SAS - Häufigkeitsverteilungen
Eine Häufigkeitsverteilung ist eine Tabelle, die die Häufigkeit der Datenpunkte in einem Datensatz zeigt. Jeder Eintrag in der Tabelle enthält die Häufigkeit oder Anzahl des Auftretens von Werten innerhalb einer bestimmten Gruppe oder eines bestimmten Intervalls. Auf diese Weise fasst die Tabelle die Verteilung der Werte in der Stichprobe zusammen.
SAS bietet eine Prozedur namens PROC FREQ um die Häufigkeitsverteilung von Datenpunkten in einem Datensatz zu berechnen.
Syntax
Die grundlegende Syntax zur Berechnung der Häufigkeitsverteilung in SAS lautet -
PROC FREQ DATA = Dataset ;
TABLES Variable_1 ;
BY Variable_2 ;Es folgt die Beschreibung der verwendeten Parameter -
Dataset ist der Name des Datensatzes.
Variables_1 ist der Variablenname des Datensatzes, dessen Häufigkeitsverteilung berechnet werden muss.
Variables_2 sind die Variablen, die das Ergebnis der Häufigkeitsverteilung kategorisiert haben.
Einzelne variable Häufigkeitsverteilung
Wir können die Häufigkeitsverteilung einer einzelnen Variablen mithilfe von bestimmen PROC FREQ.In diesem Fall zeigt das Ergebnis die Häufigkeit jedes Werts der Variablen. Das Ergebnis zeigt auch die prozentuale Verteilung, die kumulative Häufigkeit und den kumulativen Prozentsatz.
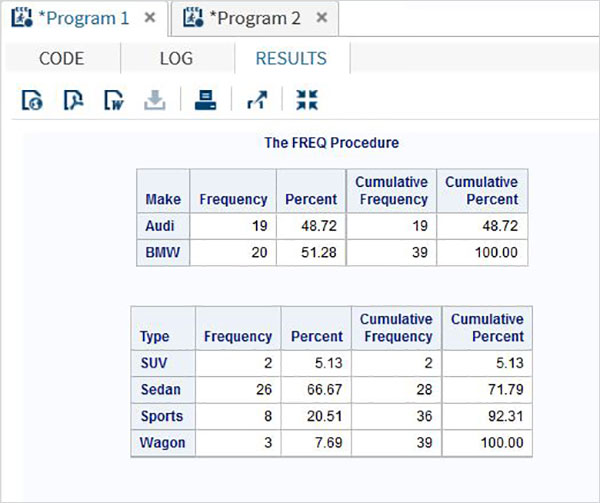
Beispiel
Im folgenden Beispiel finden wir die Häufigkeitsverteilung der variablen Leistung für den genannten Datensatz CARS1 welches aus der Bibliothek erstellt wird SASHELP.CARS.Wir können das Ergebnis in zwei Kategorien von Ergebnissen unterteilt sehen. Eine für jede Automarke.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;Wenn der obige Code ausgeführt wird, erhalten wir das folgende Ergebnis:

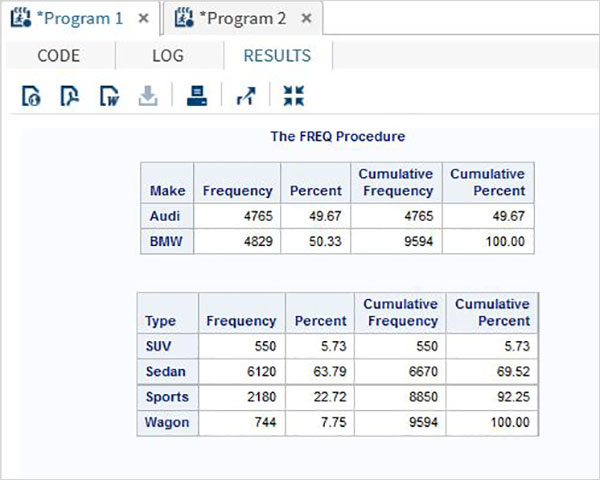
Mehrfachvariable Häufigkeitsverteilung
Wir können die Häufigkeitsverteilungen für mehrere Variablen finden, die sie in alle möglichen Kombinationen gruppieren.
Beispiel
Im folgenden Beispiel berechnen wir die Häufigkeitsverteilung für die Marke eines Autos für grouped by car type und auch die Häufigkeitsverteilung jedes Fahrzeugtyps grouped by each make.
proc FREQ data = CARS1 ;
tables make type;
run;Wenn der obige Code ausgeführt wird, erhalten wir das folgende Ergebnis:
Häufigkeitsverteilung mit Gewicht
Mit der Gewichtsoption können wir die Häufigkeitsverteilung berechnen, die mit dem Gewicht der Variablen verzerrt ist. Hier wird der Wert der Variablen als Anzahl der Beobachtungen anstelle der Anzahl der Werte verwendet.
Beispiel
Im folgenden Beispiel berechnen wir die Häufigkeitsverteilung der Variablen make und type mit dem der Leistung zugewiesenen Gewicht.
proc FREQ data = CARS1 ;
tables make type;
weight horsepower;
run;Wenn der obige Code ausgeführt wird, erhalten wir das folgende Ergebnis: