CherryPy - Kurzanleitung
CherryPy ist ein Webframework von Python, das Python-Entwicklern eine benutzerfreundliche Schnittstelle zum HTTP-Protokoll bietet. Es wird auch als Webanwendungsbibliothek bezeichnet.
CherryPy nutzt die Stärken von Python als dynamische Sprache, um das HTTP-Protokoll zu modellieren und in eine API zu binden. Es ist eines der ältesten Webframeworks für Python, das eine saubere Oberfläche und eine zuverlässige Plattform bietet.
Geschichte von CherryPy
Remi Delon veröffentlichte Ende Juni 2002 die erste Version von CherryPy. Dies war der Ausgangspunkt einer erfolgreichen Python-Webbibliothek. Remi ist ein französischer Hacker, der Python als eine der besten Alternativen für die Entwicklung von Webanwendungen vertraut hat.
Das von Remi entwickelte Projekt zog eine Reihe von Entwicklern an, die sich für den Ansatz interessierten. Der Ansatz umfasste die folgenden Funktionen:
CherryPy lag nahe am Modell-Ansicht-Controller-Muster.
Eine CherryPy-Klasse muss von der CherryPy-Engine verarbeitet und kompiliert werden, um ein in sich geschlossenes Python-Modul zu erstellen, in das die gesamte Anwendung und ein eigener integrierter Webserver eingebettet sind.
CherryPy kann eine URL und ihre Abfragezeichenfolge einem Python-Methodenaufruf zuordnen, z.
http://somehost.net/echo?message=hello would map to echo(message='hello')Während der zweijährigen Entwicklung des CherryPy-Projekts wurde es von der Community unterstützt und Remi veröffentlichte mehrere verbesserte Versionen.
Im Juni 2004 begann eine Diskussion über die Zukunft des Projekts und darüber, ob es mit derselben Architektur fortgesetzt werden sollte. Brainstorming und Diskussion durch mehrere Projektmitarbeiter führten dann zum Konzept der Objektveröffentlichungs-Engine und -Filter, die bald zu einem zentralen Bestandteil von CherryPy2 wurden. Später wurde im Oktober 2004 die erste Version von CherryPy 2 alpha als Proof of Concept von veröffentlicht diese Kernideen. CherryPy 2.0 war ein echter Erfolg. Es wurde jedoch erkannt, dass das Design noch verbessert werden konnte und überarbeitet werden musste.
Nach Diskussionen auf der Grundlage von Rückmeldungen wurde die CherryPy-API weiter modifiziert, um ihre Eleganz zu verbessern. Im Oktober 2005 wurde CherryPy 2.1.0 veröffentlicht. Nach verschiedenen Änderungen veröffentlichte das Team im April 2006 CherryPy 2.2.0.
Stärken von CherryPy
Die folgenden Funktionen von CherryPy gelten als seine Stärken:
Einfachheit
Das Entwickeln eines Projekts in CherryPy ist eine einfache Aufgabe mit wenigen Codezeilen, die gemäß den Konventionen und Einrückungen von Python entwickelt wurden.
CherryPy ist auch sehr modular. Die Hauptkomponenten werden mit dem richtigen Logikkonzept gut verwaltet und übergeordnete Klassen können auf untergeordnete Klassen erweitert werden.
Leistung
CherryPy nutzt die gesamte Leistung von Python. Es bietet auch Tools und Plugins, leistungsstarke Erweiterungspunkte, die für die Entwicklung erstklassiger Anwendungen erforderlich sind.
Open Source
CherryPy ist ein Open-Source-Python-Webframework (lizenziert unter der Open-Source-BSD-Lizenz). Dies bedeutet, dass dieses Framework zu NULL-Kosten kommerziell verwendet werden kann.
Community-Hilfe
Es hat eine engagierte Community, die umfassende Unterstützung bei verschiedenen Arten von Fragen und Antworten bietet. Die Community versucht, den Entwicklern vom Anfänger bis zum Fortgeschrittenen umfassende Unterstützung zu bieten.
Einsatz
Es gibt kostengünstige Möglichkeiten, die Anwendung bereitzustellen. CherryPy enthält einen eigenen produktionsbereiten HTTP-Server zum Hosten Ihrer Anwendung. CherryPy kann auch auf jedem WSGI-kompatiblen Gateway bereitgestellt werden.
CherryPy wird wie die meisten Open-Source-Projekte in Paketen geliefert, die auf verschiedene Arten heruntergeladen und installiert werden können.
- Mit einem Tarball
- Verwenden von easy_install
- Subversion verwenden
Bedarf
Die Grundvoraussetzungen für die Installation des CherryPy-Frameworks sind:
- Python mit Version 2.4 oder höher
- CherryPy 3.0
Das Installieren eines Python-Moduls wird als einfacher Vorgang angesehen. Die Installation beinhaltet die Verwendung der folgenden Befehle.
python setup.py build
python setup.py installDie Pakete von Python werden in den folgenden Standardverzeichnissen gespeichert:
- Unter UNIX oder Linux
/usr/local/lib/python2.4/site-packages
or
/usr/lib/python2.4/site-packages- Unter Microsoft Windows
C:\Python or C:\Python2x- Unter Mac OS
Python:Lib:site-packageInstallation mit Tarball
Ein Tarball ist ein komprimiertes Archiv von Dateien oder ein Verzeichnis. Das CherryPy-Framework bietet für jede seiner Versionen (Alpha, Beta und Stable) einen Tarball.
Es enthält den vollständigen Quellcode der Bibliothek. Der Name stammt von dem in UNIX und anderen Betriebssystemen verwendeten Dienstprogramm.
Hier sind die Schritte für die Installation von CherryPy mit Teerball -
Step 1 - Laden Sie die Version gemäß den Benutzeranforderungen von herunter http://download.cherrypy.org/
Step 2- Suchen Sie nach dem Verzeichnis, in das Tarball heruntergeladen wurde, und dekomprimieren Sie es. Geben Sie für das Linux-Betriebssystem den folgenden Befehl ein:
tar zxvf cherrypy-x.y.z.tgzUnter Microsoft Windows kann der Benutzer ein Dienstprogramm wie 7-Zip oder Winzip verwenden, um das Archiv über eine grafische Oberfläche zu dekomprimieren.
Step 3 - Wechseln Sie in das neu erstellte Verzeichnis und verwenden Sie den folgenden Befehl, um CherryPy zu erstellen. -
python setup.py buildFür die globale Installation sollte der folgende Befehl verwendet werden:
python setup.py installInstallation mit easy_install
Das Python Enterprise Application Kit (PEAK) bietet ein Python-Modul mit dem Namen Easy Install. Dies erleichtert die Bereitstellung der Python-Pakete. Dieses Modul vereinfacht das Herunterladen, Erstellen und Bereitstellen von Python-Anwendungen und -Produkten.
Die einfache Installation muss vor der Installation von CherryPy im System installiert werden.
Step 1 - Laden Sie das Modul ez_setup.py von herunter http://peak.telecommunity.com und führen Sie es mit den Administratorrechten auf dem Computer aus: python ez_setup.py.
Step 2 - Mit dem folgenden Befehl wird Easy Install installiert.
easy_install product_nameStep 3- easy_install durchsucht den Python Package Index (PyPI) nach dem angegebenen Produkt. PyPI ist ein zentrales Informationsspeicher für alle Python-Produkte.
Verwenden Sie den folgenden Befehl, um die neueste verfügbare Version von CherryPy bereitzustellen:
easy_install cherrypyStep 4 - easy_install lädt dann CherryPy herunter, erstellt es und installiert es global in Ihrer Python-Umgebung.
Installation mit Subversion
Die Installation von CherryPy mit Subversion wird in den folgenden Situationen empfohlen:
Eine Funktion ist vorhanden oder ein Fehler wurde behoben und ist nur in Code verfügbar, der sich in der Entwicklung befindet.
Wenn der Entwickler an CherryPy selbst arbeitet.
Wenn der Benutzer einen Zweig vom Hauptzweig im Versionskontroll-Repository benötigt.
Zur Fehlerbehebung der vorherigen Version.
Das Grundprinzip der Subversionierung besteht darin, ein Repository zu registrieren und jede der Versionen zu verfolgen, die eine Reihe von Änderungen enthalten.
Befolgen Sie diese Schritte, um die Installation von CherryPy mit Subversion− zu verstehen
Step 1 - Um die neueste Version des Projekts zu verwenden, muss der Trunk-Ordner im Subversion-Repository überprüft werden.
Step 2 - Geben Sie den folgenden Befehl über eine Shell ein
svn co http://svn.cherrypy.org/trunk cherrypyStep 3 - Erstellen Sie nun ein CherryPy-Verzeichnis und laden Sie den vollständigen Quellcode herunter.
Installation testen
Es muss überprüft werden, ob die Anwendung ordnungsgemäß im System installiert wurde oder nicht, genau wie bei Anwendungen wie Java.
Sie können eine der drei im vorherigen Kapitel genannten Methoden auswählen, um CherryPy in Ihrer Umgebung zu installieren und bereitzustellen. CherryPy muss wie folgt aus der Python-Shell importieren können:
import cherrypy
cherrypy.__version__
'3.0.0'Wenn CherryPy nicht global in der Python-Umgebung des lokalen Systems installiert ist, müssen Sie die Umgebungsvariable PYTHONPATH festlegen. Andernfalls wird ein Fehler auf folgende Weise angezeigt:
import cherrypy
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ImportError: No module named cherrypyEs gibt einige wichtige Schlüsselwörter, die definiert werden müssen, um die Funktionsweise von CherryPy zu verstehen. Die Schlüsselwörter und Definitionen lauten wie folgt:
| S.No. | Schlüsselwort & Definition |
|---|---|
| 1. | Web Server Es ist eine Schnittstelle, die sich mit dem HTTP-Protokoll befasst. Ziel ist es, die HTTP-Anforderungen so in den Anwendungsserver umzuwandeln, dass sie die Antworten erhalten. |
| 2. | Application Es ist eine Software, die Informationen sammelt. |
| 3. | Application server Es ist die Komponente, die eine oder mehrere Anwendungen enthält |
| 4. | Web application server Es ist die Kombination aus Webserver und Anwendungsserver. |
Beispiel
Das folgende Beispiel zeigt einen Beispielcode von CherryPy -
import cherrypy
class demoExample:
def index(self):
return "Hello World!!!"
index.exposed = True
cherrypy.quickstart(demoExample())Lassen Sie uns jetzt verstehen, wie der Code funktioniert -
Das Paket mit dem Namen CherryPy wird immer in die angegebene Klasse importiert, um eine ordnungsgemäße Funktion sicherzustellen.
Im obigen Beispiel wurde die Funktion benannt index gibt den Parameter "Hello World !!!" zurück.
Die letzte Zeile startet den Webserver und ruft die angegebene Klasse (hier demoExample) auf und gibt den im Standardfunktionsindex angegebenen Wert zurück.
Der Beispielcode gibt die folgende Ausgabe zurück:

CherryPy verfügt über einen eigenen Web-Server (HTTP). Aus diesem Grund ist CherryPy in sich geschlossen und ermöglicht es Benutzern, eine CherryPy-Anwendung innerhalb von Minuten nach Erhalt der Bibliothek auszuführen.
Das web server fungiert als Gateway zur Anwendung, mit deren Hilfe alle Anforderungen und Antworten im Auge behalten werden.
Um den Webserver zu starten, muss ein Benutzer den folgenden Aufruf tätigen:
cherryPy.server.quickstart()Das internal engine of CherryPy ist verantwortlich für die folgenden Aktivitäten -
- Erstellung und Verwaltung von Anforderungs- und Antwortobjekten.
- Steuern und Verwalten des CherryPy-Prozesses.
CherryPy - Konfiguration
Das Framework verfügt über ein eigenes Konfigurationssystem, mit dem Sie den HTTP-Server parametrisieren können. Die Einstellungen für die Konfiguration können entweder in einer Textdatei mit einer Syntax nahe dem INI-Format oder als vollständiges Python-Wörterbuch gespeichert werden.
Um die CherryPy-Serverinstanz zu konfigurieren, muss der Entwickler den globalen Abschnitt der Einstellungen verwenden.
global_conf = {
'global': {
'server.socket_host': 'localhost',
'server.socket_port': 8080,
},
}
application_conf = {
'/style.css': {
'tools.staticfile.on': True,
'tools.staticfile.filename': os.path.join(_curdir, 'style.css'),
}
}
This could be represented in a file like this:
[global]
server.socket_host = "localhost"
server.socket_port = 8080
[/style.css]
tools.staticfile.on = True
tools.staticfile.filename = "/full/path/to.style.css"HTTP-Konformität
CherryPy hat sich langsam weiterentwickelt, beinhaltet jedoch die Zusammenstellung von HTTP-Spezifikationen mit Unterstützung von HTTP / 1.0, die später mit Unterstützung von HTTP / 1.1 übertragen werden.
CherryPy soll unter bestimmten Bedingungen mit HTTP / 1.1 kompatibel sein, da es alle erforderlichen und erforderlichen Ebenen implementiert, jedoch nicht alle Soll-Ebenen der Spezifikation. Daher unterstützt CherryPy die folgenden Funktionen von HTTP / 1.1:
Wenn ein Client behauptet, HTTP / 1.1 zu unterstützen, muss er bei jeder Anforderung mit der angegebenen Protokollversion ein Headerfeld senden. Ist dies nicht der Fall, stoppt CherryPy die Verarbeitung der Anforderung sofort.
CherryPy generiert ein Datums-Header-Feld, das in allen Konfigurationen verwendet wird.
CherryPy kann den Antwortstatuscode (100) mit Unterstützung von Clients verarbeiten.
Der in CherryPy integrierte HTTP-Server unterstützt dauerhafte Verbindungen, die in HTTP / 1.1 standardmäßig verwendet werden, mithilfe des Headers "Verbindung: Keep-Alive".
CherryPy verarbeitet korrekt aufgeteilte Anfragen und Antworten.
CherryPy unterstützt Anforderungen auf zwei verschiedene Arten: If-Modified-Since- und If-Unmodified-Since-Header und sendet Antworten gemäß den Anforderungen entsprechend.
CherryPy erlaubt jede HTTP-Methode.
CherryPy verarbeitet die Kombinationen von HTTP-Versionen zwischen dem Client und den für den Server festgelegten Einstellungen.
Multithread-Anwendungsserver
CherryPy basiert auf dem Multithreading-Konzept. Jedes Mal, wenn ein Entwickler einen Wert in den CherryPy-Namespace erhält oder festlegt, erfolgt dies in der Multithread-Umgebung.
Sowohl cherrypy.request als auch cherrypy.response sind Thread-Datencontainer. Dies bedeutet, dass Ihre Anwendung sie unabhängig aufruft, indem sie weiß, welche Anforderung zur Laufzeit über sie übertragen wird.
Anwendungsserver, die das Thread-Muster verwenden, werden nicht hoch geschätzt, da die Verwendung von Threads die Wahrscheinlichkeit von Problemen aufgrund von Synchronisationsanforderungen erhöht.
Die anderen Alternativen umfassen -
Multiprozessmuster
Jede Anfrage wird von einem eigenen Python-Prozess bearbeitet. Hier können Leistung und Stabilität des Servers als besser angesehen werden.
Asynchrones Muster
Hier erfolgt das Akzeptieren neuer Verbindungen und das Zurücksenden der Daten an den Client asynchron vom Anforderungsprozess. Diese Technik ist bekannt für ihre Effizienz.
URL-Versand
Die CherryPy-Community möchte flexibler sein und andere Lösungen für Disponenten wären willkommen. CherryPy 3 bietet andere integrierte Dispatcher und eine einfache Möglichkeit, eigene Dispatcher zu schreiben und zu verwenden.
- Anwendungen zur Entwicklung von HTTP-Methoden. (GET, POST, PUT usw.)
- Diejenige, die die Routen in der URL definiert - Routes Dispatcher
HTTP Method Dispatcher
In einigen Anwendungen sind URIs unabhängig von der Aktion, die vom Server auf der Ressource ausgeführt werden soll.
Zum Beispiel,http://xyz.com/album/delete/10
Die URI enthält die Operation, die der Client ausführen möchte.
Standardmäßig wird der CherryPy-Dispatcher folgendermaßen zugeordnet:
album.delete(12)Der oben genannte Dispatcher wird korrekt erwähnt, kann jedoch auf folgende Weise unabhängig gemacht werden:
http://xyz.com/album/10Der Benutzer kann sich fragen, wie der Server die genaue Seite versendet. Diese Informationen werden von der HTTP-Anforderung selbst übertragen. Wenn eine Anforderung vom Client an den Server eingeht, sieht CherryPy als der am besten geeignete Handler aus. Der Handler ist die Darstellung der Ressource, auf die der URI abzielt.
DELETE /album/12 HTTP/1.1Routen Dispatcher
Hier ist eine Liste der Parameter für die beim Versand erforderliche Methode -
Der Parameter name ist der eindeutige Name für die zu verbindende Route.
Die Route ist das Muster für URIs.
Der Controller ist die Instanz, die Seitenhandler enthält.
Die Verwendung des Routen-Dispatchers verbindet ein Muster, das mit URIs übereinstimmt, und ordnet einen bestimmten Seitenhandler zu.
Beispiel
Nehmen wir ein Beispiel, um zu verstehen, wie es funktioniert -
import random
import string
import cherrypy
class StringMaker(object):
@cherrypy.expose
def index(self):
return "Hello! How are you?"
@cherrypy.expose
def generate(self, length=9):
return ''.join(random.sample(string.hexdigits, int(length)))
if __name__ == '__main__':
cherrypy.quickstart(StringMaker ())Befolgen Sie die unten angegebenen Schritte, um die Ausgabe des obigen Codes zu erhalten -
Step 1 - Speichern Sie die oben genannte Datei als tutRoutes.py.
Step 2 - Besuchen Sie die folgende URL -
http://localhost:8080/generate?length=10Step 3 - Sie erhalten folgende Ausgabe -

In CherryPy bieten integrierte Tools eine einzige Schnittstelle zum Aufrufen der CherryPy-Bibliothek. Die in CherryPy definierten Tools können auf folgende Arten implementiert werden:
- Aus den Konfigurationseinstellungen
- Als Python-Dekorator oder über das spezielle Attribut _cp_config eines Seitenhandlers
- Als Python-Aufruf, der von jeder Funktion aus angewendet werden kann
Grundlegendes Authentifizierungstool
Der Zweck dieses Tools besteht darin, der in der Anwendung entworfenen Anwendung eine grundlegende Authentifizierung bereitzustellen.
Argumente
Dieses Tool verwendet die folgenden Argumente:
| Name | Standard | Beschreibung |
|---|---|---|
| Reich | N / A | Zeichenfolge, die den Realm-Wert definiert. |
| Benutzer | N / A | Wörterbuch der Form - Benutzername: Passwort oder eine aufrufbare Python-Funktion, die ein solches Wörterbuch zurückgibt. |
| Verschlüsseln | Keiner | Python callable wird verwendet, um das vom Client zurückgegebene Kennwort zu verschlüsseln und mit dem im Benutzerwörterbuch angegebenen verschlüsselten Kennwort zu vergleichen. |
Beispiel
Nehmen wir ein Beispiel, um zu verstehen, wie es funktioniert -
import sha
import cherrypy
class Root:
@cherrypy.expose
def index(self):
return """
<html>
<head></head>
<body>
<a href = "admin">Admin </a>
</body>
</html>
"""
class Admin:
@cherrypy.expose
def index(self):
return "This is a private area"
if __name__ == '__main__':
def get_users():
# 'test': 'test'
return {'test': 'b110ba61c4c0873d3101e10871082fbbfd3'}
def encrypt_pwd(token):
return sha.new(token).hexdigest()
conf = {'/admin': {'tools.basic_auth.on': True,
tools.basic_auth.realm': 'Website name',
'tools.basic_auth.users': get_users,
'tools.basic_auth.encrypt': encrypt_pwd}}
root = Root()
root.admin = Admin()
cherrypy.quickstart(root, '/', config=conf)Das get_usersDie Funktion gibt ein fest codiertes Wörterbuch zurück, ruft aber auch die Werte aus einer Datenbank oder einem anderen Ort ab. Der Klassenadministrator enthält diese Funktion, die ein in CherryPy integriertes Authentifizierungstool verwendet. Die Authentifizierung verschlüsselt das Kennwort und die Benutzer-ID.
Das grundlegende Authentifizierungstool ist nicht wirklich sicher, da das Kennwort von einem Eindringling codiert und decodiert werden kann.
Caching-Tool
Der Zweck dieses Tools besteht darin, das Speicher-Caching von von CherryPy generierten Inhalten bereitzustellen.
Argumente
Dieses Tool verwendet die folgenden Argumente:
| Name | Standard | Beschreibung |
|---|---|---|
| invalid_methods | ("POST", "PUT", "DELETE") | Tupel von Zeichenfolgen von HTTP-Methoden, die nicht zwischengespeichert werden sollen. Diese Methoden machen auch alle zwischengespeicherten Kopien der Ressource ungültig (löschen). |
| cache_Class | MemoryCache | Klassenobjekt, das zum Zwischenspeichern verwendet werden soll |
Dekodierungswerkzeug
Der Zweck dieses Tools besteht darin, die Parameter für eingehende Anforderungen zu dekodieren.
Argumente
Dieses Tool verwendet die folgenden Argumente:
| Name | Standard | Beschreibung |
|---|---|---|
| Codierung | Keiner | Es sucht nach dem Inhaltstyp-Header |
| Standardcodierung | "UTF-8" | Standardcodierung, die verwendet wird, wenn keine bereitgestellt oder gefunden wird. |
Beispiel
Nehmen wir ein Beispiel, um zu verstehen, wie es funktioniert -
import cherrypy
from cherrypy import tools
class Root:
@cherrypy.expose
def index(self):
return """
<html>
<head></head>
<body>
<form action = "hello.html" method = "post">
<input type = "text" name = "name" value = "" />
<input type = ”submit” name = "submit"/>
</form>
</body>
</html>
"""
@cherrypy.expose
@tools.decode(encoding='ISO-88510-1')
def hello(self, name):
return "Hello %s" % (name, )
if __name__ == '__main__':
cherrypy.quickstart(Root(), '/')Der obige Code nimmt eine Zeichenfolge vom Benutzer und leitet den Benutzer zur Seite "hello.html" weiter, wo er als "Hallo" mit dem angegebenen Namen angezeigt wird.
Die Ausgabe des obigen Codes lautet wie folgt:
hello.html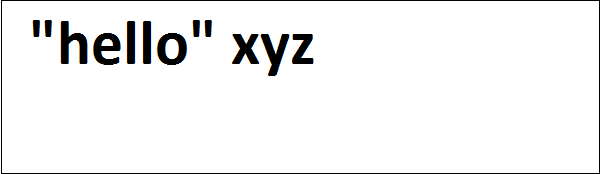
Full-Stack-Anwendungen bieten die Möglichkeit, eine neue Anwendung über einen Befehl oder die Ausführung der Datei zu erstellen.
Betrachten Sie die Python-Anwendungen wie das web2py-Framework. Das gesamte Projekt / die gesamte Anwendung wird in Bezug auf das MVC-Framework erstellt. Ebenso ermöglicht CherryPy dem Benutzer, das Layout des Codes gemäß seinen Anforderungen einzurichten und zu konfigurieren.
In diesem Kapitel erfahren Sie ausführlich, wie Sie eine CherryPy-Anwendung erstellen und ausführen.
Dateisystem
Das Dateisystem der Anwendung wird im folgenden Screenshot gezeigt -
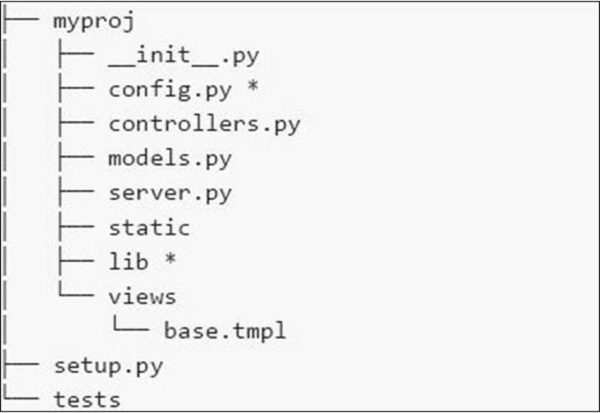
Hier ist eine kurze Beschreibung der verschiedenen Dateien, die wir im Dateisystem haben -
config.py- Jede Anwendung benötigt eine Konfigurationsdatei und eine Möglichkeit zum Laden. Diese Funktionalität kann in config.py definiert werden.
controllers.py- MVC ist ein beliebtes Entwurfsmuster, dem die Benutzer folgen. In der Datei controller.py werden alle Objekte implementiert, die auf der Datei cherrypy.tree bereitgestellt werden .
models.py - Diese Datei interagiert direkt mit der Datenbank für einige Dienste oder zum Speichern persistenter Daten.
server.py - Diese Datei interagiert mit dem produktionsbereiten Webserver, der ordnungsgemäß mit dem Load Balancing-Proxy funktioniert.
Static - Es enthält alle CSS- und Bilddateien.
Views - Es enthält alle Vorlagendateien für eine bestimmte Anwendung.
Beispiel
Lassen Sie uns die Schritte zum Erstellen einer CherryPy-Anwendung im Detail lernen.
Step 1 - Erstellen Sie eine Anwendung, die die Anwendung enthalten soll.
Step 2- Erstellen Sie im Verzeichnis ein Python-Paket, das dem Projekt entspricht. Erstellen Sie das gedit-Verzeichnis und fügen Sie die Datei _init_.py in dasselbe ein.
Step 3 - Fügen Sie dem Paket die Datei controller.py mit dem folgenden Inhalt hinzu: -
#!/usr/bin/env python
import cherrypy
class Root(object):
def __init__(self, data):
self.data = data
@cherrypy.expose
def index(self):
return 'Hi! Welcome to your application'
def main(filename):
data = {} # will be replaced with proper functionality later
# configuration file
cherrypy.config.update({
'tools.encode.on': True, 'tools.encode.encoding': 'utf-8',
'tools.decode.on': True,
'tools.trailing_slash.on': True,
'tools.staticdir.root': os.path.abspath(os.path.dirname(__file__)),
})
cherrypy.quickstart(Root(data), '/', {
'/media': {
'tools.staticdir.on': True,
'tools.staticdir.dir': 'static'
}
})
if __name__ == '__main__':
main(sys.argv[1])Step 4- Stellen Sie sich eine Anwendung vor, in der der Benutzer den Wert über ein Formular eingibt. Nehmen wir zwei Formulare in die Anwendung auf: index.html und submit.html.
Step 5 - Im obigen Code für Steuerungen haben wir index()Dies ist eine Standardfunktion und wird zuerst geladen, wenn ein bestimmter Controller aufgerufen wird.
Step 6 - Die Umsetzung der index() Methode kann folgendermaßen geändert werden:
@cherrypy.expose
def index(self):
tmpl = loader.load('index.html')
return tmpl.generate(title='Sample').render('html', doctype='html')Step 7- Dadurch wird index.html beim Starten der angegebenen Anwendung geladen und an den angegebenen Ausgabestream weitergeleitet. Die Datei index.html lautet wie folgt:
index.html
<!DOCTYPE html >
<html>
<head>
<title>Sample</title>
</head>
<body class = "index">
<div id = "header">
<h1>Sample Application</h1>
</div>
<p>Welcome!</p>
<div id = "footer">
<hr>
</div>
</body>
</html>Step 8 - Es ist wichtig, der Root-Klasse in eine Methode hinzuzufügen controller.py Wenn Sie ein Formular erstellen möchten, das Werte wie Namen und Titel akzeptiert.
@cherrypy.expose
def submit(self, cancel = False, **value):
if cherrypy.request.method == 'POST':
if cancel:
raise cherrypy.HTTPRedirect('/') # to cancel the action
link = Link(**value)
self.data[link.id] = link
raise cherrypy.HTTPRedirect('/')
tmp = loader.load('submit.html')
streamValue = tmp.generate()
return streamValue.render('html', doctype='html')Step 9 - Der Code, der in submit.html enthalten sein soll, lautet wie folgt: -
<!DOCTYPE html>
<head>
<title>Input the new link</title>
</head>
<body class = "submit">
<div id = " header">
<h1>Submit new link</h1>
</div>
<form action = "" method = "post">
<table summary = "">
<tr>
<th><label for = " username">Your name:</label></th>
<td><input type = " text" id = " username" name = " username" /></td>
</tr>
<tr>
<th><label for = " url">Link URL:</label></th>
<td><input type = " text" id=" url" name= " url" /></td>
</tr>
<tr>
<th><label for = " title">Title:</label></th>
<td><input type = " text" name = " title" /></td>
</tr>
<tr>
<td></td>
<td>
<input type = " submit" value = " Submit" />
<input type = " submit" name = " cancel" value = "Cancel" />
</td>
</tr>
</table>
</form>
<div id = "footer">
</div>
</body>
</html>Step 10 - Sie erhalten folgende Ausgabe -
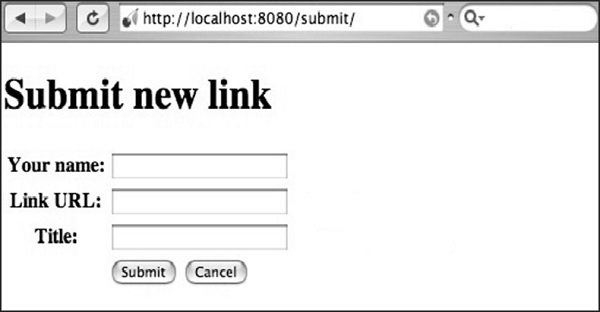
Hier wird der Methodenname als „POST“ definiert. Es ist immer wichtig, die in der Datei angegebene Methode zu überprüfen. Wenn die Methode die POST-Methode enthält, sollten die Werte in der Datenbank in den entsprechenden Feldern erneut überprüft werden.
Wenn die Methode die Methode "GET" enthält, werden die zu speichernden Werte in der URL angezeigt.
Ein Webdienst ist eine Reihe von webbasierten Komponenten, die beim Datenaustausch zwischen der Anwendung oder den Systemen helfen und auch offene Protokolle und Standards enthalten. Es kann im Web veröffentlicht, verwendet und gefunden werden.
Es gibt verschiedene Arten von Webdiensten wie RWS (RESTfUL Web Service), WSDL, SOAP und viele mehr.
REST - Repräsentativer Staatstransfer
Eine Art von RAS-Protokoll, das den Status vom Client zum Server überträgt und zum Bearbeiten des Status verwendet werden kann, anstatt Remote-Prozeduren aufzurufen.
Definiert keine spezifische Codierung oder Struktur und Möglichkeiten zur Rückgabe nützlicher Fehlermeldungen.
Verwendet HTTP- "Verben", um Statusübertragungsvorgänge auszuführen.
Die Ressourcen werden anhand der URL eindeutig identifiziert.
Es ist keine API, sondern eine API-Transportschicht.
REST verwaltet die Nomenklatur der Ressourcen in einem Netzwerk und bietet einen einheitlichen Mechanismus zum Ausführen von Vorgängen für diese Ressourcen. Jede Ressource wird durch mindestens eine Kennung identifiziert. Wenn die REST-Infrastruktur auf der Basis von HTTP implementiert ist, werden diese Bezeichner als bezeichnetUniform Resource Identifiers (URIs).
Im Folgenden sind die beiden allgemeinen Teilmengen der URI-Gruppe aufgeführt:
| Teilmenge | Vollständige Form | Beispiel |
|---|---|---|
| URL | Uniform Resource Locator | http://www.gmail.com/ |
| URNE | Einheitlicher Ressourcenname | Urne: isbn: 0-201-71088-9 Urne: uuid: 13e8cf26-2a25-11db-8693-000ae4ea7d46 |
Bevor wir die Implementierung der CherryPy-Architektur verstehen, konzentrieren wir uns auf die Architektur von CherryPy.
CherryPy enthält die folgenden drei Komponenten:
cherrypy.engine - Es steuert den Prozessstart / -abbau und die Ereignisbehandlung.
cherrypy.server - Es konfiguriert und steuert den WSGI- oder HTTP-Server.
cherrypy.tools - Eine Toolbox mit Dienstprogrammen, die orthogonal zur Verarbeitung einer HTTP-Anforderung sind.
REST-Schnittstelle über CherryPy
Der RESTful-Webdienst implementiert jeden Abschnitt der CherryPy-Architektur mithilfe der folgenden Schritte:
- Authentication
- Authorization
- Structure
- Encapsulation
- Fehlerbehandlung
Authentifizierung
Die Authentifizierung hilft bei der Validierung der Benutzer, mit denen wir interagieren. CherryPy enthält Tools für jede Authentifizierungsmethode.
def authenticate():
if not hasattr(cherrypy.request, 'user') or cherrypy.request.user is None:
# < Do stuff to look up your users >
cherrypy.request.authorized = False # This only authenticates.
Authz must be handled separately.
cherrypy.request.unauthorized_reasons = []
cherrypy.request.authorization_queries = []
cherrypy.tools.authenticate = \
cherrypy.Tool('before_handler', authenticate, priority=10)Die obige Funktion authenticate () hilft dabei, die Existenz der Clients oder Benutzer zu überprüfen. Die integrierten Tools helfen dabei, den Prozess systematisch abzuschließen.
Genehmigung
Die Autorisierung hilft bei der Aufrechterhaltung der Vernunft des Prozesses über URI. Der Prozess hilft auch beim Morphing von Objekten durch Benutzer-Token-Leads.
def authorize_all():
cherrypy.request.authorized = 'authorize_all'
cherrypy.tools.authorize_all = cherrypy.Tool('before_handler', authorize_all, priority=11)
def is_authorized():
if not cherrypy.request.authorized:
raise cherrypy.HTTPError("403 Forbidden",
','.join(cherrypy.request.unauthorized_reasons))
cherrypy.tools.is_authorized = cherrypy.Tool('before_handler', is_authorized,
priority = 49)
cherrypy.config.update({
'tools.is_authorized.on': True,
'tools.authorize_all.on': True
})Die integrierten Autorisierungstools helfen bei der systematischen Behandlung der Routinen, wie im vorherigen Beispiel erwähnt.
Struktur
Das Beibehalten einer API-Struktur hilft dabei, die Arbeitslast beim Zuordnen des URI der Anwendung zu verringern. Es ist immer notwendig, die API erkennbar und sauber zu halten. Die Grundstruktur der API für das CherryPy-Framework sollte Folgendes enthalten:
- Konten und Benutzer
- Autoresponder
- Contact
- File
- Folder
- Liste und Feld
- Nachricht und Stapel
Verkapselung
Encapsulation hilft bei der Erstellung von APIs, die leichtgewichtig, für Menschen lesbar und für verschiedene Clients zugänglich sind. Die Liste der Elemente zusammen mit dem Erstellen, Abrufen, Aktualisieren und Löschen erfordert die Kapselung der API.
Fehlerbehandlung
Dieser Prozess verwaltet etwaige Fehler, wenn die API nicht auf den jeweiligen Instinkt ausgeführt werden kann. Zum Beispiel ist 400 für eine fehlerhafte Anforderung und 403 für eine nicht autorisierte Anforderung.
Beispiel
Betrachten Sie das Folgende als Beispiel für Datenbank-, Validierungs- oder Anwendungsfehler.
import cherrypy
import json
def error_page_default(status, message, traceback, version):
ret = {
'status': status,
'version': version,
'message': [message],
'traceback': traceback
}
return json.dumps(ret)
class Root:
_cp_config = {'error_page.default': error_page_default}
@cherrypy.expose
def index(self):
raise cherrypy.HTTPError(500, "Internal Sever Error")
cherrypy.quickstart(Root())Der obige Code erzeugt die folgende Ausgabe -

Die Verwaltung der API (Application Programming Interface) ist über CherryPy dank der integrierten Zugriffstools einfach.
HTTP-Methoden
Die Liste der HTTP-Methoden, die mit den Ressourcen arbeiten, lautet wie folgt:
| S.No. | HTTP-Methode und Betrieb |
|---|---|
| 1. | HEAD Ruft die Ressourcenmetadaten ab. |
| 2. | GET Ruft die Ressourcenmetadaten und -inhalte ab. |
| 3. | POST Fordert den Server auf, eine neue Ressource unter Verwendung der im Anforderungshauptteil enthaltenen Daten zu erstellen. |
| 4. | PUT Fordert den Server auf, eine vorhandene Ressource durch die im Anforderungshauptteil enthaltene zu ersetzen. |
| 5. | DELETE Fordert den Server auf, die durch diesen URI identifizierte Ressource zu entfernen. |
| 6. | OPTIONS Fordert den Server auf, Details zu Funktionen entweder global oder spezifisch für eine Ressource zurückzugeben. |
Atom Publishing Protocol (APP)
APP ist aus der Atom-Community als Protokoll auf Anwendungsebene über HTTP entstanden, um das Veröffentlichen und Bearbeiten von Webressourcen zu ermöglichen. Die Nachrichteneinheit zwischen einem APP-Server und einem Client basiert auf dem Atom XML-Dokumentformat.
Das Atom Publishing-Protokoll definiert eine Reihe von Vorgängen zwischen einem APP-Dienst und einem Benutzeragenten unter Verwendung von HTTP und seinen Mechanismen sowie des Atom-XML-Dokumentformats als Nachrichteneinheit.
APP definiert zunächst ein Servicedokument, das dem Benutzeragenten den URI der verschiedenen Sammlungen bereitstellt, die vom APP-Service bereitgestellt werden.
Beispiel
Nehmen wir ein Beispiel, um zu demonstrieren, wie APP funktioniert -
<?xml version = "1.0" encoding = "UTF-8"?>
<service xmlns = "http://purl.org/atom/app#" xmlns:atom = "http://www.w3.org/2005/Atom">
<workspace>
<collection href = "http://host/service/atompub/album/">
<atom:title> Albums</atom:title>
<categories fixed = "yes">
<atom:category term = "friends" />
</categories>
</collection>
<collection href = "http://host/service/atompub/film/">
<atom:title>Films</atom:title>
<accept>image/png,image/jpeg</accept>
</collection>
</workspace>
</service>APP gibt an, wie die grundlegenden CRUD-Operationen für ein Mitglied einer Sammlung oder die Sammlung selbst mithilfe von HTTP-Methoden ausgeführt werden sollen, wie in der folgenden Tabelle beschrieben.
| Betrieb | HTTP-Methode | Statuscode | Inhalt |
|---|---|---|---|
| Abrufen | BEKOMMEN | 200 | Ein Atom-Eintrag, der die Ressource darstellt |
| Erstellen | POST | 201 | Der URI der neu erstellten Ressource über die Header Location und Content-Location |
| Aktualisieren | STELLEN | 200 | Ein Atom-Eintrag, der die Ressource darstellt |
| Löschen | LÖSCHEN | 200 | Keiner |
Die Präsentationsschicht stellt sicher, dass die Kommunikation, die sie durchläuft, auf die beabsichtigten Empfänger abzielt. CherryPy verwaltet die Arbeit der Präsentationsschicht durch verschiedene Template-Engines.
Eine Vorlagen-Engine nimmt die Eingabe der Seite mithilfe der Geschäftslogik auf und verarbeitet sie dann zur letzten Seite, die nur die beabsichtigte Zielgruppe anspricht.
Kid - Die Template Engine
Kid ist eine einfache Vorlagen-Engine, die den Namen der zu verarbeitenden Vorlage (obligatorisch) und die Eingabe der Daten enthält, die beim Rendern der Vorlage übergeben werden sollen.
Beim erstmaligen Erstellen der Vorlage erstellt Kid ein Python-Modul, das als zwischengespeicherte Version der Vorlage bereitgestellt werden kann.
Das kid.Template Die Funktion gibt eine Instanz der Vorlagenklasse zurück, mit der der Ausgabeinhalt gerendert werden kann.
Die Vorlagenklasse bietet die folgenden Befehle:
| S.No. | Befehl & Beschreibung |
|---|---|
| 1. | serialize Es gibt den Ausgabeinhalt als Zeichenfolge zurück. |
| 2. | generate Es gibt den Ausgabeinhalt als Iterator zurück. |
| 3. | write Der Ausgabeinhalt wird in ein Dateiobjekt ausgegeben. |
Die von diesen Befehlen verwendeten Parameter lauten wie folgt:
| S.No. | Befehl & Beschreibung |
|---|---|
| 1. | encoding Es informiert darüber, wie der Ausgabeinhalt codiert wird |
| 2. | fragment Es ist ein boolescher Wert, der XML-Prolog oder Doctype mitteilt |
| 3. | output Diese Art der Serialisierung wird zum Rendern des Inhalts verwendet |
Beispiel
Nehmen wir ein Beispiel, um zu verstehen, wie kid funktioniert -
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html xmlns:py = "http://purl.org/kid/ns#">
<head>
<title>${title}</title> <link rel = "stylesheet" href = "style.css" /> </head> <body> <p>${message}</p>
</body>
</html>
The next step after saving the file is to process the template via the Kid engine.
import kid
params = {'title': 'Hello world!!', 'message': 'CherryPy.'}
t = kid.Template('helloworld.kid', **params)
print t.serialize(output='html')Kinderattribute
Das Folgende sind die Attribute von Kid -
XML-basierte Template-Sprache
Es ist eine XML-basierte Sprache. Eine Kid-Vorlage muss ein wohlgeformtes XML-Dokument mit den richtigen Namenskonventionen sein.
Kid implementiert Attribute in den XML-Elementen, um die zugrunde liegende Engine für die Aktion zu aktualisieren, die zum Erreichen des Elements ausgeführt werden soll. Um Überschneidungen mit anderen vorhandenen Attributen im XML-Dokument zu vermeiden, hat Kid einen eigenen Namespace eingeführt.
<p py:if = "...">...</p>Variable Substitution
Kid wird mit einem Variablensubstitutionsschema und einem einfachen Ansatz geliefert - $ {Variablenname}.
Die Variablen können entweder in Attributen von Elementen oder als Textinhalt eines Elements verwendet werden. Kid bewertet die Variable jedes Mal, wenn die Ausführung stattfindet.
Wenn der Benutzer die Ausgabe einer Literalzeichenfolge als $ {Something} benötigt, kann sie mithilfe der Variablensubstitution durch Verdoppeln des Dollarzeichens maskiert werden.
Bedingte Erklärung
Zum Umschalten verschiedener Fälle in der Vorlage wird die folgende Syntax verwendet:
<tag py:if = "expression">...</tag>Tag ist hier der Name des Elements, zum Beispiel DIV oder SPAN.
Der Ausdruck ist ein Python-Ausdruck. Wenn es als Boolescher Wert True ergibt, wird das Element in den Ausgabeinhalt aufgenommen, oder es ist nicht Teil des Ausgabeinhalts.
Schleifenmechanismus
Zum Schleifen eines Elements in Kid wird die folgende Syntax verwendet:
<tag py:for = "expression">...</tag>Hier ist Tag der Name des Elements. Der Ausdruck ist ein Python-Ausdruck, zum Beispiel für den Wert in [...].
Beispiel
Der folgende Code zeigt, wie der Schleifenmechanismus funktioniert -
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
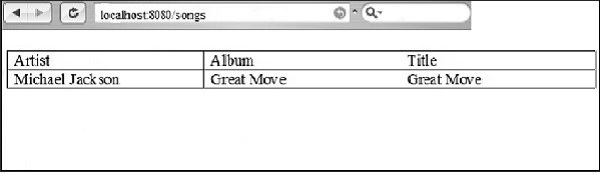
<title>${title}</title> <link rel = "stylesheet" href = "style.css" /> </head> <body> <table> <caption>A few songs</caption> <tr> <th>Artist</th> <th>Album</th> <th>Title</th> </tr> <tr py:for = "info in infos"> <td>${info['artist']}</td>
<td>${info['album']}</td> <td>${info['song']}</td>
</tr>
</table>
</body>
</html>
import kid
params = discography.retrieve_songs()
t = kid.Template('songs.kid', **params)
print t.serialize(output='html')Das output für den obigen Code mit dem Schleifenmechanismus ist wie folgt -
Bis zum Jahr 2005 bestand das Muster in allen Webanwendungen darin, eine HTTP-Anforderung pro Seite zu verwalten. Für die Navigation von einer Seite zu einer anderen Seite musste die gesamte Seite geladen werden. Dies würde die Leistung auf einem höheren Niveau reduzieren.
Somit gab es einen Anstieg in rich client applications die verwendet, um AJAX, XML und JSON mit ihnen einzubetten.
AJAX
Asynchrones JavaScript und XML (AJAX) ist eine Technik zum Erstellen schneller und dynamischer Webseiten. Mit AJAX können Webseiten asynchron aktualisiert werden, indem kleine Datenmengen hinter den Kulissen mit dem Server ausgetauscht werden. Dies bedeutet, dass es möglich ist, Teile einer Webseite zu aktualisieren, ohne die gesamte Seite neu zu laden.
Google Maps, Google Mail, YouTube und Facebook sind einige Beispiele für AJAX-Anwendungen.
Ajax basiert auf der Idee, HTTP-Anfragen mit JavaScript zu senden. Insbesondere stützt sich AJAX auf das XMLHttpRequest-Objekt und seine API, um diese Vorgänge auszuführen.
JSON
JSON ist eine Möglichkeit, serialisierte JavaScript-Objekte so zu transportieren, dass die JavaScript-Anwendung sie auswerten und in JavaScript-Objekte umwandeln kann, die später bearbeitet werden können.
Wenn der Benutzer beispielsweise den Server nach einem im JSON-Format formatierten Albumobjekt anfordert, gibt der Server die Ausgabe wie folgt zurück:
{'description': 'This is a simple demo album for you to test', 'author': ‘xyz’}Jetzt sind die Daten ein assoziatives JavaScript-Array und auf das Beschreibungsfeld kann über - zugegriffen werden
data ['description'];Anwenden von AJAX auf die Anwendung
Betrachten Sie die Anwendung, die einen Ordner mit dem Namen "media" mit index.html und dem Jquery-Plugin sowie eine Datei mit AJAX-Implementierung enthält. Betrachten wir den Namen der Datei als "ajax_app.py".
ajax_app.py
import cherrypy
import webbrowser
import os
import simplejson
import sys
MEDIA_DIR = os.path.join(os.path.abspath("."), u"media")
class AjaxApp(object):
@cherrypy.expose
def index(self):
return open(os.path.join(MEDIA_DIR, u'index.html'))
@cherrypy.expose
def submit(self, name):
cherrypy.response.headers['Content-Type'] = 'application/json'
return simplejson.dumps(dict(title="Hello, %s" % name))
config = {'/media':
{'tools.staticdir.on': True,
'tools.staticdir.dir': MEDIA_DIR,}
}
def open_page():
webbrowser.open("http://127.0.0.1:8080/")
cherrypy.engine.subscribe('start', open_page)
cherrypy.tree.mount(AjaxApp(), '/', config=config)
cherrypy.engine.start()Die Klasse "AjaxApp" leitet zur Webseite "index.html" weiter, die im Medienordner enthalten ist.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
" http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns = "http://www.w3.org/1999/xhtml" lang = "en" xml:lang = "en">
<head>
<title>AJAX with jQuery and cherrypy</title>
<meta http-equiv = " Content-Type" content = " text/html; charset=utf-8" />
<script type = " text/javascript" src = " /media/jquery-1.4.2.min.js"></script>
<script type = " text/javascript">
$(function() { // When the testform is submitted... $("#formtest").submit(function() {
// post the form values via AJAX...
$.post('/submit', {name: $("#name").val()}, function(data) {
// and set the title with the result
$("#title").html(data['title']) ;
});
return false ;
});
});
</script>
</head>
<body>
<h1 id = "title">What's your name?</h1>
<form id = " formtest" action = " #" method = " post">
<p>
<label for = " name">Name:</label>
<input type = " text" id = "name" /> <br />
<input type = " submit" value = " Set" />
</p>
</form>
</body>
</html>Die Funktion für AJAX ist in <script> -Tags enthalten.
Ausgabe
Der obige Code erzeugt die folgende Ausgabe -

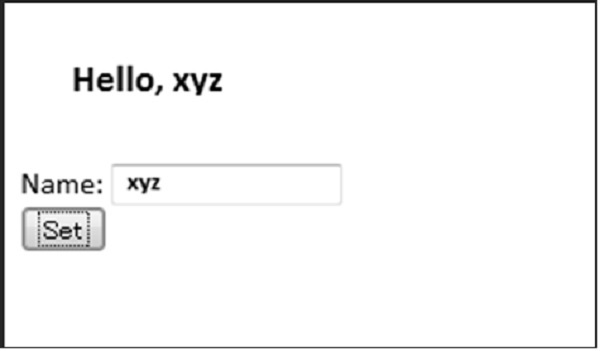
Sobald der Wert vom Benutzer übermittelt wurde, wird die AJAX-Funktionalität implementiert und der Bildschirm wie unten gezeigt zum Formular umgeleitet.
In diesem Kapitel konzentrieren wir uns darauf, wie eine Anwendung im CherryPy-Framework erstellt wird.
Erwägen PhotoblogAnwendung für die Demo-Anwendung von CherryPy. Eine Photoblog-Anwendung ist ein normales Blog, aber der Haupttext sind Fotos anstelle von Text. Der Hauptfang der Photoblog-Anwendung besteht darin, dass sich der Entwickler mehr auf Design und Implementierung konzentrieren kann.
Grundstruktur - Gestaltung von Entitäten
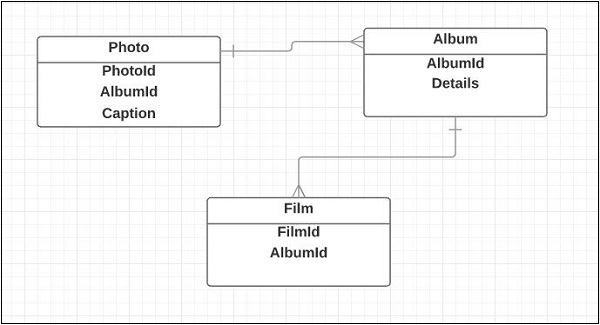
Die Entitäten entwerfen die Grundstruktur einer Anwendung. Im Folgenden sind die Entitäten für die Photoblog-Anwendung aufgeführt:
- Film
- Photo
- Album
Das folgende ist ein grundlegendes Klassendiagramm für die Entitätsbeziehung -
Entwurfsstruktur
Wie im vorherigen Kapitel erläutert, entspricht die Entwurfsstruktur des Projekts dem folgenden Screenshot:

Betrachten Sie die angegebene Anwendung, die Unterverzeichnisse für die Photoblog-Anwendung enthält. Die Unterverzeichnisse sind Foto, Album und Film, einschließlich controller.py, models.py und server.py.
Funktionell bietet die Photoblog-Anwendung APIs zum Bearbeiten dieser Entitäten über die herkömmliche CRUD-Schnittstelle - Erstellen, Abrufen, Aktualisieren und Löschen.
Verbindung zur Datenbank
Ein Speichermodul enthält eine Reihe von Operationen; Verbindung mit der Datenbank ist eine der Operationen.
Da es sich um eine vollständige Anwendung handelt, ist die Verbindung mit der Datenbank für die API und zur Aufrechterhaltung der Funktionalität zum Erstellen, Abrufen, Aktualisieren und Löschen obligatorisch.
import dejavu
arena = dejavu.Arena()
from model import Album, Film, Photo
def connect():
conf = {'Connect': "host=localhost dbname=Photoblog user=test password=test"}
arena.add_store("main", "postgres", conf)
arena.register_all(globals())Die Arena im obigen Code wird unsere Schnittstelle zwischen dem zugrunde liegenden Speichermanager und der Geschäftslogikschicht sein.
Die Verbindungsfunktion fügt dem Arena-Objekt einen Speichermanager für ein PostgreSQL-RDBMS hinzu.
Sobald die Verbindung hergestellt ist, können wir Formulare gemäß den Geschäftsanforderungen erstellen und die Bearbeitung der Anwendung abschließen.
Das Wichtigste vor dem Erstellen einer Anwendung ist entity mapping und Entwerfen der Struktur der Anwendung.
Testen ist ein Prozess, bei dem die Anwendung aus verschiedenen Perspektiven durchgeführt wird, um -
- Hier finden Sie die Liste der Probleme
- Finden Sie Unterschiede zwischen dem erwarteten und dem tatsächlichen Ergebnis, der Ausgabe, den Zuständen usw.
- Verstehen Sie die Implementierungsphase.
- Finden Sie die Anwendung nützlich für realistische Zwecke.
Das Ziel des Testens besteht nicht darin, den Entwickler zu beschuldigen, sondern Tools bereitzustellen und die Qualität zu verbessern, um den Zustand der Anwendung zu einem bestimmten Zeitpunkt abzuschätzen.
Tests müssen im Voraus geplant werden. Dies erfordert die Definition des Testzwecks, das Verständnis des Umfangs der Testfälle, die Erstellung der Liste der Geschäftsanforderungen und die Kenntnis der Risiken, die mit den verschiedenen Phasen des Projekts verbunden sind.
Testen ist definiert als eine Reihe von Aspekten, die auf einem System oder einer Anwendung validiert werden müssen. Es folgt eine Liste dercommon test approaches - -
Unit testing- Dies wird normalerweise von den Entwicklern selbst durchgeführt. Damit soll überprüft werden, ob eine Codeeinheit wie erwartet funktioniert oder nicht.
Usability testing- Entwickler vergessen normalerweise, dass sie eine Anwendung für Endbenutzer schreiben, die keine Systemkenntnisse haben. Usability-Tests bestätigen die Vor- und Nachteile des Produkts.
Functional/Acceptance testing - Während Usability-Tests prüfen, ob eine Anwendung oder ein System verwendbar ist, stellen Funktionstests sicher, dass alle angegebenen Funktionen implementiert sind.
Load and performance testing- Dies wird durchgeführt, um zu verstehen, ob sich das System an die durchzuführenden Last- und Leistungstests anpassen kann. Dies kann zu Änderungen an der Hardware, zur Optimierung von SQL-Abfragen usw. führen.
Regression testing - Es wird überprüft, ob aufeinanderfolgende Releases eines Produkts keine der vorherigen Funktionen beeinträchtigen.
Reliability and resilience testing - Zuverlässigkeitstests helfen bei der Validierung der Systemanwendung mit der Aufteilung einer oder mehrerer Komponenten.
Unit Testing
Photoblog-Anwendungen verwenden ständig Komponententests, um Folgendes zu überprüfen:
- Neue Funktionen funktionieren korrekt und wie erwartet.
- Bestehende Funktionen werden durch die neue Code-Version nicht beeinträchtigt.
- Mängel sind behoben und bleiben behoben.
Python wird mit einem Standard-Unittest-Modul geliefert, das einen anderen Ansatz für Unit-Tests bietet.
Gerätetest
unittest basiert auf JUnit, einem Java-Unit-Test-Paket, das von Kent Beck und Erich Gamma entwickelt wurde. Unit-Tests geben einfach definierte Daten zurück. Scheinobjekte können definiert werden. Diese Objekte ermöglichen das Testen anhand einer Schnittstelle unseres Designs, ohne sich auf die Gesamtanwendung verlassen zu müssen. Sie bieten auch die Möglichkeit, Tests im Isolationsmodus auszuführen, einschließlich anderer Tests.
Definieren wir eine Dummy-Klasse folgendermaßen:
import unittest
class DummyTest(unittest.TestCase):
def test_01_forward(self):
dummy = Dummy(right_boundary=3)
self.assertEqual(dummy.forward(), 1)
self.assertEqual(dummy.forward(), 2)
self.assertEqual(dummy.forward(), 3)
self.assertRaises(ValueError, dummy.forward)
def test_02_backward(self):
dummy = Dummy(left_boundary=-3, allow_negative=True)
self.assertEqual(dummy.backward(), -1)
self.assertEqual(dummy.backward(), -2)
self.assertEqual(dummy.backward(), -3)
self.assertRaises(ValueError, dummy.backward)
def test_03_boundaries(self):
dummy = Dummy(right_boundary=3, left_boundary=-3,allow_negative=True)
self.assertEqual(dummy.backward(), -1)
self.assertEqual(dummy.backward(), -2)
self.assertEqual(dummy.forward(), -1)
self.assertEqual(dummy.backward(), -2)
self.assertEqual(dummy.backward(), -3)Die Erklärung für den Code lautet wie folgt:
Das unittest-Modul sollte importiert werden, um Unit-Test-Funktionen für die angegebene Klasse bereitzustellen.
Eine Klasse sollte durch Unterklasse unittest erstellt werden.
Jede Methode im obigen Code beginnt mit einem Worttest. Alle diese Methoden werden von unittest handler aufgerufen.
Die Assert / Fail-Methoden werden vom Testfall aufgerufen, um die Ausnahmen zu verwalten.
Betrachten Sie dies als Beispiel für die Ausführung eines Testfalls -
if __name__ == '__main__':
unittest.main()Das Ergebnis (Ausgabe) zum Ausführen des Testfalls lautet wie folgt:
----------------------------------------------------------------------
Ran 3 tests in 0.000s
OKFunktionsprüfung
Sobald die Anwendungsfunktionalitäten gemäß den Anforderungen Gestalt annehmen, kann eine Reihe von Funktionstests die Richtigkeit der Anwendung in Bezug auf die Spezifikation überprüfen. Der Test sollte jedoch für eine bessere Leistung automatisiert werden, was die Verwendung von Produkten von Drittanbietern wie Selen erfordern würde.
CherryPy bietet integrierte Funktionen wie Hilfsklassen, um das Schreiben von Funktionstests zu vereinfachen.
Lasttest
Abhängig von der Anwendung, die Sie schreiben, und Ihren Erwartungen hinsichtlich des Volumens müssen Sie möglicherweise Last- und Leistungstests durchführen, um potenzielle Engpässe in der Anwendung zu erkennen, die verhindern, dass sie ein bestimmtes Leistungsniveau erreicht.
In diesem Abschnitt wird nicht detailliert beschrieben, wie ein Leistungs- oder Auslastungstest durchgeführt wird, da er aus dem FunkLoad-Paket stammt.
Das grundlegende Beispiel für FunkLoad lautet wie folgt:
from funkload.FunkLoadTestCase
import FunkLoadTestCase
class LoadHomePage(FunkLoadTestCase):
def test_homepage(self):
server_url = self.conf_get('main', 'url')
nb_time = self.conf_getInt('test_homepage', 'nb_time')
home_page = "%s/" % server_url
for i in range(nb_time):
self.logd('Try %i' % i)
self.get(home_page, description='Get gome page')
if __name__ in ('main', '__main__'):
import unittest
unittest.main()Hier ist eine detaillierte Erklärung des obigen Codes -
Der Testfall muss von der FunkLoadTestCase-Klasse erben, damit FunkLoad seine interne Aufgabe erfüllen kann, zu verfolgen, was während des Tests passiert.
Der Klassenname ist wichtig, da FunkLoad anhand des Klassennamens nach einer Datei sucht.
Die entworfenen Testfälle haben direkten Zugriff auf die Konfigurationsdateien. Die Methoden Get () und post () werden einfach für den Server aufgerufen, um die Antwort zu erhalten.
Dieses Kapitel konzentriert sich mehr auf CherryPy-basierte SSL-Anwendungen, die über den integrierten CherryPy-HTTP-Server aktiviert werden.
Aufbau
In einer Webanwendung sind verschiedene Ebenen von Konfigurationseinstellungen erforderlich.
Web server - Mit dem HTTP-Server verknüpfte Einstellungen
Engine - Einstellungen für das Hosting der Engine
Application - Anwendung, die vom Benutzer verwendet wird
Einsatz
Die Bereitstellung der CherryPy-Anwendung wird als recht einfache Methode angesehen, bei der alle erforderlichen Pakete über den Python-Systempfad verfügbar sind. In einer gemeinsam genutzten Web-gehosteten Umgebung befindet sich der Webserver im Front-End, sodass der Host-Anbieter die Filteraktionen ausführen kann. Der Front-End-Server kann Apache oder seinlighttpd.
In diesem Abschnitt werden einige Lösungen zum Ausführen einer CherryPy-Anwendung hinter den Webservern Apache und lighttpd vorgestellt.
cherrypy
def setup_app():
class Root:
@cherrypy.expose
def index(self):
# Return the hostname used by CherryPy and the remote
# caller IP address
return "Hello there %s from IP: %s " %
(cherrypy.request.base, cherrypy.request.remote.ip)
cherrypy.config.update({'server.socket_port': 9091,
'environment': 'production',
'log.screen': False,
'show_tracebacks': False})
cherrypy.tree.mount(Root())
if __name__ == '__main__':
setup_app()
cherrypy.server.quickstart()
cherrypy.engine.start()SSL
SSL (Secure Sockets Layer)kann in CherryPy-basierten Anwendungen unterstützt werden. Um die SSL-Unterstützung zu aktivieren, müssen die folgenden Anforderungen erfüllt sein:
- Lassen Sie das PyOpenSSL-Paket in der Benutzerumgebung installieren
- Haben Sie ein SSL-Zertifikat und einen privaten Schlüssel auf dem Server
Erstellen eines Zertifikats und eines privaten Schlüssels
Beschäftigen wir uns mit den Anforderungen des Zertifikats und des privaten Schlüssels -
- Zunächst benötigt der Benutzer einen privaten Schlüssel -
openssl genrsa -out server.key 2048- Dieser Schlüssel ist nicht durch ein Passwort geschützt und daher schwach geschützt.
- Der folgende Befehl wird ausgegeben:
openssl genrsa -des3 -out server.key 2048Das Programm benötigt eine Passphrase. Wenn Sie in Ihrer OpenSSL-Version eine leere Zeichenfolge angeben können, tun Sie dies. Andernfalls geben Sie eine Standard-Passphrase ein und entfernen Sie sie wie folgt aus dem generierten Schlüssel:
openssl rsa -in server.key -out server.key- Das Zertifikat wird wie folgt erstellt:
openssl req -new -key server.key -out server.csrBei diesem Vorgang werden Sie aufgefordert, einige Details einzugeben. Dazu muss der folgende Befehl ausgegeben werden:
openssl x509 -req -days 60 -in server.csr -signkey
server.key -out server.crtDas neu unterschriebene Zertifikat ist 60 Tage gültig.
Der folgende Code zeigt die Implementierung -
import cherrypy
import os, os.path
localDir = os.path.abspath(os.path.dirname(__file__))
CA = os.path.join(localDir, 'server.crt')
KEY = os.path.join(localDir, 'server.key')
def setup_server():
class Root:
@cherrypy.expose
def index(self):
return "Hello there!"
cherrypy.tree.mount(Root())
if __name__ == '__main__':
setup_server()
cherrypy.config.update({'server.socket_port': 8443,
'environment': 'production',
'log.screen': True,
'server.ssl_certificate': CA,
'server.ssl_private_key': KEY})
cherrypy.server.quickstart()
cherrypy.engine.start()Der nächste Schritt ist das Starten des Servers. Wenn Sie erfolgreich sind, wird die folgende Meldung auf Ihrem Bildschirm angezeigt:
HTTP Serving HTTPS on https://localhost:8443/