Spark SQL - Einführung
Spark führt ein Programmiermodul für die strukturierte Datenverarbeitung namens Spark SQL ein. Es bietet eine Programmierabstraktion namens DataFrame und kann als verteilte SQL-Abfrage-Engine fungieren.
Funktionen von Spark SQL
Im Folgenden sind die Funktionen von Spark SQL aufgeführt:
Integrated- Mischen Sie SQL-Abfragen nahtlos mit Spark-Programmen. Mit Spark SQL können Sie strukturierte Daten als verteiltes Dataset (RDD) in Spark mit integrierten APIs in Python, Scala und Java abfragen. Diese enge Integration erleichtert das Ausführen von SQL-Abfragen neben komplexen Analysealgorithmen.
Unified Data Access- Laden und Abfragen von Daten aus verschiedenen Quellen. Schema-RDDs bieten eine einzige Schnittstelle für die effiziente Arbeit mit strukturierten Daten, einschließlich Apache Hive-Tabellen, Parkettdateien und JSON-Dateien.
Hive Compatibility- Führen Sie unveränderte Hive-Abfragen für vorhandene Lager aus. Spark SQL verwendet das Hive-Frontend und den MetaStore erneut und bietet Ihnen so die vollständige Kompatibilität mit vorhandenen Hive-Daten, Abfragen und UDFs. Installieren Sie es einfach neben Hive.
Standard Connectivity- Stellen Sie eine Verbindung über JDBC oder ODBC her. Spark SQL enthält einen Servermodus mit JDBC- und ODBC-Konnektivität nach Industriestandard.
Scalability- Verwenden Sie dieselbe Engine für interaktive und lange Abfragen. Spark SQL nutzt das RDD-Modell, um die Fehlertoleranz bei mittleren Abfragen zu unterstützen und es auch auf große Jobs skalieren zu können. Machen Sie sich keine Sorgen, wenn Sie eine andere Engine für historische Daten verwenden.
Spark SQL-Architektur
Die folgende Abbildung erläutert die Architektur von Spark SQL -
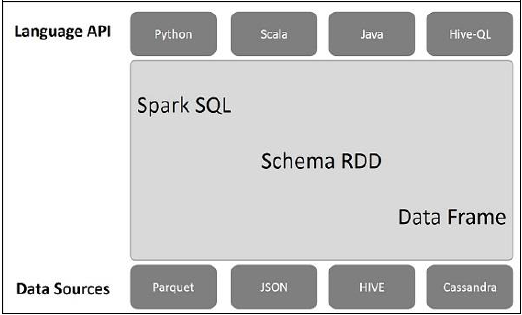
Diese Architektur enthält drei Ebenen: Sprach-API, Schema-RDD und Datenquellen.
Language API- Spark ist mit verschiedenen Sprachen und Spark SQL kompatibel. Es wird auch von dieser Sprach-API (Python, Scala, Java, HiveQL) unterstützt.
Schema RDD- Spark Core verfügt über eine spezielle Datenstruktur namens RDD. Im Allgemeinen funktioniert Spark SQL mit Schemas, Tabellen und Datensätzen. Daher können wir das Schema RDD als temporäre Tabelle verwenden. Wir können dieses Schema RDD als Datenrahmen bezeichnen.
Data Sources- Normalerweise ist die Datenquelle für Spark-Core eine Textdatei, eine Avro-Datei usw. Die Datenquellen für Spark SQL sind jedoch unterschiedlich. Dies sind Parkettdatei, JSON-Dokument, HIVE-Tabellen und Cassandra-Datenbank.
Wir werden in den folgenden Kapiteln mehr darüber diskutieren.