Objektorientiertes Python - Objektserialisierung
Bei der Datenspeicherung handelt es sich bei der Serialisierung um die Übersetzung von Datenstrukturen oder Objektzuständen in ein Format, das gespeichert (z. B. in einer Datei oder einem Speicherpuffer) oder später übertragen und rekonstruiert werden kann.
Bei der Serialisierung wird ein Objekt in ein Format umgewandelt, das gespeichert werden kann, um es später deserialisieren und das ursprüngliche Objekt aus dem serialisierten Format neu erstellen zu können.
Essiggurke
Beizen ist der Prozess, bei dem eine Python-Objekthierarchie in einen Byte-Stream (normalerweise nicht lesbar) konvertiert wird, um in eine Datei geschrieben zu werden. Dies wird auch als Serialisierung bezeichnet. Das Aufheben der Auswahl ist die umgekehrte Operation, bei der ein Bytestream wieder in eine funktionierende Python-Objekthierarchie konvertiert wird.
Pickle ist die einfachste Methode zum Speichern des Objekts. Das Python Pickle-Modul ist eine objektorientierte Methode zum direkten Speichern von Objekten in einem speziellen Speicherformat.
Was kann ich tun?
- Pickle kann Wörterbücher und Listen sehr einfach speichern und reproduzieren.
- Speichert Objektattribute und stellt sie in demselben Status wieder her.
Was kann Gurke nicht?
- Es wird kein Objektcode gespeichert. Nur die Attributwerte.
- Es können keine Dateihandles oder Verbindungssockets gespeichert werden.
Kurz gesagt, Beizen ist eine Möglichkeit, Datenvariablen in Dateien zu speichern und abzurufen, aus denen Variablen Listen, Klassen usw. sein können.
Um etwas einzulegen, müssen Sie -
- Gurke importieren
- Schreiben Sie eine Variable in eine Datei, so etwas wie
pickle.dump(mystring, outfile, protocol),wobei das 3. Argumentprotokoll optional ist Um etwas zu entfernen, müssen Sie -
Gurke importieren
Schreiben Sie eine Variable in eine Datei, so etwas wie
myString = pickle.load(inputfile)Methoden
Die Pickle-Schnittstelle bietet vier verschiedene Methoden.
dump() - Die dump () -Methode wird in eine geöffnete Datei (dateiähnliches Objekt) serialisiert.
dumps() - Serialisiert zu einem String
load() - Deserialisiert von einem offenen Objekt.
loads() - Deserialisiert aus einer Zeichenfolge.
Basierend auf dem obigen Verfahren finden Sie unten ein Beispiel für das „Beizen“.
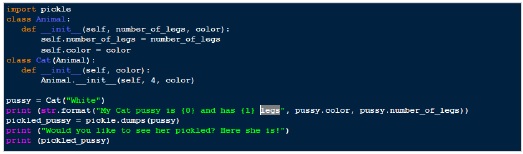
Ausgabe
My Cat pussy is White and has 4 legs
Would you like to see her pickled? Here she is!
b'\x80\x03c__main__\nCat\nq\x00)\x81q\x01}q\x02(X\x0e\x00\x00\x00number_of_legsq\x03K\x04X\x05\x00\x00\x00colorq\x04X\x05\x00\x00\x00Whiteq\x05ub.'Im obigen Beispiel haben wir eine Instanz einer Cat-Klasse erstellt und diese dann ausgewählt und unsere „Cat“ -Instanz in ein einfaches Array von Bytes umgewandelt.
Auf diese Weise können wir das Byte-Array einfach in einer Binärdatei oder in einem Datenbankfeld speichern und es zu einem späteren Zeitpunkt von unserer Speicherunterstützung wieder in seine ursprüngliche Form zurückversetzen.
Wenn Sie eine Datei mit einem eingelegten Objekt erstellen möchten, können Sie die dump () -Methode (anstelle der dumps * () * one) verwenden, die auch eine geöffnete Binärdatei übergibt, und das Beizergebnis wird automatisch in der Datei gespeichert.
[….]
binary_file = open(my_pickled_Pussy.bin', mode='wb')
my_pickled_Pussy = pickle.dump(Pussy, binary_file)
binary_file.close()Unpickling
Der Prozess, bei dem ein binäres Array in eine Objekthierarchie konvertiert wird, wird als Aufheben der Auswahl bezeichnet.
Der Aufhebungsprozess wird mithilfe der Funktion load () des Pickle-Moduls durchgeführt und gibt eine vollständige Objekthierarchie aus einem einfachen Byte-Array zurück.
Verwenden wir die Ladefunktion in unserem vorherigen Beispiel.
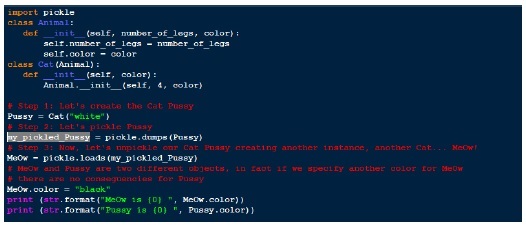
Ausgabe
MeOw is black
Pussy is whiteJSON
JSON (JavaScript Object Notation) war Teil der Python-Standardbibliothek, einem kompakten Datenaustauschformat. Menschen können leicht lesen und schreiben. Es ist einfach zu analysieren und zu generieren.
Aufgrund seiner Einfachheit ist JSON eine Methode zum Speichern und Austauschen von Daten, die über die JSON-Syntax erfolgt und in vielen Webanwendungen verwendet wird. Da es in einem für Menschen lesbaren Format vorliegt, kann dies neben seiner Effektivität bei der Arbeit mit APIs einer der Gründe für die Verwendung bei der Datenübertragung sein.
Ein Beispiel für JSON-formatierte Daten lautet wie folgt:
{"EmployID": 40203, "Name": "Zack", "Age":54, "isEmployed": True}Python macht es einfach, mit Json-Dateien zu arbeiten. Das dafür vorgesehene Modul ist das JSON-Modul. Dieses Modul sollte in Ihrer Python-Installation enthalten (integriert) sein.
Lassen Sie uns sehen, wie wir das Python-Wörterbuch in JSON konvertieren und in eine Textdatei schreiben können.
JSON zu Python
Das Lesen von JSON bedeutet das Konvertieren von JSON in einen Python-Wert (Objekt). Die json-Bibliothek analysiert JSON in ein Wörterbuch oder eine Liste in Python. Zu diesem Zweck verwenden wir die Funktion load () (Laden aus einer Zeichenfolge) wie folgt:

Ausgabe

Unten finden Sie eine Beispiel-JSON-Datei.
data1.json
{"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}}Der obige Inhalt (Data1.json) sieht aus wie ein herkömmliches Wörterbuch. Wir können pickle verwenden, um diese Datei zu speichern, aber die Ausgabe ist nicht von Menschen lesbar.
JSON (Java Script Object Notification) ist ein sehr einfaches Format und dies ist einer der Gründe für seine Beliebtheit. Schauen wir uns nun die json-Ausgabe über das folgende Programm an.
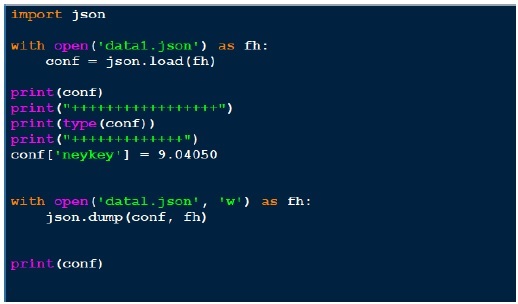
Ausgabe
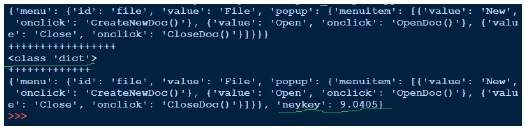
Oben öffnen wir die json-Datei (data1.json) zum Lesen, holen den Datei-Handler und übergeben sie an json.load und holen das Objekt zurück. Wenn wir versuchen, die Ausgabe des Objekts zu drucken, entspricht dies der JSON-Datei. Obwohl der Typ des Objekts ein Wörterbuch ist, wird es als Python-Objekt ausgegeben. Das Schreiben an den Json ist einfach, da wir diese Gurke gesehen haben. Oben laden wir die JSON-Datei, fügen ein weiteres Schlüsselwertpaar hinzu und schreiben es in dieselbe JSON-Datei zurück. Wenn wir nun data1.json sehen, sieht es anders aus .ie nicht im gleichen Format wie zuvor.
Fügen Sie die paar Argumente in unsere letzte Zeile des Programms ein, damit unsere Ausgabe gleich aussieht (lesbares Format).
json.dump(conf, fh, indent = 4, separators = (‘,’, ‘: ‘))Ähnlich wie bei pickle können wir den String mit Dumps drucken und mit Loads laden. Unten ist ein Beispiel dafür,
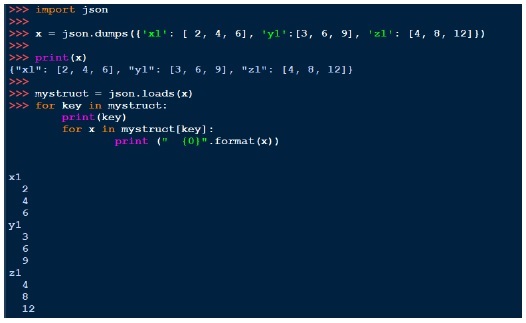
YAML
YAML ist möglicherweise der benutzerfreundlichste Standard für die Serialisierung von Daten für alle Programmiersprachen.
Das Python-Yaml-Modul heißt Pyaml
YAML ist eine Alternative zu JSON -
Human readable code - YAML ist das am besten lesbare Format, so dass sogar der Inhalt der Titelseite in YAML angezeigt wird, um dies zu verdeutlichen.
Compact code - In YAML verwenden wir Leerzeicheneinrückungen, um Strukturen und keine Klammern zu kennzeichnen.
Syntax for relational data - Für interne Referenzen verwenden wir Anker (&) und Aliase (*).
One of the area where it is used widely is for viewing/editing of data structures - Zum Beispiel Konfigurationsdateien, Dumping beim Debuggen und Dokumentenkopfzeilen.
YAML installieren
Da yaml kein eingebautes Modul ist, müssen wir es manuell installieren. Der beste Weg, um Yaml auf einem Windows-Computer zu installieren, ist über Pip. Führen Sie den folgenden Befehl auf Ihrem Windows-Terminal aus, um yaml zu installieren.
pip install pyaml (Windows machine)
sudo pip install pyaml (*nix and Mac)Wenn Sie den obigen Befehl ausführen, wird auf dem Bildschirm Folgendes angezeigt, basierend auf der aktuellen Version.
Collecting pyaml
Using cached pyaml-17.12.1-py2.py3-none-any.whl
Collecting PyYAML (from pyaml)
Using cached PyYAML-3.12.tar.gz
Installing collected packages: PyYAML, pyaml
Running setup.py install for PyYAML ... done
Successfully installed PyYAML-3.12 pyaml-17.12.1Um es zu testen, gehen Sie zur Python-Shell und importieren Sie das yaml-Modul. Importieren Sie yaml. Wenn kein Fehler gefunden wird, können wir sagen, dass die Installation erfolgreich ist.
Schauen wir uns nach der Installation von pyaml den folgenden Code an:
script_yaml1.py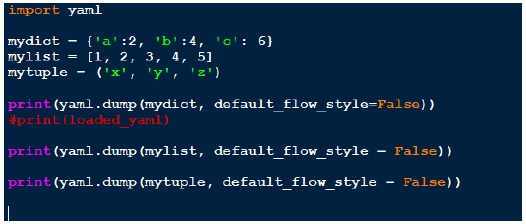
Oben haben wir drei verschiedene Datenstrukturen erstellt: Wörterbuch, Liste und Tupel. Auf jeder Struktur machen wir yaml.dump. Wichtig ist, wie die Ausgabe auf dem Bildschirm angezeigt wird.
Ausgabe
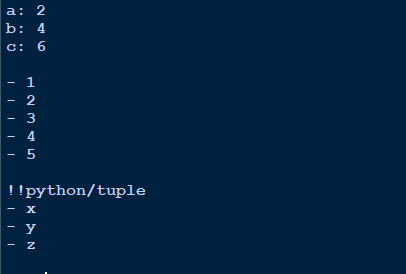
Die Wörterbuchausgabe sieht sauber aus .ie. Schlüsselwert.
Leerraum zum Trennen verschiedener Objekte.
Liste wird mit Bindestrich (-) notiert
Tupel wird zuerst mit !! Python / Tupel und dann im gleichen Format wie Listen angezeigt.
Laden einer Yaml-Datei
Nehmen wir also an, ich habe eine Yaml-Datei, die Folgendes enthält:
---
# An employee record
name: Raagvendra Joshi
job: Developer
skill: Oracle
employed: True
foods:
- Apple
- Orange
- Strawberry
- Mango
languages:
Oracle: Elite
power_builder: Elite
Full Stack Developer: Lame
education:
4 GCSEs
3 A-Levels
MCA in something called comSchreiben wir nun einen Code zum Laden dieser yaml-Datei über die Funktion yaml.load. Unten ist Code für das gleiche.
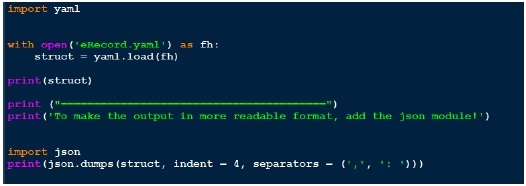
Da die Ausgabe nicht so gut lesbar aussieht, verschönere ich sie am Ende mit json. Vergleichen Sie die Ausgabe, die wir erhalten haben, und die tatsächliche Yaml-Datei, die wir haben.
Ausgabe

Einer der wichtigsten Aspekte der Softwareentwicklung ist das Debuggen. In diesem Abschnitt werden verschiedene Möglichkeiten des Python-Debuggens entweder mit integriertem Debugger oder mit Debuggern von Drittanbietern beschrieben.
PDB - Der Python-Debugger
Das Modul PDB unterstützt das Setzen von Haltepunkten. Ein Haltepunkt ist eine absichtliche Pause des Programms, in der Sie weitere Informationen zum Programmstatus erhalten.
Fügen Sie die Linie ein, um einen Haltepunkt festzulegen
pdb.set_trace()Beispiel
pdb_example1.py
import pdb
x = 9
y = 7
pdb.set_trace()
total = x + y
pdb.set_trace()Wir haben einige Haltepunkte in dieses Programm eingefügt. Das Programm wird an jedem Haltepunkt angehalten (pdb.set_trace ()). Um den Inhalt einer Variablen anzuzeigen, geben Sie einfach den Variablennamen ein.
c:\Python\Python361>Python pdb_example1.py
> c:\Python\Python361\pdb_example1.py(8)<module>()
-> total = x + y
(Pdb) x
9
(Pdb) y
7
(Pdb) total
*** NameError: name 'total' is not defined
(Pdb)Drücken Sie c oder fahren Sie mit der Programmausführung bis zum nächsten Haltepunkt fort.
(Pdb) c
--Return--
> c:\Python\Python361\pdb_example1.py(8)<module>()->None
-> total = x + y
(Pdb) total
16Schließlich müssen Sie viel größere Programme debuggen - Programme, die Unterprogramme verwenden. Und manchmal liegt das Problem, das Sie suchen, in einer Unterroutine. Betrachten Sie das folgende Programm.
import pdb
def squar(x, y):
out_squared = x^2 + y^2
return out_squared
if __name__ == "__main__":
#pdb.set_trace()
print (squar(4, 5))Wenn Sie nun das obige Programm ausführen,
c:\Python\Python361>Python pdb_example2.py
> c:\Python\Python361\pdb_example2.py(10)<module>()
-> print (squar(4, 5))
(Pdb)Wir können benutzen ?um Hilfe zu erhalten, aber der Pfeil zeigt die Zeile an, die ausgeführt werden soll. An dieser Stelle ist es hilfreich, s zu drückens in diese Linie treten.
(Pdb) s
--Call--
>c:\Python\Python361\pdb_example2.py(3)squar()
-> def squar(x, y):Dies ist ein Aufruf einer Funktion. Wenn Sie einen Überblick darüber erhalten möchten, wo Sie sich in Ihrem Code befinden, versuchen Sie l -
(Pdb) l
1 import pdb
2
3 def squar(x, y):
4 -> out_squared = x^2 + y^2
5
6 return out_squared
7
8 if __name__ == "__main__":
9 pdb.set_trace()
10 print (squar(4, 5))
[EOF]
(Pdb)Sie können n drücken, um zur nächsten Zeile zu gelangen. Zu diesem Zeitpunkt befinden Sie sich in der Methode out_squared und haben Zugriff auf die Variable, die in der Funktion .ie x und y deklariert ist.
(Pdb) x
4
(Pdb) y
5
(Pdb) x^2
6
(Pdb) y^2
7
(Pdb) x**2
16
(Pdb) y**2
25
(Pdb)Wir können also sehen, dass der Operator ^ nicht das ist, was wir wollten, stattdessen müssen wir den Operator ** verwenden, um Quadrate zu erstellen.
Auf diese Weise können wir unser Programm innerhalb der Funktionen / Methoden debuggen.
Protokollierung
Das Protokollierungsmodul ist seit Python Version 2.3 Teil der Python Standard Library. Da es sich um ein integriertes Modul handelt, können alle Python-Module an der Protokollierung teilnehmen, sodass unser Anwendungsprotokoll Ihre eigene Nachricht enthalten kann, die in Nachrichten vom Modul eines Drittanbieters integriert ist. Es bietet viel Flexibilität und Funktionalität.
Vorteile der Protokollierung
Diagnostic logging - Es zeichnet Ereignisse auf, die sich auf den Betrieb der Anwendung beziehen.
Audit logging - Es zeichnet Ereignisse für die Geschäftsanalyse auf.
Nachrichten werden mit den Schweregraden "Schweregrad" und "Minu" geschrieben und protokolliert
DEBUG (debug()) - Diagnosemeldungen für die Entwicklung.
INFO (info()) - Standard-Fortschrittsmeldungen.
WARNING (warning()) - ein nicht schwerwiegendes Problem festgestellt.
ERROR (error()) - ist auf einen möglicherweise schwerwiegenden Fehler gestoßen.
CRITICAL (critical()) - normalerweise ein schwerwiegender Fehler (Programm stoppt).
Schauen wir uns das folgende einfache Programm an:
import logging
logging.basicConfig(level=logging.INFO)
logging.debug('this message will be ignored') # This will not print
logging.info('This should be logged') # it'll print
logging.warning('And this, too') # It'll printOben protokollieren wir Nachrichten mit Schweregrad. Zuerst importieren wir das Modul, rufen basicConfig auf und legen die Protokollierungsstufe fest. Das oben festgelegte Level ist INFO. Dann haben wir drei verschiedene Anweisungen: Debug-Anweisung, Info-Anweisung und eine Warnanweisung.
Ausgabe von logging1.py
INFO:root:This should be logged
WARNING:root:And this, tooDa sich die Info-Anweisung unter der Debug-Anweisung befindet, kann die Debug-Meldung nicht angezeigt werden. Um die Debug-Anweisung auch im Output-Terminal zu erhalten, müssen wir lediglich die basicConfig-Ebene ändern.
logging.basicConfig(level = logging.DEBUG)Und in der Ausgabe können wir sehen,
DEBUG:root:this message will be ignored
INFO:root:This should be logged
WARNING:root:And this, tooDas Standardverhalten bedeutet auch, dass eine Warnung angezeigt wird, wenn keine Protokollierungsstufe festgelegt wird. Kommentieren Sie einfach die zweite Zeile des obigen Programms aus und führen Sie den Code aus.
#logging.basicConfig(level = logging.DEBUG)Ausgabe
WARNING:root:And this, tooIn Python integrierte Protokollierungsstufe sind tatsächlich Ganzzahlen.
>>> import logging
>>>
>>> logging.DEBUG
10
>>> logging.CRITICAL
50
>>> logging.WARNING
30
>>> logging.INFO
20
>>> logging.ERROR
40
>>>Wir können die Protokollnachrichten auch in der Datei speichern.
logging.basicConfig(level = logging.DEBUG, filename = 'logging.log')Jetzt werden alle Protokollnachrichten in die Datei (logging.log) in Ihrem aktuellen Arbeitsverzeichnis anstatt in den Bildschirm verschoben. Dies ist ein viel besserer Ansatz, da wir die Nachrichten, die wir erhalten haben, nachträglich analysieren können.
Wir können den Datumsstempel auch mit unserer Protokollnachricht festlegen.
logging.basicConfig(level=logging.DEBUG, format = '%(asctime)s %(levelname)s:%(message)s')Ausgabe wird so etwas wie bekommen,
2018-03-08 19:30:00,066 DEBUG:this message will be ignored
2018-03-08 19:30:00,176 INFO:This should be logged
2018-03-08 19:30:00,201 WARNING:And this, tooBenchmarking
Beim Benchmarking oder Profiling wird im Wesentlichen getestet, wie schnell Ihr Code ausgeführt wird und wo die Engpässe liegen. Der Hauptgrund dafür ist die Optimierung.
timeit
Python wird mit einem integrierten Modul namens timeit geliefert. Sie können damit kleine Codefragmente zeitlich festlegen. Das timeit-Modul verwendet plattformspezifische Zeitfunktionen, damit Sie möglichst genaue Timings erhalten.
Auf diese Weise können wir zwei von jedem erbeutete Codesendungen vergleichen und dann die Skripte optimieren, um eine bessere Leistung zu erzielen.
Das timeit-Modul verfügt über eine Befehlszeilenschnittstelle, kann aber auch importiert werden.
Es gibt zwei Möglichkeiten, ein Skript aufzurufen. Verwenden wir zuerst das Skript. Führen Sie dazu den folgenden Code aus und sehen Sie sich die Ausgabe an.
import timeit
print ( 'by index: ', timeit.timeit(stmt = "mydict['c']", setup = "mydict = {'a':5, 'b':10, 'c':15}", number = 1000000))
print ( 'by get: ', timeit.timeit(stmt = 'mydict.get("c")', setup = 'mydict = {"a":5, "b":10, "c":15}', number = 1000000))Ausgabe
by index: 0.1809192126703489
by get: 0.6088525265034692Oben verwenden wir zwei verschiedene Methoden .ie per Index und greifen auf den Wörterbuchschlüsselwert zu. Wir führen die Anweisung 1 Million Mal aus, da sie für sehr kleine Daten zu schnell ausgeführt wird. Jetzt können wir den Indexzugriff im Vergleich zum get viel schneller sehen. Wir können den Code mehrfach ausführen und es wird geringfügige Abweichungen in der Zeitausführung geben, um ein besseres Verständnis zu erhalten.
Eine andere Möglichkeit besteht darin, den obigen Test in der Befehlszeile auszuführen. Machen wir das,
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict['c']"
1000000 loops, best of 3: 0.187 usec per loop
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict.get('c')"
1000000 loops, best of 3: 0.659 usec per loopDie oben genannten Ausgaben können je nach Systemhardware und der aktuellen Ausführung aller Anwendungen auf Ihrem System variieren.
Im Folgenden können wir das timeit-Modul verwenden, wenn wir eine Funktion aufrufen möchten. Da wir innerhalb der zu testenden Funktion mehrere Anweisungen hinzufügen können.
import timeit
def testme(this_dict, key):
return this_dict[key]
print (timeit.timeit("testme(mydict, key)", setup = "from __main__ import testme; mydict = {'a':9, 'b':18, 'c':27}; key = 'c'", number = 1000000))Ausgabe
0.7713474590139164