Splunk - Quelltypen
Alle an Splunk eingehenden Daten werden zuerst von der eingebauten Datenverarbeitungseinheit beurteilt und bestimmten Datentypen und Kategorien zugeordnet. Wenn es sich beispielsweise um ein Protokoll vom Apache-Webserver handelt, kann Splunk dies erkennen und aus den gelesenen Daten entsprechende Felder erstellen.
Diese Funktion in Splunk wird als Erkennung von Quelltypen bezeichnet und verwendet dazu die integrierten Quelltypen, die als "vorab trainierte" Quelltypen bezeichnet werden.
Dies erleichtert die Analyse, da der Benutzer die Daten nicht manuell klassifizieren und den Feldern der eingehenden Daten Datentypen zuweisen muss.
Unterstützte Quelltypen
Die unterstützten Quelltypen in Splunk können durch Hochladen einer Datei über das angezeigt werden Add DataFunktion und wählen Sie dann das Dropdown-Menü für den Quelltyp aus. Im folgenden Bild haben wir eine CSV-Datei hochgeladen und dann nach allen verfügbaren Optionen gesucht.
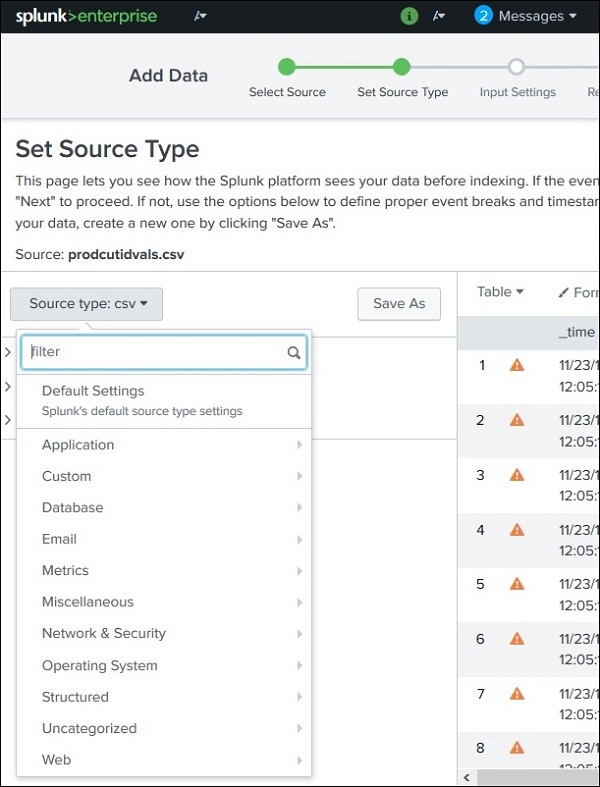
Quelltyp-Unterkategorie
Selbst in diesen Kategorien können wir weiter klicken, um alle unterstützten Unterkategorien anzuzeigen. Wenn Sie also die Datenbankkategorie auswählen, finden Sie die verschiedenen Datenbanktypen und die unterstützten Dateien, die Splunk erkennen kann.
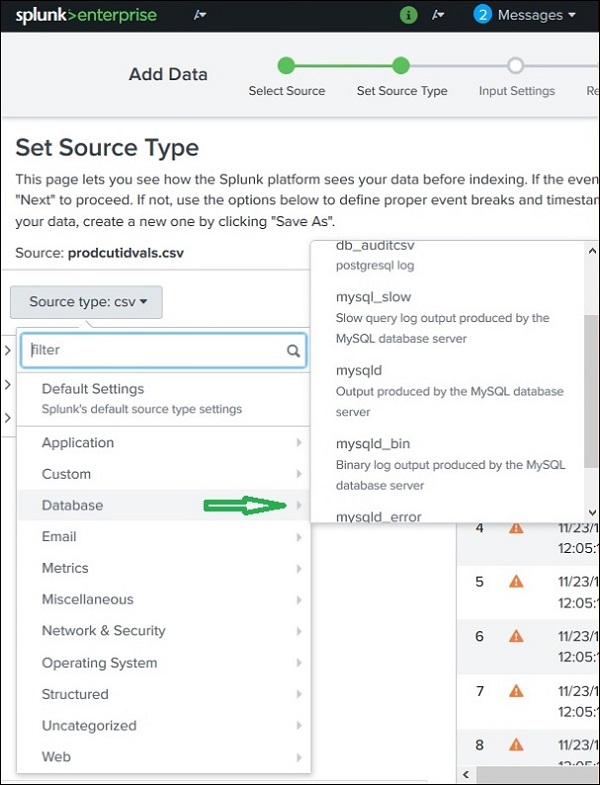
Vorgefertigte Quelltypen
In der folgenden Tabelle sind einige der wichtigen vorab trainierten Quelltypen aufgeführt, die Splunk erkennt -
| Name des Quelltyps | Natur |
|---|---|
| access_combined | NCSA-Webserverprotokolle im kombinierten NCSA-Format (können von Apache oder anderen Webservern generiert werden) |
| access_combined_wcookie | NCSA-Webserverprotokolle im kombinierten NCSA-Format (können von Apache oder anderen Webservern generiert werden), wobei am Ende ein Cookie-Feld hinzugefügt wird |
| apache_error | Standard-Apache-Webserver-Fehlerprotokoll |
| linux_messages_syslog | Standard Linux Syslog (/ var / log / messages auf den meisten Plattformen) |
| log4j | Log4j-Standardausgabe, die von einem beliebigen J2EE-Server mit log4j erstellt wird |
| mysqld_error | Standard-MySQL-Fehlerprotokoll |