Hadoop - Soluciones de Big Data
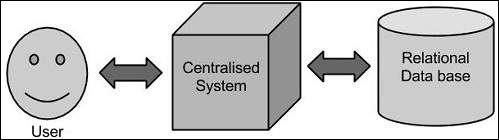
Enfoque tradicional
En este enfoque, una empresa tendrá una computadora para almacenar y procesar grandes datos. Para fines de almacenamiento, los programadores tomarán la ayuda de los proveedores de bases de datos que elijan, como Oracle, IBM, etc. En este enfoque, el usuario interactúa con la aplicación, que a su vez maneja la parte del almacenamiento y análisis de datos.
Limitación
Este enfoque funciona bien con aquellas aplicaciones que procesan datos menos voluminosos que pueden ser acomodados por servidores de bases de datos estándar, o hasta el límite del procesador que está procesando los datos. Pero cuando se trata de lidiar con grandes cantidades de datos escalables, es una tarea agitada procesar dichos datos a través de un cuello de botella único en la base de datos.
Solución de Google
Google resolvió este problema utilizando un algoritmo llamado MapReduce. Este algoritmo divide la tarea en partes pequeñas y las asigna a muchas computadoras, y recopila los resultados de ellas que, cuando se integran, forman el conjunto de datos de resultados.

Hadoop
Utilizando la solución proporcionada por Google, Doug Cutting y su equipo desarrolló un proyecto de código abierto llamado HADOOP.
Hadoop ejecuta aplicaciones utilizando el algoritmo MapReduce, donde los datos se procesan en paralelo con otros. En resumen, Hadoop se utiliza para desarrollar aplicaciones que podrían realizar análisis estadísticos completos sobre grandes cantidades de datos.
