Apache Tajo - Kurzanleitung
Verteiltes Data Warehouse-System
Data Warehouse ist eine relationale Datenbank, die eher für Abfragen und Analysen als für die Transaktionsverarbeitung konzipiert ist. Es ist eine themenorientierte, integrierte, zeitvariante und nichtflüchtige Datenerfassung. Diese Daten helfen Analysten, fundierte Entscheidungen in einem Unternehmen zu treffen, aber das relationale Datenvolumen wird von Tag zu Tag erhöht.
Um die Herausforderungen zu bewältigen, teilt das verteilte Data Warehouse-System Daten für die Online-Analyse (OLAP) über mehrere Datenrepositorys hinweg. Jedes Data Warehouse kann einer oder mehreren Organisationen gehören. Es führt einen Lastausgleich und eine Skalierbarkeit durch. Metadaten werden repliziert und zentral verteilt.
Apache Tajo ist ein verteiltes Data Warehouse-System, das das Hadoop Distributed File System (HDFS) als Speicherschicht verwendet und anstelle des MapReduce-Frameworks über eine eigene Engine zur Ausführung von Abfragen verfügt.
Übersicht über SQL unter Hadoop
Hadoop ist ein Open-Source-Framework, mit dem Big Data in einer verteilten Umgebung gespeichert und verarbeitet werden kann. Es ist extrem schnell und leistungsstark. Hadoop verfügt jedoch nur über eingeschränkte Abfragefunktionen, sodass die Leistung mithilfe von SQL unter Hadoop noch verbessert werden kann. Auf diese Weise können Benutzer über einfache SQL-Befehle mit Hadoop interagieren.
Einige Beispiele für SQL in Hadoop-Anwendungen sind Hive, Impala, Drill, Presto, Spark, HAWQ und Apache Tajo.
Was ist Apache Tajo?
Apache Tajo ist ein relationales und verteiltes Datenverarbeitungsframework. Es wurde für eine geringe Latenz und eine skalierbare Ad-hoc-Abfrageanalyse entwickelt.
Tajo unterstützt Standard-SQL und verschiedene Datenformate. Die meisten Tajo-Abfragen können ohne Änderungen ausgeführt werden.
Tajo hat fault-tolerance durch einen Neustartmechanismus für fehlgeschlagene Aufgaben und eine erweiterbare Engine zum Umschreiben von Abfragen.
Tajo führt das Notwendige aus ETL (Extract Transform and Load process)Operationen zum Zusammenfassen großer in HDFS gespeicherter Datensätze. Es ist eine alternative Wahl zu Hive / Pig.
Die neueste Version von Tajo bietet eine bessere Konnektivität zu Java-Programmen und Datenbanken von Drittanbietern wie Oracle und PostGreSQL.
Eigenschaften von Apache Tajo
Apache Tajo hat die folgenden Funktionen -
- Überlegene Skalierbarkeit und optimierte Leistung
- Geringe Wartezeit
- Benutzerdefinierte Funktionen
- Framework für die Verarbeitung von Zeilen- / Spaltenspeichern.
- Kompatibilität mit HiveQL und Hive MetaStore
- Einfacher Datenfluss und einfache Wartung.
Vorteile von Apache Tajo
Apache Tajo bietet folgende Vorteile:
- Einfach zu verwenden
- Vereinfachte Architektur
- Kostenbasierte Abfrageoptimierung
- Ausführungsplan für vektorisierte Abfragen
- Schnelle Lieferung
- Einfacher E / A-Mechanismus und unterstützt verschiedene Arten von Speicher.
- Fehlertoleranz
Anwendungsfälle von Apache Tajo
Im Folgenden sind einige Anwendungsfälle von Apache Tajo aufgeführt:
Data Warehousing und Analyse
Das koreanische Unternehmen SK Telecom führte Tajo mit Daten im Wert von 1,7 Terabyte aus und stellte fest, dass Abfragen schneller als Hive oder Impala ausgeführt werden konnten.
Datenerkennung
Der koreanische Musik-Streaming-Dienst Melon verwendet Tajo für die analytische Verarbeitung. Tajo führt ETL-Jobs (Extract-Transform-Load-Prozess) 1,5- bis 10-mal schneller aus als Hive.
Protokollanalyse
Bluehole Studio, ein in Korea ansässiges Unternehmen, entwickelte TERA - ein Fantasy-Multiplayer-Online-Spiel. Das Unternehmen verwendet Tajo zur Analyse von Spielprotokollen und zur Ermittlung der Hauptursachen für Unterbrechungen der Servicequalität.
Speicher- und Datenformate
Apache Tajo unterstützt die folgenden Datenformate:
- JSON
- Textdatei (CSV)
- Parquet
- Sequenzdatei
- AVRO
- Protokollpuffer
- Apache Orc
Tajo unterstützt die folgenden Speicherformate:
- HDFS
- JDBC
- Amazon S3
- Apache HBase
- Elasticsearch
Die folgende Abbildung zeigt die Architektur von Apache Tajo.

In der folgenden Tabelle werden die einzelnen Komponenten ausführlich beschrieben.
| S.No. | Komponentenbeschreibung |
|---|---|
| 1 | Client Client sendet die SQL-Anweisungen an den Tajo-Master, um das Ergebnis zu erhalten. |
| 2 | Master Master ist der Hauptdämon. Es ist für die Abfrageplanung verantwortlich und der Koordinator für die Mitarbeiter. |
| 3 | Catalog server Pflegt die Tabellen- und Indexbeschreibungen. Es ist in den Master-Daemon eingebettet. Der Katalogserver verwendet Apache Derby als Speicherschicht und stellt eine Verbindung über den JDBC-Client her. |
| 4 | Worker Der Masterknoten weist den Arbeitsknoten eine Aufgabe zu. TajoWorker verarbeitet Daten. Mit zunehmender Anzahl von TajoWorkern steigt auch die Verarbeitungskapazität linear an. |
| 5 | Query Master Der Tajo-Master weist dem Abfrage-Master eine Abfrage zu. Der Query Master ist für die Steuerung eines verteilten Ausführungsplans verantwortlich. Es startet den TaskRunner und plant Aufgaben für TaskRunner. Die Hauptaufgabe des Abfrage-Masters besteht darin, die ausgeführten Aufgaben zu überwachen und an den Master-Knoten zu melden. |
| 6 | Node Managers Verwaltet die Ressource des Worker-Knotens. Es entscheidet über die Zuweisung von Anforderungen an den Knoten. |
| 7 | TaskRunner Dient als lokale Abfrageausführungs-Engine. Es wird zum Ausführen und Überwachen des Abfrageprozesses verwendet. Der TaskRunner verarbeitet jeweils eine Aufgabe. Es hat die folgenden drei Hauptattribute:
|
| 8 | Query Executor Es wird verwendet, um eine Abfrage auszuführen. |
| 9 | Storage service Verbindet den zugrunde liegenden Datenspeicher mit Tajo. |
Arbeitsablauf
Tajo verwendet das Hadoop Distributed File System (HDFS) als Speicherschicht und verfügt anstelle des MapReduce-Frameworks über eine eigene Engine zur Ausführung von Abfragen. Ein Tajo-Cluster besteht aus einem Hauptknoten und einer Anzahl von Arbeitern über Clusterknoten hinweg.
Der Master ist hauptsächlich für die Abfrageplanung und der Koordinator für die Mitarbeiter verantwortlich. Der Master unterteilt eine Abfrage in kleine Aufgaben und weist sie Arbeitern zu. Jeder Worker verfügt über eine lokale Abfrage-Engine, die einen gerichteten azyklischen Graphen physikalischer Operatoren ausführt.
Darüber hinaus kann Tajo den verteilten Datenfluss flexibler steuern als MapReduce und Indizierungstechniken unterstützen.
Die webbasierte Oberfläche von Tajo bietet folgende Funktionen:
- Option, um herauszufinden, wie die übermittelten Abfragen geplant sind
- Option, um herauszufinden, wie die Abfragen auf Knoten verteilt sind
- Option zum Überprüfen des Status des Clusters und der Knoten
Um Apache Tajo zu installieren, muss auf Ihrem System die folgende Software installiert sein:
- Hadoop Version 2.3 oder höher
- Java Version 1.7 oder höher
- Linux oder Mac OS
Fahren wir nun mit den folgenden Schritten fort, um Tajo zu installieren.
Überprüfen der Java-Installation
Hoffentlich haben Sie Java Version 8 bereits auf Ihrem Computer installiert. Jetzt müssen Sie nur noch fortfahren, indem Sie es überprüfen.
Verwenden Sie zur Überprüfung den folgenden Befehl:
$ java -versionWenn Java erfolgreich auf Ihrem Computer installiert wurde, wird möglicherweise die aktuelle Version des installierten Java angezeigt. Wenn Java nicht installiert ist, führen Sie die folgenden Schritte aus, um Java 8 auf Ihrem Computer zu installieren.
Laden Sie JDK herunter
Laden Sie die neueste Version von JDK herunter, indem Sie den folgenden Link besuchen, und laden Sie dann die neueste Version herunter.
https://www.oracle.com
Die neueste Version ist JDK 8u 92 und die Datei ist “jdk-8u92-linux-x64.tar.gz”. Bitte laden Sie die Datei auf Ihren Computer herunter. Extrahieren Sie anschließend die Dateien und verschieben Sie sie in ein bestimmtes Verzeichnis. Stellen Sie nun die Java-Alternativen ein. Schließlich wird Java auf Ihrem Computer installiert.
Überprüfen der Hadoop-Installation
Sie haben bereits installiert Hadoopauf Ihrem System. Überprüfen Sie es nun mit dem folgenden Befehl:
$ hadoop versionWenn mit Ihrem Setup alles in Ordnung ist, können Sie die Version von Hadoop sehen. Wenn Hadoop nicht installiert ist, laden Sie Hadoop herunter und installieren Sie es über den folgenden Link:https://www.apache.org
Apache Tajo Installation
Apache Tajo bietet zwei Ausführungsmodi - den lokalen Modus und den vollständig verteilten Modus. Führen Sie nach Überprüfung der Java- und Hadoop-Installation die folgenden Schritte aus, um den Tajo-Cluster auf Ihrem Computer zu installieren. Eine Tajo-Instanz im lokalen Modus erfordert sehr einfache Konfigurationen.
Laden Sie die neueste Version von Tajo herunter, indem Sie den folgenden Link besuchen: https://www.apache.org/dyn/closer.cgi/tajo
Jetzt können Sie die Datei herunterladen “tajo-0.11.3.tar.gz” von Ihrer Maschine.
Teerdatei extrahieren
Extrahieren Sie die TAR-Datei mit dem folgenden Befehl:
$ cd opt/ $ tar tajo-0.11.3.tar.gz
$ cd tajo-0.11.3Umgebungsvariable festlegen
Fügen Sie die folgenden Änderungen hinzu “conf/tajo-env.sh” Datei
$ cd tajo-0.11.3
$ vi conf/tajo-env.sh
# Hadoop home. Required
export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2
# The java implementation to use. Required.
export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/Hier müssen Sie den Hadoop- und Java-Pfad zu angeben “tajo-env.sh”Datei. Speichern Sie nach den Änderungen die Datei und beenden Sie das Terminal.
Starten Sie Tajo Server
Führen Sie den folgenden Befehl aus, um den Tajo-Server zu starten:
$ bin/start-tajo.shSie erhalten eine Antwort ähnlich der folgenden:
Starting single TajoMaster
starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../
localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/
Tajo master web UI: http://local:26080
Tajo Client Service: local:26002Geben Sie nun den Befehl "jps" ein, um die laufenden Daemons anzuzeigen.
$ jps
1010 TajoWorker
1140 Jps
933 TajoMasterStarten Sie Tajo Shell (Tsql)
Verwenden Sie den folgenden Befehl, um den Tajo-Shell-Client zu starten:
$ bin/tsqlSie erhalten folgende Ausgabe:
welcome to
_____ ___ _____ ___
/_ _/ _ |/_ _/ /
/ // /_| |_/ // / /
/_//_/ /_/___/ \__/ 0.11.3
Try \? for help.Beenden Sie Tajo Shell
Führen Sie den folgenden Befehl aus, um Tsql zu beenden -
default> \q
bye!Hier bezieht sich die Standardeinstellung auf den Katalog in Tajo.
Web-Benutzeroberfläche
Geben Sie die folgende URL ein, um die Tajo-Web-Benutzeroberfläche zu starten: http://localhost:26080/
Sie sehen nun den folgenden Bildschirm, der der ExecuteQuery-Option ähnelt.

Stoppen Sie Tajo
Verwenden Sie den folgenden Befehl, um den Tajo-Server zu stoppen:
$ bin/stop-tajo.shSie erhalten folgende Antwort:
localhost: stopping worker
stopping masterDie Konfiguration von Tajo basiert auf dem Konfigurationssystem von Hadoop. In diesem Kapitel werden die Tajo-Konfigurationseinstellungen ausführlich erläutert.
Grundeinstellungen
Tajo verwendet die folgenden zwei Konfigurationsdateien:
- catalog-site.xml - Konfiguration für den Katalogserver.
- tajo-site.xml - Konfiguration für andere Tajo-Module.
Konfiguration im verteilten Modus
Das Setup im verteilten Modus wird auf dem Hadoop Distributed File System (HDFS) ausgeführt. Befolgen Sie die Schritte zum Konfigurieren des Tajo-Setups für den verteilten Modus.
tajo-site.xml
Diese Datei ist verfügbar @ /path/to/tajo/confVerzeichnis und fungiert als Konfiguration für andere Tajo-Module. Wenden Sie die folgenden Änderungen an an, um in einem verteilten Modus auf Tajo zuzugreifen“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://hostname:port/tajo</value>
</property>
<property>
<name>tajo.master.umbilical-rpc.address</name>
<value>hostname:26001</value>
</property>
<property>
<name>tajo.master.client-rpc.address</name>
<value>hostname:26002</value>
</property>
<property>
<name>tajo.catalog.client-rpc.address</name>
<value>hostname:26005</value>
</property>Hauptknotenkonfiguration
Tajo verwendet HDFS als primären Speichertyp. Die Konfiguration ist wie folgt und sollte hinzugefügt werden“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://namenode_hostname:port/path</value>
</property>Katalogkonfiguration
Wenn Sie den Katalogdienst anpassen möchten, kopieren Sie $path/to/Tajo/conf/catalogsite.xml.template zu $path/to/Tajo/conf/catalog-site.xml und fügen Sie nach Bedarf eine der folgenden Konfigurationen hinzu.
Zum Beispiel, wenn Sie verwenden “Hive catalog store” Um auf Tajo zuzugreifen, sollte die Konfiguration wie folgt aussehen:
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HCatalogStore</value>
</property>Wenn Sie speichern müssen MySQL Katalog, dann wenden Sie die folgenden Änderungen an -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>Ebenso können Sie die anderen von Tajo unterstützten Kataloge in der Konfigurationsdatei registrieren.
Arbeiterkonfiguration
Standardmäßig speichert der TajoWorker temporäre Daten im lokalen Dateisystem. Es ist in der Datei "tajo-site.xml" wie folgt definiert:
<property>
<name>tajo.worker.tmpdir.locations</name>
<value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value>
</property>Wählen Sie die folgende Konfiguration aus, um die Kapazität zum Ausführen von Aufgaben für jede Worker-Ressource zu erhöhen:
<property>
<name>tajo.worker.resource.cpu-cores</name>
<value>12</value>
</property>
<property>
<name>tajo.task.resource.min.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>tajo.worker.resource.disks</name>
<value>4</value>
</property>Wählen Sie die folgende Konfiguration aus, damit der Tajo-Worker in einem dedizierten Modus ausgeführt wird:
<property>
<name>tajo.worker.resource.dedicated</name>
<value>true</value>
</property>In diesem Kapitel werden wir die Tajo Shell-Befehle im Detail verstehen.
Um die Tajo-Shell-Befehle auszuführen, müssen Sie den Tajo-Server und die Tajo-Shell mit den folgenden Befehlen starten:
Server starten
$ bin/start-tajo.shStarten Sie Shell
$ bin/tsqlDie obigen Befehle sind jetzt zur Ausführung bereit.
Meta-Befehle
Lassen Sie uns nun das diskutieren Meta Commands. Tsql-Meta-Befehle beginnen mit einem Backslash(‘\’).
Hilfebefehl
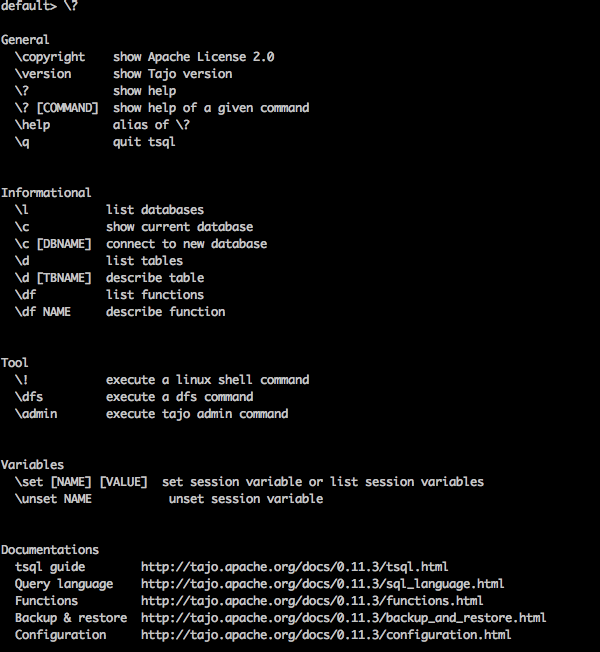
“\?” Mit dem Befehl wird die Hilfeoption angezeigt.
Query
default> \?Result
Obenstehendes \?Befehl listet alle grundlegenden Verwendungsoptionen in Tajo auf. Sie erhalten folgende Ausgabe:
Datenbank auflisten
Verwenden Sie den folgenden Befehl, um alle Datenbanken in Tajo aufzulisten:
Query
default> \lResult
Sie erhalten folgende Ausgabe:
information_schema
defaultDerzeit haben wir keine Datenbank erstellt, daher werden zwei integrierte Tajo-Datenbanken angezeigt.
Aktuelle Datenbank
\c Mit dieser Option wird der aktuelle Datenbankname angezeigt.
Query
default> \cResult
Sie sind jetzt als Benutzer "Benutzername" mit der Datenbank "Standard" verbunden.
Listen Sie die integrierten Funktionen auf
Geben Sie die Abfrage wie folgt ein, um alle integrierten Funktionen aufzulisten:
Query
default> \dfResult
Sie erhalten folgende Ausgabe:

Funktion beschreiben
\df function name - Diese Abfrage gibt die vollständige Beschreibung der angegebenen Funktion zurück.
Query
default> \df sqrtResult
Sie erhalten folgende Ausgabe:

Terminal verlassen
Geben Sie die folgende Abfrage ein, um das Terminal zu beenden:
Query
default> \qResult
Sie erhalten folgende Ausgabe:
bye!Admin-Befehle
Tajo Shell bietet \admin Option zum Auflisten aller Administratorfunktionen.
Query
default> \adminResult
Sie erhalten folgende Ausgabe:

Cluster-Info
Verwenden Sie die folgende Abfrage, um die Clusterinformationen in Tajo anzuzeigen
Query
default> \admin -clusterResult
Sie erhalten folgende Ausgabe:

Meister zeigen
Die folgende Abfrage zeigt die aktuellen Stamminformationen an.
Query
default> \admin -showmastersResult
localhostEbenso können Sie andere Admin-Befehle ausprobieren.
Sitzungsvariablen
Der Tajo-Client stellt über eine eindeutige Sitzungs-ID eine Verbindung zum Master her. Die Sitzung ist aktiv, bis der Client getrennt wird oder abläuft.
Der folgende Befehl wird verwendet, um alle Sitzungsvariablen aufzulisten.
Query
default> \setResult
'SESSION_LAST_ACCESS_TIME' = '1470206387146'
'CURRENT_DATABASE' = 'default'
‘USERNAME’ = 'user'
'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c'
'TIMEZONE' = 'Asia/Kolkata'
'FETCH_ROWNUM' = '200'
‘COMPRESSED_RESULT_TRANSFER' = 'false'Das \set key val setzt die benannte Sitzungsvariable key mit dem Wert val. Zum Beispiel,
Query
default> \set ‘current_database’='default'Result
usage: \set [[NAME] VALUE]Hier können Sie den Schlüssel und den Wert in der \setBefehl. Wenn Sie die Änderungen rückgängig machen müssen, verwenden Sie die\unset Befehl.
Um eine Abfrage in einer Tajo-Shell auszuführen, öffnen Sie Ihr Terminal, wechseln Sie in das installierte Tajo-Verzeichnis und geben Sie den folgenden Befehl ein:
$ bin/tsqlSie sehen nun die Antwort wie im folgenden Programm gezeigt -
default>Sie können jetzt Ihre Abfragen ausführen. Andernfalls können Sie Ihre Abfragen über die Webkonsolenanwendung unter der folgenden URL ausführen:http://localhost:26080/
Primitive Datentypen
Apache Tajo unterstützt die folgende Liste primitiver Datentypen:
| S.No. | Datentyp & Beschreibung |
|---|---|
| 1 | integer Wird zum Speichern eines ganzzahligen Werts mit 4 Byte Speicher verwendet. |
| 2 | tinyint Der winzige ganzzahlige Wert beträgt 1 Byte |
| 3 | smallint Wird zum Speichern eines kleinen Integer-2-Byte-Werts verwendet. |
| 4 | bigint Der Ganzzahlwert für den großen Bereich hat 8 Byte Speicherplatz. |
| 5 | boolean Gibt true / false zurück. |
| 6 | real Wird zum Speichern von echtem Wert verwendet. Die Größe beträgt 4 Bytes. |
| 7 | float Gleitkomma-Genauigkeitswert mit 4 oder 8 Byte Speicherplatz. |
| 8 | double Doppelpunktgenauigkeitswert in 8 Bytes gespeichert. |
| 9 | char[(n)] Zeichenwert. |
| 10 | varchar[(n)] Nicht-Unicode-Daten variabler Länge. |
| 11 | number Dezimalwerte. |
| 12 | binary Binärwerte. |
| 13 | date Kalenderdatum (Jahr, Monat, Tag). Example - DATUM '2016-08-22' |
| 14 | time Tageszeit (Stunde, Minute, Sekunde, Millisekunde) ohne Zeitzone. Werte dieses Typs werden in der Sitzungszeitzone analysiert und gerendert. |
| 15 | timezone Tageszeit (Stunde, Minute, Sekunde, Millisekunde) mit einer Zeitzone. Werte dieses Typs werden unter Verwendung der Zeitzone aus dem Wert gerendert. Example - ZEIT '01: 02: 03.456 Asien / Kolkata ' |
| 16 | timestamp Sofortige Uhrzeit, die Datum und Uhrzeit ohne Zeitzone enthält. Example - TIMESTAMP '2016-08-22 03: 04: 05.321' |
| 17 | text Unicode-Text variabler Länge. |
Die folgenden Operatoren werden in Tajo verwendet, um die gewünschten Operationen auszuführen.
| S.No. | Betreiber & Beschreibung |
|---|---|
| 1 | Rechenzeichen Presto unterstützt arithmetische Operatoren wie +, -, *, /,%. |
| 2 | Vergleichsoperatoren <,>, <=,> =, =, <> |
| 3 | Logische Operatoren UND ODER NICHT |
| 4 | String-Operatoren Das '||' Der Operator führt eine Zeichenfolgenverkettung durch. |
| 5 | Bereichsoperatoren Der Bereichsoperator wird verwendet, um den Wert in einem bestimmten Bereich zu testen. Tajo unterstützt die Operatoren ZWISCHEN, IST NULL, IST NICHT NULL. |
Ab sofort war Ihnen bekannt, dass Sie einfache grundlegende Abfragen in Tajo ausführen. In den nächsten Kapiteln werden wir die folgenden SQL-Funktionen diskutieren:
- Mathematische Funktionen
- String-Funktionen
- DateTime-Funktionen
- JSON-Funktionen
Mathematische Funktionen arbeiten mit mathematischen Formeln. In der folgenden Tabelle wird die Liste der Funktionen ausführlich beschrieben.
| S.No. | Bedienungsanleitung |
|---|---|
| 1 | abs (x) Gibt den absoluten Wert von x zurück. |
| 2 | cbrt (x) Gibt die Kubikwurzel von x zurück. |
| 3 | Decke (x) Gibt den auf die nächste Ganzzahl aufgerundeten x-Wert zurück. |
| 4 | Boden (x) Gibt x auf die nächste Ganzzahl abgerundet zurück. |
| 5 | Pi() Gibt den pi-Wert zurück. Das Ergebnis wird als doppelter Wert zurückgegeben. |
| 6 | Bogenmaß (x) wandelt den Winkel x in Bogenmaß um. |
| 7 | Grad (x) Gibt den Gradwert für x zurück. |
| 8 | pow (x, p) Gibt die Potenz des Wertes 'p' auf den x-Wert zurück. |
| 9 | div (x, y) Gibt das Teilungsergebnis für die angegebenen zwei x, y-Ganzzahlwerte zurück. |
| 10 | exp (x) Gibt die Euler-Nummer zurück e zur Macht einer Zahl erhoben. |
| 11 | sqrt (x) Gibt die Quadratwurzel von x zurück. |
| 12 | Zeichen (x) Gibt die Signum-Funktion von x zurück, dh -
|
| 13 | mod (n, m) Gibt den Modul (Rest) von n geteilt durch m zurück. |
| 14 | rund (x) Gibt den gerundeten Wert für x zurück. |
| 15 | cos (x) Gibt den Kosinuswert (x) zurück. |
| 16 | asin (x) Gibt den inversen Sinuswert (x) zurück. |
| 17 | acos (x) Gibt den inversen Kosinuswert (x) zurück. |
| 18 | atan (x) Gibt den inversen Tangentenwert (x) zurück. |
| 19 | atan2 (y, x) Gibt den inversen Tangentenwert (y / x) zurück. |
Datentypfunktionen
In der folgenden Tabelle sind die in Apache Tajo verfügbaren Datentypfunktionen aufgeführt.
| S.No. | Bedienungsanleitung |
|---|---|
| 1 | to_bin (x) Gibt die binäre Darstellung der Ganzzahl zurück. |
| 2 | to_char (int, text) Konvertiert eine Ganzzahl in eine Zeichenfolge. |
| 3 | to_hex (x) Konvertiert den x-Wert in hexadezimal. |
In der folgenden Tabelle sind die Zeichenfolgenfunktionen in Tajo aufgeführt.
| S.No. | Bedienungsanleitung |
|---|---|
| 1 | concat (string1, ..., stringN) Verketten Sie die angegebenen Zeichenfolgen. |
| 2 | Länge (Zeichenfolge) Gibt die Länge der angegebenen Zeichenfolge zurück. |
| 3 | niedriger (String) Gibt das Kleinbuchstabenformat für die Zeichenfolge zurück. |
| 4 | obere (Zeichenfolge) Gibt das Großbuchstabenformat für die angegebene Zeichenfolge zurück. |
| 5 | ascii (Stringtext) Gibt den ASCII-Code des ersten Zeichens des Textes zurück. |
| 6 | bit_length (String-Text) Gibt die Anzahl der Bits in einer Zeichenfolge zurück. |
| 7 | char_length (Zeichenfolgentext) Gibt die Anzahl der Zeichen in einer Zeichenfolge zurück. |
| 8 | octet_length (Zeichenfolgentext) Gibt die Anzahl der Bytes in einer Zeichenfolge zurück. |
| 9 | Digest (Eingabetext, Methodentext) Berechnet die DigestHash der Zeichenfolge. Hier bezieht sich die zweite arg-Methode auf die Hash-Methode. |
| 10 | initcap (Zeichenfolgentext) Konvertiert den ersten Buchstaben jedes Wortes in Großbuchstaben. |
| 11 | md5 (Zeichenfolgentext) Berechnet die MD5 Hash der Zeichenfolge. |
| 12 | links (String-Text, int-Größe) Gibt die ersten n Zeichen in der Zeichenfolge zurück. |
| 13 | rechts (String-Text, int-Größe) Gibt die letzten n Zeichen in der Zeichenfolge zurück. |
| 14 | Suchen (Quelltext, Zieltext, Startindex) Gibt den Speicherort des angegebenen Teilstrings zurück. |
| 15 | strposb (Quelltext, Zieltext) Gibt die binäre Position des angegebenen Teilstrings zurück. |
| 16 | substr (Quelltext, Startindex, Länge) Gibt den Teilstring für die angegebene Länge zurück. |
| 17 | trim (Zeichenfolgentext [, Zeichentext]) Entfernt die Zeichen (standardmäßig ein Leerzeichen) vom Anfang / Ende / beiden Enden der Zeichenfolge. |
| 18 | split_part (Zeichenfolgentext, Trennzeichen, Feld int) Teilt eine Zeichenfolge am Trennzeichen und gibt das angegebene Feld zurück (von eins gezählt). |
| 19 | regexp_replace (Zeichenfolgentext, Mustertext, Ersatztext) Ersetzt Teilzeichenfolgen, die mit einem bestimmten Muster für reguläre Ausdrücke übereinstimmen. |
| 20 | umgekehrt (Zeichenfolge) Für die Zeichenfolge wird eine umgekehrte Operation ausgeführt. |
Apache Tajo unterstützt die folgenden DateTime-Funktionen.
| S.No. | Bedienungsanleitung |
|---|---|
| 1 | add_days (Datum Datum oder Zeitstempel, int Tag Gibt das Datum zurück, das um den angegebenen Tageswert hinzugefügt wurde. |
| 2 | add_months (Datum, Datum oder Zeitstempel, int Monat) Gibt das Datum zurück, das um den angegebenen Monatswert hinzugefügt wurde. |
| 3 | aktuelles Datum() Gibt das heutige Datum zurück. |
| 4 | aktuelle Uhrzeit() Gibt die heutige Zeit zurück. |
| 5 | Auszug (Jahrhundert von Datum / Zeitstempel) Extrahiert Jahrhundert aus dem angegebenen Parameter. |
| 6 | Auszug (Tag von Datum / Zeitstempel) Extrahiert den Tag aus dem angegebenen Parameter. |
| 7 | Auszug (Jahrzehnt von Datum / Zeitstempel) Extrahiert ein Jahrzehnt aus dem angegebenen Parameter. |
| 8 | Auszug (Tag / Tag Datum / Zeitstempel) Extrahiert den Wochentag aus dem angegebenen Parameter. |
| 9 | Auszug (Doy aus Datum / Zeitstempel) Extrahiert den Tag des Jahres aus dem angegebenen Parameter. |
| 10 | Extrakt auswählen (Stunde vom Zeitstempel) Extrahiert die Stunde aus dem angegebenen Parameter. |
| 11 | Extrakt auswählen (Isodow aus Zeitstempel) Extrahiert den Wochentag aus dem angegebenen Parameter. Dies ist bis auf Sonntag identisch mit Dow. Dies entspricht der Nummerierung des Wochentags nach ISO 8601. |
| 12 | Extrakt auswählen (isoyear ab Datum) Extrahiert das ISO-Jahr ab dem angegebenen Datum. Das ISO-Jahr kann sich vom Gregorianischen Jahr unterscheiden. |
| 13 | Extrakt (Mikrosekunden von der Zeit) Extrahiert Mikrosekunden aus dem angegebenen Parameter. Das Sekundenfeld, einschließlich Bruchteilen, multipliziert mit 1 000 000; |
| 14 | Auszug (Jahrtausend aus Zeitstempel) Extrahiert Millennium aus dem angegebenen Parameter. Ein Millennium entspricht 1000 Jahren. Daher begann das dritte Jahrtausend am 1. Januar 2001. |
| 15 | Extrakt (Millisekunden ab Zeit) Extrahiert Millisekunden aus dem angegebenen Parameter. |
| 16 | Auszug (Minute aus Zeitstempel) Extrahiert die Minute aus dem angegebenen Parameter. |
| 17 | Auszug (Viertel aus Zeitstempel) Extrahiert ein Viertel des Jahres (1 - 4) aus dem angegebenen Parameter. |
| 18 | date_part (Feldtext, Quelldatum oder Zeitstempel oder Uhrzeit) Extrahiert das Datumsfeld aus dem Text. |
| 19 | jetzt() Gibt den aktuellen Zeitstempel zurück. |
| 20 | to_char (Zeitstempel, Text formatieren) Konvertiert den Zeitstempel in Text. |
| 21 | to_date (src text, format text) Konvertiert Text in Datum. |
| 22 | to_timestamp (src text, format text) Konvertiert Text in Zeitstempel. |
Die JSON-Funktionen sind in der folgenden Tabelle aufgeführt:
| S.No. | Bedienungsanleitung |
|---|---|
| 1 | json_extract_path_text (js on text, json_path text) Extrahiert eine JSON-Zeichenfolge aus einer JSON-Zeichenfolge basierend auf dem angegebenen JSON-Pfad. |
| 2 | json_array_get (json_array text, index int4) Gibt das Element am angegebenen Index in das JSON-Array zurück. |
| 3 | json_array_contains (json_ array text, Wert beliebig) Stellen Sie fest, ob der angegebene Wert im JSON-Array vorhanden ist. |
| 4 | json_array_length (json_ar ray text) Gibt die Länge des JSON-Arrays zurück. |
In diesem Abschnitt werden die Tajo DDL-Befehle erläutert. Tajo hat eine eingebaute Datenbank namensdefault.
Datenbankanweisung erstellen
Create Databaseist eine Anweisung zum Erstellen einer Datenbank in Tajo. Die Syntax für diese Anweisung lautet wie folgt:
CREATE DATABASE [IF NOT EXISTS] <database_name>Abfrage
default> default> create database if not exists test;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
OKDatenbank ist der Namespace in Tajo. Eine Datenbank kann mehrere Tabellen mit einem eindeutigen Namen enthalten.
Aktuelle Datenbank anzeigen
Geben Sie den folgenden Befehl ein, um den aktuellen Datenbanknamen zu überprüfen:
Abfrage
default> \cErgebnis
Die obige Abfrage generiert das folgende Ergebnis.
You are now connected to database "default" as user “user1".
default>Verbindung zur Datenbank herstellen
Ab sofort haben Sie eine Datenbank mit dem Namen "test" erstellt. Die folgende Syntax wird verwendet, um die Testdatenbank zu verbinden.
\c <database name>Abfrage
default> \c testErgebnis
Die obige Abfrage generiert das folgende Ergebnis.
You are now connected to database "test" as user “user1”.
test>Sie können jetzt die Änderungen der Eingabeaufforderung von der Standarddatenbank zur Testdatenbank sehen.
Datenbank löschen
Verwenden Sie die folgende Syntax, um eine Datenbank zu löschen:
DROP DATABASE <database-name>Abfrage
test> \c default
You are now connected to database "default" as user “user1".
default> drop database test;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
OKEine Tabelle ist eine logische Ansicht einer Datenquelle. Es besteht aus einem logischen Schema, Partitionen, einer URL und verschiedenen Eigenschaften. Eine Tajo-Tabelle kann ein Verzeichnis in HDFS, eine einzelne Datei, eine HBase-Tabelle oder eine RDBMS-Tabelle sein.
Tajo unterstützt die folgenden zwei Arten von Tabellen:
- externer Tisch
- interne Tabelle
Externe Tabelle
Externe Tabelle benötigt die Eigenschaft location, wenn die Tabelle erstellt wird. Wenn Ihre Daten beispielsweise bereits als Text- / JSON-Dateien oder als HBase-Tabelle vorhanden sind, können Sie sie als externe Tajo-Tabelle registrieren.
Die folgende Abfrage ist ein Beispiel für die Erstellung externer Tabellen.
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';Hier,
External keyword- Hiermit wird eine externe Tabelle erstellt. Dies hilft beim Erstellen einer Tabelle am angegebenen Speicherort.
Beispiel bezieht sich auf den Tabellennamen.
Location- Es ist ein Verzeichnis für HDFS, Amazon S3, HBase oder ein lokales Dateisystem. Verwenden Sie die folgenden URI-Beispiele, um Verzeichnisseigenschaften für Verzeichnisse zuzuweisen:
HDFS - hdfs: // localhost: port / path / to / table
Amazon S3 - s3: // Bucket-Name / Tabelle
local file system - Datei: /// Pfad / zu / Tabelle
Openstack Swift - swift: // Bucket-Name / Tabelle
Tabelleneigenschaften
Eine externe Tabelle hat die folgenden Eigenschaften:
TimeZone - Benutzer können eine Zeitzone zum Lesen oder Schreiben einer Tabelle angeben.
Compression format- Wird verwendet, um die Datengröße kompakt zu machen. Beispielsweise wird die Text- / JSON-Datei verwendetcompression.codec Eigentum.
Interne Tabelle
Eine interne Tabelle wird auch als bezeichnet Managed Table. Es wird an einem vordefinierten physischen Speicherort erstellt, der als Tablespace bezeichnet wird.
Syntax
create table table1(col1 int,col2 text);Standardmäßig verwendet Tajo "tajo.warehouse.directory" in "conf / tajo-site.xml". Um der Tabelle einen neuen Speicherort zuzuweisen, können Sie die Tablespace-Konfiguration verwenden.
Tablespace
Der Tablespace wird verwendet, um Speicherorte im Speichersystem zu definieren. Es wird nur für interne Tabellen unterstützt. Sie können über ihre Namen auf die Tablespaces zugreifen. Jeder Tabellenbereich kann einen anderen Speichertyp verwenden. Wenn Sie dann keine Tabellenbereiche angeben, verwendet Tajo den Standardtabellenbereich im Stammverzeichnis.
Tablespace-Konfiguration
Du hast “conf/tajo-site.xml.template”in Tajo. Kopieren Sie die Datei und benennen Sie sie in um“storagesite.json”. Diese Datei dient als Konfiguration für Tablespaces. Tajo-Datenformate verwenden die folgende Konfiguration:
HDFS-Konfiguration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}HBase-Konfiguration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}Konfiguration der Textdatei
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
“uri”: “hdfs://localhost:9000/path/to/Tajo”
}
}
}Tablespace-Erstellung
Auf die internen Tabellendatensätze von Tajo kann nur von einer anderen Tabelle aus zugegriffen werden. Sie können es mit Tablespace konfigurieren.
Syntax
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name]
[using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]Hier,
IF NOT EXISTS - Dies vermeidet einen Fehler, wenn nicht bereits dieselbe Tabelle erstellt wurde.
TABLESPACE - Diese Klausel wird verwendet, um den Tabellenbereichsnamen zuzuweisen.
Storage type - Tajo-Daten unterstützen Formate wie Text, JSON, HBase, Parkett, Sequenzdatei und ORC.
AS select statement - Wählen Sie Datensätze aus einer anderen Tabelle aus.
Tablespace konfigurieren
Starten Sie Ihre Hadoop-Dienste und öffnen Sie die Datei “conf/storage-site.json”Fügen Sie dann die folgenden Änderungen hinzu:
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}Hier bezieht sich Tajo auf die Daten vom HDFS-Standort und space1ist der Tablespace-Name. Wenn Sie die Hadoop-Dienste nicht starten, können Sie den Tablespace nicht registrieren.
Abfrage
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;Die obige Abfrage erstellt eine Tabelle mit dem Namen "table1" und "space1" bezieht sich auf den Tabellenbereichsnamen.
Datenformate
Tajo unterstützt Datenformate. Lassen Sie uns jedes der Formate einzeln im Detail durchgehen.
Text
Die Klartextdatei einer durch Zeichen getrennten Werte stellt einen tabellarischen Datensatz dar, der aus Zeilen und Spalten besteht. Jede Zeile ist eine einfache Textzeile.
Tabelle erstellen
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;Hier, “customers.csv” Datei bezieht sich auf eine durch Kommas getrennte Wertedatei im Tajo-Installationsverzeichnis.
Verwenden Sie die folgende Abfrage, um eine interne Tabelle im Textformat zu erstellen:
default> create table customer(id int,name text,address text,age int) using text;In der obigen Abfrage haben Sie keinen Tabellenbereich zugewiesen, sodass der Standardtabellenbereich von Tajo verwendet wird.
Eigenschaften
Ein Textdateiformat hat die folgenden Eigenschaften:
text.delimiter- Dies ist ein Trennzeichen. Standard ist '|'.
compression.codec- Dies ist ein Komprimierungsformat. Standardmäßig ist es deaktiviert. Sie können die Einstellungen mit dem angegebenen Algorithmus ändern.
timezone - Die Tabelle zum Lesen oder Schreiben.
text.error-tolerance.max-num - Die maximale Anzahl von Toleranzstufen.
text.skip.headerlines - Die Anzahl der Kopfzeilen pro übersprungen.
text.serde - Dies ist die Serialisierungseigenschaft.
JSON
Apache Tajo unterstützt das JSON-Format zum Abfragen von Daten. Tajo behandelt ein JSON-Objekt als SQL-Datensatz. Ein Objekt entspricht einer Zeile in einer Tajo-Tabelle. Betrachten wir "array.json" wie folgt:
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}Wechseln Sie nach dem Erstellen dieser Datei zur Tajo-Shell und geben Sie die folgende Abfrage ein, um eine Tabelle im JSON-Format zu erstellen.
Abfrage
default> create external table sample (num1 int,num2 text,num3 float)
using json location ‘json/array.json’;Denken Sie immer daran, dass die Dateidaten mit dem Tabellenschema übereinstimmen müssen. Andernfalls können Sie die Spaltennamen weglassen und * verwenden, für das keine Spaltenliste erforderlich ist.
Verwenden Sie die folgende Abfrage, um eine interne Tabelle zu erstellen:
default> create table sample (num1 int,num2 text,num3 float) using json;Parkett
Parkett ist ein säulenförmiges Speicherformat. Tajo verwendet das Parkettformat für einen einfachen, schnellen und effizienten Zugriff.
Tabellenerstellung
Die folgende Abfrage ist ein Beispiel für die Tabellenerstellung:
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;Das Parkettdateiformat hat die folgenden Eigenschaften:
parquet.block.size - Größe einer Zeilengruppe, die im Speicher gepuffert wird.
parquet.page.size - Die Seitengröße dient zur Komprimierung.
parquet.compression - Der Komprimierungsalgorithmus zum Komprimieren von Seiten.
parquet.enable.dictionary - Der boolesche Wert dient zum Aktivieren / Deaktivieren der Wörterbuchcodierung.
RCFile
RCFile ist die Datensatzspalten-Datei. Es besteht aus binären Schlüssel / Wert-Paaren.
Tabellenerstellung
Die folgende Abfrage ist ein Beispiel für die Tabellenerstellung:
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;RCFile hat die folgenden Eigenschaften:
rcfile.serde - Benutzerdefinierte Deserializer-Klasse.
compression.codec - Komprimierungsalgorithmus.
rcfile.null - NULL Zeichen.
SequenceFile
SequenceFile ist ein grundlegendes Dateiformat in Hadoop, das aus Schlüssel / Wert-Paaren besteht.
Tabellenerstellung
Die folgende Abfrage ist ein Beispiel für die Tabellenerstellung:
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;Diese Sequenzdatei ist Hive-kompatibel. Dies kann in Hive geschrieben werden als,
CREATE TABLE table1 (id int, name string, score float, type string)
STORED AS sequencefile;ORC
ORC (Optimized Row Columnar) ist ein Spaltenspeicherformat von Hive.
Tabellenerstellung
Die folgende Abfrage ist ein Beispiel für die Tabellenerstellung:
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;Das ORC-Format hat die folgenden Eigenschaften:
orc.max.merge.distance - ORC-Datei wird gelesen, sie wird zusammengeführt, wenn der Abstand geringer ist.
orc.stripe.size - Dies ist die Größe jedes Streifens.
orc.buffer.size - Der Standardwert ist 256 KB.
orc.rowindex.stride - Dies ist der ORC-Indexschritt in Anzahl der Zeilen.
Im vorherigen Kapitel haben Sie verstanden, wie Sie Tabellen in Tajo erstellen. In diesem Kapitel wird die SQL-Anweisung in Tajo erläutert.
Tabellenanweisung erstellen
Erstellen Sie vor dem Erstellen einer Tabelle eine Textdatei „students.csv“ im Pfad des Tajo-Installationsverzeichnisses wie folgt:
students.csv
| Ich würde | Name | Adresse | Alter | Markierungen |
|---|---|---|---|---|
| 1 | Adam | 23 New Street | 21 | 90 |
| 2 | Amit | 12 Alte Straße | 13 | 95 |
| 3 | Bob | 10 Cross Street | 12 | 80 |
| 4 | David | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 North Street | 12 | 55 |
| 7 | Jack | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 South Street | 12 | 70 |
| 9 | Maria | 5 West Street | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
Nachdem die Datei erstellt wurde, wechseln Sie zum Terminal und starten Sie den Tajo-Server und die Shell nacheinander.
Datenbank erstellen
Erstellen Sie eine neue Datenbank mit dem folgenden Befehl:
Abfrage
default> create database sampledb;
OKStellen Sie eine Verbindung zu der Datenbank "sampledb" her, die jetzt erstellt wird.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.Erstellen Sie dann eine Tabelle in "sampledb" wie folgt:
Abfrage
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
OKHier wird die externe Tabelle erstellt. Jetzt müssen Sie nur noch den Speicherort der Datei eingeben. Wenn Sie die Tabelle von hdfs zuweisen müssen, verwenden Sie hdfs anstelle von file.
Als nächstes die “students.csv”Datei enthält durch Kommas getrennte Werte. Dastext.delimiter Feld ist mit ',' belegt.
Sie haben "mytable" jetzt erfolgreich in "sampledb" erstellt.
Tabelle anzeigen
Verwenden Sie die folgende Abfrage, um Tabellen in Tajo anzuzeigen.
Abfrage
sampledb> \d
mytable
sampledb> \d mytableErgebnis
Die obige Abfrage generiert das folgende Ergebnis.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4Listentabelle
Geben Sie die folgende Abfrage ein, um alle Datensätze in der Tabelle abzurufen:
Abfrage
sampledb> select * from mytable;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.

Tabellenanweisung einfügen
Tajo verwendet die folgende Syntax, um Datensätze in eine Tabelle einzufügen.
Syntax
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;Tajos Einfügeanweisung ähnelt der INSERT INTO SELECT Anweisung von SQL.
Abfrage
Erstellen wir eine Tabelle, um Tabellendaten einer vorhandenen Tabelle zu überschreiben.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dErgebnis
Die obige Abfrage generiert das folgende Ergebnis.
mytable
testDatensätze einfügen
Geben Sie die folgende Abfrage ein, um Datensätze in die Testtabelle einzufügen.
Abfrage
sampledb> insert overwrite into test select * from mytable;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
Progress: 100%, response time: 0.518 secHier überschreiben "mytable" -Datensätze die "test" -Tabelle. Wenn Sie die "test" -Tabelle nicht erstellen möchten, weisen Sie sofort den physischen Pfad zu, wie in einer alternativen Option zum Einfügen von Abfragen angegeben.
Datensätze abrufen
Verwenden Sie die folgende Abfrage, um alle Datensätze in der Testtabelle aufzulisten:
Abfrage
sampledb> select * from test;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.

Diese Anweisung wird verwendet, um Spalten einer vorhandenen Tabelle hinzuzufügen, zu entfernen oder zu ändern.
Verwenden Sie zum Umbenennen der Tabelle die folgende Syntax:
Alter table table1 RENAME TO table2;Abfrage
sampledb> alter table test rename to students;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
OKVerwenden Sie die folgende Abfrage, um den geänderten Tabellennamen zu überprüfen.
sampledb> \d
mytable
studentsJetzt wird die Tabelle "Test" in die Tabelle "Schüler" geändert.
Spalte hinzufügen
Geben Sie die folgende Syntax ein, um eine neue Spalte in die Tabelle "Schüler" einzufügen:
Alter table <table_name> ADD COLUMN <column_name> <data_type>Abfrage
sampledb> alter table students add column grade text;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
OKEigenschaft festlegen
Diese Eigenschaft wird verwendet, um die Eigenschaft der Tabelle zu ändern.
Abfrage
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKHier werden Komprimierungstyp und Codec-Eigenschaften zugewiesen.
Verwenden Sie Folgendes, um die Eigenschaft des Texttrennzeichens zu ändern:
Abfrage
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKErgebnis
Die obige Abfrage generiert das folgende Ergebnis.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTDas obige Ergebnis zeigt, dass die Eigenschaften der Tabelle mithilfe der Eigenschaft "SET" geändert werden.
Wählen Sie Anweisung
Die SELECT-Anweisung wird verwendet, um Daten aus einer Datenbank auszuwählen.
Die Syntax für die Select-Anweisung lautet wie folgt:
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Wo Klausel
Die Where-Klausel wird verwendet, um Datensätze aus der Tabelle zu filtern.
Abfrage
sampledb> select * from mytable where id > 5;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
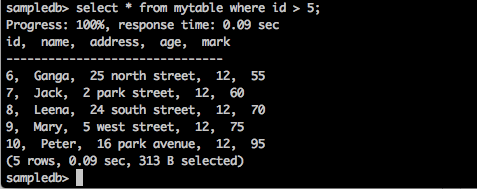
Die Abfrage gibt die Datensätze der Schüler zurück, deren ID größer als 5 ist.
Abfrage
sampledb> select * from mytable where name = ‘Peter’;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12Das Ergebnis filtert nur Peters Datensätze.
Eindeutige Klausel
Eine Tabellenspalte kann doppelte Werte enthalten. Das Schlüsselwort DISTINCT kann verwendet werden, um nur unterschiedliche (unterschiedliche) Werte zurückzugeben.
Syntax
SELECT DISTINCT column1,column2 FROM table_name;Abfrage
sampledb> select distinct age from mytable;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12Die Abfrage gibt das unterschiedliche Alter der Schüler aus zurück mytable.
Gruppieren nach Klausel
Die GROUP BY-Klausel wird in Zusammenarbeit mit der SELECT-Anweisung verwendet, um identische Daten in Gruppen anzuordnen.
Syntax
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;Abfrage
select age,sum(mark) as sumofmarks from mytable group by age;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
age, sumofmarks
-------------------------------
13, 145
12, 610In der Spalte "mytable" gibt es zwei Arten von Altersgruppen - 12 und 13. Jetzt gruppiert die Abfrage die Datensätze nach Alter und erzeugt die Summe der Noten für das entsprechende Alter der Schüler.
Klausel haben
Mit der HAVING-Klausel können Sie Bedingungen angeben, die filtern, welche Gruppenergebnisse in den Endergebnissen angezeigt werden. Die WHERE-Klausel legt Bedingungen für die ausgewählten Spalten fest, während die HAVING-Klausel Bedingungen für die durch die GROUP BY-Klausel erstellten Gruppen festlegt.
Syntax
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]Abfrage
sampledb> select age from mytable group by age having sum(mark) > 200;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
age
-------------------------------
12Die Abfrage gruppiert die Datensätze nach Alter und gibt das Alter zurück, wenn die Bedingungsergebnissumme (Markierung)> 200 ist.
Order By-Klausel
Die ORDER BY-Klausel wird verwendet, um die Daten in aufsteigender oder absteigender Reihenfolge basierend auf einer oder mehreren Spalten zu sortieren. Die Tajo-Datenbank sortiert Abfrageergebnisse standardmäßig in aufsteigender Reihenfolge.
Syntax
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];Abfrage
sampledb> select * from mytable where mark > 60 order by name desc;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.

Die Abfrage gibt die Namen der Schüler in absteigender Reihenfolge zurück, deren Noten größer als 60 sind.
Indexanweisung erstellen
Mit der Anweisung CREATE INDEX werden Indizes in Tabellen erstellt. Der Index dient zum schnellen Abrufen von Daten. Die aktuelle Version unterstützt den Index nur für einfache TEXT-Formate, die in HDFS gespeichert sind.
Syntax
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }Abfrage
create index student_index on mytable(id);Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
id
———————————————Geben Sie die folgende Abfrage ein, um den zugewiesenen Index für die Spalte anzuzeigen.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )Hier wird in Tajo standardmäßig die Methode TWO_LEVEL_BIN_TREE verwendet.
Drop Table-Anweisung
Die Anweisung "Tabelle löschen" wird verwendet, um eine Tabelle aus der Datenbank zu löschen.
Syntax
drop table table name;Abfrage
sampledb> drop table mytable;Geben Sie die folgende Abfrage ein, um zu überprüfen, ob die Tabelle aus der Tabelle entfernt wurde.
sampledb> \d mytable;Ergebnis
Die obige Abfrage generiert das folgende Ergebnis.
ERROR: relation 'mytable' does not existSie können die Abfrage auch mit dem Befehl "\ d" überprüfen, um die verfügbaren Tajo-Tabellen aufzulisten.
In diesem Kapitel werden die Aggregat- und Fensterfunktionen ausführlich erläutert.
Aggregationsfunktionen
Aggregatfunktionen erzeugen ein einzelnes Ergebnis aus einer Reihe von Eingabewerten. In der folgenden Tabelle wird die Liste der Aggregatfunktionen ausführlich beschrieben.
| S.No. | Bedienungsanleitung |
|---|---|
| 1 | AVG (exp) Mittelung einer Spalte aller Datensätze in einer Datenquelle. |
| 2 | CORR (Ausdruck1, Ausdruck2) Gibt den Korrelationskoeffizienten zwischen einer Reihe von Zahlenpaaren zurück. |
| 3 | ANZAHL() Gibt die Zahlenzeilen zurück. |
| 4 | MAX (Ausdruck) Gibt den größten Wert der ausgewählten Spalte zurück. |
| 5 | MIN (Ausdruck) Gibt den kleinsten Wert der ausgewählten Spalte zurück. |
| 6 | SUMME (Ausdruck) Gibt die Summe der angegebenen Spalte zurück. |
| 7 | LAST_VALUE (Ausdruck) Gibt den letzten Wert der angegebenen Spalte zurück. |
Fensterfunktion
Die Fensterfunktionen werden für eine Reihe von Zeilen ausgeführt und geben für jede Zeile einen einzelnen Wert aus der Abfrage zurück. Der Begriff Fenster hat die Bedeutung eines Zeilensatzes für die Funktion.
Die Fensterfunktion in einer Abfrage definiert das Fenster mithilfe der OVER () -Klausel.
Das OVER() Klausel hat die folgenden Funktionen -
- Definiert Fensterpartitionen, um Gruppen von Zeilen zu bilden. (PARTITION BY-Klausel)
- Ordnet Zeilen innerhalb einer Partition. (ORDER BY-Klausel)
In der folgenden Tabelle werden die Fensterfunktionen ausführlich beschrieben.
| Funktion | Rückgabetyp | Beschreibung |
|---|---|---|
| Rang() | int | Gibt den Rang der aktuellen Zeile mit Lücken zurück. |
| row_num () | int | Gibt die aktuelle Zeile innerhalb ihrer Partition zurück und zählt von 1. |
| Blei (Wert [, Offset Ganzzahl [, Standard beliebig]]) | Entspricht dem Eingabetyp | Gibt den Wert zurück, der in der Zeile ausgewertet wird, die Zeilen nach der aktuellen Zeile innerhalb der Partition versetzt ist. Wenn keine solche Zeile vorhanden ist, wird der Standardwert zurückgegeben. |
| Verzögerung (Wert [, Offset-Ganzzahl [, Standard beliebig]]) | Entspricht dem Eingabetyp | Gibt den Wert zurück, der in der Zeile ausgewertet wird, die Zeilen vor der aktuellen Zeile innerhalb der Partition versetzt ist. |
| first_value (Wert) | Entspricht dem Eingabetyp | Gibt den ersten Wert der Eingabezeilen zurück. |
| last_value (Wert) | Entspricht dem Eingabetyp | Gibt den letzten Wert der Eingabezeilen zurück. |
In diesem Kapitel werden die folgenden wichtigen Abfragen erläutert.
- Predicates
- Explain
- Join
Lassen Sie uns fortfahren und die Abfragen durchführen.
Prädikate
Prädikat ist ein Ausdruck, der verwendet wird, um wahre / falsche Werte und UNBEKANNT auszuwerten. Prädikate werden in der Suchbedingung von WHERE-Klauseln und HAVING-Klauseln und anderen Konstrukten verwendet, für die ein Boolescher Wert erforderlich ist.
IN Prädikat
Legt fest, ob der Wert des zu testenden Ausdrucks mit einem Wert in der Unterabfrage oder in der Liste übereinstimmt. Unterabfrage ist eine gewöhnliche SELECT-Anweisung mit einer Ergebnismenge aus einer Spalte und einer oder mehreren Zeilen. Diese Spalte oder alle Ausdrücke in der Liste müssen denselben Datentyp wie der zu testende Ausdruck haben.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
Die obige Abfrage generiert das folgende Ergebnis.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueDie Abfrage gibt Datensätze von zurück mytable für die Schüler ID 2,3 und 4.
Query
select id,name,address from mytable where id not in(2,3,4);Result
Die obige Abfrage generiert das folgende Ergebnis.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenueDie obige Abfrage gibt Datensätze von zurück mytable wo Studenten nicht in 2,3 und 4 ist.
Wie Prädikat
Das LIKE-Prädikat vergleicht die im ersten Ausdruck zur Berechnung des Zeichenfolgenwerts angegebene Zeichenfolge, die als zu testender Wert bezeichnet wird, mit dem Muster, das im zweiten Ausdruck zur Berechnung des Zeichenfolgenwerts definiert ist.
Das Muster kann eine beliebige Kombination von Platzhaltern enthalten, z.
Unterstreichen Sie das Symbol (_), das anstelle eines einzelnen Zeichens im zu testenden Wert verwendet werden kann.
Prozentzeichen (%), das eine beliebige Zeichenfolge mit null oder mehr Zeichen im zu testenden Wert ersetzt.
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
Die obige Abfrage generiert das folgende Ergebnis.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95Die Abfrage gibt Datensätze aus der mytable der Schüler zurück, deren Namen mit 'A' beginnen.
Query
select * from mytable where name like ‘_a%';Result
Die obige Abfrage generiert das folgende Ergebnis.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75Die Abfrage gibt Datensätze von zurück mytable von jenen Schülern, deren Namen mit 'a' als zweitem Zeichen beginnen.
Verwenden des NULL-Werts in Suchbedingungen
Lassen Sie uns nun verstehen, wie der NULL-Wert in den Suchbedingungen verwendet wird.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
Die obige Abfrage generiert das folgende Ergebnis.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)Hier ist das Ergebnis wahr, sodass alle Namen aus der Tabelle zurückgegeben werden.
Query
Lassen Sie uns nun die Abfrage mit der Bedingung NULL überprüfen.
default> select name from mytable where name is null;Result
Die obige Abfrage generiert das folgende Ergebnis.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)Erklären
Explainwird verwendet, um einen Abfrageausführungsplan zu erhalten. Es zeigt eine logische und globale Planausführung einer Anweisung.
Logische Planabfrage
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
Die obige Abfrage generiert das folgende Ergebnis.

Das Abfrageergebnis zeigt ein logisches Planformat für die angegebene Tabelle. Der logische Plan gibt die folgenden drei Ergebnisse zurück:
- Zielliste
- Out Schema
- Im Schema
Globale Planabfrage
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
Die obige Abfrage generiert das folgende Ergebnis.

Hier zeigt der globale Plan die Ausführungsblock-ID, die Ausführungsreihenfolge und ihre Informationen.
Tritt bei
SQL-Joins werden verwendet, um Zeilen aus zwei oder mehr Tabellen zu kombinieren. Im Folgenden sind die verschiedenen Arten von SQL-Joins aufgeführt:
- Innere Verbindung
- {LINKS | RECHTS | FULL} OUTER JOIN
- Cross Join
- Selbst beitreten
- Natürliche Verbindung
Betrachten Sie die folgenden zwei Tabellen, um Verknüpfungsvorgänge auszuführen.
Tabelle 1 - Kunden
| Ich würde | Name | Adresse | Alter |
|---|---|---|---|
| 1 | Kunde 1 | 23 Alte Straße | 21 |
| 2 | Kunde 2 | 12 New Street | 23 |
| 3 | Kunde 3 | 10 Express Avenue | 22 |
| 4 | Kunde 4 | 15 Express Avenue | 22 |
| 5 | Kunde 5 | 20 Garden Street | 33 |
| 6 | Kunde 6 | 21 North Street | 25 |
Tabelle 2 - Kundenbestellung
| Ich würde | Auftragsnummer | Emp Id |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
Lassen Sie uns nun fortfahren und die SQL-Verknüpfungsoperationen für die beiden oben genannten Tabellen ausführen.
Inner Join
Der innere Join wählt alle Zeilen aus beiden Tabellen aus, wenn zwischen den Spalten in beiden Tabellen eine Übereinstimmung besteht.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
Die obige Abfrage generiert das folgende Ergebnis.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105Die Abfrage entspricht fünf Zeilen aus beiden Tabellen. Daher wird das Alter der übereinstimmenden Zeilen aus der ersten Tabelle zurückgegeben.
Linke äußere Verbindung
Ein linker äußerer Join behält alle Zeilen der "linken" Tabelle bei, unabhängig davon, ob es eine Zeile gibt, die mit der "rechten" Tabelle übereinstimmt oder nicht.
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
Die obige Abfrage generiert das folgende Ergebnis.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,Hier gibt der linke äußere Join Namensspaltenzeilen aus der Kundentabelle (links) und Empid-Spaltenübereinstimmungszeilen aus der Tabelle customer_order (rechts) zurück.
Right Outer Join
Ein rechter äußerer Join behält alle Zeilen der "rechten" Tabelle bei, unabhängig davon, ob es eine Zeile gibt, die mit der "linken" Tabelle übereinstimmt.
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
Die obige Abfrage generiert das folgende Ergebnis.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105Hier gibt der Right Outer Join die Empid-Zeilen aus der Tabelle customer_order (rechts) und die mit der Namensspalte übereinstimmenden Zeilen aus der Kundentabelle zurück.
Volle äußere Verbindung
Der vollständige äußere Join behält alle Zeilen sowohl aus der linken als auch aus der rechten Tabelle bei.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
Die obige Abfrage generiert das folgende Ergebnis.

Die Abfrage gibt alle übereinstimmenden und nicht übereinstimmenden Zeilen sowohl aus den Tabellen customers als auch aus den Tabellen customer_order zurück.
Cross Join
Dies gibt das kartesische Produkt der Datensatzgruppen aus den zwei oder mehr verknüpften Tabellen zurück.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
Die obige Abfrage generiert das folgende Ergebnis.
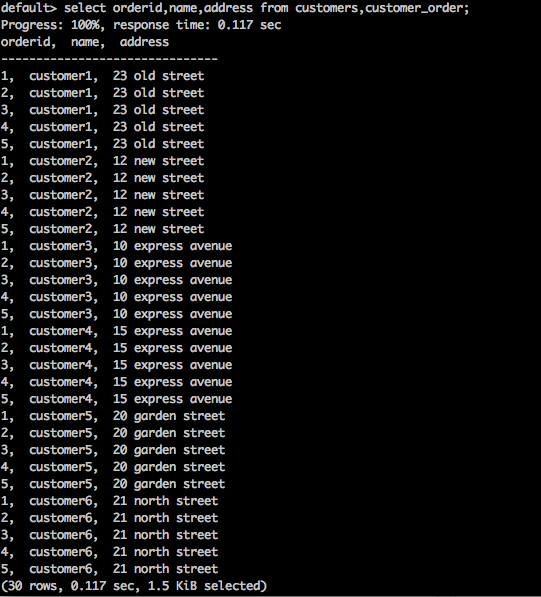
Die obige Abfrage gibt das kartesische Produkt der Tabelle zurück.
Natürliche Verbindung
Ein Natural Join verwendet keinen Vergleichsoperator. Es verkettet nicht wie ein kartesisches Produkt. Wir können eine natürliche Verknüpfung nur durchführen, wenn zwischen den beiden Beziehungen mindestens ein gemeinsames Attribut vorhanden ist.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
Die obige Abfrage generiert das folgende Ergebnis.

Hier gibt es eine gemeinsame Spalten-ID, die zwischen zwei Tabellen vorhanden ist. Unter Verwendung dieser gemeinsamen Spalte wird dieNatural Join verbindet beide Tabellen.
Selbst beitreten
Der SQL SELF JOIN wird verwendet, um eine Tabelle mit sich selbst zu verbinden, als wäre die Tabelle zwei Tabellen, wobei mindestens eine Tabelle in der SQL-Anweisung vorübergehend umbenannt wird.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
Die obige Abfrage generiert das folgende Ergebnis.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6Die Abfrage verbindet eine Kundentabelle mit sich selbst.
Tajo unterstützt verschiedene Speicherformate. Um die Konfiguration des Speicher-Plugins zu registrieren, sollten Sie die Änderungen zur Konfigurationsdatei "storage-site.json" hinzufügen.
storage-site.json
Die Struktur ist wie folgt definiert:
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}Jede Speicherinstanz wird durch URI identifiziert.
PostgreSQL Storage Handler
Tajo unterstützt den PostgreSQL-Speicherhandler. Benutzerabfragen können auf Datenbankobjekte in PostgreSQL zugreifen. Es ist der Standard-Speicherhandler in Tajo, sodass Sie ihn einfach konfigurieren können.
Aufbau
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}Hier, “database1” bezieht sich auf postgreSQL Datenbank, die der Datenbank zugeordnet ist “sampledb” in Tajo.
Apache Tajo unterstützt die HBase-Integration. Dies ermöglicht uns den Zugriff auf HBase-Tabellen in Tajo. HBase ist eine verteilte spaltenorientierte Datenbank, die auf dem Hadoop-Dateisystem basiert. Es ist Teil des Hadoop-Ökosystems, das zufälligen Lese- / Schreibzugriff in Echtzeit auf Daten im Hadoop-Dateisystem bietet. Die folgenden Schritte sind erforderlich, um die HBase-Integration zu konfigurieren.
Umgebungsvariable festlegen
Fügen Sie der Datei "conf / tajo-env.sh" die folgenden Änderungen hinzu.
$ vi conf/tajo-env.sh
# HBase home directory. It is opitional but is required mandatorily to use HBase.
# export HBASE_HOME = path/to/HBaseNachdem Sie den HBase-Pfad eingefügt haben, setzt Tajo die HBase-Bibliotheksdatei auf den Klassenpfad.
Erstellen Sie eine externe Tabelle
Erstellen Sie eine externe Tabelle mit der folgenden Syntax:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;Um auf HBase-Tabellen zugreifen zu können, müssen Sie den Tablespace-Speicherort konfigurieren.
Hier,
Table- Legen Sie den Namen der hbase-Ursprungstabelle fest. Wenn Sie eine externe Tabelle erstellen möchten, muss die Tabelle in HBase vorhanden sein.
Columns- Schlüssel bezieht sich auf den HBase-Zeilenschlüssel. Die Anzahl der Spalteneinträge muss der Anzahl der Tajo-Tabellenspalten entsprechen.
hbase.zookeeper.quorum - Legen Sie die Quorumadresse des Tierpflegers fest.
hbase.zookeeper.property.clientPort - Stellen Sie den Zookeeper-Client-Port ein.
Query
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';Hier legt das Feld Standortpfad die Port-ID des Zookeeper-Clients fest. Wenn Sie den Port nicht festlegen, verweist Tajo auf die Eigenschaft der Datei hbase-site.xml.
Tabelle in HBase erstellen
Sie können die interaktive HBase-Shell mit dem Befehl "hbase shell" starten, wie in der folgenden Abfrage gezeigt.
Query
/bin/hbase shellResult
Die obige Abfrage generiert das folgende Ergebnis.
hbase(main):001:0>Schritte zum Abfragen von HBase
Um HBase abzufragen, müssen Sie die folgenden Schritte ausführen:
Step 1 - Leiten Sie die folgenden Befehle an die HBase-Shell, um eine "Tutorial" -Tabelle zu erstellen.
Query
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'Step 2 - Geben Sie nun den folgenden Befehl in der hbase-Shell ein, um die Daten in eine Tabelle zu laden.
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shellStep 3 - Kehren Sie nun zur Tajo-Shell zurück und führen Sie den folgenden Befehl aus, um die Metadaten der Tabelle anzuzeigen. -
default> \d students;
table name: default.students
table path:
store type: HBASE
number of rows: unknown
volume: 0 B
Options:
'columns' = ':key,info:id,content:name'
'table' = 'students'
schema:
rowkey TEXT
id INT4
name TEXTStep 4 - Um die Ergebnisse aus der Tabelle abzurufen, verwenden Sie die folgende Abfrage:
Query
default> select * from studentsResult
Die obige Abfrage ruft das folgende Ergebnis ab:
rowkey, id, name
-------------------------------
row-01, 001, Adam
row-02, 002, Amit
row-03 003, BobTajo unterstützt den HiveCatalogStore für die Integration in Apache Hive. Diese Integration ermöglicht Tajo den Zugriff auf Tabellen in Apache Hive.
Umgebungsvariable festlegen
Fügen Sie der Datei "conf / tajo-env.sh" die folgenden Änderungen hinzu.
$ vi conf/tajo-env.sh
export HIVE_HOME = /path/to/hiveNachdem Sie den Hive-Pfad eingefügt haben, setzt Tajo die Hive-Bibliotheksdatei auf den Klassenpfad.
Katalogkonfiguration
Fügen Sie der Datei "conf / catalog-site.xml" die folgenden Änderungen hinzu.
$ vi conf/catalog-site.xml
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HiveCatalogStore</value>
</property>Sobald der HiveCatalogStore konfiguriert ist, können Sie in Tajo auf die Tabelle von Hive zugreifen.
Swift ist ein verteilter und konsistenter Objekt- / Blob-Speicher. Swift bietet Cloud-Speichersoftware an, mit der Sie viele Daten mit einer einfachen API speichern und abrufen können. Tajo unterstützt die Swift-Integration.
Das Folgende sind die Voraussetzungen für eine schnelle Integration -
- Swift
- Hadoop
Core-site.xml
Fügen Sie der hadoop-Datei "core-site.xml" die folgenden Änderungen hinzu:
<property>
<name>fs.swift.impl</name>
<value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value>
<description>File system implementation for Swift</description>
</property>
<property>
<name>fs.swift.blocksize</name>
<value>131072</value>
<description>Split size in KB</description>
</property>Dies wird für Hadoop verwendet, um auf die Swift-Objekte zuzugreifen. Nachdem Sie alle Änderungen vorgenommen haben, wechseln Sie in das Tajo-Verzeichnis, um die Umgebungsvariable Swift festzulegen.
conf / tajo-env.h
Öffnen Sie die Tajo-Konfigurationsdatei und fügen Sie die Umgebungsvariable wie folgt hinzu:
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jarJetzt kann Tajo die Daten mit Swift abfragen.
Tabelle erstellen
Erstellen wir eine externe Tabelle, um wie folgt auf Swift-Objekte in Tajo zuzugreifen:
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';Nachdem die Tabelle erstellt wurde, können Sie die SQL-Abfragen ausführen.
Apache Tajo bietet eine JDBC-Schnittstelle zum Verbinden und Ausführen von Abfragen. Wir können dieselbe JDBC-Schnittstelle verwenden, um Tajo von unserer Java-basierten Anwendung aus zu verbinden. Lassen Sie uns nun verstehen, wie Sie Tajo verbinden und die Befehle in unserer Java-Beispielanwendung mithilfe der JDBC-Schnittstelle in diesem Abschnitt ausführen.
Laden Sie den JDBC-Treiber herunter
Laden Sie den JDBC-Treiber herunter, indem Sie den folgenden Link besuchen: http://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar.
Jetzt wurde die Datei "tajo-jdbc-0.11.3.jar" auf Ihren Computer heruntergeladen.
Klassenpfad festlegen
Um den JDBC-Treiber in Ihrem Programm zu verwenden, legen Sie den Klassenpfad wie folgt fest:
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATHVerbinde dich mit Tajo
Apache Tajo stellt einen JDBC-Treiber als einzelne JAR-Datei zur Verfügung und ist verfügbar @ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar.
Die Verbindungszeichenfolge zum Verbinden des Apache Tajo hat das folgende Format:
jdbc:tajo://host/
jdbc:tajo://host/database
jdbc:tajo://host:port/
jdbc:tajo://host:port/databaseHier,
host - Der Hostname des TajoMaster.
port- Die Portnummer, die der Server abhört. Die Standardportnummer ist 26002.
database- Der Datenbankname. Der Standarddatenbankname ist Standard.
Java-Anwendung
Lassen Sie uns nun die Java-Anwendung verstehen.
Codierung
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo://localhost/default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}Die Anwendung kann mit den folgenden Befehlen kompiliert und ausgeführt werden.
Zusammenstellung
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.javaAusführung
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSampleErgebnis
Die obigen Befehle erzeugen das folgende Ergebnis:
ID: 1;
Name: Adam
ID: 2;
Name: Amit
ID: 3;
Name: Bob
ID: 4;
Name: David
ID: 5;
Name: Esha
ID: 6;
Name: Ganga
ID: 7;
Name: Jack
ID: 8;
Name: Leena
ID: 9;
Name: Mary
ID: 10;
Name: PeterApache Tajo unterstützt die benutzerdefinierten / benutzerdefinierten Funktionen (UDFs). Die benutzerdefinierten Funktionen können in Python erstellt werden.
Die benutzerdefinierten Funktionen sind einfach Python-Funktionen mit Decorator “@output_type(<tajo sql datatype>)” wie folgt -
@ouput_type(“integer”)
def sum_py(a, b):
return a + b;Die Python-Skripte mit UDFs können durch Hinzufügen der folgenden Konfiguration in registriert werden “tajosite.xml”.
<property>
<name>tajo.function.python.code-dir</name>
<value>file:///path/to/script1.py,file:///path/to/script2.py</value>
</property>Sobald die Skripte registriert sind, starten Sie den Cluster neu und die UDFs sind direkt in der SQL-Abfrage wie folgt verfügbar:
select sum_py(10, 10) as pyfn;Apache Tajo unterstützt auch benutzerdefinierte Aggregatfunktionen, jedoch keine benutzerdefinierten Fensterfunktionen.