Sqoop - Einführung
Das traditionelle Anwendungsverwaltungssystem, dh die Interaktion von Anwendungen mit relationalen Datenbanken mithilfe von RDBMS, ist eine der Quellen, die Big Data generieren. Solche von RDBMS generierten Big Data werden in Relational gespeichertDatabase Servers in der relationalen Datenbankstruktur.
Als Big Data-Speicher und -Analysatoren wie MapReduce, Hive, HBase, Cassandra, Pig usw. des Hadoop-Ökosystems ins Bild kamen, benötigten sie ein Tool für die Interaktion mit den relationalen Datenbankservern, um die darin enthaltenen Big Data zu importieren und zu exportieren. Hier nimmt Sqoop einen Platz im Hadoop-Ökosystem ein, um eine praktikable Interaktion zwischen dem relationalen Datenbankserver und dem HDFS von Hadoop zu ermöglichen.
Sqoop - "SQL zu Hadoop und Hadoop zu SQL"
Sqoop ist ein Tool zum Übertragen von Daten zwischen Hadoop und relationalen Datenbankservern. Es wird verwendet, um Daten aus relationalen Datenbanken wie MySQL, Oracle in Hadoop HDFS zu importieren und aus dem Hadoop-Dateisystem in relationale Datenbanken zu exportieren. Es wird von der Apache Software Foundation bereitgestellt.
Wie funktioniert Sqoop?
Das folgende Bild beschreibt den Workflow von Sqoop.
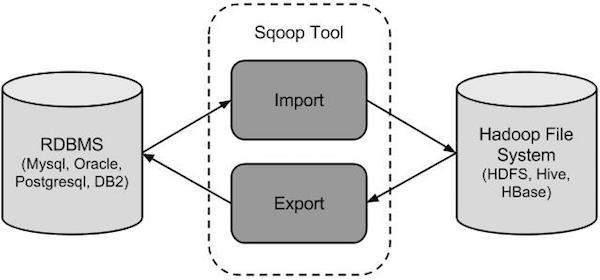
Sqoop Import
Das Import-Tool importiert einzelne Tabellen aus RDBMS in HDFS. Jede Zeile in einer Tabelle wird in HDFS als Datensatz behandelt. Alle Datensätze werden als Textdaten in Textdateien oder als Binärdaten in Avro- und Sequenzdateien gespeichert.
Sqoop Export
Das Export-Tool exportiert eine Reihe von Dateien aus HDFS zurück in ein RDBMS. Die als Eingabe für Sqoop angegebenen Dateien enthalten Datensätze, die als Zeilen in der Tabelle aufgerufen werden. Diese werden gelesen und in eine Reihe von Datensätzen analysiert und mit einem benutzerdefinierten Trennzeichen getrennt.