IMS DB - Procesamiento DL / I
IMS DB almacena datos en diferentes niveles. Los datos se recuperan e insertan emitiendo llamadas DL / I desde un programa de aplicación. Discutiremos sobre las llamadas DL / I en detalle en los próximos capítulos. Los datos se pueden procesar de las dos formas siguientes:
- Tratamiento secuencial
- Procesamiento aleatorio
Tratamiento secuencial
Cuando los segmentos se recuperan secuencialmente de la base de datos, DL / I sigue un patrón predefinido. Entendamos el procesamiento secuencial de IMS DB.
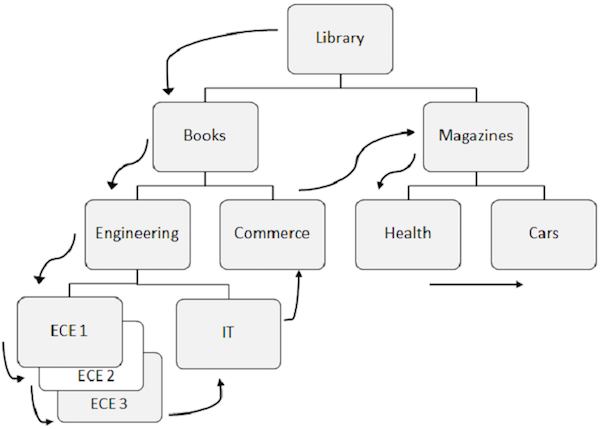
A continuación se enumeran los puntos a tener en cuenta sobre el procesamiento secuencial:
El patrón predefinido para acceder a los datos en DL / I es primero en la jerarquía, luego de izquierda a derecha.
Primero se recupera el segmento raíz, luego DL / I se mueve al primer hijo izquierdo y baja hasta el nivel más bajo. En el nivel más bajo, recupera todas las apariciones de segmentos gemelos. Luego pasa al segmento correcto.
Para comprender mejor, observe las flechas en la figura anterior que muestran el flujo para acceder a los segmentos. La biblioteca es el segmento raíz y el flujo comienza desde allí y va hasta los automóviles para acceder a un solo registro. El mismo proceso se repite para todas las ocurrencias para obtener todos los registros de datos.
Al acceder a los datos, el programa utiliza el position en la base de datos que ayuda a recuperar e insertar segmentos.
Procesamiento aleatorio
El procesamiento aleatorio también se conoce como procesamiento directo de datos en IMS DB. Tomemos un ejemplo para comprender el procesamiento aleatorio en IMS DB:
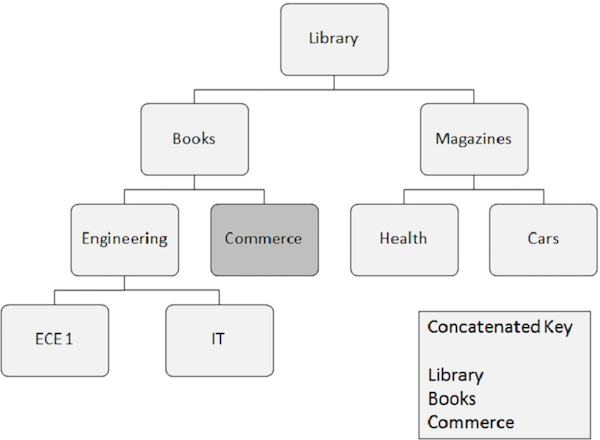
A continuación se enumeran los puntos a tener en cuenta sobre el procesamiento aleatorio:
La ocurrencia de segmento que debe recuperarse aleatoriamente requiere campos clave de todos los segmentos de los que depende. Estos campos clave los proporciona el programa de aplicación.
Una clave concatenada identifica completamente la ruta desde el segmento raíz hasta el segmento que desea recuperar.
Suponga que desea recuperar una ocurrencia del segmento Comercio, luego debe proporcionar los valores de campo clave concatenados de los segmentos de los que depende, como Biblioteca, Libros y Comercio.
El procesamiento aleatorio es más rápido que el secuencial. En el escenario del mundo real, las aplicaciones combinan métodos de procesamiento secuenciales y aleatorios para lograr los mejores resultados.
Campo clave
Puntos a tener en cuenta:
Un campo clave también se conoce como campo de secuencia.
Un campo clave está presente dentro de un segmento y se usa para recuperar la ocurrencia del segmento.
Un campo clave gestiona la aparición del segmento en orden ascendente.
En cada segmento, solo se puede utilizar un campo como campo clave o campo de secuencia.
Campo de búsqueda
Como se mencionó, solo se puede utilizar un campo como campo clave. Si desea buscar el contenido de otros campos de segmento que no son campos clave, el campo que se utiliza para recuperar los datos se conoce como campo de búsqueda.