KNIME - Erstellen Sie Ihr eigenes Modell
In diesem Kapitel erstellen Sie Ihr eigenes Modell für maschinelles Lernen, um die Anlagen anhand einiger beobachteter Merkmale zu kategorisieren. Wir werden das bekannte verwendeniris Datensatz von UCI Machine Learning Repositoryfür diesen Zweck. Der Datensatz enthält drei verschiedene Pflanzenklassen. Wir werden unser Modell trainieren, um eine unbekannte Pflanze in eine dieser drei Klassen einzuteilen.
Wir beginnen mit der Erstellung eines neuen Workflows in KNIME zur Erstellung unserer Modelle für maschinelles Lernen.
Workflow erstellen
Um einen neuen Workflow zu erstellen, wählen Sie die folgende Menüoption in der KNIME-Workbench.
File → NewSie sehen den folgenden Bildschirm -

Wähle aus New KNIME Workflow Option und klicken Sie auf die NextTaste. Im nächsten Bildschirm werden Sie nach dem gewünschten Namen für den Workflow und dem Zielordner zum Speichern gefragt. Geben Sie diese Informationen wie gewünscht ein und klicken Sie aufFinish um einen neuen Arbeitsbereich zu erstellen.
Ein neuer Arbeitsbereich mit dem angegebenen Namen wird dem hinzugefügt Workspace Ansicht wie hier gesehen -
Sie fügen nun die verschiedenen Knoten in diesem Arbeitsbereich hinzu, um Ihr Modell zu erstellen. Bevor Sie Knoten hinzufügen, müssen Sie die herunterladen und vorbereiteniris Datensatz für unsere Verwendung.
Datensatz vorbereiten
Laden Sie den Iris-Datensatz von der UCI Machine Learning Repository-Site herunter . Laden Sie den Iris-Datensatz herunter . Die heruntergeladene Datei iris.data liegt im CSV-Format vor. Wir werden einige Änderungen daran vornehmen, um die Spaltennamen hinzuzufügen.
Öffnen Sie die heruntergeladene Datei in Ihrem bevorzugten Texteditor und fügen Sie am Anfang die folgende Zeile hinzu.
sepal length, petal length, sepal width, petal width, classWenn unsere File Reader Der Knoten liest diese Datei und verwendet automatisch die obigen Felder als Spaltennamen.
Nun werden Sie verschiedene Knoten hinzufügen.
Dateireader hinzufügen
Gehe zum Node Repository Geben Sie "Datei" in das Suchfeld ein, um die zu finden File ReaderKnoten. Dies ist im folgenden Screenshot zu sehen -

Wählen Sie und doppelklicken Sie auf File Readerum den Knoten zum Arbeitsbereich hinzuzufügen. Alternativ können Sie die Drag & Drop-Funktion verwenden, um den Knoten zum Arbeitsbereich hinzuzufügen. Nachdem der Knoten hinzugefügt wurde, müssen Sie ihn konfigurieren. Klicken Sie mit der rechten Maustaste auf den Knoten und wählen Sie die ausConfigureMenüoption. Sie haben dies in der vorherigen Lektion getan.
Der Einstellungsbildschirm sieht nach dem Laden der Datendatei folgendermaßen aus.

Um Ihren Datensatz zu laden, klicken Sie auf BrowseKlicken Sie auf die Schaltfläche und wählen Sie den Speicherort Ihrer iris.data-Datei aus. Der Knoten lädt den Inhalt der Datei, der im unteren Bereich des Konfigurationsfelds angezeigt wird. Wenn Sie zufrieden sind, dass die Datendatei ordnungsgemäß gefunden und geladen wurde, klicken Sie aufOK Schaltfläche, um den Konfigurationsdialog zu schließen.
Sie werden diesem Knoten nun einige Anmerkungen hinzufügen. Klicken Sie mit der rechten Maustaste auf den Knoten und wählen SieNew Workflow AnnotationMenüoption. Auf dem Bildschirm wird ein Anmerkungsfeld angezeigt, wie im folgenden Screenshot gezeigt:
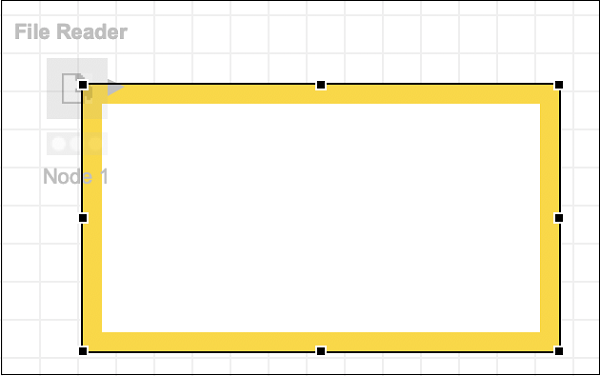
Klicken Sie in das Feld und fügen Sie die folgende Anmerkung hinzu:
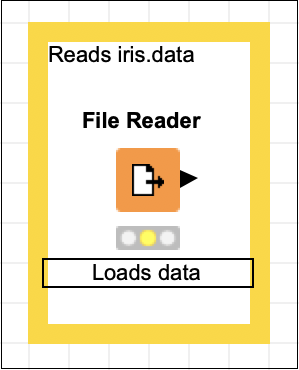
Reads iris.dataKlicken Sie auf eine beliebige Stelle außerhalb des Felds, um den Bearbeitungsmodus zu verlassen. Ändern Sie die Größe und platzieren Sie die Box wie gewünscht um den Knoten. Zum Schluss doppelklicken Sie aufNode 1 Text unter dem Knoten, um diese Zeichenfolge wie folgt zu ändern:
Loads dataZu diesem Zeitpunkt würde Ihr Bildschirm wie folgt aussehen:
Wir werden jetzt einen neuen Knoten hinzufügen, um unser geladenes Dataset in Training und Test zu unterteilen.
Partitionierungsknoten hinzufügen
In dem Node Repository Geben Sie im Suchfenster einige Zeichen ein, um das zu finden Partitioning Knoten, wie im Screenshot unten zu sehen -
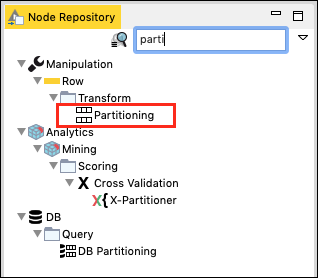
Fügen Sie den Knoten zu unserem Arbeitsbereich hinzu. Stellen Sie die Konfiguration wie folgt ein:
Relative (%) : 95
Draw RandomlyDer folgende Screenshot zeigt die Konfigurationsparameter.

Stellen Sie als Nächstes die Verbindung zwischen den beiden Knoten her. Klicken Sie dazu auf die Ausgabe desFile Reader Knoten, halten Sie die Maustaste gedrückt, eine Gummibandlinie würde erscheinen, ziehen Sie es auf die Eingabe von PartitioningKnoten, lassen Sie die Maustaste los. Es wird nun eine Verbindung zwischen den beiden Knoten hergestellt.
Fügen Sie die Anmerkung hinzu, ändern Sie die Beschreibung, positionieren Sie den Knoten und die Anmerkungsansicht wie gewünscht. Ihr Bildschirm sollte zu diesem Zeitpunkt wie folgt aussehen:

Als nächstes werden wir die hinzufügen k-Means Knoten.
Hinzufügen eines k-Means-Knotens
Wähle aus k-MeansKnoten aus dem Repository und fügen Sie es dem Arbeitsbereich hinzu. Wenn Sie Ihr Wissen über den k-Means-Algorithmus auffrischen möchten, schlagen Sie einfach seine Beschreibung in der Beschreibungsansicht der Workbench nach. Dies wird im folgenden Screenshot gezeigt -

Im Übrigen können Sie die Beschreibung verschiedener Algorithmen im Beschreibungsfenster nachschlagen, bevor Sie eine endgültige Entscheidung treffen, welche verwendet werden sollen.
Öffnen Sie den Konfigurationsdialog für den Knoten. Wir werden die Standardeinstellungen für alle Felder verwenden, wie hier gezeigt -

Klicken OK um die Standardeinstellungen zu übernehmen und den Dialog zu schließen.
Stellen Sie die Anmerkung und Beschreibung auf Folgendes ein:
Anmerkung: Klassifizieren Sie Cluster
Beschreibung: Führen Sie das Clustering durch
Verbinden Sie den oberen Ausgang des Partitioning Knoten zur Eingabe von k-MeansKnoten. Positionieren Sie Ihre Artikel neu und Ihr Bildschirm sollte wie folgt aussehen:

Als nächstes werden wir eine hinzufügen Cluster Assigner Knoten.
Cluster Assigner hinzufügen
Das Cluster Assignerweist einem vorhandenen Satz von Prototypen neue Daten zu. Es sind zwei Eingaben erforderlich - das Prototypmodell und die Datentabelle, die die Eingabedaten enthält. Schlagen Sie die Beschreibung des Knotens im Beschreibungsfenster nach, das im folgenden Screenshot dargestellt ist.

Für diesen Knoten müssen Sie also zwei Verbindungen herstellen -
Die Ausgabe des PMML-Cluster-Modells von Partitioning Knoten → Prototypen Eingabe von Cluster Assigner
Zweite Partitionsausgabe von Partitioning Knoten → Eingabedaten von Cluster Assigner
Diese beiden Verbindungen sind im folgenden Screenshot dargestellt -

Das Cluster Assignerbenötigt keine spezielle Konfiguration. Akzeptieren Sie einfach die Standardeinstellungen.
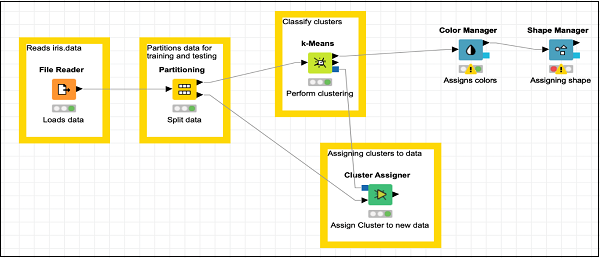
Fügen Sie diesem Knoten nun einige Anmerkungen und Beschreibungen hinzu. Ordnen Sie Ihre Knoten neu an. Ihr Bildschirm sollte wie folgt aussehen:

Zu diesem Zeitpunkt ist unser Clustering abgeschlossen. Wir müssen die Ausgabe grafisch visualisieren. Dazu fügen wir ein Streudiagramm hinzu. Wir werden die Farben und Formen für drei Klassen im Streudiagramm unterschiedlich einstellen. Daher werden wir die Ausgabe von filternk-Means Knoten zuerst durch die Color Manager Knoten und dann durch Shape Manager Knoten.
Farbmanager hinzufügen
Suchen Sie die Color ManagerKnoten im Repository. Fügen Sie es dem Arbeitsbereich hinzu. Übernehmen Sie die Standardeinstellungen der Konfiguration. Beachten Sie, dass Sie den Konfigurationsdialog öffnen und drücken müssenOKdie Standardeinstellungen zu akzeptieren. Legen Sie den Beschreibungstext für den Knoten fest.
Stellen Sie eine Verbindung vom Ausgang von her k-Means zum Eingang von Color Manager. Ihr Bildschirm würde zu diesem Zeitpunkt wie folgt aussehen:

Shape Manager hinzufügen
Suchen Sie die Shape Managerim Repository und fügen Sie es dem Arbeitsbereich hinzu. Überlassen Sie die Konfiguration den Standardeinstellungen. Wie beim vorherigen müssen Sie den Konfigurationsdialog öffnen und drückenOKStandardeinstellungen festlegen. Stellen Sie die Verbindung vom Ausgang von herColor Manager zum Eingang von Shape Manager. Legen Sie die Beschreibung für den Knoten fest.
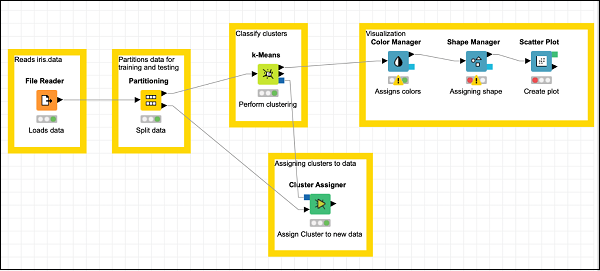
Ihr Bildschirm sollte wie folgt aussehen:
Jetzt fügen Sie den letzten Knoten in unserem Modell hinzu, und das ist das Streudiagramm.
Streudiagramm hinzufügen
Lokalisieren Scatter PlotKnoten im Repository und fügen Sie es dem Arbeitsbereich hinzu. Verbinden Sie den Ausgang vonShape Manager zum Eingang von Scatter Plot. Übernehmen Sie die Standardeinstellungen für die Konfiguration. Stellen Sie die Beschreibung ein.
Fügen Sie abschließend den kürzlich hinzugefügten drei Knoten eine Gruppenanmerkung hinzu
Anmerkung: Visualisierung
Positionieren Sie die Knoten wie gewünscht neu. Ihr Bildschirm sollte zu diesem Zeitpunkt wie folgt aussehen.
Damit ist die Aufgabe des Modellbaus abgeschlossen.