Hadoop - Guía rápida
"El 90% de los datos mundiales se generó en los últimos años".
Debido a la llegada de nuevas tecnologías, dispositivos y medios de comunicación como los sitios de redes sociales, la cantidad de datos producidos por la humanidad crece rápidamente cada año. La cantidad de datos producidos por nosotros desde el principio de los tiempos hasta 2003 fue de 5 mil millones de gigabytes. Si acumula los datos en forma de discos, es posible que llene todo un campo de fútbol. Se creó la misma cantidad cada dos días en2011, y cada diez minutos en 2013. Esta tasa sigue creciendo enormemente. Aunque toda esta información producida es significativa y puede ser útil cuando se procesa, se está descuidando.
¿Qué es Big Data?
Big dataes una colección de grandes conjuntos de datos que no se pueden procesar mediante técnicas informáticas tradicionales. No es una técnica o una herramienta única, sino que se ha convertido en un tema completo, que involucra diversas herramientas, técnicas y marcos.
¿Qué viene bajo Big Data?
Big data involucra los datos producidos por diferentes dispositivos y aplicaciones. A continuación se presentan algunos de los campos que se encuentran bajo el paraguas de Big Data.
Black Box Data - Es un componente de helicópteros, aviones y jets, etc. Captura voces de la tripulación de vuelo, grabaciones de micrófonos y auriculares, y la información de desempeño de la aeronave.
Social Media Data - Las redes sociales como Facebook y Twitter contienen información y las opiniones publicadas por millones de personas en todo el mundo.
Stock Exchange Data - Los datos de la bolsa de valores contienen información sobre las decisiones de "compra" y "venta" tomadas por los clientes sobre una acción de diferentes empresas.
Power Grid Data - Los datos de la red eléctrica contienen información consumida por un nodo en particular con respecto a una estación base.
Transport Data - Los datos de transporte incluyen modelo, capacidad, distancia y disponibilidad de un vehículo.
Search Engine Data - Los motores de búsqueda recuperan gran cantidad de datos de diferentes bases de datos.

Por lo tanto, Big Data incluye un gran volumen, alta velocidad y variedad extensible de datos. Los datos que contiene serán de tres tipos.
Structured data - Datos relacionales.
Semi Structured data - Datos XML.
Unstructured data - Word, PDF, texto, registros de medios.
Beneficios de Big Data
Con la información almacenada en la red social como Facebook, las agencias de marketing están conociendo la respuesta de sus campañas, promociones y otros medios publicitarios.
Utilizando la información de las redes sociales, como las preferencias y la percepción del producto de sus consumidores, las empresas de productos y las organizaciones minoristas están planificando su producción.
Utilizando los datos relacionados con el historial médico previo de los pacientes, los hospitales están proporcionando un mejor y más rápido servicio.
Tecnologías de Big Data
Las tecnologías de big data son importantes para proporcionar un análisis más preciso, lo que puede conducir a una toma de decisiones más concreta que resulte en una mayor eficiencia operativa, reducciones de costos y menores riesgos para el negocio.
Para aprovechar el poder de los macrodatos, necesitaría una infraestructura que pueda administrar y procesar grandes volúmenes de datos estructurados y no estructurados en tiempo real y que pueda proteger la privacidad y seguridad de los datos.
Hay varias tecnologías en el mercado de diferentes proveedores, incluidos Amazon, IBM, Microsoft, etc., para manejar big data. Mientras analizamos las tecnologías que manejan big data, examinamos las siguientes dos clases de tecnología:
Big Data operativo
Esto incluye sistemas como MongoDB que brindan capacidades operativas para cargas de trabajo interactivas en tiempo real donde los datos se capturan y almacenan principalmente.
Los sistemas de Big Data NoSQL están diseñados para aprovechar las nuevas arquitecturas de computación en la nube que han surgido durante la última década para permitir que los cálculos masivos se ejecuten de manera económica y eficiente. Esto hace que las cargas de trabajo de big data operativas sean mucho más fáciles de administrar, más económicas y más rápidas de implementar.
Algunos sistemas NoSQL pueden proporcionar información sobre patrones y tendencias basados en datos en tiempo real con una codificación mínima y sin la necesidad de científicos de datos e infraestructura adicional.
Big Data analítico
Estos incluyen sistemas como los sistemas de base de datos de procesamiento masivo paralelo (MPP) y MapReduce que brindan capacidades analíticas para análisis retrospectivos y complejos que pueden tocar la mayoría o todos los datos.
MapReduce proporciona un nuevo método de análisis de datos que es complementario a las capacidades proporcionadas por SQL, y un sistema basado en MapReduce que se puede escalar desde servidores únicos a miles de máquinas de gama alta y baja.
Estas dos clases de tecnología son complementarias y con frecuencia se implementan juntas.
Sistemas operacionales vs analíticos
| Operacional | Analítico | |
|---|---|---|
| Latencia | 1 ms - 100 ms | 1 min - 100 min |
| Concurrencia | 1000 - 100.000 | 1 - 10 |
| Patrón de acceso | Escribe y lee | Lee |
| Consultas | Selectivo | No selectivo |
| Alcance de los datos | Operacional | Retrospectivo |
| Usuario final | Cliente | Científico de datos |
| Tecnología | NoSQL | MapReduce, base de datos MPP |
Desafíos de Big Data
Los principales desafíos asociados con big data son los siguientes:
- Captura de datos
- Curation
- Storage
- Searching
- Sharing
- Transfer
- Analysis
- Presentation
Para cumplir con los desafíos anteriores, las organizaciones normalmente necesitan la ayuda de servidores empresariales.
Enfoque tradicional
En este enfoque, una empresa tendrá una computadora para almacenar y procesar grandes datos. Para propósitos de almacenamiento, los programadores tomarán la ayuda de su elección de proveedores de bases de datos como Oracle, IBM, etc. En este enfoque, el usuario interactúa con la aplicación, que a su vez maneja la parte del almacenamiento y análisis de datos.
Limitación
Este enfoque funciona bien con aquellas aplicaciones que procesan datos menos voluminosos que pueden ser acomodados por servidores de bases de datos estándar, o hasta el límite del procesador que está procesando los datos. Pero cuando se trata de lidiar con grandes cantidades de datos escalables, es una tarea agitada procesar dichos datos a través de un cuello de botella único en la base de datos.
Solución de Google
Google resolvió este problema utilizando un algoritmo llamado MapReduce. Este algoritmo divide la tarea en partes pequeñas y las asigna a muchas computadoras, y recopila los resultados de ellas que, cuando se integran, forman el conjunto de datos de resultados.

Hadoop
Utilizando la solución proporcionada por Google, Doug Cutting y su equipo desarrolló un proyecto de código abierto llamado HADOOP.
Hadoop ejecuta aplicaciones utilizando el algoritmo MapReduce, donde los datos se procesan en paralelo con otros. En resumen, Hadoop se utiliza para desarrollar aplicaciones que podrían realizar análisis estadísticos completos en grandes cantidades de datos.

Hadoop es un marco de trabajo de código abierto de Apache escrito en Java que permite el procesamiento distribuido de grandes conjuntos de datos en grupos de computadoras utilizando modelos de programación simples. La aplicación del marco de trabajo Hadoop funciona en un entorno que proporciona almacenamiento y computación distribuidos entre grupos de computadoras. Hadoop está diseñado para escalar de un solo servidor a miles de máquinas, cada una de las cuales ofrece computación y almacenamiento local.
Arquitectura Hadoop
En esencia, Hadoop tiene dos capas principales, a saber:
- Capa de procesamiento / computación (MapReduce) y
- Capa de almacenamiento (sistema de archivos distribuido Hadoop).

Mapa reducido
MapReduce es un modelo de programación paralelo para escribir aplicaciones distribuidas diseñado en Google para el procesamiento eficiente de grandes cantidades de datos (conjuntos de datos de varios terabytes), en grandes grupos (miles de nodos) de hardware básico de una manera confiable y tolerante a fallas. El programa MapReduce se ejecuta en Hadoop, que es un marco de código abierto Apache.
Sistema de archivos distribuido Hadoop
El sistema de archivos distribuido de Hadoop (HDFS) se basa en el sistema de archivos de Google (GFS) y proporciona un sistema de archivos distribuido que está diseñado para ejecutarse en hardware básico. Tiene muchas similitudes con los sistemas de archivos distribuidos existentes. Sin embargo, las diferencias con otros sistemas de archivos distribuidos son significativas. Es altamente tolerante a fallas y está diseñado para implementarse en hardware de bajo costo. Proporciona acceso de alto rendimiento a los datos de la aplicación y es adecuado para aplicaciones que tienen grandes conjuntos de datos.
Además de los dos componentes principales mencionados anteriormente, el marco de Hadoop también incluye los siguientes dos módulos:
Hadoop Common - Estas son bibliotecas y utilidades de Java requeridas por otros módulos de Hadoop.
Hadoop YARN - Este es un marco para la programación de trabajos y la gestión de recursos del clúster.
¿Cómo funciona Hadoop?
Es bastante costoso construir servidores más grandes con configuraciones pesadas que manejen el procesamiento a gran escala, pero como alternativa, puede unir muchas computadoras básicas con una sola CPU, como un solo sistema distribuido funcional y prácticamente, las máquinas agrupadas pueden leer el conjunto de datos en paralelo y proporcionan un rendimiento mucho mayor. Además, es más económico que un servidor de gama alta. Entonces, este es el primer factor de motivación detrás del uso de Hadoop que se ejecuta en máquinas agrupadas y de bajo costo.
Hadoop ejecuta código en un grupo de computadoras. Este proceso incluye las siguientes tareas principales que realiza Hadoop:
Los datos se dividen inicialmente en directorios y archivos. Los archivos se dividen en bloques de tamaño uniforme de 128M y 64M (preferiblemente 128M).
Luego, estos archivos se distribuyen en varios nodos del clúster para su posterior procesamiento.
HDFS, que está en la parte superior del sistema de archivos local, supervisa el procesamiento.
Los bloques se replican para manejar fallas de hardware.
Comprobando que el código se ejecutó correctamente.
Realización de la ordenación que tiene lugar entre el mapa y reducir etapas.
Envío de los datos ordenados a una determinada computadora.
Escribir los registros de depuración para cada trabajo.
Ventajas de Hadoop
El marco Hadoop permite al usuario escribir y probar rápidamente sistemas distribuidos. Es eficiente y distribuye automáticamente los datos y el trabajo entre las máquinas y, a su vez, utiliza el paralelismo subyacente de los núcleos de la CPU.
Hadoop no depende del hardware para proporcionar tolerancia a fallas y alta disponibilidad (FTHA), sino que la biblioteca de Hadoop en sí ha sido diseñada para detectar y manejar fallas en la capa de aplicación.
Los servidores se pueden agregar o eliminar del clúster de forma dinámica y Hadoop continúa funcionando sin interrupciones.
Otra gran ventaja de Hadoop es que además de ser de código abierto, es compatible en todas las plataformas ya que está basado en Java.
Hadoop es compatible con la plataforma GNU / Linux y sus variantes. Por lo tanto, tenemos que instalar un sistema operativo Linux para configurar el entorno Hadoop. En caso de que tenga un sistema operativo que no sea Linux, puede instalar un software Virtualbox en él y tener Linux dentro de Virtualbox.
Configuración previa a la instalación
Antes de instalar Hadoop en el entorno Linux, necesitamos configurar Linux usando ssh(Cubierta segura). Siga los pasos que se indican a continuación para configurar el entorno Linux.
Crear un usuario
Al principio, se recomienda crear un usuario separado para Hadoop para aislar el sistema de archivos Hadoop del sistema de archivos Unix. Siga los pasos que se indican a continuación para crear un usuario:
Abra la raíz con el comando "su".
Cree un usuario desde la cuenta raíz usando el comando "useradd username".
Ahora puede abrir una cuenta de usuario existente usando el comando "su nombre de usuario".
Abra la terminal de Linux y escriba los siguientes comandos para crear un usuario.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdConfiguración de SSH y generación de claves
La configuración de SSH es necesaria para realizar diferentes operaciones en un clúster, como iniciar, detener, operaciones de shell de demonio distribuidas. Para autenticar diferentes usuarios de Hadoop, es necesario proporcionar un par de claves pública / privada para un usuario de Hadoop y compartirlo con diferentes usuarios.
Los siguientes comandos se utilizan para generar un par clave-valor mediante SSH. Copie el formulario de claves públicas id_rsa.pub en Authorized_keys y proporcione al propietario permisos de lectura y escritura en el archivo Authorized_keys respectivamente.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keysInstalación de Java
Java es el principal requisito previo para Hadoop. En primer lugar, debe verificar la existencia de java en su sistema usando el comando "java -version". La sintaxis del comando de la versión java se proporciona a continuación.
$ java -versionSi todo está en orden, le dará el siguiente resultado.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Si java no está instalado en su sistema, siga los pasos que se indican a continuación para instalar java.
Paso 1
Descargue java (JDK <última versión> - X64.tar.gz) visitando el siguiente enlace www.oracle.com
Luego jdk-7u71-linux-x64.tar.gz se descargará en su sistema.
Paso 2
Generalmente, encontrará el archivo java descargado en la carpeta Descargas. Verifíquelo y extraiga eljdk-7u71-linux-x64.gz archivo usando los siguientes comandos.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzPaso 3
Para que Java esté disponible para todos los usuarios, debe moverlo a la ubicación “/ usr / local /”. Abra root y escriba los siguientes comandos.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitEtapa 4
Para configurar PATH y JAVA_HOME variables, agregue los siguientes comandos a ~/.bashrc archivo.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=$PATH:$JAVA_HOME/binAhora aplique todos los cambios en el sistema en ejecución actual.
$ source ~/.bashrcPaso 5
Utilice los siguientes comandos para configurar alternativas de Java:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarAhora verifique el comando java -version desde la terminal como se explicó anteriormente.
Descargando Hadoop
Descargue y extraiga Hadoop 2.4.1 de la base del software Apache usando los siguientes comandos.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitModos de operación de Hadoop
Una vez que haya descargado Hadoop, puede operar su clúster de Hadoop en uno de los tres modos admitidos:
Local/Standalone Mode - Después de descargar Hadoop en su sistema, de forma predeterminada, se configura en modo independiente y se puede ejecutar como un único proceso java.
Pseudo Distributed Mode- Es una simulación distribuida en una sola máquina. Cada demonio de Hadoop, como hdfs, yarn, MapReduce, etc., se ejecutará como un proceso java independiente. Este modo es útil para el desarrollo.
Fully Distributed Mode- Este modo está completamente distribuido con un mínimo de dos o más máquinas como grupo. Nos encontraremos con este modo en detalle en los próximos capítulos.
Instalación de Hadoop en modo independiente
Aquí discutiremos la instalación de Hadoop 2.4.1 en modo autónomo.
No hay demonios en ejecución y todo se ejecuta en una única JVM. El modo autónomo es adecuado para ejecutar programas MapReduce durante el desarrollo, ya que es fácil probarlos y depurarlos.
Configuración de Hadoop
Puede configurar las variables de entorno de Hadoop agregando los siguientes comandos a ~/.bashrc archivo.
export HADOOP_HOME=/usr/local/hadoopAntes de continuar, debe asegurarse de que Hadoop esté funcionando bien. Simplemente emita el siguiente comando:
$ hadoop versionSi todo está bien con su configuración, entonces debería ver el siguiente resultado:
Hadoop 2.4.1
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Significa que la configuración del modo independiente de Hadoop está funcionando bien. De forma predeterminada, Hadoop está configurado para ejecutarse en modo no distribuido en una sola máquina.
Ejemplo
Veamos un ejemplo simple de Hadoop. La instalación de Hadoop proporciona el siguiente archivo jar de MapReduce de ejemplo, que proporciona una funcionalidad básica de MapReduce y se puede utilizar para calcular, como el valor Pi, el recuento de palabras en una lista de archivos determinada, etc.
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarTengamos un directorio de entrada donde empujaremos algunos archivos y nuestro requisito es contar el número total de palabras en esos archivos. Para calcular el número total de palabras, no necesitamos escribir nuestro MapReduce, siempre que el archivo .jar contenga la implementación para el recuento de palabras. Puede probar otros ejemplos utilizando el mismo archivo .jar; simplemente emita los siguientes comandos para verificar los programas funcionales MapReduce compatibles con el archivo hadoop-mapreduce-examples-2.2.0.jar.
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jarPaso 1
Cree archivos de contenido temporal en el directorio de entrada. Puede crear este directorio de entrada en cualquier lugar donde desee trabajar.
$ mkdir input $ cp $HADOOP_HOME/*.txt input $ ls -l inputLe dará los siguientes archivos en su directorio de entrada:
total 24
-rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt
-rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt
-rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txtEstos archivos se han copiado del directorio de inicio de instalación de Hadoop. Para su experimento, puede tener conjuntos de archivos grandes y diferentes.
Paso 2
Comencemos el proceso de Hadoop para contar el número total de palabras en todos los archivos disponibles en el directorio de entrada, de la siguiente manera:
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input outputPaso 3
El paso 2 realizará el procesamiento requerido y guardará la salida en el archivo output / part-r00000, que puede verificar usando -
$cat output/*Enumerará todas las palabras junto con sus recuentos totales disponibles en todos los archivos disponibles en el directorio de entrada.
"AS 4
"Contribution" 1
"Contributor" 1
"Derivative 1
"Legal 1
"License" 1
"License"); 1
"Licensor" 1
"NOTICE” 1
"Not 1
"Object" 1
"Source” 1
"Work” 1
"You" 1
"Your") 1
"[]" 1
"control" 1
"printed 1
"submitted" 1
(50%) 1
(BIS), 1
(C) 1
(Don't) 1
(ECCN) 1
(INCLUDING 2
(INCLUDING, 2
.............Instalación de Hadoop en modo pseudo distribuido
Siga los pasos que se indican a continuación para instalar Hadoop 2.4.1 en modo pseudodistribuido.
Paso 1: configuración de Hadoop
Puede configurar las variables de entorno de Hadoop agregando los siguientes comandos a ~/.bashrc archivo.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOMEAhora aplique todos los cambios en el sistema en ejecución actual.
$ source ~/.bashrcPaso 2: configuración de Hadoop
Puede encontrar todos los archivos de configuración de Hadoop en la ubicación "$ HADOOP_HOME / etc / hadoop". Es necesario realizar cambios en esos archivos de configuración de acuerdo con su infraestructura de Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPara desarrollar programas de Hadoop en Java, debe restablecer las variables de entorno de Java en hadoop-env.sh archivo reemplazando JAVA_HOME value con la ubicación de java en su sistema.
export JAVA_HOME=/usr/local/jdk1.7.0_71La siguiente es la lista de archivos que debe editar para configurar Hadoop.
core-site.xml
los core-site.xml El archivo contiene información como el número de puerto utilizado para la instancia de Hadoop, la memoria asignada para el sistema de archivos, el límite de memoria para almacenar los datos y el tamaño de los búferes de lectura / escritura.
Abra core-site.xml y agregue las siguientes propiedades entre las etiquetas <configuration>, </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
los hdfs-site.xmlEl archivo contiene información como el valor de los datos de replicación, la ruta del nodo de nombre y las rutas del nodo de datos de sus sistemas de archivos locales. Significa el lugar donde desea almacenar la infraestructura de Hadoop.
Asumamos los siguientes datos.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeAbra este archivo y agregue las siguientes propiedades entre las etiquetas <configuration> </configuration> en este archivo.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>Note - En el archivo anterior, todos los valores de propiedad están definidos por el usuario y puede realizar cambios de acuerdo con su infraestructura de Hadoop.
yarn-site.xml
Este archivo se utiliza para configurar hilo en Hadoop. Abra el archivo yarn-site.xml y agregue las siguientes propiedades entre las etiquetas <configuration>, </configuration> en este archivo.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Este archivo se usa para especificar qué marco MapReduce estamos usando. De forma predeterminada, Hadoop contiene una plantilla de yarn-site.xml. En primer lugar, es necesario copiar el archivo demapred-site.xml.template a mapred-site.xml archivo usando el siguiente comando.
$ cp mapred-site.xml.template mapred-site.xmlAbierto mapred-site.xml y agregue las siguientes propiedades entre las etiquetas <configuration>, </configuration> en este archivo.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Verificación de la instalación de Hadoop
Los siguientes pasos se utilizan para verificar la instalación de Hadoop.
Paso 1: configuración del nodo de nombre
Configure el nodo de nombre utilizando el comando “hdfs namenode -format” de la siguiente manera.
$ cd ~
$ hdfs namenode -formatEl resultado esperado es el siguiente.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Paso 2: verificar Hadoop dfs
El siguiente comando se utiliza para iniciar dfs. La ejecución de este comando iniciará su sistema de archivos Hadoop.
$ start-dfs.shEl resultado esperado es el siguiente:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Paso 3: verificación del guión de hilo
El siguiente comando se utiliza para iniciar el guión de hilo. La ejecución de este comando iniciará sus demonios de hilo.
$ start-yarn.shLa salida esperada de la siguiente manera:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outPaso 4: acceder a Hadoop en el navegador
El número de puerto predeterminado para acceder a Hadoop es 50070. Utilice la siguiente URL para obtener los servicios de Hadoop en el navegador.
http://localhost:50070/
Paso 5: verificar todas las aplicaciones para el clúster
El número de puerto predeterminado para acceder a todas las aplicaciones del clúster es 8088. Utilice la siguiente URL para visitar este servicio.
http://localhost:8088/
Hadoop File System se desarrolló utilizando un diseño de sistema de archivos distribuido. Se ejecuta en hardware básico. A diferencia de otros sistemas distribuidos, HDFS es altamente tolerante a fallas y está diseñado con hardware de bajo costo.
HDFS contiene una gran cantidad de datos y proporciona un acceso más fácil. Para almacenar datos tan grandes, los archivos se almacenan en varias máquinas. Estos archivos se almacenan de manera redundante para rescatar al sistema de posibles pérdidas de datos en caso de falla. HDFS también hace que las aplicaciones estén disponibles para procesamiento paralelo.
Características de HDFS
- Es adecuado para el almacenamiento y procesamiento distribuidos.
- Hadoop proporciona una interfaz de comando para interactuar con HDFS.
- Los servidores integrados de namenode y datanode ayudan a los usuarios a verificar fácilmente el estado del clúster.
- Transmisión de acceso a los datos del sistema de archivos.
- HDFS proporciona permisos y autenticación de archivos.
Arquitectura HDFS
A continuación se muestra la arquitectura de un sistema de archivos Hadoop.
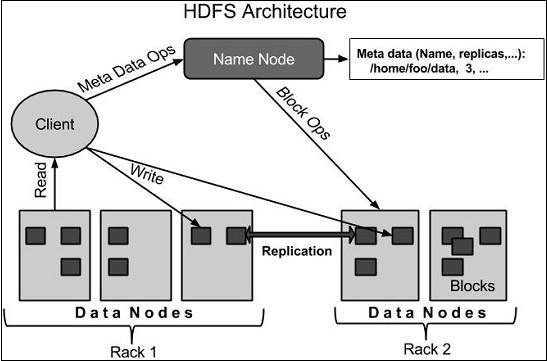
HDFS sigue la arquitectura maestro-esclavo y tiene los siguientes elementos.
Namenode
The namenode is the commodity hardware that contains the GNU/Linux operating system and the namenode software. It is a software that can be run on commodity hardware. The system having the namenode acts as the master server and it does the following tasks −
Manages the file system namespace.
Regulates client’s access to files.
It also executes file system operations such as renaming, closing, and opening files and directories.
Datanode
The datanode is a commodity hardware having the GNU/Linux operating system and datanode software. For every node (Commodity hardware/System) in a cluster, there will be a datanode. These nodes manage the data storage of their system.
Datanodes perform read-write operations on the file systems, as per client request.
They also perform operations such as block creation, deletion, and replication according to the instructions of the namenode.
Block
Generally the user data is stored in the files of HDFS. The file in a file system will be divided into one or more segments and/or stored in individual data nodes. These file segments are called as blocks. In other words, the minimum amount of data that HDFS can read or write is called a Block. The default block size is 64MB, but it can be increased as per the need to change in HDFS configuration.
Goals of HDFS
Fault detection and recovery − Since HDFS includes a large number of commodity hardware, failure of components is frequent. Therefore HDFS should have mechanisms for quick and automatic fault detection and recovery.
Huge datasets − HDFS should have hundreds of nodes per cluster to manage the applications having huge datasets.
Hardware at data − A requested task can be done efficiently, when the computation takes place near the data. Especially where huge datasets are involved, it reduces the network traffic and increases the throughput.
Starting HDFS
Initially you have to format the configured HDFS file system, open namenode (HDFS server), and execute the following command.
$ hadoop namenode -formatAfter formatting the HDFS, start the distributed file system. The following command will start the namenode as well as the data nodes as cluster.
$ start-dfs.shListing Files in HDFS
After loading the information in the server, we can find the list of files in a directory, status of a file, using ‘ls’. Given below is the syntax of ls that you can pass to a directory or a filename as an argument.
$ $HADOOP_HOME/bin/hadoop fs -ls <args>Inserting Data into HDFS
Assume we have data in the file called file.txt in the local system which is ought to be saved in the hdfs file system. Follow the steps given below to insert the required file in the Hadoop file system.
Step 1
You have to create an input directory.
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/inputStep 2
Transfer and store a data file from local systems to the Hadoop file system using the put command.
$ $HADOOP_HOME/bin/hadoop fs -put /home/file.txt /user/inputStep 3
You can verify the file using ls command.
$ $HADOOP_HOME/bin/hadoop fs -ls /user/inputRetrieving Data from HDFS
Assume we have a file in HDFS called outfile. Given below is a simple demonstration for retrieving the required file from the Hadoop file system.
Step 1
Initially, view the data from HDFS using cat command.
$ $HADOOP_HOME/bin/hadoop fs -cat /user/output/outfileStep 2
Get the file from HDFS to the local file system using get command.
$ $HADOOP_HOME/bin/hadoop fs -get /user/output/ /home/hadoop_tp/Shutting Down the HDFS
You can shut down the HDFS by using the following command.
$ stop-dfs.shThere are many more commands in "$HADOOP_HOME/bin/hadoop fs" than are demonstrated here, although these basic operations will get you started. Running ./bin/hadoop dfs with no additional arguments will list all the commands that can be run with the FsShell system. Furthermore, $HADOOP_HOME/bin/hadoop fs -help commandName will display a short usage summary for the operation in question, if you are stuck.
A table of all the operations is shown below. The following conventions are used for parameters −
"<path>" means any file or directory name.
"<path>..." means one or more file or directory names.
"<file>" means any filename.
"<src>" and "<dest>" are path names in a directed operation.
"<localSrc>" and "<localDest>" are paths as above, but on the local file system.All other files and path names refer to the objects inside HDFS.
| Sr.No | Command & Description |
|---|---|
| 1 | -ls <path> Lists the contents of the directory specified by path, showing the names, permissions, owner, size and modification date for each entry. |
| 2 | -lsr <path> Behaves like -ls, but recursively displays entries in all subdirectories of path. |
| 3 | -du <path> Shows disk usage, in bytes, for all the files which match path; filenames are reported with the full HDFS protocol prefix. |
| 4 | -dus <path> Like -du, but prints a summary of disk usage of all files/directories in the path. |
| 5 | -mv <src><dest> Moves the file or directory indicated by src to dest, within HDFS. |
| 6 | -cp <src> <dest> Copies the file or directory identified by src to dest, within HDFS. |
| 7 | -rm <path> Removes the file or empty directory identified by path. |
| 8 | -rmr <path> Removes the file or directory identified by path. Recursively deletes any child entries (i.e., files or subdirectories of path). |
| 9 | -put <localSrc> <dest> Copies the file or directory from the local file system identified by localSrc to dest within the DFS. |
| 10 | -copyFromLocal <localSrc> <dest> Identical to -put |
| 11 | -moveFromLocal <localSrc> <dest> Copies the file or directory from the local file system identified by localSrc to dest within HDFS, and then deletes the local copy on success. |
| 12 | -get [-crc] <src> <localDest> Copies the file or directory in HDFS identified by src to the local file system path identified by localDest. |
| 13 | -getmerge <src> <localDest> Retrieves all files that match the path src in HDFS, and copies them to a single, merged file in the local file system identified by localDest. |
| 14 | -cat <filen-ame> Displays the contents of filename on stdout. |
| 15 | -copyToLocal <src> <localDest> Identical to -get |
| 16 | -moveToLocal <src> <localDest> Works like -get, but deletes the HDFS copy on success. |
| 17 | -mkdir <path> Creates a directory named path in HDFS. Creates any parent directories in path that are missing (e.g., mkdir -p in Linux). |
| 18 | -setrep [-R] [-w] rep <path> Sets the target replication factor for files identified by path to rep. (The actual replication factor will move toward the target over time) |
| 19 | -touchz <path> Creates a file at path containing the current time as a timestamp. Fails if a file already exists at path, unless the file is already size 0. |
| 20 | -test -[ezd] <path> Returns 1 if path exists; has zero length; or is a directory or 0 otherwise. |
| 21 | -stat [format] <path> Prints information about path. Format is a string which accepts file size in blocks (%b), filename (%n), block size (%o), replication (%r), and modification date (%y, %Y). |
| 22 | -tail [-f] <file2name> Shows the last 1KB of file on stdout. |
| 23 | -chmod [-R] mode,mode,... <path>... Changes the file permissions associated with one or more objects identified by path.... Performs changes recursively with R. mode is a 3-digit octal mode, or {augo}+/-{rwxX}. Assumes if no scope is specified and does not apply an umask. |
| 24 | -chown [-R] [owner][:[group]] <path>... Sets the owning user and/or group for files or directories identified by path.... Sets owner recursively if -R is specified. |
| 25 | -chgrp [-R] group <path>... Sets the owning group for files or directories identified by path.... Sets group recursively if -R is specified. |
| 26 | -help <cmd-name> Returns usage information for one of the commands listed above. You must omit the leading '-' character in cmd. |
MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters of commodity hardware in a reliable manner.
What is MapReduce?
MapReduce is a processing technique and a program model for distributed computing based on java. The MapReduce algorithm contains two important tasks, namely Map and Reduce. Map takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs). Secondly, reduce task, which takes the output from a map as an input and combines those data tuples into a smaller set of tuples. As the sequence of the name MapReduce implies, the reduce task is always performed after the map job.
The major advantage of MapReduce is that it is easy to scale data processing over multiple computing nodes. Under the MapReduce model, the data processing primitives are called mappers and reducers. Decomposing a data processing application into mappers and reducers is sometimes nontrivial. But, once we write an application in the MapReduce form, scaling the application to run over hundreds, thousands, or even tens of thousands of machines in a cluster is merely a configuration change. This simple scalability is what has attracted many programmers to use the MapReduce model.
The Algorithm
Generally MapReduce paradigm is based on sending the computer to where the data resides!
MapReduce program executes in three stages, namely map stage, shuffle stage, and reduce stage.
Map stage − The map or mapper’s job is to process the input data. Generally the input data is in the form of file or directory and is stored in the Hadoop file system (HDFS). The input file is passed to the mapper function line by line. The mapper processes the data and creates several small chunks of data.
Reduce stage − This stage is the combination of the Shuffle stage and the Reduce stage. The Reducer’s job is to process the data that comes from the mapper. After processing, it produces a new set of output, which will be stored in the HDFS.
During a MapReduce job, Hadoop sends the Map and Reduce tasks to the appropriate servers in the cluster.
The framework manages all the details of data-passing such as issuing tasks, verifying task completion, and copying data around the cluster between the nodes.
Most of the computing takes place on nodes with data on local disks that reduces the network traffic.
After completion of the given tasks, the cluster collects and reduces the data to form an appropriate result, and sends it back to the Hadoop server.

Inputs and Outputs (Java Perspective)
The MapReduce framework operates on <key, value> pairs, that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
The key and the value classes should be in serialized manner by the framework and hence, need to implement the Writable interface. Additionally, the key classes have to implement the Writable-Comparable interface to facilitate sorting by the framework. Input and Output types of a MapReduce job − (Input) <k1, v1> → map → <k2, v2> → reduce → <k3, v3>(Output).
| Input | Output | |
|---|---|---|
| Map | <k1, v1> | list (<k2, v2>) |
| Reduce | <k2, list(v2)> | list (<k3, v3>) |
Terminology
PayLoad − Applications implement the Map and the Reduce functions, and form the core of the job.
Mapper − Mapper maps the input key/value pairs to a set of intermediate key/value pair.
NamedNode − Node that manages the Hadoop Distributed File System (HDFS).
DataNode − Node where data is presented in advance before any processing takes place.
MasterNode − Node where JobTracker runs and which accepts job requests from clients.
SlaveNode − Node where Map and Reduce program runs.
JobTracker − Schedules jobs and tracks the assign jobs to Task tracker.
Task Tracker − Tracks the task and reports status to JobTracker.
Job − A program is an execution of a Mapper and Reducer across a dataset.
Task − An execution of a Mapper or a Reducer on a slice of data.
Task Attempt − A particular instance of an attempt to execute a task on a SlaveNode.
Example Scenario
Given below is the data regarding the electrical consumption of an organization. It contains the monthly electrical consumption and the annual average for various years.
| Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec | Avg | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
If the above data is given as input, we have to write applications to process it and produce results such as finding the year of maximum usage, year of minimum usage, and so on. This is a walkover for the programmers with finite number of records. They will simply write the logic to produce the required output, and pass the data to the application written.
But, think of the data representing the electrical consumption of all the largescale industries of a particular state, since its formation.
When we write applications to process such bulk data,
They will take a lot of time to execute.
There will be a heavy network traffic when we move data from source to network server and so on.
To solve these problems, we have the MapReduce framework.
Input Data
The above data is saved as sample.txtand given as input. The input file looks as shown below.
1979 23 23 2 43 24 25 26 26 26 26 25 26 25
1980 26 27 28 28 28 30 31 31 31 30 30 30 29
1981 31 32 32 32 33 34 35 36 36 34 34 34 34
1984 39 38 39 39 39 41 42 43 40 39 38 38 40
1985 38 39 39 39 39 41 41 41 00 40 39 39 45Example Program
Given below is the program to the sample data using MapReduce framework.
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits {
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable ,/*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()) {
lasttoken = s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > {
//Reduce function
public void reduce( Text key, Iterator <IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int maxavg = 30;
int val = Integer.MIN_VALUE;
while (values.hasNext()) {
if((val = values.next().get())>maxavg) {
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception {
JobConf conf = new JobConf(ProcessUnits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}Guarde el programa anterior como ProcessUnits.java. La compilación y ejecución del programa se explica a continuación.
Programa de Compilación y Ejecución de Unidades de Procesos
Supongamos que estamos en el directorio de inicio de un usuario de Hadoop (por ejemplo, / home / hadoop).
Siga los pasos que se indican a continuación para compilar y ejecutar el programa anterior.
Paso 1
El siguiente comando es crear un directorio para almacenar las clases java compiladas.
$ mkdir unitsPaso 2
Descargar Hadoop-core-1.2.1.jar,que se utiliza para compilar y ejecutar el programa MapReduce. Visite el siguiente enlace mvnrepository.com para descargar el archivo jar. Supongamos que la carpeta descargada es/home/hadoop/.
Paso 3
Los siguientes comandos se utilizan para compilar ProcessUnits.java programa y creando un frasco para el programa.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java
$ jar -cvf units.jar -C units/ .Etapa 4
El siguiente comando se utiliza para crear un directorio de entrada en HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirPaso 5
El siguiente comando se usa para copiar el archivo de entrada llamado sample.txten el directorio de entrada de HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dirPaso 6
El siguiente comando se usa para verificar los archivos en el directorio de entrada.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Paso 7
El siguiente comando se usa para ejecutar la aplicación Eleunit_max tomando los archivos de entrada del directorio de entrada.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirEspere un momento hasta que se ejecute el archivo. Después de la ejecución, como se muestra a continuación, la salida contendrá el número de divisiones de entrada, el número de tareas del mapa, el número de tareas reductoras, etc.
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read = 61
FILE: Number of bytes written = 279400
FILE: Number of read operations = 0
FILE: Number of large read operations = 0
FILE: Number of write operations = 0
HDFS: Number of bytes read = 546
HDFS: Number of bytes written = 40
HDFS: Number of read operations = 9
HDFS: Number of large read operations = 0
HDFS: Number of write operations = 2 Job Counters
Launched map tasks = 2
Launched reduce tasks = 1
Data-local map tasks = 2
Total time spent by all maps in occupied slots (ms) = 146137
Total time spent by all reduces in occupied slots (ms) = 441
Total time spent by all map tasks (ms) = 14613
Total time spent by all reduce tasks (ms) = 44120
Total vcore-seconds taken by all map tasks = 146137
Total vcore-seconds taken by all reduce tasks = 44120
Total megabyte-seconds taken by all map tasks = 149644288
Total megabyte-seconds taken by all reduce tasks = 45178880
Map-Reduce Framework
Map input records = 5
Map output records = 5
Map output bytes = 45
Map output materialized bytes = 67
Input split bytes = 208
Combine input records = 5
Combine output records = 5
Reduce input groups = 5
Reduce shuffle bytes = 6
Reduce input records = 5
Reduce output records = 5
Spilled Records = 10
Shuffled Maps = 2
Failed Shuffles = 0
Merged Map outputs = 2
GC time elapsed (ms) = 948
CPU time spent (ms) = 5160
Physical memory (bytes) snapshot = 47749120
Virtual memory (bytes) snapshot = 2899349504
Total committed heap usage (bytes) = 277684224
File Output Format Counters
Bytes Written = 40Paso 8
El siguiente comando se utiliza para verificar los archivos resultantes en la carpeta de salida.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Paso 9
El siguiente comando se usa para ver la salida en Part-00000 archivo. Este archivo es generado por HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000A continuación se muestra la salida generada por el programa MapReduce.
1981 34
1984 40
1985 45Paso 10
El siguiente comando se utiliza para copiar la carpeta de salida de HDFS al sistema de archivos local para su análisis.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs get output_dir /home/hadoopComandos importantes
Todos los comandos de Hadoop son invocados por el $HADOOP_HOME/bin/hadoopmando. Al ejecutar el script de Hadoop sin argumentos, se imprime la descripción de todos los comandos.
Usage - COMANDO hadoop [--config confdir]
La siguiente tabla enumera las opciones disponibles y su descripción.
| No Señor. | Opción y descripción |
|---|---|
| 1 | namenode -format Formatea el sistema de archivos DFS. |
| 2 | secondarynamenode Ejecuta el nodo de nombre secundario DFS. |
| 3 | namenode Ejecuta el nodo de nombre DFS. |
| 4 | datanode Ejecuta un nodo de datos DFS. |
| 5 | dfsadmin Ejecuta un cliente de administración DFS. |
| 6 | mradmin Ejecuta un cliente de administración Map-Reduce. |
| 7 | fsck Ejecuta una utilidad de verificación del sistema de archivos DFS. |
| 8 | fs Ejecuta un cliente de usuario de sistema de archivos genérico. |
| 9 | balancer Ejecuta una utilidad de equilibrio de clústeres. |
| 10 | oiv Aplica el visor de fsimage sin conexión a un fsimage. |
| 11 | fetchdt Obtiene un token de delegación del NameNode. |
| 12 | jobtracker Ejecuta el nodo de seguimiento de trabajos de MapReduce. |
| 13 | pipes Ejecuta un trabajo de tuberías. |
| 14 | tasktracker Ejecuta un nodo de seguimiento de tareas de MapReduce. |
| 15 | historyserver Ejecuta servidores de historial de trabajos como un demonio independiente. |
| dieciséis | job Manipula los trabajos de MapReduce. |
| 17 | queue Obtiene información sobre JobQueues. |
| 18 | version Imprime la versión. |
| 19 | jar <jar> Ejecuta un archivo jar. |
| 20 | distcp <srcurl> <desturl> Copia archivos o directorios de forma recursiva. |
| 21 | distcp2 <srcurl> <desturl> DistCp versión 2. |
| 22 | archive -archiveName NAME -p <parent path> <src>* <dest> Crea un archivo hadoop. |
| 23 | classpath Imprime la ruta de clases necesaria para obtener el jar de Hadoop y las bibliotecas necesarias. |
| 24 | daemonlog Obtener / establecer el nivel de registro para cada demonio |
Cómo interactuar con trabajos de MapReduce
Uso: trabajo de hadoop [GENERIC_OPTIONS]
Las siguientes son las opciones genéricas disponibles en un trabajo de Hadoop.
| No Señor. | GENERIC_OPTION y descripción |
|---|---|
| 1 | -submit <job-file> Envía el trabajo. |
| 2 | -status <job-id> Imprime el mapa y reduce el porcentaje de finalización y todos los contadores de trabajos. |
| 3 | -counter <job-id> <group-name> <countername> Imprime el valor del contador. |
| 4 | -kill <job-id> Mata el trabajo. |
| 5 | -events <job-id> <fromevent-#> <#-of-events> Imprime los detalles de los eventos recibidos por jobtracker para el rango dado. |
| 6 | -history [all] <jobOutputDir> - history < jobOutputDir> Imprime los detalles del trabajo, los detalles de las propinas fallidas y eliminadas. Para ver más detalles sobre el trabajo, como las tareas exitosas y los intentos realizados para cada tarea, especifique la opción [todos]. |
| 7 | -list[all] Muestra todos los trabajos. -La lista muestra solo los trabajos que aún no se han completado. |
| 8 | -kill-task <task-id> Mata la tarea. Las tareas eliminadas NO se cuentan como intentos fallidos. |
| 9 | -fail-task <task-id> Fracasa la tarea. Las tareas fallidas se contabilizan como intentos fallidos. |
| 10 | -set-priority <job-id> <priority> Cambia la prioridad del trabajo. Los valores de prioridad permitidos son MUY_ALTA, ALTA, NORMAL, BAJA, MUY_BAJA |
Para ver el estado del trabajo
$ $HADOOP_HOME/bin/hadoop job -status <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -status job_201310191043_0004Para ver el historial del directorio de salida del trabajo
$ $HADOOP_HOME/bin/hadoop job -history <DIR-NAME> e.g. $ $HADOOP_HOME/bin/hadoop job -history /user/expert/outputPara matar el trabajo
$ $HADOOP_HOME/bin/hadoop job -kill <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -kill job_201310191043_0004La transmisión de Hadoop es una utilidad que viene con la distribución de Hadoop. Esta utilidad le permite crear y ejecutar trabajos Map / Reduce con cualquier ejecutable o script como mapeador y / o reductor.
Ejemplo usando Python
Para la transmisión de Hadoop, estamos considerando el problema del recuento de palabras. Cualquier trabajo en Hadoop debe tener dos fases: mapeador y reductor. Hemos escrito códigos para el asignador y el reductor en el script de Python para ejecutarlo en Hadoop. También se puede escribir lo mismo en Perl y Ruby.
Código de fase del asignador
!/usr/bin/python
import sys
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Break the line into words
words = myline.split()
# Iterate the words list
for myword in words:
# Write the results to standard output
print '%s\t%s' % (myword, 1)Asegúrese de que este archivo tenga permiso de ejecución (chmod + x / home / expert / hadoop-1.2.1 / mapper.py).
Código de fase del reductor
#!/usr/bin/python
from operator import itemgetter
import sys
current_word = ""
current_count = 0
word = ""
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Split the input we got from mapper.py word,
count = myline.split('\t', 1)
# Convert count variable to integer
try:
count = int(count)
except ValueError:
# Count was not a number, so silently ignore this line continue
if current_word == word:
current_count += count
else:
if current_word:
# Write result to standard output print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# Do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)Guarde los códigos de asignador y reductor en mapper.py y reducer.py en el directorio de inicio de Hadoop. Asegúrese de que estos archivos tengan permiso de ejecución (chmod + x mapper.py y chmod + x reducer.py). Como Python es sensible a la sangría, el mismo código se puede descargar desde el siguiente enlace.
Ejecución del programa WordCount
$ $HADOOP_HOME/bin/hadoop jar contrib/streaming/hadoop-streaming-1.
2.1.jar \
-input input_dirs \
-output output_dir \
-mapper <path/mapper.py \
-reducer <path/reducer.pyDonde "\" se usa para la continuación de la línea para una legibilidad clara.
Por ejemplo,
./bin/hadoop jar contrib/streaming/hadoop-streaming-1.2.1.jar -input myinput -output myoutput -mapper /home/expert/hadoop-1.2.1/mapper.py -reducer /home/expert/hadoop-1.2.1/reducer.pyCómo funciona la transmisión
En el ejemplo anterior, tanto el asignador como el reductor son scripts de Python que leen la entrada desde la entrada estándar y emiten la salida a la salida estándar. La utilidad creará un trabajo Mapa / Reducir, enviará el trabajo a un clúster apropiado y monitoreará el progreso del trabajo hasta que se complete.
Cuando se especifica un script para los mapeadores, cada tarea del mapeador iniciará el script como un proceso separado cuando se inicializa el mapeador. A medida que se ejecuta la tarea del asignador, convierte sus entradas en líneas y alimenta las líneas a la entrada estándar (STDIN) del proceso. Mientras tanto, el asignador recopila las salidas orientadas a la línea de la salida estándar (STDOUT) del proceso y convierte cada línea en un par clave / valor, que se recopila como la salida del asignador. De forma predeterminada, el prefijo de una línea hasta el primer carácter de tabulación es la clave y el resto de la línea (excluyendo el carácter de tabulación) será el valor. Si no hay un carácter de tabulación en la línea, toda la línea se considera la clave y el valor es nulo. Sin embargo, esto se puede personalizar, según sea necesario.
Cuando se especifica una secuencia de comandos para reductores, cada tarea de reductor iniciará la secuencia de comandos como un proceso independiente y luego se inicializará el reductor. A medida que se ejecuta la tarea del reductor, convierte sus pares clave / valores de entrada en líneas y alimenta las líneas a la entrada estándar (STDIN) del proceso. Mientras tanto, el reductor recopila las salidas orientadas a la línea de la salida estándar (STDOUT) del proceso, convierte cada línea en un par clave / valor, que se recopila como la salida del reductor. De forma predeterminada, el prefijo de una línea hasta el primer carácter de tabulación es la clave y el resto de la línea (excluyendo el carácter de tabulación) es el valor. Sin embargo, esto se puede personalizar según los requisitos específicos.
Comandos importantes
| Parámetros | Opciones | Descripción |
|---|---|---|
| -directorio de entrada / nombre-archivo | Necesario | Ingrese la ubicación para el mapeador. |
| -nombre-directorio de salida | Necesario | Ubicación de salida para reductor. |
| -mapeador ejecutable o script o JavaClassName | Necesario | Mapeador ejecutable. |
| -reducer ejecutable o script o JavaClassName | Necesario | Reductor ejecutable. |
| -archivo nombre-archivo | Opcional | Hace que el mapeador, reductor o combinador ejecutable esté disponible localmente en los nodos de cálculo. |
| -inputformat JavaClassName | Opcional | La clase que proporcione debe devolver pares clave / valor de la clase Text. Si no se especifica, TextInputFormat se utiliza como predeterminado. |
| -outputformat JavaClassName | Opcional | La clase que proporcione debe incluir pares clave / valor de la clase de texto. Si no se especifica, TextOutputformat se utiliza como predeterminado. |
| -particionador JavaClassName | Opcional | Clase que determina a qué reducción se envía una clave. |
| -combiner streamingCommand o JavaClassName | Opcional | Combiner ejecutable para salida de mapas. |
| -cmdenv nombre = valor | Opcional | Pasa la variable de entorno a los comandos de transmisión. |
| -lector de entrada | Opcional | Para compatibilidad con versiones anteriores: especifica una clase de lector de registros (en lugar de una clase de formato de entrada). |
| -verboso | Opcional | Salida detallada. |
| -lazyOutput | Opcional | Crea resultados de forma perezosa. Por ejemplo, si el formato de salida se basa en FileOutputFormat, el archivo de salida se crea solo en la primera llamada a output.collect (o Context.write). |
| -numReduceTasks | Opcional | Especifica el número de reductores. |
| -mapdebug | Opcional | Script para llamar cuando falla la tarea de mapa. |
| -reducebug | Opcional | Secuencia de comandos para llamar cuando falla la tarea de reducción. |
Este capítulo explica la configuración del clúster Hadoop Multi-Node en un entorno distribuido.
Como no se puede demostrar todo el clúster, estamos explicando el entorno del clúster de Hadoop utilizando tres sistemas (un maestro y dos esclavos); a continuación se muestran sus direcciones IP.
- Maestro de Hadoop: 192.168.1.15 (maestro de hadoop)
- Esclavo de Hadoop: 192.168.1.16 (hadoop-esclavo-1)
- Esclavo de Hadoop: 192.168.1.17 (hadoop-esclavo-2)
Siga los pasos que se indican a continuación para configurar el clúster de varios nodos de Hadoop.
Instalación de Java
Java es el principal requisito previo para Hadoop. En primer lugar, debe verificar la existencia de java en su sistema usando "java -version". La sintaxis del comando de la versión java se proporciona a continuación.
$ java -versionSi todo funciona bien, le dará el siguiente resultado.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Si java no está instalado en su sistema, siga los pasos dados para instalar java.
Paso 1
Descargue java (JDK <última versión> - X64.tar.gz) visitando el siguiente enlace www.oracle.com
Luego jdk-7u71-linux-x64.tar.gz se descargará en su sistema.
Paso 2
Generalmente, encontrará el archivo java descargado en la carpeta Descargas. Verifíquelo y extraiga eljdk-7u71-linux-x64.gz archivo usando los siguientes comandos.
$ cd Downloads/ $ ls
jdk-7u71-Linux-x64.gz
$ tar zxf jdk-7u71-Linux-x64.gz $ ls
jdk1.7.0_71 jdk-7u71-Linux-x64.gzPaso 3
Para que Java esté disponible para todos los usuarios, debe moverlo a la ubicación “/ usr / local /”. Abra la raíz y escriba los siguientes comandos.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitEtapa 4
Para configurar PATH y JAVA_HOME variables, agregue los siguientes comandos a ~/.bashrc archivo.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/binAhora verifique el java -versioncomando desde el terminal como se explicó anteriormente. Siga el proceso anterior e instale java en todos los nodos de su clúster.
Crear cuenta de usuario
Cree una cuenta de usuario del sistema en los sistemas maestro y esclavo para usar la instalación de Hadoop.
# useradd hadoop
# passwd hadoopMapeo de los nodos
Tienes que editar hosts presentar en /etc/ carpeta en todos los nodos, especifique la dirección IP de cada sistema seguida de sus nombres de host.
# vi /etc/hosts
enter the following lines in the /etc/hosts file.
192.168.1.109 hadoop-master
192.168.1.145 hadoop-slave-1
192.168.56.1 hadoop-slave-2Configurar el inicio de sesión basado en claves
Configure ssh en cada nodo de modo que puedan comunicarse entre sí sin que se le solicite una contraseña.
# su hadoop
$ ssh-keygen -t rsa $ ssh-copy-id -i ~/.ssh/id_rsa.pub tutorialspoint@hadoop-master
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp1@hadoop-slave-1 $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp2@hadoop-slave-2
$ chmod 0600 ~/.ssh/authorized_keys $ exitInstalación de Hadoop
En el servidor maestro, descargue e instale Hadoop usando los siguientes comandos.
# mkdir /opt/hadoop
# cd /opt/hadoop/
# wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.1/hadoop-1.2.0.tar.gz
# tar -xzf hadoop-1.2.0.tar.gz
# mv hadoop-1.2.0 hadoop
# chown -R hadoop /opt/hadoop
# cd /opt/hadoop/hadoop/Configurando Hadoop
Debe configurar el servidor Hadoop realizando los siguientes cambios como se indica a continuación.
core-site.xml
Abre el core-site.xml archivo y edítelo como se muestra a continuación.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>hdfs-site.xml
Abre el hdfs-site.xml archivo y edítelo como se muestra a continuación.
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop/dfs/name/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>mapred-site.xml
Abre el mapred-site.xml archivo y edítelo como se muestra a continuación.
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
</configuration>hadoop-env.sh
Abre el hadoop-env.sh archivo y edite JAVA_HOME, HADOOP_CONF_DIR y HADOOP_OPTS como se muestra a continuación.
Note - Configure JAVA_HOME según la configuración de su sistema.
export JAVA_HOME=/opt/jdk1.7.0_17
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
export HADOOP_CONF_DIR=/opt/hadoop/hadoop/confInstalación de Hadoop en servidores esclavos
Instale Hadoop en todos los servidores esclavos siguiendo los comandos dados.
# su hadoop
$ cd /opt/hadoop $ scp -r hadoop hadoop-slave-1:/opt/hadoop
$ scp -r hadoop hadoop-slave-2:/opt/hadoopConfiguración de Hadoop en el servidor maestro
Abra el servidor maestro y configúrelo siguiendo los comandos dados.
# su hadoop
$ cd /opt/hadoop/hadoopConfigurar el nodo maestro
$ vi etc/hadoop/masters
hadoop-masterConfiguración de nodo esclavo
$ vi etc/hadoop/slaves
hadoop-slave-1
hadoop-slave-2Nodo de nombre de formato en Hadoop Master
# su hadoop
$ cd /opt/hadoop/hadoop $ bin/hadoop namenode –format
11/10/14 10:58:07 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop-master/192.168.1.109
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.2.0
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1479473;
compiled by 'hortonfo' on Mon May 6 06:59:37 UTC 2013
STARTUP_MSG: java = 1.7.0_71
************************************************************/
11/10/14 10:58:08 INFO util.GSet: Computing capacity for map BlocksMap
editlog=/opt/hadoop/hadoop/dfs/name/current/edits
………………………………………………….
………………………………………………….
………………………………………………….
11/10/14 10:58:08 INFO common.Storage: Storage directory
/opt/hadoop/hadoop/dfs/name has been successfully formatted.
11/10/14 10:58:08 INFO namenode.NameNode:
SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/192.168.1.15
************************************************************/Inicio de los servicios de Hadoop
El siguiente comando es para iniciar todos los servicios de Hadoop en Hadoop-Master.
$ cd $HADOOP_HOME/sbin
$ start-all.shAgregar un nuevo nodo de datos en el clúster de Hadoop
A continuación, se muestran los pasos a seguir para agregar nuevos nodos a un clúster de Hadoop.
Redes
Agregue nuevos nodos a un clúster de Hadoop existente con alguna configuración de red adecuada. Suponga la siguiente configuración de red.
Para la configuración de un nuevo nodo:
IP address : 192.168.1.103
netmask : 255.255.255.0
hostname : slave3.inAgregar usuario y acceso SSH
Agregar un usuario
En un nuevo nodo, agregue el usuario "hadoop" y establezca la contraseña del usuario de Hadoop en "hadoop123" o cualquier cosa que desee mediante los siguientes comandos.
useradd hadoop
passwd hadoopConfiguración de contraseña menos conectividad de maestro a esclavo nuevo.
Ejecute lo siguiente en el maestro
mkdir -p $HOME/.ssh
chmod 700 $HOME/.ssh ssh-keygen -t rsa -P '' -f $HOME/.ssh/id_rsa
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
chmod 644 $HOME/.ssh/authorized_keys Copy the public key to new slave node in hadoop user $HOME directory
scp $HOME/.ssh/id_rsa.pub [email protected]:/home/hadoop/Ejecute lo siguiente en los esclavos
Inicie sesión en hadoop. Si no es así, inicie sesión como usuario de hadoop.
su hadoop ssh -X [email protected]Copie el contenido de la clave pública en el archivo "$HOME/.ssh/authorized_keys" y luego cambie el permiso para el mismo ejecutando los siguientes comandos.
cd $HOME mkdir -p $HOME/.ssh
chmod 700 $HOME/.ssh cat id_rsa.pub >>$HOME/.ssh/authorized_keys
chmod 644 $HOME/.ssh/authorized_keysVerifique el inicio de sesión ssh desde la máquina maestra. Ahora compruebe si puede acceder al nuevo nodo sin una contraseña del maestro.
ssh [email protected] or hadoop@slave3Establecer el nombre de host del nuevo nodo
Puede establecer el nombre de host en el archivo /etc/sysconfig/network
On new slave3 machine
NETWORKING = yes
HOSTNAME = slave3.inPara que los cambios sean efectivos, reinicie la máquina o ejecute el comando hostname en una nueva máquina con el nombre de host correspondiente (reiniciar es una buena opción).
En la máquina del nodo esclavo3 -
nombre de host esclavo3.in
Actualizar /etc/hosts en todas las máquinas del clúster con las siguientes líneas:
192.168.1.102 slave3.in slave3Ahora intente hacer ping a la máquina con nombres de host para verificar si se está resolviendo a IP o no.
En una nueva máquina de nodo -
ping master.inInicie el DataNode en un nodo nuevo
Inicie el demonio de nodo de datos manualmente usando $HADOOP_HOME/bin/hadoop-daemon.sh script. Se pondrá en contacto automáticamente con el maestro (NameNode) y se unirá al clúster. También debemos agregar el nuevo nodo al archivo conf / slaves en el servidor maestro. Los comandos basados en script reconocerán el nuevo nodo.
Iniciar sesión en un nuevo nodo
su hadoop or ssh -X [email protected]Inicie HDFS en un nodo esclavo recién agregado mediante el siguiente comando
./bin/hadoop-daemon.sh start datanodeVerifique la salida del comando jps en un nuevo nodo. Tiene el siguiente aspecto.
$ jps
7141 DataNode
10312 JpsEliminar un DataNode del clúster de Hadoop
Podemos eliminar un nodo de un clúster sobre la marcha, mientras se ejecuta, sin pérdida de datos. HDFS proporciona una función de desmantelamiento, que garantiza que la eliminación de un nodo se realice de forma segura. Para usarlo, siga los pasos que se indican a continuación:
Paso 1: iniciar sesión en master
Inicie sesión en el usuario principal de la máquina donde está instalado Hadoop.
$ su hadoopPaso 2: cambiar la configuración del clúster
Se debe configurar un archivo de exclusión antes de iniciar el clúster. Agregue una clave llamada dfs.hosts.exclude a nuestro$HADOOP_HOME/etc/hadoop/hdfs-site.xmlarchivo. El valor asociado con esta clave proporciona la ruta completa a un archivo en el sistema de archivos local de NameNode que contiene una lista de máquinas a las que no se les permite conectarse a HDFS.
Por ejemplo, agregue estas líneas a etc/hadoop/hdfs-site.xml archivo.
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt</value>
<description>DFS exclude</description>
</property>Paso 3: determinar los hosts que se deben retirar
Cada máquina que se desmantelará debe agregarse al archivo identificado por hdfs_exclude.txt, un nombre de dominio por línea. Esto evitará que se conecten al NameNode. Contenido del"/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt" El archivo se muestra a continuación, si desea eliminar DataNode2.
slave2.inPaso 4: forzar la recarga de la configuración
Ejecuta el comando "$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes" sin las comillas.
$ $HADOOP_HOME/bin/hadoop dfsadmin -refreshNodesEsto obligará a NameNode a volver a leer su configuración, incluido el archivo de "exclusiones" recién actualizado. Desmantelará los nodos durante un período de tiempo, lo que permitirá que los bloques de cada nodo se repliquen en las máquinas que están programadas para permanecer activas.
En slave2.in, verifique la salida del comando jps. Después de un tiempo, verá que el proceso de DataNode se cierra automáticamente.
Paso 5: apagar los nodos
Una vez que se ha completado el proceso de desmantelamiento, el hardware desmantelado se puede apagar de forma segura para su mantenimiento. Ejecute el comando de informe a dfsadmin para verificar el estado del retiro. El siguiente comando describirá el estado del nodo de retiro y los nodos conectados al clúster.
$ $HADOOP_HOME/bin/hadoop dfsadmin -reportPaso 6: vuelva a editar el archivo de exclusión
Una vez que las máquinas se han dado de baja, se pueden eliminar del archivo 'excluidas'. Corriendo"$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes"de nuevo leerá el archivo de exclusiones en el NameNode; permitir que los DataNodes se vuelvan a unir al clúster después de que se haya completado el mantenimiento, o se necesite capacidad adicional en el clúster nuevamente, etc.
Special Note- Si se sigue el proceso anterior y el proceso del rastreador de tareas todavía se está ejecutando en el nodo, debe cerrarse. Una forma es desconectar la máquina como hicimos en los pasos anteriores. El Maestro reconocerá el proceso automáticamente y lo declarará muerto. No es necesario seguir el mismo proceso para eliminar el rastreador de tareas porque NO es muy importante en comparación con el DataNode. DataNode contiene los datos que desea eliminar de forma segura sin pérdida de datos.
El rastreador de tareas se puede ejecutar / apagar sobre la marcha con el siguiente comando en cualquier momento.
$ $HADOOP_HOME/bin/hadoop-daemon.sh stop tasktracker $HADOOP_HOME/bin/hadoop-daemon.sh start tasktracker