Plotly - Histogramm
Ein von Karl Pearson eingeführtes Histogramm ist eine genaue Darstellung der Verteilung numerischer Daten, die eine Schätzung der Wahrscheinlichkeitsverteilung einer kontinuierlichen Variablen (CORAL) darstellt. Es sieht ähnlich aus wie ein Balkendiagramm, aber ein Balkendiagramm bezieht zwei Variablen, während ein Histogramm nur eine bezieht.
Ein Histogramm erfordert bin (oder bucket), der den gesamten Wertebereich in eine Reihe von Intervallen unterteilt - und dann zählt, wie viele Werte in jedes Intervall fallen. Die Bins werden normalerweise als aufeinanderfolgende, nicht überlappende Intervalle einer Variablen angegeben. Die Behälter müssen benachbart sein und sind oft gleich groß. Über dem Behälter wird ein Rechteck mit einer Höhe erstellt, die proportional zur Häufigkeit ist - der Anzahl der Fälle in jedem Behälter.
Das Histogramm-Trace-Objekt wird von zurückgegeben go.Histogram()Funktion. Die Anpassung erfolgt durch verschiedene Argumente oder Attribute. Ein wesentliches Argument ist, dass x oder y auf eine Liste gesetzt werden.numpy array oder Pandas dataframe object welches in Behältern verteilt werden soll.
Standardmäßig verteilt Plotly die Datenpunkte in automatisch dimensionierten Behältern. Sie können jedoch eine benutzerdefinierte Behältergröße definieren. Geben Sie dazu autobins auf false annbins (Anzahl der Fächer), Start- und Endwerte sowie Größe.
Der folgende Code generiert ein einfaches Histogramm, das die Verteilung der Noten von Schülern in einem Klasseneingang zeigt (Größe automatisch) -
import numpy as np
x1 = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27])
data = [go.Histogram(x = x1)]
fig = go.Figure(data)
iplot(fig)Die Ausgabe ist wie unten gezeigt -

Das go.Histogram() Funktion akzeptiert histnorm, der die Art der Normalisierung angibt, die für diese Histogrammspur verwendet wird. Die Standardeinstellung ist "". Die Spanne jedes Balkens entspricht der Anzahl der Vorkommen (dh der Anzahl der Datenpunkte, die in den Behältern liegen). Wenn zugewiesen"percent" / "probability"Die Spanne jedes Balkens entspricht dem Prozentsatz / Bruchteil der Vorkommen in Bezug auf die Gesamtzahl der Stichprobenpunkte. Wenn es gleich "density"entspricht die Spanne jedes Balkens der Anzahl der Vorkommen in einem Bin geteilt durch die Größe des Bin-Intervalls.
Es gibt auch histfunc Parameter, dessen Standardwert ist count. Infolgedessen entspricht die Höhe des Rechtecks über einem Bin der Anzahl der Datenpunkte. Es kann auf Summe, Durchschnitt, Min oder Max eingestellt werden.
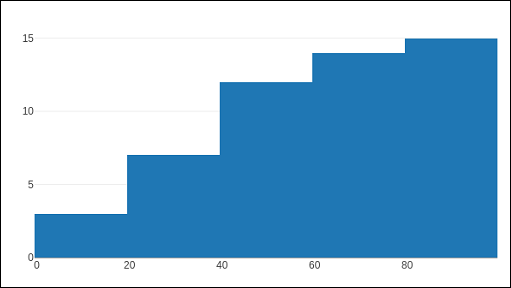
Das histogram()Die Funktion kann so eingestellt werden, dass die kumulative Verteilung der Werte in aufeinanderfolgenden Bins angezeigt wird. Dafür müssen Sie einstellencumulative propertyaktiviert. Ergebnis kann wie folgt gesehen werden -
data=[go.Histogram(x = x1, cumulative_enabled = True)]
fig = go.Figure(data)
iplot(fig)Die Ausgabe ist wie unten erwähnt -