Apache Solr - Guía rápida
Solr es una plataforma de búsqueda de código abierto que se utiliza para crear search applications. Fue construido sobreLucene(motor de búsqueda de texto completo). Solr está preparado para la empresa, es rápido y altamente escalable. Las aplicaciones creadas con Solr son sofisticadas y ofrecen un alto rendimiento.
Era Yonik Seelyquien creó Solr en 2004 para agregar capacidades de búsqueda al sitio web de la empresa de CNET Networks. En enero de 2006, se convirtió en un proyecto de código abierto bajo la Apache Software Foundation. Su última versión, Solr 6.0, fue lanzada en 2016 con soporte para la ejecución de consultas SQL paralelas.
Solr se puede utilizar junto con Hadoop. Como Hadoop maneja una gran cantidad de datos, Solr nos ayuda a encontrar la información requerida de una fuente tan grande. No solo búsqueda, Solr también se puede utilizar para fines de almacenamiento. Como otras bases de datos NoSQL, es unnon-relational data storage y processing technology.
En resumen, Solr es un motor de búsqueda / almacenamiento escalable, listo para implementar, optimizado para buscar grandes volúmenes de datos centrados en texto.
Características de Apache Solr
Solr es un resumen de la API de Java de Lucene. Por lo tanto, con Solr, puede aprovechar todas las funciones de Lucene. Echemos un vistazo a algunas de las características más destacadas de Solr:
Restful APIs- Para comunicarse con Solr, no es obligatorio tener conocimientos de programación Java. En su lugar, puede utilizar servicios de descanso para comunicarse con él. Ingresamos documentos en Solr en formatos de archivo como XML, JSON y .CSV y obtenemos resultados en los mismos formatos de archivo.
Full text search - Solr proporciona todas las capacidades necesarias para una búsqueda de texto completo, como tokens, frases, corrector ortográfico, comodines y autocompletar.
Enterprise ready - Según la necesidad de la organización, Solr se puede implementar en cualquier tipo de sistemas (grandes o pequeños) como autónomos, distribuidos, en la nube, etc.
Flexible and Extensible - Al extender las clases de Java y configurarlas en consecuencia, podemos personalizar los componentes de Solr fácilmente.
NoSQL database - Solr también se puede usar como base de datos NOSQL a gran escala de datos donde podemos distribuir las tareas de búsqueda a lo largo de un clúster.
Admin Interface - Solr proporciona una interfaz de usuario fácil de usar, fácil de usar y con funciones, mediante la cual podemos realizar todas las tareas posibles, como administrar registros, agregar, eliminar, actualizar y buscar documentos.
Highly Scalable - Mientras usamos Solr con Hadoop, podemos escalar su capacidad agregando réplicas.
Text-Centric and Sorted by Relevance - Solr se utiliza principalmente para buscar documentos de texto y los resultados se entregan de acuerdo con la relevancia con la consulta del usuario en orden.
A diferencia de Lucene, no necesita tener conocimientos de programación Java mientras trabaja con Apache Solr. Proporciona un maravilloso servicio listo para implementar para crear un cuadro de búsqueda con autocompletar, que Lucene no proporciona. Con Solr, podemos escalar, distribuir y administrar índices para aplicaciones a gran escala (Big Data).
Lucene en aplicaciones de búsqueda
Lucene es una biblioteca de búsqueda simple pero poderosa basada en Java. Se puede utilizar en cualquier aplicación para agregar capacidad de búsqueda. Lucene es una biblioteca escalable y de alto rendimiento que se utiliza para indexar y buscar prácticamente cualquier tipo de texto. La biblioteca de Lucene proporciona las operaciones básicas que requiere cualquier aplicación de búsqueda, comoIndexing y Searching.
Si tenemos un portal web con un gran volumen de datos, lo más probable es que necesitemos un motor de búsqueda en nuestro portal para extraer información relevante de la enorme cantidad de datos. Lucene funciona como el corazón de cualquier aplicación de búsqueda y proporciona las operaciones vitales relacionadas con la indexación y la búsqueda.
Un motor de búsqueda se refiere a una enorme base de datos de recursos de Internet como páginas web, grupos de noticias, programas, imágenes, etc. Ayuda a localizar información en la World Wide Web.
Los usuarios pueden buscar información pasando consultas al motor de búsqueda en forma de palabras clave o frases. Luego, el motor de búsqueda busca en su base de datos y devuelve enlaces relevantes al usuario.
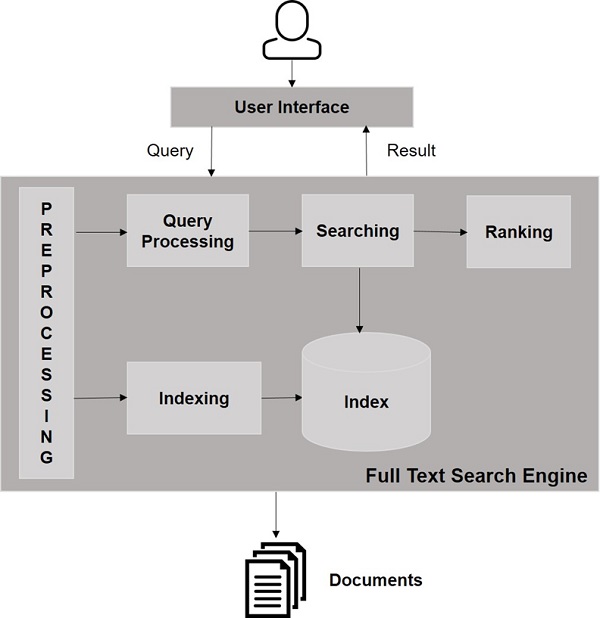
Componentes del motor de búsqueda
Generalmente, hay tres componentes básicos de un motor de búsqueda que se enumeran a continuación:
Web Crawler - Los rastreadores web también se conocen como spiders o bots. Es un componente de software que atraviesa la web para recopilar información.
Database- Toda la información de la Web se almacena en bases de datos. Contienen un gran volumen de recursos web.
Search Interfaces- Este componente es una interfaz entre el usuario y la base de datos. Ayuda al usuario a buscar en la base de datos.
¿Cómo funcionan los motores de búsqueda?
Se requiere cualquier aplicación de búsqueda para realizar algunas o todas las siguientes operaciones.
| Paso | Título | Descripción |
|---|---|---|
1 |
Adquirir contenido sin procesar |
El primer paso de cualquier aplicación de búsqueda es recopilar el contenido de destino sobre el que se realizará la búsqueda. |
2 |
Construye el documento |
El siguiente paso es crear los documentos a partir del contenido sin procesar que la aplicación de búsqueda pueda comprender e interpretar fácilmente. |
3 |
Analizar el documento |
Antes de que pueda comenzar la indexación, se debe analizar el documento. |
4 |
Indexando el documento |
Una vez que los documentos están construidos y analizados, el siguiente paso es indexarlos para que este documento se pueda recuperar en base a ciertas claves, en lugar de todo el contenido del documento. La indexación es similar a los índices que tenemos al final de un libro, donde las palabras comunes se muestran con sus números de página para que estas palabras se puedan rastrear rápidamente, en lugar de buscar en el libro completo. |
5 |
Interfaz de usuario para búsqueda |
Una vez que una base de datos de índices está lista, la aplicación puede realizar operaciones de búsqueda. Para ayudar al usuario a realizar una búsqueda, la aplicación debe proporcionar una interfaz de usuario donde el usuario pueda ingresar texto e iniciar el proceso de búsqueda. |
6 |
Crear consulta |
Una vez que el usuario realiza una solicitud para buscar un texto, la aplicación debe preparar un objeto de consulta utilizando ese texto, que luego puede usarse para consultar la base de datos del índice para obtener detalles relevantes. |
7 |
Consulta de busqueda |
Con el objeto de consulta, se comprueba la base de datos del índice para obtener los detalles relevantes y los documentos de contenido. |
8 |
Renderizar resultados |
Una vez que se recibe el resultado requerido, la aplicación debe decidir cómo mostrar los resultados al usuario mediante su interfaz de usuario. |
Eche un vistazo a la siguiente ilustración. Muestra una vista general de cómo funcionan los motores de búsqueda.
Además de estas operaciones básicas, las aplicaciones de búsqueda también pueden proporcionar una interfaz de administración-usuario para ayudar a los administradores a controlar el nivel de búsqueda según los perfiles de usuario. El análisis de los resultados de la búsqueda es otro aspecto importante y avanzado de cualquier aplicación de búsqueda.
En este capítulo, discutiremos cómo configurar Solr en un entorno Windows. Para instalar Solr en su sistema Windows, debe seguir los pasos que se detallan a continuación:
Visite la página de inicio de Apache Solr y haga clic en el botón de descarga.
Seleccione uno de los espejos para obtener un índice de Apache Solr. Desde allí descarga el archivo llamadoSolr-6.2.0.zip.
Mueva el archivo de la downloads folder al directorio requerido y descomprímalo.
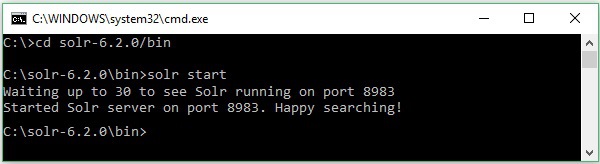
Suponga que descargó el archivo Solr y lo extrajo en la unidad C. En tal caso, puede iniciar Solr como se muestra en la siguiente captura de pantalla.
Para verificar la instalación, use la siguiente URL en su navegador.
http://localhost:8983/
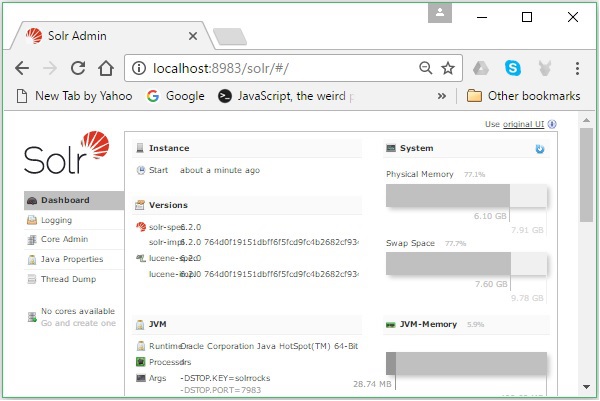
Si el proceso de instalación es exitoso, podrá ver el panel de la interfaz de usuario de Apache Solr como se muestra a continuación.
Configuración del entorno Java
También podemos comunicarnos con Apache Solr usando bibliotecas Java; pero antes de acceder a Solr usando la API de Java, debe establecer la ruta de clase para esas bibliotecas.
Configuración de la ruta de clases
Selecciona el classpath a las bibliotecas Solr en el .bashrcarchivo. Abierto.bashrc en cualquiera de los editores como se muestra a continuación.
$ gedit ~/.bashrcEstablecer classpath para bibliotecas Solr (lib carpeta en HBase) como se muestra a continuación.
export CLASSPATH = $CLASSPATH://home/hadoop/Solr/lib/*Esto es para evitar la excepción de "clase no encontrada" al acceder a HBase mediante la API de Java.
Solr se puede utilizar junto con Hadoop. Como Hadoop maneja una gran cantidad de datos, Solr nos ayuda a encontrar la información requerida de una fuente tan grande. En esta sección, comprendamos cómo puede instalar Hadoop en su sistema.
Descargando Hadoop
A continuación se detallan los pasos a seguir para descargar Hadoop en su sistema.
Step 1- Vaya a la página de inicio de Hadoop. Puede utilizar el enlace: www.hadoop.apache.org/ . Haga clic en el enlaceReleases, como se destaca en la siguiente captura de pantalla.
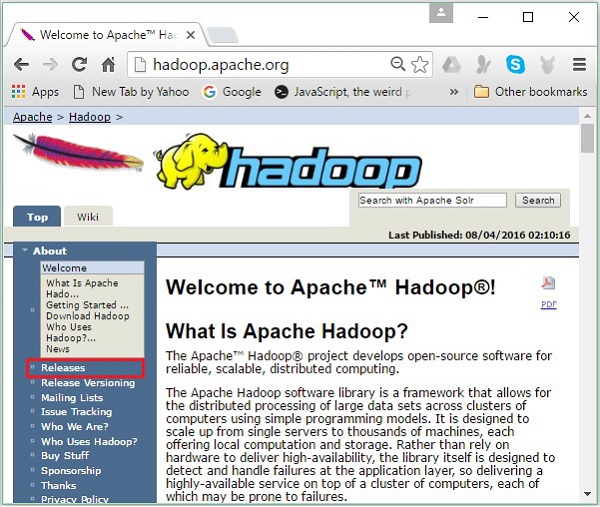
Te redirigirá a la Apache Hadoop Releases página que contiene enlaces para espejos de archivos fuente y binarios de varias versiones de Hadoop de la siguiente manera:
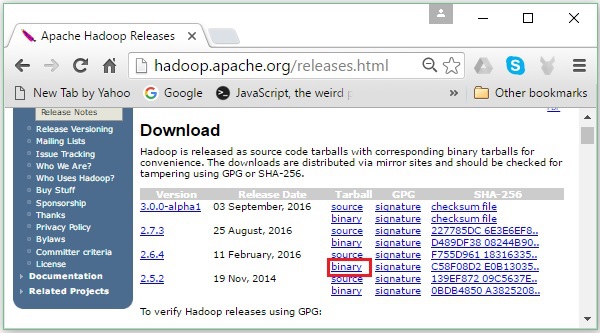
Step 2 - Seleccione la última versión de Hadoop (en nuestro tutorial, es 2.6.4) y haga clic en su binary link. Lo llevará a una página donde están disponibles espejos para el binario de Hadoop. Haga clic en uno de estos espejos para descargar Hadoop.
Descarga Hadoop desde el símbolo del sistema
Abra la terminal de Linux e inicie sesión como superusuario.
$ su
password:Vaya al directorio donde necesita instalar Hadoop y guarde el archivo allí usando el enlace copiado anteriormente, como se muestra en el siguiente bloque de código.
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzDespués de descargar Hadoop, extráigalo usando los siguientes comandos.
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitInstalación de Hadoop
Siga los pasos que se indican a continuación para instalar Hadoop en modo pseudodistribuido.
Paso 1: Configurar Hadoop
Puede configurar las variables de entorno de Hadoop agregando los siguientes comandos a ~/.bashrc archivo.
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOMEA continuación, aplique todos los cambios en el sistema en ejecución actual.
$ source ~/.bashrcPaso 2: Configuración de Hadoop
Puede encontrar todos los archivos de configuración de Hadoop en la ubicación "$ HADOOP_HOME / etc / hadoop". Es necesario realizar cambios en esos archivos de configuración de acuerdo con su infraestructura de Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPara desarrollar programas Hadoop en Java, debe restablecer las variables de entorno de Java en hadoop-env.sh archivo reemplazando JAVA_HOME valor con la ubicación de Java en su sistema.
export JAVA_HOME = /usr/local/jdk1.7.0_71La siguiente es la lista de archivos que debe editar para configurar Hadoop:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
los core-site.xml El archivo contiene información como el número de puerto utilizado para la instancia de Hadoop, la memoria asignada para el sistema de archivos, el límite de memoria para almacenar los datos y el tamaño de los búferes de lectura / escritura.
Abra core-site.xml y agregue las siguientes propiedades dentro de las etiquetas <configuration>, </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
los hdfs-site.xml el archivo contiene información como el valor de los datos de replicación, namenode camino, y datanoderutas de sus sistemas de archivos locales. Significa el lugar donde desea almacenar la infraestructura de Hadoop.
Asumamos los siguientes datos.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeAbra este archivo y agregue las siguientes propiedades dentro de las etiquetas <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - En el archivo anterior, todos los valores de propiedad están definidos por el usuario y puede realizar cambios de acuerdo con su infraestructura de Hadoop.
yarn-site.xml
Este archivo se utiliza para configurar hilo en Hadoop. Abra el archivo yarn-site.xml y agregue las siguientes propiedades entre las etiquetas <configuration>, </configuration> en este archivo.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Este archivo se utiliza para especificar qué marco MapReduce estamos usando. De forma predeterminada, Hadoop contiene una plantilla de yarn-site.xml. En primer lugar, es necesario copiar el archivo demapred-site,xml.template a mapred-site.xml archivo usando el siguiente comando.
$ cp mapred-site.xml.template mapred-site.xmlAbierto mapred-site.xml y agregue las siguientes propiedades dentro de las etiquetas <configuration>, </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Verificación de la instalación de Hadoop
Los siguientes pasos se utilizan para verificar la instalación de Hadoop.
Paso 1: Configuración del nodo de nombre
Configure el namenode usando el comando "hdfs namenode –format" de la siguiente manera.
$ cd ~
$ hdfs namenode -formatEl resultado esperado es el siguiente.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Paso 2: Verificación de Hadoop dfs
El siguiente comando se usa para iniciar Hadoop dfs. La ejecución de este comando iniciará su sistema de archivos Hadoop.
$ start-dfs.shLa salida esperada es la siguiente:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Paso 3: Verificación del guión de hilo
El siguiente comando se utiliza para iniciar el script de Yarn. La ejecución de este comando iniciará sus demonios Yarn.
$ start-yarn.shLa salida esperada de la siguiente manera:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outPaso 4: Acceder a Hadoop en el navegador
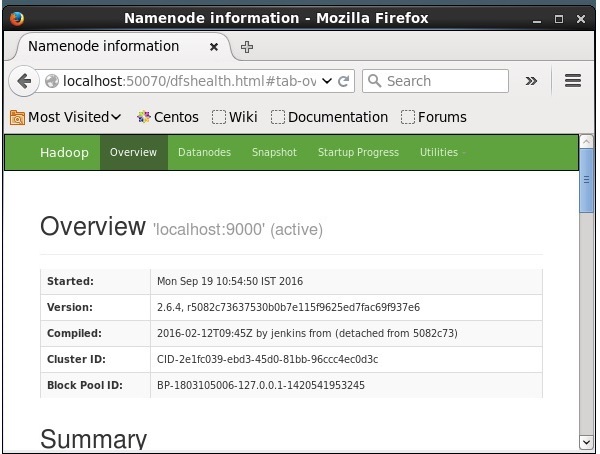
El número de puerto predeterminado para acceder a Hadoop es 50070. Utilice la siguiente URL para obtener los servicios de Hadoop en el navegador.
http://localhost:50070/
Instalación de Solr en Hadoop
Siga los pasos que se indican a continuación para descargar e instalar Solr.
Paso 1
Abra la página de inicio de Apache Solr haciendo clic en el siguiente enlace: https://lucene.apache.org/solr/
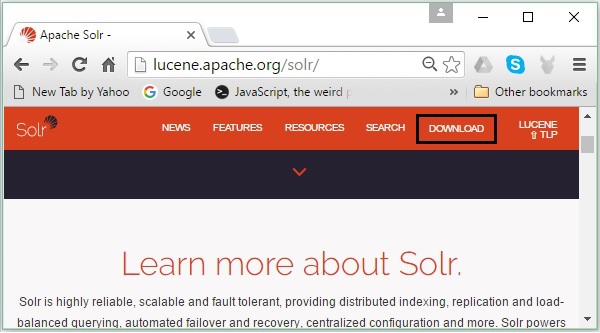
Paso 2
Haga clic en el download button(resaltado en la captura de pantalla anterior). Al hacer clic, será redirigido a la página donde tiene varios espejos de Apache Solr. Seleccione un espejo y haga clic en él, que lo redireccionará a una página donde puede descargar los archivos fuente y binarios de Apache Solr, como se muestra en la siguiente captura de pantalla.
Paso 3
Al hacer clic, una carpeta llamada Solr-6.2.0.tqzse descargará en la carpeta de descargas de su sistema. Extrae el contenido de la carpeta descargada.
Etapa 4
Cree una carpeta llamada Solr en el directorio de inicio de Hadoop y mueva el contenido de la carpeta extraída a ella, como se muestra a continuación.
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/Verificación
Navegar por el bin carpeta del directorio de inicio de Solr y verifique la instalación utilizando el version opción, como se muestra en el siguiente bloque de código.
$ cd bin/
$ ./Solr version
6.2.0Estableciendo hogar y camino
Abre el .bashrc archivo usando el siguiente comando -
[Hadoop@localhost ~]$ source ~/.bashrcAhora configure los directorios de inicio y ruta para Apache Solr de la siguiente manera:
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/Abra la terminal y ejecute el siguiente comando:
[Hadoop@localhost Solr]$ source ~/.bashrcAhora, puede ejecutar los comandos de Solr desde cualquier directorio.
En este capítulo, discutiremos la arquitectura de Apache Solr. La siguiente ilustración muestra un diagrama de bloques de la arquitectura de Apache Solr.
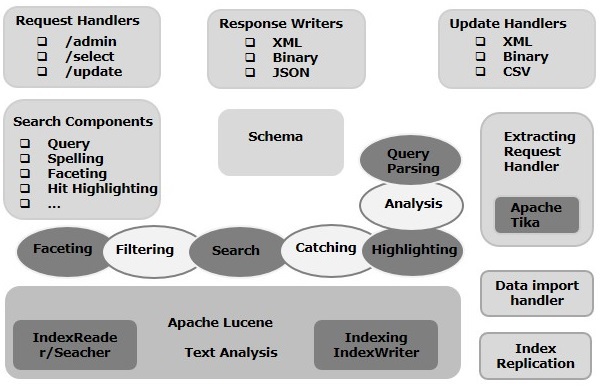
Arquitectura Solr ─ Bloques de construcción
Los siguientes son los principales bloques de construcción (componentes) de Apache Solr:
Request Handler- Las solicitudes que enviamos a Apache Solr son procesadas por estos controladores de solicitudes. Las solicitudes pueden ser solicitudes de consulta o solicitudes de actualización de índice. Según nuestro requisito, debemos seleccionar el controlador de solicitudes. Para pasar una solicitud a Solr, generalmente asignaremos el controlador a un determinado punto final de URI y la solicitud especificada será atendida por él.
Search Component- Un componente de búsqueda es un tipo (característica) de búsqueda proporcionada en Apache Solr. Puede ser revisión ortográfica, consulta, facetado, resaltado de marca, etc. Estos componentes de búsqueda se registran comosearch handlers. Se pueden registrar varios componentes en un controlador de búsqueda.
Query Parser- El analizador de consultas Apache Solr analiza las consultas que pasamos a Solr y verifica las consultas en busca de errores sintácticos. Después de analizar las consultas, las traduce a un formato que Lucene entiende.
Response Writer- Un escritor de respuestas en Apache Solr es el componente que genera la salida formateada para las consultas del usuario. Solr admite formatos de respuesta como XML, JSON, CSV, etc. Tenemos diferentes escritores de respuesta para cada tipo de respuesta.
Analyzer/tokenizer- Lucene reconoce datos en forma de tokens. Apache Solr analiza el contenido, lo divide en tokens y pasa estos tokens a Lucene. Un analizador de Apache Solr examina el texto de los campos y genera una secuencia de tokens. Un tokenizador rompe el flujo de tokens preparado por el analizador en tokens.
Update Request Processor - Siempre que enviamos una solicitud de actualización a Apache Solr, la solicitud se ejecuta a través de un conjunto de complementos (firma, registro, indexación), conocidos colectivamente como update request processor. Este procesador es responsable de modificaciones como eliminar un campo, agregar un campo, etc.
En este capítulo, intentaremos comprender el significado real de algunos de los términos que se utilizan con frecuencia al trabajar en Solr.
Terminología general
La siguiente es una lista de términos generales que se utilizan en todos los tipos de configuraciones de Solr:
Instance - Como un tomcat instance o un jetty instance, este término se refiere al servidor de aplicaciones, que se ejecuta dentro de una JVM. El directorio de inicio de Solr proporciona una referencia a cada una de estas instancias de Solr, en las que se pueden configurar uno o más núcleos para que se ejecuten en cada instancia.
Core - Mientras ejecuta múltiples índices en su aplicación, puede tener múltiples núcleos en cada instancia, en lugar de múltiples instancias, cada una con un núcleo.
Home - El término $ SOLR_HOME se refiere al directorio de inicio que tiene toda la información sobre los núcleos y sus índices, configuraciones y dependencias.
Shard - En entornos distribuidos, los datos se dividen entre varias instancias de Solr, donde cada fragmento de datos se puede llamar como un Shard. Contiene un subconjunto de todo el índice.
Terminología de SolrCloud
En un capítulo anterior, discutimos cómo instalar Apache Solr en modo independiente. Tenga en cuenta que también podemos instalar Solr en modo distribuido (entorno de nube) donde Solr se instala en un patrón maestro-esclavo. En el modo distribuido, el índice se crea en el servidor maestro y se replica en uno o más servidores esclavos.
Los términos clave asociados con Solr Cloud son los siguientes:
Node - En la nube de Solr, cada instancia de Solr se considera una node.
Cluster - Todos los nodos del entorno combinados forman un cluster.
Collection - Un clúster tiene un índice lógico que se conoce como collection.
Shard - Un fragmento es una parte de la colección que tiene una o más réplicas del índice.
Replica - En Solr Core, una copia del fragmento que se ejecuta en un nodo se conoce como replica.
Leader - También es una réplica del fragmento, que distribuye las solicitudes de Solr Cloud a las réplicas restantes.
Zookeeper - Es un proyecto de Apache que Solr Cloud utiliza para la configuración y coordinación centralizada, para administrar el clúster y elegir un líder.
Archivos de configuración
Los archivos de configuración principales en Apache Solr son los siguientes:
Solr.xml- Es el archivo en el directorio $ SOLR_HOME que contiene información relacionada con Solr Cloud. Para cargar los núcleos, Solr se refiere a este archivo, que ayuda a identificarlos.
Solrconfig.xml - Este archivo contiene las definiciones y configuraciones específicas del núcleo relacionadas con el manejo de solicitudes y el formato de respuesta, junto con la indexación, configuración, administración de memoria y realización de confirmaciones.
Schema.xml - Este archivo contiene el esquema completo junto con los campos y tipos de campo.
Core.properties- Este archivo contiene las configuraciones específicas del núcleo. Es referido paracore discovery, ya que contiene el nombre del núcleo y la ruta del directorio de datos. Se puede utilizar en cualquier directorio, que luego se tratará como elcore directory.
Comenzando Solr
Después de instalar Solr, busque el bin carpeta en el directorio de inicio de Solr e inicie Solr con el siguiente comando.
[Hadoop@localhost ~]$ cd
[Hadoop@localhost ~]$ cd Solr/
[Hadoop@localhost Solr]$ cd bin/
[Hadoop@localhost bin]$ ./Solr startEste comando inicia Solr en segundo plano, escuchando en el puerto 8983 mostrando el siguiente mensaje.
Waiting up to 30 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid = 6035). Happy searching!Comenzando Solr en primer plano
Si empiezas Solr utilizando el startcomando, luego Solr se iniciará en segundo plano. En su lugar, puede iniciar Solr en primer plano utilizando el–f option.
[Hadoop@localhost bin]$ ./Solr start –f
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/extraction/lib/xmlbeans-2.6.0.jar' to
classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/dist/Solr-cell-6.2.0.jar' to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/carrot2-guava-18.0.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/attributes-binder1.3.1.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/simple-xml-2.7.1.jar'
to classloader
……………………………………………………………………………………………………………………………………………………………………………………………………………
………………………………………………………………………………………………………………………………………………………………………………………………….
12901 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.u.UpdateLog
Took 24.0ms to seed version buckets with highest version 1546058939881226240 12902
INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample]
o.a.s.c.CoreContainer registering core: Solr_sample
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.u.UpdateLog Took
16.0ms to seed version buckets with highest version 1546058939894857728
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.c.CoreContainer
registering core: my_coreIniciando Solr en otro puerto
Utilizando –p option del start comando, podemos iniciar Solr en otro puerto, como se muestra en el siguiente bloque de código.
[Hadoop@localhost bin]$ ./Solr start -p 8984
Waiting up to 30 seconds to see Solr running on port 8984 [-]
Started Solr server on port 8984 (pid = 10137). Happy searching!Detener a Solr
Puede detener Solr usando el stop mando.
$ ./Solr stopEste comando detiene Solr y muestra un mensaje como se muestra a continuación.
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6035 to stop gracefully.Reiniciando Solr
los restartcomando de Solr detiene Solr durante 5 segundos y lo inicia de nuevo. Puede reiniciar Solr usando el siguiente comando:
./Solr restartEste comando reinicia Solr, mostrando el siguiente mensaje:
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6671 to stop gracefully.
Waiting up to 30 seconds to see Solr running on port 8983 [|] [/]
Started Solr server on port 8983 (pid = 6906). Happy searching!Solr ─ comando de ayuda
los help El comando de Solr se puede usar para verificar el uso del indicador de Solr y sus opciones.
[Hadoop@localhost bin]$ ./Solr -help
Usage: Solr COMMAND OPTIONS
where COMMAND is one of: start, stop, restart, status, healthcheck,
create, create_core, create_collection, delete, version, zk
Standalone server example (start Solr running in the background on port 8984):
./Solr start -p 8984
SolrCloud example (start Solr running in SolrCloud mode using localhost:2181
to connect to Zookeeper, with 1g max heap size and remote Java debug options enabled):
./Solr start -c -m 1g -z localhost:2181 -a "-Xdebug -
Xrunjdwp:transport = dt_socket,server = y,suspend = n,address = 1044"
Pass -help after any COMMAND to see command-specific usage information,
such as: ./Solr start -help or ./Solr stop -helpSolr ─ comando de estado
Esta statusEl comando de Solr se puede utilizar para buscar y descubrir las instancias de Solr en ejecución en su computadora. Puede proporcionarle información sobre una instancia de Solr, como su versión, uso de memoria, etc.
Puede verificar el estado de una instancia de Solr, usando el comando de estado de la siguiente manera:
[Hadoop@localhost bin]$ ./Solr statusAl ejecutarse, el comando anterior muestra el estado de Solr de la siguiente manera:
Found 1 Solr nodes:
Solr process 6906 running on port 8983 {
"Solr_home":"/home/Hadoop/Solr/server/Solr",
"version":"6.2.0 764d0f19151dbff6f5fcd9fc4b2682cf934590c5 -
mike - 2016-08-20 05:41:37",
"startTime":"2016-09-20T06:00:02.877Z",
"uptime":"0 days, 0 hours, 5 minutes, 14 seconds",
"memory":"30.6 MB (%6.2) of 490.7 MB"
}Administrador de Solr
Después de iniciar Apache Solr, puede visitar la página de inicio del Solr web interface utilizando la siguiente URL.
Localhost:8983/Solr/La interfaz de Solr Admin aparece de la siguiente manera:
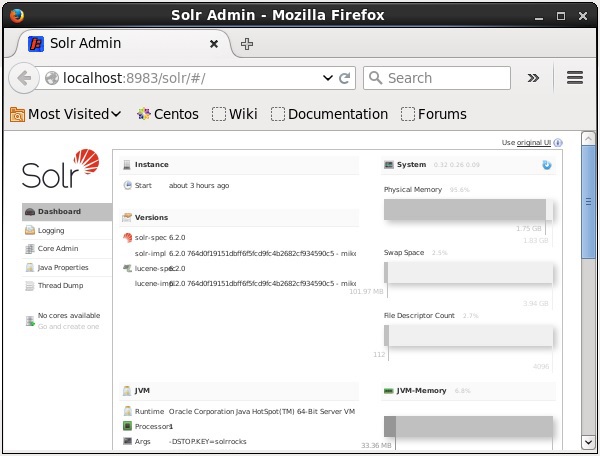
Un Solr Core es una instancia en ejecución de un índice de Lucene que contiene todos los archivos de configuración de Solr necesarios para usarlo. Necesitamos crear un Solr Core para realizar operaciones como indexar y analizar.
Una aplicación de Solr puede contener uno o varios núcleos. Si es necesario, dos núcleos en una aplicación Solr pueden comunicarse entre sí.
Crear un núcleo
Después de instalar e iniciar Solr, puede conectarse al cliente (interfaz web) de Solr.
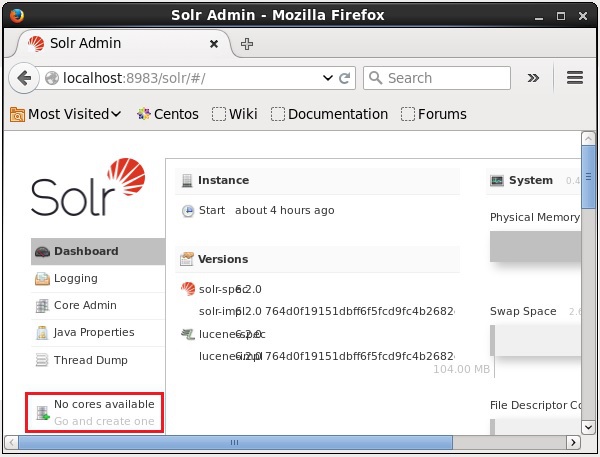
Como se destaca en la siguiente captura de pantalla, inicialmente no hay núcleos en Apache Solr. Ahora, veremos cómo crear un núcleo en Solr.
Usando el comando crear
Una forma de crear un núcleo es crear un schema-less core utilizando el create comando, como se muestra a continuación -
[Hadoop@localhost bin]$ ./Solr create -c Solr_sampleAquí, estamos intentando crear un núcleo llamado Solr_sampleen Apache Solr. Este comando crea un núcleo que muestra el siguiente mensaje.
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/Solr_sample
Creating new core 'Solr_sample' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=Solr_sample&instanceD
ir = Solr_sample {
"responseHeader":{
"status":0,
"QTime":11550
},
"core":"Solr_sample"
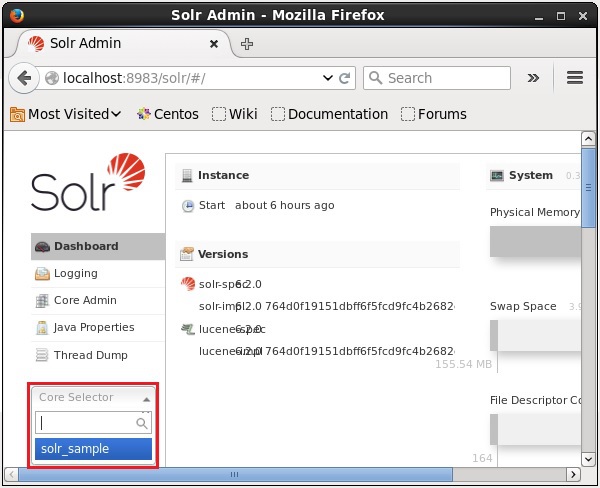
}Puede crear varios núcleos en Solr. En el lado izquierdo del Administrador de Solr, puede ver uncore selector donde puede seleccionar el núcleo recién creado, como se muestra en la siguiente captura de pantalla.
Usando el comando create_core
Alternativamente, puede crear un núcleo usando el create_coremando. Este comando tiene las siguientes opciones:
| -C core_name | Nombre del núcleo que querías crear |
| -pags port_name | Puerto en el que desea crear el núcleo |
| -re conf_dir | Directorio de configuración del puerto |
Veamos cómo puedes usar el create_coremando. Aquí, intentaremos crear un núcleo llamadomy_core.
[Hadoop@localhost bin]$ ./Solr create_core -c my_coreAl ejecutarse, el comando anterior crea un núcleo que muestra el siguiente mensaje:
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/my_core
Creating new core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=my_core&instanceD
ir = my_core {
"responseHeader":{
"status":0,
"QTime":1346
},
"core":"my_core"
}Eliminar un núcleo
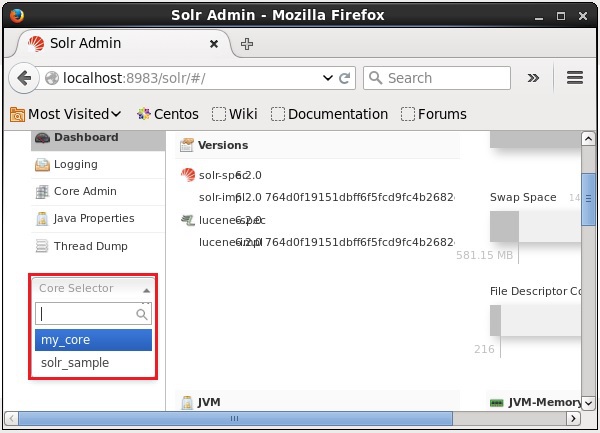
Puede eliminar un núcleo usando el deletecomando de Apache Solr. Supongamos que tenemos un núcleo llamadomy_core en Solr, como se muestra en la siguiente captura de pantalla.
Puede eliminar este núcleo usando el delete comando pasando el nombre del núcleo a este comando de la siguiente manera:
[Hadoop@localhost bin]$ ./Solr delete -c my_coreAl ejecutar el comando anterior, el núcleo especificado se eliminará mostrando el siguiente mensaje.
Deleting core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=UNLOAD&core = my_core&deleteIndex
= true&deleteDataDir = true&deleteInstanceDir = true {
"responseHeader" :{
"status":0,
"QTime":170
}
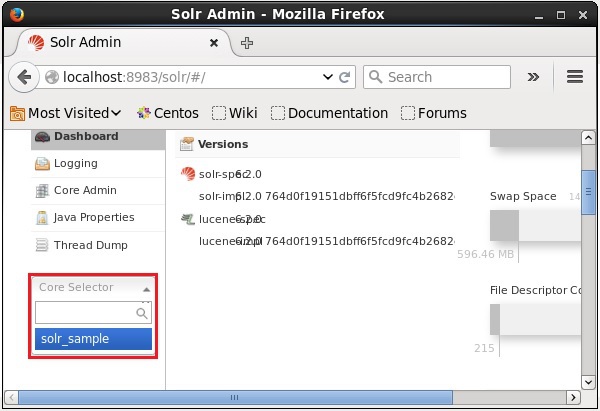
}Puede abrir la interfaz web de Solr para verificar si el núcleo se ha eliminado o no.
En general, indexinges una disposición de documentos u (otras entidades) de forma sistemática. La indexación permite a los usuarios localizar información en un documento.
La indexación recopila, analiza y almacena documentos.
La indexación se realiza para aumentar la velocidad y el rendimiento de una consulta de búsqueda mientras se encuentra un documento requerido.
Indexación en Apache Solr
En Apache Solr, podemos indexar (agregar, eliminar, modificar) varios formatos de documentos como xml, csv, pdf, etc. Podemos agregar datos al índice Solr de varias maneras.
En este capítulo, vamos a discutir la indexación:
- Usando la interfaz web de Solr.
- Usando cualquiera de las API de cliente como Java, Python, etc.
- Utilizando el post tool.
En este capítulo, discutiremos cómo agregar datos al índice de Apache Solr usando varias interfaces (línea de comando, interfaz web y API de cliente Java)
Agregar documentos usando el comando Post
Solr tiene un post comando en su bin/directorio. Con este comando, puede indexar varios formatos de archivos como JSON, XML, CSV en Apache Solr.
Navegar por el bin directorio de Apache Solr y ejecutar el –h option del comando post, como se muestra en el siguiente bloque de código.
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -hAl ejecutar el comando anterior, obtendrá una lista de opciones del post command, Como se muestra abajo.
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'Ejemplo
Supongamos que tenemos un archivo llamado sample.csv con el siguiente contenido (en el bin directorio).
| Identificación del Estudiante | Primer nombre | Apellido | Teléfono | Ciudad |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Calcuta |
| 003 | Rajesh | Khanna | 9848022339 | Delhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
El conjunto de datos anterior contiene detalles personales como identificación del estudiante, nombre, apellido, teléfono y ciudad. El archivo CSV del conjunto de datos se muestra a continuación. Aquí, debe tener en cuenta que debe mencionar el esquema, documentando su primera línea.
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, ChennaiPuede indexar estos datos en el núcleo denominado sample_Solr utilizando el post comando de la siguiente manera:
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvAl ejecutar el comando anterior, el documento dado se indexa bajo el núcleo especificado, generando el siguiente resultado.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228Visite la página de inicio de Solr Web UI usando la siguiente URL:
http://localhost:8983/
Seleccione el núcleo Solr_sample. De forma predeterminada, el controlador de solicitudes es/selecty la consulta es ":". Sin hacer ninguna modificación, haga clic en elExecuteQuery en la parte inferior de la página.
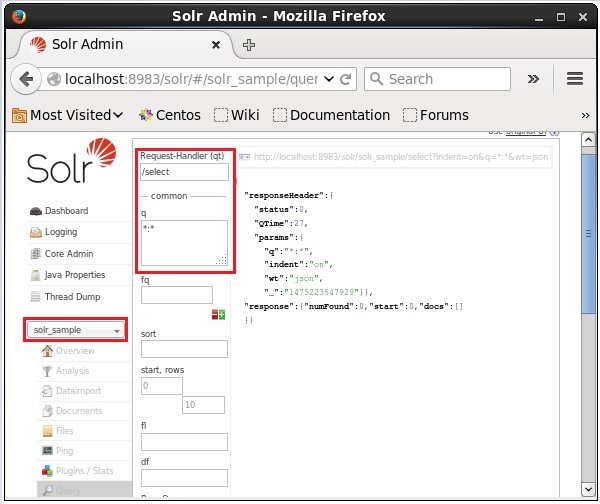
Al ejecutar la consulta, puede observar el contenido del documento CSV indexado en formato JSON (predeterminado), como se muestra en la siguiente captura de pantalla.
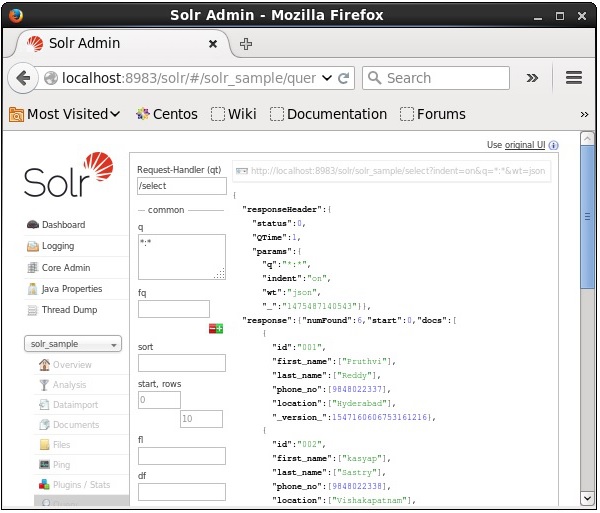
Note - De la misma forma, puede indexar otros formatos de archivo como JSON, XML, CSV, etc.
Agregar documentos usando la interfaz web de Solr
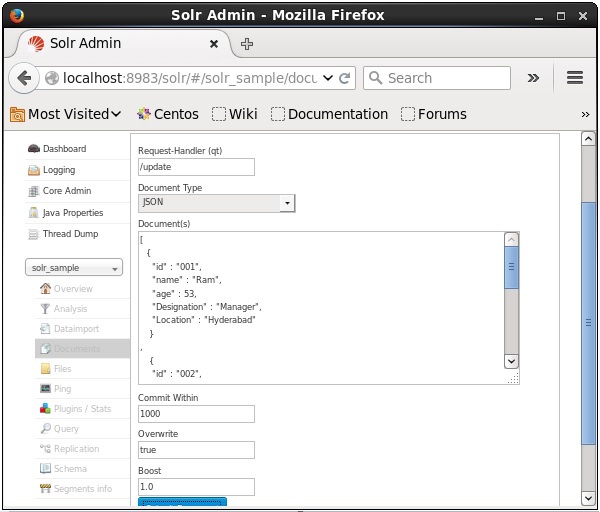
También puede indexar documentos utilizando la interfaz web proporcionada por Solr. Veamos cómo indexar el siguiente documento JSON.
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]Paso 1
Abra la interfaz web de Solr usando la siguiente URL:
http://localhost:8983/
Step 2
Seleccione el núcleo Solr_sample. De forma predeterminada, los valores de los campos Request Handler, Common Within, Overwrite y Boost son / update, 1000, true y 1.0 respectivamente, como se muestra en la siguiente captura de pantalla.
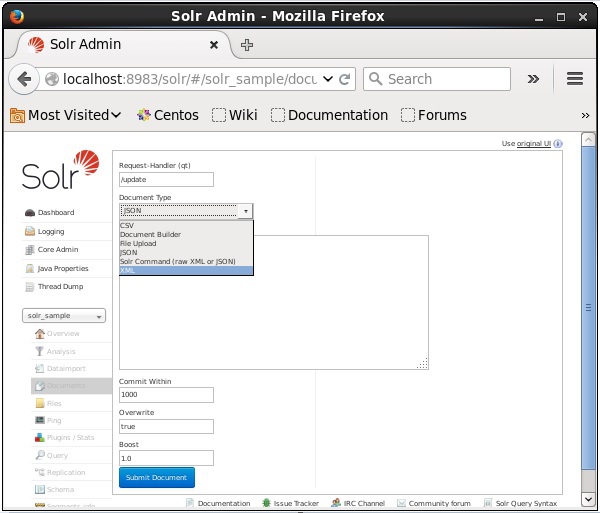
Ahora, elija el formato de documento que desee entre JSON, CSV, XML, etc. Escriba el documento que se indexará en el área de texto y haga clic en el Submit Document , como se muestra en la siguiente captura de pantalla.
Agregar documentos mediante la API de cliente Java
A continuación se muestra el programa Java para agregar documentos al índice Apache Solr. Guarde este código en un archivo con el nombreAddingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}Compile el código anterior ejecutando los siguientes comandos en la terminal:
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocumentAl ejecutar el comando anterior, obtendrá el siguiente resultado.
Documents addedEn el capítulo anterior, explicamos cómo agregar datos a Solr, que está en formatos de archivo JSON y .CSV. En este capítulo, demostraremos cómo agregar datos en el índice Apache Solr usando formato de documento XML.
Data de muestra
Supongamos que necesitamos agregar los siguientes datos al índice Solr usando el formato de archivo XML.
| Identificación del Estudiante | Primer nombre | Apellido | Teléfono | Ciudad |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Calcuta |
| 003 | Rajesh | Khanna | 9848022339 | Delhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
Agregar documentos usando XML
Para agregar los datos anteriores al índice de Solr, necesitamos preparar un documento XML, como se muestra a continuación. Guarde este documento en un archivo con el nombresample.xml.
<add>
<doc>
<field name = "id">001</field>
<field name = "first name">Rajiv</field>
<field name = "last name">Reddy</field>
<field name = "phone">9848022337</field>
<field name = "city">Hyderabad</field>
</doc>
<doc>
<field name = "id">002</field>
<field name = "first name">Siddarth</field>
<field name = "last name">Battacharya</field>
<field name = "phone">9848022338</field>
<field name = "city">Kolkata</field>
</doc>
<doc>
<field name = "id">003</field>
<field name = "first name">Rajesh</field>
<field name = "last name">Khanna</field>
<field name = "phone">9848022339</field>
<field name = "city">Delhi</field>
</doc>
<doc>
<field name = "id">004</field>
<field name = "first name">Preethi</field>
<field name = "last name">Agarwal</field>
<field name = "phone">9848022330</field>
<field name = "city">Pune</field>
</doc>
<doc>
<field name = "id">005</field>
<field name = "first name">Trupthi</field>
<field name = "last name">Mohanthy</field>
<field name = "phone">9848022336</field>
<field name = "city">Bhuwaeshwar</field>
</doc>
<doc>
<field name = "id">006</field>
<field name = "first name">Archana</field>
<field name = "last name">Mishra</field>
<field name = "phone">9848022335</field>
<field name = "city">Chennai</field>
</doc>
</add>Como puede observar, el archivo XML escrito para agregar datos al índice contiene tres etiquetas importantes, a saber, <add> </add>, <doc> </doc> y <field> </ field>.
add- Esta es la etiqueta raíz para agregar documentos al índice. Contiene uno o más documentos que se van a agregar.
doc- Los documentos que agreguemos deben estar dentro de las etiquetas <doc> </doc>. Este documento contiene los datos en forma de campos.
field - La etiqueta de campo contiene el nombre y el valor de los campos del documento.
Después de preparar el documento, puede agregar este documento al índice utilizando cualquiera de los medios discutidos en el capítulo anterior.
Suponga que el archivo XML existe en el bin directorio de Solr y se indexará en el núcleo llamado my_core, luego puede agregarlo al índice de Solr usando el post herramienta de la siguiente manera:
[Hadoop@localhost bin]$ ./post -c my_core sample.xmlAl ejecutar el comando anterior, obtendrá el siguiente resultado.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-
core6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool sample.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,
xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file sample.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.201Verificación
Visite la página de inicio de la interfaz web de Apache Solr y seleccione el núcleo my_core. Intente recuperar todos los documentos pasando la consulta ":" en el área de textoqy ejecutar la consulta. Al ejecutar, puede observar que los datos deseados se agregan al índice de Solr.
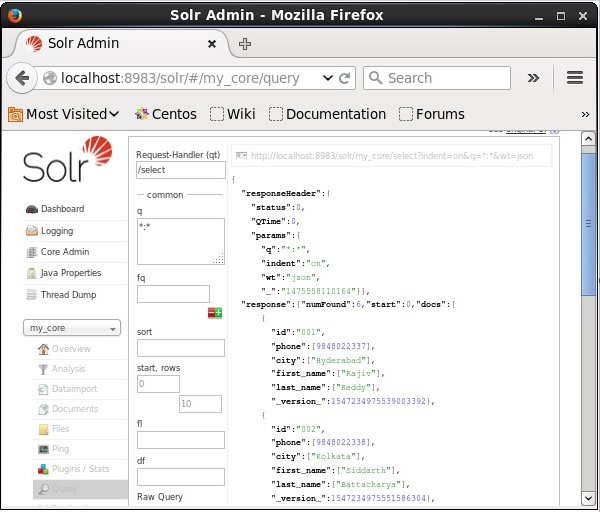
Actualización del documento mediante XML
A continuación se muestra el archivo XML utilizado para actualizar un campo en el documento existente. Guarda esto en un archivo con el nombreupdate.xml.
<add>
<doc>
<field name = "id">001</field>
<field name = "first name" update = "set">Raj</field>
<field name = "last name" update = "add">Malhotra</field>
<field name = "phone" update = "add">9000000000</field>
<field name = "city" update = "add">Delhi</field>
</doc>
</add>Como puede observar, el archivo XML escrito para actualizar datos es como el que usamos para agregar documentos. Pero la única diferencia es que usamos elupdate atributo del campo.
En nuestro ejemplo, usaremos el documento anterior e intentaremos actualizar los campos del documento con el id 001.
Suponga que el documento XML existe en el bindirectorio de Solr. Dado que estamos actualizando el índice que existe en el núcleo llamadomy_core, puedes actualizar usando el post herramienta de la siguiente manera:
[Hadoop@localhost bin]$ ./post -c my_core update.xmlAl ejecutar el comando anterior, obtendrá el siguiente resultado.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool update.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file update.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.159Verificación
Visite la página de inicio de la interfaz web de Apache Solr y seleccione el núcleo como my_core. Intente recuperar todos los documentos pasando la consulta ":" en el área de textoqy ejecutar la consulta. Al ejecutar, puede observar que el documento está actualizado.
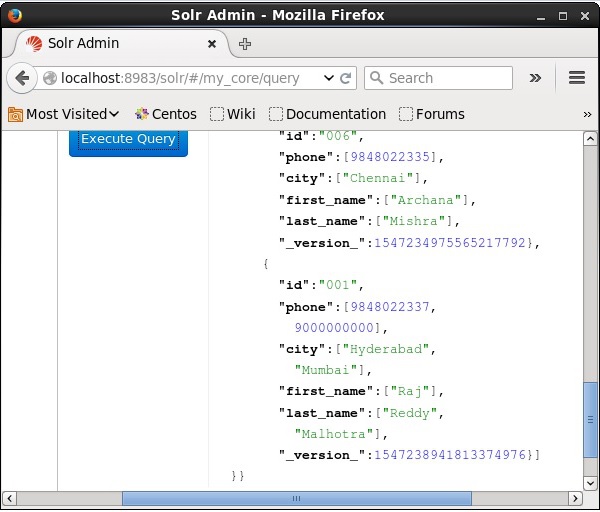
Actualización del documento mediante Java (API de cliente)
A continuación se muestra el programa Java para agregar documentos al índice Apache Solr. Guarde este código en un archivo con el nombreUpdatingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.UpdateRequest;
import org.apache.Solr.client.Solrj.response.UpdateResponse;
import org.apache.Solr.common.SolrInputDocument;
public class UpdatingDocument {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.setAction( UpdateRequest.ACTION.COMMIT, false, false);
SolrInputDocument myDocumentInstantlycommited = new SolrInputDocument();
myDocumentInstantlycommited.addField("id", "002");
myDocumentInstantlycommited.addField("name", "Rahman");
myDocumentInstantlycommited.addField("age","27");
myDocumentInstantlycommited.addField("addr","hyderabad");
updateRequest.add( myDocumentInstantlycommited);
UpdateResponse rsp = updateRequest.process(Solr);
System.out.println("Documents Updated");
}
}Compile el código anterior ejecutando los siguientes comandos en la terminal:
[Hadoop@localhost bin]$ javac UpdatingDocument
[Hadoop@localhost bin]$ java UpdatingDocumentAl ejecutar el comando anterior, obtendrá el siguiente resultado.
Documents updatedEliminar el documento
Para eliminar documentos del índice de Apache Solr, necesitamos especificar los ID de los documentos que se eliminarán entre las etiquetas <delete> </delete>.
<delete>
<id>003</id>
<id>005</id>
<id>004</id>
<id>002</id>
</delete>Aquí, este código XML se utiliza para eliminar los documentos con ID 003 y 005. Guarde este código en un archivo con el nombredelete.xml.
Si desea eliminar los documentos del índice que pertenece al núcleo llamado my_core, luego puedes publicar el delete.xml archivo usando el post herramienta, como se muestra a continuación.
[Hadoop@localhost bin]$ ./post -c my_core delete.xmlAl ejecutar el comando anterior, obtendrá el siguiente resultado.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.179Verificación
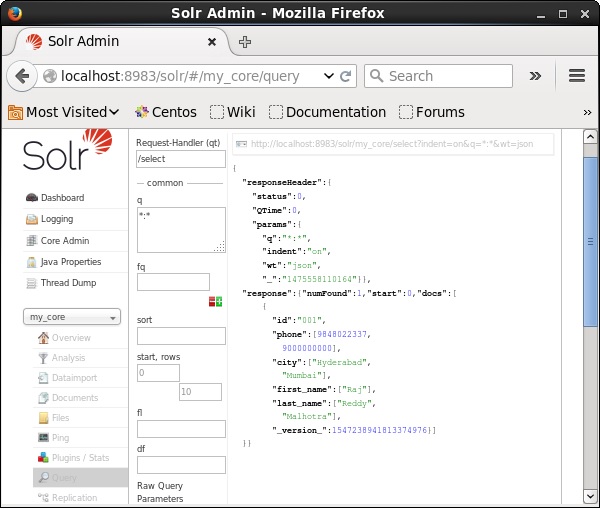
Visite la página de inicio de la interfaz web de Apache Solr y seleccione el núcleo como my_core. Intente recuperar todos los documentos pasando la consulta ":" en el área de textoqy ejecutar la consulta. Al ejecutar, puede observar que los documentos especificados se eliminan.
Eliminar un campo
A veces necesitamos eliminar documentos basados en campos que no sean ID. Por ejemplo, es posible que tengamos que eliminar los documentos de la ciudad de Chennai.
En tales casos, debe especificar el nombre y el valor del campo dentro del par de etiquetas <query> </query>.
<delete>
<query>city:Chennai</query>
</delete>Guardarlo como delete_field.xml y realizar la operación de eliminación en el núcleo llamado my_core utilizando el post herramienta de Solr.
[Hadoop@localhost bin]$ ./post -c my_core delete_field.xmlAl ejecutar el comando anterior, produce el siguiente resultado.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete_field.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete_field.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.084Verificación
Visite la página de inicio de la interfaz web de Apache Solr y seleccione el núcleo como my_core. Intente recuperar todos los documentos pasando la consulta ":" en el área de textoqy ejecutar la consulta. Al ejecutar, puede observar que los documentos que contienen el par de valores de campo especificado se eliminan.
Eliminar todos los documentos
Al igual que eliminar un campo específico, si desea eliminar todos los documentos de un índice, solo necesita pasar el símbolo “:” entre las etiquetas <query> </ query>, como se muestra a continuación.
<delete>
<query>*:*</query>
</delete>Guardarlo como delete_all.xml y realizar la operación de eliminación en el núcleo llamado my_core utilizando el post herramienta de Solr.
[Hadoop@localhost bin]$ ./post -c my_core delete_all.xmlAl ejecutar el comando anterior, produce el siguiente resultado.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool deleteAll.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file deleteAll.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.138Verificación
Visite la página de inicio de la interfaz web de Apache Solr y seleccione el núcleo como my_core. Intente recuperar todos los documentos pasando la consulta ":" en el área de textoqy ejecutar la consulta. Al ejecutar, puede observar que los documentos que contienen el par de valores de campo especificado se eliminan.
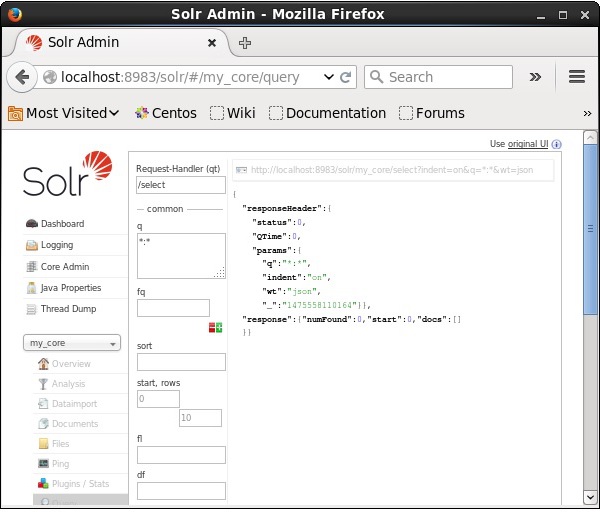
Eliminar todos los documentos usando Java (API de cliente)
A continuación se muestra el programa Java para agregar documentos al índice Apache Solr. Guarde este código en un archivo con el nombreUpdatingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class DeletingAllDocuments {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Deleting the documents from Solr
Solr.deleteByQuery("*");
//Saving the document
Solr.commit();
System.out.println("Documents deleted");
}
}Compile el código anterior ejecutando los siguientes comandos en la terminal:
[Hadoop@localhost bin]$ javac DeletingAllDocuments
[Hadoop@localhost bin]$ java DeletingAllDocumentsAl ejecutar el comando anterior, obtendrá el siguiente resultado.
Documents deletedEn este capítulo, discutiremos cómo recuperar datos usando la API de cliente Java. Supongamos que tenemos un documento .csv llamadosample.csv con el siguiente contenido.
001,9848022337,Hyderabad,Rajiv,Reddy
002,9848022338,Kolkata,Siddarth,Battacharya
003,9848022339,Delhi,Rajesh,KhannaPuede indexar estos datos en el núcleo denominado sample_Solr utilizando el post mando.
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvA continuación se muestra el programa Java para agregar documentos al índice Apache Solr. Guarde este código en un archivo con nombreRetrievingData.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrDocumentList;
public class RetrievingData {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing Solr query
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
//Adding the field to be retrieved
query.addField("*");
//Executing the query
QueryResponse queryResponse = Solr.query(query);
//Storing the results of the query
SolrDocumentList docs = queryResponse.getResults();
System.out.println(docs);
System.out.println(docs.get(0));
System.out.println(docs.get(1));
System.out.println(docs.get(2));
//Saving the operations
Solr.commit();
}
}Compile el código anterior ejecutando los siguientes comandos en la terminal:
[Hadoop@localhost bin]$ javac RetrievingData
[Hadoop@localhost bin]$ java RetrievingDataAl ejecutar el comando anterior, obtendrá el siguiente resultado.
{numFound = 3,start = 0,docs = [SolrDocument{id=001, phone = [9848022337],
city = [Hyderabad], first_name = [Rajiv], last_name = [Reddy],
_version_ = 1547262806014820352}, SolrDocument{id = 002, phone = [9848022338],
city = [Kolkata], first_name = [Siddarth], last_name = [Battacharya],
_version_ = 1547262806026354688}, SolrDocument{id = 003, phone = [9848022339],
city = [Delhi], first_name = [Rajesh], last_name = [Khanna],
_version_ = 1547262806029500416}]}
SolrDocument{id = 001, phone = [9848022337], city = [Hyderabad], first_name = [Rajiv],
last_name = [Reddy], _version_ = 1547262806014820352}
SolrDocument{id = 002, phone = [9848022338], city = [Kolkata], first_name = [Siddarth],
last_name = [Battacharya], _version_ = 1547262806026354688}
SolrDocument{id = 003, phone = [9848022339], city = [Delhi], first_name = [Rajesh],
last_name = [Khanna], _version_ = 1547262806029500416}Además de almacenar datos, Apache Solr también ofrece la posibilidad de volver a consultarlos cuando sea necesario. Solr proporciona ciertos parámetros mediante los cuales podemos consultar los datos almacenados en él.
En la siguiente tabla, hemos enumerado los diversos parámetros de consulta disponibles en Apache Solr.
| Parámetro | Descripción |
|---|---|
| q | Este es el principal parámetro de consulta de Apache Solr, los documentos se puntúan por su similitud con los términos de este parámetro. |
| fq | Este parámetro representa la consulta de filtro de Apache Solr y restringe el conjunto de resultados a los documentos que coinciden con este filtro. |
| comienzo | El parámetro de inicio representa las compensaciones de inicio para los resultados de una página; el valor predeterminado de este parámetro es 0. |
| filas | Este parámetro representa el número de documentos que se recuperarán por página. El valor predeterminado de este parámetro es 10. |
| ordenar | Este parámetro especifica la lista de campos, separados por comas, según la cual se ordenarán los resultados de la consulta. |
| Florida | Este parámetro especifica la lista de campos a devolver para cada documento en el conjunto de resultados. |
| peso | Este parámetro representa el tipo de escritor de respuesta que queríamos ver el resultado. |
Puede ver todos estos parámetros como opciones para consultar Apache Solr. Visite la página de inicio de Apache Solr. En el lado izquierdo de la página, haga clic en la opción Consulta. Aquí puede ver los campos de los parámetros de una consulta.
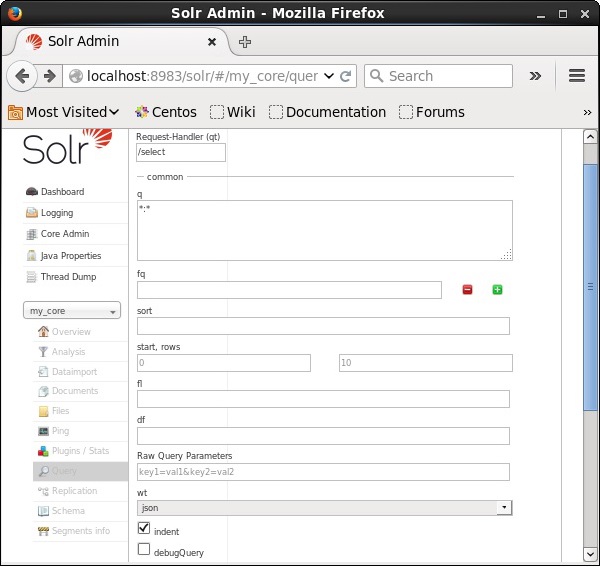
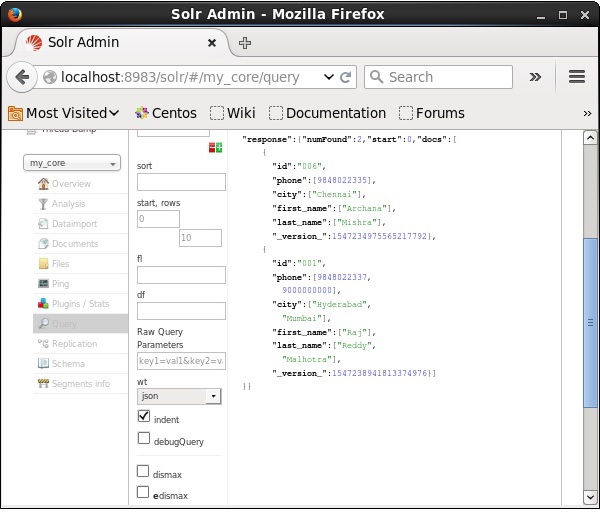
Recuperando los registros
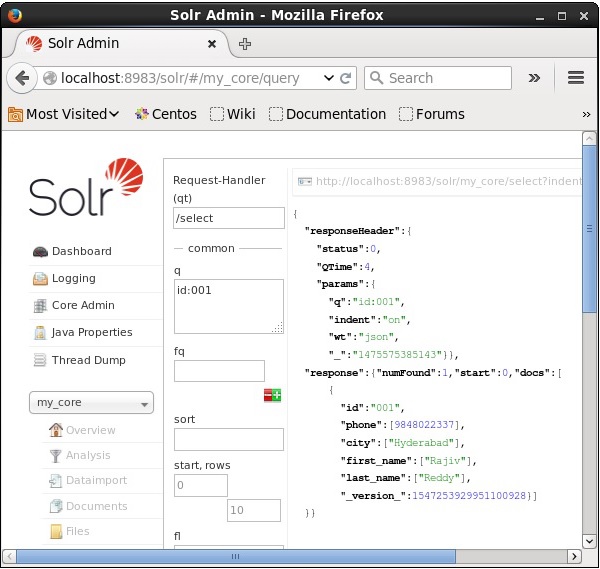
Suponga que tenemos 3 registros en el núcleo llamados my_core. Para recuperar un registro en particular del núcleo seleccionado, debe pasar los pares de nombre y valor de los campos de un documento en particular. Por ejemplo, si desea recuperar el registro con el valor del campoid, debe pasar el par nombre-valor del campo como - Id:001 como valor para el parámetro q y ejecutar la consulta.
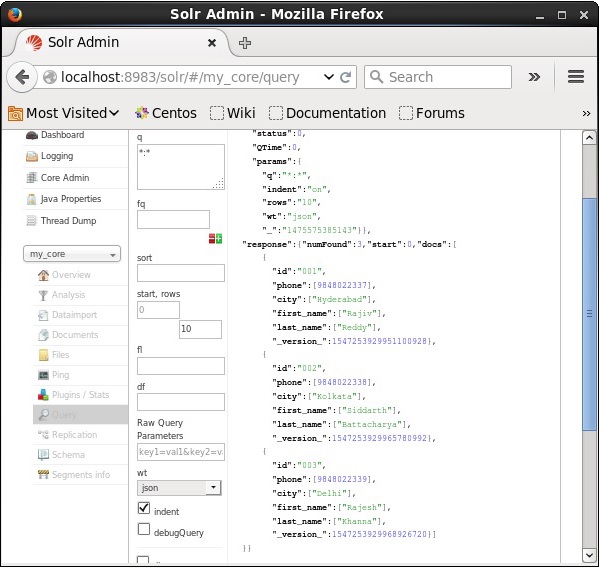
De la misma manera, puede recuperar todos los registros de un índice pasando *: * como valor al parámetro q, como se muestra en la siguiente captura de pantalla.
Recuperando del 2do registro
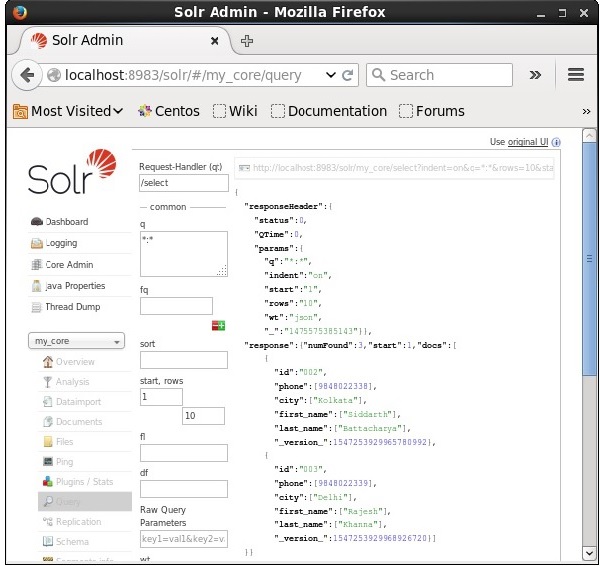
Podemos recuperar los registros del segundo registro pasando 2 como valor al parámetro start, como se muestra en la siguiente captura de pantalla.
Restricción del número de registros
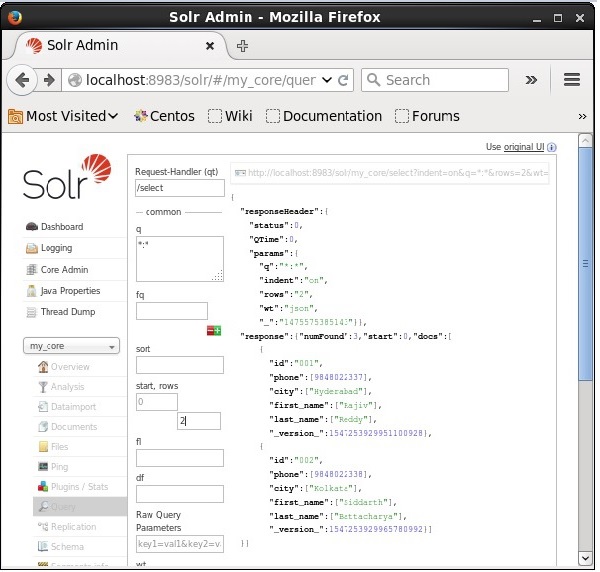
Puede restringir el número de registros especificando un valor en el rowsparámetro. Por ejemplo, podemos restringir el número total de registros en el resultado de la consulta a 2 pasando el valor 2 al parámetrorows, como se muestra en la siguiente captura de pantalla.
Tipo de escritor de respuesta
Puede obtener la respuesta en el tipo de documento requerido seleccionando uno de los valores proporcionados del parámetro wt.
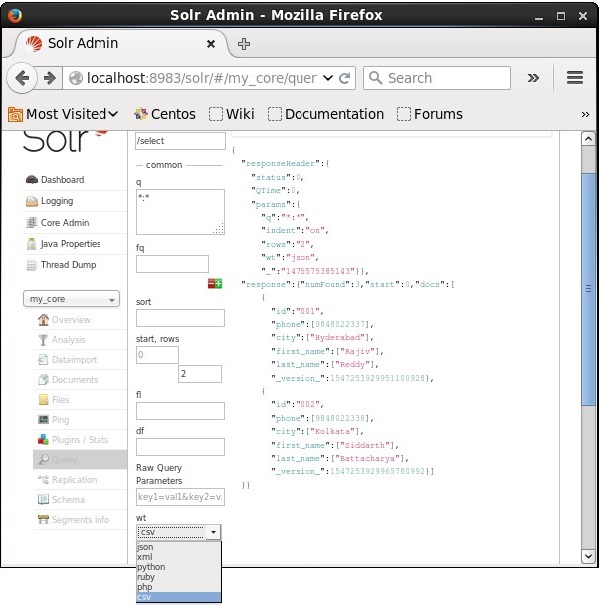
En el caso anterior, hemos elegido el .csv formato para obtener la respuesta.
Lista de campos
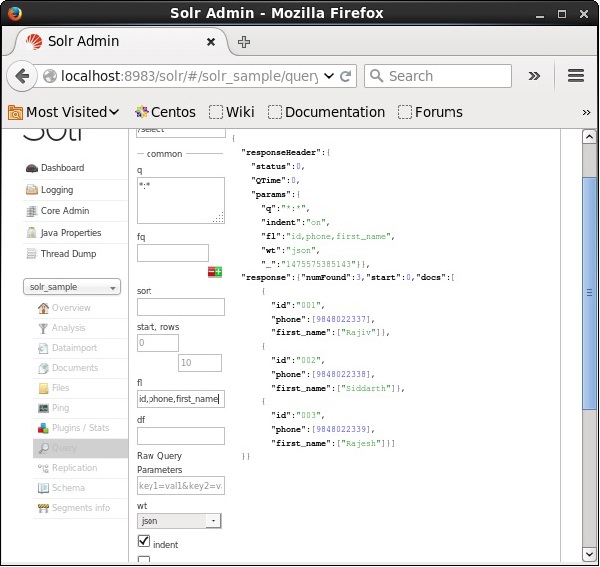
Si queremos tener campos particulares en los documentos resultantes, necesitamos pasar la lista de los campos requeridos, separados por comas, como valor a la propiedad fl.
En el siguiente ejemplo, estamos intentando recuperar los campos: id, phone, y first_name.
La creación de facetas en Apache Solr se refiere a la clasificación de los resultados de búsqueda en varias categorías. En este capítulo, discutiremos los tipos de facetas disponibles en Apache Solr:
Query faceting - Devuelve el número de documentos en los resultados de búsqueda actuales que también coinciden con la consulta dada.
Date faceting - Devuelve la cantidad de documentos que se encuentran dentro de ciertos rangos de fechas.
Los comandos de facetado se agregan a cualquier solicitud de consulta de Solr normal y los recuentos de facetado vuelven en la misma respuesta de consulta.
Ejemplo de consulta de facetas
Usando el campo faceting, podemos recuperar los recuentos de todos los términos o solo los términos superiores en cualquier campo dado.
Como ejemplo, consideremos lo siguiente books.csv archivo que contiene datos sobre varios libros.
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s
0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice
and Fire",1,fantasy
0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice
and Fire",2,fantasy
055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice
and Fire",3,fantasy
0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi
0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The
Black Company,1,fantasy
0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi
0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy
0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of
Amber,1,fantasy
0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,1,fantasy
080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,2,fantasyPubliquemos este archivo en Apache Solr usando el post herramienta.
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvAl ejecutar el comando anterior, todos los documentos mencionados en el .csv El archivo se cargará en Apache Solr.
Ahora ejecutemos una consulta facetada en el campo. author con 0 filas en la colección / núcleo my_core.
Abra la interfaz de usuario web de Apache Solr y, en el lado izquierdo de la página, marque la casilla de verificación facet, como se muestra en la siguiente captura de pantalla.
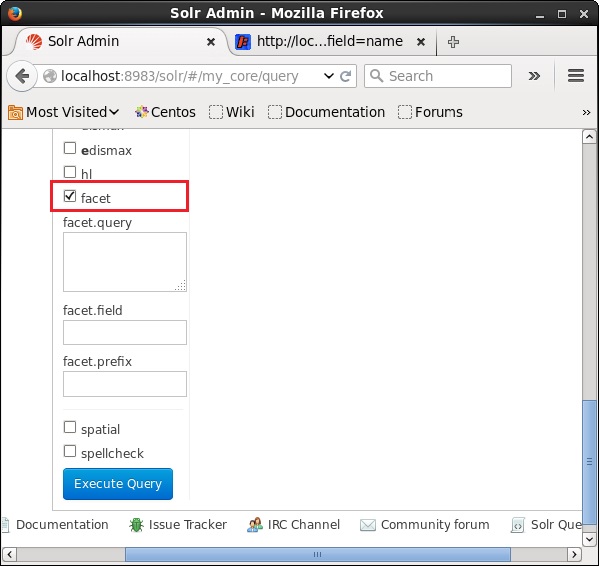
Al marcar la casilla de verificación, tendrá tres campos de texto más para pasar los parámetros de la búsqueda de facetas. Ahora, como parámetros de la consulta, pase los siguientes valores.
q = *:*, rows = 0, facet.field = authorFinalmente, ejecute la consulta haciendo clic en el Execute Query botón.
Al ejecutar, producirá el siguiente resultado.
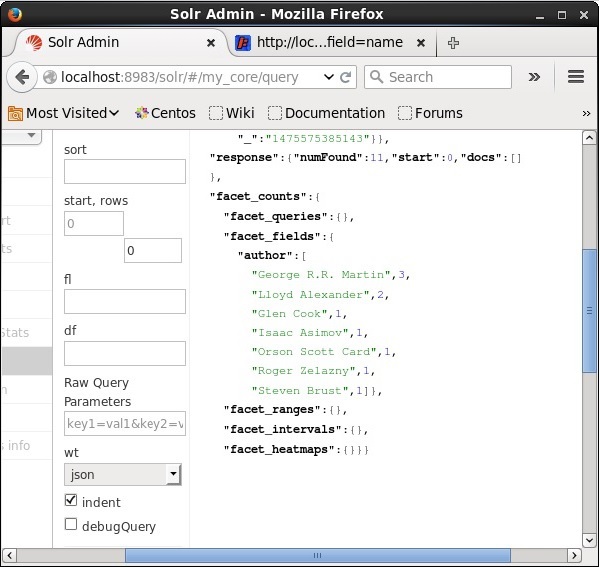
Clasifica los documentos del índice según el autor y especifica el número de libros aportados por cada autor.
Creación de facetas mediante la API de cliente Java
A continuación se muestra el programa Java para agregar documentos al índice Apache Solr. Guarde este código en un archivo con el nombreHitHighlighting.java.
import java.io.IOException;
import java.util.List;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.QueryRequest;
import org.apache.Solr.client.Solrj.response.FacetField;
import org.apache.Solr.client.Solrj.response.FacetField.Count;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrInputDocument;
public class HitHighlighting {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//String query = request.query;
SolrQuery query = new SolrQuery();
//Setting the query string
query.setQuery("*:*");
//Setting the no.of rows
query.setRows(0);
//Adding the facet field
query.addFacetField("author");
//Creating the query request
QueryRequest qryReq = new QueryRequest(query);
//Creating the query response
QueryResponse resp = qryReq.process(Solr);
//Retrieving the response fields
System.out.println(resp.getFacetFields());
List<FacetField> facetFields = resp.getFacetFields();
for (int i = 0; i > facetFields.size(); i++) {
FacetField facetField = facetFields.get(i);
List<Count> facetInfo = facetField.getValues();
for (FacetField.Count facetInstance : facetInfo) {
System.out.println(facetInstance.getName() + " : " +
facetInstance.getCount() + " [drilldown qry:" +
facetInstance.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}Compile el código anterior ejecutando los siguientes comandos en la terminal:
[Hadoop@localhost bin]$ javac HitHighlighting
[Hadoop@localhost bin]$ java HitHighlightingAl ejecutar el comando anterior, obtendrá el siguiente resultado.
[author:[George R.R. Martin (3), Lloyd Alexander (2), Glen Cook (1), Isaac
Asimov (1), Orson Scott Card (1), Roger Zelazny (1), Steven Brust (1)]]