Hive - Einführung
Der Begriff "Big Data" wird für Sammlungen großer Datenmengen verwendet, die ein großes Volumen, eine hohe Geschwindigkeit und eine Vielzahl von Daten umfassen, die von Tag zu Tag zunehmen. Mit herkömmlichen Datenverwaltungssystemen ist es schwierig, Big Data zu verarbeiten. Aus diesem Grund hat die Apache Software Foundation ein Framework namens Hadoop eingeführt, um die Herausforderungen bei der Verwaltung und Verarbeitung von Big Data zu lösen.
Hadoop
Hadoop ist ein Open-Source-Framework zum Speichern und Verarbeiten von Big Data in einer verteilten Umgebung. Es enthält zwei Module, eines ist MapReduce und eines ist Hadoop Distributed File System (HDFS).
MapReduce: Es ist ein paralleles Programmiermodell zur Verarbeitung großer Mengen strukturierter, halbstrukturierter und unstrukturierter Daten auf großen Clustern von Standardhardware.
HDFS:Das verteilte Hadoop-Dateisystem ist Teil des Hadoop-Frameworks, mit dem die Datensätze gespeichert und verarbeitet werden. Es bietet ein fehlertolerantes Dateisystem für die Ausführung auf Standardhardware.
Das Hadoop-Ökosystem enthält verschiedene Unterprojekte (Tools) wie Sqoop, Pig und Hive, die zur Unterstützung von Hadoop-Modulen verwendet werden.
Sqoop: Es wird zum Importieren und Exportieren von Daten zu und von zwischen HDFS und RDBMS verwendet.
Pig: Es ist eine prozedurale Sprachplattform, mit der ein Skript für MapReduce-Operationen entwickelt wird.
Hive: Es ist eine Plattform, die zum Entwickeln von SQL-Skripten für MapReduce-Operationen verwendet wird.
Note: Es gibt verschiedene Möglichkeiten, MapReduce-Vorgänge auszuführen:
- Der traditionelle Ansatz mit dem Java MapReduce-Programm für strukturierte, halbstrukturierte und unstrukturierte Daten.
- Der Skriptansatz für MapReduce zur Verarbeitung strukturierter und halbstrukturierter Daten mit Pig.
- Die Hive Query Language (HiveQL oder HQL) für MapReduce zur Verarbeitung strukturierter Daten mit Hive.
Was ist Hive?
Hive ist ein Data Warehouse-Infrastruktur-Tool zur Verarbeitung strukturierter Daten in Hadoop. Es befindet sich auf Hadoop, um Big Data zusammenzufassen, und erleichtert das Abfragen und Analysieren.
Ursprünglich wurde Hive von Facebook entwickelt, später wurde es von der Apache Software Foundation als Open Source unter dem Namen Apache Hive weiterentwickelt. Es wird von verschiedenen Unternehmen verwendet. Amazon verwendet es beispielsweise in Amazon Elastic MapReduce.
Bienenstock ist nicht
- Eine relationale Datenbank
- Ein Design für die OnLine-Transaktionsverarbeitung (OLTP)
- Eine Sprache für Echtzeitabfragen und Aktualisierungen auf Zeilenebene
Eigenschaften von Hive
- Es speichert das Schema in einer Datenbank und verarbeitet Daten in HDFS.
- Es ist für OLAP konzipiert.
- Es bietet eine SQL-Sprache für die Abfrage, die als HiveQL oder HQL bezeichnet wird.
- Es ist vertraut, schnell, skalierbar und erweiterbar.
Architektur des Bienenstocks
Das folgende Komponentendiagramm zeigt die Architektur von Hive:

Dieses Komponentendiagramm enthält verschiedene Einheiten. Die folgende Tabelle beschreibt jede Einheit:
| Einheitenname | Betrieb |
|---|---|
| Benutzeroberfläche | Hive ist eine Data Warehouse-Infrastruktur-Software, die eine Interaktion zwischen Benutzer und HDFS herstellen kann. Die von Hive unterstützten Benutzeroberflächen sind Hive Web UI, Hive-Befehlszeile und Hive HD Insight (unter Windows Server). |
| Meta Store | Hive wählt die entsprechenden Datenbankserver aus, um das Schema oder die Metadaten von Tabellen, Datenbanken, Spalten in einer Tabelle, deren Datentypen und HDFS-Zuordnung zu speichern. |
| HiveQL Process Engine | HiveQL ähnelt SQL zum Abfragen von Schemainformationen im Metastore. Es ist einer der Ersatz für den traditionellen Ansatz des MapReduce-Programms. Anstatt das MapReduce-Programm in Java zu schreiben, können wir eine Abfrage für den MapReduce-Job schreiben und verarbeiten. |
| Ausführungs-Engine | Der Verbindungsteil von HiveQL Process Engine und MapReduce ist Hive Execution Engine. Die Ausführungs-Engine verarbeitet die Abfrage und generiert die gleichen Ergebnisse wie die MapReduce-Ergebnisse. Es verwendet den Geschmack von MapReduce. |
| HDFS oder HBASE | Hadoop Distributed File System oder HBASE sind die Datenspeichertechniken zum Speichern von Daten im Dateisystem. |
Arbeiten von Hive
Das folgende Diagramm zeigt den Workflow zwischen Hive und Hadoop.
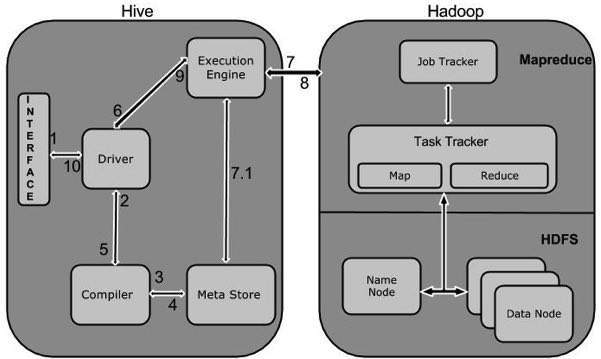
In der folgenden Tabelle wird definiert, wie Hive mit dem Hadoop-Framework interagiert:
| Schritt Nr. | Betrieb |
|---|---|
| 1 | Execute Query Die Hive-Schnittstelle wie die Befehlszeile oder die Web-Benutzeroberfläche sendet eine Abfrage zur Ausführung an den Treiber (einen beliebigen Datenbanktreiber wie JDBC, ODBC usw.). |
| 2 | Get Plan Der Treiber verwendet den Abfrage-Compiler, der die Abfrage analysiert, um die Syntax und den Abfrageplan oder die Anforderung der Abfrage zu überprüfen. |
| 3 | Get Metadata Der Compiler sendet eine Metadatenanforderung an Metastore (eine beliebige Datenbank). |
| 4 | Send Metadata Metastore sendet Metadaten als Antwort an den Compiler. |
| 5 | Send Plan Der Compiler überprüft die Anforderung und sendet den Plan erneut an den Treiber. Bis hier ist das Parsen und Kompilieren einer Abfrage abgeschlossen. |
| 6 | Execute Plan Der Treiber sendet den Ausführungsplan an die Ausführungsengine. |
| 7 | Execute Job Intern ist der Ausführungsprozess ein MapReduce-Job. Die Ausführungsengine sendet den Job an JobTracker, der sich im Knoten Name befindet, und weist diesen Job TaskTracker zu, der sich im Knoten Daten befindet. Hier führt die Abfrage den MapReduce-Job aus. |
| 7.1 | Metadata Ops Während der Ausführung kann die Ausführungsengine Metadatenoperationen mit Metastore ausführen. |
| 8 | Fetch Result Die Ausführungsengine empfängt die Ergebnisse von Datenknoten. |
| 9 | Send Results Die Ausführungs-Engine sendet diese resultierenden Werte an den Treiber. |
| 10 | Send Results Der Treiber sendet die Ergebnisse an Hive Interfaces. |