Apache Tajo - SQL-Abfragen
In diesem Kapitel werden die folgenden wichtigen Abfragen erläutert.
- Predicates
- Explain
- Join
Lassen Sie uns fortfahren und die Abfragen durchführen.
Prädikate
Prädikat ist ein Ausdruck, der verwendet wird, um wahre / falsche Werte und UNBEKANNT auszuwerten. Prädikate werden in der Suchbedingung von WHERE-Klauseln und HAVING-Klauseln und anderen Konstrukten verwendet, für die ein Boolescher Wert erforderlich ist.
IN Prädikat
Legt fest, ob der Wert des zu testenden Ausdrucks mit einem Wert in der Unterabfrage oder in der Liste übereinstimmt. Unterabfrage ist eine gewöhnliche SELECT-Anweisung mit einer Ergebnismenge aus einer Spalte und einer oder mehreren Zeilen. Diese Spalte oder alle Ausdrücke in der Liste müssen denselben Datentyp wie der zu testende Ausdruck haben.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
Die obige Abfrage generiert das folgende Ergebnis.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueDie Abfrage gibt Datensätze von zurück mytable für die Schüler ID 2,3 und 4.
Query
select id,name,address from mytable where id not in(2,3,4);Result
Die obige Abfrage generiert das folgende Ergebnis.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenueDie obige Abfrage gibt Datensätze von zurück mytable wo Studenten nicht in 2,3 und 4 ist.
Wie Prädikat
Das LIKE-Prädikat vergleicht die im ersten Ausdruck zur Berechnung des Zeichenfolgenwerts angegebene Zeichenfolge, die als zu testender Wert bezeichnet wird, mit dem Muster, das im zweiten Ausdruck zur Berechnung des Zeichenfolgenwerts definiert ist.
Das Muster kann eine beliebige Kombination von Platzhaltern enthalten, z.
Unterstreichen Sie das Symbol (_), das anstelle eines einzelnen Zeichens im zu testenden Wert verwendet werden kann.
Prozentzeichen (%), das eine beliebige Zeichenfolge mit null oder mehr Zeichen im zu testenden Wert ersetzt.
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
Die obige Abfrage generiert das folgende Ergebnis.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95Die Abfrage gibt Datensätze aus der mytable der Schüler zurück, deren Namen mit 'A' beginnen.
Query
select * from mytable where name like ‘_a%';Result
Die obige Abfrage generiert das folgende Ergebnis.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75Die Abfrage gibt Datensätze von zurück mytable von jenen Schülern, deren Namen mit 'a' als zweitem Zeichen beginnen.
Verwenden des NULL-Werts in Suchbedingungen
Lassen Sie uns nun verstehen, wie der NULL-Wert in den Suchbedingungen verwendet wird.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
Die obige Abfrage generiert das folgende Ergebnis.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)Hier ist das Ergebnis wahr, sodass alle Namen aus der Tabelle zurückgegeben werden.
Query
Lassen Sie uns nun die Abfrage mit der Bedingung NULL überprüfen.
default> select name from mytable where name is null;Result
Die obige Abfrage generiert das folgende Ergebnis.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)Erklären
Explainwird verwendet, um einen Abfrageausführungsplan zu erhalten. Es zeigt eine logische und globale Planausführung einer Anweisung.
Logische Planabfrage
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
Die obige Abfrage generiert das folgende Ergebnis.

Das Abfrageergebnis zeigt ein logisches Planformat für die angegebene Tabelle. Der logische Plan gibt die folgenden drei Ergebnisse zurück:
- Zielliste
- Out Schema
- Im Schema
Globale Planabfrage
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
Die obige Abfrage generiert das folgende Ergebnis.

Hier zeigt der globale Plan die Ausführungsblock-ID, die Ausführungsreihenfolge und ihre Informationen.
Tritt bei
SQL-Joins werden verwendet, um Zeilen aus zwei oder mehr Tabellen zu kombinieren. Im Folgenden sind die verschiedenen Arten von SQL-Joins aufgeführt:
- Innere Verbindung
- {LINKS | RECHTS | FULL} OUTER JOIN
- Cross Join
- Selbst beitreten
- Natürliche Verbindung
Betrachten Sie die folgenden zwei Tabellen, um Verknüpfungsvorgänge auszuführen.
Tabelle 1 - Kunden
| Ich würde | Name | Adresse | Alter |
|---|---|---|---|
| 1 | Kunde 1 | 23 Alte Straße | 21 |
| 2 | Kunde 2 | 12 New Street | 23 |
| 3 | Kunde 3 | 10 Express Avenue | 22 |
| 4 | Kunde 4 | 15 Express Avenue | 22 |
| 5 | Kunde 5 | 20 Garden Street | 33 |
| 6 | Kunde 6 | 21 North Street | 25 |
Tabelle 2 - Kundenbestellung
| Ich würde | Auftragsnummer | Emp Id |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
Lassen Sie uns nun fortfahren und die SQL-Verknüpfungsoperationen für die beiden oben genannten Tabellen ausführen.
Inner Join
Der innere Join wählt alle Zeilen aus beiden Tabellen aus, wenn zwischen den Spalten in beiden Tabellen eine Übereinstimmung besteht.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
Die obige Abfrage generiert das folgende Ergebnis.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105Die Abfrage entspricht fünf Zeilen aus beiden Tabellen. Daher wird das Alter der übereinstimmenden Zeilen aus der ersten Tabelle zurückgegeben.
Linke äußere Verbindung
Ein linker äußerer Join behält alle Zeilen der "linken" Tabelle bei, unabhängig davon, ob es eine Zeile gibt, die mit der "rechten" Tabelle übereinstimmt oder nicht.
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
Die obige Abfrage generiert das folgende Ergebnis.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,Hier gibt der linke äußere Join Namensspaltenzeilen aus der Kundentabelle (links) und Empid-Spaltenübereinstimmungszeilen aus der Tabelle customer_order (rechts) zurück.
Right Outer Join
Ein rechter äußerer Join behält alle Zeilen der "rechten" Tabelle bei, unabhängig davon, ob es eine Zeile gibt, die mit der "linken" Tabelle übereinstimmt.
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
Die obige Abfrage generiert das folgende Ergebnis.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105Hier gibt der Right Outer Join die Empid-Zeilen aus der Tabelle customer_order (rechts) und die mit der Namensspalte übereinstimmenden Zeilen aus der Kundentabelle zurück.
Volle äußere Verbindung
Der vollständige äußere Join behält alle Zeilen sowohl aus der linken als auch aus der rechten Tabelle bei.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
Die obige Abfrage generiert das folgende Ergebnis.

Die Abfrage gibt alle übereinstimmenden und nicht übereinstimmenden Zeilen sowohl aus den Kunden- als auch aus den Kundenbestelltabellen zurück.
Cross Join
Dies gibt das kartesische Produkt der Datensätze aus den zwei oder mehr verknüpften Tabellen zurück.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
Die obige Abfrage generiert das folgende Ergebnis.
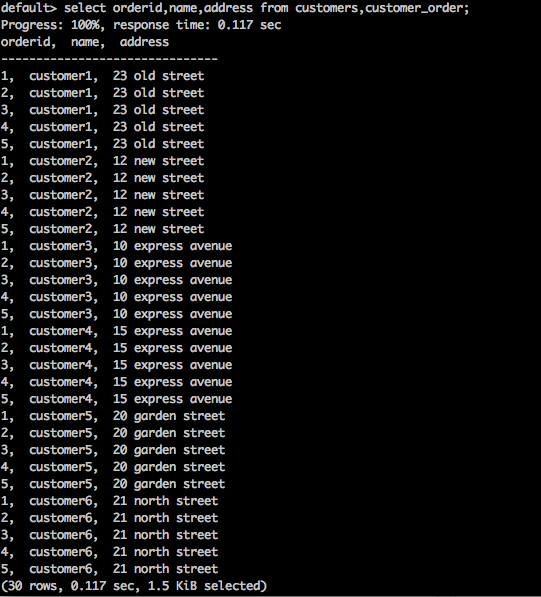
Die obige Abfrage gibt das kartesische Produkt der Tabelle zurück.
Natürliche Verbindung
Ein Natural Join verwendet keinen Vergleichsoperator. Es verkettet nicht wie ein kartesisches Produkt. Wir können eine natürliche Verknüpfung nur durchführen, wenn zwischen den beiden Beziehungen mindestens ein gemeinsames Attribut vorhanden ist.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
Die obige Abfrage generiert das folgende Ergebnis.

Hier gibt es eine gemeinsame Spalten-ID, die zwischen zwei Tabellen vorhanden ist. Unter Verwendung dieser gemeinsamen Spalte wird dieNatural Join verbindet beide Tabellen.
Selbst beitreten
Der SQL SELF JOIN wird verwendet, um eine Tabelle mit sich selbst zu verbinden, als wäre die Tabelle zwei Tabellen, wobei mindestens eine Tabelle in der SQL-Anweisung vorübergehend umbenannt wird.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
Die obige Abfrage generiert das folgende Ergebnis.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6Die Abfrage verknüpft eine Kundentabelle mit sich selbst.