Künstliche Intelligenz - Kurzanleitung
Seit der Erfindung von Computern oder Maschinen nahm ihre Fähigkeit, verschiedene Aufgaben auszuführen, exponentiell zu. Menschen haben die Leistungsfähigkeit von Computersystemen in Bezug auf ihre unterschiedlichen Arbeitsbereiche, ihre zunehmende Geschwindigkeit und ihre zeitliche Verringerung der Größe entwickelt.
Ein Zweig der Informatik namens Künstliche Intelligenz verfolgt die Schaffung von Computern oder Maschinen, die so intelligent sind wie Menschen.
Was ist künstliche Intelligenz?
Laut dem Vater der künstlichen Intelligenz, John McCarthy, ist es „die Wissenschaft und Technik, intelligente Maschinen herzustellen, insbesondere intelligente Computerprogramme“.
Künstliche Intelligenz ist ein Weg von making a computer, a computer-controlled robot, or a software think intelligentlyIn ähnlicher Weise denken die intelligenten Menschen.
KI wird erreicht, indem untersucht wird, wie das menschliche Gehirn denkt und wie Menschen lernen, entscheiden und arbeiten, während sie versuchen, ein Problem zu lösen, und dann die Ergebnisse dieser Studie als Grundlage für die Entwicklung intelligenter Software und Systeme verwendet werden.
Philosophie der KI
Während er die Kraft der Computersysteme und die Neugier des Menschen ausnutzte, fragte er sich: „Kann eine Maschine so denken und sich so verhalten wie Menschen?“
Daher begann die Entwicklung der KI mit der Absicht, ähnliche Intelligenz in Maschinen zu erzeugen, die wir beim Menschen als hoch empfinden und betrachten.
Ziele der KI
To Create Expert Systems - Die Systeme, die intelligentes Verhalten zeigen, lernen, demonstrieren, erklären und beraten ihre Benutzer.
To Implement Human Intelligence in Machines - Schaffung von Systemen, die Menschen verstehen, denken, lernen und sich wie Menschen verhalten.
Was trägt zur KI bei?
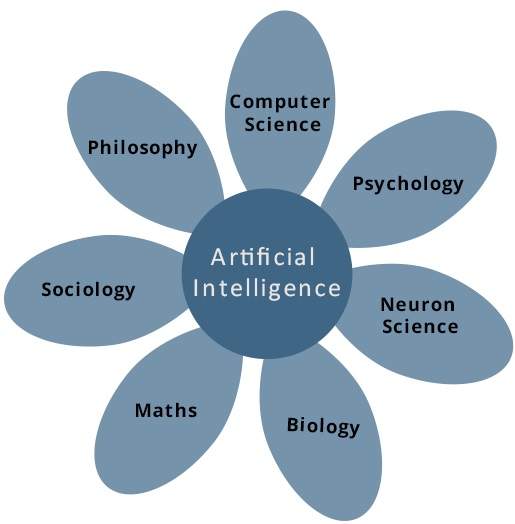
Künstliche Intelligenz ist eine Wissenschaft und Technologie, die auf Disziplinen wie Informatik, Biologie, Psychologie, Linguistik, Mathematik und Ingenieurwissenschaften basiert. Ein Hauptschwerpunkt der KI liegt in der Entwicklung von Computerfunktionen, die mit der menschlichen Intelligenz verbunden sind, wie z. B. Denken, Lernen und Problemlösen.
Aus den folgenden Bereichen können ein oder mehrere Bereiche zum Aufbau eines intelligenten Systems beitragen.
Programmieren ohne und mit KI
Die Programmierung ohne und mit KI unterscheidet sich folgendermaßen:
| Programmieren ohne KI | Programmieren mit AI |
|---|---|
| Ein Computerprogramm ohne KI kann das beantworten specific Fragen, die es lösen soll. | Ein Computerprogramm mit KI kann das beantworten generic Fragen, die es lösen soll. |
| Änderungen im Programm führen zu Änderungen in der Struktur. | KI-Programme können neue Änderungen aufnehmen, indem sie sehr unabhängige Informationen zusammenstellen. Daher können Sie auch nur eine winzige Information des Programms ändern, ohne dessen Struktur zu beeinflussen. |
| Änderungen sind nicht schnell und einfach. Dies kann zu nachteiligen Auswirkungen auf das Programm führen. | Schnelle und einfache Programmänderung. |
Was ist KI-Technik?
In der realen Welt hat das Wissen einige unerwünschte Eigenschaften -
- Sein Volumen ist riesig, fast unvorstellbar.
- Es ist nicht gut organisiert oder gut formatiert.
- Es ändert sich ständig.
KI-Technik ist eine Möglichkeit, das Wissen so zu organisieren und effizient zu nutzen, dass -
- Es sollte für die Menschen, die es bereitstellen, wahrnehmbar sein.
- Es sollte leicht zu ändern sein, um Fehler zu korrigieren.
- Es sollte in vielen Situationen nützlich sein, obwohl es unvollständig oder ungenau ist.
KI-Techniken erhöhen die Ausführungsgeschwindigkeit des komplexen Programms, mit dem es ausgestattet ist.
Anwendungen von AI
KI war in verschiedenen Bereichen dominant wie -
Gaming - KI spielt eine entscheidende Rolle in strategischen Spielen wie Schach, Poker, Tic-Tac-Toe usw., bei denen die Maschine aufgrund heuristischer Kenntnisse an eine große Anzahl möglicher Positionen denken kann.
Natural Language Processing - Es ist möglich, mit dem Computer zu interagieren, der die vom Menschen gesprochene natürliche Sprache versteht.
Expert Systems- Es gibt einige Anwendungen, die Maschinen, Software und spezielle Informationen integrieren, um Argumentation und Beratung zu vermitteln. Sie bieten den Benutzern Erklärungen und Ratschläge.
Vision Systems- Diese Systeme verstehen, interpretieren und verstehen visuelle Eingaben auf dem Computer. Zum Beispiel,
Ein Spionageflugzeug macht Fotos, mit denen räumliche Informationen oder Karten der Gebiete ermittelt werden.
Ärzte verwenden ein klinisches Expertensystem, um den Patienten zu diagnostizieren.
Die Polizei verwendet Computersoftware, die das Gesicht eines Verbrechers anhand des von einem forensischen Künstler erstellten Porträts erkennen kann.
Speech Recognition- Einige intelligente Systeme sind in der Lage, die Sprache in Form von Sätzen und deren Bedeutung zu hören und zu verstehen, während ein Mensch mit ihr spricht. Es kann mit verschiedenen Akzenten, Slang-Wörtern, Hintergrundgeräuschen, Veränderungen des menschlichen Geräusches aufgrund von Kälte usw. umgehen.
Handwriting Recognition- Die Handschrifterkennungssoftware liest den Text, der mit einem Stift auf Papier oder mit einem Stift auf dem Bildschirm geschrieben wurde. Es kann die Formen der Buchstaben erkennen und in bearbeitbaren Text umwandeln.
Intelligent Robots- Roboter können die von einem Menschen gestellten Aufgaben ausführen. Sie verfügen über Sensoren zur Erfassung physikalischer Daten aus der realen Welt wie Licht, Wärme, Temperatur, Bewegung, Schall, Stoß und Druck. Sie verfügen über effiziente Prozessoren, mehrere Sensoren und einen riesigen Speicher, um Intelligenz zu zeigen. Darüber hinaus können sie aus ihren Fehlern lernen und sich an die neue Umgebung anpassen.
Geschichte der KI
Hier ist die Geschichte der KI im 20. Jahrhundert -
| Jahr | Meilenstein / Innovation |
|---|---|
| 1923 | Das Karel Čapek-Stück mit dem Titel „Rossums Universal Robots“ (RUR) wird in London eröffnet und verwendet erstmals das englische Wort „Roboter“. |
| 1943 | Grundsteinlegung für neuronale Netze. |
| 1945 | Isaac Asimov, ein Alumni der Columbia University, prägte den Begriff Robotik . |
| 1950 | Alan Turing führte den Turing-Test zur Bewertung von Informationen ein und veröffentlichte Computing Machinery and Intelligence. Claude Shannon veröffentlichte eine detaillierte Analyse des Schachspiels als Suche. |
| 1956 | John McCarthy prägte den Begriff Künstliche Intelligenz . Demonstration des ersten laufenden KI-Programms an der Carnegie Mellon University. |
| 1958 | John McCarthy erfindet die Programmiersprache LISP für AI. |
| 1964 | Danny Bobrows Dissertation am MIT zeigte, dass Computer die natürliche Sprache gut genug verstehen können, um Algebra-Wortprobleme richtig zu lösen. |
| 1965 | Joseph Weizenbaum vom MIT baute ELIZA , ein interaktives Problem, das einen Dialog auf Englisch führt. |
| 1969 | Wissenschaftler des Stanford Research Institute entwickelten Shakey , einen Roboter, der mit Fortbewegung, Wahrnehmung und Problemlösung ausgestattet ist. |
| 1973 | Die Assembly Robotics-Gruppe an der Universität von Edinburgh baute Freddy , den berühmten schottischen Roboter, der mithilfe von Visionen Modelle lokalisieren und zusammenbauen kann. |
| 1979 | Das erste computergesteuerte autonome Fahrzeug, Stanford Cart, wurde gebaut. |
| 1985 | Harold Cohen erstellte und demonstrierte das Zeichenprogramm Aaron . |
| 1990 | Wichtige Fortschritte in allen Bereichen der KI -
|
| 1997 | Das Deep Blue Chess Program schlägt den damaligen Schachweltmeister Garry Kasparov. |
| 2000 | Interaktive Roboter-Haustiere werden im Handel erhältlich. Das MIT zeigt Kismet , einen Roboter mit einem Gesicht, das Emotionen ausdrückt. Der Roboter Nomad erkundet abgelegene Regionen der Antarktis und lokalisiert Meteoriten. |
Während Sie künstliche Intelligenz studieren, müssen Sie wissen, was Intelligenz ist. Dieses Kapitel behandelt die Idee der Intelligenz, Typen und Komponenten der Intelligenz.
Was ist Intelligenz?
Die Fähigkeit eines Systems, Beziehungen und Analogien zu berechnen, zu begründen, wahrzunehmen, aus Erfahrungen zu lernen, Informationen aus dem Gedächtnis zu speichern und abzurufen, Probleme zu lösen, komplexe Ideen zu verstehen, die natürliche Sprache fließend zu verwenden, neue Situationen zu klassifizieren, zu verallgemeinern und anzupassen.
Arten von Intelligenz
Wie von Howard Gardner, einem amerikanischen Entwicklungspsychologen, beschrieben, ist die Intelligenz vielfältig -
| Intelligenz | Beschreibung | Beispiel |
|---|---|---|
| Sprachliche Intelligenz | Die Fähigkeit, Mechanismen der Phonologie (Sprachlaute), Syntax (Grammatik) und Semantik (Bedeutung) zu sprechen, zu erkennen und zu verwenden. | Erzähler, Redner |
| Musikalische Intelligenz | Die Fähigkeit, Bedeutungen aus Klang, Tonhöhe und Rhythmus zu erschaffen, mit ihnen zu kommunizieren und sie zu verstehen. | Musiker, Sänger, Komponisten |
| Logisch-mathematische Intelligenz | Die Fähigkeit, Beziehungen ohne Handlungen oder Objekte zu nutzen und zu verstehen. Komplexe und abstrakte Ideen verstehen. | Mathematiker, Wissenschaftler |
| Räumliche Intelligenz | Die Fähigkeit, visuelle oder räumliche Informationen wahrzunehmen, zu ändern und visuelle Bilder ohne Bezug auf die Objekte neu zu erstellen, 3D-Bilder zu erstellen und sie zu verschieben und zu drehen. | Kartenleser, Astronauten, Physiker |
| Körperlich-kinästhetische Intelligenz | Die Fähigkeit, den gesamten Körper oder einen Teil davon zu verwenden, um Probleme oder Modeprodukte zu lösen, die Fein- und Grobmotorik zu kontrollieren und die Objekte zu manipulieren. | Spieler, Tänzer |
| Intrapersonelle Intelligenz | Die Fähigkeit, zwischen eigenen Gefühlen, Absichten und Motivationen zu unterscheiden. | Gautam Buddhha |
| Zwischenmenschliche Intelligenz | Die Fähigkeit, die Gefühle, Überzeugungen und Absichten anderer Menschen zu erkennen und zu unterscheiden. | Massenkommunikatoren, Interviewer |
Man kann sagen, eine Maschine oder ein System ist artificially intelligent wenn es mit mindestens einer und höchstens allen darin enthaltenen Intelligenzen ausgestattet ist.
Woraus besteht Intelligenz?
Die Intelligenz ist nicht greifbar. Es besteht aus -
- Reasoning
- Learning
- Probleme lösen
- Perception
- Sprachliche Intelligenz

Lassen Sie uns alle Komponenten kurz durchgehen -
Reasoning- Es ist die Reihe von Prozessen, die es uns ermöglichen, eine Grundlage für die Beurteilung, Entscheidungsfindung und Vorhersage zu schaffen. Es gibt im Allgemeinen zwei Arten -
| Induktives Denken | Deduktives Denken |
|---|---|
| Es führt spezifische Beobachtungen durch, um allgemeine Aussagen zu treffen. | Es beginnt mit einer allgemeinen Aussage und untersucht die Möglichkeiten, zu einer bestimmten, logischen Schlussfolgerung zu gelangen. |
| Selbst wenn alle Prämissen in einer Aussage wahr sind, lässt das induktive Denken zu, dass die Schlussfolgerung falsch ist. | Wenn etwas für eine Klasse von Dingen im Allgemeinen gilt, gilt dies auch für alle Mitglieder dieser Klasse. |
| Beispiel - "Nita ist eine Lehrerin. Nita ist fleißig. Deshalb sind alle Lehrer fleißig." | Beispiel - "Alle Frauen über 60 Jahre sind Großmütter. Shalini ist 65 Jahre alt. Daher ist Shalini eine Großmutter." |
Learning- Es ist die Aktivität, Wissen oder Fähigkeiten zu erwerben, indem man etwas studiert, übt, unterrichtet oder erlebt. Lernen erhöht das Bewusstsein für die Themen der Studie.
Die Fähigkeit zum Lernen besitzen Menschen, einige Tiere und KI-fähige Systeme. Lernen wird kategorisiert als -
Auditory Learning- Es lernt durch Zuhören und Hören. Zum Beispiel Schüler, die aufgezeichnete Audiovorträge hören.
Episodic Learning- Lernen, indem man sich an Sequenzen von Ereignissen erinnert, die man gesehen oder erlebt hat. Dies ist linear und geordnet.
Motor Learning- Es lernt durch präzise Bewegung der Muskeln. Zum Beispiel Objekte auswählen, schreiben usw.
Observational Learning- Lernen, indem man andere beobachtet und nachahmt. Zum Beispiel versucht das Kind zu lernen, indem es seine Eltern nachahmt.
Perceptual Learning- Es lernt, Reize zu erkennen, die man zuvor gesehen hat. Zum Beispiel das Identifizieren und Klassifizieren von Objekten und Situationen.
Relational Learning- Es geht darum zu lernen, zwischen verschiedenen Reizen anhand relationaler Eigenschaften und nicht anhand absoluter Eigenschaften zu unterscheiden. Zum Beispiel das Hinzufügen von "etwas weniger" Salz zum Zeitpunkt des Kochens von Kartoffeln, die beim letzten Mal salzig wurden, wenn sie mit dem Hinzufügen eines Esslöffels Salz gekocht wurden.
Spatial Learning - Es lernt durch visuelle Reize wie Bilder, Farben, Karten usw. Zum Beispiel kann eine Person eine Roadmap erstellen, bevor sie der Straße tatsächlich folgt.
Stimulus-Response Learning- Es lernt, ein bestimmtes Verhalten auszuführen, wenn ein bestimmter Reiz vorhanden ist. Zum Beispiel hebt ein Hund sein Ohr, wenn er eine Türklingel hört.
Problem Solving - Es ist der Prozess, in dem man aus einer gegenwärtigen Situation heraus eine gewünschte Lösung wahrnimmt und versucht, indem man einen Weg nimmt, der durch bekannte oder unbekannte Hürden blockiert ist.
Problemlösung umfasst auch decision makingDies ist der Prozess der Auswahl der am besten geeigneten Alternative aus mehreren Alternativen, um das gewünschte Ziel zu erreichen.
Perception - Es ist der Prozess des Erfassens, Interpretierens, Auswählens und Organisierens sensorischer Informationen.
Wahrnehmung setzt voraus sensing. Beim Menschen wird die Wahrnehmung durch Sinnesorgane unterstützt. Im Bereich der KI setzt der Wahrnehmungsmechanismus die von den Sensoren erfassten Daten auf sinnvolle Weise zusammen.
Linguistic Intelligence- Es ist die Fähigkeit, die verbale und geschriebene Sprache zu benutzen, zu verstehen, zu sprechen und zu schreiben. Es ist wichtig in der zwischenmenschlichen Kommunikation.
Unterschied zwischen menschlicher und maschineller Intelligenz
Menschen nehmen durch Muster wahr, während die Maschinen durch Regeln und Daten wahrnehmen.
Menschen speichern und rufen Informationen nach Mustern ab, Maschinen tun dies, indem sie nach Algorithmen suchen. Zum Beispiel ist die Nummer 40404040 leicht zu merken, zu speichern und abzurufen, da ihr Muster einfach ist.
Menschen können das gesamte Objekt herausfinden, selbst wenn ein Teil davon fehlt oder verzerrt ist. wohingegen die Maschinen es nicht richtig machen können.
Die Domäne der künstlichen Intelligenz ist in Breite und Breite riesig. Während wir fortfahren, betrachten wir die allgemein verbreiteten und prosperierenden Forschungsbereiche im Bereich der KI -

Sprach- und Spracherkennung
Diese beiden Begriffe sind in der Robotik, in Expertensystemen und in der Verarbeitung natürlicher Sprache üblich. Obwohl diese Begriffe synonym verwendet werden, unterscheiden sich ihre Ziele.
| Spracherkennung | Spracherkennung |
|---|---|
| The speech recognition aims at understanding and comprehending WHAT was spoken. | The objective of voice recognition is to recognize WHO is speaking. |
| It is used in hand-free computing, map, or menu navigation. | It is used to identify a person by analysing its tone, voice pitch, and accent, etc. |
| Machine does not need training for Speech Recognition as it is not speaker dependent. | This recognition system needs training as it is person oriented. |
| Speaker independent Speech Recognition systems are difficult to develop. | Speaker dependent Speech Recognition systems are comparatively easy to develop. |
Working of Speech and Voice Recognition Systems
The user input spoken at a microphone goes to sound card of the system. The converter turns the analog signal into equivalent digital signal for the speech processing. The database is used to compare the sound patterns to recognize the words. Finally, a reverse feedback is given to the database.
This source-language text becomes input to the Translation Engine, which converts it to the target language text. They are supported with interactive GUI, large database of vocabulary, etc.
Real Life Applications of Research Areas
There is a large array of applications where AI is serving common people in their day-to-day lives −
| Sr.No. | Research Areas | Real Life Application |
|---|---|---|
| 1 | Expert Systems Examples − Flight-tracking systems, Clinical systems. |

|
| 2 | Natural Language Processing Examples: Google Now feature, speech recognition, Automatic voice output. |

|
| 3 | Neural Networks Examples − Pattern recognition systems such as face recognition, character recognition, handwriting recognition. |

|
| 4 | Robotics Examples − Industrial robots for moving, spraying, painting, precision checking, drilling, cleaning, coating, carving, etc. |

|
| 5 | Fuzzy Logic Systems Examples − Consumer electronics, automobiles, etc. |

|
Task Classification of AI
The domain of AI is classified into Formal tasks, Mundane tasks, and Expert tasks.

| Task Domains of Artificial Intelligence | ||
|---|---|---|
| Mundane (Ordinary) Tasks | Formal Tasks | Expert Tasks |
Perception
|
|
|
Natural Language Processing
|
Games
|
Scientific Analysis |
| Common Sense | Verification | Financial Analysis |
| Reasoning | Theorem Proving | Medical Diagnosis |
| Planing | Creativity | |
Robotics
|
||
Humans learn mundane (ordinary) tasks since their birth. They learn by perception, speaking, using language, and locomotives. They learn Formal Tasks and Expert Tasks later, in that order.
For humans, the mundane tasks are easiest to learn. The same was considered true before trying to implement mundane tasks in machines. Earlier, all work of AI was concentrated in the mundane task domain.
Later, it turned out that the machine requires more knowledge, complex knowledge representation, and complicated algorithms for handling mundane tasks. This is the reason why AI work is more prospering in the Expert Tasks domain now, as the expert task domain needs expert knowledge without common sense, which can be easier to represent and handle.
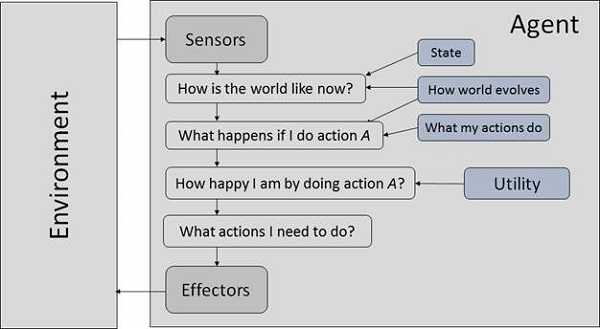
An AI system is composed of an agent and its environment. The agents act in their environment. The environment may contain other agents.
What are Agent and Environment?
An agent is anything that can perceive its environment through sensors and acts upon that environment through effectors.
A human agent has sensory organs such as eyes, ears, nose, tongue and skin parallel to the sensors, and other organs such as hands, legs, mouth, for effectors.
A robotic agent replaces cameras and infrared range finders for the sensors, and various motors and actuators for effectors.
A software agent has encoded bit strings as its programs and actions.

Agent Terminology
Performance Measure of Agent − It is the criteria, which determines how successful an agent is.
Behavior of Agent − It is the action that agent performs after any given sequence of percepts.
Percept − It is agent’s perceptual inputs at a given instance.
Percept Sequence − It is the history of all that an agent has perceived till date.
Agent Function − It is a map from the precept sequence to an action.
Rationality
Rationality is nothing but status of being reasonable, sensible, and having good sense of judgment.
Rationality is concerned with expected actions and results depending upon what the agent has perceived. Performing actions with the aim of obtaining useful information is an important part of rationality.
What is Ideal Rational Agent?
An ideal rational agent is the one, which is capable of doing expected actions to maximize its performance measure, on the basis of −
- Its percept sequence
- Its built-in knowledge base
Rationality of an agent depends on the following −
The performance measures, which determine the degree of success.
Agent’s Percept Sequence till now.
The agent’s prior knowledge about the environment.
The actions that the agent can carry out.
A rational agent always performs right action, where the right action means the action that causes the agent to be most successful in the given percept sequence. The problem the agent solves is characterized by Performance Measure, Environment, Actuators, and Sensors (PEAS).
The Structure of Intelligent Agents
Agent’s structure can be viewed as −
- Agent = Architecture + Agent Program
- Architecture = the machinery that an agent executes on.
- Agent Program = an implementation of an agent function.
Simple Reflex Agents
- They choose actions only based on the current percept.
- They are rational only if a correct decision is made only on the basis of current precept.
- Their environment is completely observable.
Condition-Action Rule − It is a rule that maps a state (condition) to an action.

Model Based Reflex Agents
They use a model of the world to choose their actions. They maintain an internal state.
Model − knowledge about “how the things happen in the world”.
Internal State − It is a representation of unobserved aspects of current state depending on percept history.
Updating the state requires the information about −
- How the world evolves.
- How the agent’s actions affect the world.

Goal Based Agents
They choose their actions in order to achieve goals. Goal-based approach is more flexible than reflex agent since the knowledge supporting a decision is explicitly modeled, thereby allowing for modifications.
Goal − It is the description of desirable situations.

Utility Based Agents
They choose actions based on a preference (utility) for each state.
Goals are inadequate when −
There are conflicting goals, out of which only few can be achieved.
Goals have some uncertainty of being achieved and you need to weigh likelihood of success against the importance of a goal.
The Nature of Environments
Some programs operate in the entirely artificial environment confined to keyboard input, database, computer file systems and character output on a screen.
In contrast, some software agents (software robots or softbots) exist in rich, unlimited softbots domains. The simulator has a very detailed, complex environment. The software agent needs to choose from a long array of actions in real time. A softbot designed to scan the online preferences of the customer and show interesting items to the customer works in the real as well as an artificial environment.
The most famous artificial environment is the Turing Test environment, in which one real and other artificial agents are tested on equal ground. This is a very challenging environment as it is highly difficult for a software agent to perform as well as a human.
Turing Test
The success of an intelligent behavior of a system can be measured with Turing Test.
Two persons and a machine to be evaluated participate in the test. Out of the two persons, one plays the role of the tester. Each of them sits in different rooms. The tester is unaware of who is machine and who is a human. He interrogates the questions by typing and sending them to both intelligences, to which he receives typed responses.
This test aims at fooling the tester. If the tester fails to determine machine’s response from the human response, then the machine is said to be intelligent.
Properties of Environment
The environment has multifold properties −
Discrete / Continuous − If there are a limited number of distinct, clearly defined, states of the environment, the environment is discrete (For example, chess); otherwise it is continuous (For example, driving).
Observable / Partially Observable − If it is possible to determine the complete state of the environment at each time point from the percepts it is observable; otherwise it is only partially observable.
Static / Dynamic − If the environment does not change while an agent is acting, then it is static; otherwise it is dynamic.
Single agent / Multiple agents − The environment may contain other agents which may be of the same or different kind as that of the agent.
Accessible / Inaccessible − If the agent’s sensory apparatus can have access to the complete state of the environment, then the environment is accessible to that agent.
Deterministic / Non-deterministic − If the next state of the environment is completely determined by the current state and the actions of the agent, then the environment is deterministic; otherwise it is non-deterministic.
Episodic / Non-episodic − In an episodic environment, each episode consists of the agent perceiving and then acting. The quality of its action depends just on the episode itself. Subsequent episodes do not depend on the actions in the previous episodes. Episodic environments are much simpler because the agent does not need to think ahead.
Searching is the universal technique of problem solving in AI. There are some single-player games such as tile games, Sudoku, crossword, etc. The search algorithms help you to search for a particular position in such games.
Single Agent Pathfinding Problems
The games such as 3X3 eight-tile, 4X4 fifteen-tile, and 5X5 twenty four tile puzzles are single-agent-path-finding challenges. They consist of a matrix of tiles with a blank tile. The player is required to arrange the tiles by sliding a tile either vertically or horizontally into a blank space with the aim of accomplishing some objective.
The other examples of single agent pathfinding problems are Travelling Salesman Problem, Rubik’s Cube, and Theorem Proving.
Search Terminology
Problem Space − It is the environment in which the search takes place. (A set of states and set of operators to change those states)
Problem Instance − It is Initial state + Goal state.
Problem Space Graph − It represents problem state. States are shown by nodes and operators are shown by edges.
Depth of a problem − Length of a shortest path or shortest sequence of operators from Initial State to goal state.
Space Complexity − The maximum number of nodes that are stored in memory.
Time Complexity − The maximum number of nodes that are created.
Admissibility − A property of an algorithm to always find an optimal solution.
Branching Factor − The average number of child nodes in the problem space graph.
Depth − Length of the shortest path from initial state to goal state.
Brute-Force Search Strategies
They are most simple, as they do not need any domain-specific knowledge. They work fine with small number of possible states.
Requirements −
- State description
- A set of valid operators
- Initial state
- Goal state description
Breadth-First Search
It starts from the root node, explores the neighboring nodes first and moves towards the next level neighbors. It generates one tree at a time until the solution is found. It can be implemented using FIFO queue data structure. This method provides shortest path to the solution.
If branching factor (average number of child nodes for a given node) = b and depth = d, then number of nodes at level d = bd.
The total no of nodes created in worst case is b + b2 + b3 + … + bd.
Disadvantage − Since each level of nodes is saved for creating next one, it consumes a lot of memory space. Space requirement to store nodes is exponential.
Its complexity depends on the number of nodes. It can check duplicate nodes.

Depth-First Search
It is implemented in recursion with LIFO stack data structure. It creates the same set of nodes as Breadth-First method, only in the different order.
As the nodes on the single path are stored in each iteration from root to leaf node, the space requirement to store nodes is linear. With branching factor b and depth as m, the storage space is bm.
Disadvantage − This algorithm may not terminate and go on infinitely on one path. The solution to this issue is to choose a cut-off depth. If the ideal cut-off is d, and if chosen cut-off is lesser than d, then this algorithm may fail. If chosen cut-off is more than d, then execution time increases.
Its complexity depends on the number of paths. It cannot check duplicate nodes.

Bidirectional Search
It searches forward from initial state and backward from goal state till both meet to identify a common state.
The path from initial state is concatenated with the inverse path from the goal state. Each search is done only up to half of the total path.
Uniform Cost Search
Sorting is done in increasing cost of the path to a node. It always expands the least cost node. It is identical to Breadth First search if each transition has the same cost.
It explores paths in the increasing order of cost.
Disadvantage − There can be multiple long paths with the cost ≤ C*. Uniform Cost search must explore them all.
Iterative Deepening Depth-First Search
It performs depth-first search to level 1, starts over, executes a complete depth-first search to level 2, and continues in such way till the solution is found.
It never creates a node until all lower nodes are generated. It only saves a stack of nodes. The algorithm ends when it finds a solution at depth d. The number of nodes created at depth d is bd and at depth d-1 is bd-1.
Comparison of Various Algorithms Complexities
Let us see the performance of algorithms based on various criteria −
| Criterion | Breadth First | Depth First | Bidirectional | Uniform Cost | Interactive Deepening |
|---|---|---|---|---|---|
| Time | bd | bm | bd/2 | bd | bd |
| Space | bd | bm | bd/2 | bd | bd |
| Optimality | Yes | No | Yes | Yes | Yes |
| Completeness | Yes | No | Yes | Yes | Yes |
Informed (Heuristic) Search Strategies
To solve large problems with large number of possible states, problem-specific knowledge needs to be added to increase the efficiency of search algorithms.
Heuristic Evaluation Functions
They calculate the cost of optimal path between two states. A heuristic function for sliding-tiles games is computed by counting number of moves that each tile makes from its goal state and adding these number of moves for all tiles.
Pure Heuristic Search
It expands nodes in the order of their heuristic values. It creates two lists, a closed list for the already expanded nodes and an open list for the created but unexpanded nodes.
In each iteration, a node with a minimum heuristic value is expanded, all its child nodes are created and placed in the closed list. Then, the heuristic function is applied to the child nodes and they are placed in the open list according to their heuristic value. The shorter paths are saved and the longer ones are disposed.
A * Search
It is best-known form of Best First search. It avoids expanding paths that are already expensive, but expands most promising paths first.
f(n) = g(n) + h(n), where
- g(n) the cost (so far) to reach the node
- h(n) estimated cost to get from the node to the goal
- f(n) estimated total cost of path through n to goal. It is implemented using priority queue by increasing f(n).
Greedy Best First Search
It expands the node that is estimated to be closest to goal. It expands nodes based on f(n) = h(n). It is implemented using priority queue.
Disadvantage − It can get stuck in loops. It is not optimal.
Local Search Algorithms
They start from a prospective solution and then move to a neighboring solution. They can return a valid solution even if it is interrupted at any time before they end.
Hill-Climbing Search
It is an iterative algorithm that starts with an arbitrary solution to a problem and attempts to find a better solution by changing a single element of the solution incrementally. If the change produces a better solution, an incremental change is taken as a new solution. This process is repeated until there are no further improvements.
function Hill-Climbing (problem), returns a state that is a local maximum.
inputs: problem, a problem
local variables: current, a node
neighbor, a node
current <-Make_Node(Initial-State[problem])
loop
do neighbor <- a highest_valued successor of current
if Value[neighbor] ≤ Value[current] then
return State[current]
current <- neighbor
endDisadvantage − This algorithm is neither complete, nor optimal.
Local Beam Search
In this algorithm, it holds k number of states at any given time. At the start, these states are generated randomly. The successors of these k states are computed with the help of objective function. If any of these successors is the maximum value of the objective function, then the algorithm stops.
Otherwise the (initial k states and k number of successors of the states = 2k) states are placed in a pool. The pool is then sorted numerically. The highest k states are selected as new initial states. This process continues until a maximum value is reached.
function BeamSearch( problem, k), returns a solution state.
start with k randomly generated states
loop
generate all successors of all k states
if any of the states = solution, then return the state
else select the k best successors
endSimulated Annealing
Annealing is the process of heating and cooling a metal to change its internal structure for modifying its physical properties. When the metal cools, its new structure is seized, and the metal retains its newly obtained properties. In simulated annealing process, the temperature is kept variable.
We initially set the temperature high and then allow it to ‘cool' slowly as the algorithm proceeds. When the temperature is high, the algorithm is allowed to accept worse solutions with high frequency.
Start
- Initialize k = 0; L = integer number of variables;
- From i → j, search the performance difference Δ.
- If Δ <= 0 then accept else if exp(-Δ/T(k)) > random(0,1) then accept;
- Repeat steps 1 and 2 for L(k) steps.
- k = k + 1;
Repeat steps 1 through 4 till the criteria is met.
End
Travelling Salesman Problem
In this algorithm, the objective is to find a low-cost tour that starts from a city, visits all cities en-route exactly once and ends at the same starting city.
Start
Find out all (n -1)! Possible solutions, where n is the total number of cities.
Determine the minimum cost by finding out the cost of each of these (n -1)! solutions.
Finally, keep the one with the minimum cost.
end
Fuzzy Logic Systems (FLS) produce acceptable but definite output in response to incomplete, ambiguous, distorted, or inaccurate (fuzzy) input.
What is Fuzzy Logic?
Fuzzy Logic (FL) is a method of reasoning that resembles human reasoning. The approach of FL imitates the way of decision making in humans that involves all intermediate possibilities between digital values YES and NO.
The conventional logic block that a computer can understand takes precise input and produces a definite output as TRUE or FALSE, which is equivalent to human’s YES or NO.
The inventor of fuzzy logic, Lotfi Zadeh, observed that unlike computers, the human decision making includes a range of possibilities between YES and NO, such as −
| CERTAINLY YES |
| POSSIBLY YES |
| CANNOT SAY |
| POSSIBLY NO |
| CERTAINLY NO |
The fuzzy logic works on the levels of possibilities of input to achieve the definite output.
Implementation
It can be implemented in systems with various sizes and capabilities ranging from small micro-controllers to large, networked, workstation-based control systems.
It can be implemented in hardware, software, or a combination of both.
Why Fuzzy Logic?
Fuzzy logic is useful for commercial and practical purposes.
- It can control machines and consumer products.
- It may not give accurate reasoning, but acceptable reasoning.
- Fuzzy logic helps to deal with the uncertainty in engineering.
Fuzzy Logic Systems Architecture
It has four main parts as shown −
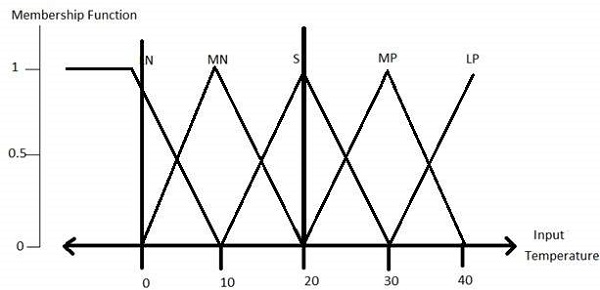
Fuzzification Module − It transforms the system inputs, which are crisp numbers, into fuzzy sets. It splits the input signal into five steps such as −
| LP | x is Large Positive |
| MP | x is Medium Positive |
| S | x is Small |
| MN | x is Medium Negative |
| LN | x is Large Negative |
Knowledge Base − It stores IF-THEN rules provided by experts.
Inference Engine − It simulates the human reasoning process by making fuzzy inference on the inputs and IF-THEN rules.
Defuzzification Module − It transforms the fuzzy set obtained by the inference engine into a crisp value.

The membership functions work on fuzzy sets of variables.
Membership Function
Membership functions allow you to quantify linguistic term and represent a fuzzy set graphically. A membership function for a fuzzy set A on the universe of discourse X is defined as μA:X → [0,1].
Here, each element of X is mapped to a value between 0 and 1. It is called membership value or degree of membership. It quantifies the degree of membership of the element in X to the fuzzy set A.
- x axis represents the universe of discourse.
- y axis represents the degrees of membership in the [0, 1] interval.
There can be multiple membership functions applicable to fuzzify a numerical value. Simple membership functions are used as use of complex functions does not add more precision in the output.
All membership functions for LP, MP, S, MN, and LN are shown as below −

The triangular membership function shapes are most common among various other membership function shapes such as trapezoidal, singleton, and Gaussian.
Here, the input to 5-level fuzzifier varies from -10 volts to +10 volts. Hence the corresponding output also changes.
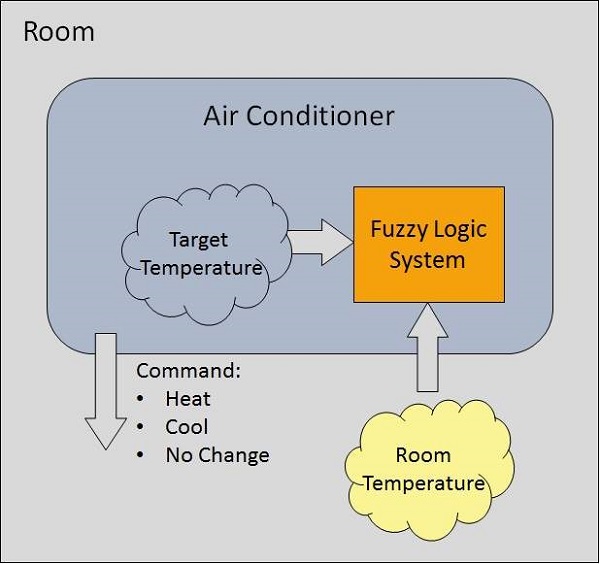
Example of a Fuzzy Logic System
Let us consider an air conditioning system with 5-level fuzzy logic system. This system adjusts the temperature of air conditioner by comparing the room temperature and the target temperature value.
Algorithm
- Define linguistic Variables and terms (start)
- Construct membership functions for them. (start)
- Construct knowledge base of rules (start)
- Convert crisp data into fuzzy data sets using membership functions. (fuzzification)
- Evaluate rules in the rule base. (Inference Engine)
- Combine results from each rule. (Inference Engine)
- Convert output data into non-fuzzy values. (defuzzification)
Development
Step 1 − Define linguistic variables and terms
Linguistic variables are input and output variables in the form of simple words or sentences. For room temperature, cold, warm, hot, etc., are linguistic terms.
Temperature (t) = {very-cold, cold, warm, very-warm, hot}
Every member of this set is a linguistic term and it can cover some portion of overall temperature values.
Step 2 − Construct membership functions for them
The membership functions of temperature variable are as shown −
Step3 − Construct knowledge base rules
Create a matrix of room temperature values versus target temperature values that an air conditioning system is expected to provide.
| RoomTemp. /Target | Very_Cold | Cold | Warm | Hot | Very_Hot |
|---|---|---|---|---|---|
| Very_Cold | No_Change | Heat | Heat | Heat | Heat |
| Cold | Cool | No_Change | Heat | Heat | Heat |
| Warm | Cool | Cool | No_Change | Heat | Heat |
| Hot | Cool | Cool | Cool | No_Change | Heat |
| Very_Hot | Cool | Cool | Cool | Cool | No_Change |
Build a set of rules into the knowledge base in the form of IF-THEN-ELSE structures.
| Sr. No. | Condition | Action |
|---|---|---|
| 1 | IF temperature=(Cold OR Very_Cold) AND target=Warm THEN | Heat |
| 2 | IF temperature=(Hot OR Very_Hot) AND target=Warm THEN | Cool |
| 3 | IF (temperature=Warm) AND (target=Warm) THEN | No_Change |
Step 4 − Obtain fuzzy value
Fuzzy set operations perform evaluation of rules. The operations used for OR and AND are Max and Min respectively. Combine all results of evaluation to form a final result. This result is a fuzzy value.
Step 5 − Perform defuzzification
Defuzzification is then performed according to membership function for output variable.

Application Areas of Fuzzy Logic
The key application areas of fuzzy logic are as given −
Automotive Systems
- Automatic Gearboxes
- Four-Wheel Steering
- Vehicle environment control
Consumer Electronic Goods
- Hi-Fi Systems
- Photocopiers
- Still and Video Cameras
- Television
Domestic Goods
- Microwave Ovens
- Refrigerators
- Toasters
- Vacuum Cleaners
- Washing Machines
Environment Control
- Air Conditioners/Dryers/Heaters
- Humidifiers
Advantages of FLSs
Mathematical concepts within fuzzy reasoning are very simple.
You can modify a FLS by just adding or deleting rules due to flexibility of fuzzy logic.
Fuzzy logic Systems can take imprecise, distorted, noisy input information.
FLSs are easy to construct and understand.
Fuzzy logic is a solution to complex problems in all fields of life, including medicine, as it resembles human reasoning and decision making.
Disadvantages of FLSs
- There is no systematic approach to fuzzy system designing.
- They are understandable only when simple.
- They are suitable for the problems which do not need high accuracy.
Natural Language Processing (NLP) refers to AI method of communicating with an intelligent systems using a natural language such as English.
Processing of Natural Language is required when you want an intelligent system like robot to perform as per your instructions, when you want to hear decision from a dialogue based clinical expert system, etc.
The field of NLP involves making computers to perform useful tasks with the natural languages humans use. The input and output of an NLP system can be −
- Speech
- Written Text
Components of NLP
There are two components of NLP as given −
Natural Language Understanding (NLU)
Understanding involves the following tasks −
- Abbildung der angegebenen Eingabe in natürlicher Sprache in nützliche Darstellungen.
- Analyse verschiedener Aspekte der Sprache.
Erzeugung natürlicher Sprache (NLG)
Es ist der Prozess, aus einer internen Repräsentation aussagekräftige Phrasen und Sätze in Form natürlicher Sprache zu erzeugen.
Es beinhaltet -
Text planning - Es umfasst das Abrufen der relevanten Inhalte aus der Wissensdatenbank.
Sentence planning - Dazu gehört die Auswahl der erforderlichen Wörter, die Bildung aussagekräftiger Phrasen und die Festlegung des Satztons.
Text Realization - Es ordnet den Satzplan der Satzstruktur zu.
Die NLU ist schwieriger als die NLG.
Schwierigkeiten in der NLU
NL hat eine extrem reiche Form und Struktur.
Es ist sehr vieldeutig. Es kann verschiedene Mehrdeutigkeitsebenen geben -
Lexical ambiguity - Es ist auf einer sehr primitiven Ebene wie der Wortebene.
Zum Beispiel das Wort "Brett" als Substantiv oder Verb behandeln?
Syntax Level ambiguity - Ein Satz kann auf verschiedene Arten analysiert werden.
Zum Beispiel: "Er hat den Käfer mit der roten Kappe angehoben." - Hat er den Käfer mit einer Kappe angehoben oder hat er einen Käfer mit roter Kappe angehoben?
Referential ambiguity- Mit Pronomen auf etwas verweisen. Zum Beispiel ging Rima nach Gauri. Sie sagte: "Ich bin müde." - Genau wer ist müde?
Eine Eingabe kann unterschiedliche Bedeutungen haben.
Viele Eingaben können dasselbe bedeuten.
NLP-Terminologie
Phonology - Es geht darum, Schall systematisch zu organisieren.
Morphology - Es ist eine Studie über die Konstruktion von Wörtern aus primitiven bedeutungsvollen Einheiten.
Morpheme - Es ist eine primitive Bedeutungseinheit in einer Sprache.
Syntax- Es bezieht sich auf das Anordnen von Wörtern, um einen Satz zu bilden. Dazu gehört auch die Bestimmung der strukturellen Rolle von Wörtern im Satz und in Phrasen.
Semantics - Es geht um die Bedeutung von Wörtern und darum, wie Wörter zu aussagekräftigen Phrasen und Sätzen kombiniert werden können.
Pragmatics - Es geht darum, Sätze in verschiedenen Situationen zu verwenden und zu verstehen und wie die Interpretation des Satzes beeinflusst wird.
Discourse - Es geht darum, wie der unmittelbar vorhergehende Satz die Interpretation des nächsten Satzes beeinflussen kann.
World Knowledge - Es beinhaltet das allgemeine Wissen über die Welt.
Schritte in NLP
Es gibt allgemeine fünf Schritte -
Lexical Analysis- Es beinhaltet die Identifizierung und Analyse der Struktur von Wörtern. Lexikon einer Sprache bedeutet die Sammlung von Wörtern und Phrasen in einer Sprache. Die lexikalische Analyse unterteilt den gesamten Teil von txt in Absätze, Sätze und Wörter.
Syntactic Analysis (Parsing)- Es beinhaltet die Analyse der Wörter im Satz auf Grammatik und die Anordnung der Wörter in einer Weise, die die Beziehung zwischen den Wörtern zeigt. Der Satz wie "Die Schule geht an den Jungen" wird vom englischen syntaktischen Analysator abgelehnt.

Semantic Analysis- Es bezieht die genaue Bedeutung oder die Wörterbuchbedeutung aus dem Text. Der Text wird auf Aussagekraft geprüft. Dazu werden syntaktische Strukturen und Objekte in der Aufgabendomäne zugeordnet. Der semantische Analysator ignoriert Sätze wie „heißes Eis“.
Discourse Integration- Die Bedeutung eines Satzes hängt von der Bedeutung des Satzes unmittelbar davor ab. Darüber hinaus bewirkt es auch die Bedeutung eines unmittelbar folgenden Satzes.
Pragmatic Analysis- Währenddessen wird das Gesagte dahingehend neu interpretiert, was es tatsächlich bedeutete. Es geht darum, jene Aspekte der Sprache abzuleiten, die reales Wissen erfordern.
Implementierungsaspekte der syntaktischen Analyse
Es gibt eine Reihe von Algorithmen, die Forscher für die syntaktische Analyse entwickelt haben, aber wir betrachten nur die folgenden einfachen Methoden:
- Kontextfreie Grammatik
- Top-Down-Parser
Lassen Sie uns sie im Detail sehen -
Kontextfreie Grammatik
Es ist die Grammatik, die aus Regeln mit einem einzelnen Symbol auf der linken Seite der Umschreiberegeln besteht. Lassen Sie uns eine Grammatik erstellen, um einen Satz zu analysieren -
"Der Vogel pickt die Körner"
Articles (DET)- a | ein | das
Nouns- Vogel | Vögel | Getreide | Körner
Noun Phrase (NP)- Artikel + Nomen | Artikel + Adjektiv + Nomen
= DET N | DET ADJ N.
Verbs- pickt | picken | gepickt
Verb Phrase (VP)- NP V | V NP
Adjectives (ADJ)- schön | klein | zwitschern
Der Analysebaum zerlegt den Satz in strukturierte Teile, damit der Computer ihn leicht verstehen und verarbeiten kann. Damit der Parsing-Algorithmus diesen Analysebaum erstellen kann, muss eine Reihe von Umschreiberegeln erstellt werden, die beschreiben, welche Baumstrukturen zulässig sind.
Diese Regeln besagen, dass ein bestimmtes Symbol im Baum durch eine Folge anderer Symbole erweitert werden kann. Gemäß der Logikregel erster Ordnung ist die Zeichenfolge, die von NP gefolgt von VP kombiniert wird, ein Satz, wenn zwei Zeichenfolgen Nomenphrase (NP) und Verbalphrase (VP) vorhanden sind. Die Umschreibregeln für den Satz lauten wie folgt:
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
Lexocon −
DET → a | das
ADJ → schön | sich niederlassen
N → Vogel | Vögel | Getreide | Körner
V → picken | pickt | picken
Der Analysebaum kann wie gezeigt erstellt werden -

Beachten Sie nun die obigen Umschreiberegeln. Da V durch beide ersetzt werden kann, "picken" oder "picken", können Sätze wie "Der Vogel pickt die Körner" fälschlicherweise zugelassen werden. dh der Subjekt-Verb-Übereinstimmungsfehler wird als korrekt genehmigt.
Merit - Der einfachste Grammatikstil, daher weit verbreitet.
Demerits −
Sie sind nicht sehr präzise. Zum Beispiel ist „Die Körner picken den Vogel“ laut Parser syntaktisch korrekt, aber selbst wenn es keinen Sinn ergibt, nimmt der Parser es als korrekten Satz.
Um eine hohe Präzision zu erzielen, müssen mehrere Grammatiksätze vorbereitet werden. Möglicherweise sind völlig andere Regelsätze zum Parsen von Singular- und Pluralvariationen, passiven Sätzen usw. erforderlich, was zur Erstellung großer Regelsätze führen kann, die nicht verwaltet werden können.
Top-Down-Parser
Hier beginnt der Parser mit dem S-Symbol und versucht, es in eine Folge von Terminalsymbolen umzuschreiben , die den Klassen der Wörter im Eingabesatz entspricht, bis es vollständig aus Terminalsymbolen besteht.
Diese werden dann mit dem Eingabesatz überprüft, um festzustellen, ob er übereinstimmt. Wenn nicht, wird der Prozess mit einem anderen Regelwerk erneut gestartet. Dies wird wiederholt, bis eine bestimmte Regel gefunden wird, die die Struktur des Satzes beschreibt.
Merit - Es ist einfach zu implementieren.
Demerits −
- Dies ist ineffizient, da der Suchvorgang wiederholt werden muss, wenn ein Fehler auftritt.
- Langsame Arbeitsgeschwindigkeit.
Expertensysteme (ES) sind einer der wichtigsten Forschungsbereiche der KI. Es wird von den Forschern der Stanford University, Abteilung Informatik, eingeführt.
Was sind Expertensysteme?
Die Expertensysteme sind Computeranwendungen, die entwickelt wurden, um komplexe Probleme in einem bestimmten Bereich auf der Ebene außergewöhnlicher menschlicher Intelligenz und Fachkenntnisse zu lösen.
Eigenschaften von Expertensystemen
- Hochleistung
- Understandable
- Reliable
- Sehr reaktionsschnell
Fähigkeiten von Expertensystemen
Die Expertensysteme sind in der Lage -
- Advising
- Unterweisung und Unterstützung des Menschen bei der Entscheidungsfindung
- Demonstrating
- Eine Lösung ableiten
- Diagnosing
- Explaining
- Eingabe interpretieren
- Ergebnisse vorhersagen
- Begründung der Schlussfolgerung
- Vorschläge für alternative Optionen zu einem Problem
Sie sind nicht in der Lage -
- Ersetzen menschlicher Entscheidungsträger
- Menschliche Fähigkeiten besitzen
- Genaue Ausgabe für unzureichende Wissensbasis
- Ihr eigenes Wissen verfeinern
Komponenten von Expertensystemen
Die Komponenten von ES umfassen -
- Wissensbasis
- Inferenz-Engine
- Benutzeroberfläche
Lassen Sie uns sie kurz nacheinander sehen -

Wissensbasis
Es enthält domänenspezifisches und qualitativ hochwertiges Wissen.
Wissen ist erforderlich, um Intelligenz zu zeigen. Der Erfolg eines ES hängt in hohem Maße von der Sammlung hochgenauer und präziser Kenntnisse ab.
Was ist Wissen?
Die Daten sind eine Sammlung von Fakten. Die Informationen sind als Daten und Fakten zur Aufgabendomäne organisiert.Data, information, und past experience zusammen werden als Wissen bezeichnet.
Komponenten der Wissensdatenbank
Die Wissensbasis eines ES ist ein Speicher von sowohl sachlichem als auch heuristischem Wissen.
Factual Knowledge - Dies sind die Informationen, die von den Wissensingenieuren und Wissenschaftlern im Aufgabenbereich allgemein akzeptiert werden.
Heuristic Knowledge - Es geht um Übung, genaues Urteilsvermögen, Bewertungsfähigkeit und Vermutung.
Wissensrepräsentation
Es ist die Methode, mit der das Wissen in der Wissensbasis organisiert und formalisiert wird. Es liegt in Form von IF-THEN-ELSE-Regeln vor.
Wissenserwerb
Der Erfolg eines Expertensystems hängt in hohem Maße von der Qualität, Vollständigkeit und Richtigkeit der in der Wissensdatenbank gespeicherten Informationen ab.
Die Wissensbasis wird durch Lesungen von verschiedenen Experten, Gelehrten und der Knowledge Engineers. Der Wissensingenieur ist eine Person mit den Qualitäten Empathie, schnelles Lernen und Fähigkeiten zur Fallanalyse.
Er erhält Informationen vom Fachexperten, indem er ihn aufzeichnet, interviewt und bei der Arbeit beobachtet usw. Anschließend kategorisiert und organisiert er die Informationen auf sinnvolle Weise in Form von IF-THEN-ELSE-Regeln, die von Interferenzmaschinen verwendet werden sollen. Der Wissensingenieur überwacht auch die Entwicklung des ES.
Inferenz-Engine
Die Verwendung effizienter Verfahren und Regeln durch die Inference Engine ist wichtig, um eine korrekte, fehlerfreie Lösung zu finden.
Bei wissensbasierter ES erfasst und manipuliert die Inference Engine das Wissen aus der Wissensbasis, um zu einer bestimmten Lösung zu gelangen.
Im Falle einer regelbasierten ES ist es -
Wendet Regeln wiederholt auf die Fakten an, die sich aus früheren Regelanwendungen ergeben.
Fügt der Wissensbasis bei Bedarf neues Wissen hinzu.
Behebt Regelkonflikte, wenn mehrere Regeln auf einen bestimmten Fall anwendbar sind.
Um eine Lösung zu empfehlen, verwendet die Inference Engine die folgenden Strategien:
- Vorwärtsverkettung
- Rückwärtsverkettung
Vorwärtsverkettung
Es ist eine Strategie eines Expertensystems, die Frage zu beantworten, “What can happen next?”
Hier folgt die Inference Engine der Kette von Bedingungen und Ableitungen und leitet schließlich das Ergebnis ab. Es berücksichtigt alle Fakten und Regeln und sortiert sie, bevor eine Lösung gefunden wird.
Diese Strategie wird befolgt, um an Schlussfolgerungen, Ergebnissen oder Effekten zu arbeiten. Zum Beispiel die Vorhersage des Aktienmarktstatus als Auswirkung von Zinsänderungen.

Rückwärtsverkettung
Mit dieser Strategie findet ein Expertensystem die Antwort auf die Frage: “Why this happened?”
Auf der Grundlage dessen, was bereits geschehen ist, versucht die Inference Engine herauszufinden, welche Bedingungen in der Vergangenheit für dieses Ergebnis hätten eintreten können. Diese Strategie wird verfolgt, um Ursache oder Grund herauszufinden. Zum Beispiel die Diagnose von Blutkrebs beim Menschen.
Benutzeroberfläche
Die Benutzeroberfläche bietet eine Interaktion zwischen dem Benutzer des ES und dem ES selbst. Es handelt sich im Allgemeinen um die Verarbeitung natürlicher Sprache, um von dem Benutzer verwendet zu werden, der mit der Aufgabendomäne vertraut ist. Der Benutzer des ES muss nicht unbedingt ein Experte für künstliche Intelligenz sein.
Es wird erklärt, wie die ES zu einer bestimmten Empfehlung gelangt ist. Die Erklärung kann in den folgenden Formen erscheinen -
- Natürliche Sprache auf dem Bildschirm angezeigt.
- Verbale Erzählungen in natürlicher Sprache.
- Auflistung der auf dem Bildschirm angezeigten Regelnummern.
Die Benutzeroberfläche macht es einfach, die Glaubwürdigkeit der Abzüge zu verfolgen.
Anforderungen an eine effiziente ES-Benutzeroberfläche
Es soll den Benutzern helfen, ihre Ziele auf kürzestem Weg zu erreichen.
Es sollte so konzipiert sein, dass es für die vorhandenen oder gewünschten Arbeitspraktiken des Benutzers geeignet ist.
Die Technologie sollte an die Anforderungen des Benutzers anpassbar sein. Nicht umgekehrt.
Benutzereingaben sollten effizient genutzt werden.
Einschränkungen für Expertensysteme
Keine Technologie kann eine einfache und vollständige Lösung bieten. Große Systeme sind teuer, erfordern erhebliche Entwicklungszeit und Computerressourcen. ES haben ihre Grenzen, die Folgendes umfassen:
- Einschränkungen der Technologie
- Schwieriger Wissenserwerb
- ES sind schwer zu warten
- Hohe Entwicklungskosten
Anwendungen des Expertensystems
Die folgende Tabelle zeigt, wo ES angewendet werden kann.
| Anwendung | Beschreibung |
|---|---|
| Design Domain | Kameraobjektivdesign, Autodesign. |
| Medizinische Domäne | Diagnosesysteme zur Ableitung der Krankheitsursache aus beobachteten Daten, Durchführung medizinischer Operationen am Menschen. |
| Überwachungssysteme | Kontinuierlicher Vergleich der Daten mit dem beobachteten System oder mit dem vorgeschriebenen Verhalten wie der Leckageüberwachung in langen Erdölpipelines. |
| Prozessleitsysteme | Steuerung eines physischen Prozesses basierend auf Überwachung. |
| Wissensdomäne | Fehler in Fahrzeugen, Computern herausfinden. |
| Finanzen / Handel | Aufdeckung möglicher Betrugsfälle, verdächtiger Transaktionen, Börsenhandel, Fluglinienplanung, Frachtplanung. |
Expertensystemtechnik
Es stehen verschiedene Ebenen von ES-Technologien zur Verfügung. Expertensystemtechnologien umfassen -
Expert System Development Environment- Die ES-Entwicklungsumgebung enthält Hardware und Tools. Sie sind -
Workstations, Minicomputer, Mainframes.
Hochrangige symbolische Programmiersprachen wie LISt PProgrammierung (LISP) und PROGrammatik en LOGique (PROLOG).
Große Datenbanken.
Tools - Sie reduzieren den Aufwand und die Kosten für die Entwicklung eines Expertensystems in hohem Maße.
Leistungsstarke Editoren und Debugging-Tools mit mehreren Fenstern.
Sie bieten Rapid Prototyping
Eingebaute Definitionen von Modell, Wissensrepräsentation und Inferenzdesign.
Shells- Eine Shell ist nichts anderes als ein Expertensystem ohne Wissensbasis. Eine Shell bietet den Entwicklern Wissenserwerb, Inferenz-Engine, Benutzeroberfläche und Erklärungsfunktion. Zum Beispiel sind unten einige Muscheln angegeben -
Java Expert System Shell (JESS), die eine vollständig entwickelte Java-API zum Erstellen eines Expertensystems bereitstellt.
Vidwan , eine Shell, die 1993 am Nationalen Zentrum für Softwaretechnologie in Mumbai entwickelt wurde. Sie ermöglicht die Wissenskodierung in Form von IF-THEN-Regeln.
Entwicklung von Expertensystemen: Allgemeine Schritte
Der Prozess der ES-Entwicklung ist iterativ. Schritte bei der Entwicklung der ES umfassen -
Problemdomäne identifizieren
- Das Problem muss für ein Expertensystem geeignet sein, um es zu lösen.
- Finden Sie die Experten im Aufgabenbereich für das ES-Projekt.
- Stellen Sie die Kosteneffizienz des Systems fest.
Entwerfen Sie das System
Identifizieren Sie die ES-Technologie
Kennen und ermitteln Sie den Grad der Integration mit den anderen Systemen und Datenbanken.
Erkennen Sie, wie die Konzepte das Domänenwissen am besten darstellen können.
Entwickeln Sie den Prototyp
Aus der Wissensdatenbank: Der Wissensingenieur arbeitet an -
- Erwerben Sie Domänenwissen vom Experten.
- Stellen Sie es in Form von If-THEN-ELSE-Regeln dar.
Testen und verfeinern Sie den Prototyp
Der Wissensingenieur testet den Prototyp anhand von Beispielfällen auf Leistungsmängel.
Endbenutzer testen die Prototypen des ES.
Entwickeln und vervollständigen Sie die ES
Testen und stellen Sie die Interaktion des ES mit allen Elementen seiner Umgebung sicher, einschließlich Endbenutzern, Datenbanken und anderen Informationssystemen.
Dokumentieren Sie das ES-Projekt gut.
Trainieren Sie den Benutzer in der Verwendung von ES.
Pflegen Sie das System
Halten Sie die Wissensdatenbank durch regelmäßige Überprüfung und Aktualisierung auf dem neuesten Stand.
Sorgen Sie für neue Schnittstellen zu anderen Informationssystemen, wenn sich diese Systeme weiterentwickeln.
Vorteile von Expertensystemen
Availability - Sie sind aufgrund der Massenproduktion von Software leicht verfügbar.
Less Production Cost- Die Produktionskosten sind angemessen. Das macht sie erschwinglich.
Speed- Sie bieten große Geschwindigkeit. Sie reduzieren den Arbeitsaufwand eines Einzelnen.
Less Error Rate - Die Fehlerrate ist im Vergleich zu menschlichen Fehlern niedrig.
Reducing Risk - Sie können in einer für den Menschen gefährlichen Umgebung arbeiten.
Steady response - Sie arbeiten stetig, ohne sich zu bewegen, zu spannen oder zu ermüden.
Die Robotik ist eine Domäne der künstlichen Intelligenz, die sich mit der Erforschung intelligenter und effizienter Roboter befasst.
Was sind Roboter?
Roboter sind die künstlichen Wirkstoffe, die in der realen Welt wirken.
Zielsetzung
Roboter zielen darauf ab, die Objekte zu manipulieren, indem sie die physikalischen Eigenschaften des Objekts wahrnehmen, auswählen, bewegen, modifizieren, zerstören oder einen Effekt erzielen, wodurch die Arbeitskräfte von sich wiederholenden Funktionen befreit werden, ohne sich zu langweilen, abzulenken oder zu erschöpfen.
Was ist Robotik?
Die Robotik ist ein Zweig der KI, der sich aus Elektrotechnik, Maschinenbau und Informatik für die Konstruktion, den Bau und die Anwendung von Robotern zusammensetzt.
Aspekte der Robotik
Die Roboter haben mechanical construction, Form oder Gestalt, um eine bestimmte Aufgabe zu erfüllen.
Sie haben electrical components welche Macht und Kontrolle der Maschinen.
Sie enthalten ein gewisses Maß an computer program Das bestimmt, was, wann und wie ein Roboter etwas tut.
Unterschied im Robotersystem und anderen KI-Programmen
Hier ist der Unterschied zwischen den beiden -
| KI-Programme | Roboter |
|---|---|
| Sie arbeiten normalerweise in computerstimulierten Welten. | Sie arbeiten in der realen physischen Welt |
| Die Eingabe in ein AI-Programm erfolgt in Symbolen und Regeln. | Eingaben in Roboter sind analoge Signale in Form von Sprachwellenformen oder Bildern |
| Sie benötigen Allzweckcomputer, auf denen sie arbeiten können. | Sie benötigen spezielle Hardware mit Sensoren und Effektoren. |
Roboterbewegung
Fortbewegung ist der Mechanismus, mit dem sich ein Roboter in seiner Umgebung bewegen kann. Es gibt verschiedene Arten von Lokomotiven -
- Legged
- Wheeled
- Kombination von Fortbewegung mit Beinen und Rädern
- Tracked Slip / Skid
Fortbewegung mit Beinen
Diese Art der Fortbewegung verbraucht mehr Kraft, während sie das Gehen, Springen, Traben, Hüpfen, Auf- oder Absteigen usw. demonstriert.
Es erfordert mehr Motoren, um eine Bewegung auszuführen. Es eignet sich sowohl für unebenes als auch für glattes Gelände, wo unregelmäßige oder zu glatte Oberflächen mehr Kraft für eine fahrbare Fortbewegung verbrauchen. Aufgrund von Stabilitätsproblemen ist die Implementierung kaum schwierig.
Es kommt mit der Vielfalt von einem, zwei, vier und sechs Beinen. Wenn ein Roboter mehrere Beine hat, ist eine Beinkoordination für die Fortbewegung erforderlich.
Die Gesamtzahl der möglichen gaits (eine periodische Abfolge von Auftriebs- und Freigabeereignissen für jedes der gesamten Beine) Ein Roboter kann abhängig von der Anzahl seiner Beine fahren.
Wenn ein Roboter k Beine hat, ist die Anzahl der möglichen Ereignisse N = (2k-1)!.
Bei einem zweibeinigen Roboter (k = 2) beträgt die Anzahl der möglichen Ereignisse N = (2k-1)! = (2 * 2-1)! = 3! = 6.
Daher gibt es sechs mögliche verschiedene Ereignisse -
- Das linke Bein anheben
- Das linke Bein loslassen
- Das rechte Bein anheben
- Das rechte Bein loslassen
- Beide Beine zusammen heben
- Beide Beine zusammen loslassen
Bei k = 6 Beinen gibt es 39916800 mögliche Ereignisse. Daher ist die Komplexität von Robotern direkt proportional zur Anzahl der Beine.

Fortbewegung auf Rädern
Es erfordert weniger Motoren, um eine Bewegung auszuführen. Die Implementierung ist wenig einfach, da bei mehr Rädern weniger Stabilitätsprobleme auftreten. Es ist energieeffizient im Vergleich zur Fortbewegung mit Beinen.
Standard wheel - Dreht sich um die Radachse und um den Kontakt
Castor wheel - Dreht sich um die Radachse und das versetzte Lenkgelenk.
Swedish 45o and Swedish 90o wheels - Omni-Rad, dreht sich um den Kontaktpunkt, um die Radachse und um die Rollen.
Ball or spherical wheel - Omnidirektionales Rad, technisch schwer zu implementieren.

Rutsch- / Rutschbewegung
Bei diesem Typ verwenden die Fahrzeuge Schienen wie in einem Panzer. Der Roboter wird gesteuert, indem die Gleise mit unterschiedlichen Geschwindigkeiten in die gleiche oder entgegengesetzte Richtung bewegt werden. Es bietet Stabilität aufgrund der großen Kontaktfläche von Gleis und Boden.

Komponenten eines Roboters
Roboter werden wie folgt konstruiert:
Power Supply - Die Roboter werden mit Batterien, Solarenergie, hydraulischen oder pneumatischen Energiequellen betrieben.
Actuators - Sie wandeln Energie in Bewegung um.
Electric motors (AC/DC) - Sie werden für Drehbewegungen benötigt.
Pneumatic Air Muscles - Sie ziehen sich fast 40% zusammen, wenn Luft angesaugt wird.
Muscle Wires - Sie ziehen sich um 5% zusammen, wenn elektrischer Strom durch sie fließt.
Piezo Motors and Ultrasonic Motors - Am besten für Industrieroboter.
Sensors- Sie bieten Kenntnisse über Echtzeitinformationen zur Aufgabenumgebung. Roboter sind mit Vision-Sensoren ausgestattet, um die Tiefe in der Umgebung zu berechnen. Ein taktiler Sensor ahmt die mechanischen Eigenschaften von Berührungsrezeptoren menschlicher Fingerspitzen nach.
Computer Vision
Dies ist eine Technologie der KI, mit der die Roboter sehen können. Die Computer Vision spielt eine wichtige Rolle in den Bereichen Sicherheit, Gesundheit, Zugang und Unterhaltung.
Computer Vision extrahiert, analysiert und erfasst automatisch nützliche Informationen aus einem einzelnen Bild oder einer Reihe von Bildern. Dieser Prozess beinhaltet die Entwicklung von Algorithmen, um ein automatisches visuelles Verständnis zu erreichen.
Hardware des Computer Vision Systems
Dies beinhaltet -
- Energieversorgung
- Bildaufnahmegerät wie Kamera
- Ein Prozessor
- Eine Software
- Ein Anzeigegerät zur Überwachung des Systems
- Zubehör wie Kameraständer, Kabel und Anschlüsse
Aufgaben des Computer Vision
OCR - Im Bereich der Computer Optical Character Reader, eine Software zum Konvertieren gescannter Dokumente in bearbeitbaren Text, die einem Scanner beiliegt.
Face Detection- Viele hochmoderne Kameras verfügen über diese Funktion, mit der Sie das Gesicht lesen und das Bild dieses perfekten Ausdrucks aufnehmen können. Es wird verwendet, um einem Benutzer den Zugriff auf die Software bei korrekter Übereinstimmung zu ermöglichen.
Object Recognition - Sie werden in Supermärkten, Kameras, High-End-Autos wie BMW, GM und Volvo installiert.
Estimating Position - Es wird die Position eines Objekts in Bezug auf die Kamera als Position des Tumors im menschlichen Körper geschätzt.
Anwendungsbereiche von Computer Vision
- Agriculture
- Autonome Fahrzeuge
- Biometrics
- Zeichenerkennung
- Forensik, Sicherheit und Überwachung
- Industrielle Qualitätsprüfung
- Gesichtserkennung
- Gestenanalyse
- Geoscience
- Medizinische Bilder
- Verschmutzungsüberwachung
- Prozesssteuerung
- Fernerkundung
- Robotics
- Transport
Anwendungen der Robotik
Die Robotik war maßgeblich an den verschiedenen Bereichen beteiligt, wie z.
Industries - Roboter werden zum Handhaben von Material, Schneiden, Schweißen, Farbbeschichten, Bohren, Polieren usw. verwendet.
Military- Autonome Roboter können während des Krieges unzugängliche und gefährliche Zonen erreichen. Ein Roboter namens Daksh , der von der Defense Research and Development Organization (DRDO) entwickelt wurde, dient dazu, lebensbedrohliche Objekte sicher zu zerstören.
Medicine - Die Roboter sind in der Lage, Hunderte von klinischen Tests gleichzeitig durchzuführen, dauerhaft behinderte Menschen zu rehabilitieren und komplexe Operationen wie Hirntumoren durchzuführen.
Exploration - Die Roboter-Kletterer, die für die Weltraumforschung eingesetzt werden, Unterwasserdrohnen, die für die Erforschung des Ozeans eingesetzt werden, sind nur einige davon.
Entertainment - Disneys Ingenieure haben Hunderte von Robotern für das Filmemachen entwickelt.
Ein weiteres Forschungsgebiet der KI, die neuronalen Netze, ist vom natürlichen neuronalen Netz des menschlichen Nervensystems inspiriert.
Was sind künstliche neuronale Netze (ANNs)?
Der Erfinder des ersten Neurocomputers, Dr. Robert Hecht-Nielsen, definiert ein neuronales Netzwerk als -
"... ein Computersystem, das aus einer Reihe einfacher, stark miteinander verbundener Verarbeitungselemente besteht, die Informationen durch ihre dynamische Zustandsantwort auf externe Eingaben verarbeiten."
Grundstruktur von ANNs
Die Idee von ANNs basiert auf der Überzeugung, dass die Arbeit des menschlichen Gehirns durch Herstellen der richtigen Verbindungen unter Verwendung von Silizium und Drähten als lebend nachgeahmt werden kann neurons und dendrites.
Das menschliche Gehirn besteht aus 86 Milliarden genannten Nervenzellen neurons. Sie sind durch mit anderen tausend Zellen verbunden Axons.Reize aus der äußeren Umgebung oder Eingaben von Sinnesorganen werden von Dendriten akzeptiert. Diese Eingänge erzeugen elektrische Impulse, die sich schnell durch das neuronale Netz bewegen. Ein Neuron kann die Nachricht dann an ein anderes Neuron senden, um das Problem zu behandeln, oder es nicht weiterleiten.

ANNs bestehen aus mehreren nodes, die biologische imitieren neuronsdes menschlichen Gehirns. Die Neuronen sind durch Verbindungen verbunden und interagieren miteinander. Die Knoten können Eingabedaten aufnehmen und einfache Operationen an den Daten ausführen. Das Ergebnis dieser Operationen wird an andere Neuronen weitergegeben. Die Ausgabe an jedem Knoten heißt itsactivation oder node value.
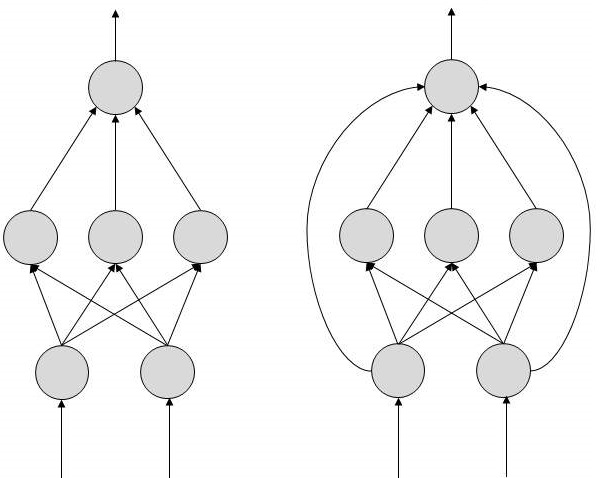
Jeder Link ist zugeordnet weight.ANNs sind lernfähig, was durch Ändern der Gewichtswerte erfolgt. Die folgende Abbildung zeigt eine einfache ANN -

Arten künstlicher neuronaler Netze
Es gibt zwei Topologien für künstliche neuronale Netze - FeedForward und Feedback.
FeedForward ANN
In dieser ANN ist der Informationsfluss unidirektional. Eine Einheit sendet Informationen an eine andere Einheit, von der sie keine Informationen empfängt. Es gibt keine Rückkopplungsschleifen. Sie werden bei der Mustererzeugung / -erkennung / -klassifizierung verwendet. Sie haben feste Ein- und Ausgänge.
FeedBack ANN
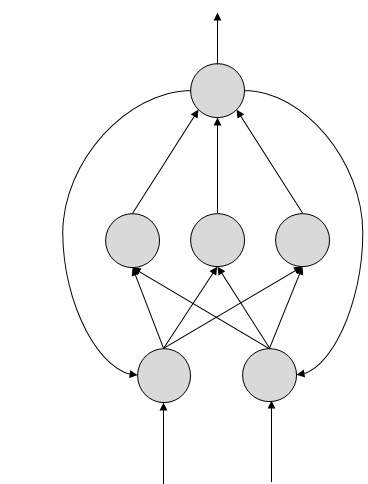
Hier sind Rückkopplungsschleifen erlaubt. Sie werden in inhaltsadressierbaren Speichern verwendet.
Arbeiten von ANNs
In den gezeigten Topologiediagrammen stellt jeder Pfeil eine Verbindung zwischen zwei Neuronen dar und gibt den Weg für den Informationsfluss an. Jede Verbindung hat ein Gewicht, eine Ganzzahl, die das Signal zwischen den beiden Neuronen steuert.
Wenn das Netzwerk eine „gute oder gewünschte“ Ausgabe generiert, müssen die Gewichte nicht angepasst werden. Wenn das Netzwerk jedoch eine "schlechte oder unerwünschte" Ausgabe oder einen Fehler erzeugt, ändert das System die Gewichte, um nachfolgende Ergebnisse zu verbessern.
Maschinelles Lernen in ANNs
ANNs sind lernfähig und müssen geschult werden. Es gibt verschiedene Lernstrategien -
Supervised Learning- Es handelt sich um einen Lehrer, der ein Gelehrter ist als der ANN selbst. Zum Beispiel füttert der Lehrer einige Beispieldaten, über die der Lehrer die Antworten bereits kennt.
Zum Beispiel Mustererkennung. Die ANN kommt beim Erkennen auf Vermutungen. Dann gibt der Lehrer dem ANN die Antworten. Das Netzwerk vergleicht dann seine Vermutungen mit den „richtigen“ Antworten des Lehrers und nimmt Anpassungen entsprechend den Fehlern vor.
Unsupervised Learning- Es ist erforderlich, wenn kein Beispieldatensatz mit bekannten Antworten vorhanden ist. Zum Beispiel nach einem versteckten Muster suchen. In diesem Fall wird das Clustering, dh das Aufteilen eines Satzes von Elementen in Gruppen nach einem unbekannten Muster, basierend auf den vorhandenen vorhandenen Datensätzen durchgeführt.
Reinforcement Learning- Diese Strategie basiert auf Beobachtung. Das ANN trifft eine Entscheidung unter Beobachtung seiner Umgebung. Wenn die Beobachtung negativ ist, passt das Netzwerk seine Gewichte an, um beim nächsten Mal eine andere erforderliche Entscheidung treffen zu können.
Back Propagation Algorithmus
Es ist der Trainings- oder Lernalgorithmus. Es lernt anhand eines Beispiels. Wenn Sie dem Algorithmus das Beispiel für die Ausführung des Netzwerks übermitteln, werden die Gewichte des Netzwerks geändert, sodass nach Abschluss des Trainings die gewünschte Ausgabe für eine bestimmte Eingabe erzeugt werden kann.
Back Propagation-Netzwerke sind ideal für einfache Mustererkennungs- und Zuordnungsaufgaben.
Bayesian Networks (BN)
Dies sind die grafischen Strukturen, die zur Darstellung der Wahrscheinlichkeitsbeziehung zwischen einer Reihe von Zufallsvariablen verwendet werden. Bayesianische Netzwerke werden auch genanntBelief Networks oder Bayes Nets. BNs Grund für unsichere Domain.
In diesen Netzwerken repräsentiert jeder Knoten eine Zufallsvariable mit bestimmten Aussagen. Beispielsweise repräsentiert in einer medizinischen Diagnosedomäne der Knoten Krebs die These, dass ein Patient Krebs hat.
Die Kanten, die die Knoten verbinden, repräsentieren probabilistische Abhängigkeiten zwischen diesen Zufallsvariablen. Wenn von zwei Knoten einer den anderen beeinflusst, müssen sie direkt in die Richtung des Effekts verbunden werden. Die Stärke der Beziehung zwischen Variablen wird durch die jedem Knoten zugeordnete Wahrscheinlichkeit quantifiziert.
Es gibt eine einzige Einschränkung für die Bögen in einem BN, dass Sie nicht einfach zu einem Knoten zurückkehren können, indem Sie gerichteten Bögen folgen. Daher werden die BNs als Directed Acyclic Graphs (DAGs) bezeichnet.
BNs können mehrwertige Variablen gleichzeitig verarbeiten. Die BN-Variablen bestehen aus zwei Dimensionen -
- Bereich von Präpositionen
- Wahrscheinlichkeit, die jeder Präposition zugeordnet ist.
Man betrachte eine endliche Menge X = {X 1 , X 2 ,…, X n } diskreter Zufallsvariablen, wobei jede Variable X i Werte aus einer endlichen Menge annehmen kann, die mit Val (X i ) bezeichnet ist. Wenn es eine gerichtete Verknüpfung von der Variablen X i zur Variablen X j gibt , ist die Variable X i ein Elternteil der Variablen X j, die direkte Abhängigkeiten zwischen den Variablen zeigt.
Die Struktur von BN ist ideal, um Vorkenntnisse und beobachtete Daten zu kombinieren. BN kann verwendet werden, um die kausalen Zusammenhänge zu lernen, verschiedene Problembereiche zu verstehen und zukünftige Ereignisse vorherzusagen, selbst wenn Daten fehlen.
Aufbau eines Bayesianischen Netzwerks
Ein Wissensingenieur kann ein Bayes'sches Netzwerk aufbauen. Es gibt eine Reihe von Schritten, die der Wissensingenieur beim Erstellen ausführen muss.
Example problem- Lungenkrebs. Ein Patient leidet an Atemnot. Er besucht den Arzt und vermutet, dass er Lungenkrebs hat. Der Arzt weiß, dass es außer Lungenkrebs verschiedene andere mögliche Krankheiten gibt, die der Patient haben könnte, wie Tuberkulose und Bronchitis.
Gather Relevant Information of Problem
- Ist der Patient Raucher? Wenn ja, dann hohe Chancen auf Krebs und Bronchitis.
- Ist der Patient Luftverschmutzung ausgesetzt? Wenn ja, welche Art von Luftverschmutzung?
- Nehmen Sie eine röntgenpositive Röntgenaufnahme, die entweder auf TB oder Lungenkrebs hinweist.
Identify Interesting Variables
Der Wissensingenieur versucht die Fragen zu beantworten -
- Welche Knoten sollen dargestellt werden?
- Welche Werte können sie annehmen? In welchem Zustand können sie sein?
Betrachten wir zunächst Knoten mit nur diskreten Werten. Die Variable muss jeweils genau einen dieser Werte annehmen.
Common types of discrete nodes are - -
Boolean nodes - Sie stellen Sätze dar und nehmen die Binärwerte TRUE (T) und FALSE (F) an.
Ordered values- Ein Knoten Verschmutzung kann Werte von {niedrig, mittel, hoch} darstellen und annehmen, die den Grad der Verschmutzung eines Patienten beschreiben.
Integral values- Ein Knoten namens Alter kann das Alter des Patienten mit möglichen Werten von 1 bis 120 darstellen. Bereits in diesem frühen Stadium werden Modellierungsentscheidungen getroffen.
Mögliche Knoten und Werte für das Beispiel Lungenkrebs -
| Knotenname | Art | Wert | Knotenerstellung |
|---|---|---|---|
| Verschmutzung | Binär | {NIEDRIG, HOCH, MITTEL} |

|
| Raucher | Boolescher Wert | {WAHR, SCHNELL} | |
| Lungenkrebs | Boolescher Wert | {WAHR, SCHNELL} | |
| Röntgen | Binär | {Positiv negativ} |
Create Arcs between Nodes
Die Topologie des Netzwerks sollte qualitative Beziehungen zwischen Variablen erfassen.
Was verursacht beispielsweise bei einem Patienten Lungenkrebs? - Verschmutzung und Rauchen. Fügen Sie dann Bögen vom Knoten Verschmutzung und vom Knoten Raucher zum Knoten Lungenkrebs hinzu.
In ähnlicher Weise ist das Röntgenergebnis positiv, wenn der Patient an Lungenkrebs leidet. Fügen Sie dann Bögen vom Knoten Lungenkrebs zum Knoten Röntgen hinzu.

Specify Topology
Herkömmlicherweise sind BNs so angeordnet, dass die Bögen von oben nach unten zeigen. Die Menge der übergeordneten Knoten eines Knotens X wird durch Eltern (X) angegeben.
Der Lungenkrebs- Knoten hat zwei Eltern (Gründe oder Ursachen): Verschmutzung und Raucher , während der Knoten Raucher ein istancestordes Knotens Röntgen . In ähnlicher Weise ist Röntgen ein Kind (Konsequenz oder Auswirkungen) des Knotens Lungenkrebs undsuccessorvon Knoten Raucher und Verschmutzung.
Conditional Probabilities
Quantifizieren Sie nun die Beziehungen zwischen verbundenen Knoten: Geben Sie dazu für jeden Knoten eine bedingte Wahrscheinlichkeitsverteilung an. Da hier nur diskrete Variablen berücksichtigt werden, erfolgt dies in Form von aConditional Probability Table (CPT).
Zunächst müssen wir für jeden Knoten alle möglichen Wertekombinationen dieser übergeordneten Knoten untersuchen. Jede solche Kombination wird als bezeichnetinstantiationdes übergeordneten Satzes. Für jede eindeutige Instanziierung von Elternknotenwerten müssen wir die Wahrscheinlichkeit angeben, die das Kind annehmen wird.
Zum Beispiel sind die Eltern des Lungenkrebs- Knotens Verschmutzung und Rauchen. Sie nehmen die möglichen Werte = {(H, T), (H, F), (L, T), (L, F)} an. Das CPT spezifiziert die Krebswahrscheinlichkeit für jeden dieser Fälle als <0,05, 0,02, 0,03, 0,001>.
Jedem Knoten ist eine bedingte Wahrscheinlichkeit wie folgt zugeordnet:

Anwendungen neuronaler Netze
Sie können Aufgaben ausführen, die für einen Menschen einfach, für eine Maschine jedoch schwierig sind -
Aerospace - Autopilot-Flugzeuge, Flugzeugfehlererkennung.
Automotive - Kfz-Leitsysteme.
Military - Waffenorientierung und -steuerung, Zielverfolgung, Objektunterscheidung, Gesichtserkennung, Signal- / Bildidentifikation.
Electronics - Codesequenzvorhersage, IC-Chip-Layout, Chipfehleranalyse, Bildverarbeitung, Sprachsynthese.
Financial - Immobilienbewertung, Kreditberater, Hypothekenprüfung, Unternehmensanleihenrating, Portfolio-Handelsprogramm, Unternehmensfinanzanalyse, Währungswertvorhersage, Dokumentenleser, Kreditantragsprüfer.
Industrial - Kontrolle des Herstellungsprozesses, Produktdesign und -analyse, Qualitätsprüfsysteme, Schweißqualitätsanalyse, Vorhersage der Papierqualität, Analyse des chemischen Produktdesigns, dynamische Modellierung chemischer Prozesssysteme, Analyse der Maschinenwartung, Ausschreibung, Planung und Verwaltung von Projekten.
Medical - Krebszellanalyse, EEG- und EKG-Analyse, prothetisches Design, Transplantationszeitoptimierer.
Speech - Spracherkennung, Sprachklassifizierung, Umwandlung von Text in Sprache.
Telecommunications - Bild- und Datenkomprimierung, automatisierte Informationsdienste, Übersetzung gesprochener Sprachen in Echtzeit.
Transportation - Diagnose des LKW-Bremssystems, Fahrzeugplanung, Routing-Systeme.
Software - Mustererkennung bei Gesichtserkennung, optischer Zeichenerkennung usw.
Time Series Prediction - ANNs werden verwendet, um Vorhersagen über Bestände und Naturkatastrophen zu treffen.
Signal Processing - Neuronale Netze können trainiert werden, um ein Audiosignal zu verarbeiten und es in den Hörgeräten entsprechend zu filtern.
Control - ANNs werden häufig verwendet, um Lenkentscheidungen für physische Fahrzeuge zu treffen.
Anomaly Detection - Da ANNs Experten im Erkennen von Mustern sind, können sie auch darauf trainiert werden, eine Ausgabe zu generieren, wenn etwas Ungewöhnliches auftritt, das nicht zum Muster passt.
KI entwickelt sich mit solch einer unglaublichen Geschwindigkeit, manchmal scheint es magisch. Forscher und Entwickler sind der Meinung, dass die KI so stark wachsen könnte, dass es für den Menschen schwierig wäre, sie zu kontrollieren.
Die Menschen entwickelten KI-Systeme, indem sie jede mögliche Intelligenz in sie einführten, für die die Menschen selbst jetzt bedroht zu sein scheinen.
Bedrohung der Privatsphäre
Ein KI-Programm, das Sprache erkennt und natürliche Sprache versteht, ist theoretisch in der Lage, jedes Gespräch über E-Mails und Telefone zu verstehen.
Bedrohung der Menschenwürde
KI-Systeme haben bereits in wenigen Branchen begonnen, die Menschen zu ersetzen. Es sollte nicht Menschen in den Sektoren ersetzen, in denen sie würdige ethische Positionen innehaben, wie Krankenpflege, Chirurg, Richter, Polizist usw.
Gefahr für die Sicherheit
Die sich selbst verbessernden KI-Systeme können so mächtig werden wie Menschen, dass es sehr schwierig sein kann, ihre Ziele zu erreichen, was zu unbeabsichtigten Konsequenzen führen kann.
Hier ist die Liste der häufig verwendeten Begriffe im Bereich der KI -
| Sr.Nr. | Begriff & Bedeutung |
|---|---|
| 1 | Agent Agenten sind Systeme oder Softwareprogramme, die autonom, zielgerichtet und auf ein oder mehrere Ziele ausgerichtet sind. Sie werden auch als Assistenten, Makler, Bots, Droiden, intelligente Agenten und Software-Agenten bezeichnet. |
| 2 | Autonomous Robot Roboter frei von externer Kontrolle oder Einflussnahme und in der Lage, sich selbstständig zu steuern. |
| 3 | Backward Chaining Strategie, aus Gründen / Ursachen eines Problems rückwärts zu arbeiten. |
| 4 | Blackboard Es ist der Speicher im Computer, der für die Kommunikation zwischen den kooperierenden Expertensystemen verwendet wird. |
| 5 | Environment Es ist der Teil der realen oder rechnerischen Welt, in dem der Agent lebt. |
| 6 | Forward Chaining Strategie der Vorbereitung auf die Lösung eines Problems. |
| 7 | Heuristics Es ist das Wissen, das auf Versuch und Irrtum, Bewertungen und Experimenten basiert. |
| 8 | Knowledge Engineering Wissen von menschlichen Experten und anderen Ressourcen erwerben. |
| 9 | Percepts Dies ist das Format, in dem der Agent Informationen über die Umgebung erhält. |
| 10 | Pruning Überschreiben unnötiger und irrelevanter Überlegungen in KI-Systemen. |
| 11 | Rule Es ist ein Format zur Darstellung der Wissensbasis im Expertensystem. Es ist in Form von IF-THEN-ELSE. |
| 12 | Shell Eine Shell ist eine Software, die beim Entwerfen der Inferenz-Engine, der Wissensdatenbank und der Benutzeroberfläche eines Expertensystems hilft. |
| 13 | Task Es ist das Ziel, das der Agent zu erreichen versucht. |
| 14 | Turing Test Ein von Allan Turing entwickelter Test, um die Intelligenz einer Maschine im Vergleich zur menschlichen Intelligenz zu testen. |