D Programmierung - Kurzanleitung
Die Programmiersprache D ist eine objektorientierte Programmiersprache für mehrere Paradigmen, die von Walter Bright von Digital Mars entwickelt wurde. Die Entwicklung begann 1999 und wurde erstmals 2001 veröffentlicht. Die Hauptversion von D (1.0) wurde 2007 veröffentlicht. Derzeit haben wir die D2-Version von D.
D ist eine Sprache mit einer Syntax im C-Stil und verwendet statische Typisierung. Es gibt viele Funktionen von C und C ++ in D, aber es gibt auch einige Funktionen aus dieser Sprache, die nicht Teil von D sind. Einige der bemerkenswerten Ergänzungen zu D umfassen:
- Unit Testing
- Echte Module
- Müllabfuhr
- Erstklassige Arrays
- Frei und offen
- Assoziative Arrays
- Dynamische Arrays
- Innere Klassen
- Closures
- Anonyme Funktionen
- Faule Bewertung
- Closures
Mehrere Paradigmen
D ist eine Programmiersprache mit mehreren Paradigmen. Die vielfältigen Paradigmen umfassen:
- Imperative
- Objektorientierter
- Meta-Programmierung
- Functional
- Concurrent
Beispiel
import std.stdio;
void main(string[] args) {
writeln("Hello World!");
}Lernen D.
Das Wichtigste beim Lernen von D ist, sich auf Konzepte zu konzentrieren und sich nicht in sprachtechnischen Details zu verlieren.
Der Zweck des Lernens einer Programmiersprache besteht darin, ein besserer Programmierer zu werden. das heißt, beim Entwerfen und Implementieren neuer Systeme und beim Verwalten alter Systeme effektiver zu werden.
Geltungsbereich von D.
Die D-Programmierung hat einige interessante Funktionen und die offizielle D-Programmierseite behauptet, dass D praktisch, leistungsstark und effizient ist. Die D-Programmierung fügt der Kernsprache, die die C-Sprache in Form von Standardbibliotheken bereitgestellt hat, viele Funktionen hinzu, wie z. B. eine anpassbare Array- und Zeichenfolgenfunktion. D ist eine ausgezeichnete Zweitsprache für fortgeschrittene Programmierer. D ist besser im Umgang mit Speicher und in der Verwaltung der Zeiger, die in C ++ häufig Probleme verursachen.
D-Programmierung ist hauptsächlich für neue Programme gedacht, die vorhandene Programme konvertieren. Es bietet integrierte Tests und Verifizierungen, ideal für große neue Projekte, die von großen Teams mit Millionen von Codezeilen geschrieben werden.
Einrichtung der lokalen Umgebung für D.
Wenn Sie weiterhin bereit sind, Ihre Umgebung für die Programmiersprache D einzurichten, benötigen Sie die folgenden zwei auf Ihrem Computer verfügbaren Softwareprogramme: (a) Texteditor, (b) D-Compiler.
Texteditor für die D-Programmierung
Dies wird verwendet, um Ihr Programm einzugeben. Beispiele für wenige Editoren sind Windows Notepad, OS Edit-Befehl, Brief, Epsilon, EMACS und vim oder vi.
Name und Version des Texteditors können auf verschiedenen Betriebssystemen variieren. Beispielsweise wird Notepad unter Windows verwendet, und vim oder vi können sowohl unter Windows als auch unter Linux oder UNIX verwendet werden.
Die Dateien, die Sie mit Ihrem Editor erstellen, werden als Quelldateien bezeichnet und enthalten Programmquellcode. Die Quelldateien für D-Programme werden mit der Erweiterung ".d".
Stellen Sie vor Beginn der Programmierung sicher, dass Sie über einen Texteditor verfügen und über genügend Erfahrung verfügen, um ein Computerprogramm zu schreiben, in einer Datei zu speichern, zu erstellen und schließlich auszuführen.
Der D-Compiler
Die meisten aktuellen D-Implementierungen werden zur effizienten Ausführung direkt in Maschinencode kompiliert.
Wir haben mehrere D-Compiler zur Verfügung und es enthält die folgenden.
DMD - Der Digital Mars D-Compiler ist der offizielle D-Compiler von Walter Bright.
GDC - Ein Front-End für das GCC-Back-End, das mit dem offenen DMD-Compiler-Quellcode erstellt wurde.
LDC - Ein Compiler, der auf dem DMD-Frontend basiert und LLVM als Compiler-Backend verwendet.
Die oben genannten verschiedenen Compiler können von D-Downloads heruntergeladen werden
Wir werden D Version 2 verwenden und empfehlen, D1 nicht herunterzuladen.
Lassen Sie uns ein helloWorld.d-Programm wie folgt haben. Wir werden dies als erstes Programm verwenden, das wir auf der von Ihnen ausgewählten Plattform ausführen.
import std.stdio;
void main(string[] args) {
writeln("Hello World!");
}Wir können die folgende Ausgabe sehen.
$ hello worldInstallation von D unter Windows
Laden Sie das Windows- Installationsprogramm herunter .
Führen Sie die heruntergeladene ausführbare Datei aus, um das D zu installieren. Befolgen Sie dazu die Anweisungen auf dem Bildschirm.
Jetzt können wir die Werbedatei helloWorld.d erstellen und ausführen, indem wir mit cd zu einem Ordner mit der Datei wechseln und dann die folgenden Schritte ausführen:
C:\DProgramming> DMD helloWorld.d
C:\DProgramming> helloWorldWir können die folgende Ausgabe sehen.
hello worldC: \ DProgramming ist der Ordner, in dem ich meine Proben speichere. Sie können es in den Ordner ändern, in dem Sie D-Programme gespeichert haben.
Installation von D unter Ubuntu / Debian
Laden Sie das Debian- Installationsprogramm herunter .
Führen Sie die heruntergeladene ausführbare Datei aus, um das D zu installieren. Befolgen Sie dazu die Anweisungen auf dem Bildschirm.
Jetzt können wir die Werbedatei helloWorld.d erstellen und ausführen, indem wir mit cd zu einem Ordner mit der Datei wechseln und dann die folgenden Schritte ausführen:
$ dmd helloWorld.d
$ ./helloWorldWir können die folgende Ausgabe sehen.
$ hello worldInstallation von D unter Mac OS X.
Laden Sie das Mac- Installationsprogramm herunter .
Führen Sie die heruntergeladene ausführbare Datei aus, um das D zu installieren. Befolgen Sie dazu die Anweisungen auf dem Bildschirm.
Jetzt können wir die Werbedatei helloWorld.d erstellen und ausführen, indem wir mit cd zu einem Ordner mit der Datei wechseln und dann die folgenden Schritte ausführen:
$ dmd helloWorld.d $ ./helloWorldWir können die folgende Ausgabe sehen.
$ hello worldInstallation von D auf Fedora
Laden Sie das Fedora- Installationsprogramm herunter .
Führen Sie die heruntergeladene ausführbare Datei aus, um das D zu installieren. Befolgen Sie dazu die Anweisungen auf dem Bildschirm.
Jetzt können wir die Werbedatei helloWorld.d erstellen und ausführen, indem wir mit cd zu einem Ordner mit der Datei wechseln und dann die folgenden Schritte ausführen:
$ dmd helloWorld.d
$ ./helloWorldWir können die folgende Ausgabe sehen.
$ hello worldInstallation von D unter OpenSUSE
Laden Sie das OpenSUSE- Installationsprogramm herunter .
Führen Sie die heruntergeladene ausführbare Datei aus, um das D zu installieren. Befolgen Sie dazu die Anweisungen auf dem Bildschirm.
Jetzt können wir die Werbedatei helloWorld.d erstellen und ausführen, indem wir mit cd zu einem Ordner mit der Datei wechseln und dann die folgenden Schritte ausführen:
$ dmd helloWorld.d $ ./helloWorldWir können die folgende Ausgabe sehen.
$ hello worldD IDE
Wir haben in den meisten Fällen IDE-Unterstützung für D in Form von Plugins. Das beinhaltet,
Visual D Plugin ist ein Plugin für Visual Studio 2005-13
DDT ist ein Eclipse-Plugin, das die Vervollständigung von Code ermöglicht und mit GDB debuggt.
Mono-D- Code-Vervollständigung, Refactoring mit Unterstützung für dmd / ldc / gdc. Es war Teil der GSoC 2012.
Code Blocks ist eine plattformübergreifende IDE, die das Erstellen, Hervorheben und Debuggen von D-Projekten unterstützt.
D ist ganz einfach zu lernen und wir können mit der Erstellung unseres ersten D-Programms beginnen!
Erstes D-Programm
Schreiben wir ein einfaches D-Programm. Alle D-Dateien haben die Erweiterung .d. Fügen Sie also den folgenden Quellcode in eine test.d-Datei ein.
import std.stdio;
/* My first program in D */
void main(string[] args) {
writeln("test!");
}Vorausgesetzt, die D-Umgebung ist korrekt eingerichtet, können Sie die Programmierung mit - ausführen.
$ dmd test.d
$ ./testWir können die folgende Ausgabe sehen.
testLassen Sie uns nun die Grundstruktur des D-Programms sehen, damit Sie die Grundbausteine der Programmiersprache D leicht verstehen können.
Import in D.
Bibliotheken, die Sammlungen wiederverwendbarer Programmteile sind, können unserem Projekt mit Hilfe des Imports zur Verfügung gestellt werden. Hier importieren wir die Standard-Io-Bibliothek, die die grundlegenden E / A-Operationen bereitstellt. writeln, das im obigen Programm verwendet wird, ist eine Funktion in der Standardbibliothek von D. Es wird zum Drucken einer Textzeile verwendet. Bibliotheksinhalte in D werden in Module gruppiert, die auf den Arten von Aufgaben basieren, die sie ausführen möchten. Das einzige Modul, das dieses Programm verwendet, ist std.stdio, das die Dateneingabe und -ausgabe übernimmt.
Hauptfunktion
Die Hauptfunktion ist das Starten des Programms und bestimmt die Ausführungsreihenfolge und wie andere Abschnitte des Programms ausgeführt werden sollen.
Token in D.
Das AD-Programm besteht aus verschiedenen Token, und ein Token ist entweder ein Schlüsselwort, ein Bezeichner, eine Konstante, ein Zeichenfolgenliteral oder ein Symbol. Die folgende D-Anweisung besteht beispielsweise aus vier Token:
writeln("test!");Die einzelnen Token sind -
writeln (
"test!"
)
;Bemerkungen
Kommentare sind wie unterstützender Text in Ihrem D-Programm und werden vom Compiler ignoriert. Mehrzeiliger Kommentar beginnt mit / * und endet mit den Zeichen * / wie unten gezeigt -
/* My first program in D */Ein einzelner Kommentar wird mit // am Anfang des Kommentars geschrieben.
// my first program in DKennungen
AD-Kennung ist ein Name, mit dem eine Variable, eine Funktion oder ein anderes benutzerdefiniertes Element identifiziert wird. Ein Bezeichner beginnt mit einem Buchstaben A bis Z oder a bis z oder einem Unterstrich _, gefolgt von null oder mehr Buchstaben, Unterstrichen und Ziffern (0 bis 9).
D erlaubt keine Interpunktionszeichen wie @, $ und% in Bezeichnern. D ist acase sensitiveProgrammiersprache. So Manpower und Manpower sind zwei verschiedene Kennungen in D. Hier sind einige Beispiele für akzeptable Identifikatoren -
mohd zara abc move_name a_123
myname50 _temp j a23b9 retValSchlüsselwörter
Die folgende Liste zeigt einige der reservierten Wörter in D. Diese reservierten Wörter dürfen nicht als Konstante, Variable oder andere Bezeichnernamen verwendet werden.
| abstrakt | alias | ausrichten | asm |
| behaupten | Auto | Körper | Bool |
| Byte | Fall | Besetzung | Fang |
| verkohlen | Klasse | const | fortsetzen |
| dchar | debuggen | Standard | delegieren |
| veraltet | tun | doppelt | sonst |
| Aufzählung | Export | extern | falsch |
| Finale | schließlich | schweben | zum |
| für jeden | Funktion | gehe zu | wenn |
| importieren | im | inout | int |
| Schnittstelle | invariant | ist | lange |
| Makro | mischen | Modul | Neu |
| Null | aus | überschreiben | Paket |
| Pragma | Privat | geschützt | Öffentlichkeit |
| echt | ref | Rückkehr | Umfang |
| kurz | statisch | struct | Super |
| Schalter | synchronisiert | Vorlage | diese |
| werfen | wahr | Versuchen | Typid |
| eine Art von | ubyte | uint | ulong |
| Union | Gerätetest | kurz | Ausführung |
| Leere | wchar | während | mit |
Leerzeichen in D.
Eine Zeile, die nur Leerzeichen enthält, möglicherweise mit einem Kommentar, wird als Leerzeile bezeichnet, und ein D-Compiler ignoriert sie vollständig.
Leerzeichen ist der Begriff, der in D verwendet wird, um Leerzeichen, Tabulatoren, Zeilenumbrüche und Kommentare zu beschreiben. Whitespace trennt einen Teil einer Anweisung von einem anderen und ermöglicht dem Interpreter zu identifizieren, wo ein Element in einer Anweisung, wie z. B. int, endet und das nächste Element beginnt. Daher in der folgenden Aussage -
local ageEs muss mindestens ein Leerzeichen (normalerweise ein Leerzeichen) zwischen lokal und Alter vorhanden sein, damit der Interpreter sie unterscheiden kann. Auf der anderen Seite in der folgenden Aussage
int fruit = apples + oranges //get the total fruitsZwischen Obst und = oder zwischen = und Äpfeln sind keine Leerzeichen erforderlich, obwohl Sie einige hinzufügen können, wenn Sie dies aus Gründen der Lesbarkeit wünschen.
Eine Variable ist nichts anderes als ein Name für einen Speicherbereich, den unsere Programme bearbeiten können. Jede Variable in D hat einen bestimmten Typ, der die Größe und das Layout des Speichers der Variablen bestimmt. den Wertebereich, der in diesem Speicher gespeichert werden kann; und die Menge von Operationen, die auf die Variable angewendet werden können.
Der Name einer Variablen kann aus Buchstaben, Ziffern und dem Unterstrich bestehen. Es muss entweder mit einem Buchstaben oder einem Unterstrich beginnen. Groß- und Kleinbuchstaben unterscheiden sich, da bei D zwischen Groß- und Kleinschreibung unterschieden wird. Basierend auf den im vorherigen Kapitel erläuterten Grundtypen gibt es die folgenden Grundvariablentypen:
| Sr.Nr. | Typ & Beschreibung |
|---|---|
| 1 | char Normalerweise ein einzelnes Oktett (ein Byte). Dies ist ein ganzzahliger Typ. |
| 2 | int Die natürlichste Ganzzahlgröße für die Maschine. |
| 3 | float Ein Gleitkommawert mit einfacher Genauigkeit. |
| 4 | double Ein Gleitkommawert mit doppelter Genauigkeit. |
| 5 | void Stellt das Fehlen eines Typs dar. |
Die Programmiersprache D ermöglicht es auch, verschiedene andere Arten von Variablen wie Aufzählung, Zeiger, Array, Struktur, Vereinigung usw. zu definieren, die in den folgenden Kapiteln behandelt werden. Lassen Sie uns in diesem Kapitel nur grundlegende Variablentypen untersuchen.
Variablendefinition in D.
Eine Variablendefinition teilt dem Compiler mit, wo und wie viel Speicherplatz für die Variable erstellt werden soll. Eine Variablendefinition gibt einen Datentyp an und enthält eine Liste einer oder mehrerer Variablen dieses Typs wie folgt:
type variable_list;Hier, type muss ein gültiger D-Datentyp sein, einschließlich char, wchar, int, float, double, bool oder eines benutzerdefinierten Objekts usw., und variable_listkann aus einem oder mehreren durch Kommas getrennten Bezeichnernamen bestehen. Einige gültige Erklärungen werden hier angezeigt -
int i, j, k;
char c, ch;
float f, salary;
double d;Die Linie int i, j, k;beide deklarieren und definieren die Variablen i, j und k; Dies weist den Compiler an, Variablen mit den Namen i, j und k vom Typ int zu erstellen.
Variablen können in ihrer Deklaration initialisiert (mit einem Anfangswert versehen) werden. Der Initialisierer besteht aus einem Gleichheitszeichen, gefolgt von einem konstanten Ausdruck wie folgt:
type variable_name = value;Beispiele
extern int d = 3, f = 5; // declaration of d and f.
int d = 3, f = 5; // definition and initializing d and f.
byte z = 22; // definition and initializes z.
char x = 'x'; // the variable x has the value 'x'.Wenn eine Variable in D deklariert wird, wird sie immer auf ihren 'Standardinitialisierer' gesetzt, auf den manuell als zugegriffen werden kann T.init wo T ist der Typ (z. int.init). Der Standardinitialisierer für Ganzzahltypen ist 0, für Boolesche Werte false und für Gleitkommazahlen NaN.
Variable Deklaration in D.
Eine Variablendeklaration gibt dem Compiler die Gewissheit, dass eine Variable mit dem angegebenen Typ und Namen vorhanden ist, sodass der Compiler mit der weiteren Kompilierung fortfahren kann, ohne vollständige Details über die Variable zu benötigen. Eine Variablendeklaration hat nur zum Zeitpunkt der Kompilierung ihre Bedeutung. Der Compiler benötigt zum Zeitpunkt der Verknüpfung des Programms eine tatsächliche Variablendeklaration.
Beispiel
Versuchen Sie das folgende Beispiel, in dem Variablen zu Beginn des Programms deklariert wurden, aber innerhalb der Hauptfunktion definiert und initialisiert werden:
import std.stdio;
int a = 10, b = 10;
int c;
float f;
int main () {
writeln("Value of a is : ", a);
/* variable re definition: */
int a, b;
int c;
float f;
/* Initialization */
a = 30;
b = 40;
writeln("Value of a is : ", a);
c = a + b;
writeln("Value of c is : ", c);
f = 70.0/3.0;
writeln("Value of f is : ", f);
return 0;
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Value of a is : 10
Value of a is : 30
Value of c is : 70
Value of f is : 23.3333L-Werte und R-Werte in D.
Es gibt zwei Arten von Ausdrücken in D -
lvalue - Ein Ausdruck, der ein Wert ist, kann entweder als linke oder rechte Seite einer Zuweisung angezeigt werden.
rvalue - Ein Ausdruck, der ein r-Wert ist, wird möglicherweise auf der rechten, aber nicht auf der linken Seite einer Zuweisung angezeigt.
Variablen sind l-Werte und können daher auf der linken Seite einer Zuweisung angezeigt werden. Numerische Literale sind r-Werte und können daher nicht zugewiesen werden und können nicht auf der linken Seite angezeigt werden. Die folgende Aussage ist gültig -
int g = 20;Das Folgende ist jedoch keine gültige Anweisung und würde einen Fehler bei der Kompilierung verursachen.
10 = 20;In der Programmiersprache D beziehen sich Datentypen auf ein umfangreiches System, das zum Deklarieren von Variablen oder Funktionen verschiedener Typen verwendet wird. Der Typ einer Variablen bestimmt, wie viel Speicherplatz sie einnimmt und wie das gespeicherte Bitmuster interpretiert wird.
Die Typen in D können wie folgt klassifiziert werden:
| Sr.Nr. | Typen & Beschreibung |
|---|---|
| 1 | Basic Types Sie sind arithmetische Typen und bestehen aus den drei Typen: (a) Ganzzahl, (b) Gleitkomma und (c) Zeichen. |
| 2 | Enumerated types Sie sind wieder arithmetische Typen. Sie werden verwendet, um Variablen zu definieren, denen im gesamten Programm nur bestimmte diskrete Ganzzahlwerte zugewiesen werden können. |
| 3 | The type void Der Typbezeichner void gibt an, dass kein Wert verfügbar ist. |
| 4 | Derived types Sie umfassen (a) Zeigertypen, (b) Array-Typen, (c) Strukturtypen, (d) Unionstypen und (e) Funktionstypen. |
Die Array- und Strukturtypen werden zusammen als Aggregattypen bezeichnet. Der Typ einer Funktion gibt den Typ des Rückgabewerts der Funktion an. Wir werden im folgenden Abschnitt grundlegende Typen sehen, während andere Typen in den kommenden Kapiteln behandelt werden.
Ganzzahlige Typen
In der folgenden Tabelle sind Standard-Integer-Typen mit ihren Speichergrößen und Wertebereichen aufgeführt.
| Art | Speichergröße | Wertebereich |
|---|---|---|
| Bool | 1 Byte | falsch oder wahr |
| Byte | 1 Byte | -128 bis 127 |
| ubyte | 1 Byte | 0 bis 255 |
| int | 4 Bytes | -2.147.483.648 bis 2.147.483.647 |
| uint | 4 Bytes | 0 bis 4,294,967,295 |
| kurz | 2 Bytes | -32.768 bis 32.767 |
| kurz | 2 Bytes | 0 bis 65.535 |
| lange | 8 Bytes | -9223372036854775808 bis 9223372036854775807 |
| ulong | 8 Bytes | 0 bis 18446744073709551615 |
Um die genaue Größe eines Typs oder einer Variablen zu erhalten, können Sie die verwenden sizeofOperator. Der Ausdruckstyp (sizeof) gibt die Speichergröße des Objekts oder Typs in Bytes an. Im folgenden Beispiel wird die Größe des Typs int auf jedem Computer ermittelt.
import std.stdio;
int main() {
writeln("Length in bytes: ", ulong.sizeof);
return 0;
}Wenn Sie das obige Programm kompilieren und ausführen, wird das folgende Ergebnis erzielt:
Length in bytes: 8Gleitkommatypen
In der folgenden Tabelle werden Standard-Gleitkommatypen mit Speichergrößen, Wertebereichen und deren Zweck aufgeführt.
| Art | Speichergröße | Wertebereich | Zweck |
|---|---|---|---|
| schweben | 4 Bytes | 1,17549e-38 bis 3,40282e + 38 | 6 Dezimalstellen |
| doppelt | 8 Bytes | 2,22507e-308 bis 1,79769e + 308 | 15 Dezimalstellen |
| echt | 10 Bytes | 3,3621e-4932 bis 1,18973e + 4932 | entweder der größte Gleitkommatyp, den die Hardware unterstützt, oder double; je nachdem, welcher Wert größer ist |
| ifloat | 4 Bytes | 1,17549e-38i bis 3,40282e + 38i | imaginärer Wert Typ des Schwimmers |
| idouble | 8 Bytes | 2,22507e-308i bis 1,79769e + 308i | imaginärer Wert Typ von doppelt |
| Ich echt | 10 Bytes | 3,3621e-4932 bis 1,18973e + 4932 | imaginärer Wert Typ von real |
| cfloat | 8 Bytes | 1,17549e-38 + 1,17549e-38i bis 3,40282e + 38 + 3,40282e + 38i | komplexer Zahlentyp aus zwei Schwimmern |
| cdouble | 16 Bytes | 2,22507e-308 + 2,22507e-308i bis 1,79769e + 308 + 1,79769e + 308i | komplexer Zahlentyp aus zwei Doppel |
| real | 20 Bytes | 3,3621e-4932 + 3,3621e-4932i bis 1,18973e + 4932 + 1,18973e + 4932i | komplexer Zahlentyp aus zwei Realzahlen |
Im folgenden Beispiel wird der von einem Float-Typ belegte Speicherplatz und seine Bereichswerte gedruckt.
import std.stdio;
int main() {
writeln("Length in bytes: ", float.sizeof);
return 0;
}Wenn Sie das obige Programm kompilieren und ausführen, wird unter Linux das folgende Ergebnis erzielt:
Length in bytes: 4Zeichentypen
In der folgenden Tabelle sind Standardzeichentypen mit Speichergrößen und deren Zweck aufgeführt.
| Art | Speichergröße | Zweck |
|---|---|---|
| verkohlen | 1 Byte | UTF-8-Codeeinheit |
| wchar | 2 Bytes | UTF-16-Codeeinheit |
| dchar | 4 Bytes | UTF-32-Codeeinheit und Unicode-Codepunkt |
Im folgenden Beispiel wird der von einem Zeichentyp belegte Speicherplatz gedruckt.
import std.stdio;
int main() {
writeln("Length in bytes: ", char.sizeof);
return 0;
}Wenn Sie das obige Programm kompilieren und ausführen, wird das folgende Ergebnis erzielt:
Length in bytes: 1Der leere Typ
Der void-Typ gibt an, dass kein Wert verfügbar ist. Es wird in zwei Arten von Situationen verwendet -
| Sr.Nr. | Typen & Beschreibung |
|---|---|
| 1 | Function returns as void Es gibt verschiedene Funktionen in D, die keinen Wert zurückgeben, oder Sie können sagen, dass sie void zurückgeben. Eine Funktion ohne Rückgabewert hat den Rückgabetyp als ungültig. Zum Beispiel,void exit (int status); |
| 2 | Function arguments as void Es gibt verschiedene Funktionen in D, die keine Parameter akzeptieren. Eine Funktion ohne Parameter kann als ungültig akzeptiert werden. Zum Beispiel,int rand(void); |
Der Leertyp wird Ihnen zu diesem Zeitpunkt möglicherweise nicht verstanden. Lassen Sie uns fortfahren und wir werden diese Konzepte in den kommenden Kapiteln behandeln.
Eine Aufzählung wird zum Definieren benannter konstanter Werte verwendet. Ein Aufzählungstyp wird mit dem deklariertenum Stichwort.
Die Enum- Syntax
Die einfachste Form einer Aufzählungsdefinition ist die folgende:
enum enum_name {
enumeration list
}Wo,
Der enum_name gibt den Namen des Aufzählungstyps an.
Die Aufzählungsliste ist eine durch Kommas getrennte Liste von Bezeichnern.
Jedes der Symbole in der Aufzählungsliste steht für einen ganzzahligen Wert, der größer ist als das vorangegangene Symbol. Standardmäßig ist der Wert des ersten Aufzählungssymbols 0. Zum Beispiel -
enum Days { sun, mon, tue, wed, thu, fri, sat };Beispiel
Das folgende Beispiel zeigt die Verwendung der Aufzählungsvariablen -
import std.stdio;
enum Days { sun, mon, tue, wed, thu, fri, sat };
int main(string[] args) {
Days day;
day = Days.mon;
writefln("Current Day: %d", day);
writefln("Friday : %d", Days.fri);
return 0;
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Current Day: 1
Friday : 5Im obigen Programm können wir sehen, wie eine Aufzählung verwendet werden kann. Zunächst erstellen wir eine Variable mit dem Namen Tag unserer benutzerdefinierten Aufzählungstage. Dann setzen wir es mit dem Punktoperator auf mon . Wir müssen die writefln-Methode verwenden, um den Wert von mon zu drucken, der gespeichert wurde. Sie müssen auch den Typ angeben. Es ist vom Typ Integer, daher verwenden wir% d zum Drucken.
Eigenschaften von benannten Enums
Das obige Beispiel verwendet einen Namen Tage für die Aufzählung und heißt benannte Aufzählungen. Diese benannten Aufzählungen haben die folgenden Eigenschaften:
Init - Es initialisiert den ersten Wert in der Aufzählung.
min - Es wird der kleinste Wert der Aufzählung zurückgegeben.
max - Es wird der größte Wert der Aufzählung zurückgegeben.
sizeof - Gibt die Größe des Speichers für die Aufzählung zurück.
Lassen Sie uns das vorherige Beispiel ändern, um die Eigenschaften zu nutzen.
import std.stdio;
// Initialized sun with value 1
enum Days { sun = 1, mon, tue, wed, thu, fri, sat };
int main(string[] args) {
writefln("Min : %d", Days.min);
writefln("Max : %d", Days.max);
writefln("Size of: %d", Days.sizeof);
return 0;
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Min : 1
Max : 7
Size of: 4Anonyme Aufzählung
Die Aufzählung ohne Namen wird als anonyme Aufzählung bezeichnet. Ein Beispiel füranonymous enum ist unten angegeben.
import std.stdio;
// Initialized sun with value 1
enum { sun , mon, tue, wed, thu, fri, sat };
int main(string[] args) {
writefln("Sunday : %d", sun);
writefln("Monday : %d", mon);
return 0;
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Sunday : 0
Monday : 1Anonyme Aufzählungen funktionieren fast genauso wie benannte Aufzählungen, haben jedoch nicht die Eigenschaften max, min und sizeof.
Aufzählung mit Basistypsyntax
Die Syntax für die Aufzählung mit Basistyp ist unten dargestellt.
enum :baseType {
enumeration list
}Einige der Basistypen umfassen long, int und string. Ein Beispiel mit long ist unten dargestellt.
import std.stdio;
enum : string {
A = "hello",
B = "world",
}
int main(string[] args) {
writefln("A : %s", A);
writefln("B : %s", B);
return 0;
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
A : hello
B : worldMehr Funktionen
Die Aufzählung in D bietet Funktionen wie die Initialisierung mehrerer Werte in einer Aufzählung mit mehreren Typen. Ein Beispiel ist unten gezeigt.
import std.stdio;
enum {
A = 1.2f, // A is 1.2f of type float
B, // B is 2.2f of type float
int C = 3, // C is 3 of type int
D // D is 4 of type int
}
int main(string[] args) {
writefln("A : %f", A);
writefln("B : %f", B);
writefln("C : %d", C);
writefln("D : %d", D);
return 0;
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
A : 1.200000
B : 2.200000
C : 3
D : 4Konstante Werte, die im Programm als Teil des Quellcodes eingegeben werden, werden aufgerufen literals.
Literale können von jedem der grundlegenden Datentypen sein und können in Ganzzahlen, Gleitkommazahlen, Zeichen, Zeichenfolgen und Boolesche Werte unterteilt werden.
Auch hier werden Literale wie reguläre Variablen behandelt, mit der Ausnahme, dass ihre Werte nach ihrer Definition nicht mehr geändert werden können.
Ganzzahlige Literale
Ein ganzzahliges Literal kann einen der folgenden Typen haben:
Decimal verwendet die normale Zahlenwiedergabe, wobei die erste Ziffer nicht 0 sein kann, da diese Ziffer für die Anzeige des Oktalsystems reserviert ist. Dies schließt 0 nicht alleine ein: 0 ist Null.
Octal verwendet 0 als Präfix für die Nummer.
Binary verwendet 0b oder 0B als Präfix.
Hexadecimal verwendet 0x oder 0X als Präfix.
Ein ganzzahliges Literal kann auch ein Suffix haben, das eine Kombination aus U und L für unsigned bzw. long ist. Das Suffix kann in Groß- oder Kleinbuchstaben und in beliebiger Reihenfolge angegeben werden.
Wenn Sie kein Suffix verwenden, wählt der Compiler selbst basierend auf der Größe des Werts zwischen int, uint, long und ulong.
Hier sind einige Beispiele für ganzzahlige Literale -
212 // Legal
215u // Legal
0xFeeL // Legal
078 // Illegal: 8 is not an octal digit
032UU // Illegal: cannot repeat a suffixIm Folgenden finden Sie weitere Beispiele für verschiedene Arten von Ganzzahlliteralen:
85 // decimal
0213 // octal
0x4b // hexadecimal
30 // int
30u // unsigned int
30l // long
30ul // unsigned long
0b001 // binaryGleitkomma-Literale
Die Gleitkomma-Literale können entweder im Dezimalsystem wie in 1.568 oder im Hexadezimalsystem wie in 0x91.bc. angegeben werden.
Im Dezimalsystem kann ein Exponent durch Hinzufügen des Zeichens e oder E und einer Zahl danach dargestellt werden. Zum Beispiel bedeutet 2.3e4 "2,3 mal 10 hoch 4". Ein "+" - Zeichen kann vor dem Wert des Exponenten angegeben werden, hat jedoch keine Auswirkung. Zum Beispiel sind 2.3e4 und 2.3e + 4 gleich.
Das vor dem Wert des Exponenten hinzugefügte Zeichen "-" ändert die Bedeutung in "geteilt durch 10 hoch". Zum Beispiel bedeutet 2.3e-2 "2.3 geteilt durch 10 hoch 2".
Im Hexadezimalsystem beginnt der Wert entweder mit 0x oder 0X. Der Exponent wird durch p oder P anstelle von e oder E angegeben. Der Exponent bedeutet nicht "10 hoch", sondern "2 hoch". Zum Beispiel bedeutet P4 in 0xabc.defP4 "abc.de mal 2 hoch 4".
Hier einige Beispiele für Gleitkomma-Literale -
3.14159 // Legal
314159E-5L // Legal
510E // Illegal: incomplete exponent
210f // Illegal: no decimal or exponent
.e55 // Illegal: missing integer or fraction
0xabc.defP4 // Legal Hexa decimal with exponent
0xabc.defe4 // Legal Hexa decimal without exponent.Standardmäßig ist der Typ eines Gleitkomma-Literal doppelt. F und F bedeuten float und der L-Bezeichner bedeutet real.
Boolesche Literale
Es gibt zwei Boolesche Literale, die Teil der Standard-D-Schlüsselwörter sind.
Ein Wert von true wahr darstellen.
Ein Wert von false falsch darstellen.
Sie sollten den Wert von true nicht gleich 1 und den Wert false gleich 0 berücksichtigen.
Zeichenliterale
Zeichenliterale werden in einfache Anführungszeichen gesetzt.
Ein Zeichenliteral kann ein einfaches Zeichen (z. B. 'x'), eine Escape-Sequenz (z. B. '\ t'), ein ASCII-Zeichen (z. B. '\ x21'), ein Unicode-Zeichen (z. B. '\ u011e') oder sein als benanntes Zeichen (zB '\ ©', '\ ♥', '\ €').
Es gibt bestimmte Zeichen in D, denen ein Backslash vorangestellt ist. Sie haben eine besondere Bedeutung und werden zur Darstellung wie Zeilenumbruch (\ n) oder Tabulator (\ t) verwendet. Hier haben Sie eine Liste einiger solcher Escape-Sequenzcodes -
| Fluchtabfolge | Bedeutung |
|---|---|
| \\ | \ Zeichen |
| \ ' | 'Charakter |
| "" | "Charakter |
| \? | ? Charakter |
| \ein | Alarm oder Glocke |
| \ b | Rücktaste |
| \ f | Formularvorschub |
| \ n | Neue Zeile |
| \ r | Wagenrücklauf |
| \ t | Horizontale Registerkarte |
| \ v | Vertikale Registerkarte |
Das folgende Beispiel zeigt einige Escape-Sequenzzeichen -
import std.stdio;
int main(string[] args) {
writefln("Hello\tWorld%c\n",'\x21');
writefln("Have a good day%c",'\x21');
return 0;
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Hello World!
Have a good day!String-Literale
String-Literale werden in doppelte Anführungszeichen gesetzt. Eine Zeichenfolge enthält Zeichen, die Zeichenliteralen ähnlich sind: einfache Zeichen, Escape-Sequenzen und universelle Zeichen.
Sie können eine lange Zeile mithilfe von Zeichenfolgenliteralen in mehrere Zeilen aufteilen und diese durch Leerzeichen trennen.
Hier sind einige Beispiele für String-Literale -
import std.stdio;
int main(string[] args) {
writeln(q"MY_DELIMITER
Hello World
Have a good day
MY_DELIMITER");
writefln("Have a good day%c",'\x21');
auto str = q{int value = 20; ++value;};
writeln(str);
}Im obigen Beispiel finden Sie die Verwendung von q "MY_DELIMITER MY_DELIMITER" zur Darstellung mehrzeiliger Zeichen. Sie können auch q {} sehen, um eine D-Sprachanweisung selbst darzustellen.
Ein Operator ist ein Symbol, das den Compiler anweist, bestimmte mathematische oder logische Manipulationen durchzuführen. Die D-Sprache ist reich an integrierten Operatoren und bietet die folgenden Arten von Operatoren:
- Rechenzeichen
- Vergleichsoperatoren
- Logische Operatoren
- Bitweise Operatoren
- Zuweisungsoperatoren
- Verschiedene Operatoren
In diesem Kapitel werden nacheinander arithmetische, relationale, logische, bitweise, Zuweisungs- und andere Operatoren erläutert.
Rechenzeichen
Die folgende Tabelle zeigt alle arithmetischen Operatoren, die von der Sprache D unterstützt werden. Variable annehmenA hält 10 und variabel B hält dann 20 -
Beispiele anzeigen
| Operator | Beschreibung | Beispiel |
|---|---|---|
| + | Es werden zwei Operanden hinzugefügt. | A + B ergibt 30 |
| - - | Es subtrahiert den zweiten Operanden vom ersten. | A - B ergibt -10 |
| * * | Es multipliziert beide Operanden. | A * B ergibt 200 |
| /. | Es teilt Zähler durch Zähler. | B / A ergibt 2 |
| %. | Es gibt den Rest einer ganzzahligen Division zurück. | B% A ergibt 0 |
| ++ | Der Inkrementoperator erhöht den ganzzahligen Wert um eins. | A ++ gibt 11 |
| - - | Der Dekrementierungsoperator verringert den ganzzahligen Wert um eins. | A-- gibt 9 |
Vergleichsoperatoren
Die folgende Tabelle zeigt alle relationalen Operatoren, die von der Sprache D unterstützt werden. Variable annehmenA hält 10 und variabel B hält 20, dann -
Beispiele anzeigen
| Operator | Beschreibung | Beispiel |
|---|---|---|
| == | Überprüft, ob die Werte von zwei Operanden gleich sind oder nicht. Wenn ja, wird die Bedingung wahr. | (A == B) ist nicht wahr. |
| ! = | Überprüft, ob die Werte von zwei Operanden gleich sind oder nicht. Wenn die Werte nicht gleich sind, wird die Bedingung wahr. | (A! = B) ist wahr. |
| > | Überprüft, ob der Wert des linken Operanden größer als der Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. | (A> B) ist nicht wahr. |
| < | Überprüft, ob der Wert des linken Operanden kleiner als der Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. | (A <B) ist wahr. |
| > = | Überprüft, ob der Wert des linken Operanden größer oder gleich dem Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. | (A> = B) ist nicht wahr. |
| <= | Überprüft, ob der Wert des linken Operanden kleiner oder gleich dem Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. | (A <= B) ist wahr. |
Logische Operatoren
Die folgende Tabelle zeigt alle logischen Operatoren, die von der Sprache D unterstützt werden. Variable annehmenA hält 1 und variabel B hält 0, dann -
Beispiele anzeigen
| Operator | Beschreibung | Beispiel |
|---|---|---|
| && | Es heißt logischer UND-Operator. Wenn beide Operanden ungleich Null sind, wird die Bedingung wahr. | (A && B) ist falsch. |
| || | Es heißt logischer ODER-Operator. Wenn einer der beiden Operanden ungleich Null ist, wird die Bedingung wahr. | (A || B) ist wahr. |
| ! | Es heißt Logical NOT Operator. Verwenden Sie diese Option, um den logischen Status des Operanden umzukehren. Wenn eine Bedingung wahr ist, macht der Operator Logical NOT false. | ! (A && B) ist wahr. |
Bitweise Operatoren
Bitweise Operatoren arbeiten mit Bits und führen bitweise Operationen durch. Die Wahrheitstabellen für &, | und ^ lauten wie folgt:
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Angenommen, A = 60; und B = 13. Im Binärformat sind sie wie folgt:
A = 0011 1100
B = 0000 1101
-----------------
A & B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~ A = 1100 0011
Die von der Sprache D unterstützten bitweisen Operatoren sind in der folgenden Tabelle aufgeführt. Angenommen, Variable A hält 60 und Variable B hält 13, dann -
Beispiele anzeigen
| Operator | Beschreibung | Beispiel |
|---|---|---|
| & | Der binäre UND-Operator kopiert ein Bit in das Ergebnis, wenn es in beiden Operanden vorhanden ist. | (A & B) ergibt 12, bedeutet 0000 1100. |
| | | Der binäre ODER-Operator kopiert ein Bit, wenn es in einem der Operanden vorhanden ist. | (A | B) ergibt 61. Mittel 0011 1101. |
| ^ | Der binäre XOR-Operator kopiert das Bit, wenn es in einem Operanden gesetzt ist, aber nicht in beiden. | (A ^ B) ergibt 49. Mittel 0011 0001 |
| ~ | Der Komplementoperator für binäre Einsen ist unär und bewirkt das Umdrehen von Bits. | (~ A) ergibt -61. Bedeutet 1100 0011 in 2er-Komplementform. |
| << | Binärer Linksschaltoperator. Der Wert der linken Operanden wird um die Anzahl der vom rechten Operanden angegebenen Bits nach links verschoben. | A << 2 ergibt 240. Bedeutet 1111 0000 |
| >> | Binärer Rechtsschieber. Der Wert der linken Operanden wird um die Anzahl der vom rechten Operanden angegebenen Bits nach rechts verschoben. | A >> 2 geben 15. Bedeutet 0000 1111. |
Zuweisungsoperatoren
Die folgenden Zuweisungsoperatoren werden von der Sprache D unterstützt:
Beispiele anzeigen
| Operator | Beschreibung | Beispiel |
|---|---|---|
| = | Es ist ein einfacher Zuweisungsoperator. Es weist dem linken Operanden Werte von Operanden auf der rechten Seite zu | C = A + B weist C den Wert von A + B zu |
| + = | Es ist ein Add AND-Zuweisungsoperator. Es fügt dem linken Operanden den rechten Operanden hinzu und weist das Ergebnis dem linken Operanden zu | C + = A entspricht C = C + A. |
| - = | Es ist ein Subtraktions- UND Zuweisungsoperator. Es subtrahiert den rechten Operanden vom linken Operanden und weist das Ergebnis dem linken Operanden zu. | C - = A entspricht C = C - A. |
| * = | Es ist ein Multiplikations- UND Zuweisungsoperator. Es multipliziert den rechten Operanden mit dem linken Operanden und weist das Ergebnis dem linken Operanden zu. | C * = A entspricht C = C * A. |
| / = | Es ist ein Divisions- UND Zuweisungsoperator. Es teilt den linken Operanden mit dem rechten Operanden und weist das Ergebnis dem linken Operanden zu. | C / = A entspricht C = C / A. |
| % = | Es ist ein Modul- UND Zuweisungsoperator. Es nimmt den Modul mit zwei Operanden und ordnet das Ergebnis dem linken Operanden zu. | C% = A entspricht C = C% A. |
| << = | Es ist Linksverschiebung UND Zuweisungsoperator. | C << = 2 ist dasselbe wie C = C << 2 |
| >> = | Es ist Rechtsverschiebung UND Zuweisungsoperator. | C >> = 2 ist dasselbe wie C = C >> 2 |
| & = | Es ist ein bitweiser UND-Zuweisungsoperator. | C & = 2 ist dasselbe wie C = C & 2 |
| ^ = | Es ist ein bitweise exklusiver ODER- und Zuweisungsoperator. | C ^ = 2 ist dasselbe wie C = C ^ 2 |
| | = | Es ist bitweise inklusive ODER- und Zuweisungsoperator | C | = 2 ist dasselbe wie C = C | 2 |
Verschiedene Operatoren - Sizeof und Ternary
Es gibt nur wenige andere wichtige Betreiber, einschließlich sizeof und ? : unterstützt von D Language.
Beispiele anzeigen
| Operator | Beschreibung | Beispiel |
|---|---|---|
| Größe von() | Gibt die Größe einer Variablen zurück. | sizeof (a), wobei a eine ganze Zahl ist, gibt 4 zurück. |
| & | Gibt die Adresse einer Variablen zurück. | &ein; gibt die tatsächliche Adresse der Variablen an. |
| * * | Zeiger auf eine Variable. | *ein; gibt einen Zeiger auf eine Variable. |
| ? :: | Bedingter Ausdruck | Wenn die Bedingung erfüllt ist, dann Wert X: Andernfalls Wert Y. |
Vorrang der Operatoren in D.
Die Operatorrangfolge bestimmt die Gruppierung von Begriffen in einem Ausdruck. Dies wirkt sich darauf aus, wie ein Ausdruck ausgewertet wird. Bestimmte Operatoren haben Vorrang vor anderen.
Beispielsweise hat der Multiplikationsoperator eine höhere Priorität als der Additionsoperator.
Betrachten wir einen Ausdruck
x = 7 + 3 * 2.
Hier wird x 13 zugewiesen, nicht 20. Der einfache Grund ist, dass der Operator * eine höhere Priorität als + hat, daher wird zuerst 3 * 2 berechnet und dann das Ergebnis zu 7 addiert.
Hier werden Operatoren mit der höchsten Priorität oben in der Tabelle angezeigt, Operatoren mit der niedrigsten Priorität unten. Innerhalb eines Ausdrucks werden zuerst Operatoren mit höherer Priorität ausgewertet.
Beispiele anzeigen
| Kategorie | Operator | Assoziativität |
|---|---|---|
| Postfix | () [] ->. ++ - - | Links nach rechts |
| Einstellig | + -! ~ ++ - - (Typ) * & sizeof | Rechts nach links |
| Multiplikativ | * /% | Links nach rechts |
| Zusatzstoff | + - | Links nach rechts |
| Verschiebung | << >> | Links nach rechts |
| Relational | << = >> = | Links nach rechts |
| Gleichberechtigung | ==! = | Links nach rechts |
| Bitweises UND | & | Links nach rechts |
| Bitweises XOR | ^ | Links nach rechts |
| Bitweises ODER | | | Links nach rechts |
| Logisches UND | && | Links nach rechts |
| Logisches ODER | || | Links nach rechts |
| Bedingt | ?: | Rechts nach links |
| Zuordnung | = + = - = * = / =% = >> = << = & = ^ = | = | Rechts nach links |
| Komma | , | Links nach rechts |
Es kann vorkommen, dass Sie einen Codeblock mehrmals ausführen müssen. Im Allgemeinen werden Anweisungen nacheinander ausgeführt: Die erste Anweisung in einer Funktion wird zuerst ausgeführt, gefolgt von der zweiten usw.
Programmiersprachen bieten verschiedene Steuerungsstrukturen, die kompliziertere Ausführungspfade ermöglichen.
Eine Schleifenanweisung führt eine Anweisung oder eine Gruppe von Anweisungen mehrmals aus. Die folgende allgemeine Form einer Schleifenanweisung wird hauptsächlich in den Programmiersprachen verwendet -

Die Programmiersprache D bietet die folgenden Arten von Schleifen, um die Schleifenanforderungen zu erfüllen. Klicken Sie auf die folgenden Links, um deren Details zu überprüfen.
| Sr.Nr. | Schleifentyp & Beschreibung |
|---|---|
| 1 | while-Schleife Es wiederholt eine Anweisung oder eine Gruppe von Anweisungen, während eine bestimmte Bedingung erfüllt ist. Es testet die Bedingung, bevor der Schleifenkörper ausgeführt wird. |
| 2 | für Schleife Es führt eine Folge von Anweisungen mehrmals aus und verkürzt den Code, der die Schleifenvariable verwaltet. |
| 3 | do ... while-Schleife Wie eine while-Anweisung, nur dass sie die Bedingung am Ende des Schleifenkörpers testet. |
| 4 | verschachtelte Schleifen Sie können eine oder mehrere Schleifen in einer anderen while-, for- oder do..while-Schleife verwenden. |
Schleifensteuerungsanweisungen
Schleifensteueranweisungen ändern die Ausführung von ihrer normalen Reihenfolge. Wenn die Ausführung einen Bereich verlässt, werden alle automatischen Objekte, die in diesem Bereich erstellt wurden, zerstört.
D unterstützt die folgenden Steueranweisungen -
| Sr.Nr. | Steueranweisung & Beschreibung |
|---|---|
| 1 | break-Anweisung Beendet die Schleifen- oder Schalteranweisung und überträgt die Ausführung an die Anweisung unmittelbar nach der Schleife oder dem Schalter. |
| 2 | Aussage fortsetzen Bewirkt, dass die Schleife den Rest ihres Körpers überspringt und ihren Zustand sofort erneut testet, bevor sie wiederholt wird. |
Die Endlosschleife
Eine Schleife wird zur Endlosschleife, wenn eine Bedingung niemals falsch wird. DasforZu diesem Zweck wird traditionell eine Schleife verwendet. Da keiner der drei Ausdrücke, die die for-Schleife bilden, erforderlich ist, können Sie eine Endlosschleife erstellen, indem Sie den bedingten Ausdruck leer lassen.
import std.stdio;
int main () {
for( ; ; ) {
writefln("This loop will run forever.");
}
return 0;
}Wenn der bedingte Ausdruck fehlt, wird angenommen, dass er wahr ist. Möglicherweise haben Sie einen Initialisierungs- und Inkrementausdruck, aber D-Programmierer verwenden häufiger das for (;;) - Konstrukt, um eine Endlosschleife zu kennzeichnen.
NOTE - Sie können eine Endlosschleife beenden, indem Sie Strg + C drücken.
Die Entscheidungsstrukturen enthalten die zu bewertende Bedingung zusammen mit den beiden auszuführenden Anweisungssätzen. Ein Satz von Anweisungen wird ausgeführt, wenn die Bedingung wahr ist, und ein anderer Satz von Anweisungen wird ausgeführt, wenn die Bedingung falsch ist.
Das Folgende ist die allgemeine Form einer typischen Entscheidungsstruktur, die in den meisten Programmiersprachen zu finden ist:
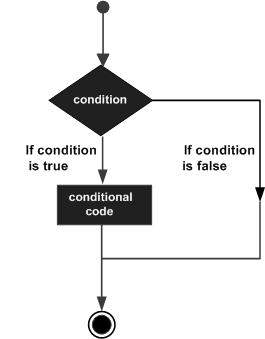
Die Programmiersprache D setzt jede voraus non-zero und non-null Werte als trueund wenn ja zero oder nulldann wird angenommen als false Wert.
Die Programmiersprache D bietet die folgenden Arten von Entscheidungsaussagen.
| Sr.Nr. | Aussage & Beschreibung |
|---|---|
| 1 | if-Anweisung Ein if statement besteht aus einem booleschen Ausdruck, gefolgt von einer oder mehreren Anweisungen. |
| 2 | if ... else-Anweisung Ein if statement kann von einem optionalen gefolgt werden else statement, wird ausgeführt, wenn der boolesche Ausdruck false ist. |
| 3 | verschachtelte if-Anweisungen Sie können eine verwenden if oder else if Aussage in einem anderen if oder else if Aussage (n). |
| 4 | switch-Anweisung EIN switch Mit der Anweisung kann eine Variable auf Gleichheit mit einer Liste von Werten getestet werden. |
| 5 | verschachtelte switch-Anweisungen Sie können eine verwenden switch Aussage in einem anderen switch Aussage (n). |
Das ? : Operator in D.
Wir haben abgedeckt conditional operator ? : im vorherigen Kapitel, das zum Ersetzen verwendet werden kann if...elseAussagen. Es hat die folgende allgemeine Form
Exp1 ? Exp2 : Exp3;Wobei Exp1, Exp2 und Exp3 Ausdrücke sind. Beachten Sie die Verwendung und Platzierung des Doppelpunkts.
Der Wert eines? Ausdruck wird wie folgt bestimmt -
Exp1 wird ausgewertet. Wenn es wahr ist, wird Exp2 ausgewertet und wird zum Wert des gesamten? Ausdruck.
Wenn Exp1 falsch ist, wird Exp3 ausgewertet und sein Wert wird zum Wert des Ausdrucks.
Dieses Kapitel beschreibt die Funktionen der D-Programmierung.
Funktionsdefinition in D.
Eine grundlegende Funktionsdefinition besteht aus einem Funktionsheader und einem Funktionskörper.
Syntax
return_type function_name( parameter list ) {
body of the function
}Hier sind alle Teile einer Funktion -
Return Type- Eine Funktion kann einen Wert zurückgeben. Dasreturn_typeist der Datentyp des Werts, den die Funktion zurückgibt. Einige Funktionen führen die gewünschten Operationen aus, ohne einen Wert zurückzugeben. In diesem Fall ist der return_type das Schlüsselwortvoid.
Function Name- Dies ist der tatsächliche Name der Funktion. Der Funktionsname und die Parameterliste bilden zusammen die Funktionssignatur.
Parameters- Ein Parameter ist wie ein Platzhalter. Wenn eine Funktion aufgerufen wird, übergeben Sie einen Wert an den Parameter. Dieser Wert wird als tatsächlicher Parameter oder Argument bezeichnet. Die Parameterliste bezieht sich auf den Typ, die Reihenfolge und die Anzahl der Parameter einer Funktion. Parameter sind optional; Das heißt, eine Funktion darf keine Parameter enthalten.
Function Body - Der Funktionskörper enthält eine Sammlung von Anweisungen, die definieren, was die Funktion tut.
Eine Funktion aufrufen
Sie können eine Funktion wie folgt aufrufen:
function_name(parameter_values)Funktionstypen in D.
Die D-Programmierung unterstützt eine Vielzahl von Funktionen, die im Folgenden aufgeführt sind.
- Reine Funktionen
- Nothrow-Funktionen
- Ref Funktionen
- Automatische Funktionen
- Variadische Funktionen
- Inout-Funktionen
- Eigenschaftsfunktionen
Die verschiedenen Funktionen werden unten erläutert.
Reine Funktionen
Reine Funktionen sind Funktionen, die nicht über ihre Argumente auf globale oder statische, veränderbare Zustände zugreifen können. Dies kann Optimierungen ermöglichen, die auf der Tatsache basieren, dass eine reine Funktion garantiert nichts mutiert, was nicht an sie übergeben wird, und in Fällen, in denen der Compiler garantieren kann, dass eine reine Funktion ihre Argumente nicht ändern kann, kann dies die volle funktionale Reinheit ermöglichen ist die Garantie, dass die Funktion immer das gleiche Ergebnis für die gleichen Argumente zurückgibt).
import std.stdio;
int x = 10;
immutable int y = 30;
const int* p;
pure int purefunc(int i,const char* q,immutable int* s) {
//writeln("Simple print"); //cannot call impure function 'writeln'
debug writeln("in foo()"); // ok, impure code allowed in debug statement
// x = i; // error, modifying global state
// i = x; // error, reading mutable global state
// i = *p; // error, reading const global state
i = y; // ok, reading immutable global state
auto myvar = new int; // Can use the new expression:
return i;
}
void main() {
writeln("Value returned from pure function : ",purefunc(x,null,null));
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Value returned from pure function : 30Nothrow-Funktionen
Nothrow-Funktionen lösen keine Ausnahmen aus, die von der Klasse Exception abgeleitet sind. Nothrow-Funktionen sind kovariant mit Wurffunktionen.
Nothrow garantiert, dass eine Funktion keine Ausnahme ausgibt.
import std.stdio;
int add(int a, int b) nothrow {
//writeln("adding"); This will fail because writeln may throw
int result;
try {
writeln("adding"); // compiles
result = a + b;
} catch (Exception error) { // catches all exceptions
}
return result;
}
void main() {
writeln("Added value is ", add(10,20));
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
adding
Added value is 30Ref Funktionen
Mit Ref-Funktionen können Funktionen als Referenz zurückgegeben werden. Dies ist analog zu den Funktionsparametern ref.
import std.stdio;
ref int greater(ref int first, ref int second) {
return (first > second) ? first : second;
}
void main() {
int a = 1;
int b = 2;
greater(a, b) += 10;
writefln("a: %s, b: %s", a, b);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
a: 1, b: 12Automatische Funktionen
Auto-Funktionen können Werte beliebigen Typs zurückgeben. Es gibt keine Einschränkung, welcher Typ zurückgegeben werden soll. Ein einfaches Beispiel für die automatische Typfunktion ist unten angegeben.
import std.stdio;
auto add(int first, double second) {
double result = first + second;
return result;
}
void main() {
int a = 1;
double b = 2.5;
writeln("add(a,b) = ", add(a, b));
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
add(a,b) = 3.5Variadische Funktionen
Variadiac-Funktionen sind solche Funktionen, bei denen die Anzahl der Parameter für eine Funktion zur Laufzeit bestimmt wird. In C gibt es eine Einschränkung, mindestens einen Parameter zu haben. Bei der D-Programmierung gibt es jedoch keine solche Einschränkung. Ein einfaches Beispiel ist unten gezeigt.
import std.stdio;
import core.vararg;
void printargs(int x, ...) {
for (int i = 0; i < _arguments.length; i++) {
write(_arguments[i]);
if (_arguments[i] == typeid(int)) {
int j = va_arg!(int)(_argptr);
writefln("\t%d", j);
} else if (_arguments[i] == typeid(long)) {
long j = va_arg!(long)(_argptr);
writefln("\t%d", j);
} else if (_arguments[i] == typeid(double)) {
double d = va_arg!(double)(_argptr);
writefln("\t%g", d);
}
}
}
void main() {
printargs(1, 2, 3L, 4.5);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
int 2
long 3
double 4.5Inout-Funktionen
Das Inout kann sowohl für Parameter- als auch für Rückgabetypen von Funktionen verwendet werden. Es ist wie eine Vorlage für veränderlich, konstant und unveränderlich. Das Veränderbarkeitsattribut wird aus dem Parameter abgeleitet. Das heißt, inout überträgt das abgeleitete Mutabilitätsattribut an den Rückgabetyp. Ein einfaches Beispiel, das zeigt, wie sich die Veränderlichkeit ändert, ist unten dargestellt.
import std.stdio;
inout(char)[] qoutedWord(inout(char)[] phrase) {
return '"' ~ phrase ~ '"';
}
void main() {
char[] a = "test a".dup;
a = qoutedWord(a);
writeln(typeof(qoutedWord(a)).stringof," ", a);
const(char)[] b = "test b";
b = qoutedWord(b);
writeln(typeof(qoutedWord(b)).stringof," ", b);
immutable(char)[] c = "test c";
c = qoutedWord(c);
writeln(typeof(qoutedWord(c)).stringof," ", c);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
char[] "test a"
const(char)[] "test b"
string "test c"Eigenschaftsfunktionen
Eigenschaften ermöglichen die Verwendung von Elementfunktionen wie Elementvariablen. Es verwendet das Schlüsselwort @property. Die Eigenschaften sind mit verwandten Funktionen verknüpft, die je nach Anforderung Werte zurückgeben. Ein einfaches Beispiel für eine Eigenschaft ist unten gezeigt.
import std.stdio;
struct Rectangle {
double width;
double height;
double area() const @property {
return width*height;
}
void area(double newArea) @property {
auto multiplier = newArea / area;
width *= multiplier;
writeln("Value set!");
}
}
void main() {
auto rectangle = Rectangle(20,10);
writeln("The area is ", rectangle.area);
rectangle.area(300);
writeln("Modified width is ", rectangle.width);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The area is 200
Value set!
Modified width is 30Zeichen sind die Bausteine von Zeichenfolgen. Jedes Symbol eines Schriftsystems wird als Zeichen bezeichnet: Buchstaben von Alphabeten, Ziffern, Satzzeichen, Leerzeichen usw. Verwirrenderweise werden die Bausteine von Zeichen selbst auch Zeichen genannt.
Der ganzzahlige Wert des Kleinbuchstabens a ist 97 und der ganzzahlige Wert der Ziffer 1 ist 49. Diese Werte wurden lediglich durch Konventionen zugewiesen, als die ASCII-Tabelle entworfen wurde.
In der folgenden Tabelle werden Standardzeichentypen mit ihren Speichergrößen und -zwecken aufgeführt.
Die Zeichen werden durch den Zeichentyp dargestellt, der nur 256 verschiedene Werte enthalten kann. Wenn Sie mit dem Zeichentyp aus anderen Sprachen vertraut sind, wissen Sie möglicherweise bereits, dass er nicht groß genug ist, um die Symbole vieler Schriftsysteme zu unterstützen.
| Art | Speichergröße | Zweck |
|---|---|---|
| verkohlen | 1 Byte | UTF-8-Codeeinheit |
| wchar | 2 Bytes | UTF-16-Codeeinheit |
| dchar | 4 Bytes | UTF-32-Codeeinheit und Unicode-Codepunkt |
Einige nützliche Zeichenfunktionen sind unten aufgeführt -
isLower - Bestimmt, ob ein Kleinbuchstabe?
isUpper - Bestimmt, ob ein Großbuchstabe?
isAlpha - Bestimmt, ob ein alphanumerisches Unicode-Zeichen (im Allgemeinen ein Buchstabe oder eine Ziffer) vorliegt?
isWhite - Bestimmt, ob ein Leerzeichen?
toLower - Es wird der Kleinbuchstabe des angegebenen Zeichens erzeugt.
toUpper - Es wird der Großbuchstabe des angegebenen Zeichens erzeugt.
import std.stdio;
import std.uni;
void main() {
writeln("Is ğ lowercase? ", isLower('ğ'));
writeln("Is Ş lowercase? ", isLower('Ş'));
writeln("Is İ uppercase? ", isUpper('İ'));
writeln("Is ç uppercase? ", isUpper('ç'));
writeln("Is z alphanumeric? ", isAlpha('z'));
writeln("Is new-line whitespace? ", isWhite('\n'));
writeln("Is underline whitespace? ", isWhite('_'));
writeln("The lowercase of Ğ: ", toLower('Ğ'));
writeln("The lowercase of İ: ", toLower('İ'));
writeln("The uppercase of ş: ", toUpper('ş'));
writeln("The uppercase of ı: ", toUpper('ı'));
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Is ğ lowercase? true
Is Ş lowercase? false
Is İ uppercase? true
Is ç uppercase? false
Is z alphanumeric? true
Is new-line whitespace? true
Is underline whitespace? false
The lowercase of Ğ: ğ
The lowercase of İ: i
The uppercase of ş: Ş
The uppercase of ı: IZeichen in D lesen
Wir können Zeichen mit readf lesen, wie unten gezeigt.
readf(" %s", &letter);Da die D-Programmierung Unicode unterstützt, müssen wir zum Lesen von Unicode-Zeichen zweimal lesen und zweimal schreiben, um das erwartete Ergebnis zu erhalten. Dies funktioniert auf dem Online-Compiler nicht. Das Beispiel ist unten dargestellt.
import std.stdio;
void main() {
char firstCode;
char secondCode;
write("Please enter a letter: ");
readf(" %s", &firstCode);
readf(" %s", &secondCode);
writeln("The letter that has been read: ", firstCode, secondCode);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Please enter a letter: ğ
The letter that has been read: ğD bietet die folgenden zwei Arten von Zeichenfolgendarstellungen:
- Zeichenarray
- Kernsprachenzeichenfolge
Zeichenarray
Wir können das Zeichenarray in einer der beiden Formen darstellen, wie unten gezeigt. Das erste Formular gibt die Größe direkt an und das zweite Formular verwendet die Dup-Methode, mit der eine beschreibbare Kopie der Zeichenfolge "Guten Morgen" erstellt wird.
char[9] greeting1 = "Hello all";
char[] greeting2 = "Good morning".dup;Beispiel
Hier ist ein einfaches Beispiel unter Verwendung der obigen einfachen Zeichenarrayformulare.
import std.stdio;
void main(string[] args) {
char[9] greeting1 = "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt er Folgendes:
Hello all
Good morningKernsprachenzeichenfolge
Zeichenfolgen sind in die Kernsprache von D integriert. Diese Zeichenfolgen sind mit dem oben gezeigten Zeichenarray kompatibel. Das folgende Beispiel zeigt eine einfache Zeichenfolgendarstellung.
string greeting1 = "Hello all";Beispiel
import std.stdio;
void main(string[] args) {
string greeting1 = "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
string greeting3 = greeting1;
writefln("%s",greeting3);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt er Folgendes:
Hello all
Good morning
Hello allString-Verkettung
Die String-Verkettung in der D-Programmierung verwendet das Tilde-Symbol (~).
Beispiel
import std.stdio;
void main(string[] args) {
string greeting1 = "Good";
char[] greeting2 = "morning".dup;
char[] greeting3 = greeting1~" "~greeting2;
writefln("%s",greeting3);
string greeting4 = "morning";
string greeting5 = greeting1~" "~greeting4;
writefln("%s",greeting5);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt er Folgendes:
Good morning
Good morningLänge der Zeichenfolge
Die Länge der Zeichenfolge in Bytes kann mit Hilfe der Längenfunktion abgerufen werden.
Beispiel
import std.stdio;
void main(string[] args) {
string greeting1 = "Good";
writefln("Length of string greeting1 is %d",greeting1.length);
char[] greeting2 = "morning".dup;
writefln("Length of string greeting2 is %d",greeting2.length);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Length of string greeting1 is 4
Length of string greeting2 is 7String-Vergleich
Der String-Vergleich ist in der D-Programmierung recht einfach. Sie können die Operatoren ==, <und> für Zeichenfolgenvergleiche verwenden.
Beispiel
import std.stdio;
void main() {
string s1 = "Hello";
string s2 = "World";
string s3 = "World";
if (s2 == s3) {
writeln("s2: ",s2," and S3: ",s3, " are the same!");
}
if (s1 < s2) {
writeln("'", s1, "' comes before '", s2, "'.");
} else {
writeln("'", s2, "' comes before '", s1, "'.");
}
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt er Folgendes:
s2: World and S3: World are the same!
'Hello' comes before 'World'.Saiten ersetzen
Wir können Strings mit dem String [] ersetzen.
Beispiel
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello world ".dup;
char[] s2 = "sample".dup;
s1[6..12] = s2[0..6];
writeln(s1);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt er Folgendes:
hello sampleIndexmethoden
Indexmethoden für die Position eines Teilstrings in einer Zeichenfolge, einschließlich indexOf und lastIndexOf, werden im folgenden Beispiel erläutert.
Beispiel
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello World ".dup;
writeln("indexOf of llo in hello is ",std.string.indexOf(s1,"llo"));
writeln(s1);
writeln("lastIndexOf of O in hello is " ,std.string.lastIndexOf(s1,"O",CaseSensitive.no));
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
indexOf.of llo in hello is 2
hello World
lastIndexOf of O in hello is 7Fälle bearbeiten
Die Methoden zum Ändern von Fällen werden im folgenden Beispiel gezeigt.
Beispiel
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello World ".dup;
writeln("Capitalized string of s1 is ",capitalize(s1));
writeln("Uppercase string of s1 is ",toUpper(s1));
writeln("Lowercase string of s1 is ",toLower(s1));
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Capitalized string of s1 is Hello world
Uppercase string of s1 is HELLO WORLD
Lowercase string of s1 is hello worldZeichen einschränken
Restzeichen in Zeichenfolgen werden im folgenden Beispiel gezeigt.
Beispiel
import std.stdio;
import std.string;
void main() {
string s = "H123Hello1";
string result = munch(s, "0123456789H");
writeln("Restrict trailing characters:",result);
result = squeeze(s, "0123456789H");
writeln("Restrict leading characters:",result);
s = " Hello World ";
writeln("Stripping leading and trailing whitespace:",strip(s));
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Restrict trailing characters:H123H
Restrict leading characters:ello1
Stripping leading and trailing whitespace:Hello WorldDie Programmiersprache D bietet eine Datenstruktur mit dem Namen arrays, in dem eine sequentielle Sammlung von Elementen desselben Typs mit fester Größe gespeichert wird. Ein Array wird zum Speichern einer Sammlung von Daten verwendet. Es ist oft sinnvoller, sich ein Array als eine Sammlung von Variablen desselben Typs vorzustellen.
Anstatt einzelne Variablen wie Nummer 0, Nummer 1, ... und Nummer 99 zu deklarieren, deklarieren Sie eine Array-Variable wie Zahlen und verwenden Zahlen [0], Zahlen [1] und ..., Zahlen [99] zur Darstellung einzelne Variablen. Auf ein bestimmtes Element in einem Array wird über einen Index zugegriffen.
Alle Arrays bestehen aus zusammenhängenden Speicherstellen. Die niedrigste Adresse entspricht dem ersten Element und die höchste Adresse dem letzten Element.
Arrays deklarieren
Um ein Array in der Programmiersprache D zu deklarieren, gibt der Programmierer den Typ der Elemente und die Anzahl der für ein Array erforderlichen Elemente wie folgt an:
type arrayName [ arraySize ];Dies wird als eindimensionales Array bezeichnet. Die arraySize muss eine Ganzzahlkonstante größer als Null sein und der Typ kann ein beliebiger gültiger Datentyp der Programmiersprache D sein. Verwenden Sie diese Anweisung, um beispielsweise ein Array mit 10 Elementen zu deklarieren, das als Balance vom Typ double bezeichnet wird.
double balance[10];Arrays initialisieren
Sie können D-Programmiersprachen-Array-Elemente entweder einzeln oder mit einer einzelnen Anweisung wie folgt initialisieren
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];Die Anzahl der Werte zwischen eckigen Klammern [] auf der rechten Seite darf nicht größer sein als die Anzahl der Elemente, die Sie für das Array zwischen eckigen Klammern [] deklarieren. Im folgenden Beispiel wird ein einzelnes Element des Arrays zugewiesen.
Wenn Sie die Größe des Arrays weglassen, wird ein Array erstellt, das gerade groß genug ist, um die Initialisierung aufzunehmen. Deshalb, wenn Sie schreiben
double balance[] = [1000.0, 2.0, 3.4, 17.0, 50.0];Dann erstellen Sie genau das gleiche Array wie im vorherigen Beispiel.
balance[4] = 50.0;Die obige Anweisung weist dem Element Nummer 5 im Array einen Wert von 50,0 zu. Array mit dem 4. Index ist das 5., dh das letzte Element, da alle Arrays 0 als Index ihres ersten Elements haben, das auch als Basisindex bezeichnet wird. Die folgende bildliche Darstellung zeigt dasselbe Array, das wir oben besprochen haben -

Zugriff auf Array-Elemente
Auf ein Element wird zugegriffen, indem der Arrayname indiziert wird. Dazu wird der Index des Elements in eckige Klammern nach dem Namen des Arrays gesetzt. Zum Beispiel -
double salary = balance[9];Die obige Erklärung nimmt 10 - te Element aus dem Array und weist den Wert des variablen Gehalt . Im folgenden Beispiel werden Deklaration, Zuweisung und Zugriff auf Arrays implementiert.
import std.stdio;
void main() {
int n[ 10 ]; // n is an array of 10 integers
// initialize elements of array n to 0
for ( int i = 0; i < 10; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Element \t Value");
// output each array element's value
for ( int j = 0; j < 10; j++ ) {
writeln(j," \t ",n[j]);
}
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Element Value
0 100
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109Statische Arrays versus dynamische Arrays
Wenn beim Schreiben eines Programms die Länge eines Arrays angegeben wird, handelt es sich bei diesem Array um ein statisches Array. Wenn sich die Länge während der Ausführung des Programms ändern kann, ist dieses Array ein dynamisches Array.
Das Definieren dynamischer Arrays ist einfacher als das Definieren von Arrays mit fester Länge, da das Weglassen der Länge ein dynamisches Array ergibt.
int[] dynamicArray;Array-Eigenschaften
Hier sind die Eigenschaften von Arrays -
| Sr.Nr. | Objektbeschreibung |
|---|---|
| 1 | .init Das statische Array gibt ein Array-Literal zurück, wobei jedes Element des Literal die Eigenschaft .init des Array-Elementtyps ist. |
| 2 | .sizeof Statisches Array gibt die Array-Länge multipliziert mit der Anzahl der Bytes pro Array-Element zurück, während dynamische Arrays die Größe der dynamischen Array-Referenz zurückgeben, die 8 in 32-Bit-Builds und 16 in 64-Bit-Builds beträgt. |
| 3 | .length Statisches Array gibt die Anzahl der Elemente im Array zurück, während dynamische Arrays verwendet werden, um die Anzahl der Elemente im Array abzurufen / festzulegen. Die Länge ist vom Typ size_t. |
| 4 | .ptr Gibt einen Zeiger auf das erste Element des Arrays zurück. |
| 5 | .dup Erstellen Sie ein dynamisches Array derselben Größe und kopieren Sie den Inhalt des Arrays hinein. |
| 6 | .idup Erstellen Sie ein dynamisches Array derselben Größe und kopieren Sie den Inhalt des Arrays hinein. Die Kopie wird als unveränderlich eingegeben. |
| 7 | .reverse Kehrt die Reihenfolge der Elemente im Array um. Gibt das Array zurück. |
| 8 | .sort Sortiert die Reihenfolge der Elemente im Array. Gibt das Array zurück. |
Beispiel
Im folgenden Beispiel werden die verschiedenen Eigenschaften eines Arrays erläutert.
import std.stdio;
void main() {
int n[ 5 ]; // n is an array of 5 integers
// initialize elements of array n to 0
for ( int i = 0; i < 5; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Initialized value:",n.init);
writeln("Length: ",n.length);
writeln("Size of: ",n.sizeof);
writeln("Pointer:",n.ptr);
writeln("Duplicate Array: ",n.dup);
writeln("iDuplicate Array: ",n.idup);
n = n.reverse.dup;
writeln("Reversed Array: ",n);
writeln("Sorted Array: ",n.sort);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Initialized value:[0, 0, 0, 0, 0]
Length: 5
Size of: 20
Pointer:7FFF5A373920
Duplicate Array: [100, 101, 102, 103, 104]
iDuplicate Array: [100, 101, 102, 103, 104]
Reversed Array: [104, 103, 102, 101, 100]
Sorted Array: [100, 101, 102, 103, 104]Mehrdimensionale Arrays in D.
Die D-Programmierung ermöglicht mehrdimensionale Arrays. Hier ist die allgemeine Form einer mehrdimensionalen Array-Deklaration -
type name[size1][size2]...[sizeN];Beispiel
Die folgende Deklaration erzeugt eine dreidimensionale 5. 10. 4 Integer Array -
int threedim[5][10][4];Zweidimensionale Arrays in D.
Die einfachste Form des mehrdimensionalen Arrays ist das zweidimensionale Array. Ein zweidimensionales Array ist im Wesentlichen eine Liste eindimensionaler Arrays. Um ein zweidimensionales ganzzahliges Array der Größe [x, y] zu deklarieren, schreiben Sie die Syntax wie folgt:
type arrayName [ x ][ y ];Wo type kann ein beliebiger gültiger D-Programmierdatentyp sein und arrayName wird eine gültige D-Programmierkennung sein.
Wobei Typ ein beliebiger gültiger D-Programmierdatentyp sein kann und arrayName eine gültige D-Programmierkennung ist.
Ein zweidimensionales Array kann als Tabelle betrachtet werden, die x Zeilen und y Spalten enthält. Ein zweidimensionales Arraya mit drei Zeilen und vier Spalten kann wie folgt dargestellt werden -
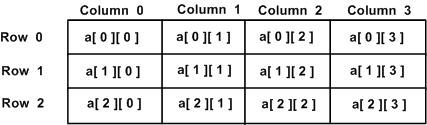
Somit ist jedes Element im Array a wird durch ein Element als identifiziert a[ i ][ j ], wo a ist der Name des Arrays und i und j sind die Indizes, die jedes Element in a eindeutig identifizieren.
Initialisieren zweidimensionaler Arrays
Mehrdimensionale Arrays können durch Angabe von Werten in Klammern für jede Zeile initialisiert werden. Das folgende Array hat 3 Zeilen und jede Zeile hat 4 Spalten.
int a[3][4] = [
[0, 1, 2, 3] , /* initializers for row indexed by 0 */
[4, 5, 6, 7] , /* initializers for row indexed by 1 */
[8, 9, 10, 11] /* initializers for row indexed by 2 */
];Die verschachtelten Klammern, die die beabsichtigte Zeile angeben, sind optional. Die folgende Initialisierung entspricht dem vorherigen Beispiel -
int a[3][4] = [0,1,2,3,4,5,6,7,8,9,10,11];Zugriff auf zweidimensionale Array-Elemente
Auf ein Element in einem zweidimensionalen Array wird mithilfe der Indizes zugegriffen, dh Zeilenindex und Spaltenindex des Arrays. Zum Beispiel
int val = a[2][3];Die obige Anweisung übernimmt das 4. Element aus der 3. Zeile des Arrays. Sie können dies im obigen Digramm überprüfen.
import std.stdio;
void main () {
// an array with 5 rows and 2 columns.
int a[5][2] = [ [0,0], [1,2], [2,4], [3,6],[4,8]];
// output each array element's value
for ( int i = 0; i < 5; i++ ) for ( int j = 0; j < 2; j++ ) {
writeln( "a[" , i , "][" , j , "]: ",a[i][j]);
}
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
a[0][0]: 0
a[0][1]: 0
a[1][0]: 1
a[1][1]: 2
a[2][0]: 2
a[2][1]: 4
a[3][0]: 3
a[3][1]: 6
a[4][0]: 4
a[4][1]: 8Allgemeine Array-Operationen in D.
Hier sind verschiedene Operationen, die an den Arrays ausgeführt werden -
Array Slicing
Wir verwenden oft einen Teil eines Arrays und das Schneiden von Arrays ist oft sehr hilfreich. Ein einfaches Beispiel für das Schneiden von Arrays ist unten dargestellt.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double[] b;
b = a[1..3];
writeln(b);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
[2, 3.4]Array-Kopieren
Wir verwenden auch das Kopieren von Arrays. Ein einfaches Beispiel für das Kopieren von Arrays ist unten dargestellt.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double b[5];
writeln("Array a:",a);
writeln("Array b:",b);
b[] = a; // the 5 elements of a[5] are copied into b[5]
writeln("Array b:",b);
b[] = a[]; // the 5 elements of a[3] are copied into b[5]
writeln("Array b:",b);
b[1..2] = a[0..1]; // same as b[1] = a[0]
writeln("Array b:",b);
b[0..2] = a[1..3]; // same as b[0] = a[1], b[1] = a[2]
writeln("Array b:",b);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Array a:[1000, 2, 3.4, 17, 50]
Array b:[nan, nan, nan, nan, nan]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 1000, 3.4, 17, 50]
Array b:[2, 3.4, 3.4, 17, 50]Array-Einstellung
Ein einfaches Beispiel zum Festlegen eines Werts in einem Array ist unten dargestellt.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5];
a[] = 5;
writeln("Array a:",a);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Array a:[5, 5, 5, 5, 5]Array-Verkettung
Ein einfaches Beispiel für die Verkettung von zwei Arrays ist unten dargestellt.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = 5;
double b[5] = 10;
double [] c;
c = a~b;
writeln("Array c: ",c);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Array c: [5, 5, 5, 5, 5, 10, 10, 10, 10, 10]Assoziative Arrays haben einen Index, der nicht unbedingt eine Ganzzahl ist und nur spärlich gefüllt werden kann. Der Index für ein assoziatives Array heißtKeyund sein Typ heißt der KeyType.
Assoziative Arrays werden deklariert, indem der KeyType in das [] einer Array-Deklaration eingefügt wird. Ein einfaches Beispiel für ein assoziatives Array ist unten dargestellt.
import std.stdio;
void main () {
int[string] e; // associative array b of ints that are
e["test"] = 3;
writeln(e["test"]);
string[string] f;
f["test"] = "Tuts";
writeln(f["test"]);
writeln(f);
f.remove("test");
writeln(f);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
3
Tuts
["test":"Tuts"]
[]Assoziatives Array initialisieren
Eine einfache Initialisierung des assoziativen Arrays ist unten dargestellt.
import std.stdio;
void main () {
int[string] days =
[ "Monday" : 0,
"Tuesday" : 1,
"Wednesday" : 2,
"Thursday" : 3,
"Friday" : 4,
"Saturday" : 5,
"Sunday" : 6 ];
writeln(days["Tuesday"]);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
1Eigenschaften des assoziativen Arrays
Hier sind die Eigenschaften eines assoziativen Arrays -
| Sr.Nr. | Objektbeschreibung |
|---|---|
| 1 | .sizeof Gibt die Größe der Referenz auf das assoziative Array zurück. Es ist 4 in 32-Bit-Builds und 8 in 64-Bit-Builds. |
| 2 | .length Gibt die Anzahl der Werte im assoziativen Array zurück. Im Gegensatz zu dynamischen Arrays ist es schreibgeschützt. |
| 3 | .dup Erstellen Sie ein neues assoziatives Array derselben Größe und kopieren Sie den Inhalt des assoziativen Arrays hinein. |
| 4 | .keys Gibt ein dynamisches Array zurück, dessen Elemente die Schlüssel im assoziativen Array sind. |
| 5 | .values Gibt ein dynamisches Array zurück, dessen Elemente die Werte im assoziativen Array sind. |
| 6 | .rehash Reorganisiert das assoziative Array an Ort und Stelle, damit Suchvorgänge effizienter sind. Rehash ist effektiv, wenn das Programm beispielsweise mit dem Laden einer Symboltabelle fertig ist und nun schnelle Suchvorgänge benötigt. Gibt einen Verweis auf das reorganisierte Array zurück. |
| 7 | .byKey() Gibt einen Delegaten zurück, der zur Verwendung als Aggregat für ein ForeachStatement geeignet ist, das über die Schlüssel des assoziativen Arrays iteriert. |
| 8 | .byValue() Gibt einen Delegaten zurück, der zur Verwendung als Aggregat geeignet ist, an ein ForeachStatement, das die Werte des assoziativen Arrays durchläuft. |
| 9 | .get(Key key, lazy Value defVal) Schlägt Schlüssel nach; Wenn es existiert, wird der entsprechende Wert zurückgegeben, andernfalls wird defVal ausgewertet und zurückgegeben. |
| 10 | .remove(Key key) Entfernt ein Objekt für den Schlüssel. |
Beispiel
Ein Beispiel für die Verwendung der obigen Eigenschaften ist unten gezeigt.
import std.stdio;
void main () {
int[string] array1;
array1["test"] = 3;
array1["test2"] = 20;
writeln("sizeof: ",array1.sizeof);
writeln("length: ",array1.length);
writeln("dup: ",array1.dup);
array1.rehash;
writeln("rehashed: ",array1);
writeln("keys: ",array1.keys);
writeln("values: ",array1.values);
foreach (key; array1.byKey) {
writeln("by key: ",key);
}
foreach (value; array1.byValue) {
writeln("by value ",value);
}
writeln("get value for key test: ",array1.get("test",10));
writeln("get value for key test3: ",array1.get("test3",10));
array1.remove("test");
writeln(array1);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
sizeof: 8
length: 2
dup: ["test":3, "test2":20]
rehashed: ["test":3, "test2":20]
keys: ["test", "test2"]
values: [3, 20]
by key: test
by key: test2
by value 3
by value 20
get value for key test: 3
get value for key test3: 10
["test2":20]D Programmierzeiger sind einfach und machen Spaß zu lernen. Einige D-Programmieraufgaben können einfacher mit Zeigern ausgeführt werden, und andere D-Programmieraufgaben, wie z. B. die dynamische Speicherzuweisung, können ohne sie nicht ausgeführt werden. Ein einfacher Zeiger ist unten gezeigt.
Anstatt direkt auf die Variable zu zeigen, zeigt der Zeiger auf die Adresse der Variablen. Wie Sie wissen, ist jede Variable ein Speicherort, und für jeden Speicherort ist eine Adresse definiert, auf die mit dem kaufmännischen Und (&) -Operator zugegriffen werden kann, der eine Adresse im Speicher angibt. Beachten Sie Folgendes, das die Adresse der definierten Variablen druckt:
import std.stdio;
void main () {
int var1;
writeln("Address of var1 variable: ",&var1);
char var2[10];
writeln("Address of var2 variable: ",&var2);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Address of var1 variable: 7FFF52691928
Address of var2 variable: 7FFF52691930Was sind Zeiger?
EIN pointerist eine Variable, deren Wert die Adresse einer anderen Variablen ist. Wie bei jeder Variablen oder Konstante müssen Sie einen Zeiger deklarieren, bevor Sie damit arbeiten können. Die allgemeine Form einer Zeigervariablendeklaration lautet -
type *var-name;Hier, typeist der Basistyp des Zeigers; Es muss ein gültiger Programmiertyp sein undvar-nameist der Name der Zeigervariable. Das Sternchen, mit dem Sie einen Zeiger deklariert haben, ist das gleiche Sternchen, das Sie für die Multiplikation verwenden. Jedoch; In dieser Anweisung wird das Sternchen verwendet, um eine Variable als Zeiger zu kennzeichnen. Es folgen die gültigen Zeigerdeklarationen -
int *ip; // pointer to an integer
double *dp; // pointer to a double
float *fp; // pointer to a float
char *ch // pointer to characterDer tatsächliche Datentyp des Werts aller Zeiger, ob Ganzzahl, Gleitkomma, Zeichen oder auf andere Weise, ist derselbe, eine lange Hexadezimalzahl, die eine Speicheradresse darstellt. Der einzige Unterschied zwischen Zeigern verschiedener Datentypen ist der Datentyp der Variablen oder Konstante, auf die der Zeiger zeigt.
Verwenden von Zeigern in der D-Programmierung
Es gibt nur wenige wichtige Operationen, wenn wir die Zeiger sehr häufig verwenden.
Wir definieren Zeigervariablen
Weisen Sie einem Zeiger die Adresse einer Variablen zu
Greifen Sie schließlich auf den Wert an der Adresse zu, die in der Zeigervariablen verfügbar ist.
Dies erfolgt mit einem unären Operator *Dies gibt den Wert der Variablen zurück, die sich an der durch ihren Operanden angegebenen Adresse befindet. Das folgende Beispiel verwendet diese Operationen -
import std.stdio;
void main () {
int var = 20; // actual variable declaration.
int *ip; // pointer variable
ip = &var; // store address of var in pointer variable
writeln("Value of var variable: ",var);
writeln("Address stored in ip variable: ",ip);
writeln("Value of *ip variable: ",*ip);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Value of var variable: 20
Address stored in ip variable: 7FFF5FB7E930
Value of *ip variable: 20Nullzeiger
Es wird immer empfohlen, den Zeiger NULL einer Zeigervariablen zuzuweisen, falls Sie keine genaue Adresse haben, die zugewiesen werden soll. Dies erfolgt zum Zeitpunkt der Variablendeklaration. Ein Zeiger, dem null zugewiesen ist, heißt anull Zeiger.
Der Nullzeiger ist eine Konstante mit dem Wert Null, die in mehreren Standardbibliotheken einschließlich iostream definiert ist. Betrachten Sie das folgende Programm -
import std.stdio;
void main () {
int *ptr = null;
writeln("The value of ptr is " , ptr) ;
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The value of ptr is nullAuf den meisten Betriebssystemen dürfen Programme unter der Adresse 0 nicht auf den Speicher zugreifen, da dieser Speicher vom Betriebssystem reserviert wird. Jedoch; die Speicheradresse 0 hat eine besondere Bedeutung; es signalisiert, dass der Zeiger nicht auf einen zugänglichen Speicherort zeigen soll.
Wenn ein Zeiger den Wert Null (Null) enthält, wird konventionell angenommen, dass er auf nichts zeigt. Um nach einem Nullzeiger zu suchen, können Sie eine if-Anweisung wie folgt verwenden:
if(ptr) // succeeds if p is not null
if(!ptr) // succeeds if p is nullWenn also alle nicht verwendeten Zeiger den Nullwert erhalten und Sie die Verwendung eines Nullzeigers vermeiden, können Sie den versehentlichen Missbrauch eines nicht initialisierten Zeigers vermeiden. Nicht initialisierte Variablen enthalten häufig einige Junk-Werte, und es wird schwierig, das Programm zu debuggen.
Zeigerarithmetik
Es gibt vier arithmetische Operatoren, die für Zeiger verwendet werden können: ++, -, + und -
Um die Zeigerarithmetik zu verstehen, betrachten wir einen ganzzahligen Zeiger mit dem Namen ptrNehmen wir an, dass 32-Bit-Ganzzahlen vorliegen, und führen Sie die folgende arithmatische Operation für den Zeiger aus:
ptr++dann ist die ptrzeigt auf die Position 1004, da jedes Mal, wenn ptr inkrementiert wird, es auf die nächste Ganzzahl zeigt. Diese Operation bewegt den Zeiger zum nächsten Speicherort, ohne den tatsächlichen Wert am Speicherort zu beeinflussen.
Wenn ptr zeigt auf ein Zeichen, dessen Adresse 1000 ist, dann zeigt die obige Operation auf die Position 1001, da das nächste Zeichen bei 1001 verfügbar sein wird.
Inkrementieren eines Zeigers
Wir bevorzugen die Verwendung eines Zeigers in unserem Programm anstelle eines Arrays, da der variable Zeiger inkrementiert werden kann, im Gegensatz zum Array-Namen, der nicht inkrementiert werden kann, da es sich um einen konstanten Zeiger handelt. Das folgende Programm erhöht den Variablenzeiger, um auf jedes nachfolgende Element des Arrays zuzugreifen:
import std.stdio;
const int MAX = 3;
void main () {
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
for (int i = 0; i < MAX; i++, ptr++) {
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Address of var[0] = 18FDBC
Value of var[0] = 10
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 200Zeiger gegen Array
Zeiger und Arrays sind eng miteinander verbunden. Zeiger und Arrays sind jedoch nicht vollständig austauschbar. Betrachten Sie zum Beispiel das folgende Programm -
import std.stdio;
const int MAX = 3;
void main () {
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
var.ptr[2] = 290;
ptr[0] = 220;
for (int i = 0; i < MAX; i++, ptr++) {
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}Im obigen Programm sehen Sie var.ptr [2], um das zweite Element festzulegen, und ptr [0], mit dem das nullte Element festgelegt wird. Der Inkrement-Operator kann mit ptr verwendet werden, nicht jedoch mit var.
Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Address of var[0] = 18FDBC
Value of var[0] = 220
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 290Zeiger auf Zeiger
Ein Zeiger auf einen Zeiger ist eine Form der Mehrfachindirektion oder eine Kette von Zeigern. Normalerweise enthält ein Zeiger die Adresse einer Variablen. Wenn wir einen Zeiger auf einen Zeiger definieren, enthält der erste Zeiger die Adresse des zweiten Zeigers, der auf die Position zeigt, die den tatsächlichen Wert enthält, wie unten gezeigt.

Eine Variable, die ein Zeiger auf einen Zeiger ist, muss als solche deklariert werden. Dazu setzen Sie ein zusätzliches Sternchen vor den Namen. Im Folgenden finden Sie beispielsweise die Syntax zum Deklarieren eines Zeigers auf einen Zeiger vom Typ int -
int **var;Wenn ein Zeiger auf einen Zeiger indirekt auf einen Zielwert zeigt, muss für den Zugriff auf diesen Wert der Sternchenoperator zweimal angewendet werden, wie im folgenden Beispiel gezeigt.
import std.stdio;
const int MAX = 3;
void main () {
int var = 3000;
writeln("Value of var :" , var);
int *ptr = &var;
writeln("Value available at *ptr :" ,*ptr);
int **pptr = &ptr;
writeln("Value available at **pptr :",**pptr);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Value of var :3000
Value available at *ptr :3000
Value available at **pptr :3000Zeiger an Funktionen übergeben
Mit D können Sie einen Zeiger auf eine Funktion übergeben. Dazu deklariert es einfach den Funktionsparameter als Zeigertyp.
Das folgende einfache Beispiel übergibt einen Zeiger auf eine Funktion.
import std.stdio;
void main () {
// an int array with 5 elements.
int balance[5] = [1000, 2, 3, 17, 50];
double avg;
avg = getAverage( &balance[0], 5 ) ;
writeln("Average is :" , avg);
}
double getAverage(int *arr, int size) {
int i;
double avg, sum = 0;
for (i = 0; i < size; ++i) {
sum += arr[i];
}
avg = sum/size;
return avg;
}Wenn der obige Code zusammen kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Average is :214.4Zeiger von Funktionen zurückgeben
Betrachten Sie die folgende Funktion, die 10 Zahlen mit einem Zeiger zurückgibt, bedeutet die Adresse des ersten Array-Elements.
import std.stdio;
void main () {
int *p = getNumber();
for ( int i = 0; i < 10; i++ ) {
writeln("*(p + " , i , ") : ",*(p + i));
}
}
int * getNumber( ) {
static int r [10];
for (int i = 0; i < 10; ++i) {
r[i] = i;
}
return &r[0];
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
*(p + 0) : 0
*(p + 1) : 1
*(p + 2) : 2
*(p + 3) : 3
*(p + 4) : 4
*(p + 5) : 5
*(p + 6) : 6
*(p + 7) : 7
*(p + 8) : 8
*(p + 9) : 9Zeiger auf ein Array
Ein Array-Name ist ein konstanter Zeiger auf das erste Element des Arrays. Daher in der Erklärung -
double balance[50];balanceist ein Zeiger auf & balance [0], die Adresse des ersten Elements der Array-Bilanz. Somit wird das folgende Programmfragment zugewiesenp die Adresse des ersten Elements von balance - -
double *p;
double balance[10];
p = balance;Es ist legal, Array-Namen als konstante Zeiger zu verwenden und umgekehrt. Daher ist * (Kontostand + 4) eine legitime Möglichkeit, auf die Daten im Kontostand zuzugreifen [4].
Sobald Sie die Adresse des ersten Elements in p gespeichert haben, können Sie mit * p, * (p + 1), * (p + 2) usw. auf Array-Elemente zugreifen. Das folgende Beispiel zeigt alle oben diskutierten Konzepte -
import std.stdio;
void main () {
// an array with 5 elements.
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double *p;
p = &balance[0];
// output each array element's value
writeln("Array values using pointer " );
for ( int i = 0; i < 5; i++ ) {
writeln( "*(p + ", i, ") : ", *(p + i));
}
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Array values using pointer
*(p + 0) : 1000
*(p + 1) : 2
*(p + 2) : 3.4
*(p + 3) : 17
*(p + 4) : 50Tupel werden zum Kombinieren mehrerer Werte als ein einziges Objekt verwendet. Tupel enthalten eine Folge von Elementen. Die Elemente können Typen, Ausdrücke oder Aliase sein. Die Anzahl und die Elemente eines Tupels sind zur Kompilierungszeit festgelegt und können zur Laufzeit nicht geändert werden.
Tupel haben Eigenschaften sowohl von Strukturen als auch von Arrays. Die Tupelelemente können von verschiedenen Typen sein, wie z. B. Strukturen. Auf die Elemente kann wie bei Arrays indiziert werden. Sie werden von der Tupel-Vorlage aus dem Modul std.typecons als Bibliotheksfunktion implementiert. Tuple verwendet für einige seiner Operationen TypeTuple aus dem Modul std.typetuple.
Tupel Mit Tupel ()
Tupel können mit der Funktion tuple () erstellt werden. Auf die Mitglieder eines Tupels wird über Indexwerte zugegriffen. Ein Beispiel ist unten gezeigt.
Beispiel
import std.stdio;
import std.typecons;
void main() {
auto myTuple = tuple(1, "Tuts");
writeln(myTuple);
writeln(myTuple[0]);
writeln(myTuple[1]);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Tuple!(int, string)(1, "Tuts")
1
TutsTupel mit Tupelvorlage
Tupel kann anstelle der Funktion tuple () auch direkt von der Tupel-Vorlage erstellt werden. Der Typ und der Name jedes Mitglieds werden als zwei aufeinanderfolgende Vorlagenparameter angegeben. Es ist möglich, über Eigenschaften auf die Mitglieder zuzugreifen, wenn diese mithilfe von Vorlagen erstellt werden.
import std.stdio;
import std.typecons;
void main() {
auto myTuple = Tuple!(int, "id",string, "value")(1, "Tuts");
writeln(myTuple);
writeln("by index 0 : ", myTuple[0]);
writeln("by .id : ", myTuple.id);
writeln("by index 1 : ", myTuple[1]);
writeln("by .value ", myTuple.value);
}Wenn der obige Code kompiliert und ausgeführt wird, wird das folgende Ergebnis erzielt
Tuple!(int, "id", string, "value")(1, "Tuts")
by index 0 : 1
by .id : 1
by index 1 : Tuts
by .value TutsErweitern von Eigenschafts- und Funktionsparametern
Die Mitglieder von Tuple können entweder durch die .expand-Eigenschaft oder durch Slicing erweitert werden. Dieser erweiterte / geschnittene Wert kann als Funktionsargumentliste übergeben werden. Ein Beispiel ist unten gezeigt.
Beispiel
import std.stdio;
import std.typecons;
void method1(int a, string b, float c, char d) {
writeln("method 1 ",a,"\t",b,"\t",c,"\t",d);
}
void method2(int a, float b, char c) {
writeln("method 2 ",a,"\t",b,"\t",c);
}
void main() {
auto myTuple = tuple(5, "my string", 3.3, 'r');
writeln("method1 call 1");
method1(myTuple[]);
writeln("method1 call 2");
method1(myTuple.expand);
writeln("method2 call 1");
method2(myTuple[0], myTuple[$-2..$]);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
method1 call 1
method 1 5 my string 3.3 r
method1 call 2
method 1 5 my string 3.3 r
method2 call 1
method 2 5 3.3 rTypeTuple
TypeTuple wird im Modul std.typetuple definiert. Eine durch Kommas getrennte Liste von Werten und Typen. Ein einfaches Beispiel mit TypeTuple finden Sie unten. TypeTuple wird zum Erstellen einer Argumentliste, einer Vorlagenliste und einer Array-Literalliste verwendet.
import std.stdio;
import std.typecons;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(int a, string b, float c, char d) {
writeln("method 1 ",a,"\t",b,"\t",c,"\t",d);
}
void method2(TL tl) {
writeln(tl[0],"\t", tl[1] );
}
void main() {
auto arguments = TypeTuple!(5, "my string", 3.3,'r');
method1(arguments);
method2(5, 6L);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
method 1 5 my string 3.3 r
5 6Das structure ist ein weiterer benutzerdefinierter Datentyp, der in der D-Programmierung verfügbar ist und es Ihnen ermöglicht, Datenelemente verschiedener Art zu kombinieren.
Strukturen werden verwendet, um einen Datensatz darzustellen. Angenommen, Sie möchten Ihre Bücher in einer Bibliothek verfolgen. Möglicherweise möchten Sie die folgenden Attribute für jedes Buch verfolgen:
- Title
- Author
- Subject
- Buch-ID
Struktur definieren
Um eine Struktur zu definieren, müssen Sie die verwenden structErklärung. Die struct-Anweisung definiert einen neuen Datentyp mit mehr als einem Mitglied für Ihr Programm. Das Format der struct-Anweisung lautet:
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];Das structure tagist optional und jede Mitgliedsdefinition ist eine normale Variablendefinition, wie z. B. int i; oder float f; oder eine andere gültige Variablendefinition. Am Ende der Strukturdefinition vor dem Semikolon können Sie eine oder mehrere Strukturvariablen angeben, die optional sind. Hier ist die Art und Weise, wie Sie die Buchstruktur deklarieren würden:
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};Zugriff auf Strukturmitglieder
Um auf ein Mitglied einer Struktur zuzugreifen, verwenden Sie die member access operator (.). Der Elementzugriffsoperator wird als Punkt zwischen dem Namen der Strukturvariablen und dem Strukturelement codiert, auf das wir zugreifen möchten. Sie würden verwendenstructSchlüsselwort zum Definieren von Variablen des Strukturtyps. Das folgende Beispiel erläutert die Verwendung der Struktur -
import std.stdio;
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( ) {
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "D Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "D Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
writeln( "Book 1 title : ", Book1.title);
writeln( "Book 1 author : ", Book1.author);
writeln( "Book 1 subject : ", Book1.subject);
writeln( "Book 1 book_id : ", Book1.book_id);
/* print Book2 info */
writeln( "Book 2 title : ", Book2.title);
writeln( "Book 2 author : ", Book2.author);
writeln( "Book 2 subject : ", Book2.subject);
writeln( "Book 2 book_id : ", Book2.book_id);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Book 1 title : D Programming
Book 1 author : Raj
Book 1 subject : D Programming Tutorial
Book 1 book_id : 6495407
Book 2 title : D Programming
Book 2 author : Raj
Book 2 subject : D Programming Tutorial
Book 2 book_id : 6495700Strukturen als Funktionsargumente
Sie können eine Struktur als Funktionsargument auf sehr ähnliche Weise übergeben wie jede andere Variable oder jeden anderen Zeiger. Sie würden auf Strukturvariablen auf ähnliche Weise zugreifen wie im obigen Beispiel -
import std.stdio;
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( ) {
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "D Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "D Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
printBook( Book1 );
/* Print Book2 info */
printBook( Book2 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495700Strukturinitialisierung
Strukturen können in zwei Formen initialisiert werden, eine mit Construtor und eine mit dem Format {}. Ein Beispiel ist unten gezeigt.
Beispiel
import std.stdio;
struct Books {
char [] title;
char [] subject = "Empty".dup;
int book_id = -1;
char [] author = "Raj".dup;
};
void main( ) {
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup, 6495407 );
printBook( Book1 );
Books Book2 = Books("D Programming".dup,
"D Programming Tutorial".dup, 6495407,"Raj".dup );
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id : 1001};
printBook( Book3 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1001Statische Mitglieder
Statische Variablen werden nur einmal initialisiert. Um beispielsweise die eindeutigen IDs für die Bücher zu haben, können wir die book_id als statisch festlegen und die Buch-ID erhöhen. Ein Beispiel ist unten gezeigt.
Beispiel
import std.stdio;
struct Books {
char [] title;
char [] subject = "Empty".dup;
int book_id;
char [] author = "Raj".dup;
static int id = 1000;
};
void main( ) {
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id );
printBook( Book1 );
Books Book2 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id);
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id:++Books.id};
printBook( Book3 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1001
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1002
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1003EIN unionist ein in D verfügbarer spezieller Datentyp, mit dem Sie verschiedene Datentypen am selben Speicherort speichern können. Sie können eine Vereinigung mit vielen Mitgliedern definieren, aber jeweils nur ein Mitglied kann einen Wert enthalten. Gewerkschaften bieten eine effiziente Möglichkeit, denselben Speicherort für mehrere Zwecke zu verwenden.
Eine Union definieren in D.
Um eine Union zu definieren, müssen Sie die Union-Anweisung auf sehr ähnliche Weise verwenden wie beim Definieren der Struktur. Die union-Anweisung definiert einen neuen Datentyp mit mehr als einem Mitglied für Ihr Programm. Das Format der Gewerkschaftserklärung lautet wie folgt:
union [union tag] {
member definition;
member definition;
...
member definition;
} [one or more union variables];Das union tagist optional und jede Mitgliedsdefinition ist eine normale Variablendefinition, wie z. B. int i; oder float f; oder eine andere gültige Variablendefinition. Am Ende der Union-Definition, vor dem letzten Semikolon, können Sie eine oder mehrere Union-Variablen angeben, dies ist jedoch optional. Hier ist die Art und Weise, wie Sie einen Vereinigungstyp namens Data definieren, der die drei Mitglieder hati, f, und str - -
union Data {
int i;
float f;
char str[20];
} data;Eine Variable von Datatype kann eine Ganzzahl, eine Gleitkommazahl oder eine Zeichenfolge speichern. Dies bedeutet, dass eine einzelne Variable (derselbe Speicherort) zum Speichern mehrerer Datentypen verwendet werden kann. Sie können je nach Anforderung beliebige integrierte oder benutzerdefinierte Datentypen innerhalb einer Union verwenden.
Das von einer Gewerkschaft belegte Gedächtnis wird groß genug sein, um das größte Mitglied der Gewerkschaft aufzunehmen. Im obigen Beispiel belegt der Datentyp beispielsweise 20 Byte Speicherplatz, da dies der maximale Speicherplatz ist, der von einer Zeichenfolge belegt werden kann. Das folgende Beispiel zeigt die Gesamtspeichergröße, die von der obigen Vereinigung belegt wird -
import std.stdio;
union Data {
int i;
float f;
char str[20];
};
int main( ) {
Data data;
writeln( "Memory size occupied by data : ", data.sizeof);
return 0;
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Memory size occupied by data : 20Zugang zu Gewerkschaftsmitgliedern
Um auf ein Gewerkschaftsmitglied zuzugreifen, verwenden wir die member access operator (.). Der Mitgliederzugriffsoperator wird als Punkt zwischen dem Namen der Gewerkschaftsvariablen und dem Gewerkschaftsmitglied codiert, auf das wir zugreifen möchten. Sie würden das Schlüsselwort union verwenden, um Variablen vom Typ union zu definieren.
Beispiel
Das folgende Beispiel erläutert die Verwendung von union -
import std.stdio;
union Data {
int i;
float f;
char str[13];
};
void main( ) {
Data data;
data.i = 10;
data.f = 220.5;
data.str = "D Programming".dup;
writeln( "size of : ", data.sizeof);
writeln( "data.i : ", data.i);
writeln( "data.f : ", data.f);
writeln( "data.str : ", data.str);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
size of : 16
data.i : 1917853764
data.f : 4.12236e+30
data.str : D ProgrammingHier sehen Sie die Werte von i und f Mitglieder der Gewerkschaft wurden beschädigt, weil der der Variablen zugewiesene Endwert den Speicherort belegt hat und dies der Grund ist, warum der Wert von str Mitglied wird sehr gut gedruckt.
Schauen wir uns nun noch einmal dasselbe Beispiel an, in dem wir jeweils eine Variable verwenden, was der Hauptzweck der Vereinigung ist -
Modifiziertes Beispiel
import std.stdio;
union Data {
int i;
float f;
char str[13];
};
void main( ) {
Data data;
writeln( "size of : ", data.sizeof);
data.i = 10;
writeln( "data.i : ", data.i);
data.f = 220.5;
writeln( "data.f : ", data.f);
data.str = "D Programming".dup;
writeln( "data.str : ", data.str);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
size of : 16
data.i : 10
data.f : 220.5
data.str : D ProgrammingHier werden alle Mitglieder sehr gut gedruckt, da jeweils ein Mitglied verwendet wird.
Bereiche sind eine Abstraktion des Elementzugriffs. Diese Abstraktion ermöglicht die Verwendung einer großen Anzahl von Algorithmen über eine große Anzahl von Containertypen. Bereiche betonen, wie auf Containerelemente zugegriffen wird, im Gegensatz dazu, wie die Container implementiert werden. Bereiche ist ein sehr einfaches Konzept, das darauf basiert, ob ein Typ bestimmte Sätze von Elementfunktionen definiert.
Bereiche sind ein wesentlicher Bestandteil von D. Ds Slices sind Implementierungen des leistungsstärksten Bereichs RandomAccessRange, und es gibt viele Bereichsfunktionen in Phobos. Viele Phobos-Algorithmen geben temporäre Bereichsobjekte zurück. Beispielsweise wählt filter () Elemente aus, die im folgenden Code größer als 10 sind, und gibt tatsächlich ein Bereichsobjekt zurück, kein Array.
Nummernkreise
Nummernkreise werden häufig verwendet und diese Nummernkreise sind vom Typ int. Einige Beispiele für Nummernkreise sind unten aufgeführt -
// Example 1
foreach (value; 3..7)
// Example 2
int[] slice = array[5..10];Phobos Ranges
Bereiche, die sich auf Strukturen und Klassenschnittstellen beziehen, sind Phobos-Bereiche. Phobos ist die offizielle Laufzeit- und Standardbibliothek, die mit dem D-Sprach-Compiler geliefert wird.
Es gibt verschiedene Arten von Bereichen, darunter -
- InputRange
- ForwardRange
- BidirectionalRange
- RandomAccessRange
- OutputRange
Eingabebereich
Der einfachste Bereich ist der Eingabebereich. Die anderen Bereiche stellen mehr Anforderungen als der Bereich, auf dem sie basieren. InputRange benötigt drei Funktionen:
empty- Gibt an, ob der Bereich leer ist. es muss true zurückgeben, wenn der Bereich als leer betrachtet wird; sonst falsch.
front - Es bietet Zugriff auf das Element am Anfang des Bereichs.
popFront() - Es verkürzt den Bereich von Anfang an, indem das erste Element entfernt wird.
Beispiel
import std.stdio;
import std.string;
struct Student {
string name;
int number;
string toString() const {
return format("%s(%s)", name, number);
}
}
struct School {
Student[] students;
}
struct StudentRange {
Student[] students;
this(School school) {
this.students = school.students;
}
@property bool empty() const {
return students.length == 0;
}
@property ref Student front() {
return students[0];
}
void popFront() {
students = students[1 .. $];
}
}
void main() {
auto school = School([ Student("Raj", 1), Student("John", 2), Student("Ram", 3)]);
auto range = StudentRange(school);
writeln(range);
writeln(school.students.length);
writeln(range.front);
range.popFront;
writeln(range.empty);
writeln(range);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
[Raj(1), John(2), Ram(3)]
3
Raj(1)
false
[John(2), Ram(3)]ForwardRange
ForwardRange erfordert zusätzlich den Funktionsteil zum Speichern des Elements von den anderen drei Funktionen von InputRange und gibt beim Aufrufen der Speicherfunktion eine Kopie des Bereichs zurück.
import std.array;
import std.stdio;
import std.string;
import std.range;
struct FibonacciSeries {
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const {
return first;
}
void popFront() {
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const {
return this;
}
}
void report(T)(const dchar[] title, const ref T range) {
writefln("%s: %s", title, range.take(5));
}
void main() {
auto range = FibonacciSeries();
report("Original range", range);
range.popFrontN(2);
report("After removing two elements", range);
auto theCopy = range.save;
report("The copy", theCopy);
range.popFrontN(3);
report("After removing three more elements", range);
report("The copy", theCopy);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Original range: [0, 1, 1, 2, 3]
After removing two elements: [1, 2, 3, 5, 8]
The copy: [1, 2, 3, 5, 8]
After removing three more elements: [5, 8, 13, 21, 34]
The copy: [1, 2, 3, 5, 8]Bidirektionaler Bereich
BidirectionalRange bietet zusätzlich zwei Elementfunktionen über die Elementfunktionen von ForwardRange. Die Back-Funktion, die der Front ähnelt, ermöglicht den Zugriff auf das letzte Element des Bereichs. Die Funktion popBack ähnelt der Funktion popFront und entfernt das letzte Element aus dem Bereich.
Beispiel
import std.array;
import std.stdio;
import std.string;
struct Reversed {
int[] range;
this(int[] range) {
this.range = range;
}
@property bool empty() const {
return range.empty;
}
@property int front() const {
return range.back; // reverse
}
@property int back() const {
return range.front; // reverse
}
void popFront() {
range.popBack();
}
void popBack() {
range.popFront();
}
}
void main() {
writeln(Reversed([ 1, 2, 3]));
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
[3, 2, 1]Infinite RandomAccessRange
opIndex () ist im Vergleich zum ForwardRange zusätzlich erforderlich. Außerdem muss der Wert einer leeren Funktion zur Kompilierungszeit als falsch bekannt sein. Ein einfaches Beispiel wird mit dem Quadratbereich erklärt, der unten gezeigt wird.
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
class SquaresRange {
int first;
this(int first = 0) {
this.first = first;
}
enum empty = false;
@property int front() const {
return opIndex(0);
}
void popFront() {
++first;
}
@property SquaresRange save() const {
return new SquaresRange(first);
}
int opIndex(size_t index) const {
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value) {
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
void main() {
auto squares = new SquaresRange();
writeln(squares[5]);
writeln(squares[10]);
squares.popFrontN(5);
writeln(squares[0]);
writeln(squares.take(50).filter!are_lastTwoDigitsSame);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
25
100
25
[100, 144, 400, 900, 1444, 1600, 2500]Finite RandomAccessRange
opIndex () und Länge sind im Vergleich zum bidirektionalen Bereich zusätzlich erforderlich. Dies wird anhand eines detaillierten Beispiels erläutert, das die zuvor verwendeten Beispiele für die Fibonacci-Serie und den Quadratbereich verwendet. Dieses Beispiel funktioniert gut mit normalem D-Compiler, aber nicht mit Online-Compiler.
Beispiel
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
struct FibonacciSeries {
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const {
return first;
}
void popFront() {
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const {
return this;
}
}
void report(T)(const dchar[] title, const ref T range) {
writefln("%40s: %s", title, range.take(5));
}
class SquaresRange {
int first;
this(int first = 0) {
this.first = first;
}
enum empty = false;
@property int front() const {
return opIndex(0);
}
void popFront() {
++first;
}
@property SquaresRange save() const {
return new SquaresRange(first);
}
int opIndex(size_t index) const {
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value) {
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
struct Together {
const(int)[][] slices;
this(const(int)[][] slices ...) {
this.slices = slices.dup;
clearFront();
clearBack();
}
private void clearFront() {
while (!slices.empty && slices.front.empty) {
slices.popFront();
}
}
private void clearBack() {
while (!slices.empty && slices.back.empty) {
slices.popBack();
}
}
@property bool empty() const {
return slices.empty;
}
@property int front() const {
return slices.front.front;
}
void popFront() {
slices.front.popFront();
clearFront();
}
@property Together save() const {
return Together(slices.dup);
}
@property int back() const {
return slices.back.back;
}
void popBack() {
slices.back.popBack();
clearBack();
}
@property size_t length() const {
return reduce!((a, b) => a + b.length)(size_t.init, slices);
}
int opIndex(size_t index) const {
/* Save the index for the error message */
immutable originalIndex = index;
foreach (slice; slices) {
if (slice.length > index) {
return slice[index];
} else {
index -= slice.length;
}
}
throw new Exception(
format("Invalid index: %s (length: %s)", originalIndex, this.length));
}
}
void main() {
auto range = Together(FibonacciSeries().take(10).array, [ 777, 888 ],
(new SquaresRange()).take(5).array);
writeln(range.save);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 777, 888, 0, 1, 4, 9, 16]OutputRange
OutputRange repräsentiert die Ausgabe von gestreamten Elementen, ähnlich wie das Senden von Zeichen an stdout. OutputRange erfordert Unterstützung für die Put-Operation (Bereich, Element). put () ist eine im Modul std.range definierte Funktion. Es bestimmt die Fähigkeiten des Bereichs und des Elements zur Kompilierungszeit und verwendet die am besten geeignete Methode zur Ausgabe der Elemente. Ein einfaches Beispiel ist unten gezeigt.
import std.algorithm;
import std.stdio;
struct MultiFile {
string delimiter;
File[] files;
this(string delimiter, string[] fileNames ...) {
this.delimiter = delimiter;
/* stdout is always included */
this.files ~= stdout;
/* A File object for each file name */
foreach (fileName; fileNames) {
this.files ~= File(fileName, "w");
}
}
void put(T)(T element) {
foreach (file; files) {
file.write(element, delimiter);
}
}
}
void main() {
auto output = MultiFile("\n", "output_0", "output_1");
copy([ 1, 2, 3], output);
copy([ "red", "blue", "green" ], output);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
[1, 2, 3]
["red", "blue", "green"]Alias, wie der Name schon sagt, bietet einen alternativen Namen für vorhandene Namen. Die Syntax für den Alias ist unten dargestellt.
alias new_name = existing_name;Das Folgende ist die ältere Syntax, nur für den Fall, dass Sie auf einige ältere Formatbeispiele verweisen. Es wird dringend davon abgeraten, dies zu verwenden.
alias existing_name new_name;Es gibt auch eine andere Syntax, die mit expression verwendet wird. Im Folgenden wird angegeben, dass der Aliasname direkt anstelle des Ausdrucks verwendet werden kann.
alias expression alias_name ;Wie Sie vielleicht wissen, bietet ein typedef die Möglichkeit, neue Typen zu erstellen. Alias kann die Arbeit eines Typedefs erledigen und noch mehr. Im Folgenden wird ein einfaches Beispiel für die Verwendung von Alias gezeigt, das den Header std.conv verwendet, der die Typkonvertierungsfunktion bereitstellt.
import std.stdio;
import std.conv:to;
alias to!(string) toString;
void main() {
int a = 10;
string s = "Test"~toString(a);
writeln(s);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Test10Im obigen Beispiel haben wir anstelle von to! String (a) den Aliasnamen toString zugewiesen, um es bequemer und verständlicher zu machen.
Alias für ein Tupel
Schauen wir uns ein anderes Beispiel an, in dem wir den Aliasnamen für ein Tupel festlegen können.
import std.stdio;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(TL tl) {
writeln(tl[0],"\t", tl[1] );
}
void main() {
method1(5, 6L);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
5 6Im obigen Beispiel wird das Typ-Tupel der Alias-Variablen zugewiesen und vereinfacht die Methodendefinition und den Zugriff auf Variablen. Diese Art des Zugriffs ist noch nützlicher, wenn wir versuchen, solche Tupel wiederzuverwenden.
Alias für Datentypen
Oft definieren wir allgemeine Datentypen, die in der gesamten Anwendung verwendet werden müssen. Wenn mehrere Programmierer eine Anwendung codieren, kann es Fälle geben, in denen eine Person int, eine andere double usw. verwendet. Um solche Konflikte zu vermeiden, verwenden wir häufig Typen für Datentypen. Ein einfaches Beispiel ist unten gezeigt.
Beispiel
import std.stdio;
alias int myAppNumber;
alias string myAppString;
void main() {
myAppNumber i = 10;
myAppString s = "TestString";
writeln(i,s);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
10TestStringAlias für Klassenvariablen
Es gibt oft eine Anforderung, bei der wir auf die Mitgliedsvariablen der Oberklasse in der Unterklasse zugreifen müssen. Dies kann mit einem Alias möglich sein, möglicherweise unter einem anderen Namen.
Wenn Sie mit dem Konzept von Klassen und Vererbung noch nicht vertraut sind, lesen Sie das Tutorial zu Klassen und Vererbung, bevor Sie mit diesem Abschnitt beginnen.
Beispiel
Ein einfaches Beispiel ist unten gezeigt.
import std.stdio;
class Shape {
int area;
}
class Square : Shape {
string name() const @property {
return "Square";
}
alias Shape.area squareArea;
}
void main() {
auto square = new Square;
square.squareArea = 42;
writeln(square.name);
writeln(square.squareArea);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Square
42Alias Dies
Alias Dies bietet die Möglichkeit der automatischen Typkonvertierung von benutzerdefinierten Typen. Die Syntax wird unten gezeigt, wo der Schlüsselwortalias und dieser auf beiden Seiten der Mitgliedsvariablen oder der Mitgliedsfunktion geschrieben sind.
alias member_variable_or_member_function this;Beispiel
Im Folgenden wird ein Beispiel gezeigt, um die Leistung des Alias zu zeigen.
import std.stdio;
struct Rectangle {
long length;
long breadth;
double value() const @property {
return cast(double) length * breadth;
}
alias value this;
}
double volume(double rectangle, double height) {
return rectangle * height;
}
void main() {
auto rectangle = Rectangle(2, 3);
writeln(volume(rectangle, 5));
}Im obigen Beispiel können Sie sehen, dass das Strukturrechteck mit Hilfe des Alias dieser Methode in einen doppelten Wert konvertiert wird.
Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
30Mixins sind Strukturen, mit denen der generierte Code in den Quellcode gemischt werden kann. Mixins können von den folgenden Typen sein -
- String Mixins
- Template Mixins
- Namensräume mischen
String Mixins
D kann Code als Zeichenfolge einfügen, solange diese Zeichenfolge zur Kompilierungszeit bekannt ist. Die Syntax von String-Mixins ist unten dargestellt -
mixin (compile_time_generated_string)Beispiel
Ein einfaches Beispiel für String-Mixins ist unten dargestellt.
import std.stdio;
void main() {
mixin(`writeln("Hello World!");`);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Hello World!Hier ist ein weiteres Beispiel, in dem wir die Zeichenfolge in der Kompilierungszeit übergeben können, damit Mixins die Funktionen zur Wiederverwendung von Code verwenden können. Es ist unten gezeigt.
import std.stdio;
string print(string s) {
return `writeln("` ~ s ~ `");`;
}
void main() {
mixin (print("str1"));
mixin (print("str2"));
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
str1
str2Template Mixins
D-Vorlagen definieren allgemeine Codemuster, damit der Compiler aus diesem Muster tatsächliche Instanzen generiert. Die Vorlagen können Funktionen, Strukturen, Gewerkschaften, Klassen, Schnittstellen und jeden anderen legalen D-Code generieren. Die Syntax von Template-Mixins ist wie folgt.
mixin a_template!(template_parameters)Ein einfaches Beispiel für String-Mixins wird unten gezeigt, in dem wir eine Vorlage mit der Klassenabteilung und einem Mixin erstellen, die eine Vorlage instanziieren und somit die Funktionen setName und printNames für das Struktur-College verfügbar machen.
Beispiel
import std.stdio;
template Department(T, size_t count) {
T[count] names;
void setName(size_t index, T name) {
names[index] = name;
}
void printNames() {
writeln("The names");
foreach (i, name; names) {
writeln(i," : ", name);
}
}
}
struct College {
mixin Department!(string, 2);
}
void main() {
auto college = College();
college.setName(0, "name1");
college.setName(1, "name2");
college.printNames();
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The names
0 : name1
1 : name2Mixin Namensräume
Mixin-Namensräume werden verwendet, um Mehrdeutigkeiten in Vorlagen-Mixins zu vermeiden. Beispielsweise kann es zwei Variablen geben, von denen eine explizit in main definiert und die andere eingemischt ist. Wenn ein eingemischter Name mit einem Namen im umgebenden Bereich identisch ist, wird der Name im umgebenden Bereich abgerufen gebraucht. Dieses Beispiel ist unten dargestellt.
Beispiel
import std.stdio;
template Person() {
string name;
void print() {
writeln(name);
}
}
void main() {
string name;
mixin Person a;
name = "name 1";
writeln(name);
a.name = "name 2";
print();
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
name 1
name 2Module sind die Bausteine von D. Sie basieren auf einem einfachen Konzept. Jede Quelldatei ist ein Modul. Dementsprechend sind die einzelnen Dateien, in die wir die Programme schreiben, einzelne Module. Standardmäßig entspricht der Name eines Moduls dem Dateinamen ohne die Erweiterung .d.
Wenn explizit angegeben, wird der Name des Moduls durch das Modulschlüsselwort definiert, das als erste Zeile ohne Kommentar in der Quelldatei angezeigt werden muss. Angenommen, der Name einer Quelldatei lautet "employee.d". Dann wird der Name des Moduls durch das Modulschlüsselwort gefolgt von einem Mitarbeiter angegeben . Es ist wie unten gezeigt.
module employee;
class Employee {
// Class definition goes here.
}Die Modulzeile ist optional. Wenn nicht angegeben, entspricht dies dem Dateinamen ohne die Erweiterung .d.
Datei- und Modulnamen
D unterstützt Unicode in Quellcode- und Modulnamen. Die Unicode-Unterstützung von Dateisystemen variiert jedoch. Obwohl die meisten Linux-Dateisysteme Unicode unterstützen, unterscheiden die Dateinamen in Windows-Dateisystemen möglicherweise nicht zwischen Klein- und Großbuchstaben. Darüber hinaus beschränken die meisten Dateisysteme die Zeichen, die in Datei- und Verzeichnisnamen verwendet werden können. Aus Gründen der Portabilität empfehle ich, in Dateinamen nur ASCII-Kleinbuchstaben zu verwenden. Beispielsweise wäre "employee.d" ein geeigneter Dateiname für eine Klasse mit dem Namen employee.
Dementsprechend würde der Name des Moduls auch aus ASCII-Buchstaben bestehen -
module employee; // Module name consisting of ASCII letters
class eëmployëë { }D Pakete
Eine Kombination verwandter Module wird als Paket bezeichnet. D-Pakete sind ebenfalls ein einfaches Konzept: Die Quelldateien, die sich im selben Verzeichnis befinden, gehören zum selben Paket. Der Name des Verzeichnisses wird zum Namen des Pakets, das auch als erster Teil der Modulnamen angegeben werden muss.
Wenn sich beispielsweise "employee.d" und "office.d" im Verzeichnis "company" befinden, werden sie durch Angabe des Verzeichnisnamens zusammen mit dem Modulnamen Teil desselben Pakets.
module company.employee;
class Employee { }Ebenso für das Büromodul -
module company.office;
class Office { }Da Paketnamen Verzeichnisnamen entsprechen, müssen die Paketnamen von Modulen, die tiefer als eine Verzeichnisebene sind, diese Hierarchie widerspiegeln. Wenn das Verzeichnis "Firma" beispielsweise ein Verzeichnis "Zweig" enthält, enthält der Name eines Moduls in diesem Verzeichnis auch Zweig.
module company.branch.employee;Verwenden von Modulen in Programmen
Das Import-Schlüsselwort, das wir bisher in fast allen Programmen verwendet haben, dient zur Einführung eines Moduls in das aktuelle Modul -
import std.stdio;Der Modulname kann auch den Paketnamen enthalten. Zum Beispiel die std. Teil oben zeigt an, dass stdio ein Modul ist, das Teil des std-Pakets ist.
Positionen der Module
Der Compiler findet die Moduldateien, indem er die Paket- und Modulnamen direkt in Verzeichnis- und Dateinamen konvertiert.
Beispielsweise würden sich die beiden Module Mitarbeiter und Büro als "Firma / Mitarbeiter.d" bzw. "Tier / Büro.d" (oder "Firma \ Mitarbeiter.d" und "Firma \ Büro.d", je nach) befinden das Dateisystem) für company.employee und company.office.
Lange und kurze Modulnamen
Die Namen, die im Programm verwendet werden, können wie unten gezeigt mit den Modul- und Paketnamen geschrieben werden.
import company.employee;
auto employee0 = Employee();
auto employee1 = company.employee.Employee();Die langen Namen werden normalerweise nicht benötigt, aber manchmal gibt es Namenskonflikte. Wenn sich der Compiler beispielsweise auf einen Namen bezieht, der in mehr als einem Modul vorkommt, kann er nicht entscheiden, welcher gemeint ist. Das folgende Programm beschreibt die langen Namen, um zwischen zwei separaten Mitarbeiterstrukturen zu unterscheiden, die in zwei separaten Modulen definiert sind: Unternehmen und Hochschule. .
Das erste Mitarbeitermodul in der Ordnerfirma lautet wie folgt.
module company.employee;
import std.stdio;
class Employee {
public:
string str;
void print() {
writeln("Company Employee: ",str);
}
}Das zweite Mitarbeitermodul in der Ordnerhochschule lautet wie folgt.
module college.employee;
import std.stdio;
class Employee {
public:
string str;
void print() {
writeln("College Employee: ",str);
}
}Das Hauptmodul in hello.d sollte in dem Ordner gespeichert werden, der die College- und Firmenordner enthält. Es ist wie folgt.
import company.employee;
import college.employee;
import std.stdio;
void main() {
auto myemployee1 = new company.employee.Employee();
myemployee1.str = "emp1";
myemployee1.print();
auto myemployee2 = new college.employee.Employee();
myemployee2.str = "emp2";
myemployee2.print();
}Das Schlüsselwort import reicht nicht aus, um Module zu Teilen des Programms zu machen. Es stellt einfach die Funktionen eines Moduls innerhalb des aktuellen Moduls zur Verfügung. So viel wird nur benötigt, um den Code zu kompilieren.
Damit das obige Programm erstellt werden kann, müssen in der Kompilierungszeile auch "company / employee.d" und "college / employee.d" angegeben werden.
Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
$ dmd hello.d company/employee.d college/employee.d -ofhello.amx
$ ./hello.amx
Company Employee: emp1
College Employee: emp2Vorlagen bilden die Grundlage für die generische Programmierung, bei der Code unabhängig von einem bestimmten Typ geschrieben wird.
Eine Vorlage ist eine Blaupause oder Formel zum Erstellen einer generischen Klasse oder Funktion.
Vorlagen sind die Funktion, mit der der Code als Muster beschrieben werden kann, damit der Compiler automatisch Programmcode generiert. Teile des Quellcodes können dem Compiler zum Ausfüllen überlassen werden, bis dieser Teil tatsächlich im Programm verwendet wird. Der Compiler füllt die fehlenden Teile aus.
Funktionsvorlage
Wenn Sie eine Funktion als Vorlage definieren, bleiben einer oder mehrere der verwendeten Typen nicht angegeben, um später vom Compiler abgeleitet zu werden. Die Typen, die nicht angegeben werden, werden in der Vorlagenparameterliste definiert, die zwischen dem Namen der Funktion und der Funktionsparameterliste liegt. Aus diesem Grund haben Funktionsvorlagen zwei Parameterlisten -
- Liste der Vorlagenparameter
- Funktionsparameterliste
import std.stdio;
void print(T)(T value) {
writefln("%s", value);
}
void main() {
print(42);
print(1.2);
print("test");
}Wenn wir den obigen Code kompilieren und ausführen, würde dies das folgende Ergebnis erzeugen:
42
1.2
testFunktionsvorlage mit mehreren Typparametern
Es kann mehrere Parametertypen geben. Sie werden im folgenden Beispiel gezeigt.
import std.stdio;
void print(T1, T2)(T1 value1, T2 value2) {
writefln(" %s %s", value1, value2);
}
void main() {
print(42, "Test");
print(1.2, 33);
}Wenn wir den obigen Code kompilieren und ausführen, würde dies das folgende Ergebnis erzeugen:
42 Test
1.2 33Klassenvorlagen
So wie wir Funktionsvorlagen definieren können, können wir auch Klassenvorlagen definieren. Das folgende Beispiel definiert die Klasse Stack und implementiert generische Methoden, um die Elemente vom Stapel zu verschieben und zu entfernen.
import std.stdio;
import std.string;
class Stack(T) {
private:
T[] elements;
public:
void push(T element) {
elements ~= element;
}
void pop() {
--elements.length;
}
T top() const @property {
return elements[$ - 1];
}
size_t length() const @property {
return elements.length;
}
}
void main() {
auto stack = new Stack!string;
stack.push("Test1");
stack.push("Test2");
writeln(stack.top);
writeln(stack.length);
stack.pop;
writeln(stack.top);
writeln(stack.length);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Test2
2
Test1
1Wir verwenden häufig Variablen, die veränderlich sind, aber es kann viele Fälle geben, in denen keine Veränderlichkeit erforderlich ist. In solchen Fällen können unveränderliche Variablen verwendet werden. Im Folgenden werden einige Beispiele aufgeführt, in denen unveränderliche Variablen verwendet werden können.
Bei mathematischen Konstanten wie pi , die sich nie ändern.
Bei Arrays, bei denen Werte beibehalten werden sollen und keine Mutationsanforderungen bestehen.
Die Unveränderlichkeit ermöglicht es zu verstehen, ob die Variablen unveränderlich oder veränderlich sind, und garantiert, dass bestimmte Operationen bestimmte Variablen nicht ändern. Es reduziert auch das Risiko bestimmter Arten von Programmfehlern. Das Unveränderlichkeitskonzept von D wird durch die Schlüsselwörter const und unveränderlich dargestellt. Obwohl die beiden Wörter selbst eine enge Bedeutung haben, sind ihre Verantwortlichkeiten in Programmen unterschiedlich und manchmal nicht kompatibel.
Das Unveränderlichkeitskonzept von D wird durch die Schlüsselwörter const und unveränderlich dargestellt. Obwohl die beiden Wörter selbst eine enge Bedeutung haben, sind ihre Verantwortlichkeiten in Programmen unterschiedlich und manchmal nicht kompatibel.
Arten unveränderlicher Variablen in D.
Es gibt drei Arten von definierenden Variablen, die niemals mutiert werden können.
- Enum-Konstanten
- unveränderliche Variablen
- const Variablen
Aufzählungskonstanten in D.
Die Enum-Konstanten ermöglichen es, konstante Werte mit aussagekräftigen Namen zu verknüpfen. Ein einfaches Beispiel ist unten gezeigt.
Beispiel
import std.stdio;
enum Day{
Sunday = 1,
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday
}
void main() {
Day day;
day = Day.Sunday;
if (day == Day.Sunday) {
writeln("The day is Sunday");
}
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The day is SundayUnveränderliche Variablen in D.
Unveränderliche Variablen können während der Ausführung des Programms ermittelt werden. Es weist den Compiler lediglich an, dass er nach der Initialisierung unveränderlich wird. Ein einfaches Beispiel ist unten gezeigt.
Beispiel
import std.stdio;
import std.random;
void main() {
int min = 1;
int max = 10;
immutable number = uniform(min, max + 1);
// cannot modify immutable expression number
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
immutable(int)4
immutable(int)100Im obigen Beispiel sehen Sie, wie es möglich ist, den Datentyp in eine andere Variable zu übertragen und beim Drucken stringof zu verwenden.
Konstantenvariablen in D.
Const-Variablen können nicht ähnlich wie unveränderlich geändert werden. unveränderliche Variablen können als unveränderliche Parameter an Funktionen übergeben werden. Daher wird empfohlen, unveränderliche Variablen über const zu verwenden. Das gleiche Beispiel, das zuvor verwendet wurde, wurde für const wie unten gezeigt geändert.
Beispiel
import std.stdio;
import std.random;
void main() {
int min = 1;
int max = 10;
const number = uniform(min, max + 1);
// cannot modify const expression number|
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}Wenn wir den obigen Code kompilieren und ausführen, würde dies das folgende Ergebnis erzeugen:
const(int)7
const(int)100Unveränderliche Parameter in D.
const löscht die Information darüber, ob die ursprüngliche Variable veränderlich oder unveränderlich ist, und übergibt sie daher bei Verwendung von unveränderlich an andere Funktionen, wobei der ursprüngliche Typ beibehalten wird. Ein einfaches Beispiel ist unten gezeigt.
Beispiel
import std.stdio;
void print(immutable int[] array) {
foreach (i, element; array) {
writefln("%s: %s", i, element);
}
}
void main() {
immutable int[] array = [ 1, 2 ];
print(array);
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
0: 1
1: 2Die Dateien werden von der dargestellten Datei - Struktur des std.stdio Modul. Eine Datei stellt eine Folge von Bytes dar, unabhängig davon, ob es sich um eine Textdatei oder eine Binärdatei handelt.
Die Programmiersprache D bietet Zugriff auf Funktionen auf hoher Ebene sowie auf Aufrufe auf niedriger Ebene (Betriebssystemebene), um Dateien auf Ihren Speichergeräten zu verarbeiten.
Dateien in D öffnen
Die Standardeingabe- und -ausgabestreams stdin und stdout sind bereits geöffnet, wenn Programme gestartet werden. Sie sind gebrauchsfertig. Andererseits müssen Dateien zuerst geöffnet werden, indem der Name der Datei und die erforderlichen Zugriffsrechte angegeben werden.
File file = File(filepath, "mode");Hier, filename ist ein Zeichenfolgenliteral, mit dem Sie die Datei und den Zugriff benennen mode kann einen der folgenden Werte haben -
| Sr.Nr. | Modus & Beschreibung |
|---|---|
| 1 | r Öffnet eine vorhandene Textdatei zum Lesen. |
| 2 | w Öffnet eine Textdatei zum Schreiben. Wenn sie nicht vorhanden ist, wird eine neue Datei erstellt. Hier beginnt Ihr Programm mit dem Schreiben von Inhalten ab dem Anfang der Datei. |
| 3 | a Öffnet eine Textdatei zum Schreiben im Anhänge-Modus. Wenn sie nicht vorhanden ist, wird eine neue Datei erstellt. Hier beginnt Ihr Programm, Inhalte an den vorhandenen Dateiinhalt anzuhängen. |
| 4 | r+ Öffnet eine Textdatei zum Lesen und Schreiben. |
| 5 | w+ Öffnet eine Textdatei zum Lesen und Schreiben. Die Datei wird zuerst auf die Länge Null gekürzt, wenn sie vorhanden ist. Andernfalls wird die Datei erstellt, wenn sie nicht vorhanden ist. |
| 6 | a+ Öffnet eine Textdatei zum Lesen und Schreiben. Es erstellt die Datei, wenn sie nicht vorhanden ist. Das Lesen beginnt von vorne, aber das Schreiben kann nur angehängt werden. |
Schließen einer Datei in D.
Verwenden Sie zum Schließen einer Datei die Funktion file.close (), in der die Datei die Dateireferenz enthält. Der Prototyp dieser Funktion ist -
file.close();Jede Datei, die von einem Programm geöffnet wurde, muss geschlossen werden, wenn das Programm die Verwendung dieser Datei beendet hat. In den meisten Fällen müssen die Dateien nicht explizit geschlossen werden. Sie werden automatisch geschlossen, wenn Dateiobjekte beendet werden.
Schreiben einer Datei in D.
file.writeln wird verwendet, um in eine geöffnete Datei zu schreiben.
file.writeln("hello");import std.stdio;
import std.file;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
}Wenn der obige Code kompiliert und ausgeführt wird, wird eine neue Datei erstellt test.txt in dem Verzeichnis, unter dem es gestartet wurde (im Programmarbeitsverzeichnis).
Lesen einer Datei in D.
Die folgende Methode liest eine einzelne Zeile aus einer Datei -
string s = file.readln();Ein vollständiges Beispiel für Lesen und Schreiben ist unten dargestellt.
import std.stdio;
import std.file;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
file = File("test.txt", "r");
string s = file.readln();
writeln(s);
file.close();
}Wenn der obige Code kompiliert und ausgeführt wird, liest er die im vorherigen Abschnitt erstellte Datei und erzeugt das folgende Ergebnis:
helloHier ist ein weiteres Beispiel für das Lesen von Dateien bis zum Ende der Datei.
import std.stdio;
import std.string;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.writeln("world");
file.close();
file = File("test.txt", "r");
while (!file.eof()) {
string line = chomp(file.readln());
writeln("line -", line);
}
}Wenn der obige Code kompiliert und ausgeführt wird, liest er die im vorherigen Abschnitt erstellte Datei und erzeugt das folgende Ergebnis:
line -hello
line -world
line -Im obigen Beispiel sehen Sie eine leere dritte Zeile, da writeln sie nach ihrer Ausführung in die nächste Zeile bringt.
Parallelität führt dazu, dass ein Programm auf mehreren Threads gleichzeitig ausgeführt wird. Ein Beispiel für ein gleichzeitiges Programm ist ein Webserver, der viele Clients gleichzeitig beantwortet. Parallelität ist bei der Nachrichtenübermittlung einfach, aber sehr schwer zu schreiben, wenn sie auf Datenaustausch basieren.
Daten, die zwischen Threads übertragen werden, werden als Nachrichten bezeichnet. Nachrichten können aus einem beliebigen Typ und einer beliebigen Anzahl von Variablen bestehen. Jeder Thread hat eine ID, mit der Empfänger von Nachrichten angegeben werden. Jeder Thread, der einen anderen Thread startet, wird als Eigentümer des neuen Threads bezeichnet.
Threads in D initiieren
Die Funktion spawn () verwendet einen Zeiger als Parameter und startet von dieser Funktion aus einen neuen Thread. Alle Operationen, die von dieser Funktion ausgeführt werden, einschließlich anderer Funktionen, die sie möglicherweise aufruft, werden auf dem neuen Thread ausgeführt. Der Eigentümer und der Arbeiter beginnen beide getrennt auszuführen, als wären sie unabhängige Programme.
Beispiel
import std.stdio;
import std.stdio;
import std.concurrency;
import core.thread;
void worker(int a) {
foreach (i; 0 .. 4) {
Thread.sleep(1);
writeln("Worker Thread ",a + i);
}
}
void main() {
foreach (i; 1 .. 4) {
Thread.sleep(2);
writeln("Main Thread ",i);
spawn(≈worker, i * 5);
}
writeln("main is done.");
}Wenn der obige Code kompiliert und ausgeführt wird, liest er die im vorherigen Abschnitt erstellte Datei und erzeugt das folgende Ergebnis:
Main Thread 1
Worker Thread 5
Main Thread 2
Worker Thread 6
Worker Thread 10
Main Thread 3
main is done.
Worker Thread 7
Worker Thread 11
Worker Thread 15
Worker Thread 8
Worker Thread 12
Worker Thread 16
Worker Thread 13
Worker Thread 17
Worker Thread 18Thread-IDs in D.
Die auf Modulebene global verfügbare Variable thisTid ist immer die ID des aktuellen Threads. Sie können die threadId auch erhalten, wenn spawn aufgerufen wird. Ein Beispiel ist unten gezeigt.
Beispiel
import std.stdio;
import std.concurrency;
void printTid(string tag) {
writefln("%s: %s, address: %s", tag, thisTid, &thisTid);
}
void worker() {
printTid("Worker");
}
void main() {
Tid myWorker = spawn(&worker);
printTid("Owner ");
writeln(myWorker);
}Wenn der obige Code kompiliert und ausgeführt wird, liest er die im vorherigen Abschnitt erstellte Datei und erzeugt das folgende Ergebnis:
Owner : Tid(std.concurrency.MessageBox), address: 10C71A59C
Worker: Tid(std.concurrency.MessageBox), address: 10C71A59C
Tid(std.concurrency.MessageBox)Nachrichtenübermittlung in D.
Die Funktion send () sendet Nachrichten und die Funktion receiveOnly () wartet auf eine Nachricht eines bestimmten Typs. Es gibt andere Funktionen mit den Namen prioritySend (), receive () und receiveTimeout (), die später erläutert werden.
Der Eigentümer im folgenden Programm sendet seinem Worker eine Nachricht vom Typ int und wartet auf eine Nachricht vom Worker vom Typ double. Die Threads senden weiterhin Nachrichten hin und her, bis der Eigentümer ein negatives int sendet. Ein Beispiel ist unten gezeigt.
Beispiel
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid) {
int value = 0;
while (value >= 0) {
value = receiveOnly!int();
auto result = to!double(value) * 5; tid.send(result);
}
}
void main() {
Tid worker = spawn(&workerFunc,thisTid);
foreach (value; 5 .. 10) {
worker.send(value);
auto result = receiveOnly!double();
writefln("sent: %s, received: %s", value, result);
}
worker.send(-1);
}Wenn der obige Code kompiliert und ausgeführt wird, liest er die im vorherigen Abschnitt erstellte Datei und erzeugt das folgende Ergebnis:
sent: 5, received: 25
sent: 6, received: 30
sent: 7, received: 35
sent: 8, received: 40
sent: 9, received: 45Nachrichtenübergabe mit Wartezeit in D.
Ein einfaches Beispiel für die Nachricht mit Wartezeit wird unten gezeigt.
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid) {
Thread.sleep(dur!("msecs")( 500 ),);
tid.send("hello");
}
void main() {
spawn(&workerFunc,thisTid);
writeln("Waiting for a message");
bool received = false;
while (!received) {
received = receiveTimeout(dur!("msecs")( 100 ), (string message) {
writeln("received: ", message);
});
if (!received) {
writeln("... no message yet");
}
}
}Wenn der obige Code kompiliert und ausgeführt wird, liest er die im vorherigen Abschnitt erstellte Datei und erzeugt das folgende Ergebnis:
Waiting for a message
... no message yet
... no message yet
... no message yet
... no message yet
received: helloEine Ausnahme ist ein Problem, das während der Ausführung eines Programms auftritt. Eine AD-Ausnahme ist eine Reaktion auf einen außergewöhnlichen Umstand, der während der Ausführung eines Programms auftritt, z. B. den Versuch, durch Null zu teilen.
Ausnahmen bieten eine Möglichkeit, die Kontrolle von einem Teil eines Programms auf einen anderen zu übertragen. Die Ausnahmebehandlung basiert auf drei Schlüsselwörterntry, catch, und throw.
throw- Ein Programm löst eine Ausnahme aus, wenn ein Problem auftritt. Dies geschieht mit athrow Stichwort.
catch- Ein Programm fängt eine Ausnahme mit einem Ausnahmebehandler an der Stelle in einem Programm ab, an der Sie das Problem behandeln möchten. Dascatch Schlüsselwort gibt das Abfangen einer Ausnahme an.
try - A. tryBlock identifiziert einen Codeblock, für den bestimmte Ausnahmen aktiviert sind. Es folgen ein oder mehrere Fangblöcke.
Angenommen, ein Block löst eine Ausnahme aus, fängt eine Methode eine Ausnahme mit einer Kombination aus try und catchSchlüsselwörter. Um den Code wird ein Try / Catch-Block platziert, der möglicherweise eine Ausnahme generiert. Code in einem try / catch-Block wird als geschützter Code bezeichnet, und die Syntax für die Verwendung von try / catch sieht wie folgt aus:
try {
// protected code
}
catch( ExceptionName e1 ) {
// catch block
}
catch( ExceptionName e2 ) {
// catch block
}
catch( ExceptionName eN ) {
// catch block
}Sie können mehrere auflisten catch Anweisungen, um verschiedene Arten von Ausnahmen abzufangen, falls Ihre try Block löst in verschiedenen Situationen mehr als eine Ausnahme aus.
Ausnahmen in D werfen
Ausnahmen können mit überall innerhalb eines Codeblocks ausgelöst werden throwAussagen. Der Operand der throw-Anweisungen bestimmt einen Typ für die Ausnahme und kann ein beliebiger Ausdruck sein, und der Typ des Ergebnisses des Ausdrucks bestimmt den Typ der ausgelösten Ausnahme.
Das folgende Beispiel löst eine Ausnahme aus, wenn eine Bedingung zum Teilen durch Null auftritt.
Beispiel
double division(int a, int b) {
if( b == 0 ) {
throw new Exception("Division by zero condition!");
}
return (a/b);
}Ausnahmen in D abfangen
Das catch Block nach dem tryBlock fängt jede Ausnahme ab. Sie können angeben, welche Art von Ausnahme Sie abfangen möchten. Dies wird durch die Ausnahmedeklaration bestimmt, die in Klammern nach dem Schlüsselwort catch angezeigt wird.
try {
// protected code
}
catch( ExceptionName e ) {
// code to handle ExceptionName exception
}Der obige Code fängt eine Ausnahme von ExceptionNameArt. Wenn Sie angeben möchten, dass ein catch-Block jede Art von Ausnahme behandeln soll, die in einem try-Block ausgelöst wird, müssen Sie wie folgt ein Auslassungszeichen zwischen die Klammern setzen, die die Ausnahmedeklaration einschließen:
try {
// protected code
}
catch(...) {
// code to handle any exception
}Das folgende Beispiel löst eine Ausnahme durch Division durch Null aus. Es ist im Fangblock gefangen.
import std.stdio;
import std.string;
string division(int a, int b) {
string result = "";
try {
if( b == 0 ) {
throw new Exception("Cannot divide by zero!");
} else {
result = format("%s",a/b);
}
} catch (Exception e) {
result = e.msg;
}
return result;
}
void main () {
int x = 50;
int y = 0;
writeln(division(x, y));
y = 10;
writeln(division(x, y));
}Wenn der obige Code kompiliert und ausgeführt wird, liest er die im vorherigen Abschnitt erstellte Datei und erzeugt das folgende Ergebnis:
Cannot divide by zero!
5Die Vertragsprogrammierung in der D-Programmierung konzentriert sich auf die Bereitstellung eines einfachen und verständlichen Mittels zur Fehlerbehandlung. Die Vertragsprogrammierung in D wird durch drei Arten von Codeblöcken implementiert:
- Körperblock
- im Block
- aus Block
Körperblock in D.
Der Bodyblock enthält den eigentlichen Funktionscode für die Ausführung. Die In- und Out-Blöcke sind optional, während der Body-Block obligatorisch ist. Eine einfache Syntax ist unten dargestellt.
return_type function_name(function_params)
in {
// in block
}
out (result) {
// in block
}
body {
// actual function block
}In Block für Vorbedingungen in D.
In Block steht für einfache Vorbedingungen, die überprüfen, ob die Eingabeparameter akzeptabel sind und in einem Bereich, der vom Code verarbeitet werden kann. Ein Vorteil eines In-Blocks besteht darin, dass alle Eingangsbedingungen zusammengehalten und vom eigentlichen Funktionskörper getrennt werden können. Eine einfache Voraussetzung für die Überprüfung des Kennworts auf seine Mindestlänge ist unten dargestellt.
import std.stdio;
import std.string;
bool isValid(string password)
in {
assert(password.length>=5);
}
body {
// other conditions
return true;
}
void main() {
writeln(isValid("password"));
}Wenn der obige Code kompiliert und ausgeführt wird, liest er die im vorherigen Abschnitt erstellte Datei und erzeugt das folgende Ergebnis:
trueOut-Blöcke für Post-Bedingungen in D.
Der out-Block kümmert sich um die Rückgabewerte der Funktion. Es wird überprüft, ob der Rückgabewert im erwarteten Bereich liegt. Im Folgenden wird ein einfaches Beispiel gezeigt, das sowohl In als auch Out enthält und Monate, Jahr in eine kombinierte Dezimalalterform konvertiert.
import std.stdio;
import std.string;
double getAge(double months,double years)
in {
assert(months >= 0);
assert(months <= 12);
}
out (result) {
assert(result>=years);
}
body {
return years + months/12;
}
void main () {
writeln(getAge(10,12));
}Wenn der obige Code kompiliert und ausgeführt wird, liest er die im vorherigen Abschnitt erstellte Datei und erzeugt das folgende Ergebnis:
12.8333Bei der bedingten Kompilierung wird ausgewählt, welcher Code kompiliert werden soll und welcher Code nicht kompiliert werden soll, ähnlich wie bei #if / #else / #endif in C und C ++. Jede Anweisung, die noch nicht kompiliert wurde, muss syntaktisch korrekt sein.
Die bedingte Kompilierung umfasst Bedingungsprüfungen, die zur Kompilierungszeit ausgewertet werden können. Bedingte Laufzeitanweisungen wie if, for, while sind keine bedingten Kompilierungsfunktionen. Die folgenden Funktionen von D sind für die bedingte Kompilierung vorgesehen:
- debug
- version
- statisch wenn
Debug-Anweisung in D.
Das Debugging ist während der Programmentwicklung hilfreich. Die als Debug gekennzeichneten Ausdrücke und Anweisungen werden nur dann in das Programm kompiliert, wenn der Compiler-Schalter -debug aktiviert ist.
debug a_conditionally_compiled_expression;
debug {
// ... conditionally compiled code ...
} else {
// ... code that is compiled otherwise ...
}Die else-Klausel ist optional. Sowohl der einzelne Ausdruck als auch der obige Codeblock werden nur kompiliert, wenn der Compiler-Schalter -debug aktiviert ist.
Anstatt vollständig entfernt zu werden, können die Zeilen stattdessen als Debug markiert werden.
debug writefln("%s debug only statement", value);Solche Zeilen sind nur dann im Programm enthalten, wenn der Compiler-Schalter -debug aktiviert ist.
dmd test.d -oftest -w -debugDebug (Tag) -Anweisung in D.
Den Debug-Anweisungen können Namen (Tags) zugewiesen werden, die selektiv in das Programm aufgenommen werden sollen.
debug(mytag) writefln("%s not found", value);Solche Zeilen sind nur dann im Programm enthalten, wenn der Compiler-Schalter -debug aktiviert ist.
dmd test.d -oftest -w -debug = mytagDie Debug-Blöcke können auch Tags haben.
debug(mytag) {
//
}Es ist möglich, mehr als ein Debug-Tag gleichzeitig zu aktivieren.
dmd test.d -oftest -w -debug = mytag1 -debug = mytag2Debug (Level) -Anweisung in D.
Manchmal ist es sinnvoller, Debug-Anweisungen nach numerischen Ebenen zu verknüpfen. Steigende Stufen können detailliertere Informationen liefern.
import std.stdio;
void myFunction() {
debug(1) writeln("debug1");
debug(2) writeln("debug2");
}
void main() {
myFunction();
}Die Debug-Ausdrücke und -Blöcke, die kleiner oder gleich der angegebenen Ebene sind, werden kompiliert.
$ dmd test.d -oftest -w -debug = 1 $ ./test
debug1Versions- (Tag) und Versions- (Level-) Anweisungen in D.
Die Version ähnelt dem Debuggen und wird auf die gleiche Weise verwendet. Die else-Klausel ist optional. Obwohl die Version im Wesentlichen genauso funktioniert wie das Debuggen, hilft die Verwendung separater Schlüsselwörter dabei, ihre nicht verwandten Verwendungen zu unterscheiden. Wie beim Debuggen kann mehr als eine Version aktiviert werden.
import std.stdio;
void myFunction() {
version(1) writeln("version1");
version(2) writeln("version2");
}
void main() {
myFunction();
}Die Debug-Ausdrücke und -Blöcke, die kleiner oder gleich der angegebenen Ebene sind, werden kompiliert.
$ dmd test.d -oftest -w -version = 1 $ ./test
version1Statisch wenn
Static if is the compile time equivalent of the if statement. Just like the if statement, static if takes a logical expression and evaluates it. Unlike the if statement, static if is not about execution flow; rather, it determines whether a piece of code should be included in the program or not.
The if expression is unrelated to the is operator that we have seen earlier, both syntactically and semantically. It is evaluated at compile time. It produces an int value, either 0 or 1; depending on the expression specified in parentheses. Although the expression that it takes is not a logical expression, the is expression itself is used as a compile time logical expression. It is especially useful in static if conditionals and template constraints.
import std.stdio;
enum Days {
sun,
mon,
tue,
wed,
thu,
fri,
sat
};
void myFunction(T)(T mytemplate) {
static if (is (T == class)) {
writeln("This is a class type");
} else static if (is (T == enum)) {
writeln("This is an enum type");
}
}
void main() {
Days day;
myFunction(day);
}When we compile and run we will get some output as follows.
This is an enum typeClasses are the central feature of D programming that supports object-oriented programming and are often called user-defined types.
A class is used to specify the form of an object and it combines data representation and methods for manipulating that data into one neat package. The data and functions within a class are called members of the class.
D Class Definitions
When you define a class, you define a blueprint for a data type. This does not actually define any data, but it defines what the class name means, that is, what an object of the class will consist of and what operations can be performed on such an object.
A class definition starts with the keyword class followed by the class name; and the class body, enclosed by a pair of curly braces. A class definition must be followed either by a semicolon or a list of declarations. For example, we defined the Box data type using the keyword class as follows −
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}The keyword public determines the access attributes of the members of the class that follow it. A public member can be accessed from outside the class anywhere within the scope of the class object. You can also specify the members of a class as private or protected which we will discuss in a sub-section.
Defining D Objects
A class provides the blueprints for objects, so basically an object is created from a class. You declare objects of a class with exactly the same sort of declaration that you declare variables of basic types. The following statements declare two objects of class Box −
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type BoxBoth of the objects Box1 and Box2 have their own copy of data members.
Accessing the Data Members
The public data members of objects of a class can be accessed using the direct member access operator (.). Let us try the following example to make the things clear −
import std.stdio;
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}
void main() {
Box box1 = new Box(); // Declare Box1 of type Box
Box box2 = new Box(); // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.height = 5.0;
box1.length = 6.0;
box1.breadth = 7.0;
// box 2 specification
box2.height = 10.0;
box2.length = 12.0;
box2.breadth = 13.0;
// volume of box 1
volume = box1.height * box1.length * box1.breadth;
writeln("Volume of Box1 : ",volume);
// volume of box 2
volume = box2.height * box2.length * box2.breadth;
writeln("Volume of Box2 : ", volume);
}When the above code is compiled and executed, it produces the following result −
Volume of Box1 : 210
Volume of Box2 : 1560It is important to note that private and protected members can not be accessed directly using direct member access operator (.). Shortly you will learn how private and protected members can be accessed.
Classes and Objects in D
So far, you have got very basic idea about D Classes and Objects. There are further interesting concepts related to D Classes and Objects which we will discuss in various sub-sections listed below −
| Sr.No. | Concept & Description |
|---|---|
| 1 | Class member functions A member function of a class is a function that has its definition or its prototype within the class definition like any other variable. |
| 2 | Class access modifiers A class member can be defined as public, private or protected. By default members would be assumed as private. |
| 3 | Constructor & destructor A class constructor is a special function in a class that is called when a new object of the class is created. A destructor is also a special function which is called when created object is deleted. |
| 4 | The this pointer in D Every object has a special pointer this which points to the object itself. |
| 5 | Pointer to D classes A pointer to a class is done exactly the same way a pointer to a structure is. In fact a class is really just a structure with functions in it. |
| 6 | Static members of a class Both data members and function members of a class can be declared as static. |
One of the most important concepts in object-oriented programming is inheritance. Inheritance allows to define a class in terms of another class, which makes it easier to create and maintain an application. This also provides an opportunity to reuse the code functionality and fast implementation time.
When creating a class, instead of writing completely new data members and member functions, the programmer can designate that the new class should inherit the members of an existing class. This existing class is called the base class, and the new class is referred to as the derived class.
The idea of inheritance implements the is a relationship. For example, mammal IS-A animal, dog IS-A mammal hence dog IS-A animal as well and so on.
Base Classes and Derived Classes in D
A class can be derived from more than one classes, which means it can inherit data and functions from multiple base classes. To define a derived class, we use a class derivation list to specify the base class(es). A class derivation list names one or more base classes and has the form −
class derived-class: base-classConsider a base class Shape and its derived class Rectangle as follows −
import std.stdio;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape {
public:
int getArea() {
return (width * height);
}
}
void main() {
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}When the above code is compiled and executed, it produces the following result −
Total area: 35Access Control and Inheritance
A derived class can access all the non-private members of its base class. Thus base-class members that should not be accessible to the member functions of derived classes should be declared private in the base class.
A derived class inherits all base class methods with the following exceptions −
- Constructors, destructors, and copy constructors of the base class.
- Overloaded operators of the base class.
Multi Level Inheritance
The inheritance can be of multiple levels and it is shown in the following example.
import std.stdio;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape {
public:
int getArea() {
return (width * height);
}
}
class Square: Rectangle {
this(int side) {
this.setWidth(side);
this.setHeight(side);
}
}
void main() {
Square square = new Square(13);
// Print the area of the object.
writeln("Total area: ", square.getArea());
}When the above code is compiled and executed, it produces the following result −
Total area: 169D allows you to specify more than one definition for a function name or an operator in the same scope, which is called function overloading and operator overloading respectively.
An overloaded declaration is a declaration that had been declared with the same name as a previous declaration in the same scope, except that both declarations have different arguments and obviously different definition (implementation).
When you call an overloaded function or operator, the compiler determines the most appropriate definition to use by comparing the argument types you used to call the function or operator with the parameter types specified in the definitions. The process of selecting the most appropriate overloaded function or operator is called overload resolution..
Function Overloading
You can have multiple definitions for the same function name in the same scope. The definition of the function must differ from each other by the types and/or the number of arguments in the argument list. You cannot overload function declarations that differ only by return type.
Example
The following example uses same function print() to print different data types −
import std.stdio;
import std.string;
class printData {
public:
void print(int i) {
writeln("Printing int: ",i);
}
void print(double f) {
writeln("Printing float: ",f );
}
void print(string s) {
writeln("Printing string: ",s);
}
};
void main() {
printData pd = new printData();
// Call print to print integer
pd.print(5);
// Call print to print float
pd.print(500.263);
// Call print to print character
pd.print("Hello D");
}When the above code is compiled and executed, it produces the following result −
Printing int: 5
Printing float: 500.263
Printing string: Hello DOperator Overloading
You can redefine or overload most of the built-in operators available in D. Thus a programmer can use operators with user-defined types as well.
Operators can be overloaded using string op followed by Add, Sub, and so on based on the operator that is being overloaded. We can overload the operator + to add two boxes as shown below.
Box opAdd(Box b) {
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}The following example shows the concept of operator overloading using a member function. Here an object is passed as an argument whose properties are accessed using this object. The object which calls this operator can be accessed using this operator as explained below −
import std.stdio;
class Box {
public:
double getVolume() {
return length * breadth * height;
}
void setLength( double len ) {
length = len;
}
void setBreadth( double bre ) {
breadth = bre;
}
void setHeight( double hei ) {
height = hei;
}
Box opAdd(Box b) {
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Main function for the program
void main( ) {
Box box1 = new Box(); // Declare box1 of type Box
Box box2 = new Box(); // Declare box2 of type Box
Box box3 = new Box(); // Declare box3 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.setLength(6.0);
box1.setBreadth(7.0);
box1.setHeight(5.0);
// box 2 specification
box2.setLength(12.0);
box2.setBreadth(13.0);
box2.setHeight(10.0);
// volume of box 1
volume = box1.getVolume();
writeln("Volume of Box1 : ", volume);
// volume of box 2
volume = box2.getVolume();
writeln("Volume of Box2 : ", volume);
// Add two object as follows:
box3 = box1 + box2;
// volume of box 3
volume = box3.getVolume();
writeln("Volume of Box3 : ", volume);
}When the above code is compiled and executed, it produces the following result −
Volume of Box1 : 210
Volume of Box2 : 1560
Volume of Box3 : 5400Operator Overloading Types
Basically, there are three types of operator overloading as listed below.
| Sr.No. | Overloading Types |
|---|---|
| 1 | Unary Operators Overloading |
| 2 | Binary Operators Overloading |
| 3 | Comparison Operators Overloading |
All D programs are composed of the following two fundamental elements −
Program statements (code) − This is the part of a program that performs actions and they are called functions.
Program data − It is the information of the program which affected by the program functions.
Encapsulation is an Object Oriented Programming concept that binds data and functions that manipulate the data together, and that keeps both safe from outside interference and misuse. Data encapsulation led to the important OOP concept of data hiding.
Data encapsulation is a mechanism of bundling the data, and the functions that use them and data abstraction is a mechanism of exposing only the interfaces and hiding the implementation details from the user.
D supports the properties of encapsulation and data hiding through the creation of user-defined types, called classes. We already have studied that a class can contain private, protected, and public members. By default, all items defined in a class are private. For example −
class Box {
public:
double getVolume() {
return length * breadth * height;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};The variables length, breadth, and height are private. This means that they can be accessed only by other members of the Box class, and not by any other part of your program. This is one way encapsulation is achieved.
To make parts of a class public (i.e., accessible to other parts of your program), you must declare them after the public keyword. All variables or functions defined after the public specifier are accessible by all other functions in your program.
Making one class a friend of another exposes the implementation details and reduces encapsulation. It is ideal to keep as many details of each class hidden from all other classes as possible.
Data Encapsulation in D
Any D program where you implement a class with public and private members is an example of data encapsulation and data abstraction. Consider the following example −
Example
import std.stdio;
class Adder {
public:
// constructor
this(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
}
void main( ) {
Adder a = new Adder();
a.addNum(10);
a.addNum(20);
a.addNum(30);
writeln("Total ",a.getTotal());
}When the above code is compiled and executed, it produces the following result −
Total 60Above class adds numbers together, and returns the sum. The public members addNum and getTotal are the interfaces to the outside world and a user needs to know them to use the class. The private member total is something that is hidden from the outside world, but is needed for the class to operate properly.
Class Designing Strategy in D
Most of us have learned through bitter experience to make class members private by default unless we really need to expose them. That is just good encapsulation.
This wisdom is applied most frequently to data members, but it applies equally to all members, including virtual functions.
An interface is a way of forcing the classes that inherit from it to have to implement certain functions or variables. Functions must not be implemented in an interface because they are always implemented in the classes that inherit from the interface.
An interface is created using the interface keyword instead of the class keyword even though the two are similar in a lot of ways. When you want to inherit from an interface and the class already inherits from another class then you need to separate the name of the class and the name of the interface with a comma.
Let us look at an simple example that explains the use of an interface.
Example
import std.stdio;
// Base class
interface Shape {
public:
void setWidth(int w);
void setHeight(int h);
}
// Derived class
class Rectangle: Shape {
int width;
int height;
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return (width * height);
}
}
void main() {
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}When the above code is compiled and executed, it produces the following result −
Total area: 35Interface with Final and Static Functions in D
An interface can have final and static method for which definitions should be included in interface itself. These functions cannot be overriden by the derived class. A simple example is shown below.
Beispiel
import std.stdio;
// Base class
interface Shape {
public:
void setWidth(int w);
void setHeight(int h);
static void myfunction1() {
writeln("This is a static method");
}
final void myfunction2() {
writeln("This is a final method");
}
}
// Derived class
class Rectangle: Shape {
int width;
int height;
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return (width * height);
}
}
void main() {
Rectangle rect = new Rectangle();
rect.setWidth(5);
rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", rect.getArea());
rect.myfunction1();
rect.myfunction2();
}Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Total area: 35
This is a static method
This is a final methodAbstraktion bezieht sich auf die Fähigkeit, eine Klasse in OOP abstrakt zu machen. Eine abstrakte Klasse kann nicht instanziiert werden. Alle anderen Funktionen der Klasse sind noch vorhanden, und auf ihre Felder, Methoden und Konstruktoren wird auf dieselbe Weise zugegriffen. Sie können einfach keine Instanz der abstrakten Klasse erstellen.
Wenn eine Klasse abstrakt ist und nicht instanziiert werden kann, hat die Klasse nur dann eine große Verwendung, wenn sie eine Unterklasse ist. Auf diese Weise entstehen normalerweise abstrakte Klassen während der Entwurfsphase. Eine übergeordnete Klasse enthält die allgemeine Funktionalität einer Sammlung untergeordneter Klassen, aber die übergeordnete Klasse selbst ist zu abstrakt, um allein verwendet zu werden.
Verwenden der abstrakten Klasse in D.
Verwenden Sie die abstractSchlüsselwort zum Deklarieren einer Klassenzusammenfassung. Das Schlüsselwort wird in der Klassendeklaration irgendwo vor dem Klassenschlüsselwort angezeigt. Das Folgende zeigt ein Beispiel dafür, wie abstrakte Klassen geerbt und verwendet werden können.
Beispiel
import std.stdio;
import std.string;
import std.datetime;
abstract class Person {
int birthYear, birthDay, birthMonth;
string name;
int getAge() {
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
}
class Employee : Person {
int empID;
}
void main() {
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
writeln(emp.name);
writeln(emp.getAge);
}Wenn wir das obige Programm kompilieren und ausführen, erhalten wir die folgende Ausgabe.
Emp1
37Abstrakte Funktionen
Ähnlich wie Funktionen können Klassen auch abstrakt sein. Die Implementierung einer solchen Funktion ist nicht in ihrer Klasse angegeben, sondern sollte in der Klasse bereitgestellt werden, die die Klasse mit abstrakter Funktion erbt. Das obige Beispiel wird mit der abstrakten Funktion aktualisiert.
Beispiel
import std.stdio;
import std.string;
import std.datetime;
abstract class Person {
int birthYear, birthDay, birthMonth;
string name;
int getAge() {
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
abstract void print();
}
class Employee : Person {
int empID;
override void print() {
writeln("The employee details are as follows:");
writeln("Emp ID: ", this.empID);
writeln("Emp Name: ", this.name);
writeln("Age: ",this.getAge);
}
}
void main() {
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
emp.print();
}Wenn wir das obige Programm kompilieren und ausführen, erhalten wir die folgende Ausgabe.
The employee details are as follows:
Emp ID: 101
Emp Name: Emp1
Age: 37