SAP BODS - Kurzanleitung
Ein Data Warehouse wird als zentrales Repository bezeichnet, in dem Daten aus einer oder mehreren heterogenen Datenquellen gespeichert werden. Data Warehouse wird zum Berichten und Analysieren von Informationen verwendet und speichert sowohl historische als auch aktuelle Daten. Die Daten im DW-System werden für analytische Berichte verwendet, die später von Geschäftsanalysten, Vertriebsmanagern oder Wissensarbeitern zur Entscheidungsfindung verwendet werden.
Die Daten im DW-System werden aus einem betrieblichen Transaktionssystem wie Vertrieb, Marketing, Personalwesen, SCM usw. geladen. Sie können den betrieblichen Datenspeicher oder andere Transformationen durchlaufen, bevor sie zur Informationsverarbeitung in das DW-System geladen werden.
Data Warehouse - Hauptmerkmale
Die Hauptmerkmale eines DW-Systems sind:
Es ist ein zentrales Datenrepository, in dem Daten aus einer oder mehreren heterogenen Datenquellen gespeichert werden.
Ein DW-System speichert sowohl aktuelle als auch historische Daten. Normalerweise speichert ein DW-System 5-10 Jahre historische Daten.
Ein DW-System wird immer von einem betrieblichen Transaktionssystem getrennt gehalten.
Die Daten im DW-System werden für verschiedene Arten der analytischen Berichterstattung verwendet, die vom vierteljährlichen bis zum jährlichen Vergleich reichen.
Notwendigkeit eines DW-Systems
Angenommen, Sie haben eine Wohnungsbaudarlehensagentur, bei der Daten aus verschiedenen Anwendungen wie Marketing, Vertrieb, ERP, HRM, MM usw. stammen. Diese Daten werden extrahiert, transformiert und in Data Warehouse geladen.
Wenn Sie beispielsweise den vierteljährlichen / jährlichen Umsatz eines Produkts vergleichen müssen, können Sie keine operative Transaktionsdatenbank verwenden, da dies das Transaktionssystem hängen lässt. Daher wird zu diesem Zweck ein Data Warehouse verwendet.
Unterschied zwischen DW und ODB
Die Unterschiede zwischen einem Data Warehouse und einer Betriebsdatenbank (Transaktionsdatenbank) sind wie folgt:
Ein Transaktionssystem ist für bekannte Workloads und Transaktionen wie das Aktualisieren eines Benutzerdatensatzes, das Durchsuchen eines Datensatzes usw. ausgelegt. Data Warehouse-Transaktionen sind jedoch komplexer und stellen eine allgemeine Form von Daten dar.
Ein Transaktionssystem enthält die aktuellen Daten einer Organisation, und Data Warehouse enthält normalerweise die historischen Daten.
Das Transaktionssystem unterstützt die parallele Verarbeitung mehrerer Transaktionen. Parallelitätskontroll- und Wiederherstellungsmechanismen sind erforderlich, um die Konsistenz der Datenbank aufrechtzuerhalten.
Eine betriebliche Datenbankabfrage ermöglicht das Lesen und Ändern von Vorgängen (Löschen und Aktualisieren), während eine OLAP-Abfrage nur den schreibgeschützten Zugriff auf gespeicherte Daten benötigt (Select-Anweisung).
DW-Architektur
Data Warehousing umfasst Datenbereinigung, Datenintegration und Datenkonsolidierung.

Ein Data Warehouse verfügt über eine dreischichtige Architektur - Data Source Layer, Integration Layer, und Presentation Layer. Die obige Abbildung zeigt die allgemeine Architektur eines Data Warehouse-Systems.
Es gibt vier Arten von Data Warehousing-Systemen.
- Datenmarkt
- Online Analytical Processing (OLAP)
- Online-Transaktionsverarbeitung (OLTP)
- Predictive Analysis (PA)
Datenmarkt
Ein Data Mart ist als einfachste Form eines Data Warehouse-Systems bekannt und besteht normalerweise aus einem einzelnen Funktionsbereich in einer Organisation wie Vertrieb, Finanzen oder Marketing usw.
Data Mart in einer Organisation und wird von einer einzigen Abteilung erstellt und verwaltet. Da es zu einer einzelnen Abteilung gehört, erhält die Abteilung normalerweise nur Daten von wenigen oder einer Art von Quellen / Anwendungen. Diese Quelle kann ein internes Betriebssystem, ein Data Warehouse oder ein externes System sein.
Online-Analyseverarbeitung
In einem OLAP-System gibt es im Vergleich zu einem Transaktionssystem weniger Transaktionen. Die ausgeführten Abfragen sind komplexer Natur und umfassen Datenaggregationen.
Was ist eine Aggregation?
Wir speichern Tabellen mit aggregierten Daten wie jährlich (1 Zeile), vierteljährlich (4 Zeilen), monatlich (12 Zeilen) oder so. Wenn jemand einen Vergleich von Jahr zu Jahr durchführen muss, wird nur eine Zeile verarbeitet. In einer nicht aggregierten Tabelle werden jedoch alle Zeilen verglichen.
SELECT SUM(salary)
FROM employee
WHERE title = 'Programmer';Effektive Maßnahmen in einem OLAP-System
Die Reaktionszeit gilt als eine der effektivsten und wichtigsten Maßnahmen in einem OLAPSystem. Aggregierte gespeicherte Daten werden in mehrdimensionalen Schemata wie Sternschemata verwaltet (Wenn Daten in hierarchischen Gruppen angeordnet sind, die häufig als Dimensionen bezeichnet werden, sowie in Fakten und aggregierten Fakten, werden sie als Schemata bezeichnet).
Die Latenz eines OLAP-Systems beträgt einige Stunden im Vergleich zu den Data Marts, bei denen eine Latenz näher an einem Tag erwartet wird.
Online-Transaktionsverarbeitung
In einem OLTP-System gibt es eine große Anzahl kurzer Online-Transaktionen wie INSERT, UPDATE und DELETE.
In einem OLTP-System ist die Verarbeitungszeit für kurze Transaktionen eine effektive Maßnahme und sehr viel kürzer. Es steuert die Datenintegrität in Umgebungen mit mehreren Zugriffen. Bei einem OLTP-System misst die Anzahl der Transaktionen pro Sekunde dieeffectiveness. Ein OLTP-Data-Warehouse-System enthält aktuelle und detaillierte Daten und wird in den Schemas des Entitätsmodells (3NF) verwaltet.
Beispiel
Tägliches Transaktionssystem in einem Einzelhandelsgeschäft, in dem die Kundendatensätze täglich eingefügt, aktualisiert und gelöscht werden. Es bietet eine sehr schnelle Abfrageverarbeitung. OLTP-Datenbanken enthalten detaillierte und aktuelle Daten. Das zum Speichern der OLTP-Datenbank verwendete Schema ist das Entitätsmodell.
Unterschiede zwischen OLTP und OLAP
Die folgenden Abbildungen zeigen die wichtigsten Unterschiede zwischen einem OLTP und OLAP System.

Indexes - Das OLTP-System verfügt nur über wenige Indizes, während in einem OLAP-System viele Indizes zur Leistungsoptimierung vorhanden sind.
Joins- In einem OLTP-System wird eine große Anzahl von Verknüpfungen und Daten normalisiert. In einem OLAP-System gibt es jedoch weniger Verknüpfungen und sie werden nicht normalisiert.
Aggregation - In einem OLTP-System werden Daten nicht aggregiert, während in einer OLAP-Datenbank mehr Aggregationen verwendet werden.
Vorausschauende Analyse
Die prädiktive Analyse ist dafür bekannt, die verborgenen Muster in Daten zu finden, die im DW-System gespeichert sind, indem verschiedene mathematische Funktionen verwendet werden, um zukünftige Ergebnisse vorherzusagen.
Das Predictive Analysis-System unterscheidet sich in seiner Verwendung von einem OLAP-System. Es wird verwendet, um sich auf zukünftige Ergebnisse zu konzentrieren. Ein OALP-System konzentriert sich auf die aktuelle und historische Datenverarbeitung für die analytische Berichterstattung.
Auf dem Markt sind verschiedene Data Warehouse- / Datenbanksysteme erhältlich, die die Funktionen eines DW-Systems erfüllen. Die gängigsten Anbieter für Data Warehouse-Systeme sind -
- Microsoft SQL Server
- Oracle Exadata
- IBM Netezza
- Teradata
- Sybase IQ
- SAP Business Warehouse (SAP BW)
SAP Business Warehouse
SAP Business Warehouseist Teil der SAP NetWeaver Release-Plattform. Vor NetWeaver 7.4 wurde es als SAP NetWeaver Business Warehouse bezeichnet.
Data Warehousing im SAP BW bedeutet Datenintegration, -transformation, -bereinigung, -speicherung und -datenbereitstellung. Der DW-Prozess umfasst die Datenmodellierung im BW-System, die Bereitstellung und Verwaltung. Das Hauptwerkzeug, mit dem DW-Aufgaben im BW-System verwaltet werden, ist die Administrations-Workbench.
Hauptmerkmale
SAP BW bietet Funktionen wie Business Intelligence, darunter Analytical Services und Business Planning, Analytical Reporting, Abfrageverarbeitung und -informationen sowie Enterprise Data Warehousing.
Es bietet eine Kombination aus Datenbanken und Datenbankverwaltungstools, die bei der Entscheidungsfindung helfen.
Weitere wichtige Funktionen des BW-Systems sind das Business Application Programming Interface (BAPI), das die Verbindung zu Nicht-SAP-R / 3-Anwendungen unterstützt, das automatische Extrahieren und Laden von Daten, ein integrierter OLAP-Prozessor, ein Metadaten-Repository, Verwaltungstools, mehrsprachige Unterstützung und eine webfähige Schnittstelle.
SAP BW wurde erstmals 1998 von SAP, einem deutschen Unternehmen, eingeführt. Das SAP-BW-System basierte auf einem modellgetriebenen Ansatz, um Enterprise Data Warehouse für SAP-R3-Daten einfach, einfach und effizienter zu gestalten.
In den letzten 16 Jahren hat sich SAP BW für viele Unternehmen zu einem der wichtigsten Systeme für die Verwaltung ihrer Data Warehousing-Anforderungen entwickelt.
Der Business Explorer (BEx) bietet eine Option für flexible Berichterstattung, strategische Analyse und operative Berichterstattung im Unternehmen.
Es wird verwendet, um Berichts-, Abfrageausführungs- und Analysefunktionen im BI-System auszuführen. Sie können aktuelle und historische Daten auch über das Web und im Excel-Format bis zu verschiedenen Details verarbeiten.
Verwenden von BEx Information Broadcasting, BI-Inhalte können per E-Mail als Dokument oder in Form von Links als Live-Daten geteilt oder Sie können auch mit SAP EP-Funktionen veröffentlichen.
Geschäftsobjekte & Produkte
SAP Business Objects ist als das am häufigsten verwendete Business Intelligence-Tool bekannt und wird zum Bearbeiten von Daten, zum Benutzerzugriff, zum Analysieren, Formatieren und Veröffentlichen von Informationen auf verschiedenen Plattformen verwendet. Es handelt sich um ein Front-End-basiertes Toolset, mit dem Geschäftsbenutzer und Entscheidungsträger aktuelle und historische Business Intelligence-Daten anzeigen, sortieren und analysieren können.
Es besteht aus folgenden Tools:
Web Intelligence
Web Intelligence (WebI) wird als das am häufigsten verwendete detaillierte Berichtstool für Geschäftsobjekte bezeichnet, das verschiedene Funktionen der Datenanalyse wie Drill, Hierarchien, Diagramme, berechnete Kennzahlen usw. unterstützt. Es ermöglicht Endbenutzern, Ad-hoc-Abfragen im Abfragebereich und zu erstellen Datenanalyse sowohl online als auch offline durchzuführen.
SAP Business Objects Xcelsius / Dashboards
Dashboards bieten Endbenutzern Funktionen zur Datenvisualisierung und zum Dashboarding. Mit diesem Tool können Sie interaktive Dashboards erstellen.
Sie können auch verschiedene Arten von Diagrammen und Grafiken hinzufügen und dynamische Dashboards für Datenvisualisierungen erstellen. Diese werden hauptsächlich in Finanzbesprechungen in einer Organisation verwendet.
Crystal Reports
Crystal Reports werden für pixelgenaue Berichte verwendet. Auf diese Weise können Benutzer Berichte erstellen, entwerfen und später zum Drucken verwenden.
Forscher
Mit dem Explorer kann ein Benutzer den Inhalt im BI-Repository durchsuchen und die besten Übereinstimmungen werden in Form von Diagrammen angezeigt. Es ist nicht erforderlich, die Abfragen aufzuschreiben, um eine Suche durchzuführen.
Verschiedene andere Komponenten und Tools, die für detaillierte Berichte, Datenvisualisierung und Dashboarding-Zwecke eingeführt wurden, sind Design Studio, Analysis Edition für Microsoft Office, BI Repository und Business Objects Mobile.
ETL steht für Extrahieren, Transformieren und Laden. Ein ETL-Tool extrahiert die Daten aus verschiedenen RDBMS-Quellsystemen, transformiert die Daten wie das Anwenden von Berechnungen, Verketten usw. und lädt die Daten dann in das Data Warehouse-System. Die Daten werden in Form von Dimensions- und Faktentabellen in das DW-System geladen.
Extraktion
Während des ETL-Ladens ist ein Staging-Bereich erforderlich. Es gibt verschiedene Gründe, warum ein Bereitstellungsbereich erforderlich ist.
Die Quellsysteme stehen nur für einen bestimmten Zeitraum zum Extrahieren von Daten zur Verfügung. Dieser Zeitraum ist kürzer als die gesamte Ladezeit der Daten. Daher können Sie im Staging-Bereich die Daten aus dem Quellsystem extrahieren und im Staging-Bereich belassen, bevor das Zeitfenster endet.
Der Staging-Bereich ist erforderlich, wenn Sie die Daten aus mehreren Datenquellen zusammenrufen oder zwei oder mehr Systeme miteinander verbinden möchten. Beispielsweise können Sie keine SQL-Abfrage ausführen, bei der zwei Tabellen aus zwei physisch unterschiedlichen Datenbanken verknüpft werden.
Der Zeitschlitz für die Datenextraktion für verschiedene Systeme variiert je nach Zeitzone und Betriebsstunden.
Aus Quellsystemen extrahierte Daten können in mehreren Data Warehouse-Systemen, Betriebsdatenspeichern usw. verwendet werden.
Mit ETL können Sie komplexe Transformationen durchführen und benötigen zusätzlichen Bereich zum Speichern der Daten.

Verwandeln
Bei der Datentransformation wenden Sie eine Reihe von Funktionen auf extrahierte Daten an, um sie in das Zielsystem zu laden. Daten, für die keine Transformation erforderlich ist, werden als direktes Verschieben oder Durchlaufen von Daten bezeichnet.
Sie können verschiedene Transformationen auf extrahierte Daten aus dem Quellsystem anwenden. Sie können beispielsweise benutzerdefinierte Berechnungen durchführen. Wenn Sie eine Umsatzsumme wünschen und diese nicht in der Datenbank enthalten ist, können Sie dieSUM Formel während der Transformation und laden Sie die Daten.
Wenn Sie beispielsweise den Vor- und Nachnamen in einer Tabelle in verschiedenen Spalten haben, können Sie vor dem Laden die Verkettung verwenden.
Belastung
Während der Ladephase werden Daten in das Endzielsystem geladen und können eine flache Datei oder ein Data Warehouse-System sein.
SAP BO Data Services ist ein ETL-Tool für Datenintegration, Datenqualität, Datenprofilerstellung und Datenverarbeitung. Sie können damit vertrauenswürdige Data-to-Data-Warehouse-Systeme für analytische Berichte integrieren und transformieren.
BO Data Services besteht aus einer UI-Entwicklungsschnittstelle, einem Metadaten-Repository, einer Datenverbindung zum Quell- und Zielsystem sowie einer Verwaltungskonsole für die Planung von Jobs.
Datenintegration & Datenmanagement
SAP BO Data Services ist ein Tool zur Datenintegration und -verwaltung und besteht aus Data Integrator Job Server und Data Integrator Designer.
Hauptmerkmale
Sie können verschiedene Datentransformationen mithilfe der Data Integrator-Sprache anwenden, um komplexe Datentransformationen anzuwenden und benutzerdefinierte Funktionen zu erstellen.
Mit Data Integrator Designer werden Echtzeit- und Stapeljobs sowie neue Projekte im Repository gespeichert.
DI Designer bietet auch eine Option für die teambasierte ETL-Entwicklung, indem ein zentrales Repository mit allen grundlegenden Funktionen bereitgestellt wird.
Der Data Integrator-Jobserver ist für die Verarbeitung von Jobs verantwortlich, die mit DI Designer erstellt wurden.
Webadministrator
Der Data Integrator-Webadministrator wird von Systemadministratoren und Datenbankadministratoren zum Verwalten von Repositorys in Datendiensten verwendet. Data Services umfasst das Metadata Repository, das Central Repository für die teambasierte Entwicklung, Job Server und Web Services.
Schlüsselfunktionen von DI Web Administrator
- Es wird zum Planen, Überwachen und Ausführen von Stapeljobs verwendet.
- Es wird für die Konfiguration und zum Starten und Stoppen von Echtzeitservern verwendet.
- Es wird zum Konfigurieren der Verwendung von Job Server, Access Server und Repository verwendet.
- Es wird zum Konfigurieren von Adaptern verwendet.
- Es wird zum Konfigurieren und Steuern aller Tools in BO Data Services verwendet.
Die Datenverwaltungsfunktion legt Wert auf Datenqualität. Dabei werden die Daten bereinigt, erweitert und konsolidiert, um korrekte Daten im DW-System zu erhalten.
In diesem Kapitel lernen wir die SAP-BODS-Architektur kennen. Die Abbildung zeigt die Architektur des BODS-Systems mit Staging-Bereich.
Quellschicht
Die Quellschicht enthält verschiedene Datenquellen wie SAP-Anwendungen und Nicht-SAP-RDBMS-Systeme. Die Datenintegration erfolgt im Staging-Bereich.
SAP Business Objects Data Services umfasst verschiedene Komponenten wie Data Service Designer, Data Services Management Console, Repository Manager, Data Services Server Manager, Werkbank usw. Das Zielsystem kann ein DW-System wie SAP HANA, SAP BW oder ein Nicht-SAP sein Data Warehouse-System.

Der folgende Screenshot zeigt die verschiedenen Komponenten von SAP BODS.

Sie können die BODS-Architektur auch in die folgenden Ebenen unterteilen:
- Webanwendungsschicht
- Datenbankserver-Schicht
- Data Services Service Layer
Die folgende Abbildung zeigt die BODS-Architektur.

Produktentwicklung - ATL, DI & DQ
Acta Technology Inc. hat SAP Business Objects Data Services entwickelt und später von Business Objects Company übernommen. Acta Technology Inc. ist ein in den USA ansässiges Unternehmen und war für die Entwicklung der First-Data-Integrationsplattform verantwortlich. Die beiden von Acta Inc. entwickelten ETL-Softwareprodukte waren dieData Integration (DI) Werkzeug und die Data Management oder Data Quality ((DQ) Werkzeug.
Business Objects, ein französisches Unternehmen, erwarb Acta Technology Inc. im Jahr 2002 und später wurden beide Produkte in umbenannt Business Objects Data Integration (BODI) Werkzeug und Business Objects Data Quality (BODQ) Werkzeug.
SAP erwarb Business Objects im Jahr 2007 und beide Produkte wurden in SAP BODI und SAP BODQ umbenannt. Im Jahr 2008 integrierte SAP beide Produkte in ein einziges Softwareprodukt mit dem Namen SAP Business Objects Data Services (BODS).
SAP BODS bietet eine Datenintegrations- und Datenverwaltungslösung. In der früheren Version von BODS war die Textdatenverarbeitungslösung enthalten.
KÖRPER - Objekte
Alle Entitäten, die in BO Data Services Designer verwendet werden, werden aufgerufen Objects. Alle Objekte wie Projekte, Jobs, Metadaten und Systemfunktionen werden in der lokalen Objektbibliothek gespeichert. Alle Objekte sind hierarchischer Natur.
Die Objekte enthalten hauptsächlich Folgendes:
Properties- Sie werden zur Beschreibung eines Objekts verwendet und haben keinen Einfluss auf dessen Betrieb. Beispiel - Name eines Objekts, Erstellungsdatum usw.
Options - Welche steuern den Betrieb von Objekten.
Arten von Objekten
Es gibt zwei Arten von Objekten im System: Wiederverwendbare Objekte und Einwegobjekte. Der Objekttyp bestimmt, wie dieses Objekt verwendet und abgerufen wird.
Wiederverwendbare Objekte
Die meisten Objekte, die im Repository gespeichert sind, können wiederverwendet werden. Wenn ein wiederverwendbares Objekt definiert und im lokalen Repository gespeichert wird, können Sie das Objekt wiederverwenden, indem Sie Aufrufe an die Definition erstellen. Jedes wiederverwendbare Objekt hat nur eine Definition, und alle Aufrufe dieses Objekts beziehen sich auf diese Definition. Wenn nun die Definition eines Objekts an einer Stelle geändert wird, ändern Sie die Objektdefinition an allen Stellen, an denen dieses Objekt angezeigt wird.
Eine Objektbibliothek wird verwendet, um die Objektdefinition zu enthalten. Wenn ein Objekt aus der Bibliothek gezogen und dort abgelegt wird, wird ein neuer Verweis auf ein vorhandenes Objekt erstellt.
Einwegobjekte
Alle Objekte, die speziell für einen Job oder Datenfluss definiert sind, werden als Einwegobjekte bezeichnet. Zum Beispiel eine bestimmte Transformation, die beim Laden von Daten verwendet wird.
BODS - Objekthierarchie
Alle Objekte sind hierarchischer Natur. Das folgende Diagramm zeigt die Objekthierarchie im SAP-BODS-System -

KÖRPER - Werkzeuge und Funktionen
Basierend auf der unten dargestellten Architektur haben wir viele Tools in SAP Business Objects Data Services definiert. Jedes Tool hat seine eigene Funktion gemäß Systemlandschaft.

Oben sind Information Platform Services für die Benutzer- und Rechte-Sicherheitsverwaltung installiert. BODS hängt von der Central Management Console ab (CMC) für Benutzerzugriff und Sicherheitsfunktion. Dies gilt für die Version 4.x. In der vorherigen Version wurde dies in der Verwaltungskonsole durchgeführt.
Data Services Designer ist ein Entwicklertool, mit dem Objekte erstellt werden, die aus Datenzuordnung, Transformation und Logik bestehen. Es basiert auf einer GUI und arbeitet als Designer für Data Services.
Repository
Das Repository wird zum Speichern von Metadaten von Objekten verwendet, die in BO Data Services verwendet werden. Jedes Repository sollte in der Central Management Console registriert sein und mit einzelnen oder mehreren Jobservern verknüpft sein, die für die Ausführung von von Ihnen erstellten Jobs verantwortlich sind.
Arten von Repositorys
Es gibt drei Arten von Repositorys.
Local Repository - Hier werden die Metadaten aller in Data Services Designer erstellten Objekte wie Projekte, Jobs, Datenfluss, Workflow usw. gespeichert.
Central Repository- Es dient zur Steuerung der Versionsverwaltung der Objekte und zur Mehrzweckentwicklung. Das zentrale Repository speichert alle Versionen eines Anwendungsobjekts. Daher können Sie zu früheren Versionen wechseln.
Profiler Repository- Hiermit werden alle Metadaten verwaltet, die sich auf Profiler-Aufgaben beziehen, die im SAP BODS Designer ausgeführt werden. Das CMS-Repository speichert Metadaten aller in CMC auf der BI-Plattform ausgeführten Aufgaben. Das Information Steward Repository speichert alle Metadaten von Profilierungsaufgaben und Objekten, die in Information Steward erstellt wurden.
Job Server
Der Jobserver wird verwendet, um die von Ihnen erstellten Echtzeit- und Stapeljobs auszuführen. Es ruft die Jobinformationen aus den jeweiligen Repositorys ab und initiiert das Datenmodul zur Ausführung des Jobs. Der Jobserver kann Echtzeit- oder geplante Jobs ausführen und verwendet Multithreading beim Speicher-Caching und Parallelverarbeitung, um die Leistung zu optimieren.
Zugriffsserver
Access Server in Data Services ist als Echtzeit-Nachrichtenbrokersystem bekannt, das die Nachrichtenanforderungen entgegennimmt, zum Echtzeitdienst wechselt und eine Nachricht in einem bestimmten Zeitrahmen anzeigt.
Data Service Management Console
Die Data Service Management Console wird verwendet, um Verwaltungsaktivitäten wie das Planen der Jobs, das Generieren der Qualitätsberichte im DS-System, die Datenvalidierung, die Dokumentation usw. auszuführen.
BODS - Benennungsstandards
Es wird empfohlen, Standard-Namenskonventionen für alle Objekte in allen Systemen zu verwenden, da Sie so Objekte in Repositorys leicht identifizieren können.
Die Tabelle zeigt die Liste der empfohlenen Namenskonventionen, die für alle Jobs und andere Objekte verwendet werden sollten.
| Präfix | Suffix | Objekt |
|---|---|---|
| DF_ | n / a | Datenfluss |
| EDF_ | _Eingang | Eingebetteter Datenfluss |
| EDF_ | _Ausgabe | Eingebetteter Datenfluss |
| RTJob_ | n / a | Echtzeitjob |
| WF_ | n / a | Arbeitsablauf |
| JOB_ | n / a | Job |
| n / a | _DS | Datenspeicher |
| DC_ | n / a | Datenkonfiguration |
| SC_ | n / a | Systemkonfiguration |
| n / a | _Memory_DS | Speicherdatenspeicher |
| PROC_ | n / a | Gespeicherte Prozedur |
Die Grundlagen von BO Data Service umfassen wichtige Objekte beim Entwerfen von Workflows wie Projekt, Job, Workflow, Datenfluss und Repositorys.
BODS - Repository & Typen
Das Repository wird zum Speichern von Metadaten von Objekten verwendet, die in BO Data Services verwendet werden. Jedes Repository sollte in der Central Management Console (CMC) registriert sein und mit einzelnen oder mehreren Jobservern verknüpft sein, die für die Ausführung der von Ihnen erstellten Jobs verantwortlich sind.
Arten von Repositorys
Es gibt drei Arten von Repositorys.
Local Repository - Hier werden die Metadaten aller in Data Services Designer erstellten Objekte wie Projekte, Jobs, Datenfluss, Workflow usw. gespeichert.
Central Repository- Es dient zur Steuerung der Versionsverwaltung der Objekte und zur Mehrzweckentwicklung. Das zentrale Repository speichert alle Versionen eines Anwendungsobjekts. Daher können Sie zu früheren Versionen wechseln.
Profiler Repository- Hiermit werden alle Metadaten verwaltet, die sich auf Profiler-Aufgaben beziehen, die im SAP BODS Designer ausgeführt werden. Das CMS-Repository speichert Metadaten aller in CMC auf der BI-Plattform ausgeführten Aufgaben. Das Information Steward Repository speichert alle Metadaten von Profilierungsaufgaben und Objekten, die in Information Steward erstellt wurden.
Um ein BODS-Repository zu erstellen, muss eine Datenbank installiert sein. Sie können SQL Server, Oracle-Datenbank, My SQL, SAP HANA, Sybase usw. verwenden.
Repository erstellen
Sie müssen die folgenden Benutzer in der Datenbank erstellen, während Sie BODS installieren, und Repositorys erstellen. Diese Benutzer müssen sich bei verschiedenen Servern wie dem CMS-Server, dem Audit-Server usw. anmelden.
Erstellen Sie von Bodsserver1 identifizierte Benutzer-BODS
- Grant Connect to BODS;
- Gewähren Sie BODS die Erstellung einer Sitzung.
- Gewähren Sie BODS DBA;
- Grant Create Any Table für BODS;
- Grant Create Any View für BODS;
- Grant Drop Any Table für BODS;
- Grant Drop Any View für BODS;
- Grant Insert Beliebige Tabelle für BODS;
- Grant Update Beliebige Tabelle für BODS;
- Gewähren Sie BODS Delete Any table.
- Ändern Sie USER BODS QUOTA UNLIMITED ON USERS;
Erstellen Sie ein von CMSserver1 identifiziertes Benutzer-CMS
- Grant Connect to CMS;
- Grant Create Session für CMS;
- Gewähren Sie DBA an CMS;
- Grant Create Any Table für CMS;
- Grant Create Any View für CMS;
- Grant Drop Any Table für CMS;
- Grant Drop Any View für CMS;
- Grant Insert Beliebige Tabelle für CMS;
- Grant Update Beliebige Tabelle für CMS;
- Grant Delete Beliebige Tabelle für CMS;
- Ändern Sie USER CMS QUOTA UNLIMITED ON USERS;
Benutzer CMSAUDIT erstellen Identifiziert durch CMSAUDITserver1
- Grant Connect to CMSAUDIT;
- Grant Create Session für CMSAUDIT;
- Gewähren Sie DBA an CMSAUDIT;
- Grant Create Any Table für CMSAUDIT;
- Grant CMSAUDIT eine beliebige Ansicht erstellen;
- Grant Drop Any Table für CMSAUDIT;
- Grant Drop Any View für CMSAUDIT;
- Grant Insert Beliebige Tabelle für CMSAUDIT;
- Grant Update Beliebige Tabelle für CMSAUDIT;
- Grant Delete Beliebige Tabelle für CMSAUDIT;
- USER CMSAUDIT QUOTA UNBEGRENZT AUF BENUTZER ändern;
So erstellen Sie nach der Installation ein neues Repository
Step 1 - Erstellen Sie eine Datenbank Local_Repound gehen Sie zu Data Services Repository Manager. Konfigurieren Sie die Datenbank als lokales Repository.

Ein neues Fenster wird geöffnet.
Step 2 - Geben Sie die Details in die folgenden Felder ein -
Repository-Typ, Datenbanktyp, Name des Datenbankservers, Port, Benutzername und Kennwort.

Step 3 - Klicken Sie auf CreateTaste. Sie erhalten folgende Meldung:

Step 4 - Melden Sie sich jetzt bei Central Management Console CMC an SAP BI Platform mit Benutzername und Passwort.
Step 5 - Klicken Sie auf der CMC-Startseite auf Data Services.

Step 6 - Aus dem Data Services Menü, Klicken Sie auf Configure a new Data Services Repository.

Step 7 - Geben Sie die Details wie im neuen Fenster angegeben ein.
- Repository-Name: Local_Repo
- Datenbanktyp: SAP HANA
- Name des Datenbankservers: am besten
- Datenbankname: LOCAL_REPO
- Nutzername:
- Password:*****

Step 8 - Klicken Sie auf die Schaltfläche Test Connection und wenn es erfolgreich ist, klicken Sie auf Save. Sobald Sie gespeichert haben, wird es in CMC unter der Registerkarte Repository angezeigt.
Step 9 - Wenden Sie Zugriffsrechte und Sicherheit auf das lokale Repository in an CMC → User and Groups.
Step 10 - Gehen Sie nach dem Zugriff zu Data Services Designer → Repository auswählen → Geben Sie den Benutzernamen und das Kennwort ein, um sich anzumelden.

Repository aktualisieren
Führen Sie die folgenden Schritte aus, um ein Repository zu aktualisieren.
Step 1 - Um ein Repository nach der Installation zu aktualisieren, erstellen Sie eine Datenbank Local_Repo und gehen Sie zu Data Services Repository Manager.
Step 2 - Konfigurieren Sie die Datenbank als lokales Repository.

Ein neues Fenster wird geöffnet.
Step 3 - Geben Sie die Details für die folgenden Felder ein.
Repository-Typ, Datenbanktyp, Name des Datenbankservers, Port, Benutzername und Kennwort.

Sie sehen die Ausgabe wie im folgenden Screenshot gezeigt.

Die Data Service Management Console (DSMC) wird verwendet, um Verwaltungsaktivitäten wie das Planen der Jobs, das Generieren von Qualitätsberichten im DS-System, die Datenvalidierung, die Dokumentation usw. auszuführen.
Sie können auf folgende Arten auf die Data Services Management Console zugreifen:
Sie können auf die Data Services Management Console zugreifen, indem Sie auf gehen Start → All Programs → Data Services → Data Service Management Console.
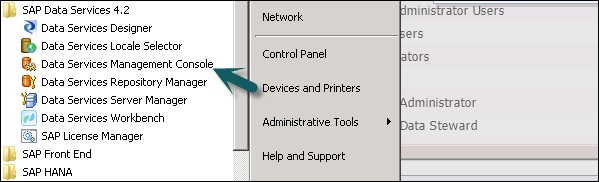
Sie können auch über auf die Datendienst-Verwaltungskonsole zugreifen Designer wenn Sie bereits angemeldet sind.
Zugriff auf die Data Services Management Console über Designer Home Page Befolgen Sie die unten angegebenen Schritte.

Führen Sie die folgenden Schritte aus, um über Tools auf die Verwaltungskonsole für Datendienste zuzugreifen:
Step 1 - Geh zu Tools → Data Services Management Console wie im folgenden Bild gezeigt.

Step 2 - Sobald Sie sich angemeldet haben Data Services Management ConsoleDer Startbildschirm wird wie im folgenden Screenshot gezeigt geöffnet. Oben sehen Sie den Benutzernamen, über den Sie angemeldet sind.
Auf der Startseite sehen Sie die folgenden Optionen:
- Administrator
- Automatische Dokumentation
- Datenvalidierung
- Auswirkungs- und Abstammungsanalyse
- Betriebs-Dashboard
- Datenqualitätsberichte

In diesem Kapitel werden die wichtigsten Funktionen der einzelnen Module der Data Services Management Console erläutert.
Administrator-Modul
Eine Administratoroption wird verwendet, um - zu verwalten
- Benutzer und Rollen
- Hinzufügen von Verbindungen zu Zugriffsservern und Repositorys
- Zugriff auf Jobdaten, die für Webdienste veröffentlicht wurden
- Zur Planung und Überwachung von Stapeljobs
- So überprüfen Sie den Zugriffsserverstatus und die Echtzeitdienste.
Sobald Sie auf die klicken AdministratorAuf der Registerkarte können Sie im linken Bereich viele Links sehen. Dies sind: Status, Stapelverarbeitung, Webservices, SAP-Verbindungen, Servergruppen, Profiler-Repositorys-Verwaltung und Auftragsausführungsverlauf.

Knoten
Die verschiedenen Knoten unter dem Administrator-Modul werden unten erläutert.
Status
Der Statusknoten wird verwendet, um den Status von Stapel- und Echtzeitjobs, den Zugriff auf den Serverstatus, Adapter- und Profiler-Repositorys sowie den anderen Systemstatus zu überprüfen.
Klicken Sie auf Status → Repository auswählen
Im rechten Bereich sehen Sie die Registerkarten der folgenden Optionen:
Batch Job Status- Hiermit wird der Status des Stapeljobs überprüft. Sie können die Auftragsinformationen wie Ablaufverfolgung, Überwachung, Fehler- und Leistungsüberwachung, Startzeit, Endzeit, Dauer usw. überprüfen.

Batch Job Configuration - Mit der Stapeljobkonfiguration können Sie den Zeitplan einzelner Jobs überprüfen oder eine Aktion hinzufügen, z. B. Ausführen, Zeitplan hinzufügen, Ausführungsbefehl exportieren.
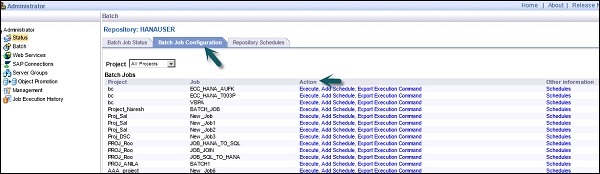
Repositories Schedules - Es wird verwendet, um Zeitpläne für alle Jobs im Repository anzuzeigen und zu konfigurieren.
Batch-Knoten
Unter dem Knoten Stapeljob sehen Sie dieselben Optionen wie oben.
| Sr. Nr. | Option & Beschreibung |
|---|---|
| 1 | Batch Job Status Zeigen Sie den Status der letzten Ausführung und detaillierte Informationen zu jedem Job an. |
| 2 | Batch Job Configuration Konfigurieren Sie Ausführungs- und Planungsoptionen für einzelne Jobs. |
| 3 | Repository Schedules Anzeigen und Konfigurieren von Zeitplänen für alle Jobs im Repository. |
Webdienstknoten
Webdienste werden verwendet, um Echtzeitjobs und Stapeljobs als Webdienstvorgang zu veröffentlichen und den Status dieser Vorgänge zu überprüfen. Dies wird auch verwendet, um die Sicherheit für Jobs zu gewährleisten, die als Webdienst veröffentlicht wurden, und um sie anzuzeigenWSDL Datei.

SAP-Verbindungen
Mit SAP Connections wird der Status überprüft oder konfiguriert RFC server interface in der Data Services Management Console.
Um den Status der RFC-Serverschnittstelle zu überprüfen, wechseln Sie zur Registerkarte Status der RFC-Serverschnittstelle. Klicken Sie auf der Registerkarte Konfiguration auf, um eine neue RFC-Serverschnittstelle hinzuzufügenAdd.
Wenn ein neues Fenster geöffnet wird, geben Sie die RFC-Serverkonfigurationsdetails ein. Klicken Sie auf Apply.

Servergruppen
Dies wird verwendet, um alle Jobserver, die demselben Repository zugeordnet sind, in einer Servergruppe zu gruppieren. Diese Registerkarte wird zum Lastenausgleich verwendet, während die Jobs in Datendiensten ausgeführt werden.
Wenn ein Job ausgeführt wird, sucht er nach dem entsprechenden Jobserver. Wenn er nicht verfügbar ist, wird der Job auf einen anderen Jobserver in derselben Gruppe verschoben. Es wird hauptsächlich in der Produktion zum Lastausgleich verwendet.

Profil-Repositorys
Wenn Sie das Profil-Repository mit dem Administrator verbinden, können Sie den Profil-Repository-Knoten erweitern. Sie können zur Statusseite Profilaufgaben wechseln.
Verwaltungsknoten
Um die Funktion der Registerkarte Administrator zu verwenden, müssen Sie mithilfe des Verwaltungsknotens Verbindungen zu den Datendiensten hinzufügen. Der Verwaltungsknoten besteht aus verschiedenen Konfigurationsoptionen für die Verwaltungsanwendung.

Auftragsausführungsverlauf
Dies wird verwendet, um den Ausführungsverlauf eines Jobs oder eines Datenflusses zu überprüfen. Mit dieser Option können Sie den Ausführungsverlauf eines Stapeljobs oder aller von Ihnen erstellten Stapeljobs überprüfen.
Wenn Sie einen Job auswählen, werden Informationen in Form einer Tabelle angezeigt, die aus Repository-Name, Jobname, Startzeit, Endzeit, Ausführungszeit, Status usw. besteht.

Data Service Designer ist ein Entwicklertool, mit dem Objekte erstellt werden, die aus Datenzuordnung, Transformation und Logik bestehen. Es basiert auf einer GUI und arbeitet als Designer für Data Services.
Mit Data Services Designer können Sie verschiedene Objekte wie Projekte, Jobs, Arbeitsabläufe, Datenabläufe, Zuordnungen, Transformationen usw. erstellen.
Führen Sie die folgenden Schritte aus, um den Data Services Designer zu starten.
Step 1 - Startpunkt → Alle Programme → SAP Data Services 4.2 → Data Services Designer.

Step 2 - Wählen Sie das Repository aus und geben Sie das Passwort für die Anmeldung ein.

Sobald Sie das Repository ausgewählt und sich beim Data Services Designer angemeldet haben, wird ein Startbildschirm angezeigt (siehe Abbildung unten).

Im linken Bereich befindet sich der Projektbereich, in dem Sie ein neues Projekt, einen neuen Job, einen neuen Datenfluss, einen neuen Arbeitsablauf usw. erstellen können. Im Projektbereich verfügen Sie über eine lokale Objektbibliothek, die aus allen in Data Services erstellten Objekten besteht.
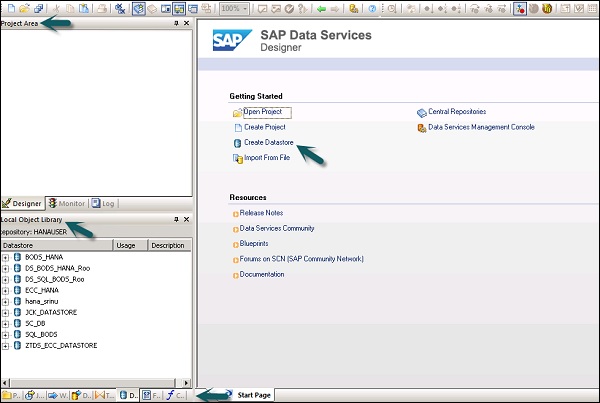
Im unteren Bereich können Sie die vorhandenen Objekte öffnen, indem Sie zu bestimmten Optionen wie Projekt, Jobs, Datenfluss, Arbeitsablauf usw. wechseln. Sobald Sie eines der Objekte im unteren Bereich ausgewählt haben, werden Ihnen bereits alle ähnlichen Objekte angezeigt im Repository unter der lokalen Objektbibliothek erstellt.
Auf der rechten Seite haben Sie einen Startbildschirm, auf dem Sie -
- Projekt erstellen
- Offenes Projekt
- Datenspeicher erstellen
- Erstellen Sie Repositorys
- Aus flacher Datei importieren
- Data Services Management Console
Um einen ETL-Flow zu entwickeln, müssen Sie zunächst Datenspeicher für das Quell- und das Zielsystem erstellen. Befolgen Sie die angegebenen Schritte, um einen ETL-Flow zu entwickeln -
Step 1 - Klicken Sie auf Create Data Stores.

Ein neues Fenster wird geöffnet.
Step 2 - Geben Sie die Datastore Name, DatastoreTyp und Datenbanktyp wie unten gezeigt. Sie können verschiedene Datenbanken als Quellsystem auswählen, wie im folgenden Screenshot gezeigt.

Step 3- Um das ECC-System als Datenquelle zu verwenden, wählen Sie SAP-Anwendungen als Datenspeichertyp. Geben Sie Benutzername und Passwort ein und aufAdvance Geben Sie auf der Registerkarte die Systemnummer und die Client-Nummer ein.

Step 4- Klicken Sie auf OK und der Datenspeicher wird zur Liste der lokalen Objektbibliothek hinzugefügt. Wenn Sie den Datenspeicher erweitern, wird keine Tabelle angezeigt.

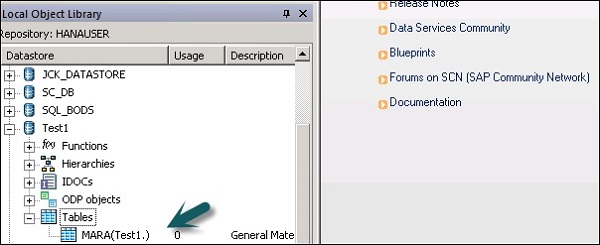
Step 5 - Um eine Tabelle aus dem ECC-System zu extrahieren, die auf das Zielsystem geladen werden soll, klicken Sie mit der rechten Maustaste auf Tabellen → Nach Namen importieren.

Step 6 - Geben Sie den Tabellennamen ein und klicken Sie auf Import. Hier wird Table-Mara verwendet, eine Standardtabelle im ECC-System.
Step 7 - Erstellen Sie auf ähnliche Weise eine Datastorefür das Zielsystem. In diesem Beispiel wird HANA als Zielsystem verwendet.

Sobald Sie auf OK klicken, wird dies angezeigt Datastore wird der lokalen Objektbibliothek hinzugefügt und enthält keine Tabelle.
Erstellen Sie einen ETL-Flow
Erstellen Sie ein neues Projekt, um einen ETL-Flow zu erstellen.
Step 1 - Klicken Sie auf die Option, Create Project. Geben Sie den Projektnamen ein und klicken Sie aufCreate. Es wird dem Projektbereich hinzugefügt.

Step 2 - Klicken Sie mit der rechten Maustaste auf den Projektnamen und erstellen Sie einen neuen Stapeljob / Echtzeitjob.

Step 3- Geben Sie den Namen des Jobs ein und drücken Sie die Eingabetaste. Dazu müssen Sie Workflow und Datenfluss hinzufügen. Wählen Sie einen Workflow aus und klicken Sie auf den Arbeitsbereich, um ihn dem Job hinzuzufügen. Geben Sie den Namen des Workflows ein und doppelklicken Sie darauf, um ihn dem Projektbereich hinzuzufügen.
Step 4- Wählen Sie auf ähnliche Weise den Datenfluss aus und bringen Sie ihn in den Projektbereich. Geben Sie den Namen des Datenflusses ein und doppelklicken Sie, um ihn unter dem neuen Projekt hinzuzufügen.

Step 5- Ziehen Sie nun die Quelltabelle unter Datenspeicher in den Arbeitsbereich. Jetzt können Sie die Zieltabelle mit ähnlichem Datentyp in den Arbeitsbereich ziehen oder eine neue Vorlagentabelle erstellen.
Um eine neue Vorlagentabelle zu erstellen, klicken Sie mit der rechten Maustaste auf die Quelltabelle: Neu hinzufügen → Vorlagentabelle.

Step 6- Geben Sie den Tabellennamen ein und wählen Sie den Datenspeicher aus der Liste als Zieldatenspeicher aus. Der Eigentümername repräsentiert den Schemanamen, unter dem die Tabelle erstellt werden muss.

Die Tabelle wird dem Arbeitsbereich mit diesem Tabellennamen hinzugefügt.
Step 7- Ziehen Sie die Zeile von der Quelltabelle in die Zieltabelle. Drücke denSave All Option oben.

Jetzt können Sie den Job mit der Data Service Management Console planen oder manuell ausführen, indem Sie mit der rechten Maustaste auf den Jobnamen klicken und Ausführen.
Datenspeicher werden verwendet, um die Verbindung zwischen einer Anwendung und der Datenbank herzustellen. Sie können den Datenspeicher direkt oder mithilfe von Adaptern erstellen. Mit dem Datenspeicher kann eine Anwendung / Software Metadaten aus einer Anwendung oder Datenbank lesen oder schreiben und in diese Datenbank oder Anwendung schreiben.
In Business Objects Data Services können Sie mithilfe des Datenspeichers eine Verbindung zu den folgenden Systemen herstellen:
- Mainframe-Systeme und Datenbank
- Anwendungen und Software mit benutzerdefinierten Adaptern
- SAP-Anwendungen, SAP BW, Oracle Apps, Siebel usw.
SAP Business Objects Data Services bietet eine Option zum Herstellen einer Verbindung mit den Mainframe-Schnittstellen über AttunityVerbinder. Verwenden vonAttunityVerbinden Sie den Datenspeicher mit der unten angegebenen Quellenliste -
- DB2 UDB für OS / 390
- DB2 UDB für OS / 400
- IMS/DB
- VSAM
- Adabas
- Flat Files unter OS / 390 und OS / 400

Mit dem Attunity-Connector können Sie mithilfe einer Software eine Verbindung zu den Mainframe-Daten herstellen. Diese Software muss manuell auf dem Mainframe-Server und dem lokalen Client-Jobserver über eine ODBC-Schnittstelle installiert werden.
Geben Sie die Details wie Host-Standort, Port, Attunity-Arbeitsbereich usw. Ein.
Erstellen Sie einen Datenspeicher für eine Datenbank
Führen Sie die folgenden Schritte aus, um einen Datenspeicher für eine Datenbank zu erstellen.
Step 1- Geben Sie den Namen des Datenspeichers, den Datenspeichertyp und den Datenbanktyp ein (siehe Abbildung unten). Sie können verschiedene Datenbanken als Quellsystem in der Liste auswählen.

Step 2- Um das ECC-System als Datenquelle zu verwenden, wählen Sie SAP-Anwendungen als Datenspeichertyp. Geben Sie Benutzername und Passwort ein. Drücke denAdvance Registerkarte und geben Sie die Systemnummer und die Client-Nummer ein.

Step 3- Klicken Sie auf OK und der Datenspeicher wird zur Liste der lokalen Objektbibliothek hinzugefügt. Wenn Sie den Datenspeicher erweitern, kann keine Tabelle angezeigt werden.
In diesem Kapitel erfahren Sie, wie Sie den Datenspeicher bearbeiten oder ändern. Führen Sie die folgenden Schritte aus, um den Datenspeicher zu ändern oder zu bearbeiten.
Step 1- Um einen Datenspeicher zu bearbeiten, klicken Sie mit der rechten Maustaste auf den Namen des Datenspeichers und klicken Sie auf Bearbeiten. Der Datenspeicher-Editor wird geöffnet.

Sie können die Verbindungsinformationen für die aktuelle Datenspeicherkonfiguration bearbeiten.
Step 2 - Klicken Sie auf Advance Klicken Sie auf die Schaltfläche, und Sie können die Client-Nummer, die System-ID und andere Eigenschaften bearbeiten.
Step 3 - Klicken Sie auf Edit Option zum Hinzufügen, Bearbeiten und Löschen der Konfigurationen.

Step 4 - Klicken Sie auf OK und die Änderungen werden übernommen.
Sie können einen Datenspeicher mit dem Speicher als Datenbanktyp erstellen. Speicherdatenspeicher werden verwendet, um die Leistung von Datenflüssen in Echtzeitjobs zu verbessern, da sie die Daten im Speicher speichern, um einen schnellen Zugriff zu ermöglichen, und nicht zur ursprünglichen Datenquelle wechseln müssen.
Ein Speicherdatenspeicher wird zum Speichern von Speichertabellenschemata im Repository verwendet. Diese Speichertabellen beziehen Daten aus Tabellen in der relationalen Datenbank oder verwenden hierarchische Datendateien wie XML-Nachrichten und IDocs. Die Speichertabellen bleiben aktiv, bis der Job ausgeführt wird und die Daten in Speichertabellen nicht zwischen verschiedenen Echtzeitjobs geteilt werden können.
Erstellen eines Speicherdatenspeichers
Führen Sie die folgenden Schritte aus, um einen Speicherdatenspeicher zu erstellen.
Step 1 - Klicken Sie auf Datenspeicher erstellen und geben Sie den Namen des Datenspeichers ein “Memory_DS_TEST”. Speichertabellen werden mit normalen RDBMS-Tabellen dargestellt und können mit Namenskonventionen identifiziert werden.
Step 2 - Wählen Sie unter Datenspeichertyp die Option Datenbank und im Datenbanktyp die Option Datenbank aus Memory. OK klicken.

Step 3 - Gehen Sie nun zu Projekt → Neu → Projekt, wie im folgenden Screenshot gezeigt.

Step 4- Erstellen Sie einen neuen Job, indem Sie mit der rechten Maustaste klicken. Fügen Sie den Arbeitsablauf und den Datenfluss wie unten gezeigt hinzu.
Step 5- Wählen Sie eine Vorlagentabelle aus und ziehen Sie sie per Drag & Drop in den Arbeitsbereich. Ein Fenster zum Erstellen einer Tabelle wird geöffnet.

Step 6- Geben Sie den Namen der Tabelle ein und wählen Sie im Datenspeicher die Option Speicherdatenspeicher. Wenn Sie eine vom System generierte Zeilen-ID wünschen, wählen Sie diecreate row idKontrollkästchen. OK klicken.
Step 7 - Verbinden Sie diese Speichertabelle mit dem Datenfluss und klicken Sie auf Save All oben.

Speichertabelle als Quelle und Ziel
So verwenden Sie eine Speichertabelle als Ziel -
Step 1- Gehen Sie zur lokalen Objektbibliothek und klicken Sie auf die Registerkarte Datenspeicher. Erweitern Sie den Speicherdatenspeicher → Tabellen erweitern.
Step 2- Wählen Sie die Speichertabelle aus, die Sie als Quell- oder Zieltabelle verwenden möchten, und ziehen Sie sie in den Workflow. Verbinden Sie diese Speichertabelle als Quelle oder Ziel im Datenfluss.
Step 3 - Klicken Sie auf save Schaltfläche zum Speichern des Jobs.
Es gibt verschiedene Datenbankanbieter, die nur einen Einweg-Kommunikationspfad von einer Datenbank zu einer anderen Datenbank bereitstellen. Diese Pfade werden als Datenbankverknüpfungen bezeichnet. In SQL Server ermöglicht der Verbindungsserver einen Einweg-Kommunikationspfad von einer Datenbank zur anderen.
Beispiel
Stellen Sie sich einen lokalen Datenbankserver mit dem Namen vor “Product” speichert die Datenbankverbindung, um auf Informationen auf dem aufgerufenen entfernten Datenbankserver zuzugreifen Customer. Jetzt können Benutzer, die mit dem Remote-Datenbankserver verbunden sind, nicht über denselben Link auf Daten im Datenbankserver-Produkt zugreifen. Benutzer, die mit verbunden sind“Customer” sollte einen separaten Link im Datenwörterbuch des Servers haben, um auf die Daten im Produktdatenbankserver zuzugreifen.
Dieser Kommunikationspfad zwischen den beiden Datenbanken wird als Datenbankverbindung bezeichnet. Die Datenspeicher, die zwischen diesen verknüpften Datenbankbeziehungen erstellt werden, werden als verknüpfte Datenspeicher bezeichnet.
Es besteht die Möglichkeit, einen Datenspeicher mit einem anderen Datenspeicher zu verbinden und eine externe Datenbankverbindung als Option des Datenspeichers zu importieren.

Mit dem Adapter-Datenspeicher können Sie Anwendungsmetadaten in das Repository importieren. Sie können auf Anwendungsmetadaten zugreifen und die Stapel- und Echtzeitdaten zwischen verschiedenen Anwendungen und Software verschieben.
Es gibt ein von SAP bereitgestelltes Adapter Software Development Kit (SDK), mit dem benutzerdefinierte Adapter entwickelt werden können. Diese Adapter werden im Data Services-Designer von Adapter-Datenspeichern angezeigt.
Um die Daten mit einem Adapter zu extrahieren oder zu laden, sollten Sie zu diesem Zweck mindestens einen Datenspeicher definieren.
Adapter-Datenspeicher - Definition
Führen Sie die folgenden Schritte aus, um den adaptiven Datenspeicher zu definieren:
Step 1 - Klicken Sie auf Create Datastore→ Geben Sie den Namen für den Datenspeicher ein. Wählen Sie Datenspeichertyp als Adapter. Wähle ausJob Server Klicken Sie in der Liste und im Namen der Adapterinstanz auf und klicken Sie auf OK.

So durchsuchen Sie Anwendungsmetadaten
Klicken Sie mit der rechten Maustaste auf den Namen des Datenspeichers und klicken Sie auf Open. Es öffnet sich ein neues Fenster mit den Quellmetadaten. Klicken Sie auf + Zeichen, um Objekte zu überprüfen, und klicken Sie mit der rechten Maustaste auf das zu importierende Objekt.
Das Dateiformat wird als eine Reihe von Eigenschaften definiert, um die Struktur von Flatfiles darzustellen. Es definiert die Metadatenstruktur. Das Dateiformat wird verwendet, um eine Verbindung zur Quell- und Zieldatenbank herzustellen, wenn Daten in den Dateien und nicht in der Datenbank gespeichert sind.
Das Dateiformat wird für die folgenden Funktionen verwendet:
- Erstellen Sie eine Dateiformatvorlage, um die Struktur einer Datei zu definieren.
- Erstellen Sie ein bestimmtes Quell- und Zieldateiformat im Datenfluss.
Der folgende Dateityp kann im Dateiformat als Quell- oder Zieldatei verwendet werden:
- Delimited
- SAP Transport
- Unstrukturierter Text
- Unstrukturierte Binärdatei
- Feste Breite
Dateiformat-Editor
Mit dem Dateiformat-Editor werden die Eigenschaften für die Dateiformatvorlagen sowie die Quell- und Zieldateiformate festgelegt.
Die folgenden Modi stehen im Dateiformat-Editor zur Verfügung:
New mode - Sie können eine neue Dateiformatvorlage erstellen.
Edit mode - Sie können eine vorhandene Dateiformatvorlage bearbeiten.
Source mode - Hier können Sie das Dateiformat einer bestimmten Quelldatei bearbeiten.
Target mode - Sie können das Dateiformat einer bestimmten Zieldatei bearbeiten.
Es gibt drei Arbeitsbereiche für den Dateiformat-Editor:
Properties Values - Hiermit werden die Werte für Dateiformateigenschaften bearbeitet.
Column Attributes - Dient zum Bearbeiten und Definieren der Spalten oder Felder in der Datei.
Data Preview - Hiermit wird angezeigt, wie sich die Einstellungen auf Beispieldaten auswirken.
Erstellen eines Dateiformats
Führen Sie die folgenden Schritte aus, um ein Dateiformat zu erstellen.
Step 1 - Gehen Sie zu Lokale Objektbibliothek → Flatfiles.

Step 2 - Klicken Sie mit der rechten Maustaste auf die Option Flat Files → Neu.

Ein neues Fenster des Dateiformat-Editors wird geöffnet.
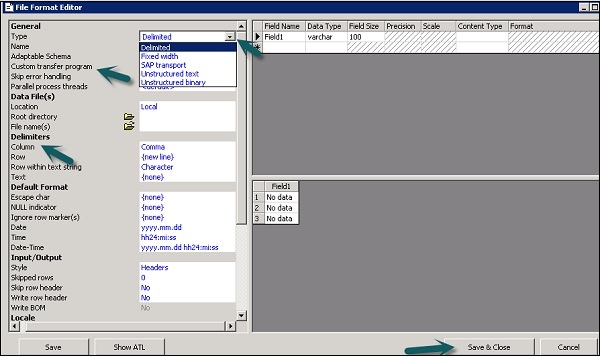
Step 3- Wählen Sie den Typ des Dateiformats. Geben Sie den Namen ein, der die Dateiformatvorlage beschreibt. Für Dateien mit begrenzter und fester Breite können Sie mit dem benutzerdefinierten Übertragungsprogramm lesen und laden. Geben Sie die anderen Eigenschaften ein, um die Dateien zu beschreiben, die diese Vorlage darstellt.
Sie können die Struktur von Spalten auch im Arbeitsbereich für Spaltenattribute für einige bestimmte Dateiformate angeben. Wenn alle Eigenschaften definiert sind, klicken Sie aufSave Taste.
Bearbeiten eines Dateiformats
Führen Sie die folgenden Schritte aus, um die Dateiformate zu bearbeiten.
Step 1 - Gehen Sie in der lokalen Objektbibliothek zu Format Tab.
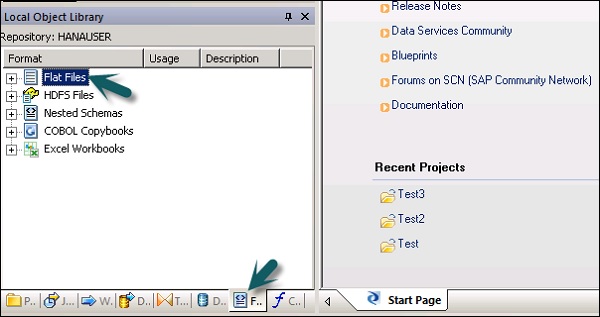
Step 2- Wählen Sie das Dateiformat aus, das Sie bearbeiten möchten. Klicken Sie mit der rechten Maustaste aufEdit Möglichkeit.

Nehmen Sie Änderungen im Dateiformat-Editor vor und klicken Sie auf Save Taste.
Sie können ein COBOL-Copybook-Dateiformat erstellen, mit dem Sie nur das Format erstellen können. Sie können die Quelle später konfigurieren, sobald Sie das Format zum Datenfluss hinzugefügt haben.
Sie können das Dateiformat erstellen und gleichzeitig mit der Datendatei verbinden. Befolgen Sie die unten angegebenen Schritte.
Step 1 - Gehen Sie zu Lokale Objektbibliothek → Dateiformat → COBOL-Copybooks.

Step 2 - Klicken Sie mit der rechten Maustaste auf New Möglichkeit.

Step 3- Geben Sie den Formatnamen ein. Gehen Sie zur Registerkarte Format → Wählen Sie das zu importierende COBOL-Copybook aus. Die Erweiterung der Datei lautet.cpy.
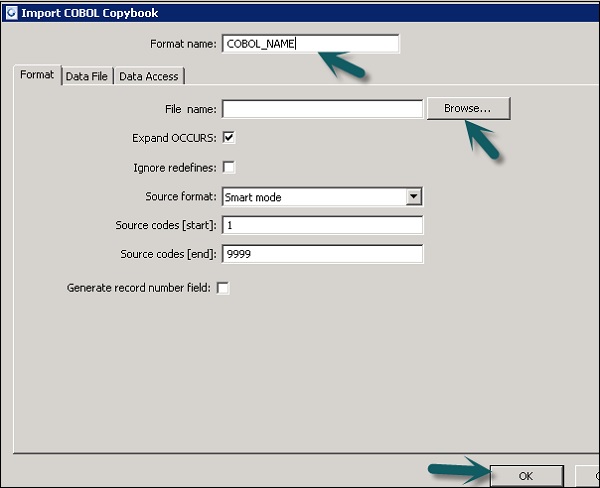
Step 4 - Klicken Sie auf OK. Dieses Dateiformat wird der lokalen Objektbibliothek hinzugefügt. Das Dialogfeld COBOL Copybook Schema Name wird geöffnet. Benennen Sie das Schema bei Bedarf um und klicken Sie aufOK.
Mithilfe von Datenbankdatenspeichern können Sie die Daten aus Tabellen und Funktionen in der Datenbank extrahieren. Wenn Sie einen Datenimport für Metadaten durchführen,Tool Mit dieser Option können Sie die Spaltennamen, Datentypen, Beschreibungen usw. bearbeiten.
Sie können die folgenden Objekte bearbeiten -
- Tabellenname
- Spaltenname
- Tabellenbeschreibung
- Spaltenbeschreibung
- Spaltendatentyp
- Spalteninhaltstyp
- Tabellenattribute
- Primärschlüssel
- Besitzername
Metadaten importieren
Führen Sie die folgenden Schritte aus, um Metadaten zu importieren:
Step 1 - Gehen Sie zu Lokale Objektbibliothek → Gehen Sie zu Datenspeicher, den Sie verwenden möchten.

Step 2 - Klicken Sie mit der rechten Maustaste auf Datenspeicher → Öffnen.
Im Arbeitsbereich werden alle Elemente angezeigt, die für den Import verfügbar sind. Wählen Sie die Elemente aus, für die Sie die Metadaten importieren möchten.

Wechseln Sie in der Objektbibliothek zum Datenspeicher, um die Liste der importierten Objekte anzuzeigen.
Sie können die Microsoft Excel-Arbeitsmappe als Datenquelle mithilfe der Dateiformate in Data Services verwenden. Die Excel-Arbeitsmappe sollte im Windows-Dateisystem oder im Unix-Dateisystem verfügbar sein.
| Sr.Nr. | Zugang & Beschreibung |
|---|---|
| 1 | In the object library, click the Formats tab. Eine Excel-Arbeitsmappe beschreibt die in einer Excel-Arbeitsmappe definierte Struktur (gekennzeichnet mit der Erweiterung .xls). Sie speichern Formatvorlagen für Excel-Datenbereiche in der Objektbibliothek. Mit der Vorlage definieren Sie das Format einer bestimmten Quelle in einem Datenfluss. SAP Data Services greift nur auf Excel-Arbeitsmappen als Quelle zu (nicht als Ziele). |
Klicken Sie mit der rechten Maustaste auf New Option und wählen Sie Excel Workbook wie im Screenshot unten gezeigt.

Datenextraktion aus XML FILE DTD, XSD
Sie können auch das XML- oder DTD-Schemadateiformat importieren.
Step 1 - Gehen Sie zu Lokale Objektbibliothek → Registerkarte Format → Verschachteltes Schema.
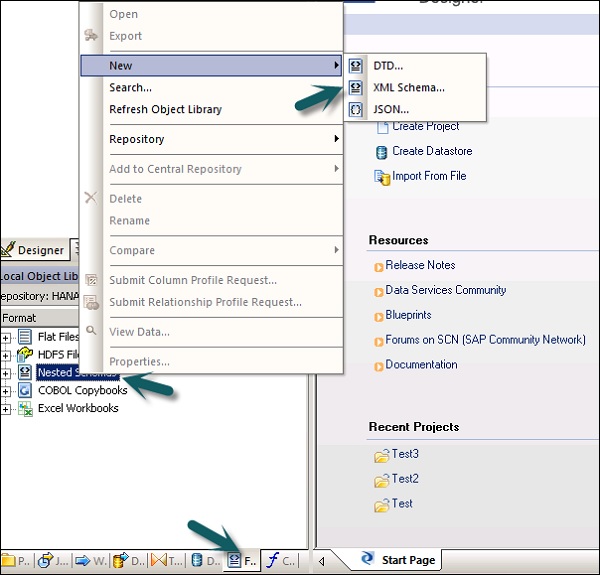
Step 2 - Zeigen Sie auf New(Sie können DTD-Datei oder XML-Schema oder JSON-Dateiformat auswählen.) Geben Sie den Namen des Dateiformats ein und wählen Sie die Datei aus, die Sie importieren möchten. OK klicken.
Datenextraktion aus COBOL Copybooks
Sie können das Dateiformat auch in COBOL-Copybooks importieren. Gehen Sie zu Lokale Objektbibliothek → Format → COBOL-Copybooks.

Der Datenfluss wird zum Extrahieren, Transformieren und Laden von Daten aus der Quelle in das Zielsystem verwendet. Alle Transformationen, Ladevorgänge und Formatierungen erfolgen im Datenfluss.
Sobald Sie einen Datenfluss in einem Projekt definiert haben, kann dieser einem Workflow oder einem ETL-Job hinzugefügt werden. Der Datenfluss kann Objekte / Informationen mithilfe von Parametern senden oder empfangen. Der Datenfluss wird im Format benanntDF_Name.

Beispiel für einen Datenfluss
Nehmen wir an, Sie möchten eine Faktentabelle im DW-System mit Daten aus zwei Tabellen im Quellsystem laden.
Der Datenfluss enthält die folgenden Objekte:
- Tabelle mit zwei Quellen
- Verknüpfung zwischen zwei Tabellen und Definition in der Abfragetransformation
- Zieltabelle

Es gibt drei Arten von Objekten, die einem Datenfluss hinzugefügt werden können. Sie sind -
- Source
- Target
- Transforms
Step 1 - Gehen Sie zur lokalen Objektbibliothek und ziehen Sie beide Tabellen in den Arbeitsbereich.

Step 2 - Um eine Abfragetransformation hinzuzufügen, ziehen Sie aus der rechten Symbolleiste.
Step 3 - Verbinden Sie beide Tabellen und erstellen Sie eine Vorlagenzieltabelle, indem Sie mit der rechten Maustaste auf das Feld Abfrage → Neu hinzufügen → Neue Vorlagentabelle klicken.

Step 4 - Geben Sie den Namen der Zieltabelle, den Namen des Datenspeichers und den Eigentümer (Schemanamen) ein, unter dem die Tabelle erstellt werden soll.
Step 5 - Ziehen Sie die Zieltabelle nach vorne und verbinden Sie sie mit der Abfragetransformation.
Parameter übergeben
Sie können auch verschiedene Parameter in den Datenfluss und aus diesem heraus übergeben. Beim Übergeben eines Parameters an einen Datenfluss verweisen Objekte im Datenfluss auf diese Parameter. Mithilfe von Parametern können Sie verschiedene Operationen an einen Datenfluss übergeben.
Beispiel - Angenommen, Sie haben einen Parameter für die letzte Aktualisierung in eine Tabelle eingegeben. Sie können nur Zeilen extrahieren, die seit der letzten Aktualisierung geändert wurden.
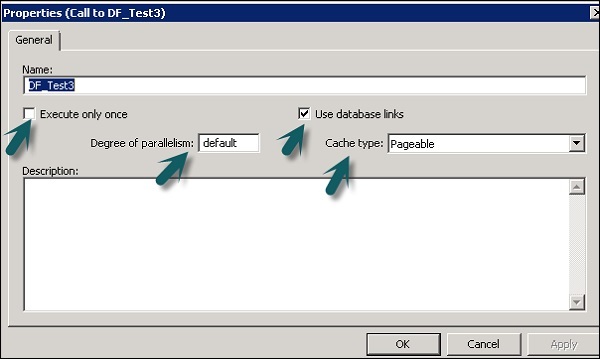
Sie können die Eigenschaften eines Datenflusses wie Einmal ausführen, Cache-Typ, Datenbankverknüpfung, Parallelität usw. ändern.
Step 1 - Um die Eigenschaften des Datenflusses zu ändern, klicken Sie mit der rechten Maustaste auf Datenfluss → Eigenschaften
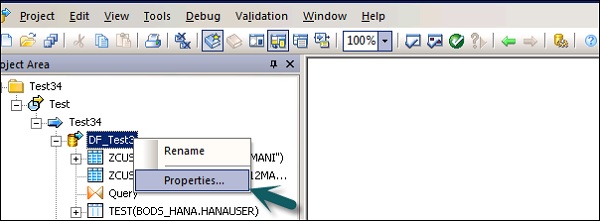
Sie können verschiedene Eigenschaften für einen Datenfluss festlegen. Die Eigenschaften sind unten angegeben.
| Sr. Nr. | Eigenschaften & Beschreibung |
|---|---|
| 1 | Execute only once Wenn Sie angeben, dass ein Datenfluss nur einmal ausgeführt werden soll, führt ein Stapeljob diesen Datenfluss nach erfolgreichem Abschluss des Datenflusses niemals erneut aus, es sei denn, der Datenfluss ist in einem Workflow enthalten, der eine Wiederherstellungseinheit ist, die und erneut ausführt wurde an anderer Stelle außerhalb der Wiederherstellungseinheit nicht erfolgreich abgeschlossen. Es wird empfohlen, einen Datenfluss nicht nur einmal als Ausführen zu markieren, wenn ein übergeordneter Workflow eine Wiederherstellungseinheit ist. |
| 2 | Use database links Datenbankverbindungen sind Kommunikationspfade zwischen einem Datenbankserver und einem anderen. Mit Datenbankverknüpfungen können lokale Benutzer auf Daten in einer entfernten Datenbank zugreifen, die sich auf dem lokalen oder einem entfernten Computer desselben oder eines anderen Datenbanktyps befinden können. |
| 3 | Degree of parallelism Der Grad der Parallelität (DOP) ist eine Eigenschaft eines Datenflusses, die definiert, wie oft jede Transformation innerhalb eines Datenflusses repliziert wird, um eine parallele Teilmenge von Daten zu verarbeiten. |
| 4 | Cache type Sie können Daten zwischenspeichern, um die Leistung von Vorgängen wie Verknüpfungen, Gruppen, Sortierungen, Filtern, Nachschlagen und Tabellenvergleichen zu verbessern. Sie können einen der folgenden Werte für die Option Cache-Typ in Ihrem Datenfluss-Eigenschaftenfenster auswählen:
|
Step 2 - Ändern Sie die Eigenschaften wie Nur einmal ausführen, Parallelitätsgrad und Cache-Typen.
Quell- und Zielobjekte
Ein Datenfluss kann Daten mithilfe der folgenden Objekte direkt extrahieren oder laden:
Source objects - Quellobjekte definieren die Quelle, aus der Daten extrahiert werden oder die Sie lesen.
Target objects - Zielobjekte definiert das Ziel, auf das Sie die Daten laden oder schreiben.
Der folgende Typ von Quellobjekt kann verwendet werden, und für die Quellobjekte werden verschiedene Zugriffsmethoden verwendet.
| Tabelle | Eine mit Spalten und Zeilen formatierte Datei, wie sie in relationalen Datenbanken verwendet wird | Direkt oder über Adapter |
| Vorlagentabelle | Eine Vorlagentabelle, die erstellt und in einem anderen Datenfluss gespeichert wurde (wird in der Entwicklung verwendet). | Direkte |
| Datei | Eine abgegrenzte oder flache Datei mit fester Breite | Direkte |
| Dokument | Eine Datei mit einem anwendungsspezifischen Format (für SQL- oder XML-Parser nicht lesbar) | Durch Adapter |
| XML-Datei | Eine mit XML-Tags formatierte Datei | Direkte |
| XML-Nachricht | Wird als Quelle für Echtzeitjobs verwendet | Direkte |
Die folgenden Zielobjekte können verwendet und verschiedene Zugriffsmethoden angewendet werden.
| Tabelle | Eine mit Spalten und Zeilen formatierte Datei, wie sie in relationalen Datenbanken verwendet wird | Direkt oder über Adapter |
| Vorlagentabelle | Eine Tabelle, deren Format auf der Ausgabe der vorhergehenden Transformation basiert (wird in der Entwicklung verwendet). | Direkte |
| Datei | Eine abgegrenzte oder flache Datei mit fester Breite | Direkte |
| Dokument | Eine Datei mit einem anwendungsspezifischen Format (für SQL- oder XML-Parser nicht lesbar) | Durch Adapter |
| XML-Datei | Eine mit XML-Tags formatierte Datei | Direkte |
| XML-Vorlagendatei | Eine XML-Datei, deren Format auf der vorhergehenden Transformationsausgabe basiert (wird in der Entwicklung hauptsächlich zum Debuggen von Datenflüssen verwendet). | Direkte |
Workflows werden verwendet, um den Prozess für die Ausführung zu bestimmen. Der Hauptzweck des Workflows besteht darin, sich auf die Ausführung der Datenflüsse vorzubereiten und den Status des Systems festzulegen, sobald die Ausführung des Datenflusses abgeschlossen ist.
Die Stapeljobs in ETL-Projekten ähneln den Workflows mit dem einzigen Unterschied, dass der Job keine Parameter enthält.
Einem Workflow können verschiedene Objekte hinzugefügt werden. Sie sind -
- Arbeitsablauf
- Datenfluss
- Scripts
- Loops
- Conditions
- Versuche oder fange Blöcke
Sie können einen Workflow auch einen anderen Workflow aufrufen lassen oder einen Workflow selbst aufrufen.
Note - Im Workflow werden Schritte in einer Reihenfolge von links nach rechts ausgeführt.
Beispiel für einen Arbeitsablauf
Angenommen, es gibt eine Faktentabelle, die Sie aktualisieren möchten, und Sie haben mit der Transformation einen Datenfluss erstellt. Wenn Sie nun die Daten aus dem Quellsystem verschieben möchten, müssen Sie die letzte Änderung für die Faktentabelle überprüfen, damit Sie nur Zeilen extrahieren, die nach der letzten Aktualisierung hinzugefügt wurden.
Um dies zu erreichen, müssen Sie ein Skript erstellen, das das Datum der letzten Aktualisierung ermittelt und dieses dann als Eingabeparameter an den Datenfluss übergibt.
Sie müssen auch prüfen, ob die Datenverbindung zu einer bestimmten Faktentabelle aktiv ist oder nicht. Wenn es nicht aktiv ist, müssen Sie einen Catch-Block einrichten, der automatisch eine E-Mail an den Administrator sendet, um über dieses Problem zu benachrichtigen.
Workflows können mit den folgenden Methoden erstellt werden:
- Objektbibliothek
- Werkzeugpalette
Erstellen eines Workflows mithilfe der Objektbibliothek
Führen Sie die folgenden Schritte aus, um einen Workflow mithilfe der Objektbibliothek zu erstellen.
Step 1 - Gehen Sie zur Registerkarte Objektbibliothek → Workflow.

Step 2 - Klicken Sie mit der rechten Maustaste auf New Möglichkeit.

Step 3 - Geben Sie den Namen des Workflows ein.
Erstellen eines Workflows mithilfe der Werkzeugpalette
Um einen Workflow mithilfe der Werkzeugpalette zu erstellen, klicken Sie auf das Symbol auf der rechten Seite und ziehen Sie den Workflow in den Arbeitsbereich.
Sie können den Workflow auch nur einmal ausführen, indem Sie zu den Eigenschaften des Workflows wechseln.
Bedingungen
Sie können dem Workflow auch Bedingungen hinzufügen. Auf diese Weise können Sie die If / Else / Then-Logik in den Workflows implementieren.
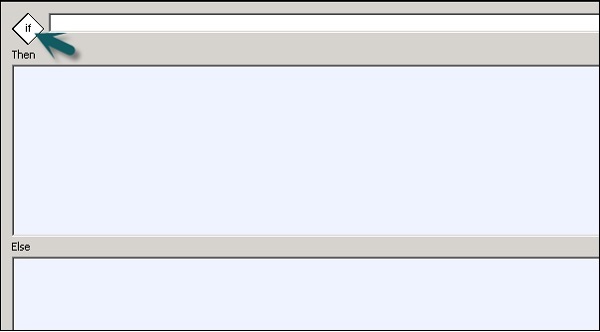
| Sr.Nr. | Bedingung & Beschreibung |
|---|---|
| 1 | If Ein boolescher Ausdruck, der TRUE oder FALSE ergibt. Sie können Funktionen, Variablen und Standardoperatoren verwenden, um den Ausdruck zu erstellen. |
| 2 | Then Workflow-Elemente, die ausgeführt werden sollen, wenn die If Ausdruck wird als WAHR ausgewertet. |
| 3 | Else (Optional) Workflow-Elemente, die ausgeführt werden sollen, wenn die If Ausdruck wird zu FALSE ausgewertet. |
Eine Bedingung definieren
Step 1 - Gehen Sie zu Workflow → Klicken Sie in der Werkzeugpalette auf der rechten Seite auf das Symbol Bedingt.
Step 2 - Doppelklicken Sie auf den Namen Conditional, um das zu öffnen If-Then–Else bedingter Editor.
Step 3- Geben Sie den Booleschen Ausdruck ein, der die Bedingung steuert. OK klicken.
Step 4 - Ziehen Sie den Datenfluss, den Sie ausführen möchten Then and Else Fenster gemäß dem Ausdruck in IF-Bedingung.

Sobald Sie die Bedingung erfüllt haben, können Sie die Bedingung debuggen und validieren.
Transformationen werden verwendet, um die Datensätze als Eingaben zu bearbeiten und eine oder mehrere Ausgaben zu erstellen. Es gibt verschiedene Transformationen, die in Data Services verwendet werden können. Die Art der Transformationen hängt von der Version und dem gekauften Produkt ab.
Folgende Arten von Transformationen sind verfügbar:
Datenintegration
Datenintegrationstransformationen werden zum Extrahieren, Transformieren und Laden von Daten in das DW-System verwendet. Es stellt die Datenintegrität sicher und verbessert die Entwicklerproduktivität.
- Data_Generator
- Data_Transfer
- Effective_Date
- Hierarchy_flattening
- Table_Comparision usw.
Datenqualität
Datenqualitätstransformationen werden verwendet, um die Datenqualität zu verbessern. Sie können einen analysierten, korrekten, standardisierten und angereicherten Datensatz aus dem Quellsystem anwenden.
- Associate
- Datenbereinigung
- DSF2 Walk Sequencer usw.
Plattform
Die Plattform wird für die Bewegung des Datensatzes verwendet. Auf diese Weise können Sie Zeilen aus zwei oder mehr Datenquellen generieren, zuordnen und zusammenführen.
- Case
- Merge
- Abfrage usw.
Textdatenverarbeitung
Mit der Textdatenverarbeitung können Sie große Mengen an Textdaten verarbeiten.
In diesem Kapitel erfahren Sie, wie Sie hinzufügen Transform zu einem Datenfluss.
Step 1 - Gehen Sie zur Registerkarte Objektbibliothek → Transformieren.
Step 2- Wählen Sie die Transformation aus, die Sie dem Datenfluss hinzufügen möchten. Wenn Sie eine Umwandlung hinzufügen, die die Option zur Auswahl der Konfiguration bietet, wird eine Eingabeaufforderung geöffnet.
Step 3 - Zeichnen Sie die Datenflussverbindung, um die Quelle mit einer Transformation zu verbinden.
Step 4 - Doppelklicken Sie auf den Transformationsnamen, um den Transformationseditor zu öffnen.
Sobald die Definition abgeschlossen ist, klicken Sie auf OK um den Editor zu schließen.
Dies ist die in Data Services am häufigsten verwendete Umwandlung. Sie können die folgenden Funktionen ausführen:
- Datenfilterung aus Quellen
- Daten aus mehreren Quellen zusammenführen
- Führen Sie Funktionen und Transformationen für Daten durch
- Spaltenzuordnung von Eingabe- zu Ausgabeschemata
- Primärschlüssel zuweisen
- Fügen Sie neue Spalten, Schemas und Funktionen hinzu, die zu Ausgabeschemas führen
Da die Abfragetransformation die am häufigsten verwendete Transformation ist, wird für diese Abfrage in der Werkzeugpalette eine Verknüpfung bereitgestellt.
Führen Sie die folgenden Schritte aus, um die Abfragetransformation hinzuzufügen:
Step 1- Klicken Sie auf die Palette des Abfragetransformationstools. Klicken Sie auf eine beliebige Stelle im Datenfluss-Arbeitsbereich. Verbinden Sie dies mit den Ein- und Ausgängen.

Wenn Sie auf das Symbol für die Abfragetransformation doppelklicken, wird ein Abfrageeditor geöffnet, mit dem Abfragevorgänge ausgeführt werden.
Die folgenden Bereiche sind in der Abfragetransformation vorhanden:
- Eingabeschema
- Ausgabeschema
- Parameters
Die Eingabe- und Ausgabeschemata enthalten Spalten, verschachtelte Schemata und Funktionen. Schema In und Schema Out zeigt das aktuell ausgewählte Schema in der Transformation an.
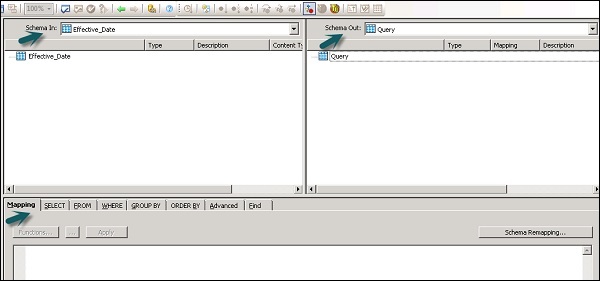
Um das Ausgabeschema zu ändern, wählen Sie das Schema in der Liste aus, klicken Sie mit der rechten Maustaste und wählen Sie Aktuell erstellen.

Datenqualitäts-Transformation
Datenqualitätstransformationen können nicht direkt mit der Upstream-Transformation verbunden werden, die verschachtelte Tabellen enthält. Um diese Transformation zu verbinden, sollten Sie eine Abfragetransformation oder eine XML-Pipeline-Transformation zwischen der Transformation aus einer verschachtelten Tabelle und der Datenqualitätstransformation hinzufügen.
Wie verwende ich die Datenqualitätsumwandlung?
Step 1 - Gehen Sie zur Registerkarte Objektbibliothek → Transformieren
Step 2 - Erweitern Sie die Datenqualitätstransformation und fügen Sie die Transformation oder Transformationskonfiguration hinzu, die Sie dem Datenfluss hinzufügen möchten.
Step 3- Zeichnen Sie die Datenflussverbindungen. Doppelklicken Sie auf den Namen der Transformation. Der Transformationseditor wird geöffnet. Wählen Sie im Eingabeschema die Eingabefelder aus, die Sie zuordnen möchten.
Note - Um Associate Transform zu verwenden, können Sie der Eingabe-Registerkarte benutzerdefinierte Felder hinzufügen.
Textdatenverarbeitungstransformation
Mit der Textdatenverarbeitungstransformation können Sie die spezifischen Informationen aus einem großen Textvolumen extrahieren. Sie können nach unternehmensspezifischen Fakten und Entitäten wie Kunden-, Produkt- und Finanzdaten suchen.
Diese Transformation überprüft auch die Beziehung zwischen Entitäten und ermöglicht die Extraktion. Die mithilfe der Textdatenverarbeitung extrahierten Daten können in Business Intelligence, Berichterstellung, Abfrage und Analyse verwendet werden.
Entitätsextraktionstransformation
In Data Services erfolgt die Textdatenverarbeitung mithilfe der Entitätsextraktion, mit der Entitäten und Fakten aus unstrukturierten Daten extrahiert werden.
Dies beinhaltet das Analysieren und Verarbeiten großer Textdatenmengen, das Suchen von Entitäten, das Zuweisen zu einem geeigneten Typ und das Präsentieren von Metadaten im Standardformat.
Die Entitätsextraktionstransformation kann Informationen aus beliebigen Text-, HTML-, XML- oder bestimmten Inhalten im Binärformat (z. B. PDF) extrahieren und strukturierte Ausgaben generieren. Sie können die Ausgabe je nach Arbeitsablauf auf verschiedene Arten verwenden. Sie können es als Eingabe für eine andere Transformation verwenden oder in mehrere Ausgabequellen wie eine Datenbanktabelle oder eine flache Datei schreiben. Die Ausgabe wird in UTF-16-Codierung generiert.
Entity Extract Transform can be used in the following scenarios −
Suchen einer bestimmten Information aus einer großen Menge an Textvolumen.
Suchen strukturierter Informationen aus unstrukturiertem Text mit vorhandenen Informationen, um neue Verbindungen herzustellen.
Berichterstattung und Analyse für die Produktqualität.
Unterschiede zwischen TDP und Datenbereinigung
Die Textdatenverarbeitung wird verwendet, um relevante Informationen aus unstrukturierten Textdaten zu finden. Die Datenbereinigung wird jedoch zur Standardisierung und Bereinigung strukturierter Daten verwendet.
| Parameter | Textdatenverarbeitung | Datenbereinigung |
|---|---|---|
| Eingabetyp | Unstrukturierte Daten | Strukturierte Daten |
| Eingabegröße | Mehr als 5 KB | Weniger als 5 KB |
| Eingabebereich | Breite Domäne mit vielen Variationen | Begrenzte Variationen |
| Mögliche Verwendung | Mögliche aussagekräftige Informationen aus unstrukturierten Daten | Qualität der Daten zum Speichern im Repository |
| Ausgabe | Erstellen Sie Anmerkungen in Form von Entitäten, Typen usw. Die Eingabe wird nicht geändert | Erstellen Sie standardisierte Felder, Eingabe wird geändert |
Die Verwaltung von Datendiensten umfasst das Erstellen von Echtzeit- und Stapeljobs, das Planen von Jobs, den eingebetteten Datenfluss, Variablen und Parameter, den Wiederherstellungsmechanismus, die Datenprofilerstellung, die Leistungsoptimierung usw.
Echtzeit-Jobs
Sie können Echtzeitjobs erstellen, um Echtzeitnachrichten im Data Services-Designer zu verarbeiten. Wie ein Stapeljob extrahiert ein Echtzeitjob die Daten, transformiert sie und lädt sie.
Jeder Echtzeitjob kann Daten aus einer einzelnen Nachricht extrahieren. Sie können auch Daten aus anderen Quellen wie Tabellen oder Dateien extrahieren.
Echtzeitjobs werden im Gegensatz zu Batchjobs nicht mit Hilfe von Triggern ausgeführt. Sie werden von Administratoren als Echtzeitdienste ausgeführt. Echtzeitdienste warten auf Nachrichten vom Zugriffsserver. Der Zugriffsserver empfängt diese Nachricht und leitet sie an Echtzeitdienste weiter, die für die Verarbeitung des Nachrichtentyps konfiguriert sind. Echtzeitdienste führen die Nachricht aus und geben das Ergebnis zurück und verarbeiten die Nachrichten weiter, bis sie eine Anweisung zum Beenden der Ausführung erhalten.
Echtzeit vs Batch Jobs
Transformationen wie die Verzweigungen und die Steuerlogik werden häufiger in Echtzeitjobs verwendet, was bei Batchjobs in Designer nicht der Fall ist.
Echtzeitjobs werden im Gegensatz zu Batchjobs nicht als Reaktion auf einen Zeitplan oder einen internen Auslöser ausgeführt.
Erstellen von Echtzeitjobs
Echtzeitjobs können mit denselben Objekten wie Datenflüssen, Arbeitsabläufen, Schleifen, Bedingungen, Skripten usw. erstellt werden.
Sie können die folgenden Datenmodelle zum Erstellen von Echtzeitjobs verwenden:
- Einzelnes Datenflussmodell
- Modell mit mehreren Datenflüssen
Einzelnes Datenflussmodell
Sie können einen Echtzeitjob mit einem einzelnen Datenfluss in seiner Echtzeitverarbeitungsschleife erstellen, der eine einzelne Nachrichtenquelle und ein einzelnes Nachrichtenziel enthält.
Creating Real Time job using single data model −
Führen Sie die angegebenen Schritte aus, um einen Echtzeitjob mit einem einzelnen Datenmodell zu erstellen.
Step 1 - Gehen Sie zu Data Services Designer → Projekt Neu → Projekt → Geben Sie den Projektnamen ein

Step 2 - Klicken Sie mit der rechten Maustaste auf den Leerraum im Projektbereich → Neuer Echtzeitjob.

Der Arbeitsbereich zeigt zwei Komponenten des Echtzeitjobs:
- RT_Process_begins
- Step_ends
Es zeigt den Beginn und das Ende eines Echtzeitjobs.

Step 3 - Um einen Echtzeitjob mit einem einzelnen Datenfluss zu erstellen, wählen Sie den Datenfluss aus der Werkzeugpalette im rechten Bereich aus und ziehen Sie ihn in den Arbeitsbereich.
Klicken Sie in die Schleife, Sie können eine Nachrichtenquelle und ein Nachrichtenziel in einer Echtzeitverarbeitungsschleife verwenden. Verbinden Sie die Start- und Endmarkierungen mit dem Datenfluss.

Step 4 - Fügen Sie nach Bedarf Konfigurationsobjekte im Datenfluss hinzu und speichern Sie den Job.
Modell mit mehreren Datenflüssen
Auf diese Weise können Sie einen Echtzeitjob mit mehreren Datenflüssen in seiner Echtzeitverarbeitungsschleife erstellen. Sie müssen auch sicherstellen, dass die Daten in jedem Datenmodell vollständig verarbeitet werden, bevor zur nächsten Nachricht übergegangen wird.
Testen von Echtzeitjobs
Sie können den Echtzeitjob testen, indem Sie die Beispielnachricht als Quellnachricht aus der Datei übergeben. Sie können überprüfen, ob die Datendienste die erwartete Zielnachricht generieren.
Um sicherzustellen, dass Ihr Job das erwartete Ergebnis liefert, können Sie den Job im Ansichtsdatenmodus ausführen. In diesem Modus können Sie Ausgabedaten erfassen, um sicherzustellen, dass Ihr Echtzeitjob ordnungsgemäß funktioniert.
Eingebettete Datenflüsse
Der eingebettete Datenfluss wird als Datenfluss bezeichnet, der von einem anderen Datenfluss im Entwurf aufgerufen wird. Der eingebettete Datenfluss kann mehrere Quellen und Ziele enthalten, aber nur eine Eingabe oder Ausgabe übergibt Daten an den Hauptdatenfluss.
Die folgenden Arten von eingebetteten Datenflüssen können verwendet werden:
One Input - Der eingebettete Datenfluss wird am Ende des Datenflusses hinzugefügt.
One Output - Der eingebettete Datenfluss wird zu Beginn eines Datenflusses hinzugefügt.
No input or output - Replizieren Sie einen vorhandenen Datenfluss.
Der eingebettete Datenfluss kann für folgenden Zweck verwendet werden:
Vereinfachung der Datenflussanzeige.
Wenn Sie die Flusslogik speichern und in anderen Datenflüssen wiederverwenden möchten.
Zum Debuggen, bei dem Sie Abschnitte des Datenflusses als eingebetteten Datenfluss erstellen und separat ausführen.
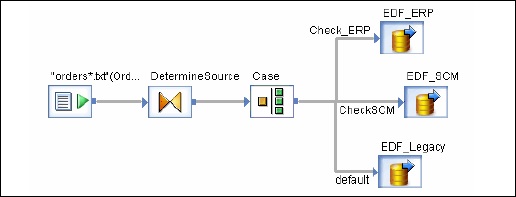
Sie können ein Objekt im vorhandenen Datenfluss auswählen. Es gibt zwei Möglichkeiten, wie ein eingebetteter Datenfluss erstellt werden kann.
Option 1
Klicken Sie mit der rechten Maustaste auf das Objekt und wählen Sie es aus, damit es eingebettete Daten fließt.

Option 2
Ziehen Sie den vollständigen und validierten Datenfluss aus der Objektbibliothek in einen offenen Datenfluss im Arbeitsbereich. Öffnen Sie als Nächstes den erstellten Datenfluss. Wählen Sie das Objekt aus, das Sie als Eingabe- und Ausgabeport verwenden möchten, und klicken Sie aufmake port für dieses Objekt.

Data Services fügen dieses Objekt als Verbindungspunkt für den eingebetteten Datenfluss hinzu.
Variablen und Parameter
Sie können lokale und globale Variablen mit Datenfluss und Arbeitsfluss verwenden, die mehr Flexibilität beim Entwerfen von Jobs bieten.
Die Hauptmerkmale sind -
Der Datentyp einer Variablen kann eine Zahl, eine Ganzzahl, eine Dezimalzahl, ein Datum oder ein Zeichenfolgenzeichen sein.
Variablen können in den Datenflüssen und Arbeitsabläufen als Funktion in der verwendet werden Where Klausel.
Lokale Variablen in Datendiensten sind auf das Objekt beschränkt, in dem sie erstellt werden.
Globale Variablen sind auf Jobs beschränkt, in denen sie erstellt werden. Mithilfe globaler Variablen können Sie zur Laufzeit Werte für globale Standardvariablen ändern.
Ausdrücke, die im Workflow und im Datenfluss verwendet werden, werden als bezeichnet parameters.
Alle Variablen und Parameter im Workflow und im Datenfluss werden im Variablen- und Parameterfenster angezeigt.
Führen Sie die folgenden Schritte aus, um Variablen und Parameter anzuzeigen:
Gehen Sie zu Extras → Variablen.

Ein neues Fenster Variables and parameterswird angezeigt. Es hat zwei Registerkarten - Definitionen und Aufrufe.
Das DefinitionsAuf der Registerkarte können Sie Variablen und Parameter erstellen und anzeigen. Sie können lokale Variablen und Parameter auf Workflow- und Datenflussebene verwenden. Globale Variablen können auf Jobebene verwendet werden.
Job |
Lokale Variablen Globale Variablen |
Ein Skript oder eine Bedingung im Job Beliebiges Objekt im Job |
Arbeitsablauf |
Lokale Variablen Parameter |
Dieser Workflow wird mithilfe eines Parameters an andere Workflows oder Datenflüsse weitergegeben. Übergeordnete Objekte zum Übergeben lokaler Variablen. Workflows können auch Variablen oder Parameter an übergeordnete Objekte zurückgeben. |
Datenfluss |
Parameter |
Eine WHERE-Klausel, eine Spaltenzuordnung oder eine Funktion im Datenfluss. Datenfluss. Datenflüsse können keine Ausgabewerte zurückgeben. |
Auf der Registerkarte Aufruf sehen Sie den Namen des Parameters, der für alle Objekte in der Definition eines übergeordneten Objekts definiert ist.
Lokale Variable definieren
Öffnen Sie zum Definieren der lokalen Variablen den Echtzeitjob.
Step 1- Gehen Sie zu Extras → Variablen. Eine neueVariables and Parameters Fenster öffnet sich.
Step 2 - Gehen Sie zu Variable → Rechtsklick → Einfügen

Es wird ein neuer Parameter erstellt $NewVariable0.
Step 3- Geben Sie den Namen der neuen Variablen ein. Wählen Sie den Datentyp aus der Liste.

Sobald es definiert ist, schließen Sie das Fenster. Auf ähnliche Weise können Sie die Parameter für Datenfluss und Workflow definieren.

Falls Ihr Job nicht erfolgreich ausgeführt wird, sollten Sie den Fehler beheben und den Job erneut ausführen. Bei fehlgeschlagenen Jobs besteht die Möglichkeit, dass einige Tabellen geladen, geändert oder teilweise geladen wurden. Sie müssen den Job erneut ausführen, um alle Daten abzurufen und doppelte oder fehlende Daten zu entfernen.
Zwei Techniken, die zur Wiederherstellung verwendet werden können, sind wie folgt:
Automatic Recovery - Auf diese Weise können Sie nicht erfolgreiche Jobs im Wiederherstellungsmodus ausführen.
Manually Recovery - Auf diese Weise können Sie die Jobs erneut ausführen, ohne eine teilweise Wiederholung der vorherigen Zeit zu berücksichtigen.
To run a job with Recovery option enabled in Designer
Step 1 - Klicken Sie mit der rechten Maustaste auf Jobname → Ausführen.

Step 2 - Speichern Sie alle Änderungen und führen Sie → Ja aus.
Step 3- Wechseln Sie zur Registerkarte Ausführung → Kontrollkästchen Wiederherstellung aktivieren. Wenn dieses Kontrollkästchen nicht aktiviert ist, können Datendienste den Job nicht wiederherstellen, wenn er fehlschlägt.

To run a job in Recovery mode from Designer
Step 1- Klicken Sie mit der rechten Maustaste und führen Sie den Job wie oben aus. Änderungen speichern.
Step 2- Gehen Sie zu den Ausführungsoptionen. Sie müssen sicherstellen, dass die OptionRecover from last failed execution Kontrollkästchen ist aktiviert.
Note- Diese Option ist nicht aktiviert, wenn ein Job noch nicht ausgeführt wurde. Dies wird als automatische Wiederherstellung eines fehlgeschlagenen Jobs bezeichnet.

Data Services Designer bietet eine Funktion zur Datenprofilerstellung, um die Qualität und Struktur von Quelldaten sicherzustellen und zu verbessern.
Mit Data Profiler können Sie -
Finden Sie Anomalien in den Quelldaten, Validierungs- und Korrekturmaßnahmen sowie die Qualität der Quelldaten.
Definieren Sie die Struktur und Beziehung der Quelldaten für eine bessere Ausführung von Jobs, Workflows und Datenflüssen.
Suchen Sie den Inhalt des Quell- und Zielsystems, um festzustellen, ob Ihr Job ein erwartetes Ergebnis liefert.
Data Profiler bietet die folgenden Informationen zur Ausführung des Profiler-Servers:
Spaltenanalyse
Basic Profiling - Enthält Informationen wie min, max, avg usw.
Detailed Profiling - Enthält Informationen wie eindeutige Anzahl, eindeutiger Prozentsatz, Median usw.
Beziehungsanalyse
Datenanomalien zwischen zwei Spalten, für die Sie eine Beziehung definieren.
Die Datenprofilerstellungsfunktion kann für Daten aus den folgenden Datenquellen verwendet werden:
- SQL Server
- Oracle
- DB2
- Attunity-Anschluss
- Sybase IQ
- Teradata
Verbindung zum Profiler Server herstellen
So stellen Sie eine Verbindung zu einem Profilserver her -
Step 1 - Gehen Sie zu Extras → Profiler Server Login

Step 2 - Geben Sie die Details wie System, Benutzername, Passwort und Authentifizierung ein.
Step 3 - Klicken Sie auf Log on Taste.
Wenn Sie verbunden sind, wird eine Liste der Profiler-Repositorys angezeigt. WählenRepository und klicken Sie auf Connect.
Die Leistung eines ETL-Jobs hängt von dem System ab, auf dem Sie die Data Services-Software verwenden, der Anzahl der Verschiebungen usw.
Es gibt verschiedene andere Faktoren, die zur Leistung einer ETL-Aufgabe beitragen. Sie sind -
Source Data Base - Die Quellendatenbank sollte so eingestellt sein, dass sie das ausführt SelectAussagen schnell. Dies kann erreicht werden, indem die Größe der Datenbank-E / A erhöht wird, der gemeinsam genutzte Puffer vergrößert wird, um mehr Daten zwischenzuspeichern, und keine Parallelität für kleine Tabellen usw. zulässig ist.
Source Operating System- Das Quellbetriebssystem sollte so konfiguriert sein, dass die Daten schnell von den Festplatten gelesen werden können. Stellen Sie das Read Ahead-Protokoll auf 64 KB ein.
Target Database - Die Zieldatenbank muss für die Ausführung konfiguriert sein INSERT und UPDATEschnell. Dies kann erfolgen durch -
- Deaktivieren der Archivprotokollierung.
- Deaktivieren der Redo-Protokollierung für alle Tabellen.
- Maximieren der Größe des gemeinsam genutzten Puffers.
Target Operating System- Das Zielbetriebssystem muss konfiguriert sein, damit die Daten schnell auf die Festplatten geschrieben werden können. Sie können asynchrone E / A aktivieren, um die Eingabe- / Ausgabeoperationen so schnell wie möglich zu gestalten.
Network - Die Netzwerkbandbreite sollte ausreichen, um die Daten von der Quelle zum Zielsystem zu übertragen.
BODS Repository Database - Um die Leistung von BODS-Jobs zu verbessern, kann Folgendes ausgeführt werden:
Monitor Sample Rate - Wenn Sie eine große Datenmenge in einem ETL-Job verarbeiten, überwachen Sie die Abtastrate auf einen höheren Wert, um die Anzahl der E / A-Aufrufe der Protokolldatei zu verringern und so die Leistung zu verbessern.
Sie können die Data Services-Protokolle auch vom Virenscan ausschließen, wenn der Virenscan auf dem Jobserver konfiguriert ist, da dies zu Leistungseinbußen führen kann
Job Server OS - In Data Services initiiert ein Datenfluss in einem Job einen ‘al_engine’Prozess, der vier Threads initiiert. Betrachten Sie für maximale Leistung ein Design, das eines ausführt‘al_engine’Prozess pro CPU zu einem Zeitpunkt. Das Job Server-Betriebssystem sollte so optimiert sein, dass alle Threads auf alle verfügbaren CPUs verteilt sind.
SAP BO Data Services unterstützen die Mehrbenutzerentwicklung, bei der jeder Benutzer an einer Anwendung in seinem eigenen lokalen Repository arbeiten kann. Jedes Team verwendet das zentrale Repository, um die Hauptkopie einer Anwendung und alle Versionen der Objekte in der Anwendung zu speichern.
Die Hauptmerkmale sind -
In SAP Data Services können Sie ein zentrales Repository zum Speichern der Teamkopie einer Anwendung erstellen. Es enthält alle Informationen, die auch im lokalen Repository verfügbar sind. Es wird jedoch nur ein Speicherort für die Objektinformationen bereitgestellt. Um Änderungen vornehmen zu können, müssen Sie im lokalen Repository arbeiten.
Sie können Objekte aus dem zentralen Repository in das lokale Repository kopieren. Wenn Sie jedoch Änderungen vornehmen müssen, müssen Sie dieses Objekt im zentralen Repository auschecken. Aus diesem Grund können die anderen Benutzer dieses Objekt nicht im zentralen Repository auschecken und daher keine Änderungen an demselben Objekt vornehmen.
Sobald Sie die Änderungen am Objekt vorgenommen haben, müssen Sie nach dem Objekt einchecken. Damit können Data Services neue geänderte Objekte im zentralen Repository speichern.
Mit Data Services können mehrere Benutzer mit lokalen Repositorys gleichzeitig eine Verbindung zum zentralen Repository herstellen, aber nur ein Benutzer kann ein bestimmtes Objekt auschecken und Änderungen daran vornehmen.
Das zentrale Repository verwaltet auch den Verlauf jedes Objekts. Sie können zur vorherigen Version eines Objekts zurückkehren, wenn die Änderungen nicht wie erforderlich resultieren.
Mehrere Benutzer
Mit SAP BO Data Services können mehrere Benutzer gleichzeitig an derselben Anwendung arbeiten. Die folgenden Begriffe sollten in einer Mehrbenutzerumgebung berücksichtigt werden:
| Sr.Nr. | Mehrbenutzer & Beschreibung |
|---|---|
| 1 | Highest level object Das Objekt der höchsten Ebene ist das Objekt, das von keinem Objekt in der Objekthierarchie abhängig ist. Wenn beispielsweise Job 1 aus Workflow 1 und Datenfluss 1 besteht, ist Job 1 das Objekt der höchsten Ebene. |
| 2 | Object dependents Objektabhängige sind Objekte, die unter dem Objekt der höchsten Ebene in der Hierarchie zugeordnet sind. Wenn beispielsweise Job 1 aus Workflow 1 besteht, der Datenfluss 1 enthält, sind sowohl Workflow 1 als auch Datenfluss 1 von Job 1 abhängig. Ferner ist Datenfluss 1 von Workflow 1 abhängig. |
| 3 | Object version Eine Objektversion ist eine Instanz eines Objekts. Jedes Mal, wenn Sie ein Objekt zum zentralen Repository hinzufügen oder einchecken, erstellt die Software eine neue Version des Objekts. Die neueste Version eines Objekts ist die letzte oder zuletzt erstellte Version. |
Um das lokale Repository in einer Mehrbenutzerumgebung zu aktualisieren, können Sie die neueste Kopie jedes Objekts aus dem zentralen Repository abrufen. Um ein Objekt zu bearbeiten, können Sie die Option zum Auschecken und Einchecken verwenden.
Es gibt verschiedene Sicherheitsparameter, die auf ein zentrales Repository angewendet werden können, um es sicher zu machen.
Verschiedene Sicherheitsparameter sind -
Authentication - Dadurch können sich nur authentische Benutzer beim zentralen Repository anmelden.
Authorization - Dadurch kann der Benutzer jedem Objekt unterschiedliche Berechtigungsstufen zuweisen.
Auditing- Dies wird verwendet, um den Verlauf aller an einem Objekt vorgenommenen Änderungen zu verwalten. Sie können alle vorherigen Versionen überprüfen und zu den älteren Versionen zurückkehren.
Nicht sicheres zentrales Repository erstellen
In einer Mehrbenutzer-Entwicklungsumgebung ist es immer ratsam, in einer zentralen Repository-Methode zu arbeiten.
Führen Sie die folgenden Schritte aus, um ein nicht sicheres zentrales Repository zu erstellen:
Step 1 - Erstellen Sie mithilfe des Datenbankverwaltungssystems eine Datenbank, die als zentrales Repository fungiert.
Step 2 - Gehen Sie zu einem Repository Manager.

Step 3- Wählen Sie den Repository-Typ als Zentral. Geben Sie die Datenbankdetails wie Benutzername und Passwort ein und klicken Sie aufCreate.

Step 4 - Um eine Verbindung zum Central Repository zu definieren, Tools → Central Repository.

Step 5 - Wählen Sie das Repository in der Central Repository-Verbindung aus und klicken Sie auf Add Symbol.

Step 6 - Geben Sie das Passwort für das zentrale Repository ein und klicken Sie auf Activate Taste.
Erstellen eines sicheren zentralen Repositorys
Wechseln Sie zum Erstellen eines sicheren zentralen Repositorys zum Repository-Manager. Wählen Sie den Repository-Typ als Zentral aus. Drücke denEnable Security Kontrollkästchen.

Für eine erfolgreiche Entwicklung in der Mehrbenutzerumgebung ist es ratsam, einige Prozesse wie Ein- und Auschecken zu implementieren.
In einer Mehrbenutzerumgebung können Sie die folgenden Prozesse verwenden:
- Filtering
- Objekte auschecken
- Check out rückgängig machen
- Objekte einchecken
- Objekte beschriften
Das Filtern ist anwendbar, wenn Sie Objekte hinzufügen, Objekte einchecken, auschecken und dem zentralen Repository beschriften.
Migrieren von Mehrbenutzerjobs
In SAP Data Services kann die Jobmigration auf verschiedenen Ebenen angewendet werden, z. B. auf Anwendungsebene, Repository-Ebene und Upgrade-Ebene.
Sie können den Inhalt eines zentralen Repositorys nicht direkt in ein anderes zentrales Repository kopieren. Sie müssen das lokale Repository verwenden.
Der erste Schritt besteht darin, die neueste Version aller Objekte vom zentralen Repository in das lokale Repository zu übertragen. Aktivieren Sie das zentrale Repository, in das Sie den Inhalt kopieren möchten. Fügen Sie alle Objekte hinzu, die Sie aus dem lokalen Repository in das zentrale Repository kopieren möchten.
Migration des zentralen Repositorys
Wenn Sie die Version von SAP Data Services aktualisieren, müssen Sie auch die Version von Repository aktualisieren.
Die folgenden Punkte sollten bei der Migration eines zentralen Repositorys zum Aktualisieren der Version berücksichtigt werden:
Erstellen Sie eine Sicherungskopie des zentralen Repositorys aller Tabellen und Objekte.
Um die Version von Objekten in Datendiensten zu verwalten, verwalten Sie für jede Version ein zentrales Repository. Erstellen Sie einen neuen zentralen Verlauf mit einer neuen Version der Data Services-Software und kopieren Sie alle Objekte in dieses Repository.
Wenn Sie eine neue Version von Data Services installieren, wird immer empfohlen, Ihr zentrales Repository auf eine neue Version von Objekten zu aktualisieren.
Aktualisieren Sie Ihr lokales Repository auf dieselbe Version, da möglicherweise verschiedene Versionen des zentralen und des lokalen Repositorys nicht gleichzeitig funktionieren.
Überprüfen Sie vor der Migration des zentralen Repositorys alle Objekte. Da Sie das zentrale und das lokale Repository nicht gleichzeitig aktualisieren, müssen alle Objekte eingecheckt werden. Sobald Sie Ihr zentrales Repository auf eine neuere Version aktualisiert haben, können Sie keine Objekte aus dem lokalen Repository einchecken, das eine ältere Version der Datendienste enthält.