Splunk - Kurzanleitung
Splunk ist eine Software, die Maschinendaten und andere Formen von Big Data verarbeitet und Erkenntnisse daraus gewinnt. Diese Maschinendaten werden von der CPU generiert, auf der ein Webserver, IOT-Geräte, Protokolle von mobilen Apps usw. ausgeführt werden. Es ist nicht erforderlich, diese Daten den Endbenutzern bereitzustellen, und sie haben keine geschäftliche Bedeutung. Sie sind jedoch äußerst wichtig, um die Leistung der Maschinen zu verstehen, zu überwachen und zu optimieren.
Splunk kann diese unstrukturierten, halbstrukturierten oder selten strukturierten Daten lesen. Nach dem Lesen der Daten können diese Daten gesucht, markiert, Berichte und Dashboards erstellt werden. Mit dem Aufkommen von Big Data ist Splunk nun in der Lage, Big Data aus verschiedenen Quellen aufzunehmen, bei denen es sich möglicherweise um Maschinendaten handelt, und Analysen für Big Data durchzuführen.
Von einem einfachen Tool für die Protokollanalyse hat sich Splunk zu einem allgemeinen Analysetool für unstrukturierte Maschinendaten und verschiedene Formen von Big Data entwickelt.
Produktkategorien
Splunk ist in drei verschiedenen Produktkategorien erhältlich:
Splunk Enterprise- Es wird von Unternehmen verwendet, die über eine große IT-Infrastruktur und ein IT-gesteuertes Geschäft verfügen. Es hilft beim Sammeln und Analysieren der Daten von Websites, Anwendungen, Geräten und Sensoren usw.
Splunk Cloud- Es handelt sich um die in der Cloud gehostete Plattform mit denselben Funktionen wie die Unternehmensversion. Es kann von Splunk selbst oder über die AWS Cloud-Plattform verwendet werden.
Splunk Light- Es ermöglicht die Suche, Berichterstellung und Benachrichtigung aller Protokolldaten in Echtzeit von einem Ort aus. Es verfügt im Vergleich zu den beiden anderen Versionen über eingeschränkte Funktionen und Merkmale.
Splunk-Funktionen
In diesem Abschnitt werden wir die wichtigen Funktionen der Enterprise Edition diskutieren -
Datenaufnahme
Splunk kann eine Vielzahl von Datenformaten wie JSON, XML und unstrukturierte Maschinendaten wie Web- und Anwendungsprotokolle aufnehmen. Die unstrukturierten Daten können nach Bedarf vom Benutzer in eine Datenstruktur modelliert werden.
Datenindizierung
Die aufgenommenen Daten werden von Splunk indiziert, um unter verschiedenen Bedingungen schneller suchen und abfragen zu können.
Datensuche
Bei der Suche in Splunk werden die indizierten Daten verwendet, um Metriken zu erstellen, zukünftige Trends vorherzusagen und Muster in den Daten zu identifizieren.
Verwenden von Warnungen
Splunk-Warnungen können verwendet werden, um E-Mails oder RSS-Feeds auszulösen, wenn in den zu analysierenden Daten bestimmte Kriterien gefunden werden.
Dashboards
Splunk-Dashboards können die Suchergebnisse in Form von Diagrammen, Berichten und Drehpunkten usw. anzeigen.
Datenmodell
Die indizierten Daten können in einen oder mehrere Datensätze modelliert werden, die auf spezialisiertem Domänenwissen basieren. Dies führt zu einer einfacheren Navigation durch die Endbenutzer, die die Geschäftsfälle analysieren, ohne die technischen Details der von Splunk verwendeten Suchverarbeitungssprache zu kennen.
In diesem Tutorial wollen wir die Enterprise-Version installieren. Diese Version steht für eine kostenlose Testversion für 60 Tage zur Verfügung, wobei alle Funktionen aktiviert sind. Sie können das Setup über den folgenden Link herunterladen, der sowohl für Windows- als auch für Linux-Plattformen verfügbar ist.
https://www.splunk.com/en_us/download/splunk-enterprise.html.
Linux-Version
Die Linux-Version wird über den oben angegebenen Download-Link heruntergeladen. Wir wählen den Pakettyp .deb, da die Installation auf einer Ubuntu-Plattform erfolgt.
Wir werden dies Schritt für Schritt lernen -
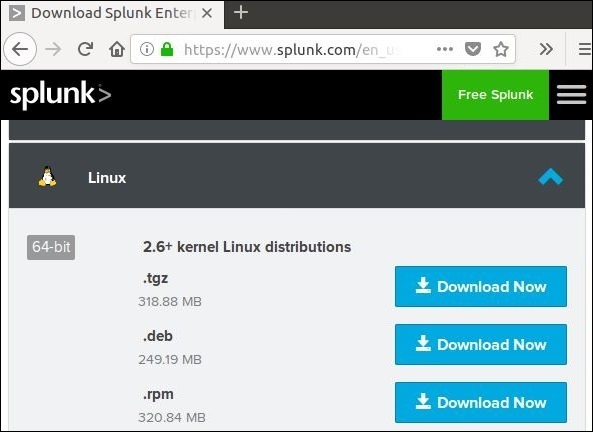
Schritt 1
Laden Sie das .deb-Paket herunter, wie im folgenden Screenshot gezeigt -
Schritt 2
Gehen Sie zum Download-Verzeichnis und installieren Sie Splunk mit dem oben heruntergeladenen Paket.
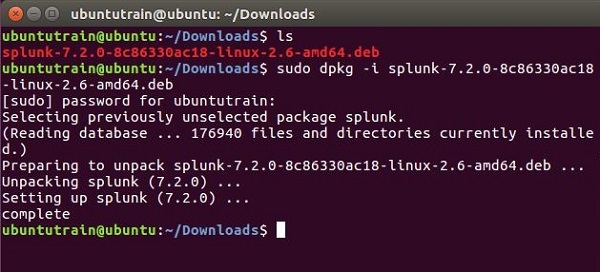
Schritt 3
Als nächstes können Sie Splunk starten, indem Sie den folgenden Befehl mit dem Argument accept accept verwenden. Sie werden nach dem Benutzernamen und dem Kennwort des Administrators gefragt, die Sie angeben und speichern sollten.
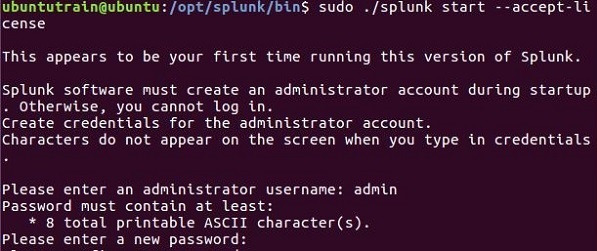
Schritt 4
Der Splunk-Server startet und erwähnt die URL, über die auf die Splunk-Schnittstelle zugegriffen werden kann.
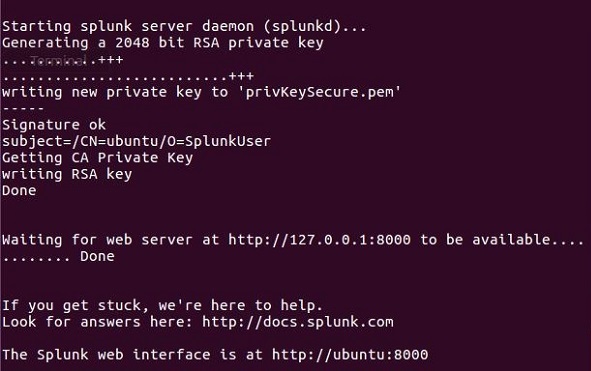
Schritt 5
Jetzt können Sie auf die Splunk-URL zugreifen und die in Schritt 3 erstellte Administrator-Benutzer-ID und das Kennwort eingeben.

Windows-Version
Die Windows-Version ist als MSI-Installationsprogramm verfügbar (siehe Abbildung unten).
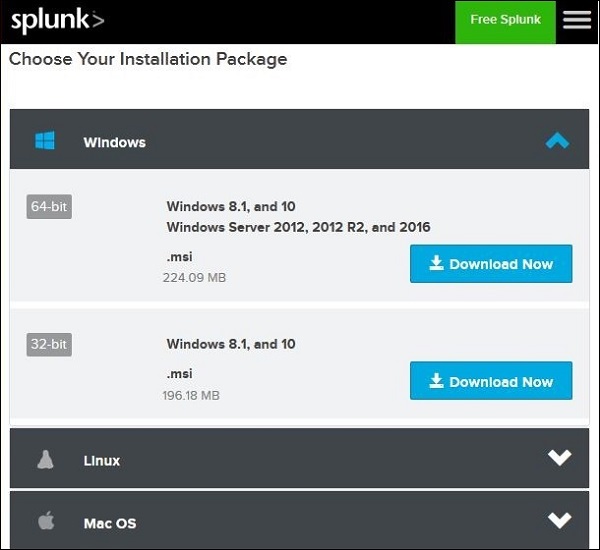
Ein Doppelklick auf das MSI-Installationsprogramm installiert die Windows-Version in einem einfachen Prozess. Die zwei wichtigen Schritte, in denen wir die richtige Wahl für eine erfolgreiche Installation treffen müssen, sind folgende.
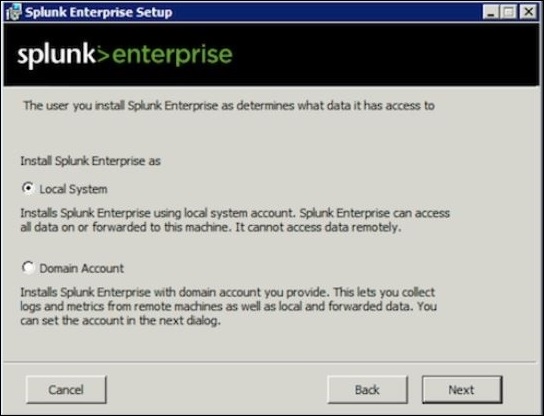
Schritt 1
Wählen Sie bei der Installation auf einem lokalen System die unten angegebene Option für das lokale System aus.
Schritt 2
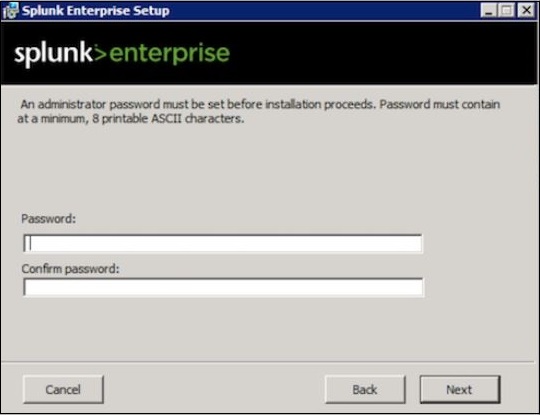
Geben Sie das Kennwort für den Administrator ein und merken Sie es sich, da es in zukünftigen Konfigurationen verwendet wird.
Schritt 3
Im letzten Schritt sehen wir, dass Splunk erfolgreich installiert wurde und über den Webbrowser gestartet werden kann.

Schritt 4
Öffnen Sie anschließend den Browser und geben Sie die angegebene URL ein. http://localhost:8000und melden Sie sich mit der Administrator-Benutzer-ID und dem Kennwort beim Splunk an.

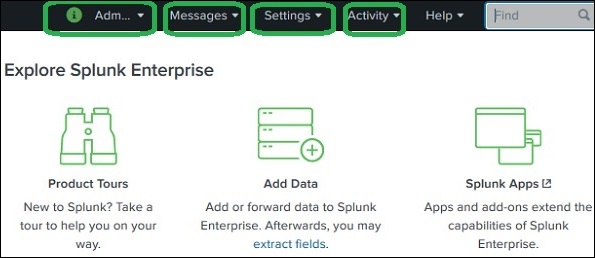
Die Splunk-Weboberfläche besteht aus allen Tools, die Sie zum Suchen, Berichten und Analysieren der aufgenommenen Daten benötigen. Dieselbe Weboberfläche bietet Funktionen zum Verwalten der Benutzer und ihrer Rollen. Es enthält auch Links für die Datenaufnahme und die in Splunk verfügbaren integrierten Apps.
Das folgende Bild zeigt den Startbildschirm nach Ihrer Anmeldung bei Splunk mit den Administratoranmeldeinformationen.
Administrator Link
In der Dropdown-Liste Administrator können Sie die Details des Administrators festlegen und bearbeiten. Wir können die Admin-E-Mail-ID und das Passwort über den folgenden Bildschirm zurücksetzen.
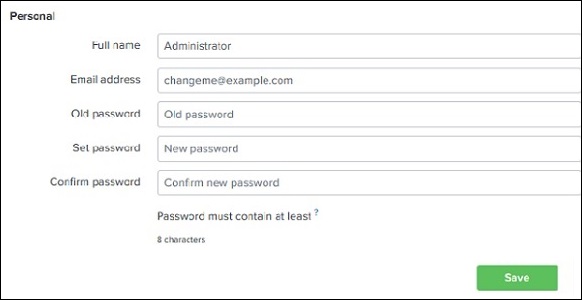
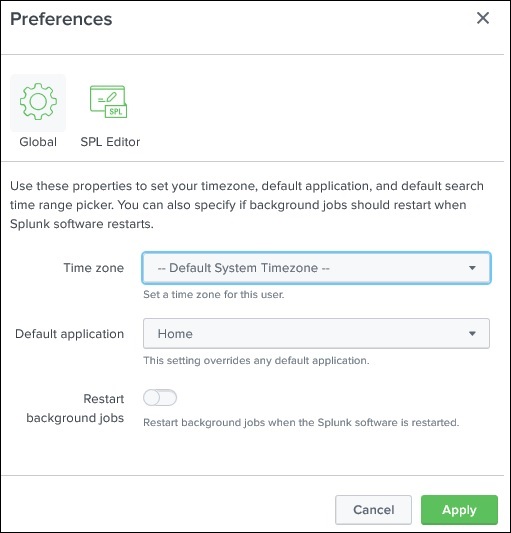
Weiter vom Administrator-Link aus können wir auch zur Voreinstellungsoption navigieren, in der wir die Zeitzone und die Heimanwendung festlegen können, auf der die Zielseite nach Ihrer Anmeldung geöffnet wird. Derzeit wird es auf der Homepage wie unten gezeigt geöffnet -
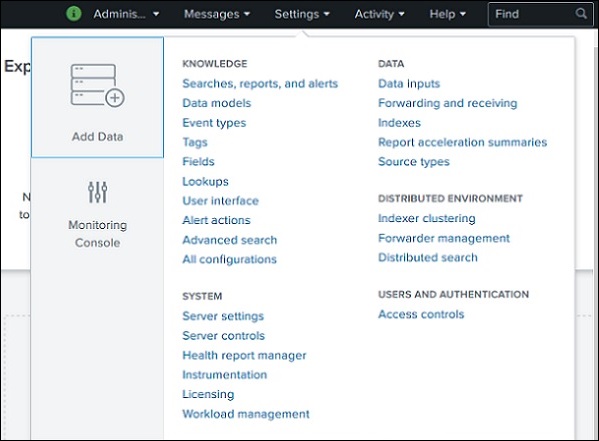
Einstellungslink
Dies ist ein Link, der alle in Splunk verfügbaren Kernfunktionen anzeigt. Sie können beispielsweise die Suchdateien und Suchdefinitionen hinzufügen, indem Sie den Suchlink wählen.
Wir werden die wichtigen Einstellungen dieser Links in den folgenden Kapiteln diskutieren.
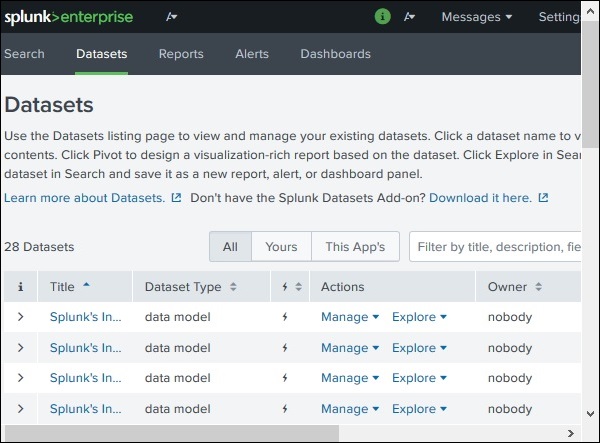
Such- und Berichtslink
Über den Such- und Berichtslink gelangen wir zu den Funktionen, in denen wir die Datensätze finden können, die zum Durchsuchen der für diese Suchvorgänge erstellten Berichte und Warnungen verfügbar sind. Es ist deutlich im folgenden Screenshot gezeigt -
Die Datenaufnahme in Splunk erfolgt über das Add DataFunktion, die Teil der Such- und Berichts-App ist. Nach dem Anmelden wird auf dem Startbildschirm der Splunk-Oberfläche das angezeigtAdd Data Symbol wie unten gezeigt.
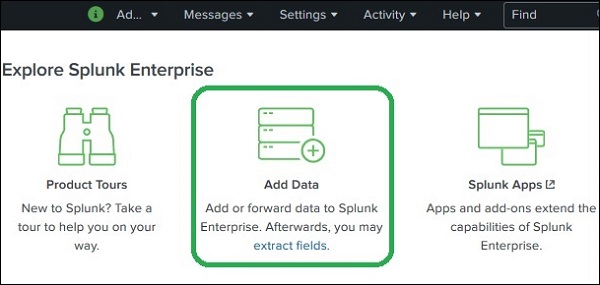
Wenn Sie auf diese Schaltfläche klicken, wird der Bildschirm angezeigt, auf dem Sie die Quelle und das Format der Daten auswählen können, die zur Analyse an Splunk gesendet werden sollen.
Daten sammeln
Wir können die Daten zur Analyse von der offiziellen Website von Splunk erhalten. Speichern Sie diese Datei und entpacken Sie sie auf Ihrem lokalen Laufwerk. Beim Öffnen des Ordners finden Sie drei Dateien mit unterschiedlichen Formaten. Dies sind die Protokolldaten, die von einigen Web-Apps generiert werden. Wir können auch einen anderen Datensatz von Splunk sammeln, der auf der offiziellen Splunk-Webseite verfügbar ist.
Wir werden Daten aus diesen beiden Sätzen verwenden, um die Funktionsweise verschiedener Funktionen von Splunk zu verstehen.
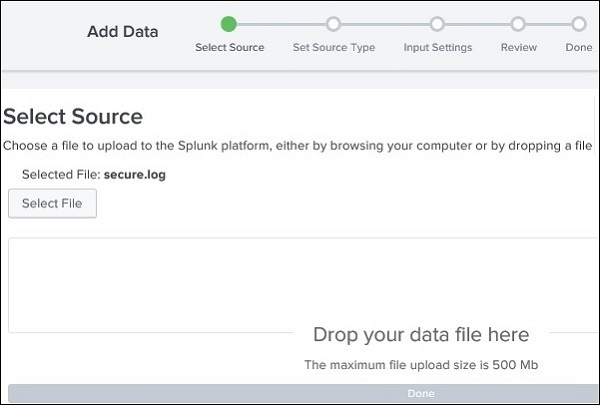
Daten hochladen
Als nächstes wählen wir die Datei, secure.log aus dem Ordner, mailsvdie wir in unserem lokalen System beibehalten haben, wie im vorherigen Absatz erwähnt. Nachdem Sie die Datei ausgewählt haben, fahren Sie mit der grünen Schaltfläche Weiter in der oberen rechten Ecke mit dem nächsten Schritt fort.
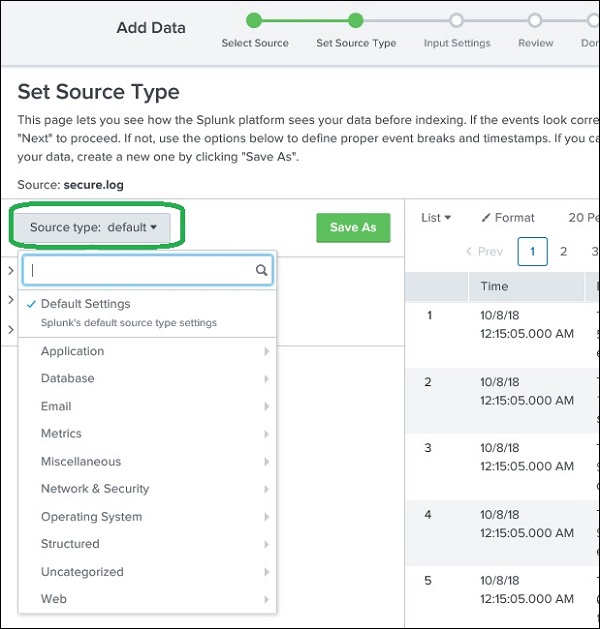
Quelltyp auswählen
Splunk verfügt über eine integrierte Funktion zum Erkennen des Typs der aufgenommenen Daten. Außerdem kann der Benutzer einen anderen Datentyp als den von Splunk ausgewählten auswählen. Wenn Sie auf die Dropdown-Liste Quelltyp klicken, werden verschiedene Datentypen angezeigt, die Splunk aufnehmen und für die Suche aktivieren kann.
Im aktuellen Beispiel unten wählen wir den Standardquellentyp.
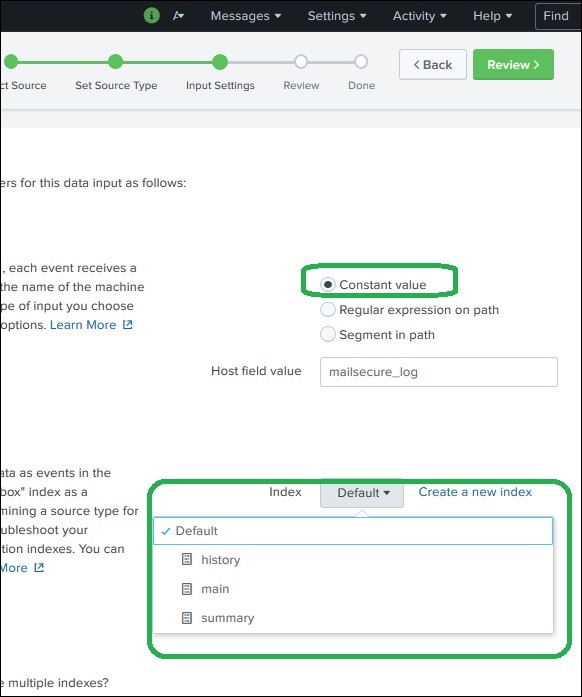
Eingabeeinstellungen
In diesem Schritt der Datenaufnahme konfigurieren wir den Hostnamen, von dem die Daten aufgenommen werden. Im Folgenden finden Sie die Optionen, aus denen Sie für den Hostnamen auswählen können:
Konstanter Wert
Dies ist der vollständige Hostname, auf dem sich die Quelldaten befinden.
Regex auf dem Weg
Wenn Sie den Hostnamen mit einem regulären Ausdruck extrahieren möchten. Geben Sie dann den regulären Ausdruck für den Host, den Sie extrahieren möchten, in das Feld Regulärer Ausdruck ein.
Segment im Pfad
Wenn Sie den Hostnamen aus einem Segment im Pfad Ihrer Datenquelle extrahieren möchten, geben Sie die Segmentnummer in das Feld Segmentnummer ein. Wenn der Pfad zur Quelle beispielsweise / var / log / lautet und Sie möchten, dass das dritte Segment (der Hostservername) der Hostwert ist, geben Sie "3" ein.
Als Nächstes wählen wir den Indextyp aus, der für die Suche in den Eingabedaten erstellt werden soll. Wir wählen die Standardindexstrategie. Der Zusammenfassungsindex erstellt nur eine Zusammenfassung der Daten durch Aggregation und erstellt einen Index dafür, während der Verlaufsindex zum Speichern des Suchverlaufs dient. Es ist deutlich im Bild unten dargestellt -
Überprüfen Sie die Einstellungen
Nachdem Sie auf die Schaltfläche Weiter geklickt haben, wird eine Zusammenfassung der von uns ausgewählten Einstellungen angezeigt. Wir überprüfen es und wählen Weiter, um das Hochladen der Daten abzuschließen.
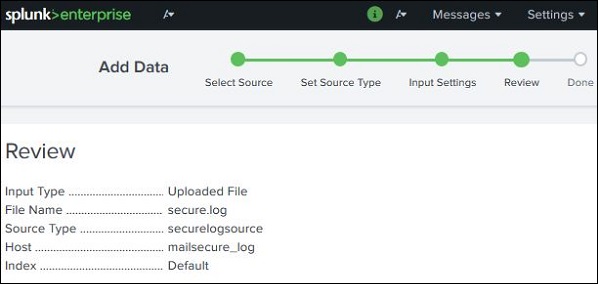
Nach Abschluss des Ladevorgangs wird der folgende Bildschirm angezeigt, in dem die erfolgreiche Datenaufnahme und weitere mögliche Maßnahmen für die Daten angezeigt werden.

Alle an Splunk eingehenden Daten werden zuerst von der eingebauten Datenverarbeitungseinheit beurteilt und bestimmten Datentypen und Kategorien zugeordnet. Wenn es sich beispielsweise um ein Protokoll vom Apache-Webserver handelt, kann Splunk dies erkennen und aus den gelesenen Daten entsprechende Felder erstellen.
Diese Funktion in Splunk wird als Erkennung von Quelltypen bezeichnet und verwendet dazu die integrierten Quelltypen, die als "vorab trainierte" Quelltypen bezeichnet werden.
Dies erleichtert die Analyse, da der Benutzer die Daten nicht manuell klassifizieren und den Feldern der eingehenden Daten Datentypen zuweisen muss.
Unterstützte Quelltypen
Die unterstützten Quelltypen in Splunk können durch Hochladen einer Datei über das angezeigt werden Add DataFunktion und wählen Sie dann das Dropdown-Menü für den Quelltyp aus. Im folgenden Bild haben wir eine CSV-Datei hochgeladen und dann nach allen verfügbaren Optionen gesucht.
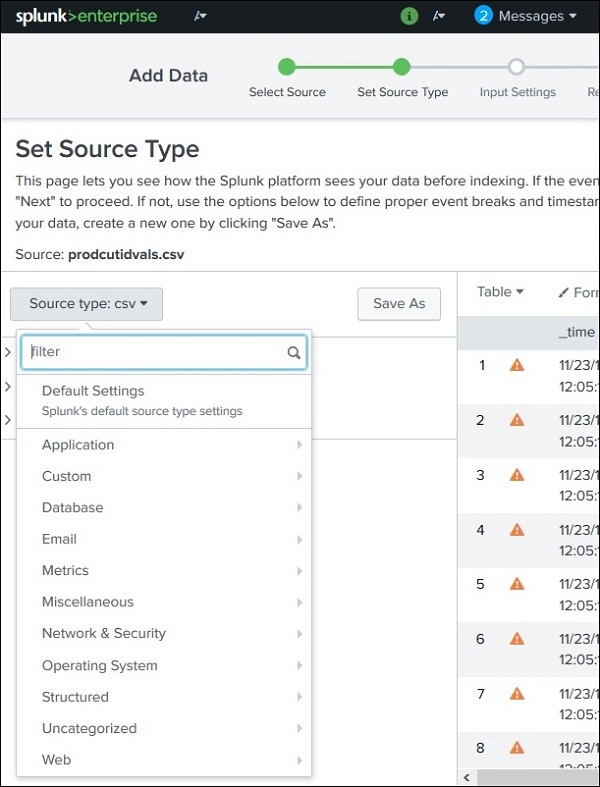
Quelltyp-Unterkategorie
Selbst in diesen Kategorien können wir weiter klicken, um alle unterstützten Unterkategorien anzuzeigen. Wenn Sie also die Datenbankkategorie auswählen, finden Sie die verschiedenen Datenbanktypen und die unterstützten Dateien, die Splunk erkennen kann.
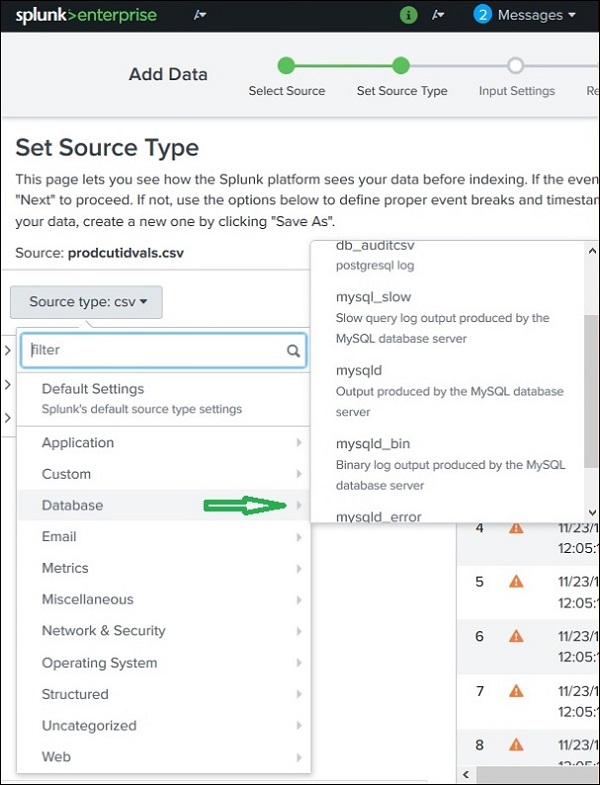
Vorgefertigte Quelltypen
In der folgenden Tabelle sind einige der wichtigen vorab trainierten Quelltypen aufgeführt, die Splunk erkennt -
| Name des Quelltyps | Natur |
|---|---|
| access_combined | NCSA-Webserverprotokolle im kombinierten NCSA-Format (können von Apache oder anderen Webservern generiert werden) |
| access_combined_wcookie | HTSA-Webserverprotokolle im kombinierten NCSA-Format (können von Apache oder anderen Webservern generiert werden), wobei am Ende ein Cookie-Feld hinzugefügt wird |
| apache_error | Standard-Apache-Webserver-Fehlerprotokoll |
| linux_messages_syslog | Standard Linux Syslog (/ var / log / messages auf den meisten Plattformen) |
| log4j | Log4j-Standardausgabe, die von einem beliebigen J2EE-Server mit log4j erstellt wird |
| mysqld_error | Standard-MySQL-Fehlerprotokoll |
Splunk verfügt über eine robuste Suchfunktion, mit der Sie den gesamten aufgenommenen Datensatz durchsuchen können. Auf diese Funktion wird über die App mit dem Namen zugegriffenSearch & Reporting Dies wird in der linken Leiste angezeigt, nachdem Sie sich bei der Weboberfläche angemeldet haben.
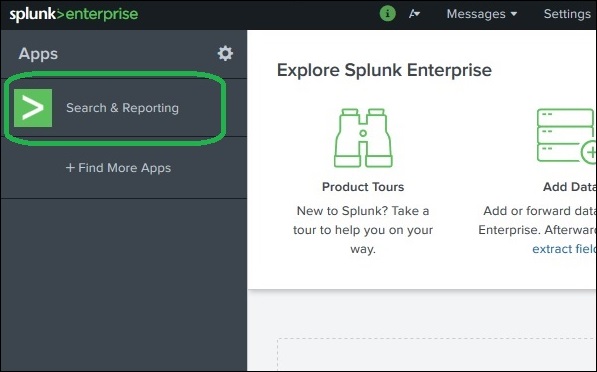
Beim Klicken auf die search & Reporting App wird uns ein Suchfeld angezeigt, in dem wir unsere Suche nach den Protokolldaten starten können, die wir im vorherigen Kapitel hochgeladen haben.
Wir geben den Hostnamen in dem unten gezeigten Format ein und klicken auf das Suchsymbol in der rechten Ecke. Dies gibt uns das Ergebnis, das den Suchbegriff hervorhebt.

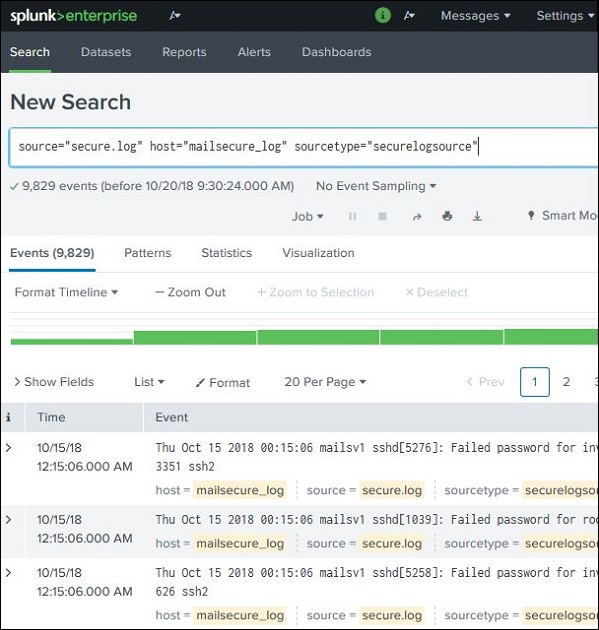
Suchbegriffe kombinieren
Wir können die für die Suche verwendeten Begriffe kombinieren, indem wir sie nacheinander schreiben, aber die Benutzersuchzeichenfolgen in doppelte Anführungszeichen setzen.
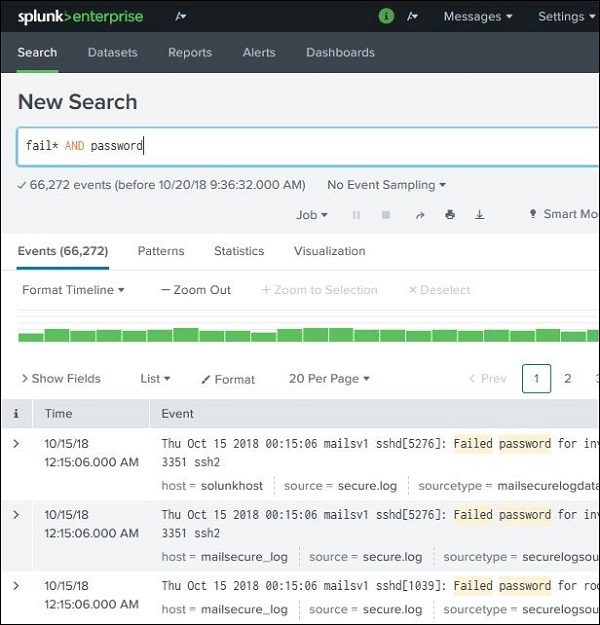
Platzhalter verwenden
Wir können Platzhalter in unserer Suchoption in Kombination mit dem verwenden AND/ORBetreiber. Bei der folgenden Suche erhalten wir das Ergebnis, bei dem die Protokolldatei die Begriffe "Fehler", "Fehler", "Fehler" usw. sowie den Begriff "Kennwort" in derselben Zeile enthält.
Suchergebnisse verfeinern
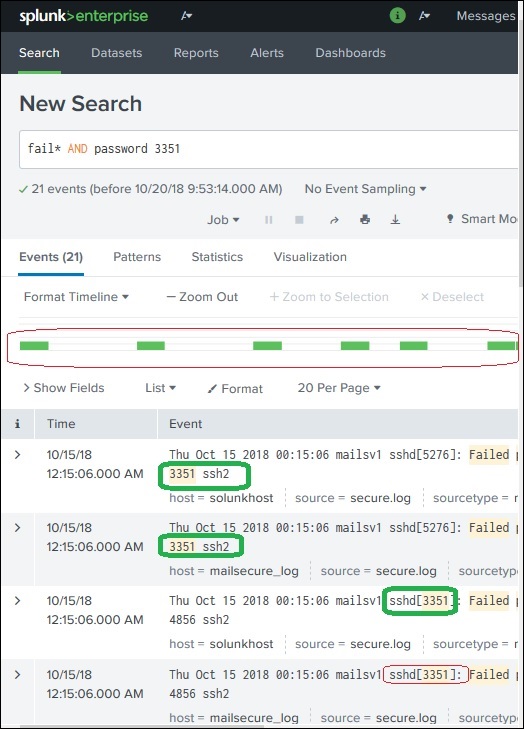
Wir können das Suchergebnis weiter verfeinern, indem wir eine Zeichenfolge auswählen und der Suche hinzufügen. Im folgenden Beispiel klicken wir auf die Zeichenfolge3351 und wählen Sie die Option Add to Search.
Nach 3351Wenn dem Suchbegriff hinzugefügt wird, erhalten wir das folgende Ergebnis, das nur die Zeilen aus dem Protokoll anzeigt, die 3351 enthalten. Markieren Sie auch, wie sich die Zeitleiste des Suchergebnisses geändert hat, während wir die Suche verfeinert haben.
Wenn Splunk die hochgeladenen Maschinendaten liest, interpretiert es die Daten und teilt sie in viele Felder auf, die eine einzige logische Tatsache über den gesamten Datensatz darstellen.
Beispielsweise kann ein einzelner Informationsdatensatz den Servernamen, den Zeitstempel des Ereignisses, den Typ des zu protokollierenden Ereignisses, ob Anmeldeversuch oder eine http-Antwort usw. enthalten. Selbst bei unstrukturierten Daten versucht Splunk, die Felder in Schlüsselwerte zu unterteilen Paare oder trennen Sie sie basierend auf den Datentypen, die sie haben, numerisch und Zeichenfolge usw.
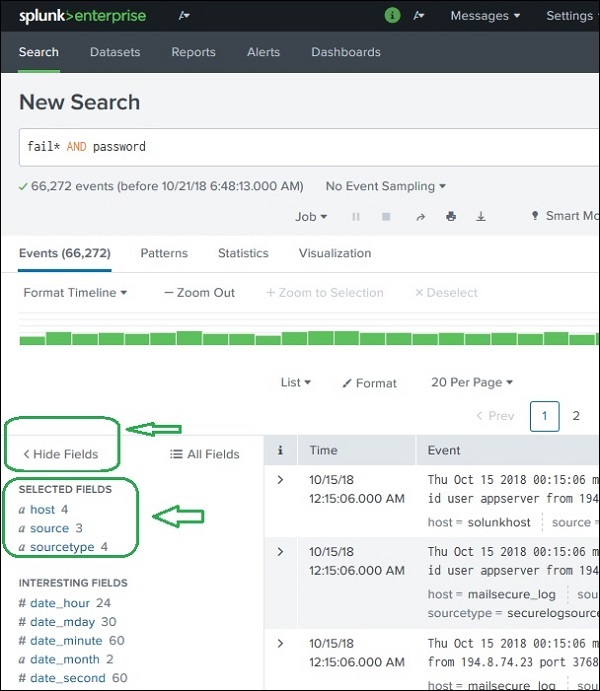
Wenn Sie mit den im vorherigen Kapitel hochgeladenen Daten fortfahren, sehen Sie die Felder aus dem secure.logKlicken Sie auf den Link Felder anzeigen, um den folgenden Bildschirm zu öffnen. Wir können die Felder feststellen, die Splunk aus dieser Protokolldatei generiert hat.
Felder auswählen
Wir können auswählen, welche Felder angezeigt werden sollen, indem wir die Felder aus der Liste aller Felder auswählen oder deren Auswahl aufheben. Klicken Sie aufall fieldsöffnet ein Fenster mit der Liste aller Felder. Einige dieser Felder sind mit Häkchen versehen, um anzuzeigen, dass sie bereits ausgewählt sind. Wir können die Kontrollkästchen verwenden, um unsere Felder für die Anzeige auszuwählen.
Neben dem Namen des Felds werden die Anzahl der unterschiedlichen Werte der Felder, der Datentyp und der Prozentsatz der Ereignisse angezeigt, in denen dieses Feld vorhanden ist.
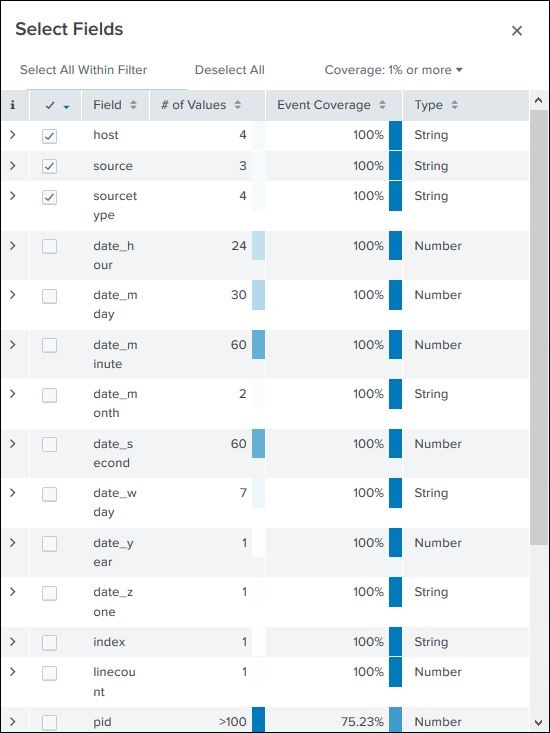
Feldzusammenfassung
Sehr detaillierte Statistiken für jedes ausgewählte Feld werden verfügbar, indem Sie auf den Namen des Feldes klicken. Es zeigt alle unterschiedlichen Werte für das Feld, ihre Anzahl und ihre Prozentsätze.
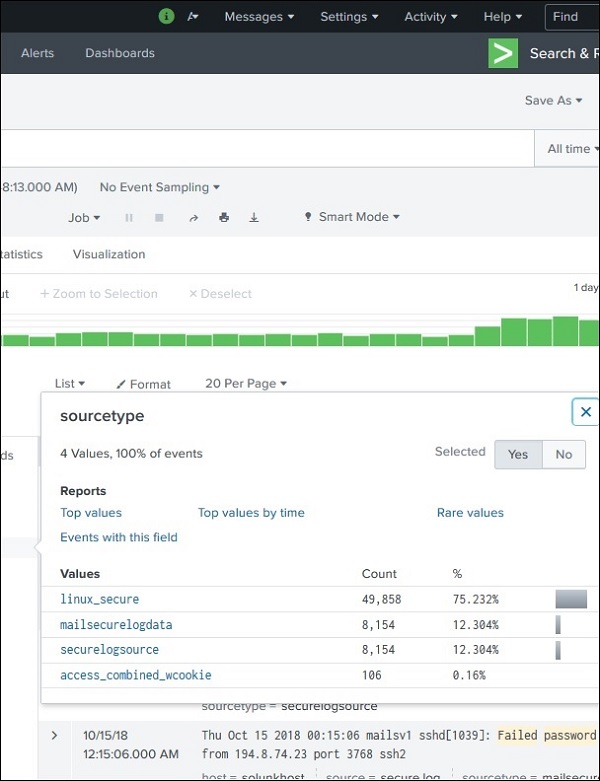
Felder in der Suche verwenden
Die Feldnamen können zusammen mit den spezifischen Werten für die Suche auch in das Suchfeld eingefügt werden. Im folgenden Beispiel möchten wir alle Datensätze für das Datum, den 15. Oktober, für den genannten Host findenmailsecure_log. Wir erhalten das Ergebnis für dieses bestimmte Datum.

Die Splunk-Weboberfläche zeigt eine Zeitleiste an, die die Verteilung von Ereignissen über einen bestimmten Zeitraum anzeigt. Es gibt voreingestellte Zeitintervalle, aus denen Sie einen bestimmten Zeitbereich auswählen oder den Zeitbereich nach Ihren Wünschen anpassen können.
Der folgende Bildschirm zeigt verschiedene voreingestellte Timeline-Optionen. Wenn Sie eine dieser Optionen auswählen, werden die Daten nur für den bestimmten Zeitraum abgerufen, den Sie mithilfe der verfügbaren benutzerdefinierten Zeitleistenoptionen auch weiter analysieren können.
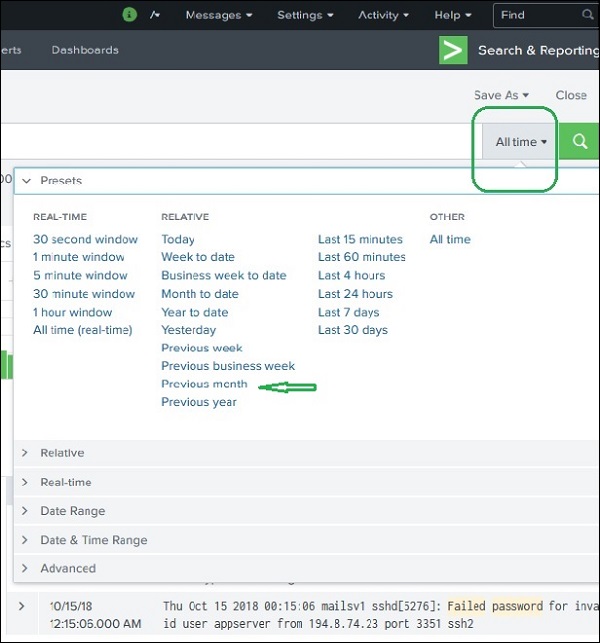
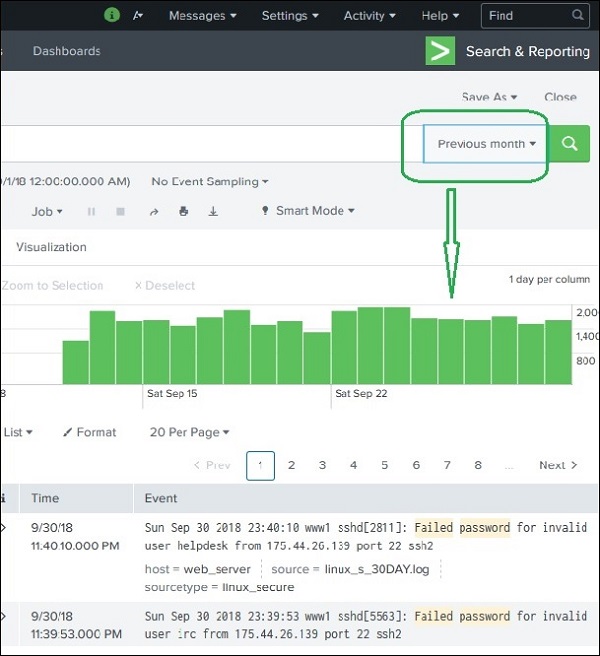
Wenn Sie beispielsweise die Option "Vorheriger Monat" auswählen, erhalten Sie das Ergebnis nur für den Vormonat, da Sie die Verteilung des Zeitdiagramms unten sehen können.
Auswahl einer Zeituntermenge
Durch Klicken und Ziehen über die Balken in der Zeitleiste können wir eine Teilmenge des bereits vorhandenen Ergebnisses auswählen. Dies führt nicht zur erneuten Ausführung der Abfrage. Es werden nur die Datensätze aus der vorhandenen Ergebnismenge herausgefiltert.
Das folgende Bild zeigt die Auswahl einer Teilmenge aus der Ergebnismenge -
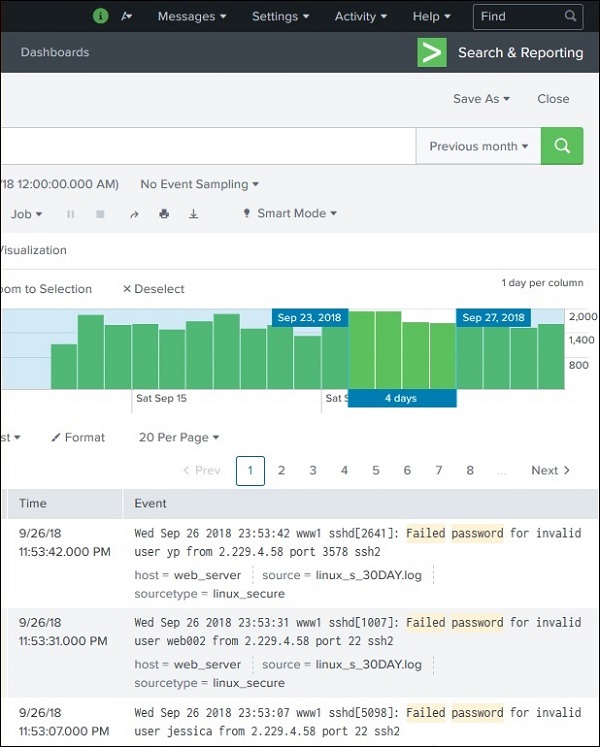
Früheste und neueste
Die beiden frühesten und spätesten Befehle können in der Suchleiste verwendet werden, um den Zeitraum anzugeben, zwischen dem Sie die Ergebnisse herausfiltern. Dies ähnelt der Auswahl der Zeituntermenge, erfolgt jedoch über Befehle und nicht über die Option, auf eine bestimmte Zeitleistenleiste zu klicken. So erhalten Sie eine genauere Kontrolle über den Datenbereich, den Sie für Ihre Analyse auswählen können.
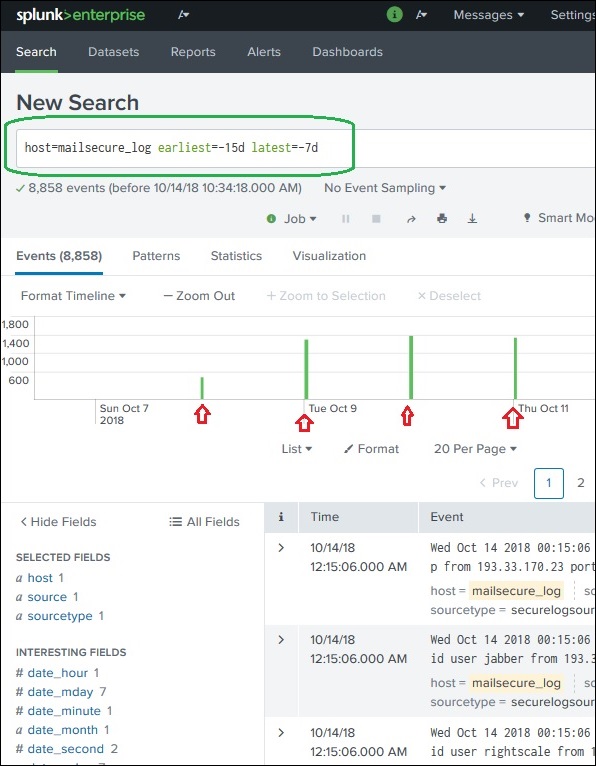
Im obigen Bild geben wir einen Zeitraum zwischen den letzten 7 Tagen und den letzten 15 Tagen an. Die Daten zwischen diesen beiden Tagen werden also angezeigt.
Veranstaltungen in der Nähe
Wir können auch Ereignisse in der Nähe einer bestimmten Zeit finden, indem wir angeben, wie nahe die Ereignisse herausgefiltert werden sollen. Wir haben die Möglichkeit, die Skala des Intervalls zu wählen, wie - Sekunden, Minuten, Tage und Woche usw.
Wenn Sie eine Suchabfrage ausführen, wird das Ergebnis als Job auf dem Splunk-Server gespeichert. Während dieser Job von einem bestimmten Benutzer erstellt wurde, kann er für andere Benutzer freigegeben werden, damit diese diese Ergebnismenge verwenden können, ohne dass die Abfrage erneut erstellt werden muss. Die Ergebnisse können auch exportiert und als Dateien gespeichert werden, die für Benutzer freigegeben werden können, die Splunk nicht verwenden.
Teilen des Suchergebnisses
Sobald eine Abfrage erfolgreich ausgeführt wurde, sehen wir einen kleinen Aufwärtspfeil in der Mitte rechts auf der Webseite. Durch Klicken auf dieses Symbol erhalten Sie eine URL, über die auf die Abfrage und das Ergebnis zugegriffen werden kann. Die Benutzer, die diesen Link verwenden, müssen eine Berechtigung erteilen. Die Berechtigung wird über die Splunk-Verwaltungsoberfläche erteilt.

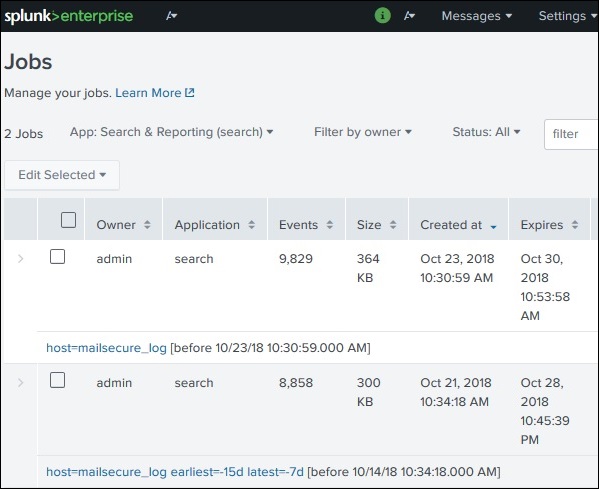
Finden der gespeicherten Ergebnisse
Die Jobs, die gespeichert werden, um von allen Benutzern mit entsprechenden Berechtigungen verwendet zu werden, können gefunden werden, indem Sie im Aktivitätsmenü in der oberen rechten Leiste der Splunk-Oberfläche nach dem Link Jobs suchen. Im folgenden Bild klicken wir auf den hervorgehobenen Link Jobs, um die gespeicherten Jobs zu finden.

Nachdem Sie auf den obigen Link geklickt haben, erhalten wir die Liste aller gespeicherten Jobs wie unten gezeigt. Er, wir müssen beachten, dass es ein Ablaufdatum gibt, in dem der gespeicherte Job automatisch aus Splunk entfernt wird. Sie können dieses Datum anpassen, indem Sie den Job auswählen, auf Ausgewählte bearbeiten klicken und dann Ablauf verlängern auswählen.
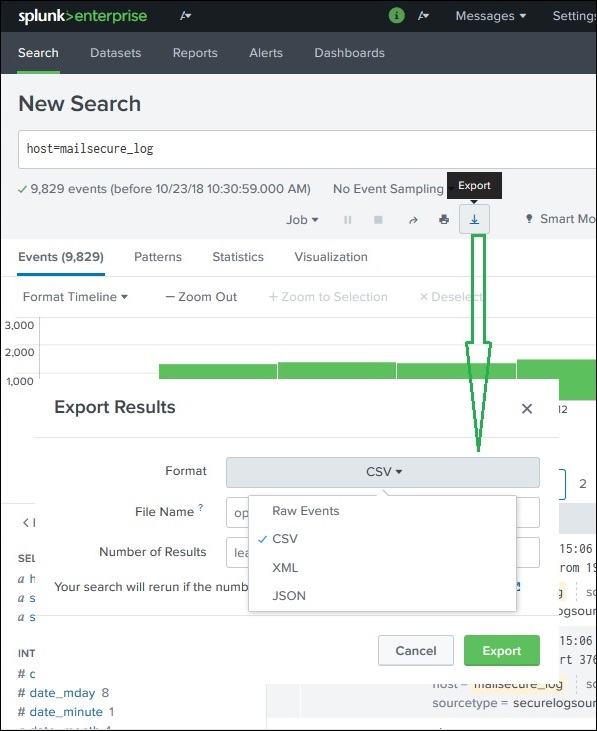
Exportieren des Suchergebnisses
Wir können auch die Ergebnisse einer Suche in eine Datei exportieren. Die drei verschiedenen Formate, die für den Export verfügbar sind, sind: CSV, XML und JSON. Durch Klicken auf die Schaltfläche Exportieren nach Auswahl der Formate wird die Datei vom lokalen Browser in das lokale System heruntergeladen. Dies wird im folgenden Bild erklärt -
Die Splunk Search Processing Language (SPL) ist eine Sprache, die viele Befehle, Funktionen, Argumente usw. enthält, die geschrieben werden, um die gewünschten Ergebnisse aus den Datensätzen zu erhalten. Wenn Sie beispielsweise eine Ergebnismenge für einen Suchbegriff erhalten, möchten Sie möglicherweise einige spezifischere Begriffe aus der Ergebnismenge herausfiltern. Dazu benötigen Sie einige zusätzliche Befehle, die dem vorhandenen Befehl hinzugefügt werden müssen. Dies wird durch Erlernen der Verwendung von SPL erreicht.
Komponenten von SPL
Die SPL besteht aus folgenden Komponenten.
Search Terms - Dies sind die Schlüsselwörter oder Ausdrücke, nach denen Sie suchen.
Commands - Die Aktion, die Sie für die Ergebnismenge ausführen möchten, wie das Ergebnis formatieren oder zählen.
Functions- Welche Berechnungen werden Sie auf die Ergebnisse anwenden? Wie Summe, Durchschnitt usw.
Clauses - So gruppieren oder benennen Sie die Felder in der Ergebnismenge um.
Lassen Sie uns alle Komponenten mit Hilfe von Bildern im folgenden Abschnitt diskutieren -
Suchbegriffe
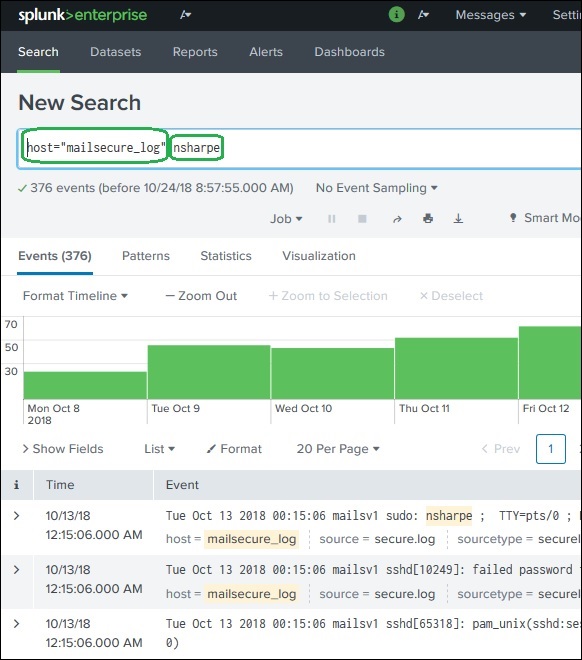
Dies sind die Begriffe, die Sie in der Suchleiste erwähnen, um bestimmte Datensätze aus dem Datensatz abzurufen, die die Suchkriterien erfüllen. Im folgenden Beispiel suchen wir nach Datensätzen, die zwei hervorgehobene Begriffe enthalten.
Befehle
Sie können viele integrierte Befehle verwenden, die SPL bereitstellt, um die Analyse der Daten in der Ergebnismenge zu vereinfachen. Im folgenden Beispiel verwenden wir den Befehl head, um nur die drei wichtigsten Ergebnisse einer Suchoperation herauszufiltern.

Funktionen
Neben Befehlen bietet Splunk auch viele integrierte Funktionen, die Eingaben von einem zu analysierenden Feld entgegennehmen und nach Anwendung der Berechnungen auf dieses Feld ausgeben können. Im folgenden Beispiel verwenden wir dieStats avg() Funktion, die den Durchschnittswert des numerischen Feldes berechnet, das als Eingabe verwendet wird.

Klauseln
Wenn wir Ergebnisse nach einem bestimmten Feld gruppieren oder ein Feld in der Ausgabe umbenennen möchten, verwenden wir das group byKlausel bzw. die as-Klausel. Im folgenden Beispiel erhalten wir die durchschnittliche Größe der Bytes jeder in der Datei vorhandenen Dateiweb_applicationLog. Wie Sie sehen können, zeigt das Ergebnis den Namen jeder Datei sowie die durchschnittlichen Bytes für jede Datei.
