Concurrencia en Python - Guía rápida
En este capítulo, comprenderemos el concepto de concurrencia en Python y aprenderemos sobre los diferentes hilos y procesos.
¿Qué es la concurrencia?
En palabras simples, la concurrencia es la ocurrencia de dos o más eventos al mismo tiempo. La concurrencia es un fenómeno natural porque muchos eventos ocurren simultáneamente en un momento dado.
En términos de programación, la concurrencia es cuando dos tareas se superponen en la ejecución. Con la programación concurrente, el rendimiento de nuestras aplicaciones y sistemas de software se puede mejorar porque podemos atender simultáneamente las solicitudes en lugar de esperar a que se complete una anterior.
Revisión histórica de concurrencia
Los siguientes puntos nos darán una breve revisión histórica de la concurrencia:
Del concepto de ferrocarriles
La concurrencia está estrechamente relacionada con el concepto de ferrocarriles. Con los ferrocarriles, existía la necesidad de manejar varios trenes en el mismo sistema ferroviario de tal manera que cada tren llegara a su destino de manera segura.
Computación concurrente en la academia
El interés por la concurrencia de las ciencias de la computación comenzó con el artículo de investigación publicado por Edsger W. Dijkstra en 1965. En este artículo, identificó y resolvió el problema de la exclusión mutua, la propiedad del control de concurrencia.
Primitivas de simultaneidad de alto nivel
En los últimos tiempos, los programadores están obteniendo soluciones concurrentes mejoradas debido a la introducción de primitivas de concurrencia de alto nivel.
Simultaneidad mejorada con lenguajes de programación
Los lenguajes de programación como Golang, Rust y Python de Google han realizado desarrollos increíbles en áreas que nos ayudan a obtener mejores soluciones simultáneas.
¿Qué son hilos y subprocesos múltiples?
Threades la unidad de ejecución más pequeña que se puede realizar en un sistema operativo. No es un programa en sí mismo, sino que se ejecuta dentro de un programa. En otras palabras, los hilos no son independientes entre sí. Cada hilo comparte sección de código, sección de datos, etc. con otros hilos. También se conocen como procesos ligeros.
Un hilo consta de los siguientes componentes:
Contador de programa que consta de la dirección de la siguiente instrucción ejecutable
Stack
Conjunto de registros
Una identificación única
Multithreading, por otro lado, es la capacidad de una CPU para administrar el uso del sistema operativo mediante la ejecución de varios subprocesos al mismo tiempo. La idea principal del subproceso múltiple es lograr el paralelismo dividiendo un proceso en varios subprocesos. El concepto de multiproceso se puede entender con la ayuda del siguiente ejemplo.
Ejemplo
Supongamos que estamos ejecutando un proceso particular en el que abrimos MS Word para escribir contenido en él. Se asignará un hilo para abrir MS Word y se requerirá otro hilo para escribir contenido en él. Y ahora, si queremos editar el existente, se requerirá otro hilo para realizar la tarea de edición y así sucesivamente.
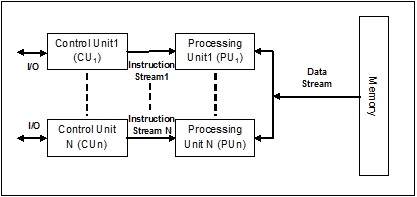
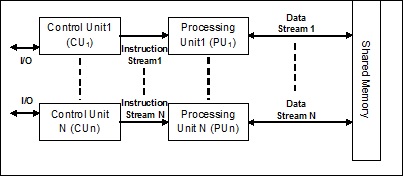
¿Qué es proceso y multiprocesamiento?
UNprocessse define como una entidad, que representa la unidad básica de trabajo a implementar en el sistema. Para decirlo en términos simples, escribimos nuestros programas informáticos en un archivo de texto y cuando ejecutamos este programa, se convierte en un proceso que realiza todas las tareas mencionadas en el programa. Durante el ciclo de vida del proceso, pasa por diferentes etapas: Inicio, Listo, Ejecución, Espera y Terminación.
El siguiente diagrama muestra las diferentes etapas de un proceso:
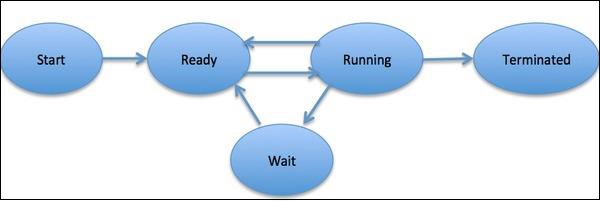
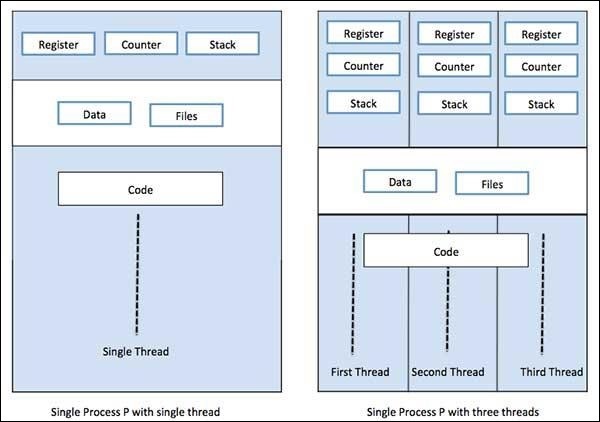
Un proceso puede tener solo un subproceso, llamado subproceso primario, o varios subprocesos que tienen su propio conjunto de registros, contador de programa y pila. El siguiente diagrama nos mostrará la diferencia:
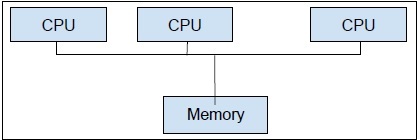
Multiprocessing,por otro lado, es el uso de dos o más CPU dentro de un solo sistema informático. Nuestro objetivo principal es aprovechar todo el potencial de nuestro hardware. Para lograr esto, necesitamos utilizar el número total de núcleos de CPU disponibles en nuestro sistema informático. El multiprocesamiento es el mejor enfoque para hacerlo.
Python es uno de los lenguajes de programación más populares. Las siguientes son algunas de las razones que lo hacen adecuado para aplicaciones concurrentes:
Azúcar sintáctica
El azúcar sintáctico es una sintaxis dentro de un lenguaje de programación que está diseñado para facilitar la lectura o la expresión. Hace que el lenguaje sea más "dulce" para el uso humano: las cosas se pueden expresar de forma más clara, más concisa o en un estilo alternativo basado en las preferencias. Python viene con métodos Magic, que se pueden definir para actuar sobre objetos. Estos métodos mágicos se utilizan como azúcar sintáctico y están vinculados a palabras clave más fáciles de entender.
Comunidad grande
El lenguaje Python ha sido testigo de una tasa de adopción masiva entre científicos de datos y matemáticos, que trabajan en el campo de la inteligencia artificial, el aprendizaje automático, el aprendizaje profundo y el análisis cuantitativo.
API útiles para programación concurrente
Python 2 y 3 tienen una gran cantidad de API dedicadas a la programación paralela / concurrente. Los más populares sonthreading, concurrent.features, multiprocessing, asyncio, gevent and greenlets, etc.
Limitaciones de Python en la implementación de aplicaciones concurrentes
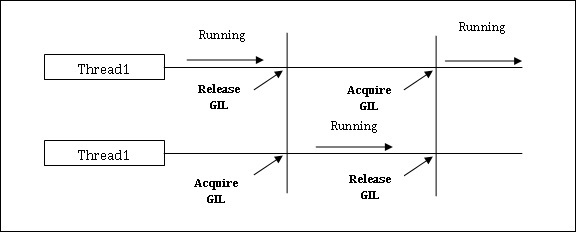
Python viene con una limitación para aplicaciones concurrentes. Esta limitación se llamaGIL (Global Interpreter Lock)está presente en Python. GIL nunca nos permite utilizar múltiples núcleos de CPU y, por lo tanto, podemos decir que no hay verdaderos hilos en Python. Podemos entender el concepto de GIL de la siguiente manera:
GIL (bloqueo de intérprete global)
Es uno de los temas más controvertidos del mundo de Python. En CPython, GIL es el mutex, el bloqueo de exclusión mutua, que hace que las cosas sean seguras para los subprocesos. En otras palabras, podemos decir que GIL evita que varios subprocesos ejecuten código Python en paralelo. El bloqueo puede ser retenido por un solo hilo a la vez y si queremos ejecutar un hilo, primero debe adquirir el bloqueo. El diagrama que se muestra a continuación le ayudará a comprender el funcionamiento de GIL.
Sin embargo, existen algunas bibliotecas e implementaciones en Python como Numpy, Jpython y IronPytbhon. Estas bibliotecas funcionan sin ninguna interacción con GIL.
Tanto la concurrencia como el paralelismo se utilizan en relación con los programas multiproceso, pero existe mucha confusión sobre la similitud y la diferencia entre ellos. La gran pregunta a este respecto: ¿es el paralelismo de concurrencia o no? Aunque ambos términos parecen bastante similares, pero la respuesta a la pregunta anterior es NO, la concurrencia y el paralelismo no son lo mismo. Ahora bien, si no son iguales, ¿cuál es la diferencia básica entre ellos?
En términos simples, la concurrencia se ocupa de administrar el acceso al estado compartido desde diferentes subprocesos y, por otro lado, el paralelismo se ocupa de utilizar múltiples CPU o sus núcleos para mejorar el rendimiento del hardware.
Concurrencia en detalle
La concurrencia es cuando dos tareas se superponen en la ejecución. Podría ser una situación en la que una aplicación avanza en más de una tarea al mismo tiempo. Podemos entenderlo esquemáticamente; múltiples tareas están progresando al mismo tiempo, de la siguiente manera:
Niveles de simultaneidad
En esta sección, discutiremos los tres niveles importantes de concurrencia en términos de programación:
Simultaneidad de bajo nivel
En este nivel de concurrencia, hay un uso explícito de operaciones atómicas. No podemos utilizar este tipo de simultaneidad para la creación de aplicaciones, ya que es muy propenso a errores y difícil de depurar. Incluso Python no admite este tipo de simultaneidad.
Simultaneidad de nivel medio
En esta concurrencia, no se utilizan operaciones atómicas explícitas. Utiliza los bloqueos explícitos. Python y otros lenguajes de programación admiten este tipo de simultaneidad. La mayoría de los programadores de aplicaciones utilizan esta simultaneidad.
Simultaneidad de alto nivel
En esta concurrencia, no se utilizan ni operaciones atómicas explícitas ni bloqueos explícitos. Python tieneconcurrent.futures módulo para soportar este tipo de concurrencia.
Propiedades de los sistemas concurrentes
Para que un programa o sistema concurrente sea correcto, debe satisfacer algunas propiedades. Las propiedades relacionadas con la terminación del sistema son las siguientes:
Propiedad de corrección
La propiedad de corrección significa que el programa o el sistema debe proporcionar la respuesta correcta deseada. Para simplificarlo, podemos decir que el sistema debe asignar correctamente el estado del programa inicial al estado final.
Propiedad de seguridad
La propiedad de seguridad significa que el programa o el sistema debe permanecer en “good” o “safe” estado y nunca hace nada “bad”.
Propiedad de vivacidad
Esta propiedad significa que un programa o sistema debe “make progress” y alcanzaría algún estado deseable.
Actores de sistemas concurrentes
Esta es una propiedad común del sistema concurrente en el que puede haber múltiples procesos e hilos, que se ejecutan al mismo tiempo para avanzar en sus propias tareas. Estos procesos e hilos se denominan actores del sistema concurrente.
Recursos de sistemas concurrentes
Los actores deben utilizar los recursos como la memoria, el disco, la impresora, etc. para realizar sus tareas.
Cierto conjunto de reglas
Cada sistema concurrente debe poseer un conjunto de reglas para definir el tipo de tareas que deben realizar los actores y el tiempo para cada una. Las tareas pueden ser adquirir bloqueos, compartir memoria, modificar el estado, etc.
Barreras de sistemas concurrentes
Intercambio de datos
Un tema importante al implementar los sistemas concurrentes es el intercambio de datos entre múltiples subprocesos o procesos. En realidad, el programador debe asegurarse de que los bloqueos protejan los datos compartidos para que todos los accesos a ellos sean serializados y solo un hilo o proceso pueda acceder a los datos compartidos a la vez. En caso de que, cuando varios subprocesos o procesos intenten acceder a los mismos datos compartidos, no todos, pero al menos uno de ellos, se bloquearían y permanecerían inactivos. En otras palabras, podemos decir que podríamos usar solo un proceso o subproceso a la vez cuando el bloqueo esté en vigor. Puede haber algunas soluciones simples para eliminar las barreras mencionadas anteriormente:
Restricción de uso compartido de datos
La solución más simple es no compartir ningún dato mutable. En este caso, no necesitamos usar bloqueo explícito y se resolvería la barrera de concurrencia debido a datos mutuos.
Asistencia de estructura de datos
Muchas veces los procesos concurrentes necesitan acceder a los mismos datos al mismo tiempo. Otra solución, además del uso de bloqueos explícitos, es usar una estructura de datos que admita el acceso concurrente. Por ejemplo, podemos usar elqueuemódulo, que proporciona colas seguras para subprocesos. También podemos usarmultiprocessing.JoinableQueue clases para la concurrencia basada en multiprocesamiento.
Transferencia de datos inmutable
A veces, la estructura de datos que estamos usando, digamos la cola de concurrencia, no es adecuada, entonces podemos pasar los datos inmutables sin bloquearlos.
Transferencia de datos mutable
Como continuación de la solución anterior, suponga que si se requiere pasar solo datos mutables, en lugar de datos inmutables, entonces podemos pasar datos mutables que son de solo lectura.
Compartir recursos de E / S
Otro tema importante en la implementación de sistemas concurrentes es el uso de recursos de E / S por subprocesos o procesos. El problema surge cuando un subproceso o proceso utiliza la E / S durante tanto tiempo y el otro permanece inactivo. Podemos ver este tipo de barrera mientras trabajamos con una aplicación pesada de E / S. Se puede entender con la ayuda de un ejemplo, la solicitud de páginas desde el navegador web. Es una aplicación pesada. Aquí, si la velocidad a la que se solicitan los datos es más lenta que la velocidad a la que se consumen, entonces tenemos una barrera de E / S en nuestro sistema concurrente.
La siguiente secuencia de comandos de Python es para solicitar una página web y obtener el tiempo que nuestra red tardó en obtener la página solicitada:
import urllib.request
import time
ts = time.time()
req = urllib.request.urlopen('http://www.tutorialspoint.com')
pageHtml = req.read()
te = time.time()
print("Page Fetching Time : {} Seconds".format (te-ts))Después de ejecutar el script anterior, podemos obtener el tiempo de recuperación de la página como se muestra a continuación.
Salida
Page Fetching Time: 1.0991398811340332 SecondsPodemos ver que el tiempo para recuperar la página es más de un segundo. Ahora, ¿qué pasa si queremos buscar miles de páginas web diferentes? Puede comprender cuánto tiempo tomaría nuestra red.
¿Qué es el paralelismo?
El paralelismo puede definirse como el arte de dividir las tareas en subtareas que se pueden procesar simultáneamente. Es opuesto a la concurrencia, como se discutió anteriormente, en la que dos o más eventos están sucediendo al mismo tiempo. Podemos entenderlo esquemáticamente; una tarea se divide en varias subtareas que se pueden procesar en paralelo, de la siguiente manera:
Para tener más idea sobre la distinción entre concurrencia y paralelismo, considere los siguientes puntos:
Concurrente pero no paralelo
Una aplicación puede ser concurrente pero no paralela significa que procesa más de una tarea al mismo tiempo, pero las tareas no se dividen en subtareas.
Paralelo pero no concurrente
Una aplicación puede ser paralela pero no simultánea, lo que significa que solo funciona en una tarea a la vez y las tareas divididas en subtareas se pueden procesar en paralelo.
Ni paralelo ni concurrente
Una aplicación no puede ser paralela ni concurrente. Esto significa que solo funciona en una tarea a la vez y la tarea nunca se divide en subtareas.
Tanto en paralelo como concurrente
Una aplicación puede ser paralela y simultánea, lo que significa que ambas funcionan en varias tareas a la vez y la tarea se divide en subtareas para ejecutarlas en paralelo.
Necesidad de paralelismo
Podemos lograr el paralelismo distribuyendo las subtareas entre diferentes núcleos de una sola CPU o entre múltiples computadoras conectadas dentro de una red.
Considere los siguientes puntos importantes para comprender por qué es necesario lograr el paralelismo:
Ejecución de código eficiente
Con la ayuda del paralelismo, podemos ejecutar nuestro código de manera eficiente. Nos ahorrará tiempo porque el mismo código en partes se ejecuta en paralelo.
Más rápido que la computación secuencial
La computación secuencial está limitada por factores físicos y prácticos debido a los cuales no es posible obtener resultados de computación más rápidos. Por otro lado, este problema se resuelve mediante la computación paralela y nos brinda resultados de computación más rápidos que la computación secuencial.
Menos tiempo de ejecución
El procesamiento en paralelo reduce el tiempo de ejecución del código del programa.
Si hablamos del ejemplo de la vida real de paralelismo, la tarjeta gráfica de nuestra computadora es el ejemplo que resalta el verdadero poder del procesamiento en paralelo porque tiene cientos de núcleos de procesamiento individuales que funcionan de forma independiente y pueden hacer la ejecución al mismo tiempo. Por esta razón, también podemos ejecutar aplicaciones y juegos de alta gama.
Comprensión de los procesadores para la implementación.
Conocemos la concurrencia, el paralelismo y la diferencia entre ellos, pero ¿qué pasa con el sistema en el que se va a implementar? Es muy necesario tener el conocimiento del sistema, sobre el cual vamos a implementar, porque nos da el beneficio de tomar decisiones informadas mientras diseñamos el software. Tenemos los siguientes dos tipos de procesadores:
Procesadores de un solo núcleo
Los procesadores de un solo núcleo son capaces de ejecutar un hilo en cualquier momento. Estos procesadores utilizancontext switchingpara almacenar toda la información necesaria para un hilo en un momento específico y luego restaurar la información más tarde. El mecanismo de cambio de contexto nos ayuda a progresar en varios subprocesos en un segundo determinado y parece que el sistema está trabajando en varias cosas.
Los procesadores de un solo núcleo tienen muchas ventajas. Estos procesadores requieren menos energía y no existe un protocolo de comunicación complejo entre varios núcleos. Por otro lado, la velocidad de los procesadores de un solo núcleo es limitada y no es adecuada para aplicaciones más grandes.
Procesadores multinúcleo
Los procesadores multinúcleo tienen varias unidades de procesamiento independientes también llamadas cores.
Estos procesadores no necesitan un mecanismo de cambio de contexto, ya que cada núcleo contiene todo lo que necesita para ejecutar una secuencia de instrucciones almacenadas.
Ciclo de búsqueda-decodificación-ejecución
Los núcleos de los procesadores de varios núcleos siguen un ciclo de ejecución. Este ciclo se llamaFetch-Decode-Executeciclo. Implica los siguientes pasos:
Ir a buscar
Este es el primer paso del ciclo, que implica la obtención de instrucciones de la memoria del programa.
Descodificar
Las instrucciones obtenidas recientemente se convertirían en una serie de señales que activarían otras partes de la CPU.
Ejecutar
Es el paso final en el que se ejecutarían las instrucciones obtenidas y decodificadas. El resultado de la ejecución se almacenará en un registro de la CPU.
Una ventaja aquí es que la ejecución en procesadores de varios núcleos es más rápida que la de los procesadores de un solo núcleo. Es adecuado para aplicaciones más grandes. Por otro lado, el protocolo de comunicación complejo entre múltiples núcleos es un problema. Varios núcleos requieren más energía que los procesadores de un solo núcleo.
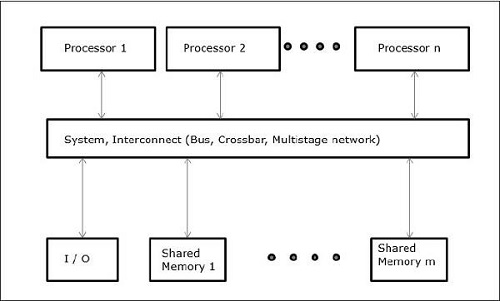
Hay diferentes estilos de arquitectura de memoria y sistema que deben tenerse en cuenta al diseñar el programa o el sistema concurrente. Es muy necesario porque un estilo de sistema y memoria puede ser adecuado para una tarea, pero puede ser propenso a errores para otra tarea.
Arquitecturas de sistemas informáticos que admiten la concurrencia
Michael Flynn en 1972 dio una taxonomía para categorizar diferentes estilos de arquitectura de sistemas informáticos. Esta taxonomía define cuatro estilos diferentes de la siguiente manera:
- Secuencia de instrucciones única, secuencia de datos única (SISD)
- Secuencia de instrucciones única, secuencia de datos múltiples (SIMD)
- Secuencia de instrucciones múltiple, secuencia de datos única (MISD)
- Flujo de instrucciones múltiples, flujo de datos múltiples (MIMD).
Secuencia de instrucciones única, secuencia de datos única (SISD)
Como sugiere el nombre, este tipo de sistemas tendrían un flujo de datos entrante secuencial y una sola unidad de procesamiento para ejecutar el flujo de datos. Son como sistemas monoprocesador con arquitectura de computación paralela. A continuación se muestra la arquitectura de SISD:
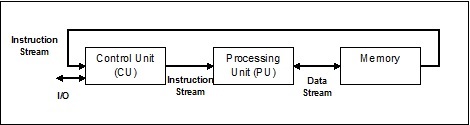
Ventajas de SISD
Las ventajas de la arquitectura SISD son las siguientes:
- Requiere menos energía.
- No hay problema de protocolo de comunicación complejo entre múltiples núcleos.
Desventajas de SISD
Las desventajas de la arquitectura SISD son las siguientes:
- La velocidad de la arquitectura SISD es limitada al igual que los procesadores de un solo núcleo.
- No es adecuado para aplicaciones más grandes.
Secuencia de instrucciones única, secuencia de datos múltiples (SIMD)
Como sugiere el nombre, este tipo de sistemas tendrían múltiples flujos de datos entrantes y un número de unidades de procesamiento que pueden actuar sobre una sola instrucción en cualquier momento. Son como sistemas multiprocesador con arquitectura de computación paralela. A continuación se muestra la arquitectura de SIMD:
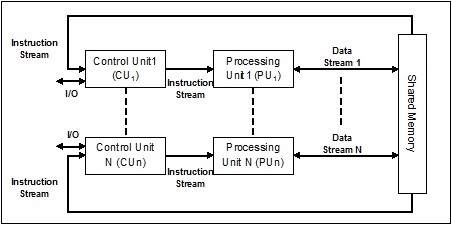
El mejor ejemplo de SIMD son las tarjetas gráficas. Estas tarjetas tienen cientos de unidades de procesamiento individuales. Si hablamos de diferencia computacional entre SISD y SIMD, entonces para agregar arreglos[5, 15, 20] y [15, 25, 10],La arquitectura del SISD tendría que realizar tres operaciones de adición diferentes. Por otro lado, con la arquitectura SIMD, podemos agregar luego en una sola operación de agregar.
Ventajas de SIMD
Las ventajas de la arquitectura SIMD son las siguientes:
La misma operación en varios elementos se puede realizar usando una sola instrucción.
El rendimiento del sistema se puede incrementar aumentando el número de núcleos del procesador.
La velocidad de procesamiento es más alta que la arquitectura SISD.
Desventajas de SIMD
Las desventajas de la arquitectura SIMD son las siguientes:
- Existe una comunicación compleja entre el número de núcleos del procesador.
- El costo es más alto que la arquitectura SISD.
Flujo de datos únicos de instrucciones múltiples (MISD)
Los sistemas con flujo MISD tienen varias unidades de procesamiento que realizan diferentes operaciones mediante la ejecución de diferentes instrucciones en el mismo conjunto de datos. A continuación se muestra la arquitectura de MISD:
Los representantes de la arquitectura de MISD aún no existen comercialmente.
Flujo de datos múltiples de instrucciones múltiples (MIMD)
En el sistema que usa la arquitectura MIMD, cada procesador en un sistema multiprocesador puede ejecutar diferentes conjuntos de instrucciones de forma independiente en los diferentes conjuntos de datos en paralelo. Es lo opuesto a la arquitectura SIMD en la que se ejecuta una sola operación en múltiples conjuntos de datos. A continuación se muestra la arquitectura de MIMD:
Un multiprocesador normal utiliza la arquitectura MIMD. Estas arquitecturas se utilizan básicamente en una serie de áreas de aplicación, como diseño asistido por computadora / fabricación asistida por computadora, simulación, modelado, interruptores de comunicación, etc.
Arquitecturas de memoria que admiten la simultaneidad
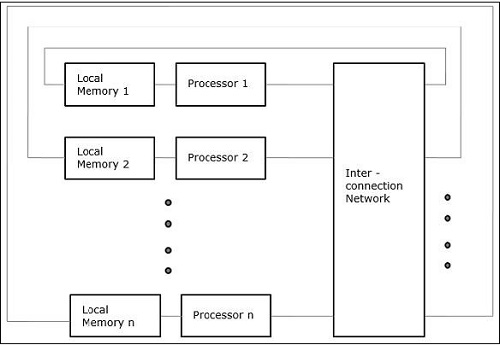
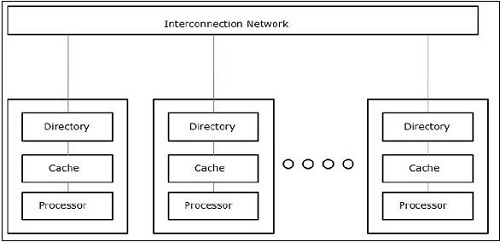
Al trabajar con conceptos como concurrencia y paralelismo, siempre es necesario acelerar los programas. Una solución encontrada por los diseñadores de computadoras es crear múltiples computadoras de memoria compartida, es decir, computadoras que tienen un solo espacio de direcciones físicas, al que acceden todos los núcleos que tiene un procesador. En este escenario, puede haber varios estilos diferentes de arquitectura, pero a continuación se muestran los tres estilos de arquitectura importantes:
UMA (acceso uniforme a la memoria)
En este modelo, todos los procesadores comparten la memoria física de manera uniforme. Todos los procesadores tienen el mismo tiempo de acceso a todas las palabras de memoria. Cada procesador puede tener una memoria caché privada. Los dispositivos periféricos siguen un conjunto de reglas.
Cuando todos los procesadores tienen el mismo acceso a todos los dispositivos periféricos, el sistema se denomina symmetric multiprocessor. Cuando solo uno o unos pocos procesadores pueden acceder a los dispositivos periféricos, el sistema se denominaasymmetric multiprocessor.
Acceso a memoria no uniforme (NUMA)
En el modelo de multiprocesador NUMA, el tiempo de acceso varía con la ubicación de la palabra de memoria. Aquí, la memoria compartida se distribuye físicamente entre todos los procesadores, llamados memorias locales. La colección de todas las memorias locales forma un espacio de direcciones global al que pueden acceder todos los procesadores.
Arquitectura de memoria caché únicamente (COMA)
El modelo COMA es una versión especializada del modelo NUMA. Aquí, todas las memorias principales distribuidas se convierten en memorias caché.
En general, como sabemos, el hilo es una cuerda retorcida muy delgada, generalmente de tela de algodón o seda y se usa para coser ropa y demás. El mismo término hilo también se utiliza en el mundo de la programación informática. Ahora bien, ¿cómo relacionamos el hilo que se usa para coser ropa y el hilo que se usa para la programación de computadoras? Los roles desempeñados por los dos subprocesos son similares aquí. En la ropa, el hilo sujeta la tela y, por el otro lado, en la programación de computadoras, el hilo sujeta el programa de computadora y permite que el programa ejecute acciones secuenciales o muchas acciones a la vez.
Threades la unidad de ejecución más pequeña en un sistema operativo. No es en sí mismo un programa, sino que se ejecuta dentro de un programa. En otras palabras, los hilos no son independientes entre sí y comparten la sección de código, la sección de datos, etc. con otros hilos. Estos subprocesos también se conocen como procesos ligeros.
Estados de hilo
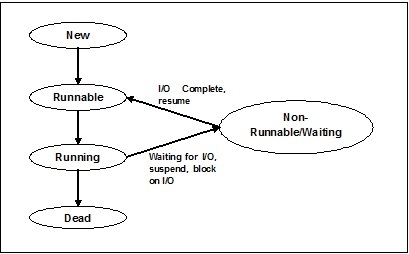
Para comprender la funcionalidad de los subprocesos en profundidad, necesitamos aprender sobre el ciclo de vida de los subprocesos o los diferentes estados de los subprocesos. Normalmente, un hilo puede existir en cinco estados distintos. Los diferentes estados se muestran a continuación:
Nuevo hilo
Un nuevo hilo comienza su ciclo de vida en el nuevo estado. Sin embargo, en esta etapa, aún no ha comenzado y no se le han asignado recursos. Podemos decir que es solo una instancia de un objeto.
Runnable
A medida que se inicia el hilo recién nacido, el hilo se vuelve ejecutable, es decir, espera para ejecutarse. En este estado, tiene todos los recursos, pero el programador de tareas aún no lo ha programado para ejecutarse.
Corriendo
En este estado, el subproceso avanza y ejecuta la tarea, que ha sido elegida por el programador de tareas para ejecutar. Ahora, el hilo puede ir al estado muerto o al estado no ejecutable / en espera.
No corriendo / esperando
En este estado, el subproceso se detiene porque está esperando la respuesta de alguna solicitud de E / S o esperando la finalización de la ejecución de otro subproceso.
Muerto
Un subproceso ejecutable entra en el estado terminado cuando completa su tarea o termina.
El siguiente diagrama muestra el ciclo de vida completo de un hilo:
Tipos de hilo
En esta sección veremos los diferentes tipos de hilo. Los tipos se describen a continuación:
Hilos de nivel de usuario
Estos son hilos administrados por el usuario.
En este caso, el núcleo de administración de subprocesos no es consciente de la existencia de subprocesos. La biblioteca de subprocesos contiene código para crear y destruir subprocesos, para pasar mensajes y datos entre subprocesos, para programar la ejecución de subprocesos y para guardar y restaurar contextos de subprocesos. La aplicación comienza con un solo hilo.
Los ejemplos de subprocesos a nivel de usuario son:
- Java threads
- POSIX threads
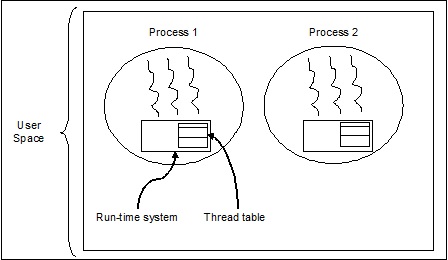
Advantages of User level Threads
Following are the different advantages of user level threads −
- Thread switching does not require Kernel mode privileges.
- User level thread can run on any operating system.
- Scheduling can be application specific in the user level thread.
- User level threads are fast to create and manage.
Disadvantages of User level Threads
Following are the different disadvantages of user level threads −
- In a typical operating system, most system calls are blocking.
- Multithreaded application cannot take advantage of multiprocessing.
Kernel Level Threads
Operating System managed threads act on kernel, which is an operating system core.
In this case, the Kernel does thread management. There is no thread management code in the application area. Kernel threads are supported directly by the operating system. Any application can be programmed to be multithreaded. All of the threads within an application are supported within a single process.
The Kernel maintains context information for the process as a whole and for individual threads within the process. Scheduling by the Kernel is done on a thread basis. The Kernel performs thread creation, scheduling and management in Kernel space. Kernel threads are generally slower to create and manage than the user threads. The examples of kernel level threads are Windows, Solaris.
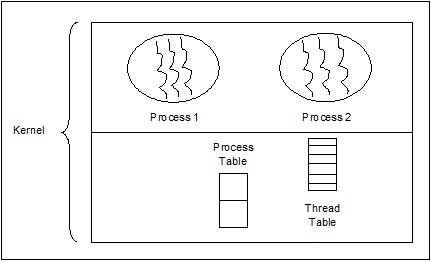
Advantages of Kernel Level Threads
Following are the different advantages of kernel level threads −
Kernel can simultaneously schedule multiple threads from the same process on multiple processes.
If one thread in a process is blocked, the Kernel can schedule another thread of the same process.
Kernel routines themselves can be multithreaded.
Disadvantages of Kernel Level Threads
Kernel threads are generally slower to create and manage than the user threads.
Transfer of control from one thread to another within the same process requires a mode switch to the Kernel.
Thread Control Block - TCB
Thread Control Block (TCB) may be defined as the data structure in the kernel of operating system that mainly contains information about thread. Thread-specific information stored in TCB would highlight some important information about each process.
Consider the following points related to the threads contained in TCB −
Thread identification − It is the unique thread id (tid) assigned to every new thread.
Thread state − It contains the information related to the state (Running, Runnable, Non-Running, Dead) of the thread.
Program Counter (PC) − It points to the current program instruction of the thread.
Register set − It contains the thread’s register values assigned to them for computations.
Stack Pointer − It points to the thread’s stack in the process. It contains the local variables under thread’s scope.
Pointer to PCB − It contains the pointer to the process that created that thread.

Relation between process & thread
In multithreading, process and thread are two very closely related terms having the same goal to make computer able to do more than one thing at a time. A process can contain one or more threads but on the contrary, thread cannot contain a process. However, they both remain the two basic units of execution. A program, executing a series of instructions, initiates process and thread both.
The following table shows the comparison between process and thread −
| Process | Thread |
|---|---|
| Process is heavy weight or resource intensive. | Thread is lightweight which takes fewer resources than a process. |
| Process switching needs interaction with operating system. | Thread switching does not need to interact with operating system. |
| In multiple processing environments, each process executes the same code but has its own memory and file resources. | All threads can share same set of open files, child processes. |
| If one process is blocked, then no other process can execute until the first process is unblocked. | While one thread is blocked and waiting, a second thread in the same task can run. |
| Multiple processes without using threads use more resources. | Multiple threaded processes use fewer resources. |
| In multiple processes, each process operates independently of the others. | One thread can read, write or change another thread's data. |
| If there would be any change in the parent process then it does not affect the child processes. | If there would be any change in the main thread then it may affect the behavior of other threads of that process. |
| To communicate with sibling processes, processes must use inter-process communication. | Threads can directly communicate with other threads of that process. |
Concept of Multithreading
As we have discussed earlier that Multithreading is the ability of a CPU to manage the use of operating system by executing multiple threads concurrently. The main idea of multithreading is to achieve parallelism by dividing a process into multiple threads. In a more simple way, we can say that multithreading is the way of achieving multitasking by using the concept of threads.
The concept of multithreading can be understood with the help of the following example.
Example
Suppose we are running a process. The process could be for opening MS word for writing something. In such process, one thread will be assigned to open MS word and another thread will be required to write. Now, suppose if we want to edit something then another thread will be required to do the editing task and so on.
The following diagram helps us understand how multiple threads exist in memory −
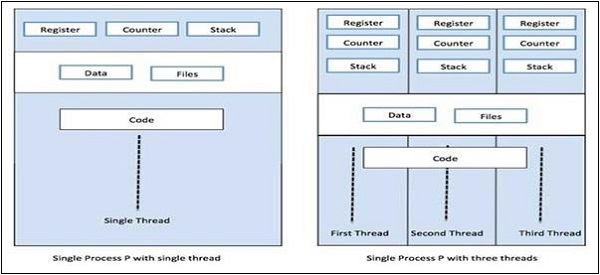
We can see in the above diagram that more than one thread can exist within one process where every thread contains its own register set and local variables. Other than that, all the threads in a process share global variables.
Pros of Multithreading
Let us now see a few advantages of multithreading. The advantages are as follows −
Speed of communication − Multithreading improves the speed of computation because each core or processor handles separate threads concurrently.
Program remains responsive − It allows a program to remain responsive because one thread waits for the input and another runs a GUI at the same time.
Access to global variables − In multithreading, all the threads of a particular process can access the global variables and if there is any change in global variable then it is visible to other threads too.
Utilization of resources − Running of several threads in each program makes better use of CPU and the idle time of CPU becomes less.
Sharing of data − There is no requirement of extra space for each thread because threads within a program can share same data.
Cons of Multithreading
Let us now see a few disadvantages of multithreading. The disadvantages are as follows −
Not suitable for single processor system − Multithreading finds it difficult to achieve performance in terms of speed of computation on single processor system as compared with the performance on multi-processor system.
Issue of security − As we know that all the threads within a program share same data, hence there is always an issue of security because any unknown thread can change the data.
Increase in complexity − Multithreading can increase the complexity of the program and debugging becomes difficult.
Lead to deadlock state − Multithreading can lead the program to potential risk of attaining the deadlock state.
Synchronization required − Synchronization is required to avoid mutual exclusion. This leads to more memory and CPU utilization.
In this chapter, we will learn how to implement threads in Python.
Python Module for Thread Implementation
Python threads are sometimes called lightweight processes because threads occupy much less memory than processes. Threads allow performing multiple tasks at once. In Python, we have the following two modules that implement threads in a program −
<_thread>module
<threading>module
The main difference between these two modules is that <_thread> module treats a thread as a function whereas, the <threading> module treats every thread as an object and implements it in an object oriented way. Moreover, the <_thread>module is effective in low level threading and has fewer capabilities than the <threading> module.
<_thread> module
In the earlier version of Python, we had the <thread> module but it has been considered as "deprecated" for quite a long time. Users have been encouraged to use the <threading> module instead. Therefore, in Python 3 the module "thread" is not available anymore. It has been renamed to "<_thread>" for backwards incompatibilities in Python3.
To generate new thread with the help of the <_thread> module, we need to call the start_new_thread method of it. The working of this method can be understood with the help of following syntax −
_thread.start_new_thread ( function, args[, kwargs] )Here −
args is a tuple of arguments
kwargs is an optional dictionary of keyword arguments
If we want to call function without passing an argument then we need to use an empty tuple of arguments in args.
This method call returns immediately, the child thread starts, and calls function with the passed list, if any, of args. The thread terminates as and when the function returns.
Example
Following is an example for generating new thread by using the <_thread> module. We are using the start_new_thread() method here.
import _thread
import time
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: unable to start thread")
while 1:
passOutput
The following output will help us understand the generation of new threads bwith the help of the <_thread> module.
Thread-1: Mon Apr 23 10:03:33 2018
Thread-2: Mon Apr 23 10:03:35 2018
Thread-1: Mon Apr 23 10:03:35 2018
Thread-1: Mon Apr 23 10:03:37 2018
Thread-2: Mon Apr 23 10:03:39 2018
Thread-1: Mon Apr 23 10:03:39 2018
Thread-1: Mon Apr 23 10:03:41 2018
Thread-2: Mon Apr 23 10:03:43 2018
Thread-2: Mon Apr 23 10:03:47 2018
Thread-2: Mon Apr 23 10:03:51 2018<threading> module
The <threading> module implements in an object oriented way and treats every thread as an object. Therefore, it provides much more powerful, high-level support for threads than the <_thread> module. This module is included with Python 2.4.
Additional methods in the <threading> module
The <threading> module comprises all the methods of the <_thread> module but it provides additional methods as well. The additional methods are as follows −
threading.activeCount() − This method returns the number of thread objects that are active
threading.currentThread() − This method returns the number of thread objects in the caller's thread control.
threading.enumerate() − This method returns a list of all thread objects that are currently active.
run() − The run() method is the entry point for a thread.
start() − The start() method starts a thread by calling the run method.
join([time]) − The join() waits for threads to terminate.
isAlive() − The isAlive() method checks whether a thread is still executing.
getName() − The getName() method returns the name of a thread.
setName() − The setName() method sets the name of a thread.
For implementing threading, the <threading> module has the Thread class which provides the following methods −
How to create threads using the <threading> module?
In this section, we will learn how to create threads using the <threading> module. Follow these steps to create a new thread using the <threading> module −
Step 1 − In this step, we need to define a new subclass of the Thread class.
Step 2 − Then for adding additional arguments, we need to override the __init__(self [,args]) method.
Step 3 − In this step, we need to override the run(self [,args]) method to implement what the thread should do when started.
Now, after creating the new Thread subclass, we can create an instance of it and then start a new thread by invoking the start(), which in turn calls the run() method.
Example
Consider this example to learn how to generate a new thread by using the <threading> module.
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Starting " + self.name)
print_time(self.name, self.counter, 5)
print ("Exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("Exiting Main Thread")
Starting Thread-1
Starting Thread-2Output
Now, consider the following output −
Thread-1: Mon Apr 23 10:52:09 2018
Thread-1: Mon Apr 23 10:52:10 2018
Thread-2: Mon Apr 23 10:52:10 2018
Thread-1: Mon Apr 23 10:52:11 2018
Thread-1: Mon Apr 23 10:52:12 2018
Thread-2: Mon Apr 23 10:52:12 2018
Thread-1: Mon Apr 23 10:52:13 2018
Exiting Thread-1
Thread-2: Mon Apr 23 10:52:14 2018
Thread-2: Mon Apr 23 10:52:16 2018
Thread-2: Mon Apr 23 10:52:18 2018
Exiting Thread-2
Exiting Main ThreadPython Program for Various Thread States
There are five thread states - new, runnable, running, waiting and dead. Among these five Of these five, we will majorly focus on three states - running, waiting and dead. A thread gets its resources in the running state, waits for the resources in the waiting state; the final release of the resource, if executing and acquired is in the dead state.
The following Python program with the help of start(), sleep() and join() methods will show how a thread entered in running, waiting and dead state respectively.
Step 1 − Import the necessary modules, <threading> and <time>
import threading
import timeStep 2 − Define a function, which will be called while creating a thread.
def thread_states():
print("Thread entered in running state")Step 3 − We are using the sleep() method of time module to make our thread waiting for say 2 seconds.
time.sleep(2)Step 4 − Now, we are creating a thread named T1, which takes the argument of the function defined above.
T1 = threading.Thread(target=thread_states)Step 5 − Now, with the help of the start() function we can start our thread. It will produce the message, which has been set by us while defining the function.
T1.start()
Thread entered in running stateStep 6 − Now, at last we can kill the thread with the join() method after it finishes its execution.
T1.join()Starting a thread in Python
In python, we can start a new thread by different ways but the easiest one among them is to define it as a single function. After defining the function, we can pass this as the target for a new threading.Thread object and so on. Execute the following Python code to understand how the function works −
import threading
import time
import random
def Thread_execution(i):
print("Execution of Thread {} started\n".format(i))
sleepTime = random.randint(1,4)
time.sleep(sleepTime)
print("Execution of Thread {} finished".format(i))
for i in range(4):
thread = threading.Thread(target=Thread_execution, args=(i,))
thread.start()
print("Active Threads:" , threading.enumerate())Salida
Execution of Thread 0 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>]
Execution of Thread 1 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>]
Execution of Thread 2 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>]
Execution of Thread 3 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>,
<Thread(Thread-3579, started 4520)>]
Execution of Thread 0 finished
Execution of Thread 1 finished
Execution of Thread 2 finished
Execution of Thread 3 finishedHilos de demonio en Python
Antes de implementar los subprocesos del demonio en Python, necesitamos conocer los subprocesos del demonio y su uso. En términos de computación, el daemon es un proceso en segundo plano que maneja las solicitudes de varios servicios como el envío de datos, transferencias de archivos, etc. Estaría inactivo si ya no se requiere. La misma tarea se puede realizar también con la ayuda de subprocesos que no son demonios. Sin embargo, en este caso, el subproceso principal debe realizar un seguimiento de los subprocesos que no son demonios manualmente. Por otro lado, si estamos usando subprocesos de demonio, el subproceso principal puede olvidarse por completo de esto y se eliminará cuando el subproceso principal salga. Otro punto importante sobre los subprocesos de demonios es que podemos optar por usarlos solo para tareas no esenciales que no nos afectarían si no se completan o se matan en el medio. A continuación se muestra la implementación de subprocesos de demonio en Python:
import threading
import time
def nondaemonThread():
print("starting my thread")
time.sleep(8)
print("ending my thread")
def daemonThread():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonThread = threading.Thread(target = nondaemonThread)
daemonThread = threading.Thread(target = daemonThread)
daemonThread.setDaemon(True)
daemonThread.start()
nondaemonThread.start()En el código anterior, hay dos funciones a saber >nondaemonThread() y >daemonThread(). La primera función imprime su estado y duerme después de 8 segundos, mientras que la función deamonThread () imprime Hola después de cada 2 segundos de forma indefinida. Podemos entender la diferencia entre subprocesos no demonio y demonio con la ayuda de la siguiente salida:
Hello
starting my thread
Hello
Hello
Hello
Hello
ending my thread
Hello
Hello
Hello
Hello
HelloLa sincronización de subprocesos puede definirse como un método con la ayuda del cual podemos estar seguros de que dos o más subprocesos simultáneos no acceden simultáneamente al segmento de programa conocido como sección crítica. Por otro lado, como sabemos esa sección crítica es la parte del programa donde se accede al recurso compartido. Por lo tanto, podemos decir que la sincronización es el proceso de asegurarse de que dos o más subprocesos no interactúen entre sí al acceder a los recursos al mismo tiempo. El siguiente diagrama muestra que cuatro subprocesos intentan acceder a la sección crítica de un programa al mismo tiempo.
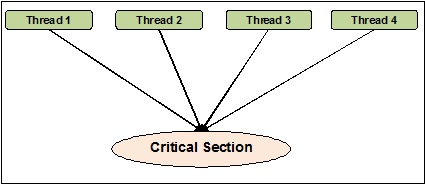
Para hacerlo más claro, suponga que dos o más subprocesos intentan agregar el objeto en la lista al mismo tiempo. Este acto no puede conducir a un final exitoso porque eliminará uno o todos los objetos o corromperá por completo el estado de la lista. Aquí, el papel de la sincronización es que solo un hilo a la vez puede acceder a la lista.
Problemas en la sincronización de subprocesos
Podríamos encontrar problemas al implementar programación concurrente o aplicar primitivas de sincronización. En esta sección, discutiremos dos temas principales. Los problemas son:
- Deadlock
- Condición de carrera
Condición de carrera
Este es uno de los principales problemas de la programación concurrente. El acceso simultáneo a los recursos compartidos puede provocar una condición de carrera. Una condición de carrera se puede definir como la ocurrencia de una condición cuando dos o más subprocesos pueden acceder a datos compartidos y luego intentar cambiar su valor al mismo tiempo. Debido a esto, los valores de las variables pueden ser impredecibles y variar según los tiempos de los cambios de contexto de los procesos.
Ejemplo
Considere este ejemplo para comprender el concepto de condición de carrera:
Step 1 - En este paso, necesitamos importar el módulo de subprocesamiento -
import threadingStep 2 - Ahora, defina una variable global, digamos x, junto con su valor como 0 -
x = 0Step 3 - Ahora, necesitamos definir el increment_global() función, que hará el incremento en 1 en esta función global x -
def increment_global():
global x
x += 1Step 4 - En este paso, definiremos el taskofThread()función, que llamará a la función increment_global () durante un número específico de veces; para nuestro ejemplo es 50000 veces -
def taskofThread():
for _ in range(50000):
increment_global()Step 5- Ahora, defina la función main () en la que se crean los subprocesos t1 y t2. Ambos se iniciarán con la ayuda de la función start () y esperarán hasta que terminen sus trabajos con la ayuda de la función join ().
def main():
global x
x = 0
t1 = threading.Thread(target= taskofThread)
t2 = threading.Thread(target= taskofThread)
t1.start()
t2.start()
t1.join()
t2.join()Step 6- Ahora, tenemos que dar el rango de cuántas iteraciones queremos llamar a la función main (). Aquí, lo llamamos 5 veces.
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))En el resultado que se muestra a continuación, podemos ver el efecto de la condición de carrera como el valor de x después de cada iteración se espera que sea 100000. Sin embargo, hay mucha variación en el valor. Esto se debe al acceso concurrente de subprocesos a la variable global compartida x.
Salida
x = 100000 after Iteration 0
x = 54034 after Iteration 1
x = 80230 after Iteration 2
x = 93602 after Iteration 3
x = 93289 after Iteration 4Lidiando con la condición de carrera usando bloqueos
Como hemos visto el efecto de la condición de carrera en el programa anterior, necesitamos una herramienta de sincronización que pueda manejar la condición de carrera entre varios subprocesos. En Python, el<threading>El módulo proporciona la clase Lock para hacer frente a la condición de carrera. Además, elLockLa clase proporciona diferentes métodos con la ayuda de los cuales podemos manejar la condición de carrera entre múltiples subprocesos. Los métodos se describen a continuación:
adquirir () método
Este método se utiliza para adquirir, es decir, bloquear un candado. Un bloqueo puede ser bloqueante o no bloqueante según el siguiente valor verdadero o falso:
With value set to True - Si se invoca el método manage () con True, que es el argumento predeterminado, la ejecución del hilo se bloquea hasta que se desbloquea el bloqueo.
With value set to False - Si se invoca el método generate () con False, que no es el argumento predeterminado, la ejecución del hilo no se bloquea hasta que se establece en true, es decir, hasta que se bloquea.
método release ()
Este método se utiliza para liberar un candado. A continuación se presentan algunas tareas importantes relacionadas con este método:
Si un candado está bloqueado, entonces el release()El método lo desbloquearía. Su trabajo es permitir que continúe exactamente un hilo si hay más de un hilo bloqueado y esperando a que el bloqueo se desbloquee.
Levantará un ThreadError si el bloqueo ya está desbloqueado.
Ahora, podemos reescribir el programa anterior con la clase de bloqueo y sus métodos para evitar la condición de carrera. Necesitamos definir el método taskofThread () con el argumento de bloqueo y luego necesitamos usar los métodos de adquisición () y liberación () para bloquear y no bloquear bloqueos para evitar la condición de carrera.
Ejemplo
A continuación se muestra un ejemplo de un programa de Python para comprender el concepto de bloqueos para lidiar con la condición de carrera:
import threading
x = 0
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target = taskofThread, args = (lock,))
t2 = threading.Thread(target = taskofThread, args = (lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))El siguiente resultado muestra que se ignora el efecto de la condición de carrera; ya que el valor de x, después de cada y cada iteración, es ahora 100000, lo que corresponde a la expectativa de este programa.
Salida
x = 100000 after Iteration 0
x = 100000 after Iteration 1
x = 100000 after Iteration 2
x = 100000 after Iteration 3
x = 100000 after Iteration 4Deadlocks: el problema de los filósofos gastronómicos
El interbloqueo es un problema problemático que uno puede enfrentar al diseñar los sistemas concurrentes. Podemos ilustrar este problema con la ayuda del problema del filósofo comedor de la siguiente manera:
Edsger Dijkstra introdujo originalmente el problema del filósofo comedor, una de las ilustraciones famosas de uno de los mayores problemas del sistema concurrente llamado punto muerto.
En este problema, hay cinco filósofos famosos sentados en una mesa redonda comiendo algo de sus cuencos. Hay cinco tenedores que pueden usar los cinco filósofos para comer su comida. Sin embargo, los filósofos deciden usar dos tenedores al mismo tiempo para comer su comida.
Ahora bien, hay dos condiciones principales para los filósofos. Primero, cada uno de los filósofos puede estar comiendo o en estado de pensamiento y segundo, primero deben obtener ambas horquillas, es decir, izquierda y derecha. El problema surge cuando cada uno de los cinco filósofos logra elegir la bifurcación izquierda al mismo tiempo. Ahora todos están esperando a que el tenedor correcto esté libre, pero nunca abandonarán su tenedor hasta que hayan comido su comida y el tenedor correcto nunca esté disponible. Por lo tanto, habría un estado de punto muerto en la mesa de la cena.
Interbloqueo en sistema concurrente
Ahora, si vemos, el mismo problema también puede surgir en nuestros sistemas concurrentes. Las bifurcaciones en el ejemplo anterior serían los recursos del sistema y cada filósofo puede representar el proceso, que compite por obtener los recursos.
Solución con el programa Python
La solución de este problema se puede encontrar dividiendo a los filósofos en dos tipos: greedy philosophers y generous philosophers. Principalmente, un filósofo codicioso intentará tomar el tenedor izquierdo y esperará hasta que esté allí. Luego esperará a que el tenedor correcto esté allí, lo recogerá, lo comerá y luego lo dejará. Por otro lado, un filósofo generoso intentará coger la bifurcación de la izquierda y si no está ahí, esperará y volverá a intentarlo pasado un tiempo. Si obtienen la bifurcación de la izquierda, intentarán obtener la correcta. Si también obtienen el tenedor correcto, comerán y soltarán ambos tenedores. Sin embargo, si no consiguen la bifurcación derecha, soltarán la bifurcación izquierda.
Ejemplo
El siguiente programa de Python nos ayudará a encontrar una solución al problema del filósofo gastronómico:
import threading
import random
import time
class DiningPhilosopher(threading.Thread):
running = True
def __init__(self, xname, Leftfork, Rightfork):
threading.Thread.__init__(self)
self.name = xname
self.Leftfork = Leftfork
self.Rightfork = Rightfork
def run(self):
while(self.running):
time.sleep( random.uniform(3,13))
print ('%s is hungry.' % self.name)
self.dine()
def dine(self):
fork1, fork2 = self.Leftfork, self.Rightfork
while self.running:
fork1.acquire(True)
locked = fork2.acquire(False)
if locked: break
fork1.release()
print ('%s swaps forks' % self.name)
fork1, fork2 = fork2, fork1
else:
return
self.dining()
fork2.release()
fork1.release()
def dining(self):
print ('%s starts eating '% self.name)
time.sleep(random.uniform(1,10))
print ('%s finishes eating and now thinking.' % self.name)
def Dining_Philosophers():
forks = [threading.Lock() for n in range(5)]
philosopherNames = ('1st','2nd','3rd','4th', '5th')
philosophers= [DiningPhilosopher(philosopherNames[i], forks[i%5], forks[(i+1)%5]) \
for i in range(5)]
random.seed()
DiningPhilosopher.running = True
for p in philosophers: p.start()
time.sleep(30)
DiningPhilosopher.running = False
print (" It is finishing.")
Dining_Philosophers()El programa anterior utiliza el concepto de filósofos codiciosos y generosos. El programa también ha utilizado elacquire() y release() métodos del Lock clase de la <threading>módulo. Podemos ver la solución en el siguiente resultado:
Salida
4th is hungry.
4th starts eating
1st is hungry.
1st starts eating
2nd is hungry.
5th is hungry.
3rd is hungry.
1st finishes eating and now thinking.3rd swaps forks
2nd starts eating
4th finishes eating and now thinking.
3rd swaps forks5th starts eating
5th finishes eating and now thinking.
4th is hungry.
4th starts eating
2nd finishes eating and now thinking.
3rd swaps forks
1st is hungry.
1st starts eating
4th finishes eating and now thinking.
3rd starts eating
5th is hungry.
5th swaps forks
1st finishes eating and now thinking.
5th starts eating
2nd is hungry.
2nd swaps forks
4th is hungry.
5th finishes eating and now thinking.
3rd finishes eating and now thinking.
2nd starts eating 4th starts eating
It is finishing.En la vida real, si un equipo de personas está trabajando en una tarea común, entonces debería haber comunicación entre ellos para terminar la tarea correctamente. La misma analogía es aplicable también a los hilos. En programación, para reducir el tiempo ideal del procesador, creamos múltiples subprocesos y asignamos diferentes subtareas a cada subproceso. Por lo tanto, debe haber una facilidad de comunicación y deben interactuar entre sí para terminar el trabajo de manera sincronizada.
Considere los siguientes puntos importantes relacionados con la intercomunicación de subprocesos:
No performance gain - Si no podemos lograr una comunicación adecuada entre subprocesos y procesos, las ganancias de rendimiento de la concurrencia y el paralelismo no sirven de nada.
Accomplish task properly - Sin un mecanismo de intercomunicación adecuado entre subprocesos, la tarea asignada no se puede completar correctamente.
More efficient than inter-process communication - La comunicación entre subprocesos es más eficiente y fácil de usar que la comunicación entre procesos porque todos los subprocesos dentro de un proceso comparten el mismo espacio de direcciones y no necesitan usar memoria compartida.
Estructuras de datos de Python para una comunicación segura para subprocesos
El código multiproceso presenta el problema de pasar información de un hilo a otro. Las primitivas de comunicación estándar no resuelven este problema. Por lo tanto, necesitamos implementar nuestro propio objeto compuesto para compartir objetos entre subprocesos para que la comunicación sea segura para subprocesos. A continuación se muestran algunas estructuras de datos, que brindan una comunicación segura para subprocesos después de realizar algunos cambios en ellas:
Conjuntos
Para usar la estructura de datos de conjunto de una manera segura para subprocesos, necesitamos extender la clase de conjunto para implementar nuestro propio mecanismo de bloqueo.
Ejemplo
Aquí hay un ejemplo de Python para extender la clase:
class extend_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(extend_class, self).__init__(*args, **kwargs)
def add(self, elem):
self._lock.acquire()
try:
super(extend_class, self).add(elem)
finally:
self._lock.release()
def delete(self, elem):
self._lock.acquire()
try:
super(extend_class, self).delete(elem)
finally:
self._lock.release()En el ejemplo anterior, un objeto de clase llamado extend_class se ha definido que se hereda aún más de Python set class. Se crea un objeto de bloqueo dentro del constructor de esta clase. Ahora, hay dos funciones:add() y delete(). Estas funciones están definidas y son seguras para subprocesos. Ambos confían en elsuper funcionalidad de clase con una excepción clave.
Decorador
Este es otro método clave para la comunicación segura con subprocesos es el uso de decoradores.
Ejemplo
Considere un ejemplo de Python que muestra cómo usar decoradores & mminus;
def lock_decorator(method):
def new_deco_method(self, *args, **kwargs):
with self._lock:
return method(self, *args, **kwargs)
return new_deco_method
class Decorator_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(Decorator_class, self).__init__(*args, **kwargs)
@lock_decorator
def add(self, *args, **kwargs):
return super(Decorator_class, self).add(elem)
@lock_decorator
def delete(self, *args, **kwargs):
return super(Decorator_class, self).delete(elem)En el ejemplo anterior, se ha definido un método decorador llamado lock_decorator que se hereda de la clase de método Python. Luego, se crea un objeto de bloqueo dentro del constructor de esta clase. Ahora, hay dos funciones: agregar () y eliminar (). Estas funciones están definidas y son seguras para subprocesos. Ambos dependen de la funcionalidad de clase superior con una excepción clave.
Liza
La estructura de datos de la lista es segura para subprocesos, estructura rápida y fácil para el almacenamiento temporal en memoria. En Cpython, el GIL protege contra el acceso concurrente a ellos. Como nos dimos cuenta de que las listas son seguras para subprocesos, pero ¿qué pasa con los datos que contienen? En realidad, los datos de la lista no están protegidos. Por ejemplo,L.append(x)no es garantía de devolver el resultado esperado si otro hilo intenta hacer lo mismo. Esto se debe a que, aunqueappend() es una operación atómica y segura para subprocesos, pero el otro subproceso está tratando de modificar los datos de la lista de manera concurrente, por lo que podemos ver los efectos secundarios de las condiciones de carrera en la salida.
Para resolver este tipo de problema y modificar de forma segura los datos, debemos implementar un mecanismo de bloqueo adecuado, que además garantice que varios subprocesos no puedan encontrarse potencialmente en condiciones de carrera. Para implementar el mecanismo de bloqueo adecuado, podemos extender la clase como hicimos en los ejemplos anteriores.
Algunas otras operaciones atómicas en las listas son las siguientes:
L.append(x)
L1.extend(L2)
x = L[i]
x = L.pop()
L1[i:j] = L2
L.sort()
x = y
x.field = y
D[x] = y
D1.update(D2)
D.keys()Aquí -
- L, L1, L2 son listas
- D, D1, D2 son dictados
- x, y son objetos
- yo, j son ints
Colas
Si los datos de la lista no están protegidos, es posible que tengamos que enfrentar las consecuencias. Es posible que obtengamos o eliminemos datos incorrectos de las condiciones de la carrera. Por eso se recomienda utilizar la estructura de datos de cola. Un ejemplo real de cola puede ser una carretera de un solo carril, donde el vehículo entra primero y sale primero. Se pueden ver más ejemplos del mundo real de las colas en las taquillas y las paradas de autobús.
Las colas son, por defecto, una estructura de datos segura para subprocesos y no debemos preocuparnos por implementar un mecanismo de bloqueo complejo. Python nos proporciona la
Tipos de colas
En esta sección, ganaremos sobre los diferentes tipos de colas. Python proporciona tres opciones de colas para usar desde el<queue> módulo -
- Colas normales (FIFO, primero en entrar, primero en salir)
- LIFO, último en entrar, primero en salir
- Priority
Aprenderemos sobre las diferentes colas en las secciones siguientes.
Colas normales (FIFO, primero en entrar, primero en salir)
Son las implementaciones de cola más utilizadas que ofrece Python. En este mecanismo de cola, quienquiera que llegue primero, recibirá el servicio primero. FIFO también se denomina colas normales. Las colas FIFO se pueden representar de la siguiente manera:

Implementación de Python de la cola FIFO
En Python, la cola FIFO se puede implementar con un solo hilo o con varios hilos.
Cola FIFO con un solo hilo
Para implementar la cola FIFO con un solo hilo, el Queueclass implementará un contenedor básico primero en entrar, primero en salir. Los elementos se agregarán a un "final" de la secuencia usandoput(), y se quita del otro extremo usando get().
Ejemplo
A continuación se muestra un programa de Python para la implementación de la cola FIFO con un solo hilo:
import queue
q = queue.Queue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end = " ")Salida
item-0 item-1 item-2 item-3 item-4 item-5 item-6 item-7El resultado muestra que el programa anterior usa un solo hilo para ilustrar que los elementos se eliminan de la cola en el mismo orden en que se insertan.
Cola FIFO con varios subprocesos
Para implementar FIFO con múltiples subprocesos, necesitamos definir la función myqueue (), que se extiende desde el módulo de cola. El funcionamiento de los métodos get () y put () es el mismo que se discutió anteriormente al implementar la cola FIFO con un solo hilo. Luego, para que sea multiproceso, necesitamos declarar e instanciar los subprocesos. Estos subprocesos consumirán la cola en forma FIFO.
Ejemplo
A continuación se muestra un programa de Python para la implementación de la cola FIFO con múltiples subprocesos
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.Queue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Salida
<Thread(Thread-3654, started 5044)> removed 0 from the queue
<Thread(Thread-3655, started 3144)> removed 1 from the queue
<Thread(Thread-3656, started 6996)> removed 2 from the queue
<Thread(Thread-3657, started 2672)> removed 3 from the queue
<Thread(Thread-3654, started 5044)> removed 4 from the queueLIFO, último en cola, primero en salir
Esta cola utiliza una analogía totalmente opuesta a las colas FIFO (primero en entrar, primero en salir). En este mecanismo de cola, el que llegue en último lugar obtendrá el servicio primero. Esto es similar a implementar la estructura de datos de la pila. Las colas LIFO resultan útiles al implementar la búsqueda en profundidad como algoritmos de inteligencia artificial.
Implementación de Python de la cola LIFO
En Python, la cola LIFO se puede implementar con un solo hilo o con varios hilos.
Cola LIFO con un solo hilo
Para implementar la cola LIFO con un solo hilo, el Queue La clase implementará un contenedor básico de último en entrar, primero en salir utilizando la estructura Queue.LifoQueue. Ahora, al llamarput(), los elementos se agregan en la cabeza del contenedor y se quitan de la cabeza también al usar get().
Ejemplo
A continuación se muestra un programa de Python para la implementación de la cola LIFO con un solo hilo:
import queue
q = queue.LifoQueue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end=" ")
Output:
item-7 item-6 item-5 item-4 item-3 item-2 item-1 item-0El resultado muestra que el programa anterior usa un solo hilo para ilustrar que los elementos se eliminan de la cola en el orden opuesto en el que se insertan.
Cola LIFO con varios subprocesos
La implementación es similar a la que hemos hecho con la implementación de colas FIFO con múltiples subprocesos. La única diferencia es que necesitamos usar elQueue clase que implementará un contenedor básico de último en entrar, primero en salir usando la estructura Queue.LifoQueue.
Ejemplo
A continuación se muestra un programa de Python para la implementación de la cola LIFO con múltiples subprocesos:
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.LifoQueue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Salida
<Thread(Thread-3882, started 4928)> removed 4 from the queue
<Thread(Thread-3883, started 4364)> removed 3 from the queue
<Thread(Thread-3884, started 6908)> removed 2 from the queue
<Thread(Thread-3885, started 3584)> removed 1 from the queue
<Thread(Thread-3882, started 4928)> removed 0 from the queueCola de prioridad
En las colas FIFO y LIFO, el orden de los elementos está relacionado con el orden de inserción. Sin embargo, hay muchos casos en los que la prioridad es más importante que el orden de inserción. Consideremos un ejemplo del mundo real. Suponga que la seguridad en el aeropuerto está revisando a personas de diferentes categorías. Las personas del VVIP, el personal de la aerolínea, el oficial de aduanas, las categorías pueden ser verificadas por prioridad en lugar de ser verificadas sobre la base de la llegada, como ocurre con los plebeyos.
Otro aspecto importante que debe tenerse en cuenta para la cola de prioridad es cómo desarrollar un programador de tareas. Un diseño común es atender la mayor parte de las tareas de los agentes en función de la prioridad en la cola. Esta estructura de datos se puede utilizar para recoger los elementos de la cola según su valor de prioridad.
Implementación de Python de Priority Queue
En Python, la cola de prioridad se puede implementar con un solo subproceso, así como con varios subprocesos.
Cola de prioridad con un solo hilo
Para implementar la cola de prioridad con un solo hilo, el Queue la clase implementará una tarea en el contenedor de prioridad usando la estructura Queue.PriorityQueue. Ahora, al llamarput(), los elementos se agregan con un valor donde el valor más bajo tendrá la prioridad más alta y, por lo tanto, se recuperará primero usando get().
Ejemplo
Considere el siguiente programa de Python para la implementación de la cola de prioridad con un solo hilo:
import queue as Q
p_queue = Q.PriorityQueue()
p_queue.put((2, 'Urgent'))
p_queue.put((1, 'Most Urgent'))
p_queue.put((10, 'Nothing important'))
prio_queue.put((5, 'Important'))
while not p_queue.empty():
item = p_queue.get()
print('%s - %s' % item)Salida
1 – Most Urgent
2 - Urgent
5 - Important
10 – Nothing importantEn el resultado anterior, podemos ver que la cola ha almacenado los elementos en función de la prioridad; menos valor tiene alta prioridad.
Cola de prioridad con subprocesos múltiples
La implementación es similar a la implementación de las colas FIFO y LIFO con múltiples subprocesos. La única diferencia es que necesitamos usar elQueue clase para inicializar la prioridad usando la estructura Queue.PriorityQueue. Otra diferencia es la forma en que se generaría la cola. En el ejemplo que se muestra a continuación, se generará con dos conjuntos de datos idénticos.
Ejemplo
El siguiente programa de Python ayuda en la implementación de la cola de prioridad con múltiples subprocesos:
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(1)
q = queue.PriorityQueue()
for i in range(5):
q.put(i,1)
for i in range(5):
q.put(i,1)
threads = []
for i in range(2):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Salida
<Thread(Thread-4939, started 2420)> removed 0 from the queue
<Thread(Thread-4940, started 3284)> removed 0 from the queue
<Thread(Thread-4939, started 2420)> removed 1 from the queue
<Thread(Thread-4940, started 3284)> removed 1 from the queue
<Thread(Thread-4939, started 2420)> removed 2 from the queue
<Thread(Thread-4940, started 3284)> removed 2 from the queue
<Thread(Thread-4939, started 2420)> removed 3 from the queue
<Thread(Thread-4940, started 3284)> removed 3 from the queue
<Thread(Thread-4939, started 2420)> removed 4 from the queue
<Thread(Thread-4940, started 3284)> removed 4 from the queueEn este capítulo, aprenderemos sobre la prueba de aplicaciones de subprocesos. También aprenderemos la importancia de las pruebas.
¿Por qué probar?
Antes de sumergirnos en la discusión sobre la importancia de las pruebas, necesitamos saber qué son las pruebas. En términos generales, las pruebas son una técnica para averiguar qué tan bien está funcionando algo. Por otro lado, específicamente si hablamos de programas de computadora o software, entonces probar es la técnica de acceder a la funcionalidad de un programa de software.
En esta sección, discutiremos la importancia de las pruebas de software. En el desarrollo de software, debe haber una doble verificación antes de entregar el software al cliente. Por eso es muy importante probar el software por parte de un equipo de pruebas experimentado. Considere los siguientes puntos para comprender la importancia de las pruebas de software:
Mejora de la calidad del software
Ciertamente, ninguna empresa quiere ofrecer software de baja calidad y ningún cliente quiere comprar software de baja calidad. Las pruebas mejoran la calidad del software al encontrar y corregir los errores que contiene.
Satisfacción de clientes
La parte más importante de cualquier negocio es la satisfacción de sus clientes. Al proporcionar software libre de errores y de buena calidad, las empresas pueden lograr la satisfacción del cliente.
Reducir el impacto de las nuevas funciones
Supongamos que hemos creado un sistema de software de 10000 líneas y necesitamos agregar una nueva característica, entonces el equipo de desarrollo estaría preocupado por el impacto de esta nueva característica en todo el software. Aquí, también, las pruebas juegan un papel vital porque si el equipo de pruebas ha realizado un buen conjunto de pruebas, puede salvarnos de posibles rupturas catastróficas.
Experiencia de usuario
Otra parte más importante de cualquier negocio es la experiencia de los usuarios de ese producto. Solo las pruebas pueden garantizar que el usuario final encuentre simple y fácil de usar el producto.
Reducir los gastos
Las pruebas pueden reducir el costo total del software al encontrar y corregir los errores en la fase de prueba de su desarrollo en lugar de corregirlo después de la entrega. Si hay un error importante después de la entrega del software, aumentaría su costo tangible, digamos en términos de gastos y costos intangibles, digamos en términos de insatisfacción del cliente, reputación negativa de la empresa, etc.
¿Qué probar?
Siempre se recomienda tener un conocimiento adecuado de lo que se va a probar. En esta sección, primero entenderemos cuál es el motivo principal del probador al probar cualquier software. Debe evitarse la cobertura de código, es decir, cuántas líneas de código llega a nuestro conjunto de pruebas, durante las pruebas. Se debe a que, durante las pruebas, centrarse solo en la cantidad de líneas de códigos no agrega valor real a nuestro sistema. Es posible que queden algunos errores, que se reflejan posteriormente en una etapa posterior incluso después de la implementación.
Considere los siguientes puntos importantes relacionados con qué probar:
Necesitamos enfocarnos en probar la funcionalidad del código en lugar de la cobertura del código.
Necesitamos probar las partes más importantes del código primero y luego avanzar hacia las partes menos importantes del código. Definitivamente ahorrará tiempo.
El probador debe tener múltiples pruebas diferentes que puedan llevar el software al límite.
Enfoques para probar programas de software concurrentes
Debido a la capacidad de utilizar la verdadera capacidad de la arquitectura de múltiples núcleos, los sistemas de software concurrentes están reemplazando a los sistemas secuenciales. En los últimos tiempos, los programas de sistema concurrentes se están utilizando en todo, desde teléfonos móviles hasta lavadoras, desde automóviles hasta aviones, etc. Debemos tener más cuidado al probar los programas de software concurrentes porque si hemos agregado varios subprocesos a la aplicación de un solo ya es un error, entonces terminaríamos con varios errores.
Las técnicas de prueba para programas de software concurrentes se centran ampliamente en seleccionar el entrelazado que exponga patrones potencialmente dañinos como condiciones de carrera, puntos muertos y violación de la atomicidad. A continuación se presentan dos enfoques para probar programas de software concurrentes:
Exploración sistemática
Este enfoque tiene como objetivo explorar el espacio de las intercalaciones de la manera más amplia posible. Tales enfoques pueden adoptar una técnica de fuerza bruta y otros adoptan una técnica de reducción de orden parcial o una técnica heurística para explorar el espacio de entrelazamientos.
Impulsado por la propiedad
Los enfoques basados en propiedades se basan en la observación de que es más probable que ocurran fallas de simultaneidad en intercalaciones que exponen propiedades específicas, como un patrón de acceso a la memoria sospechoso. Los diferentes enfoques basados en propiedades apuntan a diferentes fallas como las condiciones de carrera, los puntos muertos y la violación de la atomicidad, que depende además de una u otras propiedades específicas.
Estrategias de prueba
La estrategia de prueba también se conoce como enfoque de prueba. La estrategia define cómo se realizarían las pruebas. El enfoque de prueba tiene dos técnicas:
Proactivo
Un enfoque en el que el proceso de diseño de prueba se inicia lo antes posible para encontrar y corregir los defectos antes de que se cree la compilación.
Reactivo
Un enfoque en el que la prueba no comienza hasta que se completa el proceso de desarrollo.
Antes de aplicar cualquier estrategia o enfoque de prueba en un programa Python, debemos tener una idea básica sobre el tipo de errores que puede tener un programa de software. Los errores son los siguientes:
Errores sintácticos
Durante el desarrollo del programa, puede haber muchos errores pequeños. Los errores se deben principalmente a errores tipográficos. Por ejemplo, dos puntos faltantes o la ortografía incorrecta de una palabra clave, etc. Estos errores se deben a errores en la sintaxis del programa y no en la lógica. Por tanto, estos errores se denominan errores sintácticos.
Errores semánticos
Los errores semánticos también se denominan errores lógicos. Si hay un error lógico o semántico en el programa de software, la declaración se compilará y se ejecutará correctamente, pero no dará el resultado deseado porque la lógica no es correcta.
Examen de la unidad
Esta es una de las estrategias de prueba más utilizadas para probar programas de Python. Esta estrategia se utiliza para probar unidades o componentes del código. Por unidades o componentes, nos referimos a clases o funciones del código. La prueba unitaria simplifica la prueba de grandes sistemas de programación al probar unidades “pequeñas”. Con la ayuda del concepto anterior, las pruebas unitarias pueden definirse como un método en el que se prueban unidades individuales de código fuente para determinar si devuelven el resultado deseado.
En las secciones siguientes, aprenderemos sobre los diferentes módulos de Python para pruebas unitarias.
módulo unittest
El primer módulo para pruebas unitarias es el módulo unittest. Está inspirado en JUnit y de forma predeterminada se incluye en Python3.6. Admite la automatización de pruebas, el intercambio de códigos de configuración y cierre para pruebas, la agregación de pruebas en colecciones y la independencia de las pruebas del marco de informes.
A continuación se presentan algunos conceptos importantes respaldados por el módulo unittest
Accesorio de texto
Se utiliza para configurar una prueba de modo que pueda ejecutarse antes de comenzar la prueba y desmontarse una vez finalizada la prueba. Puede implicar la creación de una base de datos temporal, directorios, etc. necesarios antes de comenzar la prueba.
Caso de prueba
El caso de prueba verifica si una respuesta requerida proviene del conjunto específico de entradas o no. El módulo unittest incluye una clase base denominada TestCase que se puede utilizar para crear nuevos casos de prueba. Incluye dos métodos predeterminados:
setUp()- un método de gancho para configurar el dispositivo de prueba antes de ejercitarlo. Esto se llama antes de llamar a los métodos de prueba implementados.
tearDown( - un método de gancho para deconstruir el accesorio de la clase después de ejecutar todas las pruebas en la clase.
Banco de pruebas
Es una colección de conjuntos de pruebas, casos de prueba o ambos.
Corredor de prueba
Controla la ejecución de los casos de prueba o demandas y proporciona el resultado al usuario. Puede usar GUI o una interfaz de texto simple para proporcionar el resultado.
Example
El siguiente programa de Python usa el módulo unittest para probar un módulo llamado Fibonacci. El programa ayuda a calcular la serie de Fibonacci de un número. En este ejemplo, hemos creado una clase llamada Fibo_test, para definir los casos de prueba usando diferentes métodos. Estos métodos se heredan de unittest.TestCase. Usamos dos métodos predeterminados: setUp () y tearDown (). También definimos el método testfibocal. El nombre de la prueba debe comenzar con la letra prueba. En el bloque final, unittest.main () proporciona una interfaz de línea de comandos para el script de prueba.
import unittest
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return a
class Fibo_Test(unittest.TestCase):
def setUp(self):
print("This is run before our tests would be executed")
def tearDown(self):
print("This is run after the completion of execution of our tests")
def testfibocal(self):
self.assertEqual(fib(0), 0)
self.assertEqual(fib(1), 1)
self.assertEqual(fib(5), 5)
self.assertEqual(fib(10), 55)
self.assertEqual(fib(20), 6765)
if __name__ == "__main__":
unittest.main()Cuando se ejecuta desde la línea de comando, el script anterior produce una salida que se ve así:
Salida
This runs before our tests would be executed.
This runs after the completion of execution of our tests.
.
----------------------------------------------------------------------
Ran 1 test in 0.006s
OKAhora, para que quede más claro, estamos cambiando nuestro código que ayudó a definir el módulo de Fibonacci.
Considere el siguiente bloque de código como ejemplo:
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return aSe realizan algunos cambios en el bloque de código como se muestra a continuación:
def fibonacci(n):
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return aAhora, después de ejecutar el script con el código modificado, obtendremos el siguiente resultado:
This runs before our tests would be executed.
This runs after the completion of execution of our tests.
F
======================================================================
FAIL: testCalculation (__main__.Fibo_Test)
----------------------------------------------------------------------
Traceback (most recent call last):
File "unitg.py", line 15, in testCalculation
self.assertEqual(fib(0), 0)
AssertionError: 1 != 0
----------------------------------------------------------------------
Ran 1 test in 0.007s
FAILED (failures = 1)La salida anterior muestra que el módulo no ha dado la salida deseada.
Módulo Docktest
El módulo docktest también ayuda en las pruebas unitarias. También viene empaquetado con Python. Es más fácil de usar que el módulo unittest. El módulo unittest es más adecuado para pruebas complejas. Para usar el módulo doctest, necesitamos importarlo. La cadena de documentación de la función correspondiente debe tener una sesión interactiva de Python junto con sus salidas.
Si todo está bien en nuestro código, entonces no habrá salida del módulo docktest; de lo contrario, proporcionará la salida.
Ejemplo
El siguiente ejemplo de Python usa el módulo docktest para probar un módulo llamado Fibonacci, que ayuda a calcular la serie Fibonacci de un número.
import doctest
def fibonacci(n):
"""
Calculates the Fibonacci number
>>> fibonacci(0)
0
>>> fibonacci(1)
1
>>> fibonacci(10)
55
>>> fibonacci(20)
6765
>>>
"""
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return a
if __name__ == "__main__":
doctest.testmod()Podemos ver que la cadena de documentación de la función correspondiente llamada fib tenía una sesión interactiva de Python junto con las salidas. Si nuestro código está bien, entonces no habrá salida del módulo doctest. Pero para ver cómo funciona podemos ejecutarlo con la opción –v.
(base) D:\ProgramData>python dock_test.py -v
Trying:
fibonacci(0)
Expecting:
0
ok
Trying:
fibonacci(1)
Expecting:
1
ok
Trying:
fibonacci(10)
Expecting:
55
ok
Trying:
fibonacci(20)
Expecting:
6765
ok
1 items had no tests:
__main__
1 items passed all tests:
4 tests in __main__.fibonacci
4 tests in 2 items.
4 passed and 0 failed.
Test passed.Ahora, cambiaremos el código que ayudó a definir el módulo de Fibonacci.
Considere el siguiente bloque de código como ejemplo:
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return aEl siguiente bloque de código ayuda con los cambios:
def fibonacci(n):
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return aDespués de ejecutar el script incluso sin la opción –v, con el código modificado, obtendremos el resultado como se muestra a continuación.
Salida
(base) D:\ProgramData>python dock_test.py
**********************************************************************
File "unitg.py", line 6, in __main__.fibonacci
Failed example:
fibonacci(0)
Expected:
0
Got:
1
**********************************************************************
File "unitg.py", line 10, in __main__.fibonacci
Failed example:
fibonacci(10)
Expected:
55
Got:
89
**********************************************************************
File "unitg.py", line 12, in __main__.fibonacci
Failed example:
fibonacci(20)
Expected:
6765
Got:
10946
**********************************************************************
1 items had failures:
3 of 4 in __main__.fibonacci
***Test Failed*** 3 failures.Podemos ver en el resultado anterior que fallaron tres pruebas.
En este capítulo, aprenderemos a depurar aplicaciones de subprocesos. También aprenderemos la importancia de depurar.
¿Qué es la depuración?
En la programación de computadoras, la depuración es el proceso de encontrar y eliminar los errores, errores y anomalías del programa de computadora. Este proceso comienza tan pronto como se escribe el código y continúa en etapas sucesivas a medida que el código se combina con otras unidades de programación para formar un producto de software. La depuración es parte del proceso de prueba de software y es una parte integral de todo el ciclo de vida del desarrollo de software.
Depurador de Python
El depurador de Python o el pdbes parte de la biblioteca estándar de Python. Es una buena herramienta de respaldo para rastrear errores difíciles de encontrar y nos permite corregir el código defectuoso de manera rápida y confiable. Los siguientes son las dos tareas más importantes delpdp depurador -
- Nos permite comprobar los valores de las variables en tiempo de ejecución.
- También podemos recorrer el código y establecer puntos de interrupción.
Podemos trabajar con pdb de las siguientes dos formas:
- A través de la línea de comandos; esto también se llama depuración post mortem.
- Ejecutando interactivamente pdb.
Trabajando con pdb
Para trabajar con el depurador de Python, necesitamos usar el siguiente código en la ubicación donde queremos entrar en el depurador:
import pdb;
pdb.set_trace()Considere los siguientes comandos para trabajar con pdb a través de la línea de comandos.
- h(help)
- d(down)
- u(up)
- b(break)
- cl(clear)
- l(list))
- n(next))
- c(continue)
- s(step)
- r(return))
- b(break)
A continuación se muestra una demostración del comando h (ayuda) del depurador de Python:
import pdb
pdb.set_trace()
--Call--
>d:\programdata\lib\site-packages\ipython\core\displayhook.py(247)__call__()
-> def __call__(self, result = None):
(Pdb) h
Documented commands (type help <topic>):
========================================
EOF c d h list q rv undisplay
a cl debug help ll quit s unt
alias clear disable ignore longlist r source until
args commands display interact n restart step up
b condition down j next return tbreak w
break cont enable jump p retval u whatis
bt continue exit l pp run unalias where
Miscellaneous help topics:
==========================
exec pdbEjemplo
Mientras trabajamos con el depurador de Python, podemos establecer el punto de interrupción en cualquier parte del script usando las siguientes líneas:
import pdb;
pdb.set_trace()Después de establecer el punto de interrupción, podemos ejecutar el script normalmente. El script se ejecutará hasta cierto punto; hasta donde se ha establecido una línea. Considere el siguiente ejemplo donde ejecutaremos el script usando las líneas mencionadas anteriormente en varios lugares del script:
import pdb;
a = "aaa"
pdb.set_trace()
b = "bbb"
c = "ccc"
final = a + b + c
print (final)Cuando se ejecuta el script anterior, ejecutará el programa hasta que a = “aaa”, podemos verificar esto en la siguiente salida.
Salida
--Return--
> <ipython-input-7-8a7d1b5cc854>(3)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
*** NameError: name 'b' is not defined
(Pdb) p c
*** NameError: name 'c' is not definedDespués de usar el comando 'p (imprimir)' en pdb, este script solo imprime 'aaa'. A esto le sigue un error porque hemos establecido el punto de interrupción en a = "aaa".
Del mismo modo, podemos ejecutar el script cambiando los puntos de interrupción y ver la diferencia en la salida:
import pdb
a = "aaa"
b = "bbb"
c = "ccc"
pdb.set_trace()
final = a + b + c
print (final)Salida
--Return--
> <ipython-input-9-a59ef5caf723>(5)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
'bbb'
(Pdb) p c
'ccc'
(Pdb) p final
*** NameError: name 'final' is not defined
(Pdb) exitEn el siguiente script, establecemos el punto de interrupción en la última línea del programa:
import pdb
a = "aaa"
b = "bbb"
c = "ccc"
final = a + b + c
pdb.set_trace()
print (final)La salida es la siguiente:
--Return--
> <ipython-input-11-8019b029997d>(6)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
'bbb'
(Pdb) p c
'ccc'
(Pdb) p final
'aaabbbccc'
(Pdb)En este capítulo, aprenderemos cómo la evaluación comparativa y la elaboración de perfiles ayudan a abordar los problemas de rendimiento.
Supongamos que hemos escrito un código y también está dando el resultado deseado, pero ¿qué pasa si queremos ejecutar este código un poco más rápido porque las necesidades han cambiado? En este caso, necesitamos averiguar qué partes de nuestro código ralentizan todo el programa. En este caso, la evaluación comparativa y la elaboración de perfiles pueden resultar útiles.
¿Qué es el Benchmarking?
La evaluación comparativa tiene como objetivo evaluar algo en comparación con un estándar. Sin embargo, la pregunta que surge aquí es cuál sería el benchmarking y por qué lo necesitamos en el caso de la programación de software. La evaluación comparativa del código significa qué tan rápido se ejecuta el código y dónde está el cuello de botella. Una de las principales razones de la evaluación comparativa es que optimiza el código.
¿Cómo funciona la evaluación comparativa?
Si hablamos del funcionamiento de la evaluación comparativa, debemos comenzar comparando todo el programa como un estado actual, luego podemos combinar micro evaluaciones comparativas y luego descomponer un programa en programas más pequeños. Para encontrar los cuellos de botella dentro de nuestro programa y optimizarlo. En otras palabras, podemos entenderlo como dividir el gran y difícil problema en una serie de problemas más pequeños y un poco más fáciles para optimizarlos.
Módulo de Python para evaluación comparativa
En Python, tenemos un módulo predeterminado para la evaluación comparativa que se llama timeit. Con la ayuda deltimeit módulo, podemos medir el rendimiento de un pequeño fragmento de código Python dentro de nuestro programa principal.
Ejemplo
En la siguiente secuencia de comandos de Python, estamos importando el timeit módulo, que mide además el tiempo necesario para ejecutar dos funciones: functionA y functionB -
import timeit
import time
def functionA():
print("Function A starts the execution:")
print("Function A completes the execution:")
def functionB():
print("Function B starts the execution")
print("Function B completes the execution")
start_time = timeit.default_timer()
functionA()
print(timeit.default_timer() - start_time)
start_time = timeit.default_timer()
functionB()
print(timeit.default_timer() - start_time)Después de ejecutar el script anterior, obtendremos el tiempo de ejecución de ambas funciones como se muestra a continuación.
Salida
Function A starts the execution:
Function A completes the execution:
0.0014599495514175942
Function B starts the execution
Function B completes the execution
0.0017024724827479076Escribiendo nuestro propio temporizador usando la función decoradora
En Python, podemos crear nuestro propio temporizador, que actuará como el timeitmódulo. Se puede hacer con la ayuda deldecoratorfunción. A continuación se muestra un ejemplo del temporizador personalizado:
import random
import time
def timer_func(func):
def function_timer(*args, **kwargs):
start = time.time()
value = func(*args, **kwargs)
end = time.time()
runtime = end - start
msg = "{func} took {time} seconds to complete its execution."
print(msg.format(func = func.__name__,time = runtime))
return value
return function_timer
@timer_func
def Myfunction():
for x in range(5):
sleep_time = random.choice(range(1,3))
time.sleep(sleep_time)
if __name__ == '__main__':
Myfunction()El script de Python anterior ayuda a importar módulos de tiempo aleatorios. Hemos creado la función decoradora timer_func (). Este tiene la función function_timer () dentro. Ahora, la función anidada tomará el tiempo antes de llamar a la función pasada. Luego, espera a que la función regrese y toma la hora de finalización. De esta manera, finalmente podemos hacer que el script de Python imprima el tiempo de ejecución. El script generará la salida como se muestra a continuación.
Salida
Myfunction took 8.000457763671875 seconds to complete its execution.¿Qué es la elaboración de perfiles?
A veces, el programador desea medir algunos atributos como el uso de la memoria, la complejidad del tiempo o el uso de instrucciones particulares sobre los programas para medir la capacidad real de ese programa. Este tipo de medición sobre el programa se denomina elaboración de perfiles. La creación de perfiles utiliza un análisis de programa dinámico para realizar dicha medición.
En las secciones siguientes, aprenderemos sobre los diferentes módulos de Python para la creación de perfiles.
cProfile - el módulo incorporado
cProfilees un módulo integrado de Python para la creación de perfiles. El módulo es una extensión C con una sobrecarga razonable que lo hace adecuado para crear perfiles de programas de larga duración. Después de ejecutarlo, registra todas las funciones y tiempos de ejecución. Es muy poderoso, pero a veces un poco difícil de interpretar y actuar. En el siguiente ejemplo, estamos usando cProfile en el siguiente código:
Ejemplo
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target=taskofThread, args=(lock,))
t2 = threading.Thread(target= taskofThread, args=(lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))El código anterior se guarda en el thread_increment.pyarchivo. Ahora, ejecute el código con cProfile en la línea de comando de la siguiente manera:
(base) D:\ProgramData>python -m cProfile thread_increment.py
x = 100000 after Iteration 0
x = 100000 after Iteration 1
x = 100000 after Iteration 2
x = 100000 after Iteration 3
x = 100000 after Iteration 4
3577 function calls (3522 primitive calls) in 1.688 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:103(release)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:143(__init__)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:147(__enter__)
… … … …De la salida anterior, está claro que cProfile imprime todas las 3577 funciones llamadas, con el tiempo empleado en cada una y el número de veces que se han llamado. Las siguientes son las columnas que obtuvimos en la salida:
ncalls - Es el número de llamadas realizadas.
tottime - Es el tiempo total empleado en la función dada.
percall - Se refiere al cociente de tottime dividido por ncalls.
cumtime- Es el tiempo acumulado empleado en esta y todas las subfunciones. Incluso es preciso para funciones recursivas.
percall - Es el cociente de tiempo acumulado dividido por llamadas primitivas.
filename:lineno(function) - Básicamente proporciona los datos respectivos de cada función.
Supongamos que tuviéramos que crear una gran cantidad de subprocesos para nuestras tareas multiproceso. Computacionalmente sería más costoso ya que puede haber muchos problemas de rendimiento debido a demasiados subprocesos. Un problema importante podría ser que el rendimiento se limite. Podemos resolver este problema creando un grupo de hilos. Un grupo de subprocesos puede definirse como el grupo de subprocesos previamente instanciados e inactivos, que están listos para recibir trabajo. Se prefiere crear un grupo de subprocesos a crear instancias de nuevos subprocesos para cada tarea cuando necesitamos realizar una gran cantidad de tareas. Un grupo de subprocesos puede gestionar la ejecución simultánea de una gran cantidad de subprocesos de la siguiente manera:
Si un subproceso en un grupo de subprocesos completa su ejecución, ese subproceso se puede reutilizar.
Si se termina un hilo, se creará otro hilo para reemplazar ese hilo.
Módulo Python - Concurrent.futures
La biblioteca estándar de Python incluye concurrent.futuresmódulo. Este módulo se agregó en Python 3.2 para proporcionar a los desarrolladores una interfaz de alto nivel para iniciar tareas asincrónicas. Es una capa de abstracción en la parte superior de los módulos de subprocesamiento y multiprocesamiento de Python para proporcionar la interfaz para ejecutar las tareas utilizando un grupo de subprocesos o procesos.
En nuestras secciones posteriores, aprenderemos sobre las diferentes clases del módulo concurrent.futures.
Clase ejecutor
Executores una clase abstracta del concurrent.futuresMódulo de Python. No se puede usar directamente y necesitamos usar una de las siguientes subclases concretas:
- ThreadPoolExecutor
- ProcessPoolExecutor
ThreadPoolExecutor - Una subclase concreta
Es una de las subclases concretas de la clase Ejecutor. La subclase utiliza subprocesos múltiples y obtenemos un grupo de subprocesos para enviar las tareas. Este grupo asigna tareas a los subprocesos disponibles y los programa para su ejecución.
¿Cómo crear un ThreadPoolExecutor?
Con la ayuda de concurrent.futures módulo y su subclase de hormigón Executor, podemos crear fácilmente un grupo de subprocesos. Para esto, necesitamos construir unThreadPoolExecutorcon la cantidad de subprocesos que queramos en el grupo. Por defecto, el número es 5. Luego, podemos enviar una tarea al grupo de subprocesos. Cuando nosotrossubmit() una tarea, recuperamos una Future. El objeto Future tiene un método llamadodone(), que dice si el futuro se ha resuelto. Con esto, se ha establecido un valor para ese objeto futuro en particular. Cuando finaliza una tarea, el ejecutor del grupo de subprocesos establece el valor del objeto futuro.
Ejemplo
from concurrent.futures import ThreadPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ThreadPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()Salida
False
True
CompletedEn el ejemplo anterior, un ThreadPoolExecutorha sido construido con 5 hilos. Luego, se envía una tarea, que esperará 2 segundos antes de dar el mensaje, al ejecutor del grupo de subprocesos. Como se ve en el resultado, la tarea no se completa hasta 2 segundos, por lo que la primera llamada adone()devolverá False. Después de 2 segundos, la tarea está terminada y obtenemos el resultado del futuro llamando alresult() método en él.
Creación de instancias de ThreadPoolExecutor - Administrador de contexto
Otra forma de instanciar ThreadPoolExecutores con la ayuda del administrador de contexto. Funciona de forma similar al método utilizado en el ejemplo anterior. La principal ventaja de usar el administrador de contexto es que se ve bien sintácticamente. La instanciación se puede hacer con la ayuda del siguiente código:
with ThreadPoolExecutor(max_workers = 5) as executorEjemplo
El siguiente ejemplo se tomó prestado de los documentos de Python. En este ejemplo, en primer lugarconcurrent.futuresel módulo debe ser importado. Entonces una función llamadaload_url()se crea que cargará la URL solicitada. La función luego creaThreadPoolExecutorcon los 5 hilos en la piscina. losThreadPoolExecutorse ha utilizado como administrador de contexto. Podemos obtener el resultado del futuro llamando alresult() método en él.
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
with concurrent.futures.ThreadPoolExecutor(max_workers = 5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))Salida
Lo siguiente sería el resultado del script de Python anterior:
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed>
'http://www.foxnews.com/' page is 229313 bytes
'http://www.cnn.com/' page is 168933 bytes
'http://www.bbc.co.uk/' page is 283893 bytes
'http://europe.wsj.com/' page is 938109 bytesUso de la función Executor.map ()
El pitón map()La función se usa ampliamente en una serie de tareas. Una de esas tareas es aplicar una determinada función a cada elemento dentro de los iterables. De manera similar, podemos asignar todos los elementos de un iterador a una función y enviarlos como trabajos independientes a outThreadPoolExecutor. Considere el siguiente ejemplo de secuencia de comandos de Python para comprender cómo funciona la función.
Ejemplo
En este ejemplo a continuación, la función de mapa se utiliza para aplicar la square() función a cada valor en la matriz de valores.
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ThreadPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()Salida
La secuencia de comandos de Python anterior genera la siguiente salida:
4
9
16
25El grupo de procesos se puede crear y usar de la misma manera que hemos creado y usado el grupo de subprocesos. El grupo de procesos se puede definir como el grupo de procesos preinstanciados e inactivos, que están listos para recibir trabajo. Se prefiere la creación de un grupo de procesos a la creación de instancias de nuevos procesos para cada tarea cuando necesitamos realizar una gran cantidad de tareas.
Módulo Python - Concurrent.futures
La biblioteca estándar de Python tiene un módulo llamado concurrent.futures. Este módulo se agregó en Python 3.2 para proporcionar a los desarrolladores una interfaz de alto nivel para iniciar tareas asincrónicas. Es una capa de abstracción en la parte superior de los módulos de subprocesamiento y multiprocesamiento de Python para proporcionar la interfaz para ejecutar las tareas utilizando un grupo de subprocesos o procesos.
En las secciones siguientes, veremos las diferentes subclases del módulo concurrent.futures.
Clase ejecutor
Executor es una clase abstracta del concurrent.futuresMódulo de Python. No se puede usar directamente y necesitamos usar una de las siguientes subclases concretas:
- ThreadPoolExecutor
- ProcessPoolExecutor
ProcessPoolExecutor: una subclase concreta
Es una de las subclases concretas de la clase Ejecutor. Utiliza multiprocesamiento y obtenemos un conjunto de procesos para enviar las tareas. Este grupo asigna tareas a los procesos disponibles y los programa para que se ejecuten.
¿Cómo crear un ProcessPoolExecutor?
Con la ayuda del concurrent.futures módulo y su subclase de hormigón Executor, podemos crear fácilmente un conjunto de procesos. Para esto, necesitamos construir unProcessPoolExecutorcon la cantidad de procesos que queremos en el grupo. De forma predeterminada, el número es 5. A continuación, se envía una tarea al grupo de procesos.
Ejemplo
Ahora consideraremos el mismo ejemplo que usamos al crear el grupo de subprocesos, la única diferencia es que ahora usaremos ProcessPoolExecutor en vez de ThreadPoolExecutor .
from concurrent.futures import ProcessPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ProcessPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()Salida
False
False
CompletedEn el ejemplo anterior, un procesoPoolExecutorha sido construido con 5 hilos. Luego, una tarea, que esperará 2 segundos antes de dar el mensaje, se envía al ejecutor del grupo de procesos. Como se ve en el resultado, la tarea no se completa hasta 2 segundos, por lo que la primera llamada adone()devolverá False. Después de 2 segundos, la tarea está terminada y obtenemos el resultado del futuro llamando alresult() método en él.
Creación de instancias ProcessPoolExecutor - Administrador de contexto
Otra forma de crear una instancia de ProcessPoolExecutor es con la ayuda del administrador de contexto. Funciona de forma similar al método utilizado en el ejemplo anterior. La principal ventaja de usar el administrador de contexto es que se ve bien sintácticamente. La instanciación se puede hacer con la ayuda del siguiente código:
with ProcessPoolExecutor(max_workers = 5) as executorEjemplo
Para una mejor comprensión, tomamos el mismo ejemplo que se usó al crear un grupo de subprocesos. En este ejemplo, debemos comenzar importando elconcurrent.futuresmódulo. Entonces una función llamadaload_url()se crea que cargará la URL solicitada. losProcessPoolExecutorluego se crea con el número de 5 subprocesos en el grupo. El procesoPoolExecutorse ha utilizado como administrador de contexto. Podemos obtener el resultado del futuro llamando alresult() método en él.
import concurrent.futures
from concurrent.futures import ProcessPoolExecutor
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
def main():
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
if __name__ == '__main__':
main()Salida
La secuencia de comandos de Python anterior generará la siguiente salida:
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed>
'http://www.foxnews.com/' page is 229476 bytes
'http://www.cnn.com/' page is 165323 bytes
'http://www.bbc.co.uk/' page is 284981 bytes
'http://europe.wsj.com/' page is 967575 bytesUso de la función Executor.map ()
El pitón map()La función se utiliza ampliamente para realizar una serie de tareas. Una de esas tareas es aplicar una determinada función a cada elemento dentro de los iterables. Del mismo modo, podemos asignar todos los elementos de un iterador a una función y enviarlos como trabajos independientes a laProcessPoolExecutor. Considere el siguiente ejemplo de secuencia de comandos de Python para comprender esto.
Ejemplo
Consideraremos el mismo ejemplo que usamos al crear un grupo de subprocesos usando el Executor.map()función. En el ejemplo dado a continuación, la función de mapa se utiliza para aplicarsquare() función a cada valor en la matriz de valores.
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ProcessPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()Salida
La secuencia de comandos de Python anterior generará la siguiente salida
4
9
16
25¿Cuándo usar ProcessPoolExecutor y ThreadPoolExecutor?
Ahora que hemos estudiado las dos clases de Ejecutor: ThreadPoolExecutor y ProcessPoolExecutor, necesitamos saber cuándo usar qué ejecutor. Debemos elegir ProcessPoolExecutor en el caso de cargas de trabajo vinculadas a la CPU y ThreadPoolExecutor en el caso de cargas de trabajo vinculadas a E / S.
Si usamos ProcessPoolExecutor, entonces no tenemos que preocuparnos por GIL porque utiliza multiprocesamiento. Además, el tiempo de ejecución será menor en comparación conThreadPoolExecution. Considere el siguiente ejemplo de secuencia de comandos de Python para comprender esto.
Ejemplo
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()Salida
Start: 8000000 Time taken: 1.5509998798370361
Start: 7000000 Time taken: 1.3259999752044678
Total time taken: 2.0840001106262207
Example- Python script with ThreadPoolExecutor:
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()Salida
Start: 8000000 Time taken: 3.8420000076293945
Start: 7000000 Time taken: 3.6010000705718994
Total time taken: 3.8480000495910645De las salidas de ambos programas anteriores, podemos ver la diferencia de tiempo de ejecución mientras usamos ProcessPoolExecutor y ThreadPoolExecutor.
En este capítulo, nos centraremos más en la comparación entre multiprocesamiento y multiproceso.
Multiprocesamiento
Es el uso de dos o más CPU dentro de un solo sistema informático. Es el mejor enfoque para aprovechar todo el potencial de nuestro hardware utilizando el número total de núcleos de CPU disponibles en nuestro sistema informático.
Multihilo
Es la capacidad de una CPU de administrar el uso del sistema operativo ejecutando múltiples subprocesos al mismo tiempo. La idea principal del subproceso múltiple es lograr el paralelismo dividiendo un proceso en varios subprocesos.
La siguiente tabla muestra algunas de las diferencias importantes entre ellos:
| Multiprocesamiento | Multiprogramación |
|---|---|
| El multiprocesamiento se refiere al procesamiento de múltiples procesos al mismo tiempo por múltiples CPU. | La multiprogramación mantiene varios programas en la memoria principal al mismo tiempo y los ejecuta simultáneamente utilizando una sola CPU. |
| Utiliza varias CPU. | Utiliza una sola CPU. |
| Permite el procesamiento en paralelo. | Tiene lugar un cambio de contexto. |
| Menos tiempo para procesar los trabajos. | Más tiempo necesario para procesar los trabajos. |
| Facilita una utilización muy eficiente de los dispositivos del sistema informático. | Menos eficiente que el multiprocesamiento. |
| Suele ser más caro. | Estos sistemas son menos costosos. |
Eliminando el impacto del bloqueo de intérprete global (GIL)
Al trabajar con aplicaciones concurrentes, existe una limitación presente en Python llamada GIL (Global Interpreter Lock). GIL nunca nos permite utilizar múltiples núcleos de CPU y, por lo tanto, podemos decir que no hay verdaderos hilos en Python. GIL es el mutex - bloqueo de exclusión mutua, que hace que las cosas sean seguras para los subprocesos. En otras palabras, podemos decir que GIL evita que varios subprocesos ejecuten código Python en paralelo. El bloqueo puede ser retenido por un solo hilo a la vez y si queremos ejecutar un hilo, primero debe adquirir el bloqueo.
Con el uso del multiprocesamiento, podemos evitar de manera efectiva la limitación causada por GIL:
Al usar multiprocesamiento, estamos utilizando la capacidad de múltiples procesos y, por lo tanto, estamos utilizando múltiples instancias de GIL.
Debido a esto, no existe ninguna restricción para ejecutar el código de bytes de un hilo dentro de nuestros programas en cualquier momento.
Iniciar procesos en Python
Los siguientes tres métodos se pueden utilizar para iniciar un proceso en Python dentro del módulo de multiprocesamiento:
- Fork
- Spawn
- Forkserver
Creando un proceso con Fork
El comando Fork es un comando estándar que se encuentra en UNIX. Se utiliza para crear nuevos procesos denominados procesos secundarios. Este proceso hijo se ejecuta simultáneamente con el proceso denominado proceso padre. Estos procesos secundarios también son idénticos a sus procesos principales y heredan todos los recursos disponibles para el principal. Las siguientes llamadas al sistema se utilizan al crear un proceso con Fork:
fork()- Es una llamada al sistema generalmente implementada en el kernel. Se utiliza para crear una copia del proceso. P>
getpid() - Esta llamada al sistema devuelve el ID de proceso (PID) del proceso de llamada.
Ejemplo
El siguiente ejemplo de secuencia de comandos de Python le ayudará a entender cómo crear un nuevo proceso hijo y obtener los PID de los procesos hijo y padre:
import os
def child():
n = os.fork()
if n > 0:
print("PID of Parent process is : ", os.getpid())
else:
print("PID of Child process is : ", os.getpid())
child()Salida
PID of Parent process is : 25989
PID of Child process is : 25990Creando un proceso con Spawn
Spawn significa comenzar algo nuevo. Por lo tanto, generar un proceso significa la creación de un nuevo proceso por un proceso padre. El proceso padre continúa su ejecución de forma asincrónica o espera hasta que el proceso hijo finaliza su ejecución. Siga estos pasos para generar un proceso:
Importación de módulo de multiprocesamiento.
Creación del proceso del objeto.
Iniciar la actividad del proceso llamando start() método.
Esperar a que el proceso haya terminado su trabajo y salir llamando join() método.
Ejemplo
El siguiente ejemplo de secuencia de comandos de Python ayuda a generar tres procesos
import multiprocessing
def spawn_process(i):
print ('This is process: %s' %i)
return
if __name__ == '__main__':
Process_jobs = []
for i in range(3):
p = multiprocessing.Process(target = spawn_process, args = (i,))
Process_jobs.append(p)
p.start()
p.join()Salida
This is process: 0
This is process: 1
This is process: 2Creando un proceso con Forkserver
El mecanismo de servidor de bifurcación solo está disponible en aquellas plataformas UNIX seleccionadas que admiten el paso de descriptores de archivo a través de Unix Pipes. Considere los siguientes puntos para comprender el funcionamiento del mecanismo Forkserver:
Se crea una instancia de un servidor al utilizar el mecanismo Forkserver para iniciar un nuevo proceso.
Luego, el servidor recibe el comando y maneja todas las solicitudes para crear nuevos procesos.
Para crear un nuevo proceso, nuestro programa Python enviará una solicitud a Forkserver y creará un proceso para nosotros.
Por fin, podemos utilizar este nuevo proceso creado en nuestros programas.
Procesos daemon en Python
Pitón multiprocessingEl módulo nos permite tener procesos daemon a través de su opción daemonic. Los procesos daemon o los procesos que se ejecutan en segundo plano siguen un concepto similar al de los subprocesos daemon. Para ejecutar el proceso en segundo plano, necesitamos establecer el indicador daemonic en verdadero. El proceso del demonio continuará ejecutándose mientras se esté ejecutando el proceso principal y terminará después de finalizar su ejecución o cuando el programa principal sea eliminado.
Ejemplo
Aquí, estamos usando el mismo ejemplo que se usó en los subprocesos del demonio. La única diferencia es el cambio de módulo demultithreading a multiprocessingy estableciendo el indicador daemonic en verdadero. Sin embargo, habría un cambio en la salida como se muestra a continuación:
import multiprocessing
import time
def nondaemonProcess():
print("starting my Process")
time.sleep(8)
print("ending my Process")
def daemonProcess():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonProcess = multiprocessing.Process(target = nondaemonProcess)
daemonProcess = multiprocessing.Process(target = daemonProcess)
daemonProcess.daemon = True
nondaemonProcess.daemon = False
daemonProcess.start()
nondaemonProcess.start()Salida
starting my Process
ending my ProcessLa salida es diferente en comparación con la generada por los subprocesos del demonio, porque el proceso en modo sin demonio tiene una salida. Por lo tanto, el proceso demoníaco finaliza automáticamente después de que finalizan los programas principales para evitar la persistencia de los procesos en ejecución.
Terminar procesos en Python
Podemos matar o terminar un proceso inmediatamente usando el terminate()método. Usaremos este método para terminar el proceso hijo, que ha sido creado con la ayuda de function, inmediatamente antes de completar su ejecución.
Ejemplo
import multiprocessing
import time
def Child_process():
print ('Starting function')
time.sleep(5)
print ('Finished function')
P = multiprocessing.Process(target = Child_process)
P.start()
print("My Process has terminated, terminating main thread")
print("Terminating Child Process")
P.terminate()
print("Child Process successfully terminated")Salida
My Process has terminated, terminating main thread
Terminating Child Process
Child Process successfully terminatedLa salida muestra que el programa termina antes de la ejecución del proceso hijo que se ha creado con la ayuda de la función Child_process (). Esto implica que el proceso hijo se ha terminado correctamente.
Identificar el proceso actual en Python
Cada proceso en el sistema operativo tiene una identidad de proceso conocida como PID. En Python, podemos averiguar el PID del proceso actual con la ayuda del siguiente comando:
import multiprocessing
print(multiprocessing.current_process().pid)Ejemplo
El siguiente ejemplo de secuencia de comandos de Python ayuda a encontrar el PID del proceso principal, así como el PID del proceso hijo:
import multiprocessing
import time
def Child_process():
print("PID of Child Process is: {}".format(multiprocessing.current_process().pid))
print("PID of Main process is: {}".format(multiprocessing.current_process().pid))
P = multiprocessing.Process(target=Child_process)
P.start()
P.join()Salida
PID of Main process is: 9401
PID of Child Process is: 9402Usando un proceso en subclase
Podemos crear hilos subclasificando el threading.Threadclase. Además, también podemos crear procesos subclasificando elmultiprocessing.Processclase. Para usar un proceso en una subclase, debemos considerar los siguientes puntos:
Necesitamos definir una nueva subclase del Process clase.
Necesitamos anular el _init_(self [,args] ) clase.
Necesitamos anular el de la run(self [,args] ) método para implementar lo que Process
Necesitamos comenzar el proceso invocando elstart() método.
Ejemplo
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
print ('called run method in process: %s' %self.name)
return
if __name__ == '__main__':
jobs = []
for i in range(5):
P = MyProcess()
jobs.append(P)
P.start()
P.join()Salida
called run method in process: MyProcess-1
called run method in process: MyProcess-2
called run method in process: MyProcess-3
called run method in process: MyProcess-4
called run method in process: MyProcess-5Módulo de multiprocesamiento de Python - Clase de grupo
Si hablamos de paralelo simple processingtareas en nuestras aplicaciones Python, luego el módulo de multiprocesamiento nos proporciona la clase Pool. Los siguientes métodos dePool La clase se puede usar para aumentar la cantidad de procesos secundarios dentro de nuestro programa principal.
aplicar () método
Este método es similar al.submit()método de .ThreadPoolExecutor.Bloquea hasta que el resultado está listo.
método apply_async ()
Cuando necesitamos la ejecución paralela de nuestras tareas, necesitamos usar elapply_async()método para enviar tareas al grupo. Es una operación asincrónica que no bloqueará el hilo principal hasta que se ejecuten todos los procesos secundarios.
método map ()
Como el apply()método, también bloquea hasta que el resultado está listo. Es equivalente al incorporadomap() función que divide los datos iterables en varios fragmentos y los envía al grupo de procesos como tareas independientes.
método map_async ()
Es una variante del map() método como apply_async() es para el apply()método. Devuelve un objeto de resultado. Cuando el resultado está listo, se le aplica un invocable. El invocable debe completarse inmediatamente; de lo contrario, el hilo que maneja los resultados se bloqueará.
Ejemplo
El siguiente ejemplo le ayudará a implementar un grupo de procesos para realizar una ejecución en paralelo. Se ha realizado un cálculo simple del cuadrado del número aplicando elsquare() función a través del multiprocessing.Poolmétodo. Luegopool.map() se ha utilizado para enviar el 5, porque la entrada es una lista de enteros del 0 al 4. El resultado se almacenaría en p_outputs y está impreso.
def square(n):
result = n*n
return result
if __name__ == '__main__':
inputs = list(range(5))
p = multiprocessing.Pool(processes = 4)
p_outputs = pool.map(function_square, inputs)
p.close()
p.join()
print ('Pool :', p_outputs)Salida
Pool : [0, 1, 4, 9, 16]La intercomunicación de procesos significa el intercambio de datos entre procesos. Es necesario intercambiar los datos entre procesos para el desarrollo de aplicaciones paralelas. El siguiente diagrama muestra los diversos mecanismos de comunicación para la sincronización entre múltiples subprocesos:

Varios mecanismos de comunicación
En esta sección, aprenderemos sobre los distintos mecanismos de comunicación. Los mecanismos se describen a continuación:
Colas
Las colas se pueden utilizar con programas multiproceso. La clase Queue demultiprocessing módulo es similar al Queue.Queueclase. Por tanto, se puede utilizar la misma API.Multiprocessing.Queue nos proporciona un mecanismo de comunicación entre procesos FIFO (primero en entrar, primero en salir) seguro para procesos y subprocesos.
Ejemplo
A continuación, se muestra un ejemplo simple tomado de los documentos oficiales de Python sobre multiprocesamiento para comprender el concepto de clase de cola de multiprocesamiento.
from multiprocessing import Process, Queue
import queue
import random
def f(q):
q.put([42, None, 'hello'])
def main():
q = Queue()
p = Process(target = f, args = (q,))
p.start()
print (q.get())
if __name__ == '__main__':
main()Salida
[42, None, 'hello']Tubería
Es una estructura de datos, que se utiliza para comunicarse entre procesos en programas multiproceso. La función Pipe () devuelve un par de objetos de conexión conectados por una tubería que por defecto es dúplex (bidireccional). Funciona de la siguiente manera:
Devuelve un par de objetos de conexión que representan los dos extremos de la tubería.
Cada objeto tiene dos métodos: send() y recv(), para comunicarse entre procesos.
Ejemplo
A continuación se muestra un ejemplo simple tomado de los documentos oficiales de Python sobre multiprocesamiento para comprender el concepto de Pipe() función de multiprocesamiento.
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target = f, args = (child_conn,))
p.start()
print (parent_conn.recv())
p.join()Salida
[42, None, 'hello']Gerente
Manager es una clase de módulo de multiprocesamiento que proporciona una forma de coordinar la información compartida entre todos sus usuarios. Un objeto administrador controla un proceso de servidor, que administra objetos compartidos y permite que otros procesos los manipulen. En otras palabras, los gerentes brindan una forma de crear datos que se pueden compartir entre diferentes procesos. A continuación se muestran las diferentes propiedades del objeto administrador:
La propiedad principal del administrador es controlar un proceso del servidor, que administra los objetos compartidos.
Otra propiedad importante es actualizar todos los objetos compartidos cuando algún proceso lo modifica.
Ejemplo
A continuación se muestra un ejemplo que utiliza el objeto administrador para crear un registro de lista en el proceso del servidor y luego agregar un nuevo registro en esa lista.
import multiprocessing
def print_records(records):
for record in records:
print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
def insert_record(record, records):
records.append(record)
print("A New record is added\n")
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
records = manager.list([('Computers', 1), ('Histoty', 5), ('Hindi',9)])
new_record = ('English', 3)
p1 = multiprocessing.Process(target = insert_record, args = (new_record, records))
p2 = multiprocessing.Process(target = print_records, args = (records,))
p1.start()
p1.join()
p2.start()
p2.join()Salida
A New record is added
Name: Computers
Score: 1
Name: Histoty
Score: 5
Name: Hindi
Score: 9
Name: English
Score: 3Concepto de espacios de nombres en Manager
Manager Class viene con el concepto de espacios de nombres, que es un método de forma rápida para compartir varios atributos en múltiples procesos. Los espacios de nombres no presentan ningún método público al que se pueda llamar, pero tienen atributos de escritura.
Ejemplo
El siguiente ejemplo de secuencia de comandos de Python nos ayuda a utilizar espacios de nombres para compartir datos entre el proceso principal y el proceso secundario:
import multiprocessing
def Mng_NaSp(using_ns):
using_ns.x +=5
using_ns.y *= 10
if __name__ == '__main__':
manager = multiprocessing.Manager()
using_ns = manager.Namespace()
using_ns.x = 1
using_ns.y = 1
print ('before', using_ns)
p = multiprocessing.Process(target = Mng_NaSp, args = (using_ns,))
p.start()
p.join()
print ('after', using_ns)Salida
before Namespace(x = 1, y = 1)
after Namespace(x = 6, y = 10)Ctypes-Array y valor
El módulo de multiprocesamiento proporciona objetos Array y Value para almacenar los datos en un mapa de memoria compartida. Array es una matriz ctypes asignada desde la memoria compartida y Value es un objeto ctypes asignado desde la memoria compartida.
Para estar con, importar Process, Value, Array desde multiprocesamiento.
Ejemplo
El siguiente script de Python es un ejemplo tomado de documentos de Python para utilizar Ctypes Array y Value para compartir algunos datos entre procesos.
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target = f, args = (num, arr))
p.start()
p.join()
print (num.value)
print (arr[:])Salida
3.1415927
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]Comunicación de procesos secuenciales (CSP)
CSP se utiliza para ilustrar la interacción de sistemas con otros sistemas que presentan modelos concurrentes. CSP es un marco para escribir programas o programas simultáneos mediante el paso de mensajes y, por lo tanto, es eficaz para describir la concurrencia.
Biblioteca de Python - PyCSP
Para implementar primitivas centrales que se encuentran en CSP, Python tiene una biblioteca llamada PyCSP. Mantiene la implementación muy breve y legible para que se pueda entender muy fácilmente. A continuación se muestra la red de procesos básica de PyCSP:
En la red de procesos PyCSP anterior, hay dos procesos: Proceso 1 y Proceso 2. Estos procesos se comunican pasando mensajes a través de dos canales: el canal 1 y el canal 2.
Instalación de PyCSP
Con la ayuda del siguiente comando, podemos instalar la biblioteca Python PyCSP -
pip install PyCSPEjemplo
El siguiente script de Python es un ejemplo simple para ejecutar dos procesos en paralelo entre sí. Se hace con la ayuda de la biblioteca de Python PyCSP -
from pycsp.parallel import *
import time
@process
def P1():
time.sleep(1)
print('P1 exiting')
@process
def P2():
time.sleep(1)
print('P2 exiting')
def main():
Parallel(P1(), P2())
print('Terminating')
if __name__ == '__main__':
main()En el script anterior, dos funciones a saber P1 y P2 han sido creados y decorados con @process para convertirlos en procesos.
Salida
P2 exiting
P1 exiting
TerminatingLa programación impulsada por eventos se centra en eventos. Finalmente, el flujo del programa depende de los eventos. Hasta ahora, estábamos tratando con un modelo de ejecución secuencial o paralelo, pero el modelo que tiene el concepto de programación dirigida por eventos se llama modelo asincrónico. La programación impulsada por eventos depende de un bucle de eventos que siempre está atento a los nuevos eventos entrantes. El funcionamiento de la programación impulsada por eventos depende de los eventos. Una vez que un evento se repite, los eventos deciden qué ejecutar y en qué orden. El siguiente diagrama de flujo lo ayudará a comprender cómo funciona esto:
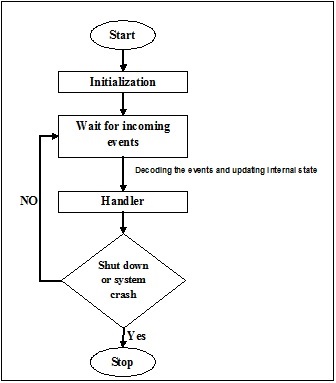
Módulo Python - Asyncio
El módulo Asyncio se agregó en Python 3.4 y proporciona infraestructura para escribir código concurrente de un solo subproceso utilizando co-rutinas. A continuación se muestran los diferentes conceptos utilizados por el módulo Asyncio:
El bucle de eventos
Event-loop es una funcionalidad para manejar todos los eventos en un código computacional. Actúa durante la ejecución de todo el programa y realiza un seguimiento de la entrada y la ejecución de eventos. El módulo Asyncio permite un único bucle de eventos por proceso. Los siguientes son algunos métodos proporcionados por el módulo Asyncio para administrar un bucle de eventos:
loop = get_event_loop() - Este método proporcionará el bucle de eventos para el contexto actual.
loop.call_later(time_delay,callback,argument) - Este método organiza la devolución de llamada que se llamará después de los segundos de time_delay dados.
loop.call_soon(callback,argument)- Este método organiza una devolución de llamada que se llamará lo antes posible. La devolución de llamada se llama después de que call_soon () regresa y cuando el control regresa al bucle de eventos.
loop.time() - Este método se utiliza para devolver la hora actual de acuerdo con el reloj interno del bucle de eventos.
asyncio.set_event_loop() - Este método establecerá el bucle de eventos para el contexto actual en el bucle.
asyncio.new_event_loop() - Este método creará y devolverá un nuevo objeto de bucle de eventos.
loop.run_forever() - Este método se ejecutará hasta que se llame al método stop ().
Ejemplo
El siguiente ejemplo de bucle de eventos ayuda a imprimir hello worldutilizando el método get_event_loop (). Este ejemplo está tomado de los documentos oficiales de Python.
import asyncio
def hello_world(loop):
print('Hello World')
loop.stop()
loop = asyncio.get_event_loop()
loop.call_soon(hello_world, loop)
loop.run_forever()
loop.close()Salida
Hello WorldFuturos
Esto es compatible con la clase concurrent.futures.Future que representa un cálculo que no se ha realizado. Existen las siguientes diferencias entre asyncio.futures.Future y concurrent.futures.Future -
Los métodos result () y exception () no toman un argumento de tiempo de espera y generan una excepción cuando el futuro aún no ha terminado.
Las devoluciones de llamada registradas con add_done_callback () siempre se llaman a través de call_soon () del bucle de eventos.
La clase asyncio.futures.Future no es compatible con las funciones wait () y as_completed () en el paquete concurrent.futures.
Ejemplo
El siguiente es un ejemplo que le ayudará a entender cómo usar la clase asyncio.futures.future.
import asyncio
async def Myoperation(future):
await asyncio.sleep(2)
future.set_result('Future Completed')
loop = asyncio.get_event_loop()
future = asyncio.Future()
asyncio.ensure_future(Myoperation(future))
try:
loop.run_until_complete(future)
print(future.result())
finally:
loop.close()Salida
Future CompletedCorutinas
El concepto de corrutinas en Asyncio es similar al concepto de objeto Thread estándar en el módulo de subprocesamiento. Ésta es la generalización del concepto de subrutina. Una corrutina se puede suspender durante la ejecución para que espere el procesamiento externo y regrese desde el punto en el que se había detenido cuando se realizó el procesamiento externo. Las siguientes dos formas nos ayudan a implementar corrutinas:
función async def ()
Este es un método para la implementación de corrutinas en el módulo Asyncio. A continuación se muestra un script de Python para el mismo:
import asyncio
async def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()Salida
First Coroutine@ asyncio.coroutine decorador
Otro método para la implementación de corrutinas es utilizar generadores con el decorador @ asyncio.coroutine. A continuación se muestra un script de Python para el mismo:
import asyncio
@asyncio.coroutine
def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()Salida
First CoroutineTareas
Esta subclase del módulo Asyncio es responsable de la ejecución de corrutinas dentro de un bucle de eventos de manera paralela. Seguir el script de Python es un ejemplo de cómo procesar algunas tareas en paralelo.
import asyncio
import time
async def Task_ex(n):
time.sleep(1)
print("Processing {}".format(n))
async def Generator_task():
for i in range(10):
asyncio.ensure_future(Task_ex(i))
int("Tasks Completed")
asyncio.sleep(2)
loop = asyncio.get_event_loop()
loop.run_until_complete(Generator_task())
loop.close()Salida
Tasks Completed
Processing 0
Processing 1
Processing 2
Processing 3
Processing 4
Processing 5
Processing 6
Processing 7
Processing 8
Processing 9Transportes
El módulo Asyncio proporciona clases de transporte para implementar varios tipos de comunicación. Estas clases no son seguras para subprocesos y siempre se emparejan con una instancia de protocolo después del establecimiento del canal de comunicación.
A continuación se muestran distintos tipos de transportes heredados de BaseTransport:
ReadTransport - Esta es una interfaz para transportes de solo lectura.
WriteTransport - Esta es una interfaz para transportes de solo escritura.
DatagramTransport - Esta es una interfaz para enviar los datos.
BaseSubprocessTransport - Similar a la clase BaseTransport.
Los siguientes son cinco métodos distintos de la clase BaseTransport que posteriormente son transitorios en los cuatro tipos de transporte:
close() - Cierra el transporte.
is_closing() - Este método devolverá verdadero si el transporte se está cerrando o ya está cerrado.
get_extra_info(name, default = none) - Esto nos dará información adicional sobre el transporte.
get_protocol() - Este método devolverá el protocolo actual.
Protocolos
El módulo Asyncio proporciona clases base que puede subclasificar para implementar sus protocolos de red. Estas clases se utilizan junto con los transportes; el protocolo analiza los datos entrantes y solicita la escritura de los datos salientes, mientras que el transporte es responsable de la E / S real y del almacenamiento en búfer. A continuación se presentan tres clases de protocolo:
Protocol - Esta es la clase base para implementar protocolos de transmisión para su uso con transportes TCP y SSL.
DatagramProtocol - Esta es la clase base para implementar protocolos de datagramas para su uso con transportes UDP.
SubprocessProtocol - Esta es la clase base para implementar protocolos que se comunican con procesos secundarios a través de un conjunto de conductos unidireccionales.
La programación reactiva es un paradigma de programación que se ocupa de los flujos de datos y la propagación del cambio. Significa que cuando un componente emite un flujo de datos, el cambio se propagará a otros componentes mediante la biblioteca de programación reactiva. La propagación del cambio continuará hasta que llegue al receptor final. La diferencia entre la programación impulsada por eventos y la reactiva es que la programación impulsada por eventos gira en torno a eventos y la programación reactiva gira en torno a los datos.
ReactiveX o RX para programación reactiva
ReactiveX o Raective Extension es la implementación más famosa de programación reactiva. El funcionamiento de ReactiveX depende de las siguientes dos clases:
Clase observable
Esta clase es la fuente del flujo de datos o eventos y empaqueta los datos entrantes para que los datos se puedan pasar de un hilo a otro. No dará datos hasta que algún observador se suscriba.
Clase de observador
Esta clase consume el flujo de datos emitido por observable. Puede haber varios observadores con observables y cada observador recibirá cada elemento de datos que se emita. El observador puede recibir tres tipos de eventos al suscribirse a observables:
on_next() event - Implica que hay un elemento en el flujo de datos.
on_completed() event - Implica el fin de la emisión y no vienen más artículos.
on_error() event - También implica fin de emisión pero en caso de que se arroje un error por observable.
RxPY - Módulo Python para programación reactiva
RxPY es un módulo de Python que se puede utilizar para programación reactiva. Necesitamos asegurarnos de que el módulo esté instalado. El siguiente comando se puede utilizar para instalar el módulo RxPY:
pip install RxPYEjemplo
A continuación se muestra un script de Python, que usa RxPY módulo y sus clases Observable y Observe forprogramación reactiva. Básicamente hay dos clases:
get_strings() - para obtener las cadenas del observador.
PrintObserver()- para imprimir las cadenas del observador. Utiliza los tres eventos de la clase de observador. También usa la clase subscribe ().
from rx import Observable, Observer
def get_strings(observer):
observer.on_next("Ram")
observer.on_next("Mohan")
observer.on_next("Shyam")
observer.on_completed()
class PrintObserver(Observer):
def on_next(self, value):
print("Received {0}".format(value))
def on_completed(self):
print("Finished")
def on_error(self, error):
print("Error: {0}".format(error))
source = Observable.create(get_strings)
source.subscribe(PrintObserver())Salida
Received Ram
Received Mohan
Received Shyam
FinishedBiblioteca PyFunctional para programación reactiva
PyFunctionales otra biblioteca de Python que se puede usar para programación reactiva. Nos permite crear programas funcionales utilizando el lenguaje de programación Python. Es útil porque nos permite crear canalizaciones de datos utilizando operadores funcionales encadenados.
Diferencia entre RxPY y PyFunctional
Ambas bibliotecas se utilizan para programación reactiva y manejan el flujo de manera similar, pero la principal diferencia entre ambas depende del manejo de los datos. RxPY maneja datos y eventos en el sistema mientras PyFunctional se centra en la transformación de datos utilizando paradigmas de programación funcional.
Instalación del módulo PyFunctional
Necesitamos instalar este módulo antes de usarlo. Se puede instalar con la ayuda del comando pip de la siguiente manera:
pip install pyfunctionalEjemplo
El siguiente ejemplo utiliza the PyFunctional módulo y su seqclase que actúa como el objeto de flujo con el que podemos iterar y manipular. En este programa, mapea la secuencia usando la función lamda que duplica cada valor, luego filtra el valor donde x es mayor que 4 y finalmente reduce la secuencia a una suma de todos los valores restantes.
from functional import seq
result = seq(1,2,3).map(lambda x: x*2).filter(lambda x: x > 4).reduce(lambda x, y: x + y)
print ("Result: {}".format(result))Salida
Result: 6