Spark SQL - Kurzanleitung
Branchen nutzen Hadoop in großem Umfang, um ihre Datensätze zu analysieren. Der Grund dafür ist, dass das Hadoop-Framework auf einem einfachen Programmiermodell (MapReduce) basiert und eine Computerlösung ermöglicht, die skalierbar, flexibel, fehlertolerant und kostengünstig ist. Hierbei besteht das Hauptanliegen darin, die Geschwindigkeit bei der Verarbeitung großer Datenmengen in Bezug auf die Wartezeit zwischen Abfragen und die Wartezeit für die Ausführung des Programms aufrechtzuerhalten.
Spark wurde von der Apache Software Foundation eingeführt, um den Prozess der Hadoop-Computercomputersoftware zu beschleunigen.
Gegen einen allgemeinen Glauben, Spark is not a modified version of Hadoopund ist nicht wirklich von Hadoop abhängig, da es über eine eigene Clusterverwaltung verfügt. Hadoop ist nur eine der Möglichkeiten, Spark zu implementieren.
Spark verwendet Hadoop auf zwei Arten - eine ist storage und zweitens ist processing. Da Spark über eine eigene Clusterverwaltungsberechnung verfügt, wird Hadoop nur zu Speicherzwecken verwendet.
Apache Spark
Apache Spark ist eine blitzschnelle Cluster-Computing-Technologie, die für schnelle Berechnungen entwickelt wurde. Es basiert auf Hadoop MapReduce und erweitert das MapReduce-Modell, um es effizient für weitere Arten von Berechnungen zu verwenden, einschließlich interaktiver Abfragen und Stream-Verarbeitung. Das Hauptmerkmal von Spark ist seinein-memory cluster computing das erhöht die Verarbeitungsgeschwindigkeit einer Anwendung.
Spark wurde entwickelt, um eine breite Palette von Workloads abzudecken, z. B. Batch-Anwendungen, iterative Algorithmen, interaktive Abfragen und Streaming. Neben der Unterstützung all dieser Workloads in einem entsprechenden System wird der Verwaltungsaufwand für die Wartung separater Tools verringert.
Entwicklung von Apache Spark
Spark ist eines von Hadoops Teilprojekten, das 2009 von Matei Zaharia in AMPLab von UC Berkeley entwickelt wurde. Es war Open Sourced im Jahr 2010 unter einer BSD-Lizenz. Es wurde 2013 an die Apache Software Foundation gespendet und jetzt ist Apache Spark seit Februar 2014 ein Apache-Projekt auf höchstem Niveau.
Funktionen von Apache Spark
Apache Spark verfügt über folgende Funktionen.
Speed- Spark hilft beim Ausführen einer Anwendung im Hadoop-Cluster, bis zu 100-mal schneller im Speicher und 10-mal schneller, wenn sie auf der Festplatte ausgeführt wird. Dies ist möglich, indem die Anzahl der Lese- / Schreibvorgänge auf die Festplatte reduziert wird. Es speichert die Zwischenverarbeitungsdaten im Speicher.
Supports multiple languages- Spark bietet integrierte APIs in Java, Scala oder Python. Daher können Sie Anwendungen in verschiedenen Sprachen schreiben. Spark bietet 80 übergeordnete Operatoren für interaktive Abfragen.
Advanced Analytics- Spark unterstützt nicht nur 'Map' und 'Reduce'. Es unterstützt auch SQL-Abfragen, Streaming-Daten, maschinelles Lernen (ML) und Graph-Algorithmen.
Funke auf Hadoop gebaut
Das folgende Diagramm zeigt drei Möglichkeiten, wie Spark mit Hadoop-Komponenten erstellt werden kann.
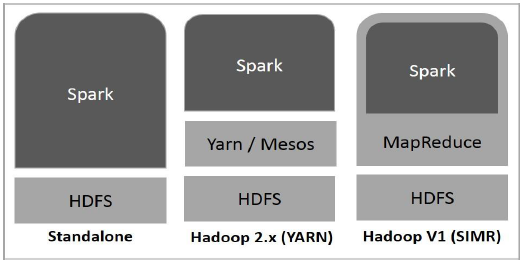
Es gibt drei Möglichkeiten der Spark-Bereitstellung, wie unten erläutert.
Standalone- Spark Standalone-Bereitstellung bedeutet, dass Spark den Platz über HDFS (Hadoop Distributed File System) einnimmt und explizit Speicherplatz für HDFS zugewiesen wird. Hier werden Spark und MapReduce nebeneinander ausgeführt, um alle Spark-Jobs im Cluster abzudecken.
Hadoop Yarn- Die Bereitstellung von Hadoop Yarn bedeutet einfach, dass Spark auf Yarn ausgeführt wird, ohne dass eine Vorinstallation oder ein Root-Zugriff erforderlich ist. Es hilft, Spark in das Hadoop-Ökosystem oder den Hadoop-Stack zu integrieren. Dadurch können andere Komponenten auf dem Stapel ausgeführt werden.
Spark in MapReduce (SIMR)- Spark in MapReduce wird verwendet, um zusätzlich zur eigenständigen Bereitstellung einen Spark-Job zu starten. Mit SIMR kann der Benutzer Spark starten und seine Shell ohne Administratorzugriff verwenden.
Komponenten von Spark
Die folgende Abbildung zeigt die verschiedenen Komponenten von Spark.
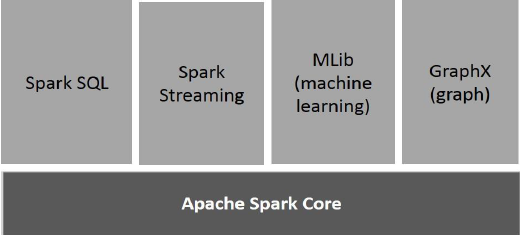
Apache Spark Core
Spark Core ist die zugrunde liegende allgemeine Ausführungs-Engine für die Spark-Plattform, auf der alle anderen Funktionen aufbauen. Es bietet In-Memory-Computing und Referenzierungsdatensätze in externen Speichersystemen.
Spark SQL
Spark SQL ist eine Komponente auf Spark Core, die eine neue Datenabstraktion namens SchemaRDD einführt, die strukturierte und halbstrukturierte Daten unterstützt.
Spark Streaming
Spark Streaming nutzt die schnelle Planungsfunktion von Spark Core, um Streaming-Analysen durchzuführen. Es nimmt Daten in Mini-Batches auf und führt RDD-Transformationen (Resilient Distributed Datasets) für diese Mini-Datenstapel durch.
MLlib (Bibliothek für maschinelles Lernen)
MLlib ist aufgrund der verteilten speicherbasierten Spark-Architektur ein Framework für verteiltes maschinelles Lernen über Spark. Laut Benchmarks wird dies von den MLlib-Entwicklern gegen die ALS-Implementierungen (Alternating Least Squares) durchgeführt. Spark MLlib ist neunmal so schnell wie die Hadoop-Version vonApache Mahout (bevor Mahout eine Spark-Schnittstelle erhielt).
GraphX
GraphX ist ein verteiltes Framework für die Grafikverarbeitung, das auf Spark aufbaut. Es bietet eine API zum Ausdrücken der Diagrammberechnung, mit der die benutzerdefinierten Diagramme mithilfe der Pregel-Abstraktions-API modelliert werden können. Es bietet auch eine optimierte Laufzeit für diese Abstraktion.
Ausfallsichere verteilte Datensätze
Resilient Distributed Datasets (RDD) ist eine grundlegende Datenstruktur von Spark. Es ist eine unveränderliche verteilte Sammlung von Objekten. Jeder Datensatz in RDD ist in logische Partitionen unterteilt, die auf verschiedenen Knoten des Clusters berechnet werden können. RDDs können alle Arten von Python-, Java- oder Scala-Objekten enthalten, einschließlich benutzerdefinierter Klassen.
Formal ist eine RDD eine schreibgeschützte, partitionierte Sammlung von Datensätzen. RDDs können durch deterministische Operationen entweder für Daten in einem stabilen Speicher oder für andere RDDs erstellt werden. RDD ist eine fehlertolerante Sammlung von Elementen, die parallel bearbeitet werden können.
Es gibt zwei Möglichkeiten, RDDs zu erstellen: parallelizing eine vorhandene Sammlung in Ihrem Treiberprogramm oder referencing a dataset in einem externen Speichersystem, z. B. einem gemeinsam genutzten Dateisystem, HDFS, HBase oder einer Datenquelle, die ein Hadoop-Eingabeformat bietet.
Spark nutzt das RDD-Konzept, um schnellere und effizientere MapReduce-Vorgänge zu erzielen. Lassen Sie uns zunächst diskutieren, wie MapReduce-Vorgänge stattfinden und warum sie nicht so effizient sind.
Die Datenfreigabe in MapReduce ist langsam
MapReduce wird häufig zum Verarbeiten und Generieren großer Datenmengen mit einem parallelen, verteilten Algorithmus in einem Cluster eingesetzt. Benutzer können parallele Berechnungen mit einer Reihe von übergeordneten Operatoren schreiben, ohne sich um die Arbeitsverteilung und die Fehlertoleranz kümmern zu müssen.
Leider besteht in den meisten aktuellen Frameworks die einzige Möglichkeit, Daten zwischen Berechnungen (z. B. zwischen zwei MapReduce-Jobs) wiederzuverwenden, darin, sie in ein externes stabiles Speichersystem (z. B. HDFS) zu schreiben. Obwohl dieses Framework zahlreiche Abstraktionen für den Zugriff auf die Rechenressourcen eines Clusters bietet, möchten Benutzer immer noch mehr.
Beide Iterative und InteractiveAnwendungen erfordern eine schnellere gemeinsame Nutzung von Daten über parallele Jobs hinweg. Der Datenaustausch in MapReduce ist aufgrund von langsamreplication, serialization, und disk IO. In Bezug auf das Speichersystem verbringen die meisten Hadoop-Anwendungen mehr als 90% der Zeit mit HDFS-Lese- / Schreibvorgängen.
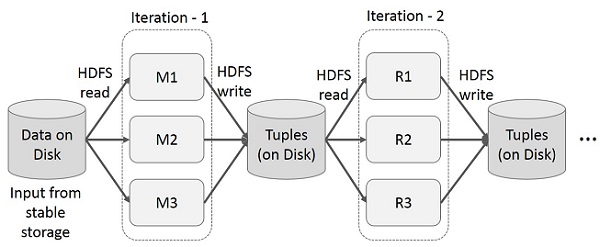
Iterative Operationen auf MapReduce
Zwischenergebnisse für mehrere Berechnungen in mehrstufigen Anwendungen wiederverwenden. In der folgenden Abbildung wird erläutert, wie das aktuelle Framework funktioniert, während die iterativen Operationen in MapReduce ausgeführt werden. Dies verursacht aufgrund der Datenreplikation, der Festplatten-E / A und der Serialisierung einen erheblichen Overhead, wodurch das System langsam wird.
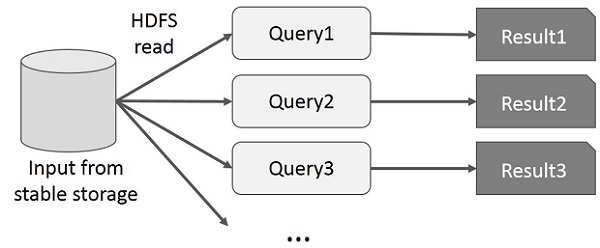
Interaktive Operationen auf MapReduce
Der Benutzer führt Ad-hoc-Abfragen für dieselbe Teilmenge von Daten aus. Bei jeder Abfrage werden die Festplatten-E / A im stabilen Speicher ausgeführt, wodurch die Ausführungszeit der Anwendung dominiert werden kann.
In der folgenden Abbildung wird erläutert, wie das aktuelle Framework beim Ausführen der interaktiven Abfragen in MapReduce funktioniert.
Datenfreigabe mit Spark RDD
Der Datenaustausch in MapReduce ist aufgrund von langsam replication, serialization, und disk IO. Die meisten Hadoop-Anwendungen verbringen mehr als 90% der Zeit mit HDFS-Lese- / Schreibvorgängen.
Um dieses Problem zu erkennen, entwickelten die Forscher ein spezielles Framework namens Apache Spark. Die Schlüsselidee von Funken istResilient Dverteilt wird DAtasets (RDD); Es unterstützt die Berechnung der In-Memory-Verarbeitung. Dies bedeutet, dass der Speicherstatus als Objekt über die Jobs hinweg gespeichert wird und das Objekt zwischen diesen Jobs gemeinsam genutzt werden kann. Die gemeinsame Nutzung von Daten im Speicher ist 10 bis 100 Mal schneller als bei Netzwerk und Festplatte.
Versuchen wir nun herauszufinden, wie iterative und interaktive Operationen in Spark RDD stattfinden.
Iterative Operationen auf Spark RDD
Die folgende Abbildung zeigt die iterativen Operationen für Spark RDD. Es speichert Zwischenergebnisse in einem verteilten Speicher anstelle eines stabilen Speichers (Festplatte) und beschleunigt das System.
Note - Wenn der verteilte Speicher (RAM) ausreicht, um Zwischenergebnisse (Status des JOB) zu speichern, werden diese Ergebnisse auf der Festplatte gespeichert
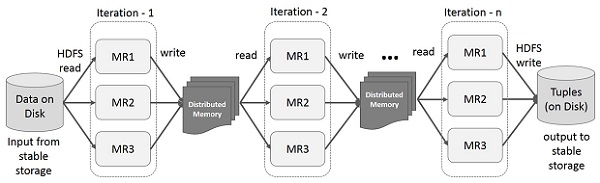
Interaktive Operationen auf Spark RDD
Diese Abbildung zeigt interaktive Vorgänge auf Spark RDD. Wenn verschiedene Abfragen wiederholt für denselben Datensatz ausgeführt werden, können diese bestimmten Daten für bessere Ausführungszeiten im Speicher gespeichert werden.

Standardmäßig kann jede transformierte RDD jedes Mal neu berechnet werden, wenn Sie eine Aktion darauf ausführen. Sie können jedoch auchpersisteine RDD im Speicher. In diesem Fall behält Spark die Elemente im Cluster bei, um beim nächsten Abfragen einen viel schnelleren Zugriff zu ermöglichen. Es gibt auch Unterstützung für persistente RDDs auf der Festplatte oder für die Replikation über mehrere Knoten.
Spark ist das Teilprojekt von Hadoop. Daher ist es besser, Spark auf einem Linux-basierten System zu installieren. Die folgenden Schritte zeigen, wie Sie Apache Spark installieren.
Schritt 1: Überprüfen der Java-Installation
Die Java-Installation ist eines der obligatorischen Dinge bei der Installation von Spark. Versuchen Sie den folgenden Befehl, um die JAVA-Version zu überprüfen.
$java -versionWenn Java bereits auf Ihrem System installiert ist, wird die folgende Antwort angezeigt:
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Wenn auf Ihrem System kein Java installiert ist, installieren Sie Java, bevor Sie mit dem nächsten Schritt fortfahren.
Schritt 2: Überprüfen der Scala-Installation
Sie sollten die Scala-Sprache verwenden, um Spark zu implementieren. Lassen Sie uns die Scala-Installation mit dem folgenden Befehl überprüfen.
$scala -versionWenn Scala bereits auf Ihrem System installiert ist, wird die folgende Antwort angezeigt:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLWenn Sie Scala nicht auf Ihrem System installiert haben, fahren Sie mit dem nächsten Schritt für die Scala-Installation fort.
Schritt 3: Scala herunterladen
Laden Sie die neueste Version von Scala herunter, indem Sie den folgenden Link herunterladen: Scala herunterladen . Für dieses Tutorial verwenden wir die Version scala-2.11.6. Nach dem Download finden Sie die Scala-TAR-Datei im Download-Ordner.
Schritt 4: Scala installieren
Befolgen Sie die unten angegebenen Schritte zur Installation von Scala.
Extrahieren Sie die Scala-TAR-Datei
Geben Sie den folgenden Befehl zum Extrahieren der Scala-TAR-Datei ein.
$ tar xvf scala-2.11.6.tgzVerschieben Sie Scala-Softwaredateien
Verwenden Sie die folgenden Befehle, um die Scala-Softwaredateien in das entsprechende Verzeichnis zu verschieben (/usr/local/scala).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exitStellen Sie PATH für Scala ein
Verwenden Sie den folgenden Befehl, um PATH für Scala festzulegen.
$ export PATH = $PATH:/usr/local/scala/binÜberprüfen der Scala-Installation
Nach der Installation ist es besser, dies zu überprüfen. Verwenden Sie den folgenden Befehl, um die Scala-Installation zu überprüfen.
$scala -versionWenn Scala bereits auf Ihrem System installiert ist, wird die folgende Antwort angezeigt:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLSchritt 5: Herunterladen von Apache Spark
Laden Sie die neueste Version von Spark herunter, indem Sie den folgenden Link herunterladen: Spark herunterladen . Für dieses Tutorial verwenden wirspark-1.3.1-bin-hadoop2.6Ausführung. Nach dem Herunterladen finden Sie die Spark-Tar-Datei im Download-Ordner.
Schritt 6: Spark installieren
Führen Sie die folgenden Schritte aus, um Spark zu installieren.
Funken-Teer extrahieren
Der folgende Befehl zum Extrahieren der Spark-Tar-Datei.
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgzVerschieben von Spark-Softwaredateien
Die folgenden Befehle zum Verschieben der Spark-Softwaredateien in das entsprechende Verzeichnis (/usr/local/spark).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exitEinrichten der Umgebung für Spark
Fügen Sie die folgende Zeile zu ~ hinzu/.bashrcDatei. Dies bedeutet, dass der PATH-Variablen der Speicherort hinzugefügt wird, an dem sich die Spark-Softwaredatei befindet.
export PATH = $PATH:/usr/local/spark/binVerwenden Sie den folgenden Befehl, um die Datei ~ / .bashrc zu beziehen.
$ source ~/.bashrcSchritt 7: Überprüfen der Spark-Installation
Schreiben Sie den folgenden Befehl zum Öffnen der Spark-Shell.
$spark-shellWenn der Funke erfolgreich installiert wurde, finden Sie die folgende Ausgabe.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Spark führt ein Programmiermodul für die strukturierte Datenverarbeitung namens Spark SQL ein. Es bietet eine Programmierabstraktion namens DataFrame und kann als verteilte SQL-Abfrage-Engine fungieren.
Funktionen von Spark SQL
Im Folgenden sind die Funktionen von Spark SQL aufgeführt:
Integrated- Mischen Sie SQL-Abfragen nahtlos mit Spark-Programmen. Mit Spark SQL können Sie strukturierte Daten als verteiltes Dataset (RDD) in Spark mit integrierten APIs in Python, Scala und Java abfragen. Diese enge Integration erleichtert das Ausführen von SQL-Abfragen neben komplexen Analysealgorithmen.
Unified Data Access- Laden und Abfragen von Daten aus verschiedenen Quellen. Schema-RDDs bieten eine einzige Schnittstelle für die effiziente Arbeit mit strukturierten Daten, einschließlich Apache Hive-Tabellen, Parkettdateien und JSON-Dateien.
Hive Compatibility- Führen Sie unveränderte Hive-Abfragen für vorhandene Lager aus. Spark SQL verwendet das Hive-Frontend und den MetaStore erneut und bietet Ihnen so die vollständige Kompatibilität mit vorhandenen Hive-Daten, Abfragen und UDFs. Installieren Sie es einfach neben Hive.
Standard Connectivity- Stellen Sie eine Verbindung über JDBC oder ODBC her. Spark SQL enthält einen Servermodus mit JDBC- und ODBC-Konnektivität nach Industriestandard.
Scalability- Verwenden Sie dieselbe Engine für interaktive und lange Abfragen. Spark SQL nutzt das RDD-Modell, um die Fehlertoleranz bei mittleren Abfragen zu unterstützen und es auch auf große Jobs skalieren zu können. Machen Sie sich keine Sorgen, wenn Sie eine andere Engine für historische Daten verwenden.
Spark SQL-Architektur
Die folgende Abbildung erläutert die Architektur von Spark SQL -
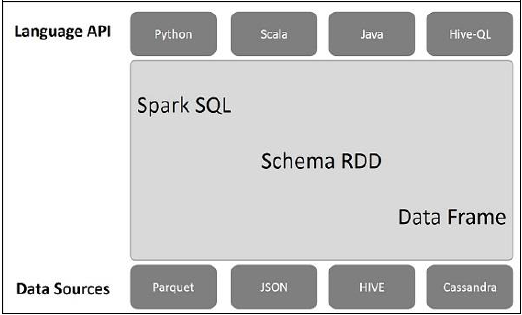
Diese Architektur enthält drei Ebenen: Sprach-API, Schema-RDD und Datenquellen.
Language API- Spark ist mit verschiedenen Sprachen und Spark SQL kompatibel. Es wird auch von dieser Sprach-API (Python, Scala, Java, HiveQL) unterstützt.
Schema RDD- Spark Core verfügt über eine spezielle Datenstruktur namens RDD. Im Allgemeinen funktioniert Spark SQL mit Schemas, Tabellen und Datensätzen. Daher können wir das Schema RDD als temporäre Tabelle verwenden. Wir können dieses Schema RDD als Datenrahmen bezeichnen.
Data Sources- Normalerweise ist die Datenquelle für Spark-Core eine Textdatei, eine Avro-Datei usw. Die Datenquellen für Spark SQL sind jedoch unterschiedlich. Dies sind Parkettdatei, JSON-Dokument, HIVE-Tabellen und Cassandra-Datenbank.
Wir werden in den folgenden Kapiteln mehr darüber diskutieren.
Ein DataFrame ist eine verteilte Sammlung von Daten, die in benannten Spalten organisiert ist. Konzeptionell entspricht es relationalen Tabellen mit guten Optimierungstechniken.
Ein DataFrame kann aus einer Reihe verschiedener Quellen wie Hive-Tabellen, strukturierten Datendateien, externen Datenbanken oder vorhandenen RDDs erstellt werden. Diese API wurde für moderne Big Data- und Data Science-Anwendungen entwickelt, die sich von diesen inspirieren lassenDataFrame in R Programming und Pandas in Python.
Funktionen von DataFrame
Hier sind einige charakteristische Merkmale von DataFrame:
Möglichkeit, die Daten in der Größe von Kilobyte bis Petabyte auf einem einzelnen Knotencluster zu einem großen Cluster zu verarbeiten.
Unterstützt verschiedene Datenformate (Avro, CSV, elastische Suche und Cassandra) und Speichersysteme (HDFS, HIVE-Tabellen, MySQL usw.).
Modernste Optimierung und Codegenerierung mit dem Spark SQL Catalyst-Optimierer (Tree Transformation Framework).
Kann über Spark-Core problemlos in alle Big Data-Tools und -Frameworks integriert werden.
Bietet API für Python-, Java-, Scala- und R-Programmierung.
SQLContext
SQLContext ist eine Klasse und wird zum Initialisieren der Funktionen von Spark SQL verwendet. Das SparkContext-Klassenobjekt (sc) wird zum Initialisieren des SQLContext-Klassenobjekts benötigt.
Der folgende Befehl wird zum Initialisieren des SparkContext über die Spark-Shell verwendet.
$ spark-shellStandardmäßig wird das SparkContext-Objekt mit dem Namen initialisiert sc wenn die Funkenschale startet.
Verwenden Sie den folgenden Befehl, um SQLContext zu erstellen.
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)Beispiel
Betrachten wir ein Beispiel für Mitarbeiterdatensätze in einer JSON-Datei mit dem Namen employee.json. Verwenden Sie die folgenden Befehle, um einen DataFrame (df) zu erstellen und ein JSON-Dokument mit dem Namen zu lesenemployee.json mit folgendem Inhalt.
employee.json - Legen Sie diese Datei in dem Verzeichnis ab, in dem sich die aktuelle befindet scala> Zeiger befindet sich.
{
{"id" : "1201", "name" : "satish", "age" : "25"}
{"id" : "1202", "name" : "krishna", "age" : "28"}
{"id" : "1203", "name" : "amith", "age" : "39"}
{"id" : "1204", "name" : "javed", "age" : "23"}
{"id" : "1205", "name" : "prudvi", "age" : "23"}
}DataFrame-Operationen
DataFrame bietet eine domänenspezifische Sprache für die strukturierte Datenmanipulation. Hier finden Sie einige grundlegende Beispiele für die strukturierte Datenverarbeitung mit DataFrames.
Führen Sie die folgenden Schritte aus, um DataFrame-Vorgänge auszuführen.
Lesen Sie das JSON-Dokument
Zuerst müssen wir das JSON-Dokument lesen. Generieren Sie darauf basierend einen DataFrame mit dem Namen (dfs).
Verwenden Sie den folgenden Befehl, um das genannte JSON-Dokument zu lesen employee.json. Die Daten werden als Tabelle mit den Feldern ID, Name und Alter angezeigt.
scala> val dfs = sqlContext.read.json("employee.json")Output - Die Feldnamen werden automatisch übernommen employee.json.
dfs: org.apache.spark.sql.DataFrame = [age: string, id: string, name: string]Zeigen Sie die Daten an
Wenn Sie die Daten im DataFrame anzeigen möchten, verwenden Sie den folgenden Befehl.
scala> dfs.show()Output - Sie können die Mitarbeiterdaten in Tabellenform anzeigen.
<console>:22, took 0.052610 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
| 23 | 1204 | javed |
| 23 | 1205 | prudvi |
+----+------+--------+Verwenden Sie die printSchema-Methode
Wenn Sie die Struktur (das Schema) des DataFrame anzeigen möchten, verwenden Sie den folgenden Befehl.
scala> dfs.printSchema()Output
root
|-- age: string (nullable = true)
|-- id: string (nullable = true)
|-- name: string (nullable = true)Verwenden Sie die Auswahlmethode
Verwenden Sie zum Abrufen den folgenden Befehl name-Spalte unter drei Spalten aus dem DataFrame.
scala> dfs.select("name").show()Output - Sie können die Werte der sehen name Säule.
<console>:22, took 0.044023 s
+--------+
| name |
+--------+
| satish |
| krishna|
| amith |
| javed |
| prudvi |
+--------+Verwenden Sie den Altersfilter
Verwenden Sie den folgenden Befehl, um die Mitarbeiter zu finden, deren Alter größer als 23 Jahre ist (Alter> 23 Jahre).
scala> dfs.filter(dfs("age") > 23).show()Output
<console>:22, took 0.078670 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
+----+------+--------+Verwenden Sie die groupBy-Methode
Verwenden Sie den folgenden Befehl, um die Anzahl der gleichaltrigen Mitarbeiter zu zählen.
scala> dfs.groupBy("age").count().show()Output - Zwei Mitarbeiter sind 23 Jahre alt.
<console>:22, took 5.196091 s
+----+-----+
|age |count|
+----+-----+
| 23 | 2 |
| 25 | 1 |
| 28 | 1 |
| 39 | 1 |
+----+-----+Programmgesteuertes Ausführen von SQL-Abfragen
Ein SQLContext ermöglicht es Anwendungen, SQL-Abfragen programmgesteuert auszuführen, während SQL-Funktionen ausgeführt werden, und gibt das Ergebnis als DataFrame zurück.
Im Hintergrund unterstützt SparkSQL im Allgemeinen zwei verschiedene Methoden zum Konvertieren vorhandener RDDs in DataFrames:
| Sr. Nr | Methoden & Beschreibung |
|---|---|
| 1 | Ableiten des Schemas mithilfe von Reflection Diese Methode generiert mithilfe der Reflexion das Schema einer RDD, die bestimmte Objekttypen enthält. |
| 2 | Programmgesteuertes Festlegen des Schemas Die zweite Methode zum Erstellen von DataFrame ist die programmgesteuerte Schnittstelle, mit der Sie ein Schema erstellen und dann auf eine vorhandene RDD anwenden können. |
Über eine DataFrame-Schnittstelle können verschiedene DataSources mit Spark SQL arbeiten. Es ist eine temporäre Tabelle und kann als normales RDD betrieben werden. Durch Registrieren eines DataFrame als Tabelle können Sie SQL-Abfragen über seine Daten ausführen.
In diesem Kapitel werden die allgemeinen Methoden zum Laden und Speichern von Daten mit verschiedenen Spark DataSources beschrieben. Anschließend werden wir die spezifischen Optionen, die für die integrierten Datenquellen verfügbar sind, ausführlich erörtern.
In SparkSQL stehen verschiedene Arten von Datenquellen zur Verfügung, von denen einige unten aufgeführt sind.
| Sr. Nr | Datenquellen |
|---|---|
| 1 | JSON-Datensätze Spark SQL kann das Schema eines JSON-Datasets automatisch erfassen und als DataFrame laden. |
| 2 | Bienenstocktische Hive wird mit der Spark-Bibliothek als HiveContext geliefert, der von SQLContext erbt. |
| 3 | Parkettdateien Parkett ist ein Spaltenformat, das von vielen Datenverarbeitungssystemen unterstützt wird. |