KDB + Architektur
Kdb + ist eine leistungsstarke Datenbank mit hohem Datenvolumen, die von Anfang an für die Verarbeitung enormer Datenmengen entwickelt wurde. Es ist vollständig 64-Bit und verfügt über eine integrierte Multi-Core-Verarbeitung und Multithreading. Dieselbe Architektur wird für Echtzeit- und historische Daten verwendet. Die Datenbank enthält eine eigene leistungsstarke Abfragesprache.q, So können Analysen direkt auf den Daten ausgeführt werden.
kdb+tick ist eine Architektur, die das Erfassen, Verarbeiten und Abfragen von Echtzeit- und historischen Daten ermöglicht.
Kdb + / tick Architektur
Die folgende Abbildung gibt einen allgemeinen Überblick über eine typische Kdb + / Tick-Architektur, gefolgt von einer kurzen Erläuterung der verschiedenen Komponenten und des Datenflusses.
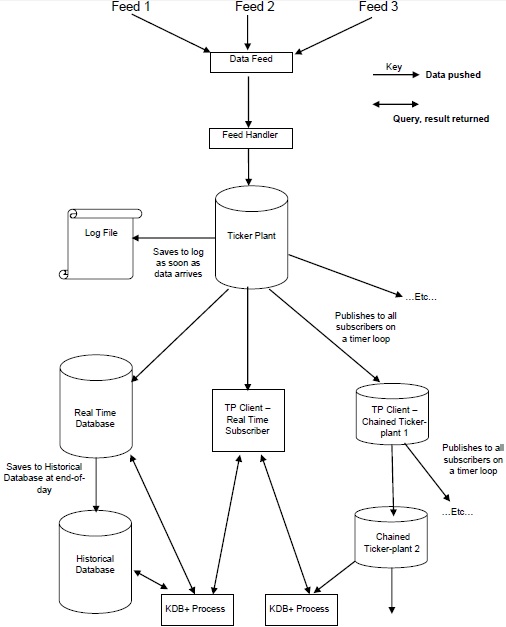
Das Data Feeds sind Zeitreihendaten, die meist von Daten-Feed-Anbietern wie Reuters, Bloomberg oder direkt von Börsen bereitgestellt werden.
Um die relevanten Daten zu erhalten, werden die Daten aus dem Datenfeed von der analysiert feed handler.
Sobald die Daten vom Feed-Handler analysiert wurden, gehen sie an die ticker-plant.
Um Daten nach einem Fehler wiederherzustellen, aktualisiert / speichert die Ticker-Anlage zuerst die neuen Daten in der Protokolldatei und aktualisiert dann ihre eigenen Tabellen.
Nach dem Aktualisieren der internen Tabellen und der Protokolldateien werden die Pünktlichkeitsschleifendaten kontinuierlich an die Echtzeitdatenbank und alle verketteten Abonnenten gesendet / veröffentlicht, die Daten angefordert haben.
Am Ende eines Geschäftstages wird die Protokolldatei gelöscht, eine neue erstellt und die Echtzeitdatenbank in der historischen Datenbank gespeichert. Sobald alle Daten in der historischen Datenbank gespeichert sind, löscht die Echtzeitdatenbank ihre Tabellen.
Komponenten der Kdb + Tick-Architektur
Daten-Feeds
Daten-Feeds können beliebige Markt- oder andere Zeitreihendaten sein. Betrachten Sie Daten-Feeds als Roheingabe für den Feed-Handler. Feeds können direkt vom Austausch (Live-Streaming-Daten), von Nachrichten- / Datenanbietern wie Thomson-Reuters, Bloomberg oder anderen externen Agenturen stammen.
Feed Handler
Ein Feed-Handler konvertiert den Datenstrom in ein Format, das zum Schreiben in kdb + geeignet ist. Es ist mit dem Daten-Feed verbunden und ruft die Daten aus dem Feed-spezifischen Format ab und konvertiert sie in eine Kdb + -Nachricht, die im Ticker-Plant-Prozess veröffentlicht wird. Im Allgemeinen wird ein Feed-Handler verwendet, um die folgenden Vorgänge auszuführen:
- Erfassen Sie Daten nach einer Reihe von Regeln.
- Übersetzen (/ bereichern) Sie diese Daten von einem Format in ein anderes.
- Fangen Sie die neuesten Werte ab.
Ticker Pflanze
Ticker Plant ist der wichtigste Bestandteil der KDB + -Architektur. Es ist die Tickeranlage, mit der die Echtzeitdatenbank oder direkte Abonnenten (Clients) verbunden sind, um auf die Finanzdaten zuzugreifen. Es arbeitet inpublish and subscribeMechanismus. Sobald Sie ein Abonnement (Lizenz) erhalten haben, wird eine Tick-Veröffentlichung (routinemäßig) vom Verlag (Ticker-Anlage) definiert. Es führt die folgenden Operationen aus:
Empfängt die Daten vom Feed-Handler.
Unmittelbar nachdem die Tickeranlage die Daten erhalten hat, speichert sie eine Kopie als Protokolldatei und aktualisiert sie, sobald die Tickeranlage eine Aktualisierung erhält, so dass wir im Falle eines Fehlers keinen Datenverlust haben sollten.
Die Kunden (Echtzeit-Abonnenten) können die Ticker-Anlage direkt abonnieren.
Am Ende eines jeden Geschäftstages, dh sobald die Echtzeitdatenbank die letzte Nachricht empfängt, speichert sie alle heutigen Daten in der historischen Datenbank und sendet sie an alle Abonnenten, die die heutigen Daten abonniert haben. Dann werden alle Tabellen zurückgesetzt. Die Protokolldatei wird auch gelöscht, sobald die Daten in der historischen Datenbank oder einem anderen direkt mit der Echtzeitdatenbank (rtdb) verknüpften Abonnenten gespeichert sind.
Infolgedessen sind die Ticker-Anlage, die Echtzeitdatenbank und die historische Datenbank rund um die Uhr in Betrieb.
Da es sich bei der Ticker-Pflanze um eine Kdb + -Anwendung handelt, können ihre Tabellen mit abgefragt werden qwie jede andere Kdb + Datenbank. Alle Ticker-Plant-Clients sollten nur als Abonnenten Zugriff auf die Datenbank haben.
Echtzeitdatenbank
Eine Echtzeitdatenbank (rdb) speichert die heutigen Daten. Es ist direkt mit der Tickeranlage verbunden. Normalerweise wird es während der Marktzeiten (eines Tages) gespeichert und am Ende des Tages in die historische Datenbank (hdb) geschrieben. Da die Daten (Rdb-Daten) im Speicher gespeichert sind, ist die Verarbeitung extrem schnell.
Da kdb + eine RAM-Größe empfiehlt, die viermal oder mehr der erwarteten Datengröße pro Tag entspricht, ist die auf rdb ausgeführte Abfrage sehr schnell und bietet eine überlegene Leistung. Da eine Echtzeitdatenbank nur die heutigen Daten enthält, ist die Datumsspalte (Parameter) nicht erforderlich.
Zum Beispiel können wir rdb-Abfragen haben wie:
select from trade where sym = `ibm
OR
select from trade where sym = `ibm, price > 100Historische Datenbank
Wenn wir die Schätzungen eines Unternehmens berechnen müssen, müssen wir seine historischen Daten verfügbar haben. Eine historische Datenbank (hdb) enthält Daten von Transaktionen, die in der Vergangenheit durchgeführt wurden. Jeder neue Tagesdatensatz wird am Ende des Tages zur Festplatte hinzugefügt. Große Tabellen in der HDB werden entweder gespreizt gespeichert (jede Spalte wird in einer eigenen Datei gespeichert) oder sie werden partitioniert nach zeitlichen Daten gespeichert. Einige sehr große Datenbanken können auch mithilfe von weiter partitioniert werdenpar.txt (Datei).
Diese Speicherstrategien (gespreizt, partitioniert usw.) sind effizient beim Suchen oder Zugreifen auf die Daten aus einer großen Tabelle.
Eine historische Datenbank kann auch für interne und externe Berichtszwecke verwendet werden, dh für Analysen. Angenommen, wir möchten die Handelsgeschäfte von IBM für einen bestimmten Tag aus dem Handelsnamen (oder einem beliebigen Namen) abrufen. Wir müssen eine Abfrage wie folgt schreiben:
thisday: 2014.10.12
select from trade where date = thisday, sym =`ibmNote - Wir werden alle diese Fragen schreiben, sobald wir einen Überblick über die q Sprache.