YAML - Kurzanleitung
YAML Ain't Markup Language ist eine Datenserialisierungssprache, die den Erwartungen des Benutzers an Daten entspricht. Es ist menschenfreundlich gestaltet und funktioniert perfekt mit anderen Programmiersprachen. Es ist nützlich, Daten zu verwalten und enthält druckbare Unicode-Zeichen. Dieses Kapitel gibt Ihnen eine Einführung in YAML und gibt Ihnen eine Vorstellung von dessen Funktionen.
Format
Betrachten Sie den unten gezeigten Text -
Quick brown fox jumped over the lazy dog.Der YAML-Text hierfür wird wie folgt dargestellt:
yaml.load(Quick brown fox jumped over the lazy dog.)
>>'Quick brown fox jumped over the lazy dog.'Beachten Sie, dass YAML den Wert im Zeichenfolgenformat verwendet und die Ausgabe wie oben erwähnt darstellt.
Beispiele
Lassen Sie uns die Formate in YAML anhand der folgenden Beispiele verstehen:
Betrachten Sie die folgende Punktnummer von „pi“ mit einem Wert von 3,1415926. In YAML wird es wie unten gezeigt als schwebende Zahl dargestellt -
>>> yaml.load('3.1415926536')
3.1415926536Angenommen, mehrere Werte sollen in eine bestimmte Datenstruktur geladen werden, wie unten erwähnt -
eggs
ham
spam
French basil salmon terrineWenn Sie dies in YAML laden, werden die Werte in einer Array-Datenstruktur übernommen, die eine Form einer Liste darstellt. Die Ausgabe ist wie unten gezeigt -
>>> yaml.load('''
- eggs
- ham
- spam
- French basil salmon terrine
''')
['eggs', 'ham', 'spam', 'French basil salmon terrine']Eigenschaften
YAML enthält eine Markup-Sprache mit einem wichtigen Konstrukt, um eine datenorientierte Sprache mit dem Dokument-Markup zu unterscheiden. Die Designziele und Funktionen von YAML sind unten angegeben -
Entspricht nativen Datenstrukturen der agilen Methodik und ihren Sprachen wie Perl, Python, PHP, Ruby und JavaScript
YAML-Daten können zwischen Programmiersprachen portiert werden
Enthält ein datenkonsistentes Datenmodell
Für Menschen leicht lesbar
Unterstützt die Verarbeitung in eine Richtung
Einfache Implementierung und Verwendung
Nachdem Sie eine Vorstellung von YAML und seinen Funktionen haben, lassen Sie uns seine Grundlagen mit Syntax und anderen Operationen lernen. Denken Sie daran, dass YAML ein lesbares strukturiertes Format enthält.
Regeln zum Erstellen einer YAML-Datei
Wenn Sie eine Datei in YAML erstellen, sollten Sie die folgenden Grundregeln beachten:
YAML unterscheidet zwischen Groß- und Kleinschreibung
Die Dateien sollten haben .yaml als Erweiterung
YAML erlaubt keine Verwendung von Registerkarten beim Erstellen von YAML-Dateien. Leerzeichen sind stattdessen erlaubt
Grundkomponenten der YAML-Datei
Die Grundkomponenten von YAML werden nachfolgend beschrieben -
Herkömmliches Blockformat
Dieses Blockformat verwendet hyphen+spaceum ein neues Element in einer angegebenen Liste zu beginnen. Beachten Sie das unten gezeigte Beispiel -
--- # Favorite movies
- Casablanca
- North by Northwest
- The Man Who Wasn't ThereInline Format
Das Inline-Format ist begrenzt durch comma and spaceund die Elemente sind in JSON enthalten. Beachten Sie das unten gezeigte Beispiel -
--- # Shopping list
[milk, groceries, eggs, juice, fruits]Folded Text
Gefalteter Text konvertiert Zeilenumbrüche in Leerzeichen und entfernt das führende Leerzeichen. Beachten Sie das unten gezeigte Beispiel -
- {name: John Smith, age: 33}
- name: Mary Smith
age: 27Die Struktur, die allen grundlegenden Konventionen von YAML folgt, ist unten dargestellt -
men: [John Smith, Bill Jones]
women:
- Mary Smith
- Susan WilliamsZusammenfassung der YAML-Grundelemente
Die Zusammenfassung der YAML-Grundelemente finden Sie hier: Kommentare in YAML beginnen mit dem (#) Zeichen.
Kommentare müssen durch Leerzeichen von anderen Token getrennt werden.
Das Einrücken von Leerzeichen wird verwendet, um die Struktur zu kennzeichnen.
Registerkarten sind nicht als Einrückung für YAML-Dateien enthalten.
Listenmitglieder werden durch einen führenden Bindestrich gekennzeichnet (-).
Listenmitglieder sind in eckigen Klammern eingeschlossen und durch Kommas getrennt.
Assoziative Arrays werden mit Doppelpunkt dargestellt ( : )im Format des Schlüsselwertpaares. Sie sind in geschweiften Klammern eingeschlossen{}.
Mehrere Dokumente mit einzelnen Streams werden durch 3 Bindestriche (---) getrennt.
Wiederholte Knoten in jeder Datei werden anfänglich durch ein kaufmännisches Und (&) und mit einem Sternchen (*) später markieren.
YAML erfordert immer Doppelpunkte und Kommas, die als Listentrennzeichen verwendet werden, gefolgt von Leerzeichen mit skalaren Werten.
Knoten sollten mit einem Ausrufezeichen gekennzeichnet sein (!) oder doppeltes Ausrufezeichen (!!), gefolgt von einer Zeichenfolge, die zu einer URI oder URL erweitert werden kann.
Einrückung und Trennung sind zwei Hauptkonzepte, wenn Sie eine Programmiersprache lernen. In diesem Kapitel werden diese beiden Konzepte im Zusammenhang mit YAML ausführlich behandelt.
Einrückung von YAML
YAML enthält keine obligatorischen Leerzeichen. Darüber hinaus besteht keine Notwendigkeit, konsistent zu sein. Die gültige YAML-Einrückung wird unten angezeigt -
a:
b:
- c
- d
- e
f:
"ghi"Beachten Sie beim Arbeiten mit Einrückungen in YAML die folgenden Regeln: Flussblöcke müssen mit mindestens einigen Leerzeichen mit der umgebenden aktuellen Blockebene vorgesehen sein.
Der Flussinhalt von YAML umfasst mehrere Zeilen. Der Beginn des Flow-Inhalts beginnt mit{ oder [.
Blocklistenelemente enthalten denselben Einzug wie die umgebende Blockebene, da - als Teil des Einzugs betrachtet wird.
Beispiel für einen beabsichtigten Block
Beachten Sie den folgenden Code, der Einrückungen mit Beispielen zeigt -
--- !clarkevans.com/^invoice
invoice: 34843
date : 2001-01-23
bill-to: &id001
given : Chris
family : Dumars
address:
lines: |
458 Walkman Dr.
Suite #292
city : Royal Oak
state : MI
postal : 48046
ship-to: *id001
product:
- sku : BL394D
quantity : 4
description : Basketball
price : 450.00
- sku : BL4438H
quantity : 1
description : Super Hoop
price : 2392.00
tax : 251.42
total: 4443.52
comments: >
Late afternoon is best.
Backup contact is Nancy
Billsmer @ 338-4338.Trennung von Saiten
Zeichenfolgen werden durch Zeichenfolgen in doppelten Anführungszeichen getrennt. Wenn Sie die Zeilenumbruchzeichen in einer bestimmten Zeichenfolge maskieren, wird diese vollständig entfernt und in einen Leerzeichenwert übersetzt.
Beispiel
In diesem Beispiel haben wir uns auf die Auflistung von Tieren konzentriert, die als Array-Struktur mit dem Datentyp der Zeichenfolge aufgeführt sind. Jedes neue Element wird mit einem Bindestrich als Präfix aufgeführt.
-
- Cat
- Dog
- Goldfish
-
- Python
- Lion
- TigerEin weiteres Beispiel zur Erläuterung der Zeichenfolgendarstellung in YAML ist unten aufgeführt.
errors:
messages:
already_confirmed: "was already confirmed, please try signing in"
confirmation_period_expired: "needs to be confirmed within %{period}, please request a new one"
expired: "has expired, please request a new one"
not_found: "not found"
not_locked: "was not locked"
not_saved:
one: "1 error prohibited this %{resource} from being saved:"
other: "%{count} errors prohibited this %{resource} from being saved:"Dieses Beispiel bezieht sich auf eine Reihe von Fehlermeldungen, die ein Benutzer verwenden kann, indem er nur den Schlüsselaspekt erwähnt und die Werte entsprechend abruft. Dieses Muster von YAML folgt der Struktur von JSON, die von Benutzern verstanden werden kann, die neu in YAML sind.
Nachdem Sie mit der Syntax und den Grundlagen von YAML vertraut sind, gehen wir weiter auf die Details ein. In diesem Kapitel erfahren Sie, wie Sie Kommentare in YAML verwenden.
YAML supports single line comments. Seine Struktur wird unten anhand eines Beispiels erläutert -
# this is single line comment.YAML does not support multi line comments. Wenn Sie Kommentare für mehrere Zeilen bereitstellen möchten, können Sie dies wie im folgenden Beispiel gezeigt tun -
# this
# is a multiple
# line commentFunktionen von Kommentaren
Die Funktionen von Kommentaren in YAML sind unten angegeben -
Ein kommentierter Block wird während der Ausführung übersprungen.
Kommentare helfen beim Hinzufügen einer Beschreibung für den angegebenen Codeblock.
Kommentare dürfen nicht in Skalaren erscheinen.
YAML enthält keine Möglichkeit, das Hash-Symbol (#) innerhalb einer mehrzeiligen Zeichenfolge zu umgehen, sodass der Kommentar nicht vom Wert der Rohzeichenfolge getrennt werden kann.
Die Kommentare innerhalb einer Sammlung werden unten angezeigt -
key: #comment 1
- value line 1
#comment 2
- value line 2
#comment 3
- value line 3Die Tastenkombination zum Kommentieren von YAML-Blöcken lautet Ctrl+Q.
Wenn Sie verwenden Sublime Text editorDie Schritte zum Kommentieren des Blocks sind unten aufgeführt -
Wählen Sie den Block aus. Verwenden Sie "STRG + /" unter Linux und Windows und "CMD + /" für Mac-Betriebssysteme. Führen Sie den Block aus.
Beachten Sie, dass die gleichen Schritte gelten, wenn Sie verwenden Visual Studio Code Editor. Es wird immer empfohlen, zu verwendenSublime Text Editor zum Erstellen von YAML-Dateien, wie sie von den meisten Betriebssystemen unterstützt werden und entwicklerfreundliche Tastenkombinationen enthalten.
YAML enthält Blockauflistungen, die Einrückungen als Gültigkeitsbereich verwenden. Hier beginnt jeder Eintrag mit einer neuen Zeile. Blocksequenzen in Sammlungen kennzeichnen jeden Eintrag mit einemdash and space(-). In YAML werden Blocksammlungsstile nicht durch einen bestimmten Indikator gekennzeichnet. Die Blockerfassung in YAML kann von anderen skalaren Größen durch Identifizierung des darin enthaltenen Schlüsselwertpaars unterschieden werden.
Zuordnungen sind die Darstellung des Schlüsselwerts, wie er in der JSON-Struktur enthalten ist. Es wird häufig in mehrsprachigen Unterstützungssystemen und der Erstellung von APIs in mobilen Anwendungen verwendet. Zuordnungen verwenden die Darstellung von Schlüsselwertpaaren mit der Verwendung voncolon and space (:).
Beispiele
Betrachten Sie ein Beispiel für eine Abfolge von Skalaren, zum Beispiel eine Liste von Ballspielern, wie unten gezeigt -
- Mark Joseph
- James Stephen
- Ken GriffeyDas folgende Beispiel zeigt die Zuordnung von Skalaren zu Skalaren -
hr: 87
avg: 0.298
rbi: 149Das folgende Beispiel zeigt die Zuordnung von Skalaren zu Sequenzen -
European:
- Boston Red Sox
- Detroit Tigers
- New York Yankees
national:
- New York Mets
- Chicago Cubs
- Atlanta BravesSammlungen können für Sequenzzuordnungen verwendet werden, die unten gezeigt werden -
-
name: Mark Joseph
hr: 87
avg: 0.278
-
name: James Stephen
hr: 63
avg: 0.288Bei Sammlungen enthält YAML Flussstile, die explizite Indikatoren verwenden, anstatt Einrückungen zur Bezeichnung des Leerzeichens zu verwenden. Die Ablaufsequenz in Sammlungen wird als durch Kommas getrennte Liste in eckigen Klammern geschrieben. Die beste Illustration für die Sammlung, die in PHP-Frameworks wie Symphony enthalten ist.
[PHP, Perl, Python]Diese Sammlungen werden in Dokumenten gespeichert. Die Trennung von Dokumenten in YAML wird mit drei Bindestrichen oder Bindestrichen (---) gekennzeichnet. Das Ende des Dokuments ist mit drei Punkten markiert (…).
Die Trennung von Dokumenten in YAML wird durch drei Striche (---) gekennzeichnet. Das Ende des Dokuments wird mit drei Punkten (…) dargestellt.
Die Dokumentdarstellung wird als Strukturformat bezeichnet, das unten erwähnt wird -
# Ranking of 1998 home runs
---
- Mark Joseph
- James Stephen
- Ken Griffey
# Team ranking
---
- Chicago Cubs
- St Louis CardinalsEin Fragezeichen mit einer Kombination aus Leerzeichen zeigt eine komplexe Zuordnung in der Struktur an. Innerhalb einer Blockauflistung kann ein Benutzer eine Struktur mit einem Bindestrich, einem Doppelpunkt und einem Fragezeichen einfügen. Das folgende Beispiel zeigt die Zuordnung zwischen Sequenzen -
- 2001-07-23
? [ New York Yankees,Atlanta Braves ]
: [ 2001-07-02, 2001-08-12, 2001-08-14]Skalare in YAML werden im Blockformat unter Verwendung eines Literaltyps geschrieben, der als (|). Es bezeichnet die Anzahl der Zeilenumbrüche. In YAML werden Skalare gefaltet geschrieben (>) wobei jede Zeile einen gefalteten Raum bezeichnet, der mit einem endet empty line oder more indented Linie.
Neue Zeilen in Literalen werden unten angezeigt -
ASCII Art
--- |
\//||\/||
// || ||__Die gefalteten Zeilenumbrüche bleiben für erhalten more indented lines und blank lines wie unten gezeigt -
>
Sammy Sosa completed another
fine season with great stats.
63 Home Runs
0.288 Batting Average
What a year!YAML-Flow-Skalare umfassen einfache Stile und Anführungszeichen. Der doppelt zitierte Stil enthält verschiedene Escape-Sequenzen. Flussskalare können mehrere Linien enthalten. Zeilenumbrüche werden in dieser Struktur immer gefaltet.
plain:
This unquoted scalar
spans many lines.
quoted: "So does this
quoted scalar.\n"In YAML werden Knoten ohne Tags mit einem bestimmten Anwendungstyp angegeben. Die Beispiele für die Tag-Spezifikation werden im Allgemeinen verwendetseq, map und strTypen für das YAML-Tag-Repository. Die Tags werden als Beispiele dargestellt, die wie folgt aufgeführt sind:
Ganzzahlige Tags
Diese Tags enthalten ganzzahlige Werte. Sie werden auch als numerische Tags bezeichnet.
canonical: 12345
decimal: +12,345
sexagecimal: 3:25:45
octal: 014
hexadecimal: 0xCGleitkommazahlen
Diese Tags enthalten Dezimal- und Exponentialwerte. Sie werden auch als Exponential-Tags bezeichnet.
canonical: 1.23015e+3
exponential: 12.3015e+02
sexagecimal: 20:30.15
fixed: 1,230.15
negative infinity: -.inf
not a number: .NaNVerschiedene Tags
Es enthält eine Vielzahl von darin eingebetteten Ganzzahl-, Gleitkomma- und Zeichenfolgenwerten. Daher nennt man es verschiedene Tags.
null: ~
true: y
false: n
string: '12345'Das folgende Beispiel in voller Länge gibt das Konstrukt von YAML an, das Symbole und verschiedene Darstellungen enthält, die beim Konvertieren oder Verarbeiten im JSON-Format hilfreich sind. Diese Attribute werden in JSON-Dokumenten auch als Schlüsselnamen bezeichnet. Diese Notationen werden aus Sicherheitsgründen erstellt.
Das obige YAML-Format repräsentiert verschiedene Attribute von Standard, Adapter und Host mit verschiedenen anderen Attributen. YAML führt außerdem ein Protokoll aller generierten Dateien, in dem die generierten Fehlermeldungen nachverfolgt werden. Beim Konvertieren der angegebenen YAML-Datei in das JSON-Format erhalten wir die gewünschte Ausgabe wie unten erwähnt -
defaults: &defaults
adapter: postgres
host: localhost
development:
database: myapp_development
<<: *defaults
test:
database: myapp_test
<<: *defaultsLassen Sie uns die YAML in das JSON-Format konvertieren und die Ausgabe überprüfen.
{
"defaults": {
"adapter": "postgres",
"host": "localhost"
},
"development": {
"database": "myapp_development",
"adapter": "postgres",
"host": "localhost"
},
"test": {
"database": "myapp_test",
"adapter": "postgres",
"host": "localhost"
}
}Der Standardschlüssel mit dem Präfix "<<: *" wird bei Bedarf eingefügt, ohne dass das gleiche Codefragment wiederholt geschrieben werden muss.
YAML folgt einem Standardverfahren für den Prozessablauf. Die native Datenstruktur in YAML enthält einfache Darstellungen wie Knoten. Es wird auch als Repräsentationsknotendiagramm bezeichnet.
Es enthält Mapping-, Sequenz- und Skalargrößen, die serialisiert werden, um einen Serialisierungsbaum zu erstellen. Bei der Serialisierung werden die Objekte mit einem Bytestrom konvertiert.
Der Serialisierungsereignisbaum hilft beim Erstellen der Darstellung von Zeichenströmen, wie im folgenden Diagramm dargestellt.
Die umgekehrte Prozedur analysiert den Bytestrom in einen serialisierten Ereignisbaum. Später werden die Knoten in ein Knotendiagramm konvertiert. Diese Werte werden später in die native YAML-Datenstruktur konvertiert. Die folgende Abbildung erklärt dies -
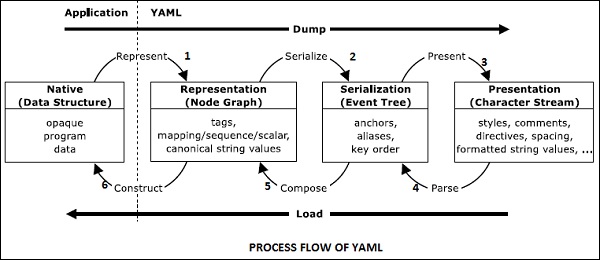
Die Informationen in YAML werden auf zwei Arten verwendet: machine processing und human consumption. Der Prozessor in YAML wird als Werkzeug für die Prozedur zum Konvertieren von Informationen zwischen komplementären Ansichten in dem oben angegebenen Diagramm verwendet. In diesem Kapitel werden die Informationsstrukturen beschrieben, die ein YAML-Prozessor in einer bestimmten Anwendung bereitstellen muss.
YAML enthält eine Serialisierungsprozedur zum Darstellen von Datenobjekten im seriellen Format. Die Verarbeitung von YAML-Informationen umfasst drei Stufen:Representation, Serialization, Presentation and parsing. Lassen Sie uns jeden von ihnen im Detail besprechen.
Darstellung
YAML repräsentiert die Datenstruktur unter Verwendung von drei Arten von Knoten: sequence, mapping und scalar.
Reihenfolge
Die Sequenz bezieht sich auf die geordnete Anzahl von Einträgen, die die ungeordnete Zuordnung des Schlüsselwertpaars abbildet. Es entspricht der Perl- oder Python-Array-Liste.
Der unten gezeigte Code ist ein Beispiel für die Sequenzdarstellung -
product:
- sku : BL394D
quantity : 4
description : Football
price : 450.00
- sku : BL4438H
quantity : 1
description : Super Hoop
price : 2392.00Kartierung
Die Zuordnung repräsentiert andererseits die Wörterbuchdatenstruktur oder die Hash-Tabelle. Ein Beispiel dafür ist unten aufgeführt -
batchLimit: 1000
threadCountLimit: 2
key: value
keyMapping: <What goes here?>Skalare
Skalare repräsentieren Standardwerte von Zeichenfolgen, Ganzzahlen, Datumsangaben und atomaren Datentypen. Beachten Sie, dass YAML auch Knoten enthält, die die Datentypstruktur angeben. Weitere Informationen zu Skalaren finden Sie in Kapitel 6 dieses Tutorials.
Serialisierung
In YAML ist ein Serialisierungsprozess erforderlich, der die benutzerfreundliche Schlüsselreihenfolge und die Ankernamen vereinfacht. Das Ergebnis der Serialisierung ist ein YAML-Serialisierungsbaum. Es kann durchlaufen werden, um eine Reihe von Ereignisaufrufen von YAML-Daten zu erzeugen.
Ein Beispiel für die Serialisierung ist unten angegeben -
consumer:
class: 'AppBundle\Entity\consumer'
attributes:
filters: ['customer.search', 'customer.order', 'customer.boolean']
collectionOperations:
get:
method: 'GET'
normalization_context:
groups: ['customer_list']
itemOperations:
get:
method: 'GET'
normalization_context:
groups: ['customer_get']Präsentation
Die endgültige Ausgabe der YAML-Serialisierung wird als Präsentation bezeichnet. Es repräsentiert einen Charakterstrom auf menschenfreundliche Weise. Der YAML-Prozessor enthält verschiedene Präsentationsdetails zum Erstellen von Streams, zum Behandeln von Einrückungen und zum Formatieren von Inhalten. Dieser vollständige Prozess richtet sich nach den Vorlieben des Benutzers.
Ein Beispiel für den YAML-Präsentationsprozess ist das Ergebnis der Erstellung eines JSON-Werts. Beachten Sie zum besseren Verständnis den unten angegebenen Code -
{
"consumer": {
"class": "AppBundle\\Entity\\consumer",
"attributes": {
"filters": [
"customer.search",
"customer.order",
"customer.boolean"
]
},
"collectionOperations": {
"get": {
"method": "GET",
"normalization_context": {
"groups": [
"customer_list"
]
}
}
},
"itemOperations": {
"get": {
"method": "GET",
"normalization_context": {
"groups": [
"customer_get"
]
}
}
}
}
}Parsing
Das Parsen ist der umgekehrte Prozess der Präsentation. Es enthält einen Strom von Zeichen und erstellt eine Reihe von Ereignissen. Die im Präsentationsprozess eingeführten Details, die Serialisierungsereignisse verursachen, werden verworfen. Der Analysevorgang kann aufgrund einer fehlerhaften Eingabe fehlschlagen. Grundsätzlich wird geprüft, ob YAML wohlgeformt ist oder nicht.
Betrachten Sie ein YAML-Beispiel, das unten erwähnt wird -
---
environment: production
classes:
nfs::server:
exports:
- /srv/share1
- /srv/share3
parameters:
paramter1Mit drei Bindestrichen stellt es den Beginn des Dokuments mit verschiedenen Attributen dar, die später darin definiert werden.
YAML lint ist der Online-Parser von YAML und hilft beim Parsen der YAML-Struktur, um zu überprüfen, ob sie gültig ist oder nicht. Der offizielle Link für YAML-Flusen ist unten aufgeführt:http://www.yamllint.com/
Sie können die Ausgabe der Analyse wie unten gezeigt sehen -
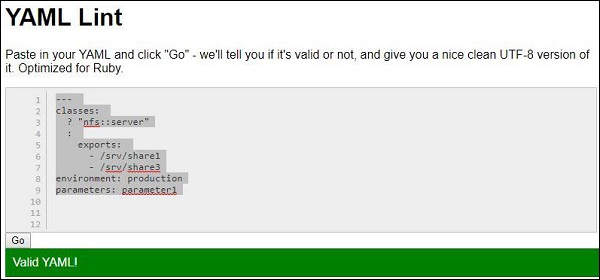
In diesem Kapitel werden die Details zu den Verfahren und Prozessen erläutert, die wir im letzten Kapitel besprochen haben. Informationsmodelle in YAML spezifizieren die Merkmale des Serialisierungs- und Präsentationsverfahrens in einem systematischen Format unter Verwendung eines bestimmten Diagramms.
Für ein Informationsmodell ist es wichtig, die Anwendungsinformationen darzustellen, die zwischen Programmierumgebungen portierbar sind.
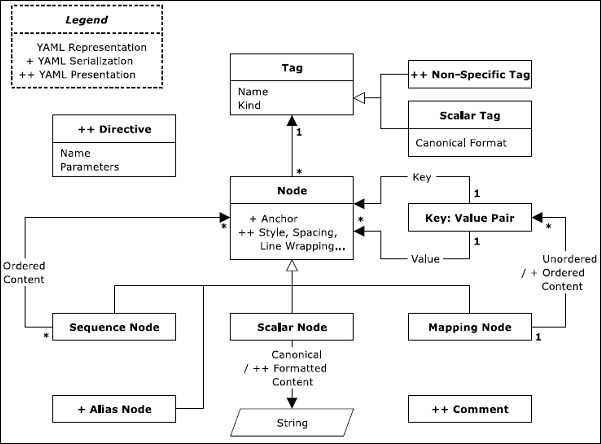
Das oben gezeigte Diagramm stellt ein normales Informationsmodell dar, das im Diagrammformat dargestellt wird. In YAML ist die Darstellung nativer Daten verwurzelt, verbunden und ein gerichteter Graph markierter Knoten. Wenn wir einen gerichteten Graphen erwähnen, enthält er eine Reihe von Knoten mit einem gerichteten Graphen. Wie im Informationsmodell erwähnt, unterstützt YAML drei Arten von Knoten, nämlich -
- Sequences
- Scalars
- Mappings
Die grundlegenden Definitionen dieser Darstellungsknoten wurden im letzten Kapitel erläutert. In diesem Kapitel konzentrieren wir uns auf die schematische Darstellung dieser Begriffe. Das folgende Sequenzdiagramm zeigt den Workflow von Legenden mit verschiedenen Arten von Tags und Mapping-Knoten.
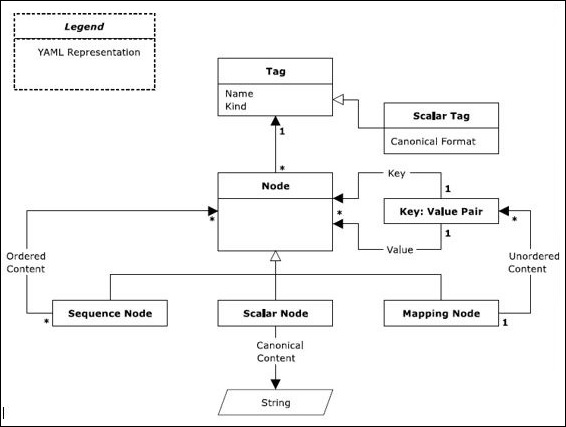
Es gibt drei Arten von Knoten: sequence node, scalar node und mapping node.
Sequenzen
Der Sequenzknoten folgt einer sequentiellen Architektur und enthält eine geordnete Reihe von null oder mehr Knoten. Eine YAML-Sequenz kann wiederholt denselben Knoten oder einen einzelnen Knoten enthalten.
Skalare
Der Inhalt von Skalaren in YAML enthält Unicode-Zeichen, die im Format mit einer Reihe von Nullen dargestellt werden können. Im Allgemeinen enthält der Skalarknoten skalare Größen.
Kartierung
Der Zuordnungsknoten enthält die Darstellung des Schlüsselwertpaars. Der Inhalt des Zuordnungsknotens enthält eine Kombination aus Schlüssel-Wert-Paar mit der obligatorischen Bedingung, dass der Schlüsselname eindeutig bleibt. Sequenzen und Zuordnungen bilden zusammen eine Sammlung.
Beachten Sie, dass Skalare, Sequenzen und Zuordnungen, wie im obigen Diagramm dargestellt, in einem systematischen Format dargestellt werden.
Verschiedene Arten von Zeichen werden für verschiedene Funktionen verwendet. Dieses Kapitel befasst sich ausführlich mit der in YAML verwendeten Syntax und konzentriert sich auf die Zeichenmanipulation.
Indikatorzeichen
Indikatorzeichen enthalten eine spezielle Semantik, mit der der Inhalt des YAML-Dokuments beschrieben wird. Die folgende Tabelle zeigt dies im Detail.
| Sr.Nr. | Charakter & Funktionalität |
|---|---|
| 1 | _ Es bezeichnet einen Blocksequenzeintrag |
| 2 | ? Es bezeichnet einen Zuordnungsschlüssel |
| 3 | : Es bezeichnet einen Zuordnungswert |
| 4 | , Es bezeichnet den Flow-Collection-Eintrag |
| 5 | [ Es startet eine Flusssequenz |
| 6 | ] Es beendet eine Flusssequenz |
| 7 | { Es wird eine Flusszuordnung gestartet |
| 8 | } Es beendet eine Flusszuordnung |
| 9 | # Es kennzeichnet die Kommentare |
| 10 | & Es bezeichnet die Ankereigenschaft des Knotens |
| 11 | * Es bezeichnet einen Aliasknoten |
| 12 | ! Es bezeichnet das Tag des Knotens |
| 13 | | Es bezeichnet einen wörtlichen Blockskalar |
| 14 | > Es bezeichnet einen gefalteten Blockskalar |
| 15 | ` Ein einfaches Anführungszeichen umgibt einen zitierten Flussskalar |
| 16 | " Das doppelte Anführungszeichen umgibt den doppelt zitierten Flussskalar |
| 17 | % Es bezeichnet die verwendete Richtlinie |
Das folgende Beispiel zeigt die in der Syntax verwendeten Zeichen -
%YAML 1.1
---
!!map {
? !!str "sequence"
: !!seq [
!!str "one", !!str "two"
],
? !!str "mapping"
: !!map {
? !!str "sky" : !!str "blue",
? !!str "sea" : !!str "green",
}
}
# This represents
# only comments.
---
!!map1 {
? !!str "anchored"
: !local &A1 "value",
? !!str "alias"
: *A1,
}
!!str "text"In diesem Kapitel lernen Sie die folgenden Aspekte von Syntaxprimitiven in YAML kennen:
- Produktionsparameter
- Einrückungsräume
- Trennräume
- Ignoriertes Zeilenpräfix
- Linienfaltung
Lassen Sie uns jeden Aspekt im Detail verstehen.
Produktionsparameter
Zu den Produktionsparametern gehören eine Reihe von Parametern und der Bereich der zulässigen Werte, die für eine bestimmte Produktion verwendet werden. Die folgende Liste von Produktionsparametern wird in YAML verwendet -
Vertiefung
Es wird durch Zeichen bezeichnet n oder mDer Zeichenstrom hängt von der Einrückungsstufe der darin enthaltenen Blöcke ab. Viele Produktionen haben diese Funktionen parametrisiert.
Kontext
Es wird mit bezeichnet c. YAML unterstützt zwei Gruppen von Kontexten:block styles und flow styles.
Stil
Es wird mit s bezeichnet. Skalare Inhalte können in einem der fünf Stile dargestellt werden:plain, double quoted and single quoted flow, literal and folded block.
Chomping
Es wird mit bezeichnet t. Blockskalare bieten viele Mechanismen, die beim Trimmen des Blocks helfen:strip, clip und keep. Chomping hilft beim Formatieren neuer Zeilenfolgen. Es wird die Blockstildarstellung verwendet. Der Chomping-Prozess erfolgt mithilfe von Indikatoren. Die Indikatoren steuern, welche Ausgabe mit Zeilenumbrüchen erzeugt werden soll. Die Zeilenumbrüche werden mit entfernt(-) Operator und Zeilenumbrüche werden mit hinzugefügt (+) Operator.
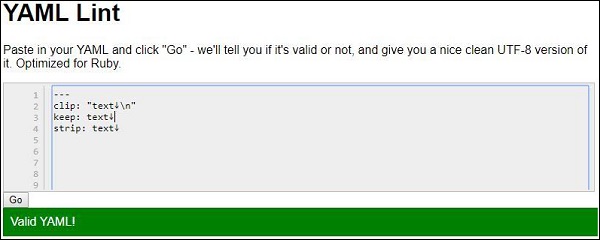
Ein Beispiel für den Chomping-Prozess ist unten dargestellt -
strip: |-
text↓
clip: |
text↓
keep: |+
text↓Die Ausgabe nach dem Parsen des angegebenen YAML-Beispiels lautet wie folgt:
Einrückungsräume
Im YAML-Zeichenstrom wird der Einzug als Zeilenumbruchzeichen mit null oder mehr Zeichen definiert. Der wichtigste zu beachtende Punkt ist, dass Einrückungen keine Tabulatorzeichen enthalten dürfen. Die Zeichen in Einrückungen sollten niemals als Teil der Inhaltsinformationen des Knotens betrachtet werden. Beachten Sie zum besseren Verständnis den folgenden Code:
%YAML 1.1
---
!!map {
? !!str "Not indented"
: !!map {
? !!str "By one space"
: !!str "By four\n spaces\n",
? !!str "Flow style"
: !!seq [
!!str "By two",
!!str "Still by two",
!!str "Again by two",
]
}
}Die Ausgabe, die Sie nach dem Einrücken sehen können, lautet wie folgt:
{
"Not indented": {
"By one space": "By four\n spaces\n",
"Flow style": [
"By two",
"Still by two",
"Again by two"
]
}
}Trennräume
YAML verwendet Leerzeichen zur Trennung zwischen Token. Der wichtigste Hinweis ist, dass die Trennung in YAML keine Tabulatorzeichen enthalten sollte.
Der folgende Code zeigt die Verwendung von Trennräumen -
{ · first: · Sammy, · last: · Sosa · }{
"\u00b7 last": "\u00b7 Sosa \u00b7",
"\u00b7 first": "\u00b7 Sammy"
}Ignoriertes Zeilenpräfix
Das leere Präfix enthält je nach Skalartyp immer einen Einzug, der auch ein führendes Leerzeichen enthält. Einfache Skalare sollten keine Tabulatorzeichen enthalten. Auf der anderen Seite können Skalare in Anführungszeichen Tabulatorzeichen enthalten. Blockskalare hängen vollständig von der Einrückung ab.
Das folgende Beispiel zeigt die systematische Arbeit mit ignorierten Zeilenpräfixen -
%YAML 1.1
---
!!map {
? !!str "plain"
: !!str "text lines",
? !!str "quoted"
: !!str "text lines",
? !!str "block"
: !!str "text·®lines\n"
}Die für die Blockströme erzielte Ausgabe ist wie folgt:
{
"plain": "text lines",
"quoted": "text lines",
"block": "text\u00b7\u00aelines\n"
}Linienfalten
Das Falten von Linien ermöglicht das Brechen langer Linien zur besseren Lesbarkeit. Mehr kurze Zeilen bedeuten eine bessere Lesbarkeit. Das Falten von Linien wird erreicht, indem die ursprüngliche Semantik der langen Linie notiert wird. Das folgende Beispiel zeigt das Falten von Linien -
%YAML 1.1
--- !!str
"specific\L\
trimmed\n\n\n\
as space"Sie können die Ausgabe für das Falten von Linien im JSON-Format wie folgt sehen:
"specific\u2028trimmed\n\n\nas space"In YAML stoßen Sie auf verschiedene Zeichenströme wie folgt:
- Directives
- Grenzmarkierungen dokumentieren
- Documents
- Kompletter Stream
In diesem Kapitel werden wir sie im Detail diskutieren.
Richtlinien
Anweisungen sind grundlegende Anweisungen, die im YAML-Prozessor verwendet werden. Direktiven sind die Präsentationsdetails wie Kommentare, die nicht im Serialisierungsbaum enthalten sind. In YAML gibt es keine Möglichkeit, private Direktiven zu definieren. In diesem Abschnitt werden verschiedene Arten von Richtlinien anhand relevanter Beispiele erläutert.
Reservierte Richtlinien
Reservierte Anweisungen werden mit drei Bindestrichen (---) initialisiert, wie im folgenden Beispiel gezeigt. Die reservierten Anweisungen werden in einen bestimmten Wert von JSON konvertiert.
%YAML 1.1
--- !!str
"foo"YAML-Richtlinie
YAML-Anweisungen sind Standardanweisungen. Bei der Konvertierung in JSON enthält der abgerufene Wert einen Schrägstrich in vorhergehenden und abschließenden Zeichen.
%YAML 1.1
---
!!str "foo"Grenzmarkierungen dokumentieren
YAML verwendet diese Markierungen, um zu ermöglichen, dass mehr als ein Dokument in einem Stream enthalten ist. Diese Markierungen werden speziell verwendet, um die Struktur des YAML-Dokuments zu vermitteln. Beachten Sie, dass eine Zeile, die mit „---“ beginnt, zum Starten eines neuen Dokuments verwendet wird.
Der folgende Code erklärt dies anhand von Beispielen -
%YAML 1.1
---
!!str "foo"
%YAML 1.1
---
!!str "bar"
%YAML 1.1
---
!!str "baz"Unterlagen
Das YAML-Dokument wird als einzelne native Datenstruktur betrachtet, die als einzelner Stammknoten dargestellt wird. Die Präsentationsdetails im YAML-Dokument wie Anweisungen, Kommentare, Einrückungen und Stile gelten nicht als darin enthaltene Inhalte.
In YAML werden zwei Arten von Dokumenten verwendet. Sie werden in diesem Abschnitt erklärt -
Explizite Dokumente
Es beginnt mit der Dokumentstartmarkierung, gefolgt von der Darstellung des Stammknotens. Das Beispiel einer expliziten YAML-Deklaration ist unten angegeben -
---
some: yaml
...Es enthält eine explizite Start- und Endmarkierung, die im angegebenen Beispiel „---“ und „…“ lautet. Beim Konvertieren der angegebenen YAML in das JSON-Format erhalten wir die Ausgabe wie unten gezeigt -
{
"some": "yaml"
}Implizite Dokumente
Diese Dokumente beginnen nicht mit einer Dokumentstartmarkierung. Beachten Sie den unten angegebenen Code -
fruits:
- Apple
- Orange
- Pineapple
- MangoWenn Sie diese Werte in das JSON-Format konvertieren, erhalten Sie die Ausgabe als einfaches JSON-Objekt (siehe unten).
{
"fruits": [
"Apple",
"Orange",
"Pineapple",
"Mango"
]
}Kompletter Stream
YAML enthält eine Folge von Bytes, die als Zeichenstrom bezeichnet werden. Der Stream beginnt mit einem Präfix, das eine Bytereihenfolge enthält, die eine Zeichenkodierung angibt. Der vollständige Stream beginnt mit einem Präfix, das eine Zeichenkodierung enthält, gefolgt von Kommentaren.
Ein Beispiel für einen vollständigen Stream (Zeichen-Stream) ist unten dargestellt -
%YAML 1.1
---
!!str "Text content\n"Jeder Präsentationsknoten enthält zwei Hauptmerkmale, die als bezeichnet werden anchor und tag. Knoteneigenschaften können mit Knoteninhalt angegeben werden, der im Zeichenstrom weggelassen wird.
Das grundlegende Beispiel für die Knotendarstellung lautet wie folgt:
%YAML 1.1
---
!!map {
? &A1 !!str "foo"
: !!str "bar",
? !!str &A2 "baz"
: *a1
}Knotenanker
Die Ankereigenschaft stellt einen Knoten für zukünftige Referenz dar. Der Zeichenstrom der YAML-Darstellung im Knoten wird mit dem bezeichnetampersand (&)Indikator. Der YAML-Prozessor muss den Ankernamen mit den darin enthaltenen Darstellungsdetails nicht beibehalten. Der folgende Code erklärt dies -
%YAML 1.1
---
!!map {
? !!str "First occurence"
: &A !!str "Value",
? !!str "Second occurence"
: *A
}Die Ausgabe von YAML, die mit Ankerknoten generiert wurde, ist unten dargestellt -
---
!!map {
? !!str "First occurence"
: !!str "Value",
? !!str "Second occurence"
: !!str "Value",
}Knoten-Tags
Die Tag-Eigenschaft repräsentiert den Typ der nativen Datenstruktur, die einen Knoten vollständig definiert. Ein Tag wird mit dem (!) Indikator. Tags werden als inhärenter Bestandteil des Darstellungsdiagramms betrachtet. Im folgenden Beispiel werden Knoten-Tags ausführlich erläutert.
%YAML 1.1
---
!!map {
? !<tag:yaml.org,2002:str> "foo"
: !<!bar> "baz"
}Knoteninhalt
Der Knoteninhalt kann in einem Flussinhalt oder Blockformat dargestellt werden. Der Blockinhalt erstreckt sich bis zum Zeilenende und verwendet Einrückungen, um die Struktur zu kennzeichnen. Jede Sammlungsart kann in einem bestimmten Sammlungsstil für einen einzelnen Fluss dargestellt oder als einzelner Block betrachtet werden. Der folgende Code erklärt dies im Detail -
%YAML 1.1
---
!!map {
? !!str "foo"
: !!str "bar baz"
}
%YAML 1.1
---
!!str "foo bar"
%YAML 1.1
---
!!str "foo bar"
%YAML 1.1
---
!!str "foo bar\n"In diesem Kapitel konzentrieren wir uns auf verschiedene Skalartypen, die zur Darstellung des Inhalts verwendet werden. In YAML können Kommentare vor oder nach skalarem Inhalt stehen. Es ist wichtig zu beachten, dass Kommentare nicht in den skalaren Inhalt aufgenommen werden sollten.
Beachten Sie, dass alle Flow-Skalarstile mehrere Zeilen enthalten können, außer bei Verwendung in mehreren Schlüsseln.
Die Darstellung der Skalare ist unten angegeben -
%YAML 1.1
---
!!map {
? !!str "simple key"
: !!map {
? !!str "also simple"
: !!str "value",
? !!str "not a simple key"
: !!str "any value"
}
}Die generierte Ausgabe von Blockskalar-Headern wird unten gezeigt -
{
"simple key": {
"not a simple key": "any value",
"also simple": "value"
}
}Skalarinhalt der Dokumentenmarkierung
Alle Zeichen in diesem Beispiel werden als Inhalt betrachtet, einschließlich der Leerzeichen.
%YAML 1.1
---
!!map {
? !!str "---"
: !!str "foo",
? !!str "...",
: !!str "bar"
}
%YAML 1.1
---
!!seq [
!!str "---",
!!str "...",
!!map {
? !!str "---"
: !!str "..."
}
]Die einfachen Zeilenumbrüche werden mit dem folgenden Beispiel dargestellt -
%YAML 1.1
---
!!str "as space \
trimmed\n\
specific\L\n\
none"Die entsprechende JSON-Ausgabe für dieselbe wird unten erwähnt -
"as space trimmed\nspecific\u2028\nnone"Flow-Stile in YAML können als natürliche Erweiterung von JSON betrachtet werden, um die faltbaren Inhaltszeilen für eine besser lesbare Funktion abzudecken, bei der Anker und Aliase zum Erstellen der Objektinstanzen verwendet werden. In diesem Kapitel konzentrieren wir uns auf die Flussdarstellung der folgenden Konzepte:
- Alias-Knoten
- Leere Knoten
- Flow Scalar-Stile
- Flow-Sammlungsstile
- Flussknoten
Das Beispiel für Alias-Knoten ist unten dargestellt.
%YAML 1.2
---
!!map {
? !!str "First occurrence"
: &A !!str "Foo",
? !!str "Override anchor"
: &B !!str "Bar",
? !!str "Second occurrence"
: *A,
? !!str "Reuse anchor"
: *B,
}Die JSON-Ausgabe des oben angegebenen Codes ist unten angegeben -
{
"First occurrence": "Foo",
"Second occurrence": "Foo",
"Override anchor": "Bar",
"Reuse anchor": "Bar"
}Knoten mit leerem Inhalt werden als leere Knoten betrachtet. Das folgende Beispiel zeigt dies -
%YAML 1.2
---
!!map {
? !!str "foo" : !!str "",
? !!str "" : !!str "bar",
}Die Ausgabe leerer Knoten in JSON wird wie folgt dargestellt:
{
"": "bar",
"foo": ""
}Flow-Skalarstile umfassen Typen in doppelten, einfachen und einfachen Anführungszeichen. Das grundlegende Beispiel dafür ist unten angegeben -
%YAML 1.2
---
!!map {
? !!str "implicit block key"
: !!seq [
!!map {
? !!str "implicit flow key"
: !!str "value",
}
]
}Die Ausgabe im JSON-Format für das oben angegebene Beispiel wird unten gezeigt -
{
"implicit block key": [
{
"implicit flow key": "value"
}
]
}Die Flow-Sammlung in YAML ist mit einer Block-Sammlung in einer anderen Flow-Sammlung verschachtelt. Flow Collection-Einträge werden mit beendetcomma (,) Indikator. Im folgenden Beispiel wird der Flow Collection-Block ausführlich erläutert.
%YAML 1.2
---
!!seq [
!!seq [
!!str "one",
!!str "two",
],
!!seq [
!!str "three",
!!str "four",
],
]Die Ausgabe für die Flusserfassung in JSON wird unten angezeigt -
[
[
"one",
"two"
],
[
"three",
"four"
]
]Flow-Stile wie JSON enthalten Start- und Endindikatoren. Der einzige Flow-Stil, der keine Eigenschaft hat, ist der einfache Skalar.
%YAML 1.2
---
!!seq [
!!seq [ !!str "a", !!str "b" ],
!!map { ? !!str "a" : !!str "b" },
!!str "a",
!!str "b",
!!str "c",]Die Ausgabe für den oben gezeigten Code im JSON-Format ist unten angegeben -
[
[
"a",
"b"
],
{
"a": "b"
},
"a",
"b",
"c"
]YAML enthält zwei Blockskalarstile: literal und folded. Blockskalare werden mit wenigen Indikatoren gesteuert, wobei ein Header vor dem Inhalt selbst steht. Ein Beispiel für blockskalare Header ist unten angegeben -
%YAML 1.2
---
!!seq [
!!str "literal\n",
!!str "·folded\n",
!!str "keep\n\n",
!!str "·strip",
]Die Ausgabe im JSON-Format mit einem Standardverhalten ist unten angegeben -
[
"literal\n",
"\u00b7folded\n",
"keep\n\n",
"\u00b7strip"
]Arten von Blockstilen
Es gibt vier Arten von Blockstilen: literal, folded, keep und stripStile. Diese Blockstile werden mithilfe des Block Chomping-Szenarios definiert. Ein Beispiel für ein Block-Chomping-Szenario ist unten angegeben -
%YAML 1.2
---
!!map {
? !!str "strip"
: !!str "# text",
? !!str "clip"
: !!str "# text\n",
? !!str "keep"
: !!str "# text\n",
}Sie können die mit drei Formaten in JSON generierte Ausgabe wie folgt sehen:
{
"strip": "# text",
"clip": "# text\n",
"keep": "# text\n"
}Das Chomping in YAML steuert die letzten Unterbrechungen und nachfolgenden Leerzeilen, die in verschiedenen Formen interpretiert werden.
Strippen
In diesem Fall werden der letzte Zeilenumbruch und leere Zeilen für den skalaren Inhalt ausgeschlossen. Sie wird durch den Chomping-Indikator „-“ angegeben.
Ausschnitt
Das Abschneiden wird als Standardverhalten betrachtet, wenn kein expliziter Chomping-Indikator angegeben ist. Das letzte Unterbrechungszeichen bleibt im Inhalt des Skalars erhalten. Das beste Beispiel für das Abschneiden ist im obigen Beispiel dargestellt. Es endet mit Newline“\n” Charakter.
Halten
Behalten bezieht sich auf die Hinzufügung mit Darstellung des Chomping-Indikators „+“. Zusätzliche erstellte Linien unterliegen keiner Faltung. Die zusätzlichen Linien unterliegen keiner Faltung.
Um Sequenzstile zu verstehen, ist es wichtig, Sammlungen zu verstehen. Das Konzept von Sammlungen und Sequenzstilen arbeitet parallel. Die Sammlung in YAML wird mit den richtigen Sequenzstilen dargestellt. Wenn Sie auf die richtige Reihenfolge von Tags verweisen möchten, beziehen Sie sich immer auf Sammlungen. Sammlungen in YAML werden durch sequentielle Ganzzahlen indiziert, die mit Null beginnen, wie in Arrays dargestellt. Der Fokus von Sequenzstilen beginnt mit Sammlungen.
Beispiel
Betrachten wir die Anzahl der Planeten im Universum als eine Sequenz, die als Sammlung erstellt werden kann. Der folgende Code zeigt, wie die Sequenzstile von Planeten im Universum dargestellt werden -
# Ordered sequence of nodes in YAML STRUCTURE
Block style: !!seq
- Mercury # Rotates - no light/dark sides.
- Venus # Deadliest. Aptly named.
- Earth # Mostly dirt.
- Mars # Seems empty.
- Jupiter # The king.
- Saturn # Pretty.
- Uranus # Where the sun hardly shines.
- Neptune # Boring. No rings.
- Pluto # You call this a planet?
Flow style: !!seq [ Mercury, Venus, Earth, Mars, # Rocks
Jupiter, Saturn, Uranus, Neptune, # Gas
Pluto ] # OverratedAnschließend sehen Sie die folgende Ausgabe für die geordnete Sequenz im JSON-Format:
{
"Flow style": [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
"Pluto"
],
"Block style": [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
"Pluto"
]
}Flusszuordnungen in YAML repräsentieren die ungeordnete Sammlung von Schlüsselwertpaaren. Sie werden auch als Mapping-Knoten bezeichnet. Beachten Sie, dass die Schlüssel eindeutig bleiben sollten. Wenn die Flow-Mapping-Struktur doppelt vorhanden ist, wird ein Fehler generiert. Die Schlüsselreihenfolge wird im Serialisierungsbaum generiert.
Beispiel
Ein Beispiel für eine Flow-Mapping-Struktur ist unten dargestellt.
%YAML 1.1
paper:
uuid: 8a8cbf60-e067-11e3-8b68-0800200c9a66
name: On formally undecidable propositions of Principia Mathematica and related systems I.
author: Kurt Gödel.
tags:
- tag:
uuid: 98fb0d90-e067-11e3-8b68-0800200c9a66
name: Mathematics
- tag:
uuid: 3f25f680-e068-11e3-8b68-0800200c9a66
name: LogicDie Ausgabe der zugeordneten Sequenz (ungeordnete Liste) im JSON-Format ist wie folgt:
{
"paper": {
"uuid": "8a8cbf60-e067-11e3-8b68-0800200c9a66",
"name": "On formally undecidable propositions of Principia Mathematica and related systems I.",
"author": "Kurt Gödel."
},
"tags": [
{
"tag": {
"uuid": "98fb0d90-e067-11e3-8b68-0800200c9a66",
"name": "Mathematics"
}
},
{
"tag": {
"uuid": "3f25f680-e068-11e3-8b68-0800200c9a66",
"name": "Logic"
}
}
]
}Wenn Sie diese Ausgabe wie oben gezeigt beobachten, wird festgestellt, dass die Schlüsselnamen in der YAML-Zuordnungsstruktur eindeutig bleiben.
Die Blocksequenzen von YAML repräsentieren eine Reihe von Knoten. Jeder Artikel ist mit einem Frühindikator „-“ gekennzeichnet. Beachten Sie, dass der Indikator „-“ in YAML durch ein Leerzeichen vom Knoten getrennt werden sollte.
Die grundlegende Darstellung der Blocksequenz ist unten angegeben -
block sequence:
··- one↓
- two : three↓Beispiel
Beachten Sie die folgenden Beispiele, um die Blocksequenzen besser zu verstehen.
Beispiel 1
port: &ports
adapter: postgres
host: localhost
development:
database: myapp_development
<<: *portsDie Ausgabe von Blocksequenzen im JSON-Format ist unten angegeben -
{
"port": {
"adapter": "postgres",
"host": "localhost"
},
"development": {
"database": "myapp_development",
"adapter": "postgres",
"host": "localhost"
}
}Ein YAML-Schema ist als eine Kombination von Tags definiert und enthält einen Mechanismus zum Auflösen unspezifischer Tags. Das ausfallsichere Schema in YAML wird so erstellt, dass es mit jedem YAML-Dokument verwendet werden kann. Es wird auch als empfohlenes Schema für ein generisches YAML-Dokument angesehen.
Typen
Es gibt zwei Arten von ausfallsicheren Schemata: Generic Mapping und Generic Sequence
Generisches Mapping
Es repräsentiert einen assoziativen Container. Hier ist jeder Schlüssel in der Zuordnung eindeutig und genau einem Wert zugeordnet. YAML enthält keine Einschränkungen für Schlüsseldefinitionen.
Ein Beispiel für die Darstellung der generischen Zuordnung ist unten angegeben.
Clark : Evans
Ingy : döt Net
Oren : Ben-Kiki
Flow style: !!map { Clark: Evans, Ingy: döt Net, Oren: Ben-Kiki }Die Ausgabe der generischen Zuordnungsstruktur im JSON-Format wird unten gezeigt -
{
"Oren": "Ben-Kiki",
"Ingy": "d\u00f6t Net",
"Clark": "Evans",
"Flow style": {
"Oren": "Ben-Kiki",
"Ingy": "d\u00f6t Net",
"Clark": "Evans"
}
}Generische Sequenz
Es repräsentiert eine Art Sequenz. Es enthält eine Sammlung, die durch sequentielle Ganzzahlen beginnend mit Null indiziert ist. Es ist vertreten mit!!seq Etikett.
Clark : Evans
Ingy : döt Net
Oren : Ben-Kiki
Flow style: !!seq { Clark: Evans, Ingy: döt Net, Oren: Ben-Kiki }Die Ausgabe für diese generische Folge von ausfallsicheren
schema is shown below:
{
"Oren": "Ben-Kiki",
"Ingy": "d\u00f6t Net",
"Clark": "Evans",
"Flow style": {
"Oren": "Ben-Kiki",
"Ingy": "d\u00f6t Net",
"Clark": "Evans"
}
}Das JSON-Schema in YAML wird als gemeinsamer Nenner der meisten modernen Computersprachen angesehen. Es ermöglicht das Parsen von JSON-Dateien. In YAML wird dringend empfohlen, andere Schemas im JSON-Schema zu berücksichtigen. Der Hauptgrund dafür ist, dass es eine benutzerfreundliche Schlüsselwertkombination enthält. Die Nachrichten können als Schlüssel codiert und bei Bedarf verwendet werden.
Das JSON-Schema ist skalar und hat keinen Wert. Ein Zuordnungseintrag im JSON-Schema wird im Format eines Schlüssel- und Wertepaars dargestellt, wobei null als gültig behandelt wird.
Beispiel
Ein Null-JSON-Schema wird wie folgt dargestellt:
!!null null: value for null key
key with null value: !!null nullDie Ausgabe der JSON-Darstellung wird unten erwähnt -
{
"null": "value for null key",
"key with null value": null
}Beispiel
Das folgende Beispiel zeigt das boolesche JSON-Schema -
YAML is a superset of JSON: !!bool true
Pluto is a planet: !!bool falseDas Folgende ist die Ausgabe für dasselbe im JSON-Format -
{
"YAML is a superset of JSON": true,
"Pluto is a planet": false
}Beispiel
Das folgende Beispiel zeigt das ganzzahlige JSON-Schema -
negative: !!int -12
zero: !!int 0
positive: !!int 34{
"positive": 34,
"zero": 0,
"negative": -12
}Beispiel
Die Tags im JSON-Schema werden im folgenden Beispiel dargestellt:
A null: null
Booleans: [ true, false ]
Integers: [ 0, -0, 3, -19 ]
Floats: [ 0., -0.0, 12e03, -2E+05 ]
Invalid: [ True, Null, 0o7, 0x3A, +12.3 ]Sie finden die JSON-Ausgabe wie unten gezeigt -
{
"Integers": [
0,
0,
3,
-19
],
"Booleans": [
true,
false
],
"A null": null,
"Invalid": [
true,
null,
"0o7",
58,
12.300000000000001
],
"Floats": [
0.0,
-0.0,
"12e03",
"-2E+05"
]
}