IMS DB - Indexación secundaria
La indexación secundaria se utiliza cuando queremos acceder a una base de datos sin utilizar la clave concatenada completa o cuando no queremos utilizar los campos primarios de la secuencia.
Segmento de puntero de índice
DL / I almacena el puntero a segmentos de la base de datos indexada en una base de datos separada. El segmento de puntero de índice es el único tipo de índice secundario. Consta de dos partes:
- Elemento de prefijo
- Elemento de datos
Elemento de prefijo
La parte del prefijo del segmento de puntero de índice contiene un puntero al segmento de destino del índice. El segmento de destino del índice es el segmento al que se puede acceder mediante el índice secundario.
Elemento de datos
El elemento de datos contiene el valor clave del segmento en la base de datos indexada sobre la que se construye el índice. Esto también se conoce como segmento fuente de índice.
Estos son los puntos clave a tener en cuenta sobre la indexación secundaria:
No es necesario que el segmento de origen del índice y el segmento de origen de destino sean iguales.
Cuando configuramos un índice secundario, DL / I lo mantiene automáticamente.
El DBA define muchos índices secundarios según las múltiples rutas de acceso. Estos índices secundarios se almacenan en una base de datos de índices separada.
No deberíamos crear más índices secundarios, ya que imponen una sobrecarga de procesamiento adicional en el DL / I.
Llaves secundarias
Puntos a tener en cuenta:
El campo del segmento de origen del índice sobre el que se crea el índice secundario se denomina clave secundaria.
Cualquier campo se puede utilizar como clave secundaria. No es necesario que sea el campo de secuencia de segmentos.
Las claves secundarias pueden ser cualquier combinación de campos individuales dentro del segmento de origen del índice.
Los valores de clave secundaria no tienen que ser únicos.
Estructuras de datos secundarias
Puntos a tener en cuenta:
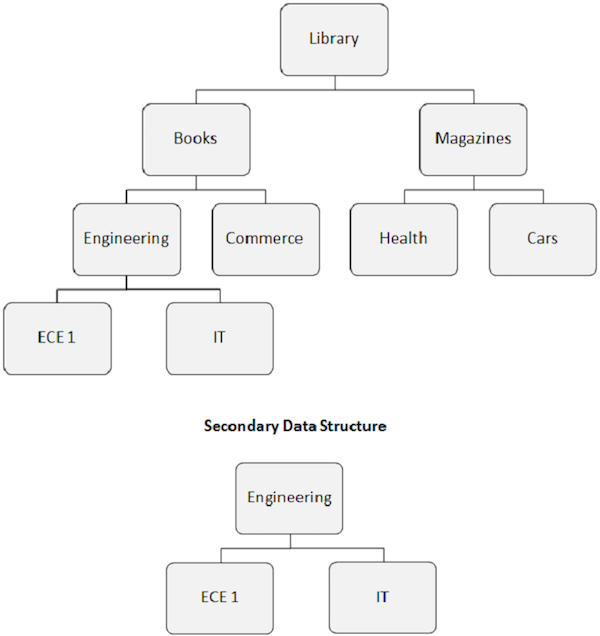
Cuando construimos un índice secundario, la estructura jerárquica aparente de la base de datos también cambia.
El segmento objetivo del índice se convierte en el segmento raíz aparente. Como se muestra en la siguiente imagen, el segmento de Ingeniería se convierte en el segmento raíz, incluso si no es un segmento raíz.
La reordenación de la estructura de la base de datos causada por el índice secundario se conoce como estructura de datos secundaria.
Las estructuras de datos secundarias no realizan cambios en la estructura de la base de datos física principal presente en el disco. Es solo una forma de alterar la estructura de la base de datos frente al programa de aplicación.
Operador AND independiente
Puntos a tener en cuenta:
Cuando se utiliza un operador AND (* o &) con índices secundarios, se conoce como operador AND dependiente.
Un AND (#) independiente nos permite especificar calificaciones que serían imposibles con un AND dependiente.
Este operador solo se puede utilizar para índices secundarios en los que el segmento de origen del índice depende del segmento de destino del índice.
Podemos codificar un SSA con un AND independiente para especificar que una ocurrencia del segmento de destino se procese en función de los campos en dos o más segmentos de origen dependientes.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.Secuenciación dispersa
Puntos a tener en cuenta:
La secuenciación dispersa también se conoce como indexación dispersa. Podemos eliminar algunos de los segmentos de origen del índice del índice utilizando una secuencia escasa con una base de datos de índice secundaria.
La secuenciación dispersa se utiliza para mejorar el rendimiento. Cuando no se utilizan algunas apariciones del segmento fuente del índice, podemos eliminarlo.
DL / I utiliza un valor de supresión o una rutina de supresión o ambos para determinar si un segmento debe indexarse.
Si el valor de un campo de secuencia en el segmento de origen del índice coincide con un valor de supresión, no se establece ninguna relación de índice.
La rutina de supresión es un programa escrito por el usuario que evalúa el segmento y determina si debe indexarse o no.
Cuando se utiliza la indexación dispersa, sus funciones son manejadas por el DL / I. No es necesario que hagamos disposiciones especiales para ello en el programa de aplicación.
Requisitos DBDGEN
Como se discutió en módulos anteriores, DBDGEN se usa para crear un DBD. Cuando creamos índices secundarios, hay dos bases de datos involucradas. Un DBA necesita crear dos DBD utilizando dos DBDGEN para crear una relación entre una base de datos indexada y una base de datos indexada secundaria.
Requisitos de PSBGEN
Después de crear el índice secundario para una base de datos, el DBA necesita crear los PSB. PSBGEN para el programa especifica la secuencia de procesamiento adecuada para la base de datos en el parámetro PROCSEQ de la macro PSB. Para el parámetro PROCSEQ, el DBA codifica el nombre DBD para la base de datos de índice secundaria.