Apache Solr: indexación de datos
En general, indexinges una disposición de documentos u (otras entidades) de forma sistemática. La indexación permite a los usuarios localizar información en un documento.
La indexación recopila, analiza y almacena documentos.
La indexación se realiza para aumentar la velocidad y el rendimiento de una consulta de búsqueda mientras se encuentra un documento requerido.
Indexación en Apache Solr
En Apache Solr, podemos indexar (agregar, eliminar, modificar) varios formatos de documentos como xml, csv, pdf, etc. Podemos agregar datos al índice Solr de varias maneras.
En este capítulo, vamos a discutir la indexación:
- Usando la interfaz web de Solr.
- Usando cualquiera de las API de cliente como Java, Python, etc.
- Utilizando la post tool.
En este capítulo, discutiremos cómo agregar datos al índice de Apache Solr usando varias interfaces (línea de comando, interfaz web y API de cliente Java)
Agregar documentos usando el comando Post
Solr tiene un post comando en su bin/directorio. Con este comando, puede indexar varios formatos de archivos como JSON, XML, CSV en Apache Solr.
Navegar por el bin directorio de Apache Solr y ejecutar el –h option del comando post, como se muestra en el siguiente bloque de código.
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -hAl ejecutar el comando anterior, obtendrá una lista de opciones del post command, Como se muestra abajo.
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'Ejemplo
Supongamos que tenemos un archivo llamado sample.csv con el siguiente contenido (en el bin directorio).
| Identificación del Estudiante | Nombre de pila | Apellido | Teléfono | Ciudad |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Calcuta |
| 003 | Rajesh | Khanna | 9848022339 | Delhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
El conjunto de datos anterior contiene detalles personales como identificación del estudiante, nombre, apellido, teléfono y ciudad. El archivo CSV del conjunto de datos se muestra a continuación. Aquí, debe tener en cuenta que debe mencionar el esquema, documentando su primera línea.
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, ChennaiPuede indexar estos datos en el núcleo denominado sample_Solr utilizando la post comando de la siguiente manera:
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvAl ejecutar el comando anterior, el documento dado se indexa bajo el núcleo especificado, generando el siguiente resultado.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228Visite la página de inicio de Solr Web UI usando la siguiente URL:
http://localhost:8983/
Seleccione el núcleo Solr_sample. De forma predeterminada, el controlador de solicitudes es/selecty la consulta es ":". Sin hacer ninguna modificación, haga clic en elExecuteQuery en la parte inferior de la página.
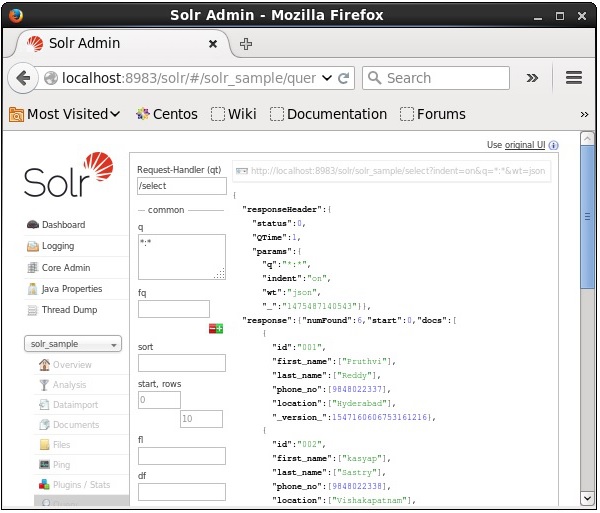
Al ejecutar la consulta, puede observar el contenido del documento CSV indexado en formato JSON (predeterminado), como se muestra en la siguiente captura de pantalla.
Note - De la misma forma, puede indexar otros formatos de archivo como JSON, XML, CSV, etc.
Agregar documentos usando la interfaz web de Solr
También puede indexar documentos utilizando la interfaz web proporcionada por Solr. Veamos cómo indexar el siguiente documento JSON.
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]Paso 1
Abra la interfaz web de Solr usando la siguiente URL:
http://localhost:8983/
Step 2
Seleccione el núcleo Solr_sample. De forma predeterminada, los valores de los campos Request Handler, Common Within, Overwrite y Boost son / update, 1000, true y 1.0 respectivamente, como se muestra en la siguiente captura de pantalla.
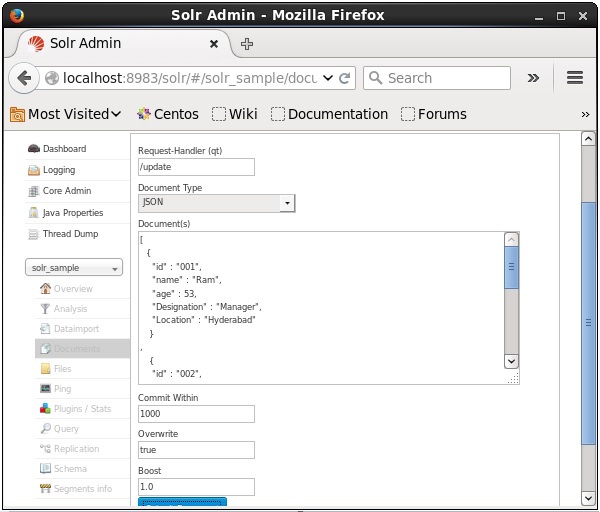
Ahora, elija el formato de documento que desee entre JSON, CSV, XML, etc. Escriba el documento que se indexará en el área de texto y haga clic en el Submit Document , como se muestra en la siguiente captura de pantalla.
Agregar documentos mediante la API de cliente Java
A continuación se muestra el programa Java para agregar documentos al índice Apache Solr. Guarde este código en un archivo con el nombreAddingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}Compile el código anterior ejecutando los siguientes comandos en la terminal:
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocumentAl ejecutar el comando anterior, obtendrá el siguiente resultado.
Documents added