YAML - Prozesse
YAML folgt einem Standardverfahren für den Prozessablauf. Die native Datenstruktur in YAML enthält einfache Darstellungen wie Knoten. Es wird auch als Repräsentationsknotendiagramm bezeichnet.
Es enthält Mapping-, Sequenz- und Skalargrößen, die serialisiert werden, um einen Serialisierungsbaum zu erstellen. Bei der Serialisierung werden die Objekte mit einem Bytestrom konvertiert.
Der Serialisierungsereignisbaum hilft beim Erstellen der Darstellung von Zeichenströmen, wie in der folgenden Abbildung dargestellt.
Die umgekehrte Prozedur analysiert den Bytestrom in einen serialisierten Ereignisbaum. Später werden die Knoten in ein Knotendiagramm konvertiert. Diese Werte werden später in die native YAML-Datenstruktur konvertiert. Die folgende Abbildung erklärt dies -
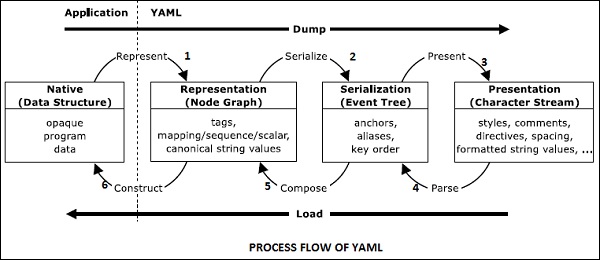
Die Informationen in YAML werden auf zwei Arten verwendet: machine processing und human consumption. Der Prozessor in YAML wird als Werkzeug für die Prozedur zum Konvertieren von Informationen zwischen komplementären Ansichten in dem oben angegebenen Diagramm verwendet. In diesem Kapitel werden die Informationsstrukturen beschrieben, die ein YAML-Prozessor in einer bestimmten Anwendung bereitstellen muss.
YAML enthält eine Serialisierungsprozedur zum Darstellen von Datenobjekten im seriellen Format. Die Verarbeitung von YAML-Informationen umfasst drei Stufen:Representation, Serialization, Presentation and parsing. Lassen Sie uns jeden von ihnen im Detail besprechen.
Darstellung
YAML repräsentiert die Datenstruktur unter Verwendung von drei Arten von Knoten: sequence, mapping und scalar.
Reihenfolge
Die Sequenz bezieht sich auf die geordnete Anzahl von Einträgen, die die ungeordnete Zuordnung des Schlüsselwertpaars abbildet. Es entspricht der Perl- oder Python-Array-Liste.
Der unten gezeigte Code ist ein Beispiel für die Sequenzdarstellung -
product:
- sku : BL394D
quantity : 4
description : Football
price : 450.00
- sku : BL4438H
quantity : 1
description : Super Hoop
price : 2392.00Kartierung
Die Zuordnung repräsentiert andererseits die Wörterbuchdatenstruktur oder die Hash-Tabelle. Ein Beispiel dafür ist unten aufgeführt -
batchLimit: 1000
threadCountLimit: 2
key: value
keyMapping: <What goes here?>Skalare
Skalare repräsentieren Standardwerte von Zeichenfolgen, Ganzzahlen, Datumsangaben und atomaren Datentypen. Beachten Sie, dass YAML auch Knoten enthält, die die Datentypstruktur angeben. Weitere Informationen zu Skalaren finden Sie in Kapitel 6 dieses Tutorials.
Serialisierung
In YAML ist ein Serialisierungsprozess erforderlich, der die benutzerfreundliche Schlüsselreihenfolge und die Ankernamen vereinfacht. Das Ergebnis der Serialisierung ist ein YAML-Serialisierungsbaum. Es kann durchlaufen werden, um eine Reihe von Ereignisaufrufen von YAML-Daten zu erzeugen.
Ein Beispiel für die Serialisierung ist unten angegeben -
consumer:
class: 'AppBundle\Entity\consumer'
attributes:
filters: ['customer.search', 'customer.order', 'customer.boolean']
collectionOperations:
get:
method: 'GET'
normalization_context:
groups: ['customer_list']
itemOperations:
get:
method: 'GET'
normalization_context:
groups: ['customer_get']Präsentation
Die endgültige Ausgabe der YAML-Serialisierung wird als Präsentation bezeichnet. Es repräsentiert einen Charakterstrom auf menschenfreundliche Weise. Der YAML-Prozessor enthält verschiedene Präsentationsdetails zum Erstellen von Streams, zum Behandeln von Einrückungen und zum Formatieren von Inhalten. Dieser vollständige Prozess richtet sich nach den Vorlieben des Benutzers.
Ein Beispiel für den YAML-Präsentationsprozess ist das Ergebnis der Erstellung eines JSON-Werts. Beachten Sie zum besseren Verständnis den unten angegebenen Code -
{
"consumer": {
"class": "AppBundle\\Entity\\consumer",
"attributes": {
"filters": [
"customer.search",
"customer.order",
"customer.boolean"
]
},
"collectionOperations": {
"get": {
"method": "GET",
"normalization_context": {
"groups": [
"customer_list"
]
}
}
},
"itemOperations": {
"get": {
"method": "GET",
"normalization_context": {
"groups": [
"customer_get"
]
}
}
}
}
}Parsing
Das Parsen ist der umgekehrte Präsentationsprozess. Es enthält einen Strom von Zeichen und erstellt eine Reihe von Ereignissen. Es werden die im Präsentationsprozess eingeführten Details verworfen, die Serialisierungsereignisse verursachen. Der Analysevorgang kann aufgrund einer fehlerhaften Eingabe fehlschlagen. Grundsätzlich wird geprüft, ob YAML wohlgeformt ist oder nicht.
Betrachten Sie ein YAML-Beispiel, das unten erwähnt wird -
---
environment: production
classes:
nfs::server:
exports:
- /srv/share1
- /srv/share3
parameters:
paramter1Mit drei Bindestrichen stellt es den Beginn des Dokuments mit verschiedenen Attributen dar, die später darin definiert werden.
YAML lint ist der Online-Parser von YAML und hilft beim Parsen der YAML-Struktur, um zu überprüfen, ob sie gültig ist oder nicht. Der offizielle Link für YAML-Flusen ist unten aufgeführt:http://www.yamllint.com/
Sie können die Ausgabe der Analyse wie unten gezeigt sehen -