enthüllen verschiedene Aspekte von Daten. Vorhersagen bilden die vierte Schicht des agilen Sprints.
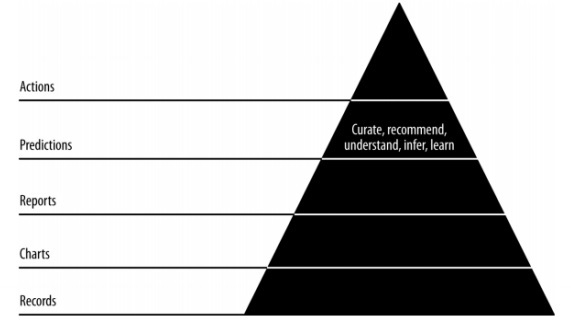
Bei Vorhersagen beziehen wir uns immer auf die vergangenen Daten und verwenden sie als Schlussfolgerungen für zukünftige Iterationen. In diesem vollständigen Prozess übertragen wir Daten von der Stapelverarbeitung historischer Daten auf Echtzeitdaten über die Zukunft.
Die Rolle von Vorhersagen umfasst Folgendes:
Vorhersagen helfen bei der Vorhersage. Einige Prognosen basieren auf statistischen Schlussfolgerungen. Einige der Vorhersagen basieren auf Meinungen von Experten.
Statistische Inferenzen sind mit Vorhersagen aller Art verbunden.
Manchmal sind Prognosen genau, manchmal sind Prognosen ungenau.
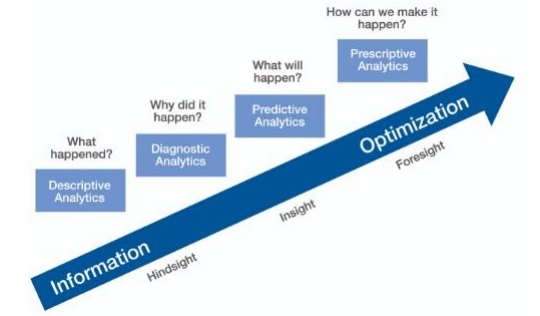
Predictive Analytics
Die prädiktive Analyse umfasst eine Vielzahl statistischer Techniken aus der prädiktiven Modellierung, dem maschinellen Lernen und dem Data Mining, die aktuelle und historische Fakten analysieren, um Vorhersagen über zukünftige und unbekannte Ereignisse zu treffen.
Predictive Analytics erfordert Trainingsdaten. Zu den geschulten Daten gehören unabhängige und abhängige Funktionen. Abhängige Funktionen sind die Werte, die ein Benutzer vorhersagen möchte. Unabhängige Features sind Features, die die Dinge beschreiben, die wir basierend auf abhängigen Features vorhersagen möchten.
Das Studium von Features wird als Feature Engineering bezeichnet. Dies ist entscheidend für Vorhersagen. Datenvisualisierung und explorative Datenanalyse sind Teile des Feature-Engineerings. diese bilden den Kern vonAgile data science.
Vorhersagen treffen
In der agilen Datenwissenschaft gibt es zwei Möglichkeiten, Vorhersagen zu treffen:
Regression
Classification
Der Aufbau einer Regression oder Klassifizierung hängt vollständig von den Geschäftsanforderungen und deren Analyse ab. Die Vorhersage kontinuierlicher Variablen führt zu einem Regressionsmodell und die Vorhersage kategorialer Variablen führt zu einem Klassifizierungsmodell.
Regression
Die Regression berücksichtigt Beispiele, die Merkmale umfassen und dadurch eine numerische Ausgabe erzeugen.
Einstufung
Die Klassifizierung nimmt die Eingabe und erzeugt eine kategoriale Klassifizierung.
Note - Der Beispieldatensatz, der die Eingabe für die statistische Vorhersage definiert und das Lernen der Maschine ermöglicht, wird als "Trainingsdaten" bezeichnet.