SAS - Verketten von Datensätzen
Mit dem können mehrere SAS-Datensätze verkettet werden, um einen einzigen Datensatz zu erhalten SETErklärung. Die Gesamtzahl der Beobachtungen im verketteten Datensatz ist die Summe der Anzahl der Beobachtungen in den Originaldatensätzen. Die Reihenfolge der Beobachtungen ist sequentiell. Allen Beobachtungen aus dem ersten Datensatz folgen alle Beobachtungen aus dem zweiten Datensatz und so weiter.
Im Idealfall haben alle kombinierten Datensätze dieselben Variablen, aber wenn sie eine unterschiedliche Anzahl von Variablen haben, werden im Ergebnis alle Variablen mit fehlenden Werten für den kleineren Datensatz angezeigt.
Syntax
Die grundlegende Syntax für die SET-Anweisung in SAS lautet -
SET data-set 1 data-set 2 data-set 3.....;Es folgt die Beschreibung der verwendeten Parameter -
data-set1,data-set2 sind Datensatznamen, die nacheinander geschrieben werden.
Beispiel
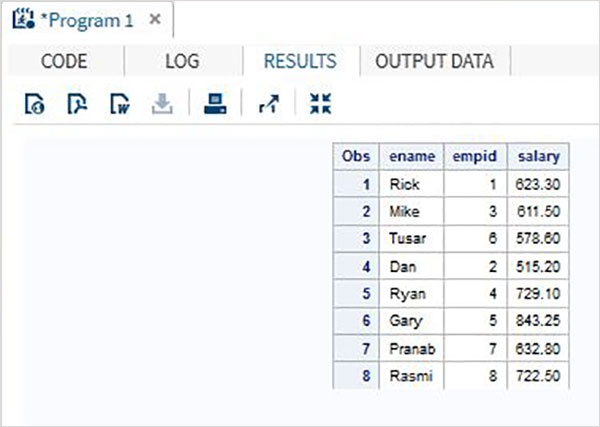
Betrachten Sie die Mitarbeiterdaten einer Organisation, die in zwei verschiedenen Datensätzen verfügbar sind, einer für die IT-Abteilung und einer für die Non-It-Abteilung. Um die vollständigen Details aller Mitarbeiter zu erhalten, verketten wir beide Datensätze mit der unten gezeigten SET-Anweisung.
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Wenn der obige Code ausgeführt wird, erhalten wir die folgende Ausgabe.
Szenarien
Wenn wir viele Variationen in den Datensätzen für die Verkettung haben, kann das Ergebnis von Variablen unterschiedlich sein, aber die Gesamtzahl der Beobachtungen im verketteten Datensatz ist immer die Summe der Beobachtungen in jedem Datensatz. Wir werden im Folgenden viele Szenarien zu dieser Variante betrachten.
Unterschiedliche Anzahl von Variablen
Wenn einer der Originaldatensätze mehr Variablen als ein anderer enthält, werden die Datensätze weiterhin kombiniert, aber im kleineren Datensatz erscheinen diese Variablen als fehlend.
Beispiel
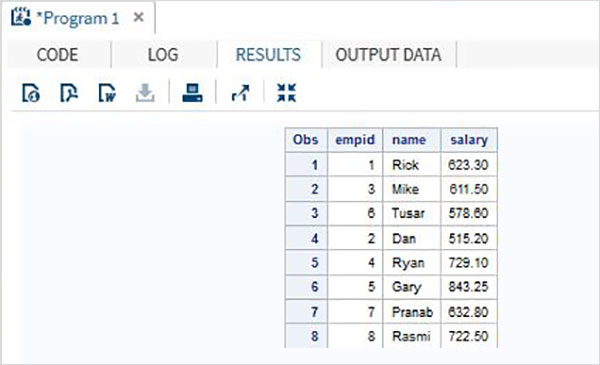
Im folgenden Beispiel enthält der erste Datensatz eine zusätzliche Variable mit dem Namen DOJ. Im Ergebnis erscheint der Wert von DOJ für den zweiten Datensatz als fehlend.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Wenn der obige Code ausgeführt wird, erhalten wir die folgende Ausgabe.

Anderer Variablenname
In diesem Szenario haben die Datensätze die gleiche Anzahl von Variablen, aber ein Variablenname unterscheidet sich zwischen ihnen. In diesem Fall erzeugt eine normale Verkettung alle Variablen in der Ergebnismenge und gibt fehlende Ergebnisse für die beiden Variablen, die sich unterscheiden. Während wir den Variablennamen in den Originaldatensätzen möglicherweise nicht ändern, können wir die RENAME-Funktion in dem von uns erstellten verketteten Datensatz anwenden. Dies führt zu demselben Ergebnis wie eine normale Verkettung, jedoch natürlich mit einem neuen Variablennamen anstelle von zwei verschiedenen Variablennamen, die im Originaldatensatz vorhanden sind.
Beispiel
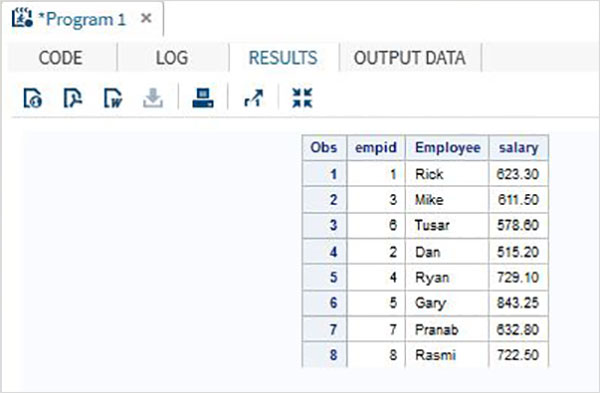
Im folgenden Beispieldatensatz hat ITDEPT den Variablennamen ename während der Datensatz NON_ITDEPT hat den Variablennamen empname.Beide Variablen repräsentieren jedoch denselben Typ (Zeichen). Wir wenden die anRENAME Funktion in der SET-Anweisung wie unten gezeigt.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;Wenn der obige Code ausgeführt wird, erhalten wir die folgende Ausgabe.
Unterschiedliche variable Längen
Wenn sich die Variablenlängen in den beiden Datensätzen von denen des verketteten Datensatzes unterscheiden, haben sie Werte, bei denen einige Daten für die Variable mit kleinerer Länge abgeschnitten werden. Es passiert, wenn der erste Datensatz eine kleinere Länge hat. Um dies zu lösen, wenden wir die höhere Länge auf beide Datensätze an, wie unten gezeigt.
Beispiel
Im folgenden Beispiel die Variable enamehat im ersten Datensatz die Länge 5 und im zweiten die Länge 7. Bei der Verkettung wenden wir die LENGTH-Anweisung im verketteten Datensatz an, um die Ename-Länge auf 7 zu setzen.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Wenn der obige Code ausgeführt wird, erhalten wir die folgende Ausgabe.